
Машинное обучение и Data Science (Часть 36): Работа с несбалансированными финансовыми рынками

Содержание
- Введение
- Недостатки несбалансированной целевой переменной в машинном обучении
- Методы решения проблемы несбалансированных наборов данных
- Выбор подходящей метрики оценки
- Советник для тестирования
- Методы избыточной выборки
- Методы неполной выборки
- Гибридные методы
- Заключение
Введение
Различные валютные рынки и финансовые инструменты демонстрируют разное поведение в разное время. Например, в то время как некоторые финансовые рынки, такие как акции и индексы, часто демонстрируют бычий тренд в долгосрочной перспективе, другие, такие как валютные рынки, часто проявляют медвежье поведение. Эта неопределенность усложняет попытки прогнозирования рынка с использованием методов искусственного интеллекта и моделей машинного обучения.

Давайте возьмем пару финансовых рынков (торговые символы) и визуализируем направления движения рынка на 1000 барах дневного таймфрейма. Если цена закрытия бара выше цены открытия, мы можем обозначить его как бычий бар (1), в противном случае — как медвежий (0).
import pandas as pd import numpy as np symbols = [ "EURUSD", "USTEC", "XAUUSD", "USDJPY", "BTCUSD", "CA60", "UK100" ] for symbol in symbols: df = pd.read_csv(fr"C:\Users\Omega Joctan\AppData\Roaming\MetaQuotes\Terminal\1640F6577B1C4EC659BF41EA9F6C38ED\MQL5\Files\{symbol}.PERIOD_D1.data.csv") df["Candle type"] = (df["Close"] > df["Open"]).astype(int) print(f"{symbol}(unique):",np.unique(df["Candle type"], return_counts=True))
Результат.
EURUSD(unique): (array([0, 1]), array([496, 504])) USTEC(unique): (array([0, 1]), array([472, 528])) XAUUSD(unique): (array([0, 1]), array([472, 528])) USDJPY(unique): (array([0, 1]), array([408, 592])) BTCUSD(unique): (array([0, 1]), array([478, 522])) CA60(unique): (array([0, 1]), array([470, 530])) UK100(unique): (array([0, 1]), array([463, 537]))
Как видно из приведенных выше результатов, ни один из торговых символов не находится в идеальном балансе, поскольку количество медвежьих и бычьих свечей, появившихся в прошлом, различается.
В том, что рынок может быть смещен в определенном направлении, нет ничего плохого, но это смещение в исторических данных может вызвать некоторые проблемы при обучении моделей машинного обучения:
Допустим, мы хотим обучить модель для USDJPY на основе текущего набора данных, содержащего 1000 баров. У нас есть 408 медвежьих свечей (отмечены как 0), что составляет 40,8% от всех торговых сигналов, в то время как у нас есть 592 бычьи свечи (отмечены как 1), что составляет 59,2% от всех торговых сигналов.
Наличие бычьих сигналов, подавляющих медвежьи, чаще всего игнорируется моделями машинного обучения, поскольку модели, как правило, отдают предпочтение наиболее доминирующему классу и, следовательно, делают прогнозы в пользу этого класса.
Поскольку все модели стремятся достичь минимально возможного значения потерь при максимально возможной точности, они будут отдавать предпочтение бычьему тренду, который наблюдался в 59,2% случаев из 100%, как простому способу достижения максимальной точности.
Если вы игнорируете все прогнозы и все, что происходит на рынке, и используете только эти данные при прогнозировании USDJPY, вы можете сказать, что все бары будут бычьими постоянно, и вы будете правы примерно в 59,2% случаев. Неплохо, правда? Нет, неправда!
Потому что, поступая таким образом, вы будете исходить из предположения, что то, что произошло в прошлом, обязательно повторится, а это совершенно неправильно в мире трейдинга.
Как видите, несбалансированная целевая переменная в данных для классификации в машинном обучении представляет собой проблему. Ниже перечислены некоторые недостатки, которые с этим связаны.
Недостатки несбалансированной целевой переменной в машинном обучении
- Низкие показатели для меньшего класса
Как я уже говорил ранее, модель смещает прогнозы в сторону преобладающего класса, поскольку оптимизирует их для достижения общей точности. Например, в данных по выявлению мошенничества (99% — нет мошенничества, 1% — мошенничество), так как большинство людей не являются мошенниками, модель может всегда показывать отсутствие мошенничества и при этом достигать 99% точности, но при этом не обнаруживать случаи мошенничества. - Вводящие в заблуждение показатели оценки
Значение точности становится ненадежным: у модели может быть общая точность 72%, и она может не знать, что один класс был предсказан с точностью 95%, а другой — с точностью 50%. - Модели переобучаются на представителях преобладающего класса
Модели могли запоминать шумы из преобладающего класса и принимать предвзятые решения вместо того, чтобы изучать общие закономерности, присутствующие в предикторах. Например, в медицинских диагностических данных, где 95% пациентов здоровы, а 5% больны, модель может полностью игнорировать случаи заболеваний. - Плохая обобщаемость по отношению неизвестным (реальным) данным
В реальных данных распределение часто и быстро меняется, и если модель обучалась в несбалансированной среде, она неизбежно потерпит неудачу.
Методы решения проблемы несбалансированных наборов данных
Теперь, когда мы знаем о недостатках, связанных с несбалансированной (смещенной) целевой переменной в задаче классификации, давайте обсудим различные способы решения этой проблемы.
01: Выбор подходящей метрики оценки
Первый способ обработки несбалансированных данных — выбор подходящей метрики оценки. Как уже говорилось, точность классификатора, которая представляет собой общее количество правильных прогнозов, деленное на общее количество прогнозов, может вводить в заблуждение при работе с несбалансированными данными.
В задачах с несбалансированными данными другие метрики, такие как точность (precision), измеряющая, насколько точно классификатор предсказывает конкретный класс, и полнота (recall), измеряющая способность классификатора идентифицировать класс, гораздо полезнее, чем метрика точности (accuracy).
При работе с несбалансированным набором данных большинство экспертов по машинному обучению используют F1-меру, поскольку она более подходит для данной задачи.
Это просто гармоническое среднее точности и полноты, представленное формулой.

Таким образом, если классификатор предсказывает принадлежность к меньшему классу, но предсказание ошибочно и количество ложноположительных результатов увеличивается, показатель точности будет низким, как и F1-мера.
Кроме того, если классификатор плохо идентифицирует меньший класс, то количество ложноотрицательных результатов увеличится, поэтому показатели полноты и F1-меры будут низкими.
F1-мера увеличивается только в том случае, если улучшается как количество, так и общее качество прогнозов.
Чтобы разобраться в этом подробнее, давайте обучим простой классификатор RandomForest на несбалансированном инструменте USDJPY.
import pandas as pd import numpy as np from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import classification_report # Global variables symbol = "USDJPY" timeframe = "PERIOD_D1" lookahead = 1 common_path = r"C:\Users\Omega Joctan\AppData\Roaming\MetaQuotes\Terminal\Common\Files" df = pd.read_csv(f"{common_path}\{symbol}.{timeframe}.data.csv") # Target variable df["future_close"] = df["Close"].shift(-lookahead) # future closing price based on lookahead value df.dropna(inplace=True) df["Signal"] = (df["future_close"] > df["Close"]).astype(int) print("Signals(unique): ",np.unique(df["Signal"], return_counts=True)) X = df.drop(columns=["Signal", "future_close"]) y = df["Signal"] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42, shuffle=False) model = RandomForestClassifier(n_estimators=100, max_depth=5, min_samples_split=3, random_state=42) model.fit(X_train, y_train)
После обучения мы можем сохранить модель в формате ONNX для последующего использования в MetaTrader 5.
from skl2onnx import convert_sklearn from skl2onnx.common.data_types import FloatTensorType import os def saveModel(model, n_features: int, technique_name: str): initial_type = [("input", FloatTensorType([None, n_features]))] onnx_model = convert_sklearn(model, initial_types=initial_type, target_opset=14) with open(os.path.join(common_path, f"{symbol}.{timeframe}.{technique_name}.onnx"), "wb") as f: f.write(onnx_model.SerializeToString())
saveModel(model=model, n_features=X_train.shape[1], technique_name="no-sampling")
Мне пришлось использовать метод составления классификационных отчетов для анализа различных показателей в составе Scikit-Learn.
Train Classification report precision recall f1-score support 0 0.98 0.41 0.57 158 1 0.68 1.00 0.81 204 accuracy 0.74 362 macro avg 0.83 0.70 0.69 362 weighted avg 0.81 0.74 0.71 362
Анализ отчета о классификации обучения
Общая точность обучения модели составляет 0,74, что на первый взгляд может показаться неплохим результатом. Однако более детальный анализ метрик по классам выявляет значительный дисбаланс в работе модели между двумя классами: класс 0 имеет очень высокую точность 0,98, но низкую полноту 0,41, что приводит к скромному показателю F1-меры 0,57.
Это означает, что, хотя модель очень уверенно предсказывает класс 0, она пропускает большое количество фактических образцов класса 0, что указывает на низкую чувствительность.
В свою очередь, для класса 1 показатель полноты равен 1,00, а F1-мера — 0,81, но точность относительно ниже — 0,68.
Это говорит о том, что модель чрезмерно смещена в сторону прогнозирования класса 1, что может привести к большому количеству ложных срабатываний.
Идеальный показатель полноты (1,00) для класса 1 является тревожным сигналом, поскольку, вероятно, указывает на переобучение или предвзятость в сторону преобладающего класса.
Модель предсказывает класс 1 почти для всего и пропускает множество фактических образцов класса 0, что подтверждается низким значением показателя полноты для класса 0, равным 0,41.
В целом, эти показатели не только демонстрируют дисбаланс, но и вызывают опасения по поводу способности модели к обобщению и ее справедливости по отношению к классам. Здесь явно что-то не так.
Давайте воспользуемся методами избыточной выборки, чтобы улучшить нашу модель и найти оптимальный баланс в прогнозировании.
Советник для тестирования
Всегда существует разница между результатами анализа модели машинного обучения, такими как отчет о классификации выше, и фактическими результатами торговли в MetaTrader 5. Поскольку мы будем сохранять модель в формате ONNX для последующего использования, мы можем создать простого торгового робота, который будет использовать модель, обученную на каждом из методов избыточной выборки (oversampling), обсуждаемых в этой статье, для принятия торговых решений на тестовой стратегии на обучающей выборке.
Использованные данные были собраны в файле Collectdata.mq5. Это скрипт, который собирает обучающие данные с 01.01.2025 по 01.01.2023. Его можно найти в приложениях к статье.
В советнике Test Resampling Techniques.mq5 мы инициализируем модель в формате ONNX, а затем используем ее для прогнозирования.
#include <Random Forest.mqh> CRandomForestClassifier random_forest; //A class for loading the RFC in ONNX format #include <Trade\Trade.mqh> #include <Trade\PositionInfo.mqh> CTrade m_trade; CPositionInfo m_position; input string symbol_ = "USDJPY"; input int magic_number= 14042025; input int slippage = 100; input ENUM_TIMEFRAMES timeframe_ = PERIOD_D1; input string technique_name = "randomoversampling"; int lookahead = 1; //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- if (!random_forest.Init(StringFormat("%s.%s.%s.onnx", symbol_, EnumToString(timeframe_), technique_name), ONNX_COMMON_FOLDER)) //Initializing the RFC in ONNX format from a commmon folder return INIT_FAILED; //--- Setting up the CTrade module m_trade.SetExpertMagicNumber(magic_number); m_trade.SetDeviationInPoints(slippage); m_trade.SetMarginMode(); m_trade.SetTypeFillingBySymbol(symbol_); //--- return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- } //+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- vector x = { iOpen(symbol_, timeframe_, 1), iHigh(symbol_, timeframe_, 1), iLow(symbol_, timeframe_, 1), iClose(symbol_, timeframe_, 1) }; long signal = random_forest.predict_bin(x); //Predicted class double proba = random_forest.predict_proba(x).Max(); //Maximum predicted probability MqlTick ticks; if (!SymbolInfoTick(symbol_, ticks)) { printf("Failed to obtain ticks information, Error = %d",GetLastError()); return; } double volume_ = SymbolInfoDouble(symbol_, SYMBOL_VOLUME_MIN); if (signal == 1) { if (!PosExists(POSITION_TYPE_BUY) && !PosExists(POSITION_TYPE_SELL)) m_trade.Buy(volume_, symbol_, ticks.ask,0,0); } if (signal == 0) { if (!PosExists(POSITION_TYPE_SELL) && !PosExists(POSITION_TYPE_BUY)) m_trade.Sell(volume_, symbol_, ticks.bid,0,0); } //--- CloseTradeAfterTime((Timeframe2Minutes(timeframe_)*lookahead)*60); //Close the trade after a certain lookahead and according the the trained timeframe } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ bool PosExists(ENUM_POSITION_TYPE type) { for (int i=PositionsTotal()-1; i>=0; i--) if (m_position.SelectByIndex(i)) if (m_position.Symbol()==symbol_ && m_position.Magic() == magic_number && m_position.PositionType()==type) return (true); return (false); } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ bool ClosePos(ENUM_POSITION_TYPE type) { for (int i=PositionsTotal()-1; i>=0; i--) if (m_position.SelectByIndex(i)) if (m_position.Symbol() == symbol_ && m_position.Magic() == magic_number && m_position.PositionType()==type) { if (m_trade.PositionClose(m_position.Ticket())) return true; } return (false); } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ void CloseTradeAfterTime(int period_seconds) { for (int i = PositionsTotal() - 1; i >= 0; i--) if (m_position.SelectByIndex(i)) if (m_position.Magic() == magic_number) if (TimeCurrent() - m_position.Time() >= period_seconds) m_trade.PositionClose(m_position.Ticket(), slippage); } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ int Timeframe2Minutes(ENUM_TIMEFRAMES tf) { switch(tf) { case PERIOD_M1: return 1; case PERIOD_M2: return 2; case PERIOD_M3: return 3; case PERIOD_M4: return 4; case PERIOD_M5: return 5; case PERIOD_M6: return 6; case PERIOD_M10: return 10; case PERIOD_M12: return 12; case PERIOD_M15: return 15; case PERIOD_M20: return 20; case PERIOD_M30: return 30; case PERIOD_H1: return 60; case PERIOD_H2: return 120; case PERIOD_H3: return 180; case PERIOD_H4: return 240; case PERIOD_H6: return 360; case PERIOD_H8: return 480; case PERIOD_H12: return 720; case PERIOD_D1: return 1440; // 1 day = 1440 minutes case PERIOD_W1: return 10080; // 1 week = 7 * 1440 minutes case PERIOD_MN1: return 43200; // Approx. 1 month = 30 * 1440 minutes default: PrintFormat("Unknown timeframe: %d", tf); return 0; } }
Поскольку мы обучили модель на целевой переменной, основанной на значении прогнозируемого значения (lookahead value), равном 1, нам необходимо закрыть сделку после того, как пройдет указанное количество баров на текущем таймфрейме. Таким образом, мы фактически гарантируем соблюдение прогнозируемого значения, поскольку удерживаем и закрываем сделки в соответствии с горизонтом прогнозирования модели.
Прежде чем рассматривать результаты торговли на моделях, обученных на данных, полученных методом избыточной выборки, посмотрим на результаты торговли на модели, обученной на обычных обучающих данных (исходных данных).
Настройки тестера.
Входные параметры: technique_name = no-sampling.
Результаты тестирования.
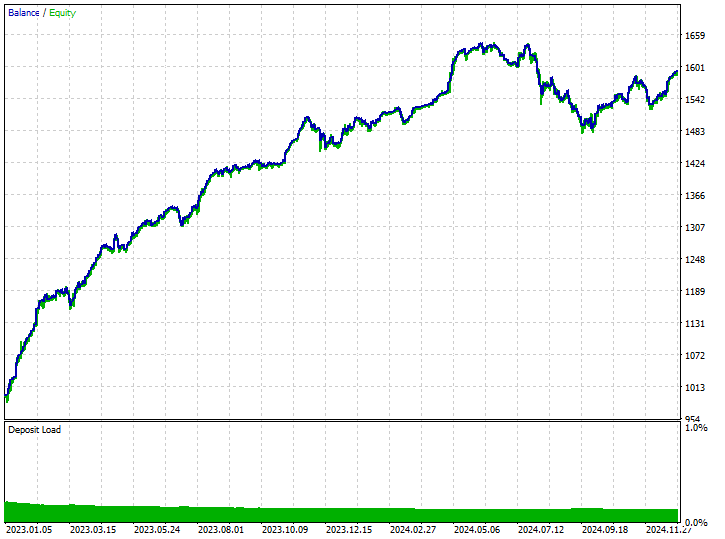
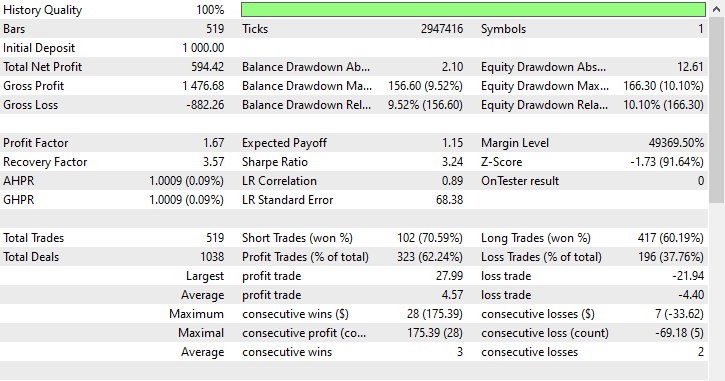
Модель смогла уловить несколько хороших сигналов и показала впечатляющие результаты в торговле, при этом прибыльные сделки составили 62,24% от всех совершенных сделок. Однако если посмотреть на количество прибыльных коротких и длинных позиций, то можно увидеть, что соотношение коротких и длинных позиций составляет 1:4.
Из 519 совершенных сделок 102 были короткими, что привело к 70,59% прибыльных сделок, в то время как из 519 совершенных сделок 417 были длинными, что привело к 60,19% точности выигрышных сделок. Здесь явно что-то не так, потому что если мы проанализируем направление свечей с 1 января 2023 года по 1 января 2025 года, исходя из значения прогнозируемого значения, равного 1:
print("classes in y: ",np.unique(y, return_counts=True))
Результат.
classes in y: (array([0, 1]), array([225, 293]))
Мы видим, что 225 свечей были медвежьими, а 293 — бычьими. Поскольку большинство свечей двигались в бычьем направлении по USDJPY за этот двухлетний период (с 1 января 2023 года по 1 января 2025 года), любая, даже неудачная, модель, благоприятствующая бычьему движению, могла бы принести прибыль.
Теперь мы видим, что единственная причина, по которой модель принесла прибыль, заключалась в том, что она отдавала предпочтение длинным позициям в 4 раза чаще, чем коротким.
Поскольку в тот период рынок в основном демонстрировал бычий тренд, модель смогла получить некоторую прибыль.
Давайте перейдем к методам перевыборки (resampling) и посмотрим, как мы можем устранить это предвзятое принятие решений в наших моделях.
Методы избыточной выборки
Случайная избыточная выборка
Это метод, используемый для устранения дисбаланса классов в наборах данных путем создания синтетических выборок меньшего класса.
Он предполагает случайный выбор существующих примеров меньших классов и их дублирование для увеличения их представленности в обучающих данных; цель метода — сбалансировать распределение классов в несбалансированных наборах данных.
Наиболее часто используемый инструмент для этой задачи - imbalanced-learn. Ниже приведен простой способ его использования.
from imblearn.over_sampling import RandomOverSampler print("b4 Target: ",np.unique(y_train, return_counts=True)) rus = RandomOverSampler(random_state=42) X_resampled, y_resampled = rus.fit_resample(X_train, y_train) print("After Target: ",np.unique(y_resampled, return_counts=True))
Результаты.
b4 Target: (array([0, 1]), array([304, 395])) After Target: (array([0, 1]), array([395, 395]))
Мы можем подогнать данные, полученные методом перевыборки, к тому же самому RandomForestClassifier, который мы использовали ранее, и наблюдать разницу в результатах по сравнению с результатами, полученными без перевыборки данных.
model.fit(X_resampled, y_resampled)
Оценка модели.
y_train_pred = model.predict(X_train) print("Train Classification report\n",classification_report(y_train, y_train_pred))
Результат.
Train Classification report precision recall f1-score support 0 0.82 0.85 0.83 158 1 0.88 0.86 0.87 204 accuracy 0.85 362 macro avg 0.85 0.85 0.85 362 weighted avg 0.85 0.85 0.85 362
Результаты указывают на значительное улучшение по всем показателям. Значения F1-меры, равные 0,87 для обоих классов, свидетельствуют о том, что модель делает непредвзятые и согласованные прогнозы, что указывает на хорошую обобщающую способность модели и равномерное распределение обучения по целевым классам.
Несмотря на свою простоту и эффективность, избыточная выборка может увеличить риск переобучения за счет создания дубликатов меньшего класса, которые не добавляют новой информации к модели.
Используя те же настройки тестера, мы можем протестировать модель, обученную на этих данных, на тестере Strategy.
Входные параметры: technique_name = randomoversampling.
Результаты тестирования.
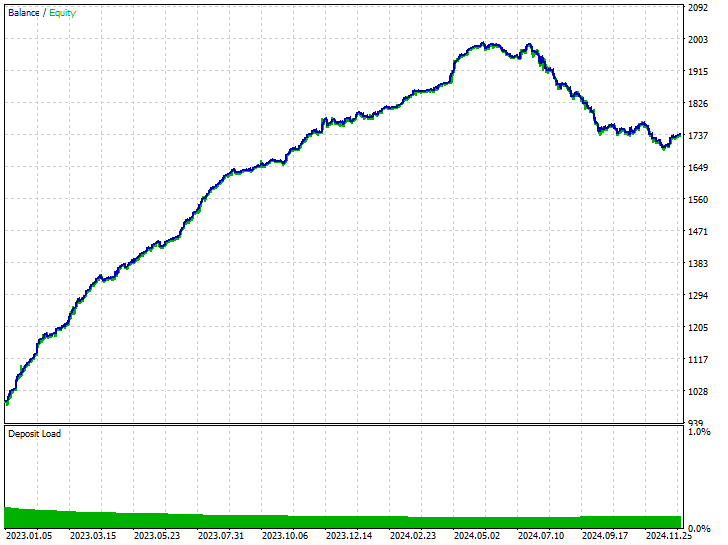
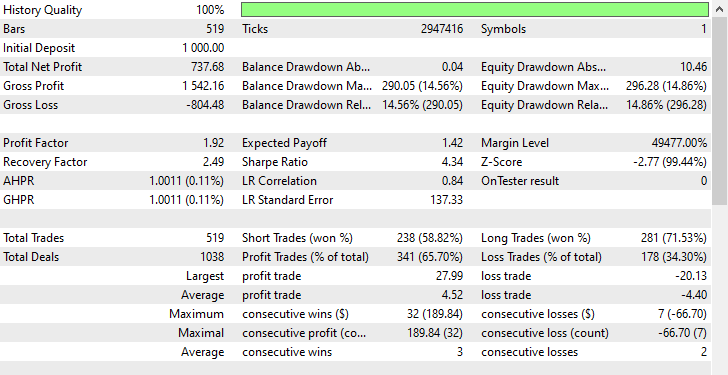
Как видите, мы наблюдаем улучшения во всех аспектах торговли, эта модель более надежна, чем та, которая была обучена на необработанных данных. Теперь робот открывает больше коротких позиций, что привело к значительному сокращению количества длинных позиций.
В ходе этого тренировочного периода рынок продемонстрировал 225 медвежьих и 293 бычьих движения соответственно, в зависимости от того, как мы сформулировали целевую переменную. Новая модель, обученная на данных с избыточной выборкой, открыла 238 коротких и 281 длинную позицию соответственно. Это хороший знак - скорее всего, модель не является предвзятой, поскольку принимает решения, основываясь на изученных закономерностях, а не на чем-либо другом.
Методы неполной выборки
Существует несколько методов неполной выборки, которые мы можем использовать, доступных в различных модулях Python. В частности:
Случайная неполная выборка
Это метод, используемый для устранения дисбаланса классов в наборах данных путем уменьшения количества выборок из преобладающего класса, чтобы сбалансировать его с меньшим классом.
Этот метод предполагает случайное или стратегическое удаление образцов из преобладающего класса.
Аналогично тому, как мы применяли избыточную выборку, мы можем уменьшить выборку преобладающего класса следующим образом.
from imblearn.under_sampling import RandomUnderSampler print("b4 Target: ",np.unique(y_train, return_counts=True)) rus = RandomUnderSampler(random_state=42) X_resampled, y_resampled = rus.fit_resample(X_train, y_train) print("After Target: ",np.unique(y_resampled, return_counts=True))
Результат.
b4 Target: (array([0, 1]), array([304, 395])) After Target: (array([0, 1]), array([304, 304]))
Случайная неполная выборка и другие методы неполной выборки могут ухудшить производительность модели, удаляя информативные образцы большинства классов, что приводит к менее репрезентативному обучающему набору данных. Это потенциально может привести к недостаточной точности подгонки модели.
Этот метод позволяет улучшить производительность модели на обучающих данных для обоих классов.
Train Classification report precision recall f1-score support 0 0.76 0.90 0.82 158 1 0.91 0.78 0.84 204 accuracy 0.83 362 macro avg 0.83 0.84 0.83 362 weighted avg 0.84 0.83 0.83 362
Используя те же настройки тестера, мы можем протестировать модель, обученную на этих данных, на тестере Strategy.
Входные параметры: technique_name = randomundersampling.
Результаты тестирования.
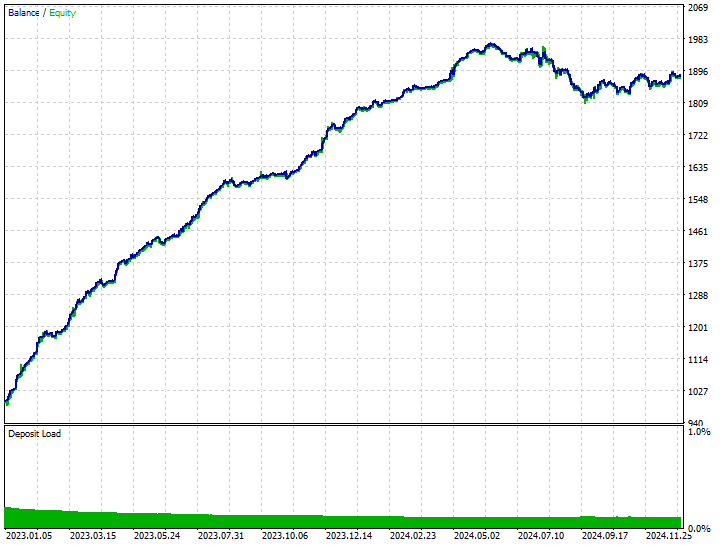
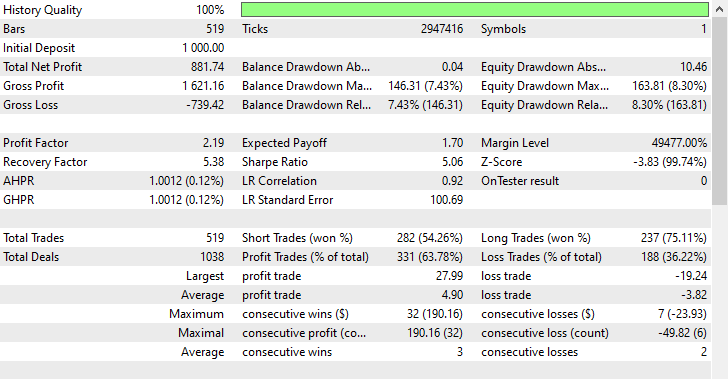
Эта методика позволила совершить 282 и 237 коротких и длинных сделок соответственно. Несмотря на то, что данная модель отдавала предпочтение коротким сделкам перед длинными (чего не наблюдалось на рынке), она все же смогла принести больше прибыли, чем несбалансированная модель, обученная на необработанных данных, и модель с избыточной выборкой, которая отдавала предпочтение бычьим движениям.
Результаты, полученные с помощью модели, показывают, что мы можем получать прибыль на рынке в обоих направлениях, независимо от того, что происходило в прошлом.
Связи Томека
Связи Томека (Tomek Links) обозначают пару экземпляров из разных классов, расположенных очень близко друг к другу и часто считающихся ближайшими соседями. Вот простое объяснение того, как работает метод связей Томека для уменьшения выборки данных в машинном обучении.
Представьте, что у нас есть две точки A и B, принадлежащие к разным классам: A принадлежит к преобладающему классу, а B — к классу меньшинства (или наоборот).
Если эти две точки (A и B) находятся близко друг к другу (являются соседями), то наблюдение из преобладающего класса (в данном случае A) будет удалено.
Этот метод помогает очистить границы принятия решений и сделать классы более четкими, одновременно удаляя некоторые образцы из преобладающего класса.
from imblearn.under_sampling import TomekLinks tl = TomekLinks() X_resampled, y_resampled = tl.fit_resample(X_train, y_train) print(f"Before --> y (unique): {np.unique(y_train, return_counts=True)}\nAfter --> y (unique): {np.unique(y_resampled, return_counts=True)}")
Результаты.
Before --> y (unique): (array([0, 1]), array([304, 395])) After --> y (unique): (array([0, 1]), array([304, 283]))
Этот метод может привести к впечатляюще сбалансированным результатам прогнозирования модели, но он ограничен бинарной классификацией, менее эффективен при работе с сильно перекрывающимися данными и, как и другие методы выборки, может привести к потере данных.
Этот метод также показал лучшие результаты на обучающих данных.
Train Classification report precision recall f1-score support 0 0.69 0.94 0.80 158 1 0.93 0.68 0.78 204 accuracy 0.79 362 macro avg 0.81 0.81 0.79 362 weighted avg 0.83 0.79 0.79 362
Используя ту же конфигурацию тестера, мы можем протестировать модель, обученную на этих данных, в тестере стратегий.
Входные параметры: technique_name = tomek-links.
Результаты тестирования.

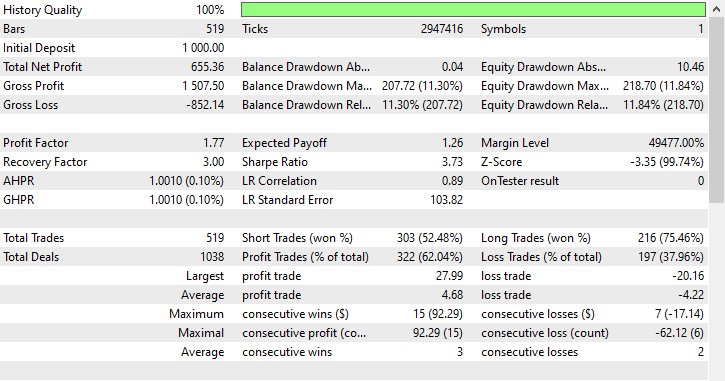
Аналогично методу случайной неполной выборки, метод связей Томека отдавал предпочтение коротким позициям, открыв 303 короткие позиции и 216 длинных, и все же смог получить прибыль.
Центроиды кластеров
Это метод уменьшения выборки, при котором преобладающий класс сокращается за счет замены его выборок центроидами кластеров (обычно полученных методом кластеризации K-средних).
Он работает следующим образом.
- Для кластеризации преобладающего класса применяется алгоритм k-средних.
- Выбирается K-число необходимых образцов.
- Большинство образцов в классе заменены центрами кластеров k.
- Полученные данные объединяются с меньшим классом для создания сбалансированного набора данных.
from imblearn.under_sampling import ClusterCentroids cc = ClusterCentroids(random_state=42) X_resampled, y_resampled = cc.fit_resample(X, y) print(f"Before --> y (unique): {np.unique(y_train, return_counts=True)}\nAfter --> y (unique): {np.unique(y_resampled, return_counts=True)}")
Результаты.
Before --> y (unique): (array([0, 1]), array([158, 204])) After --> y (unique): (array([0, 1]), array([225, 225]))
Ниже представлены результаты работы модели на обучающих данных, полученных с использованием кластерных центроидов для уменьшения выборки.
Train Classification report precision recall f1-score support 0 0.64 0.86 0.73 158 1 0.85 0.62 0.72 204 accuracy 0.73 362 macro avg 0.75 0.74 0.73 362 weighted avg 0.76 0.73 0.73 362
На данный момент этот метод демонстрирует наименьшую точность: значение 0,73 может указывать на меньшую степень переобучения модели по сравнению с предыдущими, поэтому, возможно, это лучшая из возможных моделей на данный момент. Давайте оценим ее точность в реальной торговле.
Входные параметры: technique_name = cluster-centroids.
Результаты тестирования.
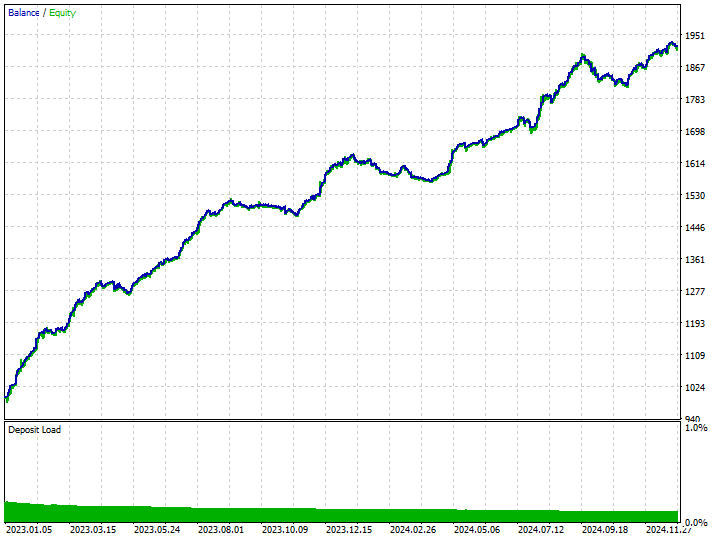
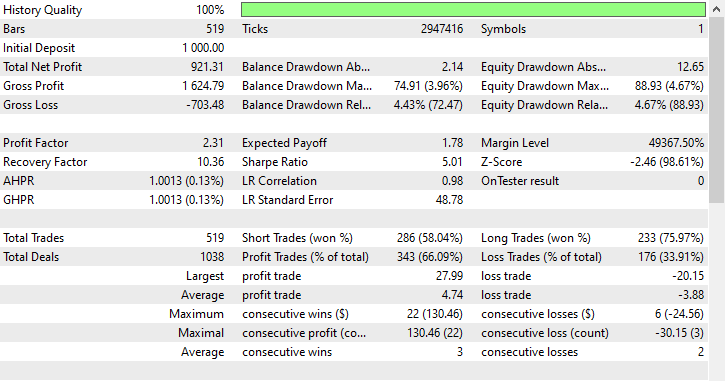
Этот метод обеспечил наибольшее количество прибыльных сделок — 343 сделки из 519, с точностью 66,09%, поскольку прибыль почти достигла первоначального депозита. Несмотря на то, что модель отдавала предпочтение коротким позициям, она очень точно предсказывала бычьи сигналы, что привело к впечатляющим 75,97% из 100% выигрышных длинных позиций.
Гибридные методы
SMOTE + связи Томека
Сначала применяется SMOTE, затем с помощью связей Томека удаляется шум.
from imblearn.combine import SMOTETomek smt = SMOTETomek(random_state=42) X_resampled, y_resampled = smt.fit_resample(X_train, y_train) print(f"Before --> y (unique): {np.unique(y_train, return_counts=True)}\nAfter --> y (unique): {np.unique(y_resampled, return_counts=True)}")
Результаты.
Before --> y (unique): (array([0, 1]), array([158, 204])) After --> y (unique): (array([0, 1]), array([159, 159]))
Ниже представлен результат работы модели, обученной на обучающих данных, перевыбранных с помощью данной методики.
Train Classification report precision recall f1-score support 0 0.74 0.73 0.73 158 1 0.79 0.80 0.80 204 accuracy 0.77 362 macro avg 0.77 0.77 0.77 362 weighted avg 0.77 0.77 0.77 362
Ниже представлены торговые результаты.
Входные параметры: technique_name = smote-tomeklinks.
Результаты тестирования.
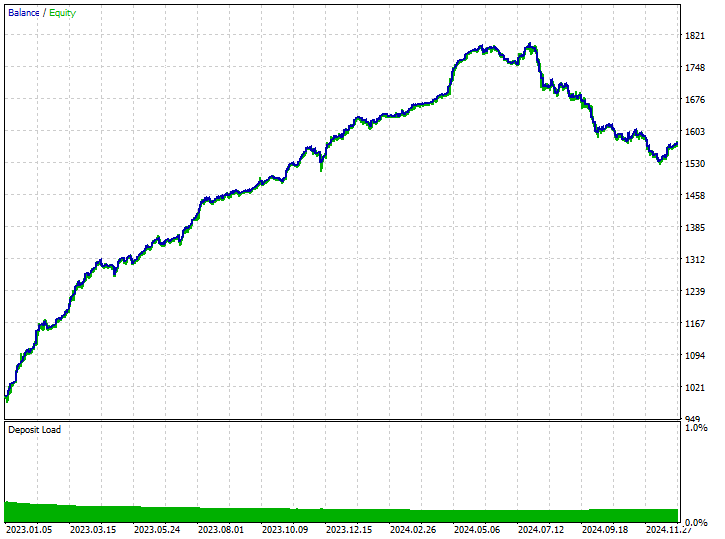
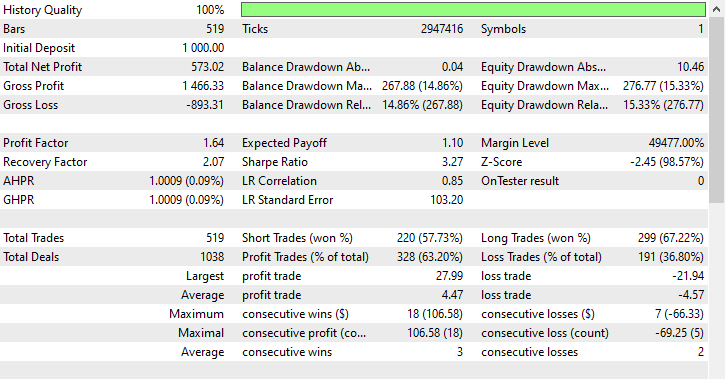
220 коротких и 299 длинных сделок соответственно. Неплохо.
SMOTE + ENN (отредактированные ближайшие соседи)
SMOTE генерирует синтетические образцы, а затем ENN удаляет неправильно классифицированные образцы.
from imblearn.combine import SMOTEENN sme = SMOTEENN(random_state=42) X_resampled, y_resampled = sme.fit_resample(X_train, y_train) print(f"Before --> y (unique): {np.unique(y_train, return_counts=True)}\nAfter --> y (unique): {np.unique(y_resampled, return_counts=True)}")
Этот метод позволил удалить огромный объем данных, в результате чего обучающая выборка сократилась до 61 образца.
Before --> y (unique): (array([0, 1]), array([158, 204])) After --> y (unique): (array([0, 1]), array([37, 24]))
Ниже представлен отчет о классификации обучающей выборки.
Train Classification report precision recall f1-score support 0 0.46 0.76 0.58 158 1 0.63 0.32 0.42 204 accuracy 0.51 362 macro avg 0.55 0.54 0.50 362 weighted avg 0.56 0.51 0.49 362
Как и ожидалась, полученная модель оказалась плохой, поскольку она была обучена на 61 образце, что недостаточно для того, чтобы любая модель смогла выявить значимые закономерности. Давайте проанализируем торговые результаты.
Входные параметры: technique_name = smote-enn.
Результаты тестирования.
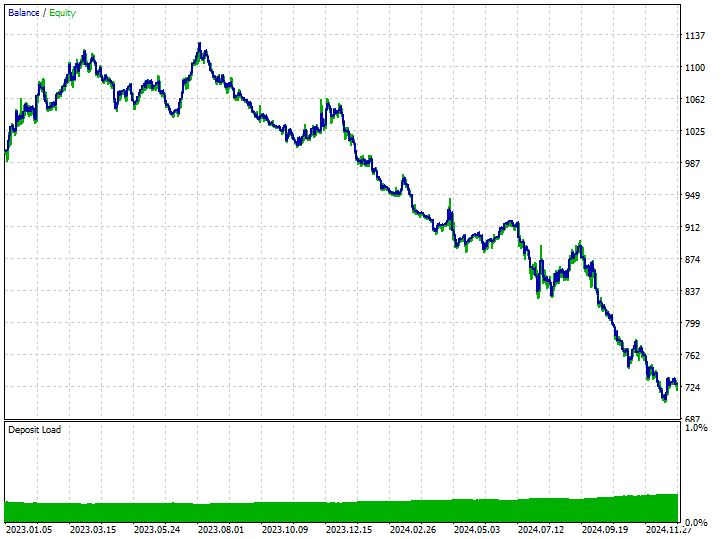
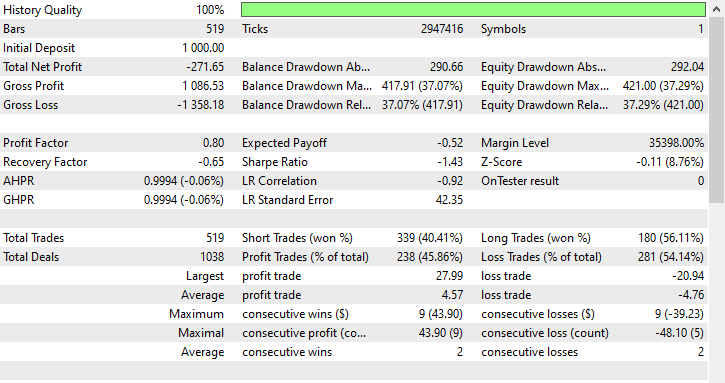
Этот метод нисколько не помог, а только усугубил ситуацию. Он исказил результаты торговли, поскольку робот открыл 180 из 519 сделок на покупку и 339 сделок на продажу.
Это не значит, что метод плохой, просто в данной ситуации он не оптимален.
Заключение
Мы живем в несовершенном мире. Не все происходящие явления имеют подходящие объяснения или четкую причину. Это справедливо и для мира трейдинга, где рынки быстро и часто меняются, в результате чего большинство наших стратегий мгновенно устаревают.
Хотя мы не можем контролировать происходящее на рынке, лучшее, что мы можем сделать, — это обеспечить наличие хотя бы надежных торговых систем и стратегий, разработанных для работы в экстремальных условиях.
Поскольку история не всегда повторяется, важно иметь сбалансированные торговые системы, способные работать на любом рынке, а также учитывающие закономерности, которые наблюдались на рынке ранее, но не слишком полагающиеся на них при принятии торговых решений. Несмотря на всю полезность этих методов, необходимо помнить об их недостатках и компромиссах, связанных с использованием методов перевыборки для данных машинного обучения. К таким недостаткам относятся риск переобучения из-за избыточной выборки, потенциальная потеря ценной информации при неполной выборке, а также внесение шума или смещения, если перевыборка проводится недостаточно тщательно.
Ключевым моментом для создания надежных моделей, хорошо адаптирующихся к невиданным ранее рыночным условиям, является поиск баланса.
Таблица вложений
| Имя файла | Описание/использование |
|---|---|
| Experts\Test Resampling Techniques.mq5 | Советник для развертывания .ONNX-файлов в MQL5 |
| Include\pandas.mqh | Библиотека Pandas для обработки и хранения данных |
| Scripts\Collectdata.mq5 | Скрипт для сбора обучающих данных |
| Common\*.onnx | Модели машинного обучения в формате ONNX |
| Common\*.csv | Использование обучающих данных различных инструментов в машинном обучении |
Перевод с английского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/en/articles/17736
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Необходимые компоненты - это последние версии всего, что импортировано в блокнот, вы можете выполнить pip install, не беспокоясь о конфликте версий. Также вы можете перейти по ссылке в таблице вложений, она приведет вас на сайт Kaggle.com, где вы сможете редактировать и изменять код.
Необъявленный идентификатор может означать, что переменная или объект не определены. Проверьте свой код или пришлите мне скриншот кода по DM.