
Машинное обучение и Data Science (Часть 38): Применение трансферного обучения (Transfer Learning) на валютных рынках

Содержание
- Что такое Transfer Learning?
- Как это работает?
- Преимущества
- Простая базовая модель
- Проблема непрерывных переменных
- Transfer Learning - трансферное обучение
- Transfer Learning в торговом роботе
- Заключительные итоги
Что такое Transfer Learning?
Transfer Learning (трансферное обучение) — это метод машинного обучения, при котором модель, обученная на одной задаче, используется в качестве основы для решения другой.
При этом вместо того, чтобы обучать модель машинного обучения с нуля, мы переносим знания, полученные предварительно обученной моделью, и дообучаем ее для новой конкретной задачи. Этот подход особенно полезен, когда:
- У нас недостаточно размеченных данных для конкретной задачи.
- Обучение модели с нуля заняло бы слишком много времени или потребовало бы чрезмерных вычислительных ресурсов.
- Текущая задача имеет сходство с той, на которой была обучена исходная модель.
Вот пример из реальной практики, где используется трансферное обучение:
Допустим, вы создаете классификатор изображений "кошка" или "собака", но у вас есть всего 1000 изображений. Обучить глубокую CNN с нуля было бы сложно. Вместо этого можно взять модель, например ResNet50 или VGG16, уже обученную на ImageNet (с миллионами изображений по 1000 классам), использовать ее сверточные слои как экстракторы признаков, добавить собственные классификационные слои и дообучить модель на меньшем наборе данных с кошками и собаками.
Этот процесс позволяет совместно использовать знания модели, что значительно упрощает работу разработчиков. Не нужно каждый раз изобретать велосипед: вместо обучения модели с нуля можно масштабироваться, используя уже существующие модели, предназначенные для схожих задач.
Считается, что большинство людей, умеющих кататься на коньках или регулярно занимающихся катанием, также неплохо справляются с лыжным спортом и наоборот, даже без интенсивной подготовки в каждом из них. Потому что эти два вида спорта имеют сходные элементы.
То же самое справедливо и для финансовых рынков. Несмотря на наличие различных инструментов (символов), представляющих разные экономические активы или финансовые рынки, большинство рынков ведут себя схожим образом, поскольку все они движимы спросом и предложением.

Если рассмотреть рынок с технической точки зрения, можно заметить, что все рынки движутся вверх и вниз, демонстрируют схожие свечные паттерны, индикаторы показывают похожие сигналы на разных инструментах и т.д. Именно поэтому мы часто изучаем торговую стратегию технического анализа на одном инструменте и затем применяем полученные знания на других рынках, независимо от различий в ценовых масштабах.
Однако модели машинного обучения зачастую не понимают, что эти рынки сопоставимы. В этой статье мы обсудим, как можно использовать Transfer Learning, чтобы помочь моделям распознавать паттерны на различных финансовых инструментах для эффективного обучения, рассмотрим преимущества и недостатки этого метода, а также важные аспекты, которые необходимо учитывать при его применении.
Как работает Transfer Learning?
Transfer learning — это эффективный способ повторного использования знаний, полученных моделью при решении одной задачи, и их применения к другой, но связанной задаче. Это экономит время и зачастую повышает качество модели.
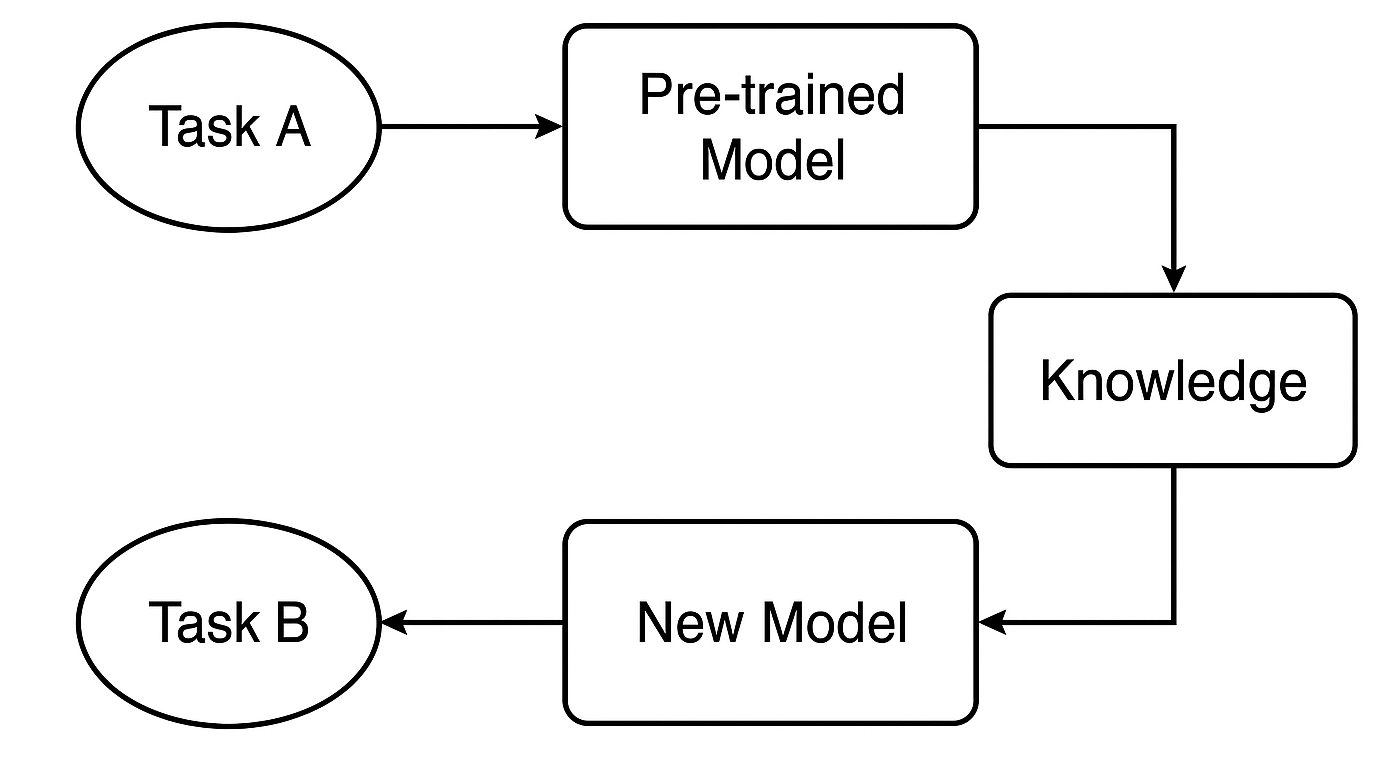
Что такое предварительно обученная модель?
Мы начинаем с модели, уже обученной на большом датасете для задачи A. Эта модель научилась распознавать общие закономерности и признаки, полезные для схожих задач.
В трейдинге, например, это может быть модель, обученная на одной стратегии или символе, которая уже понимает типичное поведение рынка, встречающееся и на других валютных инструментах.
Как переносится знание?
Если используется нейронная сеть, например CNN или RNN, можно взять ранние слои, которые улавливают общие признаки, и повторно использовать их. Эти слои служат фундаментом, выявляя широкие паттерны, полезные как для исходной, так и для новой задачи.
Дообучение для новой задачи
Затем мы адаптируем модель под задачу B (например, под другой инструмент или стратегию) и настраиваем определенные слои или параметры, чтобы она корректно работала с новыми данными. Этот этап кастомизирует модель под новую ситуацию.
Почему стоит использовать Transfer Learning?
1. Более быстрое обучение
Вместо того, чтобы начать с нуля, мы повторно используем уже извлеченные признаки. Это существенно сокращает время обучения, особенно при глубоком обучении, где таким образом можно сэкономить часы или даже дни.
2. Часто повышает точность
Модели с переносом обучения часто показывают лучшие результаты, особенно при ограниченном количестве размеченных данных. Предобученная модель уже умеет обнаруживать важные сигналы, такие как торговые сетапы или индикаторы, что помогает принимать более обоснованные решения в новой задаче.
3. Работает даже с небольшими или шумными датасетами
Получить качественные исторические или тиковые данные в MetaTrader 5 для некоторых символов бывает сложно. Некоторые инструменты просто не имеют достаточного объема данных. Используя модель, обученную на более богатом датасете, можно избежать переобучения и создать устойчивую модель даже при ограниченных данных.
4. Повторное использование знаний между инструментами
Рынки часто ведут себя схожим образом на техническом уровне. Вместо обучения новой модели для каждого символа можно использовать одни и те же знания для разных инструментов. Это экономит время и повышает согласованность результатов.
Простая базовая модель
Давайте обучим простой классификатор Random Forest в качестве отправной точки (базовой модели). Для простоты можно использовать значения OHLC (Open, High, Low, Close).
Сначала соберем OHLC-данные по основным и второстепенным валютным парам, добавим металлы.
#include <pandas.mqh> //https://www.mql5.com/en/articles/17030 input datetime start_date = D'2005.01.01'; input datetime end_date = D'2023.01.01'; input string symbols = "EURUSD|GBPUSD|AUDUSD|USDCAD|USDJPY|USDCHF|NZDUSD|EURNZD|AUDNZD|GBPNZD|NZDCHF|NZDJPY|NZDCAD|XAUUSD|XAUJPY|XAUEUR|XAUGBP"; input ENUM_TIMEFRAMES timeframe = PERIOD_D1; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { string SymbolsArr[]; ushort sep = StringGetCharacter("|",0); if (StringSplit(symbols, sep, SymbolsArr)<0) { printf("%s failed to split the symbols, Error %d",__FUNCTION__,GetLastError()); return; } //--- vector open, high, low, close; for (uint i=0; i<SymbolsArr.Size(); i++) { string symbol = SymbolsArr[i]; if (!SymbolSelect(symbol, true)) { printf("%s failed to select symbol %s, Error = %d",__FUNCTION__,symbol,GetLastError()); continue; } //--- open.CopyRates(symbol, timeframe, COPY_RATES_OPEN, start_date, end_date); high.CopyRates(symbol, timeframe, COPY_RATES_HIGH, start_date, end_date); low.CopyRates(symbol, timeframe, COPY_RATES_LOW, start_date, end_date); close.CopyRates(symbol, timeframe, COPY_RATES_CLOSE, start_date, end_date); CDataFrame df; df.insert("Open", open); df.insert("High", high); df.insert("Low", low); df.insert("Close", close); df.to_csv(StringFormat("Fxdata.%s.%s.csv",symbol,EnumToString(timeframe)), true); } }
После сбора данных можно сразу загрузить CSV-файлы в Python-скрипт.
def getXandY(symbol: str, timeframe: str, lookahead: int) -> tuple: df = pd.read_csv(f"/kaggle/input/ohlc-eurusd/Fxdata.{symbol}.{timeframe}.csv") # Target variable df["future_close"] = df["Close"].shift(-lookahead) df.dropna(inplace=True) df["Signal"] = (df["future_close"] > df["Close"]).astype(int) # Splitting data into X and y X = df.drop(columns=[ "future_close", "Signal" ]) y = df["Signal"] return (X, y)
После чтения CSV-файла функция getXandY формирует целевую переменную по простой логике: если закрытие следующей свечи выше текущего закрытия — это бычий сигнал, а если ниже — медвежий.
Создадим функцию для обучения модели на основе X и y и возврата обученной модели в виде пайплайна Scikit-learn.
def trainSymbol(X_train: pd.DataFrame, y_train: pd.DataFrame) -> Pipeline: # Training a model classifier = RandomForestClassifier(n_estimators=100, min_samples_split=3, max_depth = 5) pipeline = Pipeline([ ("scaler", RobustScaler()), ("classifier", classifier) ]) pipeline.fit(X_train, y_train) return pipeline
Также полезно реализовать функцию для оценки модели на разных инструментах.
def evalSymbol(model: Pipeline, X: pd.DataFrame , y: pd.Series) -> int: # evaluating the model preds = model.predict(X) acc = accuracy_score(y, preds) return acc
Обучим базовую модель на EURUSD и затем оценим ее результаты на остальных символах.
symbols = ["EURUSD","GBPUSD","AUDUSD","USDCAD","USDJPY","USDCHF","NZDUSD","EURNZD","AUDNZD","GBPNZD","NZDCHF","NZDJPY","NZDCAD","XAUUSD","XAUJPY","XAUEUR","XAUGBP"] # training on EURUSD lookahead = 1 X, y = getXandY(symbol=symbols[0], timeframe="PERIOD_H4", lookahead=lookahead) X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42, shuffle=True) model = trainSymbol(X_train, y_train) # Evaluating on the rest of symbols trained_symbol = symbols[0] print(f"Trained on {trained_symbol}") for symbol in symbols: X, y = getXandY(symbol=symbol, timeframe="PERIOD_H4", lookahead=1) acc = evalSymbol(model, X, y) print(f"--> {symbol} | acc: {acc}")
Результаты.
Trained on EURUSD --> EURUSD | acc: 0.5478518727715607 --> GBPUSD | acc: 0.5009182736455464 --> AUDUSD | acc: 0.5026133634694165 --> USDCAD | acc: 0.4973701860284514 --> USDJPY | acc: 0.49477401129943505 --> USDCHF | acc: 0.5078731817539895 --> NZDUSD | acc: 0.4976826463824518 --> EURNZD | acc: 0.5071507150715071 --> AUDNZD | acc: 0.5005597760895641 --> GBPNZD | acc: 0.503459397596629 --> NZDCHF | acc: 0.4990389436737423 --> NZDJPY | acc: 0.4908841561794127 --> NZDCAD | acc: 0.5023507681974645 --> XAUUSD | acc: 0.48674396277970605 --> XAUJPY | acc: 0.4816082121471343 --> XAUEUR | acc: 0.4925268155442237 --> XAUGBP | acc: 0.49455864570737607
Модель показала точность 0.54 на инструменте, на котором обучалась, а на остальных — от 0.48 до 0.50. На первый взгляд может показаться, что результаты не сильно отличаются, и модель работает на других инструментах. Однако это крайне плохой результат.
Точность 0.5 (50%) эквивалентна подбрасыванию монеты.
Хотя базовая модель вроде бы делает прогнозы на других инструментах, возникает серьезная проблема, связанная с непрерывными признаками (переменными). Я имею в виду значения OHLC.
Проблема непрерывных переменных
Раз мы хотим создать устойчивую и универсальную базовую модель, способную работать на разных символах, нам не подходят непрерывные признаки, такие как Open, High, Low и Close. Потому что они не содержат устойчивых паттернов, а лишь отражают историческое движение цены.
Кроме того, каждый инструмент имеет собственный ценовой масштаб. Например, цены закрытия сегодня выглядят так:
| SYMBOL | DAILY CLOSING PRICE |
|---|---|
| USDJPY | 142.17 |
| EURUSD | 1.13839 |
| XAUUSD | 3305.02 |
Это означает, что модель, обученная на одном инструменте, может плохо работать на других из-за различий в ценовых диапазонах.
Помимо отсутствия переносимых паттернов, модели на непрерывных переменных требуют частого переобучения, поскольку рынки регулярно достигают новых максимумов. Это увеличивает вычислительные затраты — как раз то, что мы хотим минимизировать с помощью трансферного обучения.
Только стационарные переменные могут помочь моделям машинного обучения выявлять закономерности, релевантные для разных рынков, поскольку их математическое ожидание, дисперсия и автокорреляция не изменяются со временем (остаются постоянными). Это можно наблюдать на разных инструментах.
Чтобы использовать трансферное обучение, все признаки, включая индикаторы и паттерны, должны быть постоянными или стационарными.
Например, значения индикатора RSI всегда находятся в диапазоне 0–100 независимо от инструмента, что критически важно для выявления паттернов.
Разработка признаков
Существует множество методов получения стационарных признаков. В нашем случае можно использовать процентное изменение цены закрытия, разности (diff) для каждого значения OHLC или стационарные индикаторы.
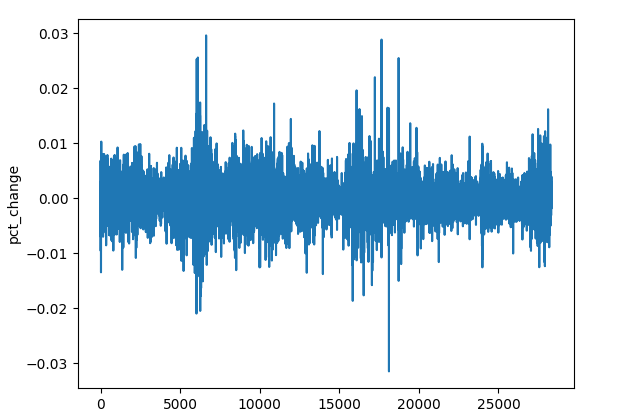
(a) Процентное изменение цены закрытия
res_df["pct_change"] = df["Close"].pct_change()
Несмотря на различия в ценовом масштабе, процентные изменения остаются сопоставимыми и подходят для универсального обнаружения паттернов.
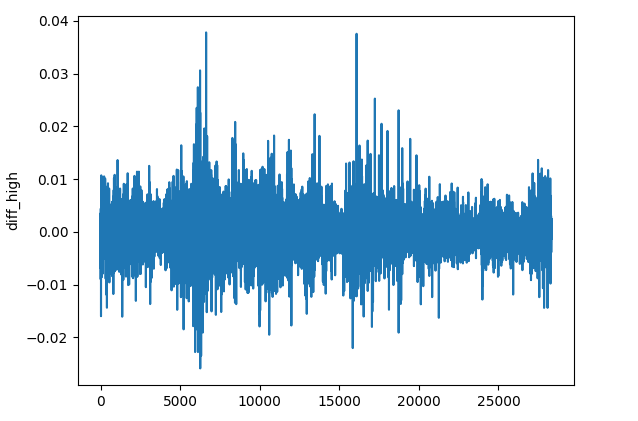
(b) Разница между значениями OHLC
res_df["diff_open"] = df["Open"].diff() res_df["diff_high"] = df["High"].diff() res_df["diff_low"] = df["Low"].diff() res_df["diff_close"] = df["Close"].diff()
Метод diff() вычисляет разницу между текущим и предыдущим значением (по умолчанию). Это позволяет отслеживать, как меняется цена на каждом баре по сравнению с предыдущим на каждом инструменте.
(с) Стационарные индикаторы
Можно добавить осцилляторы и индикаторы импульса, которые дают стационарные значения.
Индикатор | Диапазон значений |
|---|---|
# Relative Strength Index (RSI) res_df['rsi'] = ta.momentum.RSIIndicator(df["Close"], window=14).rsi() | От 0 до 100. |
# Stochastic Oscillator (Stoch) res_df['stoch_k'] = ta.momentum.StochasticOscillator(df['High'], df['Low'], df['Close'], window=14).stoch() | От 0 до 100. |
# Moving Average Convergence Divergence (MACD) res_df['macd'] = ta.trend.MACD(df["Close"]).macd() | Небольшие положительные и отрицательные значения, обычно от -0,1 до +0,1. |
# Commodity Channel Index (CCI) res_df['cci'] = ta.trend.CCIIndicator(df['High'], df['Low'], df['Close'], window=20).cci() | Обычно от -300 до +300. |
# Rate of Change (ROC) res_df['roc'] = ta.momentum.ROCIndicator(df["Close"], window=12).roc() | Неограниченная величина, может быть как отрицательной, так и положительной. |
# Ultimate Oscillator (UO) res_df['uo'] = ta.momentum.UltimateOscillator(df['High'], df['Low'], df['Close'], window1=7, window2=14, window3=28).ultimate_oscillator() | От 0 до 100. |
# Williams %R res_df['williams_r'] = ta.momentum.WilliamsRIndicator(df['High'], df['Low'], df['Close']).williams_r() | От -100 до 0. |
# Average True Range (ATR) res_df['atr'] = ta.volatility.AverageTrueRange(df['High'], df['Low'], df['Close'], window=14).average_true_range() | Неограниченные малые положительные значения. |
# Awesome Oscillator (AO) res_df['ao'] = ta.momentum.AwesomeOscillatorIndicator(df['High'], df['Low']).awesome_oscillator() | Неограниченные малые значения, обычно от -0,1 до +0,1. |
# Average Directional Index (ADX) res_df['adx'] = ta.trend.ADXIndicator(df['High'], df['Low'], df['Close'], window=14).adx() | От 0 до 100. |
# True Strength Index (TSI) res_df['tsi'] = ta.momentum.TSIIndicator(df['Close'], window_slow=25, window_fast=13).tsi() | Обычно от -100 до +100. |
Это примеры стационарных переменных, вы можете добавить и другие по своему выбору.
Все эти операции можно обернуть в отдельную функцию.
def getStationaryVars(df: pd.DataFrame) -> pd.DataFrame: res_df = pd.DataFrame() res_df["pct_change"] = df["Close"].pct_change() res_df["diff_open"] = df["Open"].diff() res_df["diff_high"] = df["High"].diff() res_df["diff_low"] = df["Low"].diff() res_df["diff_close"] = df["Close"].diff() # Relative Strength Index (RSI) res_df['rsi'] = ta.momentum.RSIIndicator(df["Close"], window=14).rsi() # Stochastic Oscillator (Stoch) res_df['stoch_k'] = ta.momentum.StochasticOscillator(df['High'], df['Low'], df['Close'], window=14).stoch() # Moving Average Convergence Divergence (MACD) res_df['macd'] = ta.trend.MACD(df["Close"]).macd() # Commodity Channel Index (CCI) res_df['cci'] = ta.trend.CCIIndicator(df['High'], df['Low'], df['Close'], window=20).cci() # .... See the code in the notebook in the attachments and above # .... # .... # True Strength Index (TSI) res_df['tsi'] = ta.momentum.TSIIndicator(df['Close'], window_slow=25, window_fast=13).tsi() return res_df
Теперь создадим базовую модель для переноса знаний между инструментами.
Transfer Learning
Трансферное обучение чаще всего применяется к глубоким моделям, преимущественно к сверточным нейронным сетям (CNN), поскольку они отлично распознают паттерны.
Обернём модель CNN в функцию trainCNN.
import tensorflow as tf from tensorflow.keras import layers, models, Model from tensorflow.keras.callbacks import EarlyStopping
def trainCNN(train_set: tuple, val_set: tuple, learning_rate: float=1e-3, epochs: int=100, batch_size: int=32): X_train, y_train = train_set X_val, y_val = val_set input_shape = X_train.shape[1:] num_classes = len(np.unique(y_train)) model = models.Sequential([ layers.Input(shape=input_shape), layers.Conv1D(64, kernel_size=3, activation='relu', padding='same'), layers.Conv1D(64, kernel_size=3, activation='relu', padding='same'), layers.GlobalAveragePooling1D(), layers.Dense(32, activation='tanh'), layers.Dense(num_classes, activation='softmax') ]) # Compile with Adam optimizer model.compile( optimizer=tf.keras.optimizers.Adam(learning_rate=learning_rate), loss='categorical_crossentropy', metrics=['accuracy'] ) # Early stopping callback early_stop = EarlyStopping( monitor='val_loss', # Watch validation loss patience=10, # Stop if no improvement restore_best_weights=True ) # Train the model model.fit( X_train, y_train, validation_data=(X_val, y_val), epochs=epochs, batch_size=batch_size, callbacks=[early_stop], verbose=1 ) # Save trained weights model.save_weights('cnn_pretrained.weights.h5') return model
Эта последовательная модель содержит два одномерных сверточных слоя (Conv1D) для извлечения признаков из входной последовательности.
Слой глобального среднего пулинга уменьшает размерность перед подачей в полносвязный слой (FNN) с активацией tanh.
Последний слой использует softmax для получения вероятностей классов.
Мы сохраняем веса модели, поскольку они представляют все изученные паттерны и могут быть переданы другой модели.
Используя EURUSD на таймфрейме H4, получаем OHLC-данные.
lookahead = 1 trained_symbol = symbols[0] timeframe = "PERIOD_H4" df = pd.read_csv(f"/kaggle/input/ohlc-eurusd/Fxdata.{trained_symbol}.{timeframe}.csv") stationary_df = getStationaryVars(df) stationary_df["Close"] = df["Close"] # add the close price for crafting the target variable X, y = getXandY(df=stationary_df, lookahead=lookahead)
Функция getXandY снова формирует целевую переменную по значению Close и параметру lookahead (1).
def getXandY(df: pd.DataFrame, lookahead: int) -> tuple: # Target variable df["future_close"] = df["Close"].shift(-lookahead) df.dropna(inplace=True) df["Signal"] = (df["future_close"] > df["Close"]).astype(int) # if next bar closed above the current one, thats a bullish signal otherwise bearish # Splitting data into X and y X = df.drop(columns=[ "Close", "future_close", "Signal" ]) y = df["Signal"] return (X, y)
Данные разделяются на обучающую и валидационную выборки, затем стандартизируются любым скейлером. В нашем случае это Robust Scaler.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, shuffle=False, random_state=42) # Scalling the data scaler = RobustScaler() X_train_scaled = scaler.fit_transform(X_train) X_test_scaled = scaler.transform(X_test)
Поскольку CNN требует 3D ввод данных, можно преобразовать эти данные так, чтобы они находились в определенном временном окне для обнаружения закономерностей на этом конкретном горизонте.
def create_sequences(X, Y, time_step): if len(X) != len(Y): raise ValueError("X and y must have the same length") X = np.array(X) Y = np.array(Y) Xs, Ys = [], [] for i in range(X.shape[0] - time_step): Xs.append(X[i:(i + time_step), :]) # Include all features with slicing Ys.append(Y[i + time_step]) return np.array(Xs), np.array(Ys)
# Prepare data within a window window = 10 X_train_seq, y_train_seq = create_sequences(X_train_scaled, y_train, window) X_test_seq, y_test_seq = create_sequences(X_test_scaled, y_test, window)
В любой задаче классификации с использованием нейронных сетей для целевой переменной применяется one-hot кодирование, поскольку помогает различать классы.
# One-hot encode the labels for multi-class classification
y_train_encoded = to_categorical(y_train_seq, num_classes=num_classes)
y_test_encoded = to_categorical(y_test_seq, num_classes=num_classes)
Наконец, мы можем обучить базовую модель.
base_model = trainCNN(train_set=(X_train_seq, y_train_encoded), val_set=(X_test_seq, y_test_encoded), learning_rate = 0.01, epochs = 1000, batch_size =32) print("Test acc: ", base_model.evaluate(X_test_seq, y_test_encoded)[1])
Результаты.
Epoch 1/1000 620/620 ━━━━━━━━━━━━━━━━━━━━ 4s 4ms/step - accuracy: 0.4994 - loss: 0.6990 - val_accuracy: 0.5023 - val_loss: 0.6938 Epoch 2/1000 620/620 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step - accuracy: 0.4976 - loss: 0.6939 - val_accuracy: 0.5023 - val_loss: 0.6936 Epoch 3/1000 620/620 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step - accuracy: 0.4977 - loss: 0.6940 - val_accuracy: 0.5023 - val_loss: 0.6938 Epoch 4/1000 620/620 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step - accuracy: 0.5034 - loss: 0.6937 - val_accuracy: 0.4977 - val_loss: 0.6962 ... ... Epoch 16/1000 620/620 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step - accuracy: 0.5039 - loss: 0.6934 - val_accuracy: 0.5023 - val_loss: 0.6932 Epoch 17/1000 620/620 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step - accuracy: 0.4988 - loss: 0.6940 - val_accuracy: 0.4977 - val_loss: 0.6937 Epoch 18/1000 620/620 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step - accuracy: 0.5013 - loss: 0.6943 - val_accuracy: 0.5023 - val_loss: 0.6931 266/266 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - accuracy: 0.5037 - loss: 0.6931 Test acc: 0.5022971034049988
Мы только что обучили базовую модель на EURUSD и получили общую точность 0,502.
Теперь давайте используем эту модель для трансферного обучения и обмена знаниями в другие модели, обученные на разных инструментах. Посмотрим, что из этого получится.
for symbol in symbols: if symbol == trained_symbol: # skip transfer learning on the trained symbol continue print(f"Symbol: {symbol}") df = pd.read_csv(f"/kaggle/input/ohlc-eurusd/Fxdata.{symbol}.{timeframe}.csv") stationary_df = getStationaryVars(df) stationary_df["Close"] = df["Close"] # we add the close price for crafting the target variable X, y = getXandY(df=stationary_df, lookahead=lookahead) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, shuffle=False, random_state=42) # Scalling the data scaler = RobustScaler() X_train_scaled = scaler.fit_transform(X_train) X_test_scaled = scaler.transform(X_test) # Prepare data within a window window = 10 X_train_seq, y_train_seq = create_sequences(X_train_scaled, y_train, window) X_test_seq, y_test_seq = create_sequences(X_test_scaled, y_test, window) # One-hot encode the labels for multi-class classification y_train_encoded = to_categorical(y_train_seq, num_classes=num_classes) y_test_encoded = to_categorical(y_test_seq, num_classes=num_classes) # Freeze all layers except the last one for layer in base_model.layers[:-1]: layer.trainable = False # Create new model using the base model's architecture model = models.clone_model(base_model) model.set_weights(base_model.get_weights()) # Recompile with lower learning rate model.compile(optimizer=tf.keras.optimizers.Adam(0.01), loss='categorical_crossentropy', metrics=['accuracy']) early_stop = EarlyStopping(monitor='val_loss', patience=10, restore_best_weights=True) history = model.fit(X_train_seq, y_train_encoded, validation_data=(X_test_seq, y_test_encoded), epochs=1000, # More epochs for fine-tuning batch_size=32, callbacks=[early_stop], verbose=1) print("Test acc:", model.evaluate(X_test_seq, y_test_encoded)[1])
Те же процессы повторяются для разделения данных, создания последовательных данных и кодирования целевой переменной. Операции указаны только для каждого символа.
Для переноса знаний создается новая модель на основе базовой, при этом замораживаются некоторые слои CNN.
Замораживаем все слои модели CNN, кроме последнего, чтобы наша модель сохранила закономерности, изученные на основе базовых данных. Это позволяет сохранить изученные паттерны и предотвратить их разрушение при дообучении.
Мы оставляем последний слой незамороженным, чтобы веса последнего слоя перекалибровались в соответствии с новыми границами принятия решений для каждого символа. По сути, мы предоставляем модели новые распределения целевой переменной и позволяем ей определять взаимосвязи между паттернами, изученными базовой моделью, и тем, что содержится в целевой переменной на этих новых данных.
Архитектура клонируется, веса загружаются из сохраненной модели. Напомню, что мы сохранили веса в функции trainCNN. Вы можете загрузить веса из файла при импорте модели откуда-либо или загрузить веса модели непосредственно из объекта модели, если базовая модель находится в том же скрипте Python или файле, как описано выше.
Компилируем модель на рыночных данных, полученных с помощью другого инструмента, отличного от того, который использовался при обучении базовой модели. Можно изменить и другие параметры.
Точность для различных валютных символов:
| SYMBOL | GBPUSD | AUDUSD | USDCAD | USDJPY | USDCHF | NZDUSD | EURNZD | AUDNZD | GBPNZD | NZDCHF | NZDJPY | NZDCAD | XAUUSD | XAUJPY | XAUEUR | XAUGBP |
| ACCURACY | 0.505 | 0.506 | 0.501 | 0.516 | 0.506 | 0.497 | 0.505 | 0.502 | 0.504 | 0.505 | 0.51 | 0.505 | 0.506 | 0.514 | 0.507 | 0.504 |
Этот результат мало что нам говорит. Посмотрим на отчет о классификации и проанализируем его более подробно.
preds = base_model.predict(X_test_seq) pred_indices = preds.argmax(axis=1) pred_class_labels = [classes_in_y[i] for i in pred_indices] print("Classification report\n", classification_report(pred_class_labels, y_test_seq))
Отчет по базовой модели.
Classification report precision recall f1-score support 0 1.00 0.50 0.66 8477 1 0.00 0.00 0.00 0 accuracy 0.50 8477 macro avg 0.50 0.25 0.33 8477 weighted avg 1.00 0.50 0.66 8477
Результаты точности на разных символах оказались ужасными. Модель продемонстрировала сильную предвзятость.
Это указывает на наличие смещения в нашей модели, которое может быть вызвано самой моделью или данными.
Существует несколько способов решения проблемы предвзятости, о которых мы говорили в прошлой статье. Но пока сделаем пару вещей:
(a) Добавим веса классов для устранения дисбаланса.
from sklearn.utils.class_weight import compute_class_weight
def trainCNN: #.... #.... y_train_integers = np.argmax(y_train, axis=1) # return to non-one hot encoded class_weights = compute_class_weight('balanced', classes=np.unique(y_train_integers), y=y_train_integers) class_weight_dict = {i: weight for i, weight in enumerate(class_weights)} # Train the model model.fit( X_train, y_train, validation_data=(X_val, y_val), epochs=epochs, batch_size=batch_size, callbacks=[early_stop], class_weight=class_weight_dict, verbose=1 )
(b) Добавим дополнительный сверточный слой и увеличим число нейронов в полносвязном слое.
def trainCNN: # ... # ... model = models.Sequential([ layers.Input(shape=input_shape), layers.Conv1D(64, kernel_size=3, activation='relu', padding='same'), layers.Conv1D(64, kernel_size=3, activation='relu', padding='same'), layers.Conv1D(32, kernel_size=3, activation='relu', padding='same'), layers.GlobalAveragePooling1D(), layers.Dense(128, activation='relu'), layers.Dense(num_classes, activation='softmax') ])
(c) Поскольку это задача бинарной классификации, в нашей целевой переменной всего два класса. 0 для сигналов на продажу и 1 для сигналов на покупку. Изменим функцию убытков на binary_crossentropy и метрику оценки для binary_accuracy.
# Compile with Adam optimizer model.compile( optimizer=tf.keras.optimizers.Adam(learning_rate=learning_rate), loss='binary_crossentropy', metrics=['binary_accuracy'] )
После переобучения модели CNN показатели значительно улучшились.
.... .... 310/310 ━━━━━━━━━━━━━━━━━━━━ 1s 3ms/step - binary_accuracy: 0.5257 - loss: 0.6920 - val_binary_accuracy: 0.5043 - val_loss: 0.6933 Epoch 7/100 310/310 ━━━━━━━━━━━━━━━━━━━━ 1s 3ms/step - binary_accuracy: 0.5259 - loss: 0.6918 - val_binary_accuracy: 0.5027 - val_loss: 0.6934 Epoch 8/100 310/310 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step - binary_accuracy: 0.5283 - loss: 0.6915 - val_binary_accuracy: 0.5042 - val_loss: 0.6936 Epoch 9/100 310/310 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step - binary_accuracy: 0.5284 - loss: 0.6912 - val_binary_accuracy: 0.5028 - val_loss: 0.6937 Epoch 10/100 310/310 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step - binary_accuracy: 0.5315 - loss: 0.6909 - val_binary_accuracy: 0.5036 - val_loss: 0.6938 Epoch 11/100 310/310 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step - binary_accuracy: 0.5295 - loss: 0.6907 - val_binary_accuracy: 0.5042 - val_loss: 0.6940 Epoch 12/100 310/310 ━━━━━━━━━━━━━━━━━━━━ 1s 3ms/step - binary_accuracy: 0.5298 - loss: 0.6904 - val_binary_accuracy: 0.5074 - val_loss: 0.6941 619/619 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step - binary_accuracy: 0.5101 - loss: 0.6926 265/265 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - binary_accuracy: 0.5018 - loss: 0.6933 Train acc: 0.5114434361457825 Test acc: 0.5050135850906372 265/265 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step Classification report precision recall f1-score support 0 0.58 0.50 0.54 4870 1 0.43 0.51 0.47 3607 accuracy 0.51 8477 macro avg 0.51 0.51 0.50 8477 weighted avg 0.52 0.51 0.51 8477
Конкретной причины для изменения параметров не было. Я просто хотел показать, что, как и в любой другой модели на основе нейронных сетей, оптимизация и настройка параметров очень важны.
Полученный результат, возможно, не является оптимальным решением, поскольку существует множество вариантов, касающихся сверточных нейронных сетей и нейронных сетей в целом.
Давайте пока оставим текущие параметры, но вы можете поэкспериментировать со значениями.
Теперь, когда у нас есть более или менее нормальная базовая модель, можно можем использовать ее для переноса знаний на другие инструменты и сохранить все эти модели в формате ONNX для тестирования в торговой среде.
Transfer Learning в торговом роботе
Для тестирования в торговой среде MetaTrader 5 необходимо сохранить модели в формате ONNX и загрузить их через язык программирования MQL5.
Импорт.
import onnxmltools import tf2onnx from skl2onnx import convert_sklearn from skl2onnx.common.data_types import FloatTensorType
Функции
def saveCNN(model, window: int, features: int, filename: str): model.output_names = ["output"] # Specifying the input signature for the model spec = (tf.TensorSpec((None, window, features), tf.float16, name="input"),) # Convert the Keras model to ONNX format onnx_model, _ = tf2onnx.convert.from_keras(model, input_signature=spec, opset=14) # Save the ONNX model to a file with open(filename, "wb") as f: f.write(onnx_model.SerializeToString())
Поскольку модели Keras не имеют поддерживаемого конвейера, как тот, который мы используем для объединения всех методов предварительной обработки с моделью Scikit-learn (а это упростило бы сохранение модели и всех ее шагов в одном файле ONNX) придется сохранять модель Keras и используемый скейлер отдельно в виде независимых файлов ONNX.
def saveScaler(scaler, features: int, filename: str): # Convert to ONNX format initial_type = [("input", FloatTensorType([None, features]))] onnx_model = convert_sklearn(scaler, initial_types=initial_type, target_opset=14) with open(filename, "wb") as f: f.write(onnx_model.SerializeToString())
Вызываем эти функции при сохранении базовой модели и предыдущих.
Сохранение базовой модели.
# .... # .... base_model = trainCNN(train_set=(X_train_seq, y_train_encoded), val_set=(X_test_seq, y_test_encoded), learning_rate = 0.01, epochs = 1000, batch_size =32) saveCNN(model=base_model, window=window, features=X_train_seq.shape[2], filename=f"{trained_symbol}.basemodel.{timeframe}.onnx") saveScaler(scaler=scaler, features=X_train.shape[1], filename=f"{trained_symbol}.{timeframe}.scaler.onnx")
Сохранение моделей, обученных с использованием трансферного обучения.
for symbol in symbols: # ... # ... history = model.fit(X_train_seq, y_train_encoded, validation_data=(X_test_seq, y_test_encoded), epochs=1000, # More epochs for fine-tuning batch_size=32, callbacks=[early_stop], verbose=1) saveCNN(model=model, window=window, features=X_train_seq.shape[2], filename=f"basesymbol={trained_symbol}.symbol={symbol}.model.{timeframe}.onnx") saveScaler(scaler=scaler, features=X_train.shape[1], filename=f"{symbol}.{timeframe}.scaler.onnx")
После сохранения файлов в общей папке можно загрузить их в советник.
#include <ta.mqh> //similar to ta in Python --> https://www.mql5.com/en/articles/16931 #include <pandas.mqh> //similar to Pandas in Python --> https://www.mql5.com/en/articles/17030 #include <CNN.mqh> //For loading Convolutional Neural networks in ONNX format --> https://www.mql5.com/en/articles/15259 #include <preprocessing.mqh> //For loading the scaler transformer #include <Trade\Trade.mqh> //The trading module #include <Trade\PositionInfo.mqh> //Position handling module CCNNClassifier cnn; RobustScaler scaler; CTrade m_trade; CPositionInfo m_position; input string base_symbol = "EURUSD"; input string symbol_ = "USDJPY"; input ENUM_TIMEFRAMES timeframe = PERIOD_H4; input uint window_ = 10; input uint lookahead = 1; input uint magic_number = 28042025; input uint slippage = 100; long classes_in_y_[] = {0, 1}; int OldNumBars = -1; //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- if (!MQLInfoInteger(MQL_TESTER)) if (!ChartSetSymbolPeriod(0, symbol_, timeframe)) { printf("%s Failed to set symbol_ = %s and timeframe = %s, Error = %d",__FUNCTION__,symbol_,EnumToString(timeframe), GetLastError()); return INIT_FAILED; } //--- string filename = StringFormat("basesymbol=%s.symbol=%s.model.%s.onnx",base_symbol, symbol_, EnumToString(timeframe)); if (!cnn.Init(filename, ONNX_COMMON_FOLDER)) { printf("%s failed to load a CNN model in ONNX format from the common folder '%s', Error = %d",__FUNCTION__,filename,GetLastError()); return INIT_FAILED; } //--- filename = StringFormat("%s.%s.scaler.onnx", symbol_, EnumToString(timeframe)); if (!scaler.Init(filename, ONNX_COMMON_FOLDER)) { printf("%s failed to load a scaler in ONNX format from the common folder '%s', Error = %d",__FUNCTION__,filename,GetLastError()); return INIT_FAILED; } }
У нас есть модуль TA из Python в MQL5, который мы обсуждали в прошлой статье. Можем вызывать функции-индикаторы и присваивать результат во фрейме схожем с Python Pandas.
CDataFrame getStationaryVars(uint start = 1, uint bars = 50) { CDataFrame df; //Dataframe object vector open, high, low, close; open.CopyRates(Symbol(), Period(), COPY_RATES_OPEN, start, bars); high.CopyRates(Symbol(), Period(), COPY_RATES_HIGH, start, bars); low.CopyRates(Symbol(), Period(), COPY_RATES_LOW, start, bars); close.CopyRates(Symbol(), Period(), COPY_RATES_CLOSE, start, bars); vector pct_change = df.pct_change(close); vector diff_open = df.diff(open); vector diff_high = df.diff(high); vector diff_low = df.diff(low); vector diff_close = df.diff(close); df.insert("pct_change", pct_change); df.insert("diff_open", open); df.insert("diff_high", high); df.insert("diff_low", low); df.insert("diff_close", close); // Relative Strength Index (RSI) vector rsi = CMomentumIndicators::RSIIndicator(close); df.insert("rsi", rsi); // Stochastic Oscillator (Stoch) vector stock_k = CMomentumIndicators::StochasticOscillator(close,high,low).stoch; df.insert("stock_k", stock_k); // Moving Average Convergence Divergence (MACD) vector macd = COscillatorIndicators::MACDIndicator(close).main; df.insert("macd", macd); // Commodity Channel Index (CCI) vector cci = COscillatorIndicators::CCIIndicator(high,low,close); df.insert("cci", cci); // Rate of Change (ROC) vector roc = CMomentumIndicators::ROCIndicator(close); df.insert("roc", roc); // Ultimate Oscillator (UO) vector uo = CMomentumIndicators::UltimateOscillator(high,low,close); df.insert("uo", uo); // Williams %R vector williams_r = CMomentumIndicators::WilliamsR(high,low,close); df.insert("williams_r", williams_r); // Average True Range (ATR) vector atr = COscillatorIndicators::ATRIndicator(high,low,close); df.insert("atr", atr); // Awesome Oscillator (AO) vector ao = CMomentumIndicators::AwesomeOscillator(high,low); df.insert("ao", ao); // Average Directional Index (ADX) vector adx = COscillatorIndicators::ADXIndicator(high,low,close).adx; df.insert("adx", adx); // True Strength Index (TSI) vector tsi = CMomentumIndicators::TSIIndicator(close); df.insert("tsi", tsi); if (MQLInfoInteger(MQL_DEBUG)) df.head(); df = df.dropna(); //Drop not-a-number variables return df; //return the last rows = window from a dataframe which is the recent information fromthe market }
На каждом баре собираются 50 предыдущих баров для расчета индикаторов, начиная с последнего закрытого бара (индекс 1).
Мф выбрали ограничение в 50 баров, чтобы оставить достаточно места для расчетов индикаторов, которые сопровождаются значениями NaN (Not a Number), а они нам не нужны.
Индикатор Awesome Oscillator чаще всего обращается к прошлому, со значением window2, равным 34. Это означает, что 50-34 = 16 — это количество подходящих данных, оставшихся для нашей модели.
Запуск в режиме отладки дает информацию на вкладке Эксперты в MetaTrader 5.
MD 0 18:17:26.145 Transfer Learning EA (USDJPY,H4) | Index | pct_change | diff_open | diff_high | diff_low | diff_close | rsi | stock_k | macd | cci | roc | uo | williams_r | atr | ao | adx | tsi | FF 0 18:17:26.145 Transfer Learning EA (USDJPY,H4) | 0 | nan | 142.67000000 | 143.08800000 | 142.49100000 | 142.68300000 | nan | nan | nan | nan | nan | nan | nan | nan | nan | 0.00000000 | nan | JO 0 18:17:26.146 Transfer Learning EA (USDJPY,H4) | 1 | -0.25300842 | 142.68400000 | 142.84900000 | 142.28700000 | 142.32200000 | nan | nan | nan | nan | nan | nan | nan | nan | nan | 0.00000000 | nan | IR 0 18:17:26.146 Transfer Learning EA (USDJPY,H4) | 2 | 0.09977375 | 142.32300000 | 142.63500000 | 141.89900000 | 142.46400000 | nan | nan | nan | nan | nan | nan | nan | nan | nan | 0.00000000 | nan | HF 0 18:17:26.146 Transfer Learning EA (USDJPY,H4) | 3 | -0.00070193 | 142.46400000 | 142.71900000 | 142.34400000 | 142.46300000 | nan | nan | nan | nan | nan | nan | nan | nan | nan | 0.00000000 | nan | GJ 0 18:17:26.146 Transfer Learning EA (USDJPY,H4) | 4 | -0.04702976 | 142.37400000 | 142.47200000 | 142.18600000 | 142.39600000 | nan | nan | nan | nan | nan | nan | nan | nan | nan | 0.00000000 | nan | IJ 0 18:17:26.146 Transfer Learning EA (USDJPY,H4) | ... | NR 0 18:17:26.146 Transfer Learning EA (USDJPY,H4) | 45 | -0.22551954 | 142.33800000 | 142.38800000 | 141.98200000 | 142.01700000 | 28.79606321 | 1.70731707 | 0.20202343 | -149.46898289 | -0.42629273 | 28.03714657 | -48.58934169 | 0.58185714 | 0.84359706 | 29.65580624 | 8.31951160 | NJ 0 18:17:26.146 Transfer Learning EA (USDJPY,H4) | 46 | 0.16054416 | 141.97800000 | 142.31600000 | 141.96400000 | 142.24500000 | 35.49705652 | 13.58800774 | 0.12993025 | -131.96513868 | -0.57316604 | 34.81743660 | -43.09139137 | 0.56978571 | 0.51217941 | 28.18573720 | 4.78996901 | HQ 0 18:17:26.146 Transfer Learning EA (USDJPY,H4) | 47 | 0.19543745 | 142.24500000 | 142.58100000 | 142.12400000 | 142.52300000 | 43.03880625 | 27.03094778 | 0.09414295 | -86.63856716 | -0.76174826 | 43.61239023 | -36.38775018 | 0.57742857 | 0.21773529 | 26.19967843 | 3.09202782 | FH 0 18:17:26.146 Transfer Learning EA (USDJPY,H4) | 48 | 0.04771160 | 142.52300000 | 142.61500000 | 142.29800000 | 142.59100000 | 44.85843867 | 30.31914894 | 0.07045611 | -66.64608781 | -0.57732936 | 49.55462139 | -34.74801061 | 0.56007143 | -0.01222353 | 24.37916904 | 2.01861384 | MQ 0 18:17:26.146 Transfer Learning EA (USDJPY,H4) | 49 | -0.19776844 | 142.59100000 | 142.75800000 | 142.25100000 | 142.30900000 | 38.91058297 | 16.68278530 | 0.02859940 | -70.14493704 | -0.77257229 | 41.99481159 | -41.54810707 | 0.52700000 | -0.13378529 | 23.02215655 | 0.05188403 |
Внутри функции OnTick первое, что мы делаем, — это вычисляем стационарные признаки. Затем выполняется операция среза (slicing), цель которой — гарантировать, что полученные данные, то есть количество баров, соответствует размеру окна, использованному при обучении модели CNN.
void OnTick() { //--- if (!isNewBar()) return; CDataFrame x_df = getStationaryVars(); //--- Check if the number of rows received after indicator calculation is >= window size if ((uint)x_df.shape()[0]<window_) { printf("%s Fatal, Data received is less than the desired window=%u. Check your indicators or increase the number of bars in the function getSationaryVars()",__FUNCTION__,window_); DebugBreak(); return; } ulong rows = (ulong)x_df.shape()[0]; ulong cols = (ulong)x_df.shape()[1]; //printf("Before scaled shape = (%I64u, %I64u)",rows, cols); matrix x = x_df.iloc((rows-window_), rows-1, 0, cols-1).m_values; }
Теперь, когда у нас есть усечённая матрица из 10 строк — в соответствии со значением окна — и 16 признаков, использованных при обучении, мы можем передать эти данные в загруженный RobustScaler, а затем направить их в модель CNN для получения финальных прогнозов.
matrix x_scaled = scaler.transform(x); //Transform the data, very important long signal = cnn.predict(x_scaled, classes_in_y_).cls; //Predicted class
Наконец, используя сигнал, полученный от модели, мы можем реализовать простую торговую стратегию: если сигнал модели равен 1 (бычий сигнал), мы открываем позицию на покупку; если же полученный сигнал равен 0 (медвежий сигнал), мы открываем позицию на продажу.
Каждая сделка будет закрываться после того, как на текущем таймфрейме сформируется количество баров, равное значению параметра lookahead.
//--- Trading functionality MqlTick ticks; if (!SymbolInfoTick(Symbol(), ticks)) { printf("Failed to obtain ticks information, Error = %d",GetLastError()); return; } double volume_ = SymbolInfoDouble(Symbol(), SYMBOL_VOLUME_MIN); if (signal == 1) //Check if there are is atleast a special pattern before opening a trade { if (!PosExists(POSITION_TYPE_BUY) && !PosExists(POSITION_TYPE_SELL)) m_trade.Buy(volume_, Symbol(), ticks.ask,0,0); } if (signal == 0) //Check if there are is atleast a special pattern before opening a trade { if (!PosExists(POSITION_TYPE_SELL) && !PosExists(POSITION_TYPE_BUY)) m_trade.Sell(volume_, Symbol(), ticks.bid,0,0); } CloseTradeAfterTime((Timeframe2Minutes(Period())*lookahead)*60); //Close the trade after a certain lookahead and according the the trained timeframe
Вот и всё. Теперь запустим этого торгового робота на нескольких инструментах, которые мы использовали в процессе переноса обучения, и проанализируем результаты его прогнозирования за период с 1 января 2023 года по 1 января 2025 года.
Timeframe: PERIOD_H4. Modelling: 1 Minute OHLC.
Symbol: XAUEUR
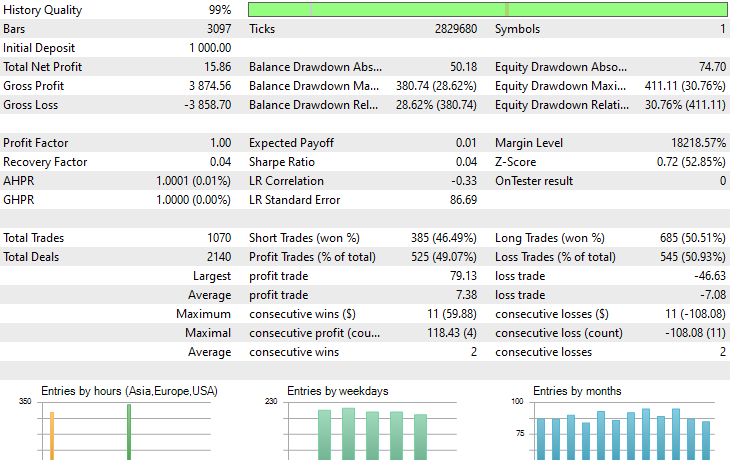
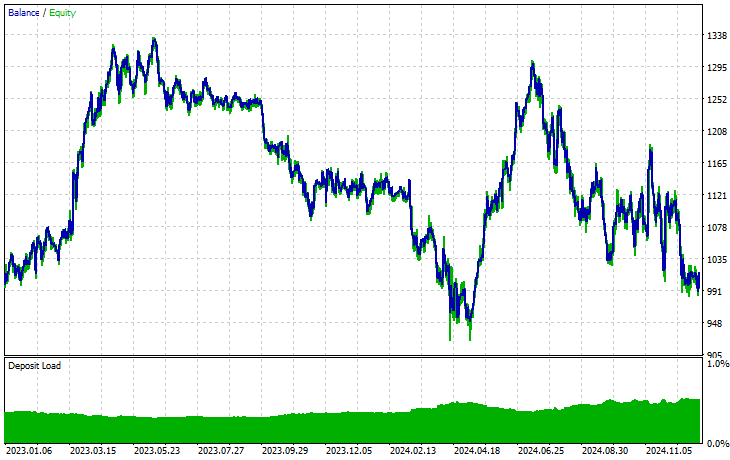
Symbol: XAUUSD
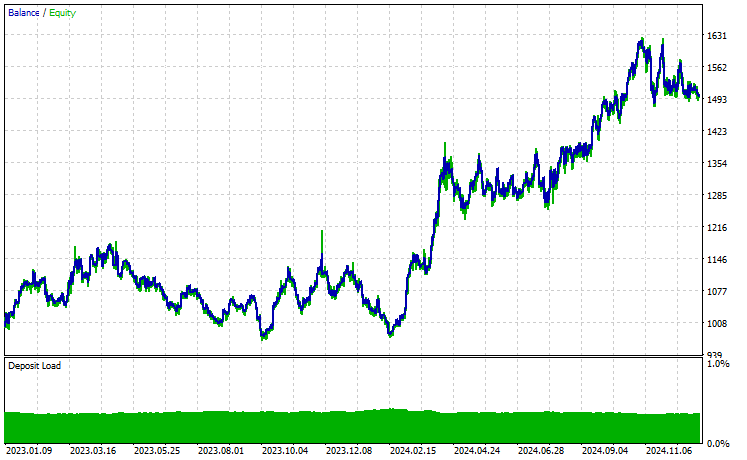
Из 17 инструментов, использованных в процессе переноса обучения на основе базовой модели, обученной на EURUSD, лишь 2 инструмента продемонстрировали нормальные результаты. Остальные показали ужасные.
Это может означать две вещи. Во-первых, паттерны, наблюдаемые на EURUSD, могут иметь сильную взаимосвязь или сходство с теми, что формируются на XAUUSD и XAUEUR. Это выглядит логично, поскольку оба этих инструмента связаны с валютами EUR и USD, которые образуют базовый символ EURUSD.
Во-вторых, это также может указывать на то, что используемые нами модели CNN являются неоптимальными, поскольку мы не проводили полноценную оптимизацию архитектуры и гиперпараметров, не говоря уже о том, что не тестировали различные базовые символы и не анализировали полученные результаты.
Можно было бы предпринять ряд дополнительных шагов, однако это выходит за рамки данной статьи. Если хотите, можете сделать это.
Заключительные выводы
Мы живем в золотую эпоху искусственного интеллекта и машинного обучения. Эти технологии развиваются быстрее, чем ожидалось, и во многом благодаря open-source сегодня можно создавать мощные модели на основе уже существующих всего несколькими строками кода — именно это мы и называем переносом обучения (transfer learning).
В области компьютерного зрения и задач, связанных с обработкой изображений, уже существуют масштабные open-source модели, такие как ResNet50, MobileNet и другие. Эти модели позволили разработчикам выйти на новый уровень и создавать по-настоящему эффективные решения в сфере ИИ. Однако финансовая область с точки зрения открытых моделей и open-source решений все еще остается недостаточно исследованной.
Цель этой статьи — показать вам возможности переноса обучения и продемонстрировать, как он может выглядеть в финансовой сфере, послужив отправной точкой для создания масштабных моделей, способных помочь в анализе финансовых рынков за счёт использования общих паттернов, присутствующих на различных инструментах.
Удачи!
Таблица вложений
Имя файла | Описание/назначение |
|---|---|
| Expert\Transfer Learning EA.mq5 | Основной советник для тестирования моделей трансферного обучения в торговой среде. |
| Include\CNN.mqh | Библиотека для загрузки и развертывания моделей CNN в файлах .onnx на MQL5. |
Include\pandas.mqh | Библиотека в стиле Pandas Python для обработки и хранения данных. |
Include\preprocessing.mqh | Содержит классы для загрузки, масштабирования и преобразования данных, представленных в формате .onnx. |
Include\ta.mqh | Библиотека с простым и удобным подходом для работы с индикаторами в MQL5. |
Scripts\CollectData.mqh | Скрипт для сбора и сохранения данных OHLC, полученных с помощью различных приборов, в CSV-файлы. |
| Python\forex-transfer-learning.ipynb | Скрипт на Python (Jupyter Notebook) для выполнения всего кода Python, описанного в этой статье. |
Common\Files\*scaler.onnx | Масштабируемые параметры предварительной обработки данных сохранены в файлах формата ONNX. |
Common\Files\*.onnx | Модели CNN сохраняются в файлах формата ONNX. |
Перевод с английского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/en/articles/17886
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования