
Нейросети в трейдинге: Рекуррентное моделирование микродвижений рынка (Энкодер)

Введение
В мире машинного обучения существует особый класс архитектурных решений, способных не просто анализировать данные, а чувствовать внутреннюю динамику. Среди них особое место занимает фреймворк EV-MGRFlowNet — результат тонкой инженерной работы, в котором исследователи предложили необычный способ моделирования движения на основе событийных потоков. Его появление стало значимым шагом в области цифрового зрения. Но истинная ценность подхода проявляется шире: принципы работы с событийными данными во многом созвучны природе финансовых рынков, где каждая сделка, изменение цены или всплеск ликвидности формирует собственное микрособытие.
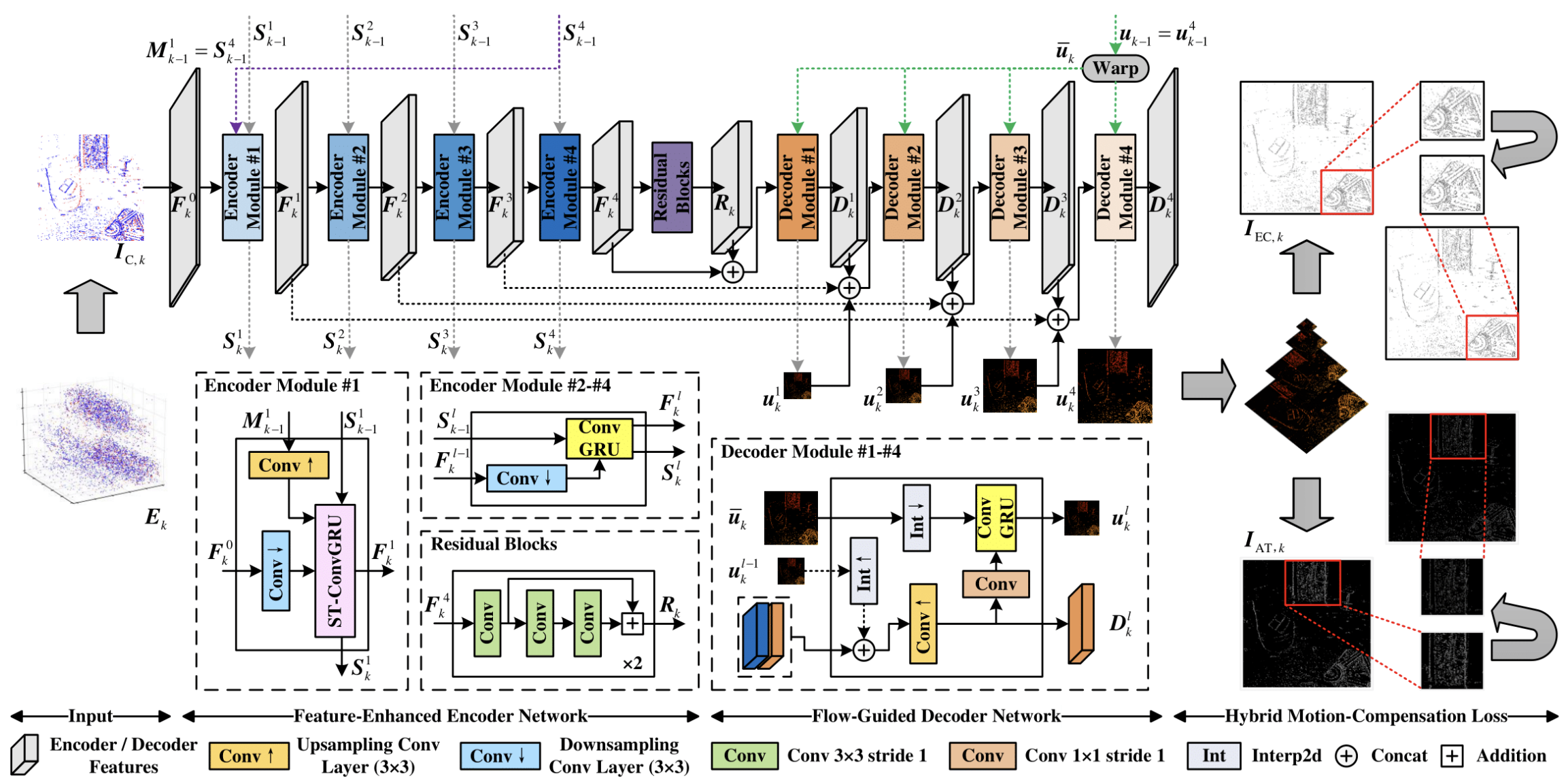
Основу EV-MGRFlowNet составляет рекуррентная архитектура Энкодер-Декодер, построенная на многоуровневом уточнении временных признаков. Исходные данные, будь то локальные вспышки в матрице камеры или тики рыночных данных, проходят через цепочку преобразований, в которой система учится видеть связную структуру движения. Именно в энкодере FERE-Net авторы реализовали одно из ключевых нововведений, позволяющих модели улавливать тонкие временные зависимости в данных.
Классическая ConvGRU обновляет память исключительно во временной оси. Каждый уровень модели получает собственный поток состояний и не взаимодействует с другими уровнями по глубине. В результате этого низкоуровневые представления нередко теряют связь с признаками, сформированными выше. ST-ConvGRU, напротив, вводит механизм межуровневой согласованности. На каждом временном шаге скрытое состояние слоя обновляется не только исходя из собственного предыдущего состояния, но и с учётом сигнала, поступившего от вышележащего уровня. Такой механизм значительно углубляет временной контекст. Модель получает возможность удерживать во времени более полные, согласованные представления движения, не теряя информации, извлечённой на других уровнях разрешения. В результате FERE-Net формирует многоуровневые временные карты, в которых сохраняются как грубые, так и тонкие, едва уловимые элементы динамики.
Декодер FGD-Net выполняет обратную функцию. Он постепенно восстанавливает карту движения, начиная с грубого уровня и переходя к всё более точным деталям. Этот процесс можно сравнить с анализом рыночного графика опытным аналитиком. Сначала он видит общее направление, затем структуру импульсов и микродвижения, определяющие итоговое поведение анализируемого временного ряда. Сквозная согласованность энкодера и декодера позволяет фреймворку формировать прогнозы, которые опираются на целостный поток.
Важная роль в обучении модели отводится гибридной функции потерь HMC-Loss, которая объединяет несколько компонент, связанных с компенсацией движения. Каждая из них отвечает за собственную грань временной согласованности. Одна помогает выравнивать последовательные события, другая сглаживает резкие переходы, а третья усиливает стабильность модели. Вместе они действуют как система стабилизаторов, заставляющая модель не просто минимизировать ошибку, а чувствовать ритм последовательности.
Перенос этих принципов в сферу финансовых рынков открывает новые аналитические возможности. Тиковые данные — это такой же поток событий, только выраженный не в пикселях, а в изменениях цены и объёмов. Они неравномерны, подвижны, чувствительны ко внешним импульсам. Именно в их хаотичности и проявляется необходимость событийного подхода. Там, где традиционные временные ряды размывают информацию, дискретизируя поток, событийные методы сохраняют естественную структуру изменений. Для нас это означает, что движение цены можно рассматривать как живую цепочку событий. И обрабатывать её в той же парадигме, что и поток данных с сенсора камеры.
Адаптация EV-MGRFlowNet к финансовым данным требует понимания функционала внутренних компонент. Какие элементы архитектуры отвечают за интерпретацию событий, а какие — за восстановление движения. В этой системе энкодер FERE-Net становится инструментом агрегирования микрособытий рынка. Он превращает последовательность тиков или ордеров в многослойное временное представление. Декодер FGD-Net, в свою очередь, извлекает из этого представления потенциальное направление движения, силу импульса или вероятность продолжения тенденции. Таким образом, фреймворк из области компьютерного зрения органично перетекает в область рыночного анализа, поскольку в обоих случаях цель одна — увидеть движение, понять его структуру и прогнозировать дальнейшее развитие.
Особая ценность подхода заключается в его масштабируемости. Поскольку модель не привязана к жёстким временным интервалам, она одинаково эффективно работает как во время быстрых всплесков волатильности, так и в периоды спокойствия. Это свойство особенно важно для прогнозирования, где малейшее изменение фазы рынка может быть критичным. Событийная модель адаптируется к плотности информации естественным образом, без искусственной подгонки под интервальные окна.
Таким образом, EV-MGRFlowNet представляет собой универсальный фреймворк для анализа событийных потоков любой природы. Авторская визуализация фреймворка представлена ниже.
Модуль ST-ConvGRU
В практической части предыдущей статьи мы подробно разобрали природу работы ST-ConvGRU и подошли к её реализации не как к формальному переписыванию уравнений, а как к инженерной задаче, где каждая деталь влияет на итоговую способность модели распознавать движение.
Напомню, что основа этого модуля — две параллельные GRU-ветки, которые действуют как два взаимосвязанных канала памяти. Первая обновляет состояние, опираясь на собственные скрытые состояния, а вторая подключает скрытое состояние вышестоящего слоя, формируя своеобразный мост между уровнями рекуррентного энкодера. Такой механизм углубляет временную согласованность, позволяя модели удерживать сигналы, которые в классическом ConvGRU неизбежно теряются между слоями.

Для финансовых рынков такая архитектура приобретает особую значимость. ST-ConvGRU позволяет улавливать то, что формируется на уровне более сложных рыночных контекстов: моментум, инерция кластера крупных сделок, накопленные сдвиги в структуре ордеров. Такая модель не просто реагирует на очередной всплеск цены — она учится понимать, из какого состояния рынка этот всплеск возник.
Мы также подчеркнули важный технический аспект. Внутренняя логика GRU-ячейки построена на поэлементных операциях. Это открывает прямую дорогу к масштабированию вычислений. Если грамотно организовать исходные данные и скрытые состояния, то любое количество GRU-ячеек можно свести к одной общей структуре и выполнить расчёты параллельно на GPU. Для нас это критично: финансовые данные часто приходят с высокой частотой, а модель должна обрабатывать длинные последовательности без задержек. Переход на OpenCL даёт возможность удерживать вычисления в реальном времени, не теряя ни точности, ни глубины анализа.
В предыдущей статье мы создали необходимые OpenCL-кернелы и тем самым заложили фундамент параллельного конвейера. Теперь наступает ключевой этап — организация всей схемы на стороне основной программы. Здесь нам предстоит связать логику ST-ConvGRU и механизм обновления временной памяти в единую рабочую структуру, способную без перебоев проходить сквозь большие массивы рыночных данных. Это шаг, где теория начинает работать на практике, а архитектура — проявлять свою силу в условиях, близких к реальным торговым сценариям.
Для реализации функционала ST-ConvGRU мы создаём новый класс CNeuronSpikeSTConvGRU, который наследует базовый функционал от объекта CNeuronSpikeActivation. Этот объект становится сердцем нашей системы. Он не просто обрабатывает данные, а удерживает их динамику во времени, аккумулируя важные сигналы, и передает их на следующие уровни модели. Внутри класса встроен ряд вспомогательных блоков, которые работают как единый механизм, обеспечивая плавный поток информации от входа к выходу.
class CNeuronSpikeSTConvGRU : public CNeuronSpikeActivation { protected: CNeuronBaseOCL cConcatenated[2]; CNeuronMultiWindowsConvOCL cFSM; CNeuronBaseOCL cSM; CNeuronConvOCL cOs; CNeuronConvOCL cOt; CNeuronBaseOCL cFo; CNeuronTransposeRCDOCL cS; CNeuronBatchNormOCL cNorm; //--- virtual bool GRU(void); virtual bool GRU_grad(void); //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput)override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *second)override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) override; public: CNeuronSpikeSTConvGRU(void) {}; ~CNeuronSpikeSTConvGRU(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint units, uint &chanels_in[], uint chanels_out, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronSpikeSTConvGRU; } //--- methods for working with files virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual void SetOpenCL(COpenCLMy *obj) override; virtual bool Clear(void) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; //--- virtual uint GetChanels(void) const { return cOt.GetFilters(); } virtual uint GetUnits(void) const { return cOt.GetUnits(); } };
Метод Init — это сердце и стартовая точка работы модуля. Он отвечает за построение всей внутренней структуры, распределение каналов и подготовку вычислительного конвейера. Представьте себе, что это инженерный чертёж модели: каждая деталь, каждый блок имеет своё место и функцию, и только вместе они образуют слаженную машину для обработки событий.
bool CNeuronSpikeSTConvGRU::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint units, uint &chanels_in[], uint chanels_out, ENUM_OPTIMIZATION optimization_type, uint batch) { if(chanels_in.Size() != 2) return false;
Здесь мы сначала проверяем корректность параметров, полученных от пользователя. Ожидается получение исходных данных в виде 2 информационных потоков — анализируемый поток событий и скрытое состояние верхнего уровня. Их размерность указывается в массиве chanels_in. Если размер массива не соответствует количеству ожидаемых потоков данных, то инициализация прерывается.
Затем управление передается родительскому классу, который обеспечивает выделение памяти, привязку к OpenCL-контексту и базовую организацию нейронной структуры. Без этой подготовки работа модуля невозможна.
if(!CNeuronSpikeActivation::Init(numOutputs, myIndex, open_cl, units * chanels_out, optimization_type, batch)) return false;
Далее создаются внутренние блоки. Первым инициализируем объект конкатенации данных, в котором собираем все исходные данные в единый поток признаков: текущие события, скрытые состояния данного модуля и объекта верхнего уровня. На этом этапе данные пока не преобразуются, а просто аккумулируются для последующей обработки.
//--- Concatenate [2*F0,S0,M0]*Units uint index = 0; if(!cConcatenated[0].Init(0, index, OpenCL, (2 * chanels_in[0] + chanels_in[1] + chanels_out)*units, optimization, iBatch)) return false; cConcatenated[0].SetActivationFunction(None);
Следующий блок, cFSM, выполняет роль фильтра и селектора признаков, превращая сырые входные данные и скрытые состояния в набор сущностей, необходимых для работы GRU-ячейки.
//--- [6*F,3*S,3*M]*Units index++; uint windows[] = { chanels_in[0], chanels_in[0], chanels_out, chanels_in[1] }; if(!cFSM.Init(0, index, OpenCL, windows, 3 * chanels_out, units, 1, optimization, iBatch)) return false; cFSM.SetActivationFunction(None);
Это не просто объединение каналов — cFSM является объектом мультиоконной свёртки, что позволяет одновременно обрабатывать несколько потоков информации и приводить их к единой размерности. Поскольку GRU использует исходные данные и скрытые состояния в трёх разных контекстах (обновление, кандидаты состояния и забывание), cFSM сразу создаёт необходимое количество проекций, чтобы каждая операция могла выполняться параллельно.
Объект cSM получает конкатенированное скрытое состояние, объединяющее контексты нижнего и верхнего уровней.
//--- [S,M]*Units index++; if(!cSM.Init(0, index, OpenCL, 2 * chanels_out * units, optimization, iBatch)) return false; cSM.SetActivationFunction(None);
По сути, это результат работы двух параллельных GRU-ячеек, которые уже обработали исходные данные и сигналы памяти, формируя согласованное представление анализируемого состояния.
Далее мы создаём объекты для интерпретации этих результатов, начиная с cConcatenated[1], который объединяет скрытые состояния с исходными данными.
//--- [F,S,M]*Units index++; if(!cConcatenated[1].Init(0, index, OpenCL, (chanels_in[0] + 2 * chanels_out)*units, optimization, iBatch)) return false;
Этот шаг необходим, чтобы подготовить информацию к вычислению управляющих сигналов.
Дальше включаются cOs — объект генерации выходного сигнала oₖ, который вычисляется на основе конкатенированных скрытых состояний и текущих исходных данных.
//--- [S]*Units index++; if(!cOs.Init(0, index, OpenCL, chanels_in[0] + 2 * chanels_out, chanels_in[0] + 2 * chanels_out, chanels_out, units, 1, optimization, iBatch)) return false; cOs.SetActivationFunction(SIGMOID);
Здесь мы используем SIGMOID, чтобы ограничить значения между 0 и 1. Это позволяет каждой единице памяти решать, какую долю информации оставить для следующего шага, а какую — отфильтровать. Для финансовых потоков это похоже на механизм выбора, какие текущие микро-импульсы и сигналы верхнего уровня действительно значимы для прогноза движения цены.
Сверточный слой cOt формирует кандидатов нового состояния, генерируя прогноз на основе обновленных скрытых состояний.
//--- [S]*Units index++; if(!cOt.Init(0, index, OpenCL, 2 * chanels_out, 2 * chanels_out, chanels_out, units, 1, optimization, iBatch)) return false; cOt.SetActivationFunction(TANH);
Результаты поэлементного умножения гейтов результатов на советующих кандидатов мы поместим в буфер cFo, который и является результатом работы модуля ST-ConvGRU.
//--- [S]*Units index++; if(!cFo.Init(0, index, OpenCL, chanels_out * units, optimization, iBatch)) return false; cFo.SetActivationFunction(None);
В контексте финансовых потоков это похоже на синтез двух перспектив: одна отражает локальные изменения, другая — глобальный контекст рынка. Конкатенация позволяет модели одновременно учитывать микроимпульсы и более крупные паттерны, формируя богатое представление о текущей динамике рынка.
Объект cS используется для выделения скрытого состояния текущего уровня из конкатенированного тензора, подготавливая его следующему временному шагу.
//--- [S]*Units index++; if(!cS.Init(0, index, OpenCL, units, 2, chanels_out, optimization, iBatch)) return false; cS.SetActivationFunction(None);
Далее мы немного отходим от авторской реализации модуля и добавляем к результатам спайковую активацию. Перед этим полученные значения проходят через блок cNorm, который выполняет пакетную нормализацию. Это критично: нормализация стабилизирует амплитуду сигналов, устраняя перепады, которые могут возникать при длинных последовательностях тиков и больших объёмах данных.
//--- [S]*Units index++; if(!cNorm.Init(0, index, OpenCL, Neurons(), iBatch, optimization)) return false; cNorm.SetActivationFunction(None); //--- return true; }
Только после этого нормализованные сигналы передаются в спайковую активацию, превращаясь в события, которые можно интерпретировать как дискретные импульсы нейронной сети. В контексте финансовых потоков это похоже на выделение ключевых микроимпульсов рынка: каждая спайковая единица сигнализирует о значимом изменении цены или объёма, позволяя модели концентрироваться на наиболее информативных событиях и эффективно накапливать историю динамики для прогнозирования.
Такой подход обеспечивает комбинацию преимуществ: точность авторской ST-ConvGRU в работе с памятью и скрытыми состояниями, а также спайковую селективность, которая помогает фильтровать шум и выделять действительно значимые события.
Когда все блоки успешно инициализированы, метод возвращает true, сигнализируя о готовности модуля.
После инициализации объекта мы переходим к алгоритму прямого прохода, реализованному в методе feedForward. Этот метод организует последовательную обработку исходных данных и скрытых состояний, превращая их в обновлённое скрытое состояние модуля и формируя сигнал для последующих слоёв.
bool CNeuronSpikeSTConvGRU::feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) { if(!NeuronOCL || !SecondInput) return false; //--- uint Fdimension = cFSM.GetWindow(0); uint Sdimension = cS.GetDimension(); uint Mdimension = cFSM.GetWindow(3); uint units = cFSM.GetUnits();
Первым делом метод проверяет корректность полученных указателей на объекты исходных данных. Если отсутствует хотя бы один поток информации, алгоритм не может работать, и процесс прерывается.
Далее извлекаются размерности ключевых блоков:
- Fdimension — размерность окна основного потока исходных данных;
- Sdimension — размерность окна скрытого состояния текущего уровня (S);
- Mdimension — размерность окна скрытого состояния верхнего уровня (M).
Эти параметры задают каркас для вычислительного процесса.
Затем начинается последовательная обработка данных. Сначала мы выделяем срытое состояние текущего уровня, полученное в результате предшествующего прямого прохода.
if(!cS.FeedForward(cSM.AsObject())) return false; if(!cSM.SwapOutputs()) return false;
После этого выполняется метод SwapOutputs объекта cSM, чтобы сохранить скрытые состояние предшествующего временного шага для целей обратного прохода.
Следующий шаг — конкатенирование анализируемых признаков со скрытыми состояниями текущего и верхнего уровней. Этот шаг формирует единый тензор признаков, который содержит всю необходимую информацию для обработки обоих GRU-ячеек.
if(!Concat(NeuronOCL.getOutput(), NeuronOCL.getOutput(), cS.getOutput(), SecondInput, cConcatenated[0].getOutput(), Fdimension, Fdimension, Sdimension, Mdimension, units)) return false;
В терминах финансовых потоков это как формирование комплексного снимка рынка на текущий тик.
После этого запускается одноименный метод cFSM, который выполняет мультиоконную свёртку и создаёт проекции для GRU.
if(!cFSM.FeedForward(cConcatenated[0].AsObject())) return false;
Затем вызывается метод GRU, который реализует обновление скрытых состояний.
if(!GRU()) return false;
Полученный тензор конкатенируем с анализируемыми признаками текущего состояния, подготавливая данные к вычислению выходного сигнала и кандидата состояния.
if(!Concat(NeuronOCL.getOutput(), cSM.getOutput(), cConcatenated[1].getOutput(), Fdimension, 2 * Sdimension, units)) return false;
Вызов метода FeedForward для объектов cOs и cOt позволяет сгенерировать гейты и кандидатов результатов ST-ConvGRU.
if(!cOs.FeedForward(cConcatenated[1].AsObject())) return false; if(!cOt.FeedForward(cSM.AsObject())) return false;
После чего метод ElementMult комбинирует их, формируя итоговый результат.
if(!ElementMult(cOs.getOutput(), cOt.getOutput(), cFo.getOutput())) return false;
На финальном этапе полученные значения нормализуются и передаются в спайковую активацию.
if(!cNorm.FeedForward(cFo.AsObject())) return false; //--- return CNeuronSpikeActivation::feedForward(cNorm.AsObject()); }
В контексте финансовых потоков метод feedForward работает как скоординированный аналитик. Он одновременно обрабатывает текущие события, учитывает контекст верхнего уровня и историю скрытых состояний, фильтрует шум и формирует аккумулированное представление рынка. Каждое обновлённое скрытое состояние становится информативным сигналом для прогнозирования движения цены, отражая как локальные микропаттерны, так и глобальные тренды.
После того как мы получили прогноз с использованием случайных параметров модели, он, естественно, будет далёк от желаемого. Поэтому следующий шаг — организация процесса обучения, который начинается с работы над ошибками. В методе calcInputGradients реализуется обратное распространение ошибки через всю структуру ST-ConvGRU.
bool CNeuronSpikeSTConvGRU::calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) { if(!NeuronOCL || !SecondGradient || !SecondInput) return false; //--- uint Fdimension = cFSM.GetWindow(0); uint Sdimension = cS.GetDimension(); uint Mdimension = cFSM.GetWindow(3); uint units = cFSM.GetUnits();
Алгоритм метода начинается с проверки корректности полученных указателей на объекты исходных данных. Если отсутствует основной поток данных, вторичный вход или буфер градиентов, процесс не может быть выполнен.
Затем извлекаются ключевые параметры: Fdimension, Sdimension, Mdimension. Это определяет каркас градиентного потока.
Далее вызывается одноименный метод родительского класса, который начинает распространение ошибки от спайковой активации.
if(!CNeuronSpikeActivation::calcInputGradients(cNorm.AsObject())) return false;
Сигнал ошибки проходит через слой нормализации к блоку результатов ST-ConvGRU.
if(!cFo.CalcHiddenGradients(cNorm.AsObject())) return false;
Метод ElementMultGrad распределяет градиенты между гейтами результатов (cOs) и кандидатами состояния (cOt), учитывая их функции активации.
if(!ElementMultGrad(cOs.getOutput(), cOs.getGradient(), cOt.getOutput(), cOt.getGradient(), cFo.getGradient(), cOs.Activation(), cOt.Activation())) return false;
Этот шаг позволяет правильно распределить ошибку по всем элементам памяти, формируя корректные сигналы для обновления весов.
Далее градиенты проходят через cSM, который соединяет нижний и верхний контекст, и через блок cConcatenated[1], распределяет ошибки в объединённом тензоре.
if(!cSM.CalcHiddenGradients(cOt.AsObject())) return false; if(!cConcatenated[1].CalcHiddenGradients(cOs.AsObject())) return false; if(!DeConcat(NeuronOCL.getGradient(), cConcatenated[1].getPrevOutput(), cConcatenated[1].getGradient(), Fdimension, 2 * Sdimension, units)) return false;
DeConcat разделяет градиенты, возвращая их в исходные блоки, а DeActivation корректирует значения с учётом функций активации.
if(cSM.Activation() != None) if(!DeActivation(cSM.getOutput(), cConcatenated[1].getPrevOutput(), cConcatenated[1].getPrevOutput(), cSM.Activation())) return false;
Затем метод SumAndNormalize аккумулирует градиенты от разных источников, обеспечивая стабильное распространение ошибки через параллельные пути.
if(!SumAndNormilize(cSM.getGradient(), cConcatenated[1].getGradient(), cSM.getGradient(), 2 * Sdimension, false, 0, 0, 0, 1)) return false;
GRU_grad выполняет распространение ошибки внутри самих GRU-ячеек, распределяя её между управляющими сигналами и кандидатным состоянием.
if(!GRU_grad()) return false;
После этого градиенты возвращаются до тензора конкатенации cConcatenated[0] через cFSM.
if(!cConcatenated[0].CalcHiddenGradients(cFSM.AsObject())) return false; if(!DeConcat(cConcatenated[0].getPrevOutput(), cConcatenated[1].getPrevOutput(), cS.getPrevOutput(), SecondGradient, cConcatenated[0].getGradient(), Fdimension, Fdimension, Sdimension, Mdimension, units)) return false;
Методы DeConcat и DeActivation восстанавливают корректные сигналы для второго входа и основного потока NeuronOCL.
if(SecondActivation != None) if(!DeActivation(SecondInput, SecondGradient, SecondGradient, SecondActivation)) return false;
На финальном этапе ошибки на уровне объекта исходных данных аккумулируются от разных информационных потоков и корректируются на производную функции активации.
if(!SumAndNormilize(NeuronOCL.getGradient(), cConcatenated[0].getPrevOutput(), NeuronOCL.getGradient(), Fdimension, false, 0, 0, 0, 1) || !SumAndNormilize(NeuronOCL.getGradient(), cConcatenated[1].getPrevOutput(), NeuronOCL.getGradient(), Fdimension, false, 0, 0, 0, 1)) return false; Deactivation(NeuronOCL) //--- return true; }
В контексте финансовых потоков метод calcInputGradients выполняет роль аналитика обратной связи. Он просматривает прогноз, сравнивает его с фактическим движением рынка, распределяет ошибку по всем слоям и каналам модуля, корректируя память и управляющие сигналы. Каждый блок модели получает точные указания, какие элементы информации были недостаточно учтены или переоценены. Это позволяет эффективно обучать модель и повышать точность прогнозов.
Этот механизм может показаться громоздким, но в многоуровневых рекуррентно-сверточных конструкциях иначе и быть не может. Каждое звено влияет на следующее, и малейшая неточность в распределении градиента мгновенно приводит к деградации обучения. Текущая реализация обеспечивает строгую последовательность вычислений и защищает модель от таких ошибок, позволяя нам уверенно двигаться дальше к настройке параметров.
Метод обновления параметров updateInputWeights оставим для самостоятельного освоения. Он интуитивен после понимания структуры градиентного потока. Полный код класса, включая все вспомогательные методы, представлен во вложении и может служить удобной основой для экспериментов и дальнейших улучшений.
Блок FERE-Net
После завершения разработки модуля ST-ConvGRU, мы подходим к новой ключевой вехе — созданию Энкодера, который станет входным препроцессорным центром всей вычислительной цепочки. Его задача — аккуратно собрать, структурировать и преобразовать поток данных так, чтобы последующие слои получали уже подготовленное, компактное и информативное представление. Для этого мы вводим специализированный объект class CNeuronFERENet.
class CNeuronFERENet : public CNeuronSpikeConvGRU { protected: CLayer cFlow; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronFERENet(void) {}; ~CNeuronFERENet(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint units, uint &chanels[], ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronFERENet; } //--- methods for working with files virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual void SetOpenCL(COpenCLMy *obj) override; virtual bool Clear(void) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; };
Новый класс наследует функциональную основу ConvGRU, но расширяет её собственным механизмом потоковой обработки, реализованным через внутренний динамический массив cFlow. В нём сосредоточена логика, обеспечивающая согласованное преобразование анализируемых данных во время прямого прохода, распределение градиентов на этапе обратного прохода, а также обновление параметров.
Инициализация объекта CNeuronFERENet открывает новый этап построения нашего энкодера — этап, в котором разрозненные элементы начинают соединяться в цельную вычислительную систему.
bool CNeuronFERENet::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint units, uint &chanels[], ENUM_OPTIMIZATION optimization_type, uint batch) { uint layers = chanels.Size() - 1; if(layers < 2) return false;
Процесс начинается с простого, но жизненно важного шага. Мы проверяем конфигурацию полученного массива размерности каналов. Это тот самый случай, когда классические принципы разработки напоминают строгого учителя — если глубины модели недостаточно, работать дальше просто нет смысла. Энкодер обязан иметь хотя бы два уровня, иначе он не сможет формировать полноценные скрытые представления.
Пройдя первичную проверку, объект обращается к одноименному методу родительского класса. Здесь закладывается фундамент: резервируются буферы, инициализируется контекст OpenCL, определяются параметры оптимизации. Всё это можно сравнить с подготовкой рабочего стола перед тонкой ручной работой — никаких случайных инструментов под рукой, всё на своих местах, всё строго под задачу.
if(!CNeuronSpikeConvGRU::Init(numOutputs, myIndex, open_cl, units, chanels[layers - 1], chanels[layers], optimization_type, batch)) return false;
Когда базовые механизмы готовы, мы начинаем собирать вычислительный конвейер энкодера. Контейнер cFlow очищается и связывается с тем же OpenCL-контекстом.
cFlow.Clear(); cFlow.SetOpenCL(OpenCL);
Такой шаг позволяет избежать лишних переключений контекстов и добиваться высокой пропускной способности при последовательной обработке данных. По сути, это создание трассы для движения сигналов, по которой дальше будут работать все слои нашего будущего энкодера.
Первым элементом этого потока становится CNeuronSpikeSTConvGRU. Это не просто входной слой, а настоящий фильтр-организатор данных, который структурирует исходный поток информации в удобную для дальнейших этапов форму.
uint index = 0; uint windows[] = { chanels[0], chanels[layers] }; CNeuronSpikeSTConvGRU* st_gru = new CNeuronSpikeSTConvGRU(); if(!st_gru || !st_gru.Init(0, index, OpenCL, units, windows, chanels[1], optimization, iBatch) || !cFlow.Add(st_gru)) { DeleteObj(st_gru) return false; }
Мы передаём ему размеры окон, число элементов и размерность признаков на выходе. Если представлять работу модели в образах, то именно этот слой выравнивает партитуру сигнала, превращая сырой поток данных в аккуратно разложенные по временным нотам фрагменты. После успешной инициализации он добавляется в вычислительный конвейер. Любая неудача приводит к аккуратной очистке памяти — никакого шанса на висящие указатели или неопределённое состояние.
Следом начинает формироваться центральная часть энкодера — цепочка CNeuronSpikeConvGRU. Каждый слой принимает результат предыдущего, постепенно уплотняя и углубляя информацию. Это похоже на последовательную работу экспертов: первый очищает сигнал, второй выявляет важные структуры, третий формирует устойчивые паттерны. Такая каскадная архитектура позволяет энкодеру извлекать многослойные скрытые зависимости и подготавливать данные для завершающей части модели.
CNeuronSpikeConvGRU* gru = NULL; for(uint i = 1; i < layers - 1; i++) { CNeuronSpikeConvGRU* gru = new CNeuronSpikeConvGRU(); if(!gru || !gru.Init(0, index, OpenCL, units, chanels[i], chanels[i + 1], optimization, iBatch) || !cFlow.Add(gru)) { DeleteObj(gru) return false; } } //--- return true; }
На каждом шаге создаётся новый объект, запускается его инициализация, и если всё проходит успешно — он вплетается в вычислительный поток. Но стоит появиться малейшему сбою, мы сразу же освобождаем ресурсы и прерываем процесс. Эта строгость — фундаментальная черта всех стабильных систем: конвейер должен быть либо собран полностью, либо не собран вовсе.
Когда цепочка завершается, и все слои аккуратно заняли свои места, метод возвращает успешный результат. Это означает, что энкодер готов к работе.
После успешной инициализации наступает момент, когда модель должна продемонстрировать свою профессиональную хватку — пройти по вычислительному конвейеру и сформировать устойчивое скрытое представление анализируемого потока. Именно это и делает метод feedForward. Здесь нет места импровизации. Каждый шаг строго выверен, а любые отклонения немедленно прерывают процесс, охраняя логику модели от повреждений.
bool CNeuronFERENet::feedForward(CNeuronBaseOCL *NeuronOCL) { CNeuronBaseOCL *prev = NeuronOCL; CNeuronBaseOCL *curr = cFlow[0];
В самом начале мы определяем две опорные переменные — prev и curr. Первая указывает на объект, чьи данные будут служить входом для текущего слоя. Вторая — на слой, который предстоит активировать. Эта пара работает как передаточный механизм: один элемент передаёт импульс, второй — принимает и преобразует.
Сразу же берётся первый элемент конвейера cFlow[0]. Это тот самый ST-ConvGRU, который мы установили в качестве входного блока. Он необычен тем, что на вход получает не только результаты предыдущего слоя, но и состояние верхнего уровня. Его роль выполняет унаследованный объект cH. Это своего рода дополнительный контекст, хранящий память о происходящем на верхнем уровне и позволяющий слою работать с временными зависимостями более гибко и дальнозорко.
if(!curr || !curr.FeedForward(prev, cH.getOutput())) return false; prev = curr;
Этот блок действует как опытный аналитик, который изучает данные не только здесь и сейчас, но и под углом предыдущих трендов — а для финансовых рядов это особенно ценно.
Если что-то идёт не так — мы немедленно прекращаем работу. Но если всё успешно, prev обновляется. Теперь он указывает уже на вычисленный результат, которым будет питаться следующий слой.
Затем мы переходим к центральной части энкодера — каскаду ConvGRU, хранящихся в cFlow. В цикле от второго и до последнего слоя каждый блок получает ровно один вход — выход предыдущего слоя, который мы аккуратно передаём через переменную prev.
for(int i = 1; i < cFlow.Total(); i++) { curr = cFlow[i]; if(!curr || !curr.FeedForward(prev)) return false; prev = curr; } //--- return CNeuronSpikeConvGRU::feedForward(prev); }
Архитектура превращается в хорошо отлаженный конвейер. Сигнал последовательно проходит фильтры, выделяющие локальные паттерны, затем свёрточно-рекуррентные модули, которые углубляют модель и извлекают более абстрактные временные зависимости.
Каждый вызов — это мини-процесс обработки данных. Вычисление проекций, обновление скрытых состояний, применение активаций, подготовка информации для последующего слоя. Каждый такой слой — это инструмент, который снимает шум, выделяет тренд или обнаруживает скрытый цикл. В итоге сигнал выходит из глубины конвейера куда более зрелым и структурированным, чем на входе.
После прохождения через весь поток cFlow, последний слой в цепочке передаётся в одноименный метод родительского класса. Это важный штрих. Наш энкодер не замыкается сам на себе, а передаёт данные дальше, к верхнему уровню модели. Здесь начинается следующий этап обработки, который уже отвечает за интеграцию полученного представления в общую структуру модели.
Таким образом, весь метод feedForward работает как элегантный дирижёр: получает сырые данные, проводит их через серию структурирующих и рекуррентных преобразований, и передаёт результат выше, гарантируя чистоту структуры и упорядоченность сигналов. И всё это — строго, цельно, без единой лишней операции, как должна вести себя хорошо спроектированная модель, предназначенная для анализа финансовых временных рядов.
Линейная структура энкодера играет нам на руку и в контексте обучения. Раз прямой проход выстроен в строгую, последовательную цепочку без разветвлений, то и обратный проход наследует ту же предсказуемую логику. Градиенты двигаются по тем же узлам, только в обратном направлении, не встречая ни скрытых развилок, ни дополнительных карманов вычислений. Для исследователя это удобство сродни работе с классическими индикаторами: если входной сигнал проходит по прямой, то и обратная волна отката столь же понятна и прозрачна.
Мы сознательно не перегружаем статью подробностями обратного прохода — все методы строго соответствуют знакомой схеме и не содержат скрытых нюансов, требующих отдельного углубления. Заинтересованный читатель без труда найдёт полный код класса во вложении и сможет изучить его в удобном темпе, сопоставляя каждую операцию с механикой прямого прохода. Такой подход позволяет сохранить фокус на архитектурной сути энкодера, не отрываясь на повторение уже знакомых паттернов вычислений.
Сегодня мы проделали впечатляющий объём работы, и самое время немного остановиться. Дадим мыслям улечься, а глазам — передохнуть. В короткой паузе есть своя мудрость: свежий взгляд завтра позволит нам уверенно довести начатое до логического завершения. Уже в следующей статье мы продолжим путь и аккуратно завершим реализацию предложенной архитектуры.
Заключение
Сегодняшняя работа стала ещё одним шагом к практической реализации архитектуры EV-MGRFlowNet средствами MQL5. Мы разобрали ключевые элементы ST-ConvGRU, заложили фундамент энкодера и показали, как эти механизмы можно адаптировать под задачи анализа рыночной динамики. По мере развития проекта структура приобретает всё более чёткие очертания, а модель — функциональную глубину, необходимую для уверенной работы с потоковыми финансовыми данными. В следующей статье мы продолжим этот путь, завершив построение архитектуры и подойдя вплотную к оценке эффективности подхода, который обещает открыть новые возможности в прогнозировании рыночных движений.
Ссылки
- EV-MGRFlowNet: Motion-Guided Recurrent Network for Unsupervised Event-based Optical Flow with Hybrid Motion-Compensation Loss
- Другие статьи серии
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Study.mq5 | Советник | Советник офлайн обучения моделей |
| 2 | StudyOnline.mq5 | Советник | Советник онлайн обучения моделей |
| 3 | Test.mq5 | Советник | Советник для тестирования модели |
| 4 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы и архитектуры моделей |
| 5 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 6 | NeuroNet.cl | Библиотека | Библиотека кода OpenCL-программы |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования