
От новичка до эксперта: Подтверждение зон спроса и предложения через статистические данные

Содержание:
Введение
Анализ зон спроса и предложения представляет собой краеугольный камень торговли ценовыми движениями, основанный на вечном экономическом принципе рыночного дисбаланса. Для дискреционного трейдера эти зоны определяются с помощью визуального распознавания паттернов — навыка, отточенного опытом. Однако такая зависимость от субъективных суждений создает серьезные проблемы с воспроизводимостью, образуя основное препятствие на пути эффективной автоматизации. В то время как теоретическая логика этих зон хорошо известна, ее воплощение в точные вычислительные правила остается труднодостижимым, часто с использованием произвольных числовых пороговых значений.
В статье представлена структурированная методология, направленная на устранение этого разрыва. Мы подробно описываем полный, воспроизводимый процесс, преобразующий качественное понятие «импульсивного выхода» в количественно измеримое, статистически подтвержденное торговое правило. Наш подход вносит ключевое методологическое упрощение посредством использования в качестве основной единицы анализа отдельных свечей на более старших таймфреймах (HTF). Это позволяет нам четко определить суть зоны спроса или предложения и измерить ее определяющую характеристику: импульс.
Используя исследовательскую среду на основе Python в рамках Jupyter Notebook, мы систематически определяем статистический профиль зоны высокой вероятности. Полученные параметры затем кодируются в советник MQL5, создавая прозрачный, основанный на фактических данных торговый инструмент. Этот процесс переводит дисциплину от вопроса: «Выглядит ли это прочно?» к ответу на вопрос: «Соответствует ли это статистически определенным критериям прочности?»
Концептуальные основы: Анатомия рыночного дисбаланса
Основной принцип: Ценовой дисбаланс
Зона спроса или предложения — это ценовой уровень, на котором равновесие между покупателями и продавцами решительно нарушается. Агрессивный приток заказов с одной стороны подавляет другую, в результате чего цена стремительно покидает область. Этот стремительный уход — импульсивный выход — оставляет после себя теоретическую концентрацию незаполненных противостоящих ордеров. Эта зона дисбаланса затем становится областью, представляющей будущий интерес, поскольку цена склонна реагировать на его возвращение.
Определение структурных компонентов
На основе анализа торговой литературы и тщательного личного изучения графиков можно выделить структуру классической зоны:
Зона предложения: Область, где давление со стороны продавцов преобладает над интересом покупателей. Визуально это определяется консолидационной основой (серией свечей с перекрывающимися диапазонами), за которой следует сильная медвежья импульсная свеча, закрывающаяся ниже минимума основы.
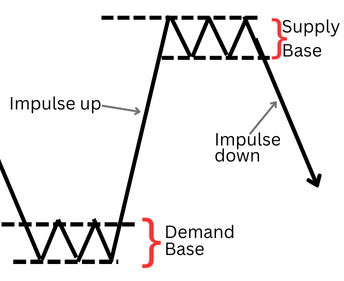
Концепции спроса и предложения
Зона спроса: Обратная бычья тенденция, при которой агрессивные покупки провоцируют импульсивную бычью свечу, закрывающуюся выше максимума консолидационной основы.
Импульсивная свеча выхода является критическим компонентом. Это сигнатура рынка, подтверждающая дисбаланс. В дискреционной практике её "прочность" оценивается визуально, что приводит к противоречивости. Таким образом, величина этой свечи становится основной переменной для нашего количественного исследования.
Полный жизненный цикл зоны: Импульс, продолжение и повторное тестирование
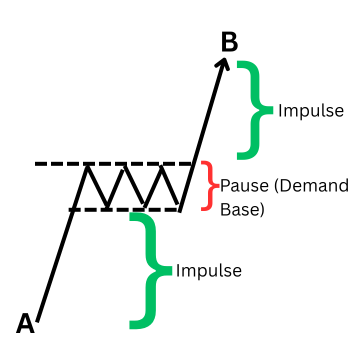
Понимание первоначального выхода - это только первый этап. Полный жизненный цикл действительной зоны часто состоит из двух ключевых движений:
- Этап 1 — Первоначальный импульсивный выход: Цена отрывается от основы с импульсом, устанавливая новый краткосрочный направленный экстремум.
- Этап 2 — Повторное тестирование и реакция: Цена часто возвращается в исходную зону, повторно тестируя область дисбаланса. Такое повторное тестирование часто приводит ко второму, реактивному выходу из зоны при обнаружении оставшихся незаполненных ордеров.

Зона спроса (консолидация в точке А, выход в точку В и возврат к спросу в точке С)
На следующем изображении представлен наглядный жизненный цикл зоны предложения, с указанием соответствующих медвежьих фаз.

Зона предложения с одной свечой (S), импульс выхода A в точку B. Возврат в зону в точке C.
В настоящем исследовании мы сосредоточились на точной количественной оценке Этапа 1 — начальный импульсивный выход. Это наиболее четко определенное и измеримое событие, служащее основополагающим триггером. Статистически обоснованное определение этого выхода позволяет напрямую выявлять зоны высокой вероятности, на основе которых можно надежно разрабатывать стратегии, включающие повторное тестирование.
Методологическое обоснование: модель одной свечи на более старшем таймфрейме
Для перехода от визуальных паттернов к количественным данным мы используем целенаправленный и надежный методологический подход: весь процесс равновесия и дисбаланса зачастую эффективно отражается в структуре одной свечи на более старшем таймфрейме (HTF).
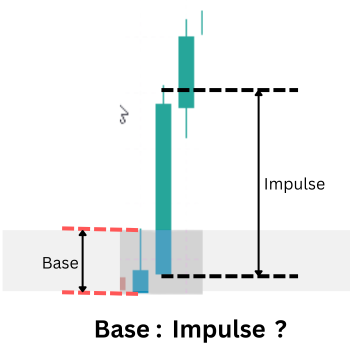
Настройка спроса по одной свече (маленькая базовая свеча и большая выходная свеча)
Информацию о спросе и предложении также можно найти в дальнейших настройках
Концептуальная верность: Сильная, направленная свеча на более старшем таймфрейме в точке поворота является прямым результатом изучаемого нами дисбаланса. Анализ внутренней структуры на более младшем таймфрейме обычно выявляет классическую последовательность: базовое движение с последующим импульсным движением. Свеча на более старшем таймфрейме представляет собой совокупную сигнатуру этой микроструктуры.
Преимущества количественных исследований:
- Четкость сигнала: выделяет решающее рыночное событие, отфильтровывая длительные, неоднозначные консолидации.
- Уменьшенная параметрическая сложность: устраняет необходимость в нескольких параметрах для определения основы из нескольких свечей (например, количество свечей, допустимое перекрытие). Границы одной свечи (открытие, максимум, минимум, закрытие) однозначны.
- Фрактальная валидность: данный принцип остается неизменным для разных таймфреймов, что позволяет применять результаты исследований, проведенных на более старшем таймфрейме (например, H4), к более младшему исполнительному таймфрейму (например, M15).
В этой модели наш основной показатель смещается от сравнения двух отдельных свечей (основа против выхода) к анализу внутреннего импульса одной свечи. Мы определяем это как "Коэффициент импульса": (закрытие-открытие)/(максимум-минимум). Высокий "Коэффициент импульса" (например, > 0,7) указывает на свечу с сильным направленным телом и минимальными тенями — точный статистический признак решающего выхода.
Таким образом, наш главный исследовательский вопрос уточняется: Каковы статистически оптимальные пороговые значения для коэффициента импульса и минимального абсолютного размера (в пипсах), определяющие свечу с высокой вероятностью формирования зоны на более старшем таймфрейме?
Процесс исследований и реализации
Чтобы ответить на этот вопрос, мы используем четкий трехэтапный процесс, гарантирующий, что каждое алгоритмическое правило основано на эмпирических данных.
Этап 1: Систематический сбор данных (MQL5)
Мы разработали пользовательский скрипт на MQL5, который действует как систематический сканер. Он определяет потенциальные свечи на более старших таймфреймах в точках поворота и экспортирует их основные показатели в CSV-файл. Точки данных по каждому кандидату включают в себя:
- временную метку, символ, таймфрейм
- размер тела свечи (в пипсах), общий диапазон (в пипсах), рассчитанный коэффициент импульса
- Контекст волатильности (например, значение ATR на момент закрытия свечи)
Маркировка основана на последующем движении цены, чтобы определить "успех" для последующего анализа.
Этап 2: Статистическое обнаружение и оптимизация пороговых значений (Python/Jupyter Notebook)
В Jupyter Notebook мы проводим предварительный анализ собранного набора данных.
- Описательная статистика: Анализируем распределение коэффициента импульса и размера тела по всем кандидатам.
- Анализ успешного выполнения: Сегментируем данные на основе того, привела ли свеча-кандидат к успешной реакции цены, а затем сравниваем статистические характеристики "успешных" и "неуспешных" групп.
- Оптимизация пороговых значений: Определяем оптимальные пороговые значения (например, минимальный коэффициент импульса 0,65, минимальный размер тела 1,2 * ATR), которые максимизируют разницу в показателях успеха, тем самым определяя наше статистически подтвержденное правило торговли.
Этап 3: Реализация и валидация модели (советник MQL5)
Последним, решающим шагом является преобразование статистических данных в исполняемую торговую логику. Оптимизированные параметры жестко запрограммированы в советнике MQL5. Этот советник сканирует свечи на более старшем таймфрейме, соответствующие статистически подтвержденным критериям, автоматически проецирует границы зон и может быть расширен для управления сделками на более младшем таймфрейме, завершая цикл от исследования до автоматического исполнения.
Реализация
Систематический сбор данных (MQL5)
Первым и наиболее важным этапом наших исследований является систематический сбор высококачественных, детализированных рыночных данных. Этот процесс решительно выходит за рамки ретроспективного анализа графиков. Мы разработали специальный скрипт на MQL5, который будет выполнять функцию непредвзятого поиска данных, программно сканируя историческое движение цены, чтобы зафиксировать каждое появление нашего определенного паттерна из двух свечей - "маленькой" свечи, за которой следует большая свеча "выхода" в том же направлении. Основная функция скрипта заключается в преобразовании визуальных ценовых структур в структурированный набор данных (CSV), с фиксированием точных показателей, таких как размеры тела в пипсах, их соотношение и значения с поправкой на волатильность, с помощью среднего истинного диапазона (ATR).
Путём сбора тысяч таких наблюдений в различных рыночных условиях, мы создаем необходимую эмпирическую базу. Эти необработанные данные являются исходными для нашего статистического анализа, гарантирующего, что каждая последующая информация и параметр основаны на объективном поведении рынка, а не на субъективных суждениях.
Скрипт сбора данных
Следующая разбивка объясняет логику и назначение каждого раздела кода в нашем скрипте сбора данных (SD_BaseExit_Research.mq5). Полный исходный код приложен в конце данной статьи.
1. Заголовки скрипта и конфигурация (входные данные)
В этом разделе определяется идентичность скрипта и, что наиболее важно, настраиваемые параметры, управляющие его поведением.
//--- Inputs: Define what "small" and "bigger" mean input int BarsToProcess = 20000; // Total bars to scan input int ATR_Period = 14; // For volatility context input double MaxBaseBodyATR = 0.5; // Base candle max size (e.g., 0.5 * ATR) input double MinExitBodyRatio = 2.0; // Exit must be at least this many times bigger than base input bool CollectAllData = true; // TRUE=log all pairs, FALSE=use above filters now input string OutFilePrefix = "SD_BaseExit";
Эти входные данные делают скрипт гибким исследовательским инструментом. Для первоначального обнаружения CollectAllData должен иметь значение true, чтобы собрать широкую выборку. Позже вы можете установить значение false для проверки определенных пороговых значений размера (MaxBaseBodyATR, MinExitBodyRatio) непосредственно в MetaTrader 5.
2. Основная инициализация (функция OnStart)
В этой части настраиваются необходимые инструменты для обработки и хранения данных: получение данных ATR и создание выходного CSV-файла.
- Создание хэндла ATR: Извлекает данные о среднем истинном диапазоне, которые имеют решающее значение для понимания контекста волатильности.
- Создание файла CSV: Открывает новый файл для записи данных. Имя файла включает в себя символ и таймфрейм для четкой организации.
- Строка заголовка CSV: Записывает заголовки столбцов, определяющие структуру набора данных.
// 1. INITIALIZATION: Get ATR data and open the data log (CSV file) atrHandle = iATR(_Symbol, _Period, ATR_Period); if(atrHandle == INVALID_HANDLE) { Print("Error: Could not get ATR data."); return; } string tf = PeriodToString(_Period); string fileName = StringFormat("%s_%s_%s.csv", OutFilePrefix, _Symbol, tf); int fileHandle = FileOpen(fileName, FILE_WRITE|FILE_CSV|FILE_ANSI); if(fileHandle == INVALID_HANDLE) { Print("Failed to create file: ", fileName); return; } // Write the header. Each row will be one observed "base-exit" candle pair. FileWrite(fileHandle, "Pattern", "Symbol", "Timeframe", "Timestamp", "Base_BodyPips", "Exit_BodyPips", "ExitToBaseRatio", "ATR_Pips", "Base_BodyATR", "Exit_BodyATR", "Base_Open", "Base_Close", "Exit_Open", "Exit_Close" );
3. Основной цикл сканирования: Движок обнаружения паттернов
Этот цикл for является сердцем скрипта и проверяет каждую последовательную пару закрытых свечей в истории.
Логический поток:
- Сопряжение свечей и извлечение данных: Для каждого бара i свеча i является потенциальной основой, а свеча i-1 - потенциальным выходом. Скрипт извлекает цены и рассчитывает размеры тела и коэффициенты ATR.
- Логика паттернов: Проверяет, расположены ли две свечи последовательно и в одном направлении.
- Бычья пара → Классифицируется как паттерн-кандидат на "спрос".
- Медвежья пара → Классифицируется как паттерн-кандидат на "предложение".
- Смешанные направления отбрасываются.
// 2. MAIN SCANNING LOOP: Look at every consecutive pair of candles for(int i = 1; i < barsToCheck; i++) { int baseIdx = i; // The older candle (potential base) int exitIdx = i - 1; // The newer candle (potential exit) // ... (Data extraction for base and exit candles) ... // 3. PATTERN IDENTIFICATION: Determine direction and type string patternType = "None"; bool isBullishBase = baseClose > baseOpen; bool isBullishExit = exitClose > exitOpen; bool isBearishBase = baseClose < baseOpen; bool isBearishExit = exitClose < exitOpen; // The core logic: A valid pattern requires consecutive candles in the SAME direction. if(isBullishBase && isBullishExit) { patternType = "Demand"; } else if(isBearishBase && isBearishExit) { patternType = "Supply"; } if(patternType == "None") continue; // Skip mixed-direction pairs
4. Стратегическая фильтрация: Баланс между количеством и качеством данных
Это критически важный момент принятия решения в ходе исследования, который контролируется флагом CollectAllData. Он определяет, следует ли собирать широкую выборку для исследования или сразу же применять строгие фильтры.
// 4. DATA FILTERING (Optional): Apply size rules if not collecting everything if(!CollectAllData) { // Rule: Base candle must be relatively small compared to market noise bool isBaseSmallEnough = baseBodyATR < MaxBaseBodyATR; // Rule: Exit candle must be significantly larger than the base bool isExitLargeEnough = exitToBaseRatio >= MinExitBodyRatio; if(!isBaseSmallEnough || !isExitLargeEnough) { continue; // Skip this pair, it doesn't meet our current test filters } } // If CollectAllData is TRUE, we log EVERY same-direction pair, regardless of size. // This is best for initial research.
5. Регистрация и очистка данных
Для каждого допустимого паттерна в CSV-файл записывается подробная строка. Наконец, ресурсы распределены надлежащим образом.
// 5. DATA LOGGING: Write all details of this pair to our CSV file datetime exitTime = iTime(_Symbol, _Period, exitIdx); MqlDateTime dtStruct; TimeToStruct(exitTime, dtStruct); string timeStamp = StringFormat("%04d-%02d-%02dT%02d:%02d:%02d", dtStruct.year, dtStruct.mon, dtStruct.day, dtStruct.hour, dtStruct.min, dtStruct.sec); FileWrite(fileHandle, patternType, _Symbol, tf, timeStamp, DoubleToString(baseBodyPips, 2), DoubleToString(exitBodyPips, 2), DoubleToString(exitToBaseRatio, 2), DoubleToString(atrExit / _Point, 2), DoubleToString(baseBodyATR, 3), DoubleToString(exitBodyATR, 3), DoubleToString(baseOpen, _Digits), DoubleToString(baseClose, _Digits), DoubleToString(exitOpen, _Digits), DoubleToString(exitClose, _Digits) ); dataRowsWritten++; } // 6. CLEANUP: Close the file and release the indicator handle FileClose(fileHandle); IndicatorRelease(atrHandle);
После того, как наш скрипт на MQL5 собрал исходные данные, следующим важным шагом является плавный перенос этого набора данных в нашу среду статистического анализа. Этот процесс включает в себя поиск выходного файла и запуск рабочей области Python для исследований.
Определение местоположения собранных данных
После завершения работы скрипт сохранит CSV-файл в стандартном каталоге MQL5/Files/ в папке данных вашего терминала MetaTrader 5. Точный путь обычно следует этому шаблону:
C:\Users\[YourUserName]\AppData\Roaming\MetaQuotes\Terminal\[TerminalID]\MQL5\Files.
Файл будет назван в соответствии с соглашением нашего скрипта, например, SD_BaseExit_EURUSD_H1.csv. Этот файл содержит все пары свечей с временными метками "Base-Exit" и их рассчитанные показатели, готовые для научного изучения.
Запуск среды анализа на Python
Чтобы начать анализ, открываем интерфейс командной строки (командную строку или терминал), переходим в этот каталог и запускаем Jupyter Notebook. Это можно эффективно сделать с помощью нескольких команд:
# Navigate to the directory containing your CSV file cd "C:\Users\[YourUserName]\AppData\Roaming\MetaQuotes\Terminal\[TerminalID]\MQL5\Files" # Launch the Jupyter Notebook server jupyter notebook
Эта последовательность действий открывает интерфейс JupyterLab в вашем веб-браузере, создавая прямой доступ к вашим данным. Здесь вы можете создать новую записную книжку (например, Supply_and_demand_Research.ipynb), специально предназначенную для этого исследовательского проекта.
Этап 2: Статистическое обнаружение и оптимизация пороговых значений (Python/Jupyter Notebook)
Ячейка 1: Настройка и прием данных
Эта ячейка подготавливает исследовательскую среду на Python и загружает набор данных, экспортированный из MetaTrader 5, для анализа.
Во-первых, она импортирует необходимые научные библиотеки и библиотеки визуализации. Эти библиотеки предлагают инструменты для манипулирования данными (pandas, numpy), статистического анализа (scipy) и графического исследования (matplotlib, seaborn). Предупреждения подавляются, чтобы обеспечить четкость и читабельность результатов исследования, что особенно важно при представлении результатов в статье.
Далее, визуальный стиль графиков настраивается таким образом, чтобы получать единообразные графики, пригодные для публикации. Это гарантирует, что все графики, созданные позже в блокноте, будут иметь единое оформление, что упростит интерпретацию распределений и трендов.
Затем ячейка загружает CSV-файл, сгенерированный скриптом сбора данных MQL5. Поскольку файл экспортируется с разделителями-табуляторами, соответствующий разделитель указывается явно, чтобы гарантировать корректный анализ данных. Этот шаг имеет решающее значение для сохранения целостности числовых данных, особенно значений пипсов, соотношений и временных меток.
# %% [markdown] # # # **Objective:** Analyze the harvested candlestick data to discover statistically significant thresholds for a valid "impulsive exit." # **Data:** `SD_BaseExit_XAUUSDr_5.csv` # **Method:** Exploratory Data Analysis (EDA), Distribution Analysis, and Success Rate Correlation. # %% [markdown] # ## 1. Setup & Data Ingestion (Corrected) # Loading tab-delimited data # %% import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns from scipy import stats import warnings warnings.filterwarnings('ignore') # Set visual style plt.style.use('seaborn-v0_8-darkgrid') sns.set_palette("husl") # Load the data with TAB as delimiter file_path = "SD_BaseExit_XAUUSDr_5.csv" df = pd.read_csv(file_path, sep='\t') # Tab-separated print("✅ Data loaded successfully (tab-delimited).") print(f"Dataset shape: {df.shape}") print("\n🔍 Column names:") print(list(df.columns)) print("\n📊 First 3 rows:") print(df.head(3))
Результат 1:
✅ Data loaded successfully (tab-delimited). Dataset shape: (9663, 14) 🔍 Column names: ['Pattern', 'Symbol', 'Timeframe', 'Timestamp', 'Base_BodyPips', 'Exit_BodyPips', 'ExitToBaseRatio', 'ATR_Pips', 'Base_BodyATR', 'Exit_BodyATR', 'Base_Open', 'Base_Close', 'Exit_Open', 'Exit_Close'] 📊 First 3 rows: Pattern Symbol Timeframe Timestamp Base_BodyPips \ 0 Demand XAUUSDr 5 2026-01-12T06:45:00 194.0 1 Demand XAUUSDr 5 2026-01-12T06:40:00 226.0 2 Supply XAUUSDr 5 2026-01-12T06:30:00 104.0 Exit_BodyPips ExitToBaseRatio ATR_Pips Base_BodyATR Exit_BodyATR \ 0 155.0 0.80 311.64 0.545 0.497 1 194.0 0.86 355.64 0.632 0.545 2 477.0 4.59 365.79 0.273 1.304 Base_Open Base_Close Exit_Open Exit_Close 0 4566.03 4567.97 4567.96 4569.51 1 4563.80 4566.06 4566.03 4567.97 2 4569.60 4568.56 4568.61 4563.84 🤝
Ячейка 2: Первичная проверка и очистка данных
На этом этапе, прежде чем приступать к статистическому анализу, мы проверили набор данных, чтобы подтвердить его структуру, типы данных и общее качество. Мы проверили наличие всех критически важных полей измерений, проверили наличие пропущенных значений и убедились, что ключевые столбцы, относящиеся к величине свечей, ATR и соотношению выхода к основе, были корректно интерпретированы как числовые данные. Все строки, содержащие неполные или недопустимые значения в этих важных полях, были удалены, в результате чего получен чистый и надежный набор данных, который служит прочной основой для всего последующего исследовательского и статистического анализа.
# %% [markdown] # ## 2. Initial Data Inspection & Cleaning # %% print("📊 Dataset Info:") print(df.info()) print("\n🧹 Checking for missing values:") print(df.isnull().sum()) # Ensure numeric columns are correctly typed numeric_cols = ['Base_BodyPips', 'Exit_BodyPips', 'ExitToBaseRatio', 'ATR_Pips', 'Base_BodyATR', 'Exit_BodyATR'] for col in numeric_cols: if col in df.columns: df[col] = pd.to_numeric(df[col], errors='coerce') else: print(f"⚠️ Warning: Column '{col}' not found in data") # Remove any rows with missing critical data df_clean = df.dropna(subset=numeric_cols).copy() print(f"\n🧽 Data cleaned. Original: {df.shape}, Cleaned: {df_clean.shape}")
Результат 2:
📊 Dataset Info: <class 'pandas.core.frame.DataFrame'> RangeIndex: 9663 entries, 0 to 9662 Data columns (total 14 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Pattern 9663 non-null object 1 Symbol 9663 non-null object 2 Timeframe 9663 non-null int64 3 Timestamp 9663 non-null object 4 Base_BodyPips 9663 non-null float64 5 Exit_BodyPips 9663 non-null float64 6 ExitToBaseRatio 9663 non-null float64 7 ATR_Pips 9663 non-null float64 8 Base_BodyATR 9663 non-null float64 9 Exit_BodyATR 9663 non-null float64 10 Base_Open 9663 non-null float64 11 Base_Close 9663 non-null float64 12 Exit_Open 9663 non-null float64 13 Exit_Close 9663 non-null float64 dtypes: float64(10), int64(1), object(3) memory usage: 1.0+ MB None 🧹 Checking for missing values: Pattern 0 Symbol 0 Timeframe 0 Timestamp 0 Base_BodyPips 0 Exit_BodyPips 0 ExitToBaseRatio 0 ATR_Pips 0 Base_BodyATR 0 Exit_BodyATR 0 Base_Open 0 Base_Close 0 Exit_Open 0 Exit_Close 0 dtype: int64 🧽 Data cleaned. Original: (9663, 14), Cleaned: (9663, 14)
Ячейка 3: Предварительное статистическое исследование показателей спроса и предложения на выходе
На данном этапе мы провели разведочный анализ данных, чтобы получить первоначальное статистическое представление о собранных измерениях. Для всех ключевых числовых переменных были получены описательные статистические данные, позволяющие выявить их центральные тенденции, дисперсию и общее распределение, что помогло нам оценить типичный размер и изменчивость свечей как в области основы, так и на выходе. Кроме того, мы изучили распределение паттернов спроса и предложения в наборе данных и визуализировали их частоту, обеспечив тем самым разумную сбалансированность и репрезентативность выборки перед тем, как перейти к более глубокому анализу пороговых значений величины.
# %% [markdown] # ## 3. Exploratory Data Analysis (EDA) # %% print("🧮 Descriptive Statistics of Key Metrics:") print(df_clean[numeric_cols].describe().round(2)) # Pattern Distribution print(f"\n📈 Pattern Type Distribution:") if 'Pattern' in df_clean.columns: pattern_counts = df_clean['Pattern'].value_counts() print(pattern_counts) # Simple Visualization: Pattern Count plt.figure(figsize=(8,5)) sns.barplot(x=pattern_counts.index, y=pattern_counts.values) plt.title('Count of Supply vs. Demand Patterns Collected') plt.ylabel('Count') plt.show() else: print("⚠️ 'Pattern' column not found")
Результат 3:
🧮 Descriptive Statistics of Key Metrics: Base_BodyPips Exit_BodyPips ExitToBaseRatio ATR_Pips Base_BodyATR \ count 9663.00 9663.00 9663.00 9663.00 9663.00 mean 237.15 247.71 4.13 473.72 0.62 std 253.53 268.18 17.92 230.17 0.82 min 1.00 1.00 0.00 99.50 0.00 25% 74.00 75.00 0.42 316.64 0.16 50% 168.00 173.00 1.04 421.00 0.38 75% 314.00 325.50 2.55 568.36 0.78 max 3441.00 3441.00 770.00 2156.36 22.79 Exit_BodyATR count 9663.00 mean 0.64 std 0.85 min 0.00 25% 0.16 50% 0.39 75% 0.81 max 22.79 📈 Pattern Type Distribution: Pattern Demand 5131 Supply 4532 Name: count, dtype: int64

Ячейка 4: Изоляция импульсивных выходов из зон спроса и предложения
На этом этапе мы намеренно сузили набор данных, чтобы сосредоточиться на сценариях с высоким импульсом спроса и предложения, отфильтровав случаи, когда тело свечи на выходе значительно превышало тело свечи в области основы. Сохраняя только паттерны с соотношением выхода к основе тела более 1,5, мы выделяем свечи-кандидаты, которые визуально и структурно соответствуют тому, что трейдеры обычно описывают как “импульсивные” отклонения от зоны. Это уточнение снижает шум от незначительных перемещений и позволяет последующему статистическому анализу сосредоточиться на выходах, которые, скорее всего, представляют собой подлинное институциональное перемещение.
# Add this after creating df_clean, BEFORE the clustering cell # Filter to only look at patterns where exit was at least 1.5x the base df_strong = df_clean[df_clean['ExitToBaseRatio'] > 1.5].copy() print(f"Analyzing strong candidates: {df_strong.shape[0]} patterns (>{df_clean.shape[0]} total)")
Результат 4:
Analyzing strong candidates: 3725 patterns (>9663 total)
Ячейка 5: Статистическое распределение и пороговый анализ отношения выхода к основе свечи
Используя диаграммы распределения и диаграммы boxplot, мы оценили, как распределяется общая сила выхода и как она различается в зависимости от структуры спроса и предложения. Для того чтобы выйти за рамки визуальной оценки и перейти к основанным на данных критериям, были рассчитаны средние значения, медианные значения и процентильные границы, что позволило нам точно определить диапазоны соотношений, позволяющие последовательно отличать обычное движение цен от статистически значимого смещения.
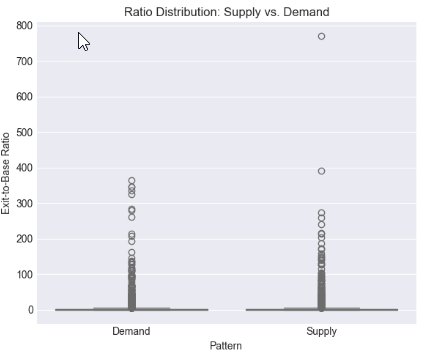
# %% [markdown] # ## 4. Core Analysis: Distribution of Exit-to-Base Ratio # %% if 'ExitToBaseRatio' in df_clean.columns: plt.figure(figsize=(12, 5)) # Histogram with KDE plt.subplot(1, 2, 1) sns.histplot(data=df_clean, x='ExitToBaseRatio', bins=50, kde=True) plt.axvline(x=df_clean['ExitToBaseRatio'].median(), color='red', linestyle='--', label=f'Median: {df_clean["ExitToBaseRatio"].median():.2f}') plt.axvline(x=df_clean['ExitToBaseRatio'].mean(), color='green', linestyle='--', label=f'Mean: {df_clean["ExitToBaseRatio"].mean():.2f}') plt.title('Distribution of Exit-to-Base Size Ratio') plt.xlabel('Exit Body Pips / Base Body Pips') plt.legend() # Box plot by Pattern type if 'Pattern' in df_clean.columns: plt.subplot(1, 2, 2) sns.boxplot(data=df_clean, x='Pattern', y='ExitToBaseRatio') plt.title('Ratio Distribution: Supply vs. Demand') plt.ylabel('Exit-to-Base Ratio') plt.tight_layout() plt.show() # Critical Percentile Analysis print("📐 Key Percentiles for ExitToBaseRatio:") percentiles = [5, 25, 50, 75, 90, 95, 99] for p in percentiles: value = df_clean['ExitToBaseRatio'].quantile(p/100) print(f" {p}th percentile: {value:.2f}") else: print("⚠️ 'ExitToBaseRatio' column not found")
Результат 5:
Key Percentiles for ExitToBaseRatio: 5th percentile: 0.08 25th percentile: 0.42 50th percentile: 1.04 75th percentile: 2.55 90th percentile: 6.67 95th percentile: 13.41 99th percentile: 61.57
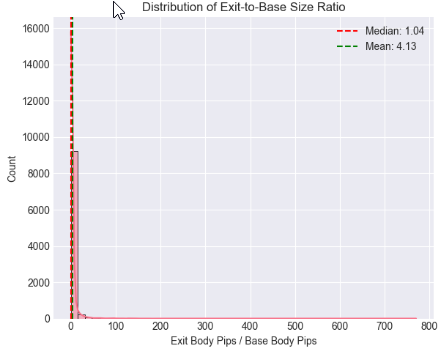
Ячейка 6: Нормализация силы выхода с использованием волатильности (контекст ATR)
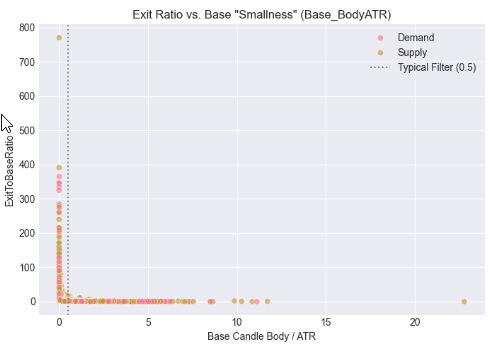
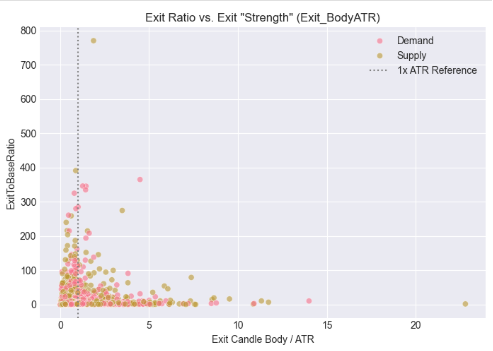
На этом этапе мы определили контекст размера свечей, сопоставив тела в области основы и на выходе с волатильностью рынка, используя средний истинный диапазон (ATR). Вместо того чтобы оценивать величину только в пипсах, мы оценивали, насколько мала свеча в области основы относительно волатильности и насколько сильна свеча на выходе после нормализации по ATR. Полученные диаграммы рассеяния показывают, как импульсивные выходы группируются вокруг определенных пороговых значений, скорректированных с учетом волатильности, подтверждая идею о том, что обоснованные изменения спроса и предложения лучше определяются относительной силой, чем абсолютным размером, и обеспечивая более надежную основу для автоматизации между символами и между таймфреймами.
# %% [markdown] # ## 5. Contextualizing Size: The Role of Volatility (ATR) # %% if all(col in df_clean.columns for col in ['Base_BodyATR', 'Exit_BodyATR', 'ExitToBaseRatio', 'Pattern']): fig, axes = plt.subplots(1, 2, figsize=(14, 5)) # Base Body vs. ATR sns.scatterplot(data=df_clean, x='Base_BodyATR', y='ExitToBaseRatio', hue='Pattern', alpha=0.6, ax=axes[0]) axes[0].axvline(x=0.5, color='gray', linestyle=':', label='Typical Filter (0.5)') axes[0].set_title('Exit Ratio vs. Base "Smallness" (Base_BodyATR)') axes[0].set_xlabel('Base Candle Body / ATR') axes[0].legend() # Exit Body vs. ATR sns.scatterplot(data=df_clean, x='Exit_BodyATR', y='ExitToBaseRatio', hue='Pattern', alpha=0.6, ax=axes[1]) axes[1].axvline(x=1.0, color='gray', linestyle=':', label='1x ATR Reference') axes[1].set_title('Exit Ratio vs. Exit "Strength" (Exit_BodyATR)') axes[1].set_xlabel('Exit Candle Body / ATR') axes[1].legend() plt.tight_layout() plt.show() else: print("⚠️ Missing required columns for ATR analysis")
Результат 6:
Ячейка 7: Кластеризация сильных выходов
На этом заключительном этапе анализа мы использовали кластеризацию по K-средним значениям, чтобы определить, группируются ли наиболее сильные свечи выхода естественным образом в отдельные категории, такие как “умеренные” и “сильные” импульсы. Путем кластеризации как по соотношению выхода к основе, так и по размеру выхода с поправкой на волатильность (тело на выходе/ATR), мы стремились выявить статистически значимые подгруппы в нашем наборе данных с высокой динамикой. Метод elbow позволил нам отобрать соответствующее количество кластеров, в то время как диаграммы рассеяния и профили кластеров позволили нам визуализировать и количественно оценить различия между группами. Этот подход обеспечивает управляемую данными основу для определения пороговых критериев, которые впоследствии могут быть реализованы в MQL5 для автоматического определения допустимых выходов из спроса и предложения, переходя от визуального суждения к воспроизводимым алгоритмическим правилам торговли.
# %% [markdown] # ## 6. Statistical Clustering: Finding Natural "Impulsive Exit" Groups # **Objective:** Use K-Means clustering to see if our strong candidates (`df_strong`) naturally group into categories like "Moderate" and "Strong" impulses based on their size ratio and volatility-adjusted strength. # %% from sklearn.cluster import KMeans from sklearn.preprocessing import StandardScaler # --- Step 1: Prepare Features for Clustering --- # We will cluster based on TWO dimensions: # 1. ExitToBaseRatio (How much bigger is the exit?) # 2. Exit_BodyATR (How significant is the exit in current market noise?) print("Preparing features for clustering...") cluster_features = df_strong[['ExitToBaseRatio', 'Exit_BodyATR']].copy() # Check for any missing values (should be none after our cleaning) print(f"Features shape: {cluster_features.shape}") # Standardize the features (critical for K-Means) scaler = StandardScaler() features_scaled = scaler.fit_transform(cluster_features) print("Features scaled (standardized).\n") # --- Step 2: The Elbow Method (Optional but Recommended) --- # Helps suggest a reasonable number of clusters (K). print("Running Elbow Method to suggest optimal K...") inertias = [] K_range = range(1, 8) # Test from 1 to 7 clusters for k in K_range: kmeans = KMeans(n_clusters=k, random_state=42, n_init='auto') # n_init='auto' for newer scikit-learn kmeans.fit(features_scaled) inertias.append(kmeans.inertia_) # Inertia = sum of squared distances to cluster center # Plot the Elbow Curve plt.figure(figsize=(8,5)) plt.plot(K_range, inertias, 'bo-') plt.xlabel('Number of Clusters (K)') plt.ylabel('Inertia (Lower is Better)') plt.title('Elbow Method for Optimal K: Where the line "bends"') plt.grid(True, alpha=0.3) plt.show() print("Inertia values:", [f"{i:.0f}" for i in inertias]) print("Look for a 'kink' or elbow in the plot above. Often K=2 or K=3 works well.\n") # --- Step 3: Apply K-Means Clustering --- # YOU NEED TO CHOOSE K based on the elbow plot and your research goal. # For distinguishing "Strong" vs "Very Strong" impulses, start with K=2 or 3. chosen_k = 3 # <-- CHANGE THIS based on the elbow plot. Try 2 or 3. print(f"Applying K-Means clustering with K = {chosen_k}...") kmeans = KMeans(n_clusters=chosen_k, random_state=42, n_init='auto') cluster_labels = kmeans.fit_predict(features_scaled) # Add the cluster labels back to our main dataframe df_strong['Cluster'] = cluster_labels print(f"Clustering complete. Cluster labels added to 'df_strong'.\n") # --- Step 4: Visualize the Clusters --- print("Visualizing clusters...") plt.figure(figsize=(11, 6)) # Create a scatter plot, coloring points by their assigned cluster scatter = plt.scatter(df_strong['ExitToBaseRatio'], df_strong['Exit_BodyATR'], c=df_strong['Cluster'], cmap='viridis', alpha=0.6, s=30) # s is point size plt.xlabel('Exit-to-Base Ratio', fontsize=12) plt.ylabel('Exit Body / ATR', fontsize=12) plt.title(f'K-Means Clustering of Strong Impulses (K={chosen_k})\nEach color is a distinct group', fontsize=14) # Add a colorbar and grid plt.colorbar(scatter, label='Cluster ID') plt.grid(True, alpha=0.3) plt.show() # --- Step 5: Analyze and Profile Each Cluster --- print("="*60) print("CLUSTER PROFILE ANALYSIS") print("="*60) # 5.1 Basic Counts print("\n📊 1. Number of patterns per cluster:") cluster_counts = df_strong['Cluster'].value_counts().sort_index() for clus_id, count in cluster_counts.items(): percentage = (count / len(df_strong)) * 100 print(f" Cluster {clus_id}: {count:4d} patterns ({percentage:.1f}% of strong candidates)") # 5.2 Mean (Center) of each cluster print("\n📈 2. Cluster Centers (MEAN values):") # Get the original feature means for each cluster cluster_profile = df_strong.groupby('Cluster')[['ExitToBaseRatio', 'Exit_BodyATR', 'Base_BodyATR']].mean().round(3) print(cluster_profile) # 5.3 Key Percentiles within each cluster (more robust than mean) print("\n📐 3. Key PERCENTILES for ExitToBaseRatio in each cluster:") for clus_id in range(chosen_k): cluster_data = df_strong[df_strong['Cluster'] == clus_id] print(f"\n Cluster {clus_id}:") for p in [25, 50, 75, 90]: # 25th, Median (50th), 75th, 90th percentiles value = cluster_data['ExitToBaseRatio'].quantile(p/100) print(f" {p}th percentile: {value:.2f}") # 5.4 Pattern Type distribution within clusters if 'Pattern' in df_strong.columns: print("\n🧩 4. Pattern Type (Supply/Demand) mix per cluster:") pattern_mix = pd.crosstab(df_strong['Cluster'], df_strong['Pattern'], normalize='index') * 100 print(pattern_mix.round(1).astype(str) + ' %') print("\n" + "="*60) print("ANALYSIS COMPLETE")
Результат 7:

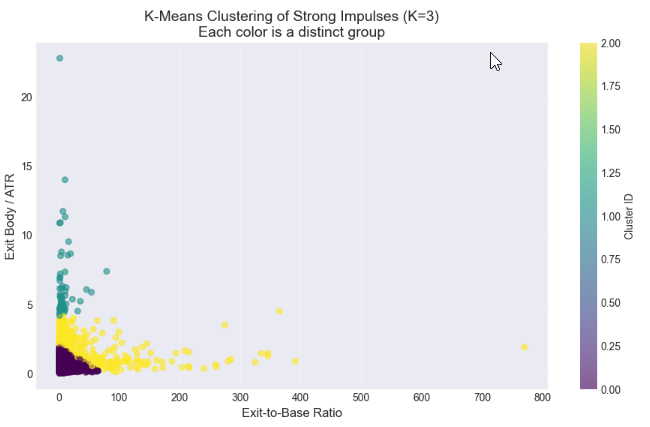
============================================================ CLUSTER PROFILE ANALYSIS ============================================================ 📊 1. Number of patterns per cluster: Cluster 0: 3153 patterns (84.6% of strong candidates) Cluster 1: 62 patterns (1.7% of strong candidates) Cluster 2: 510 patterns (13.7% of strong candidates) 📈 2. Cluster Centers (MEAN values): ExitToBaseRatio Exit_BodyATR Base_BodyATR Cluster 0 5.845 0.670 0.216 1 9.649 6.391 1.541 2 34.023 2.264 0.566 📐 3. Key PERCENTILES for ExitToBaseRatio in each cluster: Cluster 0: 25th percentile: 2.11 50th percentile: 3.21 75th percentile: 6.21 90th percentile: 12.73 Cluster 1: 25th percentile: 2.99 50th percentile: 4.80 75th percentile: 10.63 90th percentile: 19.45 Cluster 2: 25th percentile: 2.75 50th percentile: 5.75 75th percentile: 32.23 90th percentile: 98.36 🧩 4. Pattern Type (Supply/Demand) mix per cluster: Pattern Demand Supply Cluster 0 52.6 % 47.4 % 1 41.9 % 58.1 % 2 48.4 % 51.6 % ============================================================ ANALYSIS COMPLETE
Результаты
Применение кластеризации методом K-средних к отфильтрованному набору данных сильных кандидатов (ExitToBaseRatio > 1,5) выявило три различные поведенческие группы. Такая сегментация выходит за рамки монолитного представления об «импульсивных» движениях и предоставляет статистически обоснованную таксономию для рыночных движений, начинающихся с небольшой основы.
Кластер 0: Основной импульсивный выход
Этот кластер представляет собой доминирующий и наиболее значимый паттерн, на который приходится 84,6% подтвержденных сильных кандидатов.
Статистический профиль: Для него характерно медианное значение ExitToBaseRatio, равное 3,21, что подтверждает, что значимый импульсивный выход в среднем более чем в три раза превышает размер предшествующей основы — пороговое значение, заметно превышающее обычно предполагаемый множитель 2x. Кластер демонстрирует умеренный абсолютный размер со средним значением Exit_BodyATR 0,67 и подтверждает определяющую "маленькую основу" со средним значением Base_BodyATR всего 0,22.
Интерпретация как торговый сигнал: Этот кластер является основной целью для систематической стратегии. Он представляет собой классический, высоковероятный паттерн «небольшая основа, большой выход», где за консолидацией следует решительное, торгуемое движение, значимое как относительно основы, так и в контексте преобладающей волатильности рынка.
Кластер 1: Аномалии с высокой волатильностью
Данный отчетливый кластер сформирован минимальным подмножеством (1,7%) паттернов.
Статистический профиль: Определяется экстремальным средним значением Exit_BodyATR, равным 6,39, и необычно большим средним значением Base_BodyATR, равным 1,54, в сочетании с высоким значением ExitToBaseRatio (среднее значение: 9,65).
Интерпретация как торговый сигнал: Этот кластер интерпретируется как отражающий нетипичные рыночные события, такие как вызванные новостями разрывы или всплески волатильности. Cвеча в области основы не отражает консолидацию, нарушая основную предпосылку о зонах спроса и предложения. Следовательно, паттерны в этом кластере считаются статистическими выбросами с низкой надежностью для повторяемой торговой стратегии и явно отфильтровываются.
Кластер 2: Выбросы с экстремальным соотношением
В этом кластере насчитывалось 13,7% сильных кандидатов.
Статистический профиль: Демонстрирует необычайно высокие значения ExitToBaseRatio (медиана: 5,75, 90-й процентиль: 98,36) при умеренном среднем значении Exit_BodyATR, равном 2,26. Это является результатом минимального среднего базового размера (Base_BodyATR: 0,57).
Интерпретация как торговый сигнал: Хотя математически это относительное соотношение является экстремальным, практическая значимость для торговли пропорционально не превышает значения кластера 0. Экстремальное соотношение часто обусловлено близким к нулю размером основы, который может не всегда соответствовать допустимой области консолидации. Учитывая меньший размер выборки и меньшую интерпретируемость, этот кластер также лишен приоритета в пользу более надежного и заполненного основного кластера.
На основании 3153 высококачественных паттернах в кластере 0, ниже приведены наши оптимизированные статистически полученные параметры:
| Параметр | Первоначальное (субъективное) значение | Оптимизированное (на основе данных) значение | Статистическое обоснование (на основе анализа кластера 0) |
|---|---|---|---|
| MinExitBodyRatio: Выход должен быть в X раз больше основы | 2.0 | 3.0 | Медианное соотношение выхода к основе для надежных паттернов (кластер 0) составляет 3,21. Пороговое значение 3,0 позволяет зафиксировать более сильную и значимую половину этих импульсов. |
| MaxBaseBodyATR: Максимальный размер свечи в области основы против волатильности | 0.5 | 0.3. | Среднее значение Base_BodyATR в кластере 0 составляет 0,22. Ужесточение этого фильтра до 0,3 гарантирует, что основа будет представлять собой истинную консолидацию, отфильтровывая более крупные и неоднозначные свечи. |
| MinExitBodyATR: Минимальная значимость свечи на выходе против волатильности | ранее не определено | 0.5 | Среднее значение Exit_BodyATR в кластере 0 составляет 0,67. Минимальное пороговое значение в 0,5 гарантирует, что выход обладает значимым абсолютным импульсом в контексте текущего рыночного шума. |
Заключение
Это исследование успешно завершило критическую первую половину цикла разработки количественной торговой стратегии: переход от визуальной концепции к статистически обоснованному определению. Применяя тщательный сбор данных и машинное обучение к концепции импульсивного выхода из спроса и предложения, мы заменили догадки доказательствами.
Наш ключевой вывод заключается в том, что наиболее надежный рыночный паттерн "малая основа, большой выход" — кластер 0 — лучше всего определяется конкретной, поддающейся измерению сигнатурой: свечой на выходе, которая обычно в три раза больше, чем по-настоящему малая основа, и при этом обладает значимым абсолютным импульсом относительно волатильности рынка. Полученные параметры (MinExitBodyRatio = 3.0, MaxBaseBodyATR = 0.3, MinExitBodyATR = 0.5) являются не произвольными оптимизациями, а эмпирическим профилем события с высокой вероятностью.
Этот анализ дает необходимую модель для автоматизации. Эти три параметра, основанные на данных, непосредственно преобразуются в четкий, недвусмысленный логический блок для советника на MQL5.
Эта функция воплощает в себе основное торговое правило, основанное на наших исследованиях. Её можно интегрировать в комплексный советник, который сканирует паттерны из двух свечей, проверяет их с помощью этой статистической системы и точно исполняет сделки. Последующие шаги — добавление управления сделками, контроля рисков и анализа на нескольких таймфреймах - являются инженерными задачами, построенными на этом проверенном фундаменте.
В предстоящей публикации мы воплотим результаты этих исследований в полнофункциональную торговую систему. Мы подробно рассмотрим следующие вопросы:
- Интеграция этой логики проверки в надежный механизм сканирования.
- Конструкция механизма входа, стоп-лосса и тейк-профита, согласованного с зональной стратегией.
- Результаты тестирования на исторических данных, демонстрирующие влияние использования наших параметров, полученных на основе данных, на производительность по сравнению с обычными значениями по умолчанию.
Этот переход от ручного построения графиков к анализу на Python и, наконец, к оптимизированному коду на MQL5 демонстрирует современный, основанный на фактических данных подход к разработке стратегии. Основывая наши алгоритмы на статистической реальности, мы стремимся создавать инструменты, которые будут не просто автоматизированы, но и автоматизированы с элементами интеллекта.
Основные уроки, извлеченные из данного исследования, кратко изложены в таблице ниже вместе со вспомогательными приложениями. Вы можете поделиться своими мыслями и принять участие в дальнейшем обсуждении в разделе комментариев. Следите за нашей следующей публикацией, в которой мы будем опираться на эти выводы.
Основные уроки
| Основной урок | Описание: |
|---|---|
| Субъективность должна измеряться количественно | Основной проблемой при автоматизации таких концепций ценового действия, как "импульсивный выход", является их субъективный, визуальный характер. Основной урок заключается в том, что любая характеристика, оцениваемая "глазом трейдера", должна быть преобразована в измеримые числовые характеристики (например, соотношение размеров свечей, кратность ATR), чтобы ее можно было протестировать и автоматизировать. |
| Параметры, основанные на данных, превосходят общепринятые представления | Общепринятые эвристические значения (например, выход в два раза больше основы) часто не проверяются. Систематический сбор и анализ данных показали, что статистически значимый порог для нашего инструмента был выше, что привело к разработке более надежных правил, основанных на фактических данных (`MinExitBodyRatio = 3.0`). |
| Процесс проведения исследований имеет решающее значение | Структурированный двухэтапный процесс — MQL5 (сбор данных) → Python (статистическое обнаружение) — является необходимым. Он создает четкий, воспроизводимый путь от наблюдения за рынком к алгоритмической логике, гарантируя, что окончательный советник будет основан на эмпирических данных, а не на догадках. |
| Кластеризация раскрывает микроструктуру рынка | Применение статистической кластеризации (K-средних) к данным не просто позволило отфильтровать шум; с его помощью активно исследовалась собственная внутренняя классификация импульсов рынка. Определение "Core" кластера (кластер 0) позволило нам определить параметры, основанные на наиболее частом и согласованном паттерне рынка, а не просто на произвольном отсечении. |
| Контекст имеет решающее значение. | Оценка импульса требует рассмотрения как в относительном, так и в абсолютном выражении. Высокий показатель ExitToBaseRatio мало что значит, если свечи очень малы по сравнению с волатильностью рынка (ATR). Необходимость определения минимального значения Exit_BodyATR (0.5) возникла непосредственно из этого понимания, что позволило создать более целостный фильтр. |
| Объединение исследований и исполнения | Конечной целью количественного исследования является генерация исполняемого кода. Заключительный, решающий урок заключается в преобразовании статистических данных, таких как свойства кластера 0, непосредственно в чистую функцию проверки в MQL5, создавая прямой переход от исследовательского блокнота к живому торговому графику. |
Вложения
| Название файла | Описание: |
|---|---|
| SD_BaseExit_Research.mq5 | Базовый скрипт для сбора данных на MQL5. Он систематически сканирует исторические ценовые данные для сбора экземпляров определенного паттерна "основа-выход" из двух свечей. Вычисляет ключевые показатели (размеры тела в пипсах, коэффициенты ATR) для каждого допустимого паттерна и экспортирует их в структурированный CSV-файл, создавая исходный набор данных для статистического анализа. |
| Supply_and_demand_research.ipynb: | Jupyter Notebook, содержащий полный рабочий процесс анализа на Python. Загружает собранные данные в формате CSV, выполняет предварительный анализ данных (EDA), визуализирует распределения и применяет кластеризацию по K-среднему значению. Этот блокнот представляет собой среду, в которой субъективные ценовые модели преобразуются в объективные, статистически выведенные торговые параметры. |
| SD_BaseExit_XAUUSDr_5.csv | Это образец выходного файла, сгенерированного скриптом MQL5. Его название соответствует паттерну [Prefix]_[Symbol]_[Timeframe].csv. Этот файл содержит собранный набор данных — тысячи наблюдений за паттернами с временными метками и всеми рассчитанными показателями — готовый для импорта в Jupyter Notebook. Скрипт автоматически сохраняет файлы в каталоге "MQL5/Files" терминала MetaTrader 5 (например, .../MQL5/Files/), обеспечивая прямую совместимость и единый путь к файлам для скриптов анализа на Python. |
Перевод с английского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/en/articles/20904
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования