
Aprendizaje automático y Data Science (Parte 33): Pandas Dataframe en MQL5, recopilación de datos para facilitar el uso de ML

Contenido
- Introducción
- Estructuras de datos básicas en Pandas
- Dataframes de Pandas
- Añadir datos a la clase Dataframe
- Asignar un archivo CSV al DataFrame
- Visualización del contenido del DataFrame
- Exportar el DataFrame a un archivo CSV
- Selección e indexación de Dataframes
- Exploración e inspección de un DataFrame de Pandas
- Series temporales y métodos de transformación de datos
- Recopilación de datos para el aprendizaje automático
- Entrenamiento de un modelo de aprendizaje automático
- Implementación de un modelo de aprendizaje automático en MQL5
- Conclusión
Introducción
Cuando se trata de trabajar con modelos de aprendizaje automático, es esencial que tengamos la misma estructura de datos, si no los mismos valores, para todos los entornos: entrenamiento, validación y pruebas. Gracias a la compatibilidad de los modelos Open Neural Network Exchange (ONNX) con MQL5 y MetaTrader 5, hoy en día tenemos la oportunidad de importar modelos entrenados externamente al lenguaje MQL5 y utilizarlos con fines comerciales.
Dado que la mayoría de los usuarios utilizan Python para entrenar estos modelos de inteligencia artificial (IA) que luego se implementan en MetaTrader 5 a través del código MQL5, puede haber una gran diferencia en la forma en que se organizan los datos y, a menudo, incluso los valores dentro de la misma estructura de datos pueden ser ligeramente diferentes, debido a la diferencia entre las dos tecnologías.

En este artículo, vamos a imitar la biblioteca Pandas disponible en el lenguaje Python. Es una de las bibliotecas más populares, especialmente útil cuando se trata de trabajar con grandes cantidades de datos.
Dado que esta biblioteca es utilizada por científicos de datos para preparar y manipular datos utilizados en el entrenamiento de modelos de ML, al aprovechar su capacidad, nuestro objetivo es tener el mismo entorno de datos en MQL5 que en Python.
Estructuras de datos básicas en Pandas
La biblioteca Pandas proporciona dos tipos de clases para manejar datos.
- Series: Una matriz etiquetada unidimensional para almacenar datos de cualquier tipo, como números enteros, cadenas, objetos, etc.
s = pd.Series([1, 3, 5, np.nan, 6, 8])
- Dataframe: Una estructura de datos bidimensional que contiene datos como una matriz bidimensional o una tabla con filas y columnas.
Dado que una clase de datos de serie de Pandas es unidimensional, se parece más a una matriz o un vector en MQL5, por lo que no vamos a trabajar con ella. Nos centramos en el «Dataframe» bidimensional.
DataFrames de Pandas
Una vez más, esta estructura de datos contiene datos como una matriz bidimensional o una tabla con filas y columnas. En MQL5 podemos tener Arrays multidimensionales, pero el objeto bidimensional más práctico que podemos utilizar para esta tarea es una matriz.
Ahora que sabemos que en el núcleo del Dataframe de Pandas se encuentra una matriz bidimensional, podemos implementar esta base similar en nuestra clase Pandas en MQL5.
Archivo: pandas.mqh
class CDataFrame { public: string m_columns[]; //An array of string values for keeping track of the column names matrix m_values; // A 2D matrix CDataFrame(); ~CDataFrame(void); }
Necesitamos tener una matriz llamada «m_columns» para almacenar los nombres de todas las columnas del Dataframe. A diferencia de otras bibliotecas para trabajar con datos como Numpy, Pandas garantiza que los datos almacenados sean fáciles de entender para los usuarios, ya que realiza un seguimiento de los nombres de las columnas.
Pandas Dataframe en Python admite diferentes tipos de datos, como enteros, cadenas, objetos, etc.
import pandas as pd df = pd.DataFrame({ "Integers": [1,2,3,4,5], "Doubles": [0.1,0.2,0.3,0.4,0.5], "Strings": ["one","two","three","four","five"] })
No vamos a implementar esta misma flexibilidad en nuestra biblioteca MQL5 porque el objetivo de esta biblioteca es ayudarnos cuando trabajamos con modelos de aprendizaje automático, donde las variables de tipo de datos flotante y doble son las más útiles.
Por lo tanto, asegúrese de convertir (int, long, ulong, etc.) en valores de tipo de datos double y codificar todas las variables de cadena (string) que tenga antes de insertarlas en la clase Dataframe, ya que todas las variables se convertirán obligatoriamente en tipo de datos double.
Añadir datos a la clase Dataframe
Ahora que sabemos que una matriz en el núcleo de un objeto Dataframe es la responsable de almacenar todos los datos, implementemos formas de añadir información a ella.
En Python, puedes crear fácilmente un nuevo Dataframe y añadirle objetos llamando al método:
df = pd.DataFrame({
"first column": [1,2,3,4,5],
"second column": [10,20,30,40,50]
})
Debido a la sintaxis del lenguaje MQL5, no podemos hacer que una clase o un método se comporte así. Implementemos un método conocido como Insert (Insertar).
Archivo: pandas.mqh
void CDataFrame::Insert(string name, const vector &values) { //--- Check if the column exists in the m_columns array if it does exists, instead of creating a new column we modify an existing one int col_index = -1; for (int i=0; i<(int)m_columns.Size(); i++) if (name == m_columns[i]) { col_index = i; break; } //--- We check if the dimensiona are Ok if (m_values.Rows()==0) m_values.Resize(values.Size(), m_values.Cols()); if (values.Size() > m_values.Rows() && m_values.Rows()>0) //Check if the new column has a bigger size than the number of rows present in the matrix { printf("%s new column '%s' size is bigger than the dataframe",__FUNCTION__,name); return; } //--- if (col_index != -1) { m_values.Col(values, col_index); if (MQLInfoInteger(MQL_DEBUG)) printf("%s column '%s' exists, It will be modified",__FUNCTION__,name); return; } //--- If a given vector to be added to the dataframe is smaller than the number of rows present in the matrix, we fill the remaining values with Not a Number (NaN) vector temp_vals = vector::Zeros(m_values.Rows()); temp_vals.Fill(NaN); //to create NaN values when there was a dimensional mismatch for (ulong i=0; i<values.Size(); i++) temp_vals[i] = values[i]; //--- m_values.Resize(m_values.Rows(), m_values.Cols()+1); //We resize the m_values matrix to accomodate the new column m_values.Col(temp_vals, m_values.Cols()-1); //We insert the new column after the last column ArrayResize(m_columns, m_columns.Size()+1); //We increase the sice of the column names to accomodate the new column name m_columns[m_columns.Size()-1] = name; //we assign the new column to the last place in the array }
Podemos analizar la nueva información en el Dataframe de la siguiente manera:
#include <MALE5\pandas.mqh> //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- CDataFrame df; vector v1= {1,2,3,4,5}; vector v2= {10,20,30,40,50}; df.Insert("first column", v1); df.Insert("second column", v2); }
Alternativamente, podemos dotar al constructor de la clase de la capacidad de recibir una matriz y los nombres de sus columnas.
CDataFrame::CDataFrame(const string &columns, const matrix &values) { string columns_names[]; //A temporary array for obtaining column names from a string ushort sep = StringGetCharacter(",", 0); if (StringSplit(columns, sep, columns_names)<0) { printf("%s failed to obtain column names",__FUNCTION__); return; } if (columns_names.Size() != values.Cols()) //Check if the given number of column names is equal to the number of columns present in a given matrix { printf("%s dataframe's columns != columns present in the values matrix",__FUNCTION__); return; } ArrayCopy(m_columns, columns_names); //We assign the columns to the m_columns array m_values = values; //We assing the given matrix to the m_values matrix }
También podemos agregar nueva información a la clase Dataframe de la siguiente manera:
void OnStart() { //--- matrix data = { {1,10}, {2,20}, {3,30}, {4,40}, {5,50}, }; CDataFrame df("first column,second column",data); }
Te sugiero que uses el método Insert para agregar datos a la clase Dataframe en lugar de cualquier otro método para esta tarea.
Los dos métodos comentados anteriormente son útiles al preparar conjuntos de datos; también necesitamos una función para cargar los datos presentes en un conjunto de datos.
Asignar un archivo CSV al DataFrame
El método para leer un archivo CSV y asignar los valores a un DataFrame es una de las funciones más útiles de Pandas cuando se trabaja con la biblioteca en Python.
df = pd.read_csv("EURUSD.PERIOD_D1.csv")
Implementemos este método en nuestra clase MQL5:
bool CDataFrame::ReadCSV(string file_name,string delimiter=",",bool is_common=false, bool verbosity=false) { matrix mat_ = {}; int rows_total=0; int handle = FileOpen(file_name,FILE_READ|FILE_CSV|FILE_ANSI|(is_common?FILE_IS_COMMON:FILE_ANSI),delimiter); //Open a csv file ResetLastError(); if(handle == INVALID_HANDLE) //Check if the file handle is ok if not return false { printf("Invalid %s handle Error %d ",file_name,GetLastError()); Print(GetLastError()==0?" TIP | File Might be in use Somewhere else or in another Directory":""); return false; } else { int column = 0, rows=0; while(!FileIsEnding(handle)) { string data = FileReadString(handle); //--- if(rows ==0) { ArrayResize(m_columns,column+1); m_columns[column] = data; } if(rows>0) //Avoid the first column which contains the column's header mat_[rows-1,column] = (double(data)); //add a value to the matrix column++; //--- if(FileIsLineEnding(handle)) //At the end of the each line { rows++; mat_.Resize(rows,column); //Resize the matrix to accomodate new values column = 0; } } if (verbosity) //if verbosity is set to true, we print the information to let the user know the progress, Useful for debugging purposes printf("Reading a CSV file... record [%d]",rows); rows_total = rows; FileClose(handle); //Close the file after reading it } mat_.Resize(rows_total-1,mat_.Cols()); m_values = mat_; return true; }
A continuación se muestra cómo puede leer un archivo CSV y asignarlo directamente al DataFrame.
void OnStart() { //--- CDataFrame df; df.ReadCSV("EURUSD.PERIOD_D1.csv"); df.Head(); }
Visualización del contenido del DataFrame
Ya hemos visto cómo se puede agregar información a un DataFrame, pero es fundamental poder echar un vistazo rápido al DataFrame para comprender de qué se trata. En la mayoría de los casos, trabajará con grandes Dataframes que a menudo requieren volver a consultar el Dataframe para fines de exploración y recuperación.
Pandas tiene un método conocido como "head" que devuelve las primeras n filas del objeto DataFrame según su posición. Este método resulta útil para comprobar rápidamente si su objeto contiene el tipo de datos correcto.
Cuando se llama al método "head" en una celda de Jupyter Notebook con su(s) valor(es) predeterminado(s), las cinco primeras filas del DataFrame se muestran en la salida de la celda.
Archivo: main.ipynb
df = pd.read_csv("EURUSD.PERIOD_D1.csv") df.head()
Resultado:
| Open | High | Low | Close | |
|---|---|---|---|---|
| 0 | 1.09381 | 1.09548 | 1.09003 | 1.09373 |
| 1 | 1.09678 | 1.09810 | 1.09361 | 1.09399 |
| 2 | 1.09701 | 1.09973 | 1.09606 | 1.09805 |
| 3 | 1.09639 | 1.09869 | 1.09542 | 1.09742 |
| 4 | 1.10302 | 1.10396 | 1.09513 | 1.09757 |
Podemos crear una función similar para esta tarea en MQL5:
void CDataFrame::Head(const uint count=5) { // Calculate maximum width needed for each column uint num_cols = m_columns.Size(); uint col_widths[]; ArrayResize(col_widths, num_cols); for (uint col = 0; col < num_cols; col++) //Determining column width for visualizing a simple table { uint max_width = StringLen(m_columns[col]); for (uint row = 0; row < count && row < m_values.Rows(); row++) { string num_str = StringFormat("%.8f", m_values[row][col]); max_width = MathMax(max_width, StringLen(num_str)); } col_widths[col] = max_width + 4; // Extra padding for readability } // Print column headers with calculated padding string header = ""; for (uint col = 0; col < num_cols; col++) { header += StringFormat("| %-*s ", col_widths[col], m_columns[col]); } header += "|"; Print(header); // Print rows with padding for each column for (uint row = 0; row < count && row < m_values.Rows(); row++) { string row_str = ""; for (uint col = 0; col < num_cols; col++) { row_str += StringFormat("| %-*.*f ", col_widths[col], 8, m_values[row][col]); } row_str += "|"; Print(row_str); } // Print dimensions printf("(%dx%d)", m_values.Rows(), m_values.Cols()); }
Por defecto, esta función muestra las cinco primeras filas de nuestro DataFrame.
void OnStart() { //--- CDataFrame df; df.ReadCSV("EURUSD.PERIOD_D1.csv"); df.Head(); }
Resultados:
GI 0 12:37:02.983 pandas test (Volatility 75 Index,H1) | Open | High | Low | Close | RH 0 12:37:02.983 pandas test (Volatility 75 Index,H1) | 1.09381000 | 1.09548000 | 1.09003000 | 1.09373000 | GI 0 12:37:02.984 pandas test (Volatility 75 Index,H1) | 1.09678000 | 1.09810000 | 1.09361000 | 1.09399000 | DI 0 12:37:02.984 pandas test (Volatility 75 Index,H1) | 1.09701000 | 1.09973000 | 1.09606000 | 1.09805000 | EI 0 12:37:02.984 pandas test (Volatility 75 Index,H1) | 1.09639000 | 1.09869000 | 1.09542000 | 1.09742000 | CI 0 12:37:02.984 pandas test (Volatility 75 Index,H1) | 1.10302000 | 1.10396000 | 1.09513000 | 1.09757000 | FE 0 12:37:02.984 pandas test (Volatility 75 Index,H1) (1000x4)
Exportar el DataFrame a un archivo CSV
Después de recopilar todo tipo de datos en el Dataframe, debemos exportarlos fuera de MetaTrader 5, donde se llevan a cabo todos los procedimientos de aprendizaje automático.
Un archivo CSV resulta muy útil a la hora de exportar datos, sobre todo porque luego utilizaremos la biblioteca Pandas para importar el archivo CSV en lenguaje Python.
Guardemos el Dataframe que hemos extraído de un archivo CSV de nuevo en el archivo CSV.
En Python:
df.to_csv("EURUSDcopy.csv", index=False) El resultado es un archivo CSV llamado EURUSDcopy.csv.
A continuación se muestra una implementación de este método en MQL5:
bool CDataFrame::ToCSV(string csv_name, bool common=false, int digits=5, bool verbosity=false) { FileDelete(csv_name); int handle = FileOpen(csv_name,FILE_WRITE|FILE_SHARE_WRITE|FILE_CSV|FILE_ANSI|(common?FILE_COMMON:FILE_ANSI),",",CP_UTF8); //open a csv file if(handle == INVALID_HANDLE) //Check if the handle is OK { printf("Invalid %s handle Error %d ",csv_name,GetLastError()); return (false); } //--- string concstring; vector row = {}; vector colsinrows = m_values.Row(0); if (ArraySize(m_columns) != (int)colsinrows.Size()) { printf("headers=%d and columns=%d from the matrix vary is size ",ArraySize(m_columns),colsinrows.Size()); DebugBreak(); return false; } //--- string header_str = ""; for (int i=0; i<ArraySize(m_columns); i++) //We concatenate the header only separating it with a comma delimeter header_str += m_columns[i] + (i+1 == colsinrows.Size() ? "" : ","); FileWrite(handle,header_str); FileSeek(handle,0, SEEK_SET); for(ulong i=0; i<m_values.Rows() && !IsStopped(); i++) { ZeroMemory(concstring); row = m_values.Row(i); for(ulong j=0, cols =1; j<row.Size() && !IsStopped(); j++, cols++) { concstring += (string)NormalizeDouble(row[j],digits) + (cols == m_values.Cols() ? "" : ","); } if (verbosity) //if verbosity is set to true, we print the information to let the user know the progress, Useful for debugging purposes printf("Writing a CSV file... record [%d/%d]",i+1,m_values.Rows()); FileSeek(handle,0,SEEK_END); FileWrite(handle,concstring); } FileClose(handle); return (true); }
A continuación se explica cómo utilizar este método:
void OnStart() { CDataFrame df; df.ReadCSV("EURUSD.PERIOD_D1.csv"); //Assign a csv file into the dataframe df.ToCSV("EURUSDcopy.csv"); //Save the dataframe back into a CSV file as a copy }
El resultado es la creación del archivo CSV con el nombre EURUSDcopy.csv.
Ahora que hemos hablado sobre cómo crear un Dataframe, insertar valores en él, importar y exportar datos, veamos las técnicas de selección e indexación de datos.
Selección e indexación de Dataframes
En ocasiones, resulta crucial tener la capacidad de segmentar, seleccionar o acceder a partes específicas del DataFrame. Por ejemplo, al usar un modelo para hacer predicciones, es posible que desee acceder solo a los valores más recientes (la última fila) del marco de datos, mientras que, durante el entrenamiento, es posible que desee acceder a algunas filas ubicadas al principio del Dataframe.
Acceso a una columna
Para acceder a una columna, podemos implementar un operador de índice que tome valores de cadena en nuestra clase.
vector operator[] (const string index) {return GetColumn(index); } //Access a column by its name
La función «GetColumn», cuando se le proporciona un nombre de columna, devuelve un vector con sus valores cuando los encuentra.
Uso:
Print("Close column: ",df["Close"]);
Resultados:
2025.01.27 16:16:19.726 pandas test (EURUSD,H1) Close column: [1.09373,1.09399,1.09805,1.09742,1.09757,1.10297,1.10453,1.10678,1.1135,1.11594,1.11765,1.11327,1.11797,1.11107,1.1163,1.11616,1.11177,1.11141,1.11326,1.10745,1.10747,1.10111,1.10192,1.10351,1.10861,1.11106,1.1083,1.10435,1.10723,1.10483,1.1078,1.11199,1.11843,1.1161,1.11932,1.11113,1.11499,1.113,1.10852,1.10267,1.09712,1.10124,1.09928,1.09321,1.09156,1.09188,1.09236,1.09315,1.09511,1.09107,1.07913,1.08258,1.08142,1.08211,1.08551,1.0845,1.08392,1.08529,1.08905,1.08818,1.08959,1.09396,1.08986,
La indexación «loc»
Esta indexación ayuda a acceder a un grupo o filas y columnas mediante etiquetas o una matriz booleana.
En Pandas de Python:
df.loc[0] Resultados:
Open 1.09381 High 1.09548 Low 1.09003 Close 1.09373 Name: 0, dtype: float64
En MQL5 podemos implementar esto como una función regular:
vector CDataFrame::Loc(int index, uint axis=0) { if(axis == 0) { vector row = {}; //--- Convert negative index to positive if(index < 0) index = (int)m_values.Rows() + index; if(index < 0 || index >= (int)m_values.Rows()) { printf("%s Error: Row index out of bounds. Given index: %d", __FUNCTION__, index); return row; } return m_values.Row(index); } else if(axis == 1) { vector column = {}; //--- Convert negative index to positive if(index < 0) index = (int)m_values.Cols() + index; //--- Check bounds if(index < 0 || index >= (int)m_values.Cols()) { printf("%s Error: Column index out of bounds. Given index: %d", __FUNCTION__, index); return column; } return m_values.Col(index); } else printf("%s Failed, Unknown axis ",__FUNCTION__); return vector::Zeros(0); }
He añadido el argumento denominado axis para poder elegir entre obtener una fila (a lo largo del eje 0) y una columna (a lo largo del eje 1).
Cuando esta función recibe un valor negativo, accede a los elementos en orden inverso; un valor de índice de -1 es el último elemento del marco de datos (última fila cuando axis=0, última columna cuando axis=1).
Uso:
void OnStart() { //--- CDataFrame df; df.ReadCSV("EURUSD.PERIOD_D1.csv"); df.Head(); Print("First row",df.Loc(0)); //--- Print("Last 5 items in df\n",df.Tail()); Print("Last row: ",df.Loc(-1)); Print("Last Column: ",df.Loc(-1, 1)); }
Resultados:
RM 0 09:04:21.355 pandas test (EURUSD,H1) | Open | High | Low | Close | IN 0 09:04:21.355 pandas test (EURUSD,H1) | 1.09381000 | 1.09548000 | 1.09003000 | 1.09373000 | GP 0 09:04:21.355 pandas test (EURUSD,H1) | 1.09678000 | 1.09810000 | 1.09361000 | 1.09399000 | NS 0 09:04:21.355 pandas test (EURUSD,H1) | 1.09701000 | 1.09973000 | 1.09606000 | 1.09805000 | IE 0 09:04:21.355 pandas test (EURUSD,H1) | 1.09639000 | 1.09869000 | 1.09542000 | 1.09742000 | IG 0 09:04:21.355 pandas test (EURUSD,H1) | 1.10302000 | 1.10396000 | 1.09513000 | 1.09757000 | NJ 0 09:04:21.355 pandas test (EURUSD,H1) (1000x4) EO 0 09:04:21.355 pandas test (EURUSD,H1) First row[1.09381,1.09548,1.09003,1.09373] JF 0 09:04:21.355 pandas test (EURUSD,H1) Last 5 items in df DN 0 09:04:21.355 pandas test (EURUSD,H1) [[1.20796,1.21591,1.20742,1.21416] JK 0 09:04:21.355 pandas test (EURUSD,H1) [1.21023,1.21474,1.20588,1.20814] PR 0 09:04:21.355 pandas test (EURUSD,H1) [1.21089,1.21342,1.20953,1.21046] OO 0 09:04:21.355 pandas test (EURUSD,H1) [1.21281,1.21664,1.20785,1.2109] FK 0 09:04:21.355 pandas test (EURUSD,H1) [1.21444,1.21774,1.21101,1.21203]] EM 0 09:04:21.355 pandas test (EURUSD,H1) Last row: [1.21444,1.21774,1.21101,1.21203] QM 0 09:04:21.355 pandas test (EURUSD,H1) Last Column: [1.09373,1.09399,1.09805,1.09742,1.09757,1.10297,1.10453,1.10678,1.1135,1.11594,1.11765,1.11327,1.11797,1.11107,1.1163,1.11616,1.11177,1.11141,1.11326,1.10745,1.10747,1.10111,1.10192,1.10351,1.10861,1.11106,1.1083,1.10435,1.10723,1.10483,1.1078,1.11199,1.11843,1.1161,1.11932,1.11113,1.11499,1.113,1.10852,1.10267,1.09712,1.10124,1.09928,1.00063,…]
El método «iloc»
La función Iloc introducida en nuestra clase selecciona filas y columnas de un marco de datos por posiciones enteras, de forma similar al método iloc que ofrece Pandas en Python.
Este método devuelve un nuevo DataFrame que es el resultado de la operación de segmentación.
Implementación en MQL5:
CDataFrame Iloc(ulong start_row, ulong end_row, ulong start_col, ulong end_col);
Uso:
df = df.Iloc(0,100,0,3); //Slice from the first row to the 99th from the first column to the 2nd df.Head();
Resultados:
DJ 0 16:40:19.699 pandas test (EURUSD,H1) | Open | High | Low | LQ 0 16:40:19.699 pandas test (EURUSD,H1) | 1.09381000 | 1.09548000 | 1.09003000 | PM 0 16:40:19.699 pandas test (EURUSD,H1) | 1.09678000 | 1.09810000 | 1.09361000 | EI 0 16:40:19.699 pandas test (EURUSD,H1) | 1.09701000 | 1.09973000 | 1.09606000 | DE 0 16:40:19.699 pandas test (EURUSD,H1) | 1.09639000 | 1.09869000 | 1.09542000 | FQ 0 16:40:19.699 pandas test (EURUSD,H1) | 1.10302000 | 1.10396000 | 1.09513000 | GS 0 16:40:19.699 pandas test (EURUSD,H1) (100x3)
El método «at»
Este método devuelve un único valor del DataFrame.
Implementación en MQL5:
double CDataFrame::At(ulong row, string col_name) { ulong col_number = (ulong)ColNameToIndex(col_name, m_columns); return m_values[row][col_number]; }
Uso:
void OnStart() { //--- CDataFrame df; df.ReadCSV("EURUSD.PERIOD_D1.csv"); Print(df.At(0,"Close")); //Returns the first value within the Close column }
Resultados:
2025.01.27 16:47:16.701 pandas test (EURUSD,H1) 1.09373
El método «iat»
Esto nos permite acceder a un único valor en el DataFrame por posición.
Implementación en MQL5:
double CDataFrame::Iat(ulong row,ulong col) { return m_values[row][col]; }
Uso:
Print(df.Iat(0,0)); //Returns the value at first row and first colum
Resultado:
2025.01.27 16:53:32.627 pandas test (EURUSD,H1) 1.09381
Eliminar columnas del DataFrame utilizando el método "drop"
A veces ocurre que tenemos columnas no deseadas en nuestro Dataframe, o que queremos eliminar algunas variables para fines de entrenamiento. La función de arrastrar y soltar (drop) puede ayudar con esta tarea.
Implementación en MQL5:
CDataFrame CDataFrame::Drop(const string cols) { CDataFrame df; string column_names[]; ushort sep = StringGetCharacter(",",0); if(StringSplit(cols, sep, column_names) < 0) { printf("%s Failed to get the columns, ensure they are separated by a comma. Error = %d", __FUNCTION__, GetLastError()); return df; } int columns_index[]; uint size = column_names.Size(); ArrayResize(columns_index, size); if(size > m_values.Cols()) { printf("%s failed, The number of columns > columns present in the dataframe", __FUNCTION__); return df; } // Fill columns_index with column indices to drop for(uint i = 0; i < size; i++) { columns_index[i] = ColNameToIndex(column_names[i], m_columns); if(columns_index[i] == -1) { printf("%s Column '%s' not found in this DataFrame", __FUNCTION__, column_names[i]); //ArrayRemove(column_names, i, 1); continue; } } matrix new_data(m_values.Rows(), m_values.Cols() - size); string new_columns[]; ArrayResize(new_columns, (int)m_values.Cols() - size); // Populate new_data with columns not in columns_index for(uint i = 0, count = 0; i < m_values.Cols(); i++) { bool to_drop = false; for(uint j = 0; j < size; j++) { if(i == columns_index[j]) { to_drop = true; break; } } if(!to_drop) { new_data.Col(m_values.Col(i), count); new_columns[count] = m_columns[i]; count++; } } // Replace original data with the updated matrix and columns df.m_values = new_data; ArrayResize(df.m_columns, new_columns.Size()); ArrayCopy(df.m_columns, new_columns); return df; }
Uso:
void OnStart() { //--- CDataFrame df; df.ReadCSV("EURUSD.PERIOD_D1.csv"); CDataFrame new_df = df.Drop("Open,Close"); //drop the columns and assign the dataframe to a new object new_df.Head(); }
Resultados:
II 0 19:18:22.997 pandas test (EURUSD,H1) | High | Low | GJ 0 19:18:22.997 pandas test (EURUSD,H1) | 1.09548000 | 1.09003000 | EP 0 19:18:22.998 pandas test (EURUSD,H1) | 1.09810000 | 1.09361000 | CF 0 19:18:22.998 pandas test (EURUSD,H1) | 1.09973000 | 1.09606000 | RL 0 19:18:22.998 pandas test (EURUSD,H1) | 1.09869000 | 1.09542000 | MR 0 19:18:22.998 pandas test (EURUSD,H1) | 1.10396000 | 1.09513000 | DH 0 19:18:22.998 pandas test (EURUSD,H1) (1000x2)
Ahora que tenemos funciones para indexar y seleccionar algunas partes del DataFrame, implementemos varias funciones de Pandas que nos ayuden con la exploración e inspección de datos.
Exploración e inspección de un DataFrame de Pandas
La función «tail»
Este método muestra las últimas filas del DataFrame.
Implementación en MQL5:
matrix CDataFrame::Tail(uint count=5) { ulong rows = m_values.Rows(); if(count>=rows) { printf("%s count[%d] >= number of rows in the df[%d]",__FUNCTION__,count,rows); return matrix::Zeros(0,0); } ulong start = rows-count; matrix res = matrix::Zeros(count, m_values.Cols()); for(ulong i=start, row_count=0; i<rows; i++, row_count++) res.Row(m_values.Row(i), row_count); return res; }
Uso:
void OnStart() { //--- CDataFrame df; df.ReadCSV("EURUSD.PERIOD_D1.csv"); Print(df.Tail()); }Por defecto, la función devuelve las últimas 5 filas del DataFrame.
GR 0 17:06:42.044 pandas test (EURUSD,H1) [[1.20796,1.21591,1.20742,1.21416] MG 0 17:06:42.044 pandas test (EURUSD,H1) [1.21023,1.21474,1.20588,1.20814] KQ 0 17:06:42.044 pandas test (EURUSD,H1) [1.21089,1.21342,1.20953,1.21046] DK 0 17:06:42.044 pandas test (EURUSD,H1) [1.21281,1.21664,1.20785,1.2109] MO 0 17:06:42.044 pandas test (EURUSD,H1) [1.21444,1.21774,1.21101,1.21203]]
La función «info»
Esta función es muy útil para comprender la estructura del DataFrame, los tipos de datos, el uso de memoria y la presencia de valores no nulos.
A continuación se muestra su implementación en MQL5:
void CDataFrame::Info(void)
Resultados:
ES 0 17:34:04.968 pandas test (EURUSD,H1) <class 'CDataFrame'> IH 0 17:34:04.968 pandas test (EURUSD,H1) RangeIndex: 1000 entries, 0 to 999 LR 0 17:34:04.968 pandas test (EURUSD,H1) Data columns (total 4 columns): PD 0 17:34:04.968 pandas test (EURUSD,H1) # Column Non-Null Count Dtype OQ 0 17:34:04.968 pandas test (EURUSD,H1) --- ------ -------------- ----- FS 0 17:34:04.968 pandas test (EURUSD,H1) 0 Open 1000 non-null double GH 0 17:34:04.968 pandas test (EURUSD,H1) 1 High 1000 non-null double LS 0 17:34:04.968 pandas test (EURUSD,H1) 2 Low 1000 non-null double IH 0 17:34:04.968 pandas test (EURUSD,H1) 3 Close 1000 non-null double FJ 0 17:34:04.968 pandas test (EURUSD,H1) memory usage: 31.2 KB
La función «describe»
Esta función proporciona estadísticas descriptivas para todas las columnas numéricas de un DataFrame. La información que proporciona incluye la media, la desviación estándar, el recuento, el valor mínimo y el valor máximo de las columnas, sin mencionar los valores percentiles 25%, 50% y 75% de cada columna.
A continuación se muestra una descripción general de cómo se implementó la función en MQL5.
void CDataFrame::Describe(void)
Uso:
void OnStart() { //--- CDataFrame df; df.ReadCSV("EURUSD.PERIOD_D1.csv"); //Print(df.Tail()); df.Describe(); }
Resultados:
MM 0 18:10:42.459 pandas test (EURUSD,H1) Open High Low Close JD 0 18:10:42.460 pandas test (EURUSD,H1) count 1000 1000 1000 1000 HD 0 18:10:42.460 pandas test (EURUSD,H1) mean 1.104156 1.108184 1.100572 1.104306 HM 0 18:10:42.460 pandas test (EURUSD,H1) std 0.060646 0.059900 0.061097 0.060507 NQ 0 18:10:42.460 pandas test (EURUSD,H1) min 0.959290 0.967090 0.953580 0.959320 DI 0 18:10:42.460 pandas test (EURUSD,H1) 25% 1.069692 1.073520 1.066225 1.069950 DE 0 18:10:42.460 pandas test (EURUSD,H1) 50% 1.090090 1.093640 1.087100 1.090385 FN 0 18:10:42.460 pandas test (EURUSD,H1) 75% 1.142937 1.145505 1.139295 1.142365 CG 0 18:10:42.460 pandas test (EURUSD,H1) max 1.232510 1.234950 1.226560 1.232620
Obtener la forma y las columnas presentes en el DataFrame
Pandas en Python tiene métodos como pandas.DataFrame.shape que devuelve la forma del DataFrame y pandas.DataFrame.columns que devuelve las columnas presentes en el DataFrame.
En nuestra clase, podemos acceder a estos valores desde una matriz definida globalmente llamada m_values de la siguiente manera.
printf("df shape = (%dx%d)",df.m_values.Rows(),df.m_values.Cols());
Resultados:
2025.01.27 18:24:14.436 pandas test (EURUSD,H1) df shape = (1000x4)
Series temporales y métodos de transformación de datos
En esta sección, vamos a implementar algunos de los métodos que se utilizan con frecuencia para transformar los datos y analizar los cambios a lo largo del tiempo entre las filas del marco de datos.
Los métodos que se analizan en esta sección son los más utilizados en la ingeniería de características.
El método «shift()»
Desplaza el índice un número determinado de períodos y se utiliza a menudo en series temporales para comparar un valor con su valor anterior o posterior.
Implementación en MQL5:
vector CDataFrame::Shift(const vector &v, const int shift) { // Initialize a result vector filled with NaN vector result(v.Size()); result.Fill(NaN); if(shift > 0) { // Positive shift: Move elements forward for(ulong i = 0; i < v.Size() - shift; i++) result[i + shift] = v[i]; } else if(shift < 0) { // Negative shift: Move elements backward for(ulong i = -shift; i < v.Size(); i++) result[i + shift] = v[i]; } else { // Zero shift: Return the vector unchanged result = v; } return result; }
vector CDataFrame::Shift(const string index, const int shift) { vector v = this.GetColumn(index); // Initialize a result vector filled with NaN return Shift(v, shift); }
Cuando se le asigna un valor de índice positivo a esta función, mueve los elementos hacia adelante, creando efectivamente una versión retrasada de un vector o columna determinados.
void OnStart() { //--- CDataFrame df; df.ReadCSV("EURUSD.PERIOD_D1.csv"); vector close_lag_1 = df.Shift("Close", 1); //Create a previous 1 lag on the close price df.Insert("Close lag 1",close_lag_1); //Insert this new column into a dataframe df.Head(); }
Resultados:
EP 0 19:40:14.257 pandas test (EURUSD,H1) | Open | High | Low | Close | Close lag 1 | NO 0 19:40:14.257 pandas test (EURUSD,H1) | 1.09381000 | 1.09548000 | 1.09003000 | 1.09373000 | nan | PR 0 19:40:14.257 pandas test (EURUSD,H1) | 1.09678000 | 1.09810000 | 1.09361000 | 1.09399000 | 1.09373000 | ES 0 19:40:14.257 pandas test (EURUSD,H1) | 1.09701000 | 1.09973000 | 1.09606000 | 1.09805000 | 1.09399000 | PS 0 19:40:14.257 pandas test (EURUSD,H1) | 1.09639000 | 1.09869000 | 1.09542000 | 1.09742000 | 1.09805000 | PP 0 19:40:14.257 pandas test (EURUSD,H1) | 1.10302000 | 1.10396000 | 1.09513000 | 1.09757000 | 1.09742000 | QO 0 19:40:14.257 pandas test (EURUSD,H1) (1000x5)
Sin embargo, cuando se recibe una función negativa, la función crea una variable futura para una columna determinada. Esto es muy útil para crear las variables objetivo.
vector future_close_1 = df.Shift("Close", -1); //Create a future 1 variable df.Insert("Future 1 close",future_close_1); //Insert this new column into a dataframe df.Head();
Resultados:
CI 0 19:43:08.482 pandas test (EURUSD,H1) | Open | High | Low | Close | Close lag 1 | Future 1 close | GJ 0 19:43:08.482 pandas test (EURUSD,H1) | 1.09381000 | 1.09548000 | 1.09003000 | 1.09373000 | nan | 1.09399000 | MR 0 19:43:08.482 pandas test (EURUSD,H1) | 1.09678000 | 1.09810000 | 1.09361000 | 1.09399000 | 1.09373000 | 1.09805000 | FM 0 19:43:08.482 pandas test (EURUSD,H1) | 1.09701000 | 1.09973000 | 1.09606000 | 1.09805000 | 1.09399000 | 1.09742000 | IH 0 19:43:08.482 pandas test (EURUSD,H1) | 1.09639000 | 1.09869000 | 1.09542000 | 1.09742000 | 1.09805000 | 1.09757000 | OK 0 19:43:08.483 pandas test (EURUSD,H1) | 1.10302000 | 1.10396000 | 1.09513000 | 1.09757000 | 1.09742000 | 1.10297000 | GG 0 19:43:08.483 pandas test (EURUSD,H1) (1000x6)
El método «pct_change()»
Esta función calcula el cambio porcentual entre el elemento actual y el anterior. Se utiliza comúnmente en datos financieros para calcular rentabilidades.
A continuación se muestra cómo se implementa en la clase DataFrame.
vector CDataFrame::Pct_change(const string index) { vector col = GetColumn(index); return Pct_change(col); } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ vector CDataFrame::Pct_change(const vector &v) { vector col = v; ulong size = col.Size(); vector results(size); results.Fill(NaN); for(ulong i=1; i<size; i++) { double prev_value = col[i - 1]; double curr_value = col[i]; // Calculate percentage change and handle division by zero if(prev_value != 0.0) { results[i] = ((curr_value - prev_value) / prev_value) * 100.0; } else { results[i] = 0.0; // Handle division by zero case } } return results; }
Uso:
void OnStart() { //--- CDataFrame df; df.ReadCSV("EURUSD.PERIOD_D1.csv"); vector close_pct_change = df.Pct_change("Close"); df.Insert("Close pct_change", close_pct_change); df.Head(); }
Resultados:
IM 0 19:49:59.858 pandas test (EURUSD,H1) | Open | High | Low | Close | Close pct_change | CO 0 19:49:59.858 pandas test (EURUSD,H1) | 1.09381000 | 1.09548000 | 1.09003000 | 1.09373000 | nan | DS 0 19:49:59.858 pandas test (EURUSD,H1) | 1.09678000 | 1.09810000 | 1.09361000 | 1.09399000 | 0.02377186 | DD 0 19:49:59.858 pandas test (EURUSD,H1) | 1.09701000 | 1.09973000 | 1.09606000 | 1.09805000 | 0.37111857 | QE 0 19:49:59.858 pandas test (EURUSD,H1) | 1.09639000 | 1.09869000 | 1.09542000 | 1.09742000 | -0.05737444 | NF 0 19:49:59.858 pandas test (EURUSD,H1) | 1.10302000 | 1.10396000 | 1.09513000 | 1.09757000 | 0.01366842 | NJ 0 19:49:59.858 pandas test (EURUSD,H1) (1000x5)
El método «diff()»
Esta función calcula la diferencia entre el elemento actual y el anterior en una secuencia; se utiliza a menudo para encontrar cambios a lo largo del tiempo.
vector CDataFrame::Diff(const vector &v, int period=1) { vector res(v.Size()); res.Fill(NaN); for(ulong i=period; i<v.Size(); i++) res[i] = v[i] - v[i-period]; //Calculate the difference between the current value and the previous one return res; } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ vector CDataFrame::Diff(const string index, int period=1) { vector v = this.GetColumn(index); // Initialize a result vector filled with NaN return Diff(v, period); }
Uso:
void OnStart() { //--- CDataFrame df; df.ReadCSV("EURUSD.PERIOD_D1.csv"); vector diff_open = df.Diff("Open"); df.Insert("Open diff", diff_open); df.Head(); }
Resultados:
GS 0 19:54:10.283 pandas test (EURUSD,H1) | Open | High | Low | Close | Open diff | HM 0 19:54:10.283 pandas test (EURUSD,H1) | 1.09381000 | 1.09548000 | 1.09003000 | 1.09373000 | nan | OQ 0 19:54:10.283 pandas test (EURUSD,H1) | 1.09678000 | 1.09810000 | 1.09361000 | 1.09399000 | 0.00297000 | QQ 0 19:54:10.283 pandas test (EURUSD,H1) | 1.09701000 | 1.09973000 | 1.09606000 | 1.09805000 | 0.00023000 | FF 0 19:54:10.283 pandas test (EURUSD,H1) | 1.09639000 | 1.09869000 | 1.09542000 | 1.09742000 | -0.00062000 | LF 0 19:54:10.283 pandas test (EURUSD,H1) | 1.10302000 | 1.10396000 | 1.09513000 | 1.09757000 | 0.00663000 | OI 0 19:54:10.283 pandas test (EURUSD,H1) (1000x5)
El método «rolling()»
Este método proporciona una forma conveniente de realizar cálculos con ventanas móviles; es útil para quienes desean calcular los valores dentro de un período de tiempo determinado, por ejemplo, para calcular los promedios móviles de las variables en un DataFrame.
Archivo: main.ipynb Lenguaje: Python
df["Close sma_5"] = df["Close"].rolling(window=5).mean() df
A diferencia de otros métodos, el método de rodadura requiere la creación de una matriz bidimensional llena de ventanas divididas a lo largo de las filas. Dado que luego necesitamos aplicar la matriz 2D resultante a algunas funciones matemáticas de nuestra elección, es posible que tengamos que crear una estructura separada solo para esta tarea.
struct rolling_struct { public: matrix matrix__; vector Mean() { vector res(matrix__.Rows()); res.Fill(NaN); for(ulong i=0; i<res.Size(); i++) res[i] = matrix__.Row(i).Mean(); return res; } };
Podemos crear las funciones para rellenar la variable matricial denominada matrix__.
rolling_struct CDataFrame::Rolling(const vector &v, const uint window) { rolling_struct roll_res; roll_res.matrix__.Resize(v.Size(), window); roll_res.matrix__.Fill(NaN); for(ulong i = 0; i < v.Size(); i++) { for(ulong j = 0; j < window; j++) { // Calculate the index in the vector for the Rolling window ulong index = i - (window - 1) + j; if(index >= 0 && index < v.Size()) roll_res.matrix__[i][j] = v[index]; } } return roll_res; } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ rolling_struct CDataFrame::Rolling(const string index, const uint window) { vector v = GetColumn(index); return Rolling(v, window); }
Ahora podemos utilizar esta función para calcular la media de una ventana y muchas otras funciones matemáticas según nos convenga.
void OnStart() { //--- CDataFrame df; df.ReadCSV("EURUSD.PERIOD_D1.csv"); vector close_sma_5 = df.Rolling("Close", 5).Mean(); df.Insert("Close sma_5", close_sma_5); df.Head(10); }
Resultados:
RP 0 20:15:23.126 pandas test (EURUSD,H1) | Open | High | Low | Close | Close sma_5 | KP 0 20:15:23.126 pandas test (EURUSD,H1) | 1.09381000 | 1.09548000 | 1.09003000 | 1.09373000 | nan | QP 0 20:15:23.126 pandas test (EURUSD,H1) | 1.09678000 | 1.09810000 | 1.09361000 | 1.09399000 | nan | HP 0 20:15:23.126 pandas test (EURUSD,H1) | 1.09701000 | 1.09973000 | 1.09606000 | 1.09805000 | nan | GO 0 20:15:23.126 pandas test (EURUSD,H1) | 1.09639000 | 1.09869000 | 1.09542000 | 1.09742000 | nan | RR 0 20:15:23.126 pandas test (EURUSD,H1) | 1.10302000 | 1.10396000 | 1.09513000 | 1.09757000 | 1.09615200 | CR 0 20:15:23.126 pandas test (EURUSD,H1) | 1.10431000 | 1.10495000 | 1.10084000 | 1.10297000 | 1.09800000 | NS 0 20:15:23.126 pandas test (EURUSD,H1) | 1.10616000 | 1.10828000 | 1.10326000 | 1.10453000 | 1.10010800 | JS 0 20:15:23.126 pandas test (EURUSD,H1) | 1.11262000 | 1.11442000 | 1.10459000 | 1.10678000 | 1.10185400 | EP 0 20:15:23.126 pandas test (EURUSD,H1) | 1.11529000 | 1.12088000 | 1.11139000 | 1.11350000 | 1.10507000 | EP 0 20:15:23.126 pandas test (EURUSD,H1) | 1.11765000 | 1.12029000 | 1.11249000 | 1.11594000 | 1.10874400 | RO 0 20:15:23.126 pandas test (EURUSD,H1) (1000x5)
Puedes hacer mucho más con la estructura móvil y añadir más fórmulas para todas las operaciones matemáticas que quieras aplicar a la ventana móvil. Aquí encontrarás más funciones matemáticas para matrices y vectores.
Tal y como está ahora, he implementado varias funciones que se pueden aplicar a la matriz rodante;
- Std() para calcular la desviación estándar de los datos en una ventana concreta.
- Var() para calcular la varianza de la ventana.
- Skew() para calcular la asimetría de todos los datos en una ventana concreta.
- Kurtosis() para calcular la curtosis de todos los datos en una ventana determinada.
- Median() para calcular la mediana de todos los datos en una ventana determinada.
Estas son solo algunas funciones útiles imitadas de la biblioteca Pandas en Python. Ahora veamos cómo podemos usar esta biblioteca para preparar datos para el aprendizaje automático.
Vamos a recopilar los datos en MQL5, exportarlos a un archivo CSV que se importará en un script de Python, un modelo entrenado se guardará en formato ONNX, el modelo ONNX se importará y se implementará en MQL5 con el mismo enfoque de recopilación y almacenamiento de datos.
Recopilación de datos para el aprendizaje automático
Recopilemos unas 20 variables y agreguémoslas a una clase Dataframe.
- Valores Open, High, Low, y Close (OHLC).
CDataFrame df; int size = 10000; //We collect this amount of bars for training purposes vector open, high, low, close; open.CopyRates(Symbol(), PERIOD_D1, COPY_RATES_OPEN,1, size); high.CopyRates(Symbol(), PERIOD_D1, COPY_RATES_HIGH,1, size); low.CopyRates(Symbol(), PERIOD_D1, COPY_RATES_LOW,1, size); close.CopyRates(Symbol(), PERIOD_D1, COPY_RATES_CLOSE,1, size); df.Insert("open",open); df.Insert("high",high); df.Insert("low",low); df.Insert("close",close);
Estas características son esenciales, ya que ayudan a derivar más características; son, sencillamente, la base de todos los patrones que vemos en el mercado.
- Dado que el mercado de divisas está abierto durante 5 días, sumemos los valores de cierre de los 5 días anteriores (valores de cierre rezagados). Estos datos pueden ayudar a los modelos de IA a comprender los patrones a lo largo del tiempo.
int lags = 5; for (int i=1; i<=lags; i++) { vector lag = df.Shift("close", i); df.Insert("close lag_"+string(i), lag); }
Esto hace que el Dataframe tenga ahora un total de 9 variables.
- Variación porcentual diaria del precio de cierre (para detectar las variaciones diarias del precio de cierre).
vector pct_change = df.Pct_change("close"); df.Insert("close pct_change", pct_change);
- Dado que estamos trabajando en un marco temporal diario, añadamos la varianza de los 5 días para capturar los patrones de variabilidad dentro de un período móvil de 5 días.
vector var_5 = df.Rolling("close", 5).Var(); df.Insert("var close 5 days", var_5);
- Podemos agregar las características de diferenciación para ayudar a capturar la volatilidad y los movimientos de precios entre los valores OHLC.
df.Insert("open_close",open-close); df.Insert("high_low",high-low);
- Podemos añadir el precio medio, con la esperanza de que ayude a los modelos a capturar los patrones dentro de los propios valores OHLC.
df.Insert("Avg price",(open+high+low+close)/4);
- Finalmente, podemos añadir algunos indicadores a la mezcla. Voy a utilizar el método de recopilación de datos de indicadores que se describe en este artículo. No dude en utilizar cualquier método para recopilar datos sobre los indicadores si este no le conviene.
BB_res_struct bb = CTrendIndicators::BollingerBands(close,20,0,2.000000); //Calculating the bollinger band indicator df.Insert("bb_lower",bb.lower_band); //Inserting lower band values df.Insert("bb_middle",bb.middle_band); //Inserting the middle band values df.Insert("bb_upper",bb.upper_band); //Inserting the upper band values vector atr = COscillatorIndicators::ATR(high,low,close,14); //Calculating the ATR Indicator df.Insert("ATR 14",atr); //Inserting the ATR indicator values MACD_res_struct macd = COscillatorIndicators::MACD(close,12,26,9); //MACD indicator applied to the closing price df.Insert("macd histogram", macd.histogram); //Inserting the MAC historgram values df.Insert("macd main", macd.main); //Inserting the macd main line values df.Insert("macd signal", macd.signal); //Inserting the macd signal line values
Tenemos 21 variables en total.
df.Head();
Resultados:
PG 0 11:32:21.371 pandas test (EURUSD,H1) | open | high | low | close | close lag_1 | close lag_2 | close lag_3 | close lag_4 | close lag_5 | close pct_change | var close 5 days | open_close | high_low | Avg price | bb_lower | bb_middle | bb_upper | ATR 14 | macd histogram | macd main | macd signal | DD 0 11:32:21.371 pandas test (EURUSD,H1) | 1.15620000 | 1.15660000 | 1.15030000 | 1.15080000 | nan | nan | nan | nan | nan | nan | nan | 0.00540000 | 0.00630000 | 1.15347500 | nan | nan | nan | nan | nan | nan | nan | JN 0 11:32:21.371 pandas test (EURUSD,H1) | 1.15100000 | 1.15130000 | 1.14220000 | 1.14280000 | 1.15080000 | nan | nan | nan | nan | -0.69516858 | nan | 0.00820000 | 0.00910000 | 1.14682500 | nan | nan | nan | nan | nan | nan | nan | ID 0 11:32:21.371 pandas test (EURUSD,H1) | 1.14300000 | 1.15360000 | 1.14230000 | 1.15110000 | 1.14280000 | 1.15080000 | nan | nan | nan | 0.72628631 | nan | -0.00810000 | 0.01130000 | 1.14750000 | nan | nan | nan | nan | nan | nan | nan | ES 0 11:32:21.371 pandas test (EURUSD,H1) | 1.15070000 | 1.15490000 | 1.14890000 | 1.15050000 | 1.15110000 | 1.14280000 | 1.15080000 | nan | nan | -0.05212406 | nan | 0.00020000 | 0.00600000 | 1.15125000 | nan | nan | nan | nan | nan | nan | nan | LJ 0 11:32:21.371 pandas test (EURUSD,H1) | 1.14820000 | 1.14900000 | 1.13560000 | 1.13870000 | 1.15050000 | 1.15110000 | 1.14280000 | 1.15080000 | nan | -1.02564103 | 0.00002596 | 0.00950000 | 0.01340000 | 1.14287500 | nan | nan | nan | nan | nan | nan | nan | HG 0 11:32:21.371 pandas test (EURUSD,H1) (10000x22)
Echemos un vistazo al conjunto de datos por un segundo.
df.Info();
Resultados:
FN 0 12:18:01.745 pandas test (EURUSD,H1) <class 'CDataFrame'> QE 0 12:18:01.745 pandas test (EURUSD,H1) RangeIndex: 10000 entries, 0 to 9999 NL 0 12:18:01.745 pandas test (EURUSD,H1) Data columns (total 21 columns): MR 0 12:18:01.745 pandas test (EURUSD,H1) # Column Non-Null Count Dtype DI 0 12:18:01.745 pandas test (EURUSD,H1) --- ------ -------------- ----- CO 0 12:18:01.745 pandas test (EURUSD,H1) 0 open 10000 non-null double GR 0 12:18:01.746 pandas test (EURUSD,H1) 1 high 10000 non-null double LK 0 12:18:01.746 pandas test (EURUSD,H1) 2 low 10000 non-null double JF 0 12:18:01.747 pandas test (EURUSD,H1) 3 close 10000 non-null double QS 0 12:18:01.748 pandas test (EURUSD,H1) 4 close lag_1 9999 non-null double JO 0 12:18:01.748 pandas test (EURUSD,H1) 5 close lag_2 9998 non-null double GH 0 12:18:01.748 pandas test (EURUSD,H1) 6 close lag_3 9997 non-null double KD 0 12:18:01.749 pandas test (EURUSD,H1) 7 close lag_4 9996 non-null double FP 0 12:18:01.749 pandas test (EURUSD,H1) 8 close lag_5 9995 non-null double EL 0 12:18:01.750 pandas test (EURUSD,H1) 9 close pct_change 9999 non-null double ME 0 12:18:01.750 pandas test (EURUSD,H1) 10 var close 5 days 9996 non-null double GI 0 12:18:01.751 pandas test (EURUSD,H1) 11 open_close 10000 non-null double ES 0 12:18:01.752 pandas test (EURUSD,H1) 12 high_low 10000 non-null double LF 0 12:18:01.752 pandas test (EURUSD,H1) 13 Avg price 10000 non-null double DI 0 12:18:01.752 pandas test (EURUSD,H1) 14 bb_lower 9981 non-null double FQ 0 12:18:01.753 pandas test (EURUSD,H1) 15 bb_middle 9981 non-null double NQ 0 12:18:01.753 pandas test (EURUSD,H1) 16 bb_upper 9981 non-null double QI 0 12:18:01.753 pandas test (EURUSD,H1) 17 ATR 14 9986 non-null double CF 0 12:18:01.753 pandas test (EURUSD,H1) 18 macd histogram 9975 non-null double DO 0 12:18:01.754 pandas test (EURUSD,H1) 19 macd main 9975 non-null double FR 0 12:18:01.754 pandas test (EURUSD,H1) 20 macd signal 9992 non-null double FF 0 12:18:01.754 pandas test (EURUSD,H1) memory usage: 1640.6 KB
Nuestros datos utilizan alrededor de 1,6 MB de memoria, hay muchos valores nulos (NaN) que tenemos que descartar.
CDataFrame new_df = df.Dropnan(); new_df.Head();
Resultados:
JO 0 12:18:01.762 pandas test (EURUSD,H1) CDataFrame::Dropnan completed. Rows dropped: 25/10000 JR 0 12:18:01.766 pandas test (EURUSD,H1) | open | high | low | close | close lag_1 | close lag_2 | close lag_3 | close lag_4 | close lag_5 | close pct_change | var close 5 days | open_close | high_low | Avg price | bb_lower | bb_middle | bb_upper | ATR 14 | macd histogram | macd main | macd signal | FQ 0 12:18:01.766 pandas test (EURUSD,H1) | 1.23060000 | 1.23900000 | 1.20370000 | 1.21470000 | 1.23100000 | 1.23450000 | 1.21980000 | 1.22330000 | 1.22350000 | -1.32412673 | 0.00005234 | 0.01590000 | 0.03530000 | 1.22200000 | 1.16702297 | 1.20237000 | 1.23771703 | 0.01279286 | -1.19628486 | 0.02253736 | 1.21882222 | OJ 0 12:18:01.766 pandas test (EURUSD,H1) | 1.21540000 | 1.22120000 | 1.20930000 | 1.21130000 | 1.21470000 | 1.23100000 | 1.23450000 | 1.21980000 | 1.22330000 | -0.27990450 | 0.00008191 | 0.00410000 | 0.01190000 | 1.21430000 | 1.17236514 | 1.20446500 | 1.23656486 | 0.01265000 | -1.19925638 | 0.02076585 | 1.22002222 | IO 0 12:18:01.766 pandas test (EURUSD,H1) | 1.21040000 | 1.21390000 | 1.20730000 | 1.20930000 | 1.21130000 | 1.21470000 | 1.23100000 | 1.23450000 | 1.21980000 | -0.16511186 | 0.00010988 | 0.00110000 | 0.00660000 | 1.21022500 | 1.17774730 | 1.20631000 | 1.23487270 | 0.01253571 | -1.20115162 | 0.01898171 | 1.22013333 | QP 0 12:18:01.766 pandas test (EURUSD,H1) | 1.20840000 | 1.20840000 | 1.19490000 | 1.20340000 | 1.20930000 | 1.21130000 | 1.21470000 | 1.23100000 | 1.23450000 | -0.48788555 | 0.00008624 | 0.00500000 | 0.01350000 | 1.20377500 | 1.17941845 | 1.20699500 | 1.23457155 | 0.01292857 | -1.20208086 | 0.01689692 | 1.21897778 | DJ 0 12:18:01.766 pandas test (EURUSD,H1) | 1.21000000 | 1.21930000 | 1.20900000 | 1.21330000 | 1.20340000 | 1.20930000 | 1.21130000 | 1.21470000 | 1.23100000 | 0.82266910 | 0.00001558 | -0.00330000 | 0.01030000 | 1.21290000 | 1.18119695 | 1.20804500 | 1.23489305 | 0.01360714 | -1.20198373 | 0.01586072 | 1.21784444 | MS 0 12:18:01.766 pandas test (EURUSD,H1) (9975x21)
Podemos guardar este DataFrame en un archivo CSV.
string csv_name = Symbol()+".dailytf.data.csv"; new_df.ToCSV(csv_name, false, 8);
Entrenamiento de un modelo de aprendizaje automático
Comenzamos importando las bibliotecas que podríamos necesitar en un Notebook Jupyter de Python.
Archivo: main.ipynb
import pandas as pd import matplotlib.pyplot as plt import seaborn as sns from sklearn.linear_model import LinearRegression from sklearn.pipeline import Pipeline from sklearn.preprocessing import RobustScaler from sklearn.model_selection import train_test_split import skl2onnx from sklearn.metrics import r2_score sns.set_style("darkgrid")
Importamos los datos y los asignamos a un DataFrame de Pandas.
df = pd.read_csv("EURUSD.dailytf.data.csv")
Vamos a crear la variable objetivo.
df["future_close"] = df["close"].shift(-1) # Shift the close price by one to get df = df.dropna() # drop nan values caused by the shift operation
Ahora que tenemos la variable objetivo para un problema de regresión, dividamos los datos en muestras de entrenamiento y prueba.
X = df.drop(columns=[ "future_close" # drop the target veriable from the independent variables matrix ]) y = df["future_close"] # Train test split X_train, X_test, y_train, y_test = train_test_split(X, y, shuffle=False)
Hemos establecido el valor de barajado en falso para poder tratar esto como un problema de series temporales.
A continuación, envolvemos un modelo de regresión lineal en un pipeline y lo entrenamos.
pipe_model = Pipeline([ ("scaler", RobustScaler()), ("LR", LinearRegression()) ]) pipe_model.fit(X_train, y_train) # Training a Linear regression model
Resultados:
Para evaluar el modelo que tenemos, decidí predecir el objetivo basándome en los datos de entrenamiento y prueba, añadí esta información a un marco de datos Pandas y, a continuación, representé gráficamente el resultado utilizando Seaborn y Matplotlib.
# Preparing the data for plotting train_pred = pipe_model.predict(X_train) test_pred = pipe_model.predict(X_test) train_data = pd.DataFrame({ 'Index': range(len(y_train)), 'True Values': y_train, 'Predicted Values': train_pred, 'Set': 'Train' }) test_data = pd.DataFrame({ 'Index': range(len(y_test)), 'True Values': y_test, 'Predicted Values': test_pred, 'Set': 'Test' }) # figure size 750x1000 pixels fig, axes = plt.subplots(2, 1, figsize=(7.5, 10), sharex=False) # Plot Train Data sns.lineplot(ax=axes[0], data=train_data, x='Index', y='True Values', label='True Values', color='blue') sns.lineplot(ax=axes[0], data=train_data, x='Index', y='Predicted Values', label='Predicted Values', color='orange') axes[0].set_title(f'Train Set: True vs Predicted Values | Acc = {r2_score(y_train, train_pred)}', fontsize=14) axes[0].set_ylabel('Values', fontsize=12) axes[0].legend() # Plot Test Data sns.lineplot(ax=axes[1], data=test_data, x='Index', y='True Values', label='True Values', color='blue') sns.lineplot(ax=axes[1], data=test_data, x='Index', y='Predicted Values', label='Predicted Values', color='orange') axes[1].set_title(f'Test Set: True vs Predicted Values | Acc = {r2_score(y_test, test_pred)}', fontsize=14) axes[1].set_xlabel('Index', fontsize=12) axes[1].set_ylabel('Values', fontsize=12) axes[1].legend() # Final adjustments plt.tight_layout() plt.show()
Resultados:
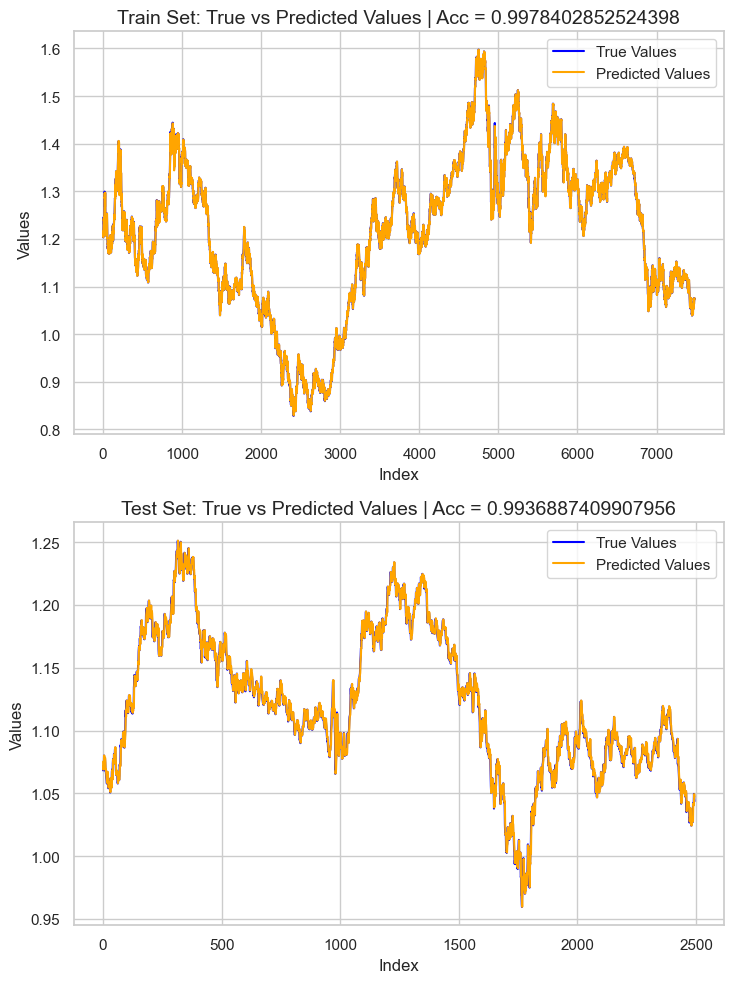
El resultado es un modelo sobreajustado con una puntuación R2 aproximada de 0,99. Esto no es una buena señal para el funcionamiento del modelo. Inspeccionemos la importancia de las características para observar cuáles estaban afectando al modelo de forma positiva; aquellas que tuvieran una influencia negativa en el modelo se eliminarán cuando se detecten.
# Extract the linear regression model from the pipeline lr_model = pipe_model.named_steps['LR'] # Get feature importance (coefficients) feature_importance = pd.Series(lr_model.coef_, index=X_train.columns) # Sort feature importance feature_importance = feature_importance.sort_values(ascending=False) print(feature_importance)
Resultados:
macd main 266.706747 close 0.093652 open 0.093435 Avg price 0.042505 close lag_1 0.006972 close lag_3 0.003645 bb_upper 0.001423 close lag_5 0.001415 bb_middle 0.000766 high_low 0.000201 bb_lower 0.000087 var close 5 days -0.000179 ATR 14 -0.000185 close pct_change -0.001046 close lag_4 -0.002636 close lag_2 -0.003881 open_close -0.004705 high -0.008575 low -0.008663 macd histogram -5504.010453 macd signal -5518.035201 dtype: float64
La característica más informativa fue la MACD principal, mientras que el histograma MACD y la señal fueron las variables menos informativas para el modelo. Eliminemos todos los valores con importancia de características negativa, volvamos a entrenar el modelo y observemos nuevamente la precisión.
X = df.drop(columns=[ "future_close", # drop the target veriable from the independent variables matrix "var close 5 days", "ATR 14", "close pct_change", "close lag_4", "close lag_2", "open_close", "high", "low", "macd histogram", "macd signal" ])
pipe_model = Pipeline([ ("scaler", MinMaxScaler()), ("LR", LinearRegression()) ]) pipe_model.fit(X_train, y_train)
La precisión del modelo reentrenado era muy similar a la del modelo anterior. El modelo seguía siendo un modelo sobreajustado. Por ahora está bien, procedamos a exportar el modelo al formato ONNX.
Implementación de un modelo de aprendizaje automático en MQL5
Dentro de nuestro Asesor Experto (Expert Advisor, EA), comenzamos añadiendo el modelo como recurso para que pueda compilarse con el programa.
Archivo: LR model Test.mq5
#resource "\\Files\\EURUSD.dailytf.model.onnx" as uchar lr_onnx[]
Importamos todas las bibliotecas necesarias: la biblioteca Pandas, ta-lib (para indicadores) y Linear Regression (para cargar el modelo).
#include <Linear Regression.mqh> #include <MALE5\pandas.mqh> #include <ta-lib.mqh> CLinearRegression lr;
Inicializamos el modelo de regresión lineal en la función OnInit.
int OnInit() { //--- if (!lr.Init(lr_onnx)) return INIT_FAILED; //--- return(INIT_SUCCEEDED); }
Lo bueno de utilizar esta biblioteca Pandas personalizada que tenemos es que no hay que empezar a escribir código desde cero para recopilar los datos de nuevo, solo tenemos que copiar el código que utilizamos, pegarlo en el asesor experto principal y realizar pequeñas modificaciones.
void OnTick() { //--- CDataFrame df; int size = 10000; //We collect this amount of bars for training purposes vector open, high, low, close; open.CopyRates(Symbol(), PERIOD_D1, COPY_RATES_OPEN,1, size); high.CopyRates(Symbol(), PERIOD_D1, COPY_RATES_HIGH,1, size); low.CopyRates(Symbol(), PERIOD_D1, COPY_RATES_LOW,1, size); close.CopyRates(Symbol(), PERIOD_D1, COPY_RATES_CLOSE,1, size); df.Insert("open",open); df.Insert("high",high); df.Insert("low",low); df.Insert("close",close); int lags = 5; for (int i=1; i<=lags; i++) { vector lag = df.Shift("close", i); df.Insert("close lag_"+string(i), lag); } vector pct_change = df.Pct_change("close"); df.Insert("close pct_change", pct_change); vector var_5 = df.Rolling("close", 5).Var(); df.Insert("var close 5 days", var_5); df.Insert("open_close",open-close); df.Insert("high_low",high-low); df.Insert("Avg price",(open+high+low+close)/4); //--- BB_res_struct bb = CTrendIndicators::BollingerBands(close,20,0,2.000000); //Calculating the bollinger band indicator df.Insert("bb_lower",bb.lower_band); //Inserting lower band values df.Insert("bb_middle",bb.middle_band); //Inserting the middle band values df.Insert("bb_upper",bb.upper_band); //Inserting the upper band values vector atr = COscillatorIndicators::ATR(high,low,close,14); //Calculating the ATR Indicator df.Insert("ATR 14",atr); //Inserting the ATR indicator values MACD_res_struct macd = COscillatorIndicators::MACD(close,12,26,9); //MACD indicator applied to the closing price df.Insert("macd histogram", macd.histogram); //Inserting the MAC historgram values df.Insert("macd main", macd.main); //Inserting the macd main line values df.Insert("macd signal", macd.signal); //Inserting the macd signal line values df.Info(); CDataFrame new_df = df.Dropnan(); new_df.Head(); string csv_name = Symbol()+".dailytf.data.csv"; new_df.ToCSV(csv_name, false, 8); }
Las modificaciones incluyen:
Modificar el tamaño de los datos que queremos. Ya no necesitamos 10.000 barras, solo necesitamos unas 30 barras porque el indicador MACD tiene un período de 26, las Bandas de Bollinger tienen un período de 20 y el ATR tiene un período de 14. Al asignarle un valor de 30, dejamos efectivamente un margen para los cálculos.
La función OnTick puede ser muy fluida y explosiva a veces; no necesitamos redefinir las variables cada vez que se recibe un nuevo tick.
No necesitamos guardar los datos en un archivo CSV, solo necesitamos que la última fila del DataFrame se asigne a un vector para introducirlo en el modelo.
Podemos agrupar estas líneas de código en una función independiente para facilitar su manejo.
vector GetData(int start_bar=1, int size=30) { open_.CopyRates(Symbol(), PERIOD_D1, COPY_RATES_OPEN,start_bar, size); high_.CopyRates(Symbol(), PERIOD_D1, COPY_RATES_HIGH,start_bar, size); low_.CopyRates(Symbol(), PERIOD_D1, COPY_RATES_LOW,start_bar, size); close_.CopyRates(Symbol(), PERIOD_D1, COPY_RATES_CLOSE,start_bar, size); df_.Insert("open",open_); df_.Insert("high",high_); df_.Insert("low",low_); df_.Insert("close",close_); int lags = 5; vector lag = {}; for (int i=1; i<=lags; i++) { lag = df_.Shift("close", i); df_.Insert("close lag_"+string(i), lag); } pct_change = df_.Pct_change("close"); df_.Insert("close pct_change", pct_change); var_5 = df_.Rolling("close", 5).Var(); df_.Insert("var close 5 days", var_5); df_.Insert("open_close",open_-close_); df_.Insert("high_low",high_-low_); df_.Insert("Avg price",(open_+high_+low_+close_)/4); //--- BB_res_struct bb = CTrendIndicators::BollingerBands(close_,20,0,2.000000); //Calculating the bollinger band indicator df_.Insert("bb_lower",bb.lower_band); //Inserting lower band values df_.Insert("bb_middle",bb.middle_band); //Inserting the middle band values df_.Insert("bb_upper",bb.upper_band); //Inserting the upper band values atr = COscillatorIndicators::ATR(high_,low_,close_,14); //Calculating the ATR Indicator df_.Insert("ATR 14",atr); //Inserting the ATR indicator values MACD_res_struct macd = COscillatorIndicators::MACD(close_,12,26,9); //MACD indicator applied to the closing price df_.Insert("macd histogram", macd.histogram); //Inserting the MAC historgram values df_.Insert("macd main", macd.main); //Inserting the macd main line values df_.Insert("macd signal", macd.signal); //Inserting the macd signal line values CDataFrame new_df = df_.Dropnan(); //Drop NaN values return new_df.Loc(-1); //return the latest row }
Así es como recopilamos inicialmente los datos para el entrenamiento; algunas de las características presentes en esta función no llegaron al modelo final debido a diversas razones, por lo que tuvimos que descartarlas, de forma similar a como las descartamos dentro del script de Python.
vector GetData(int start_bar=1, int size=30) { open_.CopyRates(Symbol(), PERIOD_D1, COPY_RATES_OPEN,start_bar, size); high_.CopyRates(Symbol(), PERIOD_D1, COPY_RATES_HIGH,start_bar, size); low_.CopyRates(Symbol(), PERIOD_D1, COPY_RATES_LOW,start_bar, size); close_.CopyRates(Symbol(), PERIOD_D1, COPY_RATES_CLOSE,start_bar, size); df_.Insert("open",open_); df_.Insert("high",high_); df_.Insert("low",low_); df_.Insert("close",close_); int lags = 5; vector lag = {}; for (int i=1; i<=lags; i++) { lag = df_.Shift("close", i); df_.Insert("close lag_"+string(i), lag); } pct_change = df_.Pct_change("close"); df_.Insert("close pct_change", pct_change); var_5 = df_.Rolling("close", 5).Var(); df_.Insert("var close 5 days", var_5); df_.Insert("open_close",open_-close_); df_.Insert("high_low",high_-low_); df_.Insert("Avg price",(open_+high_+low_+close_)/4); //--- BB_res_struct bb = CTrendIndicators::BollingerBands(close_,20,0,2.000000); //Calculating the bollinger band indicator df_.Insert("bb_lower",bb.lower_band); //Inserting lower band values df_.Insert("bb_middle",bb.middle_band); //Inserting the middle band values df_.Insert("bb_upper",bb.upper_band); //Inserting the upper band values atr = COscillatorIndicators::ATR(high_,low_,close_,14); //Calculating the ATR Indicator df_.Insert("ATR 14",atr); //Inserting the ATR indicator values MACD_res_struct macd = COscillatorIndicators::MACD(close_,12,26,9); //MACD indicator applied to the closing price df_.Insert("macd histogram", macd.histogram); //Inserting the MAC historgram values df_.Insert("macd main", macd.main); //Inserting the macd main line values df_.Insert("macd signal", macd.signal); //Inserting the macd signal line values df_ = df_.Drop( //"future_close", "var close 5 days,"+ "ATR 14,"+ "close pct_change,"+ "close lag_4,"+ "close lag_2,"+ "open_close,"+ "high,"+ "low,"+ "macd histogram,"+ "macd signal" ); CDataFrame new_df = df_.Dropnan(); return new_df.Loc(-1); //return the latest row }
En lugar de eliminar las columnas como en la función anterior, es aconsejable eliminar el código utilizado para generarlas en primer lugar, ya que esto podría reducir los cálculos innecesarios que pueden ralentizar el programa cuando hay muchas características que calcular solo para poder eliminarlas poco después.
Por ahora, seguiremos utilizando el método Drop.
Tras llamar al método Head() para ver qué contiene el DataFrame, este fue el resultado:
PM 0 15:45:36.543 LR model Test (EURUSD,H1) CDataFrame::Dropnan completed. Rows dropped: 25/30 HI 0 15:45:36.543 LR model Test (EURUSD,H1) | open | close | close lag_1 | close lag_3 | close lag_5 | high_low | Avg price | bb_lower | bb_middle | bb_upper | macd main | GK 0 15:45:36.543 LR model Test (EURUSD,H1) | 1.04057000 | 1.04079000 | 1.04057000 | 1.02806000 | 1.03015000 | 0.00575000 | 1.04176750 | 1.02125891 | 1.03177350 | 1.04228809 | 0.00028705 | QI 0 15:45:36.543 LR model Test (EURUSD,H1) | 1.04079000 | 1.04159000 | 1.04079000 | 1.04211000 | 1.02696000 | 0.00661000 | 1.04084750 | 1.02081967 | 1.03210400 | 1.04338833 | 0.00085370 | PL 0 15:45:36.543 LR model Test (EURUSD,H1) | 1.04158000 | 1.04956000 | 1.04159000 | 1.04057000 | 1.02806000 | 0.01099000 | 1.04611250 | 1.01924805 | 1.03282750 | 1.04640695 | 0.00192371 | JR 0 15:45:36.543 LR model Test (EURUSD,H1) | 1.04795000 | 1.04675000 | 1.04956000 | 1.04079000 | 1.04211000 | 0.00204000 | 1.04743000 | 1.01927184 | 1.03382650 | 1.04838116 | 0.00251595 | CP 0 15:45:36.543 LR model Test (EURUSD,H1) | 1.04675000 | 1.04370000 | 1.04675000 | 1.04159000 | 1.04057000 | 0.01049000 | 1.04664500 | 1.01938012 | 1.03447300 | 1.04956588 | 0.00270798 | CH 0 15:45:36.543 LR model Test (EURUSD,H1) (5x11)
Tenemos 11 características, el mismo número de características que se pueden ver en el modelo.
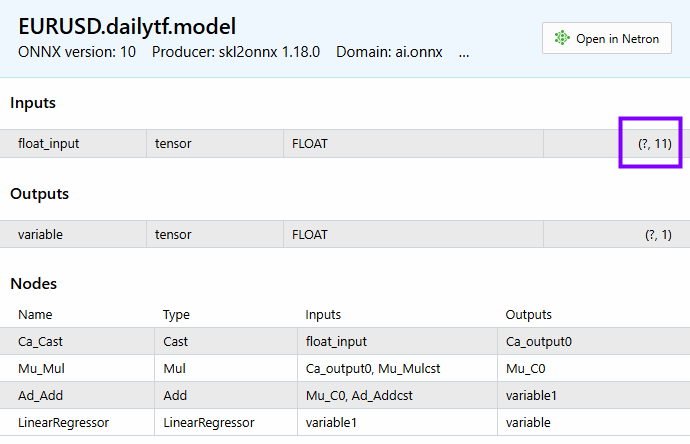
A continuación se muestra cómo podemos obtener las predicciones del modelo final.
void OnTick() { vector x = GetData(); Comment("Predicted close: ", lr.predict(x)); }
No es inteligente realizar toda la recopilación de datos y los cálculos del modelo en cada tick; necesitamos calcularlos al abrirse una nueva barra en el gráfico.
void OnTick() { if (isNewBar()) { vector x = GetData(); Comment("Predicted close: ", lr.predict(x)); } }
Desarrollé una estrategia simple para realizar una operación de compra cuando el precio de cierre previsto está por encima del precio de oferta actual y realizar una operación de venta cuando el precio de cierre previsto está por debajo del precio de demanda actual.
A continuación se muestran los resultados de la prueba de estrategias desde el 1 de noviembre de 2024 hasta el 25 de enero de 2025.
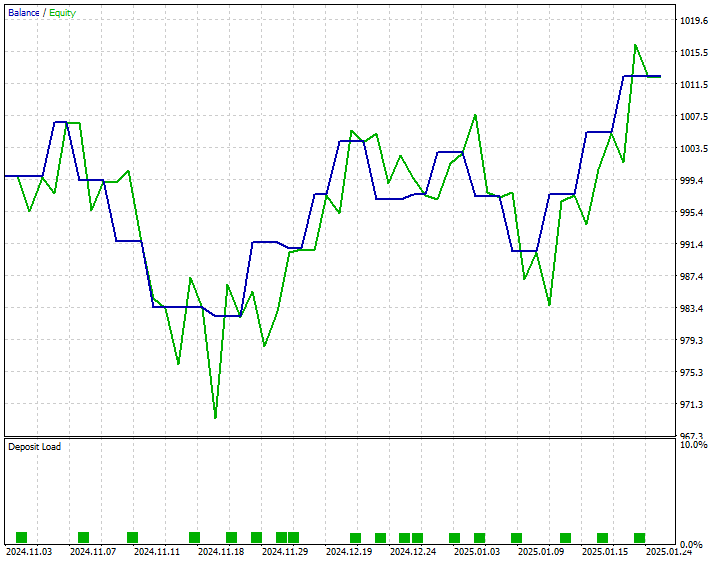
Conclusión
Ahora es fácil importar modelos sofisticados de IA a MQL5 y usarlos en MetaTrader 5 como si nada, pero aún no es fácil mantener el modelo sincronizado con una estructura de datos similar a la utilizada para el entrenamiento. En este artículo, presento una clase personalizada llamada CDataframe para ayudarnos a trabajar con datos bidimensionales en un entorno similar al de la biblioteca Pandas, muy familiar para la comunidad de aprendizaje automático y los científicos de datos provenientes de un entorno Python.
Espero que la biblioteca Pandas en MQL5 sea de gran utilidad y nos facilite mucho la vida al trabajar con datos complejos de IA en MQL5.
Saludos cordiales.
Manténgase al tanto y contribuya al desarrollo de algoritmos de aprendizaje automático para el lenguaje MQL5 en este repositorio GitHub.
Tabla de archivos adjuntos
| Nombre del archivo | Descripción/Uso |
|---|---|
| Experts\LR model Test.mq5 | Un asesor experto para la implementación del modelo de regresión lineal final. |
| Include\Linear Regression.mqh | Una biblioteca que contiene todo el código para cargar un modelo de regresión lineal en formato ONNX. |
| Include\pandas.mqh | Contiene todos los métodos personalizados de Pandas para trabajar con datos en una clase Dataframe. |
| Scripts\pandas test.mq5 | Script responsable de recopilar los datos para el entrenamiento de modelos de aprendizaje automático. |
| Python\main.ipynb | Un archivo Jupyter Notebook con todo el código para entrenar un modelo de regresión lineal utilizado en este artículo. |
| Files\ | Esta carpeta contiene un modelo de regresión lineal en modelos ONNX y archivos CSV para fines de entrenamiento de modelos de IA. |
Traducción del inglés realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/en/articles/17030
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso