
Ciência de Dados e ML (Parte 33): Dataframe do Pandas em MQL5, Coleta de Dados para Uso em ML facilitada

Conteúdo:
- Introdução
- Estruturas Básicas de Dados no Pandas
- Um Dataframe do Pandas
- Adicionando Dados à Classe Dataframe
- Atribuindo um arquivo CSV ao Dataframe
- Visualizando o Conteúdo do Dataframe
- Exportando o Dataframe para um arquivo CSV
- Seleção e Indexação do Dataframe
- Explorando e Inspecionando o Dataframe do Pandas
- Séries Temporais e Métodos de Transformação de Dados
- Coletando Dados para Aprendizado de Máquina
- Treinando um Modelo de Aprendizado de Máquina
- Implantando um Modelo de Aprendizado de Máquina em MQL5
- Conclusão
Introdução
Quando se trata de trabalhar com modelos de aprendizado de máquina, é essencial que tenhamos a mesma estrutura de dados, se não os mesmos valores, para todos os ambientes; treinamento, validação e testes. Com modelos Open Neural Network Exchange (ONNX) sendo suportados em MQL5 e MetaTrader 5, atualmente temos a oportunidade de importar modelos treinados externamente para a linguagem MQL5 e utilizá-los para fins de negociação.
Como a maioria dos usuários utiliza Python para treinar esses modelos de Inteligência Artificial (IA), que depois são implantados no MetaTrader 5 por meio de código MQL5, pode haver uma grande diferença na forma como os dados são organizados, e muitas vezes até mesmo os valores dentro da mesma estrutura de dados podem ser ligeiramente diferentes; isso ocorre devido à diferença entre as duas tecnologias.

Neste artigo, vamos imitar a biblioteca Pandas disponível na linguagem Python. Ela é uma das bibliotecas mais populares, útil particularmente quando se trata de trabalhar com grandes volumes de dados.
Como essa biblioteca é usada por cientistas de dados para preparar e manipular dados utilizados no treinamento de modelos de ML, ao aproveitar sua capacidade, buscamos ter o mesmo ambiente de dados em MQL5 que em Python.
Estruturas Básicas de Dados no Pandas
A biblioteca Pandas fornece dois tipos de classes para manipulação de dados.
- Series: um array rotulado unidimensional para armazenar dados de qualquer tipo, como inteiros, strings, objetos, etc.
s = pd.Series([1, 3, 5, np.nan, 6, 8])
- Dataframe: uma estrutura de dados bidimensional que armazena dados como um array bidimensional ou uma tabela com linhas e colunas.
Como a classe de dados pandas Series é unidimensional, ela é mais parecida com um Array ou um vetor em MQL5, não vamos trabalhar com ela. Nosso foco está no “Dataframe” bidimensional.
Um DataFrame do Pandas
Novamente, essa estrutura de dados armazena dados como um array bidimensional ou uma tabela com linhas e colunas; em MQL5 podemos ter um array bidimensional, mas o objeto bidimensional mais prático que podemos usar para essa tarefa é uma matriz.
Como agora sabemos que no núcleo do Dataframe do Pandas existe um array bidimensional, podemos implementar essa base semelhante em nossa classe Pandas em MQL5.
Arquivo: pandas.mqh
class CDataFrame { public: string m_columns[]; //An array of string values for keeping track of the column names matrix m_values; // A 2D matrix CDataFrame(); ~CDataFrame(void); }
Precisamos ter um array chamado "m_columns" para armazenar os nomes das colunas de cada coluna no Dataframe; diferentemente de outras bibliotecas para trabalhar com dados, como Numpy, o Pandas garante que os dados armazenados sejam amigáveis para humanos ao manter o controle dos nomes das colunas.
O Dataframe do Pandas em Python oferece suporte a diferentes tipos de dados, como inteiros, strings, objetos, etc.
import pandas as pd df = pd.DataFrame({ "Integers": [1,2,3,4,5], "Doubles": [0.1,0.2,0.3,0.4,0.5], "Strings": ["one","two","three","four","five"] })
Não vamos implementar essa mesma flexibilidade em nossa biblioteca MQL5 porque o objetivo desta biblioteca é nos auxiliar ao trabalhar com modelos de aprendizado de máquina, onde variáveis dos tipos de dados float e double são as mais úteis.
Portanto, certifique-se de converter (inteiros, long, ulong etc.) em valores do tipo de dado double e codificar todas as variáveis (string) que você tiver antes de inseri-las na classe Dataframe, pois todas as variáveis serão forçadas a se tornarem do tipo de dado double.
Adicionando Dados à Classe Dataframe
Agora que sabemos que uma matriz no núcleo de um objeto DataFrame é responsável por armazenar todos os dados, vamos implementar maneiras de adicionar informações a ela.
Em Python, você pode simplesmente criar um novo DataFrame e adicionar objetos a ele chamando o método;
df = pd.DataFrame({
"first column": [1,2,3,4,5],
"second column": [10,20,30,40,50]
})
Devido à sintaxe da linguagem MQL5, não podemos ter uma classe ou método que se comporte dessa forma; vamos implementar um método conhecido como Insert.
Arquivo: pandas.mqh
void CDataFrame::Insert(string name, const vector &values) { //--- Check if the column exists in the m_columns array if it does exists, instead of creating a new column we modify an existing one int col_index = -1; for (int i=0; i<(int)m_columns.Size(); i++) if (name == m_columns[i]) { col_index = i; break; } //--- We check if the dimensiona are Ok if (m_values.Rows()==0) m_values.Resize(values.Size(), m_values.Cols()); if (values.Size() > m_values.Rows() && m_values.Rows()>0) //Check if the new column has a bigger size than the number of rows present in the matrix { printf("%s new column '%s' size is bigger than the dataframe",__FUNCTION__,name); return; } //--- if (col_index != -1) { m_values.Col(values, col_index); if (MQLInfoInteger(MQL_DEBUG)) printf("%s column '%s' exists, It will be modified",__FUNCTION__,name); return; } //--- If a given vector to be added to the dataframe is smaller than the number of rows present in the matrix, we fill the remaining values with Not a Number (NaN) vector temp_vals = vector::Zeros(m_values.Rows()); temp_vals.Fill(NaN); //to create NaN values when there was a dimensional mismatch for (ulong i=0; i<values.Size(); i++) temp_vals[i] = values[i]; //--- m_values.Resize(m_values.Rows(), m_values.Cols()+1); //We resize the m_values matrix to accomodate the new column m_values.Col(temp_vals, m_values.Cols()-1); //We insert the new column after the last column ArrayResize(m_columns, m_columns.Size()+1); //We increase the sice of the column names to accomodate the new column name m_columns[m_columns.Size()-1] = name; //we assign the new column to the last place in the array }
Podemos inserir novas informações no Dataframe da seguinte forma;
#include <MALE5\pandas.mqh> //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- CDataFrame df; vector v1= {1,2,3,4,5}; vector v2= {10,20,30,40,50}; df.Insert("first column", v1); df.Insert("second column", v2); }
Alternativamente, podemos dar ao construtor da classe a capacidade de receber uma matriz e seus nomes de coluna.
CDataFrame::CDataFrame(const string &columns, const matrix &values) { string columns_names[]; //A temporary array for obtaining column names from a string ushort sep = StringGetCharacter(",", 0); if (StringSplit(columns, sep, columns_names)<0) { printf("%s failed to obtain column names",__FUNCTION__); return; } if (columns_names.Size() != values.Cols()) //Check if the given number of column names is equal to the number of columns present in a given matrix { printf("%s dataframe's columns != columns present in the values matrix",__FUNCTION__); return; } ArrayCopy(m_columns, columns_names); //We assign the columns to the m_columns array m_values = values; //We assing the given matrix to the m_values matrix }
Também podemos adicionar novas informações à classe Dataframe da seguinte forma;
void OnStart() { //--- matrix data = { {1,10}, {2,20}, {3,30}, {4,40}, {5,50}, }; CDataFrame df("first column,second column",data); }
Sugiro que você utilize o método Insert para adicionar dados à classe Dataframe, em vez de qualquer outro método para essa tarefa.
Os dois métodos discutidos anteriormente são úteis quando você está preparando conjuntos de dados; também precisamos de uma função para carregar os dados presentes em um conjunto de dados.
Atribuindo um arquivo CSV ao Dataframe
O método para ler um arquivo CSV e atribuir os valores a um Dataframe está entre as funções mais úteis do Pandas quando você está trabalhando com a biblioteca em Python.
df = pd.read_csv("EURUSD.PERIOD_D1.csv")
Vamos implementar esse método em nossa classe MQL5;
bool CDataFrame::ReadCSV(string file_name,string delimiter=",",bool is_common=false, bool verbosity=false) { matrix mat_ = {}; int rows_total=0; int handle = FileOpen(file_name,FILE_READ|FILE_CSV|FILE_ANSI|(is_common?FILE_IS_COMMON:FILE_ANSI),delimiter); //Open a csv file ResetLastError(); if(handle == INVALID_HANDLE) //Check if the file handle is ok if not return false { printf("Invalid %s handle Error %d ",file_name,GetLastError()); Print(GetLastError()==0?" TIP | File Might be in use Somewhere else or in another Directory":""); return false; } else { int column = 0, rows=0; while(!FileIsEnding(handle)) { string data = FileReadString(handle); //--- if(rows ==0) { ArrayResize(m_columns,column+1); m_columns[column] = data; } if(rows>0) //Avoid the first column which contains the column's header mat_[rows-1,column] = (double(data)); //add a value to the matrix column++; //--- if(FileIsLineEnding(handle)) //At the end of the each line { rows++; mat_.Resize(rows,column); //Resize the matrix to accomodate new values column = 0; } } if (verbosity) //if verbosity is set to true, we print the information to let the user know the progress, Useful for debugging purposes printf("Reading a CSV file... record [%d]",rows); rows_total = rows; FileClose(handle); //Close the file after reading it } mat_.Resize(rows_total-1,mat_.Cols()); m_values = mat_; return true; }
Abaixo está como você pode ler um arquivo CSV e atribuí-lo diretamente ao Dataframe.
void OnStart() { //--- CDataFrame df; df.ReadCSV("EURUSD.PERIOD_D1.csv"); df.Head(); }
Visualizando o Conteúdo do Dataframe
Vimos como você pode adicionar informações a um Dataframe, mas é muito crucial ser capaz de dar uma olhada rápida no Dataframe para ver do que ele se trata. Na maioria dos casos, você estará trabalhando com Dataframes grandes, que frequentemente exigem revisitar o Dataframe para fins de exploração e recordação.
O Pandas possui um método conhecido como "head", que retorna as primeiras n linhas do objeto Dataframe com base na posição. Esse método é útil para testar rapidamente se o seu objeto contém o tipo correto de dados.
Quando o método "head" é chamado em uma célula do Jupyter Notebook com seus valores padrão, as cinco primeiras linhas do Dataframe são exibidas na saída da célula.
Arquivo: main.ipynb
df = pd.read_csv("EURUSD.PERIOD_D1.csv") df.head()
Output (Saída)
| Open (Abertura) | High (Máxima) | Low (Mínima) | Close (Fechamento) | |
|---|---|---|---|---|
| 0 | 1.09381 | 1.09548 | 1.09003 | 1.09373 |
| 1 | 1.09678 | 1.09810 | 1.09361 | 1.09399 |
| 2 | 1.09701 | 1.09973 | 1.09606 | 1.09805 |
| 3 | 1.09639 | 1.09869 | 1.09542 | 1.09742 |
| 4 | 1.10302 | 1.10396 | 1.09513 | 1.09757 |
Podemos criar uma função semelhante para essa tarefa em MQL5.
void CDataFrame::Head(const uint count=5) { // Calculate maximum width needed for each column uint num_cols = m_columns.Size(); uint col_widths[]; ArrayResize(col_widths, num_cols); for (uint col = 0; col < num_cols; col++) //Determining column width for visualizing a simple table { uint max_width = StringLen(m_columns[col]); for (uint row = 0; row < count && row < m_values.Rows(); row++) { string num_str = StringFormat("%.8f", m_values[row][col]); max_width = MathMax(max_width, StringLen(num_str)); } col_widths[col] = max_width + 4; // Extra padding for readability } // Print column headers with calculated padding string header = ""; for (uint col = 0; col < num_cols; col++) { header += StringFormat("| %-*s ", col_widths[col], m_columns[col]); } header += "|"; Print(header); // Print rows with padding for each column for (uint row = 0; row < count && row < m_values.Rows(); row++) { string row_str = ""; for (uint col = 0; col < num_cols; col++) { row_str += StringFormat("| %-*.*f ", col_widths[col], 8, m_values[row][col]); } row_str += "|"; Print(row_str); } // Print dimensions printf("(%dx%d)", m_values.Rows(), m_values.Cols()); }
Por padrão, essa função exibe as cinco primeiras linhas do nosso Dataframe.
void OnStart() { //--- CDataFrame df; df.ReadCSV("EURUSD.PERIOD_D1.csv"); df.Head(); }
Saída
GI 0 12:37:02.983 pandas test (Volatility 75 Index,H1) | Open | High | Low | Close | RH 0 12:37:02.983 pandas test (Volatility 75 Index,H1) | 1.09381000 | 1.09548000 | 1.09003000 | 1.09373000 | GI 0 12:37:02.984 pandas test (Volatility 75 Index,H1) | 1.09678000 | 1.09810000 | 1.09361000 | 1.09399000 | DI 0 12:37:02.984 pandas test (Volatility 75 Index,H1) | 1.09701000 | 1.09973000 | 1.09606000 | 1.09805000 | EI 0 12:37:02.984 pandas test (Volatility 75 Index,H1) | 1.09639000 | 1.09869000 | 1.09542000 | 1.09742000 | CI 0 12:37:02.984 pandas test (Volatility 75 Index,H1) | 1.10302000 | 1.10396000 | 1.09513000 | 1.09757000 | FE 0 12:37:02.984 pandas test (Volatility 75 Index,H1) (1000x4)
Exportando o Dataframe para um arquivo CSV
Após coletar todos os diferentes tipos de dados no Dataframe, precisamos exportá-lo para fora do MetaTrader 5, onde ocorrem todos os procedimentos de aprendizado de máquina.
Um arquivo CSV é prático quando se trata de exportar dados, especialmente porque depois utilizaremos a biblioteca Pandas para importar o arquivo CSV na linguagem Python.
Vamos salvar o Dataframe que extraímos de um arquivo CSV de volta em um arquivo CSV.
Em Python.
df.to_csv("EURUSDcopy.csv", index=False) O resultado é um arquivo csv chamado EURUSDcopy.csv.
Abaixo está uma implementação desse método em MQL5.
bool CDataFrame::ToCSV(string csv_name, bool common=false, int digits=5, bool verbosity=false) { FileDelete(csv_name); int handle = FileOpen(csv_name,FILE_WRITE|FILE_SHARE_WRITE|FILE_CSV|FILE_ANSI|(common?FILE_COMMON:FILE_ANSI),",",CP_UTF8); //open a csv file if(handle == INVALID_HANDLE) //Check if the handle is OK { printf("Invalid %s handle Error %d ",csv_name,GetLastError()); return (false); } //--- string concstring; vector row = {}; vector colsinrows = m_values.Row(0); if (ArraySize(m_columns) != (int)colsinrows.Size()) { printf("headers=%d and columns=%d from the matrix vary is size ",ArraySize(m_columns),colsinrows.Size()); DebugBreak(); return false; } //--- string header_str = ""; for (int i=0; i<ArraySize(m_columns); i++) //We concatenate the header only separating it with a comma delimeter header_str += m_columns[i] + (i+1 == colsinrows.Size() ? "" : ","); FileWrite(handle,header_str); FileSeek(handle,0, SEEK_SET); for(ulong i=0; i<m_values.Rows() && !IsStopped(); i++) { ZeroMemory(concstring); row = m_values.Row(i); for(ulong j=0, cols =1; j<row.Size() && !IsStopped(); j++, cols++) { concstring += (string)NormalizeDouble(row[j],digits) + (cols == m_values.Cols() ? "" : ","); } if (verbosity) //if verbosity is set to true, we print the information to let the user know the progress, Useful for debugging purposes printf("Writing a CSV file... record [%d/%d]",i+1,m_values.Rows()); FileSeek(handle,0,SEEK_END); FileWrite(handle,concstring); } FileClose(handle); return (true); }
Abaixo está como usar esse método.
void OnStart() { CDataFrame df; df.ReadCSV("EURUSD.PERIOD_D1.csv"); //Assign a csv file into the dataframe df.ToCSV("EURUSDcopy.csv"); //Save the dataframe back into a CSV file as a copy }
O resultado é a criação do arquivo CSV com o nome EURUSDcopy.csv.
Agora que discutimos sobre a criação de um Dataframe, a inserção de valores nele, a importação e a exportação dos dados, vamos ver as técnicas de seleção e indexação de dados.
Seleção e Indexação do Dataframe
É muito crucial ter a capacidade de fatiar, selecionar ou acessar partes específicas do Dataframe em determinados momentos. Por exemplo; ao usar um modelo para fazer previsões, você pode querer acessar apenas os valores mais recentes (a última linha) no dataframe; enquanto isso, durante o treinamento, você pode querer acessar algumas linhas localizadas no início do Dataframe.
Acessando uma Coluna
Para acessar uma coluna, podemos implementar um operador de índice que receba valores do tipo string em nossa classe.
vector operator[] (const string index) {return GetColumn(index); } //Access a column by its name
A função "GetColumn", quando recebe um nome de coluna, retorna um vetor de seus valores quando ela é encontrada.
Uso
Print("Close column: ",df["Close"]);
Saída
2025.01.27 16:16:19.726 pandas test (EURUSD,H1) Close column: [1.09373,1.09399,1.09805,1.09742,1.09757,1.10297,1.10453,1.10678,1.1135,1.11594,1.11765,1.11327,1.11797,1.11107,1.1163,1.11616,1.11177,1.11141,1.11326,1.10745,1.10747,1.10111,1.10192,1.10351,1.10861,1.11106,1.1083,1.10435,1.10723,1.10483,1.1078,1.11199,1.11843,1.1161,1.11932,1.11113,1.11499,1.113,1.10852,1.10267,1.09712,1.10124,1.09928,1.09321,1.09156,1.09188,1.09236,1.09315,1.09511,1.09107,1.07913,1.08258,1.08142,1.08211,1.08551,1.0845,1.08392,1.08529,1.08905,1.08818,1.08959,1.09396,1.08986,
A indexação "loc"
Essa indexação ajuda a acessar um grupo de linhas e colunas por rótulo(s) ou por um array booleano.
No Pandas Python.
df.loc[0] Saídas.
Open 1.09381 High 1.09548 Low 1.09003 Close 1.09373 Name: 0, dtype: float64
Em MQL5, podemos implementar isso como uma função regular.
vector CDataFrame::Loc(int index, uint axis=0) { if(axis == 0) { vector row = {}; //--- Convert negative index to positive if(index < 0) index = (int)m_values.Rows() + index; if(index < 0 || index >= (int)m_values.Rows()) { printf("%s Error: Row index out of bounds. Given index: %d", __FUNCTION__, index); return row; } return m_values.Row(index); } else if(axis == 1) { vector column = {}; //--- Convert negative index to positive if(index < 0) index = (int)m_values.Cols() + index; //--- Check bounds if(index < 0 || index >= (int)m_values.Cols()) { printf("%s Error: Column index out of bounds. Given index: %d", __FUNCTION__, index); return column; } return m_values.Col(index); } else printf("%s Failed, Unknown axis ",__FUNCTION__); return vector::Zeros(0); }
Em MQL5, podemos implementar isso como uma função regular.
Quando essa função recebe um valor negativo, ela acessa itens em ordem reversa; um valor de índice igual a -1 é o último elemento no Dataframe (última linha quando axis=0, última coluna quando axis=1).
Uso
void OnStart() { //--- CDataFrame df; df.ReadCSV("EURUSD.PERIOD_D1.csv"); df.Head(); Print("First row",df.Loc(0)); //--- Print("Last 5 items in df\n",df.Tail()); Print("Last row: ",df.Loc(-1)); Print("Last Column: ",df.Loc(-1, 1)); }
Saída
RM 0 09:04:21.355 pandas test (EURUSD,H1) | Open | High | Low | Close | IN 0 09:04:21.355 pandas test (EURUSD,H1) | 1.09381000 | 1.09548000 | 1.09003000 | 1.09373000 | GP 0 09:04:21.355 pandas test (EURUSD,H1) | 1.09678000 | 1.09810000 | 1.09361000 | 1.09399000 | NS 0 09:04:21.355 pandas test (EURUSD,H1) | 1.09701000 | 1.09973000 | 1.09606000 | 1.09805000 | IE 0 09:04:21.355 pandas test (EURUSD,H1) | 1.09639000 | 1.09869000 | 1.09542000 | 1.09742000 | IG 0 09:04:21.355 pandas test (EURUSD,H1) | 1.10302000 | 1.10396000 | 1.09513000 | 1.09757000 | NJ 0 09:04:21.355 pandas test (EURUSD,H1) (1000x4) EO 0 09:04:21.355 pandas test (EURUSD,H1) First row[1.09381,1.09548,1.09003,1.09373] JF 0 09:04:21.355 pandas test (EURUSD,H1) Last 5 items in df DN 0 09:04:21.355 pandas test (EURUSD,H1) [[1.20796,1.21591,1.20742,1.21416] JK 0 09:04:21.355 pandas test (EURUSD,H1) [1.21023,1.21474,1.20588,1.20814] PR 0 09:04:21.355 pandas test (EURUSD,H1) [1.21089,1.21342,1.20953,1.21046] OO 0 09:04:21.355 pandas test (EURUSD,H1) [1.21281,1.21664,1.20785,1.2109] FK 0 09:04:21.355 pandas test (EURUSD,H1) [1.21444,1.21774,1.21101,1.21203]] EM 0 09:04:21.355 pandas test (EURUSD,H1) Last row: [1.21444,1.21774,1.21101,1.21203] QM 0 09:04:21.355 pandas test (EURUSD,H1) Last Column: [1.09373,1.09399,1.09805,1.09742,1.09757,1.10297,1.10453,1.10678,1.1135,1.11594,1.11765,1.11327,1.11797,1.11107,1.1163,1.11616,1.11177,1.11141,1.11326,1.10745,1.10747,1.10111,1.10192,1.10351,1.10861,1.11106,1.1083,1.10435,1.10723,1.10483,1.1078,1.11199,1.11843,1.1161,1.11932,1.11113,1.11499,1.113,1.10852,1.10267,1.09712,1.10124,1.09928,1.00063,…]
O método "iloc"
A função Iloc introduzida em nossa classe seleciona linhas e colunas de um Dataframe por posições inteiras, de forma semelhante ao método iloc oferecido pelo Pandas em Python.
Esse método retorna um novo Dataframe que é o resultado da operação de fatiamento.
Implementação em MQL.
CDataFrame Iloc(ulong start_row, ulong end_row, ulong start_col, ulong end_col);
Uso
df = df.Iloc(0,100,0,3); //Slice from the first row to the 99th from the first column to the 2nd df.Head();
Saída
DJ 0 16:40:19.699 pandas test (EURUSD,H1) | Open | High | Low | LQ 0 16:40:19.699 pandas test (EURUSD,H1) | 1.09381000 | 1.09548000 | 1.09003000 | PM 0 16:40:19.699 pandas test (EURUSD,H1) | 1.09678000 | 1.09810000 | 1.09361000 | EI 0 16:40:19.699 pandas test (EURUSD,H1) | 1.09701000 | 1.09973000 | 1.09606000 | DE 0 16:40:19.699 pandas test (EURUSD,H1) | 1.09639000 | 1.09869000 | 1.09542000 | FQ 0 16:40:19.699 pandas test (EURUSD,H1) | 1.10302000 | 1.10396000 | 1.09513000 | GS 0 16:40:19.699 pandas test (EURUSD,H1) (100x3)
O método "at"
Esse método retorna um único valor do Dataframe.
Implementação em MQL.
double CDataFrame::At(ulong row, string col_name) { ulong col_number = (ulong)ColNameToIndex(col_name, m_columns); return m_values[row][col_number]; }
Uso.
void OnStart() { //--- CDataFrame df; df.ReadCSV("EURUSD.PERIOD_D1.csv"); Print(df.At(0,"Close")); //Returns the first value within the Close column }
Saídas.
2025.01.27 16:47:16.701 pandas test (EURUSD,H1) 1.09373
O método "iat"
Isso nos permite acessar um único valor no Dataframe por posição.
Implementação em MQL.
double CDataFrame::Iat(ulong row,ulong col) { return m_values[row][col]; }
Uso
Print(df.Iat(0,0)); //Returns the value at first row and first colum
Saída.
2025.01.27 16:53:32.627 pandas test (EURUSD,H1) 1.09381
Removendo colunas do Dataframe usando o método "drop"
Às vezes acontece de termos colunas indesejadas em nosso dataframe, ou de querermos remover algumas variáveis para fins de treinamento. A função drop pode ajudar nessa tarefa.
Implementação em MQL.
CDataFrame CDataFrame::Drop(const string cols) { CDataFrame df; string column_names[]; ushort sep = StringGetCharacter(",",0); if(StringSplit(cols, sep, column_names) < 0) { printf("%s Failed to get the columns, ensure they are separated by a comma. Error = %d", __FUNCTION__, GetLastError()); return df; } int columns_index[]; uint size = column_names.Size(); ArrayResize(columns_index, size); if(size > m_values.Cols()) { printf("%s failed, The number of columns > columns present in the dataframe", __FUNCTION__); return df; } // Fill columns_index with column indices to drop for(uint i = 0; i < size; i++) { columns_index[i] = ColNameToIndex(column_names[i], m_columns); if(columns_index[i] == -1) { printf("%s Column '%s' not found in this DataFrame", __FUNCTION__, column_names[i]); //ArrayRemove(column_names, i, 1); continue; } } matrix new_data(m_values.Rows(), m_values.Cols() - size); string new_columns[]; ArrayResize(new_columns, (int)m_values.Cols() - size); // Populate new_data with columns not in columns_index for(uint i = 0, count = 0; i < m_values.Cols(); i++) { bool to_drop = false; for(uint j = 0; j < size; j++) { if(i == columns_index[j]) { to_drop = true; break; } } if(!to_drop) { new_data.Col(m_values.Col(i), count); new_columns[count] = m_columns[i]; count++; } } // Replace original data with the updated matrix and columns df.m_values = new_data; ArrayResize(df.m_columns, new_columns.Size()); ArrayCopy(df.m_columns, new_columns); return df; }
Uso
void OnStart() { //--- CDataFrame df; df.ReadCSV("EURUSD.PERIOD_D1.csv"); CDataFrame new_df = df.Drop("Open,Close"); //drop the columns and assign the dataframe to a new object new_df.Head(); }
Saída
II 0 19:18:22.997 pandas test (EURUSD,H1) | High | Low | GJ 0 19:18:22.997 pandas test (EURUSD,H1) | 1.09548000 | 1.09003000 | EP 0 19:18:22.998 pandas test (EURUSD,H1) | 1.09810000 | 1.09361000 | CF 0 19:18:22.998 pandas test (EURUSD,H1) | 1.09973000 | 1.09606000 | RL 0 19:18:22.998 pandas test (EURUSD,H1) | 1.09869000 | 1.09542000 | MR 0 19:18:22.998 pandas test (EURUSD,H1) | 1.10396000 | 1.09513000 | DH 0 19:18:22.998 pandas test (EURUSD,H1) (1000x2)
Agora que temos funções para indexação e seleção de algumas partes do Dataframe, vamos implementar várias funções do Pandas para nos ajudar com a exploração e inspeção dos dados.
Explorando e Inspecionando o Dataframe do Pandas
A função "tail"
Esse método exibe as últimas linhas do Dataframe.
Implementação em MQL5
matrix CDataFrame::Tail(uint count=5) { ulong rows = m_values.Rows(); if(count>=rows) { printf("%s count[%d] >= number of rows in the df[%d]",__FUNCTION__,count,rows); return matrix::Zeros(0,0); } ulong start = rows-count; matrix res = matrix::Zeros(count, m_values.Cols()); for(ulong i=start, row_count=0; i<rows; i++, row_count++) res.Row(m_values.Row(i), row_count); return res; }
Uso.
void OnStart() { //--- CDataFrame df; df.ReadCSV("EURUSD.PERIOD_D1.csv"); Print(df.Tail()); }Por padrão, a função retorna as 5 últimas linhas do Dataframe.
GR 0 17:06:42.044 pandas test (EURUSD,H1) [[1.20796,1.21591,1.20742,1.21416] MG 0 17:06:42.044 pandas test (EURUSD,H1) [1.21023,1.21474,1.20588,1.20814] KQ 0 17:06:42.044 pandas test (EURUSD,H1) [1.21089,1.21342,1.20953,1.21046] DK 0 17:06:42.044 pandas test (EURUSD,H1) [1.21281,1.21664,1.20785,1.2109] MO 0 17:06:42.044 pandas test (EURUSD,H1) [1.21444,1.21774,1.21101,1.21203]]
A função "info"
Essa função é muito útil para compreender a estrutura do Dataframe, os tipos de dados, o uso de memória e a presença de valores não nulos.
Abaixo está sua implementação em MQL5.
void CDataFrame::Info(void)
Saídas.
ES 0 17:34:04.968 pandas test (EURUSD,H1) <class 'CDataFrame'> IH 0 17:34:04.968 pandas test (EURUSD,H1) RangeIndex: 1000 entries, 0 to 999 LR 0 17:34:04.968 pandas test (EURUSD,H1) Data columns (total 4 columns): PD 0 17:34:04.968 pandas test (EURUSD,H1) # Column Non-Null Count Dtype OQ 0 17:34:04.968 pandas test (EURUSD,H1) --- ------ -------------- ----- FS 0 17:34:04.968 pandas test (EURUSD,H1) 0 Open 1000 non-null double GH 0 17:34:04.968 pandas test (EURUSD,H1) 1 High 1000 non-null double LS 0 17:34:04.968 pandas test (EURUSD,H1) 2 Low 1000 non-null double IH 0 17:34:04.968 pandas test (EURUSD,H1) 3 Close 1000 non-null double FJ 0 17:34:04.968 pandas test (EURUSD,H1) memory usage: 31.2 KB
A função "describe"
Essa função fornece estatísticas descritivas para todas as colunas numéricas em um Dataframe. As informações que ela fornece incluem a média, o desvio padrão, a contagem, o valor mínimo e o valor máximo das colunas, sem mencionar os valores percentis de 25%, 50% e 75% de cada coluna.
Abaixo está uma visão geral de como a função foi implementada em MQL5.
void CDataFrame::Describe(void)
Uso
void OnStart() { //--- CDataFrame df; df.ReadCSV("EURUSD.PERIOD_D1.csv"); //Print(df.Tail()); df.Describe(); }
Saídas.
MM 0 18:10:42.459 pandas test (EURUSD,H1) Open High Low Close JD 0 18:10:42.460 pandas test (EURUSD,H1) count 1000 1000 1000 1000 HD 0 18:10:42.460 pandas test (EURUSD,H1) mean 1.104156 1.108184 1.100572 1.104306 HM 0 18:10:42.460 pandas test (EURUSD,H1) std 0.060646 0.059900 0.061097 0.060507 NQ 0 18:10:42.460 pandas test (EURUSD,H1) min 0.959290 0.967090 0.953580 0.959320 DI 0 18:10:42.460 pandas test (EURUSD,H1) 25% 1.069692 1.073520 1.066225 1.069950 DE 0 18:10:42.460 pandas test (EURUSD,H1) 50% 1.090090 1.093640 1.087100 1.090385 FN 0 18:10:42.460 pandas test (EURUSD,H1) 75% 1.142937 1.145505 1.139295 1.142365 CG 0 18:10:42.460 pandas test (EURUSD,H1) max 1.232510 1.234950 1.226560 1.232620
Obtendo a Forma do Dataframe e as Colunas Presentes no Dataframe
O Pandas em Python possui métodos como pandas.DataFrame.shape, que retorna a forma do Dataframe, e pandas.DataFrame.columns, que retornam as colunas presentes no Dataframe.
Em nossa classe, podemos acessar esses valores a partir de uma matriz definida globalmente chamada m_values da seguinte forma.
printf("df shape = (%dx%d)",df.m_values.Rows(),df.m_values.Cols());
Saídas.
2025.01.27 18:24:14.436 pandas test (EURUSD,H1) df shape = (1000x4)
Séries Temporais e Métodos de Transformação de Dados
Nesta seção, vamos implementar alguns dos métodos frequentemente usados para transformar os dados e analisar mudanças ao longo do tempo entre as linhas do Dataframe.
Os métodos discutidos nesta seção são os mais utilizados quando se trata de engenharia de atributos.
O método shift()
Ele desloca o índice por um número especificado de períodos; é frequentemente usado em dados de séries temporais para comparar um valor com seu valor anterior ou futuro.
Implementação em MQL5
vector CDataFrame::Shift(const vector &v, const int shift) { // Initialize a result vector filled with NaN vector result(v.Size()); result.Fill(NaN); if(shift > 0) { // Positive shift: Move elements forward for(ulong i = 0; i < v.Size() - shift; i++) result[i + shift] = v[i]; } else if(shift < 0) { // Negative shift: Move elements backward for(ulong i = -shift; i < v.Size(); i++) result[i + shift] = v[i]; } else { // Zero shift: Return the vector unchanged result = v; } return result; }
vector CDataFrame::Shift(const string index, const int shift) { vector v = this.GetColumn(index); // Initialize a result vector filled with NaN return Shift(v, shift); }
Quando essa função recebe um valor de índice positivo, ela move os elementos para frente, efetivamente criando uma versão defasada de um determinado vetor ou coluna.
void OnStart() { //--- CDataFrame df; df.ReadCSV("EURUSD.PERIOD_D1.csv"); vector close_lag_1 = df.Shift("Close", 1); //Create a previous 1 lag on the close price df.Insert("Close lag 1",close_lag_1); //Insert this new column into a dataframe df.Head(); }
Saída
EP 0 19:40:14.257 pandas test (EURUSD,H1) | Open | High | Low | Close | Close lag 1 | NO 0 19:40:14.257 pandas test (EURUSD,H1) | 1.09381000 | 1.09548000 | 1.09003000 | 1.09373000 | nan | PR 0 19:40:14.257 pandas test (EURUSD,H1) | 1.09678000 | 1.09810000 | 1.09361000 | 1.09399000 | 1.09373000 | ES 0 19:40:14.257 pandas test (EURUSD,H1) | 1.09701000 | 1.09973000 | 1.09606000 | 1.09805000 | 1.09399000 | PS 0 19:40:14.257 pandas test (EURUSD,H1) | 1.09639000 | 1.09869000 | 1.09542000 | 1.09742000 | 1.09805000 | PP 0 19:40:14.257 pandas test (EURUSD,H1) | 1.10302000 | 1.10396000 | 1.09513000 | 1.09757000 | 1.09742000 | QO 0 19:40:14.257 pandas test (EURUSD,H1) (1000x5)
No entanto, quando um valor negativo é recebido, a função cria uma variável futura para uma determinada coluna. Isso é muito útil para criar as variáveis-alvo.
vector future_close_1 = df.Shift("Close", -1); //Create a future 1 variable df.Insert("Future 1 close",future_close_1); //Insert this new column into a dataframe df.Head();
Saída
CI 0 19:43:08.482 pandas test (EURUSD,H1) | Open | High | Low | Close | Close lag 1 | Future 1 close | GJ 0 19:43:08.482 pandas test (EURUSD,H1) | 1.09381000 | 1.09548000 | 1.09003000 | 1.09373000 | nan | 1.09399000 | MR 0 19:43:08.482 pandas test (EURUSD,H1) | 1.09678000 | 1.09810000 | 1.09361000 | 1.09399000 | 1.09373000 | 1.09805000 | FM 0 19:43:08.482 pandas test (EURUSD,H1) | 1.09701000 | 1.09973000 | 1.09606000 | 1.09805000 | 1.09399000 | 1.09742000 | IH 0 19:43:08.482 pandas test (EURUSD,H1) | 1.09639000 | 1.09869000 | 1.09542000 | 1.09742000 | 1.09805000 | 1.09757000 | OK 0 19:43:08.483 pandas test (EURUSD,H1) | 1.10302000 | 1.10396000 | 1.09513000 | 1.09757000 | 1.09742000 | 1.10297000 | GG 0 19:43:08.483 pandas test (EURUSD,H1) (1000x6)
O método pct_change()
Essa função calcula a variação percentual entre o elemento atual e o elemento anterior; ela é comumente usada em dados financeiros para calcular retornos.
Abaixo está como ela é implementada na classe DataFrame.
vector CDataFrame::Pct_change(const string index) { vector col = GetColumn(index); return Pct_change(col); } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ vector CDataFrame::Pct_change(const vector &v) { vector col = v; ulong size = col.Size(); vector results(size); results.Fill(NaN); for(ulong i=1; i<size; i++) { double prev_value = col[i - 1]; double curr_value = col[i]; // Calculate percentage change and handle division by zero if(prev_value != 0.0) { results[i] = ((curr_value - prev_value) / prev_value) * 100.0; } else { results[i] = 0.0; // Handle division by zero case } } return results; }
Uso.
void OnStart() { //--- CDataFrame df; df.ReadCSV("EURUSD.PERIOD_D1.csv"); vector close_pct_change = df.Pct_change("Close"); df.Insert("Close pct_change", close_pct_change); df.Head(); }
Saídas.
IM 0 19:49:59.858 pandas test (EURUSD,H1) | Open | High | Low | Close | Close pct_change | CO 0 19:49:59.858 pandas test (EURUSD,H1) | 1.09381000 | 1.09548000 | 1.09003000 | 1.09373000 | nan | DS 0 19:49:59.858 pandas test (EURUSD,H1) | 1.09678000 | 1.09810000 | 1.09361000 | 1.09399000 | 0.02377186 | DD 0 19:49:59.858 pandas test (EURUSD,H1) | 1.09701000 | 1.09973000 | 1.09606000 | 1.09805000 | 0.37111857 | QE 0 19:49:59.858 pandas test (EURUSD,H1) | 1.09639000 | 1.09869000 | 1.09542000 | 1.09742000 | -0.05737444 | NF 0 19:49:59.858 pandas test (EURUSD,H1) | 1.10302000 | 1.10396000 | 1.09513000 | 1.09757000 | 0.01366842 | NJ 0 19:49:59.858 pandas test (EURUSD,H1) (1000x5)
O método diff()
Essa função calcula a diferença entre o elemento atual e o seu elemento anterior em uma sequência; ela é frequentemente usada para encontrar mudanças ao longo do tempo.
vector CDataFrame::Diff(const vector &v, int period=1) { vector res(v.Size()); res.Fill(NaN); for(ulong i=period; i<v.Size(); i++) res[i] = v[i] - v[i-period]; //Calculate the difference between the current value and the previous one return res; } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ vector CDataFrame::Diff(const string index, int period=1) { vector v = this.GetColumn(index); // Initialize a result vector filled with NaN return Diff(v, period); }
Uso
void OnStart() { //--- CDataFrame df; df.ReadCSV("EURUSD.PERIOD_D1.csv"); vector diff_open = df.Diff("Open"); df.Insert("Open diff", diff_open); df.Head(); }
Saída
GS 0 19:54:10.283 pandas test (EURUSD,H1) | Open | High | Low | Close | Open diff | HM 0 19:54:10.283 pandas test (EURUSD,H1) | 1.09381000 | 1.09548000 | 1.09003000 | 1.09373000 | nan | OQ 0 19:54:10.283 pandas test (EURUSD,H1) | 1.09678000 | 1.09810000 | 1.09361000 | 1.09399000 | 0.00297000 | QQ 0 19:54:10.283 pandas test (EURUSD,H1) | 1.09701000 | 1.09973000 | 1.09606000 | 1.09805000 | 0.00023000 | FF 0 19:54:10.283 pandas test (EURUSD,H1) | 1.09639000 | 1.09869000 | 1.09542000 | 1.09742000 | -0.00062000 | LF 0 19:54:10.283 pandas test (EURUSD,H1) | 1.10302000 | 1.10396000 | 1.09513000 | 1.09757000 | 0.00663000 | OI 0 19:54:10.283 pandas test (EURUSD,H1) (1000x5)
O método rolling()
Esse método fornece uma maneira conveniente para cálculos de janelas deslizantes; ele é útil para quem deseja calcular valores dentro de um determinado tempo (período), por exemplo, calcular médias móveis de variáveis em um Dataframe.
Arquivo: main.ipynb Idioma: Python
df["Close sma_5"] = df["Close"].rolling(window=5).mean() df
Ao contrário de outros métodos, o método de rolagem requer a criação de uma matriz bidimensional repleta de janelas divididas ao longo das linhas. Como precisamos aplicar a matriz 2D resultante a algumas funções matemáticas de nossa escolha, talvez seja necessário criar uma estrutura separada apenas para essa tarefa.
struct rolling_struct { public: matrix matrix__; vector Mean() { vector res(matrix__.Rows()); res.Fill(NaN); for(ulong i=0; i<res.Size(); i++) res[i] = matrix__.Row(i).Mean(); return res; } };
Podemos criar as funções para preencher a variável matricial denominada matrix__.
rolling_struct CDataFrame::Rolling(const vector &v, const uint window) { rolling_struct roll_res; roll_res.matrix__.Resize(v.Size(), window); roll_res.matrix__.Fill(NaN); for(ulong i = 0; i < v.Size(); i++) { for(ulong j = 0; j < window; j++) { // Calculate the index in the vector for the Rolling window ulong index = i - (window - 1) + j; if(index >= 0 && index < v.Size()) roll_res.matrix__[i][j] = v[index]; } } return roll_res; } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ rolling_struct CDataFrame::Rolling(const string index, const uint window) { vector v = GetColumn(index); return Rolling(v, window); }
Agora podemos usar essa função para calcular a média de uma janela e muitas outras funções matemáticas, conforme desejarmos.
void OnStart() { //--- CDataFrame df; df.ReadCSV("EURUSD.PERIOD_D1.csv"); vector close_sma_5 = df.Rolling("Close", 5).Mean(); df.Insert("Close sma_5", close_sma_5); df.Head(10); }
Saídas.
RP 0 20:15:23.126 pandas test (EURUSD,H1) | Open | High | Low | Close | Close sma_5 | KP 0 20:15:23.126 pandas test (EURUSD,H1) | 1.09381000 | 1.09548000 | 1.09003000 | 1.09373000 | nan | QP 0 20:15:23.126 pandas test (EURUSD,H1) | 1.09678000 | 1.09810000 | 1.09361000 | 1.09399000 | nan | HP 0 20:15:23.126 pandas test (EURUSD,H1) | 1.09701000 | 1.09973000 | 1.09606000 | 1.09805000 | nan | GO 0 20:15:23.126 pandas test (EURUSD,H1) | 1.09639000 | 1.09869000 | 1.09542000 | 1.09742000 | nan | RR 0 20:15:23.126 pandas test (EURUSD,H1) | 1.10302000 | 1.10396000 | 1.09513000 | 1.09757000 | 1.09615200 | CR 0 20:15:23.126 pandas test (EURUSD,H1) | 1.10431000 | 1.10495000 | 1.10084000 | 1.10297000 | 1.09800000 | NS 0 20:15:23.126 pandas test (EURUSD,H1) | 1.10616000 | 1.10828000 | 1.10326000 | 1.10453000 | 1.10010800 | JS 0 20:15:23.126 pandas test (EURUSD,H1) | 1.11262000 | 1.11442000 | 1.10459000 | 1.10678000 | 1.10185400 | EP 0 20:15:23.126 pandas test (EURUSD,H1) | 1.11529000 | 1.12088000 | 1.11139000 | 1.11350000 | 1.10507000 | EP 0 20:15:23.126 pandas test (EURUSD,H1) | 1.11765000 | 1.12029000 | 1.11249000 | 1.11594000 | 1.10874400 | RO 0 20:15:23.126 pandas test (EURUSD,H1) (1000x5)
Você pode fazer muito mais com a estrutura rolling e adicionar mais fórmulas para todos os cálculos matemáticos que quiser aplicar à janela deslizante, mais funções matemáticas para matrizes e vetores podem ser encontradas aqui.
Até o momento, implementei várias funções que você pode aplicar à matriz rolling;
- Std() para calcular o desvio padrão dos dados em uma janela específica.
- Var() para calcular a variância da janela.
- Skew() para calcular a assimetria de todos os dados em uma janela específica.
- Kurtosis() para calcular a curtose de todos os dados em uma janela específica.
- Median() para calcular a mediana de todos os dados em uma janela específica.
Essas são apenas algumas funções úteis reproduzidas da biblioteca Pandas em Python. Agora vamos ver como podemos usar essa biblioteca para preparar dados para aprendizado de máquina.
Vamos coletar os dados em MQL5, exportá-los para um arquivo CSV que será importado em um script Python; um modelo treinado será salvo no formato ONNX, e o modelo ONNX será importado e implantado em MQL5 com a mesma abordagem de coleta e armazenamento de dados.
Coletando Dados para Aprendizado de Máquina
Vamos coletar cerca de 20 variáveis e adicioná-las a uma classe Dataframe.
- Valores de Abertura, Máxima, Mínima e Fechamento (OHLC).
CDataFrame df; int size = 10000; //We collect this amount of bars for training purposes vector open, high, low, close; open.CopyRates(Symbol(), PERIOD_D1, COPY_RATES_OPEN,1, size); high.CopyRates(Symbol(), PERIOD_D1, COPY_RATES_HIGH,1, size); low.CopyRates(Symbol(), PERIOD_D1, COPY_RATES_LOW,1, size); close.CopyRates(Symbol(), PERIOD_D1, COPY_RATES_CLOSE,1, size); df.Insert("open",open); df.Insert("high",high); df.Insert("low",low); df.Insert("close",close);
Esses atributos são essenciais, pois ajudam a derivar mais atributos; eles são simplesmente a base de todos os padrões que vemos no mercado.
- Como o mercado forex fica aberto por 5 dias, vamos adicionar os valores de fechamento dos 5 dias anteriores (valores de fechamento defasados). Esses dados podem ajudar modelos de IA a entender padrões ao longo do tempo.
int lags = 5; for (int i=1; i<=lags; i++) { vector lag = df.Shift("close", i); df.Insert("close lag_"+string(i), lag); }
Isso agora totaliza 9 variáveis no Dataframe.
- Variação percentual diária no preço de fechamento (para detectar as mudanças diárias no preço de fechamento).
vector pct_change = df.Pct_change("close"); df.Insert("close pct_change", pct_change);
- Como estamos trabalhando em um timeframe diário, vamos adicionar a variância de 5 dias para capturar os padrões de variabilidade dentro de um período móvel de 5 dias.
vector var_5 = df.Rolling("close", 5).Var(); df.Insert("var close 5 days", var_5);
- Podemos adicionar os atributos diferenciados para ajudar a capturar a volatilidade e os movimentos de preço entre os valores OHLC.
df.Insert("open_close",open-close); df.Insert("high_low",high-low);
- Podemos adicionar o preço médio, esperando que ele ajude os modelos a capturar os padrões dentro dos próprios valores OHLC.
df.Insert("Avg price",(open+high+low+close)/4);
- Por fim, podemos adicionar alguns indicadores à mistura. Vou usar a abordagem de coleta de dados de indicadores discutida em este artigo. Não hesite em usar qualquer abordagem na coleta de dados de indicadores se esta não lhe servir.
BB_res_struct bb = CTrendIndicators::BollingerBands(close,20,0,2.000000); //Calculando o indicador de Bandas de Bollinger df.Insert("bb_lower",bb.lower_band); //Inserindo os valores da banda inferior df.Insert("bb_middle",bb.middle_band); //Inserindo os valores da banda intermediária df.Insert("bb_upper",bb.upper_band); //Inserindo os valores da banda superior vector atr = COscillatorIndicators::ATR(high,low,close,14); //Calculando o indicador ATR df.Insert("ATR 14",atr); //Inserindo os valores do indicador ATR MACD_res_struct macd = COscillatorIndicators::MACD(close,12,26,9); //Indicador MACD aplicado ao preço de fechamento df.Insert("macd histogram", macd.histogram); //Inserindo os valores do histograma MACD df.Insert("macd main", macd.main); //Inserindo os valores da linha principal do MACD df.Insert("macd signal", macd.signal); //Inserindo os valores da linha de sinal do MACD
Temos 21 variáveis no total.
df.Head();
Saídas.
PG 0 11:32:21.371 pandas test (EURUSD,H1) | open | high | low | close | close lag_1 | close lag_2 | close lag_3 | close lag_4 | close lag_5 | close pct_change | var close 5 days | open_close | high_low | Avg price | bb_lower | bb_middle | bb_upper | ATR 14 | macd histogram | macd main | macd signal | DD 0 11:32:21.371 pandas test (EURUSD,H1) | 1.15620000 | 1.15660000 | 1.15030000 | 1.15080000 | nan | nan | nan | nan | nan | nan | nan | 0.00540000 | 0.00630000 | 1.15347500 | nan | nan | nan | nan | nan | nan | nan | JN 0 11:32:21.371 pandas test (EURUSD,H1) | 1.15100000 | 1.15130000 | 1.14220000 | 1.14280000 | 1.15080000 | nan | nan | nan | nan | -0.69516858 | nan | 0.00820000 | 0.00910000 | 1.14682500 | nan | nan | nan | nan | nan | nan | nan | ID 0 11:32:21.371 pandas test (EURUSD,H1) | 1.14300000 | 1.15360000 | 1.14230000 | 1.15110000 | 1.14280000 | 1.15080000 | nan | nan | nan | 0.72628631 | nan | -0.00810000 | 0.01130000 | 1.14750000 | nan | nan | nan | nan | nan | nan | nan | ES 0 11:32:21.371 pandas test (EURUSD,H1) | 1.15070000 | 1.15490000 | 1.14890000 | 1.15050000 | 1.15110000 | 1.14280000 | 1.15080000 | nan | nan | -0.05212406 | nan | 0.00020000 | 0.00600000 | 1.15125000 | nan | nan | nan | nan | nan | nan | nan | LJ 0 11:32:21.371 pandas test (EURUSD,H1) | 1.14820000 | 1.14900000 | 1.13560000 | 1.13870000 | 1.15050000 | 1.15110000 | 1.14280000 | 1.15080000 | nan | -1.02564103 | 0.00002596 | 0.00950000 | 0.01340000 | 1.14287500 | nan | nan | nan | nan | nan | nan | nan | HG 0 11:32:21.371 pandas test (EURUSD,H1) (10000x22)
Vamos dar uma olhada rápida no conjunto de dados.
df.Info();
Saída
FN 0 12:18:01.745 pandas test (EURUSD,H1) <class 'CDataFrame'> QE 0 12:18:01.745 pandas test (EURUSD,H1) RangeIndex: 10000 entries, 0 to 9999 NL 0 12:18:01.745 pandas test (EURUSD,H1) Data columns (total 21 columns): MR 0 12:18:01.745 pandas test (EURUSD,H1) # Column Non-Null Count Dtype DI 0 12:18:01.745 pandas test (EURUSD,H1) --- ------ -------------- ----- CO 0 12:18:01.745 pandas test (EURUSD,H1) 0 open 10000 non-null double GR 0 12:18:01.746 pandas test (EURUSD,H1) 1 high 10000 non-null double LK 0 12:18:01.746 pandas test (EURUSD,H1) 2 low 10000 non-null double JF 0 12:18:01.747 pandas test (EURUSD,H1) 3 close 10000 non-null double QS 0 12:18:01.748 pandas test (EURUSD,H1) 4 close lag_1 9999 non-null double JO 0 12:18:01.748 pandas test (EURUSD,H1) 5 close lag_2 9998 non-null double GH 0 12:18:01.748 pandas test (EURUSD,H1) 6 close lag_3 9997 non-null double KD 0 12:18:01.749 pandas test (EURUSD,H1) 7 close lag_4 9996 non-null double FP 0 12:18:01.749 pandas test (EURUSD,H1) 8 close lag_5 9995 non-null double EL 0 12:18:01.750 pandas test (EURUSD,H1) 9 close pct_change 9999 non-null double ME 0 12:18:01.750 pandas test (EURUSD,H1) 10 var close 5 days 9996 non-null double GI 0 12:18:01.751 pandas test (EURUSD,H1) 11 open_close 10000 non-null double ES 0 12:18:01.752 pandas test (EURUSD,H1) 12 high_low 10000 non-null double LF 0 12:18:01.752 pandas test (EURUSD,H1) 13 Avg price 10000 non-null double DI 0 12:18:01.752 pandas test (EURUSD,H1) 14 bb_lower 9981 non-null double FQ 0 12:18:01.753 pandas test (EURUSD,H1) 15 bb_middle 9981 non-null double NQ 0 12:18:01.753 pandas test (EURUSD,H1) 16 bb_upper 9981 non-null double QI 0 12:18:01.753 pandas test (EURUSD,H1) 17 ATR 14 9986 non-null double CF 0 12:18:01.753 pandas test (EURUSD,H1) 18 macd histogram 9975 non-null double DO 0 12:18:01.754 pandas test (EURUSD,H1) 19 macd main 9975 non-null double FR 0 12:18:01.754 pandas test (EURUSD,H1) 20 macd signal 9992 non-null double FF 0 12:18:01.754 pandas test (EURUSD,H1) memory usage: 1640.6 KB
Nossos dados utilizam cerca de 1,6 MB de memória; há muitos valores nulos (nan) que precisamos remover.
CDataFrame new_df = df.Dropnan(); new_df.Head();
Saída
JO 0 12:18:01.762 pandas test (EURUSD,H1) CDataFrame::Dropnan completed. Rows dropped: 25/10000 JR 0 12:18:01.766 pandas test (EURUSD,H1) | open | high | low | close | close lag_1 | close lag_2 | close lag_3 | close lag_4 | close lag_5 | close pct_change | var close 5 days | open_close | high_low | Avg price | bb_lower | bb_middle | bb_upper | ATR 14 | macd histogram | macd main | macd signal | FQ 0 12:18:01.766 pandas test (EURUSD,H1) | 1.23060000 | 1.23900000 | 1.20370000 | 1.21470000 | 1.23100000 | 1.23450000 | 1.21980000 | 1.22330000 | 1.22350000 | -1.32412673 | 0.00005234 | 0.01590000 | 0.03530000 | 1.22200000 | 1.16702297 | 1.20237000 | 1.23771703 | 0.01279286 | -1.19628486 | 0.02253736 | 1.21882222 | OJ 0 12:18:01.766 pandas test (EURUSD,H1) | 1.21540000 | 1.22120000 | 1.20930000 | 1.21130000 | 1.21470000 | 1.23100000 | 1.23450000 | 1.21980000 | 1.22330000 | -0.27990450 | 0.00008191 | 0.00410000 | 0.01190000 | 1.21430000 | 1.17236514 | 1.20446500 | 1.23656486 | 0.01265000 | -1.19925638 | 0.02076585 | 1.22002222 | IO 0 12:18:01.766 pandas test (EURUSD,H1) | 1.21040000 | 1.21390000 | 1.20730000 | 1.20930000 | 1.21130000 | 1.21470000 | 1.23100000 | 1.23450000 | 1.21980000 | -0.16511186 | 0.00010988 | 0.00110000 | 0.00660000 | 1.21022500 | 1.17774730 | 1.20631000 | 1.23487270 | 0.01253571 | -1.20115162 | 0.01898171 | 1.22013333 | QP 0 12:18:01.766 pandas test (EURUSD,H1) | 1.20840000 | 1.20840000 | 1.19490000 | 1.20340000 | 1.20930000 | 1.21130000 | 1.21470000 | 1.23100000 | 1.23450000 | -0.48788555 | 0.00008624 | 0.00500000 | 0.01350000 | 1.20377500 | 1.17941845 | 1.20699500 | 1.23457155 | 0.01292857 | -1.20208086 | 0.01689692 | 1.21897778 | DJ 0 12:18:01.766 pandas test (EURUSD,H1) | 1.21000000 | 1.21930000 | 1.20900000 | 1.21330000 | 1.20340000 | 1.20930000 | 1.21130000 | 1.21470000 | 1.23100000 | 0.82266910 | 0.00001558 | -0.00330000 | 0.01030000 | 1.21290000 | 1.18119695 | 1.20804500 | 1.23489305 | 0.01360714 | -1.20198373 | 0.01586072 | 1.21784444 | MS 0 12:18:01.766 pandas test (EURUSD,H1) (9975x21)
Podemos salvar esse Dataframe em um arquivo CSV.
string csv_name = Symbol()+".dailytf.data.csv"; new_df.ToCSV(csv_name, false, 8);
Treinando um Modelo de Aprendizado de Máquina
Começamos importando as bibliotecas que poderemos precisar em um Jupyter Notebook em Python.
Arquivo: main.ipynb
import pandas as pd import matplotlib.pyplot as plt import seaborn as sns from sklearn.linear_model import LinearRegression from sklearn.pipeline import Pipeline from sklearn.preprocessing import RobustScaler from sklearn.model_selection import train_test_split import skl2onnx from sklearn.metrics import r2_score sns.set_style("darkgrid")
Importamos os dados e os atribuímos a um Dataframe do Pandas.
df = pd.read_csv("EURUSD.dailytf.data.csv")
Vamos criar a variável-alvo.
df["future_close"] = df["close"].shift(-1) # Shift the close price by one to get df = df.dropna() # drop nan values caused by the shift operation
Agora que temos a variável-alvo para um problema de regressão, vamos dividir os dados em amostras de treinamento e teste.
X = df.drop(columns=[ "future_close" # drop the target veriable from the independent variables matrix ]) y = df["future_close"] # Train test split X_train, X_test, y_train, y_test = train_test_split(X, y, shuffle=False)
Definimos o valor de shuffle como false para que possamos tratar isso como um problema de séries temporais.
Em seguida, encapsulamos um modelo de Regressão Linear em um Pipeline e o treinamos.
pipe_model = Pipeline([ ("scaler", RobustScaler()), ("LR", LinearRegression()) ]) pipe_model.fit(X_train, y_train) # Training a Linear regression model
Saída
Para avaliar o modelo que temos, decidi prever o alvo com base nos dados de treinamento e teste, adicionar essas informações a um Dataframe do Pandas e, em seguida, plotar o resultado usando Seaborn e Matplotlib.
# Preparing the data for plotting train_pred = pipe_model.predict(X_train) test_pred = pipe_model.predict(X_test) train_data = pd.DataFrame({ 'Index': range(len(y_train)), 'True Values': y_train, 'Predicted Values': train_pred, 'Set': 'Train' }) test_data = pd.DataFrame({ 'Index': range(len(y_test)), 'True Values': y_test, 'Predicted Values': test_pred, 'Set': 'Test' }) # figure size 750x1000 pixels fig, axes = plt.subplots(2, 1, figsize=(7.5, 10), sharex=False) # Plot Train Data sns.lineplot(ax=axes[0], data=train_data, x='Index', y='True Values', label='True Values', color='blue') sns.lineplot(ax=axes[0], data=train_data, x='Index', y='Predicted Values', label='Predicted Values', color='orange') axes[0].set_title(f'Train Set: True vs Predicted Values | Acc = {r2_score(y_train, train_pred)}', fontsize=14) axes[0].set_ylabel('Values', fontsize=12) axes[0].legend() # Plot Test Data sns.lineplot(ax=axes[1], data=test_data, x='Index', y='True Values', label='True Values', color='blue') sns.lineplot(ax=axes[1], data=test_data, x='Index', y='Predicted Values', label='Predicted Values', color='orange') axes[1].set_title(f'Test Set: True vs Predicted Values | Acc = {r2_score(y_test, test_pred)}', fontsize=14) axes[1].set_xlabel('Index', fontsize=12) axes[1].set_ylabel('Values', fontsize=12) axes[1].legend() # Final adjustments plt.tight_layout() plt.show()
Saída
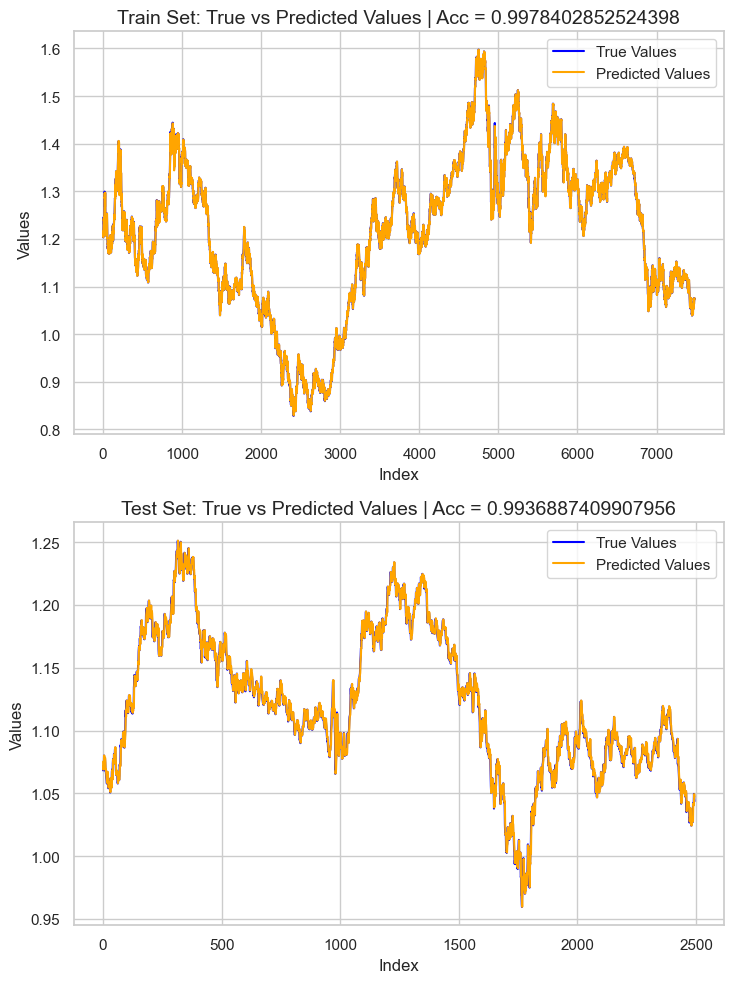
O resultado é um modelo com overfitting, com aproximadamente 0,99 de score r2. Isso não é um bom sinal para a saúde do modelo. Vamos inspecionar a importância das variáveis para observar quais atributos estão afetando o modelo de forma positiva; aqueles com influência negativa no modelo serão removidos quando detectados.
# Extract the linear regression model from the pipeline lr_model = pipe_model.named_steps['LR'] # Get feature importance (coefficients) feature_importance = pd.Series(lr_model.coef_, index=X_train.columns) # Sort feature importance feature_importance = feature_importance.sort_values(ascending=False) print(feature_importance)
Saída
macd main 266.706747 close 0.093652 open 0.093435 Avg price 0.042505 close lag_1 0.006972 close lag_3 0.003645 bb_upper 0.001423 close lag_5 0.001415 bb_middle 0.000766 high_low 0.000201 bb_lower 0.000087 var close 5 days -0.000179 ATR 14 -0.000185 close pct_change -0.001046 close lag_4 -0.002636 close lag_2 -0.003881 open_close -0.004705 high -0.008575 low -0.008663 macd histogram -5504.010453 macd signal -5518.035201 dtype: float64
O atributo mais informativo foi o macd main, enquanto o histograma do macd e o sinal do macd foram as variáveis menos informativas para o modelo. Vamos remover todos os valores com importância negativa, reentreinar o modelo e então observar a precisão novamente.
X = df.drop(columns=[ "future_close", # drop the target veriable from the independent variables matrix "var close 5 days", "ATR 14", "close pct_change", "close lag_4", "close lag_2", "open_close", "high", "low", "macd histogram", "macd signal" ])
pipe_model = Pipeline([ ("scaler", MinMaxScaler()), ("LR", LinearRegression()) ]) pipe_model.fit(X_train, y_train)
A precisão do modelo reentreinado foi muito semelhante à do modelo anterior; o modelo continuou apresentando overfitting. Tudo bem por enquanto, vamos prosseguir para exportar o modelo para o formato ONNX.
Implantando um Modelo de Aprendizado de Máquina em MQL5
Dentro do nosso Expert Advisor (EA), começamos adicionando o modelo como um recurso para que ele possa ser compilado junto com o programa.
Arquivo: LR model Test.mq5
#resource "\\Files\\EURUSD.dailytf.model.onnx" as uchar lr_onnx[]
Importamos todas as bibliotecas necessárias: a biblioteca Pandas, ta-lib (para indicadores) e Regressão Linear (para carregar o modelo).
#include <Linear Regression.mqh> #include <MALE5\pandas.mqh> #include <ta-lib.mqh> CLinearRegression lr;
Inicializamos o modelo de regressão linear na função OnInit.
int OnInit() { //--- if (!lr.Init(lr_onnx)) return INIT_FAILED; //--- return(INIT_SUCCEEDED); }
A vantagem de usar essa biblioteca Pandas personalizada que criamos é que você não precisa começar a escrever código do zero para coletar os dados novamente; basta copiar o código que usamos e colá-lo no expert advisor principal, fazendo pequenas modificações.
void OnTick() { //--- CDataFrame df; int size = 10000; //We collect this amount of bars for training purposes vector open, high, low, close; open.CopyRates(Symbol(), PERIOD_D1, COPY_RATES_OPEN,1, size); high.CopyRates(Symbol(), PERIOD_D1, COPY_RATES_HIGH,1, size); low.CopyRates(Symbol(), PERIOD_D1, COPY_RATES_LOW,1, size); close.CopyRates(Symbol(), PERIOD_D1, COPY_RATES_CLOSE,1, size); df.Insert("open",open); df.Insert("high",high); df.Insert("low",low); df.Insert("close",close); int lags = 5; for (int i=1; i<=lags; i++) { vector lag = df.Shift("close", i); df.Insert("close lag_"+string(i), lag); } vector pct_change = df.Pct_change("close"); df.Insert("close pct_change", pct_change); vector var_5 = df.Rolling("close", 5).Var(); df.Insert("var close 5 days", var_5); df.Insert("open_close",open-close); df.Insert("high_low",high-low); df.Insert("Avg price",(open+high+low+close)/4); //--- BB_res_struct bb = CTrendIndicators::BollingerBands(close,20,0,2.000000); //Calculating the bollinger band indicator df.Insert("bb_lower",bb.lower_band); //Inserting lower band values df.Insert("bb_middle",bb.middle_band); //Inserting the middle band values df.Insert("bb_upper",bb.upper_band); //Inserting the upper band values vector atr = COscillatorIndicators::ATR(high,low,close,14); //Calculating the ATR Indicator df.Insert("ATR 14",atr); //Inserting the ATR indicator values MACD_res_struct macd = COscillatorIndicators::MACD(close,12,26,9); //MACD indicator applied to the closing price df.Insert("macd histogram", macd.histogram); //Inserting the MAC historgram values df.Insert("macd main", macd.main); //Inserting the macd main line values df.Insert("macd signal", macd.signal); //Inserting the macd signal line values df.Info(); CDataFrame new_df = df.Dropnan(); new_df.Head(); string csv_name = Symbol()+".dailytf.data.csv"; new_df.ToCSV(csv_name, false, 8); }
As modificações incluem;
Modificar o tamanho dos dados que queremos. Não precisamos mais de 10000 barras; precisamos apenas de cerca de 30 barras, pois o indicador MACD tem um período de 26, as Bandas de Bollinger têm um período de 20 e o ATR tem um período de 14. Ao definir esse valor como 30, efetivamente deixamos alguma margem para os cálculos.
A função OnTick pode ser muito fluida e explosiva às vezes; não precisamos redefinir as variáveis toda vez que um novo tick é recebido.
Não precisamos salvar os dados em um arquivo CSV; precisamos apenas que a última linha do Dataframe seja atribuída a um vetor para ser inserido no modelo.
Podemos encapsular essas linhas de código em uma função independente para facilitar o trabalho.
vector GetData(int start_bar=1, int size=30) { open_.CopyRates(Symbol(), PERIOD_D1, COPY_RATES_OPEN,start_bar, size); high_.CopyRates(Symbol(), PERIOD_D1, COPY_RATES_HIGH,start_bar, size); low_.CopyRates(Symbol(), PERIOD_D1, COPY_RATES_LOW,start_bar, size); close_.CopyRates(Symbol(), PERIOD_D1, COPY_RATES_CLOSE,start_bar, size); df_.Insert("open",open_); df_.Insert("high",high_); df_.Insert("low",low_); df_.Insert("close",close_); int lags = 5; vector lag = {}; for (int i=1; i<=lags; i++) { lag = df_.Shift("close", i); df_.Insert("close lag_"+string(i), lag); } pct_change = df_.Pct_change("close"); df_.Insert("close pct_change", pct_change); var_5 = df_.Rolling("close", 5).Var(); df_.Insert("var close 5 days", var_5); df_.Insert("open_close",open_-close_); df_.Insert("high_low",high_-low_); df_.Insert("Avg price",(open_+high_+low_+close_)/4); //--- BB_res_struct bb = CTrendIndicators::BollingerBands(close_,20,0,2.000000); //Calculating the bollinger band indicator df_.Insert("bb_lower",bb.lower_band); //Inserting lower band values df_.Insert("bb_middle",bb.middle_band); //Inserting the middle band values df_.Insert("bb_upper",bb.upper_band); //Inserting the upper band values atr = COscillatorIndicators::ATR(high_,low_,close_,14); //Calculating the ATR Indicator df_.Insert("ATR 14",atr); //Inserting the ATR indicator values MACD_res_struct macd = COscillatorIndicators::MACD(close_,12,26,9); //MACD indicator applied to the closing price df_.Insert("macd histogram", macd.histogram); //Inserting the MAC historgram values df_.Insert("macd main", macd.main); //Inserting the macd main line values df_.Insert("macd signal", macd.signal); //Inserting the macd signal line values CDataFrame new_df = df_.Dropnan(); //Drop NaN values return new_df.Loc(-1); //return the latest row }
Foi assim que inicialmente coletamos os dados para treinamento; alguns dos atributos presentes nessa função não chegaram ao modelo final por vários motivos, e tivemos que removê-los, de forma semelhante ao que fizemos no script Python.
vector GetData(int start_bar=1, int size=30) { open_.CopyRates(Symbol(), PERIOD_D1, COPY_RATES_OPEN,start_bar, size); high_.CopyRates(Symbol(), PERIOD_D1, COPY_RATES_HIGH,start_bar, size); low_.CopyRates(Symbol(), PERIOD_D1, COPY_RATES_LOW,start_bar, size); close_.CopyRates(Symbol(), PERIOD_D1, COPY_RATES_CLOSE,start_bar, size); df_.Insert("open",open_); df_.Insert("high",high_); df_.Insert("low",low_); df_.Insert("close",close_); int lags = 5; vector lag = {}; for (int i=1; i<=lags; i++) { lag = df_.Shift("close", i); df_.Insert("close lag_"+string(i), lag); } pct_change = df_.Pct_change("close"); df_.Insert("close pct_change", pct_change); var_5 = df_.Rolling("close", 5).Var(); df_.Insert("var close 5 days", var_5); df_.Insert("open_close",open_-close_); df_.Insert("high_low",high_-low_); df_.Insert("Avg price",(open_+high_+low_+close_)/4); //--- BB_res_struct bb = CTrendIndicators::BollingerBands(close_,20,0,2.000000); //Calculating the bollinger band indicator df_.Insert("bb_lower",bb.lower_band); //Inserting lower band values df_.Insert("bb_middle",bb.middle_band); //Inserting the middle band values df_.Insert("bb_upper",bb.upper_band); //Inserting the upper band values atr = COscillatorIndicators::ATR(high_,low_,close_,14); //Calculating the ATR Indicator df_.Insert("ATR 14",atr); //Inserting the ATR indicator values MACD_res_struct macd = COscillatorIndicators::MACD(close_,12,26,9); //MACD indicator applied to the closing price df_.Insert("macd histogram", macd.histogram); //Inserting the MAC historgram values df_.Insert("macd main", macd.main); //Inserting the macd main line values df_.Insert("macd signal", macd.signal); //Inserting the macd signal line values df_ = df_.Drop( //"future_close", "var close 5 days,"+ "ATR 14,"+ "close pct_change,"+ "close lag_4,"+ "close lag_2,"+ "open_close,"+ "high,"+ "low,"+ "macd histogram,"+ "macd signal" ); CDataFrame new_df = df_.Dropnan(); return new_df.Loc(-1); //return the latest row }
Em vez de remover as colunas como na função acima, é mais prudente remover o código usado para produzi-las desde o início; isso pode reduzir cálculos desnecessários que podem desacelerar o programa quando há muitos atributos para calcular apenas para que sejam removidos logo depois.
Vamos manter o método Drop por enquanto.
Após chamar o método Head() para ver o que há no Dataframe, abaixo está o resultado:
PM 0 15:45:36.543 LR model Test (EURUSD,H1) CDataFrame::Dropnan completed. Rows dropped: 25/30 HI 0 15:45:36.543 LR model Test (EURUSD,H1) | open | close | close lag_1 | close lag_3 | close lag_5 | high_low | Avg price | bb_lower | bb_middle | bb_upper | macd main | GK 0 15:45:36.543 LR model Test (EURUSD,H1) | 1.04057000 | 1.04079000 | 1.04057000 | 1.02806000 | 1.03015000 | 0.00575000 | 1.04176750 | 1.02125891 | 1.03177350 | 1.04228809 | 0.00028705 | QI 0 15:45:36.543 LR model Test (EURUSD,H1) | 1.04079000 | 1.04159000 | 1.04079000 | 1.04211000 | 1.02696000 | 0.00661000 | 1.04084750 | 1.02081967 | 1.03210400 | 1.04338833 | 0.00085370 | PL 0 15:45:36.543 LR model Test (EURUSD,H1) | 1.04158000 | 1.04956000 | 1.04159000 | 1.04057000 | 1.02806000 | 0.01099000 | 1.04611250 | 1.01924805 | 1.03282750 | 1.04640695 | 0.00192371 | JR 0 15:45:36.543 LR model Test (EURUSD,H1) | 1.04795000 | 1.04675000 | 1.04956000 | 1.04079000 | 1.04211000 | 0.00204000 | 1.04743000 | 1.01927184 | 1.03382650 | 1.04838116 | 0.00251595 | CP 0 15:45:36.543 LR model Test (EURUSD,H1) | 1.04675000 | 1.04370000 | 1.04675000 | 1.04159000 | 1.04057000 | 0.01049000 | 1.04664500 | 1.01938012 | 1.03447300 | 1.04956588 | 0.00270798 | CH 0 15:45:36.543 LR model Test (EURUSD,H1) (5x11)
Temos 11 atributos; o mesmo número de atributos pode ser visto no modelo.
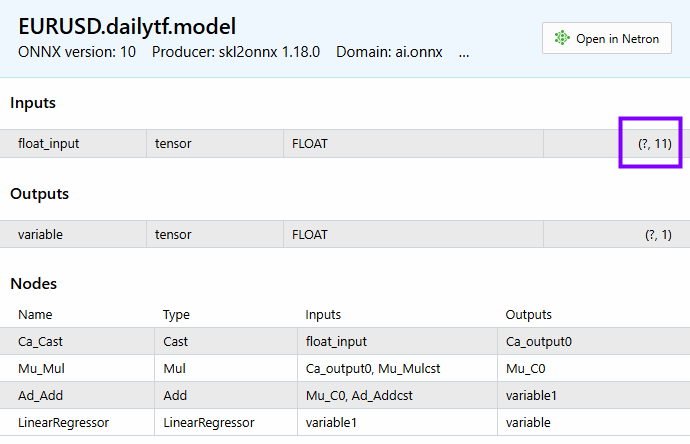
Abaixo está como podemos obter as previsões do modelo final.
void OnTick() { vector x = GetData(); Comment("Predicted close: ", lr.predict(x)); }
Não é inteligente realizar toda a coleta de dados e os cálculos do modelo a cada tick; precisamos calculá-los na abertura de uma nova barra no gráfico.
void OnTick() { if (isNewBar()) { vector x = GetData(); Comment("Predicted close: ", lr.predict(x)); } }
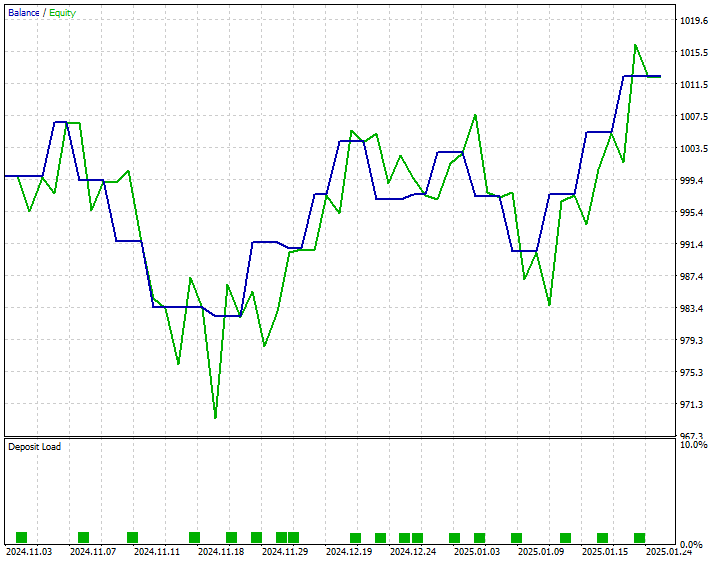
Desenvolvi uma estratégia simples para abrir uma ordem de compra sempre que o preço de fechamento previsto estiver acima do preço bid atual e abrir uma ordem de venda sempre que o preço de fechamento previsto estiver abaixo do preço ask atual.
Abaixo está o resultado do testador de estratégias de 01 de novembro de 2024 até 25 de janeiro de 2025.
Conclusão
Agora é fácil importar modelos avançados de IA para o MQL5 e utilizá-los no MetaTrader 5 sem dificuldades; ainda assim, não é fácil manter o modelo sincronizado com a estrutura de dados semelhante à utilizada no treinamento. Neste artigo, apresentei uma classe personalizada chamada CDataframe para nos auxiliar ao lidar com dados bidimensionais em um ambiente que se assemelha ao da biblioteca Pandas, muito familiar à comunidade de aprendizado de máquina e a cientistas de dados vindos do Python.
Espero que a biblioteca Pandas em MQL5 seja de grande utilidade e torne nossas vidas muito mais fáceis ao lidar com dados complexos de IA em MQL5.
Atenciosamente.
Fique atento e contribua para o desenvolvimento de algoritmos de aprendizado de máquina para a linguagem MQL5 neste repositório GitHub.
Tabela de Anexos
| Nome do arquivo | Descrição/Uso |
|---|---|
| Experts\LR model Test.mq5 | Um Expert Advisor para implantar o modelo final de regressão linear. |
| Include\Linear Regression.mqh | Uma biblioteca contendo todo o código para carregar um modelo de Regressão Linear no formato ONNX. |
| Include\pandas.mqh | Contém todos os métodos personalizados do Pandas para trabalhar com dados em uma classe Dataframe. |
| Scripts\pandas test.mq5 | Um script responsável por coletar os dados para fins de treinamento de ML. |
| Python\main.ipynb | Um arquivo Jupyter Notebook com todo o código para treinar o modelo de regressão linear utilizado neste artigo. |
| Files\ | Esta pasta contém um modelo de regressão linear em formato ONNX e arquivos CSV para fins de treinamento de modelos de IA. |
Traduzido do Inglês pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/en/articles/17030
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso