
Desenvolvimento de estratégias de trading de tendência baseadas em aprendizado de máquina
Introdução
Existem vários tipos de estratégias de trading que se mostraram eficazes na prática. Uma delas, a estratégia de retorno à média, foi analisada no artigo anterior. Neste artigo, compartilho com o leitor algumas ideias sobre como utilizar o aprendizado de máquina para criar estratégias de tendência ou de acompanhamento de tendência.
Neste trabalho será utilizado um método semelhante, por meio da clusterização dos dados, para identificar regimes de mercado. No entanto, os próprios anotadores de trades serão significativamente diferentes. Por isso, recomendo primeiro estudar o artigo anterior e só depois passar a este, como uma continuação lógica. Assim você poderá perceber a diferença entre o primeiro e o segundo tipo de estratégia, bem como a diferença na anotação dos exemplos de treinamento. Então, vamos em frente!
Como é possível anotar exemplos para estratégias de tendência
A principal diferença entre as estratégias de tendência e as estratégias de retorno à média está no fato de que, nas estratégias de tendência, é fundamental determinar com precisão a direção atual da tendência, enquanto nas estratégias de retorno à média, basta que os preços oscilem em torno de um certo valor médio e o cruzem com frequência. Pode-se dizer que essas estratégias são diametralmente opostas. Se o mean reversion implica uma alta probabilidade de reversão no movimento do preço, o trend following pressupõe a continuação da tendência atual.
Os pares de moedas costumam ser divididos em pares de tendência e pares em consolidação (flat). Naturalmente, essa divisão é bastante condicional, pois tanto uns quanto outros podem apresentar tanto períodos de tendência quanto zonas de consolidação. A diferença está mais relacionada à frequência com que se encontram em um ou outro estado. Neste artigo, não será realizado um estudo detalhado para identificar quais instrumentos são realmente de tendência. Apenas testaremos a abordagem no par de moedas EURUSD, considerado um par de tendência, em contraste com o EURGBP, analisado no artigo anterior como um exemplo de par em consolidação.
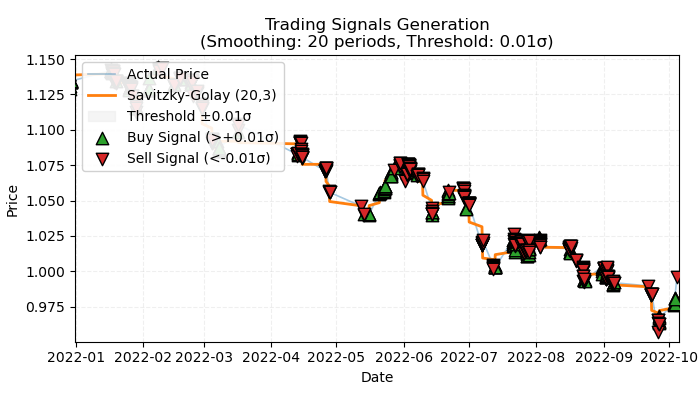
Figura 1. representação visual dos trades anotados com base em tendência
Na Figura 1 está ilustrado o princípio básico que será utilizado para a anotação de trades baseados em tendência. Para suavizar as flutuações de curto prazo causadas por ruído, utilizei novamente o filtro de Savitzky-Golay, que foi detalhado no artigo anterior. No entanto, em vez de calcular os desvios dos preços em relação ao filtro, como foi feito anteriormente, agora nos interessa a direção do filtro como indicador de tendência. Se a direção for positiva, é aberta uma posição de compra; caso contrário, uma posição de venda. Se a direção não estiver claramente definida, tais trades não são considerados no processo de aprendizado. A função de anotação inclui um filtro interno de força de tendência, ou limiar, que serve para eliminar pequenas tendências levando em conta a volatilidade, e será detalhado mais adiante.
Abordagem básica para anotação de trades de tendência
Vamos observar como a função de anotação de trades funciona internamente, para entender completamente o princípio de sua operação:
@njit def calculate_labels_trend(normalized_trend, threshold): labels = np.empty(len(normalized_trend), dtype=np.float64) for i in range(len(normalized_trend)): if normalized_trend[i] > threshold: labels[i] = 0.0 # Buy (Up trend) elif normalized_trend[i] < -threshold: labels[i] = 1.0 # Sell (Down trend) else: labels[i] = 2.0 # No signal return labels def get_labels_trend(dataset, rolling=200, polyorder=3, threshold=0.5, vol_window=50) -> pd.DataFrame: smoothed_prices = savgol_filter(dataset['close'].values, window_length=rolling, polyorder=polyorder) trend = np.gradient(smoothed_prices) vol = dataset['close'].rolling(vol_window).std().values normalized_trend = np.where(vol != 0, trend / vol, np.nan) # Set NaN where vol is 0 labels = calculate_labels_trend(normalized_trend, threshold) dataset = dataset.iloc[:len(labels)].copy() dataset['labels'] = labels dataset = dataset.dropna() # Remove rows with NaN return dataset
A função get_labels_trend processa os dados brutos — o dataset que contém a coluna "close" (preços de fechamento) — e retorna um dataframe com uma coluna adicional de rótulos anotados.
Etapas principais da anotação:
- Suavização dos preços. É utilizado o filtro de Savitzky-Golay para suavizar os preços de fechamento. Como parâmetros, são definidos o tamanho da janela de suavização e o grau do polinômio. O objetivo é eliminar ruídos e destacar a tendência principal.
smoothed_prices = savgol_filter(dataset['close'].values, window_length=rolling, polyorder=polyorder)- Cálculo da tendência. É calculado o gradiente dos preços suavizados. O gradiente indica a velocidade e a direção da variação do preço. Um gradiente positivo indica uma tendência de alta, e um gradiente negativo, uma tendência de baixa.
trend = np.gradient(smoothed_prices)
- Cálculo da volatilidade. A volatilidade é calculada como o desvio padrão dos preços de fechamento dentro de uma janela móvel. Isso ajuda a avaliar a variação do preço para normalizar a tendência.
vol = dataset['close'].rolling(vol_window).std().values- Normalização da tendência. A tendência é dividida pela volatilidade, de modo a considerar a variabilidade do mercado.
normalized_trend = np.where(vol != 0, trend / vol, np.nan)- Geração dos rótulos. Com base na tendência normalizada e no valor de limiar, são gerados os rótulos para compra e venda.
labels = calculate_labels_trend(normalized_trend, threshold)
- Uso do limiar. Essa é uma grandeza responsável por filtrar pequenas variações do gradiente. Ela é ajustada empiricamente, normalmente no intervalo de 0.01 a 0.5. Se os dados estiverem dentro dos limites do filtro, essas tendências são ignoradas por serem consideradas insignificantes.
Tomemos essa abordagem de anotação como base e criaremos anotadores adicionais de trades, a fim de ampliar as possibilidades de experimentação.
Anotação com restrição a trades estritamente lucrativos
A abordagem básica admite a presença de trades intencionalmente perdedores, pois eles podem ocorrer no final de uma tendência, antes de uma reversão. Isso é perfeitamente condizente com sinais reais de um sistema de trading, que pode eventualmente cometer erros. O importante é que a proporção de operações lucrativas seja maior que a de operações com perda. No entanto, é possível eliminar esse aspecto negativo anotando apenas trades lucrativos e ignorando os perdedores. Isso ajuda a suavizar a curva de saldo nos dados de treinamento e, possivelmente, também nos dados de teste. Abaixo está apresentado o código dessa forma de anotação.
@njit def calculate_labels_trend_with_profit(close, normalized_trend, threshold, markup, min_l, max_l): labels = np.empty(len(normalized_trend) - max_l, dtype=np.float64) for i in range(len(normalized_trend) - max_l): if normalized_trend[i] > threshold: # Проверяем условие для Buy rand = random.randint(min_l, max_l) future_pr = close[i + rand] if future_pr >= close[i] + markup: labels[i] = 0.0 # Buy (Profit reached) else: labels[i] = 2.0 # No profit elif normalized_trend[i] < -threshold: # Проверяем условие для Sell rand = random.randint(min_l, max_l) future_pr = close[i + rand] if future_pr <= close[i] - markup: labels[i] = 1.0 # Sell (Profit reached) else: labels[i] = 2.0 # No profit else: labels[i] = 2.0 # No signal return labels def get_labels_trend_with_profit(dataset, rolling=200, polyorder=3, threshold=0.5, vol_window=50, markup=0.00005, min_l=1, max_l=15) -> pd.DataFrame: # Smoothing and trend calculation smoothed_prices = savgol_filter(dataset['close'].values, window_length=rolling, polyorder=polyorder) trend = np.gradient(smoothed_prices) # Normalizing the trend by volatility vol = dataset['close'].rolling(vol_window).std().values normalized_trend = np.where(vol != 0, trend / vol, np.nan) # Removing NaN and synchronizing data valid_mask = ~np.isnan(normalized_trend) normalized_trend_clean = normalized_trend[valid_mask] close_clean = dataset['close'].values[valid_mask] dataset_clean = dataset[valid_mask].copy() # Generating labels labels = calculate_labels_trend_with_profit(close_clean, normalized_trend_clean, threshold, markup, min_l, max_l) # Trimming the dataset and adding labels dataset_clean = dataset_clean.iloc[:len(labels)].copy() dataset_clean['labels'] = labels # Filtering the results dataset_clean = dataset_clean.dropna() return dataset_clean
Principais diferenças em relação à abordagem básica:
- Foi adicionado o parâmetro min_l, que define o número mínimo de barras no futuro usado para medir a variação futura de preço em relação ao valor atual.
- Foi adicionado o parâmetro max_l, que define o número máximo de barras no futuro usado para medir essa mesma variação.
- A barra no futuro é escolhida aleatoriamente dentro do intervalo definido por esses parâmetros. É possível fixar o comprimento da verificação atribuindo os mesmos valores para min_l e max_l.
- Se a operação aberta resultar em lucro após n barras, essa operação é adicionada ao dataset de treinamento; caso contrário, é rotulada como 2.0 (sem operação).
- Foi adicionado o parâmetro markup, que deve ser definido como a média do spread + comissão + slippage do instrumento financeiro, podendo incluir uma margem de segurança. Esse valor influencia a quantidade de operações rotuladas como lucrativas: quanto maior o markup, menor será o número de trades marcados como lucrativos, já que menos deles ultrapassarão esse limiar.
Anotação com opção de escolha do filtro e restrição a operações estritamente lucrativas
Assim como no artigo anterior, queremos dispor de uma seleção de filtros, e não apenas o filtro de Savitzky-Golay. Isso permitirá gerar mais variações nas anotações e ajustar melhor o sistema de trading às particularidades de diferentes instrumentos. Proponho novamente incluir a média móvel simples, a média móvel exponencial e o spline como filtros adicionais. Apenas como exemplo, pois você poderá adicionar outros filtros da mesma forma.
@njit def calculate_labels_trend_different_filters(close, normalized_trend, threshold, markup, min_l, max_l): labels = np.empty(len(normalized_trend) - max_l, dtype=np.float64) for i in range(len(normalized_trend) - max_l): if normalized_trend[i] > threshold: # Проверяем условие для Buy rand = random.randint(min_l, max_l) future_pr = close[i + rand] if future_pr >= close[i] + markup: labels[i] = 0.0 # Buy (Profit reached) else: labels[i] = 2.0 # No profit elif normalized_trend[i] < -threshold: # Проверяем условие для Sell rand = random.randint(min_l, max_l) future_pr = close[i + rand] if future_pr <= close[i] - markup: labels[i] = 1.0 # Sell (Profit reached) else: labels[i] = 2.0 # No profit else: labels[i] = 2.0 # No signal return labels def get_labels_trend_with_profit_different_filters(dataset, method='savgol', rolling=200, polyorder=3, threshold=0.5, vol_window=50, markup=0.5, min_l=1, max_l=15) -> pd.DataFrame: # Smoothing and trend calculation close_prices = dataset['close'].values if method == 'savgol': smoothed_prices = savgol_filter(close_prices, window_length=rolling, polyorder=polyorder) elif method == 'spline': x = np.arange(len(close_prices)) spline = UnivariateSpline(x, close_prices, k=polyorder, s=rolling) smoothed_prices = spline(x) elif method == 'sma': smoothed_series = pd.Series(close_prices).rolling(window=rolling).mean() smoothed_prices = smoothed_series.values elif method == 'ema': smoothed_series = pd.Series(close_prices).ewm(span=rolling, adjust=False).mean() smoothed_prices = smoothed_series.values else: raise ValueError(f"Unknown smoothing method: {method}") trend = np.gradient(smoothed_prices) # Normalizing the trend by volatility vol = dataset['close'].rolling(vol_window).std().values normalized_trend = np.where(vol != 0, trend / vol, np.nan) # Removing NaN and synchronizing data valid_mask = ~np.isnan(normalized_trend) normalized_trend_clean = normalized_trend[valid_mask] close_clean = dataset['close'].values[valid_mask] dataset_clean = dataset[valid_mask].copy() # Generating labels labels = calculate_labels_trend_different_filters(close_clean, normalized_trend_clean, threshold, markup, min_l, max_l) # Trimming the dataset and adding labels dataset_clean = dataset_clean.iloc[:len(labels)].copy() dataset_clean['labels'] = labels # Filtering the results dataset_clean = dataset_clean.dropna() return dataset_clean
A principal modificação em relação ao algoritmo de anotação anterior é a inclusão do parâmetro method, que pode assumir os seguintes valores:
- savgol — filtro de Savitzky-Golay
- spline — interpolação por splines
- sma — suavização por média móvel simples
- ema — suavização por média móvel exponencial
Anotação baseada em filtros com diferentes períodos e restrição a operações estritamente lucrativas
Vamos agora tornar nossa percepção da realidade um pouco mais complexa e, como consequência, aprimorar o método de anotação das operações. Não há nenhuma limitação quanto ao uso de apenas um período de suavização. Podemos usar simultaneamente quantos filtros quisermos de um mesmo tipo, mas com diferentes períodos, e anotar as operações sempre que pelo menos uma das condições for atendida. Abaixo está apresentado um exemplo de tal amostrador:
@njit def calculate_labels_trend_multi(close, normalized_trends, threshold, markup, min_l, max_l): num_periods = normalized_trends.shape[0] # Number of periods labels = np.empty(len(close) - max_l, dtype=np.float64) for i in range(len(close) - max_l): # Select a random number of bars forward once for all periods rand = np.random.randint(min_l, max_l + 1) buy_signals = 0 sell_signals = 0 # Check conditions for each period for j in range(num_periods): if normalized_trends[j, i] > threshold: if close[i + rand] >= close[i] + markup: buy_signals += 1 elif normalized_trends[j, i] < -threshold: if close[i + rand] <= close[i] - markup: sell_signals += 1 # Combine signals if buy_signals > 0 and sell_signals == 0: labels[i] = 0.0 # Buy elif sell_signals > 0 and buy_signals == 0: labels[i] = 1.0 # Sell else: labels[i] = 2.0 # No signal or conflict return labels def get_labels_trend_with_profit_multi(dataset, method='savgol', rolling_periods=[10, 20, 30], polyorder=3, threshold=0.5, vol_window=50, markup=0.5, min_l=1, max_l=15) -> pd.DataFrame: """ Generates labels for trading signals (Buy/Sell) based on the normalized trend, calculated for multiple smoothing periods. Args: dataset (pd.DataFrame): DataFrame with data, containing the 'close' column. method (str): Smoothing method ('savgol', 'spline', 'sma', 'ema'). rolling_periods (list): List of smoothing window sizes. Default is [200]. polyorder (int): Polynomial order for 'savgol' and 'spline' methods. threshold (float): Threshold for the normalized trend. vol_window (int): Window for volatility calculation. markup (float): Minimum profit to confirm the signal. min_l (int): Minimum number of bars forward. max_l (int): Maximum number of bars forward. Returns: pd.DataFrame: DataFrame with added 'labels' column: - 0.0: Buy - 1.0: Sell - 2.0: No signal """ close_prices = dataset['close'].values normalized_trends = [] # Calculate normalized trend for each period for rolling in rolling_periods: if method == 'savgol': smoothed_prices = savgol_filter(close_prices, window_length=rolling, polyorder=polyorder) elif method == 'spline': x = np.arange(len(close_prices)) spline = UnivariateSpline(x, close_prices, k=polyorder, s=rolling) smoothed_prices = spline(x) elif method == 'sma': smoothed_series = pd.Series(close_prices).rolling(window=rolling).mean() smoothed_prices = smoothed_series.values elif method == 'ema': smoothed_series = pd.Series(close_prices).ewm(span=rolling, adjust=False).mean() smoothed_prices = smoothed_series.values else: raise ValueError(f"Unknown smoothing method: {method}") trend = np.gradient(smoothed_prices) vol = pd.Series(close_prices).rolling(vol_window).std().values normalized_trend = np.where(vol != 0, trend / vol, np.nan) normalized_trends.append(normalized_trend) # Transform list into 2D array normalized_trends_array = np.vstack(normalized_trends) # Remove rows with NaN valid_mask = ~np.isnan(normalized_trends_array).any(axis=0) normalized_trends_clean = normalized_trends_array[:, valid_mask] close_clean = close_prices[valid_mask] dataset_clean = dataset[valid_mask].copy() # Generate labels labels = calculate_labels_trend_multi(close_clean, normalized_trends_clean, threshold, markup, min_l, max_l) # Trim data and add labels dataset_clean = dataset_clean.iloc[:len(labels)].copy() dataset_clean['labels'] = labels # Remove remaining NaN dataset_clean = dataset_clean.dropna() return dataset_clean
Com marcador amarelo, destaquei os pontos principais aos quais você pode prestar atenção em uma análise rápida:
- A função de anotação agora aceita uma lista de comprimento arbitrário, que contém os valores dos períodos de suavização.
- No laço é realizado o cálculo dos filtros para todos os períodos definidos.
- Na função de anotação participam os gradientes das tendências para todos os filtros.
- Se ao menos uma condição de compra ou venda for atendida, considerando que não haja sinais opostos, a operação é anotada.
O módulo labeling_lib.py foi incrementado com quatro novos amostradores:
def get_labels_trend(dataset, rolling=200, polyorder=3, threshold=0.5, vol_window=50) -> pd.DataFrame: def get_labels_trend_with_profit(dataset, rolling=200, polyorder=3, threshold=0.5, def get_labels_trend_with_profit_different_filters(dataset, method='savgol', rolling=200, polyorder=3, threshold=0.5, def get_labels_trend_with_profit_multi(dataset, method='savgol', rolling_periods=[10, 20, 30], polyorder=3, threshold=0.5,
Vamos nos deter nessas variantes. Elas são plenamente suficientes para testar a ideia principal da anotação por tendência.
Processo de treinamento e teste dos modelos
A própria lógica de preparação dos dados e de aprendizado foi tomada do artigo anterior, portanto não descreveremos em detalhes suas particularidades. Mas há mudanças; por exemplo, todo o ciclo de aprendizado agora foi deslocado para uma função separada, processing, porque surgiram novas possibilidades de controle desse processo.
Antes, as operações anotadas como 2.0 eram simplesmente removidas do dataset de treinamento e não participavam de forma alguma do processo de aprendizado. Isso podia levar à perda de informação, pois ocorria lacuna na anotação das operações. Mas como incorporar essa informação ao sistema de trading, se é usado um classificador binário e as etiquetas 2.0 (sem ação) constituem uma 3ª classe?
Lembremos que participam do aprendizado dois classificadores: o primeiro é treinado para prever as etiquetas de compra e venda, e o segundo é treinado para prever o regime de mercado atual (quando operar e quando não operar). Logo, temos a possibilidade de migrar os exemplos com etiquetas 2.0 para o segundo modelo, e não perderemos informação como antes, quando removíamos tais exemplos.
def processing(iterations = 1, rolling = [10], threshold=0.01, polyorder=5, vol_window=100, use_meta_dilution = True): models = [] for i in range(iterations): data = clustering(dataset, n_clusters=hyper_params['n_clusters']) sorted_clusters = data['clusters'].unique() sorted_clusters.sort() for clust in sorted_clusters: clustered_data = data[data['clusters'] == clust].copy() if len(clustered_data) < 500: print('too few samples: {}'.format(len(clustered_data))) continue clustered_data = get_labels_trend_with_profit_multi( clustered_data, method='savgol', rolling_periods=rolling, polyorder=polyorder, threshold=threshold, vol_window=vol_window, min_l=1, max_l=15, markup=hyper_params['markup']) print(f'Iteration: {i}, Cluster: {clust}') clustered_data = clustered_data.drop(['close', 'clusters'], axis=1) meta_data = data.copy() meta_data['clusters'] = meta_data['clusters'].apply(lambda x: 1 if x == clust else 0) if use_meta_dilution: for dt in clustered_data.index: if clustered_data.loc[dt, 'labels'] == 2.0: if dt in meta_data.index: # Check if datetime exists in meta_data meta_data.loc[dt, 'clusters'] = 0 clustered_data = clustered_data.drop(clustered_data[clustered_data.labels == 2.0].index) # Синхронизация meta_data с bad_data models.append(fit_final_models(clustered_data, meta_data.drop(['close'], axis=1))) models.sort(key=lambda x: x[0]) return models
No código está indicado com marcador que os exemplos anotados como 2.0 no dataset para o primeiro modelo são selecionados no dataset para o segundo modelo pelas datas e pelas linhas correspondentes a essas datas, e na coluna clusters são colocados zeros. Se lembrarmos que os valores 1 permitem a negociação, então o segundo modelo agora irá prever não apenas o regime de mercado, mas também os maus momentos de entrada na operação segundo a versão do amostrador de operações. Em outras palavras, o segundo modelo agora irá prever não apenas o regime de mercado necessário, mas também os pontos indesejáveis de entrada no mercado.
Proponho usar de imediato o último amostrador, porque ele reuniu tudo de melhor e tem configurações flexíveis.
Realizaremos 10 ciclos de aprendizado com as seguintes configurações:
hyper_params = {
'symbol': 'EURUSD_H1',
'export_path': '/Users/dmitrievsky/Library/Containers/com.isaacmarovitz.Whisky/Bottles/54CFA88F-36A3-47F7-915A-D09B24E89192/drive_c/Program Files/MetaTrader 5/MQL5/Include/Mean reversion/',
'model_number': 0,
'markup': 0.00010,
'stop_loss': 0.00500,
'take_profit': 0.00200,
'periods': [i for i in range(5, 300, 30)],
'periods_meta': [100],
'backward': datetime(2000, 1, 1),
'forward': datetime(2024, 1, 1),
'full forward': datetime(2026, 1, 1),
'n_clusters': 10,
'rolling': [10],
}A própria função de treinamento é chamada da seguinte maneira:
dataset = get_features(get_prices()) models = processing(iterations = 10, threshold=0.001, polyorder=3, vol_window=100, use_meta_dilution = True)
No processo de aprendizado serão exibidas as estimativas R^2 para cada passagem (кластера):
Iteration: 0, Cluster: 0 R2: 0.9837358133371028 Iteration: 0, Cluster: 1 R2: 0.9002342482016827 Iteration: 0, Cluster: 2 R2: 0.9755114279213657 Iteration: 0, Cluster: 3 R2: 0.9833351908595832 Iteration: 0, Cluster: 4 R2: 0.9537875370012954 Iteration: 0, Cluster: 5 R2: 0.9863566422346429 too few samples: 471 Iteration: 0, Cluster: 7 R2: 0.9852545217737659 Iteration: 0, Cluster: 8 R2: 0.9934196831544163
Vamos testar o melhor modelo de toda a lista:
test_model(models[-1][1:], hyper_params['stop_loss'], hyper_params['take_profit'], hyper_params['forward'], plt=True)
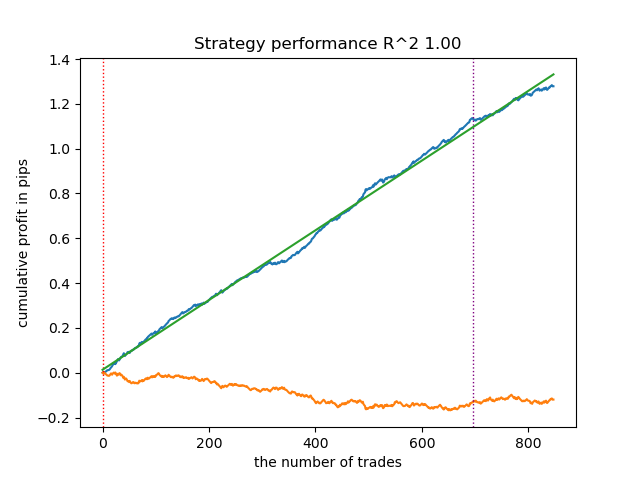
Figura 2. teste do modelo nos dados de treinamento e nos novos dados
Agora podemos chamar a função de exportação dos modelos para o terminal MetaTrader 5.
export_model_to_ONNX(model = models[-1], symbol = hyper_params['symbol'], periods = hyper_params['periods'], periods_meta = hyper_params['periods_meta'], model_number = hyper_params['model_number'], export_path = hyper_params['export_path'])
Teste final dos modelos e observações gerais sobre o algoritmo
Meu método é universal, portanto a exportação dos modelos para o terminal é feita exatamente da mesma forma descrita no artigo anterior.
Vamos observar todo o período de treinamento + teste e, em seguida, o teste separadamente. Nas figuras é possível ver que nos dados de treinamento a curva é mais suave do que nos dados de teste, que começam em 2024. Como o treinamento foi realizado de 2020 a 2024, o teste é apresentado a partir de 2019 para mostrar que, no período anterior ao treinamento, também não há total estabilidade.
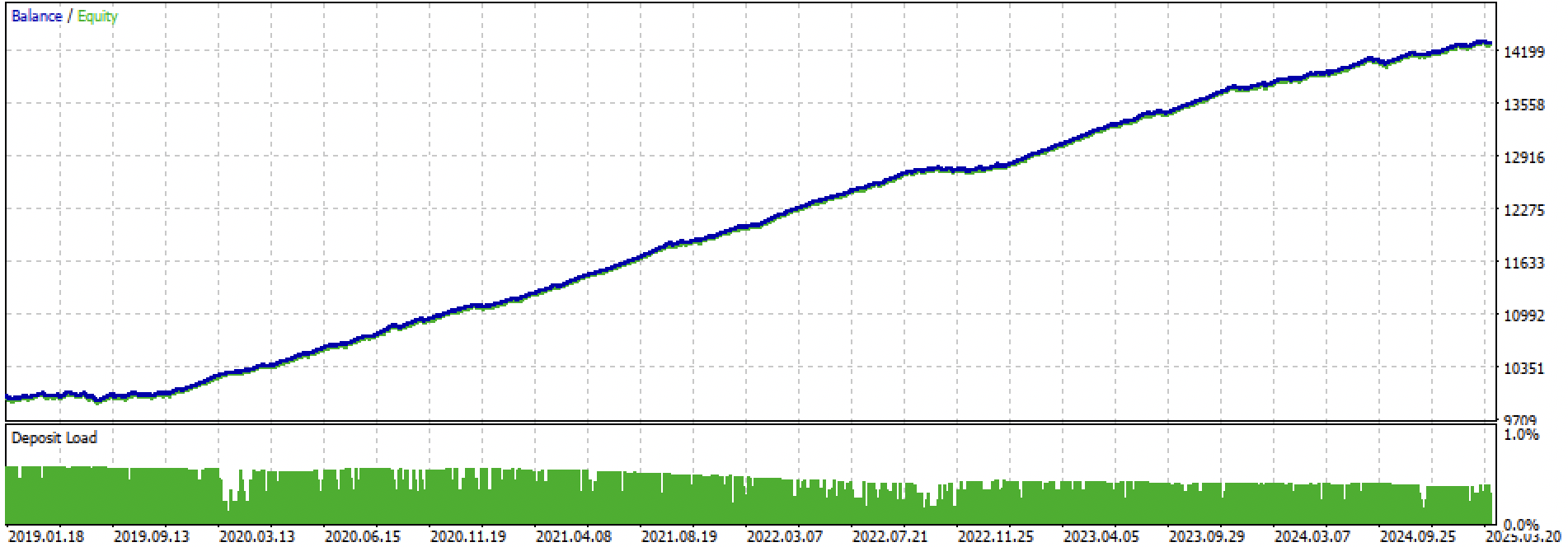
Figura 3. teste de 2019 a 2025.
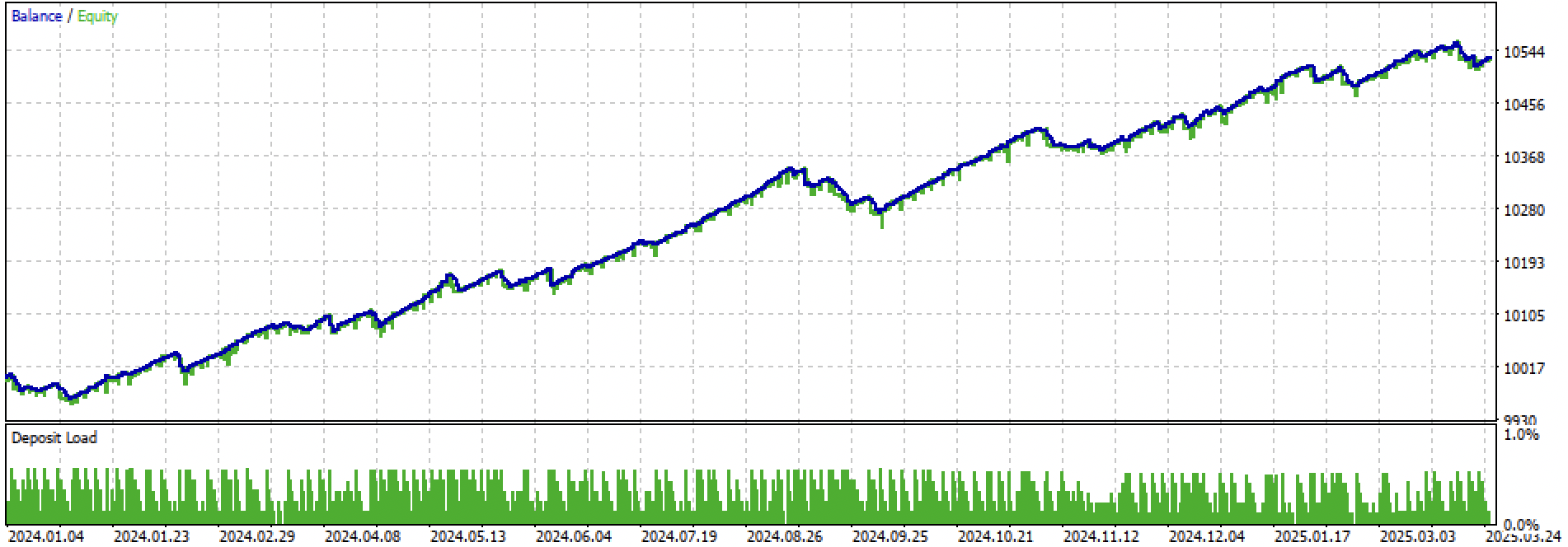
Figura 4. teste no período forward do início de 2024 até 27 de março de 2025
Com base nos experimentos realizados, concluí que as estratégias de tendência são mais sensíveis em relação ao seu desempenho em novos dados, ou que esta abordagem, em particular, não é muito eficaz na criação de estratégias de tendência para o par de moedas EURUSD. No entanto, ajustando os hiperparâmetros, é possível obter modelos com desempenho satisfatório. As desvantagens são parcialmente compensadas pelo fato de que esses modelos podem apresentar bons resultados com um stop-loss muito curto, por exemplo, de 20 pontos de quatro dígitos. Isso permite controlar o risco e desligar os modelos em tempo hábil, quando começam a apresentar degradação.
Além disso, não consegui identificar um conjunto consistente de hiperparâmetros. A impressão é de que o algoritmo, em geral, tem dificuldade em encontrar padrões estáveis ou que esses padrões simplesmente não existem.
Para combater o sobreajuste, é possível reduzir a complexidade dos modelos na função fit_final_models():
def fit_final_models(clustered, meta) -> list: # features for model\meta models. We learn main model only on filtered labels X, X_meta = clustered[clustered.columns[:-1]], meta[meta.columns[:-1]] X = X.loc[:, ~X.columns.str.contains('meta_feature')] X_meta = X_meta.loc[:, X_meta.columns.str.contains('meta_feature')] # labels for model\meta models y = clustered['labels'] y_meta = meta['clusters'] y = y.astype('int16') y_meta = y_meta.astype('int16') # train\test split train_X, test_X, train_y, test_y = train_test_split( X, y, train_size=0.7, test_size=0.3, shuffle=True) train_X_m, test_X_m, train_y_m, test_y_m = train_test_split( X_meta, y_meta, train_size=0.7, test_size=0.3, shuffle=True) # learn main model with train and validation subsets model = CatBoostClassifier(iterations=100, custom_loss=['Accuracy'], eval_metric='Accuracy', verbose=False, use_best_model=True, task_type='CPU', thread_count=-1) model.fit(train_X, train_y, eval_set=(test_X, test_y), early_stopping_rounds=15, plot=False) # learn meta model with train and validation subsets meta_model = CatBoostClassifier(iterations=100, custom_loss=['F1'], eval_metric='F1', verbose=False, use_best_model=True, task_type='CPU', thread_count=-1) meta_model.fit(train_X_m, train_y_m, eval_set=(test_X_m, test_y_m), early_stopping_rounds=15, plot=False) R2 = test_model([model, meta_model], hyper_params['stop_loss'], hyper_params['take_profit'], hyper_params['full forward']) if math.isnan(R2): R2 = -1.0 print('R2 is fixed to -1.0') print('R2: ' + str(R2)) return [R2, model, meta_model]
O número de iterações controla tanto a quantidade de divisões (splits) no modelo quanto o número de características selecionadas. Inicialmente havia 1000 iterações; reduzindo para 100, obtivemos uma melhoria no controle de ruído. O early stopping interrompe o treinamento antecipadamente, caso o erro de classificação nos dados de validação não melhore por 15 iterações consecutivas.
Isso resultou em uma curva de saldo mais ruidosa e menos elegante, porém mais homogênea.
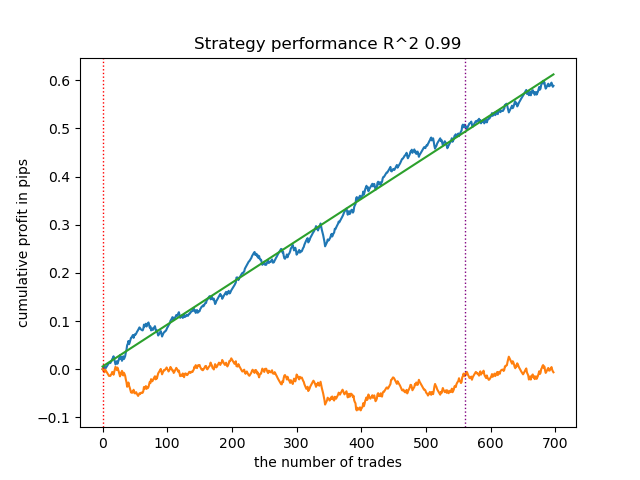
Figura 5. gráfico de saldo após a redução da complexidade dos modelos
Considerações finais
Criar estratégias de tendência com base em clusterização e classificação binária é uma tarefa mais complexa. São necessários novos insights sobre como esse tipo de abordagem pode ser aprimorado. Um problema evidente é que os preços dos ativos financeiros tendem a sair do intervalo de valores sobre o qual o modelo foi treinado. Isso difere do aprendizado em instrumentos laterais (flat), onde os preços nos novos dados costumam estar dentro da faixa observada durante o treinamento. Quando são utilizados atributos baseados em diferenças de preço, o modelo novamente mostra baixa capacidade de generalização.
Com este artigo, decidi concluir meus experimentos com o método de clusterização de regimes de mercado, e nas próximas publicações você encontrará novas ideias ainda mais interessantes.
Ao artigo estão anexados os seguintes materiais:
| Nome do arquivo | Descrição |
|---|---|
| labeling_lib.py | Biblioteca atualizada de amostradores |
| trend_following.py | Script para treinamento dos modelos |
| cat model_EURUSD_H1_0.onnx | Modelo principal, pasta include |
| catmodel_m_EURUSD_H1_0.onnx | Meta-modelo, pasta include |
| EURUSD_H1_ONNX_include_0.mqh | Arquivo de cabeçalho |
| trend_following.mq5 | Código-fonte do EA |
| trend_following.ex5 | Bot compilado |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/17526
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
Então, o resultado não é ruim. A primavera de 2025 é um mercado diferente.
Acho que o eurodólar em geral não está sendo muito bom em previsões ultimamente. As negociações planas/tendências não funcionam.
Somente as negociações de compra funcionam em mercados com boa tendência (por exemplo, ouro), como no último artigo. Em barras, não em scalping.
Em eurodólares e unidirecionais não funcionam.
Acho que o eurodólar em geral não está sendo muito bom em previsões ultimamente. As tendências planas não estão funcionando.
Somente as operações de compra funcionam em títulos com boa tendência (observe o ouro), como no último artigo. Em barras, não em scalping.
No Eurodólar, as unidirecionais não funcionam.
Mas se o mercado mudar, o ts morrerá. Sem um supervisor automático, ele já é um semi-manual.
Mas se o mercado mudar, o tc estará morto. Sem um invigilante automático, ele já é um semi-manipulador
Como posso obter esse robô 🤖?