
Aprendizado de máquina em trading direcional de tendência com o exemplo do ouro
Introdução
Nos últimos tempos, estudamos a criação de sistemas de trading simétricos sob a ótica da classificação binária. Partimos do pressuposto de que as operações de compra e venda podem ser bem separadas no espaço de características, ou seja, existe uma certa fronteira de separação (hiperplano) que permite ao algoritmo de aprendizado de máquina prever igualmente bem posições longas e curtas.
Na prática, isso nem sempre acontece, especialmente para instrumentos de trading com comportamento de tendência, como alguns metais, índices e também criptomoedas. Em situações nas quais o ativo apresenta uma tendência direcional bem definida, sistemas de trading que envolvem tanto compras quanto vendas podem ser excessivamente arriscados, e a distribuição geral dessas operações pode se tornar fortemente assimétrica, levando a classificações incorretas e a um grande número de erros.
Nesses casos, um sistema de trading bidirecional pode se mostrar ineficiente, sendo mais apropriado concentrar-se na negociação em uma única direção. Este artigo busca esclarecer as possibilidades do aprendizado de máquina na criação de estratégias unidirecionais desse tipo.
Proponho repensar as abordagens de inferência causal e adaptá-las à tarefa de trading em uma única direção.
Tomaremos como base os materiais dos artigos anteriores:
- Validação cruzada e fundamentos da inferência causal
- Inferência causal em tarefas de classificação de séries temporais
- Tester rápido de estratégias de trading em Python
Recomendo fortemente a leitura desses artigos para uma compreensão mais completa da ideia de inferência causal e dos testes.
Criação de um sampler de operações em uma direção definida
Como antes realizávamos simultaneamente a rotulação das operações de compra e venda, é necessário modificar o rotulador de operações de modo que ele marque apenas as operações do lado escolhido. Abaixo é apresentado um exemplo desse sampler, que será utilizado neste artigo:
@njit def calculate_labels_one_direction(close_data, markup, min, max, direction): labels = [] for i in range(len(close_data) - max): rand = random.randint(min, max) curr_pr = close_data[i] future_pr = close_data[i + rand] if direction == "sell": if (future_pr + markup) < curr_pr: labels.append(1.0) else: labels.append(0.0) if direction == "buy": if (future_pr - markup) > curr_pr: labels.append(1.0) else: labels.append(0.0) return labels def get_labels_one_direction(dataset, markup, min = 1, max = 15, direction = 'buy') -> pd.DataFrame: close_data = dataset['close'].values labels = calculate_labels_one_direction(close_data, markup, min, max, direction) dataset = dataset.iloc[:len(labels)].copy() dataset['labels'] = labels dataset = dataset.dropna() return dataset
Foi adicionado um novo parâmetro "direction", com o qual é possível definir a direção necessária para a rotulação das operações, seja de compra ou de venda. Agora, a classe com rótulo "1" indica que existe uma operação para a direção escolhida, enquanto a classe com rótulo "0" indica que naquele momento é melhor não abrir operação. Nos parâmetros também é definida uma duração aleatória da operação dentro do intervalo {min, max}, medida pelo número de barras decorridas desde a abertura da operação. Trata-se de um sampler simples, mas que se mostrou bastante eficaz para esse tipo de estratégia.
Modificação do tester customizado de estratégias
Agora é necessária uma lógica de teste diferente para estratégias unidirecionais, portanto, é preciso modificar o próprio tester de estratégias para que ele corresponda a essa lógica. No módulo "tester_lib.py" foram adicionadas funções para o teste em uma única direção. Vamos analisá-las em detalhes.
A função process_data_one_direction() processa os dados para o trading em uma única direção:
@jit(nopython=True) def process_data_one_direction(close, labels, metalabels, stop, take, markup, forward, backward, direction): last_deal = 2 last_price = 0.0 report = [0.0] chart = [0.0] line_f = 0 line_b = 0 for i in range(len(close)): line_f = len(report) if i <= forward else line_f line_b = len(report) if i <= backward else line_b pred = labels[i] pr = close[i] pred_meta = metalabels[i] # 1 = allow trades if last_deal == 2 and pred_meta == 1: last_price = pr last_deal = 2 if pred < 0.5 else 1 continue if last_deal == 1 and direction == 'buy': if (-markup + (pr - last_price) >= take) or (-markup + (last_price - pr) >= stop): last_deal = 2 profit = -markup + (pr - last_price) report.append(report[-1] + profit) chart.append(chart[-1] + profit) continue if last_deal == 1 and direction == 'sell': if (-markup + (pr - last_price) >= stop) or (-markup + (last_price - pr) >= take): last_deal = 2 profit = -markup + (last_price - pr) report.append(report[-1] + profit) chart.append(chart[-1] + (pr - last_price)) continue # close deals by signals if last_deal == 1 and pred < 0.5 and direction == 'buy': last_deal = 2 profit = -markup + (pr - last_price) report.append(report[-1] + profit) chart.append(chart[-1] + profit) continue if last_deal == 1 and pred < 0.5 and direction == 'sell': last_deal = 2 profit = -markup + (last_price - pr) report.append(report[-1] + profit) chart.append(chart[-1] + (pr - last_price)) continue return np.array(report), np.array(chart), line_f, line_b
A principal diferença em relação à função base é que agora são usados flags com indicação explícita sobre qual tipo de operação será utilizado no tester: compra ou venda. A função é muito rápida graças à aceleração com Numba, e realiza uma passagem pelo histórico de cotações, calculando o lucro de cada operação. Observe que o tester é capaz de fechar operações tanto pelos sinais do modelo quanto por stop-loss e take-profit, dependendo de qual condição ocorrer primeiro. Isso permite selecionar modelos ainda na etapa de treinamento, levando em conta o nível de risco aceitável para você.
A função tester_one_direction() processa o dataset rotulado, que contém preços e rótulos, e passa esses dados para a função process_data_one_direction(), depois coleta o resultado para posterior plotagem no gráfico.
def tester_one_direction(*args): ''' This is a fast strategy tester based on numba List of parameters: dataset: must contain first column as 'close' and last columns with "labels" and "meta_labels" stop: stop loss value take: take profit value forward: forward time interval backward: backward time interval markup: markup value direction: buy/sell plot: false/true ''' dataset, stop, take, forward, backward, markup, direction, plot = args forw = dataset.index.get_indexer([forward], method='nearest')[0] backw = dataset.index.get_indexer([backward], method='nearest')[0] close = dataset['close'].to_numpy() labels = dataset['labels'].to_numpy() metalabels = dataset['meta_labels'].to_numpy() report, chart, line_f, line_b = process_data_one_direction(close, labels, metalabels, stop, take, markup, forw, backw, direction) y = report.reshape(-1, 1) X = np.arange(len(report)).reshape(-1, 1) lr = LinearRegression() lr.fit(X, y) l = 1 if lr.coef_[0][0] >= 0 else -1 if plot: plt.plot(report) plt.axvline(x=line_f, color='purple', ls=':', lw=1, label='OOS') plt.axvline(x=line_b, color='red', ls=':', lw=1, label='OOS2') plt.plot(lr.predict(X)) plt.title("Strategy performance R^2 " + str(format(lr.score(X, y) * l, ".2f"))) plt.xlabel("the number of trades") plt.ylabel("cumulative profit in pips") plt.show() return lr.score(X, y) * l
A função test_model_one_direction() recebe as previsões do modelo nos dados selecionados. Essas previsões são passadas para a função tester_one_direction() para gerar o resultado do teste desse modelo.
def test_model_one_direction(dataset: pd.DataFrame, result: list, stop: float, take: float, forward: float, backward: float, markup: float, direction: str, plt = False): ext_dataset = dataset.copy() X = ext_dataset[ext_dataset.columns[1:]] ext_dataset['labels'] = result[0].predict_proba(X)[:,1] ext_dataset['meta_labels'] = result[1].predict_proba(X)[:,1] ext_dataset['labels'] = ext_dataset['labels'].apply(lambda x: 0.0 if x < 0.5 else 1.0) ext_dataset['meta_labels'] = ext_dataset['meta_labels'].apply(lambda x: 0.0 if x < 0.5 else 1.0) return tester_one_direction(ext_dataset, stop, take, forward, backward, markup, direction, plt)
O meta-learner como o coração do sistema de trading
Vamos analisar o primeiro meta-learner apresentado no artigo sobre validação cruzada, e tentarei oferecer uma explicação lógica de por que ele funciona melhor no caso das estratégias unidirecionais do que nas bidirecionais.
def meta_learner(folds_number: int, iter: int, depth: int, l_rate: float) -> pd.DataFrame: dataset = get_labels_one_direction(get_features(get_prices()), markup=hyper_params['markup'], min=1, max=15, direction=hyper_params['direction']) data = dataset[(dataset.index < hyper_params['forward']) & (dataset.index > hyper_params['backward'])].copy() X = data[data.columns[1:-2]] y = data['labels'] B_S_B = pd.DatetimeIndex([]) # learn meta model with CV method meta_model = CatBoostClassifier(iterations = iter, max_depth = depth, learning_rate=l_rate, verbose = False) cv = StratifiedKFold(n_splits=folds_number, shuffle=False) predicted = cross_val_predict(meta_model, X, y, method='predict_proba', cv=cv) coreset = X.copy() coreset['labels'] = y coreset['labels_pred'] = [x[0] < 0.5 for x in predicted] coreset['labels_pred'] = coreset['labels_pred'].apply(lambda x: 0 if x < 0.5 else 1) # select bad samples (bad labels indices) diff_negatives = coreset['labels'] != coreset['labels_pred'] B_S_B = B_S_B.append(diff_negatives[diff_negatives == True].index) to_mark = B_S_B.value_counts() marked_idx = to_mark.index data['meta_labels'] = 1.0 data.loc[data.index.isin(marked_idx), 'meta_labels'] = 0.0 data.loc[data.index.isin(marked_idx), 'labels'] = 0.0 return data[data.columns[:]]
Para maior clareza, abaixo é mostrada a estrutura da função do meta-learner em forma de blocos principais, cada um responsável por uma funcionalidade específica.
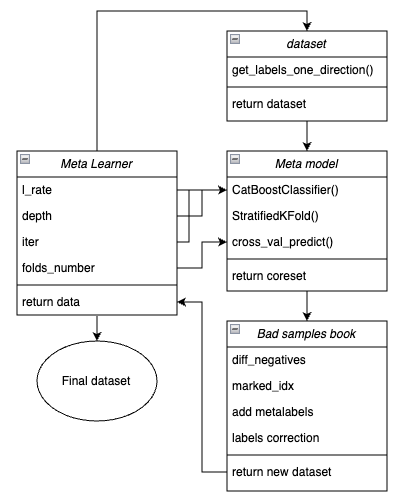
Fig. 1. Representação esquemática da função meta_learner()
É importante lembrar que o meta-learner atua como uma engrenagem de transmissão entre os dados brutos e o modelo final. Ele assume a principal responsabilidade pelo pré-processamento eficiente, criando meta-rótulos ("meta labels") por meio de um meta-modelo. A singularidade da função que desenvolvi está no fato de ela gerar datasets limpos e bem preparados, o que resulta em modelos e sistemas de trading robustos.
Parâmetros de entrada da função:
- l_rate (learning rate) — é o passo do gradiente para a meta-modelo ou para o classificador CatBoost. É definido dentro do intervalo {0.01, 0.5}. O algoritmo é sensível a esse parâmetro.
- depth — é responsável pela profundidade das árvores de decisão que são construídas em cada iteração do treinamento do classificador CatBoost. O intervalo recomendado de valores é {1, 6}.
- iter — é o número de iterações de treinamento, recomendado no intervalo {5, 25}.
- folds_number — é o número de folds para a validação cruzada. Normalmente, {5, 15} folds são suficientes.
Mecanismo de funcionamento da função:
- É criado um dataset com características e rótulos. Como sampler, é utilizada a função get_labels_one_direction(), descrita anteriormente.
- Com esses dados, o meta-learner é treinado com os parâmetros definidos, em modo de validação cruzada, por meio da função StratifiedKFold(). Essa função divide os dados de treinamento em vários folds, levando em consideração o balanceamento entre as classes. Em cada fold ocorre o treinamento da meta-modelo, e em seguida são salvas todas as previsões. Isso é necessário para obter uma estimativa não tendenciosa dos erros do modelo nos dados de treinamento. Essas previsões serão usadas para comparação com os rótulos originais.
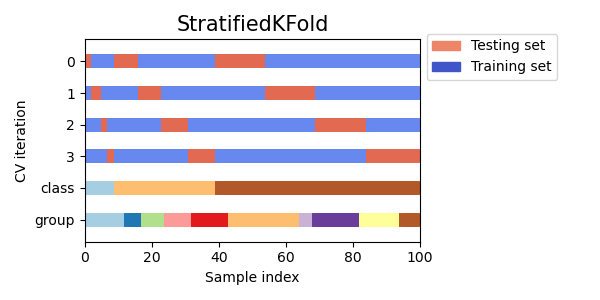
Figura 2. Esquema de divisão de dados em dobras pela função StratifiedKFold()
- É criado um dataset separado chamado coreset, no qual são armazenados tanto os rótulos originais quanto os previstos via validação cruzada.
- É criada uma variável separada chamada diff_negatives, que armazena flags binários indicando as correspondências entre rótulos originais e previstos.
- É criada uma "livro de maus exemplos" B_S_B (Bad Samples Book), no qual são registrados os índices temporais das linhas do dataset cujas previsões não coincidiram com os rótulos originais.
- São determinados os índices únicos dos exemplos incorretamente previstos em todos os folds.
- É criada uma coluna adicional 'meta_labels' no dataset original, e todas as observações recebem o valor '1' (pode operar).
- Para todos os exemplos que foram previstos incorretamente durante o processo de validação cruzada, é atribuído o valor '0' na coluna 'meta_labels' (não operar).
- Para todos esses exemplos incorretos, na coluna 'labels', que contém os rótulos para o modelo principal, também são atribuídos os valores '0' (não operar).
- A função retorna o dataset modificado.
Inferência causal mais robusta
Na seção anterior foi apresentado o meta-learner básico, através do qual é mais fácil explicar o conceito principal. Nesta seção, tornaremos a abordagem um pouco mais complexa e examinaremos diretamente o processo de inferência causal. Adaptei a função de inferência causal do artigo referenciado para o caso do trading unidirecional. Ela é mais avançada e possui uma funcionalidade mais flexível.
def meta_learners(models_number: int, iterations: int, depth: int, bad_samples_fraction: float): dataset = get_labels_one_direction(get_features(get_prices()), markup=hyper_params['markup'], min=1, max=15, direction=hyper_params['direction']) data = dataset[(dataset.index < hyper_params['forward']) & (dataset.index > hyper_params['backward'])].copy() X = data[data.columns[1:-2]] y = data['labels'] BAD_WAIT = pd.DatetimeIndex([]) BAD_TRADE = pd.DatetimeIndex([]) for i in range(models_number): X_train, X_val, y_train, y_val = train_test_split( X, y, train_size = 0.5, test_size = 0.5, shuffle = True) # learn debias model with train and validation subsets meta_m = CatBoostClassifier(iterations = iterations, depth = depth, custom_loss = ['Accuracy'], eval_metric = 'Accuracy', verbose = False, use_best_model = True) meta_m.fit(X_train, y_train, eval_set = (X_val, y_val), plot = False) coreset = X.copy() coreset['labels'] = y coreset['labels_pred'] = meta_m.predict_proba(X)[:, 1] coreset['labels_pred'] = coreset['labels_pred'].apply(lambda x: 0 if x < 0.5 else 1) # add bad samples of this iteration (bad labels indices) coreset_w = coreset[coreset['labels']==0] coreset_t = coreset[coreset['labels']==1] diff_negatives_w = coreset_w['labels'] != coreset_w['labels_pred'] diff_negatives_t = coreset_t['labels'] != coreset_t['labels_pred'] BAD_WAIT = BAD_WAIT.append(diff_negatives_w[diff_negatives_w == True].index) BAD_TRADE = BAD_TRADE.append(diff_negatives_t[diff_negatives_t == True].index) to_mark_w = BAD_WAIT.value_counts() to_mark_t = BAD_TRADE.value_counts() marked_idx_w = to_mark_w[to_mark_w > to_mark_w.mean() * bad_samples_fraction].index marked_idx_t = to_mark_t[to_mark_t > to_mark_t.mean() * bad_samples_fraction].index data['meta_labels'] = 1.0 data.loc[data.index.isin(marked_idx_w), 'meta_labels'] = 0.0 data.loc[data.index.isin(marked_idx_t), 'meta_labels'] = 0.0 data.loc[data.index.isin(marked_idx_t), 'labels'] = 0.0 return data[data.columns[:]]
Abaixo é apresentada a estrutura da função do meta-learner em forma de blocos principais, responsáveis por diferentes funcionalidades.
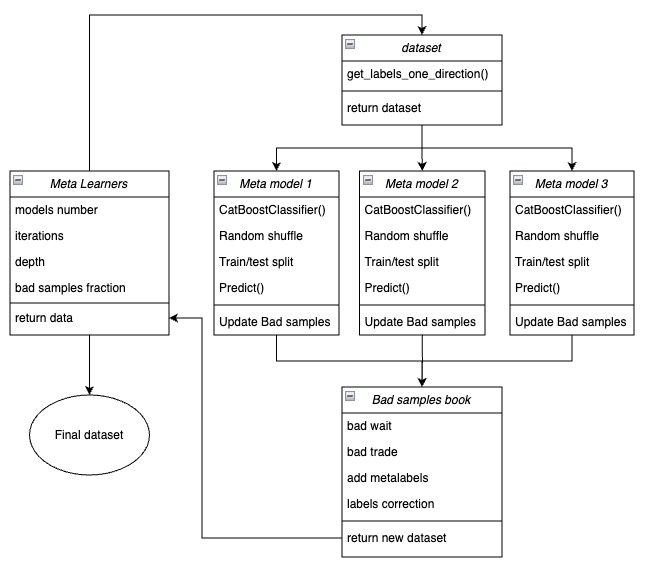
Fig. 3. Representação esquemática da função meta_learners()
A característica distintiva dessa função é que ela possui várias “cabeças” de meta-modelos, que são treinadas em subconjuntos aleatórios do dataset original, selecionados pelo método bootstrap com reposição. Esse método permite gerar múltiplas subamostras a partir do dataset original. Com esse conjunto de pseudoamostras é possível avaliar características estatísticas e probabilísticas.
Por exemplo, estamos interessados na média que indica o quão bem determinado exemplo, retirado da população geral, é previsto se treinássemos os modelos em diferentes subamostras dessa população. Isso nos fornece uma representação menos enviesada de cada exemplo do conjunto, os quais, então, podem ser rotulados como exemplos bons ou ruins com maior grau de confiança.
Parâmetros de entrada da função:
- models number — número de meta-modelos envolvidos no algoritmo. Intervalo recomendado de valores {5, 100}.
- iterations — número de iterações de treinamento para cada modelo. Intervalo recomendado de valores {15, 35}.
- depth — profundidade das árvores de decisão construídas em cada iteração do treinamento do classificador CatBoost. Intervalo recomendado de valores {1, 6}.
- bad samples fraction — proporção de exemplos que serão rotulados como “ruins”. Intervalo recomendado de valores {0.4, 0.9}.
Mecanismo de funcionamento da função:
- É criado um dataset com características e rótulos referentes à direção de trading definida.
- Em um laço, cada meta-modelo é treinado em dados de treinamento e validação escolhidos aleatoriamente pelo método bootstrap.
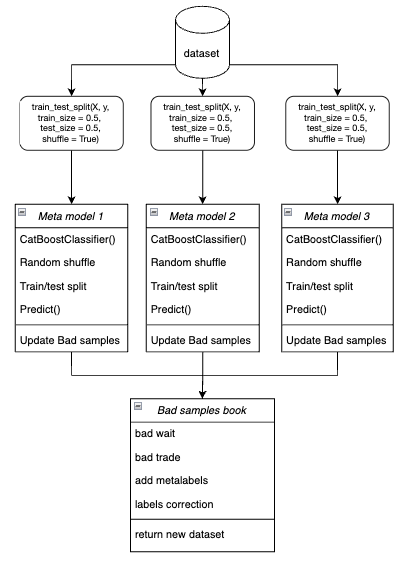
Figura 4. Representação esquemática da amostragem bootstrap
- Para cada modelo, suas previsões são comparadas com os rótulos reais. Os índices dos casos incorretamente classificados são salvos no livro de maus exemplos.
- É calculada a média do número de índices incorretamente previstos em todas as passagens.
- Os índices que apresentam a maior quantidade de previsões incorretas e que excedem a média multiplicada pelo limite são adicionados à coluna "meta_labels" com valor zero (proibido operar).
- Os rótulos 'labels' também são zerados segundo o mesmo princípio.
A filosofia por trás do uso do meta-learner para trading unidirecional:
- O código do meta-learner resolve a tarefa de filtrar sinais “ruins” dentro do dataset rotulado.
- Simplificação da tarefa de classificação. As características são otimizadas apenas para um tipo de padrão (por exemplo, continuação de tendência).
- Em um mercado em tendência, mesmo com o equilíbrio de classes (50% compras / 50% vendas), permanece a assimetria. As compras a favor da tendência apresentam padrões mais estáveis, enquanto as vendas contra a tendência estão frequentemente associadas a eventos ruidosos (correções, falsos reversos), que são difíceis de prever.
- Para vendas em uma tendência de alta, a maioria dos sinais são inicialmente falsos (falsos positivos), o que leva a erros de classificação. Assim, no caso de um sistema de trading bidirecional, as operações de compra e de venda têm naturezas diferentes e não podem ser comparadas.
- Em um sistema unidirecional, os erros estão relacionados apenas a entradas falsas na direção da tendência (por exemplo, uma entrada antes de uma correção). O meta-learner identifica eficientemente esses casos, pois eles possuem características bem definidas (como sobrecompra). Em um sistema bidirecional, os erros incluem falsas compras e falsas vendas, que podem apresentar padrões semelhantes. O meta-learner não consegue separar de forma confiável o “ruído” dos sinais reais, já que as características de compra e venda estão misturadas.
- Em um sistema unidirecional, o modelo foca em um único tipo de não estacionariedade (por exemplo, fortalecimento da tendência), e as características se adaptam à fase atual do mercado.
- Em um sistema bidirecional existem duas não estacionariedades (tendência + correções), o que exige o dobro de dados e torna a generalização mais difícil.
Resultado:
- A tarefa de classificação é simplificada — é suficiente prever corretamente apenas uma classe em vez de duas.
- O ruído é reduzido — a meta-modelo final filtra apenas um tipo de erro.
- A validação cruzada melhora — a estratificação funciona corretamente.
- A não estacionariedade da tendência é considerada — o modelo se adapta apenas a uma fase do mercado.
Importante observar sobre os meta-learners:
Os meta-learners não devem ser confundidos com a meta-modelo final, que é treinada sobre os rótulos preparados pelos próprios meta-learners. Os meta-learners não são modelos finais, sendo utilizados apenas na etapa de pré-processamento. Como base, podem ser usados quaisquer algoritmos de classificação binária, incluindo regressão logística, redes neurais, modelos baseados em árvores e outras abordagens exóticas. Além disso, é possível empregar modelos de regressão com pequenas modificações no código, o que foge ao escopo deste artigo e poderá ser tratado em trabalhos futuros. Por conveniência, utilizo o classificador binário CatBoost, por estar habituado a trabalhar com ele.
Aspectos relacionados às características para o treinamento
Como já mencionado anteriormente, operar em uma única direção simplifica a tarefa de classificação. As características são otimizadas apenas para um tipo de padrão (por exemplo, de compra), portanto, não há necessidade de utilizar características simétricas. Podem ser consideradas características simétricas tanto a série temporal original com diferentes defasagens temporais, cujos valores correspondem a operações de compra e venda, quanto diversos tipos de derivados (como variações de preço) e outros osciladores. Já as características não simétricas incluem a volatilidade em diferentes janelas temporais, pois ela reflete apenas o ritmo de variação dos preços, mas não a sua direção. Neste projeto, será utilizada a volatilidade com diferentes janelas definidas na variável 'periods'.
Segue o código completo que implementa a criação das características:
def get_features(data: pd.DataFrame) -> pd.DataFrame: pFixed = data.copy() pFixedC = data.copy() count = 0 for i in hyper_params['periods']: pFixed[str(count)] = pFixedC.rolling(i).std() count += 1 return pFixed.dropna()
Os períodos das janelas móveis para o cálculo dessas características são definidos em um dicionário. Eles podem ser alterados livremente para observar o impacto no desempenho dos modelos.
hyper_params = {
'periods': [i for i in range(5, 300, 30)],
}
Neste exemplo, criamos 10 características, sendo a primeira com período 5, e cada período subsequente aumentando em 30, até chegar a 300:
>>> [i for i in range(5, 300, 30)] [5, 35, 65, 95, 125, 155, 185, 215, 245, 275]
Treinamento e teste dos modelos unidirecionais
hyper_params = {
'symbol': 'XAUUSD_H1',
'export_path': '/drive_c/Program Files/MetaTrader 5/MQL5/Include/Mean reversion/',
'model_number': 0,
'markup': 0.25,
'stop_loss': 10.0000,
'take_profit': 5.0000,
'direction': 'buy',
'periods': [i for i in range(5, 300, 30)],
'backward': datetime(2020, 1, 1),
'forward': datetime(2024, 1, 1),
'full forward': datetime(2026, 1, 1),
}
models = []
for i in range(10):
print('Learn ' + str(i) + ' model')
models.append(fit_final_models(meta_learner(5, 15, 3, 0.1)))
# models.append(fit_final_models(meta_learners(25, 15, 3, 0.8)))Primeiro testaremos o primeiro meta-learner, enquanto o segundo ficará comentado. Escolheremos a direção de compra como a preferencial, já que o ouro atualmente apresenta uma tendência de alta. O treinamento ocorrerá de 2020 até 2024, e o período de teste será de janeiro de 2024 até 1º de abril de 2025.
O meta-learner tem as seguintes configurações
- 5 folds para a validação cruzada
- 15 iterações de treinamento para o algoritmo CatBoost
- profundidade da árvore em cada iteração igual a 3
- taxa de aprendizado de 0.1
Assim se apresenta o melhor modelo no tester de estratégias para a direção 'buy':
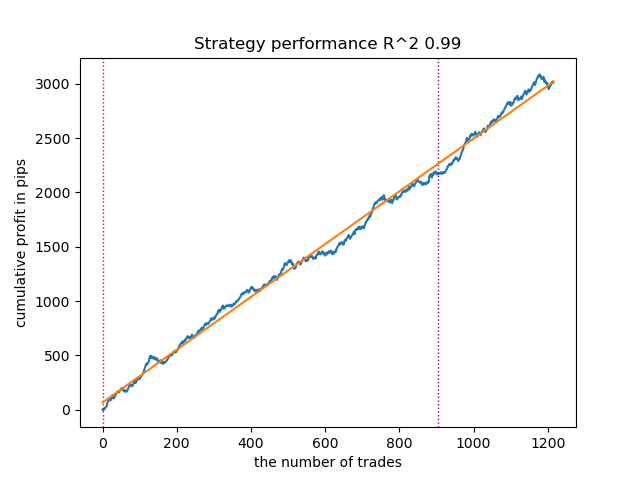
Fig. 5. Resultados do teste das características da função meta_learner() na direção das compras
Para comparação, assim se apresenta o melhor modelo para a direção 'sell':
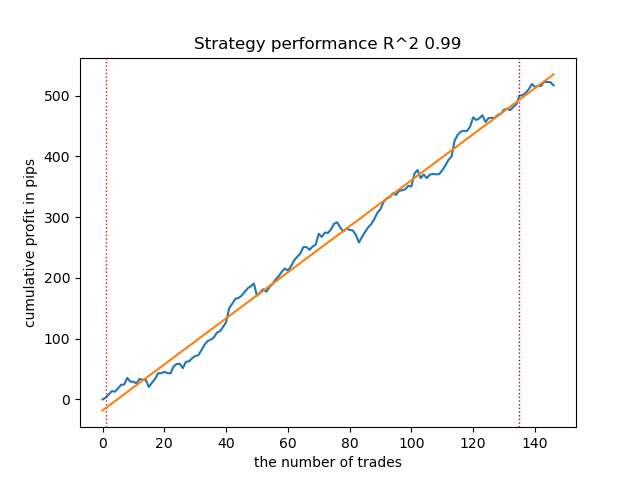
Fig. 6. Resultados do teste das características da função meta_learner() na direção das vendas
O algoritmo aprendeu a prever operações tanto na direção de compra quanto na de venda. No entanto, as operações de venda foram significativamente menores, o que é natural em um mercado de tendência de alta. A meta-modelo apresentou bom desempenho mesmo sem ajuste de seus hiperparâmetros, o que pôde ser observado tanto na fase de treinamento quanto no teste em propagação para frente.
Agora vamos analisar o meta-learner mais avançado. Repetiremos as mesmas operações com a função meta_learners(). Descomentaremos essa função e comentaremos a anterior:
models = [] for i in range(10): print('Learn ' + str(i) + ' model') # models.append(fit_final_models(meta_learner(5, 15, 3, 0.1))) models.append(fit_final_models(meta_learners(25, 15, 3, 0.8)))
O meta-learner tem as seguintes configurações
- 25 “cabeças” ou meta-modelos
- 15 iterações de treinamento para o algoritmo CatBoost em cada modelo
- profundidade da árvore em cada iteração igual a 3
- 0.8 para o parâmetro "bad_samples_fraction", que define a porcentagem de exemplos ruins mantidos no dataset de treinamento. Um valor de 0.1 corresponde a uma filtragem muito forte, enquanto 0.9 resultará em uma filtragem mais branda.
Assim se apresenta o melhor modelo no tester de estratégias para a direção 'buy':
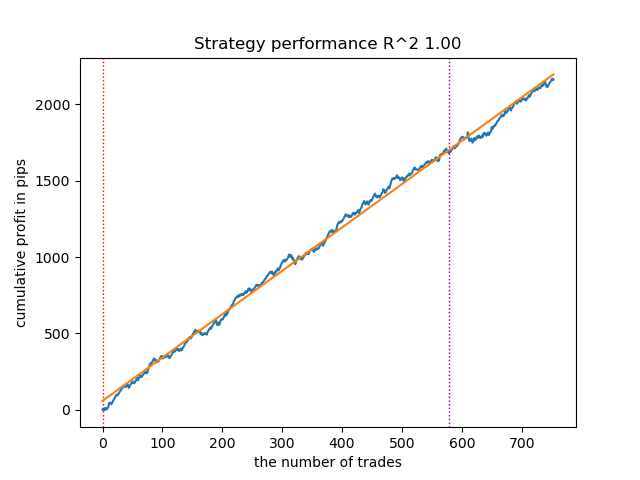
Fig. 7. Resultados do teste das características de meta_learners() na direção das compras
Para comparação, assim se apresenta o melhor modelo para a direção 'sell':
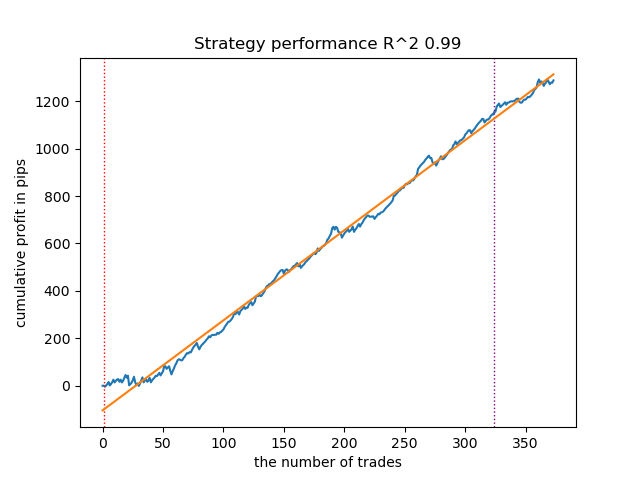
Fig. 8. Resultados do teste das características da função meta_learners() na direção das vendas
A função mais avançada dos meta-learners apresentou curvas mais suaves e bem definidas. O equilíbrio entre as operações de compra e venda foi mantido. É evidente que a melhor estratégia é a de compra. Após o treinamento dos modelos e a seleção do melhor, eles podem ser exportados para o terminal MetaTrader 5. É possível utilizar ambas as estratégias, mas, como a estratégia de posições curtas se mostrou menos eficaz, optaremos apenas pela estratégia de posições longas.
Abaixo é apresentada uma tabela que mostra como os resultados do treinamento dependem dos parâmetros do meta-learner avançado:
| Nome do parâmetro: | Influência na qualidade da filtragem: |
|---|---|
| models_number: int | Quanto maior o número de “cabeças” ou meta-modelos, menos enviesada será a avaliação dos exemplos ruins. O tamanho do dataset de treinamento influencia a escolha da quantidade de modelos. Quanto maior o histórico, maior pode ser o número necessário de modelos. É recomendável experimentar, variando esse parâmetro no intervalo de 5 a 100. |
| iterations: int | Afeta diretamente a velocidade da filtragem. Quanto mais iterações de treinamento cada meta-learner tiver, mais lento será o processo. Valores baixos podem levar a um subtreinamento, o que, por sua vez, pode resultar em uma filtragem mais rígida e em menor número de operações geradas. Recomenda-se definir entre 5 e 50. |
| depth: int | A profundidade da árvore é definida no intervalo de 1 a 6. Em cada iteração, o algoritmo constrói uma árvore com a profundidade especificada. Utilizo profundidade 3, mas é possível experimentar valores diferentes. |
| bad_samples_fraction: float | Afeta a seleção final dos exemplos ruins e o número de operações resultantes. O valor 0.9 corresponde a uma filtragem “suave”, com um número maior de operações de saída. O valor 0.5 corresponde a uma filtragem “rígida”, resultando, portanto, em um número menor de operações na saída. |
Toques finais: exportação dos modelos e criação do EA (Expert Advisor) de trading
A exportação dos modelos é feita exatamente da mesma forma apresentada em outros artigos. Para isso, basta selecionar o modelo desejado na lista ordenada de modelos e chamar a função de exportação.
models.sort(key=lambda x: x[0]) data = get_features(get_prices()) test_model_one_direction(data, models[-1][1:], hyper_params['stop_loss'], hyper_params['take_profit'], hyper_params['forward'], hyper_params['backward'], hyper_params['markup'], hyper_params['direction'], plt=True) export_model_to_ONNX(models[-1], 0)
A lógica do robô de trading foi modificada de modo que ele opere apenas em uma única direção, conforme o modelo exportado.
input bool direction = true; //True = Buy, False = Sell
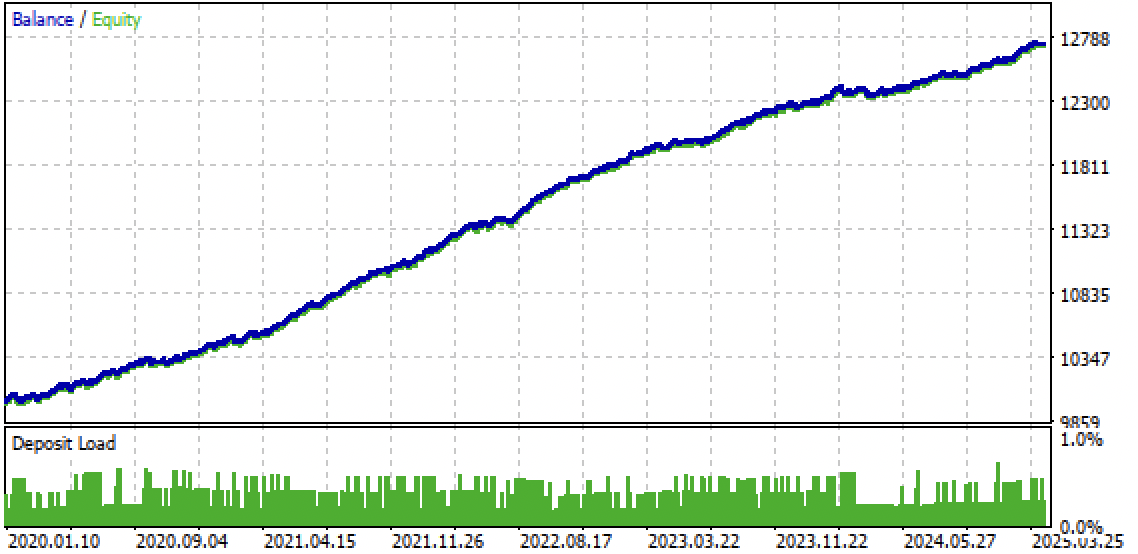
Fig. 9. Teste do bot no terminal Meta Trader 5
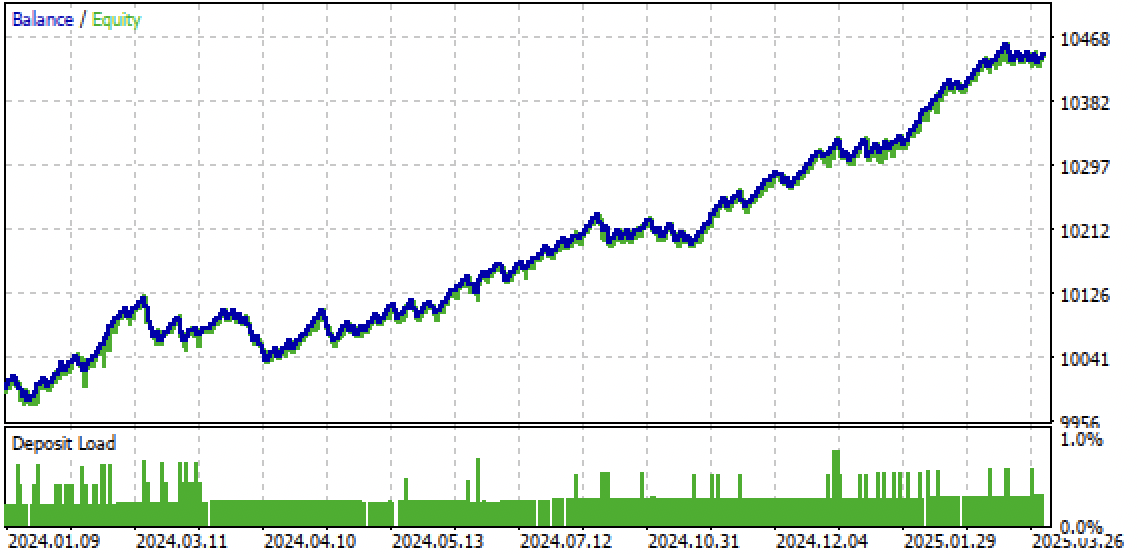
Fig. 10. teste somente no período futuro a partir do início de 2024g
Considerações finais
A ideia de estratégias unidirecionais baseadas em aprendizado de máquina me pareceu bastante interessante, por isso realizei uma série de experimentos, incluindo a abordagem proposta neste artigo. Embora não seja a única possível, ela cumpre bem o objetivo proposto. Tais estratégias dependentes de tendência podem demonstrar boa eficácia desde que a tendência persista. Por isso, é essencial acompanhar as mudanças globais de tendência e ajustar esses sistemas de acordo com a situação atual do mercado.
O arquivo Python files.zip contém os seguintes arquivos para desenvolvimento no ambiente Python:
| Nome do arquivo | Descrição |
|---|---|
| causal one direction.py | Script principal para o treinamento dos modelos |
| labeling_lib.py | Módulo atualizado com os rotuladores de operações |
| tester_lib.py | Tester customizado atualizado para estratégias baseadas em aprendizado de máquina |
| XAUUSD_H1.csv | Arquivo com as cotações exportadas do terminal MetaTrader 5 |
O arquivo MQL5 files.zip contém os arquivos para o terminal MetaTrader 5:
| Nome do arquivo | Descrição |
|---|---|
| one direction.ex5 | Bot compilado a partir do código deste artigo |
| one direction.mq5 | Código-fonte do bot apresentado no artigo |
| pasta Include//Trend following | Contém os modelos ONNX e o arquivo de cabeçalho necessário para a integração com o bot |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/17654
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso