
Identificação e classificação de padrões fractais por meio de aprendizado de máquina
Introdução
No primeiro artigo analisamos detalhadamente os aspectos fundamentais da teoria multifractal do mercado. Nele, falamos sobre o fato de que os gráficos de cotações são capazes de formar determinadas estruturas recorrentes sob a influência de informações externas que as organizam. Os participantes do mercado criam um sistema dinâmico complexo que possui elementos de memória, que assume a forma de determinadas simetrias de mercado, isto é, padrões. Esses padrões podem evoluir ao longo do tempo ou podem se repetir. Graças à autossimilaridade das estruturas fractais do mercado, os padrões podem ser expressos em diferentes escalas temporais.
Neste artigo será proposta uma abordagem original para a busca e classificação de padrões fractais. O estudo será conduzido na linguagem Python, com a possibilidade de exportação dos modelos finais para o terminal MetaTrader 5 no formato ONNX.
Antes de iniciar o trabalho, certifique-se de que todos os pacotes e módulos necessários estejam instalados. Parte dos módulos importados encontra-se no anexo ao artigo.
import pandas as pd import math from datetime import datetime from catboost import CatBoostClassifier from sklearn.model_selection import train_test_split from bots.botlibs.labeling_lib import * from bots.botlibs.tester_lib import test_model from bots.botlibs.export_lib import export_model_to_ONNX
Implementação da função de busca de padrões fractais
Neste artigo proponho uma abordagem simples para a busca de estruturas de mercado multifractais simétricas por meio da correlação. Podemos estudar tanto padrões fractais quanto multifractais, que se distinguem pela invariância de escala, ou seja, possuem tamanhos diferentes. Para isso, é necessário implementar a busca de padrões por meio da correlação em diferentes escalas temporais, que serão definidas nas configurações. A seguir é apresentada uma função que calcula a correlação em uma janela deslizante considerando o comprimento variável dos padrões.
@njit def calculate_symmetric_correlation_dynamic(data, min_window_size, max_window_size): n = len(data) min_w = max(2, min_window_size) max_w = max(min_w, max_window_size) num_correlations = max(0, n - min_w + 1) if num_correlations == 0: return np.zeros(0, dtype=np.float64), np.zeros(0, dtype=np.int64) correlations = np.zeros(num_correlations, dtype=np.float64) best_window_sizes = np.full(num_correlations, -1, dtype=np.int64) for i in range(num_correlations): max_abs_corr_for_i = -1.0 best_corr_for_i = 0.0 current_best_w = -1 current_max_w = min(max_w, n - i) start_w = min_w if start_w % 2 != 0: start_w += 1 for w in range(start_w, current_max_w + 1, 2): if w < 2 or i + w > n: continue half_window = w // 2 window = data[i : i + w] first_half = window[:half_window] second_half = (window[half_window:] * -1)[::-1] std1 = np.std(first_half) std2 = np.std(second_half) if std1 > 1e-9 and std2 > 1e-9: mean1 = np.mean(first_half) mean2 = np.mean(second_half) cov = np.mean((first_half - mean1) * (second_half - mean2)) corr = cov / (std1 * std2) if abs(corr) > max_abs_corr_for_i: max_abs_corr_for_i = abs(corr) best_corr_for_i =corr current_best_w = w correlations[i] = best_corr_for_i best_window_sizes[i] = current_best_w return correlations, best_window_sizes
Para acelerar o loop com cálculos do mesmo tipo, pois loops funcionam lentamente em Python, utiliza-se o decorador @njit, que acelera os cálculos por meio do pacote Numba.
Como entrada, a função recebe um dataframe com os preços de fechamento, bem como o tamanho mínimo e máximo da "janela" para os padrões. Por exemplo, queremos calcular a correlação para padrões cujo comprimento varia de 100 a 200 barras. Então definimos as configurações correspondentes, após o que, para cada novo ponto inicial e para cada comprimento de padrão definido, verifica-se a correlação entre sua parte esquerda e a parte direita invertida em espelho. A inversão da parte direita é destacada com um marcador amarelo. Isso é muito importante, pois estamos buscando simetria nos dados.
Os valores das melhores correlações absolutas, para cada ponto inicial, são registrados no array correlations[]. O tamanho da janela, isto é, o comprimento do padrão, correspondente à melhor correlação, é registrado em outro array best_window_sizes[]. Assim, a função retorna os valores máximos de correlação e o padrão correspondente a ela, para cada ponto inicial.
Verificação visual dos padrões encontrados
Após o cálculo de todos os padrões, podemos avaliar visualmente a correção do funcionamento do nosso algoritmo. Para isso, proponho mais uma função, que exibirá os principais padrões encontrados com base no maior coeficiente de correlação de Pearson em valor absoluto.
def plot_best_n_patterns(data, min_window_size, max_window_size, n_best): # 1. Calculate correlations and best window sizes corrs, window_sizes = calculate_symmetric_correlation_dynamic(data, min_window_size, max_window_size) # 2. Find N best patterns # Assuming -1 in window_sizes means invalid/not found by the calculation logic valid_calc_mask = window_sizes != -1 if not np.any(valid_calc_mask): print("No suitable patterns found (all window sizes were marked as -1 by calculation).") return filtered_corrs = corrs[valid_calc_mask] filtered_window_sizes = window_sizes[valid_calc_mask] original_indices_all = np.arange(len(corrs)) filtered_start_indices = original_indices_all[valid_calc_mask] if len(filtered_corrs) == 0: print("No suitable patterns found after filtering out -1 window_sizes.") return # Sort by absolute correlation value in descending order sorted_indices_of_filtered = np.argsort(np.abs(filtered_corrs))[::-1] # Determine how many of the top patterns to consider num_to_consider = min(n_best, len(sorted_indices_of_filtered)) if num_to_consider == 0: print("No patterns to plot (either n_best is too small, or no patterns passed the initial filter).") return # Pre-filter these top candidates to find those actually plottable (even window size >= 2) patterns_to_plot_details = [] for i in range(num_to_consider): idx_in_filtered_arrays = sorted_indices_of_filtered[i] # Index within the already filtered (by valid_calc_mask) arrays w_best_candidate = filtered_window_sizes[idx_in_filtered_arrays] actual_data_start_index = filtered_start_indices[idx_in_filtered_arrays] correlation_value = filtered_corrs[idx_in_filtered_arrays] # Check if the window size is valid for plotting (even and sufficiently large) if w_best_candidate >= 2 and w_best_candidate % 2 == 0 : patterns_to_plot_details.append({ "original_rank_in_consider_list": i, # Rank among the num_to_consider items "data_start_index": actual_data_start_index, "correlation": correlation_value, "window_size": int(w_best_candidate) # Ensure it's int }) else: print(f"Info: Top candidate (originally rank {i+1} among considered, " f"Start Index: {actual_data_start_index}) " f"skipped due to invalid window size for plotting: {w_best_candidate} (must be even and >= 2).") num_actually_plotted = len(patterns_to_plot_details) fig, ax = plt.subplots(1, 1, figsize=(10, 5)) # Single axes for combined plot title_fontsize = 12 label_fontsize = 10 legend_fontsize = 8 tick_labelsize = 9 if num_actually_plotted == 0: # This message is shown if, out of the top 'num_to_consider' patterns, none had a valid window size for plotting. print("No patterns with valid window sizes (even, >=2) found among the top candidates to display on the chart.") ax.text(0.5, 0.5, "No valid patterns to display on the chart.", horizontalalignment='center', verticalalignment='center', transform=ax.transAxes, fontsize=title_fontsize, color='red') ax.set_xticks([]) ax.set_yticks([]) fig.suptitle(f"Symmetric Patterns Overlaid", fontsize=title_fontsize) # Generic title else: # Generate distinct colors for each pattern that will actually be plotted plot_colors = plt.cm.viridis(np.linspace(0, 1, num_actually_plotted)) for plot_idx, pattern_info in enumerate(patterns_to_plot_details): actual_data_start_index = pattern_info["data_start_index"] correlation_value = pattern_info["correlation"] w_best = pattern_info["window_size"] half_window = w_best // 2 # Ensure indices are within data bounds if actual_data_start_index + w_best > len(data): print(f"Warning: Pattern P{plot_idx+1} (Idx:{actual_data_start_index}, W:{w_best}) extends beyond data length {len(data)}. Skipping.") continue left_part_data = data[actual_data_start_index : actual_data_start_index + half_window] right_part_data = data[actual_data_start_index + half_window : actual_data_start_index + w_best] x_indices = np.arange(w_best) # X-axis relative to pattern start current_color = plot_colors[plot_idx] # Plot left part ax.plot(x_indices[:half_window], left_part_data, color=current_color, linestyle='-', label=f"P{plot_idx+1} (Idx:{actual_data_start_index}, W:{w_best}, C:{correlation_value:.2f})") # Plot right part ax.plot(x_indices[half_window:], right_part_data, color=current_color, linestyle='--') # Add a vertical line to mark the split point for this pattern ax.axvline(x=half_window - 0.5, color=current_color, linestyle=':', linewidth=1, alpha=0.6) ax.set_xlabel("Index within Pattern Window", fontsize=label_fontsize) ax.set_ylabel("Data Value", fontsize=label_fontsize) ax.tick_params(axis='both', which='major', labelsize=tick_labelsize) ax.grid(True) ax.legend(fontsize=legend_fontsize, loc='best') # Add a text note to explain line styles fig.text(0.99, 0.01, 'Solid: Left Part, Dashed: Right Part (Original)', horizontalalignment='right', verticalalignment='bottom', fontsize=legend_fontsize - 1, color='dimgray', transform=fig.transFigure) fig.suptitle(f"Top {num_actually_plotted} Symmetric Patterns Overlaid", fontsize=title_fontsize) plt.tight_layout(rect=[0, 0.03, 1, 0.96]) # Adjust rect for suptitle and fig.text plt.show()
Essa função é relativamente extensa em termos de código, mas o principal volume de código nela é responsável pela ordenação e pela plotagem dos padrões. Primeiro é realizado o cálculo dos próprios padrões, depois eles são ordenados pelos valores do coeficiente de correlação. Determina-se a posição de cada padrão no histórico de cotações e ele é enviado para plotagem. O resultado do funcionamento dessa função é apresentado abaixo.
Na primeira imagem vemos um padrão selecionado que possui a correlação absoluta máxima. Ele se assemelha a um topo, local ou global, que simboliza uma reversão de tendência. A linha vertical tracejada indica a divisão da série em duas partes de mesmo comprimento. A parte direita da série é invertida, isto é, todos os valores são multiplicados por -1 e, em seguida, invertidos. Depois disso, calcula-se a correlação entre os trechos esquerdo e direito. Nos gráficos não são apresentadas as partes direitas invertidas, mas sim a série original de cotações.
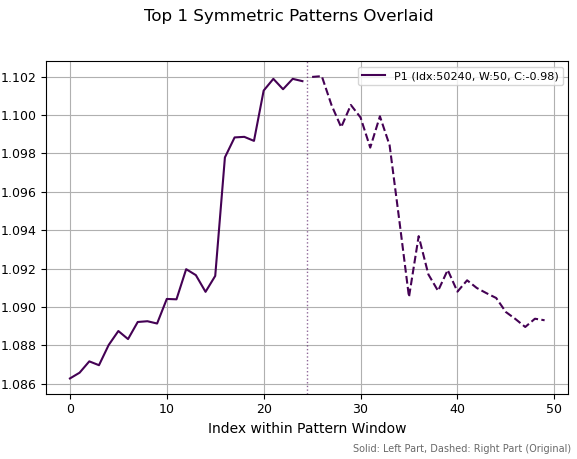
Fig 1. Melhor padrão com período 50 e correlação -0.98
Na segunda figura, exibi os cinco melhores padrões com período 50. Três deles se assemelham a topos, dois a um fundo e mais um, a uma continuação de tendência de alta. A escala à esquerda mostra os níveis históricos de preço aos quais esses padrões correspondem.
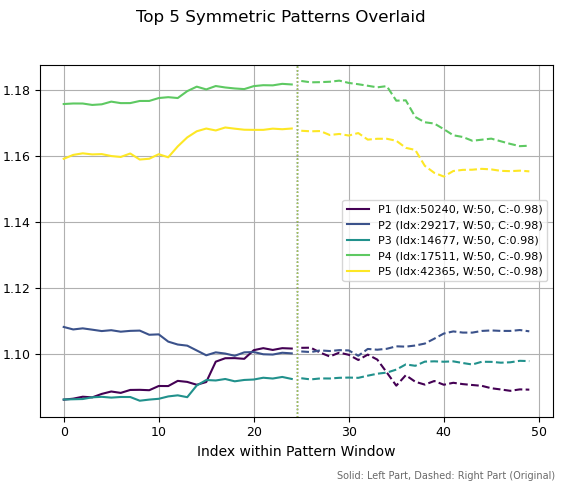
Fig 2. Top cinco padrões com período 50
Se aumentarmos os períodos dos padrões para 150 barras, observam-se estruturas completamente diferentes. Foram encontrados três padrões semelhantes, na parte superior. Isso ocorreu porque um pequeno deslocamento no histórico levou à detecção da mesma estrutura. Os outros dois padrões resultaram diferentes entre si.
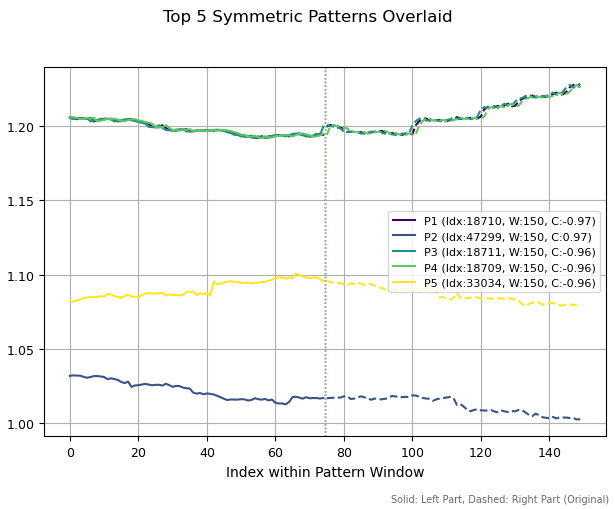
Fig 3. Top cinco padrões com período 150
Se aumentarmos a janela de cálculo dos padrões para 250, entre os melhores voltam a aparecer padrões idênticos, mas com um pequeno deslocamento no histórico. Também podem ser observadas determinadas formações de reversão, pois suas correlações são negativas.
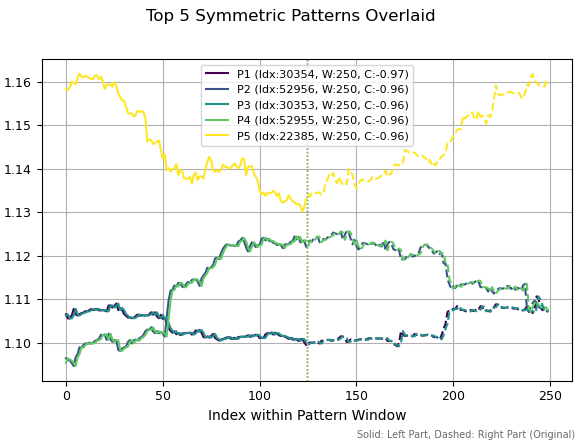
Fig 4. Top cinco padrões com período 250
Essas ilustrações demonstram a grande diversidade de estruturas de mercado autoafins, ou seja, autossimilares. Teoricamente, essa diversidade pode ser limitada apenas pelo comprimento da série analisada. Nesse caso, torna-se bastante difícil determinar qual padrão específico terá potencial preditivo e qual não terá. O estudo de cada uma dessas estruturas individualmente poderia levar meses. Aqui o aprendizado de máquina nos ajudará, pois com ele é possível realizar a classificação de todos os padrões simultaneamente.
É perfeitamente possível que a busca por estruturas por meio da correlação não seja ideal e que fosse necessário considerar outros métodos de avaliação mais precisos. No entanto, essa abordagem é um bom ponto de partida para pesquisas futuras e é intuitivamente compreensível. Agora é necessário definir como analisar esses fractais de mercado e construir, com base neles, um sistema de negociação utilizando aprendizado de máquina.
Rotulagem de operações com base em estruturas simétricas
A função de busca de estruturas simétricas é, de certa forma, uma função de data mining. Definimos critérios claros sobre o que estamos procurando nos dados, isto é, estruturas fractais autossimilares. Em seguida, é necessário coletar e classificar as informações obtidas. Mas isso ainda não será suficiente, pois será preciso conceber uma forma de rotulagem de operações com base nesses dados, o que faremos nesta seção.
Proponho o seguinte método de rotulagem de operações para posterior classificação. Ele não é o único possível, mas reflete a compreensão do autor sobre como isso pode ser implementado. Considero que são necessárias pesquisas adicionais sobre esse tema, mas por enquanto nos limitaremos ao método de rotulagem existente.
@njit def generate_future_outcome_labels_for_patterns( close_data_len, # Total length of the original close_data correlations_at_window_start, # Correlation array window_sizes_at_window_start, # Array of window sizes source_close_data, # Full close_data array correlation_threshold, min_future_horizon, # Minimum horizon for determining the future price max_future_horizon, # Maximum horizon markup_points # "Markup" for determining a significant price change ): labels = np.full(close_data_len, 2.0, dtype=np.float64) # 2.0: no signal/neutral/no pattern num_potential_windows = len(correlations_at_window_start) for idx_window_start in range(num_potential_windows): corr_value = correlations_at_window_start[idx_window_start] w = window_sizes_at_window_start[idx_window_start] # Condition 1: The correlation should be strong enough if abs(corr_value) < correlation_threshold: continue # Condition 2: A valid window should be found if w < 2: continue # The point in time (index) when the correlation pattern is fully formed signal_time_idx = idx_window_start + w - 1 if signal_time_idx >= close_data_len: # Theoretically, this should not happen continue # Array for storing labels for the entire pattern (both left and right parts) pattern_labels = [] # Calculate individual marks for all points of the pattern for point_idx in range(idx_window_start, signal_time_idx + 1): # Current price for this particular point current_price = source_close_data[point_idx] # Define the forecast horizon current_horizon = min_future_horizon if max_future_horizon > min_future_horizon: current_horizon = random.randint(min_future_horizon, max_future_horizon) # Index of future price relative to the current point future_price_idx = point_idx + current_horizon if future_price_idx >= close_data_len: continue future_price = source_close_data[future_price_idx] # Define a label for the current point current_label = 2.0 # Neutral by default if future_price > current_price + markup_points: current_label = 0.0 # Price increased elif future_price < current_price - markup_points: current_label = 1.0 # Price fell # Add the label to the array if it is not neutral if current_label != 2.0: pattern_labels.append(current_label) # If there are no significant marks in the pattern, move on to the next pattern if len(pattern_labels) == 0: continue # Calculate the average mark for all points of the pattern avg_label = 0.0 for l in pattern_labels: avg_label += l avg_label /= len(pattern_labels) # Define a common label for the entire pattern pattern_label = 0.0 if avg_label < 0.5 else 1.0 # Assign this label to all points of the pattern for i in range(idx_window_start, signal_time_idx + 1): labels[i] = pattern_label return labels
A função generate_future_outcome_labels_for_patterns() implementa a seguinte funcionalidade:
- Como entrada, recebe o array original de preços, o array de correlações e o array de comprimentos dos padrões correspondentes às maiores correlações para um determinado ponto de dados. A função também recebe o horizonte mínimo e máximo de previsão, em barras.
- Inicialmente, todas as operações são rotuladas como 2.0, não negociar.
- Em um loop, é verificado o valor da correlação para cada ponto da série temporal. Se a correlação exceder correlation_threshhold, essa observação passa por processamento adicional, caso contrário, o rótulo para esse exemplo permanece 2.0.
- Em seguida, ao longo de todo o comprimento do padrão definido pela correlação máxima, são calculadas as operações com base nas futuras variações de preço. Para cada ponto: se o preço subiu, o rótulo é 0, compra, se o preço caiu, é 1, venda. Calcula-se o valor médio das operações e, para cada observação do padrão atual, é atribuído o rótulo médio.
A filosofia dessa abordagem consiste no fato de que estruturas com alta correlação possuem "memória" de suas condições iniciais e apresentam certo grau de regularidade. Isso significa que as observações dentro delas são melhor previsíveis, mas, para evitar sobreajuste, atribuímos um rótulo médio a cada observação. Por outro lado, as observações dentro de estruturas com baixa correlação são mal previsíveis, pois apresentam menor regularidade.
Como resultado, exploramos o seguinte princípio: um modelo determinará a qualidade do padrão, isto é, se vale a pena negociar no momento ou não, e outro modelo determinará a direção da negociação. A tarefa de aproximar todos os padrões possíveis e as direções de negociação será atribuída ao aprendizado de máquina.
Em seguida, precisaremos de mais uma função orquestradora, que será chamada diretamente para a rotulagem de operações.
Função final de rotulagem com base em padrões fractais
Chegou o momento de reunir tudo e escrever um rotulador de operações pronto para uso.
def get_fractal_pattern_labels_from_future_outcome( dataset, min_window_size=6, max_window_size=60, correlation_threshold=0.7, min_future_horizon=5, max_future_horizon=5, markup_points=0.00010, ): if 'close' not in dataset.columns: raise ValueError("Dataset must contain a 'close' column.") close_data = dataset['close'].values n_data = len(close_data) if min_window_size < 2: min_window_size = 2 if max_window_size < min_window_size: max_window_size = min_window_size if min_future_horizon <= 0: raise ValueError("min_future_horizon must be > 0") if max_future_horizon < min_future_horizon: raise ValueError("max_future_horizon must be >= min_future_horizon") correlations_at_start, best_window_sizes_at_start = calculate_symmetric_correlation_dynamic( close_data, min_window_size, max_window_size, ) labels = generate_future_outcome_labels_for_patterns( n_data, correlations_at_start, best_window_sizes_at_start, close_data, correlation_threshold, min_future_horizon, max_future_horizon, markup_points ) result_df = dataset.copy() result_df['labels'] = pd.Series(labels, index=dataset.index) return result_df
A função get_fractal_pattern_labels_from_future_outcome() é chamada diretamente para a rotulagem do seu dataset:
- como entrada, é fornecido um dataframe que deve conter a coluna "close" com os preços de fechamento, bem como features, opcionalmente;
- define-se o comprimento mínimo e máximo dos padrões que participarão da rotulagem de operações;
- define-se o limiar de correlação, que permite ajustar a "precisão" dos padrões que participam da rotulagem;
- o tempo mínimo e máximo de manutenção das posições, em barras, para a rotulagem das operações também deve ser definido;
- opcionalmente, pode-se definir o markup.
Essa função recebe um dataset com preços de fechamento e realiza a rotulagem das operações com base em padrões fractais, adicionando a ele a coluna "labels" com os rótulos atribuídos.
Treinamento do modelo de aprendizado de máquina com base na rotulagem fractal
Agora tudo está pronto para os experimentos, e já podemos treinar os modelos. Como dados iniciais, utilizei cotações horárias do EURUSD de 2010 até o momento atual.
Como features, decidiu-se utilizar desvios padrão em janelas deslizantes de diferentes períodos:
def get_features(data: pd.DataFrame) -> pd.DataFrame: pFixed = data.copy() pFixedC = data.copy() count = 0 for i in hyper_params['periods']: pFixed[str(count)] = pFixedC.rolling(i).std() count += 1 return pFixed.dropna()
Em seguida, é necessário definir corretamente os hiperparâmetros do modelo:
# set hyper parameters hyper_params = { 'symbol': 'EURUSD_H1', 'export_path': '/Users/dmitrievsky/Library//drive_c/Program Files/MetaTrader 5/MQL5/Include/Trend following/', 'model_number': 0, 'markup': 0.00010, 'stop_loss': 0.00500, 'take_profit': 0.00500, 'periods': [i for i in range(15, 300, 30)], 'backward': datetime(2010, 1, 1), 'forward': datetime(2024, 1, 1), }
- o stop loss e o take profit são iguais e correspondem a 500 pontos de cinco dígitos;
- em seguida, é necessário especificar o caminho para exportação dos modelos treinados para a sua pasta;
- os períodos das features, isto é, dos desvios padrão, serão definidos no intervalo de 15 a 300, com passo 30, no total foram obtidas 10 features;
- período de treinamento de 2010 a 2024, o restante são dados fora do treinamento.
O loop principal de treinamento permite treinar várias modelos de uma só vez, nele também é possível testar diferentes hiperparâmetros:
# fit the models models = [] for i in range(10): print('Learn ' + str(i) + ' model') dataset = get_features(get_prices()) data = dataset[(dataset.index < hyper_params['forward']) & (dataset.index > hyper_params['backward'])].copy() data = get_fractal_pattern_labels_from_future_outcome(data, 100, 100, 0.9, 15, 25, 0.00010) models.append(fit_final_models(data))
No loop, primeiro obtemos os preços e as features, depois definimos os intervalos de tempo nos quais o modelo será treinado.
Para a função get_fractal_pattern_labels_from_future_outcome() passamos os seguintes parâmetros:
- dataframe original com preços e features
- janela mínima para o cálculo da correlação
- janela máxima para o cálculo da correlação
- limiar do coeficiente de correlação para os padrões, por padrão 0.9
- horizonte mínimo de previsão, em barras
- horizonte máximo de previsão, em barras
- markup em pontos
Em seguida, os dados rotulados são passados para a função que realiza o treinamento de dois classificadores:
def fit_final_models(dataset: pd.DataFrame) -> list: feature_columns = dataset.columns[1:-1] # 1. Data for the main model # Filter the dataset: only those examples where 'labels' are equal to 0 or 1 are used for the main model. main_model_df = dataset[dataset['labels'].isin([0, 1])].copy() X = main_model_df[feature_columns] y = main_model_df['labels'].astype('int16') # 2. Data for the meta model X_meta = dataset[feature_columns] # Modify labels for the meta model: if 'labels' contains 1 or 0, then the new label is 1, if 2, then 0. y_meta = dataset['labels'].apply(lambda label_val: 1 if label_val in [0, 1] else 0).astype('int16') # For the main model train_X, test_X, train_y, test_y = train_test_split( X, y, train_size=0.7, test_size=0.3, shuffle=True) # For the meta model train_X_m, test_X_m, train_y_m, test_y_m = train_test_split( X_meta, y_meta, train_size=0.7, test_size=0.3, shuffle=True) # Train the main model model = CatBoostClassifier(iterations=1000, custom_loss=['Accuracy'], eval_metric='Accuracy', verbose=False, use_best_model=True, task_type='CPU', ) # Check if the samples are empty after splitting (unlikely if X is large enough) if not train_X.empty and not test_X.empty: model.fit(train_X, train_y, eval_set=(test_X, test_y), early_stopping_rounds=25, plot=False) elif not train_X.empty: # If the test sample is empty, but the training sample exists print("Warning: The test sample (test_X) for the main model is empty. The model is trained without eval_set.") model.fit(train_X, train_y, early_stopping_rounds=15, plot=False) # use_best_model may not work correctly without eval_set else: # If the training set is empty print("Error: The training set (train_X) for the main model is empty. The model cannot be trained.") # In this case, test_model will most likely throw an error later. # Return R2=-1 and the untrained model, the meta model will also not make sense without the main one. print("R2 is fixed at -1.0, models are not trained.") return [-1.0, model, None] # model - instance, but not trained # Meta model training meta_model = CatBoostClassifier(iterations=1000, custom_loss=['F1'], eval_metric='F1', verbose=False, use_best_model=True, task_type='CPU', ) if not train_X_m.empty and not test_X_m.empty: meta_model.fit(train_X_m, train_y_m, eval_set=(test_X_m, test_y_m), early_stopping_rounds=25, plot=False) elif not train_X_m.empty: print("Warning: The test sample (test_X_m) for the meta model is empty. The meta model is trained without eval_set.") meta_model.fit(train_X_m, train_y_m, early_stopping_rounds=25, plot=False) else: print("Error: The training set (train_X_m) for the meta model is empty. The meta model cannot be trained.") print("R2 fixed as -1.0.") return [-1.0, model, meta_model] # meta_model - instance, but not trained data_for_test = get_features(get_prices()) R2 = test_model(data_for_test, [model, meta_model], hyper_params['stop_loss'], hyper_params['take_profit'], hyper_params['forward'], hyper_params['backward'], hyper_params['markup'], plt=False) if math.isnan(R2): R2 = -1.0 print('R2 fixed as -1.0') print('R2: ' + str(R2)) result = [R2, model, meta_model] return result
Em negrito estão destacados os pontos aos quais se deve prestar atenção especial. O modelo principal é treinado para prever apenas os rótulos 0 ou 1, enquanto o meta-modelo adicional prevê se vale a pena negociar ou não.
Teste e resultados finais
Para começar, vale dizer que testei o algoritmo apenas em um único par de moedas, EURUSD. Consegui selecionar o tamanho da janela dos fractais financeiros que melhor funciona em novos dados. Ele é igual a 100. Os parâmetros ideais do algoritmo já estão definidos no código, portanto você pode reproduzir o resultado por conta própria.
O gráfico de saldo nos dados de treinamento e de teste tem a seguinte aparência:
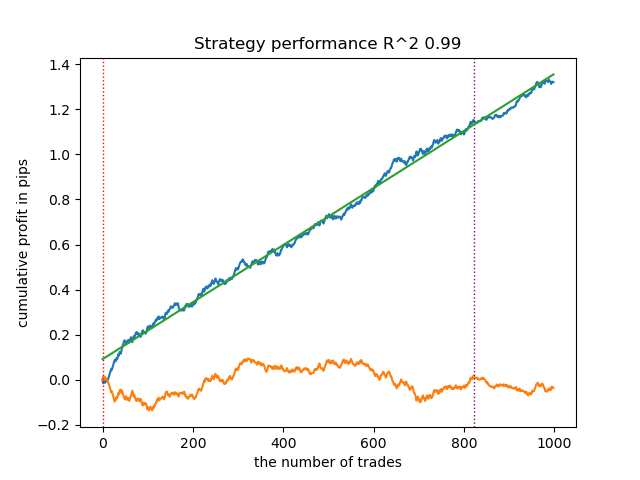
Fig 5. Teste do algoritmo com base na rotulagem fractal
Existe uma dependência direta entre o limiar de correlação e os resultados de negociação em novos dados. Por exemplo, para um limiar de 0.7, o gráfico de saldo já indica um sobreajuste evidente. Isso reflete o fato de que uma correlação fraca entre dois trechos da série temporal leva a uma dependência fraca. A dependência fraca, por sua vez, não permite classificar corretamente padrões confiáveis, pois junto com eles são misturados padrões não confiáveis.
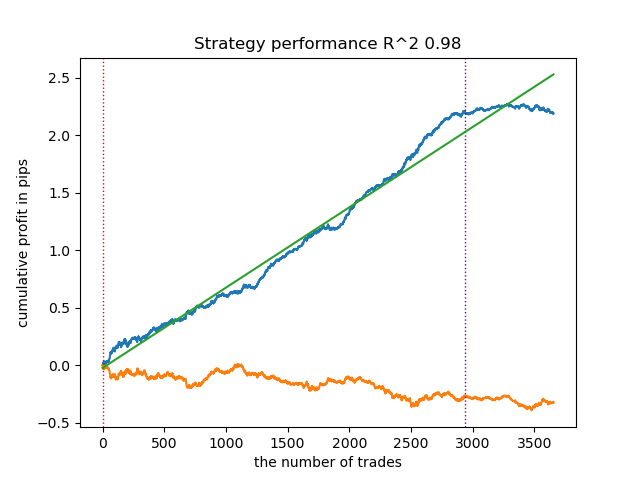
Fig 6. Teste do algoritmo com limiar de 0.7
Fica a impressão de que a definição correta dos padrões é criticamente importante. São necessárias pesquisas adicionais e novos insights sobre como organizar da forma mais qualitativa possível a busca por estruturas fractais.
A qualidade e a quantidade das features também influenciam os resultados da classificação. Se, em vez de desvios padrão, forem utilizados incrementos, o gráfico de saldo apresentará uma aparência diferente.
Também é necessário submeter a análise e a uma crítica fundamentada o método de rotulagem de operações com base nos padrões encontrados.
A análise dos erros dos modelos CatBoost mostra que os modelos são treinados com baixo erro:
>>> models[-1][1].get_best_score()['validation'] {'Accuracy': 0.9700523560209424, 'Logloss': 0.17002244404784328} >>> models[-1][2].get_best_score()['validation'] {'Logloss': 0.25629795409043277, 'F1': 0.8455473098330242} >>>
Exportação e teste dos modelos no terminal MetaTrader 5
Para exportar os modelos, é necessário chamar a função:
export_model_to_ONNX(model = models[-1], symbol = hyper_params['symbol'], periods = hyper_params['periods'], periods_meta = hyper_params['periods'], model_number = hyper_params['model_number'], export_path = hyper_params['export_path'])
Após a exportação e a compilação do EA (Expert Advisor), foram obtidos os seguintes resultados:
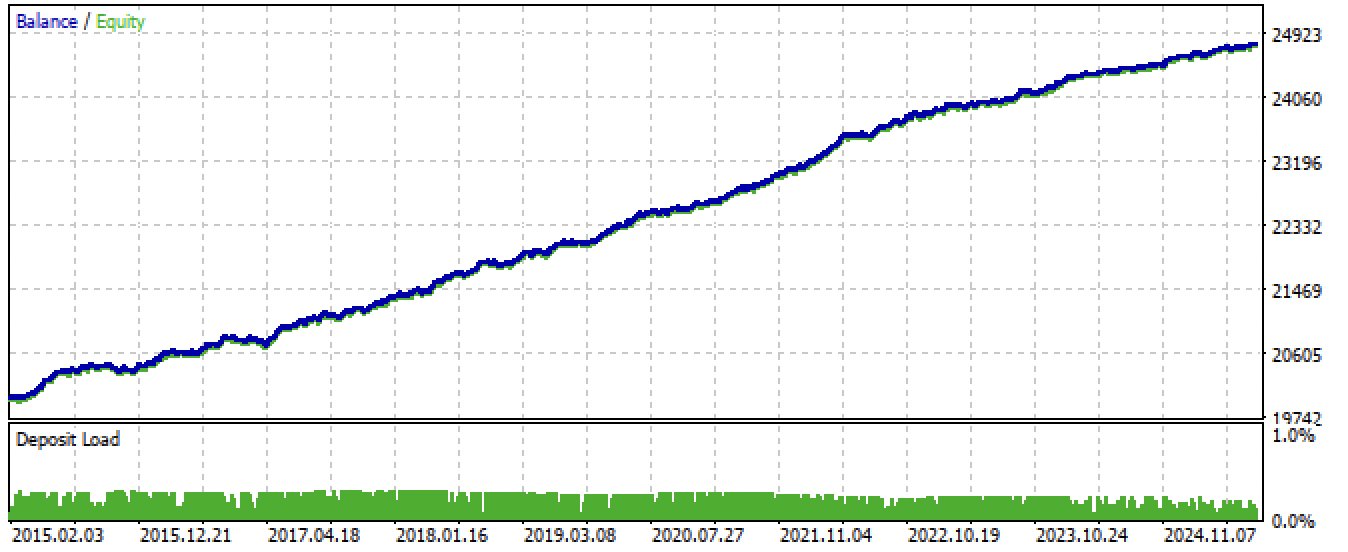
Fig 7. Teste do robô por todo o período
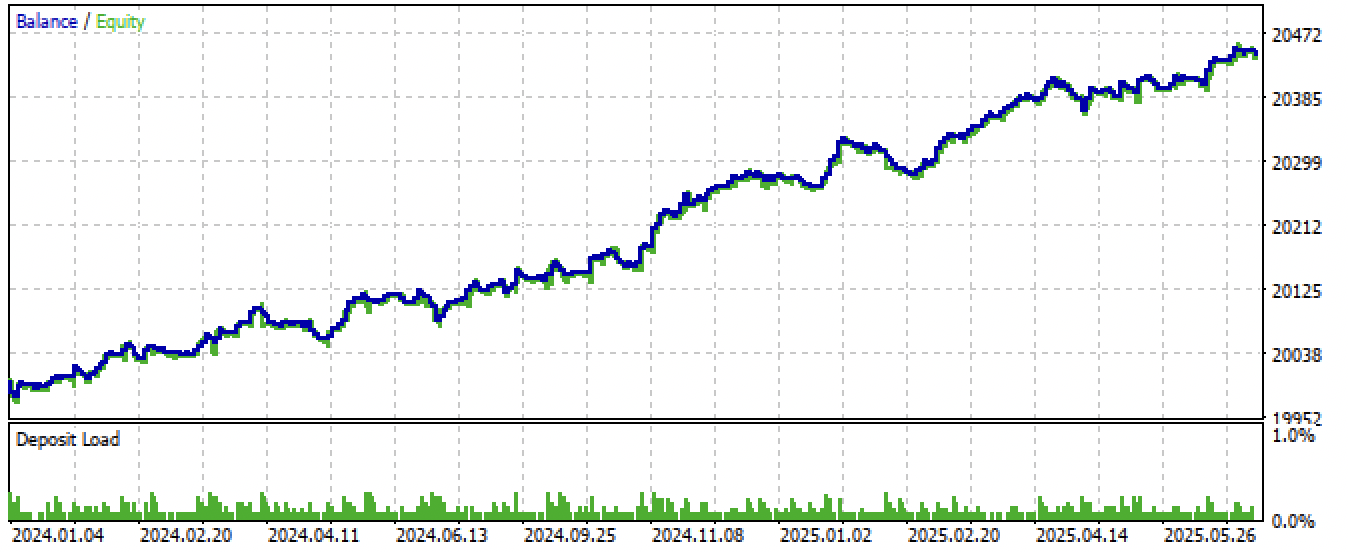
Fig 8. Teste do robô em novos dados
Considerações finais
Neste artigo abordamos o tema intrigante da análise fractal e da previsão de mercados por meio de aprendizado de máquina. Estes são apenas os primeiros passos no caminho para o estudo das diversas estruturas fractais que se formam nos gráficos de cotações financeiras.
Cabe destacar que a busca por meio da correlação pode não refletir completamente as dependências entre as séries passadas e futuras de cotações, e esse tema exige pesquisas adicionais. Por exemplo, em vez da análise de correlação, a análise de regressão pode ser mais adequada. Ao mesmo tempo, o algoritmo atual é capaz de demonstrar capacidades preditivas razoáveis quando devidamente configurado, o que confirma a presença de estruturas fractais autossimilares nas séries temporais financeiras.
O arquivo Python files.zip contém os seguintes arquivos para desenvolvimento no ambiente Python:
| Nome do arquivo | Descrição |
|---|---|
| fractal patterns.py | Script principal para o treinamento dos modelos |
| labeling_lib.py | Módulo atualizado com rotuladores de operações |
| tester_lib.py | Testador de estratégias customizado atualizado, baseado em aprendizado de máquina |
| export_lib.py | Módulo para exportação dos modelos para o terminal |
| EURUSD_H1.csv | Arquivo com cotações exportadas do terminal MetaTrader 5 |
O arquivo MQL5 files.zip contém os arquivos para o terminal MetaTrader 5:
| Nome do arquivo | Descrição |
|---|---|
| fractal trader.ex5 | Robô compilado deste artigo |
| fractal trader.mq5 | Código-fonte do robô do artigo |
| pasta Include//Trend following | Contém os modelos ONNX e o arquivo de cabeçalho para conexão com o robô |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/18566
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
Não estou me referindo apenas a este artigo. Ele não é um artigo ruim, dentro da tendência geral. Trata-se de outra coisa.
"Ainda não descobri como levar em conta a variabilidade dos fractais ao longo do tempo" - enquanto isso, esse é um parâmetro fundamental que determina a eficácia de qualquer previsão.
E esse não é apenas o seu problema, é um problema global - mudança de todos os coeficientes com variáveis ao longo do tempo.
Para entender a essência do problema, você precisa ir mais além e repensar os conceitos iniciais. Por exemplo, a maioria dos fractais não é autossimilar, 1 dólar em 2000 não é igual a 1 dólar em 2025 (ou seja, 1 não é igual a 1).
Muitos outros exemplos podem ser dados, na sociedade (economia) prevalece a distribuição de Pareto, não a distribuição de Gauss, portanto, a maioria dos métodos estatísticos não se aplica à análise de mercado etc.
O sucesso de Simons sugere que há uma solução para o problema, mas é preciso procurar em outro lugar.
Acho que a solução dele é a arbitragem. Muitas estratégias de arbitragem também param de funcionar com o tempo.
Acho que ele está se referindo à arbitragem. Muitas estratégias de arbitragem também param de funcionar com o tempo.
Ele tem espaços multidimensionais.
Ele tem espaços multidimensionais.
Hilbert?
Em geral, quase não há informações detalhadas sobre os métodos de trabalho de Simons, e isso é compreensível. Mas sabe-se que ele dobrou seu capital a cada ano e, no final de sua vida, sua fortuna foi estimada em mais de 20 bilhões.
Mas a questão não é ele, é a possibilidade de encontrar uma fórmula. Espaços multidimensionais é a terminologia atual para as ideias pitagóricas. É um tópico muito profundo. A multifractalidade também pode ser vista como um análogo primitivo do espaço multidimensional, em que os vértices e os gráficos são projeções em um gráfico de movimentos ocultos. Se o tópico for interessante para você, posso compartilhar minhas considerações - desenvolvimentos, mas é melhor que seja por correspondência individual.
Em geral, quase não há informações detalhadas sobre os métodos de trabalho de Simons, o que é compreensível. Mas sabe-se que ele dobrou seu capital a cada ano e, no final de sua vida, sua fortuna foi estimada em mais de 20 bilhões.
Mas a questão não é ele, é a possibilidade de encontrar uma fórmula. Espaços multidimensionais é a terminologia atual para as ideias pitagóricas. É um tópico muito profundo. A multifractalidade também pode ser vista como um análogo primitivo do espaço multidimensional, em que os vértices e os gráficos são projeções em um gráfico de movimentos ocultos. Se o tópico for interessante para você, posso compartilhar minhas considerações - desenvolvimentos, mas é melhor que seja por correspondência individual.
Parece que o artigo anterior apenas descreveu a formação de atratores ocultos (auto-organização) sob a influência de condições externas, que podem ser definidas por meio do espaço multidimensional de recursos.