
Trading por algoritmo: IA e seu caminho para os topos dourados
Introdução
A evolução do entendimento das capacidades dos métodos de aprendizado de máquina no trading levou à criação de diferentes algoritmos que resolvem igualmente bem a mesma tarefa, mas que são essencialmente distintos. Nesta artigo será novamente analisado um sistema de trading de tendência unidirecional, usando o ouro como exemplo, mas aplicando um algoritmo de clusterização.
- No artigo anterior, foram descritos dois algoritmos de inferência causal para criar uma estratégia de tendência similar para o ouro.
- No artigo sobre clusterização de séries temporais, foram considerados diferentes modos de clusterização em tarefas de trading.
- A criação de uma estratégia de retorno à média, por meio de um algoritmo de clusterização já havia sido apresentada anteriormente.
- O desenvolvimento de um sistema de trading de tendência baseado em clusterização também destacou as capacidades desse método.
Ao observarmos esse importante método de análise e previsão de séries temporais sob diferentes ângulos, é possível identificar suas vantagens e desvantagens em comparação com outras formas de criação de sistemas de trading baseadas exclusivamente na análise e previsão de séries temporais financeiras. Em alguns casos, esses algoritmos se mostram bastante eficientes, superando os métodos clássicos tanto na velocidade de criação quanto na qualidade dos sistemas de negociação resultantes.
Neste artigo, vamos nos concentrar no trading unidirecional, quando o algoritmo abre apenas operações de compra ou de venda. Como algoritmos básicos, serão usados o CatBoost e o K-Means. O CatBoost é o modelo base, atuando como um classificador binário para classificar operações. Já o K-Means é utilizado para identificar regimes de mercado na etapa de preprocessamento.
Preparação para o trabalho e importação dos módulos
import math import pandas as pd from datetime import datetime from catboost import CatBoostClassifier from sklearn.model_selection import train_test_split from sklearn.cluster import KMeans from bots.botlibs.labeling_lib import * from bots.botlibs.tester_lib import tester_one_direction from bots.botlibs.export_lib import export_model_to_ONNX import time
No código são usados apenas pacotes confiáveis e amplamente acessíveis, tais como:
- Pandas: responsável pelo trabalho com tabelas de dados (dataframes)
- Scikit-learn: contém várias funções para preprocessamento e aprendizado de máquina, incluindo algoritmos de clusterização
- CatBoost: algoritmo poderoso de gradient boosting da empresa Yandex
Foram importados módulos separados que eu mesmo criei:
- labeling_lib: contém funções de amostradores para a rotulação de operações
- tester_lib: nele estão localizados os testadores de estratégias baseadas em aprendizado de máquina
- export_lib: módulo para exportar modelos treinados para o terminal Meta Trader 5 no formato ONNX
Obtenção dos dados e criação das características
def get_prices() -> pd.DataFrame:
p = pd.read_csv('files/'+hyper_params['symbol']+'.csv', sep='\s+')
pFixed = pd.DataFrame(columns=['time', 'close'])
pFixed['time'] = p['<DATE>'] + ' ' + p['<TIME>']
pFixed['time'] = pd.to_datetime(pFixed['time'], format='mixed')
pFixed['close'] = p['<CLOSE>']
pFixed.set_index('time', inplace=True)
pFixed.index = pd.to_datetime(pFixed.index, unit='s')
return pFixed.dropna() No código está implementado o carregamento de cotações a partir de arquivo, para facilitar a obtenção de dados de diferentes fontes. São usados apenas preços de fechamento. Com base nesses dados são criadas as características.
def get_features(data: pd.DataFrame) -> pd.DataFrame: pFixed = data.copy() pFixedC = data.copy() count = 0 for i in hyper_params['periods']: pFixed[str(count)] = pFixedC.rolling(i).std() count += 1 for i in hyper_params['periods_meta']: pFixed[str(count)+'meta_feature'] = pFixedC.rolling(i).std() count += 1
As características são divididas em dois grupos:
- Características principais para o treinamento do modelo base, que prevê a direção do trading.
- Meta-características adicionais para a clusterização. Elas são usadas para dividir os dados brutos em clusters (regimes de mercado).
Neste exemplo, como características é usada a volatilidade (desvios padrão dos preços em janelas móveis de período definido). Mas também vamos testar outras características, por exemplo médias móveis e inclinações das distribuições.
Clusterização dos regimes de mercado
def clustering(dataset, n_clusters: int) -> pd.DataFrame: data = dataset[(dataset.index < hyper_params['forward']) & (dataset.index > hyper_params['backward'])].copy() meta_X = data.loc[:, data.columns.str.contains('meta_feature')] data['clusters'] = KMeans(n_clusters=n_clusters).fit(meta_X).labels_ return data
A função recebe um dataframe com preços e características e usa as meta-características adicionais para a clusterização em uma quantidade definida de clusters (geralmente 10). Para a clusterização é usado o algoritmo K-Means. Depois disso, para cada linha do dataframe é atribuída uma etiqueta de cluster que corresponde àquela observação. E retorna-se o dataframe com a coluna adicional "clusters".
Função para o treinamento dos classificadores
def fit_final_models(clustered, meta) -> list: # features for model\meta models. We learn main model only on filtered labels X, X_meta = clustered[clustered.columns[:-1]], meta[meta.columns[:-1]] X = X.loc[:, ~X.columns.str.contains('meta_feature')] X_meta = X_meta.loc[:, X_meta.columns.str.contains('meta_feature')] # labels for model\meta models y = clustered['labels'] y_meta = meta['clusters'] y = y.astype('int16') y_meta = y_meta.astype('int16') # train\test split train_X, test_X, train_y, test_y = train_test_split( X, y, train_size=0.7, test_size=0.3, shuffle=True) train_X_m, test_X_m, train_y_m, test_y_m = train_test_split( X_meta, y_meta, train_size=0.7, test_size=0.3, shuffle=True) # learn main model with train and validation subsets model = CatBoostClassifier(iterations=500, custom_loss=['Accuracy'], eval_metric='Accuracy', verbose=False, use_best_model=True, task_type='CPU', thread_count=-1) model.fit(train_X, train_y, eval_set=(test_X, test_y), early_stopping_rounds=25, plot=False) # learn meta model with train and validation subsets meta_model = CatBoostClassifier(iterations=300, custom_loss=['F1'], eval_metric='F1', verbose=False, use_best_model=True, task_type='CPU', thread_count=-1) meta_model.fit(train_X_m, train_y_m, eval_set=(test_X_m, test_y_m), early_stopping_rounds=15, plot=False) R2 = test_model_one_direction([model, meta_model], hyper_params['stop_loss'], hyper_params['take_profit'], hyper_params['full forward'], hyper_params['backward'], hyper_params['markup'], hyper_params['direction'], plt=False) if math.isnan(R2): R2 = -1.0 print('R2 is fixed to -1.0') print('R2: ' + str(R2)) return [R2, model, meta_model]
Para o treinamento são usados dois modelos. O primeiro é treinado nas características principais e nas etiquetas, e o segundo é treinado nas meta-características e nas meta-etiquetas. Se para o primeiro modelo as etiquetas são as direções das operações, para o segundo modelo as etiquetas são os números dos clusters. 1 — quando os dados correspondem ao cluster necessário, e 0 — quando os dados correspondem a todos os demais clusters.
Antes do treinamento os dados são divididos em treinamento e validação na proporção 70/30, para que o CatBoost tenha menos sobreajuste. Ele usa os dados de validação para parada antecipada, quando o erro neles deixa de cair durante o treinamento. Em seguida é escolhido o melhor modelo, que tem o menor erro de previsão nos dados de validação.
Depois do treinamento dos modelos, eles são enviados para a função de teste, para avaliar a curva de balanço por meio de R^2. Isso é necessário para posterior ordenação dos modelos e escolha do melhor.
Função de teste dos modelos
def test_model_one_direction( result: list, stop: float, take: float, forward: float, backward: float, markup: float, direction: str, plt = False): pr_tst = get_features(get_prices()) X = pr_tst[pr_tst.columns[1:]] X_meta = X.copy() X = X.loc[:, ~X.columns.str.contains('meta_feature')] X_meta = X_meta.loc[:, X_meta.columns.str.contains('meta_feature')] pr_tst['labels'] = result[0].predict_proba(X)[:,1] pr_tst['meta_labels'] = result[1].predict_proba(X_meta)[:,1] pr_tst['labels'] = pr_tst['labels'].apply(lambda x: 0.0 if x < 0.5 else 1.0) pr_tst['meta_labels'] = pr_tst['meta_labels'].apply(lambda x: 0.0 if x < 0.5 else 1.0) return tester_one_direction(pr_tst, stop, take, forward, backward, markup, direction, plt)
A função recebe dois modelos treinados (o principal e o meta-modelo), além dos demais parâmetros necessários para o teste no testador customizado de estratégias. Depois disso, é criado novamente um dataframe com preços e características, que são alimentadas nesses modelos para gerar previsões. As previsões obtidas são registradas nas colunas "labels" e "meta_labels" desse dataframe.
No final é chamada a função do testador customizado, que está localizada no módulo conectado tester_lib.py, que executa o teste dos modelos no histórico e retorna a métrica R^2.
Função de rotulação das operações
O módulo labeling_lib.py contém um amostrador destinado à rotulação das operações somente no sentido selecionado:
@njit def calculate_labels_one_direction(close_data, markup, min, max, direction): labels = [] for i in range(len(close_data) - max): rand = random.randint(min, max) curr_pr = close_data[i] future_pr = close_data[i + rand] if direction == "sell": if (future_pr + markup) < curr_pr: labels.append(1.0) else: labels.append(0.0) if direction == "buy": if (future_pr - markup) > curr_pr: labels.append(1.0) else: labels.append(0.0) return labels def get_labels_one_direction(dataset, markup, min = 1, max = 15, direction = 'buy') -> pd.DataFrame: close_data = dataset['close'].values labels = calculate_labels_one_direction(close_data, markup, min, max, direction) dataset = dataset.iloc[:len(labels)].copy() dataset['labels'] = labels dataset = dataset.dropna() return dataset
Ciclo principal de treinamento
# LEARNING LOOP dataset = get_features(get_prices()) // получение цен и признаков models = [] // создание пустого списка моделей for i in range(1): // цикл задает сколько попыток обучения нужно выполнить start_time = time.time() data = clustering(dataset, n_clusters=hyper_params['n_clusters']) // добавление номеров кластеров к данным sorted_clusters = data['clusters'].unique() // определение уникальных кластеров sorted_clusters.sort() // сортировка кластеров по возрастанию for clust in sorted_clusters: // цикл по всем кластерам clustered_data = data[data['clusters'] == clust].copy() // выбор данных для одного гластера if len(clustered_data) < 500: print('too few samples: {}'.format(len(clustered_data))) // проверка на достаточность обучающих примеров continue clustered_data = get_labels_one_direction(clustered_data, // разметка сделок для выбранного кластера markup=hyper_params['markup'], min=1, max=15, direction=hyper_params['direction']) print(f'Iteration: {i}, Cluster: {clust}') clustered_data = clustered_data.drop(['close', 'clusters'], axis=1)// удаление цен закрытия и номеров кластеров meta_data = data.copy() // создание данных для мета-модели meta_data['clusters'] = meta_data['clusters'].apply(lambda x: 1 if x == clust else 0) // размтка текущего кластера как "1" models.append(fit_final_models(clustered_data, meta_data.drop(['close'], axis=1))) // обучение моделей и добавление их в список end_time = time.time() print("Время выполнения: ", end_time - start_time)
No ciclo de treinamento são usadas sequencialmente todas as funções descritas anteriormente:
- Do arquivo são carregadas as cotações para um dataframe e são criadas as características
- Cria-se uma lista vazia que armazenará os modelos treinados
- Define-se a quantidade de iterações (tentativas) de treinamento nos mesmos dados, para eliminar flutuações aleatórias dos modelos
- Acontece a clusterização das meta-características e é adicionada a coluna "clusters" aos dados
- No ciclo, para cada cluster, são selecionados os dados que pertencem somente a ele
- Os dados de cada cluster são rotulados, ou seja, são criadas etiquetas de classes para o modelo principal
- Cria-se um dataset adicional para o meta-modelo, que aprende a identificar o cluster definido entre todos os outros
- Ambos os datasets são enviados para a função de treinamento, que executa o treinamento dos dois classificadores
- Os modelos treinados são adicionados à lista
Processo de treinamento e teste dos modelos
Os hiperparâmetros (configurações gerais) do algoritmo são colocados em um dicionário:
hyper_params = {
'symbol': 'XAUUSD_H1',
'export_path': '/drive_c/Program Files/MetaTrader 5/MQL5/Include/Mean reversion/',
'model_number': 0,
'markup': 0.2,
'stop_loss': 10.000,
'take_profit': 5.000,
'periods': [i for i in range(5, 300, 30)],
'periods_meta': [5],
'backward': datetime(2020, 1, 1),
'forward': datetime(2024, 1, 1),
'full forward': datetime(2026, 1, 1),
'direction': 'buy',
'n_clusters': 10,
} O treinamento será feito no período de 2020 a 2024, e o período de teste, desde o início de 2024 até hoje.
É muito importante definir corretamente os seguintes parâmetros:
- markup - 0.2 — este é o spread médio do símbolo XAUUSD. Se você definir um spread muito pequeno ou muito grande, os resultados dos testes podem ficar irreais. Além disso, aqui também entram perdas adicionais ligadas a slippage e comissões, caso existam.
- stop loss — tamanho do stop em pontos do símbolo.
- take profit — tamanho do take em pontos. Deve-se considerar que as operações são fechadas tanto pelos sinais do modelo quanto pelo atingimento de stop-loss ou take-profit.
- periods — lista com os valores de períodos para as características principais. No geral, dez períodos são suficientes, começando em cinco e com passo de 30.
- periods meta — lista com valores de períodos para as meta-características. Para determinar regimes de mercado não é necessário um grande número de características. Normalmente é uma única característica, por exemplo o desvio padrão dos últimos 5 barras.
- direction — vamos usar apenas "buy", porque o ouro tem tendência de alta.
- n_clusters — quantidade de regimes (clusters) para a clusterização. Normalmente uso 10.
Treinamento nos desvios padrão
Primeiro vamos usar apenas os desvios padrão como características, portanto a função de criação das características ficará assim:
def get_features(data: pd.DataFrame) -> pd.DataFrame: pFixed = data.copy() pFixedC = data.copy() count = 0 for i in hyper_params['periods']: pFixed[str(count)] = pFixedC.rolling(i).std() count += 1 for i in hyper_params['periods_meta']: pFixed[str(count)+'meta_feature'] = pFixedC.rolling(i).std() count += 1 return pFixed.dropna()
Vamos executar um ciclo de treinamento, no qual obteremos as seguintes informações:
Iteration: 0, Cluster: 0 R2: 0.989543793954197 Iteration: 0, Cluster: 1 R2: 0.9697821077241253 too few samples: 19 too few samples: 238 Iteration: 0, Cluster: 4 R2: 0.9852770333065658 Iteration: 0, Cluster: 5 R2: 0.7723040599270985 too few samples: 87 Iteration: 0, Cluster: 7 R2: 0.9970885055361235 Iteration: 0, Cluster: 8 R2: 0.9524980839809385 too few samples: 446 Время выполнения: 2.140070915222168
Foi feita a tentativa de treinar dez modelos para dez regimes de mercado. Nem todos os regimes se mostraram úteis, porque alguns deles continham exemplos de treinamento (operações) em quantidade muito pequena. Eles não passaram pelo filtro de quantidade mínima de operações, por isso não foram usados no treinamento.
O melhor regime de mercado (cluster) de número 7 mostrou R^2 0.99. Este é um bom candidato a melhor modelo para trading. O tempo de execução de todo o ciclo de treinamento foi de apenas 2 segundos, o que é muito rápido.
Depois de ordenar os modelos, vamos testar o melhor:
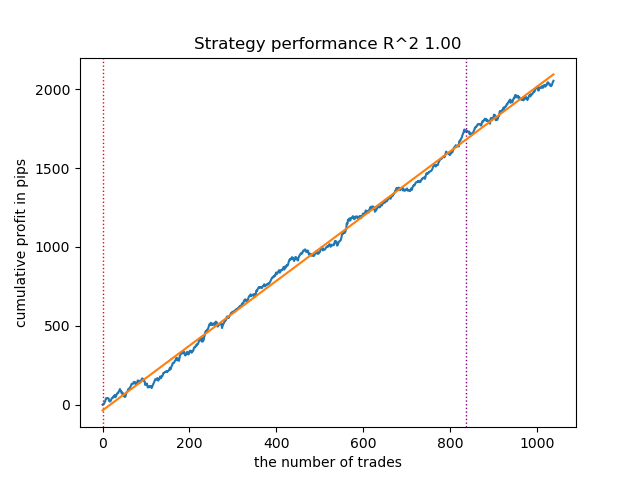
Figura 1. Teste do melhor modelo após ordenação
O modelo seguinte também se mostrou suficientemente bom e tem uma grande quantidade de operações:
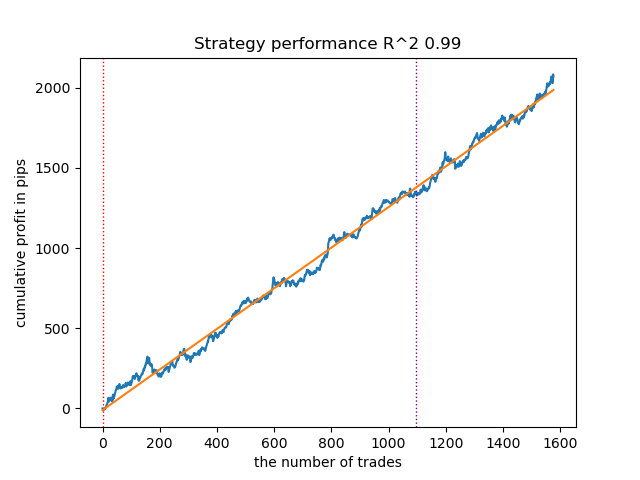
Figura 2. Teste do segundo modelo no ranking
Como o treinamento e os testes dos modelos são muito rápidos, é possível reiniciar o ciclo muitas vezes, obtendo modelos da mais alta qualidade. Por exemplo, depois da próxima reinicialização e ordenação, foi obtida esta variante:
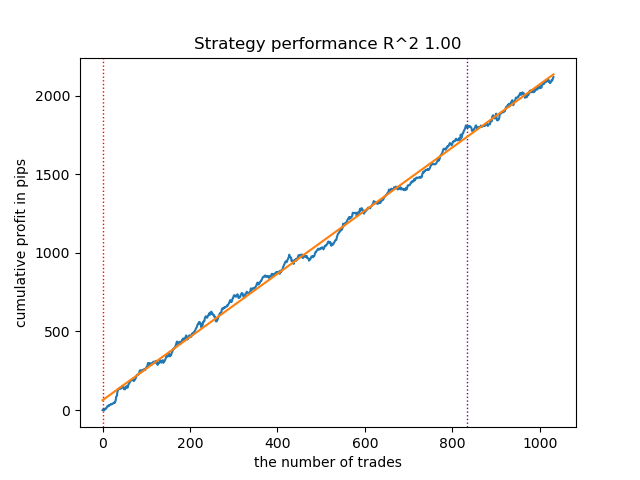
Figura 3. Teste do melhor modelo após o ciclo de treinamento repetido
Treinamento em médias móveis e desvios padrão
Vamos alterar nossas características e observar como os modelos vão se comportar.
def get_features(data: pd.DataFrame) -> pd.DataFrame: pFixed = data.copy() pFixedC = data.copy() count = 0 for i in hyper_params['periods']: pFixed[str(count)] = pFixedC.rolling(i).mean() count += 1 for i in hyper_params['periods_meta']: pFixed[str(count)+'meta_feature'] = pFixedC.rolling(i).std() count += 1 return pFixed.dropna()
Como características principais serão usadas médias móveis simples, e como meta-características, os desvios padrão.
Vamos iniciar o ciclo de treinamento e observar os melhores modelos:
Iteration: 0, Cluster: 0 R2: 0.9312180471969619 Iteration: 0, Cluster: 1 R2: 0.9839766532391275 too few samples: 101 Iteration: 0, Cluster: 3 R2: 0.9643925934007344 too few samples: 299 Iteration: 0, Cluster: 5 R2: 0.9960009821184868 too few samples: 19 Iteration: 0, Cluster: 7 R2: 0.9557947960449501 Iteration: 0, Cluster: 8 R2: 0.9747160963596306 Iteration: 0, Cluster: 9 R2: 0.5526910449937035 Время выполнения: 2.8627688884735107
Assim se apresenta no testador o melhor modelo:
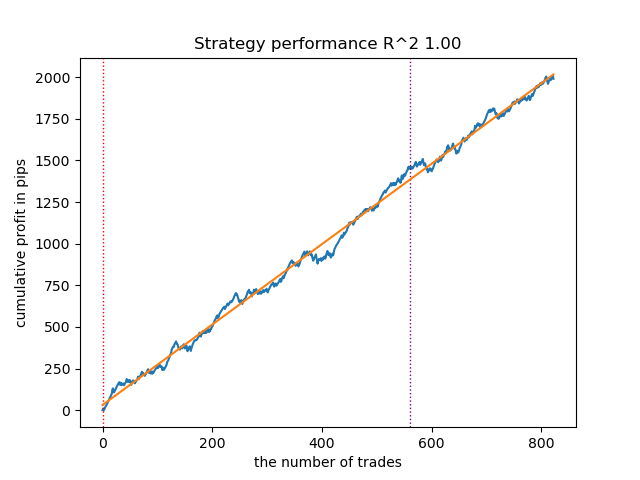
Figura 4. Teste do melhor modelo em médias móveis
O segundo melhor modelo também demonstra um bom resultado:
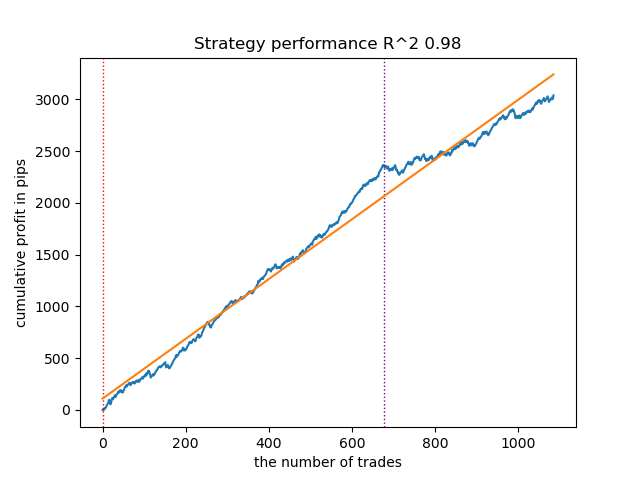
Figura 5. Teste do segundo modelo em médias móveis
Após reiniciar o ciclo de treinamento mais algumas vezes, obtive um gráfico de balanço mais suave:
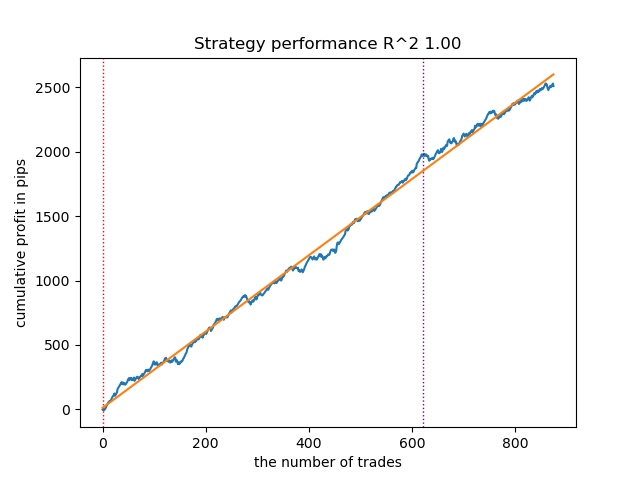
Figura 6. Teste da melhor modelo após o ciclo de treinamento repetido
Aqui eu não experimentei com a quantidade de características (lista dos seus períodos), portanto, na prática, é possível obter uma grande variedade desses modelos. As capturas de tela apresentadas apenas demonstram algumas das variantes.
Combate ao sobreajuste
Muitas vezes acontece de a complexidade excessiva do modelo causar um efeito negativo na sua capacidade de generalização. Mesmo considerando a parte de validação e a parada antecipada. Nesse caso, é possível tentar reduzir a quantidade de características e/ou diminuir a complexidade do modelo. Na terminologia do CatBoost, a complexidade do modelo significa a quantidade de iterações ou árvores de decisão construídas de forma sequencial. Na função fit_final_models() tente alterar os seguintes valores:
def fit_final_models(clustered, meta) -> list: # features for model\meta models. We learn main model only on filtered labels X, X_meta = clustered[clustered.columns[:-1]], meta[meta.columns[:-1]] X = X.loc[:, ~X.columns.str.contains('meta_feature')] X_meta = X_meta.loc[:, X_meta.columns.str.contains('meta_feature')] # labels for model\meta models y = clustered['labels'] y_meta = meta['clusters'] y = y.astype('int16') y_meta = y_meta.astype('int16') # train\test split train_X, test_X, train_y, test_y = train_test_split( X, y, train_size=0.8, test_size=0.2, shuffle=True) train_X_m, test_X_m, train_y_m, test_y_m = train_test_split( X_meta, y_meta, train_size=0.8, test_size=0.2, shuffle=True) # learn main model with train and validation subsets model = CatBoostClassifier(iterations=100, custom_loss=['Accuracy'], eval_metric='Accuracy', verbose=False, use_best_model=True, task_type='CPU', thread_count=-1) model.fit(train_X, train_y, eval_set=(test_X, test_y), early_stopping_rounds=15, plot=False)
Reduza a quantidade de iterações para 100 e o valor da parada antecipada para 15. Isso permitirá construir um modelo menos complexo.
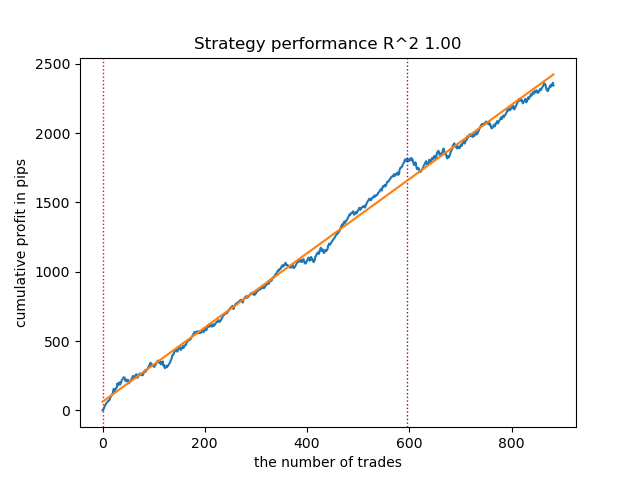
Figura 7. Testando um modelo menos complexo
Exportação dos modelos para o terminal MetaTrader 5
A função export_model_to_ONNX() do módulo export_lib() contém as seguintes linhas:
# get features code += 'void fill_arays' + symbol + '_' + str(model_number) + '( double &features[]) {\n' code += ' double pr[], ret[];\n' code += ' ArrayResize(ret, 1);\n' code += ' for(int i=ArraySize(Periods'+ symbol + '_' + str(model_number) + ')-1; i>=0; i--) {\n' code += ' CopyClose(NULL,PERIOD_H1,1,Periods' + symbol + '_' + str(model_number) + '[i],pr);\n' code += ' ret[0] = MathMean(pr);\n' code += ' ArrayInsert(features, ret, ArraySize(features), 0, WHOLE_ARRAY); }\n' code += ' ArraySetAsSeries(features, true);\n' code += '}\n\n' # get features code += 'void fill_arays_m' + symbol + '_' + str(model_number) + '( double &features[]) {\n' code += ' double pr[], ret[];\n' code += ' ArrayResize(ret, 1);\n' code += ' for(int i=ArraySize(Periods_m' + symbol + '_' + str(model_number) + ')-1; i>=0; i--) {\n' code += ' CopyClose(NULL,PERIOD_H1,1,Periods_m' + symbol + '_' + str(model_number) + '[i],pr);\n' code += ' ret[0] = MathSkewness(pr);\n' code += ' ArrayInsert(features, ret, ArraySize(features), 0, WHOLE_ARRAY); }\n' code += ' ArraySetAsSeries(features, true);\n' code += '}\n\n'
As linhas destacadas são responsáveis pelo cálculo das características no código MQL5. Caso você altere as características no script Python na função get_features(), como foi descrito acima, será necessário alterar o cálculo delas nesse código, ou você pode fazer isso diretamente no arquivo .mqh já exportado.
Por exemplo, no arquivo exportado XAUUSD_H1 ONNX include 0.mqh é necessário corrigir as seguintes linhas:
#include <Math\Stat\Math.mqh> #resource "catmodel XAUUSD_H1 0.onnx" as uchar ExtModel_XAUUSD_H1_0[] #resource "catmodel_m XAUUSD_H1 0.onnx" as uchar ExtModel2_XAUUSD_H1_0[] int PeriodsXAUUSD_H1_0[10] = {5,35,65,95,125,155,185,215,245,275}; int Periods_mXAUUSD_H1_0[1] = {5}; void fill_araysXAUUSD_H1_0( double &features[]) { double pr[], ret[]; ArrayResize(ret, 1); for(int i=ArraySize(PeriodsXAUUSD_H1_0)-1; i>=0; i--) { CopyClose(NULL,PERIOD_H1,1,PeriodsXAUUSD_H1_0[i],pr); ret[0] = MathStandardDeviation(pr); // ret[0] = MathMean(pr); ArrayInsert(features, ret, ArraySize(features), 0, WHOLE_ARRAY); } ArraySetAsSeries(features, true); } void fill_arays_mXAUUSD_H1_0( double &features[]) { double pr[], ret[]; ArrayResize(ret, 1); for(int i=ArraySize(Periods_mXAUUSD_H1_0)-1; i>=0; i--) { CopyClose(NULL,PERIOD_H1,1,Periods_mXAUUSD_H1_0[i],pr); ret[0] = MathStandardDeviation(pr); ArrayInsert(features, ret, ArraySize(features), 0, WHOLE_ARRAY); } ArraySetAsSeries(features, true); }
Agora o cálculo das características corresponde ao cálculo da função get_features(), na qual eram usados apenas os desvios padrão. Se forem usadas médias móveis, então deve-se substituir por MathMean().
Depois da compilação, já é possível testar o bot diretamente no terminal MetaTrader 5.
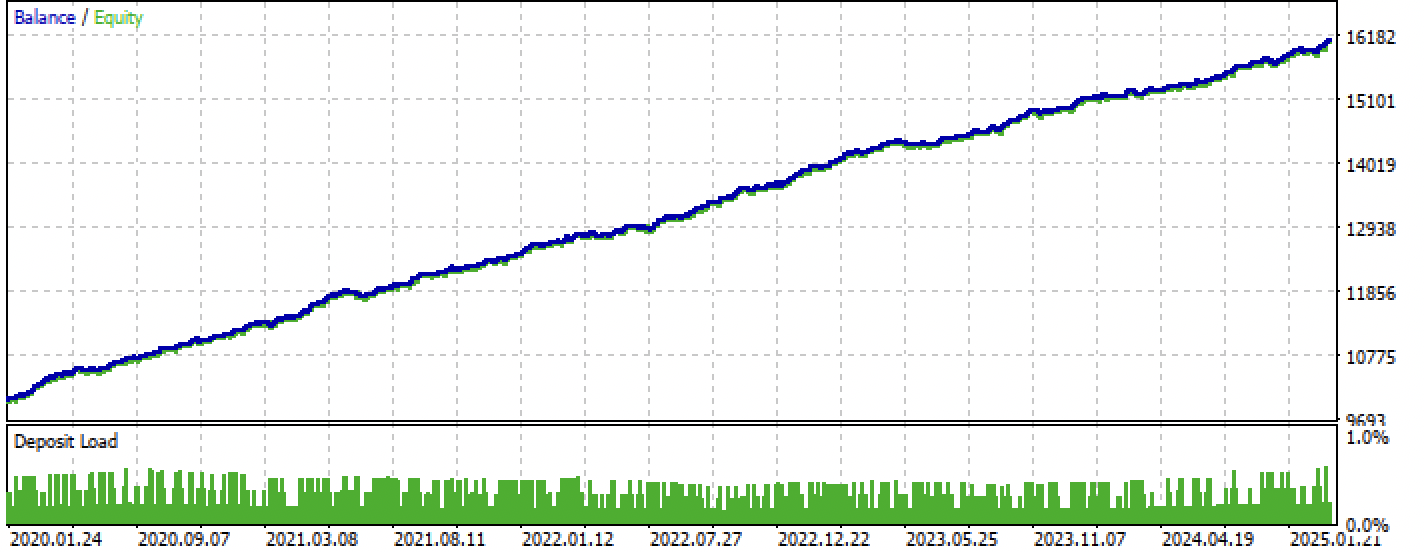
Figura 8. Testando no intervalo de treinamento + teste
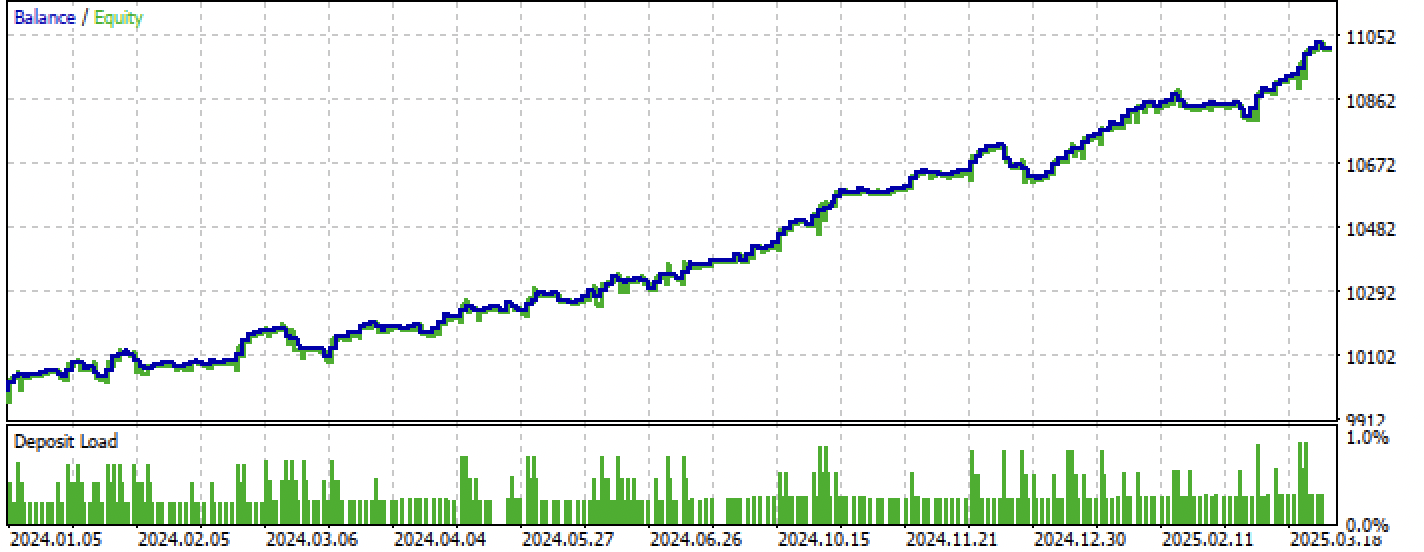
Figura 9. Testando apenas no período de teste
Considerações finais
Nesta artigo foi demonstrado mais um método de criação de estratégias de tendência unidirecional, agora baseado em clusterização. A principal diferença desse método é sua intuitividade e alta velocidade de treinamento. A qualidade dos modelos obtidos é comparável àquela da artigo anterior.
O arquivo Python files.zip contém os seguintes arquivos para desenvolvimento no ambiente Python:
| Nome do arquivo | Descrição |
|---|---|
| one direction clusters.py | Script principal para o treinamento dos modelos |
| labeling_lib.py | Módulo atualizado com rotuladores de operações |
| tester_lib.py | Testador customizado atualizado para estratégias baseadas em aprendizado de máquina |
| export_lib.py | Módulo para exportação dos modelos para o terminal |
| XAUUSD_H1.csv | Arquivo com cotações, exportado do terminal MetaTrader 5 |
O arquivo MQL5 files.zip contém arquivos para o terminal MetaTrader 5:
| Nome do arquivo | Descrição |
|---|---|
| one direction clusters.ex5 | Bot compilado desta artigo |
| one direction clusters.mq5 | Código-fonte do bot da artigo |
| pasta Include//Trend following | Estão localizados os modelos ONNX e o arquivo de cabeçalho para conexão ao bot |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/17755
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
Portanto, você tem o R2, um índice modificado, cuja eficiência é baseada no lucro em pips. E quanto ao drawdown e outros indicadores de desempenho? Se obtivermos um modelo que dê mais de 90% no treinamento e pelo menos 85% no teste, então seu índice apresentará números impressionantes. Não importa quantas vezes eu tenha executado o testador no MT5, nunca recebi um lucro no histórico. O depósito é drenado. Isso ocorre apesar do fato de seu testador em Python fornecer 0,97-0,98
Não entendo o que isso tem a ver com o CV.
Todas essas estratégias têm baixo poder de comprovação, porque se baseiam apenas no histórico de cotações não estacionárias. Mas você pode detectar tendências.Então, onde está a IA nisso? Vocês fizeram um upgrade para esse nível? Ou isso é apenas um truque comum de marketing para atrair o público?
Notei esse recurso estranho em várias publicações recentes de diferentes autores.
Não há outros modelos decentes além do catbust?
Então, onde está a IA nisso? Vocês fizeram um upgrade para esse nível? Ou isso é apenas um truque de marketing comum para atrair o público?
Notei esse recurso estranho em várias publicações recentes de diferentes autores.
Não há outros modelos decentes além do catbust?
Clickbait (abreviação popular). Não sou defensor do termo de forma alguma.
As pessoas estão acostumadas a se referir ao MO como "IA". Além disso, o TC é um complexo de diferentes algoritmos de MO, por exemplo, agrupamento e classificação.