
Desarrollo de estrategias comerciales de tendencia basadas en el aprendizaje automático
Introducción
Existen varios tipos de estrategias comerciales que han demostrado su eficacia en el trading. Una de ellas, la estrategia de retorno a la media, ya la tratamos en un artículo anterior. En este artículo, compartiremos con el lector algunas ideas sobre cómo se puede utilizar el aprendizaje automático para crear estrategias de seguimiento de tendencias.
El presente material utilizará un enfoque similar mediante la clusterización de datos para destacar los modos de mercado. Sin embargo, los propios marcadores de las transacciones serán significativamente diferentes. Por consiguiente, le recomiendo que se familiarice con el primer artículo, antes de pasar a este como continuación lógica. De esta forma puede ver la diferencia entre el primer y el segundo tipo de estrategias, así como la diferencia en el marcado de los ejemplos de entrenamiento. ¡Muy bien, vamos allá!
Cómo crear ejemplos de marcado para estrategias de tendencia
La principal diferencia entre las estrategias de tendencia y las estrategias de regreso a la media es que, para las estrategias de tendencia, resulta importante identificar la tendencia actual exacta, mientras que para las estrategias de regreso a la media, basta con que los precios fluctúen en torno a un determinado valor medio y lo crucen a menudo. Puede decirse que estas estrategias son diametralmente opuestas. Mientras que la regreso a la media implica una alta probabilidad de cambio en la dirección de los precios, el seguimiento de la tendencia implica la continuación de la tendencia actual.
Los tipos de cambio suelen dividirse en pares de divisas planos y de tendencia. Obviamente, se trata de una división muy condicional, ya que tanto las tendencias como las zonas de consolidación pueden estar presentes en ambos. En este caso, la división se produce más bien según la frecuencia con la que se encuentran en uno u otro estado. En este artículo no haremos un estudio detallado sobre qué herramientas son realmente de tendencia. Simplemente probaremos el enfoque con el par de divisas EURUSD, que se considera un par de divisas de tendencia, a diferencia de EURGBP, que se consideró plano en el artículo anterior.
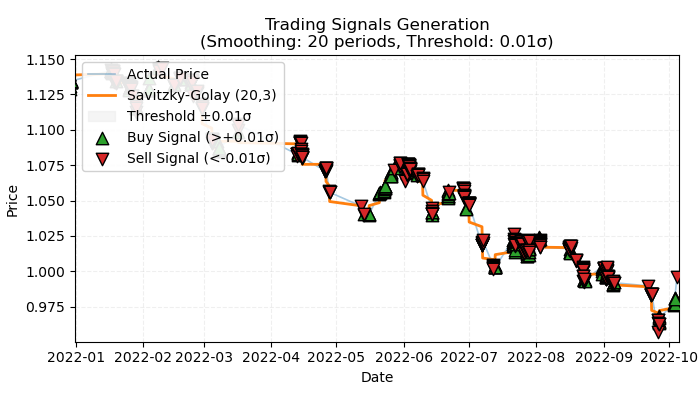
Fig 1. representación visual de las transacciones marcadas por tendencia
La fig. 1 muestra el principio básico que se utilizará para marcar las transacciones en una tendencia. Para suavizar las fluctuaciones de ruido a corto plazo, hemos usado de nuevo el filtro Savitsky-Golei que analizamos con detalle en el artículo anterior. Pero en lugar de contar las desviaciones del precio con respecto al filtro, como hicimos la última vez, ahora nos interesará la dirección del filtro como tendencia. Si la dirección es positiva, se realizará una transacción de compra, en caso contrario, de venta. Si no se da ninguna indicación, estas transacciones no se contabilizarán en el proceso de aprendizaje. La función de marcado implica un filtro o umbral de intensidad de tendencia incorporado que filtra las tendencias menores con volatilidad y que se analizará más adelante.
Enfoque básico para marcar transacciones en la tendencia
Veamos cómo opera la función de marcado de transacciones:
@njit def calculate_labels_trend(normalized_trend, threshold): labels = np.empty(len(normalized_trend), dtype=np.float64) for i in range(len(normalized_trend)): if normalized_trend[i] > threshold: labels[i] = 0.0 # Buy (Up trend) elif normalized_trend[i] < -threshold: labels[i] = 1.0 # Sell (Down trend) else: labels[i] = 2.0 # No signal return labels def get_labels_trend(dataset, rolling=200, polyorder=3, threshold=0.5, vol_window=50) -> pd.DataFrame: smoothed_prices = savgol_filter(dataset['close'].values, window_length=rolling, polyorder=polyorder) trend = np.gradient(smoothed_prices) vol = dataset['close'].rolling(vol_window).std().values normalized_trend = np.where(vol != 0, trend / vol, np.nan) # Set NaN where vol is 0 labels = calculate_labels_trend(normalized_trend, threshold) dataset = dataset.iloc[:len(labels)].copy() dataset['labels'] = labels dataset = dataset.dropna() # Remove rows with NaN return dataset
La función get_labels_trend procesa los datos de origen: dataset, que contiene la columna "close" (precios de cierre) y devuelve el frame de datos con la columna añadida de etiquetas marcadas.
Etapas clave del marcado:
- Suavizado de precios. El filtro Savitzky-Golei se utiliza para suavizar los precios de cierre. Como parámetros se ofrecen la longitud de la ventana de suavizado y el grado polinómico. El objetivo es eliminar el ruido y destacar la tendencia principal.
smoothed_prices = savgol_filter(dataset['close'].values, window_length=rolling, polyorder=polyorder)- Cálculo de la tendencia. Se calcula el gradiente de los precios suavizados. El gradiente muestra la tasa de variación de los precios y su dirección. Un gradiente positivo indica una tendencia alcista, mientras que un gradiente negativo muestra una tendencia bajista.
trend = np.gradient(smoothed_prices)
- Cálculo de la volatilidad. La volatilidad se calcula como la desviación típica de los precios de cierre en una ventana móvil. Esto ayuda a estimar la variabilidad de los precios para normalizar la tendencia.
vol = dataset['close'].rolling(vol_window).std().values- Normalización de tendencias. La tendencia se divide en volatilidad para considerar la variabilidad del mercado.
normalized_trend = np.where(vol != 0, trend / vol, np.nan)- Generación de etiquetas. Según la tendencia normalizada y el umbral, se generan etiquetas de compra y venta.
labels = calculate_labels_trend(normalized_trend, threshold)
- Uso del umbral. Es el valor que se encarga de filtrar las pequeñas desviaciones del gradiente. Se elige de forma empírica, normalmente entre 0,01 y 0,5. Si los datos se encuentran dentro de los límites del filtro, esas tendencias se ignorarán por resultar insignificantes.
Tomaremos este enfoque de marcado como línea de base y escribiremos marcados de transacciones adicionales para tener más espacio para la experimentación.
Marcado con restricción de las transacciones estrictamente rentables
El enfoque básico asume la presencia de transacciones de antemano perdedoras, porque pueden estar al final de la tendencia, después de lo cual se produce la inversión. Esto se corresponde con las señales reales del sistema comercial, cuando este puede estar equivocado. Lo único que importa es la relación porcentual entre transacciones rentables y perdedoras, de modo que siempre esté a favor de las rentables. Pero podemos librarnos de esta desventaja marcando solo las transacciones rentables e ignorando las perdedoras. Esto permitirá suavizar la curva de equilibrio en los datos de entrenamiento y, posiblemente, en los de prueba. A continuación le mostramos el código correspondiente.
@njit def calculate_labels_trend_with_profit(close, normalized_trend, threshold, markup, min_l, max_l): labels = np.empty(len(normalized_trend) - max_l, dtype=np.float64) for i in range(len(normalized_trend) - max_l): if normalized_trend[i] > threshold: # Проверяем условие для Buy rand = random.randint(min_l, max_l) future_pr = close[i + rand] if future_pr >= close[i] + markup: labels[i] = 0.0 # Buy (Profit reached) else: labels[i] = 2.0 # No profit elif normalized_trend[i] < -threshold: # Проверяем условие для Sell rand = random.randint(min_l, max_l) future_pr = close[i + rand] if future_pr <= close[i] - markup: labels[i] = 1.0 # Sell (Profit reached) else: labels[i] = 2.0 # No profit else: labels[i] = 2.0 # No signal return labels def get_labels_trend_with_profit(dataset, rolling=200, polyorder=3, threshold=0.5, vol_window=50, markup=0.00005, min_l=1, max_l=15) -> pd.DataFrame: # Smoothing and trend calculation smoothed_prices = savgol_filter(dataset['close'].values, window_length=rolling, polyorder=polyorder) trend = np.gradient(smoothed_prices) # Normalizing the trend by volatility vol = dataset['close'].rolling(vol_window).std().values normalized_trend = np.where(vol != 0, trend / vol, np.nan) # Removing NaN and synchronizing data valid_mask = ~np.isnan(normalized_trend) normalized_trend_clean = normalized_trend[valid_mask] close_clean = dataset['close'].values[valid_mask] dataset_clean = dataset[valid_mask].copy() # Generating labels labels = calculate_labels_trend_with_profit(close_clean, normalized_trend_clean, threshold, markup, min_l, max_l) # Trimming the dataset and adding labels dataset_clean = dataset_clean.iloc[:len(labels)].copy() dataset_clean['labels'] = labels # Filtering the results dataset_clean = dataset_clean.dropna() return dataset_clean
Las principales diferencias con el planteamiento básico son:
- Hemos añadido el parámetro min_l, que define el número mínimo de barras en el futuro por el que se mide el cambio de precio futuro comparado con el actual.
- También hemos añadido el parámetro max_l, que define el número máximo de barras en el futuro con respecto al cual se miden los cambios de precio futuros en comparación con los precios actuales.
- La barra del futuro se selecciona aleatoriamente dentro del intervalo fijado por estos parámetros. Podemos hacer que la longitud de comprobación sea fija estableciendo los mismos valores.
- Si una transacción abierta + n barras por delante ha generado beneficios, dicha transacción se añadirá al conjunto de datos de entrenamiento; de lo contrario, se marcará como 2,0 (sin transacción).
- Hemos añadido el parámetro markup, que se debe establecer como una media de spread+comisión+deslizamiento en un instrumento comercial; se puede establecer con cierto margen de sobra. Este valor afectará al número de transacciones rentables marcadas, cuanto más alto sea, menos transacciones se marcarán como rentables porque no han superado este umbral.
Marcado con posibilidad de selección de filtro y con restricción a transacciones estrictamente rentables
Al igual que en el artículo anterior, queremos tener alguna opción de elegir filtros, no solo el Savitzky-Golei. Esto permitirá tener más variaciones de marcado y ajustar mejor el sistema comercial a las peculiaridades de los distintos instrumentos comerciales. Le sugiero añadir de nuevo la media móvil simple, la media móvil exponencial y el spline como filtros adicionales. Solo a modo de ejemplo, porque podrá añadir filtros suyos propios por analogía.
@njit def calculate_labels_trend_different_filters(close, normalized_trend, threshold, markup, min_l, max_l): labels = np.empty(len(normalized_trend) - max_l, dtype=np.float64) for i in range(len(normalized_trend) - max_l): if normalized_trend[i] > threshold: # Проверяем условие для Buy rand = random.randint(min_l, max_l) future_pr = close[i + rand] if future_pr >= close[i] + markup: labels[i] = 0.0 # Buy (Profit reached) else: labels[i] = 2.0 # No profit elif normalized_trend[i] < -threshold: # Проверяем условие для Sell rand = random.randint(min_l, max_l) future_pr = close[i + rand] if future_pr <= close[i] - markup: labels[i] = 1.0 # Sell (Profit reached) else: labels[i] = 2.0 # No profit else: labels[i] = 2.0 # No signal return labels def get_labels_trend_with_profit_different_filters(dataset, method='savgol', rolling=200, polyorder=3, threshold=0.5, vol_window=50, markup=0.5, min_l=1, max_l=15) -> pd.DataFrame: # Smoothing and trend calculation close_prices = dataset['close'].values if method == 'savgol': smoothed_prices = savgol_filter(close_prices, window_length=rolling, polyorder=polyorder) elif method == 'spline': x = np.arange(len(close_prices)) spline = UnivariateSpline(x, close_prices, k=polyorder, s=rolling) smoothed_prices = spline(x) elif method == 'sma': smoothed_series = pd.Series(close_prices).rolling(window=rolling).mean() smoothed_prices = smoothed_series.values elif method == 'ema': smoothed_series = pd.Series(close_prices).ewm(span=rolling, adjust=False).mean() smoothed_prices = smoothed_series.values else: raise ValueError(f"Unknown smoothing method: {method}") trend = np.gradient(smoothed_prices) # Normalizing the trend by volatility vol = dataset['close'].rolling(vol_window).std().values normalized_trend = np.where(vol != 0, trend / vol, np.nan) # Removing NaN and synchronizing data valid_mask = ~np.isnan(normalized_trend) normalized_trend_clean = normalized_trend[valid_mask] close_clean = dataset['close'].values[valid_mask] dataset_clean = dataset[valid_mask].copy() # Generating labels labels = calculate_labels_trend_different_filters(close_clean, normalized_trend_clean, threshold, markup, min_l, max_l) # Trimming the dataset and adding labels dataset_clean = dataset_clean.iloc[:len(labels)].copy() dataset_clean['labels'] = labels # Filtering the results dataset_clean = dataset_clean.dropna() return dataset_clean
El principal cambio con respecto al algoritmo de marcado anterior será la adición de un parámetro method que puede tomar los siguientes valores:
- savgol — filtro de Savitzky-Golei
- spline — interpolación con splines
- sma — suavizado por media móvil simple
- ema — suavizado por media móvil exponencial.
Marcado basado en filtros con diferentes periodos y con restricción de las transacciones estrictamente rentables
Vamos a complicar un poco nuestra percepción de la realidad y, por extensión, la forma en que marcamos las transacciones. No existe ninguna prohibición de usar únicamente el periodo de suavizado seleccionado. Podemos utilizar cualquier número de filtros del mismo tipo con diferentes periodos a la vez y marcar las transacciones cuando al menos una de las condiciones haya funcionado. A continuación le mostramos una variante de dicho muestrario:
@njit def calculate_labels_trend_multi(close, normalized_trends, threshold, markup, min_l, max_l): num_periods = normalized_trends.shape[0] # Number of periods labels = np.empty(len(close) - max_l, dtype=np.float64) for i in range(len(close) - max_l): # Select a random number of bars forward once for all periods rand = np.random.randint(min_l, max_l + 1) buy_signals = 0 sell_signals = 0 # Check conditions for each period for j in range(num_periods): if normalized_trends[j, i] > threshold: if close[i + rand] >= close[i] + markup: buy_signals += 1 elif normalized_trends[j, i] < -threshold: if close[i + rand] <= close[i] - markup: sell_signals += 1 # Combine signals if buy_signals > 0 and sell_signals == 0: labels[i] = 0.0 # Buy elif sell_signals > 0 and buy_signals == 0: labels[i] = 1.0 # Sell else: labels[i] = 2.0 # No signal or conflict return labels def get_labels_trend_with_profit_multi(dataset, method='savgol', rolling_periods=[10, 20, 30], polyorder=3, threshold=0.5, vol_window=50, markup=0.5, min_l=1, max_l=15) -> pd.DataFrame: """ Generates labels for trading signals (Buy/Sell) based on the normalized trend, calculated for multiple smoothing periods. Args: dataset (pd.DataFrame): DataFrame with data, containing the 'close' column. method (str): Smoothing method ('savgol', 'spline', 'sma', 'ema'). rolling_periods (list): List of smoothing window sizes. Default is [200]. polyorder (int): Polynomial order for 'savgol' and 'spline' methods. threshold (float): Threshold for the normalized trend. vol_window (int): Window for volatility calculation. markup (float): Minimum profit to confirm the signal. min_l (int): Minimum number of bars forward. max_l (int): Maximum number of bars forward. Returns: pd.DataFrame: DataFrame with added 'labels' column: - 0.0: Buy - 1.0: Sell - 2.0: No signal """ close_prices = dataset['close'].values normalized_trends = [] # Calculate normalized trend for each period for rolling in rolling_periods: if method == 'savgol': smoothed_prices = savgol_filter(close_prices, window_length=rolling, polyorder=polyorder) elif method == 'spline': x = np.arange(len(close_prices)) spline = UnivariateSpline(x, close_prices, k=polyorder, s=rolling) smoothed_prices = spline(x) elif method == 'sma': smoothed_series = pd.Series(close_prices).rolling(window=rolling).mean() smoothed_prices = smoothed_series.values elif method == 'ema': smoothed_series = pd.Series(close_prices).ewm(span=rolling, adjust=False).mean() smoothed_prices = smoothed_series.values else: raise ValueError(f"Unknown smoothing method: {method}") trend = np.gradient(smoothed_prices) vol = pd.Series(close_prices).rolling(vol_window).std().values normalized_trend = np.where(vol != 0, trend / vol, np.nan) normalized_trends.append(normalized_trend) # Transform list into 2D array normalized_trends_array = np.vstack(normalized_trends) # Remove rows with NaN valid_mask = ~np.isnan(normalized_trends_array).any(axis=0) normalized_trends_clean = normalized_trends_array[:, valid_mask] close_clean = close_prices[valid_mask] dataset_clean = dataset[valid_mask].copy() # Generate labels labels = calculate_labels_trend_multi(close_clean, normalized_trends_clean, threshold, markup, min_l, max_l) # Trim data and add labels dataset_clean = dataset_clean.iloc[:len(labels)].copy() dataset_clean['labels'] = labels # Remove remaining NaN dataset_clean = dataset_clean.dropna() return dataset_clean
Marcado en amarillo hemos resaltado los puntos principales a los que podemos prestar atención con un vistazo rápido:
- La función de marcado ahora acepta una lista de longitud arbitraria que contenga valores de periodo de suavizado.
- El ciclo calcula los filtros para todos los periodos especificados.
- La función de marcado implica gradientes de tendencia en todos los filtros.
- Si al menos una condición para la compra o la venta ha funcionado, considerando que no haya señales contrarias, se realizará la transacción.
El módulo labelling_lib.py se ha actualizado con cuatro nuevos muestreadores:
def get_labels_trend(dataset, rolling=200, polyorder=3, threshold=0.5, vol_window=50) -> pd.DataFrame: def get_labels_trend_with_profit(dataset, rolling=200, polyorder=3, threshold=0.5, def get_labels_trend_with_profit_different_filters(dataset, method='savgol', rolling=200, polyorder=3, threshold=0.5, def get_labels_trend_with_profit_multi(dataset, method='savgol', rolling_periods=[10, 20, 30], polyorder=3, threshold=0.5,
Vamos a centrarnos en estas opciones. Son suficientes para probar la idea principal del marcado de tendencia.
Proceso de entrenamiento y prueba de modelos
La propia lógica de preparación y entrenamiento de los datos está tomada del último artículo, por lo que no describiremos sus características en detalle. Pero si hay ciertos cambios; por ejemplo, el ciclo de entrenamiento al completo se sitúa ahora en una función processing separada, por eso hay nuevas posibilidades de gestionar este proceso.
Antes, las transacciones marcadas como 2,0 simplemente se eliminaban del conjunto de datos de entrenamiento y no participaban de ninguna manera en el proceso de entrenamiento. Esto podría dar lugar a una pérdida de información al haber omisiones en el margen de beneficio de las transacciones. Pero, ¿cómo incorporar esta información al sistema comercial si se utiliza un clasificador binario y las etiquetas 2.0 (sin acción) representan la clase 3?
Recordemos que hay dos clasificadores implicados en el entrenamiento; el primero de ello está entrenado para predecir etiquetas de compra y venta, y el segundo está entrenado para predecir el modo actual del mercado (cuándo comerciar y cuándo no). De este modo, podemos migrar ejemplos con etiquetas 2.0 al segundo modelo sin perder información, como ocurría antes al eliminar esos ejemplos.
def processing(iterations = 1, rolling = [10], threshold=0.01, polyorder=5, vol_window=100, use_meta_dilution = True): models = [] for i in range(iterations): data = clustering(dataset, n_clusters=hyper_params['n_clusters']) sorted_clusters = data['clusters'].unique() sorted_clusters.sort() for clust in sorted_clusters: clustered_data = data[data['clusters'] == clust].copy() if len(clustered_data) < 500: print('too few samples: {}'.format(len(clustered_data))) continue clustered_data = get_labels_trend_with_profit_multi( clustered_data, method='savgol', rolling_periods=rolling, polyorder=polyorder, threshold=threshold, vol_window=vol_window, min_l=1, max_l=15, markup=hyper_params['markup']) print(f'Iteration: {i}, Cluster: {clust}') clustered_data = clustered_data.drop(['close', 'clusters'], axis=1) meta_data = data.copy() meta_data['clusters'] = meta_data['clusters'].apply(lambda x: 1 if x == clust else 0) if use_meta_dilution: for dt in clustered_data.index: if clustered_data.loc[dt, 'labels'] == 2.0: if dt in meta_data.index: # Check if datetime exists in meta_data meta_data.loc[dt, 'clusters'] = 0 clustered_data = clustered_data.drop(clustered_data[clustered_data.labels == 2.0].index) # Синхронизация meta_data с bad_data models.append(fit_final_models(clustered_data, meta_data.drop(['close'], axis=1))) models.sort(key=lambda x: x[0]) return models
El código muestra con un marcador que los ejemplos etiquetados como 2.0 en el conjunto de datos para el primer modelo se seleccionan en el conjunto de datos para el segundo modelo según las fechas y filas correspondientes a esas fechas, y la columna clusters se establece en ceros. Si recordamos que las unidades permiten comerciar, el segundo modelo ahora pronosticará no solo el modo de mercado, sino también los puntos de entrada malos según la versión del muestreador de transacciones. En otras palabras, el segundo modelo pronosticará ahora no solo el modo de mercado necesario, sino también los puntos de entrada no deseados.
Le sugiero utilizar directamente el último muestreador, porque incorpora lo mejor de lo mejor y tiene ajustes flexibles.
Vamos a realizar 10 ciclos de entrenamiento con estos ajustes:
hyper_params = {
'symbol': 'EURUSD_H1',
'export_path': '/Users/dmitrievsky/Library/Containers/com.isaacmarovitz.Whisky/Bottles/54CFA88F-36A3-47F7-915A-D09B24E89192/drive_c/Program Files/MetaTrader 5/MQL5/Include/Mean reversion/',
'model_number': 0,
'markup': 0.00010,
'stop_loss': 0.00500,
'take_profit': 0.00200,
'periods': [i for i in range(5, 300, 30)],
'periods_meta': [100],
'backward': datetime(2000, 1, 1),
'forward': datetime(2024, 1, 1),
'full forward': datetime(2026, 1, 1),
'n_clusters': 10,
'rolling': [10],
}La propia función de entrenamiento se llama de este modo:
dataset = get_features(get_prices()) models = processing(iterations = 10, threshold=0.001, polyorder=3, vol_window=100, use_meta_dilution = True)
Durante el entrenamiento, se mostrarán las puntuaciones R^2 de cada pasada (clúster):
Iteration: 0, Cluster: 0 R2: 0.9837358133371028 Iteration: 0, Cluster: 1 R2: 0.9002342482016827 Iteration: 0, Cluster: 2 R2: 0.9755114279213657 Iteration: 0, Cluster: 3 R2: 0.9833351908595832 Iteration: 0, Cluster: 4 R2: 0.9537875370012954 Iteration: 0, Cluster: 5 R2: 0.9863566422346429 too few samples: 471 Iteration: 0, Cluster: 7 R2: 0.9852545217737659 Iteration: 0, Cluster: 8 R2: 0.9934196831544163
Probaremos el mejor modelo de toda la lista:
test_model(models[-1][1:], hyper_params['stop_loss'], hyper_params['take_profit'], hyper_params['forward'], plt=True)
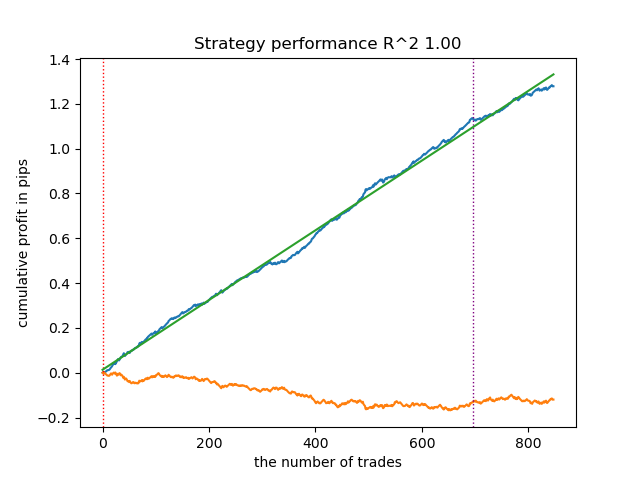
Fig. 2. Prueba del modelo con los datos de entrenamiento y los nuevos datos.
Ahora podemos llamar a la función de exportación de modelos al terminal Meta Trader 5.
export_model_to_ONNX(model = models[-1], symbol = hyper_params['symbol'], periods = hyper_params['periods'], periods_meta = hyper_params['periods_meta'], model_number = hyper_params['model_number'], export_path = hyper_params['export_path'])
Pruebas finales de los modelos y observaciones generales sobre el algoritmo
Nuestro enfoque es universal, por lo que la exportación de modelos al terminal se realizará exactamente del mismo modo que se describe en el artículo anterior.
Veamos al completo el periodo de entrenamiento + prueba y la prueba por separado. Las cifras muestran que la curva es más suave en los datos de entrenamiento que en los datos de prueba, que comienzan en 2024. Dado que el entrenamiento se ha realizado de 2020 a 2024, la prueba se da a partir de 2019 para mostrar que el periodo anterior a el entrenamiento tampoco es del todo suave.
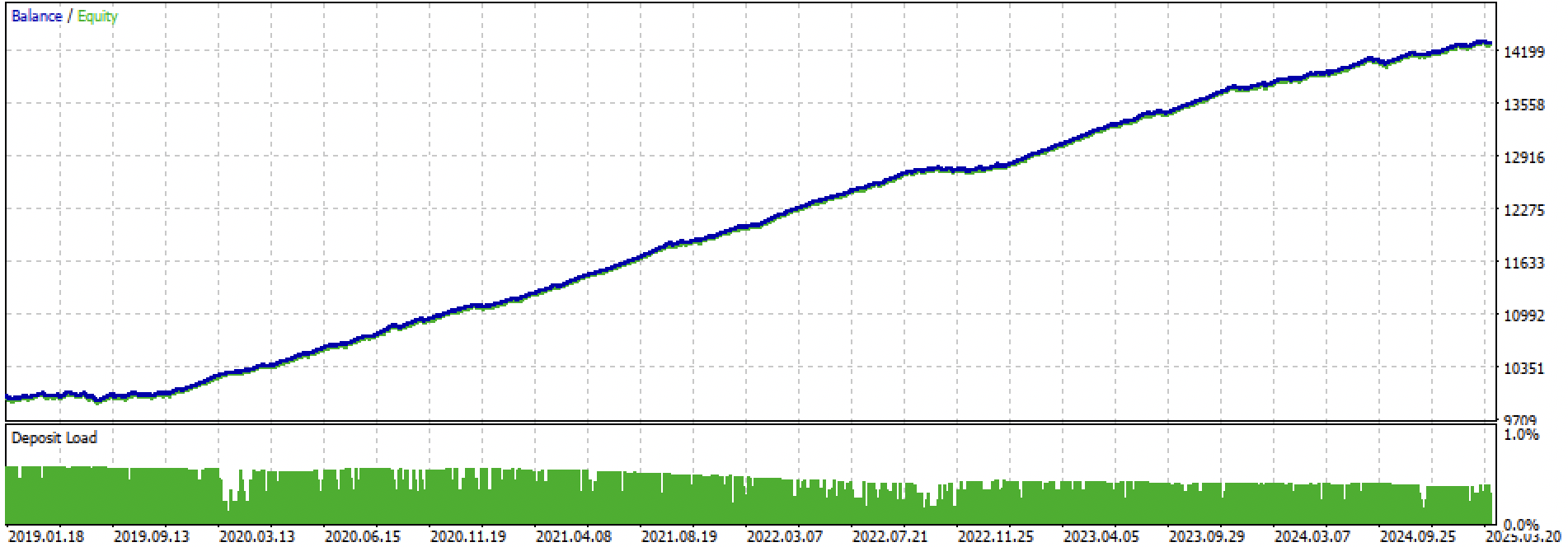
Figura 3. pruebas de 2019 a 2025.
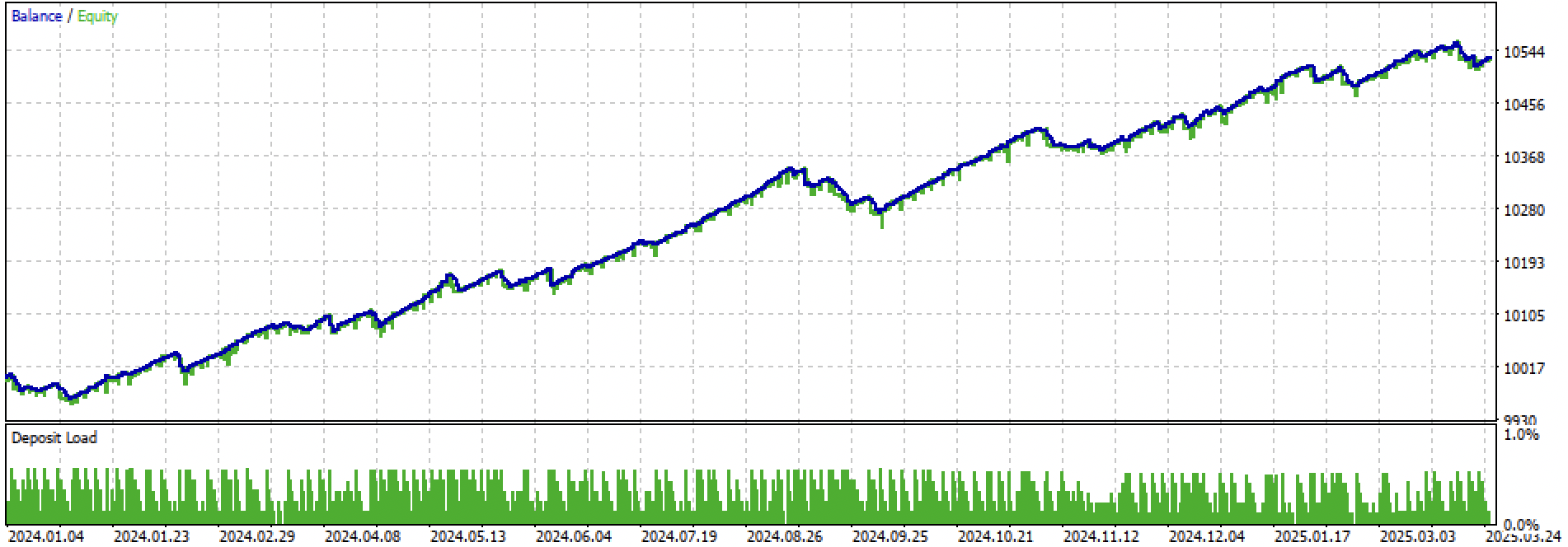
Fig. 4. Pruebas sobre el periodo forward desde principios de 2024 hasta el 27 de marzo de 2025.
Usando como base los experimentos realizados, hemos llegado a la conclusión de que las estrategias de tendencia son más caprichosas en lo que respecta a su trabajo con datos nuevos, o bien este enfoque no se las arregla bien con la creación de este tipo de estrategias en el par de divisas EURUSD. No obstante, experimentando con los ajustes de los hiperparámetros, podemos obtener modelos razonablemente buenos. Las desventajas se compensan parcialmente por el hecho de que estos modelos son capaces de mostrar buenos resultados con un stop loss muy corto, por ejemplo 20 puntos de 4 dígitos. Esto permite controlar los riesgos y desconectar los modelos a tiempo cuando estos empiezan a fallar.
Tampoco hemos podido identificar ningún conjunto significativo de hiperparámetros. Daba la impresión de que el algoritmo busca débilmente algunos patrones estables, o simplemente no los hay.
Para combatir el sobreentrenamiento, podemos reducir la complejidad de los modelos en la función fit_final_models():
def fit_final_models(clustered, meta) -> list: # features for model\meta models. We learn main model only on filtered labels X, X_meta = clustered[clustered.columns[:-1]], meta[meta.columns[:-1]] X = X.loc[:, ~X.columns.str.contains('meta_feature')] X_meta = X_meta.loc[:, X_meta.columns.str.contains('meta_feature')] # labels for model\meta models y = clustered['labels'] y_meta = meta['clusters'] y = y.astype('int16') y_meta = y_meta.astype('int16') # train\test split train_X, test_X, train_y, test_y = train_test_split( X, y, train_size=0.7, test_size=0.3, shuffle=True) train_X_m, test_X_m, train_y_m, test_y_m = train_test_split( X_meta, y_meta, train_size=0.7, test_size=0.3, shuffle=True) # learn main model with train and validation subsets model = CatBoostClassifier(iterations=100, custom_loss=['Accuracy'], eval_metric='Accuracy', verbose=False, use_best_model=True, task_type='CPU', thread_count=-1) model.fit(train_X, train_y, eval_set=(test_X, test_y), early_stopping_rounds=15, plot=False) # learn meta model with train and validation subsets meta_model = CatBoostClassifier(iterations=100, custom_loss=['F1'], eval_metric='F1', verbose=False, use_best_model=True, task_type='CPU', thread_count=-1) meta_model.fit(train_X_m, train_y_m, eval_set=(test_X_m, test_y_m), early_stopping_rounds=15, plot=False) R2 = test_model([model, meta_model], hyper_params['stop_loss'], hyper_params['take_profit'], hyper_params['full forward']) if math.isnan(R2): R2 = -1.0 print('R2 is fixed to -1.0') print('R2: ' + str(R2)) return [R2, model, meta_model]
El número de iteraciones es responsable del número de divisiones del modelo y del número de características seleccionadas. Inicialmente había 1000 iteraciones, que hemos reducido a 100. La parada temprana detiene el entrenamiento antes de tiempo si el error de clasificación en los datos de validación no mejora en 15 iteraciones.
Esto le ha dado un equilibrio más ruidoso y lo ha hecho más homogéneo pero menos bello.
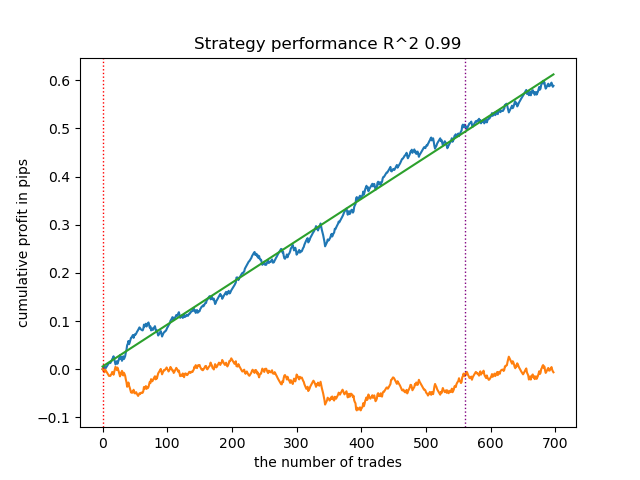
Fig. 5. gráfico de balance tras reducir la complejidad de los modelos
Conclusión
Las estrategias de tendencia basadas en la clusterización y la clasificación binaria son más difíciles de crear. Necesitamos nuevas ideas sobre cómo hacerlo. Se observa un cierto problema cuando los precios de los activos financieros van más allá del rango de valores sobre el que se ha entrenado el modelo, a diferencia del entrenamiento con instrumentos planos, en el que es más probable que los precios de los nuevos datos coincidan con aquellos con los que se ha entrenado el modelo. Si aplicamos signos basados en las diferencias de precio, el modelo vuelve a mostrar una escasa generalizabilidad.
Con este artículo hemos decidido resumir nuestros experimentos con el enfoque por clusterización de modos de mercado y nos esperan nuevas ideas aún más interesantes.
Los siguientes materiales se adjuntan a este artículo:
| Nombre del archivo | Descripción |
|---|---|
| labeling_lib.py | Biblioteca de muestreadores actualizada |
| trend_following.py | Script para entrenar modelos |
| cat model_EURUSD_H1_0.onnx | Modelo básico, carpeta incluida |
| catmodel_m_EURUSD_H1_0.onnx | Metamodelo, carpeta include |
| EURUSD_H1_ONNX_include_0.mqh | Archivo de encabezado |
| trend_following.mq5 | Código fuente del asesor experto |
| trend_following.ex5 | Bot compilado |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/17526
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
Entonces el resultado no es malo. La primavera de 2025 es un mercado diferente.
Supongo que el eurodólar en general no es muy bueno prediciendo últimamente. Las operaciones planas/de tendencia no funcionan.
Sólo las operaciones de compra funcionan en los que tienen buena tendencia (por ejemplo, el oro), como en el último artículo. En barras, no scalping.
En Eurodólar y unidireccionales no funcionan.
Supongo que el eurodólar en general no es muy bueno prediciendo últimamente. Ts plana / tendencia no están funcionando.
Sólo las operaciones de compra funcionan en los de buena tendencia (obsérvese el oro), como en el último artículo. En barras, no scalping.
En eurodólar y unidireccionales no funcionan.
Pero si el mercado cambia, el ts morirá. sin un supervisor automático, ya es un semi-manual
Pero si el mercado cambia, tc está muerto. sin un invigilador automático, ya es un semi-corredor
¿Cómo puedo conseguir este robot 🤖