
使用机器学习开发趋势交易策略
概述
多种类型的交易策略已证明其在交易中的有效性。其中一种策略 —— 均值回归策略,我们在之前的文章中已经介绍过。在这篇文章中,我决定与读者分享一些关于如何使用机器学习来创建基于趋势或趋势跟踪策略的想法。
本文将使用基于数据聚类的类似方法来识别市场机制。然而,实际的交易标注会有很大差异。因此,我建议先阅读第一篇文章,然后再阅读本文,因为这是合乎逻辑的延续。这将使您能够看到第一种和第二种策略之间的差异,以及标记训练示例的差异。那么,我们开始吧!
趋势跟踪策略的数据标记方法
趋势跟踪策略和均值回归策略的主要区别在于,对于趋势跟踪策略,准确识别当前趋势至关重要。对于均值回归策略,价格在某个平均值附近波动并经常越过它就足够了。可以说,这些策略是截然相反的。如果均值回归意味着价格走势方向发生逆转的可能性很高,那么趋势跟踪意味着当前趋势的延续。
货币对通常被分为区间震荡(横盘整理)或趋势性走势。当然,这只是一个相对笼统的分类,因为趋势和盘整区域都可能出现在这两种类型中。在这里,这种区别更多地取决于它们处于一种状态或另一种状态的频率。在本文中,我们不会详细研究哪些工具是真正的趋势。我们将以 EURUSD 货币对为例来测试这种方法,因为 EURUSD 被认为是趋势货币对,而 EURGBP 则在前一篇文章中被研究为区间震荡货币对。
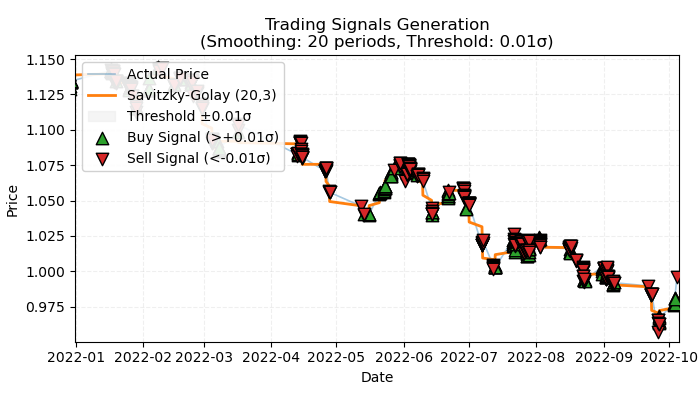
图1. 标记基于趋势交易的可视化表示
图 1 说明了用于标记基于趋势的交易的基本原理。为了平滑短期噪声波动,我再次使用了 Savitzky-Golay 滤波器,该滤波器在前一篇文章中已详细讨论过。然而,我们现在对过滤器的方向感兴趣,将其作为趋势的指标,而不是像上次那样计算与过滤器的价格偏差。如果方向为正,则标记为买入交易;否则,将标记为卖出交易。如果方向不明确,则此类交易将被排除在训练过程之外。标签函数包含一个嵌入式趋势强度过滤器或阈值,它根据波动性过滤掉不重要的趋势,下面将对此进行讨论。
一种用于标记基于趋势的交易的基本方法
为了全面了解其机制,让我们从内部探索交易标记函数。
@njit def calculate_labels_trend(normalized_trend, threshold): labels = np.empty(len(normalized_trend), dtype=np.float64) for i in range(len(normalized_trend)): if normalized_trend[i] > threshold: labels[i] = 0.0 # Buy (Up trend) elif normalized_trend[i] < -threshold: labels[i] = 1.0 # Sell (Down trend) else: labels[i] = 2.0 # No signal return labels def get_labels_trend(dataset, rolling=200, polyorder=3, threshold=0.5, vol_window=50) -> pd.DataFrame: smoothed_prices = savgol_filter(dataset['close'].values, window_length=rolling, polyorder=polyorder) trend = np.gradient(smoothed_prices) vol = dataset['close'].rolling(vol_window).std().values normalized_trend = np.where(vol != 0, trend / vol, np.nan) # Set NaN where vol is 0 labels = calculate_labels_trend(normalized_trend, threshold) dataset = dataset.iloc[:len(labels)].copy() dataset['labels'] = labels dataset = dataset.dropna() # Remove rows with NaN return dataset
get_labels_trend 函数处理原始数据 —— 包含“close”列(收盘价)的数据集,并返回一个添加了标记信号列的数据帧。
关键标注步骤:
- 价格平滑。 采用 Savitzky-Golay 滤波器对收盘价进行平滑处理。参数包括平滑窗口长度和多项式阶数。目标是消除噪音,突出潜在趋势。
smoothed_prices = savgol_filter(dataset['close'].values, window_length=rolling, polyorder=polyorder) - 趋势计算。计算平滑价格的梯度。梯度表示价格变化的速度和方向。正梯度表示上升趋势,负梯度表示下降趋势。
trend = np.gradient(smoothed_prices)
- 波动率计算。波动率计算为滚动窗口内收盘价的标准差。这有助于评估价格波动,以使趋势规范化。
vol = dataset['close'].rolling(vol_window).std().values - 趋势规范化。趋势除以波动率,以反映市场波动性。
normalized_trend = np.where(vol != 0, trend / vol, np.nan) - 标记生成。买卖信号的标记是根据规范化趋势和阈值生成的。
labels = calculate_labels_trend(normalized_trend, threshold)
- 阈值应用。此值过滤掉微小的梯度偏差。此值是根据经验选择的,通常在 0.01 - 0.5 的范围内。位于筛选边界内的趋势被视为无关紧要而忽略不计。
我们将以此标记方法为基础,编写更多标记器,以便进行更多实验。
仅限盈利性交易的标记限制
基本方法固有地包括一些亏损交易,因为它们可能发生在趋势反转前的最后阶段。这对应于真实的交易系统信号,但这些信号也可能出错。重要的是盈利交易与亏损交易的百分比,这应该有利于盈利交易。然而,我们可以通过只标记盈利交易而忽略亏损交易来消除这一缺陷。这有助于平滑训练数据以及可能还有测试数据的公平性曲线。下面给出这种标记的代码。
@njit def calculate_labels_trend_with_profit(close, normalized_trend, threshold, markup, min_l, max_l): labels = np.empty(len(normalized_trend) - max_l, dtype=np.float64) for i in range(len(normalized_trend) - max_l): if normalized_trend[i] > threshold: # Проверяем условие для Buy rand = random.randint(min_l, max_l) future_pr = close[i + rand] if future_pr >= close[i] + markup: labels[i] = 0.0 # Buy (Profit reached) else: labels[i] = 2.0 # No profit elif normalized_trend[i] < -threshold: # Проверяем условие для Sell rand = random.randint(min_l, max_l) future_pr = close[i + rand] if future_pr <= close[i] - markup: labels[i] = 1.0 # Sell (Profit reached) else: labels[i] = 2.0 # No profit else: labels[i] = 2.0 # No signal return labels def get_labels_trend_with_profit(dataset, rolling=200, polyorder=3, threshold=0.5, vol_window=50, markup=0.00005, min_l=1, max_l=15) -> pd.DataFrame: # Smoothing and trend calculation smoothed_prices = savgol_filter(dataset['close'].values, window_length=rolling, polyorder=polyorder) trend = np.gradient(smoothed_prices) # Normalizing the trend by volatility vol = dataset['close'].rolling(vol_window).std().values normalized_trend = np.where(vol != 0, trend / vol, np.nan) # Removing NaN and synchronizing data valid_mask = ~np.isnan(normalized_trend) normalized_trend_clean = normalized_trend[valid_mask] close_clean = dataset['close'].values[valid_mask] dataset_clean = dataset[valid_mask].copy() # Generating labels labels = calculate_labels_trend_with_profit(close_clean, normalized_trend_clean, threshold, markup, min_l, max_l) # Trimming the dataset and adding labels dataset_clean = dataset_clean.iloc[:len(labels)].copy() dataset_clean['labels'] = labels # Filtering the results dataset_clean = dataset_clean.dropna() return dataset_clean
与基本方法的主要区别:
- 新增了 min_l 参数,用于定义衡量价格变化所需的未来柱形的最小数量。
- 新增了 max_l 参数,用于定义衡量价格变化的未来柱形的最大数量。
- 从这些参数设定的范围内随机选择一个未来的柱形。可以通过将两个参数设置为相同的值来实现固定长度检查。
- 如果在 + n 根柱形开仓后获得利润,则该交易将被添加到训练数据集中,否则将被标记为 2.0(无交易)。
- 已添加 markup 参数,该参数应设置为交易工具的平均点差 + 佣金 + 滑点,可能还会加上预付款。该值会影响标记为盈利交易的数量 —— 该值越高,标记为盈利的交易就越少,因为它们未能达到该阈值。
标记带有筛选选择选项和严格的盈利交易限制
和上一篇文章一样,我们希望有多种筛选器可供选择,而不仅仅是 Savitzky-Golay。这样可以有更多标记变化,并使交易系统更好地适应不同工具的特性。我建议添加简单移动平均线、指数移动平均线和样条曲线作为附加筛选器。仅作为例子,您可以类比添加自己的例子。
@njit def calculate_labels_trend_different_filters(close, normalized_trend, threshold, markup, min_l, max_l): labels = np.empty(len(normalized_trend) - max_l, dtype=np.float64) for i in range(len(normalized_trend) - max_l): if normalized_trend[i] > threshold: # Проверяем условие для Buy rand = random.randint(min_l, max_l) future_pr = close[i + rand] if future_pr >= close[i] + markup: labels[i] = 0.0 # Buy (Profit reached) else: labels[i] = 2.0 # No profit elif normalized_trend[i] < -threshold: # Проверяем условие для Sell rand = random.randint(min_l, max_l) future_pr = close[i + rand] if future_pr <= close[i] - markup: labels[i] = 1.0 # Sell (Profit reached) else: labels[i] = 2.0 # No profit else: labels[i] = 2.0 # No signal return labels def get_labels_trend_with_profit_different_filters(dataset, method='savgol', rolling=200, polyorder=3, threshold=0.5, vol_window=50, markup=0.5, min_l=1, max_l=15) -> pd.DataFrame: # Smoothing and trend calculation close_prices = dataset['close'].values if method == 'savgol': smoothed_prices = savgol_filter(close_prices, window_length=rolling, polyorder=polyorder) elif method == 'spline': x = np.arange(len(close_prices)) spline = UnivariateSpline(x, close_prices, k=polyorder, s=rolling) smoothed_prices = spline(x) elif method == 'sma': smoothed_series = pd.Series(close_prices).rolling(window=rolling).mean() smoothed_prices = smoothed_series.values elif method == 'ema': smoothed_series = pd.Series(close_prices).ewm(span=rolling, adjust=False).mean() smoothed_prices = smoothed_series.values else: raise ValueError(f"Unknown smoothing method: {method}") trend = np.gradient(smoothed_prices) # Normalizing the trend by volatility vol = dataset['close'].rolling(vol_window).std().values normalized_trend = np.where(vol != 0, trend / vol, np.nan) # Removing NaN and synchronizing data valid_mask = ~np.isnan(normalized_trend) normalized_trend_clean = normalized_trend[valid_mask] close_clean = dataset['close'].values[valid_mask] dataset_clean = dataset[valid_mask].copy() # Generating labels labels = calculate_labels_trend_different_filters(close_clean, normalized_trend_clean, threshold, markup, min_l, max_l) # Trimming the dataset and adding labels dataset_clean = dataset_clean.iloc[:len(labels)].copy() dataset_clean['labels'] = labels # Filtering the results dataset_clean = dataset_clean.dropna() return dataset_clean
与之前的标注算法相比,主要变化是增加了 method 参数,该参数可以取以下值:
- savgol - Savitzky-Golay 筛选器
- spline - 样条插值
- sma - 简单移动平均平滑法
- ema - 指数移动平均平滑法。
基于不同周期和严格盈利交易限制的过滤器进行标记
让我们把对现实的感知变得复杂化,从而也让交易标记方法变得复杂化。使用单个选定的平滑周期没有限制。可以同时使用具有不同时段的多个相同类型的筛选器,在至少满足一个条件时标记交易。下面给出一个此类采样器的示例:
@njit def calculate_labels_trend_multi(close, normalized_trends, threshold, markup, min_l, max_l): num_periods = normalized_trends.shape[0] # Number of periods labels = np.empty(len(close) - max_l, dtype=np.float64) for i in range(len(close) - max_l): # Select a random number of bars forward once for all periods rand = np.random.randint(min_l, max_l + 1) buy_signals = 0 sell_signals = 0 # Check conditions for each period for j in range(num_periods): if normalized_trends[j, i] > threshold: if close[i + rand] >= close[i] + markup: buy_signals += 1 elif normalized_trends[j, i] < -threshold: if close[i + rand] <= close[i] - markup: sell_signals += 1 # Combine signals if buy_signals > 0 and sell_signals == 0: labels[i] = 0.0 # Buy elif sell_signals > 0 and buy_signals == 0: labels[i] = 1.0 # Sell else: labels[i] = 2.0 # No signal or conflict return labels def get_labels_trend_with_profit_multi(dataset, method='savgol', rolling_periods=[10, 20, 30], polyorder=3, threshold=0.5, vol_window=50, markup=0.5, min_l=1, max_l=15) -> pd.DataFrame: """ Generates labels for trading signals (Buy/Sell) based on the normalized trend, calculated for multiple smoothing periods. Args: dataset (pd.DataFrame): DataFrame with data, containing the 'close' column. method (str): Smoothing method ('savgol', 'spline', 'sma', 'ema'). rolling_periods (list): List of smoothing window sizes. Default is [200]. polyorder (int): Polynomial order for 'savgol' and 'spline' methods. threshold (float): Threshold for the normalized trend. vol_window (int): Window for volatility calculation. markup (float): Minimum profit to confirm the signal. min_l (int): Minimum number of bars forward. max_l (int): Maximum number of bars forward. Returns: pd.DataFrame: DataFrame with added 'labels' column: - 0.0: Buy - 1.0: Sell - 2.0: No signal """ close_prices = dataset['close'].values normalized_trends = [] # Calculate normalized trend for each period for rolling in rolling_periods: if method == 'savgol': smoothed_prices = savgol_filter(close_prices, window_length=rolling, polyorder=polyorder) elif method == 'spline': x = np.arange(len(close_prices)) spline = UnivariateSpline(x, close_prices, k=polyorder, s=rolling) smoothed_prices = spline(x) elif method == 'sma': smoothed_series = pd.Series(close_prices).rolling(window=rolling).mean() smoothed_prices = smoothed_series.values elif method == 'ema': smoothed_series = pd.Series(close_prices).ewm(span=rolling, adjust=False).mean() smoothed_prices = smoothed_series.values else: raise ValueError(f"Unknown smoothing method: {method}") trend = np.gradient(smoothed_prices) vol = pd.Series(close_prices).rolling(vol_window).std().values normalized_trend = np.where(vol != 0, trend / vol, np.nan) normalized_trends.append(normalized_trend) # Transform list into 2D array normalized_trends_array = np.vstack(normalized_trends) # Remove rows with NaN valid_mask = ~np.isnan(normalized_trends_array).any(axis=0) normalized_trends_clean = normalized_trends_array[:, valid_mask] close_clean = close_prices[valid_mask] dataset_clean = dataset[valid_mask].copy() # Generate labels labels = calculate_labels_trend_multi(close_clean, normalized_trends_clean, threshold, markup, min_l, max_l) # Trim data and add labels dataset_clean = dataset_clean.iloc[:len(labels)].copy() dataset_clean['labels'] = labels # Remove remaining NaN dataset_clean = dataset_clean.dropna() return dataset_clean
需要注意的要点(在概念上突出显示):
- 标记函数现在接受包含平滑周期值的任意长度的列表。
- 筛选器会在一个循环中针对所有指定的时段进行计算。
- 所有筛选器的趋势梯度都参与了标记函数。
- 如果满足至少一个买入或卖出条件,且没有相反的信号,则该交易会被标记为买入或卖出。
labeling_lib.py 模块新增了四个采样器:
def get_labels_trend(dataset, rolling=200, polyorder=3, threshold=0.5, vol_window=50) -> pd.DataFrame: def get_labels_trend_with_profit(dataset, rolling=200, polyorder=3, threshold=0.5, def get_labels_trend_with_profit_different_filters(dataset, method='savgol', rolling=200, polyorder=3, threshold=0.5, def get_labels_trend_with_profit_multi(dataset, method='savgol', rolling_periods=[10, 20, 30], polyorder=3, threshold=0.5,
我们就先讨论这些变体吧,它们足以用于检验趋势标记的核心思想。
模型训练和测试过程
数据准备和训练的核心逻辑借鉴了前一篇文章,因此不会详细描述其细节。但是,有一些变化:整个训练周期现在被移至一个单独的 processing 函数中,从而为管理该过程提供了新的能力。
以前,标记为 2.0 的交易会被直接从训练数据集中删除,而不会参与学习。这可能会导致标记序列出现空缺,从而造成信息丢失。但是,如果使用二元分类器,而 2.0 标签(无操作)代表第三类,那么如何将此信息纳入交易系统呢?
让我们回想一下,训练中涉及两个分类器:第一个学习预测买入/卖出标记,第二个学习预测当前的市场状况(何时交易,何时不交易)。这意味着我们可以将带有 2.0 标签的示例迁移到第二个模型,从而保留信息而不是丢弃信息。
def processing(iterations = 1, rolling = [10], threshold=0.01, polyorder=5, vol_window=100, use_meta_dilution = True): models = [] for i in range(iterations): data = clustering(dataset, n_clusters=hyper_params['n_clusters']) sorted_clusters = data['clusters'].unique() sorted_clusters.sort() for clust in sorted_clusters: clustered_data = data[data['clusters'] == clust].copy() if len(clustered_data) < 500: print('too few samples: {}'.format(len(clustered_data))) continue clustered_data = get_labels_trend_with_profit_multi( clustered_data, method='savgol', rolling_periods=rolling, polyorder=polyorder, threshold=threshold, vol_window=vol_window, min_l=1, max_l=15, markup=hyper_params['markup']) print(f'Iteration: {i}, Cluster: {clust}') clustered_data = clustered_data.drop(['close', 'clusters'], axis=1) meta_data = data.copy() meta_data['clusters'] = meta_data['clusters'].apply(lambda x: 1 if x == clust else 0) if use_meta_dilution: for dt in clustered_data.index: if clustered_data.loc[dt, 'labels'] == 2.0: if dt in meta_data.index: # Check if datetime exists in meta_data meta_data.loc[dt, 'clusters'] = 0 clustered_data = clustered_data.drop(clustered_data[clustered_data.labels == 2.0].index) # Синхронизация meta_data с bad_data models.append(fit_final_models(clustered_data, meta_data.drop(['close'], axis=1))) models.sort(key=lambda x: x[0]) return models
代码显示,第一个模型数据集中标记为 2.0 的示例,根据其对应的日期/行,在第二个模型数据集中被选中,并且在 clusters 列中设置为零。考虑到允许交易,第二个模型现在不仅会预测市场状况,还会根据交易样本预测不理想的交易入场点。换句话说,第二个模型现在将预测所需的市场制度和不理想的市场进入点。
我建议立即使用最后一个采样器,因为它包含了所有最好的功能,并且设置灵活。
让我们使用以下设置进行 10 个训练周期:
hyper_params = {
'symbol': 'EURUSD_H1',
'export_path': '/Users/dmitrievsky/Library/Containers/com.isaacmarovitz.Whisky/Bottles/54CFA88F-36A3-47F7-915A-D09B24E89192/drive_c/Program Files/MetaTrader 5/MQL5/Include/Mean reversion/',
'model_number': 0,
'markup': 0.00010,
'stop_loss': 0.00500,
'take_profit': 0.00200,
'periods': [i for i in range(5, 300, 30)],
'periods_meta': [100],
'backward': datetime(2000, 1, 1),
'forward': datetime(2024, 1, 1),
'full forward': datetime(2026, 1, 1),
'n_clusters': 10,
'rolling': [10],
} 训练函数本身的调用方式如下:
dataset = get_features(get_prices()) models = processing(iterations = 10, threshold=0.001, polyorder=3, vol_window=100, use_meta_dilution = True)
训练过程中,将显示每次通过(聚类)的 R^2 分数:
Iteration: 0, Cluster: 0 R2: 0.9837358133371028 Iteration: 0, Cluster: 1 R2: 0.9002342482016827 Iteration: 0, Cluster: 2 R2: 0.9755114279213657 Iteration: 0, Cluster: 3 R2: 0.9833351908595832 Iteration: 0, Cluster: 4 R2: 0.9537875370012954 Iteration: 0, Cluster: 5 R2: 0.9863566422346429 too few samples: 471 Iteration: 0, Cluster: 7 R2: 0.9852545217737659 Iteration: 0, Cluster: 8 R2: 0.9934196831544163
让我们测试一下列表中最好的模型:
test_model(models[-1][1:], hyper_params['stop_loss'], hyper_params['take_profit'], hyper_params['forward'], plt=True)
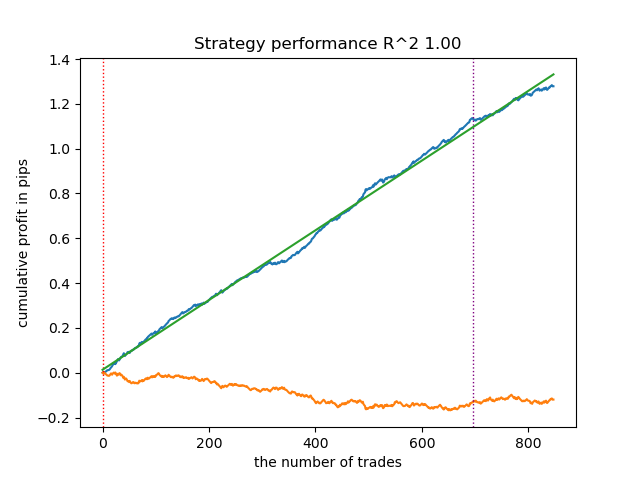
图 2. 模型在训练数据和新数据上的测试
现在我们可以调用该函数将模型导出到 MetaTrader 5 终端。
export_model_to_ONNX(model = models[-1], symbol = hyper_params['symbol'], periods = hyper_params['periods'], periods_meta = hyper_params['periods_meta'], model_number = hyper_params['model_number'], export_path = hyper_params['export_path'])
最终模型测试和算法概述
我的方法是通用的,因此将模型导出到终端的方式与前一篇文章中描述的完全相同。
让我们分别看一下整个训练+测试阶段和单独的测试阶段。数据显示,从 2024 年开始,训练数据的净值曲线比测试数据的净值曲线更平滑。由于训练从 2020 年到 2024 年进行,因此测试结果从 2019 年开始显示,以证明训练前的时期也不是完全平稳的。
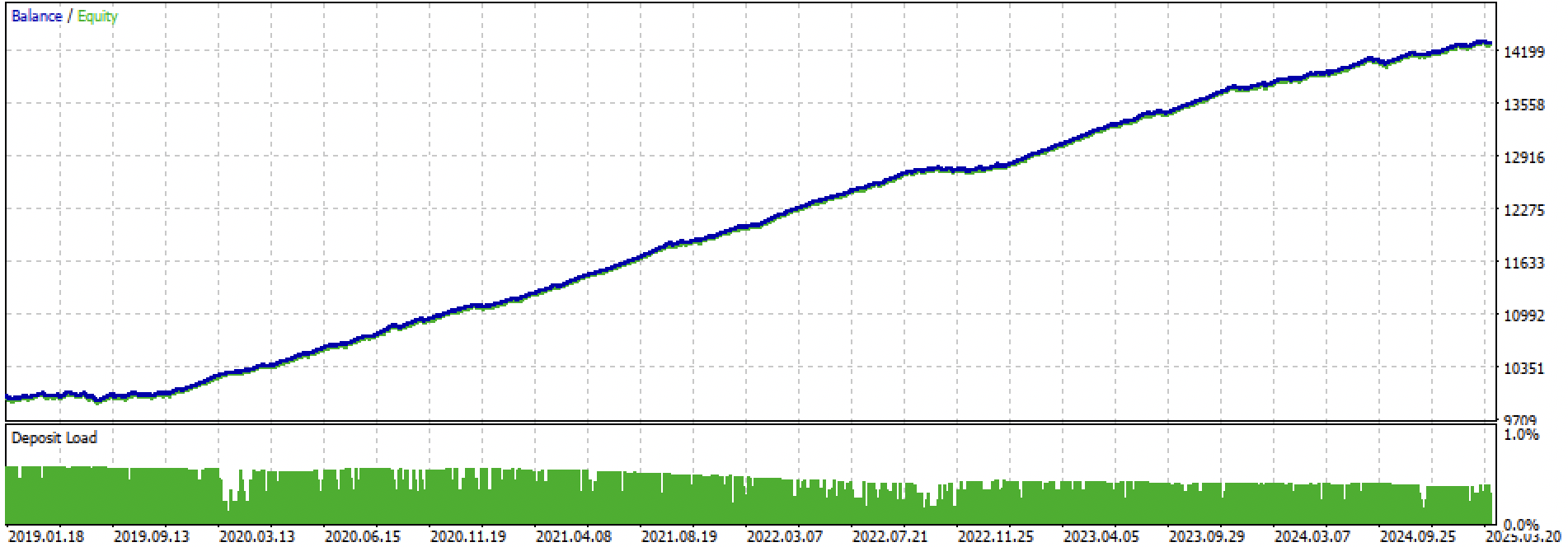
图 3. 2019 年至 2025 年的测试。
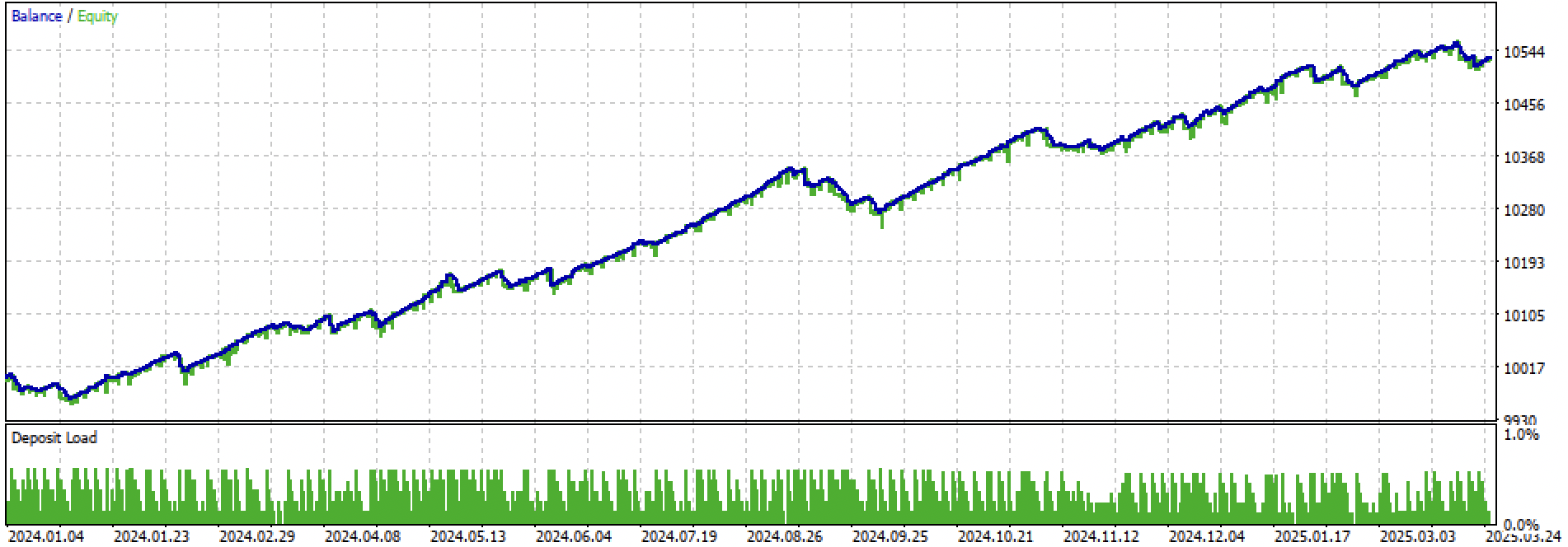
图 4. 2024 年初至 2025 年 3 月 27 日前向测试
根据已进行的实验,我的结论是,趋势跟踪策略在新数据上的表现比较挑剔,或者说这种方法在 EURUSD 货币对上创建此类策略的效果并不理想。然而,通过实验超参数调整,可以获得相当好的模型。这些缺点部分地被这样一个事实所弥补,即这些模型可以在非常短的止损时间内显示出良好的结果,例如在 20 个 4 位数的点内。这允许在模型开始失效时进行风险控制和及时停用。
此外,我无法识别任何重要的超参数集。我得到的印象是,该算法在寻找任何稳定模式方面从根本上来说都很弱,或者根本不存在这样的模式。
为了防止过拟合,可以在 fit_final_models() 函数中降低模型复杂度:
def fit_final_models(clustered, meta) -> list: # features for model\meta models. We learn main model only on filtered labels X, X_meta = clustered[clustered.columns[:-1]], meta[meta.columns[:-1]] X = X.loc[:, ~X.columns.str.contains('meta_feature')] X_meta = X_meta.loc[:, X_meta.columns.str.contains('meta_feature')] # labels for model\meta models y = clustered['labels'] y_meta = meta['clusters'] y = y.astype('int16') y_meta = y_meta.astype('int16') # train\test split train_X, test_X, train_y, test_y = train_test_split( X, y, train_size=0.7, test_size=0.3, shuffle=True) train_X_m, test_X_m, train_y_m, test_y_m = train_test_split( X_meta, y_meta, train_size=0.7, test_size=0.3, shuffle=True) # learn main model with train and validation subsets model = CatBoostClassifier(iterations=100, custom_loss=['Accuracy'], eval_metric='Accuracy', verbose=False, use_best_model=True, task_type='CPU', thread_count=-1) model.fit(train_X, train_y, eval_set=(test_X, test_y), early_stopping_rounds=15, plot=False) # learn meta model with train and validation subsets meta_model = CatBoostClassifier(iterations=100, custom_loss=['F1'], eval_metric='F1', verbose=False, use_best_model=True, task_type='CPU', thread_count=-1) meta_model.fit(train_X_m, train_y_m, eval_set=(test_X_m, test_y_m), early_stopping_rounds=15, plot=False) R2 = test_model([model, meta_model], hyper_params['stop_loss'], hyper_params['take_profit'], hyper_params['full forward']) if math.isnan(R2): R2 = -1.0 print('R2 is fixed to -1.0') print('R2: ' + str(R2)) return [R2, model, meta_model]
迭代次数控制模型中的分割次数和选定特征的数量。最初是 1000 次迭代;我们将其减少到 100 次。如果验证数据上的分类错误在连续 15 次迭代中没有改善,提前停止会过早停止训练。
这导致净值曲线更加嘈杂、更加均匀,但“美观”程度有所降低。
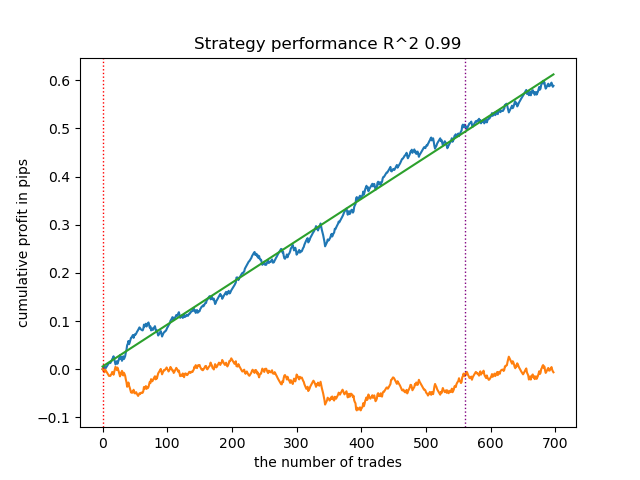
图 5. 降低模型复杂度后的净值曲线。
结论
基于聚类和二元分类创建趋势跟踪策略更具挑战性。需要新的见解来了解如何做到这一点。一个具体的问题似乎是金融资产价格超出了模型训练的价值范围。与盘整型工具的训练不同,盘整型工具上新数据的价格通常与训练期间看到的价格相对应。如果应用基于价格差异的特征,该模型再次表现出较差的泛化能力。
通过这篇文章,我旨在总结我对市场制度聚类方法的实验,在你们面前还有新的、更有趣的想法。
附件材料:
| 文件名称 | 描述 |
|---|---|
| labeling_lib.py | 更新后的采样器库 |
| trend_ollowing.py | 模型训练脚本 |
| cat model_EURUSD_H1_0.onnx | 主模型,包含文件夹 |
| catmodel_m_EURUSD_H1_0.onnx | 元模型,包含文件夹 |
| EURUSD_H1_ONNX_include_0.mqh | 头文件 |
| trend_ollowing.mq5 | EA 交易来源 |
| trend_ollowing.ex5 | 编译好的机器人 |
本文由MetaQuotes Ltd译自俄文
原文地址: https://www.mql5.com/ru/articles/17526
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。
结果还不错。2025 年的春天是一个不同的市场。
我想,欧元最近的预测能力一般。持平/趋势交易不起作用。
只有买入交易对趋势良好的货币(如黄金)有效,如上一篇文章所述。在条形图上,不是剥头皮。
欧洲美元和单向交易不起作用。
我想欧元最近的预测能力一般。平盘/趋势预测都不奏效。
只有买入交易在趋势良好的货币(注意黄金)上才有效,如上一篇文章所述。在条形图上,不是剥头皮。
欧洲美元和单向交易不起作用。
但如果市场发生变化,ts 就会失效。没有自动监督器,它已经是一本半手册了
但是,如果市场发生变化,TC 就死定了。
如何获得这个机器人 🤖?