
Explorando modelos de regressão para inferência causal e trading
Introdução
Ao longo de uma série de artigos, exploramos diferentes formas de classificação de séries temporais, mas ainda não havíamos abordado os modelos de regressão. Diferentemente da classificação binária, os modelos de regressão permitem prever não a probabilidade de uma observação pertencer a uma ou outra classe, mas sim valores contínuos, o que amplia as possibilidades de aplicação na criação de sistemas de trading automatizados.
A classificação binária é uma tarefa fundamental de machine learning cujo objetivo é classificar os dados de entrada em uma de duas categorias ou classes distintas. No contexto de um robô de trading no Forex, isso normalmente significa prever um sinal de "compra" (representado por 0) ou de "venda" (representado por 1). Essa abordagem reduz a dinâmica complexa do mercado a uma simples decisão direcional.
A limitação interna mais relevante da classificação binária para o trading quantitativo é sua incapacidade de quantificar a magnitude ou a intensidade do movimento de preço previsto. Um classificador binário apenas indica se o preço vai subir ou cair, sem fornecer qualquer informação sobre o quanto se espera que ele varie. A ausência desse nível de detalhe limita de forma fundamental a complexidade das decisões de trading.
A precisão das previsões do classificador, por si só, não leva em conta a magnitude da variação e, por isso, não é muito útil para o trading. Esse ponto é fundamental, pois destaca que uma alta precisão na identificação da direção, por exemplo, acertar a direção correta em 70% dos casos, não leva automaticamente à lucratividade no trading.
Há uma observação importante: alta precisão na identificação da direção não garante lucratividade. Por exemplo, é possível acertar em 30% dos casos e ainda assim ser lucrativo, ou acertar em 70% dos casos e operar no prejuízo. Isso mostra que o resultado líquido de uma estratégia de trading é determinado pela magnitude do lucro nas operações vencedoras em comparação com a magnitude das perdas nas operações perdedoras, e não simplesmente pela porcentagem de acertos.
Um modelo de classificação binária, ao tratar todos os acertos direcionais da mesma forma, independentemente da oscilação real do preço, não consegue diferenciar um movimento pequeno e pouco relevante de um movimento expressivo e altamente lucrativo. Isso pode levar a um cenário em que muitas operações vencedoras pequenas sejam anuladas por algumas operações perdedoras grandes, ou o contrário, resultando em um resultado financeiro total negativo (PnL), apesar da aparente alta precisão.
A ausência de uma avaliação quantitativa do movimento do preço significa que o robô de trading não consegue priorizar operações com maior lucro esperado nem evitar operações em que a perda potencial supera significativamente o ganho potencial, mesmo quando a direção é prevista corretamente. Sem informação sobre a magnitude, o robô opera com um ponto cego em relação ao impacto financeiro real de suas decisões, o que leva a retornos acumulados subótimos ou até negativos, apesar de uma alta taxa de acerto com base na direção.
Modificação da função de rotulação
Vamos supor o seguinte cenário: há uma série temporal financeira que precisa ser prevista com base em um conjunto de características. No caso da classificação binária, é possível definir a direção da operação futura (compra ou venda), e esses rótulos são sempre fixos. Não podemos rotulá-los de outra forma para obter uma estimativa mais precisa da magnitude dos futuros desvios de preço. As operações acabam sendo tratadas como equivalentes, independentemente de quanto o preço realmente mudou.
Agora imagine que podemos prever não apenas a direção da operação, mas também a magnitude da variação futura. Isso permitirá ajustar o sistema de trading com mais precisão por meio da criação de filtros adicionais, que ajudarão a identificar apenas as oscilações de preço previstas que sejam relevantes para o trading e a descartar as insignificantes.
Para treinar um modelo de regressão, é necessário preparar as características e os alvos de treinamento. As características podem ser comuns ao classificador e ao regressor, enquanto os alvos serão diferentes.
Vamos escrever uma função simples que implementa a rotulação dos exemplos para um modelo de regressão:
@njit def calculate_labels_r(close_data, min_val, max_val): labels = [] for i in range(len(close_data) - max_val): rand = random.randint(min_val, max_val) labels.append(close_data[i + rand] - close_data[i]) return labels def get_labels_r(dataset, min = 1, max = 15) -> pd.DataFrame: # Extract closing prices from the dataset close_data = dataset['close'].values labels = calculate_labels_r(close_data, min, max) # Trim the dataset to match the length of calculated labels dataset = dataset.iloc[:len(labels)].copy() # Add the calculated labels as a new column dataset['labels'] = labels # Remove rows with NaN values (potentially introduced in 'calculate_labels') dataset = dataset.dropna() return dataset
A principal diferença em relação à rotulação para classificação binária é que agora determinamos as variações de preço, subtraindo o preço atual do preço futuro, em vez de apenas definir a direção, compra ou venda. O código foi acelerado com Numba, por isso a rotulação dos alvos é feita muito rapidamente.
A função acima considera apenas a diferença entre um preço futuro escolhido aleatoriamente no intervalo {min_val; max_val} e o preço atual. Isso pode não ser totalmente correto, pois não leva em conta os desvios intermediários, que podem ser significativos. Eu proponho mais uma modificação na função de cálculo dos desvios, apresentada abaixo.
@njit def calculate_labels_mean_r(close_data, min_val, max_val): labels = [] for i in range(len(close_data) - max_val): # Calculate the average price value in the window from min_val to max_val future_prices = close_data[i + min_val : i + max_val + 1] mean_future_price = np.mean(future_prices) # Calculate the difference between the average future value and the current price labels.append(mean_future_price - close_data[i]) return labels def get_labels_r(dataset, min = 1, max = 15) -> pd.DataFrame: # Extract closing prices from the dataset close_data = dataset['close'].values # Calculate buy/hold labels based on future price movements labels = calculate_labels_mean_r(close_data, min, max) # Trim the dataset to match the length of calculated labels dataset = dataset.iloc[:len(labels)].copy() # Add the calculated labels as a new column dataset['labels'] = labels # Remove rows with NaN values (potentially introduced in 'calculate_labels') dataset = dataset.dropna() return dataset
Agora a função considera todos os desvios no intervalo especificado, calculando o valor médio. Depois disso, é calculada a diferença entre o valor médio dos preços futuros e o preço atual. Assim, a função get_labels_r() agora chama a função de rotulação calculate_labels_mean_r(), e não calculate_labels_r(), como antes. Você pode experimentar chamando diferentes funções de rotulação.
Adição do sistema de inferência causal
Para previsões mais refinadas, vamos usar um algoritmo semelhante ao descrito no artigo sobre inferência causal. A principal diferença será o uso de um regressor em vez de um classificador.
def meta_learners(data, models_number: int, iterations: int, depth: int): data = data.copy() data = data[(data.index < hyper_params['forward']) & (data.index > hyper_params['backward'])].copy() X = data[data.columns[1:-1]] y = data['labels'] data['meta_labels'] = 0 for i in range(models_number): X_train, X_val, y_train, y_val = train_test_split( X, y, train_size = 0.5, test_size = 0.5, shuffle = True) # fit debias model with train and validation subsets meta_m = CatBoostRegressor(iterations = iterations, depth = depth, verbose = False, use_best_model = True) meta_m.fit(X_train, y_train, eval_set = (X_val, y_val), plot = False) coreset = X.copy() coreset['labels'] = y coreset['labels_pred'] = meta_m.predict(X) data['meta_labels'] += abs(coreset['labels'] - coreset['labels_pred']) data['meta_labels'] = data['meta_labels'] / models_number return data
A função treina vários regressores em subconjuntos aleatórios dos dados do dataset original e, em seguida, compara os alvos reais com os previstos. Dessa forma, o meta-modelo passará a prever não 0 ou 1, isto é, operar ou não operar, mas sim os valores médios dos desvios entre as previsões e os valores reais. Assim, poderemos filtrar previsões que se desviam fortemente dos valores esperados.
Treinamento e teste dos modelos treinados
Para testar os modelos de regressão, o testador foi modificado e recebeu o sufixo "r". Chegou a hora de treinar alguns modelos. Neste artigo, vou treinar 10 modelos e escolher o que eu considerar mais adequado.
hyper_params = {
'symbol': 'EURUSD_H1',
'export_path': '/Users/dmitrievsky/drive_c/Program Files/MetaTrader 5/MQL5/Include/Trend following/',
'model_number': 0,
'markup': 0.00010,
'stop_loss': 0.00500,
'take_profit': 0.00200,
'periods': [i for i in range(5, 100, 30)],
'backward': datetime(2010, 1, 1),
'forward': datetime(2024, 1, 1),
}
models = []
for i in range(10):
print('Learn ' + str(i) + ' model')
data = get_labels_r(get_features(get_prices()), min=1, max=15)
dataset = meta_learners(data=data, models_number=5, iterations=15, depth=3)
models.append(fit_final_models(dataset, tol=3e-2)) Aqui vale destacar o parâmetro tol, que é passado para a função de treinamento dos modelos finais. Como queremos tornar o modelo principal o mais confiável possível, não faz sentido treiná-lo com todos os exemplos. Vamos treiná-lo apenas com os exemplos cujas previsões se desviam dos valores reais em menos do que o valor de tol.
Como os desvios das previsões são calculados efetivamente em pontos, então tol=3e-2 significará uma diferença máxima de 0.03, ou 300 pontos de 4 dígitos. Isso pode parecer grande demais como filtro, mas vale considerar que essa é uma diferença em valores absolutos, já que as previsões podem ser tanto positivas quanto negativas. Você pode experimentar esse parâmetro. A própria função está mostrada abaixo.
def fit_final_models(dataset, tol=1e-2) -> list: # features for model\meta models. We learn main model only on filtered labels X = dataset[dataset['meta_labels'] < tol] X, X_meta = X[X.columns[1:-2]], dataset[dataset.columns[1:-2]] # labels for model\meta models y = dataset[dataset['meta_labels'] < tol] y, y_meta = y[y.columns[-2]], dataset[dataset.columns[-1]] # fit main model with train and validation subsets model = RandomForestRegressor(n_estimators=50, max_depth=10) model.fit(X, y) # fit meta model with train and validation subsets meta_model = RandomForestRegressor(n_estimators=50, max_depth=10) meta_model.fit(X_meta, y_meta) data = get_features(get_prices()) R2 = test_model_r(data, [model, meta_model], hyper_params['stop_loss'], hyper_params['take_profit'], hyper_params['forward'], hyper_params['backward'], hyper_params['markup'], plt=False) if math.isnan(R2): R2 = -1.0 print('R2 is fixed to -1.0') print('R2: ' + str(R2)) result = [R2, model, meta_model] return result
Agora vamos ordenar os modelos e chamar a função do testador customizado:
models.sort(key=lambda x: x[0]) data = get_features(get_prices()) test_model_r(data, models[-1][1:], hyper_params['stop_loss'], hyper_params['take_profit'], hyper_params['forward'], hyper_params['backward'], hyper_params['markup'], plt=True)
O modelo está sobreajustado e apresenta desempenho ruim em dados novos:
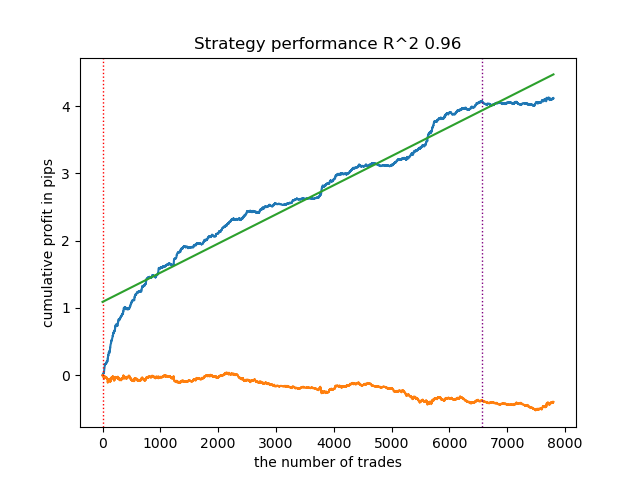
Fig. 1. teste do modelo com rotulagem básica
Vamos realizar exatamente as mesmas manipulações, mas agora tomando como base o rotulador de operações calculate_labels_mean_r(), que calcula os preços futuros médios.
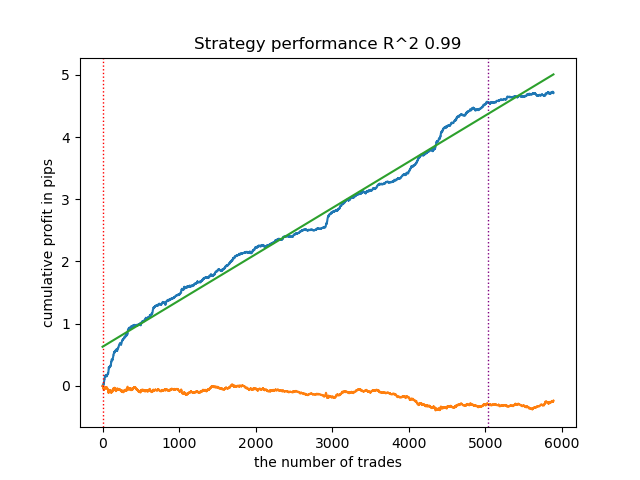
Fig. 2. teste do modelo com rotulagem média
O segundo rotulador de operações, em média, mostra resultados mais estáveis em dados novos. Ao que tudo indica, isso está relacionado ao fato de ele considerar o valor médio dos preços futuros.
No testador customizado, ainda não foi adicionada a possibilidade de definir limiares para o modelo principal de regressão, por isso ele apenas divide as previsões dos modelos em positivas e negativas, o que significa que os sinais ainda são bastante grosseiros. Mas vamos corrigir isso diretamente no terminal MetaTrader 5.
Exportação dos modelos para o terminal MetaTrader 5
Agora precisamos exportar os modelos para o terminal no formato ONNX e configurar o sistema de trading. A função de exportação tem a estrutura habitual:
export_model_to_ONNX(model = models[-1], symbol = hyper_params['symbol'], periods = hyper_params['periods'], periods_meta = hyper_params['periods'], model_number = hyper_params['model_number'], export_path = hyper_params['export_path'])
Vale observar que não consegui conectar os modelos de regressão CatBoost em formato ONNX ao terminal, por isso usei random forest.
A dimensionalidade do tensor de entrada é ajustada automaticamente de acordo com os hiperparâmetros, isto é, a quantidade de características, definidos antes do início do treinamento. Em seguida, os modelos são convertidos para o formato ONNX com a função convert_sklearn() e salvos em disco no diretório que você especificou nos hiperparâmetros.
def export_model_to_ONNX(**kwargs): model = kwargs.get('model') symbol = kwargs.get('symbol') periods = kwargs.get('periods') periods_meta = kwargs.get('periods_meta') model_number = kwargs.get('model_number') export_path = kwargs.get('export_path') initial_type = [('float_input', FloatTensorType([None, len(hyper_params['periods'])]))] onnx_model = convert_sklearn(model[1], initial_types=initial_type) # save main model to ONNX with open(export_path +'catmodel ' + symbol + ' ' + str(model_number) +'.onnx', "wb") as f: f.write(onnx_model.SerializeToString()) onnx_model_meta = convert_sklearn(model[2], initial_types=initial_type) # save meta model to ONNX with open(export_path +'catmodel_m ' + symbol + ' ' + str(model_number) +'.onnx', "wb") as f: f.write(onnx_model_meta.SerializeToString()) code = '#include <Math\Stat\Math.mqh>' code += '\n' code += '#resource "catmodel '+ symbol + ' '+str(model_number)+'.onnx" as uchar ExtModel_' + symbol + '_' + str(model_number) + '[]' code += '\n' code += '#resource "catmodel_m '+ symbol + ' '+str(model_number)+'.onnx" as uchar ExtModel2_' + symbol + '_' + str(model_number) + '[]' code += '\n\n' code += 'int Periods' + symbol + '_' + str(model_number) + '[' + str(len(periods)) + \ '] = {' + ','.join(map(str, periods)) + '};' code += '\n' code += 'int Periods_m' + symbol + '_' + str(model_number) + '[' + str(len(periods_meta)) + \ '] = {' + ','.join(map(str, periods_meta)) + '};' code += '\n\n' # get features code += 'void fill_arays' + symbol + '_' + str(model_number) + '( double &features[]) {\n' code += ' double pr[], ret[];\n' code += ' ArrayResize(ret, 1);\n' code += ' for(int i=ArraySize(Periods'+ symbol + '_' + str(model_number) + ')-1; i>=0; i--) {\n' code += ' CopyClose(NULL,PERIOD_H1,1,Periods' + symbol + '_' + str(model_number) + '[i],pr);\n' code += ' ret[0] = MathStandardDeviation(pr);\n' code += ' ArrayInsert(features, ret, ArraySize(features), 0, WHOLE_ARRAY); }\n' code += ' ArraySetAsSeries(features, true);\n' code += '}\n\n' # get features code += 'void fill_arays_m' + symbol + '_' + str(model_number) + '( double &features[]) {\n' code += ' double pr[], ret[];\n' code += ' ArrayResize(ret, 1);\n' code += ' for(int i=ArraySize(Periods_m' + symbol + '_' + str(model_number) + ')-1; i>=0; i--) {\n' code += ' CopyClose(NULL,PERIOD_H1,1,Periods_m' + symbol + '_' + str(model_number) + '[i],pr);\n' code += ' ret[0] = MathStandardDeviation(pr);\n' code += ' ArrayInsert(features, ret, ArraySize(features), 0, WHOLE_ARRAY); }\n' code += ' ArraySetAsSeries(features, true);\n' code += '}\n\n' file = open(export_path + str(symbol) + ' ONNX include' + ' ' + str(model_number) + '.mqh', "w") file.write(code) file.close() print('The file ' + 'ONNX include' + '.mqh ' + 'has been written to disk')
Configuração dos limiares no terminal MetaTrader 5
Agora que obtivemos dois modelos de regressão em vez de dois classificadores, passamos a ter a possibilidade de definir limiares numéricos específicos.
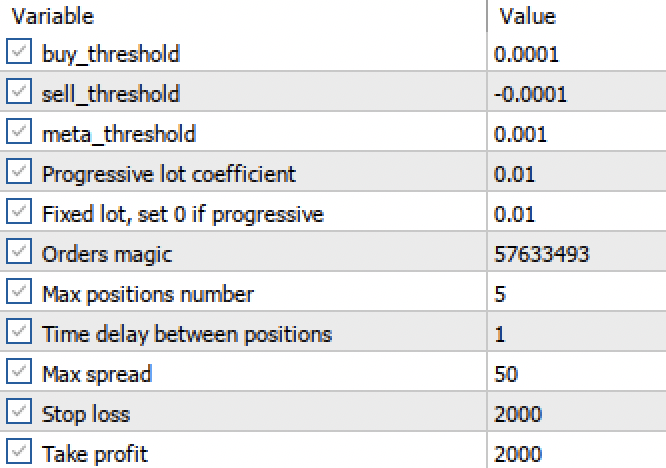
Fig. 3. configuração dos limiares de ativação dos sinais no terminal
- Os limiares buy_threshhold e sell_threshhold são responsáveis por filtrar os sinais do modelo principal de regressão. Se o sinal estiver abaixo desse limiar, as operações não serão abertas. Por exemplo, se a variação de preço prevista for inferior a 10 pontos, abrir essa operação não faz muito sentido, pois ela não cobrirá o spread e a comissão.
- O limiar meta_threshhold filtra os sinais do modelo principal com base na inferência causal descrita anteriormente. Ele verifica o quanto a previsão provavelmente difere da variação futura real. Se a diferença for grande demais, as operações também não serão abertas.
Agora vamos testar nosso modelo no testador MetaTrader 5 com os limiares definidos:
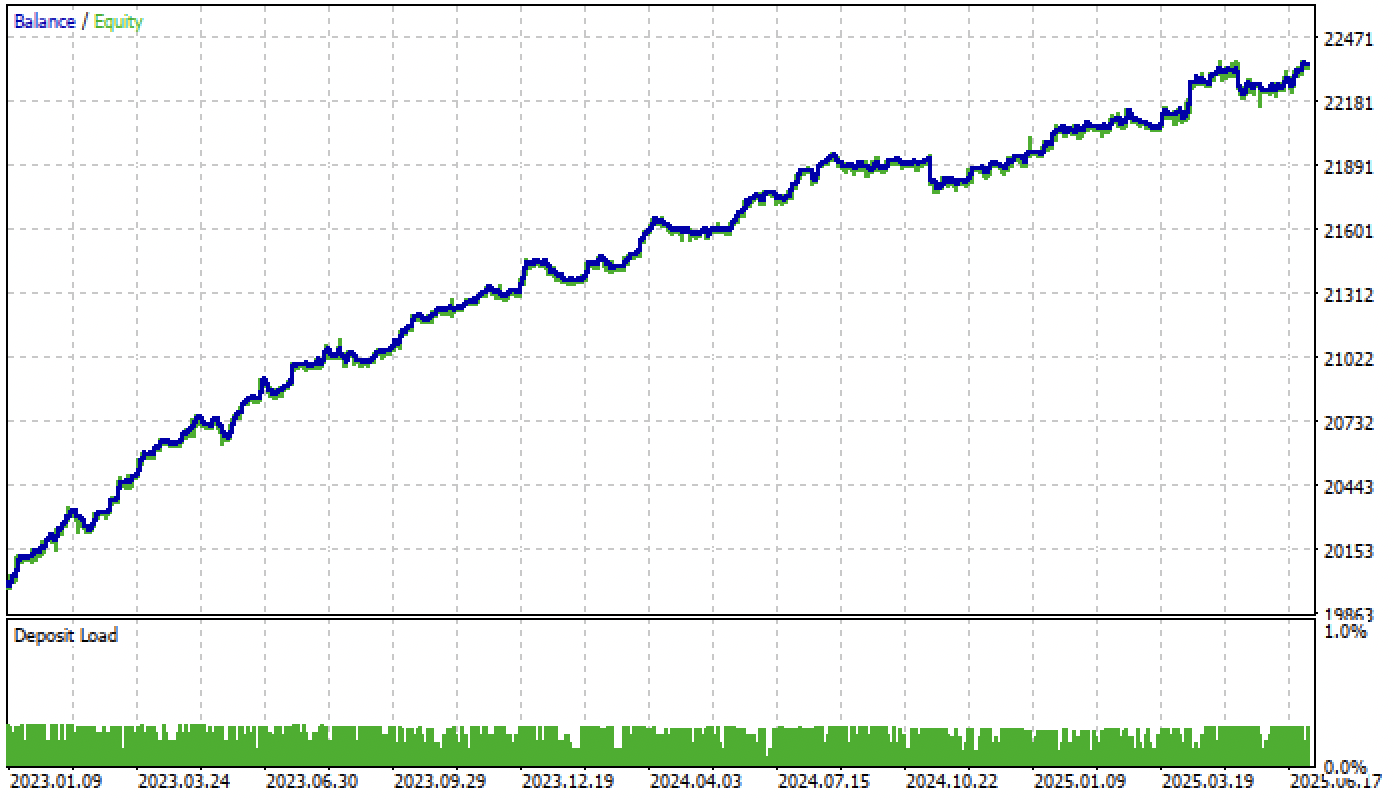
Fig. 4. teste do modelo com limiares definidos
Lembro que o período de propagação para frente começa no início de 2024, e agora o modelo o atravessa com estabilidade suficiente. Isso reforça a importância de definir e ajustar corretamente os limiares. Você pode otimizar os valores dos limiares por conta própria.
A variedade de modelos pode ser grande, dependendo do tipo de características, nesta matéria, ambos os modelos são treinados com desvios padrão, assim como dos parâmetros dos próprios modelos. Por exemplo, foi treinado mais um modelo com outros parâmetros, que apresentou bom desempenho em dados novos mesmo sem ajuste de limiares.
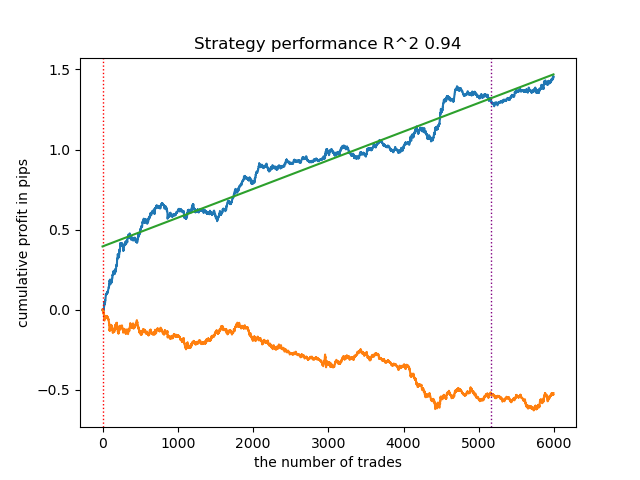
Fig. 5. treinamento e teste de outro modelo, com outros parâmetros de treinamento
E, após o ajuste dos limiares, o modelo mostrou crescimento consistente desde o início de 2024.
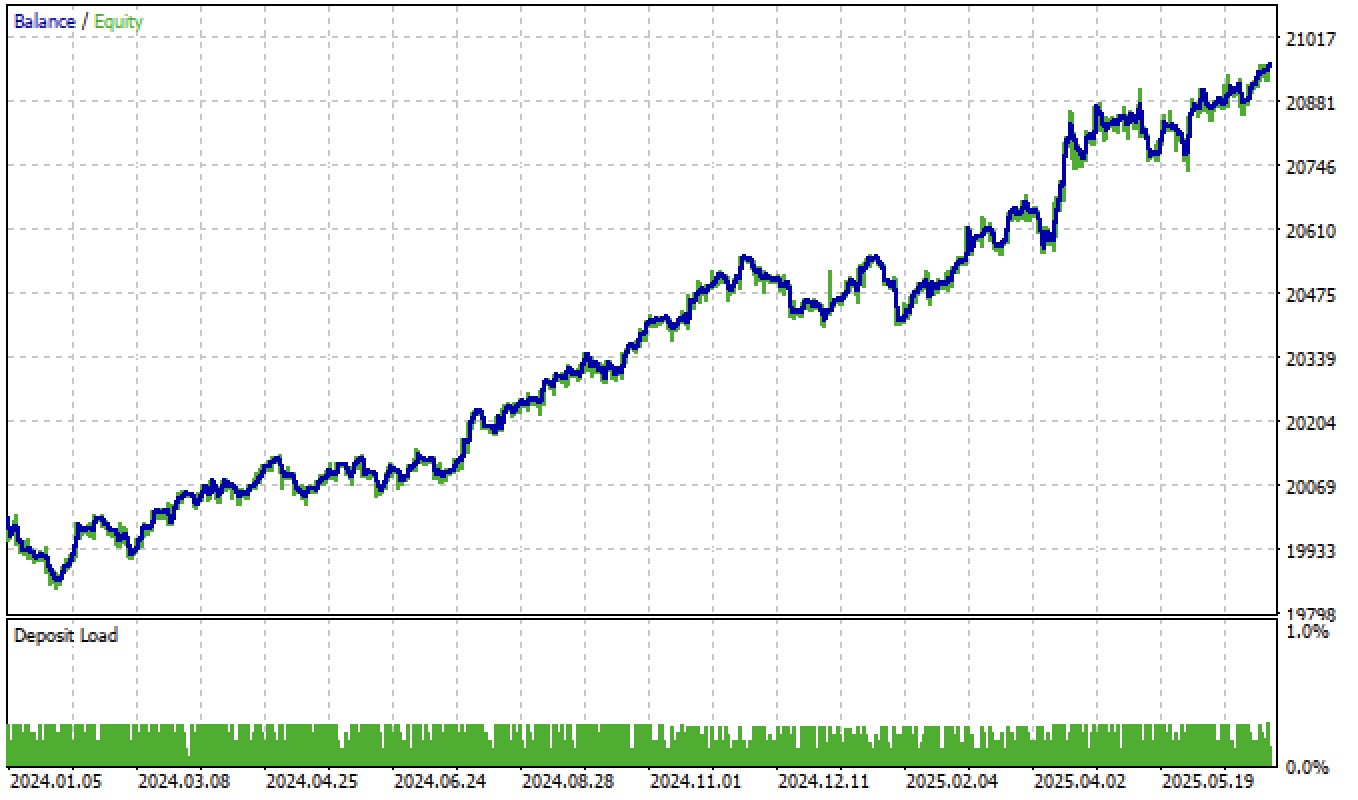
Fig. 6. teste do modelo no terminal após ajuste dos limiares
O teste dos modelos com base no segundo rotulador de operações e na filtragem por limiares produz resultados ainda mais interessantes e refinados:
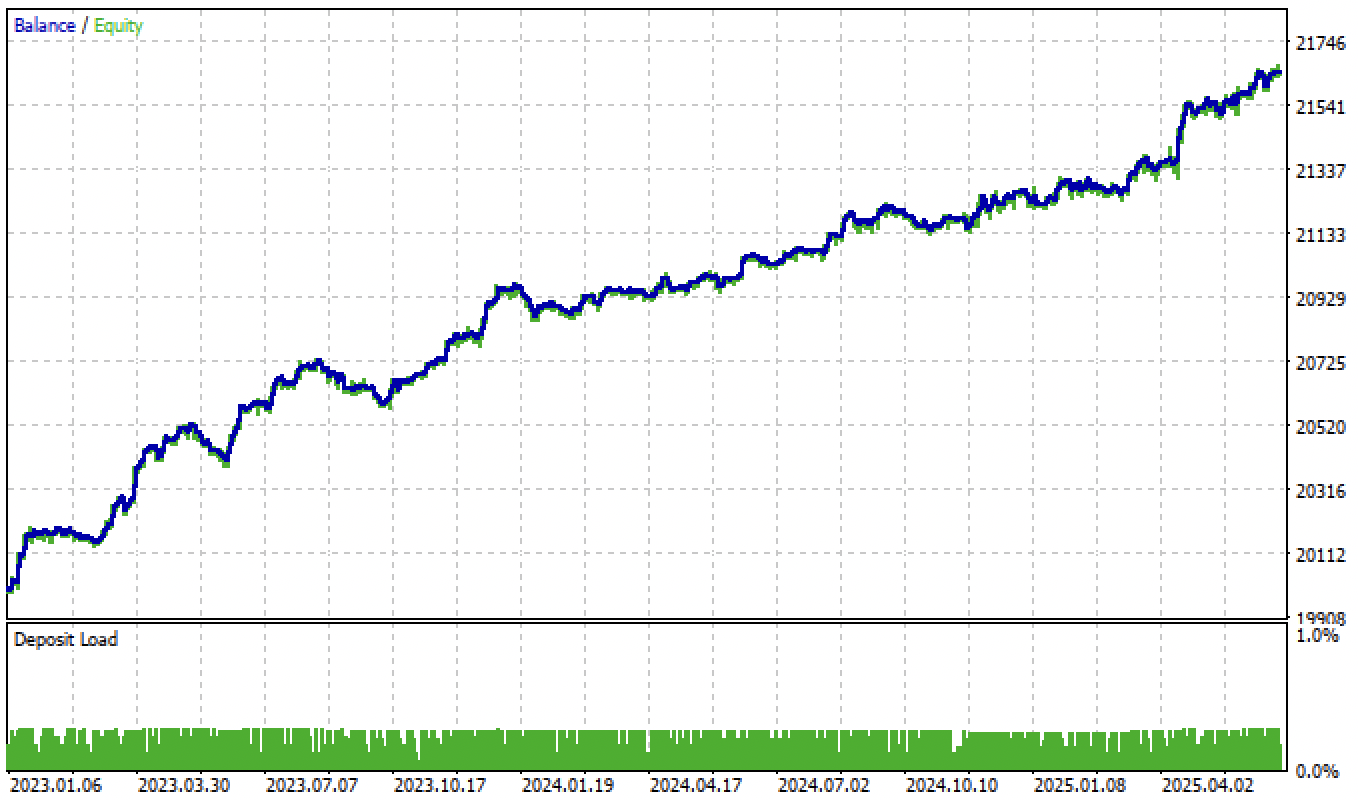
Fig. 7. teste do modelo com base no rotulador de operações médio e tol = 1e-2
Se alterar o parâmetro tol no treinamento de 1e-2 para 1e-3, os resultados serão ainda melhores:
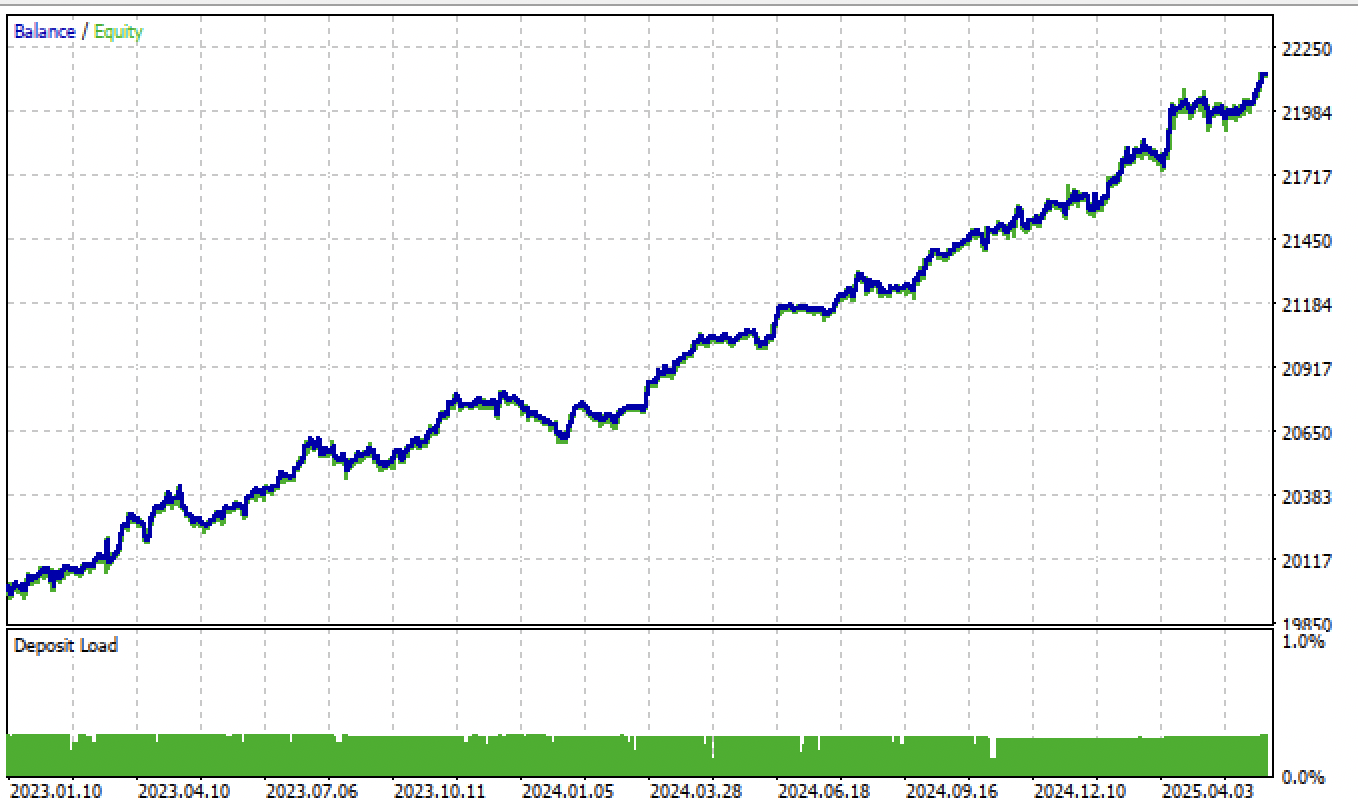
Fig. 8. teste do modelo com base no rotulador de operações médio e tol = 1e-3
Informações adicionais
Para exportar os modelos, é necessário instalar e importar o pacote skl2onnx:
from skl2onnx import convert_sklearn from skl2onnx.common.data_types import FloatTensorType
Também foi alterado o código de execução dos modelos ONNX no código do robô de trading para que ele processe corretamente os novos modelos de regressão:
vectorf y_main(1), y_meta(1); OnnxRun(ExtHandle, ONNX_DEBUG_LOGS, f, y_main); OnnxRun(ExtHandle2, ONNX_DEBUG_LOGS, f_m, y_meta); float sig = y_main[0]; float meta_sig = y_meta[0];
Foram adicionadas novas variáveis "input" para ajuste e otimização dos limiares:
input double buy_threshold = 0.00001; input double sell_threshold = -0.00001; input double meta_threshold = 0.001;
O acesso aos nomes dos modelos ONNX agora é feito por meio de diretivas #define, o que simplifica a conexão de modelos com outros nomes:
#define model ExtModel_EURUSD_H1_0 #define model_m ExtModel2_EURUSD_H1_0 #define periods PeriodsEURUSD_H1_0 #define periods_m Periods_mEURUSD_H1_0 #define fill_arrays fill_araysEURUSD_H1_0 #define fill_arrays_m fill_arays_mEURUSD_H1_0
Os sinais de trading são formados quando as condições são acionadas de acordo com os limiares:
if((Ask-Bid < max_spread*_Point) && MathAbs(meta_sig) < meta_threshold && AllowTrade(OrderMagic)) if(countOrders(OrderMagic) < max_orders && CheckMoneyForTrade(_Symbol, LotsOptimized(), ORDER_TYPE_BUY)) { double l = LotsOptimized(); if(sig > buy_threshold && Allow_Buy) { int res = -1; do { double stop = Bid - stoploss * _Point; double take = Ask + takeprofit * _Point; res = mytrade.PositionOpen(_Symbol, ORDER_TYPE_BUY, l, Ask, stop, take, bot_comment); Sleep(50); } while(res == -1); } else { if(sig < sell_threshold && Allow_Sell) { int res = -1; do { double stop = Ask + stoploss * _Point; double take = Bid - takeprofit * _Point; res = mytrade.PositionOpen(_Symbol, ORDER_TYPE_SELL, l, Bid, stop, take, bot_comment); Sleep(50); } while(res == -1); } } }
O testador de estratégias modificado e a função de exportação dos modelos foram adicionados aos módulos correspondentes e anexados ao artigo.
Considerações finais
Neste artigo, descrevi uma forma possível, mas não a única, de construir sistemas de trading com base em modelos de regressão. Essa abordagem permite ajustar com mais precisão robôs baseados em machine learning. Ela também permite transformar modelos sabidamente deficitários em modelos lucrativos por meio do ajuste de limiares. Você pode usar quaisquer características e/ou rotuladores de operações, além de testar esse algoritmo em outros instrumentos de trading e em outras escalas temporais.
O arquivo Python files.zip contém os seguintes arquivos para desenvolvimento no ambiente Python:
| Nome do arquivo | Descrição |
|---|---|
| causal regression.py | Script principal para o treinamento dos modelos |
| labeling_lib.py | Módulo atualizado com rotuladores de operações |
| tester_lib.py | Testador de estratégias customizado atualizado, baseado em aprendizado de máquina |
| export_lib.py | Módulo para exportação dos modelos para o terminal |
| EURUSD_H1.csv | Arquivo com cotações exportadas do terminal MetaTrader 5 |
O arquivo MQL5 files.zip contém os arquivos para o terminal MetaTrader 5:
| Nome do arquivo | Descrição |
|---|---|
| regression trader.ex5 | Robô compilado deste artigo |
| regression trader.mq5 | Código-fonte do robô do artigo |
| pasta Include//Trend following | Contém os modelos ONNX e o arquivo de cabeçalho para conexão com o robô |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/18603
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
Eu uso o causal_regression_orig.py para produzir o arquivo de cabeçalho do ea e, em seguida, compilo o ea.
O resultado é a imagem test_result abaixo.
Há muito menos negociações do que a que você postou.
Então, qual é a diferença entre elas?
Há muitas negociações no testador python? Se sim, você precisa reconfigurar os limites para a abertura de negociações no programa mql5, talvez eles sejam muito grandes.
Este é o resultado do testador python, eu uso o mesmo código que você anexou nesta postagem. Verifiquei no painel de configuração do testador do mt5 que o buy_threshold e o sell_threshold são 0,0001 e -0,0001, o mesmo que a configuração desta postagem.
Verifiquei o código e não sabia qual era a diferença entre eles.
Este é o resultado do testador python, eu usei o mesmo código que você anexou nesta postagem. Verifiquei no painel de configuração do testador do mt5, o buy_threshold e o sell_threshold são 0,0001 e -0,0001, o mesmo que a configuração desta postagem.
Verifiquei o código e não sabia qual era a diferença entre eles.
Saudações, Maxim, muito obrigado por compartilhar conosco.
Pergunta. Depois de calcular o ONNX para um novo ticker e colocá-lo na pasta Trend Following, como posso ter certeza de que o EA começará a usar os dados treinados para o novo ticker? Para outros tickers, mesmo que eu exclua o ONNX_EURUSD e coloque outro, o EA se comporta de forma idêntica. Preciso alterar alguma coisa no Expert Advisor MQL5 ao mudar o ticker?
Saudações, Maxim, muito obrigado por compartilhar conosco.
Pergunta. Depois de calcular o ONNX para um novo ticker e colocá-lo na pasta Trend Following, como posso ter certeza de que o EA começará a usar os dados treinados para o novo ticker? Para outros tickers, mesmo que eu exclua o ONNX_EURUSD e coloque outro, o EA se comporta de forma idêntica. Preciso alterar alguma coisa no Expert Advisor MQL5 ao mudar o ticker?
Olá, você precisa conectar o arquivo .mqh com o novo ticker no código do EA.
Ou seja, altere o arquivo selecionado para outro arquivo com um nome diferente, que foi gerado pelo script python.