
機械学習を用いたトレンド取引戦略の開発
はじめに
取引戦略には、これまでに有効性が実証されてきたさまざまなタイプがあります。そのひとつである平均回帰戦略については、前回の記事で取り上げました。本記事では、機械学習を用いてトレンド型、あるいはトレンドフォロー型の戦略を構築するためのアイデアを読者の皆様と共有したいと思います。
本記事では、市場のレジームを識別するために、データクラスタリングに基づく類似のアプローチを採用します。ただし、実際に取引ラベルを付与するラベリング手法は、前回の記事とは大きく異なります。そのため、まず前回の記事を確認した上で、本記事を論理的な続編として読み進めることをお勧めします。そうすることで、2種類の戦略の違いや、学習データにおけるラベリング方法の違いをより明確に理解できるはずです。それでは、始めましょう。
トレンドフォロー型戦略のデータラベリング手法
トレンドフォロー型戦略と平均回帰型戦略の主な違いは、トレンドフォロー型では現在のトレンドを正確に特定することが重要である点です。一方、平均回帰型戦略では、価格がある平均値の周囲で変動し、頻繁にクロスすることが確認できれば十分です。言い換えれば、これらの戦略は性質的に正反対であると言えます。平均回帰は価格変動方向の反転が高確率で起こることを前提としているのに対し、トレンドフォローは現在のトレンドが継続することを前提としています。
通貨ペアはしばしば、レンジ(横ばい)型またはトレンド型に分類されます。もちろん、これはあくまで条件付きの分類であり、どちらのタイプにもトレンドや保ち合いゾーンが現れる可能性があります。ここでの区別は、どちらの状態にあることが多いか、という頻度に基づいたものです。本記事では、どの通貨ペアが本当にトレンドを形成しているかを詳細に分析することはせず、前回の記事でレンジ型として扱ったEURGBPと対照的に、トレンド型とされるEURUSDを対象としてアプローチを検証します。
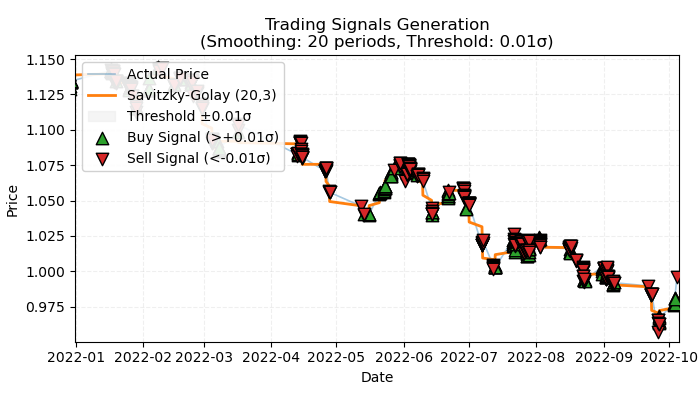
図1:トレンドベース取引のラベルの可視化
図1は、トレンドベース取引にラベルを付与する際の基本原理を示しています。短期的なノイズを平滑化するために、前回の記事で詳しく紹介したSavitzky–Golayフィルタを再び使用しています。ただし、前回のように価格のフィルタからの乖離を計算するのではなく、今回はフィルタの方向性をトレンドの指標として使用します。方向が正であれば買いのラベルを付与し、方向が負であれば売りのラベルを付与します。方向が定義されていない場合、そのようなサンプルは学習プロセスから除外されます。ラベリング関数には、トレンド強度フィルタ(閾値)が組み込まれており、ボラティリティに応じてノイズに近いトレンドを除外する仕組みになっています。この点については、後ほど詳しく説明します。
トレンドベース取引の基本的なラベリング手法
その仕組みを完全に理解するために、取引シグナルラベリング関数の内部処理を詳しく見ていきましょう。
@njit def calculate_labels_trend(normalized_trend, threshold): labels = np.empty(len(normalized_trend), dtype=np.float64) for i in range(len(normalized_trend)): if normalized_trend[i] > threshold: labels[i] = 0.0 # Buy (Up trend) elif normalized_trend[i] < -threshold: labels[i] = 1.0 # Sell (Down trend) else: labels[i] = 2.0 # No signal return labels def get_labels_trend(dataset, rolling=200, polyorder=3, threshold=0.5, vol_window=50) -> pd.DataFrame: smoothed_prices = savgol_filter(dataset['close'].values, window_length=rolling, polyorder=polyorder) trend = np.gradient(smoothed_prices) vol = dataset['close'].rolling(vol_window).std().values normalized_trend = np.where(vol != 0, trend / vol, np.nan) # Set NaN where vol is 0 labels = calculate_labels_trend(normalized_trend, threshold) dataset = dataset.iloc[:len(labels)].copy() dataset['labels'] = labels dataset = dataset.dropna() # Remove rows with NaN return dataset
get_labels_trend関数は、close(終値)列を含む生データセットを処理し、ラベル付きシグナル列を追加したDataFrameを返します。
ラベリングの主な手順は以下の通りです。
- 価格の平滑化:終値にSavitzky–Golayフィルタを適用して平滑化します。パラメータには、平滑化の窓幅と多項式の次数を指定します。目的は短期的なノイズを除去し、基礎となるトレンドを明確にすることです。
smoothed_prices = savgol_filter(dataset['close'].values, window_length=rolling, polyorder=polyorder) - トレンドの計算:平滑化された価格の勾配を計算します。勾配は価格変化の方向と大きさを示します。正の勾配は上昇傾向を示し、負の勾配は下降傾向を示します。
trend = np.gradient(smoothed_prices)
- ボラティリティの計算:ローリングウィンドウで終値の標準偏差を計算し、ボラティリティを求めます。これはトレンドの正規化に使用し、市場の変動性を考慮するためです。
vol = dataset['close'].rolling(vol_window).std().values - トレンドの正規化:トレンドをボラティリティで割ることで、市場の変動性を考慮した正規化トレンドを計算します。
normalized_trend = np.where(vol != 0, trend / vol, np.nan) - ラベルの生成:正規化トレンドと閾値に基づき、買いおよび売りシグナルのラベルを生成します。
labels = calculate_labels_trend(normalized_trend, threshold)
- 閾値の適用:閾値は小さな勾配変動を除外するために使用します。経験的に0.01 〜 0.5の範囲で選択されます。閾値の範囲内に収まるトレンドは、重要でないものとして無視されます。
このラベリング手法を基本として、追加のラベリング手法を作成することで、実験用の選択肢を増やすことが可能です。
利益が出る取引のみを対象としたラベリング
基本的なラベリング手法では、トレンドの末端で反転が起こる直前などに負ける取引も含まれてしまいます。これは現実の取引システムでも起こりうる信号の誤りに相当します。重要なのは、利益の出る取引と損失となる取引の割合であり、その比率が利益の出る取引に有利であることです。しかし、利益が出る取引のみをラベリングして出ない取引は無視することで、この欠点を解消することができます。これにより、学習結果に基づくエクイティカーブが滑らかになり、場合によってはテストデータ上でも効果が期待できます。以下にこのようなラベリングのコードを示します。
@njit def calculate_labels_trend_with_profit(close, normalized_trend, threshold, markup, min_l, max_l): labels = np.empty(len(normalized_trend) - max_l, dtype=np.float64) for i in range(len(normalized_trend) - max_l): if normalized_trend[i] > threshold: # Проверяем условие для Buy rand = random.randint(min_l, max_l) future_pr = close[i + rand] if future_pr >= close[i] + markup: labels[i] = 0.0 # Buy (Profit reached) else: labels[i] = 2.0 # No profit elif normalized_trend[i] < -threshold: # Проверяем условие для Sell rand = random.randint(min_l, max_l) future_pr = close[i + rand] if future_pr <= close[i] - markup: labels[i] = 1.0 # Sell (Profit reached) else: labels[i] = 2.0 # No profit else: labels[i] = 2.0 # No signal return labels def get_labels_trend_with_profit(dataset, rolling=200, polyorder=3, threshold=0.5, vol_window=50, markup=0.00005, min_l=1, max_l=15) -> pd.DataFrame: # Smoothing and trend calculation smoothed_prices = savgol_filter(dataset['close'].values, window_length=rolling, polyorder=polyorder) trend = np.gradient(smoothed_prices) # Normalizing the trend by volatility vol = dataset['close'].rolling(vol_window).std().values normalized_trend = np.where(vol != 0, trend / vol, np.nan) # Removing NaN and synchronizing data valid_mask = ~np.isnan(normalized_trend) normalized_trend_clean = normalized_trend[valid_mask] close_clean = dataset['close'].values[valid_mask] dataset_clean = dataset[valid_mask].copy() # Generating labels labels = calculate_labels_trend_with_profit(close_clean, normalized_trend_clean, threshold, markup, min_l, max_l) # Trimming the dataset and adding labels dataset_clean = dataset_clean.iloc[:len(labels)].copy() dataset_clean['labels'] = labels # Filtering the results dataset_clean = dataset_clean.dropna() return dataset_clean
基本手法との主な違い
- min_lパラメータが追加されています。これは、価格変化を測定するために参照する将来バー数の最小値を定義します。
- max_lパラメータが追加されています。これは、価格変化を測定するために参照する将来バー数の最大値を定義します。
- 将来バーは、これらのパラメータで指定された範囲内からランダムに選択されます。固定長でのチェックをおこないたい場合は、両方のパラメータを同じ値に設定することで実現できます。
- 取引開始からn本先のバーで利益が出ている場合、その取引は学習データセットに追加されます。そうでない場合は、2.0(取引なし)としてラベリングされます。
- markupパラメータが追加されています。これは、対象とする取引銘柄における平均スプレッド+手数料+スリッページ程度(必要に応じて証拠金を加えた値)に設定する必要があります。この値は、利益が出る取引としてラベリングされる件数に影響します。値が大きいほど、この閾値を超えられない取引が増えるため、利益が出る取引としてラベリングされる数は少なくなります。
フィルタ選択オプション付きで利益が出る取引に限定したラベリング
前回の記事と同様に、ここでもSavitzky–Golayフィルタのみに限定せず、複数のフィルタを選択できるようにしたいと考えます。これにより、ラベリングのバリエーションを増やすことができ、取引システムを各金融商品の特性により適応させやすくなります。ここでは追加のフィルタとして、単純移動平均(SMA)、指数移動平均(EMA)、およびスプラインを提案します。あくまで例として示すものであり、同様の方法で独自のフィルタを追加することも可能です。
@njit def calculate_labels_trend_different_filters(close, normalized_trend, threshold, markup, min_l, max_l): labels = np.empty(len(normalized_trend) - max_l, dtype=np.float64) for i in range(len(normalized_trend) - max_l): if normalized_trend[i] > threshold: # Проверяем условие для Buy rand = random.randint(min_l, max_l) future_pr = close[i + rand] if future_pr >= close[i] + markup: labels[i] = 0.0 # Buy (Profit reached) else: labels[i] = 2.0 # No profit elif normalized_trend[i] < -threshold: # Проверяем условие для Sell rand = random.randint(min_l, max_l) future_pr = close[i + rand] if future_pr <= close[i] - markup: labels[i] = 1.0 # Sell (Profit reached) else: labels[i] = 2.0 # No profit else: labels[i] = 2.0 # No signal return labels def get_labels_trend_with_profit_different_filters(dataset, method='savgol', rolling=200, polyorder=3, threshold=0.5, vol_window=50, markup=0.5, min_l=1, max_l=15) -> pd.DataFrame: # Smoothing and trend calculation close_prices = dataset['close'].values if method == 'savgol': smoothed_prices = savgol_filter(close_prices, window_length=rolling, polyorder=polyorder) elif method == 'spline': x = np.arange(len(close_prices)) spline = UnivariateSpline(x, close_prices, k=polyorder, s=rolling) smoothed_prices = spline(x) elif method == 'sma': smoothed_series = pd.Series(close_prices).rolling(window=rolling).mean() smoothed_prices = smoothed_series.values elif method == 'ema': smoothed_series = pd.Series(close_prices).ewm(span=rolling, adjust=False).mean() smoothed_prices = smoothed_series.values else: raise ValueError(f"Unknown smoothing method: {method}") trend = np.gradient(smoothed_prices) # Normalizing the trend by volatility vol = dataset['close'].rolling(vol_window).std().values normalized_trend = np.where(vol != 0, trend / vol, np.nan) # Removing NaN and synchronizing data valid_mask = ~np.isnan(normalized_trend) normalized_trend_clean = normalized_trend[valid_mask] close_clean = dataset['close'].values[valid_mask] dataset_clean = dataset[valid_mask].copy() # Generating labels labels = calculate_labels_trend_different_filters(close_clean, normalized_trend_clean, threshold, markup, min_l, max_l) # Trimming the dataset and adding labels dataset_clean = dataset_clean.iloc[:len(labels)].copy() dataset_clean['labels'] = labels # Filtering the results dataset_clean = dataset_clean.dropna() return dataset_clean
前回のラベリングアルゴリズムとの主な違いはmethodパラメータが追加された点です。このパラメータには、以下の値を指定できます。
- savgol:Savitzky–Golayフィルタ
- spline:スプライン補間
- sma:単純移動平均による平滑化
- ema:指数移動平均による平滑化
フィルタ選択オプションおよび利益が出る取引限定によるラベリング
現実に対する捉え方をより複雑にし、それに伴って取引シグナルラベリング手法も複雑化させてみましょう。単一の平滑化期間のみを使用するという制約はありません。同一タイプのフィルタを異なる期間で複数同時に使用することができ、少なくとも1つの条件が満たされた場合に取引をラベリングします。そのようなサンプラーの例を以下に示します。
@njit def calculate_labels_trend_multi(close, normalized_trends, threshold, markup, min_l, max_l): num_periods = normalized_trends.shape[0] # Number of periods labels = np.empty(len(close) - max_l, dtype=np.float64) for i in range(len(close) - max_l): # Select a random number of bars forward once for all periods rand = np.random.randint(min_l, max_l + 1) buy_signals = 0 sell_signals = 0 # Check conditions for each period for j in range(num_periods): if normalized_trends[j, i] > threshold: if close[i + rand] >= close[i] + markup: buy_signals += 1 elif normalized_trends[j, i] < -threshold: if close[i + rand] <= close[i] - markup: sell_signals += 1 # Combine signals if buy_signals > 0 and sell_signals == 0: labels[i] = 0.0 # Buy elif sell_signals > 0 and buy_signals == 0: labels[i] = 1.0 # Sell else: labels[i] = 2.0 # No signal or conflict return labels def get_labels_trend_with_profit_multi(dataset, method='savgol', rolling_periods=[10, 20, 30], polyorder=3, threshold=0.5, vol_window=50, markup=0.5, min_l=1, max_l=15) -> pd.DataFrame: """ Generates labels for trading signals (Buy/Sell) based on the normalized trend, calculated for multiple smoothing periods. Args: dataset (pd.DataFrame): DataFrame with data, containing the 'close' column. method (str): Smoothing method ('savgol', 'spline', 'sma', 'ema'). rolling_periods (list): List of smoothing window sizes. Default is [200]. polyorder (int): Polynomial order for 'savgol' and 'spline' methods. threshold (float): Threshold for the normalized trend. vol_window (int): Window for volatility calculation. markup (float): Minimum profit to confirm the signal. min_l (int): Minimum number of bars forward. max_l (int): Maximum number of bars forward. Returns: pd.DataFrame: DataFrame with added 'labels' column: - 0.0: Buy - 1.0: Sell - 2.0: No signal """ close_prices = dataset['close'].values normalized_trends = [] # Calculate normalized trend for each period for rolling in rolling_periods: if method == 'savgol': smoothed_prices = savgol_filter(close_prices, window_length=rolling, polyorder=polyorder) elif method == 'spline': x = np.arange(len(close_prices)) spline = UnivariateSpline(x, close_prices, k=polyorder, s=rolling) smoothed_prices = spline(x) elif method == 'sma': smoothed_series = pd.Series(close_prices).rolling(window=rolling).mean() smoothed_prices = smoothed_series.values elif method == 'ema': smoothed_series = pd.Series(close_prices).ewm(span=rolling, adjust=False).mean() smoothed_prices = smoothed_series.values else: raise ValueError(f"Unknown smoothing method: {method}") trend = np.gradient(smoothed_prices) vol = pd.Series(close_prices).rolling(vol_window).std().values normalized_trend = np.where(vol != 0, trend / vol, np.nan) normalized_trends.append(normalized_trend) # Transform list into 2D array normalized_trends_array = np.vstack(normalized_trends) # Remove rows with NaN valid_mask = ~np.isnan(normalized_trends_array).any(axis=0) normalized_trends_clean = normalized_trends_array[:, valid_mask] close_clean = close_prices[valid_mask] dataset_clean = dataset[valid_mask].copy() # Generate labels labels = calculate_labels_trend_multi(close_clean, normalized_trends_clean, threshold, markup, min_l, max_l) # Trim data and add labels dataset_clean = dataset_clean.iloc[:len(labels)].copy() dataset_clean['labels'] = labels # Remove remaining NaN dataset_clean = dataset_clean.dropna() return dataset_clean
注目すべきポイント(概念的な要点)
- ラベリング関数は、平滑化期間の値を含む任意長のリストを受け取るようになっています。
- 指定されたすべての期間について、ループ内でフィルタが計算されます。
- すべてのフィルタにおけるトレンド勾配がラベリング関数に反映されます。
- 買いまたは売りの条件が少なくとも1つ満たされ、かつ反対方向のシグナルが存在しない場合に、取引がラベリングされます。
labeling_lib.pyモジュールには、4つの新しいサンプラーが追加されました。
def get_labels_trend(dataset, rolling=200, polyorder=3, threshold=0.5, vol_window=50) -> pd.DataFrame: def get_labels_trend_with_profit(dataset, rolling=200, polyorder=3, threshold=0.5, def get_labels_trend_with_profit_different_filters(dataset, method='savgol', rolling=200, polyorder=3, threshold=0.5, def get_labels_trend_with_profit_multi(dataset, method='savgol', rolling_periods=[10, 20, 30], polyorder=3, threshold=0.5,
ここでは、これらのバリエーションまでにしておきましょう。トレンドラベリングという中核的なアイデアを検証するには、これらで十分です。
モデルの学習およびテストプロセス
データ準備および学習に関する中核的なロジックは前回の記事から流用しているため、ここでは詳細な説明はおこないません。ただし、いくつかの変更点があります。学習サイクル全体が個別の処理関数に移され、プロセス管理に関する新たな機能が追加されています。
従来は、2.0とラベリングされた取引は学習データセットから削除され、学習には使用されていませんでした。この方法では、ラベル系列に欠損が生じ、情報が失われる可能性があります。しかし、バイナリ分類器を使用し、2.0ラベル(取引なし)を第3のクラスとして扱う場合、この情報をどのように取引システムに組み込めばよいのでしょうか。
ここで、学習には2つの分類器が関与していることを思い出してください。1つ目は買い/売りのラベルを予測する分類器、2つ目は現在の市場レジーム(取引すべきか、取引すべきでないか)を予測する分類器です。この構成により、2.0ラベルを持つサンプルを第2のモデルに移行させることが可能になります。これにより、データを破棄することなく、情報を保持したまま活用できます。
def processing(iterations = 1, rolling = [10], threshold=0.01, polyorder=5, vol_window=100, use_meta_dilution = True): models = [] for i in range(iterations): data = clustering(dataset, n_clusters=hyper_params['n_clusters']) sorted_clusters = data['clusters'].unique() sorted_clusters.sort() for clust in sorted_clusters: clustered_data = data[data['clusters'] == clust].copy() if len(clustered_data) < 500: print('too few samples: {}'.format(len(clustered_data))) continue clustered_data = get_labels_trend_with_profit_multi( clustered_data, method='savgol', rolling_periods=rolling, polyorder=polyorder, threshold=threshold, vol_window=vol_window, min_l=1, max_l=15, markup=hyper_params['markup']) print(f'Iteration: {i}, Cluster: {clust}') clustered_data = clustered_data.drop(['close', 'clusters'], axis=1) meta_data = data.copy() meta_data['clusters'] = meta_data['clusters'].apply(lambda x: 1 if x == clust else 0) if use_meta_dilution: for dt in clustered_data.index: if clustered_data.loc[dt, 'labels'] == 2.0: if dt in meta_data.index: # Check if datetime exists in meta_data meta_data.loc[dt, 'clusters'] = 0 clustered_data = clustered_data.drop(clustered_data[clustered_data.labels == 2.0].index) # Синхронизация meta_data с bad_data models.append(fit_final_models(clustered_data, meta_data.drop(['close'], axis=1))) models.sort(key=lambda x: x[0]) return models
コードでは、第1のモデル用データセットにおいて2.0とラベリングされたサンプルが、対応する日付/行に基づいて第2のモデル用データセットに抽出され、clusters列にはゼロが設定されていることが示されています。ここで、1が取引を許可することを示すことを思い出すと、第2のモデルは、市場レジームだけでなく、取引サンプラーに基づく望ましくない取引エントリーポイントも予測することになります。言い換えると、第2のモデルは、必要な市場レジームと、望ましくない市場エントリーポイントの両方を予測するようになります。
すべての最良の機能を取り込み、柔軟な設定が可能なため、最後のサンプラーを直ちに使用することを提案します。
それでは、以下の設定で10回の学習サイクルを実行してみましょう。
hyper_params = {
'symbol': 'EURUSD_H1',
'export_path': '/Users/dmitrievsky/Library/Containers/com.isaacmarovitz.Whisky/Bottles/54CFA88F-36A3-47F7-915A-D09B24E89192/drive_c/Program Files/MetaTrader 5/MQL5/Include/Mean reversion/',
'model_number': 0,
'markup': 0.00010,
'stop_loss': 0.00500,
'take_profit': 0.00200,
'periods': [i for i in range(5, 300, 30)],
'periods_meta': [100],
'backward': datetime(2000, 1, 1),
'forward': datetime(2024, 1, 1),
'full forward': datetime(2026, 1, 1),
'n_clusters': 10,
'rolling': [10],
} 学習関数自体は次のように呼び出されます。
dataset = get_features(get_prices()) models = processing(iterations = 10, threshold=0.001, polyorder=3, vol_window=100, use_meta_dilution = True)
学習中、各パス(クラスタ)の決定係数が表示されます。
Iteration: 0, Cluster: 0 R2: 0.9837358133371028 Iteration: 0, Cluster: 1 R2: 0.9002342482016827 Iteration: 0, Cluster: 2 R2: 0.9755114279213657 Iteration: 0, Cluster: 3 R2: 0.9833351908595832 Iteration: 0, Cluster: 4 R2: 0.9537875370012954 Iteration: 0, Cluster: 5 R2: 0.9863566422346429 too few samples: 471 Iteration: 0, Cluster: 7 R2: 0.9852545217737659 Iteration: 0, Cluster: 8 R2: 0.9934196831544163
リスト全体から最適なモデルをテストしてみましょう。
test_model(models[-1][1:], hyper_params['stop_loss'], hyper_params['take_profit'], hyper_params['forward'], plt=True)
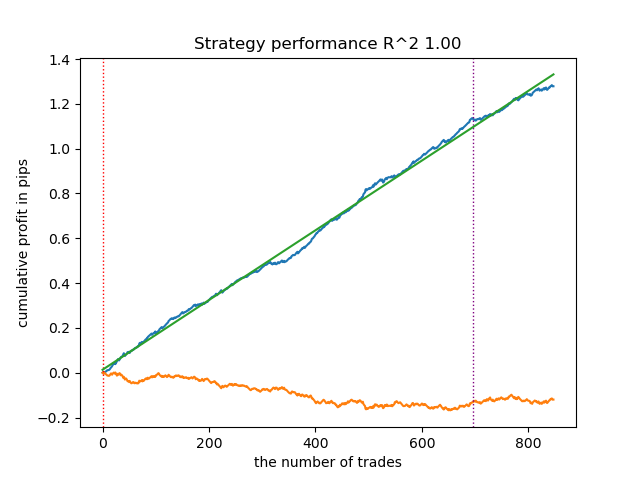
図2:学習と新規データによるモデルテスト
これで、MetaTrader 5ターミナルにモデルをエクスポートする関数を呼び出すことができます。
export_model_to_ONNX(model = models[-1], symbol = hyper_params['symbol'], periods = hyper_params['periods'], periods_meta = hyper_params['periods_meta'], model_number = hyper_params['model_number'], export_path = hyper_params['export_path'])
最終モデルのテストとアルゴリズムに関する総合的な所見
私のアプローチは汎用的であるため、モデルのターミナルへのエクスポートは、前回の記事で説明した方法とまったく同じ手順でおこなわれます。
ここでは、学習+テスト期間全体と、テスト期間のみを別々に見てみましょう。図からわかる通り、2024年以降のテストデータに比べ、学習データ上ではエクイティカーブがより滑らかです。学習は2020年から2024年にかけておこなわれたため、テストは2019年から示しています。これは、学習前の期間でもカーブが完全に滑らかではないことを示すためです。
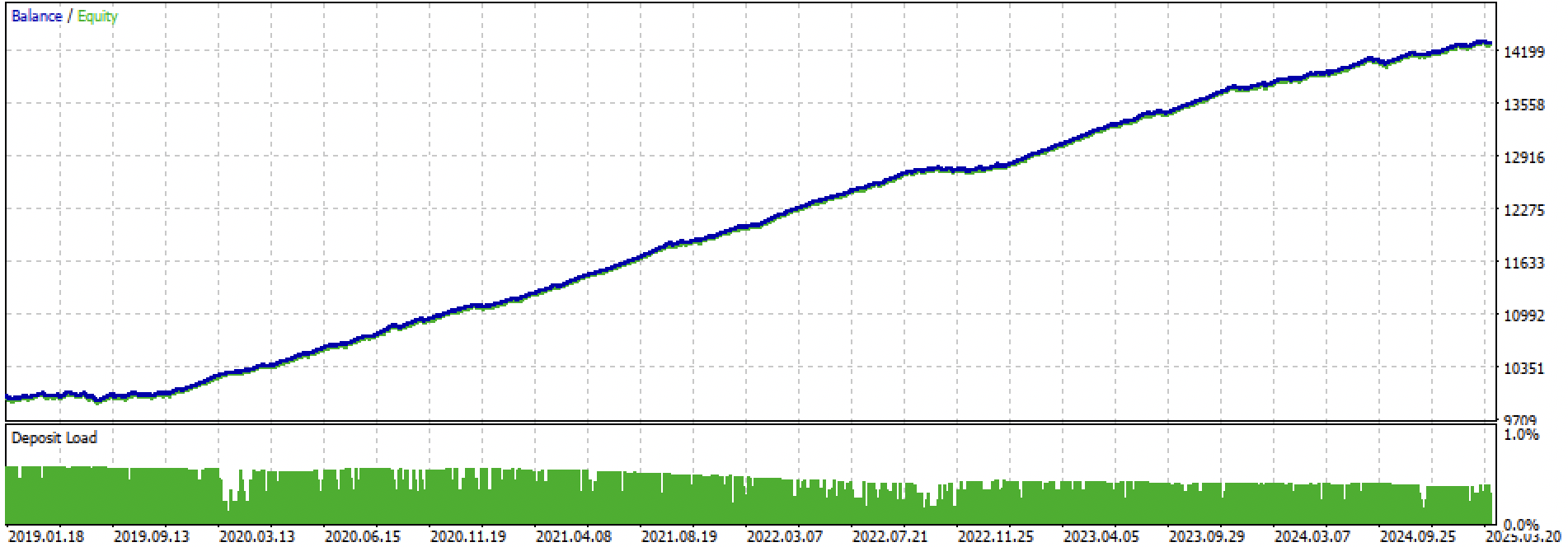
図3:2019年から2025年までのテスト
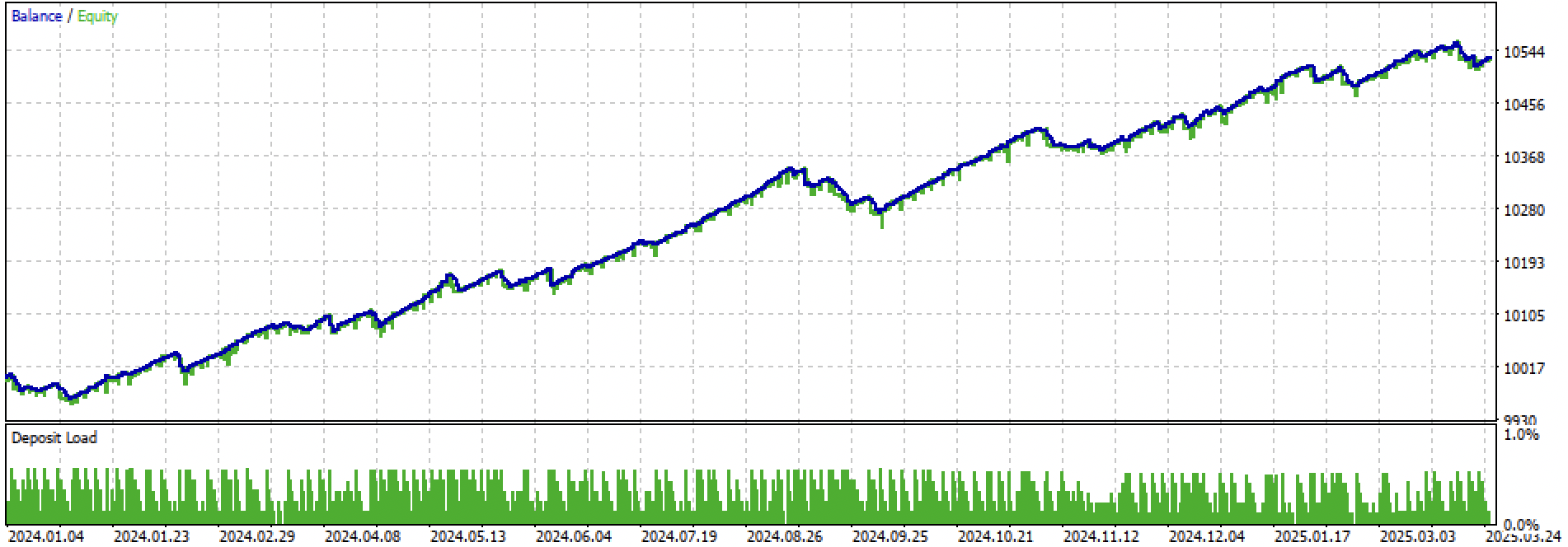
図4:2024年初頭から2025年3月27日までの期間のテスト
実験結果に基づくと、トレンドフォロー型戦略は、新しいデータに対するパフォーマンスが不安定になりやすい、あるいはこの手法ではEURUSDペアに対するトレンドフォロー戦略の生成が十分にうまくいかないことが分かります。それでも、ハイパーパラメータ調整を試みることで、合理的に良好なモデルを得ることは可能です。欠点は、非常に短いストップロス(例:20ポイント、4桁表記)で良好な結果を示すことができる点で部分的に補われます。これにより、リスク管理やモデルが機能しなくなった場合の迅速な停止が可能になります。
また、有意なハイパーパラメータの組み合わせを特定することはできませんでした。アルゴリズムが本質的に安定したパターンを見つけるのが苦手である、あるいはそもそもそのようなパターンが存在しない、という印象を受けました。
過学習に対抗するためには、fit_final_models()関数内でモデルの複雑さを減らすことが可能です。
def fit_final_models(clustered, meta) -> list: # features for model\meta models. We learn main model only on filtered labels X, X_meta = clustered[clustered.columns[:-1]], meta[meta.columns[:-1]] X = X.loc[:, ~X.columns.str.contains('meta_feature')] X_meta = X_meta.loc[:, X_meta.columns.str.contains('meta_feature')] # labels for model\meta models y = clustered['labels'] y_meta = meta['clusters'] y = y.astype('int16') y_meta = y_meta.astype('int16') # train\test split train_X, test_X, train_y, test_y = train_test_split( X, y, train_size=0.7, test_size=0.3, shuffle=True) train_X_m, test_X_m, train_y_m, test_y_m = train_test_split( X_meta, y_meta, train_size=0.7, test_size=0.3, shuffle=True) # learn main model with train and validation subsets model = CatBoostClassifier(iterations=100, custom_loss=['Accuracy'], eval_metric='Accuracy', verbose=False, use_best_model=True, task_type='CPU', thread_count=-1) model.fit(train_X, train_y, eval_set=(test_X, test_y), early_stopping_rounds=15, plot=False) # learn meta model with train and validation subsets meta_model = CatBoostClassifier(iterations=100, custom_loss=['F1'], eval_metric='F1', verbose=False, use_best_model=True, task_type='CPU', thread_count=-1) meta_model.fit(train_X_m, train_y_m, eval_set=(test_X_m, test_y_m), early_stopping_rounds=15, plot=False) R2 = test_model([model, meta_model], hyper_params['stop_loss'], hyper_params['take_profit'], hyper_params['full forward']) if math.isnan(R2): R2 = -1.0 print('R2 is fixed to -1.0') print('R2: ' + str(R2)) return [R2, model, meta_model]
反復回数は、モデル内での分割数および選択される特徴量の数を制御します。当初は1000回の反復でしたが、これを100回に減らしました。また、アーリーストッピングは、検証データ上の分類誤差が15回連続で改善しない場合に、学習を途中で停止させます。
これにより、エクイティカーブはややノイズが多く、均一になりましたが、以前ほど「美しい」形状ではなくなりました。
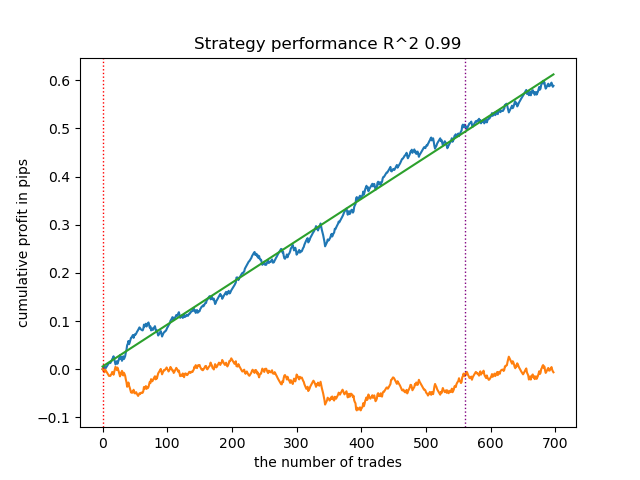
図5:モデルの複雑さを軽減した後の株式曲線
結論
クラスタリングとバイナリ分類に基づくトレンドフォロー型戦略の作成は、より困難であることが分かりました。今後、この手法をどのように実現できるかについて、新たな知見が必要です。特に問題となるのは、モデルが学習した値の範囲外で金融資産の価格が動く点です。レンジ相場型の銘柄で学習する場合とは異なり、新しいデータにおいても価格が学習時に見た値に比較的近い場合が多いのですが、トレンド型ではこの前提が成り立ちません。さらに、価格差に基づく特徴量を適用した場合、モデルは再び汎化能力が低いことを示します。
本記事では、市場レジームクラスタリングアプローチを用いた実験をまとめることを目的としました。ここから先には、より興味深い新しいアイデアが待っています。
添付資料:
| ファイル名 | 説明 |
|---|---|
| labeling_lib.py | 更新済みサンプラーライブラリ |
| trend_following.py | モデル学習スクリプト |
| cat model_EURUSD_H1_0.onnx | メインモデル、インクルードフォルダ |
| catmodel_m_EURUSD_H1_0.onnx | メタモデル、インクルードフォルダ |
| EURUSD_H1_ONNX_include_0.mqh | ヘッダファイル |
| trend_following.mq5 | 取引EAのソースコード |
| trend_following.ex5 | コンパイル済みボット |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/17526
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
それなら結果は悪くない。2025年の春は別の市場だ。
最近のユーロドルは全般的に予想が苦手なのだろう。横ばい/トレンドトレードは機能しない。
前回の記事のように、トレンドの良いもの(金など)には買いトレードしか通用しない。スキャルピングではなく、バーで。
ユーロドルや一方向の取引は機能しない。
最近のユーロドルは全般的に予想が苦手なようだ。フラット/トレンドのツがうまくいっていない。
前回の記事のように、トレンドの良いもの(金に注目)には買いトレードしか通用しない。スキャルピングではなく、バーで。
ユーロドルや一方向性のものはうまくいかない。
しかし、相場が変われば、tsは死んでしまう。自動監督者がいなければ、それはすでに半手帳である。
しかし、もし市場が変われば、TCは死んでしまうだろう。自動インビジケーターがいなければ、それはすでに準ハンドラーだ
このロボット🤖はどうやったら手に入りますか?