
Redes neurais em trading: Aprendizado dependente de contexto com memória (Conclusão)

Introdução
No artigo anterior, conhecemos o framework MacroHFT, desenvolvido para trading de alta frequência (HFT) com criptomoedas. Este framework representa uma abordagem moderna, combinando métodos de aprendizado por reforço dependente de contexto e o uso de memória, que permite uma adaptação eficiente às condições dinâmicas do mercado e minimização de riscos.
O princípio de fonctionnement do MacroHFT é baseado em duas etapas de aprendizado dos seus componentes individuais. Na primeira etapa, ocorre a classificação dos estados de mercado com base na direção da tendência e no nível de volatilidade. Esse processo permite identificar os principais estados do mercado, que em seguida são usados para o treinamento de subagentes especializados. Cada subagente é otimizado para atuar em determinados cenários. Na segunda etapa, realiza-se o treinamento do hiperagente, equipado com um módulo de memória, que coordena o trabalho dos subagentes. Esse módulo leva em consideração os dados históricos e permite tomar decisões mais precisas com base na experiência anterior.
A arquitetura do MacroHFT inclui diversos componentes-chave. O primeiro deles — o módulo de pré-processamento de dados — executa a filtragem e normalização das informações de mercado recebidas. Isso permite eliminar ruídos e melhorar a qualidade dos dados, o que é fundamental para a análise subsequente.
Os subagentes são modelos de aprendizado profundo treinados para cenários de mercado específicos. Eles utilizam métodos de aprendizado por reforço para se adaptar a condições complexas e de rápida mudança. O elemento final é o hiperagente com memória. Ele integra os resultados do trabalho dos subagentes, analisando o histórico de eventos e o estado atual do mercado. Com isso, alcança-se alta precisão nas previsões e resistência a picos de mercado.
A integração de todos esses componentes permite ao MacroHFT não apenas funcionar de maneira eficaz em condições de alta instabilidade dos mercados, mas também proporcionar uma melhoria significativa nos indicadores de lucratividade.
A visualização autoral do framework MacroHFT é apresentada abaixo.
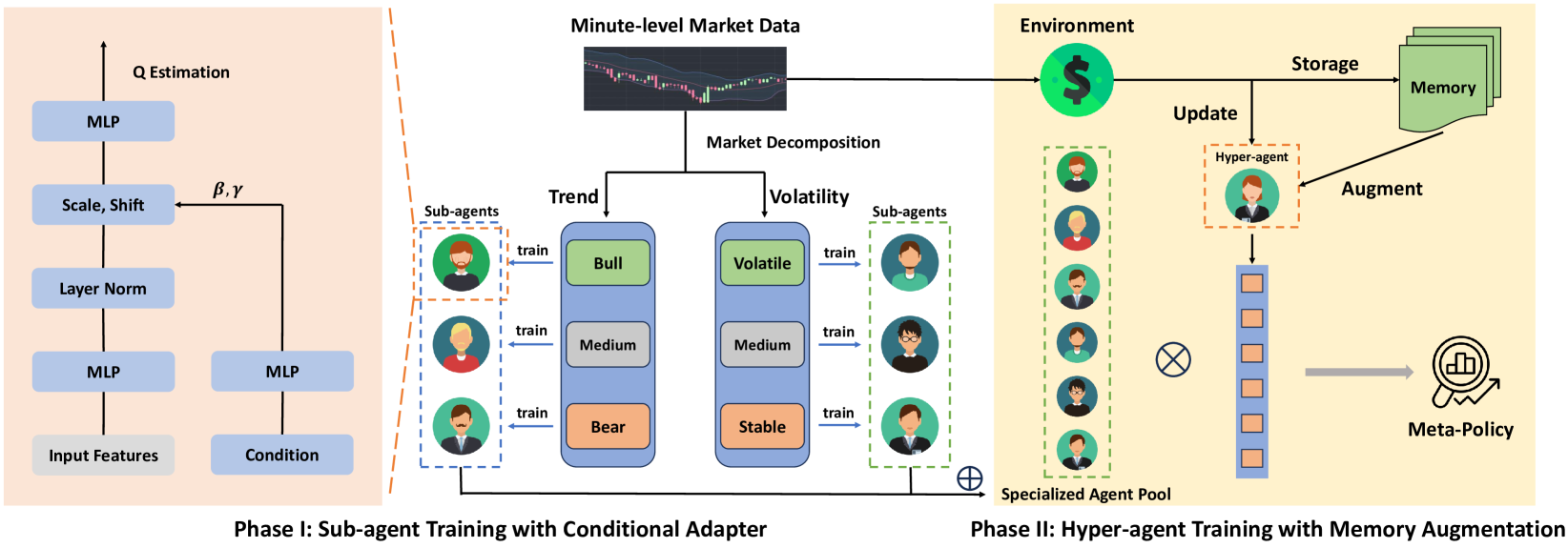
Na parte prática do artigo anterior, criamos o objeto do hiperagente e implementamos o algoritmo de sua interação com os subagentes. Hoje, vamos dar continuidade ao trabalho iniciado, concentrando-nos em novos aspectos da arquitetura do MacroHFT.
Módulo de gerenciamento de risco
No artigo anterior, preparamos o funcionamento do hiperagente no formato do objeto CNeuronMacroHFTHyperAgent e desenvolvemos os algoritmos de sua interação com os subagentes. Além disso, escolhemos utilizar, como subagentes, os agentes-analistas previamente criados com uma arquitetura mais sofisticada. À primeira vista, isso seria suficiente para a implementação do framework MacroHFT, no entanto, a implementação atual possui certas limitações: os subagentes e o hiperagente analisam exclusivamente o estado do ambiente. Isso permite prever movimentos futuros de preço, determinar a direção das operações de trading e estabelecer níveis de stop-loss e take-profit. Porém, essa abordagem não abrange o aspecto da definição do volume das operações de trading, o que é um elemento importante da estratégia geral.
O uso simples de um tamanho fixo de lote, ou o cálculo do volume com base em um nível fixo de risco considerando o stop-loss previsto e os fundos disponíveis na conta, é claro, é possível. No entanto, é necessário considerar que cada previsão possui um nível individual de confiança na sua concretização. É lógico supor que esse nível de confiança deve desempenhar um papel central na determinação do volume da operação. Um alto nível de confiança na previsão permite abrir operações com maior volume, o que contribui para a maximização da lucratividade geral do trading, enquanto um nível de confiança baixo exige uma abordagem mais conservadora.
Considerando esses fatores, foi tomada a decisão de complementar a implementação com um módulo de gerenciamento de risco. Esse módulo será integrado à arquitetura existente para garantir uma abordagem flexível e adaptável ao controle do volume das operações. A introdução do gerenciamento de risco permitirá melhorar a resiliência do modelo frente às condições de mercado instáveis, algo especialmente relevante em um contexto de trading de alta frequência.
É importante observar que, neste caso, estamos implementando um algoritmo de gerenciamento de risco que será parcialmente "desvinculado" da análise direta do estado do ambiente. Em vez disso, o foco principal será na avaliação do impacto das ações do agente sobre o resultado financeiro. A ideia é associar cada operação de trading à variação do saldo da conta e identificar padrões que caracterizem a eficácia da política adotada. Pressupõe-se que o aumento no número de operações lucrativas, combinado com uma elevação consistente do saldo, será um indicador de sucesso da política atual, o que, por sua vez, permitirá aumentar justificadamente o nível de risco por operação. Ao mesmo tempo, um crescimento na proporção de operações com prejuízo servirá como sinal para a aplicação de estratégias mais conservadoras voltadas à redução de riscos. Essa abordagem permitirá não apenas uma melhor adaptação às condições de mercado em mudança, mas também aumentará a eficácia geral na gestão de capital. Além disso, para aprimorar a qualidade da análise, prepararemos diversas projeções do estado da conta, cada uma representando diferentes aspectos do seu estado atual e histórico. Isso permitirá avaliar com mais precisão a eficácia da estratégia e adaptá-la rapidamente às mudanças do mercado.
O algoritmo de gerenciamento de risco será implementado dentro do objeto CNeuronMacroHFTvsRiskManager, cuja estrutura é apresentada abaixo.
class CNeuronMacroHFTvsRiskManager : public CResidualConv { protected: CNeuronBaseOCL caAccountProjection[2]; CNeuronMemoryDistil cMemoryAccount; CNeuronMemoryDistil cMemoryAction; CNeuronRelativeCrossAttention cCrossAttention; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; public: CNeuronMacroHFTvsRiskManager(void) {}; ~CNeuronMacroHFTvsRiskManager(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint stack_size, uint nactions, uint account_decr, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronMacroHFTvsRiskManager; } //--- virtual bool Save(const int file_handle) override; virtual bool Load(const int file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual bool Clear(void) override; };
Na estrutura apresentada, podemos observar um conjunto padrão de métodos sobrescrevíveis e vários objetos internos que desempenham um papel fundamental na implementação do mecanismo de gerenciamento de risco descrito acima. A funcionalidade dos objetos declarados será explorada em mais detalhes na descrição dos algoritmos dos métodos da classe, o que permitirá compreender mais a fundo a lógica de sua utilização.
Todos os objetos internos da nossa classe de gerenciamento de risco são declarados como estáticos, o que permite simplificar significativamente a estrutura do objeto. Em particular, isso possibilita deixar os construtores e destrutores vazios, já que eles não exigem operações adicionais para inicializar ou liberar a memória associada a esses objetos. A inicialização de todos os objetos herdados e declarados é realizada no método Init, que é responsável por configurar a arquitetura da classe no momento de sua criação.
Nos parâmetros desta classe, recebemos um conjunto de constantes que permite interpretar de forma inequívoca a arquitetura do objeto que está sendo criado.
bool CNeuronMacroHFTvsRiskManager::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint stack_size, uint nactions, uint account_decr, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CResidualConv::Init(numOutputs, myIndex, open_cl, 3, 3, (nactions + 2) / 3, optimization_type, batch)) return false;
No corpo do método, chamamos imediatamente o método homônimo da classe pai. Neste caso, trata-se de um objeto de bloco convolucional com realimentação. É importante destacar que, na saída desse módulo, esperamos obter um tensor que representa uma matriz de decisões de trading. Cada linha dessa matriz descreve uma operação individual e contém um vetor com os parâmetros da operação: volume, stop-loss e take-profit. Para que a análise das operações seja organizada corretamente, consideramos as operações de compra e venda como linhas separadas, o que nos permite analisar cada operação de trading de forma independente.
Na configuração das operações convolucionais, o tamanho da janela de convolução e seu passo foram definidos como 3, o que corresponde ao número de parâmetros na descrição da operação de trading.
Em seguida, analisaremos o processo de inicialização dos objetos internos. Aqui, é importante destacar que o módulo de gerenciamento de riscos se baseia em duas fontes principais de dados: as ações do agente e o vetor que descreve o estado analisado da conta. O fluxo principal de informações, representado pelas ações do agente, é recebido como um objeto de camada neural. O fluxo secundário, que contém a descrição do estado da conta, é transmitido por meio de um buffer de dados.
Para garantir o funcionamento correto de todos os componentes internos, é necessário que ambos os fluxos de dados estejam representados por objetos de camadas neurais. Portanto, o primeiro passo é a inicialização de uma camada neural totalmente conectada, na qual serão transferidos os dados do segundo fluxo de informações.
int index = 0; if(!caAccountProjection[0].Init(0, index, OpenCL, account_decr, optimization, iBatch)) return false;
Na etapa seguinte, adiciona-se uma camada totalmente conectada, destinada à formação de projeções da descrição do estado da conta recebida. Essa camada treinável cria um tensor que contém várias projeções do estado da conta analisado em subespaços de dimensionalidade definida. A quantidade de projeções e a dimensionalidade dos subespaços são passadas como parâmetros do método pela aplicação chamadora, o que garante uma configuração flexível da operação da camada para diferentes tarefas.
index++; if(!caAccountProjection[1].Init(0, index, OpenCL, window * units_count, optimization, iBatch)) return false;
Os dados brutos recebidos pelo módulo de gerenciamento de risco fornecem apenas uma descrição estática do estado analisado. No entanto, para uma análise precisa da eficácia da política adotada pelo agente, é necessário considerar as mudanças dinâmicas. Para isso, são utilizados módulos de memória em ambas as rotas de informação, que registram a sequência temporal dos dados. O ponto-chave é definir a melhor abordagem para lidar com o módulo de memória do fluxo de informações sobre o estado da conta: preservar o vetor original ou suas projeções. Parte-se da suposição de que o vetor original possui tamanho reduzido, o que o torna mais adequado ao uso eficiente de recursos. Além disso, as projeções geradas após o uso do módulo de memória oferecem mais informações, pois enriquecem os dados estáticos originais com informações sobre a dinâmica do saldo da conta.
index++; if(!cMemoryAccount.Init(caAccountProjection[1].Neurons(), index, OpenCL, account_decr, window_key, 1, heads, stack_size, optimization, iBatch)) return false;
O módulo de memória para as operações de trading propostas pelo agente funciona no nível de cada operação individual.
index++; if(!cMemoryAction.Init(0, index, OpenCL, 3, window_key, (nactions + 2) / 3, heads, stack_size, optimization, iBatch)) return false;
Para realizar uma análise mais eficaz da política utilizada, é empregado um módulo de atenção cruzada. Esse módulo permite correlacionar as últimas ações do agente com a dinâmica das mudanças no estado da conta de trading, revelando a dependência entre as decisões tomadas e os resultados financeiros obtidos ao longo do processo de trading.
index++; if(!cCrossAttention.Init(0, index, OpenCL, 3, window_key, (nactions + 2) / 3, heads, window, units_count, optimization, iBatch)) return false; //--- return true; }
Com isso, finaliza-se o processo de inicialização dos objetos internos, o que também marca o encerramento da execução do método. Resta apenas retornar o resultado lógico das operações para o programa chamador.
Após concluída a etapa de inicialização do objeto de gerenciamento de risco, iniciamos a construção do algoritmo de propagação para frente dentro do método feedForward.
bool CNeuronMacroHFTvsRiskManager::feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) { if(caAccountProjection[0].getOutput() != SecondInput) { if(!caAccountProjection[0].SetOutput(SecondInput, true)) return false; }
Nos parâmetros do método, recebemos ponteiros para dois objetos de dados brutos. Um desses objetos é apresentado na forma de um buffer de dados, cuja informação deve ser transferida para um objeto interno especialmente criado de camada neural. No entanto, em vez de copiar totalmente os dados do buffer para a camada neural, adotamos uma abordagem mais eficiente: substituímos o ponteiro para o buffer de resultados do objeto interno por um ponteiro que faz referência ao buffer de dados brutos recebido. Isso permite acelerar significativamente o processo de processamento.
Em seguida, enriquecemos os dados brutos de ambos os fluxos de informação com dados adicionais sobre a dinâmica acumulada. Para isso, os dados são passados por módulos de memória especializados, que acumulam informações sobre estados e alterações anteriores. Isso permite levar em conta as dependências temporais e preservar o contexto, o que contribui para um processamento mais preciso das informações.
if(!cMemoryAccount.FeedForward(caAccountProjection[0].AsObject())) return false; if(!cMemoryAction.FeedForward(NeuronOCL)) return false;
Com base nos dados enriquecidos com informações sobre estados anteriores, são formadas projeções do vetor que descreve o estado da conta analisada. Essas projeções servem de base para uma análise abrangente, permitindo uma compreensão mais profunda da dinâmica das alterações no saldo e a avaliação do impacto das ações anteriores sobre o estado atual da conta.
if(!caAccountProjection[1].FeedForward(cMemoryAccount.AsObject())) return false;
Após a conclusão da etapa de pré-processamento dos dados brutos, passamos à análise do impacto da política comportamental do agente sobre o resultado financeiro por meio do bloco de atenção cruzada. A correlação entre as ações do agente e as mudanças nos indicadores financeiros permite identificar a relação entre as decisões tomadas e os resultados obtidos.
if(!cCrossAttention.FeedForward(cMemoryAction.AsObject(), caAccountProjection[1].getOutput())) return false;
O último "toque" na formulação da decisão final de trading é feito por meio dos mecanismos da classe pai, que realiza o processamento final das informações.
return CResidualConv::feedForward(cCrossAttention.AsObject());
}
O resultado lógico da execução das operações é retornado ao programa chamador e encerramos o método.
Os métodos de propagação reversa seguem algoritmos lineares e, acredito, não trarão dificuldades durante o estudo independente. Por isso, finalizamos aqui a análise do objeto de gerenciamento de risco. O código completo da classe apresentada e de todos os seus métodos pode ser consultado no anexo.
Arquitetura do modelo
Estamos dando continuidade à implementação das abordagens do framework MacroHFT utilizando os recursos do MQL5. E a próxima etapa será a construção da arquitetura do modelo treinável. Neste caso, vamos treinar apenas um modelo Ator, cuja arquitetura é definida no método CreateDescriptions.
bool CreateDescriptions(CArrayObj *&actor) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; }
Nos parâmetros do método, recebemos um ponteiro para o objeto de array dinâmico destinado ao registro da arquitetura do modelo a ser criado. E no corpo do método verificamos imediatamente a validade do ponteiro recebido. Se necessário, criamos uma nova instância do objeto de array dinâmico.
Em seguida, criamos a descrição de uma camada totalmente conectada, que neste caso é usada para receber os dados brutos e deve ter tamanho suficiente para aceitar o tensor com a descrição do estado analisado do ambiente.
//--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Gostaria de lembrar que os dados brutos são recebidos diretamente do terminal. E o bloco de pré-processamento desses dados está organizado na forma de uma camada de normalização em lote.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Após a normalização, a descrição do estado do ambiente é transmitida à camada criada por nós dentro do framework MacroHFT.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMacroHFT; //--- Windows { int temp[] = {BarDescr, 120, NActions}; //Window, Stack Size, N Actions if(ArrayCopy(descr.windows, temp) < int(temp.Size())) return false; } descr.count = HistoryBars; descr.window_out = 32; descr.step = 4; // Heads descr.layers =3; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Vale observar que o framework MacroHFT foi desenvolvido para operar no timeframe de 1 minuto. Por isso, a pilha de memória dos estados do ambiente foi aumentada para 120 elementos, o que corresponde a uma sequência de 2 horas. Isso permite levar melhor em conta a dinâmica das mudanças no mercado, garantindo previsões mais precisas e decisões mais fundamentadas dentro da estratégia de trading.
Como já foi mencionado anteriormente, esse módulo se concentra exclusivamente na análise do estado do ambiente e não oferece funcionalidade para avaliação de riscos. Por isso, em seguida, adicionamos o módulo de gerenciamento de risco.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMacroHFTvsRiskManager; //--- Windows { int temp[] = {3, 15, NActions,AccountDescr}; //Window, Stack Size, N Actions, Account Description if(ArrayCopy(descr.windows, temp) < int(temp.Size())) return false; } descr.count = 10; descr.window_out = 16; descr.step = 4; // Heads descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Neste caso, reduzimos a pilha de memória para 15 elementos, o que ajuda a diminuir o volume de dados processados e permite focar em uma dinâmica de mais curto prazo. Isso assegura uma reação mais rápida às mudanças.
Na saída do módulo de gerenciamento de risco, obtemos valores normalizados. E para trazê-los ao espaço de ações requerido pelo Agente, utilizamos uma camada convolucional com a função de ativação apropriada.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvSAMOCL; descr.count = NActions / 3; descr.window = 3; descr.step = 3; descr.window_out = 3; descr.activation = SIGMOID; descr.optimization = ADAM; descr.probability = Rho; if(!actor.Add(descr)) { delete descr; return false; } //--- return true; }
Ao final da execução do método, retornamos o resultado lógico das operações ao programa chamador.
É importante observar que, neste caso, não utilizamos a "cabeça" estocástica do agente. Na minha opinião, em condições de trading de alta frequência, sua utilização apenas adicionaria ruído desnecessário. Em estratégias de alta frequência, é fundamental reduzir ao máximo o número de fatores aleatórios, a fim de garantir respostas rápidas e bem fundamentadas às mudanças do mercado.
Treinamento do modelo
Neste estágio, concluímos a implementação da nossa visão dos métodos propostos pelos autores do framework MacroHFT, utilizando os recursos do MQL5. Criamos a descrição da arquitetura do modelo treinável. E chegou o momento de iniciar o treinamento do modelo. Mas antes, precisamos montar o conjunto de dados de treinamento. Afinal, anteriormente treinávamos os modelos com dados do timeframe de uma hora. Neste caso, porém, precisaremos de informações do timeframe de um minuto.
E aqui vale destacar que a redução do timeframe leva a um aumento no volume de informações. É evidente que, em um mesmo intervalo histórico, obtemos 60 vezes mais barras. Isso resulta em um aumento proporcional no conjunto de dados de treinamento, mantendo todos os outros parâmetros constantes. E somos praticamente obrigados a adotar medidas para reduzir esse volume. Há duas abordagens possíveis: reduzir o período de treinamento ou diminuir a quantidade de passagens armazenadas no conjunto de dados.
Foi decidido manter o período de treinamento em um ano, que, na minha opinião, é o intervalo mínimo de tempo necessário para se obter alguma noção de sazonalidade. No entanto, o comprimento de cada passagem foi limitado a um mês. Para cada mês, foram armazenadas duas passagens de políticas aleatórias, o que resulta em um total de apenas 24 passagens. Isso, obviamente, é insuficiente para um treinamento completo, mas, mesmo assim, o arquivo gerado com o conjunto de dados de treinamento ultrapassou 3 GB.
Essas limitações no processo de coleta do conjunto de dados de treinamento se mostraram bastante restritivas. E creio que ninguém nutre ilusões quanto à obtenção de resultados lucrativos com o uso de políticas de comportamento aleatórias por parte do agente. É evidente que em todas as passagens houve uma rápida perda do saldo da conta. E, para evitar o encerramento do teste por stop-out, limitamos o nível mínimo de saldo no qual o EA gera decisões de trading. Isso nos permitiu manter, no conjunto de treinamento, todos os estados do ambiente durante o período analisado, embora sem recompensas pelas operações realizadas.
Vale também esclarecer que os autores do framework MacroHFT utilizaram uma lista própria de indicadores técnicos durante o treinamento do modelo de trading com criptomoedas. Essa lista pode ser consultada no anexo do artigo original.
Nós optamos por manter a lista anterior de indicadores analisados, o que nos permitirá comparar a eficácia da solução implementada com as modelos anteriores que já foram construídos e treinados. Essa abordagem garante uma avaliação objetiva, pois, ao utilizar os mesmos indicadores das versões anteriores, podemos comparar diretamente os resultados e identificar os pontos fortes e fracos do novo modelo.
A coleta de dados do conjunto de treinamento é realizada pelo EA "...\MacroHFT\Research.mq5". No contexto deste trabalho, proponho analisarmos apenas o método de processamento de ticks OnTick, dentro do qual está implementado o algoritmo principal de obtenção de dados do terminal e execução de operações de trading.
void OnTick() { //--- if(!IsNewBar()) return;
No corpo do método, começamos verificando se ocorreu o evento de abertura de uma nova barra, e somente nesse caso as operações seguintes são executadas. Primeiro, atualizamos os dados dos indicadores técnicos analisados e carregamos os dados históricos do movimento de preços.
int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), HistoryBars, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); Symb.Refresh(); Symb.RefreshRates();
Em seguida, organizamos um laço no qual formamos o buffer de descrição do estado do ambiente com base nos dados recebidos do terminal.
float atr = 0; for(int b = 0; b < (int)HistoryBars; b++) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- int shift = b * BarDescr; sState.state[shift] = (float)(Rates[b].close - open); sState.state[shift + 1] = (float)(Rates[b].high - open); sState.state[shift + 2] = (float)(Rates[b].low - open); sState.state[shift + 3] = (float)(Rates[b].tick_volume / 1000.0f); sState.state[shift + 4] = rsi; sState.state[shift + 5] = cci; sState.state[shift + 6] = atr; sState.state[shift + 7] = macd; sState.state[shift + 8] = sign; } bState.AssignArray(sState.state);
É importante observar que os valores dos osciladores apresentam forma comparável e mantêm a distribuição dos dados ao longo do tempo. Para alcançar esse efeito, ao analisar os indicadores de movimento de preços, usamos exclusivamente as diferenças entre eles, o que permite preservar a estabilidade da distribuição e evitar oscilações excessivas que poderiam distorcer os resultados da análise.
Na próxima etapa, criamos o vetor de descrição do estado da conta, levando em consideração as posições abertas e os resultados financeiros obtidos. Para isso, primeiro reunimos informações sobre as posições em aberto.
sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; double position_discount = 0; double multiplyer = 1.0 / (60.0 * 60.0 * 10.0); int total = PositionsTotal(); datetime current = TimeCurrent(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; double profit = PositionGetDouble(POSITION_PROFIT); switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += profit; break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += profit; break; } position_discount += profit - (current - PositionGetInteger(POSITION_TIME)) * multiplyer * MathAbs(profit); } sState.account[2] = (float)buy_value; sState.account[3] = (float)sell_value; sState.account[4] = (float)buy_profit; sState.account[5] = (float)sell_profit; sState.account[6] = (float)position_discount; sState.account[7] = (float)Rates[0].time;
Geramos as harmônicas do carimbo de tempo.
bTime.Clear(); double time = (double)Rates[0].time; double x = time / (double)(D'2024.01.01' - D'2023.01.01'); bTime.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_MN1); bTime.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_W1); bTime.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_D1); bTime.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(bTime.GetIndex() >= 0) bTime.BufferWrite();
E somente após concluída essa etapa preparatória, reunimos todas as informações sobre os resultados financeiros em um único buffer de dados.
bAccount.Clear(); bAccount.Add((float)((sState.account[0] - PrevBalance) / PrevBalance)); bAccount.Add((float)(sState.account[1] / PrevBalance)); bAccount.Add((float)((sState.account[1] - PrevEquity) / PrevEquity)); bAccount.Add(sState.account[2]); bAccount.Add(sState.account[3]); bAccount.Add((float)(sState.account[4] / PrevBalance)); bAccount.Add((float)(sState.account[5] / PrevBalance)); bAccount.Add((float)(sState.account[6] / PrevBalance)); bAccount.AddArray(GetPointer(bTime)); //--- if(bAccount.GetIndex() >= 0) if(!bAccount.BufferWrite()) return;
Agora que todos os dados brutos necessários estão preparados, verificamos o valor do saldo e, caso seja suficiente para realizar operações de trading, executamos a propagação para frente do modelo.
double min_lot = Symb.LotsMin(); double step_lot = Symb.LotsStep(); double stops = MathMax(Symb.StopsLevel(), 1) * Symb.Point(); //--- vector<float> temp; if(sState.account[0] > 50) { if(!Actor.feedForward((CBufferFloat*)GetPointer(bState), 1, false, GetPointer(bAccount))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); return; } Actor.getResults(temp); if(temp.Size() < NActions) temp = vector<float>::Zeros(NActions); //--- for(int i = 0; i < NActions; i++) { float random = float(rand() / 32767.0 * 5 * min_lot - min_lot); temp[i] += random; } } else temp = vector<float>::Zeros(NActions);
Para aumentar a capacidade de diversificação do ambiente, adicionamos um pouco de ruído à decisão de trading gerada. Isso pode parecer supérfluo no uso de políticas aleatórias durante a fase inicial, mas será útil ao atualizar o conjunto de treinamento com o uso de uma política pré-treinada.
Caso o saldo atinja o limite inferior, o vetor de decisões de trading é preenchido com valores nulos, o que implica ausência de operações.
A partir daí, trabalhamos com o vetor de decisões de trading obtido. Inicialmente, eliminamos os volumes de operações contrárias.
PrevBalance = sState.account[0]; PrevEquity = sState.account[1]; //--- if(temp[0] >= temp[3]) { temp[0] -= temp[3]; temp[3] = 0; } else { temp[3] -= temp[0]; temp[0] = 0; }
Depois, verificamos os parâmetros da posição comprada. Se não estiver prevista no vetor de decisão de trading, então verificamos e fechamos todas as posições compradas anteriormente abertas.
//--- buy control if(temp[0] < min_lot || (temp[1] * MaxTP * Symb.Point()) <= stops || (temp[2] * MaxSL * Symb.Point()) <= stops) { if(buy_value > 0) CloseByDirection(POSITION_TYPE_BUY); }
Se for necessário abrir ou manter uma posição comprada, primeiro ajustamos os parâmetros da operação conforme necessário e corrigimos os níveis de trading das posições já abertas.
else { double buy_lot = min_lot + MathRound((double)(temp[0] - min_lot) / step_lot) * step_lot; double buy_tp = NormalizeDouble(Symb.Ask() + temp[1] * MaxTP * Symb.Point(), Symb.Digits()); double buy_sl = NormalizeDouble(Symb.Ask() - temp[2] * MaxSL * Symb.Point(), Symb.Digits()); if(buy_value > 0) TrailPosition(POSITION_TYPE_BUY, buy_sl, buy_tp);
Em seguida, ajustamos o volume das posições em aberto, por meio de incremento ou fechamento parcial.
if(buy_value != buy_lot) { if(buy_value > buy_lot) ClosePartial(POSITION_TYPE_BUY, buy_value - buy_lot); else Trade.Buy(buy_lot - buy_value, Symb.Name(), Symb.Ask(), buy_sl, buy_tp); } }
Os parâmetros das posições vendidas são processados de forma análoga.
//--- sell control if(temp[3] < min_lot || (temp[4] * MaxTP * Symb.Point()) <= stops || (temp[5] * MaxSL * Symb.Point()) <= stops) { if(sell_value > 0) CloseByDirection(POSITION_TYPE_SELL); } else { double sell_lot = min_lot + MathRound((double)(temp[3] - min_lot) / step_lot) * step_lot;; double sell_tp = NormalizeDouble(Symb.Bid() - temp[4] * MaxTP * Symb.Point(), Symb.Digits()); double sell_sl = NormalizeDouble(Symb.Bid() + temp[5] * MaxSL * Symb.Point(), Symb.Digits()); if(sell_value > 0) TrailPosition(POSITION_TYPE_SELL, sell_sl, sell_tp); if(sell_value != sell_lot) { if(sell_value > sell_lot) ClosePartial(POSITION_TYPE_SELL, sell_value - sell_lot); else Trade.Sell(sell_lot - sell_value, Symb.Name(), Symb.Bid(), sell_sl, sell_tp); } }
Após a realização das operações de trading, é formado o vetor de recompensas.
sState.rewards[0] = bAccount[0]; sState.rewards[1] = 1.0f - bAccount[1]; if((buy_value + sell_value) == 0) sState.rewards[2] -= (float)(atr / PrevBalance); else sState.rewards[2] = 0;
Em seguida, todos os dados acumulados são transferidos para o buffer de armazenamento de dados da amostra de treinamento, e passamos a aguardar o evento de abertura de uma nova barra.
for(ulong i = 0; i < NActions; i++) sState.action[i] = temp[i]; if(!Base.Add(sState)) ExpertRemove(); }
Vale destacar que, caso não seja possível adicionar novos dados ao buffer de treinamento, inicializamos o encerramento do programa. Isso pode ocorrer tanto em razão de algum erro quanto pelo preenchimento completo do buffer.
O código completo deste EA pode ser consultado no anexo.
A coleta direta do conjunto de dados de treinamento é realizada no testador de estratégias do MetaTrader 5 por meio da execução de uma otimização lenta.

É evidente que o conjunto de dados coletado, com um número limitado de passagens, exige uma abordagem específica para o treinamento do modelo. Especialmente se considerarmos que grande parte dos dados consiste exclusivamente de informações sobre o estado do ambiente, o que por sua vez limita as possibilidades de aprendizado. Nessas condições, me parece que a abordagem mais adequada é aquela em que o modelo é treinado com base em "quase ideais" decisões de trading. Esse método, que já utilizamos no treinamento de diversos modelos recentes, permite aproveitar ao máximo os dados disponíveis, mesmo que sejam limitados.
Além disso, vale ressaltar que o programa de treinamento do modelo trabalha exclusivamente com o conjunto de dados de treinamento e é independente do timeframe ou do ativo financeiro utilizado na coleta dos dados. Isso nos dá uma vantagem significativa, pois podemos utilizar o programa de treinamento desenvolvido anteriormente sem necessidade de modificar seu algoritmo. Dessa forma, conseguimos utilizar de forma eficiente os recursos e métodos existentes, economizando tempo e esforço, sem comprometer a qualidade do treinamento do modelo.
Testes
Realizamos um extenso trabalho de implementação da nossa interpretação dos métodos propostos pelos autores do framework MacroHFT, utilizando MQL5. Agora chegou o momento de avaliar a eficácia dos métodos implementados com base em dados históricos reais.
Deve-se observar que a versão apresentada neste trabalho difere significativamente da original, inclusive no que diz respeito aos indicadores técnicos utilizados. Isso, sem dúvida, terá impacto nos resultados obtidos, e por esse motivo, podemos falar apenas em uma avaliação preliminar da eficácia dos métodos implementados no contexto dessas modificações.
Para o treinamento do modelo, utilizamos dados do par de moedas EURUSD referentes ao ano de 2024 no timeframe de um minuto (M1). Os parâmetros dos indicadores analisados foram mantidos inalterados, o que permitiu focar na avaliação do desempenho dos próprios algoritmos e abordagens, eliminando a influência de alterações nas configurações dos indicadores. O procedimento de coleta do conjunto de dados de treinamento e o treinamento do modelo foram apresentados anteriormente.
O teste do modelo treinado foi realizado com os dados históricos disponíveis de janeiro de 2025. Os resultados dos testes estão apresentados a seguir.


E aqui vale mencionar que, durante mais de duas semanas do período de teste, o modelo realizou apenas 8 operações, o que é, sem dúvida, pouco para um EA voltado ao trading de alta frequência. Por outro lado, chama atenção a eficácia das operações realizadas — apenas uma delas resultou em prejuízo. Isso permitiu registrar o nível do profit factor em 2.47.

Ao analisar detalhadamente o histórico das operações realizadas, é possível notar a presença de "reforço" em um movimento de tendência de alta.
Considerações finais
Conhecemos o framework MacroHFT, que representa uma ferramenta inovadora e promissora para o trading de alta frequência em mercados de criptomoedas. Uma das principais características desse framework é sua capacidade de considerar tanto os contextos macroeconômicos quanto os aspectos da dinâmica local de mercado. Essa combinação possibilita uma adaptação eficaz às condições voláteis dos mercados financeiros e a tomada de decisões de trading mais fundamentadas.
Na parte prática do nosso trabalho, implementamos nossa própria visão das abordagens propostas, utilizando os recursos do MQL5, realizando algumas adaptações no funcionamento do framework. Treinamos o modelo com dados históricos reais e conduzimos testes fora do conjunto de treinamento. Naturalmente, ficamos desapontados com o número de operações realizadas, que está muito aquém do esperado para estratégias de alta frequência. Isso talvez esteja relacionado à falta de otimização dos indicadores técnicos utilizados ou à limitação do conjunto de dados de treinamento — mas verificar essas hipóteses exigirá um aprofundamento adicional. No entanto, os resultados dos testes demonstraram a capacidade do modelo em identificar padrões realmente consistentes, o que resultou em uma alta proporção de operações lucrativas na amostra de teste.
Links
- MacroHFT: Memory Augmented Context-aware Reinforcement Learning On High Frequency Trading
- Outros artigos da série
Programas utilizados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | Research.mq5 | Expert Advisor | EA para coleta de amostras |
| 2 | ResearchRealORL.mq5 | Expert Advisor | EA para coleta de amostras com método Real-ORL |
| 3 | Study.mq5 | Expert Advisor | EA para treinamento de modelos |
| 4 | Test.mq5 | Expert Advisor | EA para teste do modelo |
| 5 | Trajectory.mqh | Biblioteca de classe | Estrutura para descrição do estado do sistema e arquitetura dos modelos |
| 6 | NeuroNet.mqh | Biblioteca de classe | Biblioteca de classes para criação de rede neural |
| 7 | NeuroNet.cl | Biblioteca | Biblioteca com código para programa OpenCL |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/16993
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.


- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso