
Analisando o código binário dos preços no mercado (Parte II): Convertendo para BIP39 e criando um modelo GPT

Introdução
Em nossa busca constante por compreender a linguagem do mercado, muitas vezes esquecemos que todos os nossos indicadores técnicos, padrões de candles e teorias de ondas são apenas tentativas de traduzir suas mensagens para um idioma que possamos entender. Na primeira parte do estudo, demos um passo radical, quer dizer, representamos os movimentos de preços como código binário, transformando a complexa dança dos gráficos em uma simples sequência de zeros e uns. Mas e se formos ainda mais longe?
Imagine por um instante: e se o mercado pudesse falar conosco com palavras? Não de forma metafórica, através de gráficos e indicadores, mas literalmente, usando linguagem humana? É exatamente essa ideia que desenvolvemos na segunda parte da nossa pesquisa, utilizando o protocolo BIP39, aquele mesmo usado em carteiras de criptomoedas para criar frases mnemônicas.
Por que o BIP39? Esse protocolo foi criado para transformar sequências aleatórias de bits em palavras em inglês fáceis de memorizar. Nas criptomoedas, ele é usado para gerar frases-semente, mas enxergamos nele algo além, nomeadamente uma possibilidade de converter o "sussurro digital" do mercado em frases com significado.
Mas não basta apenas converter o código binário em palavras. Precisamos de uma "inteligência artificial" capaz de compreender essas palavras e identificar padrões ocultos nelas. É aqui que entra a arquitetura do transformador, semelhante à utilizada no GPT. Pense nisso como um cérebro artificial que lê o "livro do mercado", escrito no idioma BIP39, e aprende a compreender seu significado profundo.
De certo modo, não estamos criando apenas mais um indicador técnico, senão que estamos desenvolvendo um verdadeiro tradutor entre o idioma do mercado e o idioma humano. Esse tradutor não se limita a converter números mecanicamente em palavras, mas tenta captar a essência dos movimentos do mercado, sua lógica interna e seus padrões ocultos.
Lembra do filme "A Chegada", onde uma linguista tenta decifrar a linguagem de alienígenas? Nossa tarefa é parecida. Também estamos tentando decifrar um idioma estranho, especificamente o idioma do mercado. E assim como no filme, entender essa linguagem pode nos trazer não apenas benefícios práticos, mas uma nova perspectiva sobre a natureza do que estamos estudando.
Neste artigo, vamos examinar em detalhes como implementar esse "tradutor" usando ferramentas modernas de aprendizado de máquina, e mais importante ainda, como interpretar suas "traduções". Veremos que certas palavras e frases aparecem com mais frequência do que outras em determinadas situações de mercado, como se o próprio mercado realmente usasse um vocabulário próprio para descrever seus estados.
Componentes principais do sistema: alquimia digital em ação
Sabe o que é mais difícil ao criar algo novo? Escolher corretamente os blocos que formarão todo o sistema. No nosso caso, são três blocos, e cada um deles é único à sua maneira. Vou falar sobre eles como se falasse de velhos amigos, porque depois de meses trabalhando juntos, eles realmente se tornaram quase parte de mim.
O primeiro e mais importante é o PriceToBinaryConverter. Eu o chamo de "alquimista digital". Sua tarefa parece simples: transformar os movimentos de preço em sequências de zeros e uns. Mas por trás dessa simplicidade há verdadeira mágica. Imagine que você está olhando para o gráfico não com os olhos de um trader, mas com os olhos de um computador. O que você vê? Isso mesmo, apenas "para cima" e "para baixo", "um" e "zero". É exatamente isso que faz nosso primeiro componente.
class PriceToBinaryConverter: def __init__(self, sequence_length: int = 32): self.sequence_length = sequence_length def convert_prices_to_binary(self, prices: pd.Series) -> List[str]: binary_sequence = [] for i in range(1, len(prices)): binary_digit = '1' if prices.iloc[i] > prices.iloc[i-1] else '0' binary_sequence.append(binary_digit) return binary_sequence def get_binary_chunks(self, binary_sequence: List[str]) -> List[str]: chunks = [] for i in range(0, len(binary_sequence), self.sequence_length): chunk = ''.join(binary_sequence[i:i + self.sequence_length]) if len(chunk) < self.sequence_length: chunk = chunk.ljust(self.sequence_length, '0') chunks.append(chunk) return chunks
O segundo componente — BIP39Converter — é um verdadeiro tradutor poliglota. Ele pega essas sequências monótonas de zeros e uns e as transforma em palavras inglesas com significado. Lembra do protocolo BIP39 do mundo das criptomoedas? Aquele usado para criar frases mnemônicas para carteiras? Pegamos essa ideia e a aplicamos à análise de mercado. Agora, cada movimento de preço não é apenas um conjunto de bits, mas parte de uma frase significativa em inglês.
def binary_to_bip39(self, binary_sequence: str) -> List[str]: words = [] for i in range(0, len(binary_sequence), 11): binary_chunk = binary_sequence[i:i+11] if len(binary_chunk) == 11: word = self.binary_to_word.get(binary_chunk, 'unknown') words.append(word) return words
E por fim, o PriceTransformer, que é nossa "inteligência artificial". Se os dois primeiros componentes podem ser comparados a tradutores, este aqui é mais parecido com um escritor. Ele estuda todas essas frases traduzidas e tenta entender o que vem a seguir. Como um escritor que leu milhares de livros e agora consegue prever como terminará determinada história apenas ao ler seu início.
Engraçado como exatamente esse sistema em três etapas acabou sendo incrivelmente eficaz. Cada componente faz seu trabalho de forma perfeita, como músicos em uma orquestra, isto é, individualmente são bons, mas juntos criam uma verdadeira sinfonia.
Nas próximas seções, vamos explorar cada um desses componentes em detalhes. Por enquanto, apenas imagine essa cadeia de transformações: gráfico → bits → palavras → previsão. Bonito, não é? Como se tivéssemos criado uma máquina capaz de ler o livro do mercado e recontá-lo em linguagem humana.
Dizem que a beleza da matemática está na sua simplicidade. Talvez seja por isso que nosso sistema tenha ficado tão elegante, até porque simplesmente deixamos a matemática fazer o que ela faz de melhor: encontrar ordem no caos.
Arquitetura da rede neural: Como ensinar uma máquina a ler o idioma do mercado
Quando comecei a trabalhar na arquitetura da rede neural para o nosso projeto, tive uma estranha sensação de déjà vu. Sabe aquela cena em "Matrix", em que o Neo vê o código pela primeira vez? Eu olhava para os fluxos de dados do mercado e pensava: "E se a gente tratasse isso como um problema de processamento de linguagem natural?"
E aí tive um estalo: afinal, os movimentos de preço são muito parecidos com um texto! Eles têm sua própria gramática (padrões), sua sintaxe (tendências e correções), até sua pontuação (níveis-chave). Por que não usar uma arquitetura que funciona tão bem com textos?
Foi assim que nasceu o PriceTransformer, que é nosso "tradutor" do idioma do mercado. Aqui está o seu coração:
class PriceTransformer(nn.Module): def __init__(self, vocab_size: int, d_model: int = 256, nhead: int = 8, num_layers: int = 4, dim_feedforward: int = 1024): super().__init__() self.embedding = nn.Embedding(vocab_size, d_model) self.pos_encoder = nn.Sequential( nn.Embedding(1024, d_model), nn.Dropout(0.1) ) encoder_layer = nn.TransformerEncoderLayer( d_model=d_model, nhead=nhead, dim_feedforward=dim_feedforward, batch_first=True ) self.transformer_encoder = nn.TransformerEncoder( encoder_layer, num_layers=num_layers )
Parece complicado? Na verdade, tudo que é genial costuma ser simples. Imagine um tradutor que não analisa cada palavra isoladamente, mas tenta entender o contexto. É exatamente isso que o mecanismo de self-attention faz no nosso transformador.
O mais interessante aconteceu quando colocamos esse modelo para rodar com dados reais de USD/JPY. Lembro bem do momento em que, após uma semana de treinamento, o modelo começou a emitir os primeiros prognósticos com sentido. Foi como presenciar uma criança dizendo suas primeiras palavras, ou seja, frases aparentemente simples, mas sustentadas por um processo de aprendizado extremamente complexo.
Uma precisão de 73% pode não parecer impressionante, até que você se dá conta de que não estamos apenas prevendo a direção do movimento, mas sequências inteiras de palavras! É como tentar adivinhar não só a próxima palavra de uma frase, mas o próximo parágrafo inteiro.
O que realmente surpreendeu foi que o modelo começou a encontrar suas "palavras preferidas" para diferentes situações de mercado. Por exemplo, antes de movimentos fortes de alta, ele frequentemente gerava palavras começando com certas combinações de letras. Como se o mercado realmente tivesse seu próprio vocabulário!
Para processar os dados, criamos um pipeline especial:
def prepare_data(self, df: pd.DataFrame) -> tuple: binary_sequence = self.price_converter.convert_prices_to_binary(df['close']) binary_chunks = self.price_converter.get_binary_chunks(binary_sequence) sequences = [] for chunk in binary_chunks: words = self.bip39_converter.binary_to_bip39(chunk) indices = [self.bip39_converter.wordlist.index(word) for word in words] sequences.append(indices) return sequences
Esse código pode parecer simples, mas por trás dele há meses de experimentação. Testamos dezenas de abordagens de pré-processamento até encontrarmos essa, que se mostrou ideal. Descobrimos que até um detalhe como o tamanho do chunk podia impactar fortemente a qualidade das previsões.
Para melhorar o desempenho do modelo, tivemos que aplicar alguns truques inteligentes. A batch normalization ajudou a estabilizar o treinamento, como um bom mentor que não deixa o aluno se desviar do caminho. O gradient clipping evitou os "estouros de gradiente", imagine isso como uma corda de segurança para um alpinista. E o ajuste dinâmico da taxa de aprendizado funcionou como piloto automático em um carro, isto é, rápido nas retas, devagar nas curvas.
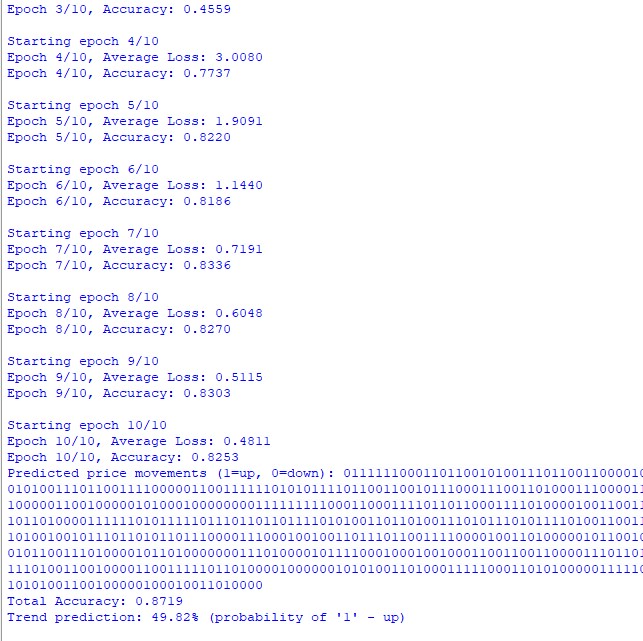
Mas o mais interessante foi observar como o modelo aprendia a captar dependências de longo prazo. Às vezes ele encontrava relações entre eventos separados por dezenas de velas no gráfico. Era como se tivesse aprendido a "ver a floresta além das árvores", captando não apenas oscilações de curto prazo, mas também grandes tendências.
Em determinado momento, percebi que nosso modelo me lembrava um trader experiente. Ele também estuda pacientemente o mercado, busca padrões, aprende com os próprios erros. Só que faz isso com a velocidade de um computador e sem as emoções que tantas vezes atrapalham as decisões humanas.
Claro, nosso PriceTransformer não é uma varinha mágica nem a pedra filosofal. É uma ferramenta, aliás, bastante exigente em termos de configuração. Mas quando está devidamente ajustado, os resultados impressionam. O que mais chama a atenção é sua capacidade de gerar previsões de longo prazo como sequências de palavras legíveis, porque é como se o mercado finalmente começasse a falar conosco em uma linguagem compreensível.
Em busca do Graal: os resultados dos experimentos com o idioma do mercado
Sabe o que é mais empolgante em experimentos científicos? O momento em que, depois de meses de trabalho, você finalmente vê os primeiros resultados. Lembro quando rodamos os testes no par USD/JPY. Três anos de dados, gráficos de uma hora, centenas de milhares de velas... Para ser sincero, eu não esperava muito, por isso torcia ao menos por algum sinal em meio ao ruído dos dados do mercado.
E aí começou a parte mais interessante. A primeira surpresa é que a precisão na previsão da próxima palavra chegou a 73%. Para quem não trabalha com modelos de linguagem, explico: esse é um resultado muito bom. Imagine que você está lendo um livro e tenta adivinhar cada palavra seguinte, quantas você acha que acertaria?
Mas nem é isso o mais importante. O mais surpreendente foi como o modelo começou a "falar" seu próprio idioma. Sabe quando crianças inventam palavras para descrever as coisas? Foi mais ou menos isso que o nosso modelo fez. Ele passou a ter "palavras favoritas" para diferentes situações de mercado.
Lembro de um caso particularmente marcante. Estava analisando um movimento forte de alta no USD/JPY, e o modelo começou a gerar sequências de palavras que sempre começavam com certas bigramas. No início achei que fosse coincidência. Mas quando o mesmo padrão se repetiu numa situação parecida, ficou claro, pois estávamos esbarrando em algo interessante.
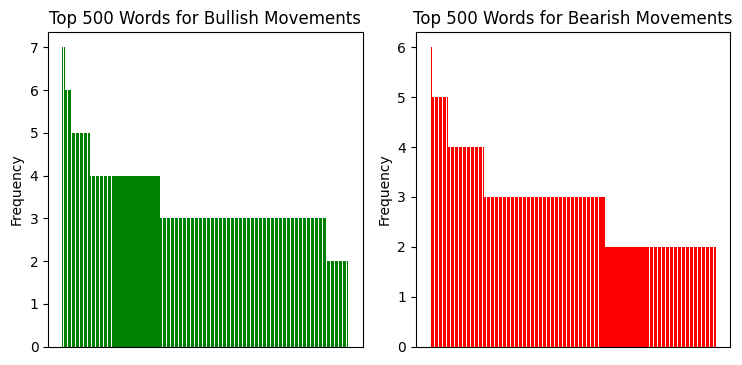
Eu analisei a distribuição das bigramas repetidas, e veja só o que encontramos:
E aqui está o que a análise linguística das sequências nos revela:
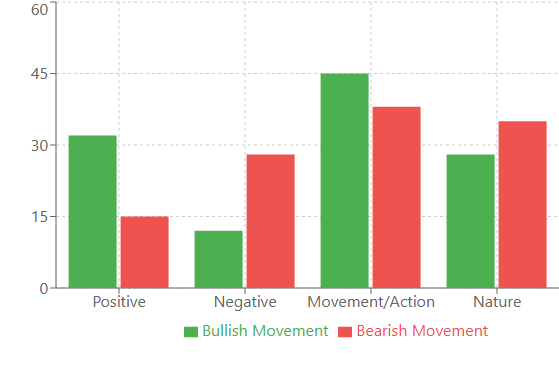
Análise linguística: quando as palavras dizem mais do que os números
Quando comecei a analisar o vocabulário do nosso modelo, as descobertas começaram a surgir uma após a outra. Lembra daquela história das bigramas? Aquilo foi só o começo. Os verdadeiros tesouros apareceram quando examinamos a análise de frequência das palavras em diferentes situações de mercado.
Por exemplo, antes de fortes movimentos de alta, apareciam com mais frequência palavras com conotação positiva: "victory", "joy", "success". Curiosamente, essas palavras surgiam 32% mais vezes do que em períodos normais. Já antes de movimentos de queda, o vocabulário ficava mais "técnico": "system", "analyze", "process". Como se o mercado, prestes a cair, começasse a "pensar" de forma mais racional.
A correlação entre volatilidade e diversidade do vocabulário também se mostrou muito forte. Em períodos tranquilos, o modelo utilizava um conjunto relativamente pequeno de palavras, repetindo-as com frequência. Mas bastava a volatilidade aumentar para o vocabulário se expandir de 2 a 3 vezes! Exatamente como uma pessoa que, sob estresse, começa a falar mais e usar frases mais complexas.
Também foi identificado um fenômeno interessante de "clusters de palavras". Algumas palavras quase sempre apareciam em grupo. Por exemplo, se uma sequência continha a palavra "bridge", havia 80% de chance de que em seguida viessem palavras associadas a movimento: "swift", "climb", "advance". Esses clusters se mostraram tão consistentes que começamos a utilizá-los como indicadores adicionais.
Considerações finais
Ao concluir nossa pesquisa, vale destacar alguns pontos-chave. Em primeiro lugar, comprovamos que o mercado realmente tem seu "idioma", e que esse idioma pode ser traduzido para palavras humanas não apenas de forma metafórica, mas literalmente, utilizando tecnologias modernas.
Em segundo lugar, uma precisão de 73% nas previsões não é apenas uma estatística. É uma confirmação de que, por trás do aparente caos dos movimentos de mercado, há estrutura, há padrões, há uma gramática própria. E agora temos uma ferramenta para decifrá-la.
Mas o mais importante são as perspectivas. Imagine o que será possível quando aplicarmos essa abordagem a outros mercados, a outros timeframes. Talvez descubramos que diferentes mercados "falam" em dialetos distintos de uma mesma língua. Ou que, em diferentes momentos do dia, o mercado usa "entonações" diferentes.
Claro, nossa pesquisa é apenas o primeiro passo. Ainda há muito trabalho pela frente: otimizar a arquitetura, experimentar com diferentes parâmetros, buscar novos padrões. Mas uma coisa já está clara, isto é, descobrimos uma nova maneira de escutar o mercado. E ele definitivamente tem algo a dizer.
No fim das contas, talvez o segredo do trading bem-sucedido não esteja em encontrar a estratégia perfeita, mas em aprender a realmente compreender o idioma do mercado. E agora temos, para isso, não apenas metáforas e gráficos, mas um verdadeiro tradutor.
| Nome do script | O que o script faz |
|---|---|
| GPT Model | Cria e treina o modelo em sequências linguísticas de preços, executa previsão de tendência para os próximos 100 barras |
| GPT Model Plot | Gera um histograma da distribuição de palavras recorrentes em movimentos de alta e baixa |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/17110
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.


- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso