
Redes neuronales en el trading: Aprendizaje multitarea basado en el modelo ResNeXt (Final)

Introducción
En el artículo anterior, presentamos los aspectos teóricos del framework de aprendizaje multitarea basado en la arquitectura ResNeXt, propuesto para construir sistemas de análisis de mercados financieros. El aprendizaje multitarea (Multi-Task Learning, MTL) utiliza un único codificador para procesar los datos de origen y varias "cabezas" especializadas (salidas), cada una dedicada a una tarea distinta. Este planteamiento tiene varias ventajas.
En primer lugar, el uso de un codificador común facilita la identificación de los patrones universales más estables en los datos, que resultan útiles para resolver diversos problemas. A diferencia de los enfoques tradicionales, en los que cada modelo se entrena con un subconjunto separado de datos, la arquitectura multitarea genera representaciones que contienen patrones más fundamentales. Esto hace que el modelo resulte más versátil y robusto ante la presencia de ruido en los datos de origen.
En segundo lugar, el entrenamiento conjunto de varias tareas reduce la probabilidad de sobreentrenamiento del modelo. Si una de las subtareas encuentra datos de baja calidad o poco valor, las demás tareas compensan este efecto gracias a la estructura general del codificador. Esto mejora la estabilidad y solidez del modelo, sobre todo en mercados financieros muy volátiles.
En tercer lugar, este enfoque resulta más eficiente en términos de recursos informáticos. En lugar de entrenar varios modelos distintos que realizan funciones relacionadas, el aprendizaje multitarea permite usar un único codificador, lo cual reduce la redundancia computacional y acelera el proceso de aprendizaje. Esto resulta especialmente importante en el trading algorítmico, donde el rendimiento del modelo resulta fundamental para tomar decisiones comerciales oportunas.
En los mercados financieros, el MTL ofrece la ventaja añadida de poder analizar simultáneamente múltiples factores de mercado. Por ejemplo, el modelo puede prever simultáneamente la volatilidad, identificar las tendencias del mercado, valorar el riesgo y tener en cuenta el trasfondo de las noticias. La interconexión de estos aspectos hace del aprendizaje multitarea una poderosa herramienta para modelizar sistemas de mercado complejos y pronosticar con mayor precisión la dinámica de los precios.
Una de las principales ventajas del aprendizaje multitarea es su capacidad para cambiar de forma dinámica las prioridades entre distintas subtareas. Esto significa que el modelo puede adaptarse a los cambios del entorno de mercado centrándose más en los aspectos que más influyen en la actual evolución de los precios.
La arquitectura ResNeXt, elegida por los autores del framework como base del codificador, se caracteriza por su modularidad y su alta eficiencia. Usa convoluciones grupales que pueden mejorar considerablemente el rendimiento del modelo sin aumentar significativamente la complejidad computacional. Esto resulta especialmente importante para procesar grandes flujos de datos de mercado en tiempo real. La flexibilidad de la arquitectura también permite ajustar los parámetros del modelo para tareas específicas: variar la profundidad de la red, la configuración de los bloques convolucionales y los métodos de normalización de datos, lo cual hace posible adaptar el sistema a distintas condiciones de trabajo.
La combinación del aprendizaje multitarea y la arquitectura ResNeXt crea una potente herramienta analítica capaz de integrar y procesar diversas fuentes de información de forma eficaz. Este planteamiento no solo mejora la precisión de las previsiones, sino que permite al sistema adaptarse rápidamente a los cambios del mercado identificando dependencias y patrones ocultos. La selección automática de características significativas hace que el modelo resulte más robusto frente a las anomalías y minimiza el impacto del ruido aleatorio del mercado.
En la parte práctica del artículo anterior, analizamos con detalle la implementación de los componentes clave de la arquitectura ResNeXt usando MQL5. En el curso de este artículo, vamos a crear un módulo convolucional grupal con enlace residual, representado como un objeto CNeuronResNeXtBlock. Este enfoque permite una gran flexibilidad del sistema, escalabilidad y eficacia en el procesamiento de los datos financieros.
En este artículo, abandonaremos la creación del codificador como objeto monolítico. En su lugar, los usuarios podrán diseñar su propia arquitectura de codificador usando los bloques de construcción ya implementados. Esto no solo aportará flexibilidad al sistema, sino que ampliará la adaptabilidad del sistema a distintos tipos de datos financieros y estrategias comerciales. Hoy nos centraremos en el desarrollo y entrenamiento de modelos dentro de un framework de aprendizaje multitarea.
Arquitectura de los modelos
Antes de proceder a la aplicación técnica, debemos determinar las tareas clave que deben realizar los modelos. Uno de ellos cumplirá la función de Agente responsable de formar los parámetros de las operaciones comerciales, y generará parámetros de transacción similares a los de las arquitecturas comentadas anteriormente. Este planteamiento evita la duplicación excesiva de cálculos, mejora la coherencia de las previsiones y crea una estrategia de toma de decisiones unificada.
Sin embargo, esta estructura no despliega el potencial del aprendizaje multitarea. Para obtener el efecto deseado, añadiremos al sistema un modelo adicional entrenado para predecir las tendencias futuras del mercado. Este bloque predictivo mejorará la precisión de las previsiones y la solidez del modelo ante los cambios bruscos del mercado. En condiciones de gran volatilidad del mercado, este mecanismo permitirá al modelo adaptarse rápidamente a la nueva información y tomar decisiones comerciales con mayor precisión.
La incorporación de múltiples tareas a un único modelo creará un sistema analítico completo capaz de considerar múltiples factores del mercado e interactuar con ellos en tiempo real. Se espera que este enfoque ofrezca un mayor grado de síntesis de conocimientos, mejore la precisión de las previsiones y minimice los riesgos asociados a decisiones comerciales erróneas.
La arquitectura de los modelos entrenados se presenta en el método CreateDescriptions. En los parámetros del método obtenemos 2 punteros a los objetos de array dinámicos en los que tenemos que escribir la arquitectura de los modelos.
bool CreateDescriptions(CArrayObj *&actor, CArrayObj *&probability) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!probability) { probability = new CArrayObj(); if(!probability) return false; }
Una característica clave de la aplicación es la creación de 2 modelos especializados: el Actor y modelo predictivo responsable de la evaluación probabilística de la próxima dirección del movimiento de los precios. El Codificador del estado del entorno está integrado directamente en la arquitectura del Actor, lo que le permite generar vistas enriquecidas de los datos del mercado y considerar dependencias complejas. A su vez, el segundo modelo obtiene datos de entrada del espacio latente del Actor, usando sus representaciones entrenadas para formar predicciones más precisas. Este planteamiento no solo mejora la eficacia de las previsiones, sino que también reduce la carga computacional garantizando que ambos modelos funcionen de manera coherente dentro de un único sistema.
En el cuerpo del método comprobamos directamente la relevancia de los punteros recibidos y, si es necesario, creamos nuevas instancias de objetos de array dinámicos.
A continuación pasamos a crear la arquitectura de nuestro Actor, empezando por el Codificador del entorno. Primero está la capa neuronal básica para registrar los datos de origen. El tamaño de la capa se determina según la cantidad de datos que se vayan a analizar.
//--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
No usamos funciones de activación porque, de hecho, trasladamos los datos de origen del entorno al búfer de resultados de esta capa. En nuestro caso, estos datos proceden directamente del terminal, lo cual nos permite conservar su estructura original. Sin embargo, este enfoque tiene un inconveniente importante: la falta de preprocesamiento puede afectar negativamente a la entrenabilidad del modelo, ya que los datos de origen contienen valores heterogéneos que se distinguen en su escala y distribución.
Para superar este inconveniente, se aplica un mecanismo de normalización por lotes inmediatamente después de la primera capa. Este realiza una normalización preliminar de los datos, llevándolos a una escala común y mejorando su comparabilidad. Esto mejora enormemente la estabilidad del entrenamiento, acelera la convergencia del modelo y disminuye el riesgo de explosión o desvanecimiento del gradiente. Como resultado, incluso al trabajar con datos de mercado muy volátiles, el modelo es capaz de generar representaciones más precisas y coherentes, lo que resulta fundamental para posteriores análisis multitarea.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
A continuación, usamos una capa convolucional que realiza una transformación del espacio de características, llevándolas a un tamaño normalizado. Así se crea una visión unificada de los datos que garantiza la coherencia en los siguientes niveles de procesamiento. Como función de activación se usa Leaky ReLU (LReLU), que ayuda a reducir la influencia de las fluctuaciones menores y el ruido aleatorio, preservando al mismo tiempo las características importantes de los datos de origen.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = HistoryBars; descr.window = BarDescr; descr.step = BarDescr; descr.window_out = 128; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Una vez finalizado el preprocesamiento de los datos, pasamos a diseñar la arquitectura del Codificador de estado del entorno, que desempeña un papel clave en el análisis y la interpretación de los datos de origen. La principal tarea del Codificador consiste en identificar patrones estables y estructuras ocultas en el conjunto de datos analizados, lo que permite crear su representación informativa para su posterior procesamiento por modelos de toma de decisiones.
Nuestro Codificador se construirá a partir de 3 bloques consecutivos de la arquitectura ResNeXt, cada uno de los cuales utilizará convoluciones grupales para realizar una extracción eficaz de las características. En cada bloque se aplica un filtro convolucional con un tamaño de ventana de 3 elementos de la serie temporal multivariante analizada y un paso convolucional de 2 elementos. Esto garantiza que la dimensionalidad de la secuencia original se reduzca a la mitad en cada bloque.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronResNeXtBlock; //--- Chanels { int temp[] = {128, 256}; //In, Out if(ArrayCopy(descr.windows, temp) < int(temp.Size())) return false; } //--- Units and Groups { int temp[] = {HistoryBars, 4, 32}; //Units, Group Size, Groups if(ArrayCopy(descr.units, temp) < int(temp.Size())) return false; } descr.window = 3; descr.step = 2; descr.window_out = 1; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } int units_out = (descr.units[0] - descr.window + descr.step - 1) / descr.step + 1;
Según los principios de la arquitectura ResNeXt, la reducción de la dimensionalidad de las series temporales multivariantes analizadas se compensa con un aumento proporcional de la dimensionalidad de las características. Este enfoque preserva el carácter informativo de los datos al ofreciendo una representación más detallada de las características estructurales de las series temporales.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronResNeXtBlock; //--- Chanels { int temp[] = {256, 512}; //In, Out if(ArrayCopy(descr.windows, temp) < int(temp.Size())) return false; } //--- Units and Groups { int temp[] = {units_out, 4, 64}; //Units, Group Size, Groups if(ArrayCopy(descr.units, temp) < int(temp.Size())) return false; } descr.window = 3; descr.step = 2; descr.window_out = 1; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } units_out = (descr.units[0] - descr.window + descr.step - 1) / descr.step + 1;
Además, conforme aumenta la dimensionalidad del espacio de características, ampliamos proporcionalmente el número de grupos convolucionales manteniendo fijo el tamaño de cada grupo. Esto permite que la arquitectura se amplíe de forma eficiente, equilibrando la complejidad computacional con la capacidad del modelo para extraer patrones complejos de los datos.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronResNeXtBlock; //--- Chanels { int temp[] = {256, 512}; //In, Out if(ArrayCopy(descr.windows, temp) < int(temp.Size())) return false; } //--- Units and Groups { int temp[] = {units_out, 4, 64}; //Units, Group Size, Groups if(ArrayCopy(descr.units, temp) < int(temp.Size())) return false; } descr.window = 3; descr.step = 2; descr.window_out = 1; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } units_out = (descr.units[0] - descr.window + descr.step - 1) / descr.step + 1;
Tras 3 bloques de ResNeXt, la dimensionalidad de las características aumentó a 1024 con una reducción proporcional de la longitud de la secuencia analizada.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronResNeXtBlock; //--- Chanels { int temp[] = {512, 1024}; //In, Out if(ArrayCopy(descr.windows, temp) < int(temp.Size())) return false; } //--- Units and Groups { int temp[] = {units_out, 4, 128}; //Units, Group Size, Groups if(ArrayCopy(descr.units, temp) < int(temp.Size())) return false; } descr.window = 3; descr.step = 2; descr.window_out = 1; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } units_out = (descr.units[0] - descr.window + descr.step - 1) / descr.step + 1;
Y además, la arquitectura ResNeXt posibilita la compresión de la secuencia analizada a lo largo de la dimensión temporal, destacando solo las características más relevantes del estado del entorno analizado. Para ello, primero transponemos los datos recibidos:
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = units_out; descr.window = 1024; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
A continuación, aplicamos una capa de pooling que reduce la dimensionalidad de los datos conservando las características más relevantes. Esto permite que el modelo se centre en las características clave, eliminando el ruido innecesario y ofreciendo una representación más compacta de los datos de origen.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronProofOCL; descr.count = 1024; descr.step = descr.window = units_out; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Recuerde el número de secuencia de esta capa. Esta es la última capa de nuestro Codificador del estado del entorno y precisamente de esta capa tomaremos los datos de entrada para el segundo modelo.
A continuación viene nuestro decodificador de agentes, que consta de dos capas consecutivas completamente conectadas.
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.activation = SIGMOID; descr.batch = 1e4; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NActions; descr.activation = SIGMOID; descr.batch = 1e4; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Ambas capas usan la sigmoidea como función de activación y reducen gradualmente la dimensionalidad del tensor al espacio de acciones de un Agente determinado.
Aquí cabe señalar aquí que el Agente anteriormente creado solo analiza el estado inicial del entorno y carece por completo de un módulo de gestión de riesgos. Esta deficiencia se compensa añadiendo una capa de agente de gestión de riesgos construida como parte de la aplicación del framework MacroHFT.
//--- layer 10 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMacroHFTvsRiskManager; //--- Windows { int temp[] = {3, 15, NActions, AccountDescr}; //Window, Stack Size, N Actions, Account Description if(ArrayCopy(descr.windows, temp) < int(temp.Size())) return false; } descr.count = 10; descr.window_out = 16; descr.step = 4; // Heads descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Y añadimos una capa convolucional con una función de activación sigmoidal que llevará los resultados del agente a un espacio de valores determinado. Para ello, usamos una ventana convolucional igual a 3, que corresponde a los parámetros de una sola transacción. Este enfoque nos permitirá obtener características coherentes de las transacciones.
//--- layer 11 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = NActions / 3; descr.window = 3; descr.step = 3; descr.window_out = 3; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
El siguiente paso consiste en describir el modelo para predecir las probabilidades del próximo movimiento de precios. Como hemos mencionado anteriormente, nuestro modelo predictivo obtiene los datos de entrada del estado latente del Agente. Para garantizar la coherencia entre la dimensionalidad del estado latente y la capa de datos de origen del segundo modelo, hemos decidido renunciar al ajuste manual de la arquitectura. En su lugar, extraemos las descripciones de las capas de estado latente de la descripción de la arquitectura del Agente.
//--- Probability probability.Clear(); //--- Input layer CLayerDescription *latent = actor.At(LatentLayer); if(!latent) return false;
Los parámetros de la descripción de estado latente extraída los transmitimos a la capa de datos de origen del nuevo modelo.
if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = latent.count; descr.activation = latent.activation; descr.optimization = ADAM; if(!probability.Add(descr)) { delete descr; return false; }
Utilizar el estado latente de otro modelo como datos de entrada nos permite usar datos ya procesados y comparables para el análisis. Lo cual significa que no necesitamos utilizar una capa de normalización por lotes para el procesamiento inicial de los datos de origen. La salida del bloque ResNeXt se usa para normalizar los resultados.
Para obtener predicciones de la próxima dirección del movimiento de los precios, usamos 2 capas consecutivas totalmente conectadas con una función de activación sigmoidal entre ellas.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.activation = SIGMOID; descr.batch = 1e4; descr.optimization = ADAM; if(!probability.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = NActions / 3; descr.activation = None; descr.batch = 1e4; descr.optimization = ADAM; if(!probability.Add(descr)) { delete descr; return false; }
Luego trasladamos los resultados de las capas totalmente conectadas al espacio de probabilidades utilizando la función SoftMax.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; prev_count = descr.count = prev_count; descr.step = 1; descr.activation = None; descr.batch = 1e4; descr.optimization = ADAM; if(!probability.Add(descr)) { delete descr; return false; } //--- return true; }
Debemos señalar que nuestro modelo predice probabilidades solo para dos direcciones de movimiento de los precios: alcista y bajista. La probabilidad de movimiento plano no se tiene en cuenta de forma intencional, porque incluso una tendencia lateral supone en realidad una serie de fluctuaciones de precios a corto plazo con aproximadamente la misma amplitud y direcciones opuestas. Este enfoque permite que el modelo se centre en identificar patrones dinámicos fundamentales del mercado sin malgastar recursos computacionales en describir estados planos complejos pero menos sustanciales.
Una vez completada la descripción de la arquitectura del modelo, solo nos queda devolver el resultado lógico de las operaciones al programa que realiza la llamada y finalizar el método.
Entrenamiento de modelos
Ahora que ya hemos decidido la arquitectura de los modelos, podemos pasar a la siguiente etapa: el entrenamiento. Para ello, usaremos la muestra de entrenamiento recogida mientras trabajábamos en el framework MacroHFT. El proceso de montaje de la muestra de entrenamiento se describe detalladamente en el artículo correspondiente. Permítame recordarle que la muestra de entrenamiento anterior se recoge en los datos históricos del par de divisas EURUSD del marco temporal M1 para todo el año 2024.
Sin embargo, para entrenar los modelos, tenemos que introducir algunos cambios en el algoritmo del asesor experto "...\MQL5\Experts\ResNeXt\Study.mq5". En el marco del presente artículo, le propongo centrarnos en considerar únicamente el algoritmo del método Train. Al fin y al cabo, es donde se organiza todo el proceso de aprendizaje.
void Train(void) { //--- vector<float> probability = vector<float>::Full(Buffer.Size(), 1.0f / Buffer.Size());
Al principio del método de aprendizaje, solemos calcular los vectores de probabilidad de selección de diferentes trayectorias según sus rendimientos. Así se corrige el desequilibrio entre episodios rentables y no rentables, ya que en la mayoría de los casos el número de secuencias no rentables supera sobradamente al de las rentables. Sin embargo, en este trabajo, los modelos se entrenan sobre trayectorias casi perfectas, en las que la secuencia de acciones de los agentes se forma según los datos históricos de los movimientos de precios. De este modo, el vector de probabilidad se rellena con valores iguales, lo cual garantiza que toda la muestra de entrenamiento esté representada de forma homogénea. Este enfoque permite al modelo explorar las características clave de los datos del mercado sin desplazar artificialmente las prioridades hacia algunos escenarios en detrimento de otros, lo cual contribuye a una mayor generalizabilidad y solidez del modelo.
A continuación, declaramos una serie de variables locales necesarias para el almacenamiento temporal de los datos durante la ejecución de las operaciones.
vector<float> result, target, state; matrix<float> fstate = matrix<float>::Zeros(1, NForecast * BarDescr); bool Stop = false; //--- uint ticks = GetTickCount();
Con esto concluyen los trabajos preparatorios. Asimismo, creamos un sistema de ciclos de entrenamiento de modelos.
Nótese aquí que la arquitectura ResNeXt no usa directamente bloques de recurrencia. Y para su entrenamiento resulta razonable utilizar el entrenamiento dentro de un ciclo de selección aleatoria de estados de la muestra de entrenamiento. Sin embargo, hemos añadido un agente de gestión de riesgos que usa módulos de memoria para las decisiones tomadas y los cambios en el estado de la cuenta como resultado de esas decisiones. El entrenamiento de este módulo exige respetar la secuencia histórica de los datos de origen.
En el cuerpo del ciclo externo, muestreamos el estado inicial del minilote de la secuencia histórica a partir de la muestra de entrenamiento.
for(int iter = 0; (iter < Iterations && !IsStopped() && !Stop); iter += Batch) { int tr = SampleTrajectory(probability); int start = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2 - NForecast - Batch)); if(start <= 0) { iter -= Batch; continue; }
Y limpiamos la memoria de bloques de recurrencia.
if(!Actor.Clear()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Aquí, rellenamos el vector de valores objetivo previos de las acciones del Agente con valores nulos, y después, organizamos un ciclo anidado de iteración de los estados del minilote en su secuencia histórica.
result = vector<float>::Zeros(NActions); for(int i = start; i < MathMin(Buffer[tr].Total, start + Batch); i++) { if(!state.Assign(Buffer[tr].States[i].state) || MathAbs(state).Sum() == 0 || !bState.AssignArray(state)) { iter -= Batch + start - i; break; }
En el cuerpo del ciclo anidado, primero transferimos las descripciones del estado del entorno de la muestra de entrenamiento al búfer correspondiente. Y luego procedemos a la formación de la descripción tensorial del estado de la cuenta. Aquí prepararemos los armónicos temporales del estado del entorno analizado.
//--- bTime.Clear(); double time = (double)Buffer[tr].States[i].account[7]; double x = time / (double)(D'2024.01.01' - D'2023.01.01'); bTime.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_MN1); bTime.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_W1); bTime.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_D1); bTime.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(bTime.GetIndex() >= 0) bTime.BufferWrite();
Extraemos del búfer de reproducción de experiencias los datos de balance y patrimonio.
//--- Account float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1];
También calculamos el rendimiento de la última transacción objetivo, que potencialmente podríamos obtener en la barra histórica anterior.
float profit = float(bState[0] / _Point * (result[0] - result[3]));
Al preparar el vector de descripción del estado de la cuenta, partimos del supuesto de que en la barra anterior se han cerrado todas las posiciones abiertas disponibles y se ha realizado una transacción potencial de la operación objetivo formada en la iteración anterior del ciclo de entrenamiento anidado. No resulta difícil adivinar que en la primera iteración de este ciclo el vector de acciones objetivo se rellenará con valores cero (ninguna operación comercial). En consecuencia, el coeficiente de cambio de balance será igual a "1", así que formamos indicadores de equidad basados en el beneficio potencial de la última barra calculado anteriormente.
bAccount.Clear(); bAccount.Add(1); bAccount.Add((PrevEquity + profit) / PrevEquity); bAccount.Add(profit / PrevEquity); bAccount.Add(MathMax(result[0] - result[3], 0)); bAccount.Add(MathMax(result[3] - result[0], 0)); bAccount.Add((bAccount[3] > 0 ? profit / PrevEquity : 0)); bAccount.Add((bAccount[4] > 0 ? profit / PrevEquity : 0)); bAccount.Add(0); bAccount.AddArray(GetPointer(bTime)); if(bAccount.GetIndex() >= 0) bAccount.BufferWrite();
En consecuencia, la información sobre las posiciones abiertas también se forma sobre la base de la operación comercial objetivo.
Tras generar los datos de entrada, realizamos una pasada directa de los modelos entrenados. En primer lugar, llamamos al método de pasada directa del Agente pasándole los datos de origen generados anteriormente.
//--- Feed Forward if(!Actor.feedForward((CBufferFloat*)GetPointer(bState), 1, false, GetPointer(bAccount))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Y, a continuación, llamamos al método similar del modelo predictivo de probabilidades del próximo movimiento de precios. Aquí utilizamos el estado latente del Agente como datos de entrada.
if(!Probability.feedForward(GetPointer(Actor), LatentLayer, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
El siguiente paso consistirá en generar los valores objetivo para entrenar los modelos. Como ya hemos mencionado, tenemos previsto entrenar los modelos con "trayectorias casi perfectas". Por ello, formaremos los valores objetivo "mirando hacia el futuro" usando los datos de nuestra muestra de entrenamiento. Para ello, extraemos los datos históricos reales posteriores del estado del entorno de la muestra de entrenamiento para un horizonte de planificación determinado y los transferimos a una matriz en la que cada barra estará representada por una fila independiente.
//--- Look for target target = vector<float>::Zeros(NActions); bActions.AssignArray(target); if(!state.Assign(Buffer[tr].States[i + NForecast].state) || !state.Resize(NForecast * BarDescr) || MathAbs(state).Sum() == 0) { iter -= Batch + start - i; break; } if(!fstate.Resize(1, NForecast * BarDescr) || !fstate.Row(state, 0) || !fstate.Reshape(NForecast, BarDescr)) { iter -= Batch + start - i; break; }
Aquí cabe señalar que los datos que hemos extraído están en una secuencia histórica inversa. Por consiguiente, organizamos un ciclo de permutación de las filas de nuestra matriz.
for(int j = 0; j < NForecast / 2; j++) { if(!fstate.SwapRows(j, NForecast - j - 1)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } }
Ahora, teniendo los datos sobre el próximo movimiento del precio, procedemos a la formación del vector de la operación comercial objetivo. Aquí es donde el algoritmo se ramifica, según la operación comercial anterior. En otras palabras, la operación comercial anterior cambia el objetivo del Agente en esta fase. Y tiene mucho sentido. Si hay una posición abierta, buscamos un punto de salida, y si no hay una posición abierta, buscamos un punto de entrada.
Si nuestra operación objetivo en la iteración anterior era abrir una posición larga, comprobamos si el nivel de stop loss se alcanza en un futuro previsible.
target = fstate.Col(0).CumSum(); if(result[0] > result[3]) { float tp = 0; float sl = 0; float cur_sl = float(-(result[2] > 0 ? result[2] : 1) * MaxSL * Point()); int pos = 0; for(int j = 0; j < NForecast; j++) { tp = MathMax(tp, target[j] + fstate[j, 1] - fstate[j, 0]); pos = j; if(cur_sl >= target[j] + fstate[j, 2] - fstate[j, 0]) break; sl = MathMin(sl, target[j] + fstate[j, 2] - fstate[j, 0]); }
En este caso, usamos el precio máximo hasta que se alcance el nivel de stop loss como valor objetivo de take profit.
Los valores obtenidos se transfieren como parámetros de la operación objetivo de compra, a la vez que se ponen a cero los parámetros de la operación de venta.
if(tp > 0) { sl = float(MathMin(MathAbs(sl) / (MaxSL * Point()), 1)); tp = float(MathMin(tp / (MaxTP * Point()), 1)); result[0] = MathMax(result[0] - result[3], 0.011f); result[1] = tp; result[2] = sl; for(int j = 3; j < NActions; j++) result[j] = 0; bActions.AssignArray(result); } }
Luego realizamos operaciones similares para encontrar el punto de salida de la posición corta.
else { if(result[0] < result[3]) { float tp = 0; float sl = 0; float cur_sl = float((result[5] > 0 ? result[5] : 1) * MaxSL * Point()); int pos = 0; for(int j = 0; j < NForecast; j++) { tp = MathMin(tp, target[j] + fstate[j, 2] - fstate[j, 0]); pos = j; if(cur_sl <= target[j] + fstate[j, 1] - fstate[j, 0]) break; sl = MathMax(sl, target[j] + fstate[j, 1] - fstate[j, 0]); } if(tp < 0) { sl = float(MathMin(MathAbs(sl) / (MaxSL * Point()), 1)); tp = float(MathMin(-tp / (MaxTP * Point()), 1)); result[3] = MathMax(result[3] - result[0], 0.011f); result[4] = tp; result[5] = sl; for(int j = 0; j < 3; j++) result[j] = 0; bActions.AssignArray(result); } }
Si no haya ninguna posición abierta, buscamos un punto de entrada. Para ello, determinamos la dirección de la próxima tendencia del movimiento de los precios.
ulong argmin = target.ArgMin(); ulong argmax = target.ArgMax(); while(argmax > 0 && argmin > 0) { if(argmax < argmin && target[argmax]/2 > MathAbs(target[argmin])) break; if(argmax > argmin && target[argmax] < MathAbs(target[argmin]/2)) break; target.Resize(MathMin(argmax, argmin)); argmin = target.ArgMin(); argmax = target.ArgMax(); }
Si se da un próximo movimiento al alza del precio, definimos los parámetros de la operación de compra. Los parámetros de la operación comercial se definen de forma similar a la búsqueda del punto de salida. En este caso, el stop loss se fija en el nivel del valor máximo.
if(argmin == 0 || (argmax < argmin && argmax > 0)) { float tp = 0; float sl = 0; float cur_sl = - float(MaxSL * Point()); ulong pos = 0; for(ulong j = 0; j < argmax; j++) { tp = MathMax(tp, target[j] + fstate[j, 1] - fstate[j, 0]); pos = j; if(cur_sl >= target[j] + fstate[j, 2] - fstate[j, 0]) break; sl = MathMin(sl, target[j] + fstate[j, 2] - fstate[j, 0]); } if(tp > 0) { sl = (float)MathMax(MathMin(MathAbs(sl) / (MaxSL * Point()), 1), 0.01); tp = (float)MathMin(tp / (MaxTP * Point()), 1); result[0] = float(MathMax(Buffer[tr].States[i].account[0]/100*0.01, 0.011)); result[1] = tp; result[2] = sl; for(int j = 3; j < NActions; j++) result[j] = 0; bActions.AssignArray(result); } }
De la misma forma, definimos los parámetros de una operación de venta en caso de que se dé un movimiento bajista de los precios.
else { if(argmax == 0 || argmax > argmin) { float tp = 0; float sl = 0; float cur_sl = float(MaxSL * Point()); ulong pos = 0; for(ulong j = 0; j < argmin; j++) { tp = MathMin(tp, target[j] + fstate[j, 2] - fstate[j, 0]); pos = j; if(cur_sl <= target[j] + fstate[j, 1] - fstate[j, 0]) break; sl = MathMax(sl, target[j] + fstate[j, 1] - fstate[j, 0]); } if(tp < 0) { sl = (float)MathMax(MathMin(MathAbs(sl) / (MaxSL * Point()), 1), 0.01); tp = (float)MathMin(-tp / (MaxTP * Point()), 1); result[3] = float(MathMax(Buffer[tr].States[i].account[0]/100*0.01,0.011)); result[4] = tp; result[5] = sl; for(int j = 0; j < 3; j++) result[j] = 0; bActions.AssignArray(result); } } } } }
Después de generar el tensor de operación objetivo, podemos realizar operaciones de pasada inversa en nuestro Agente para minimizar la desviación de la solución comercial generada con respecto al objetivo.
//--- Actor Policy if(!Actor.backProp(GetPointer(bActions), (CBufferFloat*)GetPointer(bAccount), GetPointer(bGradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
A continuación, deberemos formar los valores objetivo del modelo predictivo. Aquí, creo que resulta obvio que la operación de compra se corresponde con una tendencia alcista y la operación de venta se corresponde con una tendencia bajista. Como las operaciones se basan en el análisis de datos históricos, confiamos al 100% en la tendencia futura. Por lo tanto, el valor objetivo de la tendencia correspondiente será 1 y 0 para la tendencia opuesta.
target = vector<float>::Zeros(NActions / 3); for(int a = 0; a < NActions; a += 3) target[a / 3] = float(result[a] > 0);
Ahora también podemos realizar operaciones de pasada inversa para el modelo predictivo. Al hacerlo, ajustamos los parámetros del codificador del estado del entorno, lo cual resulta coherente con los enfoques de aprendizaje multitarea.
if(!Result.AssignArray(target) || !Probability.backProp(Result, GetPointer(Actor), LatentLayer) || !Actor.backPropGradient((CBufferFloat*)NULL, (CBufferFloat*)NULL, LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Solo nos queda informar al usuario sobre el progreso del entrenamiento y pasar a la siguiente iteración del sistema de ciclos.
if(GetTickCount() - ticks > 500) { double percent = double(iter + i - start) * 100.0 / (Iterations); string str = StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Actor", percent, Actor.getRecentAverageError()); str += StringFormat("%-13s %6.2f%% -> Error %15.8f\n", "Probability", percent, Probability.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
Tras completar con éxito un número determinado de iteraciones de entrenamiento, eliminamos el campo de comentarios del gráfico donde informábamos al usuario sobre el progreso del entrenamiento del modelo.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Actor", Actor.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Probability", Probability.getRecentAverageError()); ExpertRemove(); //--- }
Luego enviamos los resultados del entrenamiento al registro del terminal e iniciamos el proceso de finalización del programa de entrenamiento. El código completo del modelo de programa de entrenamiento figura en el material adjunto a este artículo.
A continuación, pasamos directamente al proceso de entrenamiento del modelo. Para ello, vamos al terminal MetaTrade 5 y ejecutamos el asesor experto creado anteriormente en el modo de tiempo real. El asesor experto creado por nosotros no realiza operaciones comerciales, por lo que su trabajo no conlleva riesgos para el balance de la cuenta.
Aquí debemos señalar que estamos realizando un entrenamiento simultáneo de ambos modelos. Pero hay un matiz a considerar en el trabajo del Agente. Como ya hemos mencionado, hemos añadido un bloque de gestión de riesgos a la arquitectura del modelo anterior, utilizando los módulos de memoria del estado de la cuenta y de las decisiones tomadas. Al mismo tiempo, la información de la representación latente del Agente se almacena en el módulo de memoria de acciones previas.
No obstante, si nos remitimos al código de entrenamiento del modelo presentado anteriormente, podemos observar la formación del vector de descripciones del estado de la cuenta basado en los valores objetivo. Y entonces se produce un desequilibrio: la unidad de gestión de riesgos valora el reequilibrio a la luz de una política de comportamiento completamente distinta. Para minimizar este efecto, hemos decidido realizar la entrenamiento en 2 fases.
En la primera fase del entrenamiento, fijamos un tamaño del minilote igual a un estado.
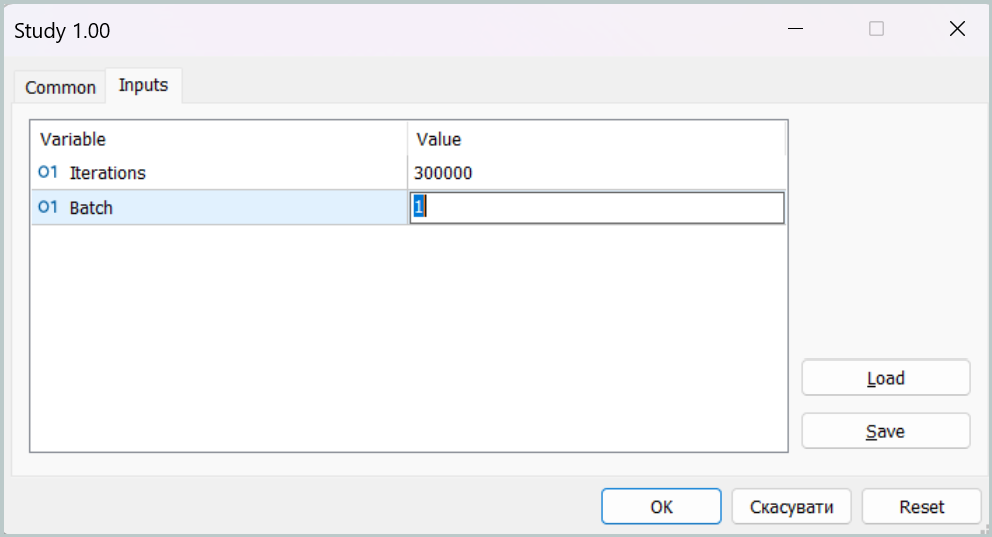
Este conjunto de parámetros permite desactivar realmente el funcionamiento de los módulos de memoria durante la primera fase del entrenamiento. Este no es, por supuesto, el modo objetivo de nuestro modelo, pero en este modo podemos acercar la política de comportamiento del Agente tanto como sea posible al objetivo, minimizando la brecha entre las operaciones previstas y nuestro objetivo.
En la segunda etapa del entrenamiento, aumentamos el tamaño del minilote, estableciéndolo aunque sea como un poco mayor al tamaño de los módulos de memoria. Esto nos permitirá afinar más el funcionamiento del modelo, incluido el funcionamiento de la gestión de riesgos para controlar la influencia de la política utilizada en los estados de la cuenta.
Ensayos con modelos
Una vez entrenados los modelos, pasamos a la fase de prueba de la política resultante de comportamiento del Agente. Y aquí debemos decir algo sobre los cambios introducidos en el algoritmo del programa de pruebas. Los ajustes del algoritmo tienen un carácter puntual. Por ello, no revisaremos el código al completo; podrá analizarlo por su cuenta en el archivo adjunto. Indicaremos únicamente que hemos añadido al algoritmo del programa nuestro modelo de predicción de las probabilidades del próximo movimiento. Y las transacciones comerciales se realizan solo si coinciden la dirección de la operación comercial del Agente y la tendencia más probable.
Vamos a probar la política entrenada en el simulador de estrategias de MetaTrader 5 con los datos históricos de enero de 2025 preservando otros parámetros de la recopilación de muestras de entrenamiento. Resulta sencillo ver que el periodo de prueba no está incluido en la muestra de entrenamiento. Esto permite aproximar al máximo las condiciones de ensayo al modo de funcionamiento real con datos desconocidos.
Ahora presentamos los resultados de las pruebas.
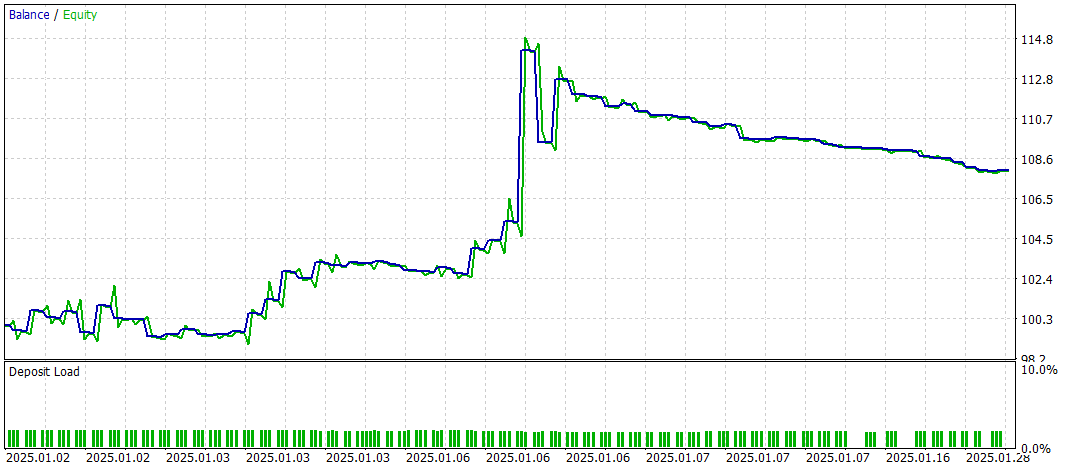
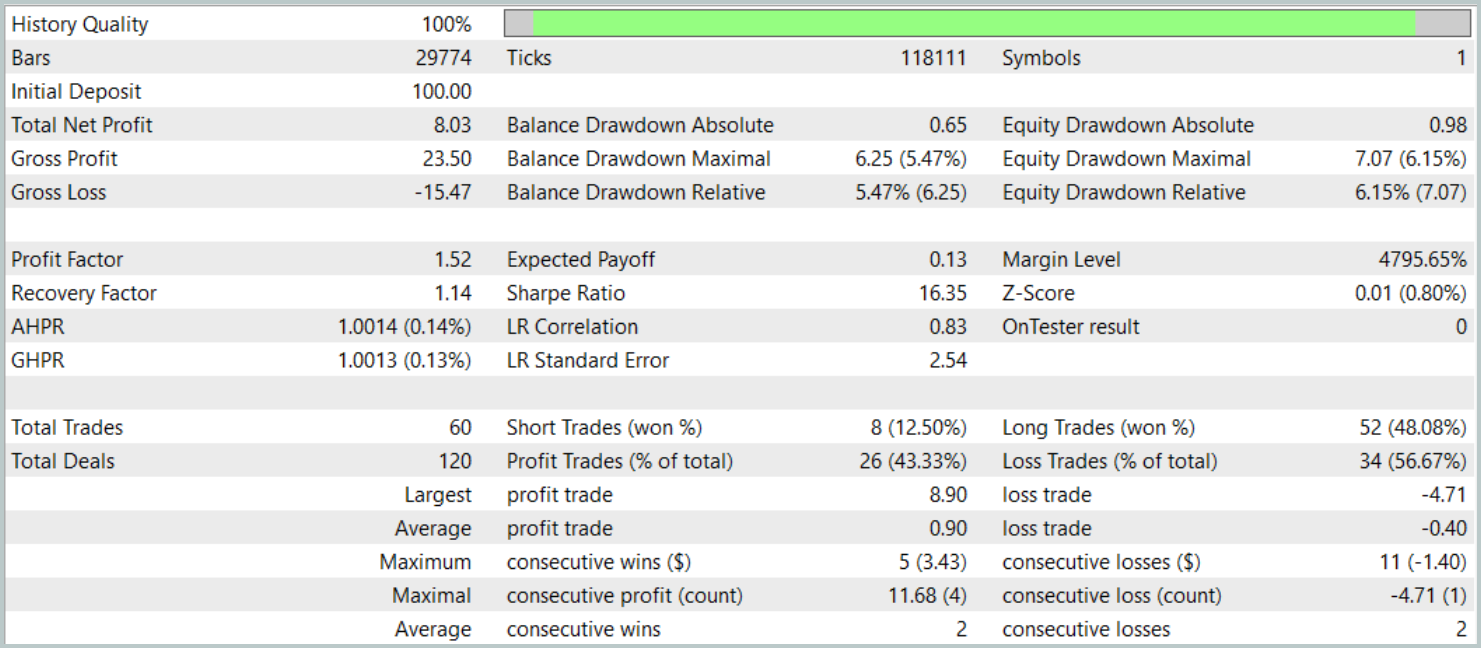
Durante el periodo de prueba, el modelo ha realizado 60 transacciones, lo que supone una media de unas 3 transacciones por día de negociación. Más del 43% de las posiciones abiertas se han cerrado con beneficios. Dado que las transacciones media y máxima rentables casi duplican los indicadores correspondientes de las transacciones deficitarias, la prueba ha concluido con un resultado financiero positivo. Mientras tanto, el factor de beneficio se ha registrado en 1,52 y el factor de recuperación ha alcanzado 1,14.
Conclusión
El framework de aprendizaje multitarea considerado, basado en la arquitectura ResNeXt, abre nuevas posibilidades para el análisis de los mercados financieros. Usando un codificador común y varias "cabezas" especializadas, el modelo es capaz de identificar eficazmente patrones coherentes en los datos, adaptarse a las cambiantes condiciones del mercado y ofrecer previsiones más precisas. El uso del entrenamiento multitarea minimiza el riesgo de sobreentrenamiento, pues el modelo se entrena con varias tareas simultáneamente, lo que contribuye a la formación de percepciones más generalizadas del mercado.
Además, la gran modularidad de la arquitectura ResNeXt permite personalizar los parámetros del modelo según las condiciones específicas de trabajo, lo que lo convierte en una herramienta universal para el trading algorítmico.
La implementación presentada de nuestra propia visión de los enfoques propuestos usando MQL5 ha demostrado su eficacia en el análisis de series temporales y la previsión de tendencias de mercado. La inclusión de un bloque adicional para la previsión de las tendencias del mercado ha reforzado significativamente las capacidades analíticas del modelo, haciéndolo más robusto frente a cambios inesperados en los precios.
En conjunto, el sistema propuesto muestra un potencial significativo para su aplicación comercial automatizada y el análisis algorítmico de datos financieros. Sin embargo, antes de usar el modelo en condiciones reales de mercado, deberemos entrenarlo con una muestra de entrenamiento más representativa, con las consiguientes pruebas exhaustivas.
Enlaces
- Aggregated Residual Transformations for Deep Neural Networks
- Collaborative Optimization in Financial Data Mining Through Deep Learning and ResNeXt
- Otros artículos de la serie
Programas usados en el artículo
| # | Nombre | Tipo | Descripción |
|---|---|---|---|
| 1 | Research.mq5 | Asesor | Asesor de recopilación de datos |
| 2 | ResearchRealORL.mq5 | Asesor | Asesor de recopilación de ejemplos con el método Real-ORL |
| 3 | Study.mq5 | Asesor | Asesor de entrenamiento de modelos |
| 4 | Test.mq5 | Asesor | Asesor para la prueba de modelos |
| 5 | Trajectory.mqh | Biblioteca de clases | Estructura de descripción del estado del sistema y la arquitectura del modelo |
| 6 | NeuroNet.mqh | Biblioteca de clases | Biblioteca de clases para crear una red neuronal |
| 7 | NeuroNet.cl | Biblioteca | Biblioteca de código del programa OpenCL |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/17157
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso