
Нейросети в трейдинге: Мультизадачное обучение на основе модели ResNeXt (Окончание)

Введение
В предыдущей статье мы познакомились с теоретическими аспектами фреймворка мультизадачного обучения на основе архитектуры ResNeXt, предложенного для построения систем анализа финансовых рынков. Многозадачное обучение (Multi-Task Learning, MTL) использует единый энкодер для обработки исходных данных и несколько специализированных "голов" (выходов), каждая из которых предназначена для решения своей задачи. Такой подход даёт ряд преимуществ.
Во-первых, использование общего энкодера способствует выявлению наиболее устойчивых универсальных паттернов в данных, которые оказываются полезными при решении разноплановых задач. В отличие от традиционных подходов, где каждая модель обучается на отдельном подмножестве данных, многозадачная архитектура формирует представления, содержащие более фундаментальные закономерности. Это делает модель более универсальной и устойчивой к наличию шума в исходных данных.
Во-вторых, совместное обучение нескольких задач снижает вероятность переобучения модели. Если одна из подзадач сталкивается с некачественными или малозначимыми данными, другие задачи компенсируют этот эффект за счёт общей структуры энкодера. Это улучшает стабильность и надёжность модели, особенно в условиях высокой изменчивости финансовых рынков.
В-третьих, такой подход более эффективен с точки зрения вычислительных ресурсов. Вместо обучения нескольких отдельных моделей, которые выполняют смежные функции, многозадачное обучение позволяет использовать единый энкодер, снижая вычислительную избыточность и ускоряя процесс обучения. Это особенно важно в алгоритмическом трейдинге, где быстродействие модели критично для принятия своевременных торговых решений.
В условиях финансовых рынков MTL даёт дополнительные преимущества за счёт возможности одновременного анализа множества рыночных факторов. Например, модель может одновременно прогнозировать волатильность, определять рыночные тренды, оценивать риск и учитывать новостной фон. Взаимосвязанность этих аспектов делает многозадачное обучение мощным инструментом для моделирования сложных рыночных систем и более точного прогнозирования динамики цен.
Одним из ключевых преимуществ многозадачного обучения является его способность динамически изменять приоритеты между разными подзадачами. Это означает, что модель может адаптироваться к изменениям рыночной среды, уделяя больше внимания тем аспектам, которые оказывают наибольшее влияние на текущее движения цен.
Архитектура ResNeXt, выбранная авторами фреймворка в качестве основы энкодера, отличается модульностью и высокой эффективностью. Она использует групповые свёртки, что позволяет существенно повысить производительность модели без значительного увеличения вычислительной сложности. Это особенно важно для обработки больших потоков рыночных данных в реальном времени. Гибкость архитектуры также позволяет настраивать параметры модели под конкретные задачи: варьировать глубину сети, конфигурацию свёрточных блоков и методы нормализации данных, что даёт возможность адаптировать систему к разным условиям работы.
Сочетание многозадачного обучения и архитектуры ResNeXt создаёт мощный аналитический инструмент, который способен эффективно интегрировать и обрабатывать разнообразные источники информации. Такой подход не только улучшает точность прогнозов, но и позволяет системе оперативно адаптироваться к рыночным изменениям, выявляя скрытые зависимости и паттерны. Автоматическое выделение значимых признаков делает модель более устойчивой к аномалиям и позволяет минимизировать влияние случайных рыночных шумов.
В практической части предыдущей статьи мы детально рассмотрели реализацию ключевых компонентов архитектуры ResNeXt средствами MQL5. В ходе работы был создан модуль групповой свертки с остаточной связью, представленный в виде объекта CNeuronResNeXtBlock. Такой подход позволяет обеспечить высокую гибкость системы, её масштабируемость и эффективность при обработке финансовых данных.
В данной работе мы откажемся от создания энкодера в виде монолитного объекта. Вместо этого, пользователи получат возможность самостоятельно конструировать архитектуру энкодера, используя уже реализованные строительные блоки. Это обеспечит не только гибкость, но и расширит возможности адаптации системы к различным типам финансовых данных и торговых стратегий. Сегодня основное внимание будет сосредоточено на разработке и обучении моделей в рамках фреймворка многозадачного обучения.
Архитектура моделей
Перед тем как приступить к технической реализации, необходимо определить ключевые задачи, решаемые моделями. Одна из них будет выполнять функцию Агента, отвечая за формирование параметров торговых операций. Она будет генерировать параметры сделки, аналогично рассмотренным ранее архитектурам. Такой подход позволяет избежать избыточного дублирования вычислений, повысить согласованность прогнозов и создать единую стратегию принятия решений.
Однако, такая структура не раскрывает потенциал многозадачного обучения. Для получения желаемого эффекта, в систему будет добавлена дополнительная модель, обучаемая прогнозированию будущих рыночных тенденций. Этот предсказательный блок позволит повысить точность прогнозирования и устойчивость модели к внезапным рыночным изменениям. В условиях высокой рыночной волатильности этот механизм позволит модели оперативно адаптироваться к новой информации и принимать более точные торговые решения.
Включение нескольких задач в единую модель создаст комплексную аналитическую систему, способную учитывать множество рыночных факторов и взаимодействовать с ними в режиме реального времени. Ожидается, что такой подход обеспечит более высокую степень обобщения знаний, позволит улучшить точность прогнозов и минимизировать риски, связанные с ошибочными торговыми решениями.
Архитектура обучаемых моделей представлена в методе CreateDescriptions. В параметрах метода мы получаем 2 указателя на объекты динамических массивов, в которые нам и предстоит записать архитектуру моделей.
bool CreateDescriptions(CArrayObj *&actor, CArrayObj *&probability) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!probability) { probability = new CArrayObj(); if(!probability) return false; }
Ключевой особенностью реализации является создание двух специализированных моделей: Актера и прогнозной модели, отвечающей за вероятностную оценку предстоящего направления движения цены. Энкодер состояния окружающей среды интегрирован непосредственно в архитектуру Актера, что позволяет ему формировать богатые представления рыночных данных и учитывать сложные зависимости. В свою очередь, вторая модель получает исходные данные из латентного пространства Актера, используя его обученные представления для формирования более точных предсказаний. Такой подход не только повышает эффективность прогнозирования, но и снижает вычислительную нагрузку, обеспечивая согласованную работу обеих моделей в рамках единой системы.
В теле метода мы сразу проверяем актуальность полученных указателей и, при необходимости, создаём новые экземпляры объектов динамических массивов.
Затем мы переходим к созданию архитектуры нашего Актера, начиная с Энкодера окружающей среды. Первым идет базовый нейронный слой для записи исходных данных. Размер слоя определяется, исходя из объема анализируемых данных.
//--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Мы не используем функции активации, так как, фактически, в буфер результатов данного слоя мы переносим исходные данные, получаемые от окружающей среды. В нашем случае, эти данные поступают непосредственно из терминала, что позволяет сохранить их исходную структуру. Однако, такой подход имеет существенный недостаток: отсутствие предварительной обработки может негативно сказаться на обучаемости модели, так как исходные данные содержат разнородные значения, отличающиеся по масштабу и распределению.
Для устранения этого недостатка, сразу после первого слоя применяется механизм пакетной нормализации. Он выполняет предварительную стандартизацию данных, приводя их к единому масштабу и улучшая их сопоставимость. Это значительно повышает стабильность обучения, ускоряет сходимость модели и снижает риск появления градиентного взрыва или затухания. В результате, даже при работе с высоковолатильными рыночными данными, модель получает возможность формировать более точные и согласованные представления, что критически важно для дальнейшего многозадачного анализа.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Далее мы используем сверточный слой, который выполняет преобразование пространства признаков, приводя их к стандартизированному размеру. Это позволяет создать единое представление данных, обеспечивая согласованность на последующих уровнях обработки. В качестве функции активации используется Leaky ReLU (LReLU), что способствует снижению влияния незначительных флуктуаций и случайного шума, сохраняя при этом важные особенности исходных данных.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = HistoryBars; descr.window = BarDescr; descr.step = BarDescr; descr.window_out = 128; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
После завершения предварительной обработки данных мы приступаем к проектированию архитектуры Энкодера состояния окружающей среды, который играет ключевую роль в анализе и интерпретации исходных данных. Основная задача Энкодера заключается в выявлении устойчивых закономерностей и скрытых структур в анализируемом наборе данных, что позволяет создать их информативное представление для последующей обработки моделями принятия решений.
Наш Энкодер будет построен из 3 последовательных блоков архитектуры ResNeXt, каждый из которых использует групповые свёртки для эффективного извлечения признаков. В каждом блоке применяется свёрточный фильтр с размером окна в 3 элемента анализируемого многомерного временного ряда и шагом свёртки — 2 элемента. Это обеспечивает уменьшение размерности исходной последовательности вдвое в каждом блоке.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronResNeXtBlock; //--- Chanels { int temp[] = {128, 256}; //In, Out if(ArrayCopy(descr.windows, temp) < int(temp.Size())) return false; } //--- Units and Groups { int temp[] = {HistoryBars, 4, 32}; //Units, Group Size, Groups if(ArrayCopy(descr.units, temp) < int(temp.Size())) return false; } descr.window = 3; descr.step = 2; descr.window_out = 1; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } int units_out = (descr.units[0] - descr.window + descr.step - 1) / descr.step + 1;
В соответствии с принципами построения архитектуры ResNeXt, уменьшение размерности анализируемого многомерного временного ряда компенсируется пропорциональным увеличением размерности признаков. Такой подход позволяет сохранить информативность данных, обеспечивая более детальное представление структурных особенностей временного ряда.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronResNeXtBlock; //--- Chanels { int temp[] = {256, 512}; //In, Out if(ArrayCopy(descr.windows, temp) < int(temp.Size())) return false; } //--- Units and Groups { int temp[] = {units_out, 4, 64}; //Units, Group Size, Groups if(ArrayCopy(descr.units, temp) < int(temp.Size())) return false; } descr.window = 3; descr.step = 2; descr.window_out = 1; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } units_out = (descr.units[0] - descr.window + descr.step - 1) / descr.step + 1;
Кроме того, с увеличением размерности признакового пространства мы пропорционально расширяем количество групп свёртки, сохраняя фиксированным размер каждой группы. Это позволяет эффективно масштабировать архитектуру, обеспечивая баланс между вычислительной сложностью и способностью модели извлекать сложные закономерности из данных.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronResNeXtBlock; //--- Chanels { int temp[] = {256, 512}; //In, Out if(ArrayCopy(descr.windows, temp) < int(temp.Size())) return false; } //--- Units and Groups { int temp[] = {units_out, 4, 64}; //Units, Group Size, Groups if(ArrayCopy(descr.units, temp) < int(temp.Size())) return false; } descr.window = 3; descr.step = 2; descr.window_out = 1; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } units_out = (descr.units[0] - descr.window + descr.step - 1) / descr.step + 1;
После 3 блоков ResNeXt, размерность признаков увеличилась до 1024 с пропорциональным сокращением длины анализируемой последовательности.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronResNeXtBlock; //--- Chanels { int temp[] = {512, 1024}; //In, Out if(ArrayCopy(descr.windows, temp) < int(temp.Size())) return false; } //--- Units and Groups { int temp[] = {units_out, 4, 128}; //Units, Group Size, Groups if(ArrayCopy(descr.units, temp) < int(temp.Size())) return false; } descr.window = 3; descr.step = 2; descr.window_out = 1; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } units_out = (descr.units[0] - descr.window + descr.step - 1) / descr.step + 1;
И далее архитектурой ResNeXt предусмотрено сжатие анализируемой последовательности по измерению времени, выделяя лишь наиболее значимые характеристики анализируемого состояния окружающей среды. Для этого, мы сначала транспонируем полученные данные:
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = units_out; descr.window = 1024; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
А затем применяется слой пулинга, который выполняет понижение размерности данных, сохраняя при этом наиболее значимые характеристики. Это позволяет модели концентрироваться на ключевых признаках, устраняя лишний шум и обеспечивая более компактное представление исходных данных.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronProofOCL; descr.count = 1024; descr.step = descr.window = units_out; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Запомните порядковый номер этого слоя. Это последний слой нашего Энкодера состояния окружающей среды и именно с него мы будем брать исходные данные для второй модели.
Далее идет Декодер нашего Агента, состоящий из двух последовательных полносвязных слоев.
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.activation = SIGMOID; descr.batch = 1e4; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NActions; descr.activation = SIGMOID; descr.batch = 1e4; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Оба слоя используют сигмоиду в качестве функции активации и постепенно понижают размерность тензора до заданного пространства действий Агента.
Здесь следует обратить внимание, что созданный выше Агент анализирует только исходное состояние окружающей среды и полностью лишен модуля риск-менеджмента. Мы компенсируем этот недостаток, добавив слоя агента риск-менеджмента, построенного в рамках реализации фреймворка MacroHFT.
//--- layer 10 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMacroHFTvsRiskManager; //--- Windows { int temp[] = {3, 15, NActions, AccountDescr}; //Window, Stack Size, N Actions, Account Description if(ArrayCopy(descr.windows, temp) < int(temp.Size())) return false; } descr.count = 10; descr.window_out = 16; descr.step = 4; // Heads descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
И добавим сверточный слой с сигмовидной функцией активации, который приведет результаты работы агента в заданное пространство значений. Мы используем окно свертки равное 3, что соответствует параметрам одной сделки. Такой подход позволит получить согласованные характеристики сделок.
//--- layer 11 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = NActions / 3; descr.window = 3; descr.step = 3; descr.window_out = 3; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Следующим этапом мы переходим к описанию модели прогнозирования вероятностей предстоящего ценового движения. Как уже было сказано выше, наша прогностическая модель получает исходные данные из латентного состояния Агента. Для обеспечения согласованности размерности латентного состояния и слоя исходных данных второй модели мы решили отказаться от ручной корректировки архитектуры. Вместо этого, мы извлекаем описания слоя латентного состояния из описания архитектуры Агента.
//--- Probability probability.Clear(); //--- Input layer CLayerDescription *latent = actor.At(LatentLayer); if(!latent) return false;
Параметры извлеченного описания латентного состояния мы перенесем в слой исходных данных новой модели.
if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = latent.count; descr.activation = latent.activation; descr.optimization = ADAM; if(!probability.Add(descr)) { delete descr; return false; }
Использование латентного состояния другой модели в качестве исходных данных позволяет нам использовать для анализа уже обработанные и сопоставимые данные. А значит, нам нет необходимости использовать слой пакетной нормализации для первичной обработки исходных данных. Тем более, на выходе ResNeXt блока осуществляется нормализация результатов.
Для получения прогнозных значений предстоящего направления ценового движения, мы используем 2 последовательных полносвязных слоя с сигмовидной функцией активации между ними.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.activation = SIGMOID; descr.batch = 1e4; descr.optimization = ADAM; if(!probability.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = NActions / 3; descr.activation = None; descr.batch = 1e4; descr.optimization = ADAM; if(!probability.Add(descr)) { delete descr; return false; }
Результаты работы полносвязных слоев мы переводим в вероятностное пространство с помощью функции SoftMax.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; prev_count = descr.count = prev_count; descr.step = 1; descr.activation = None; descr.batch = 1e4; descr.optimization = ADAM; if(!probability.Add(descr)) { delete descr; return false; } //--- return true; }
Важно отметить, что наша модель прогнозирует вероятности только для двух направлений ценового движения: восходящего и нисходящего. Вероятность флетового движения намеренно не учитывается, поскольку даже боковой тренд на самом деле представляет собой череду краткосрочных ценовых колебаний, имеющих примерно одинаковую амплитуду и противоположные направления. Такой подход позволяет модели концентрироваться на выявлении фундаментальных динамических паттернов рынка, не теряя вычислительные ресурсы на описание сложных, но менее значимых флетовых состояний.
После завершения описания архитектуры моделей, нам остается вернуть логический результат выполнения операций вызывающей программе и завершить работу метода.
Обучение моделей
Теперь, когда мы определились с архитектурой моделей, можно прейти к следующему этапу — обучению. Для этого воспользуемся обучающей выборкой, собранной при работе над фреймворком MacroHFT. Подробно процесс сборки обучающей выборки описан в соответствующей статье. Напомню, что указанная обучающая выборка собрана на исторических данных валютной пары EURUSD за весь 2024 год таймфрейм M1.
Однако, для обучения моделей нам потребуется внести некоторые правки в алгоритм эксперта "…\MQL5\Experts\ResNeXt\Study.mq5". В рамках данной статьи предлагаю остановиться на рассмотрении алгоритма только метода Train. Ведь именно в нем организован весь процесс обучения.
void Train(void) { //--- vector<float> probability = vector<float>::Full(Buffer.Size(), 1.0f / Buffer.Size());
Вначале метода обучения мы обычно вычисляем векторы вероятностей выбора различных траекторий, основываясь на их доходности. Это позволяет скорректировать дисбаланс между прибыльными и убыточными эпизодами, поскольку в большинстве случаев количество убыточных последовательностей значительно превышает число прибыльных. Однако, в данной работе обучение моделей планируется на практически идеальных траекториях, где последовательность действий агента формируется в соответствии с историческими данными ценового движения. В связи с этим, вектор вероятностей заполняется равными значениями, что обеспечивает равномерное представление всей обучающей выборки. Такой подход позволяет модели изучить ключевые особенности рыночных данных без искусственного смещения приоритетов в сторону одних сценариев за счёт других, что способствует лучшей обобщающей способности и устойчивости модели.
Затем объявляем ряд локальных переменных, необходимых для временного хранения данных в процессе выполнения операций.
vector<float> result, target, state; matrix<float> fstate = matrix<float>::Zeros(1, NForecast * BarDescr); bool Stop = false; //--- uint ticks = GetTickCount();
На этом завершается подготовительная работа. И далее мы создаем систему циклов обучения моделей.
Здесь следует обратить внимание, что непосредственно архитектура ResNeXt не использует рекуррентных блоков. И для её обучения целесообразно использовать обучение внутри одного цикла случайного выбора состояний из обучающей выборки. Однако, мы добавили агент риск-менеджмента, который использует модули памяти принятых решений и изменения состояния счета в результате их выполнения. Обучение этого модуля требует соблюдения исторической последовательности исходных данных.
В теле внешнего цикла мы сэмплируем начальное состояние мини-пакета исторической последовательности из обучающей выборки.
for(int iter = 0; (iter < Iterations && !IsStopped() && !Stop); iter += Batch) { int tr = SampleTrajectory(probability); int start = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2 - NForecast - Batch)); if(start <= 0) { iter -= Batch; continue; }
И очищаем память рекуррентных блоков.
if(!Actor.Clear()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Тут же мы заполняем нулевыми значениями вектор предыдущих целевых значений действий Агента, а затем, организовываем вложенный цикл перебора состояний мини-пакета в их исторической последовательности.
result = vector<float>::Zeros(NActions); for(int i = start; i < MathMin(Buffer[tr].Total, start + Batch); i++) { if(!state.Assign(Buffer[tr].States[i].state) || MathAbs(state).Sum() == 0 || !bState.AssignArray(state)) { iter -= Batch + start - i; break; }
В теле вложенного цикла сначала перенесем описания состояния окружающей среды из обучающей выборки в соответствующий буфер. А затем перейдем к формированию тензора описания состояния счета. Здесь мы подготовим гармоники временной метки анализируемого состояния окружающей среды.
//--- bTime.Clear(); double time = (double)Buffer[tr].States[i].account[7]; double x = time / (double)(D'2024.01.01' - D'2023.01.01'); bTime.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_MN1); bTime.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_W1); bTime.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_D1); bTime.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(bTime.GetIndex() >= 0) bTime.BufferWrite();
Извлекаем из буфера воспроизведения опыта данные о балансе и эквити.
//--- Account float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1];
А так же посчитаем доходность последней целевой торговой операции, которую мы могли потенциально получить на предшествующем историческом баре.
float profit = float(bState[0] / _Point * (result[0] - result[3]));
При подготовке вектора описания состояния счета мы исходим из предположения, что на предыдущем баре были закрыты все имеющиеся открытые позиции и совершена потенциальная сделка целевой операции, сформированной на предыдущей итерации вложенного цикла обучения. Не сложно догадаться, что на первой итерации данного цикла вектор целевых действий заполнен нулевыми значениями (отсутствие торговой операции). Следовательно, коэффициент изменения баланса равен "1", а показатели эквити формируем, исходя из потенциальной прибыли последнего бара, посчитанной выше.
bAccount.Clear(); bAccount.Add(1); bAccount.Add((PrevEquity + profit) / PrevEquity); bAccount.Add(profit / PrevEquity); bAccount.Add(MathMax(result[0] - result[3], 0)); bAccount.Add(MathMax(result[3] - result[0], 0)); bAccount.Add((bAccount[3] > 0 ? profit / PrevEquity : 0)); bAccount.Add((bAccount[4] > 0 ? profit / PrevEquity : 0)); bAccount.Add(0); bAccount.AddArray(GetPointer(bTime)); if(bAccount.GetIndex() >= 0) bAccount.BufferWrite();
Соответственно, информация об открытых позиций формируется также на основании целевой торговой операции.
После формирования исходных данных, мы осуществляем прямой проход обучаемых моделей. Сначала вызываем метод прямого прохода Агента, передав ему сформированные выше исходные данные.
//--- Feed Forward if(!Actor.feedForward((CBufferFloat*)GetPointer(bState), 1, false, GetPointer(bAccount))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
А затем, вызываем аналогичный метод прогностической модели вероятностей предстоящего ценового движения. Здесь мы используем латентное состояние Агента в качестве исходных данных.
if(!Probability.feedForward(GetPointer(Actor), LatentLayer, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Следующим этапом нам предстоит сформировать целевые значения для обучения моделей. Как было сказано выше, мы планируем обучать модели в условиях "почти идеальных траекторий". Следовательно, целевые значения сформируем, "заглянув в будущее" с помощью данных нашей обучающей выборки. Для этого мы извлекаем реальные последующие исторические данные состояния окружающей среды из обучающей выборки на заданный горизонт планирования и переносим их в матрицу, где каждый бар будет представлен отдельной строкой.
//--- Look for target target = vector<float>::Zeros(NActions); bActions.AssignArray(target); if(!state.Assign(Buffer[tr].States[i + NForecast].state) || !state.Resize(NForecast * BarDescr) || MathAbs(state).Sum() == 0) { iter -= Batch + start - i; break; } if(!fstate.Resize(1, NForecast * BarDescr) || !fstate.Row(state, 0) || !fstate.Reshape(NForecast, BarDescr)) { iter -= Batch + start - i; break; }
Здесь стоит обратить внимание, что извлеченные нами данные находятся в обратной исторической последовательности. Поэтому мы организуем цикл перестановки строк нашей матрицы.
for(int j = 0; j < NForecast / 2; j++) { if(!fstate.SwapRows(j, NForecast - j - 1)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } }
Теперь, имея данные о предстоящем ценовом движении, мы переходим к формированию вектора целевой торговой операции. Здесь осуществляется разветвление алгоритма, в зависимости от предыдущей торговой операции. Иными словами, предыдущая торговая операция меняет цель Агента на данном этапе. И это вполне логично. При наличии открытой позиции, мы ищем точку выхода, а при отсутствии таковой — точку входа.
Если на предыдущей итерации нашей целевой операцией было открытие длинной позиции, то мы проверяем достижение уровня стоп-лосса в обозримом будущем.
target = fstate.Col(0).CumSum(); if(result[0] > result[3]) { float tp = 0; float sl = 0; float cur_sl = float(-(result[2] > 0 ? result[2] : 1) * MaxSL * Point()); int pos = 0; for(int j = 0; j < NForecast; j++) { tp = MathMax(tp, target[j] + fstate[j, 1] - fstate[j, 0]); pos = j; if(cur_sl >= target[j] + fstate[j, 2] - fstate[j, 0]) break; sl = MathMin(sl, target[j] + fstate[j, 2] - fstate[j, 0]); }
При этом, в максимальную цену до момента достижения уровня стоп-лосса мы используем в качестве целевого значения тейк-профита.
Полученные значения переносим в качестве параметров целевой операции на покупку, одновременно обнуляем параметры сделки на продажу.
if(tp > 0) { sl = float(MathMin(MathAbs(sl) / (MaxSL * Point()), 1)); tp = float(MathMin(tp / (MaxTP * Point()), 1)); result[0] = MathMax(result[0] - result[3], 0.011f); result[1] = tp; result[2] = sl; for(int j = 3; j < NActions; j++) result[j] = 0; bActions.AssignArray(result); } }
Аналогичные операции проводим для поиска точки выхода из короткой позиции.
else { if(result[0] < result[3]) { float tp = 0; float sl = 0; float cur_sl = float((result[5] > 0 ? result[5] : 1) * MaxSL * Point()); int pos = 0; for(int j = 0; j < NForecast; j++) { tp = MathMin(tp, target[j] + fstate[j, 2] - fstate[j, 0]); pos = j; if(cur_sl <= target[j] + fstate[j, 1] - fstate[j, 0]) break; sl = MathMax(sl, target[j] + fstate[j, 1] - fstate[j, 0]); } if(tp < 0) { sl = float(MathMin(MathAbs(sl) / (MaxSL * Point()), 1)); tp = float(MathMin(-tp / (MaxTP * Point()), 1)); result[3] = MathMax(result[3] - result[0], 0.011f); result[4] = tp; result[5] = sl; for(int j = 0; j < 3; j++) result[j] = 0; bActions.AssignArray(result); } }
В случае отсутствия открытой позиции, мы осуществляем поиск точки входа. Для этого мы определим направление предстоящей тенденции ценового движения.
ulong argmin = target.ArgMin(); ulong argmax = target.ArgMax(); while(argmax > 0 && argmin > 0) { if(argmax < argmin && target[argmax]/2 > MathAbs(target[argmin])) break; if(argmax > argmin && target[argmax] < MathAbs(target[argmin]/2)) break; target.Resize(MathMin(argmax, argmin)); argmin = target.ArgMin(); argmax = target.ArgMax(); }
В случае предстоящего восходящего движения цены, мы определяем параметры сделки на покупку. Параметры торговой операции определяются аналогично поиску точки выхода. При этом стоп-лосс устанавливается на уровень максимального значения.
if(argmin == 0 || (argmax < argmin && argmax > 0)) { float tp = 0; float sl = 0; float cur_sl = - float(MaxSL * Point()); ulong pos = 0; for(ulong j = 0; j < argmax; j++) { tp = MathMax(tp, target[j] + fstate[j, 1] - fstate[j, 0]); pos = j; if(cur_sl >= target[j] + fstate[j, 2] - fstate[j, 0]) break; sl = MathMin(sl, target[j] + fstate[j, 2] - fstate[j, 0]); } if(tp > 0) { sl = (float)MathMax(MathMin(MathAbs(sl) / (MaxSL * Point()), 1), 0.01); tp = (float)MathMin(tp / (MaxTP * Point()), 1); result[0] = float(MathMax(Buffer[tr].States[i].account[0]/100*0.01, 0.011)); result[1] = tp; result[2] = sl; for(int j = 3; j < NActions; j++) result[j] = 0; bActions.AssignArray(result); } }
Таким же образом определяем параметры сделки на продажу в случае нисходящего ценового движения.
else { if(argmax == 0 || argmax > argmin) { float tp = 0; float sl = 0; float cur_sl = float(MaxSL * Point()); ulong pos = 0; for(ulong j = 0; j < argmin; j++) { tp = MathMin(tp, target[j] + fstate[j, 2] - fstate[j, 0]); pos = j; if(cur_sl <= target[j] + fstate[j, 1] - fstate[j, 0]) break; sl = MathMax(sl, target[j] + fstate[j, 1] - fstate[j, 0]); } if(tp < 0) { sl = (float)MathMax(MathMin(MathAbs(sl) / (MaxSL * Point()), 1), 0.01); tp = (float)MathMin(-tp / (MaxTP * Point()), 1); result[3] = float(MathMax(Buffer[tr].States[i].account[0]/100*0.01,0.011)); result[4] = tp; result[5] = sl; for(int j = 0; j < 3; j++) result[j] = 0; bActions.AssignArray(result); } } } } }
После формирования целевого тензора торговой операции, мы можем осуществить операции обратного прохода нашего Агента с целью минимизации отклонения сгенерированного торгового решения от целевого.
//--- Actor Policy if(!Actor.backProp(GetPointer(bActions), (CBufferFloat*)GetPointer(bAccount), GetPointer(bGradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Далее нам предстоит сформировать целевые значения прогностической модели. Здесь, я думаю, очевидно, что сделка на покупку соответствует восходящей тенденции, а на продажу — нисходящей. Так как сделки сформированы на основании анализа исторических данных, то у нас есть 100% уверенность в предстоящей тенденции. Следовательно, целевое значение соответствующей тенденции равно 1 и 0 для противоположной.
target = vector<float>::Zeros(NActions / 3); for(int a = 0; a < NActions; a += 3) target[a / 3] = float(result[a] > 0);
Теперь мы можем осуществить операции обратного прохода и для прогностической модели. При этом, мы корректируем параметры энкодера состояния окружающей среды, что соответствует подходам мультизадачного обучения.
if(!Result.AssignArray(target) || !Probability.backProp(Result, GetPointer(Actor), LatentLayer) || !Actor.backPropGradient((CBufferFloat*)NULL, (CBufferFloat*)NULL, LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Нам остается проинформировать пользователя о ходе процесса обучения и перейти к следующей итерации системы циклов.
if(GetTickCount() - ticks > 500) { double percent = double(iter + i - start) * 100.0 / (Iterations); string str = StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Actor", percent, Actor.getRecentAverageError()); str += StringFormat("%-13s %6.2f%% -> Error %15.8f\n", "Probability", percent, Probability.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
После успешного выполнения заданного количества итераций обучения, мы очищаем поле комментариев графика, где мы информировали пользователя о ходе обучения моделей.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Actor", Actor.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Probability", Probability.getRecentAverageError()); ExpertRemove(); //--- }
Результаты обучения выводим в журнал терминала и инициализируем процесс завершения работы программы обучения. С полным кодом программы обучения моделей вы можете ознакомиться в материалах, прикрепленным к статье.
Следующим этапом мы переходим непосредственно к процессу обучению моделей. С этой целью мы переходим в терминал MetaTrade 5 и осуществляем запуск вышесозданного советника в режиме реального времени. Созданный нами советник не совершает торговых операций, поэтому его работа не несет рисков для баланса счета.
Здесь надо обратить внимание, что мы осуществляем одновременное обучение обеих моделей. Но есть один нюанс в работе Агента. Как уже было сказано выше, в архитектуру указанной модели был добавлен блок риск менеджмента, использующий модули памяти состояния счета и принятых решений. При этом, в модуль памяти предшествующих действий сохраняется информация из латентного представления Агента.
Однако, если обратиться к представленному выше коду обучения моделей, то можно заметить формирование вектора описания состояния счета на основании целевых значений. И тут возникает дисбаланс — блок риск-менеджмента оценивает изменение баланса в свете совершенно иной политики поведения. Для минимизации этого эффекта было принято решения о проведении обучения в 2 этапа.
На первом этапе обучения мы устанавливаем размер мини-пакета равный одному состоянию.
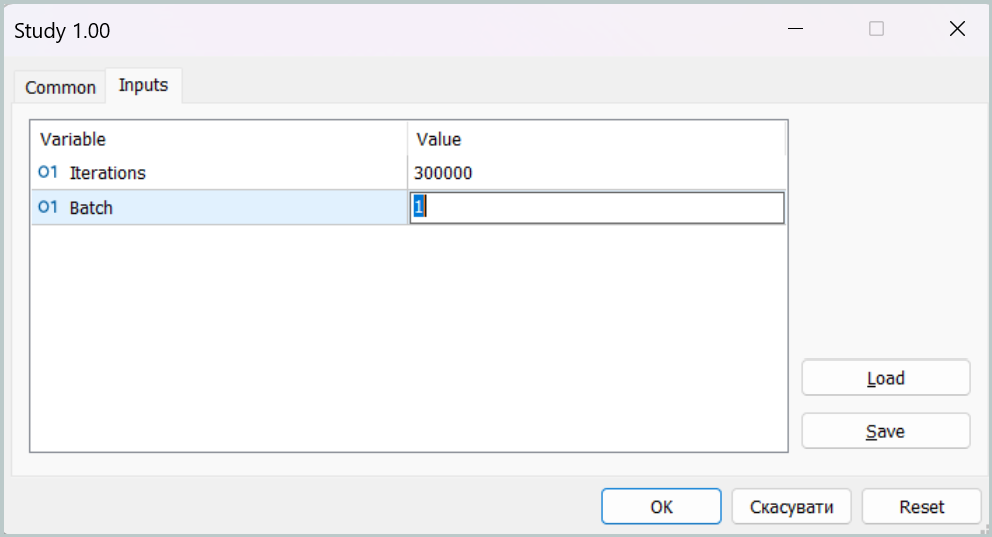
Такой набор параметров позволяет фактически отключить работу модулей памяти на первом этапе обучения. Это, конечно, не целевой режим работы нашей модели, но в таком режиме мы можем максимально приблизить политику поведения Агента к целевой, минимизируя разрыв между прогнозными и целевыми торговыми операциями.
На втором этапе обучения мы увеличиваем размер мини-пакета, установив его хотя бы немного больше объема модулей памяти. Это позволит нам провести более тонкую настройку работы модели, включая работу риск-менеджмента по контролю влияния используемой политики на состояния счета.
Тестирование моделей
После обучения моделей переходим к этапу тестирования полученной политики поведения Агента. И здесь надо немного сказать об изменениях, внесенных в алгоритм программы тестирования. Корректировки алгоритма носят точечный характер. Поэтому мы не будем полностью рассматривать код, с которым вы можете самостоятельно ознакомиться во вложении. Обратим внимание лишь, что в алгоритм работы программы мы добавили нашу модель прогнозирования вероятностей предстоящего движения. И торговая операция совершается лишь в случае совпадения направления торговой операции Агента и наиболее вероятной тенденции.
Тестирование обученной политики мы осуществляем в тестере стратегий MetaTrader 5 на исторических данных Января 2025 года с полным сохранение прочих параметров сбора обучающей выборки. Легко заметить, что период тестирования не входит в обучающую выборку. Это позволяет максимально приблизить условия тестирования к реальному режиму работу на неизвестных данных.
Результаты тестирования представлены ниже.
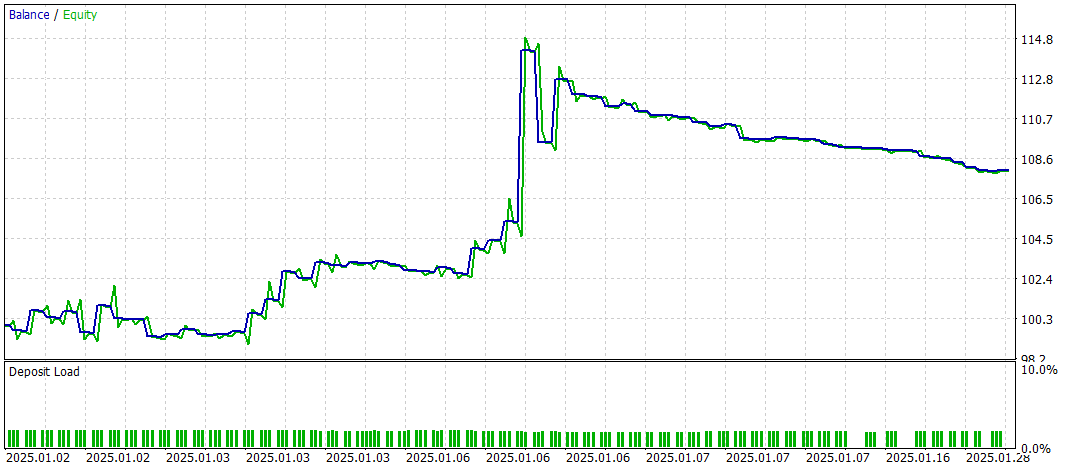
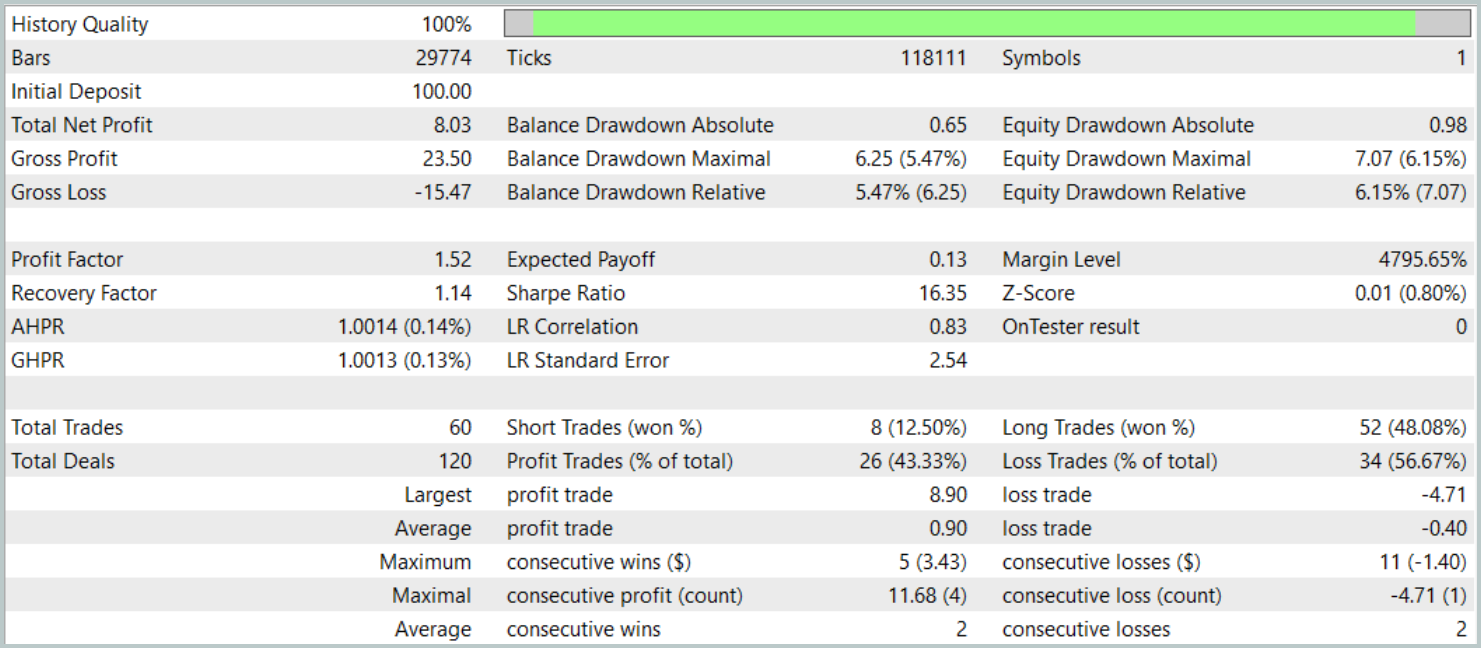
За период тестирования модель совершила 60 торговых операций, что в среднем составляет около 3 сделок в торговые сутки. Более 43% открытых позиций были закрыты с прибылью. Благодаря тому, что средняя и максимальная прибыльная сделка почти в два раза превышают соответствующие показатели убыточных операций, тестирование завершилось с положительным финансовым результатом. При этом профит-фактор зафиксирован на уровне 1.52, а фактор восстановления достиг отметки 1.14.
Заключение
Рассмотренный фреймворк многозадачного обучения на основе архитектуры ResNeXt открывает новые возможности для анализа финансовых рынков. Благодаря использованию общего энкодера и специализированных "голов", модель способна эффективно выявлять устойчивые закономерности в данных, адаптироваться к изменяющимся рыночным условиям и обеспечивать более точные прогнозы. Применение многозадачного обучения позволяет минимизировать риск переобучения, так как модель обучается на нескольких задачах одновременно, что способствует формированию более обобщённых представлений о рынке.
Кроме того, высокая модульность архитектуры ResNeXt позволяет настраивать параметры модели в зависимости от конкретных условий работы, что делает её универсальным инструментом для алгоритмического трейдинга.
Представленная реализация собственного видения предложенных подходов средствами MQL5 показала эффективность при анализе временных рядов и прогнозирования рыночных трендов. Включение дополнительного блока прогнозирования рыночных трендов значительно усилило аналитические возможности модели, сделав её более устойчивой к неожиданным изменениям цен.
В целом, предложенная система демонстрирует значительный потенциал для применения в автоматизированном трейдинге и алгоритмическом анализе финансовых данных. Однако, перед использованием модели в реальных рыночных условиях требуется обучение модели на более представительной обучающей выборке с последующим всесторонни тестированием.
Ссылки
- Aggregated Residual Transformations for Deep Neural Networks
- Collaborative Optimization in Financial Data Mining Through Deep Learning and ResNeXt
- Другие статьи серии
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Research.mq5 | Советник | Советник сбора примеров |
| 2 | ResearchRealORL.mq5 | Советник | Советник сбора примеров методом Real-ORL |
| 3 | Study.mq5 | Советник | Советник обучения моделей |
| 4 | Test.mq5 | Советник | Советник для тестирования модели |
| 5 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы и архитектуры моделей |
| 6 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 7 | NeuroNet.cl | Библиотека | Библиотека кода OpenCL-программы |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования