
Neuronale Netze im Handel: Multi-Task-Lernen auf der Grundlage des ResNeXt-Modells (letzter Teil)

Einführung
Im vorangegangenen Artikel haben wir uns mit den theoretischen Aspekten eines auf der Architektur von ResNeXt basierenden Multi-Task-Learning-Rahmens vertraut gemacht, der für den Aufbau von Finanzmarktanalysesystemen vorgeschlagen wurde. Beim Multi-Task-Learning (MTL) wird ein einziger Encoder zur Verarbeitung der Eingabedaten und mehrere spezialisierte „Köpfe“ (Ausgänge) verwendet, die jeweils für die Lösung einer bestimmten Aufgabe konzipiert sind. Dieser Ansatz bietet eine Reihe von Vorteilen.
Erstens erleichtert die Verwendung eines gemeinsamen Kodierers die Extraktion der robustesten und universellsten Muster in den Daten, die sich bei verschiedenen Aufgaben als nützlich erweisen. Im Gegensatz zu traditionellen Ansätzen, bei denen jedes Modell auf einer separaten Teilmenge von Daten trainiert wird, bildet eine Multi-Task-Architektur Repräsentationen, die grundlegendere Regelmäßigkeiten erfassen. Dadurch ist das Modell universeller einsetzbar und widerstandsfähiger gegen Störungen in den Rohdaten.
Zweitens verringert das gemeinsame Training mehrerer Aufgaben die Wahrscheinlichkeit einer Überanpassung des Modells. Stößt eine der Teilaufgaben auf minderwertige oder wenig informative Daten, kompensieren die anderen Aufgaben diesen Effekt durch die gemeinsame Encoderstruktur. Dies verbessert die Stabilität und Zuverlässigkeit des Modells, insbesondere unter den sehr volatilen Bedingungen der Finanzmärkte.
Drittens ist dieser Ansatz effizienter im Hinblick auf den Einsatz von Rechenressourcen. Anstatt mehrere unabhängige Modelle zu trainieren, die zusammenhängende Funktionen ausführen, ermöglicht das Multi-Task-Lernen die Verwendung eines einzigen Encoders, wodurch Rechenredundanz reduziert und der Trainingsprozess beschleunigt wird. Dies ist besonders wichtig für den algorithmischen Handel, bei dem die Modelllatenz entscheidend ist, um zeitnahe Handelsentscheidungen zu treffen.
Im Zusammenhang mit den Finanzmärkten bietet die MTL zusätzliche Vorteile, da sie die gleichzeitige Analyse mehrerer Marktfaktoren ermöglicht. So kann ein Modell beispielsweise gleichzeitig die Volatilität vorhersagen, Markttrends erkennen, das Risiko bewerten und den Nachrichtenhintergrund einbeziehen. Die Interdependenz dieser Aspekte macht das Multi-Tasking-Lernen zu einem leistungsfähigen Instrument für die Modellierung komplexer Marktsysteme und für genauere Prognosen der Preisdynamik.
Einer der Hauptvorteile des Multi-Task-Lernens ist die Fähigkeit, die Prioritäten zwischen verschiedenen Teilaufgaben dynamisch zu verschieben. Dies bedeutet, dass sich das Modell an Veränderungen des Marktumfelds anpassen kann und sich stärker auf die Aspekte konzentriert, die den größten Einfluss auf die aktuellen Kursbewegungen haben.
Die Architektur ResNeXt, die von den Autoren des Frameworks als Basis für den Encoder gewählt wurde, zeichnet sich durch ihre Modularität und hohe Effizienz aus. Es verwendet gruppierte Faltungen, die die Leistung des Modells erheblich verbessern, ohne die Komplexität der Berechnungen wesentlich zu erhöhen. Dies ist besonders wichtig für die Verarbeitung großer Ströme von Marktdaten in Echtzeit. Die Flexibilität der Architektur erlaubt es auch, die Modellparameter auf spezifische Aufgaben zuzuschneiden: durch Variation der Netztiefe, der Faltungsblockkonfigurationen und der Datennormalisierungsmethoden lässt sich das System an unterschiedliche Betriebsbedingungen anpassen.
Durch die Kombination von Multi-Task-Learning und der ResNeXt-Architektur entsteht ein leistungsstarkes Analysewerkzeug, das in der Lage ist, verschiedene Informationsquellen effizient zu integrieren und zu verarbeiten. Dieser Ansatz verbessert nicht nur die Prognosegenauigkeit, sondern ermöglicht es dem System auch, sich schnell an Marktveränderungen anzupassen und versteckte Abhängigkeiten und Muster aufzudecken. Die automatische Extraktion signifikanter Merkmale macht das Modell robuster gegenüber Anomalien und trägt dazu bei, die Auswirkungen des zufälligen Marktrauschens zu minimieren.
Im praktischen Teil des vorangegangenen Artikels haben wir die Implementierung der Schlüsselkomponenten der ResNeXt-Architektur mit MQL5 im Detail untersucht. Während dieser Arbeit wurde ein gruppiertes Faltungsmodul mit einer Residuenverbindung geschaffen, das als CNeuronResNeXtBlock Objekt implementiert wurde. Dieser Ansatz gewährleistet eine hohe Systemflexibilität, Skalierbarkeit und Effizienz bei der Verarbeitung von Finanzdaten.
In der vorliegenden Arbeit gehen wir davon ab, den Encoder als ein monolithisches Objekt zu gestalten. Stattdessen können die Nutzer die Encoder-Architektur selbst aufbauen, indem sie die bereits implementierten Bausteine verwenden. Dadurch wird nicht nur eine größere Flexibilität erreicht, sondern auch die Fähigkeit des Systems erweitert, sich an verschiedene Arten von Finanzdaten und Handelsstrategien anzupassen. Heute liegt der Schwerpunkt auf der Entwicklung und dem Training von Modellen im Rahmen des Multi-Task-Learnings.
Modell der Architektur
Bevor mit der technischen Umsetzung begonnen wird, ist es notwendig, die wichtigsten Aufgaben zu definieren, die durch die Modelle gelöst werden. Einer von ihnen übernimmt die Rolle eines Agenten, der für die Erstellung der Parameter der Handelsoperationen verantwortlich ist. Er wird Handelsparameter erzeugen, ähnlich wie bei den zuvor besprochenen Architekturen. Dieser Ansatz trägt dazu bei, übermäßige Doppelarbeit bei den Berechnungen zu vermeiden, die Konsistenz der Prognosen zu verbessern und eine einheitliche Entscheidungsstrategie zu entwickeln.
Eine solche Struktur schöpft jedoch das Potenzial des Multi-Task-Lernens nicht vollständig aus. Um den gewünschten Effekt zu erzielen, wird dem System ein zusätzliches Modell hinzugefügt, das für die Vorhersage künftiger Markttrends trainiert wird. Dieser Vorhersageblock wird die Prognosegenauigkeit verbessern und die Widerstandsfähigkeit des Modells gegenüber plötzlichen Marktveränderungen erhöhen. Unter Bedingungen hoher Marktvolatilität ermöglicht dieser Mechanismus dem Modell, sich schnell an neue Informationen anzupassen und präzisere Handelsentscheidungen zu treffen.
Durch die Integration mehrerer Aufgaben in ein einziges Modell wird ein umfassendes Analysesystem geschaffen, das in der Lage ist, zahlreiche Marktfaktoren zu berücksichtigen und mit ihnen in Echtzeit zu interagieren. Es wird erwartet, dass dieser Ansatz ein höheres Maß an Wissensverallgemeinerung bietet, die Prognosegenauigkeit verbessert und die Risiken im Zusammenhang mit fehlerhaften Handelsentscheidungen minimiert.
Die Architektur der trainierten Modelle wird in der Methode CreateDescriptions definiert. Die Methodenparameter enthalten zwei Zeiger auf dynamische Array-Objekte, in die die Modellarchitekturen geschrieben werden.
bool CreateDescriptions(CArrayObj *&actor, CArrayObj *&probability) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!probability) { probability = new CArrayObj(); if(!probability) return false; }
Ein wesentliches Merkmal der Implementierung ist die Erstellung von zwei spezialisierten Modellen: dem Akteur und einem Prognosemodell, das für die probabilistische Einschätzung der kommenden Kursbewegungsrichtung verantwortlich ist. Der Encoder des Umgebungszustands ist direkt in die Akteurs-Architektur integriert, sodass er umfangreiche Darstellungen von Marktdaten bilden und komplexe Abhängigkeiten erfassen kann. Das zweite Modell wiederum erhält seinen Input aus dem latenten Raum des Akteurs und nutzt seine gelernten Repräsentationen, um genauere Vorhersagen zu treffen. Dieser Ansatz verbessert nicht nur die Effizienz der Vorhersage, sondern verringert auch die Rechenlast, indem er den koordinierten Betrieb beider Modelle innerhalb eines einheitlichen Systems gewährleistet.
Im Hauptteil der Methode wird zunächst die Gültigkeit der empfangenen Zeiger überprüft und gegebenenfalls neue Instanzen der dynamischen Array-Objekte erstellt.
Als Nächstes wird die Architektur des Akteurs aufgebaut, beginnend mit dem Umgebungscodierer. Die erste Komponente ist eine neuronale Basisschicht, die zur Aufzeichnung der rohen Eingabedaten verwendet wird. Die Größe dieser Schicht wird durch das Volumen der analysierten Daten bestimmt.
//--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Es werden keine Aktivierungsfunktionen angewendet, da der Ausgabepuffer dieser Schicht im Wesentlichen direkt die aus der Umgebung gewonnenen Rohdaten speichert. In unserem Fall werden diese Daten direkt vom Endgerät empfangen, sodass ihre ursprüngliche Struktur erhalten bleibt. Dieser Ansatz hat jedoch einen erheblichen Nachteil: Die fehlende Vorverarbeitung kann sich negativ auf die Trainierbarkeit des Modells auswirken, da die Rohdaten heterogene Werte enthalten, die sich in Umfang und Verteilung unterscheiden.
Um dieses Problem zu entschärfen, wird unmittelbar nach der ersten Schicht ein Stapelnormalisierungsmechanismus angewendet. Sie führt eine vorläufige Datenstandardisierung durch, indem sie die Eingaben auf einen gemeinsamen Maßstab bringt und ihre Vergleichbarkeit verbessert. Dadurch wird die Stabilität des Trainings erheblich verbessert, die Konvergenz des Modells beschleunigt und das Risiko einer Gradientenexplosion oder eines Verschwindens der Gradienten verringert. Selbst bei der Arbeit mit stark schwankenden Marktdaten gewinnt das Modell dadurch die Fähigkeit, genauere und konsistentere Darstellungen zu bilden, was für die anschließende Multi-Task-Analyse von entscheidender Bedeutung ist.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Als Nächstes verwenden wir eine Faltungsschicht, die den Merkmalsraum transformiert und ihn auf eine standardisierte Dimensionalität bringt. Auf diese Weise kann eine einheitliche Datendarstellung geschaffen werden, die die Konsistenz in den nachfolgenden Verarbeitungsstufen gewährleistet. Es wird die Aktivierungsfunktion Leaky ReLU (LReLU) verwendet, die dazu beiträgt, den Einfluss kleinerer Schwankungen und zufälligen Rauschens zu verringern und gleichzeitig die wichtigen Merkmale der ursprünglichen Daten zu erhalten.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = HistoryBars; descr.window = BarDescr; descr.step = BarDescr; descr.window_out = 128; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Nach Abschluss der vorläufigen Datenvorverarbeitung gehen wir dazu über, die Architektur des Environment State Encoder zu entwerfen, der eine Schlüsselrolle bei der Analyse und Interpretation der rohen Eingabedaten spielt. Das Hauptziel des Encoders besteht darin, stabile Muster und verborgene Strukturen innerhalb des analysierten Datensatzes zu erkennen, die die Bildung einer informativen Darstellung für die anschließende Verarbeitung durch Entscheidungsmodelle ermöglichen.
Unser Encoder besteht aus drei sequentiellen ResNeXt-Architekturblöcken, von denen jeder gruppierte Faltungen für eine effiziente Merkmalsextraktion verwendet. In jedem Block wird ein Faltungsfilter mit einer Fenstergröße von 3 Elementen der analysierten mehrdimensionalen Zeitreihe und einer Faltungsschrittweite von 2 Elementen angewendet. Dadurch wird sichergestellt, dass die Dimensionalität der ursprünglichen Sequenz in jedem Block halbiert wird.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronResNeXtBlock; //--- Chanels { int temp[] = {128, 256}; //In, Out if(ArrayCopy(descr.windows, temp) < int(temp.Size())) return false; } //--- Units and Groups { int temp[] = {HistoryBars, 4, 32}; //Units, Group Size, Groups if(ArrayCopy(descr.units, temp) < int(temp.Size())) return false; } descr.window = 3; descr.step = 2; descr.window_out = 1; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } int units_out = (descr.units[0] - descr.window + descr.step - 1) / descr.step + 1;
Gemäß den Prinzipien der ResNeXt-Architektur wird die Verringerung der Dimensionalität der analysierten mehrdimensionalen Zeitreihen durch eine proportionale Erhöhung der Merkmalsdimensionalität kompensiert. Bei diesem Ansatz bleibt die Informativität der Daten erhalten, während gleichzeitig eine detailliertere Darstellung der strukturellen Merkmale der Zeitreihen möglich ist.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronResNeXtBlock; //--- Chanels { int temp[] = {256, 512}; //In, Out if(ArrayCopy(descr.windows, temp) < int(temp.Size())) return false; } //--- Units and Groups { int temp[] = {units_out, 4, 64}; //Units, Group Size, Groups if(ArrayCopy(descr.units, temp) < int(temp.Size())) return false; } descr.window = 3; descr.step = 2; descr.window_out = 1; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } units_out = (descr.units[0] - descr.window + descr.step - 1) / descr.step + 1;
Darüber hinaus wird mit zunehmender Dimensionalität des Merkmalsraums die Anzahl der Faltungsgruppen proportional erhöht, während die Größe der einzelnen Gruppen konstant bleibt. Dadurch lässt sich die Architektur effizient skalieren, wobei ein Gleichgewicht zwischen der Rechenkomplexität und der Fähigkeit des Modells, komplexe Muster aus den Daten zu extrahieren, gewahrt bleibt.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronResNeXtBlock; //--- Chanels { int temp[] = {256, 512}; //In, Out if(ArrayCopy(descr.windows, temp) < int(temp.Size())) return false; } //--- Units and Groups { int temp[] = {units_out, 4, 64}; //Units, Group Size, Groups if(ArrayCopy(descr.units, temp) < int(temp.Size())) return false; } descr.window = 3; descr.step = 2; descr.window_out = 1; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } units_out = (descr.units[0] - descr.window + descr.step - 1) / descr.step + 1;
Nach drei ResNeXt-Blöcken erhöht sich die Merkmalsdimensionalität auf 1024, wobei sich die Länge der analysierten Sequenz proportional verringert.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronResNeXtBlock; //--- Chanels { int temp[] = {512, 1024}; //In, Out if(ArrayCopy(descr.windows, temp) < int(temp.Size())) return false; } //--- Units and Groups { int temp[] = {units_out, 4, 128}; //Units, Group Size, Groups if(ArrayCopy(descr.units, temp) < int(temp.Size())) return false; } descr.window = 3; descr.step = 2; descr.window_out = 1; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } units_out = (descr.units[0] - descr.window + descr.step - 1) / descr.step + 1;
Als Nächstes sieht die ResNeXt-Architektur eine Komprimierung der analysierten Sequenz entlang der Zeitdimension vor, wobei nur die wichtigsten Merkmale des analysierten Umgebungszustands erhalten bleiben. Dazu transponieren wir zunächst die resultierenden Daten:
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = units_out; descr.window = 1024; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Dann verwenden wir eine Pooling-Schicht, die die Dimensionalität der Daten reduziert und gleichzeitig die wichtigsten Merkmale beibehält. Dadurch kann sich das Modell auf die wichtigsten Merkmale konzentrieren, unnötiges Rauschen eliminieren und eine kompaktere Darstellung der Originaldaten liefern.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronProofOCL; descr.count = 1024; descr.step = descr.window = units_out; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Merken Sie sich die Ordnungszahl dieser Ebene. Dies ist die letzte Schicht unseres Environment State Encoders, von der wir die Eingabedaten für das zweite Modell übernehmen werden.
Als Nächstes folgt der Decoder unseres Agenten, der aus zwei sequentiellen, vollständig verbundenen Schichten besteht.
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.activation = SIGMOID; descr.batch = 1e4; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NActions; descr.activation = SIGMOID; descr.batch = 1e4; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Beide Schichten verwenden die Sigmoidfunktion als Aktivierungsfunktion und reduzieren die Dimensionen des Tensors schrittweise auf den vordefinierten Aktionsraum des Agenten.
An dieser Stelle sei darauf hingewiesen, dass der oben erstellte Agent nur den Rohzustand der Umgebung analysiert und über kein Risikomanagementmodul verfügt. Wir kompensieren diese Einschränkung, indem wir eine Schicht von Risikomanagement-Agenten hinzufügen, die innerhalb der MacroHFT Rahmen implementiert ist.
//--- layer 10 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMacroHFTvsRiskManager; //--- Windows { int temp[] = {3, 15, NActions, AccountDescr}; //Window, Stack Size, N Actions, Account Description if(ArrayCopy(descr.windows, temp) < int(temp.Size())) return false; } descr.count = 10; descr.window_out = 16; descr.step = 4; // Heads descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Außerdem fügen wir eine Faltungsschicht mit einer Sigmoid-Aktivierungsfunktion hinzu, die die Ausgaben des Agenten auf den angegebenen Wertebereich abbildet. Wir verwenden ein Faltungsfenster der Größe 3, was den Parametern eines einzelnen Handelsgeschäfts entspricht. Dieser Ansatz ermöglicht es, konsistente Handelsmerkmale zu erhalten.
//--- layer 11 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = NActions / 3; descr.window = 3; descr.step = 3; descr.window_out = 3; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Im nächsten Schritt beschreiben wir das Modell zur Vorhersage der Wahrscheinlichkeiten der kommenden Kursbewegungen. Wie bereits erwähnt, erhält unser Vorhersagemodell seine Eingabedaten aus dem latenten Zustand des Agenten. Um die dimensionale Konsistenz zwischen dem latenten Zustand und der Eingabeschicht des zweiten Modells zu gewährleisten, haben wir beschlossen, auf manuelle Architekturanpassungen zu verzichten. Stattdessen extrahieren wir die Beschreibung der latenten Zustandsschicht aus der Architekturbeschreibung des Agenten.
//--- Probability probability.Clear(); //--- Input layer CLayerDescription *latent = actor.At(LatentLayer); if(!latent) return false;
Die Parameter der extrahierten latenten Zustandsbeschreibung werden dann in die Eingabeschicht des neuen Modells übertragen.
if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = latent.count; descr.activation = latent.activation; descr.optimization = ADAM; if(!probability.Add(descr)) { delete descr; return false; }
Die Verwendung des latenten Zustands eines anderen Modells als Eingabedaten ermöglicht es uns, mit bereits verarbeiteten und miteinander vergleichbaren Daten zu arbeiten. Folglich ist es nicht notwendig, eine Batch-Normalisierungsschicht für die primäre Eingabevorverarbeitung anzuwenden. Außerdem sind die Ausgaben der ResNeXt-Blöcke bereits normalisiert.
Um Vorhersagewerte für die bevorstehende Kursbewegung zu erhalten, verwenden wir zwei aufeinander folgende, voll verknüpfte Schichten mit einer Sigmoid-Aktivierungsfunktion zwischen ihnen.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.activation = SIGMOID; descr.batch = 1e4; descr.optimization = ADAM; if(!probability.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = NActions / 3; descr.activation = None; descr.batch = 1e4; descr.optimization = ADAM; if(!probability.Add(descr)) { delete descr; return false; }
Die Ausgaben der vollständig verknüpften Schichten werden dann mithilfe der SoftMax-Funktion in einen probabilistischen Raum abgebildet.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; prev_count = descr.count = prev_count; descr.step = 1; descr.activation = None; descr.batch = 1e4; descr.optimization = ADAM; if(!probability.Add(descr)) { delete descr; return false; } //--- return true; }
Es ist wichtig zu beachten, dass unser Modell nur Wahrscheinlichkeiten für zwei Richtungen der Preisbewegung vorhersagt: aufwärts und abwärts. Die Wahrscheinlichkeit einer flachen (seitwärts gerichteten) Bewegung wird bewusst nicht berücksichtigt, da auch ein seitwärts gerichteter Markt in der Praxis eine Abfolge von kurzfristigen Kursschwankungen mit annähernd gleicher Amplitude und entgegengesetzter Richtung darstellt. Dieser Ansatz ermöglicht es dem Modell, sich auf die Identifizierung grundlegender dynamischer Marktmuster zu konzentrieren, ohne Rechenressourcen für die Beschreibung komplexer, aber weniger bedeutsamer flacher Zustände zu verschwenden.
Nachdem die Beschreibung der Modellarchitekturen abgeschlossen ist, muss nur noch das logische Ergebnis der durchgeführten Operationen an das aufrufende Programm zurückgegeben und die Methodenausführung beendet werden.
Modelltraining
Nachdem wir nun die Modellarchitekturen definiert haben, können wir zur nächsten Phase übergehen – dem Training. Zu diesem Zweck werden wir den Trainingsdatensatz verwenden, der während der Entwicklung des MacroHFT-Rahmens gesammelt wurde. Der Prozess der Datensatzerstellung wird in dem entsprechenden Artikel ausführlich beschrieben. Ich möchte Sie daran erinnern, dass dieser Trainingsdatensatz mit historischen Daten des Währungspaares EURUSD für das gesamte Jahr 2024 auf dem Zeitrahmen M1 erstellt wurde.
Um die Modelle zu trainieren, müssen wir jedoch einige Änderungen am Expert Advisor-Algorithmus vornehmen, der sich in ...\MQL5\Experts\ResNeXt\Study.mq5 befindet. Im Rahmen dieses Artikels werden wir uns ausschließlich auf die Train-Methode konzentrieren, da hier der gesamte Trainingsprozess organisiert ist.
void Train(void) { //--- vector<float> probability = vector<float>::Full(Buffer.Size(), 1.0f / Buffer.Size());
Zu Beginn der Trainingsmethode werden in der Regel Wahrscheinlichkeitsvektoren für die Auswahl verschiedener Trajektorien auf der Grundlage ihrer Rentabilität berechnet. Auf diese Weise kann das Ungleichgewicht zwischen profitablen und unprofitablen Episoden korrigiert werden, da in den meisten Fällen die Anzahl der Verlustsequenzen die Anzahl der profitablen Sequenzen deutlich übersteigt. In der vorliegenden Arbeit sollen die Modelle jedoch auf nahezu idealen Trajektorien trainiert werden, wobei die Abfolge der Aktionen des Agenten in Übereinstimmung mit historischen Preisbewegungsdaten gebildet wird. Dadurch wird der Wahrscheinlichkeitsvektor mit gleichen Werten gefüllt, was eine einheitliche Darstellung des gesamten Trainingsdatensatzes gewährleistet. Dieser Ansatz ermöglicht es dem Modell, die wichtigsten Merkmale der Marktdaten zu erlernen, ohne die Prioritäten künstlich in Richtung bestimmter Szenarien auf Kosten anderer zu verzerren. Dies verbessert die Verallgemeinerungsfähigkeit und die Robustheit des Modells.
Als Nächstes deklarieren wir eine Reihe lokaler Variablen, die für die temporäre Datenspeicherung während der Ausführung von Operationen benötigt werden.
vector<float> result, target, state; matrix<float> fstate = matrix<float>::Zeros(1, NForecast * BarDescr); bool Stop = false; //--- uint ticks = GetTickCount();
Damit sind die vorbereitenden Arbeiten abgeschlossen. Anschließend erstellen wir das System der Trainingsschleifen für die Modelle.
Es ist anzumerken, dass die ResNeXt-Architektur selbst keine rekurrenten Blöcke verwendet. Daher ist es sinnvoll, das Lernen in einer einzigen Schleife mit Zufallsstichproben aus dem Trainingsdatensatz durchzuführen. Wir haben jedoch einen Risikomanagement-Agenten hinzugefügt, der Speichermodule für frühere Entscheidungen und die daraus resultierenden Änderungen des Kontostands verwendet. Das Training dieses Moduls erfordert die Beibehaltung der historischen Abfolge der Eingabedaten.
Im Hauptteil der äußeren Schleife wird der Anfangszustand einer historischen Mini-Batch-Sequenz aus dem Trainingsdatensatz ausgewählt.
for(int iter = 0; (iter < Iterations && !IsStopped() && !Stop); iter += Batch) { int tr = SampleTrajectory(probability); int start = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2 - NForecast - Batch)); if(start <= 0) { iter -= Batch; continue; }
Anschließend löschen wir den Speicher der wiederkehrenden Blöcke.
if(!Actor.Clear()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Als Nächstes füllen wir den Vektor der früheren Zielwerte der Aktionen des Agenten mit Nullwerten und führen dann eine verschachtelte Schleife durch die Mini-Batch-Zustände, die ihrer historischen Abfolge folgt.
result = vector<float>::Zeros(NActions); for(int i = start; i < MathMin(Buffer[tr].Total, start + Batch); i++) { if(!state.Assign(Buffer[tr].States[i].state) || MathAbs(state).Sum() == 0 || !bState.AssignArray(state)) { iter -= Batch + start - i; break; }
Im Hauptteil der verschachtelten Schleife übertragen wir zunächst die Beschreibungen des Umgebungszustands aus dem Trainingsdatensatz in den entsprechenden Puffer. Danach geht es an die Bildung des Tensors, der den Kontostand beschreibt. Hier generieren wir die Schwingungen des Zeitstempels, der dem analysierten Umgebungszustand entspricht.
//--- bTime.Clear(); double time = (double)Buffer[tr].States[i].account[7]; double x = time / (double)(D'2024.01.01' - D'2023.01.01'); bTime.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_MN1); bTime.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_W1); bTime.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_D1); bTime.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(bTime.GetIndex() >= 0) bTime.BufferWrite();
Wir extrahieren Bilanz- und Eigenkapitaldaten aus dem Erfahrungswiedergabepuffer.
//--- Account float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1];
Wir berechnen auch die Rentabilität der letzten Ziel-Handelsoperation, die wir möglicherweise auf dem vorherigen historischen Balken hätten erzielen können.
float profit = float(bState[0] / _Point * (result[0] - result[3]));
Bei der Erstellung des Vektors zur Beschreibung des Kontostandes gehen wir davon aus, dass am vorherigen Balken alle bestehenden offenen Positionen geschlossen wurden und ein potenzieller Handel der Zieloperation, die in der vorherigen Iteration der verschachtelten Trainingsschleife gebildet wurde, ausgeführt wurde. Es ist leicht zu erkennen, dass bei der ersten Iteration dieser Schleife der Zielaktionsvektor mit Nullwerten gefüllt wird (d. h. keine Handelsoperation). Folglich ist der Gleichgewichtsveränderungskoeffizient gleich „1“, und die Aktienindikatoren werden auf der Grundlage des potenziellen Gewinns des letzten Balkens gebildet, der zuvor berechnet wurde.
bAccount.Clear(); bAccount.Add(1); bAccount.Add((PrevEquity + profit) / PrevEquity); bAccount.Add(profit / PrevEquity); bAccount.Add(MathMax(result[0] - result[3], 0)); bAccount.Add(MathMax(result[3] - result[0], 0)); bAccount.Add((bAccount[3] > 0 ? profit / PrevEquity : 0)); bAccount.Add((bAccount[4] > 0 ? profit / PrevEquity : 0)); bAccount.Add(0); bAccount.AddArray(GetPointer(bTime)); if(bAccount.GetIndex() >= 0) bAccount.BufferWrite();
Dementsprechend werden auch Informationen über offene Positionen auf der Grundlage der Ziel-Handelsoperation gebildet.
Nach der Bildung der Eingabedaten führen wir einen Vorwärtsdurchlauf der trainierten Modelle durch. Zunächst rufen wir die Vorwärtsdurchlauf-Methode des Agenten auf und übergeben die oben vorbereiteten Eingabedaten.
//--- Feed Forward if(!Actor.feedForward((CBufferFloat*)GetPointer(bState), 1, false, GetPointer(bAccount))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Dann rufen wir die entsprechende Methode des Vorhersagemodells für die Wahrscheinlichkeiten der bevorstehenden Preisbewegung auf, wobei wir den latenten Zustand des Agenten als Eingabedaten verwenden.
if(!Probability.feedForward(GetPointer(Actor), LatentLayer, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Der nächste Schritt ist die Erstellung von Zielwerten für das Training der Modelle. Wie bereits erwähnt, planen wir, die Modelle unter „nahezu perfekten Trajektorien“ zu trainieren. Die Zielwerte werden also durch einen „Blick in die Zukunft“ anhand der Daten aus unserem Trainingsdatensatz gebildet. Zu diesem Zweck extrahieren wir aus dem Trainingsdatensatz die tatsächlichen nachfolgenden historischen Umweltzustandsdaten über einen bestimmten Planungshorizont und übertragen sie in eine Matrix, in der jeder Balken durch eine eigene Zeile dargestellt wird.
//--- Look for target target = vector<float>::Zeros(NActions); bActions.AssignArray(target); if(!state.Assign(Buffer[tr].States[i + NForecast].state) || !state.Resize(NForecast * BarDescr) || MathAbs(state).Sum() == 0) { iter -= Batch + start - i; break; } if(!fstate.Resize(1, NForecast * BarDescr) || !fstate.Row(state, 0) || !fstate.Reshape(NForecast, BarDescr)) { iter -= Batch + start - i; break; }
Es ist zu beachten, dass die extrahierten Daten in umgekehrter historischer Reihenfolge angeordnet sind. Deshalb organisieren wir eine Schleife, um die Zeilen dieser Matrix neu zu ordnen.
for(int j = 0; j < NForecast / 2; j++) { if(!fstate.SwapRows(j, NForecast - j - 1)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } }
Nun, da wir Daten über die bevorstehende Preisbewegung haben, gehen wir dazu über, den Zielvektor für die Handelsoperation zu bilden. In dieser Phase verzweigt sich der Algorithmus je nach der vorherigen Handelsoperation. Mit anderen Worten: Der vorherige Handelsvorgang ändert das Ziel des Agenten in dieser Phase. Und das ist ganz logisch. Wenn es eine offene Position gibt, suchen wir nach einem Ausstiegspunkt; wenn es keinen gibt, suchen wir nach einem Einstiegspunkt.
Wenn in der vorherigen Iteration die Zieloperation die Eröffnung einer Kaufposition war, prüfen wir, ob das Stop-Loss-Niveau in absehbarer Zeit erreicht wird.
target = fstate.Col(0).CumSum(); if(result[0] > result[3]) { float tp = 0; float sl = 0; float cur_sl = float(-(result[2] > 0 ? result[2] : 1) * MaxSL * Point()); int pos = 0; for(int j = 0; j < NForecast; j++) { tp = MathMax(tp, target[j] + fstate[j, 1] - fstate[j, 0]); pos = j; if(cur_sl >= target[j] + fstate[j, 2] - fstate[j, 0]) break; sl = MathMin(sl, target[j] + fstate[j, 2] - fstate[j, 0]); }
In diesem Fall wird der Höchstkurs bis zum Erreichen des Stop-Loss-Niveaus als Zielwert für die Gewinnmitnahme verwendet.
Die erhaltenen Werte werden als Parameter der Ziel-Kaufoperation übertragen, während die Parameter der Verkaufsoperation gleichzeitig auf Null zurückgesetzt werden.
if(tp > 0) { sl = float(MathMin(MathAbs(sl) / (MaxSL * Point()), 1)); tp = float(MathMin(tp / (MaxTP * Point()), 1)); result[0] = MathMax(result[0] - result[3], 0.011f); result[1] = tp; result[2] = sl; for(int j = 3; j < NActions; j++) result[j] = 0; bActions.AssignArray(result); } }
Analoge Operationen werden bei der Suche nach einem Ausstiegspunkt aus einer Verkaufsposition durchgeführt.
else { if(result[0] < result[3]) { float tp = 0; float sl = 0; float cur_sl = float((result[5] > 0 ? result[5] : 1) * MaxSL * Point()); int pos = 0; for(int j = 0; j < NForecast; j++) { tp = MathMin(tp, target[j] + fstate[j, 2] - fstate[j, 0]); pos = j; if(cur_sl <= target[j] + fstate[j, 1] - fstate[j, 0]) break; sl = MathMax(sl, target[j] + fstate[j, 1] - fstate[j, 0]); } if(tp < 0) { sl = float(MathMin(MathAbs(sl) / (MaxSL * Point()), 1)); tp = float(MathMin(-tp / (MaxTP * Point()), 1)); result[3] = MathMax(result[3] - result[0], 0.011f); result[4] = tp; result[5] = sl; for(int j = 0; j < 3; j++) result[j] = 0; bActions.AssignArray(result); } }
Wenn es keine offene Position gibt, suchen wir nach einem Einstiegspunkt. Dazu bestimmen wir die Richtung des kommenden Preistrends.
ulong argmin = target.ArgMin(); ulong argmax = target.ArgMax(); while(argmax > 0 && argmin > 0) { if(argmax < argmin && target[argmax]/2 > MathAbs(target[argmin])) break; if(argmax > argmin && target[argmax] < MathAbs(target[argmin]/2)) break; target.Resize(MathMin(argmax, argmin)); argmin = target.ArgMin(); argmax = target.ArgMax(); }
Im Falle einer erwarteten Aufwärtsbewegung des Preises definieren wir die Parameter für einen Kauf. Die Parameter der Handelsoperation werden ähnlich wie bei der Exit-Point-Suche bestimmt. Der Stop-Loss wird in Höhe des Maximalwertes gesetzt.
if(argmin == 0 || (argmax < argmin && argmax > 0)) { float tp = 0; float sl = 0; float cur_sl = - float(MaxSL * Point()); ulong pos = 0; for(ulong j = 0; j < argmax; j++) { tp = MathMax(tp, target[j] + fstate[j, 1] - fstate[j, 0]); pos = j; if(cur_sl >= target[j] + fstate[j, 2] - fstate[j, 0]) break; sl = MathMin(sl, target[j] + fstate[j, 2] - fstate[j, 0]); } if(tp > 0) { sl = (float)MathMax(MathMin(MathAbs(sl) / (MaxSL * Point()), 1), 0.01); tp = (float)MathMin(tp / (MaxTP * Point()), 1); result[0] = float(MathMax(Buffer[tr].States[i].account[0]/100*0.01, 0.011)); result[1] = tp; result[2] = sl; for(int j = 3; j < NActions; j++) result[j] = 0; bActions.AssignArray(result); } }
In ähnlicher Weise bestimmen wir die Parameter eines Verkaufsgeschäfts im Falle einer Abwärtsbewegung.
else { if(argmax == 0 || argmax > argmin) { float tp = 0; float sl = 0; float cur_sl = float(MaxSL * Point()); ulong pos = 0; for(ulong j = 0; j < argmin; j++) { tp = MathMin(tp, target[j] + fstate[j, 2] - fstate[j, 0]); pos = j; if(cur_sl <= target[j] + fstate[j, 1] - fstate[j, 0]) break; sl = MathMax(sl, target[j] + fstate[j, 1] - fstate[j, 0]); } if(tp < 0) { sl = (float)MathMax(MathMin(MathAbs(sl) / (MaxSL * Point()), 1), 0.01); tp = (float)MathMin(-tp / (MaxTP * Point()), 1); result[3] = float(MathMax(Buffer[tr].States[i].account[0]/100*0.01,0.011)); result[4] = tp; result[5] = sl; for(int j = 0; j < 3; j++) result[j] = 0; bActions.AssignArray(result); } } } } }
Nachdem wir den Zieltensor einer Handelsoperation gebildet haben, können wir Backpropagation-Operationen unseres Agenten durchführen, um die Abweichung der generierten Handelsentscheidung von der Zielentscheidung zu minimieren.
//--- Actor Policy if(!Actor.backProp(GetPointer(bActions), (CBufferFloat*)GetPointer(bAccount), GetPointer(bGradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Als Nächstes müssen wir die Zielwerte für das Prognosemodell formulieren. Ich denke, es ist offensichtlich, dass ein Kaufgeschäft einem Aufwärtstrend und ein Verkaufsgeschäft einem Abwärtstrend entspricht. Da die Trades auf der Analyse historischer Daten basieren, haben wir 100% Vertrauen in den kommenden Trend. Daher ist der Zielwert für den entsprechenden Trend 1 und für den entgegengesetzten Trend 0.
target = vector<float>::Zeros(NActions / 3); for(int a = 0; a < NActions; a += 3) target[a / 3] = float(result[a] > 0);
Jetzt können wir auch Backpropagation-Operationen auf das Vorhersagemodell anwenden. Dabei passen wir die Parameter des Umgebungszustands-Encoders an, was mit Multitasking-Lernansätzen vereinbar ist.
if(!Result.AssignArray(target) || !Probability.backProp(Result, GetPointer(Actor), LatentLayer) || !Actor.backPropGradient((CBufferFloat*)NULL, (CBufferFloat*)NULL, LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Jetzt müssen wir den Nutzer nur noch über den Fortschritt des Lernprozesses informieren und zur nächsten Iteration des Schleifensystems übergehen.
if(GetTickCount() - ticks > 500) { double percent = double(iter + i - start) * 100.0 / (Iterations); string str = StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Actor", percent, Actor.getRecentAverageError()); str += StringFormat("%-13s %6.2f%% -> Error %15.8f\n", "Probability", percent, Probability.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
Nach erfolgreichem Abschluss einer bestimmten Anzahl von Trainingsiterationen löschen wir die Kommentare auf dem Chart, mit denen wir den Nutzer über den Fortschritt des Modelltrainings informieren.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Actor", Actor.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Probability", Probability.getRecentAverageError()); ExpertRemove(); //--- }
Wir geben die Trainingsergebnisse in das Protokoll aus und initialisieren die Beendigung des Trainingsprogramms. Den vollständigen Code des Modellschulungsprogramms finden Sie im Anhang.
Der nächste Schritt besteht darin, direkt mit dem Modelltraining zu beginnen. Zu diesem Zweck wechseln wir zum MetaTrader 5 Terminal und starten den erstellten Expert Advisor im Echtzeitmodus. Der EA führt keine Handelsoperationen aus, sodass sein Betrieb kein Risiko für den Kontostand darstellt.
Es ist zu beachten, dass wir beide Modelle gleichzeitig trainieren. Es gibt jedoch eine Nuance in der Funktionsweise des Agenten. Wie bereits erwähnt, wurde die Architektur dieses Modells um einen Risikomanagement-Block erweitert, der Speichermodule für den Kontostand und frühere Entscheidungen verwendet. Gleichzeitig werden die Informationen aus der latenten Repräsentation des Agenten im Speichermodul für frühere Handlungen gespeichert.
Wenn wir jedoch den oben vorgestellten Trainingscode betrachten, sehen wir, dass der Vektor zur Beschreibung des Kontostands auf der Grundlage von Zielwerten gebildet wird. Dadurch entsteht ein Ungleichgewicht: Der Risikomanagement-Block bewertet die Veränderungen des Saldos im Rahmen einer völlig anderen Verhaltenspolitik. Um diesen Effekt zu minimieren, habe ich beschlossen, die Ausbildung in zwei Phasen durchzuführen.
In der ersten Trainingsstufe setzen wir die Größe der Mini-Batches auf einen einzigen Zustand fest.
Mit einer solchen Parameterkonfiguration werden die Speichermodule während der ersten Trainingsstufe effektiv deaktiviert. Dies ist natürlich nicht die Zielbetriebsart unseres Modells, aber in dieser Betriebsart können wir die Verhaltenspolitik des Agenten so nahe wie möglich an die Zielbetriebsart heranführen und die Lücke zwischen den prognostizierten und den angestrebten Handelsoperationen minimieren.
In der zweiten Trainingsphase wird die Größe der Mini-Batches erhöht, sodass sie mindestens etwas größer ist als die Kapazität der Speichermodule. Dies ermöglicht uns eine Feinabstimmung des Modells, einschließlich der Funktionsweise der Risikomanagementkomponente, die die Auswirkungen der gewählten Politik auf den Kontostand kontrolliert.
Modellversuche
Nach dem Training der Modelle wird die daraus resultierende Agentenverhaltenspolitik getestet. An dieser Stelle ist es notwendig, kurz die Änderungen zu erwähnen, die am Algorithmus des Prüfprogramms vorgenommen wurden. Diese Anpassungen sind lokaler Natur. Wir werden daher nicht den gesamten Code überprüfen, den Sie im Anhang selbständig untersuchen können. Wir möchten nur anmerken, dass wir die Programmlogik um unser Modell der Wahrscheinlichkeitsprognose für die bevorstehende Preisentwicklung ergänzt haben. Eine Handelsoperation wird nur ausgeführt, wenn die Richtung der Handelsoperation des Agenten mit dem wahrscheinlichsten Trend übereinstimmt.
Wir testen die trainierte Strategie im MetaTrader 5 Strategy Tester mit historischen Daten vom Januar 2025, wobei alle anderen Parameter, die für die Zusammenstellung des Trainingsdatensatzes verwendet wurden, vollständig erhalten bleiben. Der Testzeitraum wurde nicht in den Trainingsdatensatz aufgenommen. Dadurch kommen die Testbedingungen dem realen Betrieb mit ungesehenen Daten so nahe wie möglich.
Die Testergebnisse sind wie folgt:
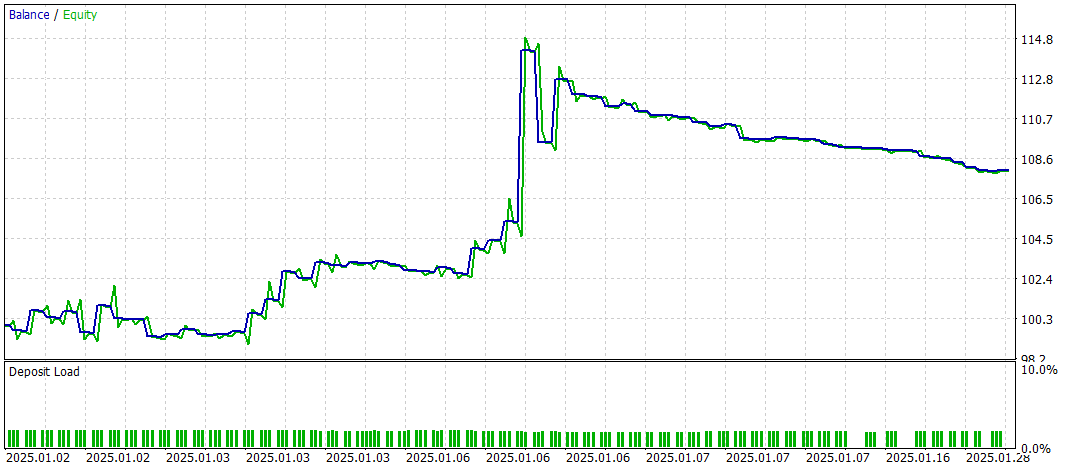
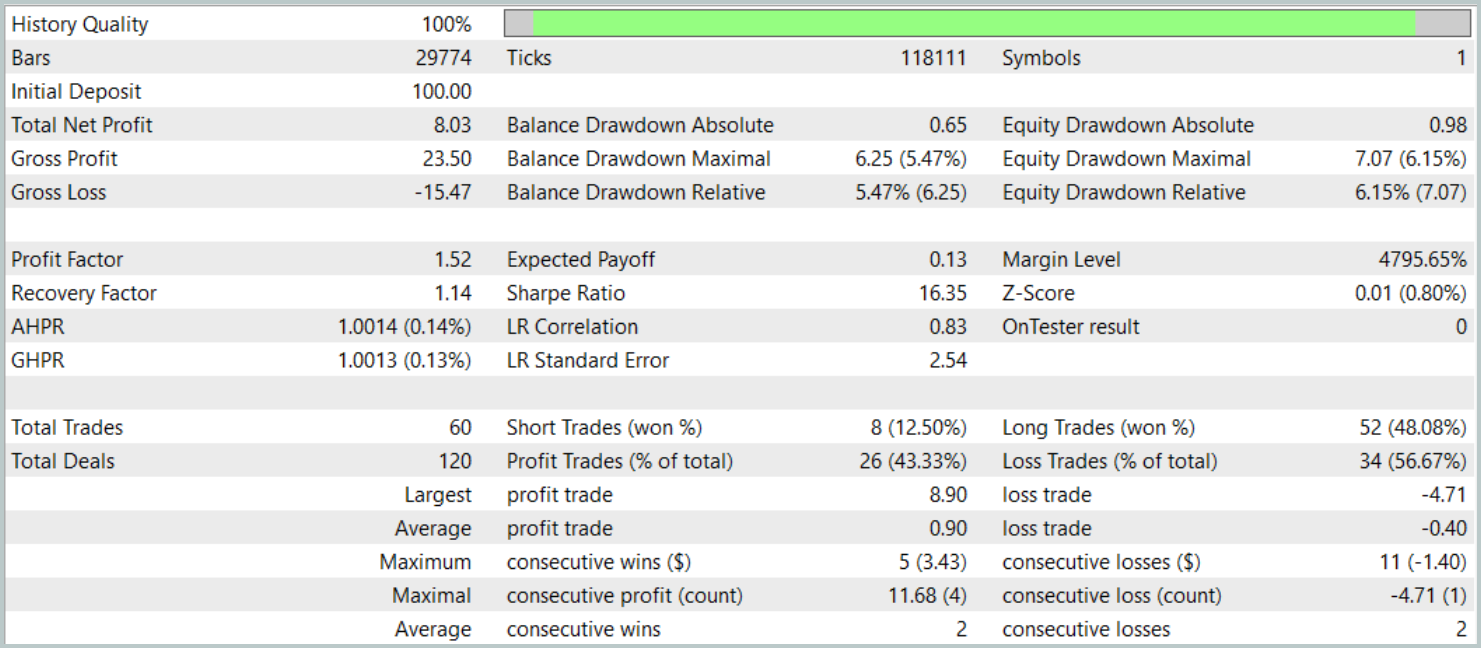
Während des Testzeitraums führte das Modell 60 Handelsoperationen durch, was im Durchschnitt etwa 3 Handelsgeschäfte pro Handelstag entspricht. Mehr als 43 % der eröffneten Positionen wurden mit einem Gewinn geschlossen. Da die durchschnittlichen und maximalen Gewinne fast doppelt so hoch waren wie die entsprechenden Werte der Verluste, schloss der Test mit einem positiven finanziellen Ergebnis ab. Der Gewinnfaktor wurde mit 1,52 angegeben, während der Rückgewinnungsfaktor 1,14 erreichte.
Schlussfolgerung
Das in diesem Artikel besprochene Multi-Task-Learning-Framework auf Basis der ResNeXt-Architektur eröffnet neue Möglichkeiten für die Finanzmarktanalyse. Dank der Verwendung eines gemeinsamen Kodierers und spezieller „Köpfe“ ist das Modell in der Lage, stabile Muster in Daten zu erkennen, sich an veränderte Marktbedingungen anzupassen und genauere Prognosen zu liefern. Die Anwendung des Multi-Task-Lernens trägt dazu bei, das Risiko der Überanpassung zu minimieren, da das Modell für mehrere Aufgaben gleichzeitig trainiert wird, was zur Bildung von allgemeineren Marktdarstellungen beiträgt.
Darüber hinaus ermöglicht die hohe Modularität der ResNeXt-Architektur die Abstimmung von Modellparametern in Abhängigkeit von spezifischen Betriebsbedingungen, was es zu einem vielseitigen Werkzeug für den algorithmischen Handel macht.
Die vorgestellte Implementierung unserer Interpretation der vorgeschlagenen Ansätze unter Verwendung von MQL5 hat ihre Wirksamkeit bei der Zeitreihenanalyse und der Vorhersage von Markttrends bewiesen. Durch die Aufnahme eines zusätzlichen Blocks für Markttrendprognosen wurden die analytischen Fähigkeiten des Modells erheblich verbessert, sodass es widerstandsfähiger gegen unerwartete Preisänderungen ist.
Insgesamt zeigt das vorgeschlagene System ein erhebliches Anwendungspotenzial für den automatisierten Handel und die algorithmische Analyse von Finanzdaten. Bevor das Modell jedoch unter realen Marktbedingungen eingesetzt werden kann, muss es mit einem repräsentativeren Trainingsdatensatz trainiert und anschließend umfassend getestet werden.
Referenzen
- Aggregated Residual Transformations for Deep Neural Networks
- Collaborative Optimization in Financial Data Mining Through Deep Learning and ResNeXt
- Andere Artikel aus dieser Reihe
Programme, die im diesem Artikel verwendet werden
| # | Name | Typ | Beschreibung |
|---|---|---|---|
| 1 | Research.mq5 | Expert Advisor | Expert Advisor für die Probenahme |
| 2 | ResearchRealORL.mq5 | Expert Advisor | Expert Advisor für die Probenahme mit der Real-ORL-Methode |
| 3 | Study.mq5 | Expert Advisor | Modellausbildung Expert Advisor |
| 4 | Test.mq5 | Expert Advisor | Modellprüfung Expert Advisor |
| 5 | Trajectory.mqh | Klassenbibliothek | Struktur der Beschreibung des Systemzustands und der Modellarchitektur |
| 6 | NeuroNet.mqh | Klassenbibliothek | Eine Bibliothek von Klassen zur Erstellung eines neuronalen Netzes |
| 7 | NeuroNet.cl | Code Base | OpenCL-Programmcode |
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/17157
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.