
取引におけるニューラルネットワーク:ResNeXtモデルに基づくマルチタスク学習(最終回)

はじめに
前回の記事では、金融市場分析システムの構築を目的として提案された、ResNeXtアーキテクチャに基づくマルチタスク学習フレームワークの理論的側面に触れました。マルチタスク学習(MTL)は、単一のエンコーダーで入力データを処理し、それぞれ特定のタスクを解決するために設計された複数の専門化された「ヘッド」(出力)を使用します。このアプローチにはいくつかの利点があります。
まず、共有エンコーダーを使用することで、複数のタスクにわたって有用な、最も堅牢で普遍的なパターンの抽出が容易になります。従来のアプローチでは、各モデルが個別のデータサブセットで学習されますが、マルチタスクアーキテクチャではより基本的な規則性を捉える表現が形成されます。これにより、モデルは汎用性が高く、生データ中のノイズに対してもより強靭になります。
次に、複数タスクの共同学習により、モデルの過学習の可能性が低減されます。サブタスクのひとつが低品質または情報量の少ないデータに直面しても、他のタスクが共有エンコーダー構造を通じてこの影響を補償します。これにより、特に金融市場のように変動が激しい環境下でも、モデルの安定性と信頼性が向上します。
さらに、このアプローチは計算資源の面でも効率的です。関連する機能を持つ複数の独立モデルを学習する代わりに、単一のエンコーダーを使用することで計算の冗長性が削減され、学習プロセスが高速化されます。これは、アルゴリズム取引のようにモデルの応答速度がタイムリーな取引判断に直結する場合に特に重要です。
金融市場の文脈では、MTLは複数の市場要因を同時に分析できるという追加的な利点を提供します。たとえば、モデルはボラティリティの予測、市場トレンドの識別、リスク評価、ニュース背景の統合を同時におこなうことができます。これらの要素の相互依存性により、マルチタスク学習は複雑な市場システムのモデリングや、価格動向のより正確な予測に強力な手法となります。
マルチタスク学習の重要な利点のひとつは、異なるサブタスク間で優先度を動的にシフトできる点です。つまり、市場環境の変化に応じて、現在の価格変動に最も影響を与える側面にモデルが重点を置くことが可能です。
フレームワークのエンコーダーの基盤として採用されたResNeXtアーキテクチャは、モジュール性と高効率が特徴です。グループ畳み込みを使用することで、計算量を大幅に増やさずにモデル性能を向上させます。これは、リアルタイムで大量の市場データを処理する際に特に重要です。アーキテクチャの柔軟性により、ネットワークの深さ、畳み込みブロックの構成、データ正規化方法をタスクに応じて調整でき、さまざまな運用条件にシステムを適応させることが可能です。
マルチタスク学習とResNeXtアーキテクチャの組み合わせにより、多様な情報源を効率的に統合し、処理できる強力な分析ツールが生まれます。このアプローチは、予測精度を向上させるだけでなく、市場変動に迅速に適応し、隠れた依存関係やパターンを明らかにします。重要な特徴の自動抽出により、モデルは異常値に対してより頑健になり、ランダムな市場ノイズの影響を最小化します。
前回の記事の実践部分では、MQL5を用いたResNeXtアーキテクチャの主要コンポーネントの実装を詳細に検討しました。この作業では、残差接続を持つグループ化畳み込みモジュールを作成し、CNeuronResNeXtBlockオブジェクトとして実装しました。このアプローチにより、金融データ処理におけるシステムの柔軟性、拡張性、効率性が確保されます。
今回の記事では、エンコーダーをモノリシックなオブジェクトとして作成する方法から離れます。代わりに、ユーザーは既に実装されたビルディングブロックを使用して、エンコーダーアーキテクチャを自分で構築できるようになります。これにより、柔軟性が向上するだけでなく、さまざまな種類の金融データや取引戦略にシステムを適応させる能力も拡張されます。本記事では、マルチタスク学習フレームワーク内でのモデルの開発と学習に焦点を当てます。
モデルアーキテクチャ
技術的実装に進む前に、まずモデルが解決する主要なタスクを定義する必要があります。タスクのひとつはエージェントの役割を果たし、取引操作のパラメータを生成します。このタスクでは、前述のアーキテクチャと同様に取引パラメータが出力されます。このアプローチにより、計算の過剰な重複を避け、予測の一貫性を向上させ、統一された意思決定戦略を確立することができます。
しかし、この構造だけではマルチタスク学習の潜在能力を十分に活用できません。望ましい効果を得るために、追加のモデルをシステムに加え、将来の市場動向を予測するように学習させます。この予測ブロックにより、予測精度が向上し、市場の急変に対するモデルの耐性も強化されます。市場の変動が激しい条件下でも、この仕組みによりモデルは新しい情報に迅速に適応し、より正確な取引判断を下せるようになります。
複数のタスクを単一モデルに統合することで、数多くの市場要因を考慮し、それらとリアルタイムで相互作用できる包括的な分析システムが構築されます。このアプローチにより、知識の一般化の度合いが高まり、予測精度が向上し、誤った取引判断に伴うリスクが最小化されます。
学習済みモデルのアーキテクチャは、CreateDescriptionsメソッド内で定義されます。メソッドのパラメータには、モデルアーキテクチャが書き込まれる動的配列オブジェクトへのポインタが2つ渡されます。
bool CreateDescriptions(CArrayObj *&actor, CArrayObj *&probability) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!probability) { probability = new CArrayObj(); if(!probability) return false; }
この実装の重要な特徴は、Actorと呼ばれる専門化モデルと、今後の価格変動方向の確率評価を担当する予測モデルの2つを作成することです。環境状態エンコーダーはActorアーキテクチャに直接統合されており、市場データのリッチな表現を形成し、複雑な依存関係を捉えます。予測モデルはActorの潜在空間から入力を受け取り、学習済み表現を用いてより正確な予測を生成します。このアプローチにより、予測効率の向上だけでなく、計算負荷の軽減と両モデルの統合運用が可能になります。
メソッドの本体では、まず受け取ったポインタの有効性を確認し、必要に応じて動的配列オブジェクトの新規インスタンスを作成します。
次に、Actorのアーキテクチャ構築に進み、まず環境エンコーダーを作成します。最初のコンポーネントは、生の入力データを記録するベースニューラル層です。この層のサイズは解析対象データの量によって決まります。
//--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
この層には活性化関数を適用しません。なぜなら、この層の出力バッファは本質的に環境から取得した生データを直接格納するためです。私たちの場合、これらのデータはターミナルから直接取得されるため、元の構造を保持することが可能です。ただし、このアプローチには欠点があります。前処理をおこなわないため、スケールや分布の異なる異質な値を含む生データが、モデルの学習可能性に悪影響を与える可能性があります。
この問題を軽減するため、最初の層の直後にバッチ正規化を適用します。これにより、入力データを共通のスケールに標準化し、比較可能性を向上させます。これにより、学習の安定性が向上し、モデルの収束が加速され、勾配消失や爆発のリスクが低減されます。その結果、市場データが非常に変動的であっても、モデルはより正確で一貫性のある表現を形成できるようになり、これは後続のマルチタスク分析において非常に重要です。
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
次に、特徴空間を変換する畳み込み層を使用し、データを標準化された次元に整えます。これにより、統一されたデータ表現を作成し、後続の処理段階における一貫性を確保します。活性化関数にはLeaky ReLU (LReLU)を使用し、小さな変動やランダムノイズの影響を軽減しつつ、元のデータの重要な特徴を保持します。
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = HistoryBars; descr.window = BarDescr; descr.step = BarDescr; descr.window_out = 128; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
前処理が完了した後、次に環境状態エンコーダーのアーキテクチャ設計に進みます。エンコーダーは、生の入力データを分析して解釈する上で重要な役割を果たします。エンコーダーの主な目的は、解析対象データセット内の安定したパターンや隠れた構造を特定し、意思決定モデルが後続で処理可能な情報豊富な表現を形成することです。
私たちのエンコーダーは、3つの連続したResNeXtアーキテクチャブロックで構成されており、各ブロックは効率的な特徴抽出のためにグループ畳み込みを使用します。各ブロックでは、解析対象の多次元時系列の3要素のウィンドウサイズで畳み込みフィルタを適用し、ストライドは2要素です。これにより、各ブロックで元の系列の次元が半分に削減されます。
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronResNeXtBlock; //--- Chanels { int temp[] = {128, 256}; //In, Out if(ArrayCopy(descr.windows, temp) < int(temp.Size())) return false; } //--- Units and Groups { int temp[] = {HistoryBars, 4, 32}; //Units, Group Size, Groups if(ArrayCopy(descr.units, temp) < int(temp.Size())) return false; } descr.window = 3; descr.step = 2; descr.window_out = 1; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } int units_out = (descr.units[0] - descr.window + descr.step - 1) / descr.step + 1;
ResNeXtアーキテクチャの原則に従い、解析対象の多次元時系列の次元削減は、特徴次元の比例的な増加によって補償されます。このアプローチにより、データの情報量を維持しつつ、時系列の構造的特徴をより詳細に表現することができるようになります。
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronResNeXtBlock; //--- Chanels { int temp[] = {256, 512}; //In, Out if(ArrayCopy(descr.windows, temp) < int(temp.Size())) return false; } //--- Units and Groups { int temp[] = {units_out, 4, 64}; //Units, Group Size, Groups if(ArrayCopy(descr.units, temp) < int(temp.Size())) return false; } descr.window = 3; descr.step = 2; descr.window_out = 1; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } units_out = (descr.units[0] - descr.window + descr.step - 1) / descr.step + 1;
さらに、特徴空間の次元が増加するにつれて、各グループのサイズを固定したまま、畳み込みグループの数を比例的に拡張します。これにより、アーキテクチャは効率的にスケールし、計算コストとデータから複雑なパターンを抽出するモデル能力とのバランスを維持できます。
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronResNeXtBlock; //--- Chanels { int temp[] = {256, 512}; //In, Out if(ArrayCopy(descr.windows, temp) < int(temp.Size())) return false; } //--- Units and Groups { int temp[] = {units_out, 4, 64}; //Units, Group Size, Groups if(ArrayCopy(descr.units, temp) < int(temp.Size())) return false; } descr.window = 3; descr.step = 2; descr.window_out = 1; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } units_out = (descr.units[0] - descr.window + descr.step - 1) / descr.step + 1;
3つのResNeXtブロックを経た後、特徴次元は1024に増加し、解析対象の系列の長さは比例して短縮されます。
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronResNeXtBlock; //--- Chanels { int temp[] = {512, 1024}; //In, Out if(ArrayCopy(descr.windows, temp) < int(temp.Size())) return false; } //--- Units and Groups { int temp[] = {units_out, 4, 128}; //Units, Group Size, Groups if(ArrayCopy(descr.units, temp) < int(temp.Size())) return false; } descr.window = 3; descr.step = 2; descr.window_out = 1; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } units_out = (descr.units[0] - descr.window + descr.step - 1) / descr.step + 1;
次に、ResNeXtアーキテクチャでは、解析対象の系列を時間軸に沿って圧縮し、環境状態の最も重要な特徴のみを保持することが可能です。そのために、まず得られたデータを転置します。
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = units_out; descr.window = 1024; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
その後、プーリング層を使用します。この層は、データの次元を削減しつつ、最も重要な特徴を保持します。これにより、モデルは主要な特徴に集中でき、不要なノイズを排除し、元のデータをよりコンパクトに表現することが可能となります。
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronProofOCL; descr.count = 1024; descr.step = descr.window = units_out; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
この層の順序番号を覚えておいてください。これは環境状態エンコーダーの最終層であり、2番目のモデルへの入力データはこの層から取得します。
次に、エージェントのデコーダーに進みます。デコーダーは、2つの連続した全結合層で構成されています。
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.activation = SIGMOID; descr.batch = 1e4; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NActions; descr.activation = SIGMOID; descr.batch = 1e4; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
両方の層ではシグモイド関数を活性化関数として使用し、テンソルの次元を段階的に縮小して、エージェントに定義された行動空間へと変換します。
ここで注意すべき点として、上記で作成したエージェントは生の環境状態のみを分析しており、リスク管理モジュールを一切備えていません。この制約を補うため、MacroHFTフレームワーク内に実装されたリスク管理用のエージェント層を追加します。
//--- layer 10 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMacroHFTvsRiskManager; //--- Windows { int temp[] = {3, 15, NActions, AccountDescr}; //Window, Stack Size, N Actions, Account Description if(ArrayCopy(descr.windows, temp) < int(temp.Size())) return false; } descr.count = 10; descr.window_out = 16; descr.step = 4; // Heads descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
さらに、シグモイド活性化関数を用いた畳み込み層を追加し、エージェントの出力を所定の値空間へとマッピングします。畳み込みウィンドウのサイズは3とし、これは1回の取引に対応するパラメータ数に相当します。このアプローチにより、一貫性のある取引特性を得ることが可能となります。
//--- layer 11 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = NActions / 3; descr.window = 3; descr.step = 3; descr.window_out = 3; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
次の段階では、今後の価格変動確率を予測するモデルの記述に進みます。前述のとおり、この予測モデルはエージェントの潜在状態から入力データを受け取ります。潜在状態と2番目のモデルの入力層との間で次元の整合性を確保するため、手動によるアーキテクチャ調整はおこなわないことにしました。その代わりに、エージェントのアーキテクチャ記述から潜在状態層の記述を抽出します。
//--- Probability probability.Clear(); //--- Input layer CLayerDescription *latent = actor.At(LatentLayer); if(!latent) return false;
抽出された潜在状態の記述に含まれるパラメータは、その後、新しいモデルの入力層に引き継がれます。
if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = latent.count; descr.activation = latent.activation; descr.optimization = ADAM; if(!probability.Add(descr)) { delete descr; return false; }
別のモデルの潜在状態を入力データとして使用することで、すでに処理され、相互に比較可能なデータを扱うことができます。そのため、一次的な入力前処理としてバッチ正規化層を適用する必要はありません。さらに、ResNeXtブロックの出力はすでに正規化されています。
今後の価格変動方向に対する予測値を得るために、間にシグモイド活性化関数を挟んだ2つの全結合層を使用します。
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.activation = SIGMOID; descr.batch = 1e4; descr.optimization = ADAM; if(!probability.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = NActions / 3; descr.activation = None; descr.batch = 1e4; descr.optimization = ADAM; if(!probability.Add(descr)) { delete descr; return false; }
その後、全結合層の出力はSoftMax関数を用いて確率空間へとマッピングされます。
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; prev_count = descr.count = prev_count; descr.step = 1; descr.activation = None; descr.batch = 1e4; descr.optimization = ADAM; if(!probability.Add(descr)) { delete descr; return false; } //--- return true; }
本モデルが予測するのは、価格変動の方向についての2つの確率、すなわち上昇と下落のみである点に注意することが重要です。フラット(横ばい)な動きの確率は意図的に考慮していません。なぜなら、実際の横ばい相場であっても、それはおおむね同程度の振幅を持ち、互いに逆方向を向いた短期的な価格変動の連続として表現できるためです。このアプローチにより、計算資源を複雑で重要度の低いフラット状態の記述に費やすことなく、モデルは市場の本質的な動的パターンの識別に集中できます。
モデルアーキテクチャの記述が完了すると、あとは実行された処理の論理的な結果を呼び出し元のプログラムに返し、メソッドの実行を終了するだけです。
モデルの学習
モデルアーキテクチャを定義したので、次の段階である学習に進みます。この目的のために、MacroHFTフレームワークの開発過程で収集された学習データセットを使用します。データセットの構築プロセスについては、対応する記事で詳しく説明されています。改めて述べておくと、この学習データセットは、EURUSD通貨ペアの2024年通年分の履歴データをM1時間足で使用して構築されています。
ただし、モデルを学習させるためには、...\MQL5\Experts\ResNeXt\Study.mq5に配置されているエキスパートアドバイザー(EA)アルゴリズムにいくつかの修正を加える必要があります。本記事では、学習プロセス全体が構成されているTrainメソッドのみに焦点を当てて解説します。
void Train(void) { //--- vector<float> probability = vector<float>::Full(Buffer.Size(), 1.0f / Buffer.Size());
学習メソッドの冒頭では、通常、各軌道の収益性に基づいて異なる軌道を選択するための確率ベクトルを計算します。これは、ほとんどの場合、損失となるシーケンスの数が利益を生むシーケンスの数を大きく上回るため、利益エピソードと非利益エピソードの間に生じる不均衡を補正することを可能にします。しかしこの研究では、モデルはほぼ理想的な軌道で学習される予定であり、エージェントの行動系列は履歴価格変動データに基づいて形成されます。その結果、確率ベクトルはすべて同一の値で満たされ、学習データセット全体が均等に表現されるようになります。このアプローチにより、特定のシナリオを他より優先させるような人工的なバイアスをかけることなく、市場データの主要な特性を学習することができます。その結果、汎化能力が向上し、モデルのロバスト性も高まります。
次に、処理の実行中に一時的なデータを格納するために必要となる複数のローカル変数を宣言します。
vector<float> result, target, state; matrix<float> fstate = matrix<float>::Zeros(1, NForecast * BarDescr); bool Stop = false; //--- uint ticks = GetTickCount();
これで準備作業は完了です。続いて、モデルを学習させるための学習ループの構築に進みます。
ResNeXtアーキテクチャ自体は再帰ブロックを使用していない点に注意する必要があります。そのため、その学習には、学習データセットからランダムに状態をサンプリングする単一ループ内での学習を適用するのが合理的です。しかし、本システムには、過去の意思決定や、それらの実行によって生じた口座状態の変化を記憶するメモリモジュールを使用するリスク管理エージェントを追加しています。このモジュールの学習には、入力データの履歴シーケンスを保持する必要があります。
外側のループ本体では、学習データセットからミニバッチの履歴シーケンスの初期状態をサンプリングします。
for(int iter = 0; (iter < Iterations && !IsStopped() && !Stop); iter += Batch) { int tr = SampleTrajectory(probability); int start = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2 - NForecast - Batch)); if(start <= 0) { iter -= Batch; continue; }
次に、再帰ブロックのメモリをクリアします。
if(!Actor.Clear()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
続いて、エージェントの行動に対する直前のターゲット値ベクトルをゼロで初期化し、その後、履歴シーケンスに従ってミニバッチ状態を処理するネストされたループを実行します。
result = vector<float>::Zeros(NActions); for(int i = start; i < MathMin(Buffer[tr].Total, start + Batch); i++) { if(!state.Assign(Buffer[tr].States[i].state) || MathAbs(state).Sum() == 0 || !bState.AssignArray(state)) { iter -= Batch + start - i; break; }
ネストされたループの本体では、まず学習データセットから環境状態の記述を対応するバッファへ転送します。その後、口座状態を表すテンソルの形成に進みます。ここでは、解析対象の環境状態に対応するタイムスタンプの高調波成分を生成します。
//--- bTime.Clear(); double time = (double)Buffer[tr].States[i].account[7]; double x = time / (double)(D'2024.01.01' - D'2023.01.01'); bTime.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_MN1); bTime.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_W1); bTime.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_D1); bTime.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(bTime.GetIndex() >= 0) bTime.BufferWrite();
次に、経験再生バッファから残高と有効証拠金のデータを抽出します。
//--- Account float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1];
また、前の履歴バーにおいて、潜在的に得られた可能性のある直前のターゲット取引操作の収益性を計算します。
float profit = float(bState[0] / _Point * (result[0] - result[3]));
口座状態の記述ベクトルを準備する際、前のバーでは既存のすべてのオープンポジションがクローズされ、ネストされた学習ループの前回イテレーションで形成されたターゲット取引が実行されたと仮定します。このループの最初のイテレーションでは、ターゲット行動ベクトルはゼロで満たされている(すなわち取引なし)ため、残高変化係数は「1」となり、有効証拠金の指標は先に計算した直前バーの潜在利益に基づいて形成されます。
bAccount.Clear(); bAccount.Add(1); bAccount.Add((PrevEquity + profit) / PrevEquity); bAccount.Add(profit / PrevEquity); bAccount.Add(MathMax(result[0] - result[3], 0)); bAccount.Add(MathMax(result[3] - result[0], 0)); bAccount.Add((bAccount[3] > 0 ? profit / PrevEquity : 0)); bAccount.Add((bAccount[4] > 0 ? profit / PrevEquity : 0)); bAccount.Add(0); bAccount.AddArray(GetPointer(bTime)); if(bAccount.GetIndex() >= 0) bAccount.BufferWrite();
これに従い、ポジションに関する情報も、ターゲット取引操作に基づいて形成されます。
入力データの形成後、学習中のモデルに対してフィードフォワード処理を実行します。まず、上で準備した入力データを渡してエージェントの順伝播メソッドを呼び出します。
//--- Feed Forward if(!Actor.feedForward((CBufferFloat*)GetPointer(bState), 1, false, GetPointer(bAccount))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
次に、エージェントの潜在状態を入力として使用し、今後の価格変動確率を予測するモデルの対応メソッドを呼び出します。
if(!Probability.feedForward(GetPointer(Actor), LatentLayer, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
次のステップは、モデルを訓練するための目標値を生成することです。前述のとおり、この研究では「ほぼ完全な軌道」に基づいてモデルを学習させます。そのため、学習データセットを用いて将来を「先読み」する形でターゲット値を形成します。具体的には、指定された計画ホライズンにわたる実際の将来の環境状態データを学習データセットから抽出し、各バーを1行とする行列へ格納します。
//--- Look for target target = vector<float>::Zeros(NActions); bActions.AssignArray(target); if(!state.Assign(Buffer[tr].States[i + NForecast].state) || !state.Resize(NForecast * BarDescr) || MathAbs(state).Sum() == 0) { iter -= Batch + start - i; break; } if(!fstate.Resize(1, NForecast * BarDescr) || !fstate.Row(state, 0) || !fstate.Reshape(NForecast, BarDescr)) { iter -= Batch + start - i; break; }
抽出されたデータは履歴順が逆になっている点に注意が必要です。そのため、この行列の行を並べ替えるためのループを構成します。
for(int j = 0; j < NForecast / 2; j++) { if(!fstate.SwapRows(j, NForecast - j - 1)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; } }
将来の価格変動に関するデータが得られたので、ターゲット取引操作ベクトルの形成に進みます。この段階では、直前の取引操作に応じてアルゴリズムが分岐します。つまり、直前の取引内容が、この時点でのエージェントのターゲットを変更します。これは論理的な挙動です。ポジションがある場合は決済ポイントを探し、ない場合はエントリーポイントを探します。
前回の反復でロングポジションを開く操作がターゲットであった場合、予測可能な将来においてストップロス水準に到達するかどうかを確認します。
target = fstate.Col(0).CumSum(); if(result[0] > result[3]) { float tp = 0; float sl = 0; float cur_sl = float(-(result[2] > 0 ? result[2] : 1) * MaxSL * Point()); int pos = 0; for(int j = 0; j < NForecast; j++) { tp = MathMax(tp, target[j] + fstate[j, 1] - fstate[j, 0]); pos = j; if(cur_sl >= target[j] + fstate[j, 2] - fstate[j, 0]) break; sl = MathMin(sl, target[j] + fstate[j, 2] - fstate[j, 0]); }
この場合、ストップロス水準に到達するまでの最大価格が、ターゲットのテイクプロフィット値として使用されます。
得られた値は買い取引のターゲットパラメータとして設定され、同時に売り取引のパラメータはゼロにリセットされます。
if(tp > 0) { sl = float(MathMin(MathAbs(sl) / (MaxSL * Point()), 1)); tp = float(MathMin(tp / (MaxTP * Point()), 1)); result[0] = MathMax(result[0] - result[3], 0.011f); result[1] = tp; result[2] = sl; for(int j = 3; j < NActions; j++) result[j] = 0; bActions.AssignArray(result); } }
ショートポジションからの決済ポイントを探索する場合も、同様の処理がおこなわれます。
else { if(result[0] < result[3]) { float tp = 0; float sl = 0; float cur_sl = float((result[5] > 0 ? result[5] : 1) * MaxSL * Point()); int pos = 0; for(int j = 0; j < NForecast; j++) { tp = MathMin(tp, target[j] + fstate[j, 2] - fstate[j, 0]); pos = j; if(cur_sl <= target[j] + fstate[j, 1] - fstate[j, 0]) break; sl = MathMax(sl, target[j] + fstate[j, 1] - fstate[j, 0]); } if(tp < 0) { sl = float(MathMin(MathAbs(sl) / (MaxSL * Point()), 1)); tp = float(MathMin(-tp / (MaxTP * Point()), 1)); result[3] = MathMax(result[3] - result[0], 0.011f); result[4] = tp; result[5] = sl; for(int j = 0; j < 3; j++) result[j] = 0; bActions.AssignArray(result); } }
ポジションが存在しない場合は、エントリーポイントを探索します。そのために、今後の価格トレンドの方向を判定します。
ulong argmin = target.ArgMin(); ulong argmax = target.ArgMax(); while(argmax > 0 && argmin > 0) { if(argmax < argmin && target[argmax]/2 > MathAbs(target[argmin])) break; if(argmax > argmin && target[argmax] < MathAbs(target[argmin]/2)) break; target.Resize(MathMin(argmax, argmin)); argmin = target.ArgMin(); argmax = target.ArgMax(); }
価格の上昇が予測される場合には、買い取引のパラメータを定義します。取引パラメータの決定方法は、決済ポイント探索時と同様です。ストップロスは最大値の水準に設定されます。
if(argmin == 0 || (argmax < argmin && argmax > 0)) { float tp = 0; float sl = 0; float cur_sl = - float(MaxSL * Point()); ulong pos = 0; for(ulong j = 0; j < argmax; j++) { tp = MathMax(tp, target[j] + fstate[j, 1] - fstate[j, 0]); pos = j; if(cur_sl >= target[j] + fstate[j, 2] - fstate[j, 0]) break; sl = MathMin(sl, target[j] + fstate[j, 2] - fstate[j, 0]); } if(tp > 0) { sl = (float)MathMax(MathMin(MathAbs(sl) / (MaxSL * Point()), 1), 0.01); tp = (float)MathMin(tp / (MaxTP * Point()), 1); result[0] = float(MathMax(Buffer[tr].States[i].account[0]/100*0.01, 0.011)); result[1] = tp; result[2] = sl; for(int j = 3; j < NActions; j++) result[j] = 0; bActions.AssignArray(result); } }
同様に、価格下落が予測される場合には、売り取引のパラメータを決定します。
else { if(argmax == 0 || argmax > argmin) { float tp = 0; float sl = 0; float cur_sl = float(MaxSL * Point()); ulong pos = 0; for(ulong j = 0; j < argmin; j++) { tp = MathMin(tp, target[j] + fstate[j, 2] - fstate[j, 0]); pos = j; if(cur_sl <= target[j] + fstate[j, 1] - fstate[j, 0]) break; sl = MathMax(sl, target[j] + fstate[j, 1] - fstate[j, 0]); } if(tp < 0) { sl = (float)MathMax(MathMin(MathAbs(sl) / (MaxSL * Point()), 1), 0.01); tp = (float)MathMin(-tp / (MaxTP * Point()), 1); result[3] = float(MathMax(Buffer[tr].States[i].account[0]/100*0.01,0.011)); result[4] = tp; result[5] = sl; for(int j = 0; j < 3; j++) result[j] = 0; bActions.AssignArray(result); } } } } }
取引操作のターゲットテンソルが形成された後、生成された取引判断とターゲットとの乖離を最小化するために、エージェントに対してバックプロパゲーション処理を実行します。
//--- Actor Policy if(!Actor.backProp(GetPointer(bActions), (CBufferFloat*)GetPointer(bAccount), GetPointer(bGradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
次に、予測モデル用のターゲット値を形成します。買い取引が上昇トレンドに対応し、売り取引が下降トレンドに対応することは明らかです。取引は履歴データ分析に基づいて形成されているため、将来のトレンドについては100%の確信があります。そのため、該当するトレンドのターゲット値は1、反対方向は0とします。
target = vector<float>::Zeros(NActions / 3); for(int a = 0; a < NActions; a += 3) target[a / 3] = float(result[a] > 0);
これで、予測モデルに対してもバックプロパゲーション操作を実行できます。この際、環境状態エンコーダーのパラメータも同時に調整されており、これはマルチタスク学習のアプローチと整合しています。
if(!Result.AssignArray(target) || !Probability.backProp(Result, GetPointer(Actor), LatentLayer) || !Actor.backPropGradient((CBufferFloat*)NULL, (CBufferFloat*)NULL, LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
最後に、学習プロセスの進捗状況をユーザーに通知し、ループシステムの次の反復へ進みます。
if(GetTickCount() - ticks > 500) { double percent = double(iter + i - start) * 100.0 / (Iterations); string str = StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Actor", percent, Actor.getRecentAverageError()); str += StringFormat("%-13s %6.2f%% -> Error %15.8f\n", "Probability", percent, Probability.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
指定された回数の学習の反復が正常に完了した後、モデル学習の進捗を通知するために使用していたチャートコメントをクリアします。
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Actor", Actor.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Probability", Probability.getRecentAverageError()); ExpertRemove(); //--- }
学習結果をログに出力し、学習プログラムの終了処理を初期化します。モデル学習プログラムの全コードは添付ファイルで確認できます。
次のステップでは、実際のモデル学習プロセスに進みます。この目的のため、MetaTrader 5ターミナルに切り替え、作成したEAをリアルタイムモードで起動します。EAは取引操作を実行しないため、アカウント残高にリスクを与えることはありません。
両モデルの同時学習をおこなうことに注意してください。ただし、エージェントの動作には1つのニュアンスがあります。前述のとおり、このモデルのアーキテクチャには、口座状態や過去の意思決定のメモリモジュールを使用するリスク管理ブロックが追加されています。同時に、エージェントの潜在表現からの情報は、過去の行動のメモリモジュールに保存されます。
しかし、上で示した学習コードを見ると、口座状態の記述ベクトルはターゲット値に基づいて形成されていることがわかります。これにより不均衡が生じます。リスク管理ブロックは、まったく異なる行動方針の文脈で残高変動を評価してしまうのです。この影響を最小化するため、学習は2段階で実施することにしました。
学習の第一段階では、ミニバッチサイズを単一状態に設定します。
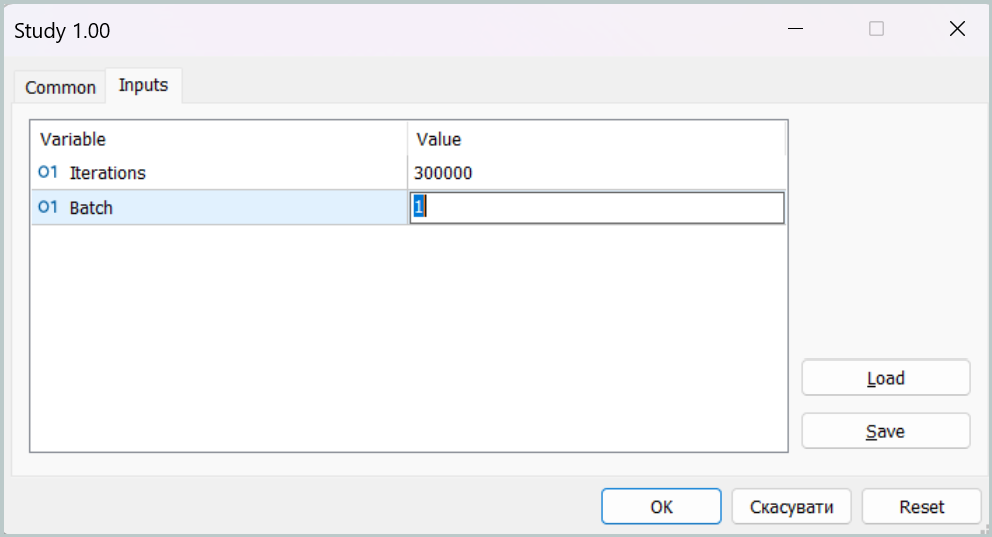
このようなパラメータ設定により、第一段階の学習ではメモリモジュールが事実上無効化されます。これはもちろんモデルの本来の動作モードではありませんが、このモードでエージェントの行動方針をターゲットに可能な限り近づけ、予測取引操作とターゲット取引操作のギャップを最小化することができます。
第二段階の学習では、ミニバッチサイズを増やし、メモリモジュールの容量より少なくともわずかに大きく設定します。これにより、選択された方針が口座状態に与える影響を制御するリスク管理コンポーネントを含め、モデルを微調整することが可能になります。
モデルのテスト
モデルの学習が完了した後、得られたエージェントの行動方針のテストに進みます。ここでは、テストプログラムのアルゴリズムに導入された変更について簡単に触れる必要があります。これらの調整は局所的なものであり、添付ファイルで独自に確認できるため、コード全体はレビューしません。特筆すべき点として、今後の価格変動の確率予測モデルをプログラムのロジックに追加しました。エージェントの取引操作の方向が最も確からしいトレンドと一致する場合のみ、取引操作が実行されます。
学習済みの方針は、MetaTrader 5のストラテジーテスターで2025年1月の履歴データを使用してテストします。学習データセットを構築する際に使用したその他のパラメータはすべて保持します。テスト期間のデータは学習データセットに含まれていないため、未学習データでの実運用にできるだけ近い条件でテストできます。
以下にそのテスト結果を示します。
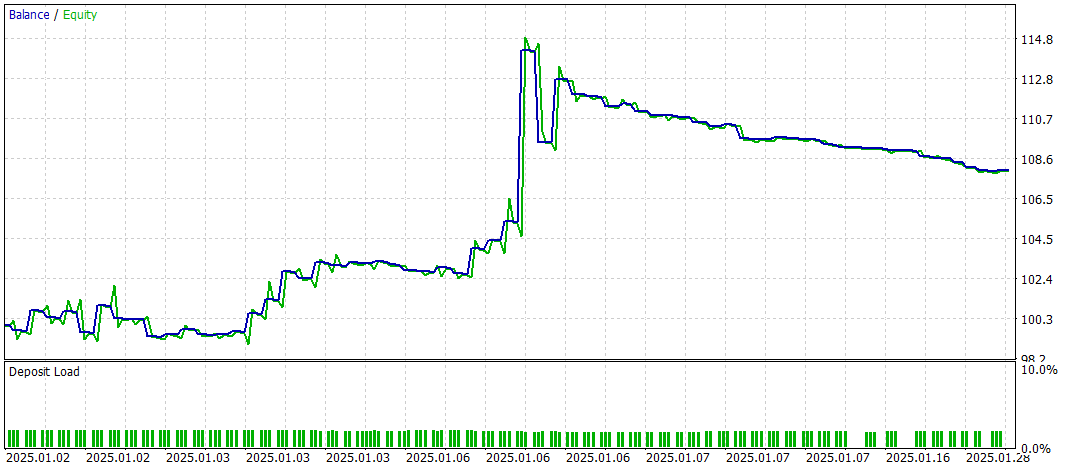
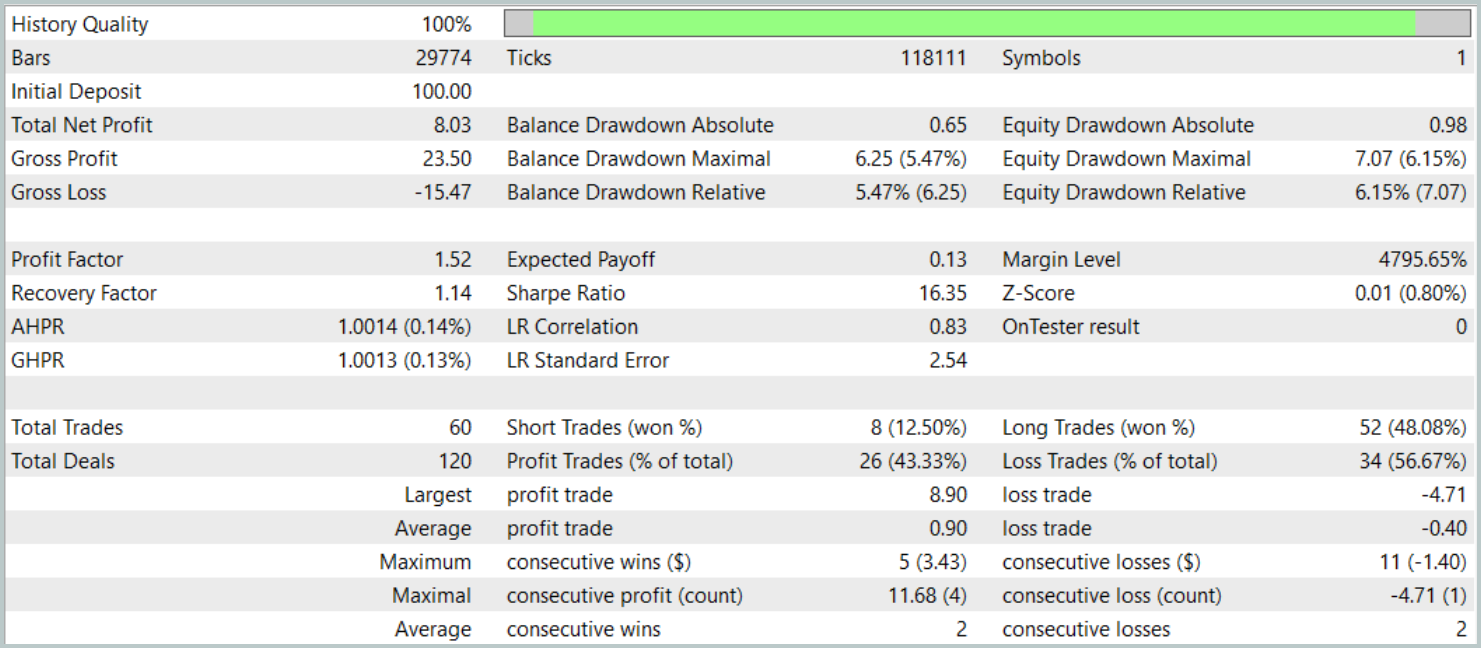
テスト期間中、モデルは合計60回の取引操作を実行し、1営業日あたり約3回の取引に相当します。ポジションの43%以上が利益確定で決済されました。平均および最大の利益取引が損失取引の対応する指標のおよそ2倍であったため、テストはプラスの財務結果で終了しました。プロフィットファクターは1.52、リカバリーファクターは1.14となりました。
結論
本記事で解説したResNeXtアーキテクチャに基づくマルチタスク学習フレームワークは、金融市場分析に新たな可能性を開きます。共有エンコーダーと専門化された「ヘッド」の利用により、モデルはデータ中の安定したパターンを効果的に識別し、市場状況の変化に適応し、より正確な予測を提供することが可能です。マルチタスク学習の適用により、複数のタスクを同時に学習することで過学習のリスクを最小化し、より一般化された市場表現の形成に寄与します。
さらに、ResNeXtアーキテクチャの高いモジュール性により、特定の運用条件に応じたモデルパラメータの調整が可能となり、アルゴリズムトレーディングにおける汎用的なツールとして活用できます。
MQL5を用いた提案手法の実装例では、時系列分析や市場トレンド予測において有効性が示されました。加えて、市場トレンド予測ブロックを追加することで、モデルの解析能力が大幅に向上し、予期せぬ価格変動にもより強靭に対応できるようになりました。
総じて、本提案システムは自動取引や金融データのアルゴリズム分析において大きな応用可能性を示しています。しかし、モデルを実際の市場環境で運用する前には、より代表性の高い学習データセットで学習させた上で、包括的なテストを行う必要があります。
参照文献
- Aggregated Residual Transformations for Deep Neural Networks
- Collaborative Optimization in Financial Data Mining Through Deep Learning and ResNeXt
- Other articles from this series
記事で使用されているプログラム
| # | 名前 | 種類 | 説明 |
|---|---|---|---|
| 1 | Research.mq5 | EA | サンプル収集用EA |
| 2 | ResearchRealORL.mq5 | EA | Real-ORL法を用いたサンプル収集用EA |
| 3 | Study.mq5 | EA | モデル学習用EA |
| 4 | Test.mq5 | EA | モデルテスト用EA |
| 5 | Trajectory.mqh | クラスライブラリ | システム状態とモデルアーキテクチャ記述構造 |
| 6 | NeuroNet.mqh | クラスライブラリ | ニューラルネットワークを作成するためのクラスのライブラリ |
| 7 | NeuroNet.cl | コードベース | OpenCLプログラムコード |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/17157
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索