
Ciência de Dados e Aprendizado de Máquina (Parte 14): aplicando mapas de Kohonen nos mercados

Introdução
Os Mapas de Kohonen ou mapas Auto-Organizáveis (SOM) ou Mapa de Características Auto-Organizáveis (SOFM) são uma técnica de aprendizado de máquina não supervisionada usada para produzir uma representação de baixa dimensão (tipicamente bidimensional) de um conjunto de dados de dimensão superior, preservando a estrutura topológica dos dados. Por exemplo; Um conjunto de dados com p variáveis medidas em n observações poderia ser representado como clusters (agrupamentos) de observações com valores semelhantes para as variáveis. Esses clusters então poderiam ser visualizados como um "mapa bidimensional" de modo que observações em clusters próximos tenham valores mais semelhantes do que as observações em clusters distais. Isso pode tornar os dados de alta dimensão mais fáceis de visualizar e analisar.
Os mapas de Kohonen foram desenvolvidos por um matemático finlandês conhecido como Teuvo Kohonen na década de 1980.
Visão geral
Um mapa de Kohonen consiste em uma grade de neurônios que estão conectados aos seus neurônios vizinhos. Durante o treinamento, os dados de entrada são apresentados à rede, e cada neurônio calcula sua semelhança com os dados de entrada. O neurônio com a maior semelhança é chamado de vencedor e seus pesos são ajustados para melhor corresponder aos dados de entrada.

Com o tempo, os neurônios vizinhos também ajustam seus pesos para se tornarem mais semelhantes ao neurônio vencedor, resultando em uma ordenação topológica dos neurônios no mapa. Esse processo de auto-organização permite que o mapa de Kohonen represente relações complexas entre os dados de entrada em um espaço de dimensão inferior, tornando-o útil para visualização de agrupamentos de dados.
Algoritmo de aprendizagem
O objetivo deste algoritmo no mapa auto-organizável é fazer com que diferentes partes da rede respondam de maneira semelhante a certos padrões de entrada. Isso é parcialmente motivado pela forma como as informações visuais, auditivas e outras são tratadas em algumas partes do cérebro humano.
Vejamos como este algoritmo funciona quando se trata de termos matemáticos e código MQL5.
Passos Envolvidos no Algoritmo
Existem quatro etapas principais a considerar ao tentar codificar este algoritmo:
Etapa 01: Inicializar os pesos![]() . É possível assumir valores aleatórios. Outros parâmetros, como a taxa de aprendizado e o número de clusters, também são inicializados nesta etapa.
. É possível assumir valores aleatórios. Outros parâmetros, como a taxa de aprendizado e o número de clusters, também são inicializados nesta etapa.
CKohonenMaps::CKohonenMaps(matrix &matrix_, bool save_clusters=true, uint clusters=2, double alpha=0.01, uint epochs=100) { Matrix = matrix_; n = (uint)matrix_.Cols(); rows = matrix_.Rows(); m = clusters; cluster_tensor = new CTensors(m); w_matrix =matrix_utils.Random(0.0, 1.0, n, m, RANDOM_STATE); }
Como de costume, os parâmetros são inicializados no construtor da classe dos mapas de Kohonen.
Os mapas de Kohonen são uma técnica de mineração de dados. Depois de tudo dito e feito, precisamos obter os dados minerados, é por isso que você vê o argumento booleano save_clusters=true, isso nos permitirá obter os clusters que os mapas de Kohonen obtiveram para nós.
Etapa 02: Calcular a distância euclidiana entre todas as entradas e seus respectivos pesos.
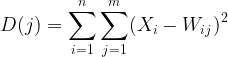
Onde:
![]() = Vetor de entrada
= Vetor de entrada
![]() = Vetor de pesos
= Vetor de pesos
double CKohonenMaps:: Euclidean_distance(const vector &v1, const vector &v2) { double dist = 0; if(v1.Size() != v2.Size()) Print(__FUNCTION__, " v1 and v2 not matching in size"); else { double c = 0; for(ulong i=0; i<v1.Size(); i++) c += MathPow(v1[i] - v2[i], 2); dist = MathSqrt(c); } return(dist); }
Para aplicar esta fórmula e esclarecer tudo, precisamos de um conjunto de dados simples para nos ajudar na codificação e nos testes.
matrix Matrix = { {1.2, 2.3}, {0.7, 1.8}, {3.6, 4.8}, {2.8, 3.9}, {5.2, 6.7}, {4.8, 5.6} }; maps = new CKohonenMaps(Matrix); //Giving our kohonen maps class data
Quando o construtor é chamado e os pesos são gerados, abaixo estão as saídas:
CS 0 15:52:27.572 Self Organizing map (EURUSD,H1) w Matrix CS 0 15:52:27.572 Self Organizing map (EURUSD,H1) [[0.005340739158299509,0.01220740379039888] CS 0 15:52:27.572 Self Organizing map (EURUSD,H1) [0.5453352458265939,0.9172643208105716]] CS 0 15:52:27.572 Self Organizing map (EURUSD,H1) Matrix CS 0 15:52:27.572 Self Organizing map (EURUSD,H1) [[1.2,2.3] CS 0 15:52:27.572 Self Organizing map (EURUSD,H1) [0.7,1.8] CS 0 15:52:27.572 Self Organizing map (EURUSD,H1) [3.6,4.8] CS 0 15:52:27.572 Self Organizing map (EURUSD,H1) [2.8,3.9] CS 0 15:52:27.572 Self Organizing map (EURUSD,H1) [5.2,6.7] CS 0 15:52:27.572 Self Organizing map (EURUSD,H1) [4.8,5.6]]
Você deve ter notado que nossa arquitetura de rede neural é uma [2 entradas e 2 saídas]. É por isso que temos uma matriz 2x2 de pesos. Esta matriz foi gerada considerando [2 colunas de matriz de entrada marcadas como n e 2 clusters selecionados marcados como m]. Linha de código que vimos na primeira parte:
w_matrix =matrix_utils.Random(0.0, 1.0, n, m, RANDOM_STATE);A arquitetura da nossa rede neural dos mapas de Kohonen é a seguinte:
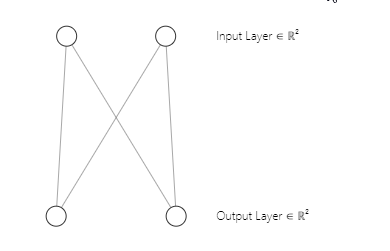
Etapa 03: Encontre o índice da unidade vencedora i para que D(j) seja mínimo. Em outras palavras, encontre o cluster da unidade, isso me traz a um assunto importante sobre o aprendizado competitivo dos mapas de Kohonen.
Aprendizado Competitivo.
Um mapa auto-organizável é um tipo de rede neural artificial que, ao contrário de outros tipos de redes neurais artificiais que são treinadas usando aprendizado com correção de erros, como retropropagação com gradiente descendente, os mapas de Kohonen são treinados usando aprendizado competitivo.
No aprendizado competitivo, os neurônios no mapa de Kohonen competem entre si para se tornar o "vencedor" sendo o neurônio que é mais semelhante aos dados de entrada.
Durante a fase de treinamento, cada ponto de dados de entrada é apresentado ao mapa de Kohonen, e a similaridade entre os dados de entrada e o vetor de pesos de cada neurônio é calculada. O neurônio cujo vetor de pesos é mais semelhante aos dados de entrada é chamado de vencedor ou "unidade de melhor correspondência" (best matching unit, BMU).
O BMU é selecionado com base na menor distância euclidiana entre os dados de entrada e o vetor de pesos do neurônio. O neurônio vencedor então atualiza seu vetor de pesos para se tornar mais semelhante aos dados de entrada. A fórmula de atualização de peso usada é conhecida como a regra de aprendizado de Kohonen, que move o vetor de peso do neurônio vencedor e seus neurônios vizinhos mais próximos dos dados de entrada.
Para codificar esta etapa 03 são necessárias algumas linhas de código.
vector D(m); //Euclidean distance btn clusters | Remember m is the number of clusters selected for (ulong i=0; i<rows; i++) { for (ulong j=0; j<m; j++) { D[j] = Euclidean_distance(Matrix.Row(i),w_matrix.Col(j)); } #ifdef DEBUG_MODE Print("Euc distance ",D," Winning cluster ",D.ArgMin()); #endif
Lembre-se sempre, o neurônio que produz a classe com a menor distância euclidiana de todas é o cluster vencedor.
Por meio do aprendizado competitivo, o mapa de Kohonen aprende a criar uma representação topológica dos dados de entrada em um espaço de dimensão inferior, preservando as relações entre os dados de entrada.
Etapa 04: Atualização dos pesos.
A atualização dos pesos pode ser alcançada usando a fórmula abaixo.
![]()
Onde:
![]() — Novo vetor de pesos
— Novo vetor de pesos
![]() — Vetor de pesos antigo
— Vetor de pesos antigo
![]() — Taxa de aprendizado
— Taxa de aprendizado
![]() — Vetor de entrada
— Vetor de entrada
Abaixo está o código para esta fórmula:
//--- weights update ulong min = D.ArgMin(); //winning cluster vector w_new = w_matrix.Col(min) + (alpha * (Matrix.Row(i) - w_matrix.Col(min))); w_matrix.Col(w_new, min);
Ao contrário de outros tipos de redes neurais artificiais, onde todos os pesos para uma camada específica se envolvem, os mapas de Kohonen levam em consideração os pesos para um cluster específico e os usam para se envolver na busca por aquele cluster apenas.
Terminamos com as etapas e nosso algoritmo está completo, hora de rodar para ver como tudo funciona.
Abaixo está todo o código para o algoritmo até este ponto.
CKohonenMaps::CKohonenMaps(matrix &matrix_, bool save_clusters=true, uint clusters=2, double alpha=0.01, uint epochs=100) { Matrix = matrix_; n = (uint)matrix_.Cols(); rows = matrix_.Rows(); m = clusters; cluster_tensor = new CTensors(m); w_matrix =matrix_utils.Random(0.0, 1.0, n, m, RANDOM_STATE); vector D(m); //Euclidean distance btn clusters for (uint epoch=0; epoch<epochs; epoch++) { double epoch_start = GetMicrosecondCount()/(double)1e6, epoch_stop=0; for (ulong i=0; i<rows; i++) { for (ulong j=0; j<m; j++) { D[j] = Euclidean_distance(Matrix.Row(i),w_matrix.Col(j)); } #ifdef DEBUG_MODE Print("Euc distance ",D," Winning cluster ",D.ArgMin()); #endif //--- weights update ulong min = D.ArgMin(); vector w_new = w_matrix.Col(min) + (alpha * (Matrix.Row(i) - w_matrix.Col(min))); w_matrix.Col(w_new, min); } epoch_stop =GetMicrosecondCount()/(double)1e6; printf("Epoch [%d/%d] | %sElapsed ",epoch+1,epochs, CalcTimeElapsed(epoch_stop-epoch_start)); } //end of training //--- #ifdef DEBUG_MODE Print("\nNew weights\n",w_matrix); #endif }
Saídas:
CS 0 04:13:26.617 Self Organizing map (EURUSD,H1) Euc distance [2.122748018266242,1.822857430002081] Winning cluster 1 CS 0 04:13:26.617 Self Organizing map (EURUSD,H1) Euc distance [1.434132188481296,1.100846180984197] Winning cluster 1 CS 0 04:13:26.617 Self Organizing map (EURUSD,H1) Euc distance [5.569896531530945,5.257391342266398] Winning cluster 1 CS 0 04:13:26.617 Self Organizing map (EURUSD,H1) Euc distance [4.36622216533946,4.000958814345993] Winning cluster 1 CS 0 04:13:26.617 Self Organizing map (EURUSD,H1) Euc distance [8.053842751911217,7.646959164093921] Winning cluster 1 CS 0 04:13:26.617 Self Organizing map (EURUSD,H1) Euc distance [6.966950064745546,6.499246789416081] Winning cluster 1 CS 0 04:13:26.617 Self Organizing map (EURUSD,H1) Epoch [1/100] | 0.000 Seconds Elapsed .... .... .... CS 0 04:13:26.622 Self Organizing map (EURUSD,H1) Euc distance [0.7271897806071723,4.027137175049654] Winning cluster 0 CS 0 04:13:26.622 Self Organizing map (EURUSD,H1) Euc distance [0.08133608432880858,4.734224801594559] Winning cluster 0 CS 0 04:13:26.622 Self Organizing map (EURUSD,H1) Euc distance [4.18281664576938,0.5635073709012016] Winning cluster 1 CS 0 04:13:26.622 Self Organizing map (EURUSD,H1) Euc distance [2.979092473547668,1.758946102746018] Winning cluster 1 CS 0 04:13:26.622 Self Organizing map (EURUSD,H1) Euc distance [6.664860479474853,1.952054507391296] Winning cluster 1 CS 0 04:13:26.622 Self Organizing map (EURUSD,H1) Euc distance [5.595867985957728,0.8907607121421737] Winning cluster 1 CS 0 04:13:26.622 Self Organizing map (EURUSD,H1) Epoch [100/100] | 0.000 Seconds Elapsed CS 0 04:13:26.622 Self Organizing map (EURUSD,H1) CS 0 04:13:26.622 Self Organizing map (EURUSD,H1) New weights CS 0 04:13:26.622 Self Organizing map (EURUSD,H1) [[0.75086979456201,4.028060179594681] CS 0 04:13:26.622 Self Organizing map (EURUSD,H1) [1.737580668068743,5.173650598091957]]
Ótimo, tudo funciona, nossos mapas de Kohonen foram capazes de agrupar nossa matriz primária.
matrix Matrix = { {1.2, 2.3}, //Into cluster 0 {0.7, 1.8}, //Into cluster 0 {3.6, 4.8}, //Into cluster 1 {2.8, 3.9}, //Into cluster 1 {5.2, 6.7}, //Into cluster 1 {4.8, 5.6} //Into cluster 1 };
Isso é exatamente o que deveria ser, isso é ótimo, no entanto, apresentar essa saída e visualizá-las em um gráfico não é uma tarefa tão simples quanto parece. Temos dois clusters, uma é uma matriz 2x2 e a outra é uma matriz 4x2. Uma tem 4 valores e a outra tem 8 valores. Se você se lembra no artigo sobre Clustering K-Means, tive dificuldades para apresentar os clusters devido a esta diferença no tamanho dos clusters, desta vez foram tomadas medidas extremas.
Tensores em Aprendizado de Máquina
Um tensor é uma generalização de vetores e matrizes dentro de uma matriz multidimensional. Simplesmente, um tensor é uma matriz que contém matrizes e vetores no interior, em python, é assim;
# create tensor from numpy import array T = array([ [[1,2,3], [4,5,6], [7,8,9]], [[11,12,13], [14,15,16], [17,18,19]], [[21,22,23], [24,25,26], [27,28,29]], ])
Os tensores são a estrutura de dados fundamental usada por frameworks de aprendizado de máquina, como TensorFlow, PyTorch e Keras.
Os tensores são usados em algoritmos de aprendizado de máquina para operações como multiplicação de matrizes, convolução e união. Os tensores também são usados para armazenar e manipular os pesos e vieses das redes neurais durante o treinamento e a inferência. No geral, os Tensores são uma estrutura de dados crucial no aprendizado de máquina que permite um cálculo eficiente e a representação de dados complexos.
Tive que importar a biblioteca Tensors.mqh. Leia sobre isso na minha wiki do GitHub.
Adicionei tensores para nos ajudar com a coleta de clusters para cada tensor.
CKohonenMaps::CKohonenMaps(matrix &matrix_, bool save_clusters=true, uint clusters=2, double alpha=0.01, uint epochs=100) { Matrix = matrix_; n = (uint)matrix_.Cols(); rows = matrix_.Rows(); m = clusters; cluster_tensor = new CTensors(m); w_matrix =matrix_utils.Random(0.0, 1.0, n, m, RANDOM_STATE); Print("w Matrix\n",w_matrix,"\nMatrix\n",Matrix); vector D(m); //Euclidean distance btn clusters for (uint epoch=0; epoch<epochs; epoch++) { double epoch_start = GetMicrosecondCount()/(double)1e6, epoch_stop=0; for (ulong i=0; i<rows; i++) { for (ulong j=0; j<m; j++) { D[j] = Euclidean_distance(Matrix.Row(i),w_matrix.Col(j)); } #ifdef DEBUG_MODE Print("Euc distance ",D," Winning cluster ",D.ArgMin()); #endif //--- weights update ulong min = D.ArgMin(); if (epoch == epochs-1) //last iteration cluster_tensor.TensorAppend(Matrix.Row(i), min); vector w_new = w_matrix.Col(min) + (alpha * (Matrix.Row(i) - w_matrix.Col(min))); w_matrix.Col(w_new, min); //Print("New w_Matrix\n ",w_matrix); } epoch_stop =GetMicrosecondCount()/(double)1e6; printf("Epoch [%d/%d] | %sElapsed ",epoch+1,epochs, CalcTimeElapsed(epoch_stop-epoch_start)); } //end of the training //--- #ifdef DEBUG_MODE Print("\nNew weights\n",w_matrix); #endif //--- Print("\nclusters"); cluster_tensor.TensorPrint(); }
Saídas:
CS 0 04:13:26.624 Self Organizing map (EURUSD,H1) clusters CS 0 04:13:26.624 Self Organizing map (EURUSD,H1) TENSOR INDEX <<0>> CS 0 04:13:26.624 Self Organizing map (EURUSD,H1) [[1.2,2.3] CS 0 04:13:26.624 Self Organizing map (EURUSD,H1) [0.7,1.8]] CS 0 04:13:26.624 Self Organizing map (EURUSD,H1) TENSOR INDEX <<1>> CS 0 04:13:26.624 Self Organizing map (EURUSD,H1) [[3.6,4.8] CS 0 04:13:26.624 Self Organizing map (EURUSD,H1) [2.8,3.9] CS 0 04:13:26.624 Self Organizing map (EURUSD,H1) [5.2,6.7] CS 0 04:13:26.624 Self Organizing map (EURUSD,H1) [4.8,5.6]]
Ótimo, agora os clusters estão armazenados em seus respectivos tensores, é hora de fazer algo útil com isso.
Extraindo os Clusters
Vamos extrair os clusters salvando-os em arquivos CSV.
matrix mat= {}; if (save_clusters) for (uint i=0; i<this.cluster_tensor.TENSOR_DIMENSION; i++) { mat = this.cluster_tensor.Tensor(i); //Obtain a matrix located at I index in a cluster tensor string header[]; ArrayResize(header, (int)mat.Cols()); for (int k=0; k<ArraySize(header); k++) header[k] = "col"+string(k); if (this.matrix_utils.WriteCsv("SOM\\Cluster"+string(i+1)+".csv",mat,header)) Print("Clusters CSV files saved under the directory Files\\SOM"); }
Os arquivos serão armazenados no diretório SOM dentro do diretório pai Files.
Terminamos de extrair os dados, mas a parte essencial dos mapas de Kohonen é visualizar os clusters e traçar os mapas que o algoritmo preparou para nós. Bibliotecas Python e outros frameworks geralmente usam mapas de calor, vamos usar o gráfico de curvas para esta biblioteca.
vector v; matrix plotmatrix(rows, m); for (uint i=0; i<this.cluster_tensor.TENSOR_DIMENSION; i++) { mat = this.cluster_tensor.Tensor(i); v = this.matrix_utils.MatrixToVector(mat); plotmatrix.Col(v, i); } this.plt.ScatterCurvePlotsMatrix("kom",plotmatrix,"Map","clusters","clusters");
Saídas:
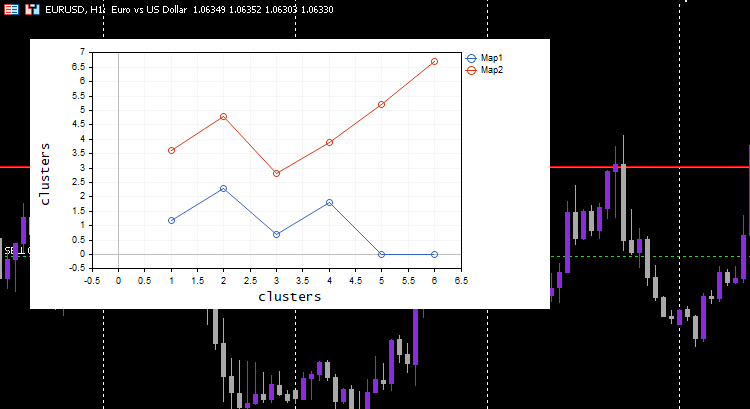
Legal, tudo funciona e o gráfico conseguiu visualizar bem os dados conforme pretendido, vamos tentar o algoritmo em algo útil.
Agrupamento de valores do indicador.
Vamos coletar 100 barras para 5 indicadores diferentes de médias móveis e tentar agrupá-los usando mapas de Kohonen. Esses indicadores serão do mesmo gráfico, período e preço aplicado, exceto pelos períodos que serão diferentes para cada indicador.
#include <MALE5\Neural Networks\kohonen maps.mqh> #include <MALE5\matrix_utils.mqh> CMatrixutils matrix_utils; CKohonenMaps *maps; input int bars = 100; int handles[5]; int period[5] = {10,20,30,50,100}; matrix Matrix(bars,5); //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- vector v; for (int i=0; i<5; i++) { handles[i] = iMA(Symbol(),PERIOD_CURRENT,period[i],0,MODE_LWMA,PRICE_CLOSE); matrix_utils.CopyBufferVector(handles[i],0,0,bars, v); Matrix.Col(v, i); //store indicators into a matrix } maps = new CKohonenMaps(Matrix,true,2,0.01,1000); //--- return(INIT_SUCCEEDED); }
Escolhi a taxa de aprendizado/alfa = 0,01 e as épocas = 1000, abaixo estão os mapas de Kohonen.
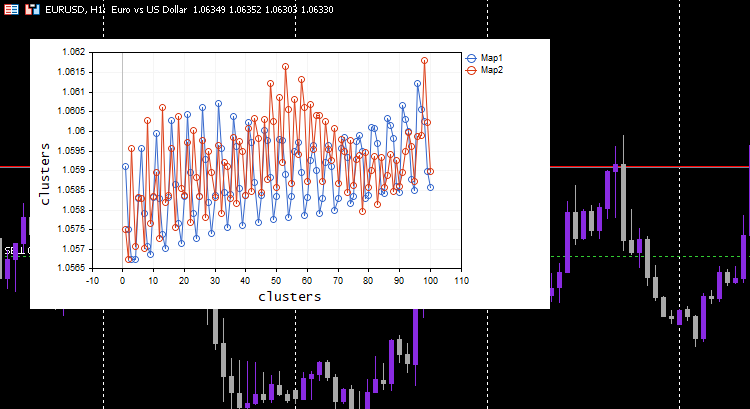
Parece estranho, tive que inspecionar os registros para esse comportamento estranho e encontrei.
CS 0 06:19:59.911 Self Organizing map (EURUSD,H1) clusters CS 0 06:19:59.911 Self Organizing map (EURUSD,H1) TENSOR INDEX <<0>> CS 0 06:19:59.911 Self Organizing map (EURUSD,H1) [[1.059108363197969,1.057514381244092,1.056754472954214,1.056739184229631,1.058300613902105] CS 0 06:19:59.911 Self Organizing map (EURUSD,H1) [1.059578181379783,1.057915286006,1.057066064352063,1.056875795994335,1.05831249905062] .... .... CS 0 06:19:59.912 Self Organizing map (EURUSD,H1) [1.063954363197777,1.061619428863266,1.061092386932678,1.060653270504107,1.059293304991227] CS 0 06:19:59.912 Self Organizing map (EURUSD,H1) [1.065106545015954,1.062409714577555,1.061610946072463,1.06098919991587,1.059488318852614…] CS 0 06:19:59.912 Self Organizing map (EURUSD,H1) TENSOR INDEX <<1>> CS 0 06:19:59.912 Self Organizing map (EURUSD,H1) [] CS 0 06:19:59.912 Self Organizing map (EURUSD,H1) CMatrixutils::MatrixToVector Failed to turn the matrix to a vector rows 0 cols 0
O Tensor para o segundo cluster estava vazio, o que significa que o algoritmo não o previu, todos os dados foram previstos para pertencer ao cluster 0.
Sempre Normalize suas Variáveis
Eu já disse isso algumas vezes e continuarei dizendo, normalizar seus dados de entrada é essencial para todos os modelos de aprendizado de máquina que você encontra. Mais uma vez, a importância da normalização prova ser significativa. Vamos ver o resultado depois que os dados foram normalizados.
Eu escolhi a técnica de normalização do escalonamento Min-Max
#include <MALE5\Neural Networks\kohonen maps.mqh> #include <MALE5\preprocessing.mqh> #include <MALE5\matrix_utils.mqh> CPreprocessing *pre_processing; CMatrixutils matrix_utils; CKohonenMaps *maps; input int bars = 100; int handles[5]; int period[5] = {10,20,30,50,100}; matrix Matrix(bars,5); //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- vector v; for (int i=0; i<5; i++) { handles[i] = iMA(Symbol(),PERIOD_CURRENT,period[i],0,MODE_LWMA,PRICE_CLOSE); matrix_utils.CopyBufferVector(handles[i],0,0,bars, v); Matrix.Col(v, i); } pre_processing = new CPreprocessing(Matrix, NORM_MIN_MAX_SCALER); maps = new CKohonenMaps(Matrix,true,2,0.01,1000); //--- return(INIT_SUCCEEDED); }
Desta vez, belos mapas de Kohonen foram mostrados no gráfico.
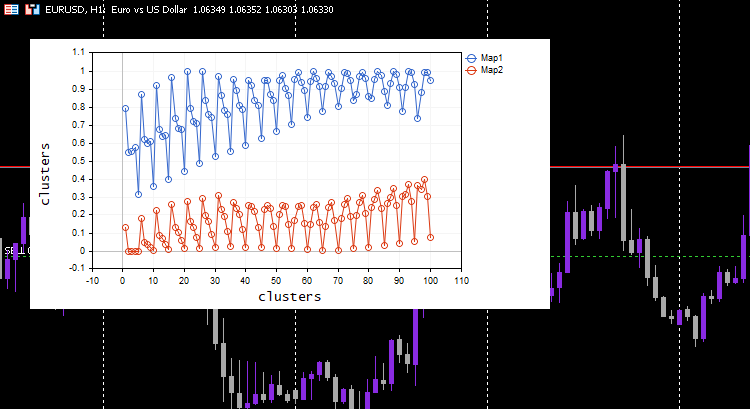
Ótimo, mas normalizar os dados transforma os dados em valores menores, mas, como alguém que apenas quer agrupar seus dados para entender os padrões e usar os dados extraídos em outros programas, esse processo de normalização precisa ser integrado ao cerne do algoritmo. Os dados precisam ser normalizados e re-normalizados para que os clusters obtidos estejam nos valores originais, já que as técnicas de agrupamento não mudam os dados, apenas os agrupam. O processo de normalização e re-normalização pode ser feito com sucesso usando esta classe de pré-processamento.
CKohonenMaps::CKohonenMaps(matrix &matrix_, bool save_clusters=true, uint clusters=2, double alpha=0.01, uint epochs=100, norm_technique NORM_TECHNIQUE=NORM_MIN_MAX_SCALER) { Matrix = matrix_; n = (uint)matrix_.Cols(); rows = matrix_.Rows(); m = clusters; pre_processing = new CPreprocessing(Matrix, NORM_TECHNIQUE); cluster_tensor = new CTensors(m); w_matrix =matrix_utils.Random(0.0, 1.0, n, m, RANDOM_STATE); #ifdef DEBUG_MODE Print("w Matrix\n",w_matrix,"\nMatrix\n",Matrix); #endif vector D(m); //Euclidean distance btn clusters for (uint epoch=0; epoch<epochs; epoch++) { double epoch_start = GetMicrosecondCount()/(double)1e6, epoch_stop=0; for (ulong i=0; i<rows; i++) { for (ulong j=0; j<m; j++) { D[j] = Euclidean_distance(Matrix.Row(i),w_matrix.Col(j)); } #ifdef DEBUG_MODE Print("Euc distance ",D," Winning cluster ",D.ArgMin()); #endif //--- weights update ulong min = D.ArgMin(); if (epoch == epochs-1) //last iteration cluster_tensor.TensorAppend(Matrix.Row(i), min); vector w_new = w_matrix.Col(min) + (alpha * (Matrix.Row(i) - w_matrix.Col(min))); w_matrix.Col(w_new, min); } epoch_stop =GetMicrosecondCount()/(double)1e6; printf("Epoch [%d/%d] | %sElapsed ",epoch+1,epochs, CalcTimeElapsed(epoch_stop-epoch_start)); } //end of the training //--- #ifdef DEBUG_MODE Print("\nNew weights\n",w_matrix); #endif //--- matrix mat= {}; vector v; matrix plotmatrix(rows, m); for (uint i=0; i<this.cluster_tensor.TENSOR_DIMENSION; i++) { mat = this.cluster_tensor.Tensor(i); v = this.matrix_utils.MatrixToVector(mat); plotmatrix.Col(v, i); } this.plt.ScatterCurvePlotsMatrix("kom",plotmatrix,"Map","clusters","clusters"); //--- if (save_clusters) for (uint i=0; i<this.cluster_tensor.TENSOR_DIMENSION; i++) { mat = this.cluster_tensor.Tensor(i); pre_processing.ReverseNormalization(mat); cluster_tensor.TensorAdd(mat, i); string header[]; ArrayResize(header, (int)mat.Cols()); for (int k=0; k<ArraySize(header); k++) header[k] = "col"+string(k); if (this.matrix_utils.WriteCsv("SOM\\Cluster"+string(i+1)+".csv",mat,header)) Print("Clusters CSV files saved under the directory Files\\SOM"); } //--- Print("\nclusters"); cluster_tensor.TensorPrint(); }
Para mostrar como isso funciona, tive que voltar ao conjunto de dados simples que tínhamos no início.
matrix Matrix = { {1.2, 2.3}, {0.7, 1.8}, {3.6, 4.8}, {2.8, 3.9}, {5.2, 6.7}, {4.8, 5.6} }; maps = new CKohonenMaps(Matrix,true,2,0.01,1000);
Saídas:
CS 0 07:14:44.660 Self Organizing map (EURUSD,H1) w Matrix CS 0 07:14:44.660 Self Organizing map (EURUSD,H1) [[0.005340739158299509,0.01220740379039888] CS 0 07:14:44.660 Self Organizing map (EURUSD,H1) [0.5453352458265939,0.9172643208105716]] CS 0 07:14:44.660 Self Organizing map (EURUSD,H1) Matrix CS 0 07:14:44.660 Self Organizing map (EURUSD,H1) [[0.1111111111111111,0.1020408163265306] CS 0 07:14:44.660 Self Organizing map (EURUSD,H1) [0,0] CS 0 07:14:44.660 Self Organizing map (EURUSD,H1) [0.6444444444444445,0.6122448979591836] CS 0 07:14:44.660 Self Organizing map (EURUSD,H1) [0.4666666666666666,0.4285714285714285] CS 0 07:14:44.660 Self Organizing map (EURUSD,H1) [1,1] CS 0 07:14:44.660 Self Organizing map (EURUSD,H1) [0.911111111111111,0.7755102040816325]] CS 0 07:14:44.660 Self Organizing map (EURUSD,H1) Epoch [1/1000] | 0.000 Seconds Elapsed CS 0 07:14:44.660 Self Organizing map (EURUSD,H1) Epoch [2/1000] | 0.000 Seconds Elapsed CS 0 07:14:44.660 Self Organizing map (EURUSD,H1) Epoch [3/1000] | 0.000 Seconds Elapsed ... ... ... CS 0 07:14:44.674 Self Organizing map (EURUSD,H1) Epoch [999/1000] | 0.000 Seconds Elapsed CS 0 07:14:44.674 Self Organizing map (EURUSD,H1) Epoch [1000/1000] | 0.000 Seconds Elapsed CS 0 07:14:44.674 Self Organizing map (EURUSD,H1) CS 0 07:14:44.674 Self Organizing map (EURUSD,H1) New weights CS 0 07:14:44.674 Self Organizing map (EURUSD,H1) [[0.1937869656464888,0.8527427060068337] CS 0 07:14:44.674 Self Organizing map (EURUSD,H1) [0.1779676215121214,0.7964618795904062]] CS 0 07:14:44.725 Self Organizing map (EURUSD,H1) Clusters CSV files saved under the directory Files\SOM CS 0 07:14:44.726 Self Organizing map (EURUSD,H1) Clusters CSV files saved under the directory Files\SOM CS 0 07:14:44.726 Self Organizing map (EURUSD,H1) CS 0 07:14:44.726 Self Organizing map (EURUSD,H1) clusters CS 0 07:14:44.726 Self Organizing map (EURUSD,H1) TENSOR INDEX <<0>> CS 0 07:14:44.726 Self Organizing map (EURUSD,H1) [[1.2,2.3] CS 0 07:14:44.726 Self Organizing map (EURUSD,H1) [0.7,1.8] CS 0 07:14:44.726 Self Organizing map (EURUSD,H1) [2.8,3.899999999999999]] CS 0 07:14:44.727 Self Organizing map (EURUSD,H1) TENSOR INDEX <<1>> CS 0 07:14:44.727 Self Organizing map (EURUSD,H1) [[3.600000000000001,4.8] CS 0 07:14:44.727 Self Organizing map (EURUSD,H1) [5.2,6.7] CS 0 07:14:44.727 Self Organizing map (EURUSD,H1) [4.8,5.6]]
Este processo funciona como mágica, apesar de um modelo de aprendizado de máquina usar os dados normalizados, o modelo será capaz de agrupar os dados e ainda poder dar os dados não normalizados/originais como se nada tivesse acontecido. Note que os clusters plotados eram dados normalizados, isso é importante porque é difícil plotar dados com escalas diferentes neles. Desta vez, a plotagem para os clusters no conjunto de dados de teste simples foi muito melhor:
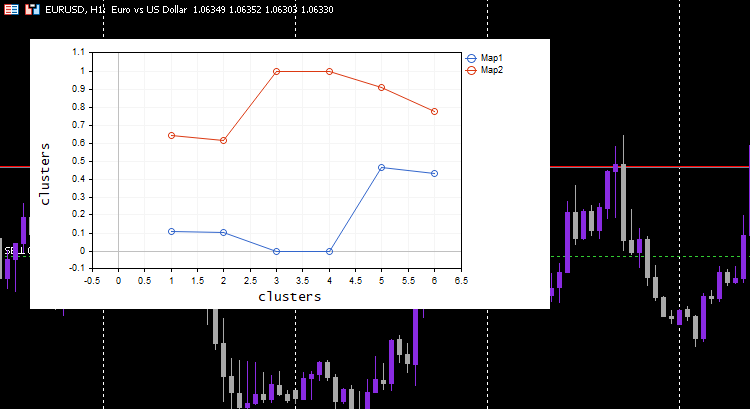
Expandindo os Mapas de Kohonen
Embora os mapas de Kohonen e outras técnicas de mineração de dados não tenham sido criados principalmente para tentar fazer previsões, uma vez que eles possuem os parâmetros aprendidos que são os pesos, podemos estendê-los para nos permitir obter os clusters quando fornecemos novos dados a eles.
uint CKohonenMaps::KOMPredCluster(vector &v) { vector temp_v = v; pre_processing.Normalization(v); if (n != v.Size()) { Print("Can't predict the cluster | the input vector size is not the same as the trained matrix cols"); return(-1); } vector D(m); //Euclidean distance btn clusters for (ulong j=0; j<m; j++) D[j] = Euclidean_distance(v, w_matrix.Col(j)); v.Copy(temp_v); return((uint)D.ArgMin()); } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ vector CKohonenMaps::KOMPredCluster(matrix &matrix_) { vector v(n); if (n != matrix_.Cols()) { Print("Can't predict the cluster | the input matrix Cols is not the same size as the trained matrix cols"); return (v); } for (ulong i=0; i<matrix_.Rows(); i++) v[i] = KOMPredCluster(matrix_.Row(i)); return(v); }
Vamos dar a eles os novos dados que eles não viram. Você e eu sabemos a que cluster pertencem [0.5, 1.5] e [5.5, 6]. Estes dados pertencem aos clusters 0 e 1, respectivamente.
maps = new CKohonenMaps(Matrix,true,2,0.01,1000); //Training matrix new_data = { {0.5,1.5}, {5.5, 6.0} }; Print("new data\n",new_data,"\nprediction clusters\n",maps.KOMPredCluster(new_data)); //using it for predictions
Saídas:
CS 0 07:46:00.857 Self Organizing map (EURUSD,H1) new data CS 0 07:46:00.857 Self Organizing map (EURUSD,H1) [[0.5,1.5] CS 0 07:46:00.857 Self Organizing map (EURUSD,H1) [5.5,6]] CS 0 07:46:00.857 Self Organizing map (EURUSD,H1) prediction clusters CS 0 07:46:00.857 Self Organizing map (EURUSD,H1) [0,1]
Legal, os mapas de Kohonen os predisseram corretamente.
Mapas de Kohonen no Testador de Estratégia

O algoritmo funciona perfeitamente e eu consegui notar que ele prediz o cluster 0 quando o mercado está em alta e vice-versa. Não tenho certeza se a implicação é correta, pois ainda não analisei bem o comportamento. Eu deixo isso para você. Se for o caso, podemos até usar os mapas de Kohonen como um indicador, porque é isso que a maioria dos indicadores faz.
Vantagens dos Mapas de Kohonen
Os mapas de Kohonen têm várias vantagens, incluindo:
- A capacidade de capturar relações não lineares entre os dados de entrada e o mapa de saída significa que eles podem lidar com padrões e estruturas complexas nos dados que podem não ser facilmente capturados por métodos lineares.
- Eles podem encontrar padrões e estruturas nos dados sem a necessidade de rotulá-los. Isso pode ser útil em situações onde dados rotulados são escassos ou caros para serem obtidos.
- Ajudam a reduzir a dimensionalidade dos dados de entrada, mapeando-os para um espaço de menor dimensão. Isso pode ajudar a reduzir a complexidade computacional de uma tarefa subsequente, como regressão e classificação.
- Preservam relações topológicas entre os dados de entrada e o mapa de saída. Isso significa que os neurônios vizinhos no mapa correspondem a regiões semelhantes no espaço de entrada, o que pode auxiliar na exploração e visualização dos dados.
- Podem ser robustos a ruídos e outliers nos dados de entrada, desde que o ruído não seja muito grande.
Desvantagens dos Mapas de Kohonen
- A qualidade dos Mapas Auto-Organizáveis finais pode ser sensível à inicialização do vetor de peso. Se a inicialização for ruim, o SOM pode convergir para uma solução subótima ou ficar preso em um mínimo local.
- Sensíveis à afinação de parâmetros: O desempenho do SOM pode ser sensível à escolha de hiperparâmetros, como a taxa de aprendizado, a função de vizinhança e o número de neurônios. Ajustar esses parâmetros pode ser demorado e requerer conhecimento de domínio.
- Computacionalmente caro e intensivo em memória para grandes conjuntos de dados. O tamanho do SOM escala com o número de pontos de dados de entrada, portanto, grandes conjuntos de dados podem exigir um grande número de neurônios e um longo tempo de treinamento.
- Falta de critérios formais de convergência: Ao contrário de alguns algoritmos de aprendizado de máquina, como as redes neurais, não existem critérios formais de convergência para os SOMs. Isso pode dificultar a determinação de quando o treinamento convergiu e quando parar o treinamento.
Considerações finais
Como vimos, os mapas de Kohonen foram capazes de identificar relações não lineares nos dados e agrupar os dados em seus respectivos grupos. No entanto, os traders devem estar cientes das possíveis desvantagens dos mapas de Kohonen, como a sensibilidade à inicialização, a falta de convergência formal e outras desvantagens discutidas acima. Em geral, os mapas de Kohonen têm o potencial de ser uma valiosa adição à caixa de ferramentas de um trader, mas, como qualquer ferramenta, eles devem ser usados com cuidado e atenção às suas forças e fraquezas. De modo geral, os mapas de Kohonen podem ser uma ajuda valiosa no conjunto de ferramentas de um trader, mas, como qualquer ferramenta, devem ser usados com cuidado e atenção.
Cuide-se.
Acompanhe o desenvolvimento e as mudanças deste algoritmo no meu repositório do GitHub https://github.com/MegaJoctan/MALE5.
| Arquivo | Conteúdo e uso |
|---|---|
| Self Organizing map.mq5 | Arquivo Expert Advisor para testar o algoritmo discutido neste artigo |
| kohonen maps.mqh | Biblioteca contendo o algoritmo do mapa Kohonen |
| plots.mqh | Biblioteca contendo funções para desenhar gráficos em um gráfico no MT5 |
| preprocessing.mqh | Funções para normalizar e pré-processar dados de entrada |
| matrix_utils.mqh | Contém funções adicionais para operações de matriz em MQL5 |
| Tensors.mqh | Biblioteca contendo classes para criar tensores |
Artigos relacionados:
-
Matrix Utils, estendendo as matrizes e a funcionalidade da biblioteca padrão de vetores
-
Ciência de Dados e Aprendizado de Máquina (Parte 06): Gradiente descendente
Traduzido do Inglês pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/en/articles/12261
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso