
Data Science e Machine Learning (Parte 23): Por que o LightGBM e o XGBoost superam muitos modelos de IA?

O que são Árvores com Boosting de Gradiente?
Árvores de Decisão com Boosting de Gradiente (GBDT) são uma técnica poderosa de machine learning usada principalmente para tarefas de regressão e classificação. Elas combinam as previsões de vários aprendizes fracos, geralmente árvores de decisão, para criar um modelo preditivo forte.
A ideia central é construir modelos sequencialmente, cada novo modelo tentando corrigir os erros cometidos pelos anteriores.
Essas árvores com boosting, como:
- Extreme Gradient Boosting (XGBoost): que é uma implementação popular e eficiente do boosting de gradiente,
- Light Gradient Boosting Machine (LightGBM): que foi projetada para alto desempenho e eficiência, especialmente com grandes conjuntos de dados.
- CatBoost: que lida automaticamente com recursos categóricos e é robusto contra overfitting.
Ganharam muita popularidade na comunidade de machine learning como os algoritmos preferidos de muitas equipes vencedoras em competições de machine learning. Neste artigo, vamos descobrir como podemos usar esses modelos precisos em nossas aplicações de trading.
Conceitos-Chave
Boosting
- Boosting é uma técnica de aprendizado em conjunto que combina vários aprendizes fracos (modelos que performam um pouco melhor do que uma adivinhação aleatória) para formar um aprendiz forte.
- Cada novo modelo foca nos erros dos modelos anteriores, melhorando gradualmente o desempenho geral.
Descida de Gradiente
- O boosting de gradiente usa a descida de gradiente para minimizar uma função de perda, que é a diferença entre os valores previstos e os reais.
- Ao adicionar iterativamente novos modelos que apontam na direção do gradiente da função de perda, o modelo em conjunto é refinado.
Com apenas algumas linhas de código, essas árvores com boosting podem não apenas fornecer uma precisão razoável, mas também levar seu projeto de ciência de dados para o próximo nível.
import lightgbm as lgb train_data = lgb.Dataset(X_train, label=y_train) # preparing data the lightgbm way val_data = lgb.Dataset(X_test, label=y_test, reference=train_data) params = { 'boosting_type': 'gbdt', # Gradient Boosting Decision Tree 'objective': 'binary', # For binary classification (use 'regression' for regression tasks) 'metric': ['auc','binary_logloss'], # Evaluation metric 'num_leaves': 10, # Number of leaves in one tree 'n_estimators' : 100, # number of trees 'max_depth': 5, 'learning_rate': 0.05, # Learning rate 'feature_fraction': 0.9 # Fraction of features to be used for each boosting round } # Train the model with evaluation results stored num_round = 100 bst = lgb.train(params, train_data, num_round, valid_sets=[train_data, val_data]) y_pred = bst.predict(X_test, num_iteration=bst.best_iteration) # For binary classification, you might want to threshold the predictions y_pred_binary = np.round(y_pred) print("Classification Report\n", classification_report(y_test, y_pred_binary))
Resultados:
Classification Report precision recall f1-score support 0.0 0.70 0.75 0.73 104 1.0 0.71 0.66 0.68 96 accuracy 0.70 200 macro avg 0.71 0.70 0.70 200 weighted avg 0.71 0.70 0.70 200
Eu apliquei os mesmos dados em outros classificadores populares.
| Classificador | Relatório de Classificação |
|---|---|
| Regressão Logística | precision recall f1-score support 0.0 0.69 0.76 0.72 104 1.0 0.71 0.62 0.66 96 accuracy 0.69 200 macro avg 0.70 0.69 0.69 200 weighted avg 0.70 0.69 0.69 200 |
| Árvore de Decisão | precision recall f1-score support 0.0 0.62 0.61 0.61 104 1.0 0.59 0.60 0.59 96 accuracy 0.60 200 macro avg 0.60 0.60 0.60 200 weighted avg 0.61 0.60 0.61 200 |
| Naive Bayes | precision recall f1-score support 0.0 0.64 0.84 0.73 104 1.0 0.73 0.49 0.59 96 accuracy 0.67 200 macro avg 0.69 0.67 0.66 200 weighted avg 0.68 0.67 0.66 200 |
| K-Nearest Neighbors | precision recall f1-score support 0.0 0.68 0.73 0.71 104 1.0 0.69 0.64 0.66 96 accuracy 0.69 200 macro avg 0.69 0.68 0.68 200 weighted avg 0.69 0.69 0.68 200 |
| Máquina de Vetores de Suporte | precision recall f1-score support 0.0 0.69 0.69 0.69 104 1.0 0.66 0.66 0.66 96 accuracy 0.68 200 macro avg 0.67 0.67 0.67 200 weighted avg 0.67 0.68 0.67 200 |
O modelo LightGBM foi o que apresentou maior precisão em comparação aos outros classificadores para o mesmo problema. Você pode ter notado que nem me preocupei em normalizar os dados de entrada, mas o modelo ainda conseguiu superar os outros. Como sabemos, a normalização é crucial para o desempenho dos modelos de machine learning, mas o LightGBM parece desafiar essa ideia. Essa é uma das coisas que tornam esses modelos interessantes.
Vamos analisar a diferença entre GBDT (LightGBM e XGBoost) e outros classificadores de machine learning.
Árvores de Decisão com Boosting de Gradiente (LightGBM & XGBoost) vs. Outros Classificadores
| LightGBM & XGBoost | Outros Classificadores |
|---|---|
| Eles não requerem escalonamento de características, pois são baseados em árvores de decisão, que são insensíveis à escala das características de entrada. | Algoritmos como K-Nearest Neighbors (K-NN) e Máquina de Vetores de Suporte (SVM), que dependem da distância entre os pontos de dados, não podem ter um bom desempenho em um conjunto de dados com características em escalas diferentes. O escalonamento é muito importante para a maioria dos classificadores. |
Tanto XGBoost quanto LightGBM têm mecanismos embutidos que podem lidar com valores ausentes. Eles podem aprender a lidar com dados ausentes, atribuindo esses valores a qualquer um dos lados de uma divisão durante o treinamento ou criando um ramo específico para esse valor ausente em uma árvore e entendendo seu padrão separadamente. | Na maioria das vezes, não conseguem lidar com valores ausentes. Esses valores ausentes podem diminuir a precisão. |
Ajuste de parâmetros é importante, mas não é obrigatório; esses modelos apresentam um desempenho razoável com os parâmetros padrão. O ajuste de hiperparâmetros ainda é crucial para alcançar o desempenho ideal. | Modelos classificadores como redes neurais são muito sensíveis aos hiperparâmetros. Os parâmetros padrão não ajudarão. |
Agora que vimos como LightGBM e XGBoost se comparam a outros classificadores de machine learning, vamos dissecar um modelo de cada vez, começando com o XGBoost.
O que é o Extreme Gradient Boosting (XGBoost)?
XGBoost é uma biblioteca de boosting de gradiente distribuído otimizada, projetada para o treinamento eficiente e escalável de modelos de machine learning. Dentro dela, há um método de aprendizado em conjunto que combina as previsões de vários modelos fracos para produzir uma previsão mais forte.
Como o XGBoost Funciona?
Para entender como o XGBoost funciona, vamos compreender sua teoria.
Inicialização
Ele começa com uma previsão inicial, geralmente a média dos valores-alvo para regressão ou o logaritmo das probabilidades para classificação.
Boosting Iterativo
- Cálculo dos Resíduos: A cada iteração
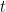 , calcula-se os resíduos (erros) das previsões feitas pelo conjunto atual de modelos.
, calcula-se os resíduos (erros) das previsões feitas pelo conjunto atual de modelos.
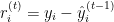
Onde:
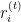 é o resíduo para a
é o resíduo para a 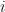 -ésima observação na iteração
-ésima observação na iteração 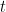 .
. é o valor-alvo real.
é o valor-alvo real.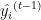 é o valor previsto na iteração
é o valor previsto na iteração 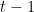 .
.
- Ajustando uma Nova Árvore: Ajusta-se uma nova árvore de decisão aos resíduos. A árvore é construída para prever os resíduos do modelo atual.
As folhas da árvore representam os ajustes previstos para as previsões do modelo atual.
- Atualizando o Modelo: Adiciona-se as previsões da nova árvore às previsões do modelo atual, geralmente escalonadas por uma taxa de aprendizado
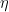 .
.
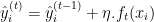
Onde: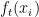 é a previsão da nova árvore na iteração
é a previsão da nova árvore na iteração 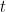 para a entrada
para a entrada 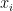 .
.
Funções Objetivo
A função objetivo no XGBoost consiste em duas partes:
- A função de perda, que mede o quão bem o modelo se ajusta aos dados de treinamento. Funções de perda comuns incluem erro quadrático médio para regressão e perda logarítmica para classificação.
- O termo de regularização, que é responsável por penalizar a complexidade do modelo para evitar overfitting. O XGBoost usa tanto regularização L1 (Lasso) quanto L2 (Ridge).
A função objetivo a ser minimizada é:
![]()
Onde:
![]() é o termo de perda.
é o termo de perda.
![]() É o termo de regularização para a
É o termo de regularização para a ![]() -ésima árvore.
-ésima árvore.
![]() é o número de observações.
é o número de observações.
![]() é o número de árvores.
é o número de árvores.
Gradiente e Hessiano
O XGBoost usa a expansão de Taylor de segunda ordem (gradiente e hessiano) para aproximar a função de perda para o cálculo eficiente das divisões ótimas. O gradiente é a primeira derivada da função de perda em relação à previsão, enquanto o hessiano é a segunda derivada da função de perda em relação à previsão.
Poda de Árvores
As árvores são crescidas iterativamente e podadas para otimizar a função objetivo. A poda ajuda a evitar overfitting removendo nós que não fornecem uma melhoria significativa na função objetivo.
A taxa de aprendizado η escala a contribuição de cada árvore para controlar o tamanho do passo no processo de boosting. Taxas de aprendizado menores geralmente exigem mais árvores.
Implementando o XGBoost em Python
São necessárias apenas algumas linhas de código para implementar o modelo XGBoost em Python. Como é uma biblioteca separada, você precisa instalá-la primeiro, se ainda não o fez.
pip install xgboost
Precisamos importar a função Pipeline do Scikit-learn. Isso nos ajudará a criar um objeto de machine learning com pré-processamento e outros passos necessários.
from sklearn.pipeline import Pipeline
Como mencionado anteriormente, as árvores com boosting podem ter um bom desempenho mesmo sem normalizar os dados, no entanto, adicioná-la não causará mal algum, além de nos oferecer várias vantagens, como ajudar a mitigar problemas de instabilidade numérica causados por números grandes que podem ser resultado de multiplicações de matrizes em nossos modelos. Vamos adicionar a normalização como uma boa prática enquanto criamos um pipeline para o modelo e ajustamos aos dados de treinamento.
Python:
# Create a pipeline with a scaler and the XGBoost classifier pipe = Pipeline([ ("scaler", StandardScaler()), ("xgb", xgb.XGBClassifier(**params)) ]) # Fit the pipeline to the training data pipe.fit(X_train, y_train)
O modelo XGBoost vem com alguns parâmetros que são cruciais para entender não apenas como eles funcionam, mas também como ajustá-los para um melhor desempenho.
Python:
params = {
'objective': 'binary:logistic',
'learning_rate': 0.05,
'max_depth': 5,
'n_estimators': 100,
'colsample_bytree': 0.9,
'subsample': 0.9,
'eval_metric': ['auc', 'logloss']
} | Parâmetro | Descrição | Ajuste |
|---|---|---|
| Objetivo | Este parâmetro especifica a tarefa de aprendizado e o objetivo correspondente. O 'binary ' usado acima é utilizado para classificação binária com regressão logística. Ele gera saídas de probabilidade. | Objetivos comuns incluem 'reg
' para regressão, 'binary
' para classificação binária e 'multi
' para classificação multiclasse. Sempre escolha o objetivo com base na natureza do seu problema. |
| learning_rate | Também conhecida como eta ( Uma taxa de aprendizado mais baixa torna o modelo mais robusto ao evitar o overfitting, mas exige mais rodadas de boosting e vice-versa. | Taxas de aprendizado mais baixas (por exemplo, 0.01-0.1) tendem a exigir mais árvores (maior n_estimators), mas podem melhorar a estabilidade e o desempenho do modelo. É uma boa ideia começar com um valor moderado (por exemplo, 0.1) e ajustar com base no desempenho da validação cruzada. |
| max_depth | Este é o valor máximo da profundidade da árvore. Aumentar esse valor torna o modelo mais complexo e mais propenso ao overfitting. Controla a complexidade do modelo. Árvores mais profundas capturam mais padrões entre os recursos, o que aumenta o risco de overfitting. | Valores comuns variam de 3 a 10. Utilize validação cruzada para encontrar a profundidade ideal. |
| n_estimators | Este é o número de rodadas de boosting ou árvores a serem construídas. Mais árvores aumentam o tempo de computação e são propensas a overfitting. | O "early stopping" pode ser utilizado na validação cruzada para encontrar o número adequado de árvores. |
| colsample_bytree | É a razão de amostragem de colunas ao construir cada árvore. Um valor de 0.9 (usado no código acima) significa que 90% dos recursos serão usados para construir cada árvore. Ajuda a reduzir o overfitting, introduzindo aleatoriedade no nível das colunas. Também pode acelerar o treinamento e tornar o modelo mais robusto. | Os valores normalmente variam de 0.3 a 1.0. Valores mais altos usam mais recursos, enquanto valores mais baixos introduzem mais aleatoriedade. |
| subsample | A razão de amostragem das instâncias de treinamento. Um valor de 0.9 significa que 90% dos dados de treinamento serão usados para construir cada árvore. Semelhante ao colsample_bytree, este parâmetro reduz o overfitting adicionando aleatoriedade no nível dos dados e pode melhorar a generalização. | OOs valores normalmente variam de 0.5 a 1.0. Valores mais altos usam mais dados, enquanto valores mais baixos introduzem mais aleatoriedade. |
| eval_metric | As métricas de avaliação a serem utilizadas durante o treinamento. Métricas de avaliação múltiplas podem fornecer uma visão mais abrangente do desempenho do modelo. | Métricas comuns incluem 'rmse' para regressão, 'logloss' para classificação e 'error' para classificação binária. Sempre escolha métricas que se alinhem à natureza do seu problema e objetivos. |
Agora que já treinamos o modelo. Vamos testá-lo e observar seu desempenho.
Python:
y_pred = pipe.predict(X_test)
# For binary classification, you might want to threshold the predictions since these are probabilities
y_pred_binary = np.round(y_pred)
# Confusion Matrix
cm = confusion_matrix(y_test, y_pred_binary)
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.xlabel("Predicted Label")
plt.ylabel("True Label")
plt.title("Confusion Matrix")
plt.savefig("confusion-matrix xgboost") # Display the heatmap
print("Classification Report\n",
classification_report(y_test, y_pred_binary)) 
Classification Report precision recall f1-score support 0.0 0.71 0.73 0.72 104 1.0 0.70 0.68 0.69 96 accuracy 0.70 200 macro avg 0.70 0.70 0.70 200 weighted avg 0.70 0.70 0.70 200
O modelo fez um ótimo trabalho nas previsões fora da amostra. Ele foi 71% e 70% preciso para sinais de baixa (classe 0) e alta (classe 1), respectivamente.
Agora que discutimos o XGBoost, vamos dissecar o LightGBM e ver do que se trata.
O que é o Light Gradient Boosting Machine (LightGBM)?
Este é um framework de machine learning de código aberto, especificamente projetado para eficiência, escalabilidade e precisão. Ele foi desenvolvido pela Microsoft como parte de um kit de ferramentas de aprendizado de máquina distribuído e foi lançado em 24 de abril de 2017.
O LightGBM foi construído com base nas Árvores de Decisão com Boosting de Gradiente existentes, como o XGBoost. Ele oferece várias melhorias importantes descritas abaixo.
Melhorias do Light GBM
Precisão. Embora priorize velocidade e eficiência de memória, o LightGBM não compromete a precisão. As técnicas empregadas são projetadas para alcançar desempenho similar ou até melhor em comparação com os modelos GBDT anteriores.
Como o LightGBM Funciona?
O LightGBM funciona da mesma forma que o XGBoost quando se trata da teoria matemática, com uma leve mudança em como as árvores são construídas. Vamos olhar os conceitos principais por trás do LightGBM.
Boosting. Igual ao XGBoost, no boosting de gradiente, cada novo modelo visa corrigir os erros cometidos pelos modelos anteriores, ajustando-se aos resíduos (erros).
Árvores de Decisão. Enquanto o XGBoost usa crescimento de árvore nível a nível, o que significa que ele cresce a árvore em profundidade e equilibra a árvore de maneira mais uniforme. o LightGBM tem crescimento de árvore folha a folha, o que pode criar árvores mais profundas e mais complexas.

Como esses dois modelos são muito semelhantes em seu funcionamento, vamos ver sua tabela de diferenças para nos ajudar a compreendê-los bem por meio da comparação.
As diferenças entre XGBoost e Light GBM
| Aspecto | XGBoost | LightGBM |
|---|---|---|
| Estratégia de Crescimento da Árvore | Crescimento nível a nível (cresce as árvores em profundidade, árvores mais equilibradas) | Crescimento folha a folha (cresce a folha com a maior redução de perda primeiro, potencialmente árvores mais profundas) |
| Tratamento de Valores Ausentes | Aprende a direção ideal para lidar com valores ausentes durante o treinamento | Pode lidar com valores ausentes diretamente, divide os dados em categorias de não-ausentes e ausentes |
| Regularização | Usa regularização L1 (Lasso) e L2 (Ridge) para penalizar a complexidade do modelo | Usa regularização L2, com foco maior em evitar o overfitting |
| Técnica de Amostragem | Usa boosting de gradiente tradicional com todos os dados | Amostragem de um Lado com Base no Gradiente (GOSS) para focar em pontos de dados importantes com grandes gradientes |
| Tratamento de Recursos | Requer codificação one-hot ou outro pré-processamento para variáveis categóricas | Suporta recursos categóricos nativamente usando Agrupamento Exclusivo de Recursos (EFB) |
| Consciência de Esparsidade | Otimizado para dados esparsos, usa um algoritmo consciente de esparsidade para eficiência de memória e computação | Lida com dados esparsos de forma eficiente, possui técnicas de otimização semelhantes ao XGBoost |
| Algoritmo de Busca de Divisão | Usa algoritmos aproximados e esboços de quantis para busca eficiente de divisão por padrão | Usa algoritmos baseados em histogramas para busca de divisão mais rápida e eficiência de memória |
| Processamento Paralelo | Suporta computação paralela e distribuída para processamento de dados em larga escala. | Também suporta computação paralela e distribuída, otimizada para grandes conjuntos de dados. |
| Velocidade de Treinamento | Geralmente mais lenta em comparação ao LightGBM devido ao crescimento nível a nível. | Geralmente mais rápida devido ao crescimento folha a folha e técnicas eficientes de amostragem. |
| Flexibilidade e Personalização | Altamente flexível, suporta funções de perda personalizadas e métricas de avaliação. | Também altamente flexível, com amplas opções de personalização para o processo de boosting. |
Implementando o Light GBM em Python
Como visto anteriormente, são necessárias apenas algumas linhas de código para implementar um modelo Light GBM. Vamos implementá-lo desta vez dentro de um pipeline, da mesma forma que fizemos com o XGBoost.
Precisamos instalá-lo primeiro.
pip install lightgbm
O Light GBM também possui alguns parâmetros que são importantes de entender.
| Parâmetro | Descrição | Ajuste |
|---|---|---|
| boosting_type | Tipo de algoritmo de boosting a ser usado. O padrão é 'gbdt' (Árvore de Decisão com Boosting de Gradiente). | Os valores típicos são 'gbdt', 'dart', 'goss'. 'gbdt' é o mais comum. Escolha com base no seu conjunto de dados e experimentação. |
| Objetivo | Especifica a tarefa de aprendizado e o objetivo correspondente. 'binary' é usado para classificação binária. | Objetivos comuns incluem 'regression' para tarefas de regressão e 'binary' para classificação binária. Sempre escolha com base na natureza do seu problema. |
| metric | Métrica(s) de avaliação a ser(em) usada(s) durante o treinamento. 'auc' e 'binary_logloss' são comuns para classificação binária. | Os valores típicos variam de 20 a 50. Aumentar o num_leaves pode capturar padrões mais complexos, mas pode levar ao overfitting. Use validação cruzada para encontrar o valor ideal. |
| num_leaves | Número máximo de folhas em uma árvore. Um valor mais alto aumenta a complexidade do modelo e vice-versa. | Os valores típicos variam de 20 a 50. Aumentar esse valor pode capturar padrões mais complexos, mas pode levar ao overfitting. |
| n_estimators | Número de rodadas de boosting (árvores). Mais árvores geralmente aumentam o tempo de computação e o risco de overfitting. | Use early stopping na validação cruzada para determinar o número apropriado de árvores. Comece com um valor moderado (por exemplo, 100) e ajuste com base no desempenho. |
| max_depth | Profundidade máxima de uma árvore. Aumentar esse valor torna o modelo mais complexo e propenso ao overfitting. | Valores comuns variam de 3 a 10. Árvores mais profundas capturam mais padrões, mas aumentam o risco de overfitting. Use validação cruzada para encontrar a profundidade ideal. |
| learning_rate | Tamanho do passo em cada iteração ao se mover em direção ao mínimo da função de perda. Valores mais baixos tornam o modelo mais robusto, mas exigem mais rodadas de boosting. | Taxas de aprendizado mais baixas (por exemplo, 0.01-0.1) exigem mais árvores (n_estimators mais alto), mas podem melhorar a estabilidade e o desempenho do modelo. Comece com um valor moderado (por exemplo, 0.1) e ajuste com base no desempenho da validação cruzada. |
| feature_fraction | Fração de recursos a ser usada em cada rodada de boosting. Um valor de 0.9 significa que 90% dos recursos serão usados para construir cada árvore. | Os valores normalmente variam de 0.3 a 1.0. Valores mais altos usam mais recursos, enquanto valores mais baixos introduzem mais aleatoriedade. Ajuda a reduzir o overfitting ao introduzir aleatoriedade no nível de recursos. |
Para mais informações sobre esses hiperparâmetros, consulte a documentação vinculada ao final do artigo. Agora, vamos treinar o modelo Light GBM.
Python:
params = { 'boosting_type': 'gbdt', # Gradient Boosting Decision Tree 'objective': 'binary', # For binary classification (use 'regression' for regression tasks) 'metric': ['auc','binary_logloss'], # Evaluation metric 'num_leaves': 25, # Number of leaves in one tree 'n_estimators' : 100, # number of trees 'max_depth': 5, 'learning_rate': 0.05, # Learning rate 'feature_fraction': 0.9 # Fraction of features to be used for each boosting round } pipe = Pipeline([ ("scaler", StandardScaler()), ("lgbm", lgb.LGBMClassifier(**params)) ]) # Fit the pipeline to the training data pipe.fit(X_train, y_train)
Saídas do console:
[LightGBM] [Warning] feature_fraction is set=0.9, colsample_bytree=1.0 will be ignored. Current value: feature_fraction=0.9 [LightGBM] [Warning] feature_fraction is set=0.9, colsample_bytree=1.0 will be ignored. Current value: feature_fraction=0.9 [LightGBM] [Info] Number of positive: 398, number of negative: 402 [LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000177 seconds. You can set `force_col_wise=true` to remove the overhead. [LightGBM] [Info] Total Bins 1594 [LightGBM] [Info] Number of data points in the train set: 800, number of used features: 8 [LightGBM] [Info] [binary:BoostFromScore]: pavg=0.497500 -> initscore=-0.010000 [LightGBM] [Info] Start training from score -0.010000 [LightGBM] [Warning] No further splits with positive gain, best gain: -inf [LightGBM] [Warning] No further splits with positive gain, best gain: -inf [LightGBM] [Warning] No further splits with positive gain, best gain: -inf [LightGBM] [Warning] No further splits with positive gain, best gain: -inf [LightGBM] [Warning] No further splits with positive gain, best gain: -inf
Não podemos entender seu desempenho por enquanto, vamos fornecer novos dados ao modelo treinado e observar o desempenho.
y_pred = pipe.predict(X_test) # Changes from bst to pipe
# For binary classification, you might want to threshold the predictions
y_pred_binary = np.round(y_pred)
# Confusion Matrix
cm = confusion_matrix(y_test, y_pred_binary)
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.xlabel("Predicted Label")
plt.ylabel("True Label")
plt.title("Confusion Matrix")
plt.savefig("confusion-matrix lightgbm") # Display the heatmap
print("Classification Report\n",
classification_report(y_test, y_pred_binary)) 
Classification Report precision recall f1-score support 0.0 0.69 0.72 0.70 104 1.0 0.68 0.65 0.66 96 accuracy 0.69 200 macro avg 0.68 0.68 0.68 200 weighted avg 0.68 0.69 0.68 200
Ótimo, o modelo tem 69% de precisão na amostra de teste. Agora que temos esses dois modelos bem treinados, vamos salvar ambos no formato ONNX, que podemos implantar no MQL5.
Salvando XGBoost e LightGBM no ONNX.
Salvar esses dois modelos pode ser complicado, já que ambos vêm separadamente em suas bibliotecas personalizadas. O processo de salvamento não é tão simples quanto salvar modelos do Scikit-learn, TensorFlow ou Keras. Para mais informações, consulte a documentação do ONNX sobre como salvar Light GBM e XGBoost.
Vamos começar salvando o modelo Light GBM, o processo é o mesmo para ambos os modelos.
Salvando o modelo LightGBM | Código Python:
from skl2onnx.common.data_types import FloatTensorType from skl2onnx import convert_sklearn, to_onnx, update_registered_converter from skl2onnx.common.shape_calculator import calculate_linear_classifier_output_shapes from onnxmltools.convert.xgboost.operator_converters.XGBoost import convert_xgboost from onnxmltools.convert import convert_xgboost as convert_xgboost_booster update_registered_converter( lgb.LGBMClassifier, "GBMClassifier", calculate_linear_classifier_output_shapes, convert_lightgbm, options={"nocl": [False], "zipmap": [True, False, "columns"]}, ) model_onnx = convert_sklearn( pipe, "pipeline_lightgbm", [("input", FloatTensorType([None, X_train.shape[1]]))], target_opset={"": 12, "ai.onnx.ml": 2}, ) # And save. with open("lightgbm.eurusd.h1.onnx", "wb") as f: f.write(model_onnx.SerializeToString())
Carregando o modelo ONNX no MQL5
update_registered_converter( xgb.XGBClassifier, "XGBClassifier", calculate_linear_classifier_output_shapes, convert_xgboost, options={"nocl": [False], "zipmap": [True, False, "columns"]}, ) model_onnx = convert_sklearn( pipe, "pipeline_xgboost", [("input", FloatTensorType([None, X_train.shape[1]]))], target_opset={"": 12, "ai.onnx.ml": 2}, ) # And save. with open("xgboost.eurusd.h1.onnx", "wb") as f: f.write(model_onnx.SerializeToString())
Carregando modelo ONNX em MQL5
Carregar modelos Gradient Boosted Decision Trees (GBDT) pode ser complicado, diferente de carregar outros modelos, apesar de o processo ser o mesmo.
MQL5 | LightGBM.mqh
bool CLightGBM::OnnxLoad(long &handle) { //--- since not all sizes defined in the input tensor we must set them explicitly //--- first index - batch size, second index - series size, third index - number of series (only Close) OnnxTypeInfo type_info; //Getting onnx information for Reference In case you forgot what the loaded ONNX is all about long input_count=OnnxGetInputCount(handle); if (MQLInfoInteger(MQL_DEBUG)) Print("model has ",input_count," input(s)"); for(long i=0; i<input_count; i++) { string input_name=OnnxGetInputName(handle,i); if (MQLInfoInteger(MQL_DEBUG)) Print(i," input name is ",input_name); if(OnnxGetInputTypeInfo(handle,i,type_info)) { if (MQLInfoInteger(MQL_DEBUG)) PrintTypeInfo(i,"input",type_info); ArrayCopy(inputs, type_info.tensor.dimensions); } } long output_count=OnnxGetOutputCount(handle); if (MQLInfoInteger(MQL_DEBUG)) Print("model has ",output_count," output(s)"); for(long i=0; i<output_count; i++) { string output_name=OnnxGetOutputName(handle,i); if (MQLInfoInteger(MQL_DEBUG)) Print(i," output name is ",output_name); if(OnnxGetOutputTypeInfo(handle,i,type_info)) { if (MQLInfoInteger(MQL_DEBUG)) PrintTypeInfo(i,"output",type_info); ArrayCopy(outputs, type_info.tensor.dimensions); } } //--- replace(inputs); replace(outputs); //--- Setting the input size for (long i=0; i<input_count; i++) if (!OnnxSetInputShape(handle, i, inputs)) //Giving the Onnx handle the input shape { printf("Failed to set the input shape Err=%d",GetLastError()); DebugBreak(); return false; } //--- Setting the output size for(long i=0; i<output_count; i++) { if(!OnnxSetOutputShape(handle,i,outputs)) { printf("Failed to set the Output[%d] shape Err=%d",i,GetLastError()); //DebugBreak(); //return false; } } initialized = true; Print("ONNX model Initialized"); return true; }
Saídas | Aba de Experts:
JM 0 10:49:34.197 LightGBM EA (EURUSD,H1) model has 1 input(s)
MG 0 10:49:34.197 LightGBM EA (EURUSD,H1) 0 input name is input
KM 0 10:49:34.198 LightGBM EA (EURUSD,H1) type ONNX_TYPE_TENSOR
CF 0 10:49:34.198 LightGBM EA (EURUSD,H1) data type ONNX_TYPE_TENSOR
HP 0 10:49:34.198 LightGBM EA (EURUSD,H1) shape [-1, 8]
EI 0 10:49:34.198 LightGBM EA (EURUSD,H1) 0 input shape must be defined explicitly before model inference
RN 0 10:49:34.198 LightGBM EA (EURUSD,H1) shape of input data can be reduced to [8] if undefined dimension set to 1
EM 0 10:49:34.198 LightGBM EA (EURUSD,H1) model has 2 output(s)
MJ 0 10:49:34.198 LightGBM EA (EURUSD,H1) 0 output name is output_label
MR 0 10:49:34.198 LightGBM EA (EURUSD,H1) type ONNX_TYPE_TENSOR
EI 0 10:49:34.198 LightGBM EA (EURUSD,H1) data type ONNX_TYPE_TENSOR
RK 0 10:49:34.198 LightGBM EA (EURUSD,H1) shape [-1]
RN 0 10:49:34.198 LightGBM EA (EURUSD,H1) 0 output shape must be defined explicitly before model inference
GJ 0 10:49:34.198 LightGBM EA (EURUSD,H1) 1 output name is output_probability
OR 0 10:49:34.198 LightGBM EA (EURUSD,H1) type ONNX_TYPE_SEQUENCE
KN 0 10:49:34.198 LightGBM EA (EURUSD,H1) data type ONNX_TYPE_SEQUENCE
OF 0 10:49:34.198 LightGBM EA (EURUSD,H1) no dimensions defined for 1 output
HM 0 10:49:34.198 LightGBM EA (EURUSD,H1) Failed to set the Output[1] shape Err=5802
IH 0 10:49:34.198 LightGBM EA (EURUSD,H1) ONNX model Initialized
Se você observar o modelo mais de perto em Netron:

A primeira camada de saída é do tipo tensor com um array de inteiros 1D de tamanho desconhecido. Redimensionar esta camada para a forma de 1 deve funcionar bem. Quanto à segunda camada de saída, há uma sequência com um mapa (semelhante a um dicionário em Python) com dois arrays dimensionais 1D de tamanhos desconhecidos, um para rótulos e o outro para probabilidades. Isso é como ZipMap coloca, caso você esteja se perguntando.
Definir o tamanho dessa segunda camada de saída usando OnnxSetOutputShape para esse tipo de objeto complexo é difícil e pode gerar erros estranhos que não consegui resolver. No entanto, redimensionar para 1 funciona, embora lance um aviso, mas ainda assim funciona. Quando você executa o modelo ONNX da maneira correta. Leia mais...
float output_data[]; struct Map { ulong key[]; float value[]; } output_data_map[]; //--- ArrayResize(output_data, outputs.Size()); if (!OnnxRun(onnx_handle, ONNX_DATA_TYPE_FLOAT, x_float, output_data, output_data_map)) { printf("Failed to get predictions from Onnx err %d",GetLastError()); return proba; }
Dentro das classes Light GBM e XGBoost, temos os seguintes métodos:
MQL5 | LightGBM.mqh
class CLightGBM { bool initialized; long onnx_handle; void PrintTypeInfo(const long num,const string layer,const OnnxTypeInfo& type_info); long inputs[], outputs[]; void replace(long &arr[]) { for (uint i=0; i<arr.Size(); i++) if (arr[i] < 0) arr[i] = UNDEFINED_REPLACE; } bool OnnxLoad(long &handle); public: CLightGBM(void); ~CLightGBM(void); virtual bool Init(const uchar &onnx_buff[], ulong flags=ONNX_DEFAULT); //Initilaized ONNX model from a resource uchar array with default flag virtual bool Init(string onnx_filename, uint flags=ONNX_DEFAULT); //Initializes the ONNX model from a .onnx filename given virtual long predict_bin(const vector &x); //REturns the predictions for the current given matrix | useful in real-time prediction virtual vector predict_proba(const vector &x); //Returns the predictions in probability terms | useful in real-time prediction virtual matrix predict_proba(const matrix &x); //Returns the predicted probability for the whole matrix | useful for testing virtual vector predict_bin(const matrix &x); //gives out the vector for all the predictions | useful for testing };
Usando LightGBM e XGBoost no Trading
Após o modelo ser inicializado na função OnInit.
MQL5 | LightGBM EA.mq5
int OnInit() { if (!lgbm.Init(lightgbm_onnx)) return INIT_FAILED; }
Os modelos ONNX carregados podem ser implantados com os dados coletados da mesma forma que os dados de treinamento.
void OnTick() { int size = CopyRates(Symbol(), PERIOD_CURRENT, 1, 1, rates_x); //We copy only one recent-closed bar //--- if (NewBar()) { vector x = { rates_x[0].open, rates_x[0].high, rates_x[0].low, rates_x[0].close, rates_x[0].close-rates_x[0].open, rates_x[0].high-rates_x[0].low, rates_x[0].close-rates_x[0].low, rates_x[0].close-rates_x[0].high }; long signal = lgbm.predict_bin(x); Comment("Signal: ",signal); }
Vamos criar uma estratégia de negociação simples baseada nos sinais obtidos.
if (NewBar()) //Trade at the opening of a new candle { vector x = { rates_x[0].open, rates_x[0].high, rates_x[0].low, rates_x[0].close, rates_x[0].close-rates_x[0].open, rates_x[0].high-rates_x[0].low, rates_x[0].close-rates_x[0].low, rates_x[0].close-rates_x[0].high }; long signal = lgbm.predict_bin(x); Comment("Signal: ",signal); //--- MqlTick ticks; SymbolInfoTick(Symbol(), ticks); if (signal==1) //if the signal is bullish { if (!PosExists(POSITION_TYPE_BUY)) //There are no buy positions m_trade.Buy(lotsize, Symbol(), ticks.ask, ticks.bid-stoploss*Point(), ticks.ask+takeprofit*Point()); //Open a buy trade } else //Bearish signal { if (!PosExists(POSITION_TYPE_SELL)) //There are no Sell positions m_trade.Sell(lotsize, Symbol(), ticks.bid, ticks.ask+stoploss*Point(), ticks.bid-takeprofit*Point()); //open a sell trade } }
Eu executei um teste no Strategy-tester, em um período de 1 hora no EURUSD de 01.01.2023 a 23.05.2024.
LightGBM:

XGBoost:

Ambos os modelos tiveram perdas. O XGBoost teve 8 dólares a menos de perdas que o LightGBM. Ambos tiveram gráficos de saldo que se pareciam muito.

O relatório do Strategy Tester não pode nos dizer se os modelos estão fazendo bem o trabalho para o qual foram treinados, que é prever o movimento da próxima barra. Como sabemos, muitas coisas devem ser consideradas para tornar um Expert Advisor lucrativo.
Para entender como os modelos estavam se saindo, vamos criar um script para coletar dados da mesma maneira que coletamos os dados de treinamento. Fazendo isso, criamos uma variável alvo.
void OnStart() { //--- if (!lgb.Init(lightgbm_onnx)) return; //--- custom out-of-sample testing int bars = 9000; int start = 1000; MqlRates rates_x[]; ArraySetAsSeries(rates_x, true); int size = CopyRates(Symbol(), PERIOD_CURRENT, start, bars, rates_x); //We start at the bar 1000 and collect 9000 candles backward MqlRates rates_y[]; ArraySetAsSeries(rates_y, true); CopyRates(Symbol(), PERIOD_CURRENT, start-1, bars, rates_y); //We do the same thing here but we only collect one bar forward making sure we get the prediction for the next candle //--- vector actual(size), predictions(size); for (int i=0; i<size; i++) { vector x = { rates_x[i].open, rates_x[i].high, rates_x[i].low, rates_x[i].close, rates_x[i].close-rates_x[i].open, rates_x[i].high-rates_x[i].low, rates_x[i].close-rates_x[i].low, rates_x[i].close-rates_x[i].high }; actual[i] = rates_y[i].close > rates_x[i].open ? 1 : 0; //making the target variable predictions[i] = (double)lgb.predict_bin(x); } Metrics::classification_report(actual, predictions); }
Resultados | Aba de Experts:
EG 0 15:18:16.874 LightGBM Performance TestScript (EURUSD,H1) Confusion Matrix
PO 0 15:18:16.874 LightGBM Performance TestScript (EURUSD,H1) [[2857,1503]
CI 0 15:18:16.874 LightGBM Performance TestScript (EURUSD,H1) [926,3714]]
FM 0 15:18:16.874 LightGBM Performance TestScript (EURUSD,H1)
NF 0 15:18:16.874 LightGBM Performance TestScript (EURUSD,H1) Classification Report
HJ 0 15:18:16.874 LightGBM Performance TestScript (EURUSD,H1)
KP 0 15:18:16.874 LightGBM Performance TestScript (EURUSD,H1) [CLS] precision recall specificity f1 score support
QQ 0 15:18:16.874 LightGBM Performance TestScript (EURUSD,H1) [0.0] 0.76 0.66 0.80 0.70 4360
CQ 0 15:18:16.874 LightGBM Performance TestScript (EURUSD,H1) [1.0] 0.71 0.80 0.66 0.75 4640
HS 0 15:18:16.874 LightGBM Performance TestScript (EURUSD,H1)
NK 0 15:18:16.874 LightGBM Performance TestScript (EURUSD,H1) accuracy 0.73 9000
RG 0 15:18:16.874 LightGBM Performance TestScript (EURUSD,H1) average 0.73 0.73 0.73 0.73 9000
LI 0 15:18:16.874 LightGBM Performance TestScript (EURUSD,H1) Weighed avg 0.73 0.73 0.73 0.73 9000
O modelo teve 73% de precisão em dados fora da amostra. Isso nos diz que nosso modelo está funcionando bem, apesar de não conseguir produzir uma curva ascendente no Strategy Tester. Isso deve ser um bom ponto de partida para criar seus próprios Expert Advisors lucrativos feitos com GBDTs no MQL5.
Vantagens das Árvores de Decisão com Boosting de Gradiente
1. Alta Precisão Preditiva
Os GBDTs geralmente superam muitos outros algoritmos de aprendizado de máquina em termos de precisão preditiva. Isso ocorre porque eles combinam os pontos fortes das árvores de decisão com o aumento de gradiente, que melhora iterativamente o desempenho do modelo ao se concentrar nos erros das árvores anteriores.
2. Robustez contra Overfitting
O processo de reforço envolve adicionar novas árvores que corrigem os erros do conjunto existente, o que ajuda a reduzir o overfitting. Técnicas como ajuste da taxa de aprendizagem, regularização e interrupção antecipada podem aumentar ainda mais essa robustez.
3. Sem Necessidade de Pré-processamento Extenso
Os GBDTs não exigem etapas extensas de pré-processamento, como dimensionamento de recursos, tratamento de valores ausentes ou codificação de variáveis categóricas, que normalmente são necessárias para outros algoritmos, como regressão linear ou máquinas de vetores de suporte.
4. Flexibilidade e Personalização
Os GBDTs oferecem uma ampla gama de hiperparâmetros que podem ser ajustados para otimizar o desempenho de tarefas específicas. Isso inclui o número de árvores, a taxa de aprendizado, a profundidade máxima das árvores e o número mínimo de amostras necessárias para dividir um nó, entre outros.
5. Capacidade de Modelar Relações Complexas
Os GBDTs podem modelar relacionamentos não lineares complexos entre recursos e a variável alvo. Isso os torna adequados para capturar padrões complexos nos dados que modelos mais simples podem não perceber.
6. Técnicas de Regularização
Os GBDTs incluem parâmetros de regularização que ajudam a controlar a complexidade do modelo e prevenir o sobreajuste. Parâmetros como max_depth, min_samples_split e min_samples_leaf desempenham um papel crucial na regularização.
7. Escalabilidade
Implementações como XGBoost, LightGBM e CatBoost são otimizadas para velocidade e escalabilidade. Elas conseguem lidar com grandes conjuntos de dados de forma eficiente e aproveitam recursos de hardware, como computação paralela e distribuída.Como em qualquer modelo de aprendizado de máquina, esses modelos também têm desvantagens que devem ser reconhecidas, não para desencorajar o uso, mas para solidificar a compreensão.
Desvantagens das Árvores de Decisão com Gradiente Boosting
1. Complexidade Computacional. Os GBDTs podem ser computacionalmente caros para treinar, especialmente com um grande número de árvores e árvores profundas. Em grandes conjuntos de dados, o processo de treinamento pode consumir uma quantidade significativa de memória em grandes e profundos datasets.
2. Ajuste de Hiperparâmetros. Apesar de poderem funcionar com parâmetros padrão para ambos os modelos discutidos, ainda há muitos hiperparâmetros que precisam ser ajustados cuidadosamente para atingir o desempenho ideal. Parâmetros como o número de árvores, taxa de aprendizado, profundidade máxima e número mínimo de amostras por folha.
Como todos sabemos, ajustar esses parâmetros pode ser demorado e intensivo em termos computacionais.
3. Ainda Sensível a Dados Ruidosos. Como cada árvore tenta corrigir os erros das árvores anteriores, qualquer ruído nos dados pode ser amplificado pelo processo de boosting.
4. Frequentemente Requer Grandes Conjuntos de Dados.Os GBDTs frequentemente requerem uma grande quantidade de dados para alcançar um bom desempenho. Conjuntos de dados pequenos podem não fornecer informações suficientes para que o processo de boosting funcione de maneira eficaz.
A linha de fundo
As árvores com gradiente boosting são ferramentas valiosas para traders de forex, como vimos, elas superam muitos modelos de aprendizado de máquina logo de cara. As pessoas costumavam acreditar que modelos complexos baseados em redes neurais, como GRU, RNN e LSTM, eram os modelos ideais para vencer o mercado, mas isso já não é mais o caso, pois as árvores com gradiente boosting estão crescendo em popularidade na comunidade de aprendizado de máquina devido à sua simplicidade e capacidade de realizar a tarefa preditiva em questão.
Atenciosamente.
Acompanhe o desenvolvimento de modelos de aprendizado de máquina e muito mais discutido nesta série de artigos neste repositório GitHub.
O código Python discutido neste post está vinculado aqui.
Tabela de Anexos:
Consultores Especialistas | Pasta Experts:
| Nome do Arquivo | Descrição|Uso |
|---|---|
| LightGBM EA.mq5 | Um Consultor Especialista para testar o Light Gradient Boosted Machine (LightGBM) |
| XGBoost EA.mq5 | Um Consultor Especialista para testar o Extreme Gradient Boosting (XGBoost) |
Bibliotecas | Pasta Include:
| Nome do Arquivo | Descrição|Uso |
|---|---|
| LightGBM.mqh | Uma biblioteca para carregar, inicializar e implantar modelos ONNX do Light Gradient Boosted Machine (LightGBM) |
| XGBoost.mqh | Uma biblioteca para carregar, inicializar e implantar Extreme Gradient Boosting (XGBoost) modelos ONNX |
Scripts | Pasta Scripts:
| Nome do Arquivo | Descrição|Uso |
|---|---|
| LightGBM Performance TestScript.mq5 | Um script para testar o modelo LightGBM em tempo real |
Arquivos | Pasta Files:
| Nome do Arquivo | Descrição|Uso |
|---|---|
| EURUSD.PERIOD_H1.csv | Um arquivo csv contendo o conjunto de dados de treinamento |
| lightgbm.eurusd.h1.onnx xgboost.eurusd.h1.onnx | Modelos LightGBM e XGBoost no formato ONNX |
Código Python:
| Nome do Arquivo | Descrição|Uso |
|---|---|
| lightgbm-xgboost.ipynb | Jupyter notebook contendo todo o código Python discutido neste post. |
Fontes e Referências:
- Pode-se fazer melhor que o XGBoost? - Mateusz Susik (https://www.youtube.com/watch?v=5CWwwtEM2TA).
- Desbloqueando o Poder das Árvores com Gradiente Boosting (usando LightGBM) | PyData London 2022 (https://www.youtube.com/watch?v=qGsHlvE8KZM).
- Documentação LightGBM: (https://lightgbm.readthedocs.io/en/latest/Parameters.html).
- Documentação XGBoost (https://xgboost.readthedocs.io/en/stable/tutorials/model.html).
Traduzido do Inglês pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/en/articles/14926
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
Ao compilar, ele apresenta um erro