
Ciência de Dados e ML (Parte 26): A Batalha Definitiva em Previsão de Séries Temporais — Redes Neurais LSTM vs GRU

Conteúdo
- O que é uma rede neural de Memória de Longo e Curto Prazo (LSTM)?
- Matemática por trás da rede de Memória de Longo e Curto Prazo (LSTM)
- O que é uma rede neural de Unidade Recorrente com Portões (GRU)?
- Matemática por trás da rede de Unidade Recorrente com Portões (GRU)
- Construindo a classe pai para redes LSTM e GRU
- Classes filhas de redes neurais LSTM e GRU
- Treinando ambos os modelos
- Verificando a importância das variáveis em ambos os modelos
- Classificadores LSTM versus GRU no testador de estratégia
- As diferenças entre os modelos de rede neural LSTM e GRU
- Conclusão
O que é uma rede neural de Memória de Longo e Curto Prazo (LSTM)?
A Memória de Longo e Curto Prazo (LSTM) é um tipo de rede neural recorrente projetada para tarefas sequenciais, sendo excelente em capturar e utilizar dependências de longo prazo nos dados. Diferentemente das Redes Neurais Recorrentes simples (RNNs) discutidas no artigo anterior desta série (leitura obrigatória), elas não conseguem capturar dependências de longo prazo nos dados.
As LSTMs foram introduzidas para resolver o problema de memória de curto prazo que é comum nas RNNs simples.
O Problema com Redes Neurais Recorrentes Simples
As Redes Neurais Recorrentes Simples (RNNs) são projetadas para lidar com dados sequenciais, utilizando seu estado oculto interno (memória) para capturar informações sobre entradas anteriores na sequência. Apesar de sua simplicidade conceitual e sucesso inicial na modelagem de dados sequenciais, elas apresentam várias limitações.
Um problema significativo é o problema do gradiente que desaparece. Durante a retropropagação, os gradientes são usados para atualizar os pesos da rede. Nas RNNs simples, esses gradientes podem diminuir exponencialmente à medida que são propagados para trás no tempo, especialmente em sequências longas. Isso resulta na incapacidade da rede de aprender dependências de longo prazo, já que os gradientes tornam-se muito pequenos para fazer atualizações eficazes nos pesos, dificultando a captura de padrões que se estendem por muitos passos temporais.
Outro desafio é o problema do gradiente explosivo, que é o oposto do problema do gradiente que desaparece. Nesse caso, os gradientes crescem exponencialmente durante a retropropagação. Isso pode causar instabilidade numérica e tornar o processo de treinamento muito desafiador. Embora seja menos comum do que os gradientes que desaparecem, os gradientes explosivos podem causar atualizações muito grandes nos pesos da rede, efetivamente fazendo com que o processo de aprendizado falhe.
As RNNs simples também são difíceis de treinar devido à sua suscetibilidade a ambos os problemas de gradiente, o que pode tornar o processo de treinamento ineficiente e lento. Treinar RNNs simples pode ser mais caro computacionalmente e pode exigir ajustes cuidadosos dos hiperparâmetros.
Além disso, as RNNs simples são incapazes de lidar com dependências temporais complexas nos dados. Devido à sua capacidade limitada de memória, elas frequentemente têm dificuldades em entender e capturar padrões sequenciais complexos.
Para tarefas que envolvem a compreensão de dependências de longo alcance nos dados, as RNNs simples podem falhar em capturar o contexto necessário, levando a um desempenho subótimo.
Matemática por trás da rede de Memória de Longo e Curto Prazo (LSTM)
Para entender os detalhes por trás das LSTMs, primeiramente, vejamos a célula LSTM.

01: Porta de Esquecimento
Dada pela equação.
![]()
A função sigmoide ![]() recebe como entrada o estado oculto anterior
recebe como entrada o estado oculto anterior ![]() e a entrada atual
e a entrada atual ![]() . A saída
. A saída ![]() é um valor entre 0 e 1, indicando quanto de cada componente no
é um valor entre 0 e 1, indicando quanto de cada componente no ![]() (estado anterior da célula) deve ser retido.
(estado anterior da célula) deve ser retido.
![]() - Peso da porta de esquecimento.
- Peso da porta de esquecimento.
![]() - Bias da porta de esquecimento.
- Bias da porta de esquecimento.
A porta de esquecimento determina quais informações do estado anterior da célula devem ser mantidas. Ela gera um número entre 0 e 1 para cada número no estado da célula ![]() , onde 0 significa esquecer completamente e 1 significa reter completamente.
, onde 0 significa esquecer completamente e 1 significa reter completamente.
02: Porta de Entrada
Dada pela fórmula.
![]()
Uma função sigmoide ![]() determina quais valores devem ser atualizados. Esta porta controla a entrada de novos dados na célula de memória.
determina quais valores devem ser atualizados. Esta porta controla a entrada de novos dados na célula de memória.
![]() - Peso da porta de entrada.
- Peso da porta de entrada.
![]() - Bias da porta de entrada.
- Bias da porta de entrada.
Esta porta decide quais valores da nova entrada ![]() serão usados para atualizar o estado da célula. Ela regula o fluxo de novas informações para dentro da célula.
serão usados para atualizar o estado da célula. Ela regula o fluxo de novas informações para dentro da célula.
03: Célula de Memória Candidata
Dada pela equação.
![]()
Uma função tanh gera informações potenciais que poderiam ser armazenadas no estado da célula.
![]() - Peso da célula de memória candidata.
- Peso da célula de memória candidata.
![]() - Bias da célula de memória candidata.
- Bias da célula de memória candidata.
Este componente gera os novos valores candidatos que podem ser adicionados ao estado da célula. Ele utiliza a função de ativação tanh para garantir que os valores estejam entre -1 e 1.
04: Atualização do Estado da Célula
Dada pela equação.
![]()
O estado anterior da célula ![]() é multiplicado pelo
é multiplicado pelo ![]() (saída da porta de esquecimento) para descartar informações não importantes. Em seguida,
(saída da porta de esquecimento) para descartar informações não importantes. Em seguida, ![]() (saída da porta de entrada) é multiplicado por
(saída da porta de entrada) é multiplicado por ![]() (estado da célula candidata), e os resultados são somados para formar o novo estado da célula
(estado da célula candidata), e os resultados são somados para formar o novo estado da célula ![]() .
.
O estado da célula é atualizado combinando o antigo estado da célula e os valores candidatos. A saída da porta de esquecimento controla a contribuição do estado anterior da célula, enquanto a saída da porta de entrada controla a contribuição dos novos valores candidatos.
05: Porta de Saída
Dada pela equação.
![]()
Uma função sigmoide determina quais partes do estado da célula devem ser enviadas como saída. Esta porta controla a saída de informações da célula de memória.
![]() - Peso da camada de saída
- Peso da camada de saída
![]() - Bias da camada de saída.
- Bias da camada de saída.
Esta porta determina a saída final para o estado atual da célula. Ela decide quais partes do estado da célula devem ser enviadas como saída, com base na entrada ![]() e no estado oculto anterior
e no estado oculto anterior ![]() .
.
06: Atualização do Estado Oculto
Dada pela equação.
![]()
O novo estado oculto ![]() é obtido ao multiplicar a saída da porta de saída
é obtido ao multiplicar a saída da porta de saída ![]() pelo tanh do estado atualizado da célula
pelo tanh do estado atualizado da célula ![]() .
.
O estado oculto é atualizado com base no estado da célula e na decisão da porta de saída. Ele é usado como saída para o passo de tempo atual e como entrada para o próximo passo de tempo.
O que é uma Rede Neural de Unidade Recorrente com Portões (GRU)?
A Unidade Recorrente com Portões (GRU) é um tipo de Rede Neural Recorrente (RNN) que, em certos casos, tem vantagens sobre a Memória de Longo e Curto Prazo (LSTM). A GRU consome menos memória e é mais rápida do que a LSTM. No entanto, a LSTM é mais precisa ao lidar com conjuntos de dados que possuem sequências mais longas.
As LSTMs e GRUs foram introduzidas para mitigar o problema de memória de curto prazo prevalente nas redes neurais recorrentes simples. Ambas possuem memória de longo prazo ativada pelo uso das portas em suas células.
Apesar de funcionarem de maneira semelhante às RNNs simples em vários aspectos, as LSTMs e GRUs abordam o problema do gradiente que desaparece, do qual as redes recorrentes simples sofrem.
Matemática por trás da rede de Unidade Recorrente com Portões (GRU)
A imagem abaixo ilustra como a célula GRU se parece quando dissecada.

01: A Porta de Atualização
Dada pela fórmula.
![]()
Esta porta determina quanto do estado oculto anterior ![]() deve ser retido e quanto do estado oculto candidato
deve ser retido e quanto do estado oculto candidato ![]() deve ser usado para atualizar o estado oculto.
deve ser usado para atualizar o estado oculto.
A porta de atualização controla quanto do estado oculto anterior ![]() deve ser levado adiante para o próximo passo de tempo. Ela decide efetivamente o equilíbrio entre manter as informações antigas e incorporar novas informações.
deve ser levado adiante para o próximo passo de tempo. Ela decide efetivamente o equilíbrio entre manter as informações antigas e incorporar novas informações.
02: Porta de Reinicialização
Dada pela fórmula.
![]()
A função sigmoide ![]() nesta porta determina quais partes do estado oculto anterior devem ser reiniciadas antes de se combinar com a entrada atual para criar a ativação candidata.
nesta porta determina quais partes do estado oculto anterior devem ser reiniciadas antes de se combinar com a entrada atual para criar a ativação candidata.
03: Ativação Candidata
Dada pela fórmula.
![]()
A ativação candidata é calculada utilizando a entrada atual ![]() e o estado oculto reinicializado
e o estado oculto reinicializado ![]() .
.
Este componente gera novos valores potenciais para o estado oculto, que podem ser incorporados com base na decisão da porta de atualização.
04: Atualização do Estado Oculto
Dada pela fórmula.
![]()
A saída da porta de atualização ![]() controla quanto do estado oculto candidato
controla quanto do estado oculto candidato ![]() é usado para formar o novo estado oculto
é usado para formar o novo estado oculto ![]() .
.
O estado oculto é atualizado ao combinar o estado oculto anterior com o estado oculto candidato. A porta de atualização ![]() controla essa combinação, garantindo que informações relevantes do passado sejam mantidas enquanto se incorpora novas informações.
controla essa combinação, garantindo que informações relevantes do passado sejam mantidas enquanto se incorpora novas informações.
Construindo a classe pai para redes LSTM e GRU
Como as LSTM e GRU funcionam de forma semelhante em muitos aspectos e aceitam os mesmos parâmetros, pode ser uma boa ideia ter uma classe base (pai) para as funções necessárias para construir, compilar, otimizar, verificar a importância das variáveis e salvar os modelos. Esta classe será herdada nas classes filhas subsequentes de LSTM e GRU.
import tensorflow as tf from tensorflow.keras.models import Sequential from tensorflow.keras.layers import LSTM, GRU, Dense, Input, Dropout from keras.callbacks import EarlyStopping from keras.optimizers import Adam import tf2onnx import optuna import shap from sklearn.metrics import accuracy_score class RNNClassifier(): def __init__(self, time_step, x_train, y_train, x_test, y_test): self.model = None self.time_step = time_step self.x_train = x_train self.y_train = y_train self.x_test = x_test self.y_test = y_test # a crucial function that all the subclasses must implement def build_compile_and_train(self, params, verbose=0): raise NotImplementedError("Subclasses should implement this method") # a function for saving the RNN model to onnx & the Standard scaler parameters def save_onnx_model(self, onnx_file_name): # optuna objective function to oprtimize def optimize_objective(self, trial): # optimize for 50 trials by default def optimize(self, n_trials=50): def _rnn_predict(self, data): def check_feature_importance(self, feature_names):
Otimizando a LSTM e GRU usando Optuna
Como foi dito uma vez, as redes neurais são muito sensíveis a hiperparâmetros. Sem o ajuste correto e sem os parâmetros ideais, as redes neurais podem ser ineficazes.
Python
def optimize_objective(self, trial): params = { "neurons": trial.suggest_int('neurons', 10, 100), "n_hidden_layers": trial.suggest_int('n_hidden_layers', 1, 5), "dropout_rate": trial.suggest_float('dropout_rate', 0.1, 0.5), "learning_rate": trial.suggest_float('learning_rate', 1e-5, 1e-2, log=True), "hidden_activation_function": trial.suggest_categorical('hidden_activation_function', ['relu', 'tanh', 'sigmoid']), "loss_function": trial.suggest_categorical('loss_function', ['categorical_crossentropy', 'binary_crossentropy', 'mean_squared_error', 'mean_absolute_error']) } val_accuracy = self.build_compile_and_train(params, verbose=0) # we build a model with different parameters and train it, just to return a validation accuracy value return val_accuracy # optimize for 50 trials by default def optimize(self, n_trials=50): study = optuna.create_study(direction='maximize') # we want to find the model with the highest validation accuracy value study.optimize(self.optimize_objective, n_trials=n_trials) return study.best_params # returns the parameters that produced the best performing model
O método optimize_objective define a função objetivo para a otimização de hiperparâmetros usando o framework Optuna. Ele orienta o processo de otimização para encontrar o melhor conjunto de hiperparâmetros que maximizem o desempenho do modelo.
O método Optimize utiliza o Optuna para realizar a otimização de hiperparâmetros, chamando repetidamente o método optimize_objective.
Verificando a Importância das Variáveis usando SHAP
Medir o impacto das variáveis nas previsões do modelo é importante para um cientista de dados. Isso não apenas nos ajuda a identificar áreas para melhorias importantes, mas também aprofunda nossa compreensão sobre um conjunto de dados em relação a um modelo.
def check_feature_importance(self, feature_names): # Sample a subset of training data for SHAP explainer sampled_idx = np.random.choice(len(self.x_train), size=100, replace=False) explainer = shap.KernelExplainer(self._rnn_predict, self.x_train[sampled_idx].reshape(100, -1)) # Get SHAP values for the test set shap_values = explainer.shap_values(self.x_test[:100].reshape(100, -1), nsamples=100) # Update feature names for SHAP feature_names = [f'{feature}_t{t}' for t in range(self.time_step) for feature in feature_names] # Plot the SHAP values shap.summary_plot(shap_values, self.x_test[:100].reshape(100, -1), feature_names=feature_names, max_display=len(feature_names), show=False) # Adjust layout and set figure size plt.subplots_adjust(left=0.12, bottom=0.1, right=0.9, top=0.9) plt.gcf().set_size_inches(7.5, 14) plt.tight_layout() # Get the class name of the current instance class_name = self.__class__.__name__ # Create the file name using the class name file_name = f"{class_name.lower()}_feature_importance.png" plt.savefig(file_name) plt.show()
Salvando os classificadores LSTM e GRU em formatos de modelo ONNX
Finalmente, depois de construirmos os modelos, devemos salvá-los no formato ONNX, que é compatível com o MQL5.
def save_onnx_model(self, onnx_file_name):
# Convert the Keras model to ONNX
spec = (tf.TensorSpec((None, self.time_step, self.x_train.shape[2]), tf.float16, name="input"),)
self.model.output_names = ['outputs']
onnx_model, _ = tf2onnx.convert.from_keras(self.model, input_signature=spec, opset=13)
# Save the ONNX model to a file
with open(onnx_file_name, "wb") as f:
f.write(onnx_model.SerializeToString())
# Save the mean and scale parameters to binary files
scaler.mean_.tofile(f"{onnx_file_name.replace('.onnx','')}.standard_scaler_mean.bin")
scaler.scale_.tofile(f"{onnx_file_name.replace('.onnx','')}.standard_scaler_scale.bin")
Classes filhas de redes neurais LSTM e GRU
As redes neurais recorrentes funcionam de forma semelhante em muitos aspectos, e até mesmo sua implementação usando Keras segue uma abordagem e parâmetros parecidos. A principal diferença está no tipo de modelo; todo o resto permanece o mesmo.
Classificador LSTM
Python
class LSTMClassifier(RNNClassifier): def build_compile_and_train(self, params, verbose=0): self.model = Sequential() self.model.add(Input(shape=(self.time_step, self.x_train.shape[2]))) self.model.add(LSTM(units=params["neurons"], activation='relu', kernel_initializer='he_uniform')) # input layer for layer in range(params["n_hidden_layers"]): # dynamically adjusting the number of hidden layers self.model.add(Dense(units=params["neurons"], activation=params["hidden_activation_function"], kernel_initializer='he_uniform')) self.model.add(Dropout(params["dropout_rate"])) self.model.add(Dense(units=len(classes_in_y), activation='softmax', name='output_layer', kernel_initializer='he_uniform')) # the output layer # Compile the model adam_optimizer = Adam(learning_rate=params["learning_rate"]) self.model.compile(optimizer=adam_optimizer, loss=params["loss_function"], metrics=['accuracy']) if verbose != 0: self.model.summary() early_stopping = EarlyStopping(monitor='val_loss', patience=10, restore_best_weights=True) history = self.model.fit(self.x_train, self.y_train, epochs=100, batch_size=32, validation_data=(self.x_test, self.y_test), callbacks=[early_stopping], verbose=verbose) val_loss, val_accuracy = self.model.evaluate(self.x_test, self.y_test, verbose=verbose) return val_accuracy
Classificador GRU
Python
class GRUClassifier(RNNClassifier): def build_compile_and_train(self, params, verbose=0): self.model = Sequential() self.model.add(Input(shape=(self.time_step, self.x_train.shape[2]))) self.model.add(GRU(units=params["neurons"], activation='relu', kernel_initializer='he_uniform')) # input layer for layer in range(params["n_hidden_layers"]): # dynamically adjusting the number of hidden layers self.model.add(Dense(units=params["neurons"], activation=params["hidden_activation_function"], kernel_initializer='he_uniform')) self.model.add(Dropout(params["dropout_rate"])) self.model.add(Dense(units=len(classes_in_y), activation='softmax', name='output_layer', kernel_initializer='he_uniform')) # the output layer # Compile the model adam_optimizer = Adam(learning_rate=params["learning_rate"]) self.model.compile(optimizer=adam_optimizer, loss=params["loss_function"], metrics=['accuracy']) if verbose != 0: self.model.summary() early_stopping = EarlyStopping(monitor='val_loss', patience=10, restore_best_weights=True) history = self.model.fit(self.x_train, self.y_train, epochs=100, batch_size=32, validation_data=(self.x_test, self.y_test), callbacks=[early_stopping], verbose=verbose) val_loss, val_accuracy = self.model.evaluate(self.x_test, self.y_test, verbose=verbose) return val_accuracy
Como pode ser visto nas classes filhas dos classificadores, a única diferença é o tipo de modelo; tanto as LSTMs quanto as GRUs seguem uma abordagem semelhante.
Treinando ambos os modelos
Primeiramente, precisamos inicializar as instâncias das classes para ambos os modelos. Começando com o modelo LSTM.
lstm_clf = LSTMClassifier(time_step=time_step, x_train= x_train_seq, y_train= y_train_encoded, x_test= x_test_seq, y_test= y_test_encoded )
Em seguida, inicializamos o modelo GRU.
gru_clf = GRUClassifier(time_step=time_step, x_train= x_train_seq, y_train= y_train_encoded, x_test= x_test_seq, y_test= y_test_encoded )
Após otimizar ambos os modelos em 20 tentativas:
best_params = lstm_clf.optimize(n_trials=20)
best_params = gru_clf.optimize(n_trials=20) O modelo classificador LSTM na tentativa 19 foi o melhor.
[I 2024-07-01 11:14:40,588] Trial 19 finished with value: 0.5597269535064697 and parameters: {'neurons': 79, 'n_hidden_layers': 4, 'dropout_rate': 0.335909076638275, 'learning_rate': 3.0704319088493336e-05, 'hidden_activation_function': 'relu', 'loss_function': 'categorical_crossentropy'}. Best is trial 19 with value: 0.5597269535064697.
Obtendo uma precisão de aproximadamente 55,97% nos dados de validação, enquanto o modelo classificador GRU, encontrado na tentativa 3, foi o melhor entre todos.
[I 2024-07-01 11:18:52,190] Trial 3 finished with value: 0.532423198223114 and parameters: {'neurons': 55, 'n_hidden_layers': 5, 'dropout_rate': 0.2729838602302831, 'learning_rate': 0.009626688728041802, 'hidden_activation_function': 'sigmoid', 'loss_function': 'mean_squared_error'}. Best is trial 3 with value: 0.532423198223114.
Ele alcançou uma precisão de aproximadamente 53,24% nos dados de validação.
Verificando a importância das variáveis em ambos os modelos
| Classificador LSTM | Classificador GRU |
|---|---|
feature_importance = lstm_clf.check_feature_importance(X.columns) Resultado: 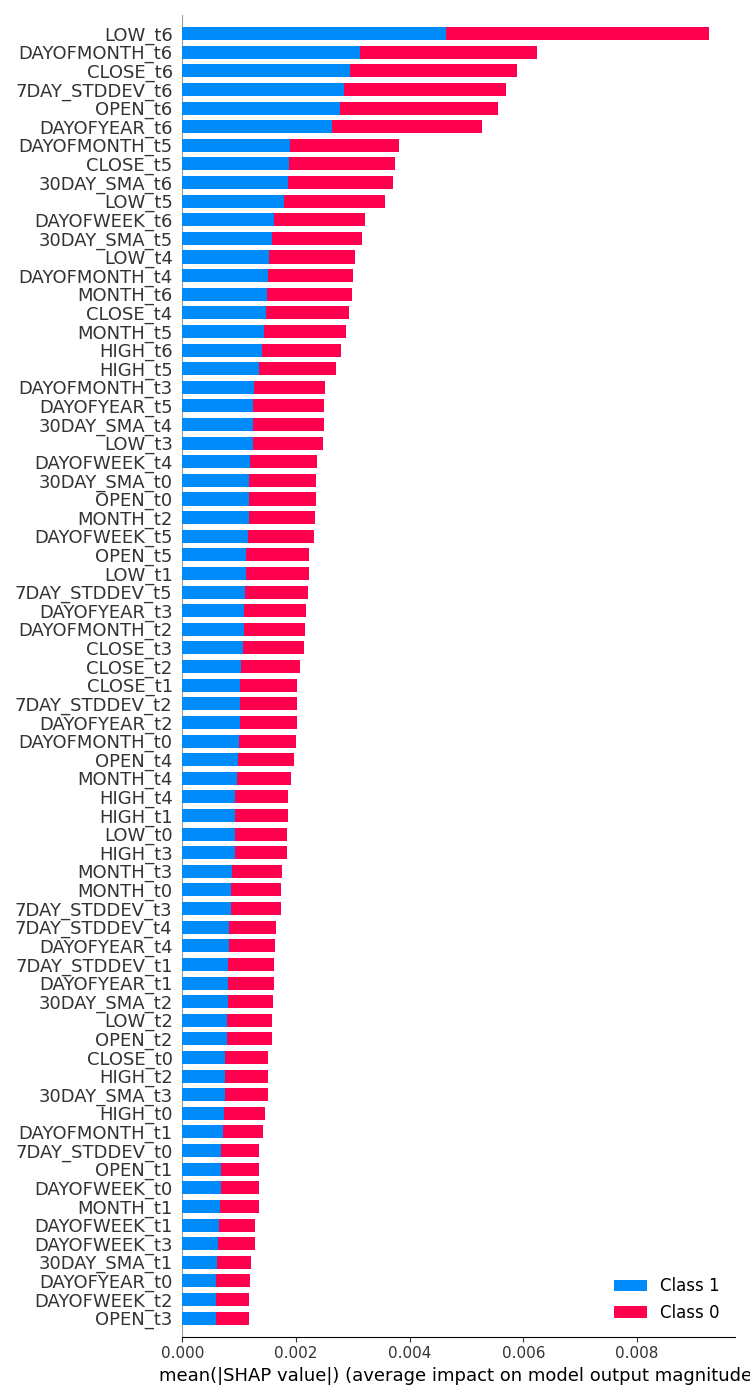 | feature_importance = gru_clf.check_feature_importance(X.columns) Resultado:  |
A importância das variáveis no classificador LSTM é de alguma forma semelhante àquela que obtivemos com o modelo RNN simples. As variáveis menos importantes são de passos de tempo mais distantes, enquanto as mais importantes são de passos de tempo mais próximos.
É como dizer que as variáveis que mais contribuem para o que acontece na barra atual são as informações das barras recentemente fechadas.
O classificador GRU teve uma opinião divergente que não parece fazer muito sentido. Isso pode ser devido à sua menor precisão.
Ele indicou que a variável mais impactante foi o dia da semana sete dias antes. Características como Abertura, Máxima, Mínima e Fechamento do valor do passo de tempo 6, que são informações muito recentes, foram colocadas no meio, indicando que tiveram uma contribuição média para o resultado final da previsão.
Classificadores LSTM versus GRU no Testador de Estratégia
Logo após o treinamento, ambos os modelos classificadores LSTM e GRU foram salvos no formato ONNX.
LSTM | Python
lstm_clf.build_compile_and_train(best_params, verbose=1) # best_params = best parameters obtained after optimization lstm_clf.save_onnx_model("lstm.EURUSD.D1.onnx")
GRU | Python
gru_clf.build_compile_and_train(best_params, verbose=1) gru_clf.save_onnx_model("gru.EURUSD.D1.onnx") # best_params = best parameters obtained after optimization
Após salvar o modelo ONNX e seus arquivos de escalonamento no diretório MQL5\Files, podemos adicionar os arquivos a ambos os Expert Advisors como arquivos de recurso.
| LSTM | GRU |
|---|---|
#resource "\\Files\\lstm.EURUSD.D1.onnx" as uchar onnx_model[]; //lstm model in onnx format #resource "\\Files\\lstm.EURUSD.D1.standard_scaler_mean.bin" as double standardization_mean[]; #resource "\\Files\\lstm.EURUSD.D1.standard_scaler_scale.bin" as double standardization_std[]; #include <MALE5\Recurrent Neural Networks(RNNs)\LSTM.mqh> CLSTM lstm; #include <MALE5\preprocessing.mqh> StandardizationScaler *scaler; //For loading the scaling technique | #resource "\\Files\\gru.EURUSD.D1.onnx" as uchar onnx_model[]; //gru model in onnx format #resource "\\Files\\gru.EURUSD.D1.standard_scaler_mean.bin" as double standardization_mean[]; #resource "\\Files\\gru.EURUSD.D1.standard_scaler_scale.bin" as double standardization_std[]; #include <MALE5\Recurrent Neural Networks(RNNs)\GRU.mqh> CGRU gru; #include <MALE5\preprocessing.mqh> StandardizationScaler *scaler; //For loading the scaling technique |
O código para o restante dos Expert Advisors permanece o mesmo como discutimos.
Usando as configurações padrão que utilizamos desde a Parte 24 desta série de artigos, onde começamos com a previsão de séries temporais.
Stop loss: 500, Take profit: 700, Slippage: 50.
Novamente, como os dados foram coletados em um período diário, pode ser uma boa ideia testá-los em um período menor para evitar erros de "fechamento do mercado" quando buscamos sinais de negociação na abertura de uma nova barra. Podemos também configurar o tipo de modelagem para preços de abertura para um teste mais rápido.

Resultados do Expert Advisor LSTM


Resultados do Expert Advisor GRU


O que podemos aprender com os resultados do Testador de Estratégia
Apesar de ser o modelo menos preciso, com 44,98%, o Expert Advisor baseado em LSTM foi o mais lucrativo, com um lucro líquido de 138 dólares, seguido pelo Expert Advisor baseado em GRU, que foi lucrativo em 45,25% das vezes, apesar de gerar um lucro líquido total de 120 dólares.
O LSTM é claramente o vencedor neste caso em termos de lucro. Apesar de o LSTM ser tecnicamente mais avançado do que outras RNNs de seu tipo, muitos fatores podem influenciar esses resultados. Todos os modelos recorrentes são bons e podem superar outros em certas situações, sinta-se à vontade para usar qualquer um dos modelos discutidos neste e no artigo anterior.
As diferenças entre os modelos de rede neural LSTM e GRU
Compreender esses modelos em comparação ajuda a decidir o que cada um oferece em contraste com o outro. Quando um deve ser usado e quando não deve. Abaixo estão suas diferenças tabuladas.
| Aspecto | LSTM | GRU |
|---|---|---|
Complexidade da Arquitetura | As LSTMs possuem um design mais complexo, com três portas (entrada, saída, esquecimento) e um estado da célula, proporcionando controle detalhado sobre quais informações são mantidas ou descartadas em cada passo de tempo. | As GRUs têm um design mais simples, com apenas duas portas (reinicialização e atualização). Essa arquitetura simples as torna mais fáceis de implementar. |
Velocidade de Treinamento | Por possuírem mais portas e um estado de célula, as LSTMs realizam mais processos e têm mais parâmetros para otimizar.Elas são mais lentas durante o treinamento. | Devido a terem menos portas e operações mais simples, elas normalmente treinam mais rápido que as LSTMs. |
Desempenho | Em problemas complexos onde capturar dependências de longo prazo é crucial, as LSTMs tendem a ter um desempenho ligeiramente melhor do que suas contrapartes. | As GRUs geralmente oferecem desempenho comparável às LSTMs para muitas tarefas. |
Manipulação de Dependências de Longo Prazo | As LSTMs são projetadas explicitamente para reter dependências de longo prazo nos dados, graças ao estado da célula e aos mecanismos de portas que controlam o fluxo de informações ao longo do tempo. | Embora as GRUs também lidem bem com dependências de longo prazo, elas podem não ser tão eficazes quanto as LSTMs na captura de dependências muito longas, devido à sua estrutura mais simples. |
| Uso de Memória | Devido à sua estrutura complexa e parâmetros adicionais, as LSTMs consomem mais memória, o que pode ser uma limitação em ambientes com recursos restritos. | As GRUs, por outro lado, são mais simples, possuem menos parâmetros e utilizam menos memória. Isso as torna mais adequadas para aplicações com recursos computacionais limitados. |
Considerações Finais
Tanto as redes neurais LSTM (Memória de Longo e Curto Prazo) quanto GRU (Unidade Recorrente com Portões) são ferramentas poderosas para traders que buscam aproveitar modelos avançados de previsão de séries temporais. Enquanto as LSTMs oferecem uma arquitetura mais elaborada que se destaca em capturar dependências de longo prazo em dados de mercado, as GRUs apresentam uma alternativa mais simples e eficiente, que pode frequentemente igualar o desempenho das LSTMs com menor custo computacional.
Esses modelos de aprendizado profundo para séries temporais (LSTM e GRU) têm sido utilizados com sucesso em vários domínios fora do mercado de câmbio, como previsão do tempo, modelagem de consumo de energia, detecção de anomalias e reconhecimento de voz. No entanto, no mercado de câmbio em constante mudança, não posso garantir tais promessas.
Este artigo teve como objetivo apenas fornecer uma compreensão aprofundada desses modelos e como eles podem ser implementados no MQL5 para negociação. Sinta-se à vontade para explorar e testar os modelos e conjuntos de dados discutidos neste artigo e compartilhe seus resultados na seção de discussão.
Atenciosamente.
Acompanhe o desenvolvimento de modelos de aprendizado de máquina e muito mais discutido nesta série de artigos neste repositório GitHub.
Tabela de Anexos
| Nome do Arquivo | Tipo de Arquivo | Descrição|Uso |
|---|---|---|
| GRU EA.mq5 LSTM EA.mq5 | Expert Advisors | Consultor Especializado baseado em GRU. Consultor Especializado baseado em LSTM. |
| gru.EURUSD.D1.onnx lstm.EURUSD.D1.onnx | Arquivos ONNX | Modelo GRU em formato ONNX. Modelo LSTM em formato ONNX. |
| lstm.EURUSD.D1.standard_scaler_mean.bin lstm.EURUSD.D1.standard_scaler_scale.bin | Arquivos Binários | Arquivos binários para o escalador de padronização usado para o modelo LSTM. |
| gru.EURUSD.D1.standard_scaler_mean.bin gru.EURUSD.D1.standard_scaler_scale.bin | Arquivos Binários | Arquivos binários para o escalador de padronização usado para o modelo GRU. |
| preprocessing.mqh | Um arquivo Include | Uma biblioteca que consiste no Escalador de Padronização |
| lstm-gru-for-forex-trading-tutorial.ipynb | r | Consiste em todo o código Python discutido neste artigo |
- Guia Ilustrado de LSTMs e GRUs: uma explicação passo a passo
- Design de decodificadores baseados em redes neurais para códigos de superfície
- Uma Rede Neural Adaptativa Anti-Ruído para Diagnóstico de Falhas em Rolamentos Sob Ruído e Condições de Carga Variáveis
Traduzido do Inglês pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/en/articles/15182
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

 Aprendendo MQL5 do iniciante ao profissional (Parte V): Principais operadores de redirecionamento do fluxo de comandos
Aprendendo MQL5 do iniciante ao profissional (Parte V): Principais operadores de redirecionamento do fluxo de comandos
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso