
Ciência de Dados e Aprendizado de Máquina (Parte 06): Gradiente Descendente

A otimização prematura é a raiz de todo o mal na programação
-Donald Knuth
Introdução
De acordo com a Wikipédia o gradiente descendente (também muitas vezes chamado de steepest descent) é um algoritmo de otimização iterativa de primeira ordem para encontrar um mínimo local de uma função diferenciável. A ideia é dar passos repetidos na direção oposta do gradiente (ou do gradiente aproximado) da função no ponto atual, pois esta é a direção de descida mais acentuada. Por outro lado, caminhar na direção do gradiente levará a um máximo local dessa função; o procedimento é então conhecido como gradiente ascendente. Basicamente, o gradiente descendente é um algoritmo de otimização usado para encontrar o mínimo de uma função:

O gradiente descendente é um algoritmo muito importante no aprendizado de máquina, pois ele nos ajuda a encontrar os parâmetros para o melhor modelo para o nosso conjunto de dados. Deixe-me primeiro explicar o termo Função custo.
Função custo
Algumas pessoas chamam isso de função de perda, ela é uma métrica para calcular o quão bom ou ruim o nosso modelo é em prever a relação entre os valores de x e y.
Existem muitas métricas que podem ser usadas para determinar como o modelo está prevendo, mas ao contrário de todas elas, a função custo encontra a perda média em todo o conjunto de dados, quanto maior a função custo, pior é o nosso modelo em encontrar as relações em nosso conjunto de dados.
O Gradiente Descendente visa minimizar a função custo porque o modelo com a função de menor custo é o melhor modelo. Para você entender o que eu acabei de explicar, vamos ver um exemplo a seguir.
Suponha que a nossa função custo seja a equação
![]()
Se nós traçarmos um gráfico desta função com python, ela ficará assim:

O primeiro passo que nós precisamos fazer para a nossa função de custo é diferenciar a função de custo, usando a Regra da Cadeia:
A equação y= (x+5)^2 é uma função composta (existe uma função dentro de outra). A função externa sendo (x+5)^2 a função interna sendo(x+5). Para diferenciar isso vamos aplicar a regra Chain, veja a imagem:

Há um vídeo com um link no final do artigo sobre eu fazendo as contas à mão, se você achou isso difícil de entender. Ok, esta função que nós acabamos de obter é o Gradiente. O processo de encontrar o gradiente de uma equação é o passo mais importante de todos eles. Eu gostaria que os meus professores de matemática me dissessem que o propósito de diferenciar a função é obter o gradiente de uma função.
Esse é o primeiro e mais importante passo, abaixo está o segundo passo.
Passo 02:
Nós nos movemos na direção negativa do gradiente, aqui surge a questão, quanto devemos nos mover? É aqui que a taxa de aprendizagem entra em jogo.
Taxa de Aprendizagem
Por definição, este é o tamanho do passo para cada iteração enquanto ele se move em direção a um mínimo de uma função de perda, vejamos o exemplo de uma pessoa descendo a montanha, seus passos são a taxa de aprendizado, quanto menores os passos, mais tempo eles levarão para chegar ao fundo da montanha e vice-versa.
Mantenha a taxa de aprendizado do algoritmo em valores menores, mas não tão pequenos, como 0.0001, ao fazer isso, você estará aumentando o tempo de execução do programa, pois poderá levar mais tempo para o algoritmo atingir os valores mínimos. Por outro lado, usar números grandes para a taxa de aprendizado fará com que o algoritmo ignore os valores mínimos que, no final, podem fazer com que você perca o valor mínimo desejado.
A taxa de aprendizado padrão é igual a 0.01.
Vamos realizar a iteração para ver como o algoritmo funciona.
Primeira iteração: Nós escolhemos qualquer ponto aleatório como sendo o ponto de partida para o nosso algoritmo, eu escolhi 0 como o primeiro valor de x agora, segue a fórmula para atualizar os valores de x

A cada iteração, nós desceremos em direção ao valor da mínima da função e assim é se dá nome Gradiente Descendente. Faz sentido agora?

Vamos ver como isso funciona em detalhes. Agora vamos calcular os valores manualmente em 2 iterações para que você tenha uma compreensão sólida do que está acontecendo:
1ª iteração:
fórmula: x1 = x0 - taxa de aprendizado * ( 2*(x+5))
x1 = 0 - 0.01 * 0.01 * 2*(0+5)
x1 = -0.01 * 10
x1 = -0.1 (finalmente)
Agora, nós finalmente atualizamos os valores atribuindo o novo valor ao valor antigo e repetimos o procedimento para o máximo de iterações até chegarmos ao mínimo de uma função:
x0 = x1
2ª iteração:
x1 = -0.1 - 0.01 * 2*(-0.1+5)
x1 = -0.198
Então: x0 = x1
Se nós repetirmos este procedimento várias vezes, a saída para as 10 primeiras iterações será:
RS 0 17:15:16.793 gradient-descent test (EURUSD,M1) Gradient Descent CostFunction CUSTOM QQ 0 17:15:16.793 gradient-descent test (EURUSD,M1) 1 x0 = 0.0000000000 x1 = -0.1000000000 CostFunction = 10.0000000000 ES 0 17:15:16.793 gradient-descent test (EURUSD,M1) 2 x0 = -0.1000000000 x1 = -0.1980000000 CostFunction = 9.8000000000 PR 0 17:15:16.793 gradient-descent test (EURUSD,M1) 3 x0 = -0.1980000000 x1 = -0.2940400000 CostFunction = 9.6040000000 LE 0 17:15:16.793 gradient-descent test (EURUSD,M1) 4 x0 = -0.2940400000 x1 = -0.3881592000 CostFunction = 9.4119200000 JD 0 17:15:16.793 gradient-descent test (EURUSD,M1) 5 x0 = -0.3881592000 x1 = -0.4803960160 CostFunction = 9.2236816000 IG 0 17:15:16.793 gradient-descent test (EURUSD,M1) 6 x0 = -0.4803960160 x1 = -0.5707880957 CostFunction = 9.0392079680 IG 0 17:15:16.793 gradient-descent test (EURUSD,M1) 7 x0 = -0.5707880957 x1 = -0.6593723338 CostFunction = 8.8584238086 JF 0 17:15:16.793 gradient-descent test (EURUSD,M1) 8 x0 = -0.6593723338 x1 = -0.7461848871 CostFunction = 8.6812553325 NI 0 17:15:16.793 gradient-descent test (EURUSD,M1) 9 x0 = -0.7461848871 x1 = -0.8312611893 CostFunction = 8.5076302258 CK 0 17:15:16.793 gradient-descent test (EURUSD,M1) 10 x0 = -0.8312611893 x1 = -0.9146359656 CostFunction = 8.3374776213
Vejamos também os outros dez valores do algoritmo quando está muito próximo do mínimo da função:
GK 0 17:15:16.800 gradient-descent test (EURUSD,M1) 1052 x0 = -4.9999999970 x1 = -4.9999999971 CostFunction = 0.0000000060 IH 0 17:15:16.800 gradient-descent test (EURUSD,M1) 1053 x0 = -4.9999999971 x1 = -4.9999999971 CostFunction = 0.0000000059 NH 0 17:15:16.800 gradient-descent test (EURUSD,M1) 1054 x0 = -4.9999999971 x1 = -4.9999999972 CostFunction = 0.0000000058 QI 0 17:15:16.800 gradient-descent test (EURUSD,M1) 1055 x0 = -4.9999999972 x1 = -4.9999999972 CostFunction = 0.0000000057 II 0 17:15:16.800 gradient-descent test (EURUSD,M1) 1056 x0 = -4.9999999972 x1 = -4.9999999973 CostFunction = 0.0000000055 RN 0 17:15:16.800 gradient-descent test (EURUSD,M1) 1057 x0 = -4.9999999973 x1 = -4.9999999973 CostFunction = 0.0000000054 KN 0 17:15:16.800 gradient-descent test (EURUSD,M1) 1058 x0 = -4.9999999973 x1 = -4.9999999974 CostFunction = 0.0000000053 JO 0 17:15:16.800 gradient-descent test (EURUSD,M1) 1059 x0 = -4.9999999974 x1 = -4.9999999974 CostFunction = 0.0000000052 JO 0 17:15:16.800 gradient-descent test (EURUSD,M1) 1060 x0 = -4.9999999974 x1 = -4.9999999975 CostFunction = 0.0000000051 QL 0 17:15:16.800 gradient-descent test (EURUSD,M1) 1061 x0 = -4.9999999975 x1 = -4.9999999975 CostFunction = 0.0000000050 QL 0 17:15:16.800 gradient-descent test (EURUSD,M1) 1062 x0 = -4.9999999975 x1 = -4.9999999976 CostFunction = 0.0000000049 HP 0 17:15:16.800 gradient-descent test (EURUSD,M1) Local miminum found =-4.999999997546217
Após 1062 (mil e sessenta e duas) iterações o algoritmo foi capaz de atingir o mínimo local desta função.
Uma coisa a notar a partir deste algoritmo
Observando os valores da Função Custo, você notará uma grande mudança nos valores no início, mas pequenas mudanças perceptíveis nos últimos valores de uma função custo.
O gradiente descendente dá passos maiores quando ele não está nem perto da mínima de uma função, mas ele dá pequenos passos quando está perto da mínima da função, a mesma coisa que você fará quando estiver perto da base da montanha, agora você sabe que o gradiente descendente é muito esperto!
No final, o mínimo local é
HP 0 17:15:16.800 gradient-descent test (EURUSD,M1) Local miminum found =-4.999999997546217
Qual é o valor exato porque o mínimo desta função é -5.0!
A Verdadeira Questão
Como o Gradiente sabe quando parar? Veja, nós podemos deixar o algoritmo continuar iterando até o infinito ou pelo menos o fim da capacidade de cálculo de um computador.
Quando a função do custo é zero é quando nós sabemos que o gradiente descendente fez seu trabalho.
Agora vamos codificar toda essa operação em MQL5:
while (true) { iterations++; x1 = x0 - m_learning_rate * CustomCostFunction(x0); printf("%d x0 = %.10f x1 = %.10f CostFunction = %.10f",iterations,x0,x1,CustomCostFunction(x0)); if (NormalizeDouble(CustomCostFunction(x0),8) == 0) { Print("Local minimum found =",x0); break; } x0 = x1; }
O bloco de código acima é aquele que conseguiu obter os resultados que nós queríamos, mas ele não está sozinho na classe CGradientDescent. A função CustomCostFunction é onde nossa equação diferenciada estava sendo mantida e calculada aqui
double CGradientDescent::CustomCostFunction(double x) { return(2 * ( x + 5 )); }
Qual é o propósito?
Alguém pode estar se perguntando qual é o propósito de todos esses cálculos quando você pode usar apenas o modelo linear padrão criado pelas bibliotecas anteriores que nós discutimos nesta série de artigos. O modelo recém criado usando os valores padrão não é necessariamente o melhor modelo, então você precisa deixar o computador aprender os melhores parâmetros para o modelo com poucos erros (melhor modelo).
Nós estamos a alguns artigos mais próximos da construção das Redes Neurais Artificiais e para que todos possam entender como as redes neurais aprendem (aprendem os padrões) no processo de retropropagação e outras técnicas, o gradiente descendente é o algoritmo mais popular que fez tudo isso possível. Sem uma compreensão sólida disso, você pode nunca entender o processo porque as coisas estão prestes a ficar complicadas.
Gradiente Descendente para um modelo de regressão
Usando o Salary Dataset, vamos construir o melhor modelo usando o gradiente descendente.

Visualização de dados em Python:
import pandas as pd import numpy as np import matplotlib.pyplot as plt data = pd.read_csv(r"C:\Users\Omega Joctan\AppData\Roaming\MetaQuotes\Terminal\892B47EBC091D6EF95E3961284A76097\MQL5\Files\Salary_Data.csv") print(data.head(10)) x = data["YearsExperience"] y = data["Salary"] plt.figure(figsize=(16,9)) plt.title("Experience vs Salary") plt.scatter(x,y,c="green") plt.xlabel(xlabel="Years of Experience") plt.ylabel(ylabel="Salary") plt.show()
Este será o nosso gráfico:

Observando o nosso conjunto de dados, você não pode deixar de notar que esse conjunto de dados é para um problema de regressão, mas nós podemos ter um milhão de modelos para nos ajudar a fazer a previsão ou o que quer que estejamos tentando alcançar.

Qual o melhor modelo a ser usado para fazer as previsões da experiência de uma pessoa e qual será o seu salário, é isso que nós vamos descobrir. Mas primeiro vamos derivar a função custo para o nosso modelo de regressão.
Teoria
Deixe-me levá-lo de volta para a Regressão linear.
Sabemos que todo modelo linear tem erros associados a ele. Nós também sabemos que nós podemos criar um milhão de linhas neste gráfico e a linha de melhor ajuste é sempre a linha com menos erros.
A função de custo representa o erro entre os nossos valores reais e os valores previstos, nós podemos escrever a fórmula para que a função de custo seja igual a:
Custo = Y real - Y previsto
Como nós estamos vendo a magnitude dos erros, nós a elevamos ao quadrado, nossa fórmula agora se torna
![]()
Mas nós estamos procurando por Erros em todo o nosso Dataset, nós precisamos fazer a soma
![]()
Por fim, nós dividimos a soma dos erros por m que é o número de itens no conjunto de dados:

Aqui está o vídeo sobre todos os procedimentos matemáticos feitos à mão.
Agora que nós temos a função custo, vamos desenvolver o gradiente descendente e encontrar os melhores parâmetros para ambos. Coeficiente X(Inclinação) denotado como Bo e interseção Y denotado como B1
double cost_B0=0, cost_B1=0; if (costFunction == MSE) { int iterations=0; for (int i=0; i<m_iterations; i++, iterations++) { cost_B0 = Mse(b0,b1,Intercept); cost_B1 = Mse(b0,b1,Slope); b0 = b0 - m_learning_rate * cost_B0; b1 = b1 - m_learning_rate * cost_B1; printf("%d b0 = %.8f cost_B0 = %.8f B1 = %.8f cost_B1 = %.8f",iterations,b0,cost_B0,b1,cost_B1); DBL_MAX_MIN(b0); DBL_MAX_MIN(cost_B0); DBL_MAX_MIN(cost_B1); if (NormalizeDouble(cost_B0,8) == 0 && NormalizeDouble(cost_B1,8) == 0) break; } printf("%d Iterations Local Minima are\nB0(Intercept) = %.5f || B1(Coefficient) = %.5f",iterations,b0,b1); }
Observamos algumas coisas do código do Gradiente Descendente:
- O processo ainda é o mesmo que nós realizamos antes, mas desta vez nós estamos encontrando e atualizando os valores de Bo e B1 duas vezes ao mesmo tempo.
- Há um número restrito de iterações, alguém disse uma vez que a melhor maneira de fazer um loop infinito é usar o loop while, nós não usamos o loop while desta vez, mas queremos limitar o número de vezes que o algoritmo funcionará para encontrar os coeficientes para o melhor modelo.
- DBL_MAX_MIN é uma função para fins de depuração responsável por verificar e nos notificar se atingimos os limites matemáticos de um computador.
Esta é a saída das operações do algoritmo. Learning Rate = 0.01 Iterations = 10000
PD 0 17:29:17.999 gradient-descent test (EURUSD,M1) [20] 91738.0000 98273.0000 101302.0000 113812.0000 109431.0000 105582.0000 116969.0000 112635.0000 122391.0000 121872.0000 JS 0 17:29:17.999 gradient-descent test (EURUSD,M1) Gradient Descent CostFunction MSE RF 0 17:29:17.999 gradient-descent test (EURUSD,M1) 0 b0 = 1520.06000000 cost_B0 = -152006.00000000 B1 = 9547.97400000 cost_B1 = -954797.40000000 OP 0 17:29:17.999 gradient-descent test (EURUSD,M1) 1 b0 = 1995.08742960 cost_B0 = -47502.74296000 B1 = 12056.69235267 cost_B1 = -250871.83526667 LP 0 17:29:17.999 gradient-descent test (EURUSD,M1) 2 b0 = 2194.02117366 cost_B0 = -19893.37440646 B1 = 12707.81767044 cost_B1 = -65112.53177770 QN 0 17:29:17.999 gradient-descent test (EURUSD,M1) 3 b0 = 2319.78332575 cost_B0 = -12576.21520809 B1 = 12868.77569178 cost_B1 = -16095.80213357 LO 0 17:29:17.999 gradient-descent test (EURUSD,M1) 4 b0 = 2425.92576238 cost_B0 = -10614.24366387 B1 = 12900.42596039 cost_B1 = -3165.02686058 GH 0 17:29:17.999 gradient-descent test (EURUSD,M1) 5 b0 = 2526.58198175 cost_B0 = -10065.62193621 B1 = 12897.99808257 cost_B1 = 242.78778134 CJ 0 17:29:17.999 gradient-descent test (EURUSD,M1) 6 b0 = 2625.48307920 cost_B0 = -9890.10974571 B1 = 12886.62268517 cost_B1 = 1137.53974060 DD 0 17:29:17.999 gradient-descent test (EURUSD,M1) 7 b0 = 2723.61498028 cost_B0 = -9813.19010723 B1 = 12872.93147573 cost_B1 = 1369.12094310 HF 0 17:29:17.999 gradient-descent test (EURUSD,M1) 8 b0 = 2821.23916252 cost_B0 = -9762.41822398 B1 = 12858.67435081 cost_B1 = 1425.71249248 <<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<< Last Iterations >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> EI 0 17:29:48.247 gradient-descent test (EURUSD,M1) 6672 b0 = 25792.20019866 cost_B0 = -0.00000001 B1 = 9449.96232146 cost_B1 = 0.00000000 NG 0 17:29:48.247 gradient-descent test (EURUSD,M1) 6673 b0 = 25792.20019866 cost_B0 = -0.00000001 B1 = 9449.96232146 cost_B1 = 0.00000000 GD 0 17:29:48.247 gradient-descent test (EURUSD,M1) 6674 b0 = 25792.20019866 cost_B0 = -0.00000001 B1 = 9449.96232146 cost_B1 = 0.00000000 PR 0 17:29:48.247 gradient-descent test (EURUSD,M1) 6675 b0 = 25792.20019866 cost_B0 = -0.00000001 B1 = 9449.96232146 cost_B1 = 0.00000000 IS 0 17:29:48.247 gradient-descent test (EURUSD,M1) 6676 b0 = 25792.20019866 cost_B0 = -0.00000001 B1 = 9449.96232146 cost_B1 = 0.00000000 RQ 0 17:29:48.247 gradient-descent test (EURUSD,M1) 6677 b0 = 25792.20019866 cost_B0 = -0.00000001 B1 = 9449.96232146 cost_B1 = 0.00000000 KN 0 17:29:48.247 gradient-descent test (EURUSD,M1) 6678 b0 = 25792.20019866 cost_B0 = -0.00000001 B1 = 9449.96232146 cost_B1 = 0.00000000 DL 0 17:29:48.247 gradient-descent test (EURUSD,M1) 6679 b0 = 25792.20019866 cost_B0 = -0.00000001 B1 = 9449.96232146 cost_B1 = 0.00000000 RM 0 17:29:48.247 gradient-descent test (EURUSD,M1) 6680 b0 = 25792.20019866 cost_B0 = -0.00000001 B1 = 9449.96232146 cost_B1 = 0.00000000 IK 0 17:29:48.247 gradient-descent test (EURUSD,M1) 6681 b0 = 25792.20019866 cost_B0 = -0.00000001 B1 = 9449.96232146 cost_B1 = 0.00000000 PH 0 17:29:48.247 gradient-descent test (EURUSD,M1) 6682 b0 = 25792.20019866 cost_B0 = -0.00000001 B1 = 9449.96232146 cost_B1 = 0.00000000 GF 0 17:29:48.247 gradient-descent test (EURUSD,M1) 6683 b0 = 25792.20019866 cost_B0 = -0.00000001 B1 = 9449.96232146 cost_B1 = 0.00000000 MG 0 17:29:48.247 gradient-descent test (EURUSD,M1) 6684 b0 = 25792.20019866 cost_B0 = -0.00000000 B1 = 9449.96232146 cost_B1 = 0.00000000 LE 0 17:29:48.247 gradient-descent test (EURUSD,M1) 6684 Iterations Local Minima are OJ 0 17:29:48.247 gradient-descent test (EURUSD,M1) B0(Intercept) = 25792.20020 || B1(Coefficient) = 9449.96232
Se nós traçarmos o gráfico usando a matplotlib

B A M, o gradiente descendente conseguiu obter com sucesso o melhor modelo de 10.000 modelos que testamos, ótimo, mas há uma etapa crucial que nós estamos perdendo que pode fazer com que o nosso modelo se comporte de maneira estranha e nos faça obter os resultados que não queremos.
Normalizando os Dados das Variáveis de Entrada da Regressão Linear
Nós sabemos que para diferentes conjuntos de dados, os melhores modelos podem ser encontrados após diferentes iterações, alguns podem levar 100 iterações para chegar aos melhores modelos e alguns podem levar 10.000 ou até um milhão de iterações para a função de custo se tornar zero, sem mencionar que, se obtivermos valores errados da taxa de aprendizagem, nós podemos acabar perdendo os mínimos locais e se errarmos esse alvo, nós vamos acabar atingindo os limites matemáticos de um computador, vamos ver isso na prática.
Taxa de Aprendizagem = 0.1 Iterações 1000
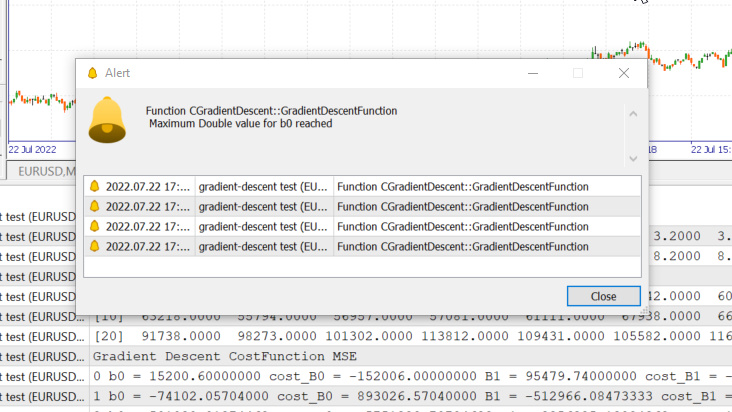
Nós acabamos de atingir o valor máximo do tipo double permitido pelo sistema. Aqui estão os nossos logs.
GM 0 17:28:14.819 gradient-descent test (EURUSD,M1) Gradient Descent CostFunction MSE OP 0 17:28:14.819 gradient-descent test (EURUSD,M1) 0 b0 = 15200.60000000 cost_B0 = -152006.00000000 B1 = 95479.74000000 cost_B1 = -954797.40000000 GR 0 17:28:14.819 gradient-descent test (EURUSD,M1) 1 b0 = -74102.05704000 cost_B0 = 893026.57040000 B1 = -512966.08473333 cost_B1 = 6084458.24733333 NM 0 17:28:14.819 gradient-descent test (EURUSD,M1) 2 b0 = 501030.91374462 cost_B0 = -5751329.70784622 B1 = 3356325.13824362 cost_B1 = -38692912.22976952 LH 0 17:28:14.819 gradient-descent test (EURUSD,M1) 3 b0 = -3150629.51591119 cost_B0 = 36516604.29655810 B1 = -21257352.71857720 cost_B1 = 246136778.56820822 KD 0 17:28:14.819 gradient-descent test (EURUSD,M1) 4 b0 = 20084177.14287909 cost_B0 = -232348066.58790281 B1 = 135309993.40314889 cost_B1 = -1565673461.21726084 OQ 0 17:28:14.819 gradient-descent test (EURUSD,M1) 5 b0 = -127706877.34210962 cost_B0 = 1477910544.84988713 B1 = -860620298.24803317 cost_B1 = 9959302916.51181984 FM 0 17:28:14.819 gradient-descent test (EURUSD,M1) 6 b0 = 812402202.33122230 cost_B0 = -9401090796.73331833 B1 = 5474519904.86084747 cost_B1 = -63351402031.08880615 JJ 0 17:28:14.819 gradient-descent test (EURUSD,M1) 7 b0 = -5167652856.43381691 cost_B0 = 59800550587.65039062 B1 = -34823489070.42410278 cost_B1 = 402980089752.84948730 MP 0 17:28:14.819 gradient-descent test (EURUSD,M1) 8 b0 = 32871653967.62362671 cost_B0 = -380393068240.57440186 B1 = 221513298448.70788574 cost_B1 = -2563367875191.31982422 MM 0 17:28:14.819 gradient-descent test (EURUSD,M1) 9 b0 = -209097460110.12799072 cost_B0 = 2419691140777.51611328 B1 = -1409052343513.33935547 cost_B1 = 16305656419620.47265625 HD 0 17:28:14.819 gradient-descent test (EURUSD,M1) 10 b0 = 1330075004152.67309570 cost_B0 = -15391724642628.00976562 B1 = 8963022367351.18359375 cost_B1 = -103720747108645.23437500 DP 0 17:28:14.819 gradient-descent test (EURUSD,M1) 11 b0 = -8460645083849.12207031 cost_B0 = 97907200880017.93750000 B1 = -57014041694401.67187500 cost_B1 = 659770640617528.50000000
Isso significa que, se nós errarmos a taxa de aprendizado, nós podemos ter uma chance pequena ou nenhuma de encontrar o melhor modelo. As chances são altas de acabarmos atingindo o limite matemático de um computador, como você acabou de ver o aviso.
Mas se eu tentar um valor igual a 0.01 para a taxa de aprendizado neste conjunto de dados, nós acabaremos não tendo problemas, embora o processo de treinamento se torne muito mais lento, mas quando eu usar essa taxa de aprendizado para esse conjunto de dados, eu vou acabar atingindo os limites matemáticos, então agora você sabe que todo conjunto de dados tem sua taxa de aprendizado, mas nós podemos não ter a chance de otimizar a taxa de aprendizado porque às vezes temos conjuntos de dados complexos com várias variáveis e também essa é uma maneira ineficaz de fazer todo este processo.
a solução para tudo isso é normalizar todo o conjunto de dados para que ele possa estar na mesma escala. Isso melhora a legibilidade quando plotamos os valores no mesmo eixo. Ele também melhora o tempo de treino porque os valores normalizados geralmente estão na faixa de 0 a 1. Também não precisamos mais nos preocupar com a taxa de aprendizado porque uma vez que temos apenas um parâmetro de taxa de aprendizado, nós podemos usá-lo para qualquer conjunto de dados que enfrentamos, por exemplo, a taxa de aprendizado de 0.01, leia mais sobre a normalização aqui.
Por último, mas não menos importante
Também sabemos que nossos valores dos dados de salário são de 39343 a 121782. Enquanto isso anos de experiência são de 1.1 a 10.5 se mantivermos os dados dessa forma, os valores para o salário são enormes que podem fazer o modelo pensar que são mais importantes do que quaisquer valores, então terão um impacto enorme em comparação com os anos de experiência. Nós precisamos que todas as variáveis independentes tenham os mesmos impactos que quaisquer outras variáveis, agora você vê como é importante normalizar os valores.
(Normalização) Escalar Min-Max
Nesta abordagem, nós normalizamos os dados para estarem dentro do intervalo de 0 e 1. A fórmula é a seguinte:

Se convertermos esta fórmula em linhas de código em MQL5, ela se tornará:
void CGradientDescent::MinMaxScaler(double &Array[]) { double mean = Mean(Array); double max,min; double Norm[]; ArrayResize(Norm,ArraySize(Array)); max = Array[ArrayMaximum(Array)]; min = Array[ArrayMinimum(Array)]; for (int i=0; i<ArraySize(Array); i++) Norm[i] = (Array[i] - min) / (max - min); printf("Scaled data Mean = %.5f Std = %.5f",Mean(Norm),std(Norm)); ArrayFree(Array); ArrayCopy(Array,Norm); }
A função std() é apenas para nos informar sobre o Desvio padrão após a normalização dos dados. Aqui está o seu código:
double CGradientDescent::std(double &data[]) { double mean = Mean(data); double sum = 0; for (int i=0; i<ArraySize(data); i++) sum += MathPow(data[i] - mean,2); return(MathSqrt(sum/ArraySize(data))); }
Agora vamos chamar tudo isso e imprimir a saída para ver o que acontece:
void OnStart() { //--- string filename = "Salary_Data.csv"; double XMatrix[]; double YMatrix[]; grad = new CGradientDescent(1, 0.01,1000); grad.ReadCsvCol(filename,1,XMatrix); grad.ReadCsvCol(filename,2,YMatrix); grad.MinMaxScaler(XMatrix); grad.MinMaxScaler(YMatrix); ArrayPrint("Normalized X",XMatrix); ArrayPrint("Normalized Y",YMatrix); grad.GradientDescentFunction(XMatrix,YMatrix,MSE); delete (grad); }
Resultado
OK 0 18:50:53.387 gradient-descent test (EURUSD,M1) Scaled data Mean = 0.44823 Std = 0.29683 MG 0 18:50:53.387 gradient-descent test (EURUSD,M1) Scaled data Mean = 0.45207 Std = 0.31838 MP 0 18:50:53.387 gradient-descent test (EURUSD,M1) Normalized X JG 0 18:50:53.387 gradient-descent test (EURUSD,M1) [ 0] 0.0000 0.0213 0.0426 0.0957 0.1170 0.1915 0.2021 0.2234 0.2234 0.2766 0.2979 0.3085 0.3085 0.3191 0.3617 ER 0 18:50:53.387 gradient-descent test (EURUSD,M1) [15] 0.4043 0.4255 0.4468 0.5106 0.5213 0.6064 0.6383 0.7234 0.7553 0.8085 0.8404 0.8936 0.9043 0.9787 1.0000 NQ 0 18:50:53.387 gradient-descent test (EURUSD,M1) Normalized Y IF 0 18:50:53.387 gradient-descent test (EURUSD,M1) [ 0] 0.0190 0.1001 0.0000 0.0684 0.0255 0.2234 0.2648 0.1974 0.3155 0.2298 0.3011 0.2134 0.2271 0.2286 0.2762 IS 0 18:50:53.387 gradient-descent test (EURUSD,M1) [15] 0.3568 0.3343 0.5358 0.5154 0.6639 0.6379 0.7151 0.7509 0.8987 0.8469 0.8015 0.9360 0.8848 1.0000 0.9939
Os gráficos agora ficarão assim:

Gradiente Descendente para a regressão logística
Já vimos como é o lado linear do gradiente descendente, agora vamos ver o lado logístico.
Aqui nós fazemos os mesmos processos que acabamos de fazer na parte de regressão linear porque os processos envolvidos são exatamente os mesmos só que o processo de diferenciação da regressão logística fica mais complexo que o de um modelo linear, vamos ver primeiro a função custo.
Conforme discutido no segundo artigo da série sobre a Regressão Logística a função custo de um modelo de regressão logística é a entropia cruzada binária ou uma função logarítmica Log Loss, exibido abaixo.

Agora vamos fazer a parte difícil primeiro, diferenciar esta função para obter o gradiente.
Depois de encontrar as derivadas

Vamos transformar as fórmulas em código MQL5 dentro da função BCE que significa Entropia Cruzada Binária.
double CGradientDescent::Bce(double Bo,double B1,Beta wrt) { double sum_sqr=0; double m = ArraySize(Y); double x[]; MatrixColumn(m_XMatrix,x,2); if (wrt == Slope) for (int i=0; i<ArraySize(Y); i++) { double Yp = Sigmoid(Bo+B1*x[i]); sum_sqr += (Y[i] - Yp) * x[i]; } if (wrt == Intercept) for (int i=0; i<ArraySize(Y); i++) { double Yp = Sigmoid(Bo+B1*x[i]); sum_sqr += (Y[i] - Yp); } return((-1/m)*sum_sqr); }
Como nós estamos lidando com o modelo de classificação, nosso conjunto de dados de escolha é o Conjunto de dados do Titanic que usamos na regressão logística. Nossa variável independente é Pclass (classe de passageiros) nossa variável dependente, por outro lado, é a Survived (Sobreviveu).

Gráfico de dispersão

Agora vamos chamar a classe Gradient Descent mas desta vez com o BCE (entropia cruzada binária) como nossa função custo.
filename = "titanic.csv"; ZeroMemory(XMatrix); ZeroMemory(YMatrix); grad.ReadCsvCol(filename,3,XMatrix); grad.ReadCsvCol(filename,2,YMatrix); grad.GradientDescentFunction(XMatrix,YMatrix,BCE); delete (grad);
Vamos ver o resultado:
CP 0 07:19:08.906 gradient-descent test (EURUSD,M1) Gradient Descent CostFunction BCE KD 0 07:19:08.906 gradient-descent test (EURUSD,M1) 0 b0 = -0.01161616 cost_B0 = 0.11616162 B1 = -0.04057239 cost_B1 = 0.40572391 FD 0 07:19:08.906 gradient-descent test (EURUSD,M1) 1 b0 = -0.02060337 cost_B0 = 0.08987211 B1 = -0.07436893 cost_B1 = 0.33796541 KE 0 07:19:08.906 gradient-descent test (EURUSD,M1) 2 b0 = -0.02743120 cost_B0 = 0.06827832 B1 = -0.10259883 cost_B1 = 0.28229898 QE 0 07:19:08.906 gradient-descent test (EURUSD,M1) 3 b0 = -0.03248925 cost_B0 = 0.05058047 B1 = -0.12626640 cost_B1 = 0.23667566 EE 0 07:19:08.907 gradient-descent test (EURUSD,M1) 4 b0 = -0.03609603 cost_B0 = 0.03606775 B1 = -0.14619252 cost_B1 = 0.19926123 CF 0 07:19:08.907 gradient-descent test (EURUSD,M1) 5 b0 = -0.03851035 cost_B0 = 0.02414322 B1 = -0.16304363 cost_B1 = 0.16851108 MF 0 07:19:08.907 gradient-descent test (EURUSD,M1) 6 b0 = -0.03994229 cost_B0 = 0.01431946 B1 = -0.17735996 cost_B1 = 0.14316329 JG 0 07:19:08.907 gradient-descent test (EURUSD,M1) 7 b0 = -0.04056266 cost_B0 = 0.00620364 B1 = -0.18958010 cost_B1 = 0.12220146 HE 0 07:19:08.907 gradient-descent test (EURUSD,M1) 8 b0 = -0.04051073 cost_B0 = -0.00051932 B1 = -0.20006123 cost_B1 = 0.10481129 ME 0 07:19:08.907 gradient-descent test (EURUSD,M1) 9 b0 = -0.03990051 cost_B0 = -0.00610216 B1 = -0.20909530 cost_B1 = 0.09034065 JQ 0 07:19:08.907 gradient-descent test (EURUSD,M1) 10 b0 = -0.03882570 cost_B0 = -0.01074812 B1 = -0.21692190 cost_B1 = 0.07826600 <<<<<< Last 10 iterations >>>>>> FN 0 07:19:09.725 gradient-descent test (EURUSD,M1) 6935 b0 = 1.44678930 cost_B0 = -0.00000001 B1 = -0.85010666 cost_B1 = 0.00000000 PN 0 07:19:09.725 gradient-descent test (EURUSD,M1) 6936 b0 = 1.44678931 cost_B0 = -0.00000001 B1 = -0.85010666 cost_B1 = 0.00000000 NM 0 07:19:09.726 gradient-descent test (EURUSD,M1) 6937 b0 = 1.44678931 cost_B0 = -0.00000001 B1 = -0.85010666 cost_B1 = 0.00000000 KL 0 07:19:09.726 gradient-descent test (EURUSD,M1) 6938 b0 = 1.44678931 cost_B0 = -0.00000001 B1 = -0.85010666 cost_B1 = 0.00000000 PK 0 07:19:09.726 gradient-descent test (EURUSD,M1) 6939 b0 = 1.44678931 cost_B0 = -0.00000001 B1 = -0.85010666 cost_B1 = 0.00000000 RK 0 07:19:09.726 gradient-descent test (EURUSD,M1) 6940 b0 = 1.44678931 cost_B0 = -0.00000001 B1 = -0.85010666 cost_B1 = 0.00000000 MJ 0 07:19:09.726 gradient-descent test (EURUSD,M1) 6941 b0 = 1.44678931 cost_B0 = -0.00000001 B1 = -0.85010666 cost_B1 = 0.00000000 HI 0 07:19:09.726 gradient-descent test (EURUSD,M1) 6942 b0 = 1.44678931 cost_B0 = -0.00000001 B1 = -0.85010666 cost_B1 = 0.00000000 CH 0 07:19:09.726 gradient-descent test (EURUSD,M1) 6943 b0 = 1.44678931 cost_B0 = -0.00000001 B1 = -0.85010666 cost_B1 = 0.00000000 MH 0 07:19:09.727 gradient-descent test (EURUSD,M1) 6944 b0 = 1.44678931 cost_B0 = -0.00000001 B1 = -0.85010666 cost_B1 = 0.00000000 QG 0 07:19:09.727 gradient-descent test (EURUSD,M1) 6945 b0 = 1.44678931 cost_B0 = -0.00000000 B1 = -0.85010666 cost_B1 = 0.00000000 NG 0 07:19:09.727 gradient-descent test (EURUSD,M1) 6945 Iterations Local Minima are MJ 0 07:19:09.727 gradient-descent test (EURUSD,M1) B0(Intercept) = 1.44679 || B1(Coefficient) = -0.85011
Não normalizamos ou dimensionamos os dados classificados para a regressão logística como fizemos na regressão linear.
Aí está o gradiente descendente para os dois modelos mais importantes do aprendizado de máquina, espero que tenha sido claro e útil. O código python usado neste artigo, assim como o conjunto de dados estão disponíveis no repositório do GitHub.
Conclusão
Vimos o gradiente descendente para uma variável independente e uma variável dependente, para várias variáveis independentes você precisa usar a forma de equações vetoriais/matrizes, acho que desta vez será fácil para qualquer um tentar descobrir sozinho, já que temos a Biblioteca para as matrizes lançada recentemente pela MQL5, sinta-se à vontade para entrar em contato comigo para qualquer ajuda com as matrizes, eu ficarei feliz em ajudar.
Cumprimentos
Saiba mais sobre Cálculo:
- https://www.youtube.com/watch?v=5yfh5cf4-0w
- https://www.youtube.com/watch?v=yg_497u6JnA
- https://www.youtube.com/watch?v=HaHsqDjWMLU
Traduzido do Inglês pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/en/articles/11200
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

 Indicador CCI. Três etapas de transformação
Indicador CCI. Três etapas de transformação
 Criação de Indicadores complexos de maneira fácil usando objetos
Criação de Indicadores complexos de maneira fácil usando objetos
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
Primeira iteração
Fórmula: x1 = x0 - Taxa de aprendizado * ( 2*(x+5) ) )
x1 = 0 - 0.01 * 0.01 * 2*(0+5)
x1 = -0.01 * 10
x1 = -0.1.
Ele diz 0,01 duas vezes.Você está confundindo as pessoas.