Ciência de Dados e Aprendizado de Máquina — Redes Neurais (Parte 02): Arquitetura das Redes Neurais Feed Forward

“Não estou sugerindo que as redes neurais sejam fáceis. Você precisa ser um especialista para fazer essas coisas funcionarem. Mas essa experiência atende a você em um espectro mais amplo de aplicativos. De certa forma, todo o esforço que anteriormente era dedicado ao desenvolvimento dos recursos agora ela é direcionada ao desenvolvimento da arquitetura, da função de perda e do esquema de otimização. O trabalho manual foi elevado a um nível mais alto de abstração.”
--Stefano Soatto
Introdução
No artigo anterior, nós discutimos os fundamentos de uma rede neural e construímos uma MLP muito básica e estática, mas nós sabemos que em aplicações da vida real não precisaremos de apenas 2 entradas e 2 nós de camadas ocultas na rede para a saída, algo que construímos da última vez.
Às vezes, uma rede que funciona melhor para o seu problema pode ser aquela com 10 nós na camada de entrada, 13 nós/neurônios na camada oculta e algo como quatro ou algo assim na camada de saída, sem falar que você terá que ajustar o número de camadas ocultas em toda a rede.
Meu ponto é que precisamos de algo dinâmico. Um código dinâmico que nós podemos alterar os parâmetros e otimizar sem interromper o programa. Se você usar a biblioteca python-keras para construir uma rede neural, você terá que fazer menos trabalho de configuração e compilação até mesmo de arquiteturas complexas, isso é algo que eu quero que sejamos capazes de alcançar na MQL5.
Assim como eu fiz na Regressão linear parte 3 que é uma leitura obrigatória nesta série de artigos, eu introduzi a forma de matriz/vetor de modelos para poder ter modelos flexíveis com um número ilimitado de entradas.
As matrizes vêm para o resgate
Todos nós sabemos que os modelos de codificação falham quando se trata de otimizar para os novos parâmetros, todo o procedimento é demorado, causa dores de cabeça, dores nas costas etc.(Não vale a pena)

Se nós olharmos mais de perto as operações por trás de uma rede neural, você notará que cada entrada é multiplicada pelo peso atribuído a ela e, em seguida, sua saída é adicionada ao viés. Isso pode ser bem tratado pelas operações de matriz.

Basicamente, nós encontramos o produto escalar da entrada e a matriz de peso e, finalmente, adicionamos ao viés.
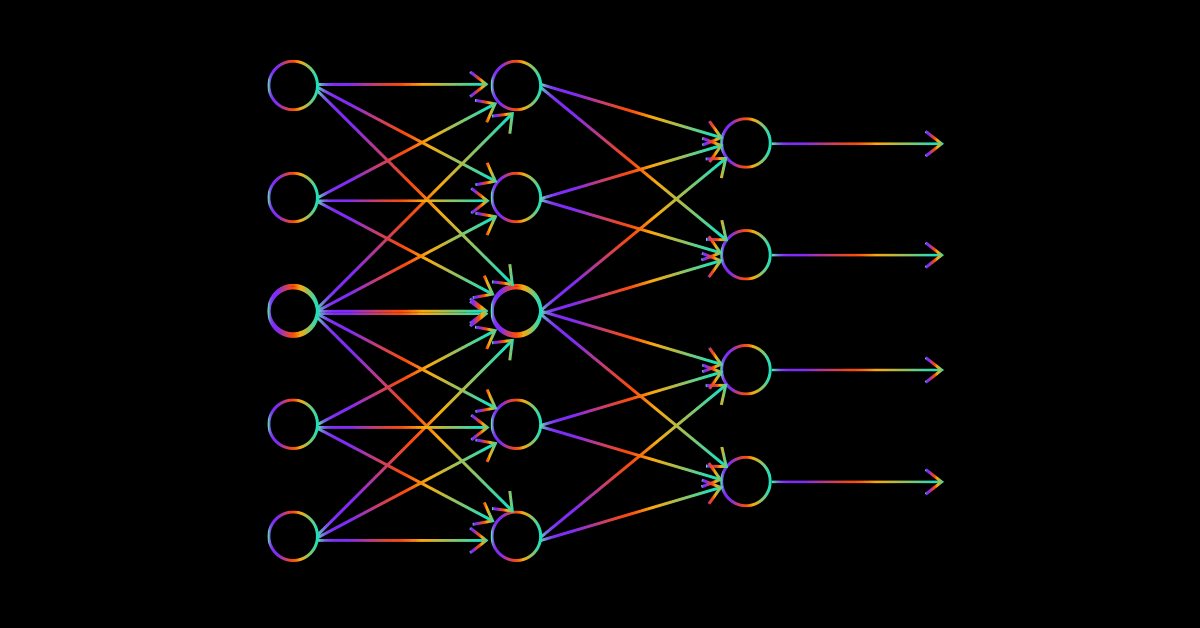
Para construir uma rede neural flexível, eu vou tentar uma arquitetura ímpar de 2 nós na camada de entrada, 4 na primeira camada oculta, 6 na segunda camada oculta e 1 na terceira camada oculta e, finalmente, um nó na camada de saída.

Isso é para testar se a nossa lógica da matriz funcionará sem problemas em todos os cenários de caso
- Quando a camada anterior (entrada) tem poucos nós numéricos que a próxima camada (camada de saída)
- Quando a camada anterior (entrada) tem muitos nós que a próxima camada
- Quando há um número igual de nós na camada de entrada e na próxima camada (saída)
Antes de nós codificarmos as operações de matriz e calcularmos os valores, vamos fazer as coisas básicas que tornarão possível toda a operação.
Gerando os pesos aleatórios e os valores de viés.
//Generate random bias for(int i=0; i<m_hiddenLayers; i++) bias[i] = MathRandom(0,1); //generate weights int sum_weights=0, L_inputs=inputs; double L_weights[]; for (int i=0; i<m_hiddenLayers; i++) { sum_weights += L_inputs * m_hiddenLayerNodes[i]; ArrayResize(Weights,sum_weights); L_inputs = m_hiddenLayerNodes[i]; } for (int j=0; j<sum_weights; j++) Weights[j] = MathRandom(0,1);
Vimos essa operação na parte anterior, mas uma coisa a notar é que esses valores de peso e viés devem ser gerados uma vez para serem usados no ciclo de épocas.
O que é uma Época?
Uma época é uma passagem completa de todos os dados na rede neural, em um feedforward é uma passagem direta completa de todas as entradas, em uma retropropagação é uma passagem inteira para frente e para trás. Em palavras simples, é quando uma rede neural viu todos os dados.
Ao contrário da MLP que vimos no artigo anterior desta vez estamos vindo com uma implementação que leva em consideração a Função de Ativação na camada de saída, algo que quem usa a keras provavelmente está familiarizado com isso, basicamente podemos ter diferentes funções de ativação na camada oculta e aquela que leva à saída na camada de saída.
CNeuralNets(fx HActivationFx,fx OActivationFx,int &NodesHL[],int outputs=NULL, bool SoftMax=false);
Preste atenção nas entradas HActivationFx, ela é para a função de ativação nas camadas ocultas, OActivationFx é para a função de ativação na camada de saída, NósHL[] é para o número de nós na camada oculta. Se esse array tiver, digamos, 3 elementos, significa que você terá 3 camadas ocultas e o número de nós nessas camadas será determinado pelos elementos presentes dentro do array, veja o código abaixo.
int hlnodes[3] = {4,6,1}; int outputs = 1; neuralnet = new CNeuralNets(SIGMOID,RELU,hlnodes,outputs);
Esta é a Arquitetura da imagem que acabamos de ver acima. O argumento de saída é opcional, se você deixar NULL a seguinte configuração será aplicada na camada de saída:
if (m_outputLayers == NULL) { if (A_fx == RELU) m_outputLayers = 1; else m_outputLayers = ArraySize(MLPInputs); }
Se você escolheu o RELU como uma função de ativação na camada oculta, a camada de saída terá um nó, caso contrário, o número de saídas na camada final será igual ao número de entradas na primeira camada. As chances são altas de que você esteja usando uma rede neural de classificação se estiver usando outra função de ativação que não seja RELU na camada oculta, portanto, a camada de saída padrão será igual ao número de colunas. Isso não é confiável, embora as saídas devam ser o número de recursos de destino do seu conjunto de dados, se você estiver tentando resolver um problema de classificação, eu encontrarei uma maneira de alterar isso nas próximas atualizações. No momento, você deve escolher manualmente o número de saída dos neurônios.
Agora, vamos chamar a função completa MLP e ver sua saída, depois eu explicarei o que foi feito para tornar as operações possíveis.
LI 0 10:10:29.995 NNTestScript (#NQ100,H1) CNeural Nets Initialized activation = SIGMOID UseSoftMax = No IF 0 10:10:29.995 NNTestScript (#NQ100,H1) biases EI 0 10:10:29.995 NNTestScript (#NQ100,H1) 0.6283 0.2029 0.1004 IQ 0 10:10:29.995 NNTestScript (#NQ100,H1) Hidden Layer 1 | Nodes 4 | Bias 0.6283 NS 0 10:10:29.995 NNTestScript (#NQ100,H1) Inputs 2 Weights 8 JD 0 10:10:29.995 NNTestScript (#NQ100,H1) 4.00000 6.00000 FL 0 10:10:29.995 NNTestScript (#NQ100,H1) 0.954 0.026 0.599 0.952 0.864 0.161 0.818 0.765 EJ 0 10:10:29.995 NNTestScript (#NQ100,H1) Arr size A 2 EM 0 10:10:29.995 NNTestScript (#NQ100,H1) AxBMatrix[0] = 3.81519 X A[0] = 4.000 B[0] = 0.954 NI 0 10:10:29.995 NNTestScript (#NQ100,H1) AxBMatrix[0] = 9.00110 X A[1] = 6.000 B[4] = 0.864 IE 0 10:10:29.995 NNTestScript (#NQ100,H1) AxBMatrix[1] = 0.10486 X A[0] = 4.000 B[1] = 0.026 DQ 0 10:10:29.995 NNTestScript (#NQ100,H1) AxBMatrix[1] = 1.06927 X A[1] = 6.000 B[5] = 0.161 MM 0 10:10:29.995 NNTestScript (#NQ100,H1) AxBMatrix[2] = 2.39417 X A[0] = 4.000 B[2] = 0.599 JI 0 10:10:29.995 NNTestScript (#NQ100,H1) AxBMatrix[2] = 7.29974 X A[1] = 6.000 B[6] = 0.818 GE 0 10:10:29.995 NNTestScript (#NQ100,H1) AxBMatrix[3] = 3.80725 X A[0] = 4.000 B[3] = 0.952 KQ 0 10:10:29.995 NNTestScript (#NQ100,H1) AxBMatrix[3] = 8.39569 X A[1] = 6.000 B[7] = 0.765 DL 0 10:10:29.995 NNTestScript (#NQ100,H1) before rows 1 cols 4 GI 0 10:10:29.995 NNTestScript (#NQ100,H1) IxWMatrix QM 0 10:10:29.995 NNTestScript (#NQ100,H1) Matrix CH 0 10:10:29.995 NNTestScript (#NQ100,H1) [ HK 0 10:10:29.995 NNTestScript (#NQ100,H1) 9.00110 1.06927 7.29974 8.39569 OO 0 10:10:29.995 NNTestScript (#NQ100,H1) ] CH 0 10:10:29.995 NNTestScript (#NQ100,H1) rows = 1 cols = 4 <<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<< End of the first Hidden Layer >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> NS 0 10:10:29.995 NNTestScript (#NQ100,H1) Hidden Layer 2 | Nodes 6 | Bias 0.2029 HF 0 10:10:29.995 NNTestScript (#NQ100,H1) Inputs 4 Weights 24 LR 0 10:10:29.995 NNTestScript (#NQ100,H1) 0.99993 0.84522 0.99964 0.99988 EL 0 10:10:29.996 NNTestScript (#NQ100,H1) 0.002 0.061 0.056 0.600 0.737 0.454 0.113 0.622 0.387 0.456 0.938 0.587 0.379 0.207 0.356 0.784 0.046 0.597 0.511 0.838 0.848 0.748 0.047 0.282 FF 0 10:10:29.996 NNTestScript (#NQ100,H1) Arr size A 4 EI 0 10:10:29.996 NNTestScript (#NQ100,H1) AxBMatrix[0] = 0.00168 X A[0] = 1.000 B[0] = 0.002 QE 0 10:10:29.996 NNTestScript (#NQ100,H1) AxBMatrix[0] = 0.09745 X A[1] = 0.845 B[6] = 0.113 MR 0 10:10:29.996 NNTestScript (#NQ100,H1) AxBMatrix[0] = 0.47622 X A[2] = 1.000 B[12] = 0.379 NN 0 10:10:29.996 NNTestScript (#NQ100,H1) AxBMatrix[0] = 0.98699 X A[3] = 1.000 B[18] = 0.511 MI 0 10:10:29.996 NNTestScript (#NQ100,H1) AxBMatrix[1] = 0.06109 X A[0] = 1.000 B[1] = 0.061 ME 0 10:10:29.996 NNTestScript (#NQ100,H1) AxBMatrix[1] = 0.58690 X A[1] = 0.845 B[7] = 0.622 PR 0 10:10:29.996 NNTestScript (#NQ100,H1) AxBMatrix[1] = 0.79347 X A[2] = 1.000 B[13] = 0.207 KN 0 10:10:29.996 NNTestScript (#NQ100,H1) AxBMatrix[1] = 1.63147 X A[3] = 1.000 B[19] = 0.838 GI 0 10:10:29.996 NNTestScript (#NQ100,H1) AxBMatrix[2] = 0.05603 X A[0] = 1.000 B[2] = 0.056 GE 0 10:10:29.996 NNTestScript (#NQ100,H1) AxBMatrix[2] = 0.38353 X A[1] = 0.845 B[8] = 0.387 GS 0 10:10:29.996 NNTestScript (#NQ100,H1) AxBMatrix[2] = 0.73961 X A[2] = 1.000 B[14] = 0.356 CO 0 10:10:29.996 NNTestScript (#NQ100,H1) AxBMatrix[2] = 1.58725 X A[3] = 1.000 B[20] = 0.848 KH 0 10:10:29.996 NNTestScript (#NQ100,H1) AxBMatrix[3] = 0.59988 X A[0] = 1.000 B[3] = 0.600 OD 0 10:10:29.996 NNTestScript (#NQ100,H1) AxBMatrix[3] = 0.98514 X A[1] = 0.845 B[9] = 0.456 LS 0 10:10:29.996 NNTestScript (#NQ100,H1) AxBMatrix[3] = 1.76888 X A[2] = 1.000 B[15] = 0.784 KO 0 10:10:29.996 NNTestScript (#NQ100,H1) AxBMatrix[3] = 2.51696 X A[3] = 1.000 B[21] = 0.748 PH 0 10:10:29.996 NNTestScript (#NQ100,H1) AxBMatrix[4] = 0.73713 X A[0] = 1.000 B[4] = 0.737 FG 0 10:10:29.996 NNTestScript (#NQ100,H1) AxBMatrix[4] = 1.53007 X A[1] = 0.845 B[10] = 0.938 RS 0 10:10:29.996 NNTestScript (#NQ100,H1) AxBMatrix[4] = 1.57626 X A[2] = 1.000 B[16] = 0.046 OO 0 10:10:29.996 NNTestScript (#NQ100,H1) AxBMatrix[4] = 1.62374 X A[3] = 1.000 B[22] = 0.047 EH 0 10:10:29.996 NNTestScript (#NQ100,H1) AxBMatrix[5] = 0.45380 X A[0] = 1.000 B[5] = 0.454 DG 0 10:10:29.996 NNTestScript (#NQ100,H1) AxBMatrix[5] = 0.95008 X A[1] = 0.845 B[11] = 0.587 PS 0 10:10:29.996 NNTestScript (#NQ100,H1) AxBMatrix[5] = 1.54675 X A[2] = 1.000 B[17] = 0.597 EO 0 10:10:29.996 NNTestScript (#NQ100,H1) AxBMatrix[5] = 1.82885 X A[3] = 1.000 B[23] = 0.282 KH 0 10:10:29.996 NNTestScript (#NQ100,H1) before rows 1 cols 6 RL 0 10:10:29.996 NNTestScript (#NQ100,H1) IxWMatrix HI 0 10:10:29.996 NNTestScript (#NQ100,H1) Matrix NS 0 10:10:29.996 NNTestScript (#NQ100,H1) [ ND 0 10:10:29.996 NNTestScript (#NQ100,H1) 0.98699 1.63147 1.58725 2.51696 1.62374 1.82885 JM 0 10:10:29.996 NNTestScript (#NQ100,H1) ] LG 0 10:10:29.996 NNTestScript (#NQ100,H1) rows = 1 cols = 6 <<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<< End of second Hidden Layer >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> ML 0 10:10:29.996 NNTestScript (#NQ100,H1) Hidden Layer 3 | Nodes 1 | Bias 0.1004 OG 0 10:10:29.996 NNTestScript (#NQ100,H1) Inputs 6 Weights 6 NQ 0 10:10:29.996 NNTestScript (#NQ100,H1) 0.76671 0.86228 0.85694 0.93819 0.86135 0.88409 QM 0 10:10:29.996 NNTestScript (#NQ100,H1) 0.278 0.401 0.574 0.301 0.256 0.870 RD 0 10:10:29.996 NNTestScript (#NQ100,H1) Arr size A 6 NO 0 10:10:29.996 NNTestScript (#NQ100,H1) AxBMatrix[0] = 0.21285 X A[0] = 0.767 B[0] = 0.278 QK 0 10:10:29.996 NNTestScript (#NQ100,H1) AxBMatrix[0] = 0.55894 X A[1] = 0.862 B[1] = 0.401 CG 0 10:10:29.996 NNTestScript (#NQ100,H1) AxBMatrix[0] = 1.05080 X A[2] = 0.857 B[2] = 0.574 DS 0 10:10:29.996 NNTestScript (#NQ100,H1) AxBMatrix[0] = 1.33314 X A[3] = 0.938 B[3] = 0.301 HO 0 10:10:29.996 NNTestScript (#NQ100,H1) AxBMatrix[0] = 1.55394 X A[4] = 0.861 B[4] = 0.256 CJ 0 10:10:29.996 NNTestScript (#NQ100,H1) AxBMatrix[0] = 2.32266 X A[5] = 0.884 B[5] = 0.870 HF 0 10:10:29.996 NNTestScript (#NQ100,H1) before rows 1 cols 1 LR 0 10:10:29.996 NNTestScript (#NQ100,H1) IxWMatrix NS 0 10:10:29.996 NNTestScript (#NQ100,H1) Matrix DF 0 10:10:29.996 NNTestScript (#NQ100,H1) [ NN 0 10:10:29.996 NNTestScript (#NQ100,H1) 2.32266 DJ 0 10:10:29.996 NNTestScript (#NQ100,H1) ] GM 0 10:10:29.996 NNTestScript (#NQ100,H1) rows = 1 cols = 1
Deixe-me visualizar a rede para que possamos ver o que foi feito apenas na primeira camada, o resto é apenas uma iteração do mesmo procedimento.

A multiplicação de matrizes conseguiu multiplicar com precisão os pesos da primeira camada para as entradas exatamente como deveria, mas codificar a lógica não é tão simples quanto parece, as coisas podem ficar um pouco confusas, veja o código abaixo. Ignora o resto do código, foca apenas na função MatrixMultiply.
void CNeuralNets::FeedForwardMLP( double &MLPInputs[], double &MLPOutput[]) { //--- m_hiddenLayers = m_hiddenLayers+1; ArrayResize(m_hiddenLayerNodes,m_hiddenLayers); m_hiddenLayerNodes[m_hiddenLayers-1] = m_outputLayers; int HLnodes = ArraySize(MLPInputs); int weight_start = 0; double Weights[], bias[]; ArrayResize(bias,m_hiddenLayers); //--- int inputs=ArraySize(MLPInputs); int w_size = 0; //size of weights int cols = inputs, rows=1; double IxWMatrix[]; //dot product matrix //Generate random bias for(int i=0; i<m_hiddenLayers; i++) bias[i] = MathRandom(0,1); //generate weights int sum_weights=0, L_inputs=inputs; double L_weights[]; for (int i=0; i<m_hiddenLayers; i++) { sum_weights += L_inputs * m_hiddenLayerNodes[i]; ArrayResize(Weights,sum_weights); L_inputs = m_hiddenLayerNodes[i]; } for (int j=0; j<sum_weights; j++) Weights[j] = MathRandom(0,1); for (int i=0; i<m_hiddenLayers; i++) { w_size = (inputs*m_hiddenLayerNodes[i]); ArrayResize(L_weights,w_size); ArrayCopy(L_weights,Weights,0,0,w_size); ArrayRemove(Weights,0,w_size); MatrixMultiply(MLPInputs,L_weights,IxWMatrix,cols,cols,rows,cols); ArrayFree(MLPInputs); ArrayResize(MLPInputs,m_hiddenLayerNodes[i]); inputs = ArraySize(MLPInputs); for(int k=0; k<ArraySize(IxWMatrix); k++) MLPInputs[k] = ActivationFx(IxWMatrix[k]+bias[i]); } }
A primeira entrada na rede na camada de entrada vem como uma matriz 1xn, o que significa que é uma linha 1, mas colunas desconhecidas (n). Inicializamos essa lógica fora antes do loop 'for' na linha
int cols = inputs, rows=1;
para obter o número total de pesos necessários para completar o processo de multiplicação, nós multiplicamos o número de camadas de entrada/camada anterior pelo número de saídas/próxima camada, neste caso, temos 2 entradas e 4 nós na primeira camada oculta, então, nós finalmente precisamos de 2x4 = 8, oito (8) valores de pesos. O truque mais importante de todos é encontrado aqui:
MatrixMultiply(MLPInputs,L_weights,IxWMatrix,cols,cols,rows,cols);
Para entender isso bem, vamos ver o que a multiplicação de matrizes faz:
void MatrixMultiply(double &A[],double &B[],double &AxBMatrix[], int colsA,int rowsB,int &new_rows,int &new_cols)
As últimas entradas new_rows, new_cols pega os novos valores atualizados para as linhas e colunas para a nova matriz, então os valores são reutilizados como o número de linhas e colunas para a próxima matriz. Lembre-se de que a entrada da próxima camada é a saída da camada anterior?
Isso é ainda mais importante para a matriz porque
- Na primeira camada, a matriz de entrada é a matriz de pesos 1x2 = 2x4: matriz de saída = 1x4
- Na segunda camada, a matriz de entrada 1x4 pondera a matriz = 4x6: a matriz de saída = 1x6
- A terceira camada entra 1x6 pesos, a matriz 6x1 sai uma matriz = 1x1
Nós sabemos que para multiplicar uma matriz, o número de colunas na primeira matriz deve ser igual ao número de linhas na segunda matriz. A matriz resultante ocupará as dimensões do número de linhas da primeira matriz e do número de colunas da segunda matriz.
Das operações acima
A primeira entrada é aquela que tem as dimensões conhecidas, mas a matriz de pesos tem 8 elementos que foram encontrados multiplicando as entradas e o número de nós na camada oculta, então nós podemos finalmente concluir que ela tem as linhas iguais ao número de colunas na camada anterior/a entrada e é basicamente isso. O processo de modificar os valores das novas linhas e novas colunas aos antigos torna esta lógica possível (Função de multiplicação dentro da matriz)
new_rows = rowsA; new_cols = colsB;
Para obter mais informações sobre as matrizes, experimentamos a biblioteca padrão de matrizes ou você pode querer tentar algo diferente que foi usado nesta biblioteca vinculada no final do artigo.
Agora que nós temos uma arquitetura flexível, vamos ver como o treinamento da rede e o treinamento e teste podem ser para essa MLP de feedforward.
Processo envolvido
- Treinamos a rede por um número x de épocas, nós encontramos o modelo com menos erros.
- Armazenamos os parâmetros do modelo no arquivo binário que nós podemos ler em outros programas, por exemplo, dentro de um Expert Advisor.
Espere um segundo, eu acabei de dizer encontramos um modelo com menos erros? Bem, nós não, isso é apenas um feedforward.
Algumas pessoas na comunidade MQL5. preferem otimizar o EA com esses parâmetros nas entradas, isso funciona, mas neste, estamos gerando os pesos e vieses apenas uma vez e os usamos para o resto das épocas da maneira que faremos retropropagação, mas a única coisa aqui é que não atualizamos esses valores depois de definidos, eles não são atualizados --period.
Usamos o número padrão de épocas definido como 1 (um).
void CNeuralNets::train_feedforwardMLP(double &XMatrix[],int epochs=1)
Você pode encontrar uma maneira de modificar o código e colocar os pesos nas entradas do script a partir daí, você pode definir o número de épocas para quaisquer valores, você não está restrito a essa maneira. A propósito, esta é uma demonstração.
Testando ou usando o modelo em dados nunca vistos
Para poder usar o modelo que treinamos, nós precisamos poder compartilhar os seus parâmetros com outros programas, isso pode ser possível usando os arquivos, já que nossos parâmetros de modelo são valores de arrays do tipo double, arquivos binários são o que nós precisamos. Lemos os arquivos binários que armazenam nossos pesos e viés e os armazenamos em seus respectivos arrays prontos para uso.
Ok, então aqui está a função responsável por treinar a rede neural.
void CNeuralNets::train_feedforwardMLP(double &XMatrix[],int epochs=1) { double MLPInputs[]; ArrayResize(MLPInputs,m_inputs); double MLPOutputs[]; ArrayResize(MLPOutputs,m_outputLayers); double Weights[], bias[]; setmodelParams(Weights,bias); //Generating random weights and bias for (int i=0; i<epochs; i++) { int start = 0; int rows = ArraySize(XMatrix)/m_inputs; { if (m_debug) printf("<<<< %d >>>",j+1); ArrayCopy(MLPInputs,XMatrix,0,start,m_inputs); FeedForwardMLP(MLPInputs,MLPOutputs,Weights,bias); start+=m_inputs; } } WriteBin(Weights,bias); }
A função setmodelParams() é uma função que gera os valores aleatórios de pesos e viés. Depois de treinar o modelo nós obtemos os valores dos pesos e viés, nós armazenamos em um arquivo binário.
WriteBin(Weights,bias);
Para demonstrar como tudo funciona na MLP, vamos usar o conjunto de dados de exemplo da vida real encontrado aqui.
O argumento XMatrix[] é uma matriz de todos os valores de entrada que nós queremos treinar o nosso modelo. Nesse caso, precisamos importar um arquivo CSV para uma matriz.

Vamos importar o conjunto de dados
Bem, eu te cubro.
double XMatrix[]; int rows,cols; CSVToMatrix(XMatrix,rows,cols,"NASDAQ_DATA.csv"); MatrixPrint(XMatrix,cols,3);
A saída do trecho de código acima:
MN 0 12:02:13.339 NNTestScript (#NQ100,H1) Matrix MI 0 12:02:13.340 NNTestScript (#NQ100,H1) [ MJ 0 12:02:13.340 NNTestScript (#NQ100,H1) 4173.800 13067.500 13386.600 34.800 RD 0 12:02:13.340 NNTestScript (#NQ100,H1) 4179.200 13094.800 13396.700 36.600 JQ 0 12:02:13.340 NNTestScript (#NQ100,H1) 4182.700 13108.000 13406.600 37.500 FK 0 12:02:13.340 NNTestScript (#NQ100,H1) 4185.800 13104.300 13416.800 37.100 ..... ..... ..... DK 0 12:02:13.353 NNTestScript (#NQ100,H1) 4332.700 14090.200 14224.600 43.700 GD 0 12:02:13.353 NNTestScript (#NQ100,H1) 4352.500 14162.000 14225.000 47.300 IN 0 12:02:13.353 NNTestScript (#NQ100,H1) 4401.900 14310.300 14226.200 56.100 DK 0 12:02:13.353 NNTestScript (#NQ100,H1) 4405.200 14312.700 14224.500 56.200 EE 0 12:02:13.353 NNTestScript (#NQ100,H1) 4415.800 14370.400 14223.200 60.000 OS 0 12:02:13.353 NNTestScript (#NQ100,H1) ] IE 0 12:02:13.353 NNTestScript (#NQ100,H1) rows = 744 cols = 4
Agora todo o arquivo CSV é armazenado dentro de XMatrix[]. Felicidades!
O bom dessa matriz resultante é que você não precisa mais se preocupar com as entradas de uma rede neural porque a variável cols obtém o número de colunas de um arquivo CSV. Estas serão as entradas de uma rede neural. Então, finalmente, aqui está como o script inteiro se parece:
//+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ #include "NeuralNets.mqh"; CNeuralNets *neuralnet; //+------------------------------------------------------------------+ void OnStart() { int hlnodes[3] = {4,6,1}; int outputs = 1; int inputs_=2; double XMatrix[]; int rows,cols; CSVToMatrix(XMatrix,rows,cols,"NASDAQ_DATA.csv"); MatrixPrint(XMatrix,cols,3); neuralnet = new CNeuralNets(SIGMOID,RELU,cols,hlnodes,outputs); neuralnet.train_feedforwardMLP(XMatrix); delete(neuralnet); }
Simples certo? Mas ainda há algumas linhas de código que temos que corrigir, dentro do train_feedforwardMLP, nós adicionamos as iterações de todo o conjunto de dados em uma única iteração de época, isso é para fazer um significado completo de uma época.
for (int i=0; i<epochs; i++) { int start = 0; int rows = ArraySize(XMatrix)/m_inputs; for (int j=0; j<rows; j++) //iterate the entire dataset in a single epoch { if (m_debug) printf("<<<< %d >>>",j+1); ArrayCopy(MLPInputs,XMatrix,0,start,m_inputs); FeedForwardMLP(MLPInputs,MLPOutputs,Weights,bias); start+=m_inputs; } }
Agora vamos ver os logs, quando executamos este programa no modo de depuração.
bool m_debug = true;
O modo de depuração pode preencher o espaço do seu disco rígido, a menos que você esteja depurando a rede neural, defina-o como false, eu executei o programa uma vez e tive registros levando até 21Mb de espaço.
Uma breve visão geral das duas iterações:
MR 0 12:23:16.485 NNTestScript (#NQ100,H1) <<<< 1 >>> DE 0 12:23:16.485 NNTestScript (#NQ100,H1) Hidden layer nodes plus the output FS 0 12:23:16.485 NNTestScript (#NQ100,H1) 4 6 1 1 KK 0 12:23:16.485 NNTestScript (#NQ100,H1) Hidden Layer 1 | Nodes 4 | Bias 0.3903 IN 0 12:23:16.485 NNTestScript (#NQ100,H1) Inputs 4 Weights 16 MJ 0 12:23:16.485 NNTestScript (#NQ100,H1) 4173.80000 13067.50000 13386.60000 34.80000 DF 0 12:23:16.485 NNTestScript (#NQ100,H1) 0.060 0.549 0.797 0.670 0.420 0.914 0.146 0.968 0.464 0.031 0.855 0.240 0.717 0.288 0.372 0.805 .... PD 0 12:23:16.485 NNTestScript (#NQ100,H1) MLP Final Output LM 0 12:23:16.485 NNTestScript (#NQ100,H1) 1.333 HP 0 12:23:16.485 NNTestScript (#NQ100,H1) <<<< 2 >>> PG 0 12:23:16.485 NNTestScript (#NQ100,H1) Hidden layer nodes plus the output JR 0 12:23:16.485 NNTestScript (#NQ100,H1) 4 6 1 1 OH 0 12:23:16.485 NNTestScript (#NQ100,H1) Hidden Layer 1 | Nodes 4 | Bias 0.3903 EI 0 12:23:16.485 NNTestScript (#NQ100,H1) Inputs 4 Weights 16 FM 0 12:23:16.485 NNTestScript (#NQ100,H1) 4179.20000 13094.80000 13396.70000 36.60000 II 0 12:23:16.486 NNTestScript (#NQ100,H1) 0.060 0.549 0.797 0.670 0.420 0.914 0.146 0.968 0.464 0.031 0.855 0.240 0.717 0.288 0.372 0.805 GJ 0 12:23:16.486 NNTestScript (#NQ100,H1)
Tudo está configurado e funcionando bem, conforme o esperado. Agora vamos armazenar o parâmetro do modelo nos arquivos binários.
Armazenando os parâmetros do modelo em um arquivo binário
bool CNeuralNets::WriteBin(double &w[], double &b[]) { string file_name_w = NULL, file_name_b= NULL; int handle_w, handle_b; file_name_w = MQLInfoString(MQL_PROGRAM_NAME)+"\\"+"model_w.bin"; file_name_b = MQLInfoString(MQL_PROGRAM_NAME)+"\\"+"model_b.bin"; FileDelete(file_name_w); FileDelete(file_name_b); handle_w = FileOpen(file_name_w,FILE_WRITE|FILE_BIN); if (handle_w == INVALID_HANDLE) { printf("Invalid %s Handle err %d",file_name_w,GetLastError()); } else FileWriteArray(handle_w,w); FileClose(handle_w); handle_b = FileOpen(file_name_b,FILE_WRITE|FILE_BIN); if (handle_b == INVALID_HANDLE) { printf("Invalid %s Handle err %d",file_name_b,GetLastError()); } else FileWriteArray(handle_b,b); FileClose(handle_b); return(true); }
Essa etapa é super importante. Como dito anteriormente, ela ajuda a compartilhar os parâmetros do modelo com outros programas, todos usando a mesma biblioteca. Os arquivos binários serão armazenados em um subdiretório com o nome do seu arquivo de script:

Um exemplo de como acessar os parâmetros do modelo em outros programas:
double weights[], bias[]; int handlew = FileOpen("NNTestScript\\model_w.bin",FILE_READ|FILE_BIN); FileReadArray(handlew,weights); FileClose(handlew); int handleb = FileOpen("NNTestScript\\model_b.bin",FILE_READ|FILE_BIN); FileReadArray(handleb,bias); FileClose(handleb); Print("bias"); ArrayPrint(bias,4); Print("Weights"); ArrayPrint(weights,4);
Saídas:
HR 0 14:14:02.380 NNTestScript (#NQ100,H1) bias DG 0 14:14:02.385 NNTestScript (#NQ100,H1) 0.0063 0.2737 0.9216 0.4435 OQ 0 14:14:02.385 NNTestScript (#NQ100,H1) Weights GG 0 14:14:02.385 NNTestScript (#NQ100,H1) [ 0] 0.5338 0.6378 0.6710 0.6256 0.8313 0.8093 0.1779 0.4027 0.5229 0.9181 0.5449 0.4888 0.9003 0.2870 0.7107 0.8477 NJ 0 14:14:02.385 NNTestScript (#NQ100,H1) [16] 0.2328 0.1257 0.4917 0.1930 0.3924 0.2824 0.4536 0.9975 0.9484 0.5822 0.0198 0.7951 0.3904 0.7858 0.7213 0.0529 EN 0 14:14:02.385 NNTestScript (#NQ100,H1) [32] 0.6332 0.6975 0.9969 0.3987 0.4623 0.4558 0.4474 0.4821 0.0742 0.5364 0.9512 0.2517 0.3690 0.4989 0.5482Ótimo, agora você pode acessar este arquivo de qualquer lugar, desde que saiba os nomes e onde encontrá-los.
Usando o modelo
Esta é a parte fácil. A função MLP feed forward foi modificada, novos pesos de entrada e viés foram adicionados, isso ajudará na execução do modelo para os dados de preços recentes ou algo assim.
void CNeuralNets::FeedForwardMLP(double &MLPInputs[],double &MLPOutput[],double &Weights[], double &bias[])
Código completo sobre como extrair os pesos e vieses e usar o modelo ao vivo. Primeiro nós lemos os parâmetros, depois nós inserimos os valores de entrada não é uma matriz de entrada porque desta vez usamos o modelo treinado para prever o resultado dos valores de entrada. A MLPOutput[] fornecerá a matriz de saída:
double weights[], bias[]; int handlew = FileOpen("NNTestScript\\model_w.bin",FILE_READ|FILE_BIN); FileReadArray(handlew,weights); FileClose(handlew); int handleb = FileOpen("NNTestScript\\model_b.bin",FILE_READ|FILE_BIN); FileReadArray(handleb,bias); FileClose(handleb); double Inputs[]; ArrayCopy(Inputs,XMatrix,0,0,cols); //copy the four first columns from this matrix double Output[]; neuralnet = new CNeuralNets(SIGMOID,RELU,cols,hlnodes,outputs); neuralnet.FeedForwardMLP(Inputs,Output,weights,bias); Print("Outputs"); ArrayPrint(Output); delete(neuralnet);
Isso deve funcionar bem.
Agora, você pode explorar vários tipos de arquitetura e diferentes opções para ver a que funciona melhor para você novamente.
A rede neural feedforward foi a primeiro e o tipo de rede neural artificial mais simples desenvolvido. Nessa rede, a informação se move em apenas uma direção: para frente dos nós de entrada, através dos nós ocultos (se houver) e para os nós de saída. Não há ciclos ou loops na rede
Este modelo que acabamos de codificar é básico e pode não necessariamente fornecer os resultados desejados, a menos que ele seja otimizado (tenho 100% de certeza) espero que você seja criativo e faça algo com isso.
Pensamentos finais
É importante entender a teoria e tudo nos bastidores de cada técnica de aprendizado de máquina, porque nós não temos pacotes de ciência de dados em MQL5, pelo menos, temos as estruturas python, mas há momentos em que podemos precisar trabalhar na MetaTrader, sem ter uma compreensão sólida da teoria por trás desses tipos de coisas, será difícil descobrir as coisas e tirar o máximo proveito do aprendizado de máquina, à medida que avançamos na importância da teoria e das coisas que discutimos anteriormente na série de artigos estão se mostrando de muita importância.
Cumprimentos.
Repositório GitHub: https://github.com/MegaJoctan/NeuralNetworks-MQL5
Leia mais sobre a minha biblioteca de Matrizes e Vetores
Leitura adicional | Livros | Referências
- Neural Networks for Pattern Recognition (Advanced Texts in Econometrics)
- Neural Networks: Tricks of the Trade (Lecture Notes in Computer Science, 7700)
- Deep Learning (Adaptive Computation and Machine Learning series)
Referência dos artigos:
- Ciência de Dados e Aprendizado de Máquina (Parte 01): Regressão Linear
- Ciência de Dados e Aprendizado de Máquina (Parte 02): Regressão Logística
- Ciência de Dados e Aprendizado de Máquina (Parte 03): Regressões Matriciais
- Ciência de Dados e Aprendizado de Máquina (Parte 06): Gradiente Descendente
- Ciência de Dados e Aprendizado de Máquina — Redes Neurais (Parte 01): Entendendo as Redes Neurais Feed Forward
Traduzido do Inglês pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/en/articles/11334
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

 Crie o seu próprio Indicador técnico
Crie o seu próprio Indicador técnico
 A matemática do mercado: lucro, prejuízo e custos
A matemática do mercado: lucro, prejuízo e custos
 Como desenvolver um sistema de negociação baseado no indicador VIDYA
Como desenvolver um sistema de negociação baseado no indicador VIDYA
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
Na minha opinião, nesse ciclo o material é muito mais bem apresentado do que, por exemplo, no ciclo "Redes neurais - é simples"...
Uma pergunta para os administradores. É possível inserir links para bibliografias pagas no código?
Na minha opinião, nesse ciclo, o material é muito mais bem apresentado do que, por exemplo, no ciclo "Neural Networks - it's easy"...
Uma pergunta para os administradores. É possível inserir links para bibliografias pagas no código?
Não, não é possível, esqueci de remover o link
O artigo contém essa informação:
Ok so here is the function responsible for training the neural network.
Estou propositalmente apresentando um trecho no idioma em que o autor escreveu o artigo.
Sinto-me constrangido em perguntar: onde está ocorrendo o aprendizado? Na minha opinião, está ocorrendo uma disseminação direta....
Isso é engraçado:
E se estiver? )))
Quando vi que havia uma seção no artigo:
Матрицы в помощь
Se de repente você precisar alterar os parâmetros de um modelo com código estático, a otimização pode levar muito tempo - é uma dor de cabeça, dor nas costas e outros problemas.
Achei que finalmente alguém descreveria o MO em termos dematrizes nativas. Mas a dor de cabeça das matrizes criadas pelo próprio usuário na forma de uma matriz unidimensional à la XMatrix[] só aumentou....
4 entradas, 1 camada oculta com 6 neurônios e uma saída?
Você não explicou bem o mais importante. Como declarar a arquitetura do modelo.
Quantas camadas ocultas posso usar?