Ciência de Dados e Aprendizado de Máquina — Redes Neurais (Parte 01): Entendendo as Redes Neurais Feed Forward

“...cansado de saber muito e entender muito pouco.”
― Jan Karon, Home to Holly Springs
Introdução
As redes neurais soam como essa coisa nova e elegante que parece um caminho a seguir para construir o santo graal dos sistemas de negociação, muitos traders ficam surpresos com os programas feitos de redes neurais, pois parecem ser bons em prever movimentos de mercado, eles são bons em qualquer tarefa em mãos. Eu também acredito que eles têm um tremendo potencial quando se trata de prever ou classificar com base em dados nunca vistos antes.
Por melhores que sejam, eles precisam ser construídos por alguém que tenha conhecimento e às vezes precisam ser otimizados para garantir que não apenas o perceptron multicamada esteja na arquitetura correta, mas também o tipo de problema é aquele que precisa da rede neural em vez de apenas um modelo de regressão linear ou logística ou qualquer outra técnica de aprendizado de máquina.
As Redes neurais, são um assunto mais amplo, assim como o aprendizado de máquina, em geral, é por isso que eu decidi adicionar um subtítulo para as redes neurais, pois eu continuarei com outros aspectos do ML no outro subtítulo da série.
Neste artigo, nós veremos o básico de uma rede neural e nós responderemos a algumas das perguntas básicas que eu considero importantes para um entusiasta de ML entender para dominar esse assunto.

O que é uma Rede Neural Artificial?
Redes Neurais Artificiais (RNAs), geralmente chamadas de redes neurais, são sistemas computacionais inspirados nas redes neurais biológicas que constituem os cérebros dos animais.
Perceptron Multicamadas vs Rede Neural Profunda
Ao discutir as redes neurais, muitas vezes você ouve as pessoas dizerem o termo Perceptron multicamada (MLP). Isso nada mais é do que o tipo mais comum de uma rede neural. Uma MLP é uma rede que consiste em uma camada de entrada, uma camada oculta e uma camada de saída. Devido à sua simplicidade, eles exigem tempos de treinamento curtos para aprender as apresentações nos dados e produzir uma saída.
Aplicações:
As MLPs geralmente são usadas para dados que não são linearmente separáveis, como a análise de regressão. Devido à sua simplicidade, eles são mais adequados para tarefas complexas de classificação e modelagem preditiva. Eles têm sido usados para traduções automáticas, previsão do tempo, detecção de fraudes, previsões do mercado de ações, previsões de classificação de crédito e muitos outros aspectos que você pode imaginar.
As Redes Neurais Profundas, por outro lado, têm uma estrutura comum, mas a única diferença é que elas compreendem muitas camadas ocultas. Se a sua rede tiver mais de três (3) camadas ocultas, considere-a uma rede neural profunda. Devido à sua natureza complexa, eles exigem longos períodos para treinar a rede nos dados de entrada, além disso, exigem computadores poderosos com unidades de processamento especializadas, como as unidades de processamento de tensor (TPU) e as Unidades de Processamento Neural (NPU).
Aplicações:
As DNNs são algoritmos poderosos devido às suas camadas profundas, portanto, geralmente são usadas para lidar com tarefas computacionais complexas, sendo a visão computacional uma dessas tarefas.
Tabela de diferenças:
| MLP | DNN |
|---|---|
| Pequeno número de camadas ocultas | Alto número de camadas ocultas |
| Períodos curtos de treinamento | Períodos longos de treinamento |
| O dispositivo habilitado para GPU é suficiente | O dispositivo de habilitação de TPU é suficiente |
Agora, vamos ver os tipos de redes neurais.
Existem muitos tipos de redes neurais, mas elas se dividem em aproximadamente três (3) classes principais;
- Redes neurais feedforward
- Redes neurais convolucionais
- Redes neurais recorrentes
01: Rede Neural Feedforward
Esta é um dos tipos mais simples de redes neurais. Em uma rede neural feed-forward, os dados passam pelos diferentes nós de entrada até chegarem a um nó de saída. Em contraste com a retropropagação, aqui os dados se movem apenas em uma direção.
Simplesmente, a retropropagação faz os mesmos processos na rede neural que o feed-forward, onde os dados são passados da camada de entrada para a camada de saída, exceto que na retropropagação após a saída da rede atingir a camada de saída, ela consegue ver o valor real de uma classe, e compará-lo com o valor que ele previu, o modelo vê o quão errado ou correto ele fez as previsões se ele fez uma previsão errada ele passa os dados para trás na rede e atualiza seus parâmetros para que ele preveja corrija próxima vez. Isto é um tipo de algoritmo autodidata.
02: Rede Neural Recorrente
Uma rede neural recorrente é um tipo de rede neural artificial na qual a saída de uma camada específica é salva e realimentada para a camada de entrada. Isso ajuda a prever o resultado da camada.
Redes neurais recorrentes são usadas para resolver problemas relacionados a
- Dados de séries temporais
- Dados de texto
- Dados de áudio
O uso mais comum em dados de texto é recomendar as próximas palavras para uma IA falar, por exemplo: Como + está + você +?

03: Rede Neural de Convolução (CNN)
As CNNs estão na moda na comunidade de aprendizado profundo. Elas prevalecem em projetos de processamento de imagem e vídeo.
Por exemplo, a IA de detecção e classificação de imagens é composta por redes neurais de convolução.

Fonte da imagem: analyticsvidhya.com
Agora que vimos os tipos de redes neurais, vamos mudar o foco para o tópico principal deste artigo Redes Neurais Feed Forward.
Redes neurais Feed Forward
Ao contrário de outros tipos mais complexos de redes neurais, não há retropropagação, o que significa que os dados fluem em uma direção apenas neste tipo de rede neural. Uma rede neural Feed Forward pode ter uma única camada oculta ou várias camadas ocultas.
Vamos ver o que faz essa rede funcionar

Camada de entrada
A partir das imagens de uma rede neural, parece que existe uma camada de entrada, mas no fundo, uma camada de entrada é apenas uma apresentação. Nenhum cálculo é executado na camada de entrada.
Camada oculta
A camada oculta é onde a maior parte do trabalho na rede é feita.
Para esclarecer as coisas, vamos dissecar o nó da segunda camada oculta.

Processos envolvidos:
- Encontrando o produto escalar das entradas e seus respectivos pesos
- Adicionando o produto escalar obtido ao viés
- O resultado do segundo procedimento é passado para a função de ativação
O que é o Viés (bias)?
O viés permite que você desloque a regressão linear para cima e para baixo para ajustar melhor a linha de previsão com os dados. Este é o mesmo que a interseção em uma linha de regressão linear.
Você entenderá bem este parâmetro na seção MLP com um único nó e uma camada oculta - modelo linear.
A importância do viés é bem explicada no Stack Overflow.
Quais são os Pesos?
Os pesos refletem o quão importante é a entrada, eles são os coeficientes da equação que você está tentando resolver. Pesos negativos reduzem o valor da saída e vice-versa. Quando uma rede neural é treinada em um conjunto de dados de treinamento, ela é inicializada com um conjunto de pesos. Esses pesos são então otimizados durante o período de treinamento e o valor ideal dos pesos é produzido.
O que é uma função de ativação?
Uma função de ativação nada mais é do que uma função matemática que recebe uma entrada e produz uma saída.
Tipos de Funções de Ativação
Existem muitas funções de ativação com suas variantes, mas aqui estão as mais usadas:
- Relu
- Sigmoide
- TanH
- Softmax
Saber qual função de ativação usar e onde usá-la é muito importante, não posso dizer quantas vezes eu vi artigos online sugerindo usar uma função de ativação em um lugar onde era irrelevante. Vamos ver isso em detalhes.
01: RELU
RELU significa Função de ativação linear retificada.
Esta é a função de ativação mais utilizada em redes neurais. É a mais simples de todas, fácil de desenvolver e fácil de interpretar a saída, por isso que ela é tão popular. Esta função produzirá a entrada diretamente se a entrada for um número positivo; caso contrário, ela produz um valor igual a zero.
Aqui está a lógica
if x < 0 : return 0
else return x
Esta função é melhor usada na resolução de problemas de regressão

Sua saída varia de zero a infinito positivo.
Seu código em MQL5 é:
double CNeuralNets::Relu(double z) { if (z < 0) return(0); else return(z); }
RELU resolve o problema do gradiente de fuga que o sigmoide e o TanH sofrem (veremos do que se trata no artigo sobre retropropagação).
02: Sigmoide
Soa familiar certo? Lembre-se da regressão logística.
Sua fórmula é dada abaixo.
![]()
Esta função é melhor para ser usada em problemas de classificação, especialmente, na classificação de uma classe ou apenas duas classes.
Sua saída varia de zero a um (termos de probabilidade).

Por exemplo, sua rede tem dois nós na saída. O primeiro nó é para classificar um gato e o outro é para um cachorro. Você pode escolher a saída se a saída do primeiro nó for maior que 0.5 para indicar que é um gato e o mesmo, mas oposto, para um cachorro.
Seu código em MQL5 é:
double CNeuralNets::Sigmoid(double z) { return(1.0/(1.0+MathPow(e,-z))); }
03: TanH
A função Tangente Hiperbólica.
É dado pela fórmula:

Seu gráfico se parece com o abaixo:

Esta função de ativação é semelhante à sigmoide, mas melhor.
Sua saída varia de -1 a 1.
Esta função é melhor usada em redes neurais de classificação multiclasse
Seu código em MQL5 é dado abaixo:
double CNeuralNets::tanh(double z) { return((MathPow(e,z) - MathPow(e,-z))/(MathPow(e,z) + MathPow(e,-z))); }
04: SoftMax
Alguém uma vez perguntou por que não há gráfico para a função SoftMax. Ao contrário de outras funções de ativação, o SoftMax não é usado nas camadas ocultas, mas apenas na camada de saída e deve ser usado somente quando você deseja converter a saída de uma rede neural multiclasse em termos de probabilidade.
O SoftMax prevê a distribuição da probabilidade multinomial.

Por exemplo, as saídas de uma rede neural de regressão são [1,3,2] se aplicarmos a função SoftMax a esta saída, a saída agora se torna [0.09003, 0.665240, 0.244728].
A saída desta função varia de 0 a 1.
Seu código MQL5 será:
void CNeuralNets::SoftMax(double &Nodes[]) { double TempArr[]; ArrayCopy(TempArr,Nodes); ArrayFree(Nodes); double proba = 0, sum=0; for (int j=0; j<ArraySize(TempArr); j++) sum += MathPow(e,TempArr[j]); for (int i=0; i<ArraySize(TempArr); i++) { proba = MathPow(e,TempArr[i])/sum; Nodes[i] = proba; } ArrayFree(TempArr); }
Agora que nós entendemos do que é composto um único Neurônio de uma camada oculta, vamos codificá-lo.
void CNeuralNets::Neuron(int HLnodes, double bias, double &Weights[], double &Inputs[], double &Outputs[] ) { ArrayResize(Outputs,HLnodes); for (int i=0, w=0; i<HLnodes; i++) { double dot_prod = 0; for(int j=0; j<ArraySize(Inputs); j++, w++) { if (m_debug) printf("i %d w %d = input %.2f x weight %.2f",i,w,Inputs[j],Weights[w]); dot_prod += Inputs[j]*Weights[w]; } Outputs[i] = ActivationFx(dot_prod+bias); } }
Dentro da ActivationFx(), temos uma escolha para qual função de ativação foi escolhida ao chamar o construtor NeuralNets.
double CNeuralNets::ActivationFx(double Q) { switch(A_fx) { case SIGMOID: return(Sigmoid(Q)); break; case TANH: return(tanh(Q)); break; case RELU: return(Relu(Q)); break; default: Print("Unknown Activation Function"); break; } return(0); }
Mais explicações sobre o código:
A função Neuron() não é apenas um único nó dentro da camada oculta, mas todas as operações de uma camada oculta são executadas dentro dessa função. Os nós em todas as camadas ocultas terão o mesmo tamanho do nó de entrada até o nó de saída final. Escolhi essa estrutura porque estou prestes a fazer alguma classificação usando essa rede neural em um conjunto de dados gerado aleatoriamente.
A função abaixo FeedForwardMLP() é uma estrutura NxN, o que significa que, se você tiver 3 nós de entrada e optar por ter 3 camadas ocultas, terá 3 nós ocultos em cada camada oculta, veja a imagem.

Aqui está a função FeedForwardMLP():
void CNeuralNets::FeedForwardMLP(int HiddenLayers, double &MLPInputs[], double &MLPWeights[], double &bias[], double &MLPOutput[]) { double L_weights[], L_inputs[], L_Out[]; ArrayCopy(L_inputs,MLPInputs); int HLnodes = ArraySize(MLPInputs); int no_weights = HLnodes*ArraySize(L_inputs); int weight_start = 0; for (int i=0; i<HiddenLayers; i++) { if (m_debug) printf("<< Hidden Layer %d >>",i+1); ArrayCopy(L_weights,MLPWeights,0,weight_start,no_weights); Neuron(HLnodes,bias[i],L_weights,L_inputs,L_Out); ArrayCopy(L_inputs,L_Out); ArrayFree(L_Out); ArrayFree(L_weights); weight_start += no_weights; } if (use_softmax) SoftMax(L_inputs); ArrayCopy(MLPOutput,L_inputs); if (m_debug) { Print("\nFinal MLP output(s)"); ArrayPrint(MLPOutput,5); } }
As operações para encontrar o produto escalar em uma rede neural podem ser tratadas por operações de matriz, mas para manter as coisas claras e fáceis para todos entenderem neste primeiro artigo, eu escolhi o método de loop, nós usaremos a multiplicação de matrizes na próxima vez.
Agora que você viu a arquitetura que acabei de escolher por padrão para construir a biblioteca. Isso agora levanta uma questão sobre a(s) arquitetura(s) de redes neurais.
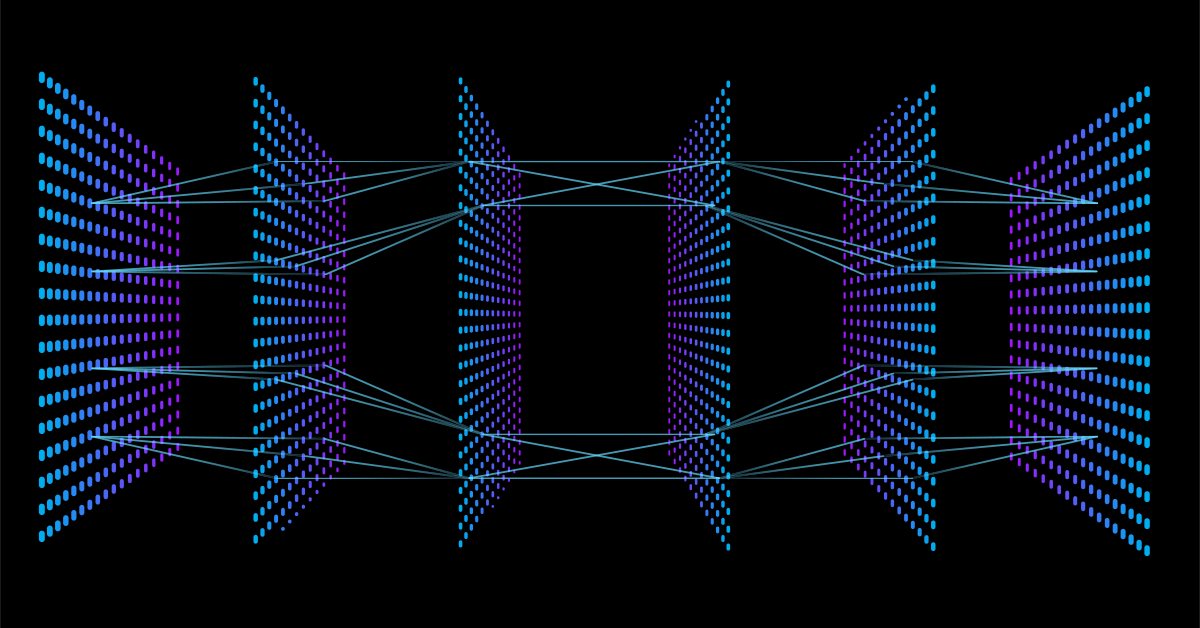
Se você for ao google e pesquisar as imagens de uma rede neural, será bombardeado por milhares se não, dez mil imagens com diferentes estruturas de redes neurais como estas por exemplo:

Uma pergunta de um milhão de dólares é: qual é a melhor arquitetura da rede neural?
"Ninguém está tão errado quanto o homem que sabe todas as respostas" -- Thomas Merton.
Vamos dividir a coisa para entender o que é necessário e o que não é.
A camada de entradaO número de entradas que compõem esta camada deve ser igual ao número de características (colunas no conjunto de dados).
A camada de saída
O tamanho (o número de neurônios) é determinado pelas classes em seu conjunto de dados para uma rede neural de classificação, para um tipo de problema de regressão o número de neurônios é determinado pela configuração do modelo escolhido. Uma camada de saída para um regressor costuma ser mais do que suficiente.
Camadas ocultas
Se o seu problema não for suficientemente complexo, uma ou duas camadas ocultas são mais do que suficientes, na verdade, duas camadas ocultas são suficientes para a grande maioria dos problemas. Mas, quantos nós você precisa em cada camada oculta? Não tenho certeza sobre isso, mas acho que depende do desempenho, isso é para você como desenvolvedor explorar e experimentar diferentes nós para ver o que funciona melhor para um determinado tipo de problema, também antes de começar a brincar com isso, você deve reconhecer outros tipos de redes neurais que discutimos anteriormente.
Há um ótimo tópico em stats.stackexchange.com sobre este assunto com o link aqui.
Eu acho que ter o mesmo número de nós que a camada de entrada para todas as camadas ocultas é ideal para uma rede neural feed-forward, que é a configuração que eu uso na maioria das vezes.
MLP com um único nó e uma única camada oculta é um modelo linear.
Se você prestar atenção nas operações feitas dentro de um único nó de uma camada oculta de uma rede neural, perceberá isso:
Q = wi * Ii + b
enquanto isso, a equação de regressão linear é;
Y = mi * xi + c
Nota alguma semelhança? Eles são a mesma coisa teoricamente, esta operação é o regressor linear isso nos traz de volta à importância do viés de uma camada oculta. O viés é uma constante para o modelo linear com o papel de adicionar a flexibilidade do nosso modelo para se ajustar ao conjunto de dados dado, sem ele todos os modelos passarão entre os eixos x e y em zero(0).

Ao treinar a rede neural, os pesos e os vieses serão atualizados. Os parâmetros que produzem menos erros para o nosso modelo serão mantidos e lembrados no conjunto de dados de teste.
Agora deixe-me construir uma MLP para classificação de duas classes para esclarecer os pontos. Antes disso, deixe-me gerar um conjunto de dados aleatório com amostras rotuladas que nós veremos por meio da nossa rede neural. A função abaixo faz um conjunto de dados aleatório, a segunda amostra sendo multiplicada por 5 a primeira sendo multiplicada por 2 apenas para obter os dados em diferentes escalas.
void MakeBlobs(int size=10) { ArrayResize(data_blobs,size); for (int i=0; i<size; i++) { data_blobs[i].sample_1 = (i+1)*(2); data_blobs[i].sample_2 = (i+1)*(5); data_blobs[i].class_ = (int)round(nn.MathRandom(0,1)); } }
Quando eu imprimo o conjunto de dados, aqui está a saída:
QK 0 18:27:57.298 TestScript (EURUSD,M1) CNeural Nets Initialized activation = SIGMOID UseSoftMax = No IR 0 18:27:57.298 TestScript (EURUSD,M1) [sample_1] [sample_2] [class_] LH 0 18:27:57.298 TestScript (EURUSD,M1) [0] 2.0000 5.0000 0 GG 0 18:27:57.298 TestScript (EURUSD,M1) [1] 4.0000 10.0000 0 NL 0 18:27:57.298 TestScript (EURUSD,M1) [2] 6.0000 15.0000 1 HJ 0 18:27:57.298 TestScript (EURUSD,M1) [3] 8.0000 20.0000 0 HQ 0 18:27:57.298 TestScript (EURUSD,M1) [4] 10.0000 25.0000 1 OH 0 18:27:57.298 TestScript (EURUSD,M1) [5] 12.0000 30.0000 1 JF 0 18:27:57.298 TestScript (EURUSD,M1) [6] 14.0000 35.0000 0 DL 0 18:27:57.298 TestScript (EURUSD,M1) [7] 16.0000 40.0000 1 QK 0 18:27:57.298 TestScript (EURUSD,M1) [8] 18.0000 45.0000 0 QQ 0 18:27:57.298 TestScript (EURUSD,M1) [9] 20.0000 50.0000 0
A próxima parte é gerar os valores de peso aleatórios e o viés,
generate_weights(weights,ArraySize(Inputs));
generate_bias(biases); Aqui está a saída:
RG 0 18:27:57.298 TestScript (EURUSD,M1) weights QS 0 18:27:57.298 TestScript (EURUSD,M1) 0.7084 -0.3984 0.6182 0.6655 -0.3276 0.8846 0.5137 0.9371 NL 0 18:27:57.298 TestScript (EURUSD,M1) biases DD 0 18:27:57.298 TestScript (EURUSD,M1) -0.5902 0.7384
Agora vamos ver todas as operações na função principal do nosso script:
#include "NeuralNets.mqh"; CNeuralNets *nn; input int batch_size =10; input int hidden_layers =2; data data_blobs[]; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- nn = new CNeuralNets(SIGMOID); MakeBlobs(batch_size); ArrayPrint(data_blobs); double Inputs[],OutPuts[]; ArrayResize(Inputs,2); ArrayResize(OutPuts,2); double weights[], biases[]; generate_weights(weights,ArraySize(Inputs)); generate_bias(biases); Print("weights"); ArrayPrint(weights); Print("biases"); ArrayPrint(biases); for (int i=0; i<batch_size; i++) { Print("Dataset Iteration ",i); Inputs[0] = data_blobs[i].sample_1; Inputs[1]= data_blobs[i].sample_2; nn.FeedForwardMLP(hidden_layers,Inputs,weights,biases,OutPuts); } delete(nn); }
Coisas a observar:
- O número de viés é o mesmo que o número de camadas ocultas.
- Número total de pesos = número de entradas ao quadrado multiplicado pelo número de camadas ocultas. Isso foi possível pelo fato de nossa rede ter o mesmo número de nós que a camada de entrada/camada anterior da rede (todas as camadas têm o mesmo número de nós da entrada para a saída).
- O mesmo princípio será seguido, digamos que se você tiver 3 nós de entrada, todas as camadas ocultas terão 3 nós, exceto a última camada onde veremos como lidar com isso.
Olhando para o conjunto de dados gerado aleatoriamente, você notará duas características/colunas de entrada no conjunto de dados e eu escolhi ter 2 camadas ocultas, aqui está uma breve visão geral em nossos logs de como nosso modelo realizará os cálculos (previna esses logs definindo o modo de depuração para false no código).
NL 0 18:27:57.298 TestScript (EURUSD,M1) Dataset Iteration 0 EJ 0 18:27:57.298 TestScript (EURUSD,M1) << Hidden Layer 1 >> GO 0 18:27:57.298 TestScript (EURUSD,M1) NS 0 18:27:57.298 TestScript (EURUSD,M1) HLNode 1 EI 0 18:27:57.298 TestScript (EURUSD,M1) i 0 w 0 = input 2.00000 x weight 0.70837 FQ 0 18:27:57.298 TestScript (EURUSD,M1) i 0 w 1 = input 5.00000 x weight -0.39838 QP 0 18:27:57.298 TestScript (EURUSD,M1) dot_Product -0.57513 + bias -0.590 = -1.16534 RH 0 18:27:57.298 TestScript (EURUSD,M1) Activation function Output =0.23770 CQ 0 18:27:57.298 TestScript (EURUSD,M1) OE 0 18:27:57.298 TestScript (EURUSD,M1) HLNode 2 CO 0 18:27:57.298 TestScript (EURUSD,M1) i 1 w 2 = input 2.00000 x weight 0.61823 FI 0 18:27:57.298 TestScript (EURUSD,M1) i 1 w 3 = input 5.00000 x weight 0.66553 PN 0 18:27:57.298 TestScript (EURUSD,M1) dot_Product 4.56409 + bias -0.590 = 3.97388 GM 0 18:27:57.298 TestScript (EURUSD,M1) Activation function Output =0.98155 DI 0 18:27:57.298 TestScript (EURUSD,M1) << Hidden Layer 2 >> GL 0 18:27:57.298 TestScript (EURUSD,M1) NF 0 18:27:57.298 TestScript (EURUSD,M1) HLNode 1 FH 0 18:27:57.298 TestScript (EURUSD,M1) i 0 w 0 = input 0.23770 x weight -0.32764 ID 0 18:27:57.298 TestScript (EURUSD,M1) i 0 w 1 = input 0.98155 x weight 0.88464 QO 0 18:27:57.298 TestScript (EURUSD,M1) dot_Product 0.79044 + bias 0.738 = 1.52884 RK 0 18:27:57.298 TestScript (EURUSD,M1) Activation function Output =0.82184 QG 0 18:27:57.298 TestScript (EURUSD,M1) IH 0 18:27:57.298 TestScript (EURUSD,M1) HLNode 2 DQ 0 18:27:57.298 TestScript (EURUSD,M1) i 1 w 2 = input 0.23770 x weight 0.51367 CJ 0 18:27:57.298 TestScript (EURUSD,M1) i 1 w 3 = input 0.98155 x weight 0.93713 QJ 0 18:27:57.298 TestScript (EURUSD,M1) dot_Product 1.04194 + bias 0.738 = 1.78034 JP 0 18:27:57.298 TestScript (EURUSD,M1) Activation function Output =0.85574 EI 0 18:27:57.298 TestScript (EURUSD,M1) GS 0 18:27:57.298 TestScript (EURUSD,M1) Final MLP output(s) OF 0 18:27:57.298 TestScript (EURUSD,M1) 0.82184 0.85574 CN 0 18:27:57.298 TestScript (EURUSD,M1) Dataset Iteration 1 KH 0 18:27:57.298 TestScript (EURUSD,M1) << Hidden Layer 1 >> EM 0 18:27:57.298 TestScript (EURUSD,M1) DQ 0 18:27:57.298 TestScript (EURUSD,M1) HLNode 1 QH 0 18:27:57.298 TestScript (EURUSD,M1) i 0 w 0 = input 4.00000 x weight 0.70837 PD 0 18:27:57.298 TestScript (EURUSD,M1) i 0 w 1 = input 10.00000 x weight -0.39838 HR 0 18:27:57.298 TestScript (EURUSD,M1) dot_Product -1.15027 + bias -0.590 = -1.74048 DJ 0 18:27:57.298 TestScript (EURUSD,M1) Activation function Output =0.14925 OP 0 18:27:57.298 TestScript (EURUSD,M1) CK 0 18:27:57.298 TestScript (EURUSD,M1) HLNode 2 MN 0 18:27:57.298 TestScript (EURUSD,M1) i 1 w 2 = input 4.00000 x weight 0.61823 NH 0 18:27:57.298 TestScript (EURUSD,M1) i 1 w 3 = input 10.00000 x weight 0.66553 HI 0 18:27:57.298 TestScript (EURUSD,M1) dot_Product 9.12817 + bias -0.590 = 8.53796 FO 0 18:27:57.298 TestScript (EURUSD,M1) Activation function Output =0.99980 RG 0 18:27:57.298 TestScript (EURUSD,M1) << Hidden Layer 2 >> IR 0 18:27:57.298 TestScript (EURUSD,M1) PD 0 18:27:57.298 TestScript (EURUSD,M1) HLNode 1 RN 0 18:27:57.298 TestScript (EURUSD,M1) i 0 w 0 = input 0.14925 x weight -0.32764 HF 0 18:27:57.298 TestScript (EURUSD,M1) i 0 w 1 = input 0.99980 x weight 0.88464 EM 0 18:27:57.298 TestScript (EURUSD,M1) dot_Product 0.83557 + bias 0.738 = 1.57397 EL 0 18:27:57.298 TestScript (EURUSD,M1) Activation function Output =0.82835 KE 0 18:27:57.298 TestScript (EURUSD,M1) GN 0 18:27:57.298 TestScript (EURUSD,M1) HLNode 2 LS 0 18:27:57.298 TestScript (EURUSD,M1) i 1 w 2 = input 0.14925 x weight 0.51367 FL 0 18:27:57.298 TestScript (EURUSD,M1) i 1 w 3 = input 0.99980 x weight 0.93713 KH 0 18:27:57.298 TestScript (EURUSD,M1) dot_Product 1.01362 + bias 0.738 = 1.75202 IR 0 18:27:57.298 TestScript (EURUSD,M1) Activation function Output =0.85221 OH 0 18:27:57.298 TestScript (EURUSD,M1) IM 0 18:27:57.298 TestScript (EURUSD,M1) Final MLP output(s) MH 0 18:27:57.298 TestScript (EURUSD,M1) 0.82835 0.85221
Agora preste atenção na saída final da MLP para todas as iterações, você notará um comportamento estranho de que as saídas tendem a ter os mesmos valores. Este problema tem várias causas, conforme discutido no Stack Overflow, sendo um deles usando a função de ativação errada na camada de saída. É aqui que entra a função de ativação do SoftMax.
Pelo que entendi a função sigmoide retorna as probabilidades somente quando há um único nó na camada de saída, que tem que classificar uma classe, neste caso você precisaria da saída de sigmoide para te dizer se algo pertence a uma determinada classe ou não, mas é outra história diferente em multiclasse. Se nós somarmos as saídas de nossos nós finais, o valor é maior que um (1) na maioria das vezes, então agora você sabe que não são probabilidades porque a probabilidade não pode ser maior que 1.
Se aplicarmos SoftMax na última camada as saídas serão.
First Iteration outputs [0.4915 0.5085] , Second Iteration Outputs [0.4940 0.5060]
você pode interpretar as saídas como [Probabilidade pertencente à classe 0 Probabilidade pertencente à classe 1] nesse caso
Bem, pelo menos agora nós temos probabilidades nas quais podemos confiar para interpretar algo significativo da nossa rede.
Pensamentos finais
Nós não terminamos com a rede neural feed-forward, mas pelo menos por enquanto você tem uma compreensão da teoria e das coisas mais importantes que serão úteis para você dominar as redes neurais em MQL5. A rede neural Feedforward desenvolvida é aquela para fins de classificação, o que significa que as funções de ativação adequadas são sigmoide e tanh, dependendo das amostras e classes que você deseja classificar em seu conjunto de dados. Nós não conseguimos alterar a camada de saída para retornar o que gostaríamos de brincar com ela e nem os nós nas camadas ocultas, a introdução de matrizes ajudará toda essa operação a se tornar dinâmica para que possamos construir uma rede neural padrão para qualquer tarefa, esse é o objetivo desta série de artigos, fique atento para mais.
Saber quando usar a rede neural também é importante porque nem todas as tarefas precisam ser resolvidas por redes neurais, se uma tarefa pode ser resolvida por regressão linear, um modelo linear pode superar a rede neural. Essa é uma das coisas a ter em mente.
Repositório do GitHub: https://github.com/MegaJoctan/NeuralNetworks-MQL5
Leitura adicional | Livros | Referências
-
Neural Networks for Pattern Recognition (Advanced Texts in Econometrics)
-
Neural Networks: Tricks of the Trade (Lecture Notes in Computer Science, 7700)
-
Deep Learning (Adaptive Computation and Machine Learning series)
Referência dos artigos:
-
Ciência de Dados e Aprendizado de Máquina (Parte 01): Regressão Linear
-
Ciência de Dados e Aprendizado de Máquina (Parte 02): Regressão Logística
-
Ciência de Dados e Aprendizado de Máquina (Parte 03): Regressões Matriciais
-
Ciência de Dados e Aprendizado de Máquina (Parte 06): Gradiente Descendente
Traduzido do Inglês pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/en/articles/11275
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

 Criação de Indicadores complexos de maneira fácil usando objetos
Criação de Indicadores complexos de maneira fácil usando objetos
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
...
Você poderia explicar isso? Ou dar alguns exemplos?
A diferença entre a otimização no testador de estratégias e a otimização dos parâmetros da rede neural é o objetivo. No testador de estratégias, tendemos a nos concentrar nos parâmetros que fornecem os resultados mais lucrativos ou, pelo menos, os resultados de negociação que desejamos, o que não significa necessariamente que a rede neural tenha um bom modelo que tenha levado a esse tipo de resultado.
Algumas pessoas preferem colocar os pesos e o viés como parâmetros de entrada dos sistemas baseados em redes neurais(Feed forward, grosso modo), mas acho que otimizar usando o testador de estratégia é basicamente encontrar os valores aleatórios dos melhores resultados(encontrar os ótimos parece depender da sorte), ao passo que, se otimizarmos usando a descida do gradiente estocástico, estaremos nos movendo em direção ao modelo com menos erros nas previsões em cada etapa.
A diferença entre a otimização no testador de estratégia e a otimização dos parâmetros da rede neural é a meta. No testador de estratégia, tendemos a nos concentrar nos parâmetros que fornecem os resultados mais lucrativos ou, pelo menos, os resultados de negociação que desejamos.
Algumas pessoas preferem colocar os pesos e o viés como parâmetros de entrada dos sistemas baseados em redes neurais(Feed forward, grosso modo), mas acho que otimizar usando o testador de estratégia é basicamente encontrar os valores aleatórios dos melhores resultados(encontrar os ótimos parece depender da sorte), ao passo que, se otimizarmos usando a descida do gradiente estocástico, estaremos nos movendo em direção ao modelo com menos erros nas previsões em cada etapa.
Obrigado por sua resposta.
Entendi seu ponto de vista.
Por que você começou da primeira parte?
artigo antigo:
CIÊNCIA DE DADOS E APRENDIZADO DE MÁQUINA (PARTE 01): REGRESSÃO LINEAR
https://www.mql5.com/pt/articles/10459
Por que você começou da primeira parte?
Artigo antigo:
CIÊNCIA DE DADOS E APRENDIZADO DE MÁQUINA (PARTE 01): REGRESSÃO LINEAR
https://www.mql5.com/pt/articles/10459
O que você quer dizer com isso?
Por que você começou da primeira parte?
artigo antigo:
CIÊNCIA DE DADOS E APRENDIZADO DE MÁQUINA (PARTE 01): REGRESSÃO LINEAR
https://www.mql5.com/pt/articles/10459