
取引におけるニューラルネットワーク:Adam-mini最適化によるメモリ消費量の削減

はじめに
ニューラルネットワークについて学び始めたとき、モデルパラメータを最適化するためのさまざまなアプローチについて説明しました。実際の作業においても、状況に応じた異なる手法が用いられますが、最もよく使用されるのは、各モデルパラメータに対して適応的に最適な学習率を調整できるAdam法です。しかし、この適応性にはトレードオフがあります。Adamアルゴリズムは、各パラメータに対して1次モーメント推定値と2次モーメント推定値を維持する必要があり、それに伴いメモリ使用量が増加します。このメモリ消費は、大規模モデルの訓練時に深刻な問題を引き起こします。特に、高いメモリ要求を持つアルゴリズムは、計算負荷をCPUにオフロードする必要があり、これがレイテンシの増加を招き、訓練プロセスの速度低下につながることがよくあります。こうした課題を踏まえ、新しい最適化手法の開発や、既存技術の改善がますます重要になっています。
2024年7月に公開された論文「Adam-mini:Use Fewer Learning Rates To Gain More」稿では有望な解決策が提案されました。著者は、メモリ消費を抑えつつ、従来のAdamと同等のパフォーマンスを維持する修正手法を導入しました。Adam-miniと呼ばれるこの新しいオプティマイザーは、モデルパラメータをブロックに分割し、ブロックごとに1つの学習率を割り当てることで、次のような利点を提供します。
- 軽量:Adam-miniは、Adamで使用される学習率の数を大幅に削減し、メモリ消費を45~50%削減します。
- 効率:リソース使用量が少ないにもかかわらず、Adam-miniは標準のAdamと同等かそれ以上のパフォーマンスを実現します。
1. Adam-miniアルゴリズム
Adam-miniの著者はAdamにおけるv(2次モーメント推定値)の役割を分析し、最適化の可能性を探求しています。Adamでは、vは各パラメータに対して個別の学習率を提供します。Transformerアーキテクチャやその他のニューラルネットワークでは、ヘッセ行列がブロック対角構造を示す傾向があることが観察されています。さらに、各Transformerブロックは異なる固有値分布を持つため、固有値の異質性を処理するために、Transformerではブロックごとに異なる学習率が必要になります。この機能はAdamのvによって提供されます。
ただし、Adamは各ブロックに学習率を割り当てるだけでなく、個々のパラメータごとにも学習率を割り当てます。パラメータの数はブロックの数を大幅に上回るため、すべてのパラメータに一意の学習率を割り当てる必要があるのか、そうでない場合、どの程度最適化できるのかといった疑問が生じます。
著者は、一般的な最適化タスクを対象にこの問題を調査し、次の結論を導きました。
- Adamは、単一の最適学習率法よりも優れたパフォーマンスを発揮する。Adamは異なるパラメータに異なる学習率を適用するため、この結果は予想されたものである。
- 密なヘッセ行列のサブブロック内では、単一の最適学習率がAdamの性能を上回る可能性がある。
- したがって、「ブロック単位」の勾配降下法に適切な学習率を適用することで、訓練効率が向上する。
ブロック対角ヘッセ行列を持つ一般的な最適化問題では、学習率の数を増やしても必ずしも追加の利点が得られるわけではありません。具体的には、各密なサブブロックに対して適切な単一の学習率を選択すれば、最適なパフォーマンスを実現できる。
Transformerベースのアーキテクチャにおいても、同様の動作が観察されています。Adam-miniの著者は4層Transformerを用いた実験をおこない、学習率の数を大幅に削減しながら、Adamと同等以上のパフォーマンスを達成できることを示しました。
ただし、最適な学習率を効率的に決定する方法については、依然として未解決の課題が残っています。
Adam-miniの目標は、網羅的なグリッド検索をおこなわずに、Adamにおける学習率のメモリ使用量を削減することです。
Adam-miniは2つのステップで構成され、ステップ1は初期化にのみ実行されます。
まず、モデルパラメータをブロックに分割します。Transformerの場合、Adam-miniの著者は、すべてのQueryおよびKeysエンティティをアテンションヘッド単位でグループ化することを提案しています。それ以外の場合は、層ごとに1つの2次モーメント推定値が使用されます。
埋め込み層は個別に処理されます。埋め込みには多くのゼロ値が含まれるため、その平均分布が元の変数の分布とは大きく異なり、従来のAdamの方が適しています。
アルゴリズムの2番目のステップでは、パラメータの各ブロック(埋め込みブロックの外側)に対して1つの学習率が使用されます。各ブロックで適切な学習率を効果的に選択するために、Adam-miniはAdamの勾配の二乗をその平均値に置き換えるだけです。Adam-miniの著者は、古典的なAdamと同様に、これらの平均値に移動平均を適用します。
設計上、Adam-miniは、Transformersの学習率の数を、パラメータごとに1つから、埋め込み層のサイズ、出力層のサイズ、および非埋め込みブロックの数の合計に減らします。メモリ節約の程度は、モデル内の非埋め込みパラメータの割合によって異なります。
Adam-miniは、特にハードウェアリソースが限られている場合に、Adamと比較して高いスループットを実現できます。これには2つの理由があります。まず、Adam-miniは更新ルールに追加の計算負荷を加えません。さらに、Adam-miniは、Adamで使用される平方根とテンソル除算の演算回数を大幅に削減します。
2番目に、メモリ使用量が少ないため、Adam-miniはGPU上でより大きなバッチサイズをサポートできると同時に、訓練のもう1つの大きなボトルネックであるGPUとCPU間の通信を削減できます。
これらの改善により、Adam-miniはメモリ消費と計算コストの両方を削減し、大規模モデルの事前訓練を高速化できます。
Adam-miniは、各ブロック内のv Adam平均を使用して、各密なヘッセ行列サブブロックの学習率を予測します。このアプローチは計算効率は高いですが、完全に最適ではない可能性があります。ただし、現在の設計は、メモリ要件を大幅に削減しつつ、Adamと同等、またはわずかに優れたパフォーマンスを実現できます。
2.MQL5での実装
Adam-mini法の理論的側面を検討した後、この記事の実践的な部分に移りましょう。この部分では、MQL5を使用して、説明したアプローチの独自のビジョンを実装します。
この作業は、以前の記事で行った作業とは大きく異なることに注意してください。通常、新しいアプローチはモデル内の単一層クラスのフレームワーク内で実装しますが、この場合は、以前に開発されたクラス全体に変更を導入する必要があります。これは、これらの各クラスに、層レベルでモデルパラメータを更新するためのアルゴリズムを定義する、オーバーライドまたは継承されたupdateInputWeightsメソッドが含まれているためです。
もちろん、一部のupdateInputWeightsメソッドは複雑なアーキテクチャコンポーネントに属しており、ネストされたオブジェクトの対応するメソッドを呼び出すだけです。前回の記事で説明したデコーダーが良い例です。このような場合、アルゴリズムは選択された最適化手法に依存しません。
bool CNeuronSTNNDecoder::updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *Context) { if(!cEncoder.UpdateInputWeights(NeuronOCL, Context)) return false; if(!CNeuronMLCrossAttentionMLKV::updateInputWeights(cEncoder.AsObject(), Context)) return false; //--- return true; }
関数呼び出しの階層を下っていくと、常に、主要なパラメータ更新アルゴリズムが実装されている基本的な「主力部分」に到達します。
2.1 基本的全結合層におけるAdam-miniの実装
そのようなクラスの1つが、基本的全結合層であるCNeuronBaseOCLです。したがって、私たちの仕事はここから始まります。
計算タスクのほとんどは並列処理のためにGPU側で実装されている点を理解しておくことが重要です。このプロセスも例外ではありません。したがって、OpenCLプログラムと対話して、UpdateWeightsAdamMiniという新しいカーネルを作成します。
実際のコードに入る前に、アーキテクチャソリューションについて簡単に説明しましょう。
まず、Adam-mini最適化手法と従来のAdamの主な違いは、主に2次モーメントvの計算にあります。Adam-miniの著者は、個々のパラメータの勾配を使用する代わりに、グループの平均値を使用することを提案しています。この単純な平均を計算するアルゴリズムは簡単です。そうすることで、各グループに対して2次モーメントの値が1つだけ保存されるため、大量のメモリが解放されます。
一方、各スレッドがブロック全体の平均を繰り返し計算するのは非効率です。全結合層の場合、Adam-mini法では1つの学習率のみを使用することが推奨されていることに注意してください。したがって、各スレッドの層のすべてのパラメータの勾配の平均を再計算することは、控えめに言っても効率的ではないようです。さらに、グローバルメモリへのアクセスにかかるコストが高いことを考慮すると、グローバルメモリアクセスを最小限に抑えながら、このプロセスを複数のスレッド間で並列化することが最善の解決策となります。しかし、これにより、スレッド間のデータ交換をどのように整理するかという問題がすぐに発生します。
以前の記事では、スレッド同期を使用してローカルグループ内でデータを交換する方法についてすでに学習しました。ただし、層のパラメータ更新プロセス全体を単一のローカルグループ内に整理することは、特に魅力的ではないようです。そのため、今回の実装では、結果のテンソルのサイズに合わせて計算される2次モーメントの数を増やすことにしました。
ご存知のとおり、全結合層のパラメータの数は、入力テンソルのサイズと結果テンソルのサイズの積です。さらに、各ニューロンにバイアスパラメータを使用すると、結果テンソルのサイズに等しい数のパラメータが追加されます。従来のAdamは、1次モーメントと2次モーメントの両方に同じ数の値を格納します。Adam-miniの実装では、保存される2次モーメント値の数が大幅に削減されます。
![]()
ここで、2次モーメントの平均値を計算するプロセスについて少し説明しましょう。1つのパラメータの誤差勾配は、層出力の誤差勾配(活性化関数の導関数によって補正)と対応する入力値の積に等しくなります。
![]()
したがって、二乗勾配の平均は次のように計算できます。
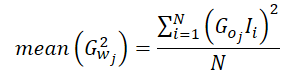
私たちの実装では、結果層内の単一のニューロンの平均勾配を計算するため、そのニューロンの勾配を方程式から除外できます。
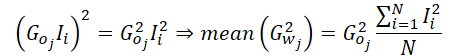
つまり、平均2次モーメントの実装では、入力データの平均の2乗値を計算するだけで済みます。そうすることで、出力勾配を格納するグローバルメモリバッファへの頻繁なアクセスが不要になります。この平均値を取得した後、出力勾配を1回だけ取得し、それを二乗して、計算された平均値を掛けます。最後に、結果の値をローカルグループ全体に配布して、さらに計算をおこないます。
計算プロセスを明確に理解できたので、UpdateWeightsAdamMiniカーネルへの実装に進むことができます。このカーネルのパラメータは、従来のAdamカーネルのパラメータとほぼ同じです。これらには5つのデータバッファと3つの定数が含まれます。
- matrix_w:層パラメータの行列
- matrix_g:層出力における誤差勾配テンソル
- matrix_i:入力データバッファ
- matrix_m:1次モーメントテンソル
- matrix_v:2次モーメントテンソル
- l:学習率
- b1:一次モーメント平滑化係数(ß1)
- b2:2次モーメント平滑化係数(ß2)
__kernel void UpdateWeightsAdamMini(__global float *matrix_w, __global const float *matrix_g, __global const float *matrix_i, __global float *matrix_m, __global float *matrix_v, const float l, const float b1, const float b2 ) { //--- inputs const size_t i = get_local_id(0); const size_t inputs = get_local_size(0) - 1; //--- outputs const size_t o = get_global_id(1); const size_t outputs = get_global_size(1);
カーネルの実行は2次元のタスク空間で計画されます。最初の次元は、入力値の数とオフセット要素の合計に対応します。2番目は結果テンソルのサイズです。カーネル本体では、まず両方の次元でスレッドを識別します。
タスク空間の1つの次元に沿ってスレッドをワークグループに結合することに注意してください。
次に、ワークグループのスレッド間でデータを交換するために、ローカルコンテキストメモリ内に配列を編成します。
__local float temp[LOCAL_ARRAY_SIZE]; const int ls = min((uint)LOCAL_ARRAY_SIZE, (uint)inputs);
次のステップは、入力データの平均二乗値を計算することです。一次モーメントの計算には入力データバッファも必要になるため、各スレッドはまずグローバル入力データバッファから対応する値を取得します。
const float inp = (i < inputs ? matrix_i[i] : 1.0f);
次に、スレッド同期を備えたループを実装します。各スレッドは、入力データ要素の2乗値をローカル配列に追加します。
int count = 0; do { if(count == (i / ls)) { int shift = i % ls; temp[shift] = (count == 0 ? 0 : temp[shift]) + ((isnan(inp) || isinf(inp)) ? 0 : inp*inp); } count++; barrier(CLK_LOCAL_MEM_FENCE); } while(count * ls < inputs);
その後、ローカル配列の要素の値を合計します。
//--- sum count = (ls + 1) / 2; do { if(i < count && (i + count) < ls) { temp[i] += temp[i + count]; temp[i + count] = 0; } count = (count + 1) / 2; barrier(CLK_LOCAL_MEM_FENCE); } while(count > 1);
1つのスレッド内で、2次モーメントの計算を実装し、それをインデックス0のローカル配列要素に保存します。
また、ローカルメモリ配列にアクセスする方が、グローバルメモリバッファにアクセスするよりもはるかに高速であることも覚えておいてください。したがって、グローバルメモリアクセス操作の数を減らすために、現在の層の結果のレベルで誤差勾配を取得し、それをインデックス1のローカル配列要素に保存します。したがって、ワークグループの残りの要素は、後続の操作を実行するときに、グローバルメモリにアクセスするのではなく、ローカルメモリから値を取得します。
ワークグループスレッドの作業を必ず同期してください。
//--- calc v if(i == 0) { temp[1] = matrix_g[o]; if(isnan(temp[1]) || isinf(temp[1])) temp[1] = 0; temp[0] /= inputs; if(isnan(temp[0]) || isinf(temp[0])) temp[0] = 1; float v = matrix_v[o]; if(isnan(v) || isinf(v)) v = 1; temp[0] = b2 * v + (1 - b2) * pow(temp[1], 2) * temp[0]; matrix_v[o] = temp[0]; } barrier(CLK_LOCAL_MEM_FENCE);
2次モーメント値はグローバルデータバッファにすぐに保存されることに注意してください。この簡単な手順により、ワークグループ内の他のスレッドからの不要なグローバルメモリアクセスが排除され、複数のスレッドからの同じグローバルバッファ要素への同時アクセスによって発生する遅延が軽減されます。
次に、私たちのアルゴリズムは古典的なAdamメソッドの操作に従います。この段階では、訓練可能なパラメータのテンソル内のオフセットを決定し、分析されたパラメータの現在の値をグローバルメモリバッファから読み込みます。
const int wi = o * (inputs + 1) + i; float weight = matrix_w[wi]; if(isnan(weight) || isinf(weight)) weight = 0;
一次モーメントの値を計算します。
float m = matrix_m[wi]; if(isnan(m) || isinf(m)) m = 0; //--- calc m m = b1 * m + (1 - b1) * temp[1] * inp; if(isnan(m) || isinf(m)) m = 0;
パラメータ調整のサイズを決定します。
float delta = l * (m / (sqrt(temp[0]) + 1.0e-37f) - (l1 * sign(weight) + l2 * weight)); if(isnan(delta) || isinf(delta)) delta = 0;
その後、パラメータ値を修正し、新しい値をグローバルデータバッファに保存します。
if(delta > 0) matrix_w[wi] = clamp(weight + delta, -MAX_WEIGHT, MAX_WEIGHT); matrix_m[wi] = m; }
ここで、一次モーメントの値を保存し、カーネル操作を完了します。
OpenCL側で変更を加えた後、メインプログラムにいくつかの編集を加える必要があります。まず、列挙に新しい最適化手法を追加します。
//+------------------------------------------------------------------+ /// Enum of optimization method used | //+------------------------------------------------------------------+ enum ENUM_OPTIMIZATION { SGD, ///< Stochastic gradient descent ADAM, ///< Adam ADAM_MINI ///< Adam-mini };
その後、CNeuronBaseOCL::updateInputWeightsメソッドに変更を加えます。ここで、変数宣言ブロックに、ワークグループのサイズを記述する配列local_work_size(以下のコードでは下線が引かれています)を追加します。この段階では、対応する最適化手法を使用する場合にのみ値が必要になるため、値を割り当てません。
bool CNeuronBaseOCL::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { if(CheckPointer(OpenCL) == POINTER_INVALID || CheckPointer(NeuronOCL) == POINTER_INVALID) return false; uint global_work_offset[2] = {0, 0}; uint global_work_size[2], local_work_size[2]; global_work_size[0] = Neurons(); global_work_size[1] = NeuronOCL.Neurons() + 1; uint rest = 0; float lt = lr;
次に、モデルパラメータを最適化するために選択された方法に応じてアルゴリズムが分岐します。実行のためにカーネルをキューに入れるアルゴリズムは、以前に検討した最適化手法で使用したのと同じものを使用するため、ここでは詳しく説明しません。
switch(NeuronOCL.Optimization()) { case SGD: ......... ......... ......... break; case ADAM: ........ ........ ........ break;
追加されたコードを見てみましょう。まず、カーネルが正しく動作するために必要なパラメータを渡します。
case ADAM_MINI: if(!OpenCL.SetArgumentBuffer(def_k_UpdateWeightsAdamMini, def_k_wuam_matrix_w, NeuronOCL.getWeightsIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_UpdateWeightsAdamMini, def_k_wuam_matrix_g, getGradientIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_UpdateWeightsAdamMini, def_k_wuam_matrix_i, NeuronOCL.getOutputIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_UpdateWeightsAdamMini, def_k_wuam_matrix_m, NeuronOCL.getFirstMomentumIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_UpdateWeightsAdamMini, def_k_wuam_matrix_v, NeuronOCL.getSecondMomentumIndex())) return false; lt = (float)(lr * sqrt(1 - pow(b2, (float)t)) / (1 - pow(b1, (float)t))); if(!OpenCL.SetArgument(def_k_UpdateWeightsAdamMini, def_k_wuam_l, lt)) return false; if(!OpenCL.SetArgument(def_k_UpdateWeightsAdamMini, def_k_wuam_b1, b1)) return false; if(!OpenCL.SetArgument(def_k_UpdateWeightsAdamMini, def_k_wuam_b2, b2)) return false;
その後、カーネルのグローバル作業と個別の作業グループのタスクスペースを定義します。
global_work_size[0] = NeuronOCL.Neurons() + 1; global_work_size[1] = Neurons(); local_work_size[0] = global_work_size[0]; local_work_size[1] = 1;
最初の次元では、グローバルとワークグループの両方で、入力データ層のサイズより1要素大きい値を指定することに注意してください。これはオフセットパラメータです。しかし、2番目の次元では、現在のニューラル層内の要素の数を全体的に示します。ワークグループの場合、このディメンションに1つの要素を指定します。これは、現在の層の1ニューロン内のワークグループの操作に対応します。
準備作業が完了すると、カーネルは実行キューに配置されます。
ResetLastError(); if(!OpenCL.Execute(def_k_UpdateWeightsAdamMini, 2, global_work_offset, global_work_size, local_work_size)) { printf("Error of execution kernel UpdateWeightsAdamMini: %d", GetLastError()); return false; } t++; break; default: return false; break; } //--- return true; }
また、誤った最適化手法が指定された場合に備えて、否定的な結果で終了する機能を追加します。
これで、基本的全結合層CNeuronBaseOCL::updateInputWeightsのパラメータ更新メソッドの実装が完了します。ただし、これらの変更の主な目的は、Adam最適化手法を使用する際のメモリ消費を削減することであることを思い出してください。したがって、Adam-mini最適化手法が選択されたときに2次モーメントバッファのサイズを縮小するには、CNeuronBaseOCL::Init初期化メソッドも調整する必要があります。これらの変更は最小限かつ対象を絞ったものであるため、この記事ではメソッドのアルゴリズムについて詳しく説明しません。代わりに、対応するバッファの初期化ブロックのみを紹介します。
if(CheckPointer(SecondMomentum) == POINTER_INVALID) { SecondMomentum = new CBufferFloat(); if(CheckPointer(SecondMomentum) == POINTER_INVALID) return false; } if(!SecondMomentum.BufferInit((optimization == ADAM_MINI ? numOutputs : count), 0)) return false; if(!SecondMomentum.BufferCreate(OpenCL)) return false;
このメソッドの完全な実装と、この記事の作成に使用されたすべてのプログラムの完全なコードは、添付ファイルで確認できます。
2.2 畳み込み層におけるAdam-mini
Transformerを含むさまざまなアーキテクチャで広く使用されているもう1つの基本的な構成要素は、畳み込み層です。
Adam-mini最適化手法をその機能に統合すると、主に畳み込み層の特殊な性質により、いくつかの独特な側面が生じます。全結合層では、各訓練可能なパラメータは、1つの入力ニューロンの値を現在の層の1つのニューロンにのみ伝達する役割を担いますが、畳み込み層では、通常、パラメータの数は少なくなりますが、各パラメータはより広範囲に使用されます。
さらに、Transformerアルゴリズムでは、畳み込み層を使用してQuery、Key、Valueエンティティを生成することに注意することが重要です。これらのエンティティには、Adam-mini法の特殊な実装が必要です。
畳み込み層内でAdam-mini法を実装する場合は、これらすべての要素を考慮する必要があります。
全結合層と同様に、OpenCL側でメソッドを実装することから始めます。ここでは、UpdateWeightsConvAdamMiniカーネルを作成します。よく知られている変数に加えて、このカーネルでは、入力データのシーケンス長と畳み込みウィンドウのストライドという2つの新しい定数が導入されています。
__kernel void UpdateWeightsConvAdamMini(__global float *matrix_w, __global const float *matrix_i, __global float *matrix_m, __global float *matrix_v, const int inputs, const float l, const float b1, const float b2, int step ) { //--- window in const size_t i = get_global_id(0); const size_t window_in = get_global_size(0) - 1; //--- window out const size_t f = get_global_id(1); const size_t window_out = get_global_size(1); //--- head window out const size_t f_h = get_local_id(1); const size_t window_out_h = get_local_size(1); //--- variable const size_t v = get_global_id(2); const size_t variables = get_global_size(2);
カーネルパラメータでは、入力データウィンドウのサイズと使用するフィルタの数を指定しないことに注意してください。これらのパラメータは、他の2つのパラメータとともにタスクスペースに移動されます。これは考慮すべき重要な側面です。
このカーネルは、3次元タスク空間で実行されるように設計されています。最初の次元は、入力ウィンドウのサイズとバイアス用の追加要素1つに対応します。ここでは、全結合層のタスク空間との一定の類似性が観察されます。
2番目の次元は使用されるフィルタの数を表し、これは論理的には全結合層の出力次元に対応します。
ワークグループについては、個々の畳み込みフィルターごとに作成するのではなく、Transformerアーキテクチャのアテンションヘッドごとにグループ化します。
ユーザーは各ヘッドに対して1つの畳み込みフィルターのみ指定できることに注意してください。この場合、各畳み込みフィルタは、全結合層の実装と同様の個別の学習率を受け取ります。
3番目の次元は、個々のユニタリシーケンスが独自の畳み込みフィルタを持つマルチモーダル時系列を処理するために導入されました。適応学習率を可能にするために、個別の2次モーメントも作成されます。
「アテンションヘッド」と「ユニタリ時系列」は混同しないように区別する必要があります。似ているように見えるかもしれませんが、役割は異なります。ユニタリ時系列は入力テンソルを除算します。アテンションヘッドは出力テンソルを分割します。
カーネル内では、タスク空間のすべての次元でスレッドを識別した後、グローバルデータバッファにメインオフセット定数を定義します。
//--- constants const int total = (inputs - window_in + step - 1) / step; const int shift_var_in = v * inputs; const int shift_var_out = v * total * window_out; const int shift_w = (f + v * window_out) * (window_in + 1) + i;
ワークグループデータ交換用のローカル配列を作成します。
__local float temp[LOCAL_ARRAY_SIZE]; const int ls = min((uint)window_in, (uint)LOCAL_ARRAY_SIZE);
準備作業の後、各パラメータの誤差勾配を収集します。
//--- calc gradient float grad = 0; for(int t = 0; t < total; t++) { if(i != window_in && (i + t * window_in) >= inputs) break; float gt = matrix_g[t * window_out + f + shift_var_out] * (i == window_in ? 1 : matrix_i[i + t * step + shift_var_in]); if(!(isnan(gt) || isinf(gt))) grad += gt; }
この場合、各グローバルスレッドは、影響を与えるすべての要素から誤差勾配を完全に収集することに注意してください。全結合層とは異なり、ここでは入力データ要素の値に結果の対応する誤差勾配をすぐに掛け合わせます。
次に、計算された誤差勾配を累積して、ローカル配列内の二乗値を合計しますが、今度はワークグループレベルでおこないます。これを実現するために、必須のスレッド同期を備えたネストされたループ構造を実装します。外側のループは、ワークグループ内のフィルターの数に対応します。内部ループは、単一のフィルターのすべてのパラメータから誤差勾配を収集します。
//--- calc sum grad int count; for(int h = 0; h < window_out_h; h++) { count = 0; do { if(h == f_h) { if(count == (i / ls)) { int shift = i % ls; temp[shift] = ((count == 0 && h == 0) ? 0 : temp[shift]) + ((isnan(grad) || isinf(grad)) ? 0 : grad * grad); } } count++; barrier(CLK_LOCAL_MEM_FENCE); } while((count * ls) < window_in); }
次に、ローカル配列の値を合計します。
count = (ls + 1) / 2; do { if(i < count && (i + count) < ls && f_h == 0) { temp[i] += temp[i + count]; temp[i + count] = 0; } count = (count + 1) / 2; barrier(CLK_LOCAL_MEM_FENCE); } while(count > 1);
また、現在のグループの2次モーメントの値も決定します。
//--- calc v if(i == 0 && f_h == 0) { temp[0] /= (window_in * window_out_h); if(isnan(temp[0]) || isinf(temp[0])) temp[0] = 1; int head = f / window_out_h; float v = matrix_v[head]; if(isnan(v) || isinf(v)) v = 1; temp[0] = clamp(b2 * v + (1 - b2) * temp[0], 1.0e-6f, 1.0e6f); matrix_v[head] = temp[0]; } barrier(CLK_LOCAL_MEM_FENCE);
次に、古典Adam法のアルゴリズムを繰り返します。ここで一次モーメントを定義します。
//--- calc m float mt = clamp(b1 * matrix_m[shift_w] + (1 - b1) * grad, -1.0e5f, 1.0e5f); if(isnan(mt) || isinf(mt)) mt = 0;
分析したパラメータの値を調整します。
float weight = clamp(matrix_w[shift_w] + l * mt / sqrt(temp[0]), -MAX_WEIGHT, MAX_WEIGHT);
そして得られた値を保存します。
if(!(isnan(weight) || isinf(weight)))
matrix_w[shift_w] = weight;
matrix_m[shift_w] = mt;
}
OpenCL側でカーネルを作成した後、メインプログラムの作業に移ります。全結合層の場合と同様に、上記で作成したカーネルの呼び出しをCNeuronConvOCL::updateInputWeightsメソッドに実装します。これを呼び出すアルゴリズムは、全結合層に対して上記で示したものと同様です。通常の畳み込み層では、各アテンションヘッドに1つのフィルタを使用し、1つのユニタリシーケンスを使用します。したがって、タスク空間の次元は次の形式になります。
uint global_work_offset_am[3] = { 0, 0, 0 }; uint global_work_size_am[3] = { iWindow + 1, iWindowOut, iVariables }; uint local_work_size_am[3] = { global_work_size_am[0], 1, 1 };
このメソッドの完全な実装は添付ファイルで確認できます。
ただし、Transformerアーキテクチャを利用するクラスの実装内で作成されたカーネルを使用することについて、少し説明したいと思います。例として、CNeuronMLMHAttentionOCLクラスを考えてみましょう。このクラスは、他のさまざまなアルゴリズムを構築するための親クラスとして機能します。
CNeuronMLMHAttentionOCLクラスには、従来の意味での畳み込み層が含まれていないことに注意することが重要です。代わりに、バッファ配列を整理し、関連するすべてのメソッドをオーバーライドします。畳み込み層のパラメータ更新は、ConvolutionUpdateWeightsメソッドで処理されます。この方法はさまざまな畳み込み層の管理に使用されるため、アテンションヘッドの数(heads)とユニタリシーケンスの数(variables)という2つの追加パラメータを追加します。他のクラスからこのメソッドにアクセスする際に発生する可能性のある問題を回避するために、これらの新しいパラメーターにはデフォルト値が与えられます。
bool CNeuronMLMHAttentionOCL::ConvolutuionUpdateWeights(CBufferFloat *weights, CBufferFloat *gradient, CBufferFloat *inputs, CBufferFloat *momentum1, CBufferFloat *momentum2, uint window, uint window_out, uint step = 0, uint heads = 0, uint variables = 1) { if(CheckPointer(OpenCL) == POINTER_INVALID || CheckPointer(weights) == POINTER_INVALID || CheckPointer(gradient) == POINTER_INVALID || CheckPointer(inputs) == POINTER_INVALID || CheckPointer(momentum1) == POINTER_INVALID) return false;
メソッド本体では、まずメソッドが呼び出し元からパラメータとして受け取るデータバッファへのポインタをチェックします。
次に、畳み込みウィンドウのストライド(step)パラメータの値を確認します。それが「0」に等しい場合は、畳み込みウィンドウに等しいステップを実行します。
if(step == 0) step = window;
この場合、パラメータに符号なしデータ型を使用していることに注意してください。したがって、負の値を含めることはできません。膨らんだパラメータ値の制御はユーザーに任せます。
次に、タスクスペースを定義します。この場合、Adam-mini最適化手法のカーネルは、他の最適化手法で使用される1次元のタスク空間とは異なる3次元のタスク空間を使用します。したがって、それを示すために別の配列を割り当てます。
uint global_work_offset[1] = {0}; uint global_work_size[1]; global_work_size[0] = weights.Total(); uint global_work_offset_am[3] = {0, 0, 0}; uint global_work_size_am[3] = {window, window_out, 1}; uint local_work_size_am[3] = {window, (heads > 0 ? window_out / heads : 1), variables};
ワークグループタスクスペースの2番目の次元を見てみましょう。メソッドパラメータでアテンションヘッドの数が指定されていない場合、各フィルタには個別の学習率が設定されます。アテンションヘッドの数が指定されている場合は、フィルタの合計数をアテンションヘッドの数で割って、アテンションヘッドあたりのフィルタの数を計算します。
このアプローチは、この方法のさまざまな使用シナリオに対応するために選択されました。CNeuronMLMHAttentionOCLクラス内では、畳み込み層は、Query、Key、Valueエンティティの形成と、データ投影(マルチヘッドアテンションダウンサンプリング層とFeedForwardブロック内)の両方に使用されます。
次のステップは、モデルパラメータに使用される最適化手法に応じてアルゴリズムを分離することです。全結合層アルゴリズムの説明と同様に、以前に実装された最適化手法がどのように機能するかについての詳細は説明しません。Adam-mini法ブロックのみを検討します。
if(weights.GetIndex() < 0) return false; float lt = 0; switch(optimization) { case SGD: ........ ........ ........ break; case ADAM: ........ ........ ........ break; case ADAM_MINI: if(CheckPointer(momentum2) == POINTER_INVALID) return false; if(gradient.GetIndex() < 0) return false; if(inputs.GetIndex() < 0) return false; if(momentum1.GetIndex() < 0) return false; if(momentum2.GetIndex() < 0) return false;
ここでは、OpenCLコンテキスト内のデータバッファへのポインタの関連性を確認します。その後、必要なすべてのパラメータをカーネルに渡します。
if(!OpenCL.SetArgumentBuffer(def_k_UpdateWeightsConvAdamMini, def_k_wucam_matrix_w, weights.GetIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_UpdateWeightsConvAdamMini, def_k_wucam_matrix_g, gradient.GetIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_UpdateWeightsConvAdamMini, def_k_wucam_matrix_i, inputs.GetIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_UpdateWeightsConvAdamMini, def_k_wucam_matrix_m, momentum1.GetIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_UpdateWeightsConvAdamMini, def_k_wucam_matrix_v, momentum2.GetIndex())) return false; lt = (float)(lr * sqrt(1 - pow(b2, t)) / (1 - pow(b1, t))); if(!OpenCL.SetArgument(def_k_UpdateWeightsConvAdamMini, def_k_wucam_inputs, inputs.Total())) return false; if(!OpenCL.SetArgument(def_k_UpdateWeightsConvAdamMini, def_k_wucam_l, lt)) return false; if(!OpenCL.SetArgument(def_k_UpdateWeightsConvAdamMini, def_k_wucam_b1, b1)) return false; if(!OpenCL.SetArgument(def_k_UpdateWeightsConvAdamMini, def_k_wucam_b2, b2)) return false; if(!OpenCL.SetArgument(def_k_UpdateWeightsConvAdamMini, def_k_wucam_step, (int)step)) return false;
タスクスペースについてはすでに前に説明しました。そして、カーネルを実行キューに入れる必要があります。
ResetLastError(); if(!OpenCL.Execute(def_k_UpdateWeightsConvAdamMini, 3, global_work_offset_am, global_work_size_am, local_work_size_am)) { string error; CLGetInfoString(OpenCL.GetContext(), CL_ERROR_DESCRIPTION, error); printf("Error of execution kernel %s Adam-Mini: %s", __FUNCSIG__, error); return false; } t++; break; //--- default: printf("Error of optimization type %s: %s", __FUNCSIG__, EnumToString(optimization)); return false; }
また、間違ったタイプのパラメータ最適化を指定した場合にエラーメッセージも追加します。
モデルパラメータを正規化する方法に関するその他のコードは変更されていません。
global_work_size[0] = window_out; OpenCL.SetArgumentBuffer(def_k_NormilizeWeights, def_k_norm_buffer, weights.GetIndex()); OpenCL.SetArgument(def_k_NormilizeWeights, def_k_norm_dimension, (int)window + 1); if(!OpenCL.Execute(def_k_NormilizeWeights, 1, global_work_offset, global_work_size)) { string error; CLGetInfoString(OpenCL.GetContext(), CL_ERROR_DESCRIPTION, error); printf("Error of execution kernel %s Normalize: %s", __FUNCSIG__, error); return false; } //--- return true; }
さらに、上記のクラスの初期化メソッドでは、全結合層の変更を説明するときに提示したアルゴリズムと同様に、2次モーメントを格納するために作成されたデータバッファのサイズを変更します。ただし、この記事ではこれについては詳しく説明しません。これらは添付ファイルで確認できる小さな編集です。
3. テスト
上記では、モデルの2つの基本クラスでのAdam-mini法の実装について説明しました。ここで、提案されたアプローチの有効性を評価します。
この記事では、新しい最適化手法を紹介しました。この最適化手法の有効性を評価するには、さまざまな最適化手法を使用してモデルの訓練プロセスを観察するのが理にかなっています。
この実験では、TPMアルゴリズムの記事からモデルを取得し、モデルのアーキテクチャを変更して、パラメータを最適化する方法のみを変更しました。
言うまでもなく、このアプローチを使用する場合、すべての訓練プログラム、データセット、および訓練プロセスは変更されません。
ご参考までに、モデルはH1時間枠のEURUSDを使用して、2023年全体の履歴データで訓練されました。すべてのインジケーターのパラメータはデフォルトに設定されました。
訓練済みのモデルをテストしたところ、従来のAdam法で訓練されたモデルと同様の結果が得られました。2024年1月のデータのテスト結果を以下に示します。

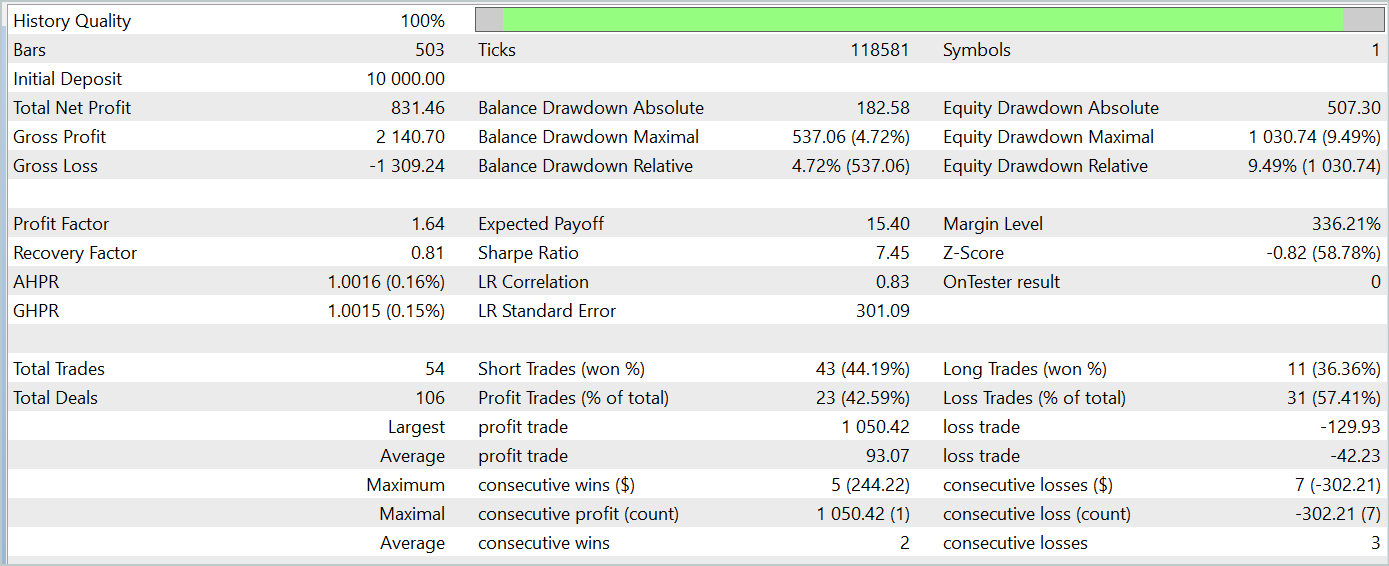
Adam-mini最適化手法の主な目的は、訓練の品質を損なうことなくメモリ消費を削減することであることに注意することが重要です。提案された手法はこの目標をうまく達成します。
結論
本記事では、大規模言語モデルの訓練におけるメモリ使用量の削減とスループットの向上を目的として開発された、新たな最適化手法Adam-miniを紹介しました。Adam-miniは、必要な学習率の数を埋め込み層のサイズ、出力層のサイズ、およびその他の層のブロック数の合計に抑えることで、メモリ効率を向上させます。そのシンプルさ、柔軟性、および高い計算効率により、ディープラーニングの幅広い応用において有望な手法となることが期待されます。
記事の実践的な部分では、提案手法を基本的なニューラルネットワーク層へ統合する方法を示しました。テスト結果は、本手法の開発者が主張する改善点を裏付けるものとなりました。
参照文献
記事で使用されているプログラム
| # | 名前 | 種類 | 詳細 |
|---|---|---|---|
| 1 | Research.mq5 | EA | コレクションEAの例 |
| 2 | ResearchRealORL.mq5 | EA | Real-ORL法による事例収集のためのEA |
| 3 | Study.mq5 | EA | モデル訓練EA |
| 4 | StudyEncoder.mq5 | EA | エンコーダー訓練EA |
| 5 | Test.mq5 | EA | モデルをテストするEA |
| 6 | Trajectory.mqh | クラスライブラリ | システム状態記述の構造体 |
| 7 | NeuroNet.mqh | クラスライブラリ | ニューラルネットワークを作成するためのクラスのライブラリ |
| 8 | NeuroNet.cl | コードベース | OpenCLプログラムコードライブラリ |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/15352
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

 初級から中級へ:変数(I)
初級から中級へ:変数(I)
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
Studyを実行すると、実行カーネルUpdateWeightsAdamMini: 5109のエラーが発生します。
こんにちは、実行ログと使用しているモデルのアーキテクチャを投稿できますか?
こんにちは、Studio Encode と Study の録画をお送りします。アーキテクチャーについては、スタディーのローソク足の本数が12本で、そのデータが11本であることを除けば、ご提示いただいたものとほぼ同じです。また、出力レイヤーには4つのパラメータしかありません。
おつかれさまでした、使用したモデルの実施登録と構造を公表していただけますか?