
取引におけるニューラルネットワーク:対照パターンTransformer

はじめに
機械学習を用いて市場状況を分析する際、私たちはしばしば個々のローソク足とその属性に注目し、より意味のある情報を提供することが多いローソク足パターンを見落としがちです。パターンは、似たような市場環境下で現れる安定したローソク足構造を表し、重要な行動傾向を明らかにすることができます。
以前、分子特性予測の分野から着想を得たMolformerフレームワークを検討しました。Molformerの著者らは、原子とモチーフの表現をひとつのシーケンスに統合し、分析対象データの構造情報にモデルがアクセスできるようにしました。しかし、このアプローチには、異なる種類のノード間の依存関係を分離するという複雑な課題が伴います。幸いにも、この問題を回避する代替手法が提案されています。
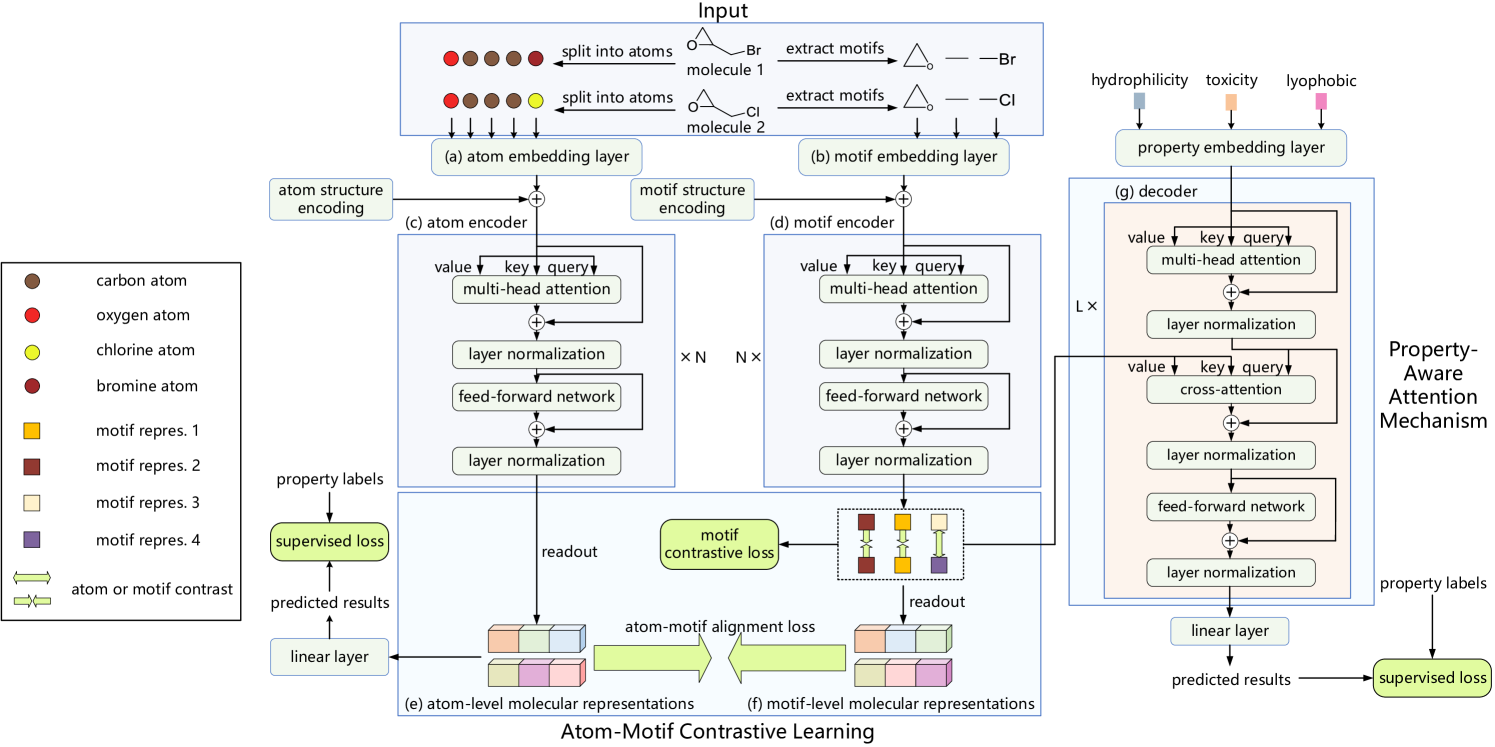
その一例が、論文「Atom-Motif Contrastive Transformer for Molecular Property Prediction」で紹介されているAtom-Motif Contrastive Transformer (AMCT)です。分子における2つの相互作用レベルを統合し、その表現能力を高めるために、AMCTの著者らは原子表現とモチーフ表現の間に対照学習を適用することを提案しました。原子とモチーフの表現は、実質的に同一の対象(分子)の異なる視点であるため、学習中に自然に整合します。この整合により、相互に自己教師ありのシグナルを提供できるようになり、学習された分子表現のロバスト性が向上します。
また、異なる分子間で同一のモチーフは類似した化学的性質を示す傾向があることが観察されています。これは、同一のモチーフが分子間で一貫した表現を持つべきことを示唆しています。そのため、対照損失(contrastive loss)を用いることで、異なる分子における同一モチーフの整合が最大化され、より区別可能なモチーフ表現が得られます。
さらに、それぞれの分子特性の決定に重要なモチーフを効果的に特定するために、著者らはCross-Attentionモジュールを通じて特性情報を統合するAttention機構を組み込みました。具体的には、このCross-Attentionモジュールが、分子特性の埋め込みとモチーフ表現との依存関係を捉えます。その結果、Cross-Attentionの重みに基づいて、重要なモチーフを特定することが可能になります。
1. AMCTアルゴリズム
モデルに入力される分子の記述は、まず原子の集合に分解され、次にモチーフの集合に分割されます。これらのシーケンスはそれぞれ、原子エンコーディング層とモチーフエンコーディング層に並列的に入力され、それぞれの埋め込み表現が生成されます。原子レベルとモチーフレベルでの分子表現を得るために、2つの独立したエンコーダが用いられます。また、予測出力を生成するために、デコーダと全結合層が使用されます。モデルの学習中には、原子-モチーフ整合損失(alignment loss)、モチーフレベルの対照損失、および特性予測損失が損失関数に含まれます。
原子のエンコーディングでは、まず原子の埋め込みが得られます。この埋め込みは、原子間の依存関係を抽出する原子エンコーダによって処理され、分子の原子レベルの表現が生成されます。
AMCTの著者らは、分子内の原子の結合関係といった構造情報をエンコードするために、ノード中心性を利用しています。中心性は各原子に対して適用されるため、単純に原子埋め込みに加算されます。
原子レベルでの依存関係は低レベルの詳細な情報をうまく捉えることができますが、異なる原子間の高次構造情報は見落とされがちです。そのため、この方法だけでは分子の特性を正確に予測するには不十分である可能性があります。この課題に対処するため、AMCTフレームワークでは、モチーフレベルでの分子表現を生成する並列的な経路を導入しています。モチーフのエンコーディングでは、まず元のデータセットからモチーフが抽出され、それが埋め込みに変換されます。これらの埋め込みはモチーフエンコーダによって処理され、モチーフ間の依存関係が捉えられます。
AMCTフレームワークでは、モチーフ間の構造情報をエンコードするためにも中心性を用い、それを対応するモチーフ埋め込みに加算します。
モチーフによって提供される追加情報を活用するために、このフレームワークでは原子レベルとモチーフレベルの分子表現間の類似性関係を考慮します。原子とモチーフの表現は本質的に同一の対象に対する異なる視点であるため、学習中に自然に整合し、自己教師あり信号を生み出します。著者らは、2つの表現を整合させるためにカルバック・ライブラー情報量を用いています。
原子-モチーフ整合損失は、分子内で作用し、同一分子内の原子とモチーフ表現間の整合性を保証することに限定されます。そこで、AMCTの著者らは、分子間の対照学習にも着目し、異なる分子間での表現の整合性を検討します。異なる分子において同一モチーフが類似した化学的性質を示す傾向があることから、これらのモチーフは分子を超えても一貫した表現を持つべきだと考えられます。これを実現するために、著者らはモチーフ対照損失を提案し、異なる分子における同一モチーフ表現の整合性を最大化し、異なるクラスに属するモチーフ表現同士は離れるようにします。
また、信頼性のある表現を得るためには、堅牢なデコーディング処理も重要です。AMCTでは 特性認識型(property-aware)デコーディングを導入しています。まず特性埋め込みを生成し、デコーダが各特性にとって本質的な分子表現を抽出します。最終的な予測は線形射影によって得られます。
このデコーダは、特性情報を取り込んだ分子表現を抽出するために設計されています。各分子特性の決定において最も重要なモチーフを特定するために、AMCTは特性認識型Attention機構を構築しています。具体的には、Cross-Attentionモジュールが用いられ、特性埋め込みがQuery、モチーフ表現がKey-Valueとして機能します。Cross-Attentionの重みが高いモチーフほど、分子特性に強い影響を与えていると見なされます。
Atom-Motif Contrastive Transformerフレームワークの著者によって提示された元のビジュアル図は以下に示されています。
2.MQL5での実装
Atom-Motif Contrastive Transformerフレームワークの理論的側面を説明したあと、この記事の実践的なセクションに進み、MQL5を使用して提案されたアプローチに関する私たち独自の見解を示します。
AMCTフレームワークは、かなり複雑で洗練された構造です。しかし、その構成ブロックを詳しく調べてみると、それらのほとんどが何らかの形で既に私たちのライブラリに実装されていることが明らかになります。とはいえ、まだ取り組むべき課題も存在します。たとえば、原子レベルとモチーフレベルでの表現の比較です。きっと同意していただけると思いますが、単に差異を識別するだけでなく、これらの差異を最小限に抑えるには、誤差勾配を両経路に適切に伝播させる必要があります。この問題を解決するにはいくつかの方法があります。
もちろん、片方の経路の出力結果をもう一方の勾配バッファにコピーし、現在モデル誤差の計算に使用している基本的なニューラル層メソッドcalcOutputGradientsを使って誤差の勾配を計算するという方法もあります。このアプローチの利点は、既存のツールを使用するため実装が簡単である点です。しかしこの方法は、比較的リソース消費が大きいという欠点があります。モデルのトレーニング中に両経路の出力データバッファを複製し、それぞれの表現について逐次的に勾配を計算する必要があるためです。
したがって、私たちはOpenCLOpenCL側に小さなカーネルを開発することを決定しました。これにより、不要なデータコピーをおこなうことなく、両経路に対して同時に誤差の勾配を求めることが可能になります。
__kernel void CalcAlignmentGradient(__global const float *matrix_o1, __global const float *matrix_o2, __global float *matrix_g1, __global float *matrix_g2, const int activation, const int add) { int i = get_global_id(0);
カーネルのパラメータとしては、4つのデータバッファへのポインタを受け取ります。これらのうち2つのバッファには、原子経路およびモチーフ経路(本プロジェクトでは、それぞれ「ローソク足」と「パターン」に相当)の出力結果が格納されています。残りの2つのバッファは、それぞれに対応する誤差勾配を格納するために使用されます。さらに、両方の経路で使用されている活性化関数へのポインタも、カーネルパラメータに含まれます。
ここで重要なのは、両経路に異なる活性化関数を使用することを明示的に制限しているという点です。これは、両経路の出力結果を正しく比較するには、同一の部分空間に属している必要があるためです。活性化関数は層の出力空間を定義するため、同じ活性化関数を使うことは論理的かつ必須の要件です。
この段階で、勾配誤差を既存のバッファに加算するか、それとも上書きするかを制御するためのフラグも導入します。
このカーネルは1次元のタスク空間で実行されるため、カーネル内で定義されたスレッドIDが、データバッファ内でのオフセットを指定する形になります。
続いて、両経路における順伝播(feed-forward pass)処理結果を格納するためのローカル変数を用意し、誤差勾配の初期値をゼロで初期化します。
const float out1 = matrix_o1[i]; const float out2 = matrix_o2[i]; float grad1 = 0; float grad2 = 0;
順伝播値の有効性を確認します。正しい数値が得られたら、偏差を計算し、活性化関数の導関数に合わせて調整します。出力は割り当てられたローカル変数に保存されます。
if(!isnan(out1) && !isinf(out1) &&
!isnan(out2) && !isinf(out2))
{
grad1 = Deactivation(out2 - out1, out1, activation);
grad2 = Deactivation(out1 - out2, out2, activation);
}
次に、計算された誤差勾配を対応するグローバルデータバッファへ転送します。受け取ったフラグに応じて、既に蓄積されている勾配値に対して新たに計算した値を加算するまたは以前の値を削除し、新しい値で上書きします。その後、カーネル操作を完了します。
if(add > 0) { matrix_g1[i] += grad1; matrix_g2[i] += grad2; } else { matrix_g1[i] = grad1; matrix_g2[i] = grad2; } }
これはOpenCLプログラムへの唯一の追加です。すべてのコードは添付ファイルにあります。
次に提案されたAMCTフレームワークのアーキテクチャを実装するメインプログラムに進みます。まず必要なのは、原子(バー)用の経路とモチーフ(パターン)用の経路という二つの処理経路です。元論文では、両方の経路に従来のTransformerアーキテクチャが使用されており、それぞれにアトムおよびモチーフの構造エンコーディングが追加されていました。しかし、私はこれを、以前の記事で検討した相対位置エンコーディング (R-MAT)を組み込んだTransformerに置き換えることを提案します。この変更により、経路アーキテクチャに関しては決着がついたようにも思えます。ただし、ひとつ重要な点があります。モチーフ(パターン)経路では、事前にパターンを抽出する前処理ステップが必要になります。そのため、私はモチーフ経路を別オブジェクトとして実装することに決めました。
2.1 モチーフ経路の構築
モチーフ経路アルゴリズムをCNeuronMotifEncoderクラスに実装します。その構造を以下に示します。
class CNeuronMotifEncoder : public CNeuronRMAT { public: CNeuronMotifEncoder(void) {}; ~CNeuronMotifEncoder(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint layers, ENUM_OPTIMIZATION optimization_type, uint batch) override; //--- virtual int Type(void) override const { return defNeuronMotifEncoder; } };
新しいオブジェクトの構造からわかるように、基盤クラスとしてCNeuronRMATを使用します。このクラスは、ニューラル層が動的配列に編成される線形モデルロジックを実装します。この設計により、Initメソッド内でパターン(モチーフ)経路の順次アーキテクチャを簡単に構築できます。必要な機能はすべて親クラスから継承されます。
初期化メソッドのパラメータ構造は、基本クラスの対応するメソッドから完全に継承されます。
bool CNeuronMotifEncoder::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint layers, ENUM_OPTIMIZATION optimization_type, uint batch) { if(units_count < 3) return false;
ただし、パターンの抽出では入力データ シーケンスの長さに制限が課せられるため、メソッド本体ですぐにチェックします。その後、これから作成するニューラル層へのポインターを格納するための動的配列を準備します。
cLayers.Clear();
ここで重要なのは、まだ親クラスのメソッドを呼び出していないという点です。つまり、親クラスから継承されたオブジェクトはすべて未初期化の状態にあります。一方で、外部プログラムから受け取ったパラメータには、親クラスのメソッドを実行するために必要な結果バッファのサイズが明示的に指定されていません。この段階で結果バッファのサイズを計算することを避けるために、まずパターン埋め込みを生成する層を初期化します。なお、個々のパターンのサイズについても、メソッドのパラメータには明記されていないため、シーケンス長に応じて動的に定義することにします。具体的には、シーケンス長が10要素を超える場合は3要素パターンを、そうでない場合は2要素パターンを解析対象とします。
int bars_to_paattern = (units_count > 10 ? 3 : 2);
畳み込み層を使用してパターン埋め込みを生成し、すぐに初期化します。作成されたニューラル層へのポインタが動的配列に追加されます。
CNeuronConvOCL *conv = new CNeuronConvOCL(); int idx = 0; int units = (int)units_count - bars_to_paattern + 1; if(!conv || !conv.Init(0, idx, open_cl, bars_to_paattern * window, window, window, units, 1, optimization_type, batch)|| !cLayers.Add(conv) ) return false; conv.SetActivationFunction(SIGMOID);
ここで重要なのは、ストライド1のオーバーラップ構造でパターンの埋め込みを構築しているという点です。1つのパターンの埋め込みサイズは、1本のローソク足を記述する際に使用されるウィンドウサイズと等しく設定されます。この手法により、入力シーケンス内に存在するパターンをより精密に分析することが可能になります。
ただし、ここではさらに一歩踏み込み、より大きなパターン(5本または3本のバーから構成されるもの)も分析対象とします。使用するバー数は、入力シーケンスの長さに応じて動的に決定されます。その後、両レベルのパターン埋め込みを連結することで、入力データに対する構造的な情報をより豊富にモデルに提供します。この機能の実装には、Molformerフレームワークの開発の一環として作成されたCNeuronMotifs層を使用します。この層の主な利点は、抽出されたパターンのテンソルと元の入力データとを連結できることにあります。そのため、この層は2番目段階のパターン抽出には適していますが、最初のパターン抽出段階では使用できません。初期段階では、バーの表現とパターンを明確に分離し、それぞれを並列の経路で分析する必要があるためです。
idx++; units = units - bars_to_paattern + 1; CNeuronMotifs *motifs = new CNeuronMotifs(); if(!motifs || !motifs.Init(0, idx, open_cl, window, bars_to_paattern, 1, units, optimization_type, batch) || !cLayers.Add(motifs) ) return false; motifs.SetActivationFunction((ENUM_ACTIVATION)conv.Activation());
生成されたパターン埋め込みは、そのままR-MAT経路に入力されます。ご存じの通り、Transformer経路の出力ベクトルのサイズは、その入力テンソルのサイズと一致します。したがって、この段階では、最終的なパターン抽出層のテンソル次元に基づいて、親ニューラル層の初期化メソッドを安全に呼び出すことができます。
if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, motifs.Neurons(), optimization_type, batch)) return false; cLayers.SetOpenCL(OpenCL);
次に、デコーダ内部の層を初期化するためのループを作成します。このループの各反復において、相対自己注意機構 (CNeuronRelativeSelfAttention)の層を1つ初期化し、続けて残差畳み込みブロック(CResidualConv)を1つ初期化します。
CNeuronRelativeSelfAttention *attention = NULL; CResidualConv *ff = NULL; units = int(motifs.Neurons() / window); for(uint i = 0; i < layers; i++) { idx++; attention = new CNeuronRelativeSelfAttention(); if(!attention || !attention.Init(0, idx, OpenCL, window, window_key, units, heads, optimization, iBatch) || !cLayers.Add(attention) ) { delete attention; return false; } idx++; ff = new CResidualConv(); if(!ff || !ff.Init(0, idx, OpenCL, window, window, units, optimization, iBatch) || !cLayers.Add(ff) ) { delete ff; return false; } }
親クラスの初期化メソッドでも同様のループを使用しました。ただし、この場合、以前に作成したパターン抽出層が削除されるため、親クラスのメソッドを再利用することはできませんでした。
次に、過度のコピー操作を避けるために、データバッファポインタを再割り当てします。
if(!SetOutput(ff.getOutput()) || !SetGradient(ff.getGradient())) return false; //--- return true; }
メソッドを終了する前に、操作結果をブール値として呼び出し元プログラムに返します。
前述のとおり、順伝播および誤差逆伝播(バックプロパゲーション)の処理機能はすべて親クラスから完全に継承されています。これにより、モチーフ経路のクラスCNeuronMotifEncoderの実装が完了します。
2.2 Relative Cross-Attentionモジュール
先にバー経路およびパターン経路を構築した際には、Relative Self-Attentionモジュールを使用しました。しかし、AMCTのデコーダ部分では、Cross-Attention機構が用いられています。そのため、フレームワーク全体の整合性と一貫性を確保するためには、相対位置エンコーディングを組み込んだCross-Attentionモジュールを新たに実装する必要があります。ここでは理論的な詳細には踏み込みません。必要な概念はすべて、R-MATフレームワークに関する記事ですでに説明されています。現在のタスクは、既存の相対自己注意の実装に対して、2番目の入力ソースを統合することです。この入力から、KeyとValueを生成するようにします。この目的のために、新たに CNeuronRelativeCrossAttentionというクラスを作成します。このクラスでは、相対エンコーディング付きのCross-Attention機構が実装されます。そして予想される通り、既存のSelf-Attentionクラスがこの新クラスの基底クラスとなります。新しいオブジェクトの構造を以下に示します。
class CNeuronRelativeCrossAttention : public CNeuronRelativeSelfAttention { protected: uint iUnitsKV; //--- CLayer cKVProjection; //--- //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override { return false; } virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) override; public: CNeuronRelativeCrossAttention(void) {}; ~CNeuronRelativeCrossAttention(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint window_kv, uint units_kv, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronRelativeCrossAttention; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
コードには、すでにおなじみのオーバーライド可能なメソッドのセットが含まれています。ここで、追加のオブジェクトへのポインタを記録するための1つの動的配列を宣言します。さらに、2番目の入力ソースのシーケンスのサイズを記録する変数を追加します。
継承されたメンバーと新しく宣言されたメンバーの両方の初期化は、Initメソッドで実行されます。
bool CNeuronRelativeCrossAttention::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint window_kv, uint units_kv, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count, optimization_type, batch)) return false;
このメソッドのパラメータには、作成されるオブジェクトのアーキテクチャを定義するために必要なすべての定数を渡します。メソッド本体では、まずニューラル層の基底クラスの該当メソッドを呼び出します。この基底メソッドは、受け取ったパラメータの検証および継承されたインターフェイスの初期化を実行します。
ここで重要なのは、直接の親クラスの初期化メソッドは意図的に使用していないという点です。これは、ほとんどの継承オブジェクトのサイズが異なるためです。親の初期化処理をそのまま実行すると、手間を省くどころか、プログラムの実行時間を増やす結果となってしまいます。したがって、このメソッド内で、親クラスで宣言されているオブジェクトの初期化も明示的に実施します。
基底クラスのメソッドが正常に完了した後、外部プログラムから受け取ったアーキテクチャ定義用の定数を、現在のオブジェクトの内部メンバ変数に保存します。
iWindow = window; iWindowKey = window_key; iUnits = units_count; iUnitsKV = units_kv; iHeads = heads;
次に、Transformerアーキテクチャに従って、Query、Key、Valueエンティティが生成される畳み込み層を初期化します。
int idx = 0; if(!cQuery.Init(0, idx, OpenCL, iWindow, iWindow, iWindowKey * iHeads, iUnits, 1, optimization, iBatch)) return false; idx++; if(!cKey.Init(0, idx, OpenCL, iWindow, iWindow, iWindowKey * iHeads, iUnitsKV, 1, optimization, iBatch)) return false; idx++; if(!cValue.Init(0, idx, OpenCL, iWindow, iWindow, iWindowKey * iHeads, iUnitsKV, 1, optimization, iBatch)) return false;
ここで注意すべき点は、KeyとValueエンティティを生成する層において、シーケンス長は2番目のデータソースに基づいて決定されるということです。一方で、各シーケンス要素のベクトルサイズは1番目のデータソースから取得されます。ただし、2番目のデータソース内の個々の要素のベクトル次元が異なる可能性がある点に注意が必要です。実際、これまでの実装では、入力シーケンスの次元整合性について明示的に対処してきませんでした。代わりに、KeyやValueの生成層で異なるウィンドウサイズを使用し、最終的な埋め込みサイズだけを揃えるという方針を取っていました。しかし、相対エンコーディングアルゴリズムでは、エンティティ間の「距離」の概念が使用されます。距離とは、同一の部分空間に存在するエンティティ間でのみ意味を持つ概念であるため、比較対象となるオブジェクト同士が互換性を持っている必要があります。この要件を満たすために、モジュールの適用範囲を狭めないよう、ここでは学習可能なデータ射影機構を使用します。この射影層によって、異なる次元を持つ入力を同じベクトル空間へと変換し、距離の計算が可能になります。この点については後ほど詳しく説明しますが、現時点ではこの要件を明確にしておくことが重要です。
なお、Relative Self-Attentionのの実装と同様に、エンティティ間の距離の尺度としては、2つの入力行列の積を使用します。ただし、この演算をおこなう前に、片方の行列を転置する必要があります。
idx++; if(!cTranspose.Init(0, idx, OpenCL, iUnits, iWindow, optimization, iBatch)) return false;
行列の乗算の結果を記録するオブジェクトも作成しましょう。
idx++; if(!cDistance.Init(0, idx, OpenCL, iUnits * iUnitsKV, optimization, iBatch)) return false;
次に、B KテンソルとB Vテンソルの生成プロセスを構築します。これまでに見てきたように、これらのテンソルは1つの隠れ層を持つMLP(多層パーセプトロン)によって生成されます。隠れ層はすべてのAttention Headで共有されており、最終層は各Attention Headに対応する個別のトークンを出力します。ここでは、各エンティティに対して、2つの連続した畳み込み層を作成します。その間に双曲線正接関数(tanh)を挿入し、非線形性を導入します。
idx++; CNeuronConvOCL *conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, idx, OpenCL, iUnits, iUnits, iWindow, iUnitsKV, 1, optimization, iBatch) || !cBKey.Add(conv)) return false; idx++; conv.SetActivationFunction(TANH); conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, idx, OpenCL, iWindow, iWindow, iWindowKey * iHeads, iUnitsKV, 1, optimization, iBatch) || !cBKey.Add(conv)) return false;
idx++; conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, idx, OpenCL, iUnits, iUnits, iWindow, iUnitsKV, 1, optimization, iBatch) || !cBValue.Add(conv)) return false; idx++; conv.SetActivationFunction(TANH); conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, idx, OpenCL, iWindow, iWindow, iWindowKey * iHeads, iUnitsKV, 1, optimization, iBatch) || !cBValue.Add(conv)) return false;
さらに、グローバルコンテキストベクトルおよび位置バイアスベクトルを生成するために、2つのMLPを追加します。これらのMLPにおいては、1番目層は固定で値「1」を持ち、第2層は学習可能であり、必要なテンソルを生成します。これらのオブジェクトへのポインタを配列cGlobalContentBiasとcGlobalPositionalBiasに格納します。
idx++; CNeuronBaseOCL *neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(iWindowKey * iHeads * iUnits, idx, OpenCL, 1, optimization, iBatch) || !cGlobalContentBias.Add(neuron)) return false; idx++; CBufferFloat *buffer = neuron.getOutput(); buffer.BufferInit(1, 1); if(!buffer.BufferWrite()) return false; neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, idx, OpenCL, iWindowKey * iHeads * iUnits, optimization, iBatch) || !cGlobalContentBias.Add(neuron)) return false;
idx++; neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(iWindowKey * iHeads * iUnits, idx, OpenCL, 1, optimization, iBatch) || !cGlobalPositionalBias.Add(neuron)) return false; idx++; buffer = neuron.getOutput(); buffer.BufferInit(1, 1); if(!buffer.BufferWrite()) return false; neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, idx, OpenCL, iWindowKey * iHeads * iUnits, optimization, iBatch) || !cGlobalPositionalBias.Add(neuron)) return false;
相対Cross-Attentionモジュールの入力データに対する前処理用オブジェクトの準備が整いました。次に、Cross-Attentionの結果を処理するためのオブジェクトの構築に移ります。このステップではまず、Multi-head Attentionの結果を格納するオブジェクトを作成し、そのポインタをcMHAttentionPooling配列に追加します。
idx++; neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, idx, OpenCL, iWindowKey * iHeads * iUnits, optimization, iBatch) || !cMHAttentionPooling.Add(neuron) ) return false;
次に、依存関係に基づくプーリング層を追加します。この層は、Multi-head Attention機構の出力を重み付きの総和として集約する役割を持ちます。各シーケンス要素に対する影響係数(重み)は、依存関係の解析に基づいて個別に決定されます。
CNeuronMHAttentionPooling *pooling = new CNeuronMHAttentionPooling(); if(!pooling || !pooling.Init(0, idx, OpenCL, iWindowKey, iUnits, iHeads, optimization, iBatch) || !cMHAttentionPooling.Add(pooling) ) return false;
重要なのは、プーリング層の出力において各シーケンス要素を記述するベクトルのサイズが、内部表現の次元に対応しており、これは入力シーケンス中の元の要素のベクトル長と異なる場合があるという点です。そのため、結果を元のデータ次元に戻すための追加のMLPスケーリングモジュールを導入します。このモジュールは、2つの畳み込み層から構成されており、その間にLeaky ReLU (LReLU)活性化関数を適用して非線形性を導入します。
//--- idx++; conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, idx, OpenCL, iWindowKey, iWindowKey, 4 * iWindow, iUnits, 1, optimization, iBatch) || !cScale.Add(conv) ) return false; conv.SetActivationFunction(LReLU); idx++; conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, idx, OpenCL, 4 * iWindow, 4 * iWindow, iWindow, iUnits, 1, optimization, iBatch) || !cScale.Add(conv) ) return false; conv.SetActivationFunction(None);
その後、誤差勾配バッファへのポインタを、モデル内の他のニューラル層とデータ交換するインターフェイスに差し替えます。
//--- if(!SetGradient(conv.getGradient(), true)) return false;
それでは、入力データソース間の次元差異の問題に戻りましょう。Cross-Attentionモジュールにおいて、第一の入力ソースはQueryエンティティを形成するために使用され、Attention機構の主たる流れとして機能します。また、残差接続にも用いられるため、この入力の次元は変更されません。したがって、両方の入力ソースの次元を揃えるために、2番目の入力ソースの値に対して射影をおこないます。この学習可能なデータ射影を実装するために、2つの連続したニューラル層を作成します。これらの層へのポインタはcKVProjection配列に格納されます。最初の層は完全結合層とし、2番目のデータソースからの生の入力を初期処理・保持する役割を担います。
cKVProjection.Clear(); cKVProjection.SetOpenCL(OpenCL); idx++; neuron = new CNeuronBaseOCL; if(!neuron || !neuron.Init(0, idx, OpenCL, window_kv * iUnitsKV, optimization, iBatch) || !cKVProjection.Add(neuron) ) return false;
2番目の畳み込み層は、目的の部分空間へのデータ射影を実行します。
idx++; conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, idx, OpenCL, window_kv, window_kv, iWindow, iUnitsKV, 1, optimization, iBatch) || !cKVProjection.Add(conv) ) return false;
これで、必要な機能を実現するためのすべてのオブジェクトが初期化されました。最後に、処理の成功・失敗を示すブール値を呼び出し元のプログラムに返し、メソッドを終了します。
//--- SetOpenCL(OpenCL); //--- return true; }
新しいオブジェクトインスタンスの初期化が完了した後、feedForwardメソッド内で順伝播アルゴリズムの構築に移ります。このアルゴリズムは2つの別々の入力ソースを必要とするため、親クラスから継承した「単一の入力ソースのみを受け取る」メソッドは常にfalseを返すようオーバーライドします。これは、そのメソッド呼び出しが無効または誤っていることを示すためです。そして、正しい順伝播の処理は、2つの入力ソースをパラメータとして受け取るメソッドの方に実装されています。
bool CNeuronRelativeCrossAttention::feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) { CNeuronBaseOCL *neuron = cKVProjection[0]; if(!neuron || !SecondInput) return false; if(neuron.getOutput() != SecondInput) if(!neuron.SetOutput(SecondInput, true)) return false;
メソッド本体内では、まず2番目の入力データソースへのポインタの有効性を確認します。ポインタが有効であれば、それをcKVProjection配列に格納されている射影モデルの最初の層に渡します。続いて、射影モデルの全層を順番に処理するループを初期化します。このループ内では、各層の順伝播メソッドを呼び出し、前のニューラル層の出力を現在の層の入力として使用します。
for(int i = 1; i < cKVProjection.Total(); i++) { neuron = cKVProjection[i]; if(!neuron || !neuron.FeedForward(cKVProjection[i - 1]) ) return false; }
2番目の入力ソースからのデータを正常に射影した後、次にQuery、Key、Valueの各エンティティを生成します。Queryエンティティは1番目の入力ソースのデータを用いて生成し、KeyおよびValueエンティティについては、2番目の入力ソースデータの射影結果を使用します。
if(!cQuery.FeedForward(NeuronOCL) || !cKey.FeedForward(neuron) || !cValue.FeedForward(neuron) ) return false;
次に、オブジェクト間の距離の係数を計算する必要があります。そのために、まず1番目の入力ソースのデータを転置します。続いて、2番目の入力ソースの射影結果に対して、この転置した1番目の入力データを掛け合わせます。
if(!cTranspose.FeedForward(NeuronOCL) || !MatMul(neuron.getOutput(), cTranspose.getOutput(), cDistance.getOutput(), iUnitsKV, iWindow, iUnits, 1) ) return false;
得られたデータ構造の係数に基づいて、BKおよびBVのバイアステンソルを形成します。まず、対応するモデルの最初の層の順伝播メソッドに対して、データ構造に関する情報を渡します。
if(!((CNeuronBaseOCL*)cBKey[0]).FeedForward(cDistance.AsObject()) || !((CNeuronBaseOCL*)cBValue[0]).FeedForward(cDistance.AsObject()) ) return false;
次に、指定されたモデルの各層を順番に処理するループを作成し、その中で入れ子になったニューラル層の順伝播メソッドを順次呼び出します。
for(int i = 1; i < cBKey.Total(); i++) if(!((CNeuronBaseOCL*)cBKey[i]).FeedForward(cBKey[i - 1])) return false;
for(int i = 1; i < cBValue.Total(); i++) if(!((CNeuronBaseOCL*)cBValue[i]).FeedForward(cBValue[i - 1])) return false;
次に、グローバルバイアスエンティティを生成します。ここでも同様のループを実装します。
for(int i = 1; i < cGlobalContentBias.Total(); i++) if(!((CNeuronBaseOCL*)cGlobalContentBias[i]).FeedForward(cGlobalContentBias[i - 1])) return false; for(int i = 1; i < cGlobalPositionalBias.Total(); i++) if(!((CNeuronBaseOCL*)cGlobalPositionalBias[i]).FeedForward(cGlobalPositionalBias[i - 1])) return false;
これで予備的なデータ処理は完了したので、結果をAttentionモジュールに渡します。
if(!AttentionOut()) return false;
Multi-head Cross-Attentionの結果をプーリングモデルに渡します。
for(int i = 1; i < cMHAttentionPooling.Total(); i++) if(!((CNeuronBaseOCL*)cMHAttentionPooling[i]).FeedForward(cMHAttentionPooling[i - 1])) return false;
次に、最初のデータソーステンソルのサイズに合わせてスケールアップします。この機能は内部スケーリングモデルによって実行されます。
if(!((CNeuronBaseOCL*)cScale[0]).FeedForward(cMHAttentionPooling[cMHAttentionPooling.Total() - 1])) return false; for(int i = 1; i < cScale.Total(); i++) if(!((CNeuronBaseOCL*)cScale[i]).FeedForward(cScale[i - 1])) return false;
次に、残差接続を追加するだけです。操作結果は、モデルの後続のニューラル層とのデータ交換インターフェイスバッファに記録されます。
if(!SumAndNormilize(NeuronOCL.getOutput(), ((CNeuronBaseOCL*)cScale[cScale.Total() - 1]).getOutput(), Output, iWindow, true, 0, 0, 0, 1)) return false; //--- return true; }
メソッドを終了する前に、処理の成功を示すブール値を呼び出し元プログラムに返します。
順伝播メソッドの実装が完了した後、誤差逆伝播アルゴリズムの実装に進みます。ご存知のように、誤差逆伝播は大きく二段階に分かれています。最終結果に対する各構成要素の寄与度に応じて誤差勾配を配分する処理は、calcInputGradientsメソッドでおこなわれます。一方、モデルの誤差を最小化するためのパラメータ最適化は、updateInputWeightsメソッドで実装されています。後者のアルゴリズムはかなり単純で、学習可能なパラメータを持つすべての内部オブジェクトに対して順次対応する updateInputWeightsメソッドを呼び出す仕組みです。一方、前者のcalcInputGradientsメソッドのアルゴリズムは、より詳細な説明が必要です。
このcalcInputGradientsメソッドのパラメータとして、2つの入力データオブジェクトへのポインタを受け取ります。これらのオブジェクトは、それぞれ対応する誤差勾配を記録するためのバッファを含んでいます。
bool CNeuronRelativeCrossAttention::calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = -1) { if(!NeuronOCL || !SecondGradient) return false;
メソッド本体では、まず受け取ったポインタの有効性を確認します。ポインタが無効または古くなっている場合、それ以降の処理は意味を成さなくなります。
順伝播処理の際に、2番目のデータソースからの入力バッファへのポインタを内部層に保存していたことを思い出してください。今回は同様に、対応する誤差勾配バッファへのポインタを設定し、さらに活性化関数の同期も同時におこないます。
CNeuronBaseOCL *neuron = cKVProjection[0]; if(!neuron) return false; if(neuron.getGradient() != SecondGradient) if(!neuron.SetGradient(SecondGradient)) return false; if(neuron.Activation() != SecondActivation) neuron.SetActivationFunction(SecondActivation);
準備フェーズが完了したら、いよいよ誤差勾配の実際の誤差逆伝播処理に進みます。ここでは、最終結果への寄与度に基づいて、すべての構成要素に誤差勾配を分配していきます。
オブジェクトの初期化時に誤差勾配バッファへのポインタを置き換えているため、誤差逆伝播は内部層を直接通じて開始されます。この段階で重要なのは、AMCTフレームワークがモチーフレベルで対照学習を導入しているという点です。この設計思想に従い、Cross-Attentionブロックの出力に対して多様性損失(diversity loss)を追加します。
if(!DiversityLoss(AsObject(), iUnits, iWindow, true)) return false;
この段階で多様性損失を導入する目的は、埋め込み部分空間における特徴表現の広がりを最大化することにあります。とりわけ、次の層へと入力される出力ベクトルの分布を広げることを意図しています。同時に、モデルオブジェクト全体を通じて勾配を誤差逆伝播させることで、両方の入力ソースから本ブロックに渡される初期データオブジェクト間の表現を間接的に分離することにもつながります。
続いて、全体の勾配は内部の結果スケーリングモデル(出力次元を整えるためのMLP)を通過していきます。
for(int i = cScale.Total() - 2; i >= 0; i--) if(!((CNeuronBaseOCL*)cScale[i]).calcHiddenGradients(cScale[i + 1])) return false; if(!((CNeuronBaseOCL*)cMHAttentionPooling[cMHAttentionPooling.Total() - 1]).calcHiddenGradients(cScale[0])) return false;
次に、プーリングモデルを使用して、ヘッド間で注意を分散します。
for(int i = cMHAttentionPooling.Total() - 2; i > 0; i--) if(!((CNeuronBaseOCL*)cMHAttentionPooling[i]).calcHiddenGradients(cMHAttentionPooling[i + 1])) return false;
AttentionGradientメソッドでは、最終出力への影響度に応じて、誤差勾配をQuery、Key、Valueの各エンティティおよび バイアステンソルにそれぞれ伝播させます。
if(!AttentionGradient()) return false;
次に、学習可能なグローバルバイアスの内部モデルに対して、逆方向のイテレーションをおこないながら、誤差勾配を分配していきます。
for(int i = cGlobalContentBias.Total() - 2; i > 0; i--) if(!((CNeuronBaseOCL*)cGlobalContentBias[i]).calcHiddenGradients(cGlobalContentBias[i + 1])) return false; for(int i = cGlobalPositionalBias.Total() - 2; i > 0; i--) if(!((CNeuronBaseOCL*)cGlobalPositionalBias[i]).calcHiddenGradients(cGlobalPositionalBias[i + 1])) return false;
同様に、 BKおよびBV オブジェクトの構造に基づいて、それぞれのバイアスエンティティ生成モデルにも誤差勾配を伝播させます。
for(int i = cBKey.Total() - 2; i >= 0; i--) if(!((CNeuronBaseOCL*)cBKey[i]).calcHiddenGradients(cBKey[i + 1])) return false; for(int i = cBValue.Total() - 2; i >= 0; i--) if(!((CNeuronBaseOCL*)cBValue[i]).calcHiddenGradients(cBValue[i + 1])) return false;
次に、誤差勾配をcDistanceデータ構造行列に伝播させます。ただし、ここには重要な注意点があります。この構造行列は、BKおよびBVの両方のエンティティ生成に使用されているため、誤差勾配は2つの情報ストリームから収集する必要があります。したがって、まずはBK側からの誤差勾配を取得します。
if(!cDistance.calcHiddenGradients(cBKey[0])) return false;
次に、このオブジェクトの誤差勾配バッファへのポインタを差し替え、BVからの勾配を取得します。その後、両モデルから得られた誤差勾配を加算し、データバッファへのポインタを元の状態に戻します。
CBufferFloat *temp = cDistance.getGradient(); if(!cDistance.SetGradient(GetPointer(cTemp), false) || !cDistance.calcHiddenGradients(cBValue[0]) || !SumAndNormilize(temp, GetPointer(cTemp), temp, iUnits, false, 0, 0, 0, 1) || !cDistance.SetGradient(temp, false) ) return false;
構造行列上で収集された誤差勾配は、入力データオブジェクトに分配されます。ただし、この場合は直接的な分配ではなく、1番目のデータソースの転置層および2番目のソースの射影モデルを通じて分配をおこないます。
neuron = cKVProjection[cKVProjection.Total() - 1]; if(!neuron || !MatMulGrad(neuron.getOutput(), neuron.getGradient(), cTranspose.getOutput(), cTranspose.getGradient(), temp, iUnitsKV, iWindow, iUnits, 1) ) return false;
次に、転置層から誤差勾配を伝播させ、1番目の入力データソースのレベルまで戻します。この時点で、得られた勾配に残差接続経路からの勾配を即座に加算します。この加算結果は、転置層の勾配バッファに書き込まれます。このバッファはサイズ的に最適であり、以前に保存されていた値は安全に破棄して問題ありません。
if(!NeuronOCL.calcHiddenGradients(cTranspose.AsObject()) || !SumAndNormilize(NeuronOCL.getGradient(), Gradient, cTranspose.getGradient(), iWindow, false, 0, 0, 0, 1)) return false;
次に、Queryエンティティに由来する1番目の入力ソースレベルで誤差勾配を計算し、それを累積データに加算します。このとき、加算結果は入力データの勾配バッファに保存されます。
if(!NeuronOCL.calcHiddenGradients(cQuery.AsObject()) || !SumAndNormilize(NeuronOCL.getGradient(), cTranspose.getGradient(), NeuronOCL.getGradient(), iWindow, false, 0, 0, 0, 1) || !DiversityLoss(NeuronOCL, iUnits, iWindow, true) ) return false;
この段階で、多様性損失も加算します。
これで1番目の入力データソースに対する勾配伝播が完了し、次に2番目のデータストリームへ進みます。
先に、構造行列からの誤差勾配を2番目の入力データソース用の内部射影モデルの最終層のバッファに保存してあります。ここに、KeyおよびValueエンティティからの誤差勾配を加算する必要があります。そのため、まず受け取り側オブジェクトの勾配バッファを差し替えます。続いて、各エンティティに対する勾配分配メソッドを順に呼び出し、中間結果を以前の累積値に加算していきます。
temp = neuron.getGradient(); if(!neuron.SetGradient(GetPointer(cTemp), false) || !neuron.calcHiddenGradients(cKey.AsObject()) || !SumAndNormilize(temp, GetPointer(cTemp), temp, iWindow, false, 0, 0, 0, 1) || !neuron.calcHiddenGradients(cValue.AsObject()) || !SumAndNormilize(temp, GetPointer(cTemp), temp, iWindow, false, 0, 0, 0, 1) || !neuron.SetGradient(temp, false) ) return false;
この段階では、射影モデルの各層を逆順に処理しながら、誤差勾配をモデル内部へと伝播させていきます。
for(int i = cKVProjection.Total() - 2; i >= 0; i--) { neuron = cKVProjection[i]; if(!neuron || !neuron.calcHiddenGradients(cKVProjection[i + 1])) return false; } //--- return true; }
重要な点として、メソッドのパラメータで外部プログラムから渡されたバッファに対して、モデルの最初の層の勾配バッファポインタを差し替えることで、冗長なデータコピーの必要がなくなりました。その結果、勾配が最初の層に伝播される際、外部システムから提供されたバッファへ自動的に書き込まれるようになります。
あとは、処理の成否を示すブール値を呼び出し元プログラムに返し、メソッドを終了させれば完了です。
これで、相対Cross-Attentionオブジェクト CNeuronRelativeCrossAttentionのメソッドの実装と解説を終了します。クラスおよびその全メソッドの完全なソースコードは添付資料にてご覧いただけます。
残念ながら、本記事の分量制限により実装が完了する前に区切りを迎えました。次回の記事で引き続き解説と実装を進めてまいります。
結論
本記事では、原子要素(ローソク足)とモチーフ(パターン)の概念を基盤としたAtom-Motif Contrastive Transformer (AMCT)フレームワークを紹介しました。本手法の核心は、対照学習を用いて、基本的な構成要素から複雑な形態に至るまで異なる構造レベルにわたる、有益なパターンと無益なパターンをモデルが識別できるようにする点にあります。これにより、モデルは市場の局所的な特徴を捉えるだけでなく、将来の市場動向予測に役立つ追加の情報を持つ意味のあるパターンを検出することが可能になります。基盤となるTransformerアーキテクチャは、ローソク足とモチーフ間の長期依存関係や複雑な相互関係を効率的にモデリングすることを可能にしています。
実践的な部分では、MQL5を用いて提案手法の実装を開始しましたが、その作業範囲は一つの記事の枠を超えるものでした。次回の記事では、この実装を続けるとともに、歴史的な市場データを用いて提案フレームワークの実際の性能評価も行う予定です。
参照文献
記事で使用されているプログラム
| # | 名前 | 種類 | 詳細 |
|---|---|---|---|
| 1 | Research.mq5 | EA | 事例収集のためのEA |
| 2 | ResearchRealORL.mq5 | EA | Real-ORL法による事例収集のためのEA |
| 3 | Study.mq5 | EA | モデル訓練EA |
| 4 | Test.mq5 | EA | モデルテストEA |
| 5 | Trajectory.mqh | クラスライブラリ | システム状態記述の構造体 |
| 6 | NeuroNet.mqh | クラスライブラリ | ニューラルネットワークを作成するためのクラスのライブラリ |
| 7 | NeuroNet.cl | ライブラリ | OpenCLプログラムコードライブラリ |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/16163
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。


 コンパイルエラーを解決した後、テスターエラーがあり、頭全体が燃えている、どこで問題を解決するために把握することはできません。
コンパイルエラーを解決した後、テスターエラーがあり、頭全体が燃えている、どこで問題を解決するために把握することはできません。
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索