
交易中的神经网络:通过Adam-mini优化减少内存消耗

概述
当我们刚开始学习神经网络时,我们讨论了各种优化模型参数的方法。在我们的工作中,我们使用了不同的方法。我最常使用的是Adam方法,它允许自适应调整每个模型参数的最优学习率。然而,这种适应性是有代价的。Adam算法使用每个模型参数的一阶和二阶矩估计,这需要占用与模型本身相当的内存。这种内存消耗在训练大规模模型时成为一个显著的问题。在实践中,维持这种高内存需求的算法通常需要将计算任务卸载到CPU,从而增加延迟并减缓训练过程。鉴于这些挑战,寻找新的优化方法或改进现有技术变得越来越必要。
2024年7月发表的论文《Adam-mini: Use Fewer Learning Rates To Gain More》中提出了一种有前景的解决方案。作者介绍了一种基于Adam优化器的改进版本,该版本在保持性能的同时降低了内存消耗。这种新的优化器被称为Adam-mini,它将模型参数分割成块,为每个块分配一个学习率,并具有以下优势:
- 轻量级:Adam-mini显著减少了Adam中使用的学习率数量,从而可以将内存消耗降低45-50%。
- 高效:尽管资源使用量较低,Adam-mini的性能却与标准Adam相当,甚至更好。
1. Adam-mini算法
Adam-mini的作者们分析了Adam中v (二阶矩估计)的作用,并探索了其优化方法。在Adam中, v为每个参数提供了一个单独的学习率。研究发现,Transformer架构和其他神经网络中的Hessian矩阵倾向于表现出近乎块对角线的结构。此外,每个Transformer块都显示出不同的特征值分布。因此,Transformers需要在不同块之间使用不同的学习率来处理特征值的异质性。而Adam中的v正好可以提供这一特性。
然而,Adam不仅仅是为每个块分配学习率:它还为每个单独的参数分配学习率。需要注意的是,参数的数量远远超过块的数量。这就引发了一个问题:是否有必要为每个参数分配一个独特学习率?如果不是单独分配,我们又能优化多少呢?
作者们在一般优化任务中研究了这个问题,并得出了以下结论:
- Adam优于单一最优学习率方法。这在意料之中,因为Adam对不同参数应用了不同的学习率。
- 然而,在一个密集的Hessian子块内,单一最优学习率可以超越 Adam's的性能。
- 因此,将最优学习率应用于“块级”梯度下降方法可以提高训练效率。
对于具有块对角线Hessian的一般优化问题,增加学习率的数量并不一定能带来额外的益处。具体来说,对于每个密集的子块,一个精心选择的学习率就足以实现最优性能。
在基于Transformer的架构中也能观察到类似的行为。Adam-mini的作者们对一个4层Transformer进行了实验,发现这些模型可以使用比Adam少得多的学习率来实现相当甚至更优的性能。
这就引发了一个关于如何高效确定最优学习率的开放性问题。
Adam-mini的目标是在不需要进行穷举网格搜索的情况下,减少Adam中学习率的内存占用。
Adam-mini包含两个步骤。第一步仅用于初始化。
首先,我们将模型参数划分为块。在Transformer的情况下,该方法的作者建议根据注意力头将所有Query和Keys实体分组。在所有其他情况下,每一层使用一个二阶矩估计。
嵌入层(Embedding layers)单独处理。对于嵌入层,经典的Adam仍然是首选,因为嵌入层包含许多0值,其均值分布与原始变量的分布有显著差异。
在算法的第二步中,每个参数块(嵌入块除外)使用一个学习率。为了有效地为每个块选择合适的学习率,Adam-mini简单地将Adam中的梯度平方替换为其均值。该方法的作者对这些均值应用了移动平均,类似于经典的Adam。
从设计上讲,Adam-mini将Transformer中每个参数的学习率数量减少到嵌入层大小、输出层大小以及非嵌入块数量的总和。节省内存的程度取决于模型中非嵌入参数的比例。
与Adam相比,Adam-mini可以实现更高的吞吐量,尤其是在硬件资源有限的情况下。其原因有两个。首先,Adam-mini在其更新规则中没有增加任何额外的计算负担。此外,Adam-mini显著减少了Adam中使用的平方根和张量除法操作的数量。
其次,由于内存占用较低, Adam-mini可以在GPU上支持更大的批量规模,同时减少GPU到CPU的通信,这是另一个主要的训练瓶颈。
这些改进使得 Adam-mini能够通过减少内存消耗和计算成本来加速大规模模型的预训练。
Adam-mini通过在每个密集的Hessian子块中使用v Adam均值来为每个子块映射一个学习率。这种方法在计算上是高效的,但可能并不完全最优。然而,当前的设计足以实现与Adam相当甚至略优的性能,同时显著降低了内存需求。
2. 在MQL5中实现
在探讨了Adam-mini方法的理论基础之后,让我们进入本文的实践部分。在这一部分中,我们将使用MQL5实现我们对上述方法的理解。
请注意,这项工作与我们之前文章中的内容有显著不同。通常情况下,我们在模型的单一层级类框架内实现新的方法。然而,在这种情况下,我们需要在之前开发的多个类中引入修改。这是因为这些类中的每一个都包含了一个重写或继承的updateInputWeights方法,该方法定义了在层级级别上更新模型参数的算法。
当然,一些updateInputWeights方法属于复杂的架构组件,在这些组件中,我们只是调用了嵌套对象的相应方法。一个很好的例子是我们在之前的文章中探讨过的 Decoder。在这种情况下,算法与所选择的优化方法无关。
bool CNeuronSTNNDecoder::updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *Context) { if(!cEncoder.UpdateInputWeights(NeuronOCL, Context)) return false; if(!CNeuronMLCrossAttentionMLKV::updateInputWeights(cEncoder.AsObject(), Context)) return false; //--- return true; }
继续深入函数调用的层次结构,我们最终总会到达那些实现主要参数更新算法的基础“核心工作”。
2.1在基本全连接层中实现Adam-mini
其中一个这样的类是我们的基本全连接层,CNeuronBaseOCL。因此,我们的工作将从这里开始。
重要的一点是要记住,大多数计算任务都是在GPU端实现的,便于并行处理。这个过程也不例外。因此,我们将与一个OpenCL程序交互,在其中我们将创建一个名为UpdateWeightsAdamMini的新内核。
在深入实际代码之前,让我们简要探讨一下我们的架构解决方案。
首先,Adam-mini优化方法与经典Adam的主要区别在于二阶矩v的计算。与使用每个单独参数的梯度不同,Adam-mini的作者建议使用一个组的平均值。计算这种简单平均值的算法非常直接。通过这种方式,我们可以释放大量内存,因为每个组只存储一个二阶矩的值。
另一方面,我们不希望在每个单独线程中重复计算整个块的平均值。回想一下,对于全连接层,Adam-mini方法建议仅使用一个学习率。因此,至少可以说,在每个线程中为层的各个参数重新计算梯度的平均值是低效的。此外,考虑到访问全局内存的高成本,最佳解决方案是在多个线程之间并行化这个过程,同时尽量减少全局内存访问。然而,这又立即引发了如何组织线程间数据交换的问题。
在之前的文章中,我们已经学会了如何通过线程同步在本地组内交换数据。然而,在一个单独的本地组内组织整个层的参数更新过程似乎并不特别吸引人。因此,在实现过程中,我决定将计算的二阶矩数量增加到与结果张量大小相匹配。
正如我们所知,全连接层的参数数量是输入张量大小与结果张量大小的乘积。此外,为每个神经元使用偏置参数会增加与结果张量大小相等的参数数量。经典的Adam为一阶矩和二阶矩都存储了相等数量的值。在Adam-mini的实现中,我们显著减少了存储的二阶矩值的数量。
![]()
现在让我们一起探讨计算二阶矩平均值的过程。1个参数的误差梯度等于层输出处的误差梯度(经过激活函数的导数修正)与相应输入值的乘积。
![]()
因此,平方梯度的平均值可以通过如下方式计算:
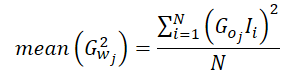
由于我们实现的是计算结果层中单个神经元的平均梯度,因此我们可以从方程中分解出该神经元的梯度。
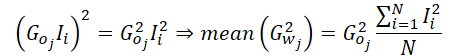
这意味着,在我们实现平均二阶矩的过程中,我们只需要计算输入数据平方值的平均值。通过这样做,我们消除了频繁访问存储输出梯度的全局内存缓冲区的需要。在获得这个平均值之后,我们只需取一次输出梯度,将其平方,然后乘以计算出的平均值。最后,我们将得到的结果值简单地分配到本地组中,以便做进一步的计算。
现在我们对计算过程有了清晰的了解,我们可以继续在UpdateWeightsAdamMini内核中实现它。这个内核的参数与经典的Adam内核几乎完全相同。包括5个数据缓冲区和3个常量:
- matrix_w — 层参数矩阵;
- matrix_g — 层输出处的误差梯度张量;
- matrix_i — 输入数据缓冲区;
- matrix_m — 一阶矩张量;
- matrix_v — 二阶矩张量;
- l — 学习率;
- b1 — 一阶矩平滑系数(ß1);
- b2 — 二阶矩平滑系数(ß2)。
__kernel void UpdateWeightsAdamMini(__global float *matrix_w, __global const float *matrix_g, __global const float *matrix_i, __global float *matrix_m, __global float *matrix_v, const float l, const float b1, const float b2 ) { //--- inputs const size_t i = get_local_id(0); const size_t inputs = get_local_size(0) - 1; //--- outputs const size_t o = get_global_id(1); const size_t outputs = get_global_size(1);
内核的执行计划在一个二维的任务空间中进行。第一维对应于输入值的数量加上偏移元素。第二维是结果张量的大小。在内核主体中,我们首先确定线程在两个维度中的位置。
请注意,我们将线程沿着任务空间的一个维度组合成工作组。
接下来,我们在本地上下文内存中组织一个数组,用于工作组内线程之间的数据交换。
__local float temp[LOCAL_ARRAY_SIZE]; const int ls = min((uint)LOCAL_ARRAY_SIZE, (uint)inputs);
下一步是计算输入数据的平方平均值。由于输入数据缓冲区也将用于计算一阶矩,因此每个线程将首先从全局输入数据缓冲区中获取相应的值。
const float inp = (i < inputs ? matrix_i[i] : 1.0f);
然后,我们将实现一个带有线程同步的循环,其中每个线程会将其输入数据元素的平方值累加到本地数组中。
int count = 0; do { if(count == (i / ls)) { int shift = i % ls; temp[shift] = (count == 0 ? 0 : temp[shift]) + ((isnan(inp) || isinf(inp)) ? 0 : inp*inp); } count++; barrier(CLK_LOCAL_MEM_FENCE); } while(count * ls < inputs);
之后,我们将对本地数组中元素的值进行求和。
//--- sum count = (ls + 1) / 2; do { if(i < count && (i + count) < ls) { temp[i] += temp[i + count]; temp[i + count] = 0; } count = (count + 1) / 2; barrier(CLK_LOCAL_MEM_FENCE); } while(count > 1);
在一个线程内,我们实现二阶矩的计算,并将其保存在本地数组索引为0的元素中。
此外,我们记得访问本地内存数组的速度比访问全局内存缓冲区要快得多。因此,为了减少全局内存访问操作的数量,我们在当前层结果的级别上获取误差梯度,并将其保存在本地数组索引为1的元素中。这样,工作组的其余元素在执行后续操作时,将从本地内存中取值,而不是访问全局内存。
确保同步工作组线程的工作。
//--- calc v if(i == 0) { temp[1] = matrix_g[o]; if(isnan(temp[1]) || isinf(temp[1])) temp[1] = 0; temp[0] /= inputs; if(isnan(temp[0]) || isinf(temp[0])) temp[0] = 1; float v = matrix_v[o]; if(isnan(v) || isinf(v)) v = 1; temp[0] = b2 * v + (1 - b2) * pow(temp[1], 2) * temp[0]; matrix_v[o] = temp[0]; } barrier(CLK_LOCAL_MEM_FENCE);
请注意,我们立即将二阶矩的值保存到全局数据缓冲区中。这个简单的步骤有助于消除工作组内其他线程的不必要的全局内存访问,减少多个线程同时访问同一个全局缓冲区元素所导致的延迟。
接下来,我们的算法遵循经典Adam方法的操作。在此阶段,我们确定可训练参数张量中的偏移量,并从全局内存缓冲区中加载当前分析的参数值。
const int wi = o * (inputs + 1) + i; float weight = matrix_w[wi]; if(isnan(weight) || isinf(weight)) weight = 0;
我们来计算一阶矩的值。
float m = matrix_m[wi]; if(isnan(m) || isinf(m)) m = 0; //--- calc m m = b1 * m + (1 - b1) * temp[1] * inp; if(isnan(m) || isinf(m)) m = 0;
确定参数调整的大小。
float delta = l * (m / (sqrt(temp[0]) + 1.0e-37f) - (l1 * sign(weight) + l2 * weight)); if(isnan(delta) || isinf(delta)) delta = 0;
之后,我们校正参数值并将其新值保存在全局数据缓冲区中。
if(delta > 0) matrix_w[wi] = clamp(weight + delta, -MAX_WEIGHT, MAX_WEIGHT); matrix_m[wi] = m; }
在这里,我们保存一阶矩的值并完成内核操作。
在对OpenCL端进行更改后,我们需要对主程序进行一系列编辑。首先,我们将为我们的枚举添加一种新的优化方法。
//+------------------------------------------------------------------+ /// Enum of optimization method used | //+------------------------------------------------------------------+ enum ENUM_OPTIMIZATION { SGD, ///< Stochastic gradient descent ADAM, ///< Adam ADAM_MINI ///< Adam-mini };
接下来,我们将对CNeuronBaseOCL::updateInputWeights方法进行更改。在变量声明块中,我们将添加一个描述工作组大小的数组,local_work_size(在下面的代码中加下划线)。在这个阶段,我们不会为它分配值,因为只有在使用相应的优化方法时它们才会派上用场。
bool CNeuronBaseOCL::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { if(CheckPointer(OpenCL) == POINTER_INVALID || CheckPointer(NeuronOCL) == POINTER_INVALID) return false; uint global_work_offset[2] = {0, 0}; uint global_work_size[2], local_work_size[2]; global_work_size[0] = Neurons(); global_work_size[1] = NeuronOCL.Neurons() + 1; uint rest = 0; float lt = lr;
接下来是根据所选择的模型参数优化方法对算法进行分支。我们将使用与之前讨论的优化方法中相同的算法来排队执行内核,因此这里不会详细说明。
switch(NeuronOCL.Optimization()) { case SGD: ......... ......... ......... break; case ADAM: ........ ........ ........ break;
让我们看一下新增的代码。首先,我们将传递内核正常工作所需的参数。
case ADAM_MINI: if(!OpenCL.SetArgumentBuffer(def_k_UpdateWeightsAdamMini, def_k_wuam_matrix_w, NeuronOCL.getWeightsIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_UpdateWeightsAdamMini, def_k_wuam_matrix_g, getGradientIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_UpdateWeightsAdamMini, def_k_wuam_matrix_i, NeuronOCL.getOutputIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_UpdateWeightsAdamMini, def_k_wuam_matrix_m, NeuronOCL.getFirstMomentumIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_UpdateWeightsAdamMini, def_k_wuam_matrix_v, NeuronOCL.getSecondMomentumIndex())) return false; lt = (float)(lr * sqrt(1 - pow(b2, (float)t)) / (1 - pow(b1, (float)t))); if(!OpenCL.SetArgument(def_k_UpdateWeightsAdamMini, def_k_wuam_l, lt)) return false; if(!OpenCL.SetArgument(def_k_UpdateWeightsAdamMini, def_k_wuam_b1, b1)) return false; if(!OpenCL.SetArgument(def_k_UpdateWeightsAdamMini, def_k_wuam_b2, b2)) return false;
接下来,我们将定义内核的全局工作任务空间以及单独的工作组任务空间。
global_work_size[0] = NeuronOCL.Neurons() + 1; global_work_size[1] = Neurons(); local_work_size[0] = global_work_size[0]; local_work_size[1] = 1;
请注意,在第一维中,无论是全局还是工作组,我们都指定了一个比输入数据层大小多1个元素的值。这是我们的偏移参数。但在第二维中,我们在全局指定了当前神经层中的元素数量。对于工作组,我们在这一维中指定1个元素。这对应于工作组在当前层的1个神经元内的操作。
在完成准备工作后,内核被放入执行队列。
ResetLastError(); if(!OpenCL.Execute(def_k_UpdateWeightsAdamMini, 2, global_work_offset, global_work_size, local_work_size)) { printf("Error of execution kernel UpdateWeightsAdamMini: %d", GetLastError()); return false; } t++; break; default: return false; break; } //--- return true; }
并且,如果指定了错误的优化方法,我们还会添加一个带有负结果的退出。
至此,我们实现了基本全连接层CNeuronBaseOCL::updateInputWeights的参数更新方法。然而,让我们回顾一下这些修改的主要目标:减少使用Adam优化方法时的内存消耗。因此,我们还必须调整CNeuronBaseOCL::Init初始化方法,以便在选择Adam-mini优化方法时减少二阶矩缓冲区的大小。由于这些更改是小范围且有针对性的,因此我不会在本文中提供该方法算法的完整描述。相反,我将只展示对应缓冲区的初始化代码块。
if(CheckPointer(SecondMomentum) == POINTER_INVALID) { SecondMomentum = new CBufferFloat(); if(CheckPointer(SecondMomentum) == POINTER_INVALID) return false; } if(!SecondMomentum.BufferInit((optimization == ADAM_MINI ? numOutputs : count), 0)) return false; if(!SecondMomentum.BufferCreate(OpenCL)) return false;
您可以在随后附加的文件中找到此方法的完整实现,以及用于准备本文的所有程序的完整代码。
2.2在卷积层中使用Adam-mini
卷积层是各种架构(包括Transformer)中广泛使用的另一个基础构建模块。
将Adam-mini优化方法整合到其功能中有一些独特的方面,这主要是由于卷积层的特定性质。与全连接层不同,在全连接层中,每个可训练参数仅负责将一个输入神经元的值传递到当前层的一个神经元,而卷积层通常参数数量较少,但每个参数的使用范围更广。
此外,重要的一点是要注意,我们在Transformer算法中使用卷积层来生成Query、Key和Value实体。这些实体需要特殊处理对Adam-mini方法的实现。
在卷积层中实现Adam-mini方法时,必须考虑所有这些因素。
与全连接层一样,我们首先在OpenCL端实现该方法。在这里,我们创建了UpdateWeightsConvAdamMini内核。除了熟悉的变量外,这个内核还引入了两个新的常量:输入数据的序列长度和卷积窗口的步长。
__kernel void UpdateWeightsConvAdamMini(__global float *matrix_w, __global const float *matrix_i, __global float *matrix_m, __global float *matrix_v, const int inputs, const float l, const float b1, const float b2, int step ) { //--- window in const size_t i = get_global_id(0); const size_t window_in = get_global_size(0) - 1; //--- window out const size_t f = get_global_id(1); const size_t window_out = get_global_size(1); //--- head window out const size_t f_h = get_local_id(1); const size_t window_out_h = get_local_size(1); //--- variable const size_t v = get_global_id(2); const size_t variables = get_global_size(2);
请注意,在内核参数中,我们没有指定输入数据窗口的大小和使用的过滤器数量。这些参数,连同另外两个参数,被移到了任务空间,这是一个需要考虑的重要方面。
这个内核被设计为在三维任务空间中执行:第一维对应于输入窗口大小加上一个额外的元素用于偏置。这里,我们可以观察到它与全连接层的任务空间有一定的相似性。
第二维表示使用的过滤器数量,这在逻辑上对应于全连接层的输出维度。
至于工作组,我们不会为每个单独的卷积过滤器创建,而是根据Transformer架构的注意力头对它们进行分组。
请注意,用户只能为每个头指定一个卷积过滤器。在这种情况下,每个卷积过滤器将获得一个单独的学习率,类似于我们对全连接层的实现。
第三维被引入用于处理多模态时间序列,其中各个单元序列有自己的卷积过滤器。为它们也创建了单独的二阶矩,以便实现自适应学习率。
必须区分“注意力头”和“单元时间序列”,它们不应被混淆。尽管它们可能看起来相似,但却扮演着不同的角色。单元时间序列对输入张量进行划分。注意力头对输出张量进行划分。
在内核中,在确定任务空间所有维度中的线程后,我们定义全局数据缓冲区中的主要偏移常量。
//--- constants const int total = (inputs - window_in + step - 1) / step; const int shift_var_in = v * inputs; const int shift_var_out = v * total * window_out; const int shift_w = (f + v * window_out) * (window_in + 1) + i;
我们为工作组数据交换创建了一个本地数组。
__local float temp[LOCAL_ARRAY_SIZE]; const int ls = min((uint)window_in, (uint)LOCAL_ARRAY_SIZE);
准备工作完成后,我们将收集每个参数的误差梯度。
//--- calc gradient float grad = 0; for(int t = 0; t < total; t++) { if(i != window_in && (i + t * window_in) >= inputs) break; float gt = matrix_g[t * window_out + f + shift_var_out] * (i == window_in ? 1 : matrix_i[i + t * step + shift_var_in]); if(!(isnan(gt) || isinf(gt))) grad += gt; }
请注意,在这种情况下,每个全局线程完全收集了其影响的所有元素的误差梯度。与全连接层不同,在这里我们立即将输入数据元素的值乘以结果的相应误差梯度。
接下来,我们将计算出的误差梯度累加起来,以在本地数组中将它们的平方值求和,但这次是在工作组级别。为了实现这一点,我们实现了一个带有强制线程同步的嵌套循环结构。外循环对应于工作组内的过滤器数量。内循环收集单个过滤器的所有参数的误差梯度。
//--- calc sum grad int count; for(int h = 0; h < window_out_h; h++) { count = 0; do { if(h == f_h) { if(count == (i / ls)) { int shift = i % ls; temp[shift] = ((count == 0 && h == 0) ? 0 : temp[shift]) + ((isnan(grad) || isinf(grad)) ? 0 : grad * grad); } } count++; barrier(CLK_LOCAL_MEM_FENCE); } while((count * ls) < window_in); }
然后我们将本地数组的值求和。
count = (ls + 1) / 2; do { if(i < count && (i + count) < ls && f_h == 0) { temp[i] += temp[i + count]; temp[i + count] = 0; } count = (count + 1) / 2; barrier(CLK_LOCAL_MEM_FENCE); } while(count > 1);
我们还将确定当前群的二阶矩的值。
//--- calc v if(i == 0 && f_h == 0) { temp[0] /= (window_in * window_out_h); if(isnan(temp[0]) || isinf(temp[0])) temp[0] = 1; int head = f / window_out_h; float v = matrix_v[head]; if(isnan(v) || isinf(v)) v = 1; temp[0] = clamp(b2 * v + (1 - b2) * temp[0], 1.0e-6f, 1.0e6f); matrix_v[head] = temp[0]; } barrier(CLK_LOCAL_MEM_FENCE);
接下来,我们重复经典的Adam方法的算法。这里我们定义一阶矩。
//--- calc m float mt = clamp(b1 * matrix_m[shift_w] + (1 - b1) * grad, -1.0e5f, 1.0e5f); if(isnan(mt) || isinf(mt)) mt = 0;
我们调整分析参数的值。
float weight = clamp(matrix_w[shift_w] + l * mt / sqrt(temp[0]), -MAX_WEIGHT, MAX_WEIGHT);
我们保存获得的值。
if(!(isnan(weight) || isinf(weight)))
matrix_w[shift_w] = weight;
matrix_m[shift_w] = mt;
}
在OpenCL端创建内核之后,我们将转向主程序的工作。与全连接层的情况一样,我们在CNeuronConvOCL::updateInputWeights方法中实现了调用上述创建的内核。其调用算法与上面为全连接层展示的算法类似。对于一个普通的卷积层,我们为每个注意力头使用一个过滤器,并占用一个单元序列。因此,任务空间的维度将呈现以下形式:
uint global_work_offset_am[3] = { 0, 0, 0 }; uint global_work_size_am[3] = { iWindow + 1, iWindowOut, iVariables }; uint local_work_size_am[3] = { global_work_size_am[0], 1, 1 };
您可以在随后附加的文件中找到此方法的完整实现。
然而,我想补充几句关于在使用Transformer架构的类的实现中使用创建的内核的内容。以CNeuronMLMHAttentionOCL类为例。这个类是构建各种其他算法的父类。
需要注意的是,CNeuronMLMHAttentionOCL类并不包含传统意义上的卷积层。相反,它组织了缓冲区数组并重写了所有相关方法。卷积层的参数更新是通过ConvolutionUpdateWeights方法处理的。由于这个方法用于管理各种卷积层,我们将添加两个额外的参数:注意力头的数量(heads)和单元序列的数量(variables)。为了避免从其他类访问此方法时可能出现的问题,这些新参数将被赋予默认值。
bool CNeuronMLMHAttentionOCL::ConvolutuionUpdateWeights(CBufferFloat *weights, CBufferFloat *gradient, CBufferFloat *inputs, CBufferFloat *momentum1, CBufferFloat *momentum2, uint window, uint window_out, uint step = 0, uint heads = 0, uint variables = 1) { if(CheckPointer(OpenCL) == POINTER_INVALID || CheckPointer(weights) == POINTER_INVALID || CheckPointer(gradient) == POINTER_INVALID || CheckPointer(inputs) == POINTER_INVALID || CheckPointer(momentum1) == POINTER_INVALID) return false;
在方法主体中,我们首先检查方法从调用者处作为参数接收的数据缓冲区指针。
接下来,我们检查卷积窗口步长(步长)参数的值。如果它等于“0”,那么我们将步长设置为等于卷积窗口的大小。
if(step == 0) step = window;
请注意,在这种情况下,我们使用无符号数据类型来表示参数。因此,它们不能包含负值。我们把对参数值膨胀的控制权留给用户。
然后我们定义任务空间。在这种情况下,Adam-mini优化方法的内核使用的是一个三维任务空间,这与其它优化方法使用的一维任务空间不同。因此,我们分配了单独的数组用于指示它。
uint global_work_offset[1] = {0}; uint global_work_size[1]; global_work_size[0] = weights.Total(); uint global_work_offset_am[3] = {0, 0, 0}; uint global_work_size_am[3] = {window, window_out, 1}; uint local_work_size_am[3] = {window, (heads > 0 ? window_out / heads : 1), variables};
让我们看一下工作组任务空间的第二维。如果方法参数中没有指定注意力头的数量,那么每个过滤器将有一个单独的学习率。如果提供了注意力头的数量,我们通过将过滤器的总数除以注意力头的数量来计算每个注意力头的过滤器数量。
选择这种方法为的是适应该方法的各种使用场景。在CNeuronMLMHAttentionOCL类中,卷积层既用于形成Query、Key和Value实体,也用于数据投影(在多头注意力下采样层和 FeedForward 块内)。
下一步是根据用于模型参数的优化方法来分离算法。就像在全连接层算法讨论中一样,我们不会深入探讨之前实现的优化方法的工作原理。我们将只考虑Adam-mini方法的代码块。
if(weights.GetIndex() < 0) return false; float lt = 0; switch(optimization) { case SGD: ........ ........ ........ break; case ADAM: ........ ........ ........ break; case ADAM_MINI: if(CheckPointer(momentum2) == POINTER_INVALID) return false; if(gradient.GetIndex() < 0) return false; if(inputs.GetIndex() < 0) return false; if(momentum1.GetIndex() < 0) return false; if(momentum2.GetIndex() < 0) return false;
在这里,我们检查OpenCL上下文中数据缓冲区指针的有效性。之后,我们将把所有必要的参数传递给内核。
if(!OpenCL.SetArgumentBuffer(def_k_UpdateWeightsConvAdamMini, def_k_wucam_matrix_w, weights.GetIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_UpdateWeightsConvAdamMini, def_k_wucam_matrix_g, gradient.GetIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_UpdateWeightsConvAdamMini, def_k_wucam_matrix_i, inputs.GetIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_UpdateWeightsConvAdamMini, def_k_wucam_matrix_m, momentum1.GetIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_UpdateWeightsConvAdamMini, def_k_wucam_matrix_v, momentum2.GetIndex())) return false; lt = (float)(lr * sqrt(1 - pow(b2, t)) / (1 - pow(b1, t))); if(!OpenCL.SetArgument(def_k_UpdateWeightsConvAdamMini, def_k_wucam_inputs, inputs.Total())) return false; if(!OpenCL.SetArgument(def_k_UpdateWeightsConvAdamMini, def_k_wucam_l, lt)) return false; if(!OpenCL.SetArgument(def_k_UpdateWeightsConvAdamMini, def_k_wucam_b1, b1)) return false; if(!OpenCL.SetArgument(def_k_UpdateWeightsConvAdamMini, def_k_wucam_b2, b2)) return false; if(!OpenCL.SetArgument(def_k_UpdateWeightsConvAdamMini, def_k_wucam_step, (int)step)) return false;
我们已经在前面展示了任务空间。现在我们只需要将内核放入执行队列。
ResetLastError(); if(!OpenCL.Execute(def_k_UpdateWeightsConvAdamMini, 3, global_work_offset_am, global_work_size_am, local_work_size_am)) { string error; CLGetInfoString(OpenCL.GetContext(), CL_ERROR_DESCRIPTION, error); printf("Error of execution kernel %s Adam-Mini: %s", __FUNCSIG__, error); return false; } t++; break; //--- default: printf("Error of optimization type %s: %s", __FUNCSIG__, EnumToString(optimization)); return false; }
我们还会在指定错误的参数优化类型时添加一条错误消息。
在模型参数归一化方面,该方法的后续代码保持不变。
global_work_size[0] = window_out; OpenCL.SetArgumentBuffer(def_k_NormilizeWeights, def_k_norm_buffer, weights.GetIndex()); OpenCL.SetArgument(def_k_NormilizeWeights, def_k_norm_dimension, (int)window + 1); if(!OpenCL.Execute(def_k_NormilizeWeights, 1, global_work_offset, global_work_size)) { string error; CLGetInfoString(OpenCL.GetContext(), CL_ERROR_DESCRIPTION, error); printf("Error of execution kernel %s Normalize: %s", __FUNCSIG__, error); return false; } //--- return true; }
此外,在上述提到的类的初始化方法中,我们修改了用于存储二阶矩的数据缓冲区的大小,这与在描述全连接层更改时展示的算法类似。然而,我不会在本文中深入探讨这一点。这些只是小的修改,您可以参考附件来了解详情。
3. 测试
上述内容描述了在我们模型的两个基础类中实现Adam-mini方法的过程。现在是时候评估所提出方法的有效性了。
在本文中,我们介绍了一种新的优化方法。为了评估这种优化方法的有效性,合乎逻辑的做法是观察使用不同优化技术的模型的训练过程。
为了进行这个实验,我从TPM算法的文章中选取了模型,并修改了模型的架构,只改变了参数优化的方法。
很明显,采用这种方法时,所有训练程序、数据集以及训练过程都保持不变。
这里提醒一下,这些模型是使用EURUSD的H1时间框架,基于2023年全年的历史数据进行训练的。所有指标的参数都设置为默认值。
在测试训练后的模型时,我们取得了与使用经典Adam方法训练的模型相似的结果。以下是基于2024年1月数据的测试结果:

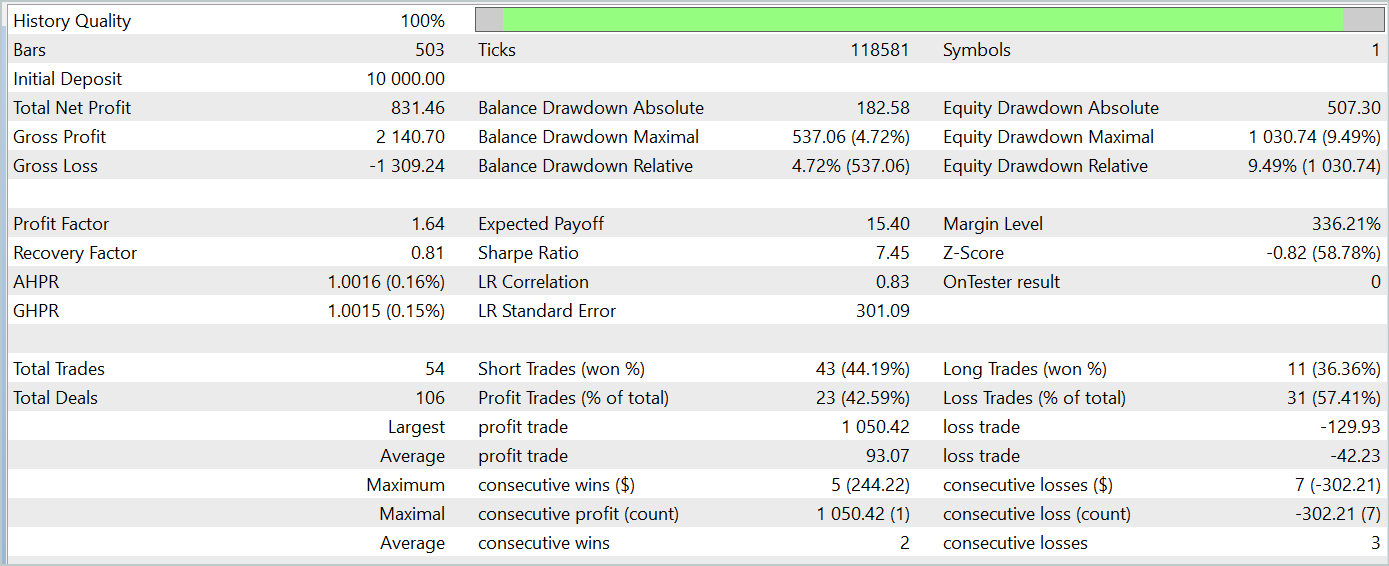
重要的一点是要注意,Adam-mini优化方法的主要目标是在不降低训练质量的前提下减少内存消耗。所提出的方法成功地实现了这一目标。
结论
在本文中,我们介绍了一种新的优化方法Adam-mini,该方法旨在减少训练大型语言模型时的内存使用并提高吞吐量。Adam-mini通过将所需学习率的数量减少到嵌入层大小、结果层大小以及其他层中块的数量之和来实现这一目标。它的简洁性、灵活性和高效性使其成为深度学习广泛应用中一个很有前景的工具。
文章的实践部分展示了将所提出的方法整合到神经网络的基本层类型中。测试结果证实了该方法作者所声明的改进。
参考文献
文中所用的程序
| # | 名称 | 类型 | 说明 |
|---|---|---|---|
| 1 | Research.mq5 | EA | 样本收集EA |
| 2 | ResearchRealORL.mq5 | EA | 使用Real-ORL方法收集示例的 EA |
| 3 | Study.mq5 | EA | 模型训练EA |
| 4 | StudyEncoder.mq5 | EA | 编码器训练EA |
| 5 | Test.mq5 | EA | 模型测试EA |
| 6 | Trajectory.mqh | 类库 | 系统状态定义结构 |
| 7 | NeuroNet.mqh | 类库 | 用于创建神经网络的类库 |
| 8 | NeuroNet.cl | 代码库 | OpenCL程序代码库 |
本文由MetaQuotes Ltd译自俄文
原文地址: https://www.mql5.com/ru/articles/15352
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。

您好,我想问一下,当我运行 Study 时,执行内核 UpdateWeightsAdamMini 出错:5109,原因是什么,如何解决?
下午好,您能公布一下您使用的模型的执行日志和架构吗?
您好,我向您发送了工作室编码和研究录音。至于结构,与您提供的几乎相同,只是研究中的蜡烛数量为 12 根,这些蜡烛的数据为 11 个。另外,在输出层中,我只有 4 个参数。
您好,请问能否公布所使用模型的注册表和架构?