
取引におけるニューラルネットワーク:対照パターンTransformer(最終回)

はじめに
Atom-Motif Contrastive Transformer (AMCT)フレームワークは、市場のトレンドやパターン予測の精度を高めるために、原子的要素と複雑な構造という2つの分析レベルを統合するシステムです。このフレームワークの核心的な考え方は、「ローソク足」とそこから形成されるパターンは、同じ市場状況を異なる視点で表現している、というものです。これにより、モデルの学習過程で両者の自然な整合性が得られます。これら異なる表現レベルに内在する追加情報を抽出することで、生成される予測の質を大幅に向上させることが可能になります。
さらに、異なる時間枠や金融商品にまたがって観察される類似の市場パターンは、一般的に類似したシグナルを生成します。そのため、対照学習手法を適用することで、重要なパターンを特定し、それらの解釈の質を向上させることができます。市場トレンドを決定づける上で重要な役割を果たすパターンをより正確に特定するために、AMCTの開発者たちはCross-Attention技術を組み込んだ特性認識型(Property-aware)Attentionメカニズムを導入しました。
以下に、著者らによって提示されたAtom-Motif Contrastive Transformerフレームワークのオリジナルの可視化図を示します。
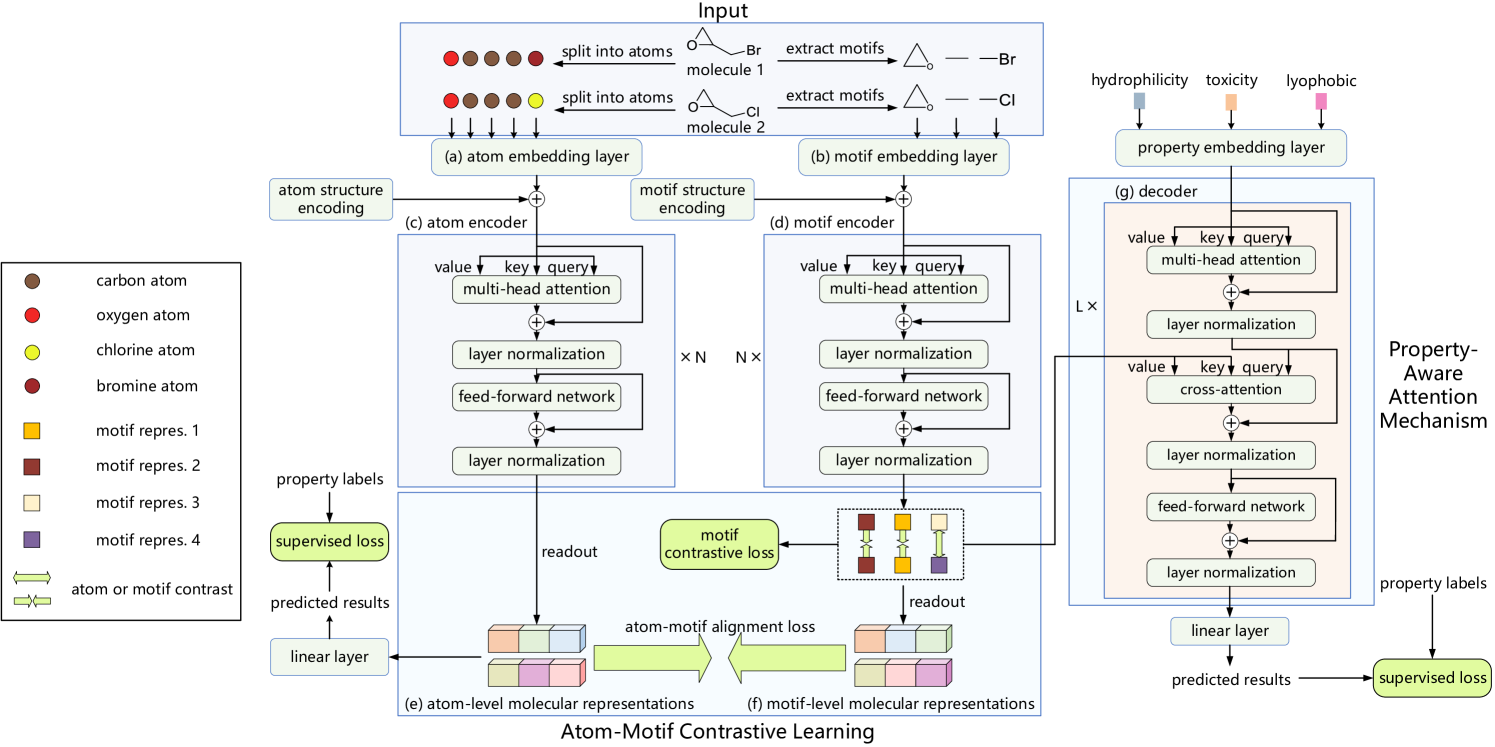
前回の記事では、ローソク足およびパターンのパイプラインの実装について解説し、市場シナリオの特性とローソク足パターンとの相互依存関係を分析するモジュールで使用する予定の相対Cross-Attentionクラスも構築しました。本日は、この作業をさらに進めていきます。
1. 特性とモチーフ間の相互依存性の分析
ここでは、特性とモチーフ間の相互依存性を分析するモジュールについて、詳しく見ていきましょう。このセクションの重要な問いのひとつは、そもそも「特性」とは何かという点です。一見すると簡単な問いに思えるかもしれませんが、実際には非常に複雑です。AMCTフレームワークの著者たちは、もともと分子構造内で検出・分析すべきさまざまな化学的特性を想定していました。では、「市場シナリオ」における特性とは何を意味するのでしょうか。そして、それらをどのように正確に記述できるのでしょうか。
たとえば、トレンドという概念を考えてみましょう。伝統的なテクニカル分析では、トレンドは通常「上昇トレンド」「下降トレンド」「レンジ(横ばい)」の3種類に分類されます。しかし、ここで疑問が生じます。この分類だけで詳細な分析は可能でしょうか。価格の動きのダイナミクスや、トレンドの強さをどのようにして正確に表現できるのでしょうか。
実際の応用課題を解決する際に、市場状況を特徴づける特性を選定しようとすると、さらなる疑問が次々と浮かんできます。
明確な解答がまだ得られていない場合は、別の視点からこの問題に取り組んでみましょう。つまり、市場の特性を人手で定義するのではなく、モデルに自ら学習させるというアプローチです。具体的には、学習用データセットから、その課題に関連する特徴を自動的に抽出させるのです。これは、RefMask3Dフレームワークで言語的プリミティブをモデルが学習する方法に似ています。私たちは、特定の応用課題の解決に最適化された学習可能な特性テンソルを生成します。このアルゴリズムは、以下に構造を示すCNeuronPropertyAwareAttentionクラスにて実装されています。
class CNeuronPropertyAwareAttention : public CNeuronRMAT { protected: CBufferFloat cTemp; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronPropertyAwareAttention(void) {}; ~CNeuronPropertyAwareAttention(void) {}; virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint properties, uint units_count, uint heads, uint layers, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronPropertyAwareAttention; } };
線形モデルアルゴリズムを実装したCNeuronRMATを親クラスとして使用しています。ご存知の通り、この親クラスの内部コンポーネントはすべて1つの動的配列にカプセル化されています。この設計により、クラス構造内に新たなメンバーオブジェクトを宣言することなく、内部アーキテクチャを柔軟に変更することが可能になります。必要なのは仮想オブジェクト初期化メソッドをオーバーライドして、必要な内部コンポーネントのシーケンスを生成することだけです。ただし、制約として、アーキテクチャは線形でなければならないという点があります。
しかし残念ながら、Cross-Attentionのアーキテクチャはこの線形性の要件を完全には満たしていません。なぜなら、Cross-Attentionは2つの別々の入力ソースを扱うためです。そのため、順伝播および誤差逆伝播(バックプロパゲーション)の両方に対して、仮想メソッドをオーバーライドする必要があります。ここでは、それらのオーバーライドされたメソッド内で実装されたアルゴリズムを詳しく見ていきましょう。
Initメソッドでは、新しいオブジェクトの初期化時に、そのオブジェクトのアーキテクチャを一意に定義する定数が渡されます。
bool CNeuronPropertyAwareAttention::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint properties, uint units_count, uint heads, uint layers, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * properties, optimization_type, batch)) return false;
メソッドの本体では、まず最初に全結合ニューラル層の基底クラスであるCNeuronBaseOCLの該当メソッドを呼び出します。
ここで重要なのは、直接の親クラスではなく、ニューラル層の基底クラスからメソッドを呼び出しているという点です。これは、初期化したいのが基底インターフェイスのみであり、内部コンポーネントの構成は本実装で完全に再定義する予定だからです。
次に、内部コンポーネントへのポインタを格納するための動的配列を準備します。
cLayers.Clear(); cLayers.SetOpenCL(OpenCL);
また、作成するオブジェクトへのポインタを一時的に保存するためのローカル変数も宣言します。
CNeuronBaseOCL *neuron=NULL; CNeuronRelativeSelfAttention *self_attention = NULL; CNeuronRelativeCrossAttention *cross_attention = NULL; CResidualConv *ff = NULL;
これで準備作業は完了したので、内部オブジェクトのシーケンス構築へと進みます。まず最初に、2つの連続した全結合層を作成し、市場の状況を特徴付けることができる学習可能な埋め込みテンソルを生成します。
int idx = 0; neuron = new CNeuronBaseOCL(); if (!neuron || !neuron.Init(window * properties, idx, OpenCL, 1, optimization, iBatch) || !cLayers.Add(neuron)) return false; CBufferFloat *temp = neuron.getOutput(); if (!temp.Fill(1)) return false; idx++; neuron = new CNeuronBaseOCL(); if (!neuron || !neuron.Init(0, idx, OpenCL, window * properties, optimization, iBatch) || !cLayers.Add(neuron)) return false;
ここでは、これまでの研究で有効性が確認された手法を適用しています。最初の層は、固定値1を出力する単一のニューロンを含んでいます。次の層では、必要な埋め込みのシーケンスを生成し、これは作成したオブジェクトの基本機能を用いて学習されます。両方のオブジェクトへのポインタは、呼び出し順に動的配列へ追加されます。
その後、従来のTransformerデコーダに近い構造の構築へと進みます。ただし、1つだけ変更点があります。それは、標準のAttentionモジュールを、解析対象のシーケンス構造に対して相対位置エンコーディングをサポートする等価なモジュールに置き換えている点です。これを実現するために、指定された内部層数と等しい回数でループを作成します。
for (uint i = 0; i < layers; i++) { idx++; self_attention = new CNeuronRelativeSelfAttention(); if (!self_attention || !self_attention.Init(0, idx, OpenCL, window, window_key, properties, heads, optimization, iBatch) || !cLayers.Add(self_attention) ) { delete self_attention; return false; }
ループ本体の中では、まず最初に相対的なSelf-Attention層を作成および初期化します。 この層は、市場状況を特徴付ける学習可能な特性の埋め込み同士の相互依存性を、現在解決中のタスクの文脈において分析する役割を担います。そのため、解析対象となるシーケンスの長さはpropertiesパラメータによって決定されます。作成されたオブジェクトへのポインタは、動的配列に追加されます。
次に、相対Cross-Attention層を作成します。
idx++; cross_attention = new CNeuronRelativeCrossAttention(); if (!cross_attention || !cross_attention.Init(0, idx, OpenCL, window, window_key, properties, heads, window, units_count, optimization, iBatch) || !cLayers.Add(cross_attention) ) { delete cross_attention; return false; }
ここでも同様に、特性の埋め込みが主要な入力ストリームとして機能し、結果テンソルの形状を決定します。その結果、feedForwardブロックにおけるシーケンスの長さも、生成された特性の数と同じに設定されます。
idx++; ff = new CResidualConv(); if (!ff || !ff.Init(0, idx, OpenCL, window, window, properties, optimization, iBatch) || !cLayers.Add(ff) ) { delete ff; return false;}
}
これらの新たに作成されたオブジェクトへのポインタを動的配列に追加し、ループの次の反復へと進みます。
指定された回数のループが正常に完了すると、動的配列には、学習可能な特性と検出されたパターン間の相互依存性を解析するモジュールの正しい実装に必要なすべてのオブジェクトが揃った状態になります。最後のステップとして、データバッファのポインタを差し替える処理をおこないます。 これにより、モデル学習時の処理回数を大幅に削減することが可能になります。
if (!SetOutput(ff.getOutput()) || !SetGradient(ff.getGradient())) return false; //--- return true;}
メソッドの最後では、一連の処理が正常に完了したかどうかを示すブール値を返し、呼び出し元のプログラムへ結果を通知します。
クラスの新しいオブジェクトの初期化が完了した後は、feedForwardメソッドで定義されたフィードフォワードパスアルゴリズムの実装へと進みます。ここで重要なのは、ブロック構造にCross-Attentionモジュールが含まれているにもかかわらず、feedForwardメソッドは入力データオブジェクトへのポインタを1つだけ受け取るという点です。これは、第2の入力ソース(すなわち「特性」)が、クラス内のオブジェクトによって内部的に生成されるためです。
bool CNeuronPropertyAwareAttention::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
メソッド本体では、受け取ったポインタの妥当性を即座に確認します。このオブジェクトは追加のデータソースとして使用されるため、そのデータバッファに直接アクセスすることになります。したがって、この段階で無効なポインタが渡されると、重大な障害が発生する可能性があります。
続いて、入力オブジェクトへのポインタを一時的に保持するためのローカル変数を宣言します。
CNeuronBaseOCL *neuron = NULL;
この変数は、ニューラル層の基底型を用いて宣言している点に注意してください。 この基底型は、内部のすべてのニューラル層オブジェクトの共通の先祖型として機能します。これにより、宣言した変数に内部コンポーネントのいずれかへのポインタを格納でき、基底インターフェイスやオーバーライドされたメソッドを利用することが可能になります。
次に、特性埋め込み生成モデルの処理に進みます。このモデルのオブジェクトは、動的配列の最初の2つの要素に格納されています。1つ目のニューラル層は固定値を持つため、2つ目のオブジェクトのfeedForwardメソッドを即座に呼び出し、1つ目の層のポインタを入力として渡します。
if (bTrain) { neuron = cLayers[1]; if (!neuron || !neuron.FeedForward(cLayers[0])) return false; }
ただし、トレーニング中には第2層のfeedForwardメソッドのみを呼び出します。これは、モデルが現在のタスクに関連する特性埋め込みをトレーニングデータから学習する段階だからです。一方、運用時には、すでに学習された特性埋め込みを使用します。そのため、この層の出力は一定となり、毎回埋め込みテンソルを再生成する必要はありません。このステップをスキップすることで、実運用時のモデルによる意思決定の遅延を削減できます。
その後は、残りの内部層を順に反復処理し、それぞれのfeedForwardメソッドを順番に呼び出します。入力には、前の層の出力と、メソッドのパラメータとして受け取った入力オブジェクトの結果バッファを渡します。
for (int i = 2; i < cLayers.Total(); i++) { neuron = cLayers[i]; if (!neuron.FeedForward(cLayers[i - 1], NeuronOCL.getOutput())) return false; } //--- return true; }
ここでの主なデータソースは、前の層の出力です。これは、市場状況の学習可能な特性の埋め込みが通過する主要なデータストリームです。これらの埋め込みは、すべてのAttentionモジュールおよびデコーダ内のfeedForwardブロックによって処理されます。一方、メソッドのパラメータとして受け取るパターン埋め込みは、分析対象の市場状況の記述から検出されたパターンを表しています。これらは、現在のコンテキストにおいて最も関連性の高い特性を強調します。その結果、デコーダは市場状況の洗練された表現を、最も重要な特徴に重点を置いた特性の集合として出力します。
すべてのループ処理が完了した後、feedForwardメソッドは、呼び出し元に処理の成功を示すブール値を返して終了します。
次に、誤差逆伝播プロセスを構築する必要があります。モデルのパラメータを更新するupdateInputWeightsメソッドは比較的単純で、各内部オブジェクトに対して対応するメソッドを順に呼び出すだけです。しかし、誤差勾配を割り当てるcalcInputGradientsメソッドには、より繊細な処理が含まれています。
ご存じのように、勾配分配アルゴリズムは、順伝播処理の情報フローを正確に反映する必要があり、順序を逆にして、最終出力への寄与に基づいてすべてのコンポーネントに誤差勾配を割り当てます。もしあるオブジェクトが複数の情報フローのデータソースとして機能する場合、それぞれのフローから誤差勾配の分担分を受け取らなければなりません。
順伝播の実装をもう一度見てください。パターン埋め込みオブジェクトのポインタは、デコーダのすべての内部ニューラル層に対してパラメータとして渡されています。当然ながら、Self-Attentionモジュールや FeedForwardモジュールはこのポインタを無視します。というのも、これらは第二の入力ソースを使用しないからです。しかし、Cross-Attentionモジュールは、デコーダの各内部層でこの埋め込みを使用します。したがって、誤差逆伝播時には、各Cross-Attentionモジュールから対応する誤差勾配を集約し、その合計をパターン埋め込みオブジェクトに適用する必要があります。
このメソッドは、パターン埋め込みオブジェクトへのポインタをパラメータの1つとして受け取ります。メソッド本体の最初のステップは、そのポインタが最新で安全に使用できることを検証することです。
bool CNeuronPropertyAwareAttention::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
次に、いくつかの準備作業を行う必要があります。ここではまず、誤差勾配の中間値を書き込む予定の、事前に初期化された補助データバッファの存在を確認します。また、そのサイズが十分であることも確認しなければなりません。確認の結果が否定的だった場合は、任意の制御ポイントで、十分なサイズの新しいデータバッファを初期化します。
if (cTemp.GetIndex() < 0 || cTemp.Total() < NeuronOCL.Neurons()) { cTemp.BufferFree(); if (!cTemp.BufferInit(NeuronOCL.Neurons(), 0) || !cTemp.BufferCreate(OpenCL)) return false; }
次に、オブジェクトパラメータで取得した誤差勾配バッファをリセットします。
if (!NeuronOCL.getGradient() || !NeuronOCL.getGradient().Fill(0)) return false;
通常、この操作はおこないません。というのも、誤差勾配の分配処理を行う際には、以前に保存された値を新しい値で上書きするからです。これは線形モデルにおいては優れた解決策です。しかし一方で、このような実装では、複数の経路から誤差勾配を集約する場合に回避策を探さなければならなくなります。
準備作業が正常に完了したら、ブロック内の内部層を逆順にループして、誤差勾配をそれぞれに割り当てます。
CNeuronBaseOCL *neuron = NULL; for (int i = cLayers.Total() - 2; i > 0; i--) { neuron = cLayers[i]; if (!neuron.calcHiddenGradients(cLayers[i + 1], NeuronOCL.getOutput(), GetPointer(cTemp), (ENUM_ACTIVATION)NeuronOCL.Activation())) return false;
ループ本体では、各内部層の誤差勾配分配メソッドを呼び出し、対応するパラメータを渡します。ただし、標準的な勾配バッファを渡す代わりに、一時的なデータ保存用バッファへのポインタを渡します。内部コンポーネントのメソッドが正常に実行された後、次にそのニューラル層のタイプを確認します。ご存じのとおり、すべての内部層が第2のデータソースを使用しているわけではありません。現在の層がCross-Attentionモジュールであると判定された場合は、第2入力ソースに関連する誤差勾配をパターン埋め込みオブジェクトのバッファに加算し、すでに蓄積された値と合計します。
if (neuron.Type() == defNeuronRelativeCrossAttention) { if (!SumAndNormilize(NeuronOCL.getGradient(), GetPointer(cTemp), NeuronOCL.getGradient(), 1, false, 0, 0, 0, 1)) return false; } //--- return true;}
すべてのループ処理が正常に完了した後、処理結果を示すブール値を呼び出し元の関数に返し、メソッドの実行を終了します。
これで、特性対応型Attentionブロックの実装が完了しました。このクラスとそのすべてのメソッドの完全なソースコードは、添付ファイルに含まれています。
2. AMCTフレームワーク
私たちは大きな進展を遂げ、Atom-Motif Contrastive Transformer (AMCT)フレームワークを構成する個々の構成ブロックの実装を完了しました。次は、これらのモジュールを統合して一貫したアーキテクチャを構築する段階です。そのために、CNeuronAMCT.と呼ばれるオブジェクトを作成します。その構造は以下のとおりです。
class CNeuronAMCT : public CNeuronBaseOCL { protected: CNeuronRMAT cAtomEncoder; CNeuronMotifEncoder cMotifEncoder; CLayer cMotifProjection; CNeuronPropertyAwareAttention cPropertyDecoder; CLayer cPropertyProjection; CNeuronBaseOCL cConcatenate; CNeuronMHAttentionPooling cPooling; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronAMCT(void) {}; ~CNeuronAMCT(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint properties, uint units_count, uint heads, uint layers, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronAMCT; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
提示された構造では、これまでに実装したオブジェクトと、さらに2つの動的配列の宣言が確認できます。これらの機能については後ほど詳しく説明します。すべてのオブジェクトはstaticとして宣言されており、そのためクラスのコンストラクタおよびデストラクタは空のままで問題ありません。継承メンバーと新規に宣言されたメンバーの初期化は、Initメソッド内で行われます。
初期化メソッドのパラメータには、作成するオブジェクトのアーキテクチャを一意に定義するための主要な定数が含まれます。
bool CNeuronAMCT::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint properties, uint units_count, uint heads, uint layers, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count, optimization_type, batch)) return false;
メソッド本体では、まず親クラスの同名メソッドを呼び出し、受け取ったパラメータの一部を渡します。
ご覧の通り、このオブジェクトの構造には、受け取ったパラメータの値を保持するための内部変数は含まれていません。クラスのアーキテクチャを定義するすべての定数は、内部オブジェクトの初期化のみに使用され、必要な値はそれら内部オブジェクトに格納されます。順伝播メソッドや誤差逆伝播メソッドでは、これら内部コンポーネントとだけやり取りをおこないます。したがって、不必要なクラスレベルの変数を導入することを避けています。
次に、内部オブジェクトの初期化に進みます。まず、ローソク足用とパターン用の2つのパイプラインを初期化します。
int idx = 0; if (!cAtomEncoder.Init(0, idx, OpenCL, window, window_key, units_count, heads, layers, optimization, iBatch)) return false; idx++; if (!cMotifEncoder.Init(0, idx, OpenCL, window, window_key, units_count, heads, layers, optimization, iBatch)) return false;
これらのパイプラインはアーキテクチャ上の違いがあるものの、どちらも同じ入力データソースを扱い、この段階では同一の初期化パラメータを受け取ります。
これら2つのパイプラインからは、分析対象の市場状況について、ローソク足レベルとパターンレベルという2つの表現が得られます。AMCTフレームワークでは、これらの表現を整合させることで、お互いの理解を深めて洗練させることを提案しています。しかし、2つのパイプラインの出力テンソルの次元が異なるため、この整合処理は非常に複雑になります。この問題に対処するため、パターンパイプラインの出力を変換する軽量なスケーリングモデルを使用します。このスケーリングモデルのオブジェクトへのポインタは、cMotifProjectionという動的配列に格納されます。
まずは、この動的配列の初期化から始めます。
cMotifProjection.Clear(); cMotifProjection.SetOpenCL(OpenCL);
パターンのシーケンス長を決定します。ご存じのように、パターンパイプラインの出力では、2つのレベルの埋め込みが連結されたテンソルが得られます。
int motifs = int(cMotifEncoder.Neurons() / window);
表現テンソルは、シーケンスの長さのみが異なり、各シーケンス要素を表すベクトルのサイズは同じであることに注意してください。したがって、スケーリング処理はテンソル内の個々の単変量シーケンスに対して行われるのが理にかなっています。そのために、まずパターンレベルの表現テンソルを転置します。
idx++; CNeuronTransposeOCL *transp = new CNeuronTransposeOCL(); if (!transp || !transp.Init(0, idx, OpenCL, motifs, window, optimization, iBatch) || !cMotifProjection.Add(transp)) return false;
次に、これらの単変量シーケンスに対して畳み込み層を適用し、スケーリングを行います。
idx++; CNeuronConvOCL *conv = new CNeuronConvOCL(); if (!conv || !conv.Init(0, idx, OpenCL, motifs, motifs, units_count, 1, window, optimization, iBatch) || !cMotifProjection.Add(conv)) return false; conv.SetActivationFunction((ENUM_ACTIVATION)cAtomEncoder.Activation());
入力ウィンドウのサイズとストライドは、いずれもパターンレベル表現のシーケンス長と等しいことに注意してください。一方で、フィルター数はローソク足レベル表現のシーケンス長に合わせて設定されています。
もう一つ重要な点は、シーケンス長と単変量シーケンスの数をどのように定義するかです。この場合、入力シーケンスは単一要素で構成されると指定します。単変量シーケンスの数は、入力の単一シーケンス要素のベクトルサイズに相当します。この設定により、入力データのそれぞれの単位シーケンスをスケーリングするために、個別の学習可能な重み行列を割り当てることができます。言い換えれば、元の入力シーケンスの各要素は、それぞれ専用の行列を使ってスケーリングされます。これにより、より柔軟で細かく調整された変換処理が可能になります。
また、畳み込みスケーリング層の出力とローソク足レベル表現パイプラインの活性化関数を同期させることも重要です。
これが完了したら、データ転置層を使ってスケーリング後のデータを元のレイアウトに戻します。
idx++; transp = new CNeuronTransposeOCL(); if (!transp || !transp.Init(0, idx, OpenCL, window, units_count, optimization, iBatch) || !cMotifProjection.Add(transp)) return false; transp.SetActivationFunction((ENUM_ACTIVATION)conv.Activation());
次に、分析対象の市場状況を特性レベルで表現することを目的とした、特性とパターンのためのCross-Attentionブロックを初期化します。
idx++; if (!cPropertyDecoder.Init(0, idx, OpenCL, window, window_key, properties, motifs, heads, layers, optimization, iBatch)) return false;
そしてついに、重要な局面に到達しました。3つの主要なブロックの出力から、分析対象の単一市場シナリオに対する3つの異なる表現が得られます。さらに、それぞれの表現は異なる次元のテンソルとして構成されています。では次に何をすべきでしょうか。?これらを実際の問題解決にどう活用すればよいでしょうか。最高の予測精度を達成するには、どれを選択すべきでしょうか。
私は3つすべての表現を活用すべきだと考えています。すでにパターン表現用のスケーリングモデルを初期化済みです。次に、特性ベースの表現をスケーリングするための同様のモデルを作成します。これらスケーリングモデルオブジェクトへのポインタは、cPropertyProjectionという動的配列に格納されます。
cPropertyProjection.Clear(); cPropertyProjection.SetOpenCL(OpenCL); idx++; transp = new CNeuronTransposeOCL(); if (!transp || !transp.Init(0, idx, OpenCL, properties, window, optimization, iBatch) || !cPropertyProjection.Add(transp)) return false; idx++; conv = new CNeuronConvOCL(); if (!conv || !conv.Init(0, idx, OpenCL, properties, properties, units_count, 1, window, optimization, iBatch) || !cPropertyProjection.Add(conv)) return false; conv.SetActivationFunction((ENUM_ACTIVATION)cAtomEncoder.Activation()); idx++; transp = new CNeuronTransposeOCL(); if (!transp || !transp.Init(0, idx, OpenCL, window, units_count, optimization, iBatch) || !cPropertyProjection.Add(transp)) return false; transp.SetActivationFunction((ENUM_ACTIVATION)conv.Activation());
統一された次元に変換された3つの表現は、ひとつのテンソルに連結されます。
idx++; if (!cConcatenate.Init(0, idx, OpenCL, 3 * window * units_count, optimization, iBatch)) return false;
私たちは、単一の市場状況に対する3つの異なる視点を組み合わせた連結テンソルを得ました。これはマルチヘッドAttentionの結果を思い起こさせないでしょうか。実際のところ、これは本質的に3つのヘッドの出力に相当し、最終的な値を導き出すために依存関係に基づくプーリング層を利用しています。
idx++; if(!cPooling.Init(0, idx, OpenCL, window, units_count, 3, optimization, iBatch)) return false;
次に、継承したインターフェイス内のデータバッファを対応するプーリングオブジェクトに置き換えます。これにより、不必要なデータコピー操作を回避できます。
if (!SetOutput(cPooling.getOutput(), true) || !SetGradient(cPooling.getGradient(), true)) return false; //--- return true; }
初期化メソッドを終了し、処理の成功を示すブール値を呼び出し元プログラムに返します。
オブジェクトの初期化メソッドを完了した後、順伝播の処理を整理していきます。通常通り、順伝播アルゴリズムはfeedForwardメソッド内に実装されます。
bool CNeuronAMCT::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!cAtomEncoder.FeedForward(NeuronOCL)) return false; if(!cMotifEncoder.FeedForward(NeuronOCL)) return false;
メソッドのパラメータの中には、生の入力データオブジェクトへのポインタが含まれており、これをすぐに2つの表現パイプライン、すなわちローソク足レベルとパターンレベルに渡します。
パターンパイプラインの出力は、特性とパターンを扱うCross-Attentionモジュールに送られます。
if(!cPropertyDecoder.FeedForward(cMotifEncoder.AsObject())) return false;
この段階で、分析対象の市場状況に対する3つの異なる表現が得られています。これらを統一されたデータスケールに変換します。そのために、まずパターンレベルの表現に対してスケーリングを適用します。
//--- Motifs projection CNeuronBaseOCL *prev = cMotifEncoder.AsObject(); CNeuronBaseOCL *current = NULL; for(int i = 0; i < cMotifProjection.Total(); i++) { current = cMotifProjection[i]; if(!current || !current.FeedForward(prev, NULL)) return false; prev = current; }
次に、特性レベルの表現に対して同様のスケーリング処理を行います。
//--- Property projection prev = cPropertyDecoder.AsObject(); for(int i = 0; i < cPropertyProjection.Total(); i++) { current = cPropertyProjection[i]; if(!current || !current.FeedForward(prev, NULL)) return false; prev = current; }
これで、3つの表現を1つのテンソルに結合できます。
//--- Concatenate uint window = cAtomEncoder.GetWindow(); uint units = cAtomEncoder.GetUnits(); prev = cMotifProjection[cMotifProjection.Total() - 1]; if(!Concat(cAtomEncoder.getOutput(), prev.getOutput(), current.getOutput(), cConcatenate.getOutput(), window, window, window, units)) return false;
プーリング層を使用して、これら3つの表現からの結果の加重集計を計算します。
//--- Out if(!cPooling.FeedForward(cConcatenate.AsObject())) return false; //--- return true; }
初期化時におこなったバッファポインタの置き換えにより、クラスインターフェイスのバッファへのデータコピーを回避できます。そのままメソッドを完了し、成功を示すブール値を呼び出し元に返します。
次のステップは、誤差逆伝播メソッドの開発です。特に注目すべきは、勾配分配メソッドであるcalcInputGradientsです。AMCTフレームワークの著者が提案する情報フロー間の分岐依存構造が、このメソッドのアルゴリズムに大きな影響を与えています。これからその実装を詳しく見ていきましょう。
いつも通り、このメソッドは前の層のオブジェクトへのポインタを受け取り、最終結果への入力データの寄与に応じて誤差勾配を伝播させます。
bool CNeuronAMCT::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
まず、ポインタの有効性を即座に確認します。無効であれば、以降の操作は意味を持ちません。
次に、誤差勾配を内部オブジェクトに順次分配していきます。特に、インターフェイスバッファのポインタ置き換えのおかげで、外部インターフェイスから内部オブジェクトへデータをコピーする必要がありません。したがって、すぐに内部オブジェクトへの誤差勾配の分配を開始できます。まずは、分析対象環境状態の3つの視点を表す連結テンソルにおける誤差勾配を計算することから始めます。
if(!cConcatenate.calcHiddenGradients(cPooling.AsObject())) return false;
次に、誤差勾配をそれぞれのパイプラインに伝播させます。ローソク足レベル表現の勾配は直ちにエンコーダへ送られます。残りの2つは、それぞれ対応するスケーリングモデルに渡されます。
uint window = cAtomEncoder.GetWindow(); uint units = cAtomEncoder.GetUnits(); CNeuronBaseOCL *motifs = cMotifProjection[cMotifProjection.Total() - 1]; CNeuronBaseOCL *prop = cPropertyProjection[cPropertyProjection.Total() - 1]; if (!motifs || !prop || !DeConcat(cAtomEncoder.getGradient(), motifs.getGradient(), prop.getGradient(), cConcatenate.getGradient(), window, window, window, units)) return false;
次に、各表現の誤差勾配をそれぞれの活性化関数に基づいて調整します。
if (cAtomEncoder.Activation() != None) { if (!DeActivation(cAtomEncoder.getOutput(), cAtomEncoder.getGradient(), cAtomEncoder.getGradient(), cAtomEncoder.Activation())) return false; if (motifs.Activation() != None) { if (!DeActivation(motifs.getOutput(), motifs.getGradient(), motifs.getGradient(), motifs.Activation())) return false; if (prop.Activation() != None) { if (!DeActivation(prop.getOutput(), prop.getGradient(), prop.getGradient(), prop.Activation())) return false;
また、ローソク足表現とパターン表現の整合処理から生じた誤差勾配も加算します。
if(!motifs.calcAlignmentGradient(cAtomEncoder.AsObject(), true)) return false;
続いて、スケーリングモデル内のニューラル層を逆順にたどりながら、誤差勾配を割り当てていきます。
for (int i = cMotifProjection.Total() - 2; i >= 0; i--) { motifs = cMotifProjection[i]; if (!motifs || !motifs.calcHiddenGradients(cMotifProjection[i + 1])) return false; }
for (int i = cPropertyProjection.Total() - 2; i >= 0; i--) { prop = cPropertyProjection[i]; if (!prop || !prop.calcHiddenGradients(cPropertyProjection[i + 1])) return false; }
特性スケーリングモデルからの誤差勾配は、特性とパターンのCross-Attentionモジュールに渡され、その後パターンエンコーダに伝播されます。
if (!cPropertyDecoder.calcHiddenGradients(cPropertyProjection[0]) || !cMotifEncoder.calcHiddenGradients(cPropertyDecoder.AsObject())) return false;
パターンエンコーダの出力もパターン表現のスケーリングモデルで使用されている点に注意が必要です。したがって、この二次的な情報フローからの誤差勾配も組み込む必要があります。そのために、まずパターンエンコーダの誤差勾配バッファへのポインタをローカル変数に保存し、次にそれを「ドナー」バッファに置き換えます。
ドナーオブジェクトとして選んだのは、3つの表現を連結する層です。この層の誤差勾配はすでに対応する情報ストリーム間で分配済みです。この層は学習可能なパラメータを持たないため、バッファを安全にクリアできます。さらに、この層はブロック内のすべての内部オブジェクトの中で最大のバッファサイズを持つため、最適なドナー候補となります。
バッファの置き換え後、スケーリングモデルから誤差勾配を取得し、両方の情報ストリームの勾配を合算して、元のバッファポインタを復元します。最後に、誤差勾配を入力データレベルに伝播させます。
CBufferFloat *temp = cMotifEncoder.getGradient(); if (!cMotifEncoder.SetGradient(cConcatenate.getGradient(), false) || !cMotifEncoder.calcHiddenGradients(cMotifProjection[0]) || !SumAndNormilize(temp, cMotifEncoder.getGradient(), temp, window, false, 0, 0, 0, 1) || !cMotifEncoder.SetGradient(temp, false) || !NeuronOCL.calcHiddenGradients(cMotifEncoder.AsObject())) return false;
入力データレベルでも同様の状況が発生します。パターンエンコーダから受け取った誤差勾配は、ローソク足エンコーダパイプラインを通じて流れてくる寄与分で増強される必要があります。これに対応して、別のバッファオブジェクトに対してもポインタ置き換えの手法を繰り返します。
temp = NeuronOCL.getGradient(); if (!NeuronOCL.SetGradient(cConcatenate.getGradient(), false) || !NeuronOCL.calcHiddenGradients(cAtomEncoder.AsObject()) || !SumAndNormilize(temp, NeuronOCL.getGradient(), temp, window, false, 0, 0, 0, 1) || !NeuronOCL.SetGradient(temp, false)) return false; //--- return true; }
誤差勾配がモデルのすべてのコンポーネントおよび入力データに完全に分配されたため、メソッドは処理結果を示すブール値を呼び出し元に返して終了します。
この実装で特に強調したい2つのポイントがあります。まず、バッファポインタの置き換え時には、必ず事前に元のバッファポインタを保存しています。ポインタ置き換えメソッドを呼び出す際には、以前のバッファオブジェクトの削除を防ぐために明示的にfalseのフラグを設定しています。この方法によりバッファは保持され、後でポインタを復元できます。もし初期化メソッドのようにtrueを使うと、既存のバッファオブジェクトが削除され、後続のアクセス時に致命的なエラーが発生します。
次に、メソッドの設計についてです。提示したアルゴリズムは、AMCT著者が提唱したパターンの対比表現学習(contrastive representation learning)を直接実装していません。ただし、相対Cross-Attentionオブジェクト内に表現の多様化機構を統合しているため、対比学習の誤差注入点を効果的に移動させています。
以上で、Atom-Motif Contrastive Transformerフレームワークのアルゴリズム構築のレビューを終わります。提示したクラスおよびメソッドの完全なソースコードは添付ファイルに含まれており、環境とのインタラクションやモデル学習プログラムの完全なコードも掲載されています。これらは以前の作品から変更なくコピーされたもので、環境インタラクション プログラムとトレーニング スクリプトも含まれています。一部の層のみ置き換えを行っています。
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronAMCT; descr.window = BarDescr; // Window (Indicators to bar) { int temp[] = {HistoryBars, 100}; // Bars, Properties if(ArrayCopy(descr.units, temp) < (int)temp.Size()) return false; } descr.window_out = EmbeddingSize / 2; // Key Dimension descr.layers = 5; // Layers descr.step = 4; // Heads descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
学習可能なモデルのアーキテクチャの詳細な説明も添付ファイルにて確認してください。
3.テスト
私たちはAtom-Motif Contrastive TransformerフレームワークをMQL5で大幅に実装し終え、次にその手法の実際の効果を評価する段階に入りました。そのために、新しいオブジェクトを使って実際の過去データでモデルを学習し、その後、学習セット外の期間においてMetaTrader 5のストラテジーテスターで学習済み方策の検証を行います。
通常通り、モデルの学習は2023年の全期間をカバーする事前収集済みのトレーニングデータセットでオフラインで実施します。学習は反復的に行われ、数回の反復後にトレーニングデータセットが更新されます。これにより、現在の方策に基づくエージェントの行動を最も正確に評価できます。
学習の結果、トレーニングセットおよびテストセットの両方で利益を生み出せるモデルを得ました。ただし、ひとつ注意点があります。得られたモデルは非常に少数の取引しかおこないません。テスト期間は3か月にまで延長しました。以下にそのテスト結果を示します。
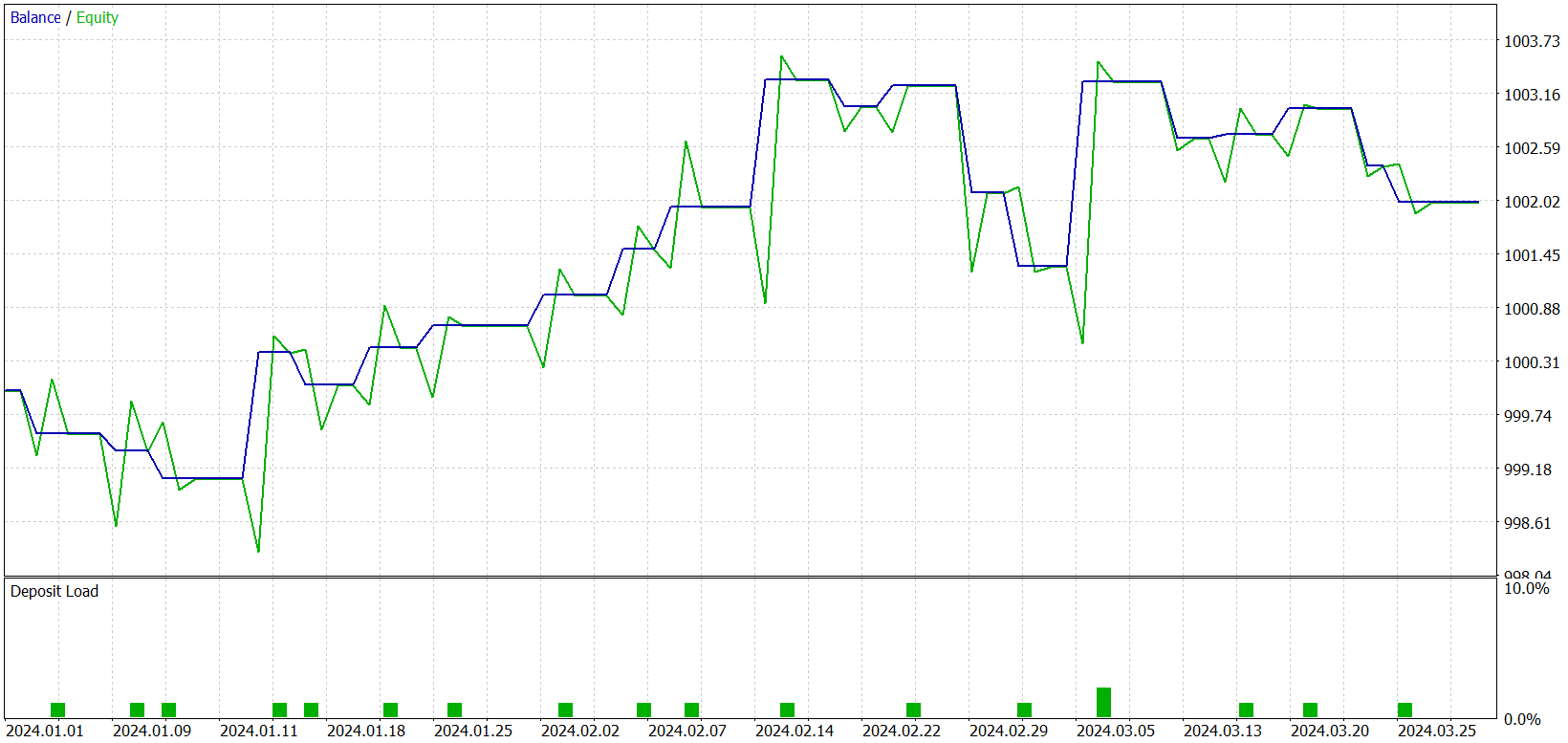
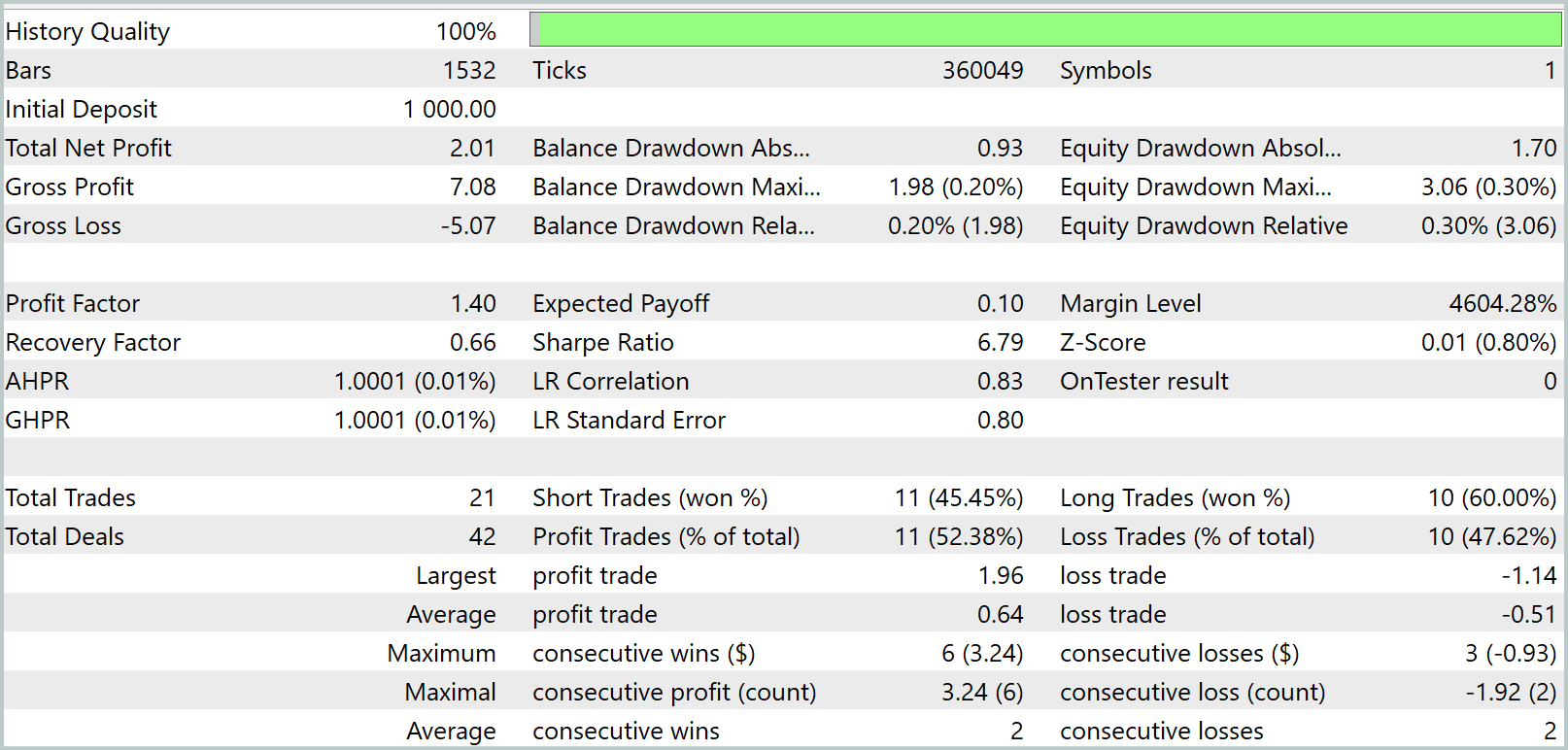
結果から分かるように、3か月のテスト期間中、モデルはわずか21回のトレードを実行し、そのうち約半数が利益確定となりました。残高グラフを見ると、最初の1か月半ほどは上昇し、その後は横ばいの動きとなっています。これはまったく予想通りの動作です。私たちのモデルは、トレーニングデータセットに存在する市場状況からのみ統計を収集します。統計モデルとして、トレーニングセットは代表性が必要です。残高グラフから、1年分のトレーニングデータセットは、約1.2か月から1.5か月先までの代表性を提供していると結論付けられます。
したがって、10年分のデータセットでモデルをトレーニングすれば、1年間安定してパフォーマンスを発揮できるモデルが得られる可能性があると推測されます。さらに、大きなトレーニングセットはより多くの重要なパターンや学習可能な特性の特定を可能にし、取引頻度の増加も期待できます。しかし、これらの仮説を確認または否定するには、モデルを用いたさらなる検証が必要です。
結論
これまでの2回の記事では、原子要素(ローソク足)とモチーフ(パターン)という概念に基づくAtom-Motif Contrastive Transformer(AMCT)フレームワークを探りました。この手法の主なアイデアは、対比学習を用いて、要素レベルから複雑な構造に至るまで複数のレベルで情報を持つパターンとそうでないパターンを区別することにあります。これにより、モデルは局所的な価格変動を捉えるだけでなく、市場の振る舞いをより正確に予測するための付加的な洞察を与える重要なパターンも検出可能となります。このフレームワークの基盤となるTransformerアーキテクチャは、ローソク足とパターン間の長期依存関係や複雑な関係性を効果的に識別します。
実践面では、これらのアプローチをMQL5で実装し、モデルを学習させ、実際の過去データでテストを行いました。残念ながら、得られたモデルはトレード活動がまばらでした。それでもなお、明らかな可能性が示されており、今後の研究でさらに発展させていきたいと考えています。
参照文献
記事で使用されているプログラム
| # | 名前 | 種類 | 詳細 |
|---|---|---|---|
| 1 | Research.mq5 | EA | 事例収集のためのEA |
| 2 | ResearchRealORL.mq5 | EA | Real-ORL法による事例収集のためのEA |
| 3 | Study.mq5 | EA | モデル訓練EA |
| 4 | Test.mq5 | EA | モデルテストEA |
| 5 | Trajectory.mqh | クラスライブラリ | システム状態記述の構造体 |
| 6 | NeuroNet.mqh | クラスライブラリ | ニューラルネットワークを作成するためのクラスのライブラリ |
| 7 | NeuroNet.cl | ライブラリ | OpenCLプログラムコードライブラリ |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/16192
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索