
取引におけるニューラルネットワーク:パターンTransformerを用いた市場分析

はじめに
過去10年間にわたり、ディープラーニング(DL)はさまざまな分野で大きな進展を遂げており、これらの進歩は金融市場の研究者たちの注目を集めています。DLの成功に触発され、多くの研究者が市場のトレンド予測や複雑なデータ間の関係性の分析への応用を目指しています。このような分析において重要な側面のひとつが、生データの表現形式です。この形式は、分析対象となる金融商品間の関係性や構造を正確に保持する必要があります。しかしながら、現在の多くのモデルは同種グラフ(homogeneous graph)を用いており、市場パターンに伴う豊富な意味情報を十分に捉えることができません。自然言語処理におけるNgramの活用に似て、市場で頻出するパターンを活用することで、より精密な関連性の把握やトレンド予測が可能となるのです。
この課題に対処するために、私たちは化学元素分析の分野からアプローチを取り入れることにしました。市場パターンと同様に、モチーフ(意味を持つサブグラフ)は分子構造の中で頻出し、分子の特性を明らかにする手がかりとなります。ここでは、論文「Molformer:Motif-based Transformer on 3D Heterogeneous Molecular Graphs」で提案されたMolformerフレームワークについて見ていきましょう。
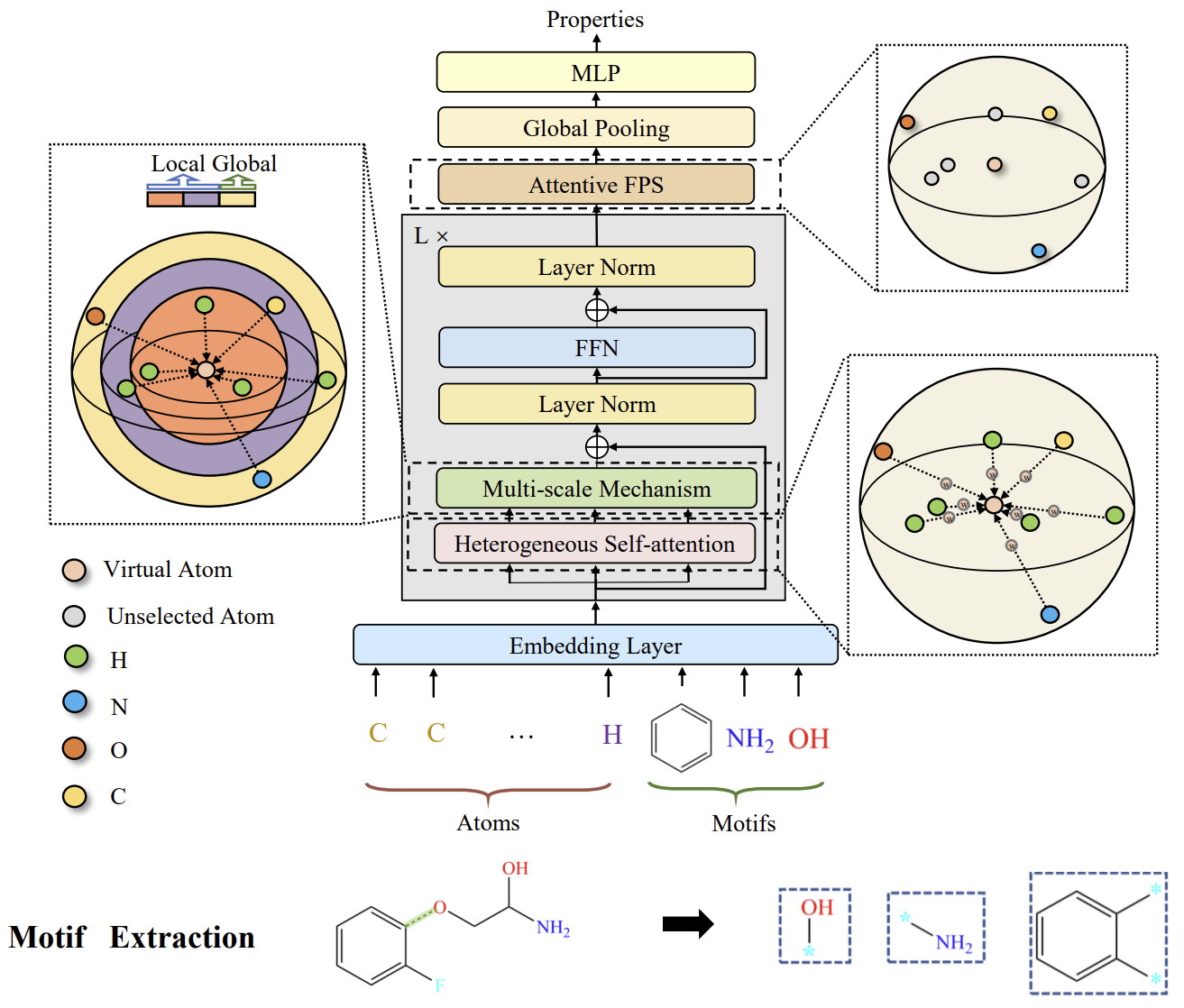
Molformerの著者らは、モデルの入力として新しい異種分子グラフ(HMG: Heterogeneous Molecular Graph)を定義しています。この設計は原子レベルおよびモチーフレベルのノードを含み、異なるレベルのノードを統合的に扱うためのインターフェイスを提供します。また、原子の意味的な区分けが不適切であった場合に発生する誤りの伝播を防止する設計にもなっています。モチーフに関しては、分子の種類によって異なる手法が用いられています。小分子については、化学のドメイン知識に基づいた官能基をモチーフの語彙集合とし、一方、連続するアミノ酸で構成されるタンパク質については、強化学習(RL: Reinforcement Learning)に基づいたインテリジェントなモチーフ抽出手法が導入され、最も重要なアミノ酸の部分配列を同定します。
このHMGとの整合性を保つために、MolformerはTransformerアーキテクチャに基づいた等変幾何モデルを導入しています。Molformerは、これまでに提案されてきたTransformerベースのモデルと比較して、以下の2つの主要な点で際立っています。まず、異種(Heterogeneous) Self-Attention(HSA)を用いて、異なるレベルのノード間の相互作用を捉えます。次に、注意型(Attentive) Farthest Point Sampling (AFPS)アルゴリズムを導入し、ノードの特徴を集約して分子全体の表現を獲得します。
著者らの論文では、この手法が化学産業における課題に対して有効であることが、実験によって示されています。この手法が金融市場におけるトレンド予測タスクの解決にどのように応用できるかを、これから検討していきましょう。
1. Molformerアルゴリズム
モチーフとは、頻繁に出現するサブ構造パターンを指し、複雑な分子構造の構成要素として機能します。モチーフは分子全体の豊富な生化学的特性を内包しており、小分子においては、重要な機能を持つモチーフを特定するための標準的な基準が化学分野で確立されています。大きなタンパク質分子では、モチーフは立体構造上の局所領域や、タンパク質間で共通して見られるアミノ酸配列に相当し、それらの機能に影響を与えます。各モチーフは通常ごく少数の要素で構成されており、二次構造要素間の接続を記述することができます。この特性に基づいて、Molformerフレームワークの著者らは、強化学習(RL: Reinforcement Learning)を用いたヒューリスティックなアプローチを考案し、タンパク質モチーフの発見をおこないました。彼らは、4つのアミノ酸で構成されるモチーフに注目しています。これらは最小のポリペプチドを形成し、タンパク質中で明確な機能特性を持ちます。この段階での主な目的は、K個の四重アミノ酸マトリクスの中から、特定タスクに最も適した語彙集合𝓥を特定することです。すべての可能な組み合わせを検討するのではなく、下流のデータセットに存在する四重アミノ酸のみを対象とすることで、実際的な実装が可能となっています。
学習された語彙𝓥は、モチーフ抽出のひな形として、また下流タスクにおけるHMG(Heterogeneous Molecular Graph)構築にも用いられます。このHMGMolformerが訓練され、その有効性が報酬rとして定義され、方策勾配を通じてパラメータθの更新がおこなわれます。結果として、エージェントは特定のタスクに最適な四重モチーフの語彙を選択することができるようになります。
注目すべき点として、提案されたモチーフマイニングプロセスは1ステップのゲームとして定式化されており、ポリシーネットワークπθは1イテレーションにつき語彙𝓥を一度だけ生成します。したがって、このトラジェクトリ(経路)は1つのアクションから構成され、選択された語彙𝓥に基づくMolformerの出力が、報酬の一部となります。
このフレームワークの著者らは、モチーフと原子を分離し、モチーフをHMGを構成する新たなノードとして扱っています。これにより、モチーフレベルと原子レベルの表現が切り離され、モチーフレベルでの意味的な情報抽出がより正確に行えるようになります。
これは、自然言語における「語句」と「単語」の関係に似ており、分子中のモチーフは原子よりも高次の意味的情報を持っているとされます。そのため、モチーフは原子レベルの要素の機能的役割を定義する上で重要な役割を果たします。Molformerの著者らは、各モチーフカテゴリを新しいノードタイプとして扱い、HMGの入力を構築します。HMGにはモチーフレベルと原子レベルの両方のノードが含まれており、各モチーフの位置は、その構成要素の3D座標の重み付き和として表現されます。これは、単語分割に似ており、マルチレベルノードで構成されたHMGは、意味分割の誤りによるエラー伝播を防ぎ、原子情報を活用して分子表現の学習を効果的に導きます。
Molformerは、Transformerアーキテクチャを3D HMG向けに改良し、いくつかの新しい構成要素を組み込んでいます。各エンコーダブロックは、異種Self-Attention(HSA)、FeedForwardネットワーク(FFN)、および2段階の正規化から成り立ちます。これに続き、注意型(Attentive) Farthest Point Sampling(AFPS)によって適応的な分子表現が生成され、それが全結合型の予測器に入力されて、様々な下流タスクでの物性予測がおこなわれます。
HMGがN+Mノードで構成された後は、モデルに対して多階層ノード間の相互作用を区別できる能力を持たせる必要があります。そのため、著者らは関数φ(i,j)→Zを導入し、任意の2ノード間の関係を「原子-原子」「原子-モチーフ」「モチーフ-モチーフ」の3種類に分類します。そして、それぞれの関係性に応じて、学習可能なスカラーbφ(i,j)を用いることで、HMG内での階層的関係を適応的に処理できるようにします。
さらに著者らは、分子の三次元構造の利用にも着目しています。3Dの並進や回転といったグローバルな変換に対するロバスト性(回転・平行移動不変性)は、分子表現学習の基本的な前提です。そのため、ノード間の距離行列𝑫に対して畳み込み演算を適用することで、この不変性を確保します。
加えて、スパースな3D空間においては局所的な文脈の利用が重要であることが分かっています。Self-Attentionは大域的パターン検出には優れる一方で、局所的な文脈を見落としがちであるという課題があります。この観察に基づき、著者らはSelf-Attentionに距離ベースの制約を課し、局所と全体の両方の文脈からマルチスケールパターンを抽出する手法を開発しました。具体的には、各スケールsにおいて、ある距離閾値τsを超えるノードをマスク処理し、異なるスケールで抽出された特徴を統合してマルチスケール表現を形成し、それをFFNに入力します。
Molformerフレームワークのオリジナルの視覚化を以下に示します。
2.MQL5での実装
Molformer手法の理論的側面を確認した後、この記事の実践的な部分に進み、MQL5を使用して提案されたアプローチの解釈を実装します。前回の作業と同様に、フレームワークを実装するプロセス全体を、定期的な操作を実行する個別のモジュールに分割します。
2.1 アテンションプーリング
まず最初に、R-MAT手法の著者が提案した依存性ベースのプーリングアルゴリズムを、単独で機能するクラスとして切り出して実装していきます。
Molformerフレームワークの実装を、R-MAT手法からのアプローチを取り入れることから始めるのは意外に思われるかもしれません。しかし、この2つの手法は、どちらも化学業界における類似の課題に対処するために提案されたものです。私たちの見解では、両者の間には共通点がいくつかあり、それらを活用する価値があります。依存性ベースのプーリングアルゴリズムは、そうした共通点のひとつです。
このアルゴリズムの処理を整理して、以下に示す構造のCNeuronMHAttentionPoolingクラスとしてまとめていきます。
class CNeuronMHAttentionPooling : public CNeuronBaseOCL { protected: uint iWindow; uint iHeads; uint iUnits; CLayer cNeurons; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronMHAttentionPooling(void) {}; ~CNeuronMHAttentionPooling(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint units_count, uint heads, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronMHAttentionPooling; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
このクラスでは、3つの内部変数と、動的配列を1つ宣言します。この配列には、呼び出された順に内部オブジェクトへのポインタを格納していきます。配列自体は静的に宣言されているため、コンストラクタおよびデストラクタには特別な処理を記述する必要はありません。継承されたオブジェクトおよび新たに宣言されたすべてのオブジェクトの初期化は、Initメソッド内でおこないます。このメソッドは、作成されるオブジェクトのアーキテクチャを明確に定義する定数値を引数として受け取ります。
bool CNeuronMHAttentionPooling::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint units_count, uint heads, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count, optimization_type, batch)) return false;
オブジェクト初期化メソッドの本体では、まず同名の親クラスのメソッドを呼び出します。この親クラスのメソッド内には、必要な制御の一部や、継承されたオブジェクトの初期化アルゴリズムがすでに実装されています。その後、外部プログラムから受け取った定数を、クラス内の内部変数に格納します。
iWindow = window; iUnits = units_count; iHeads = heads;
動的配列を準備します。
cNeurons.Clear(); cNeurons.SetOpenCL(OpenCL);
そして、ネストされたオブジェクトの構造を作成し始めます。ここでは、双曲線正接を使用してニューラル層間の非線形性を作成する2層MLPを作成します。
int idx = 0; CNeuronConvOCL *conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, idx, OpenCL, iWindow*iHeads, iWindow*iHeads, 4*iWindow, iUnits, 1, optimization, iBatch) || !cNeurons.Add(conv) ) return false; idx++; conv.SetActivationFunction(TANH); conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, idx, OpenCL, 4*iWindow, 4*iWindow, iHeads, iUnits, 1, optimization, iBatch) || !cNeurons.Add(conv) ) return false;
MLPの出力は、シーケンスの個々の要素に関してSoftmax関数によって正規化されます。
idx++; conv.SetActivationFunction(None); CNeuronSoftMaxOCL *softmax = new CNeuronSoftMaxOCL(); if(!softmax || !softmax.Init(0, idx, OpenCL, iHeads * iUnits, optimization, iBatch) || !cNeurons.Add(softmax) ) return false; softmax.SetHeads(iUnits); //--- return true; }
操作の成功を示すブール値の結果を呼び出し元プログラムに返すことで、メソッドを終了します。
ここで重要なのは、データバッファに対してポインタの差し替えなどは一切行っていないという点です。これは、このクラスで生成されるオブジェクトが中間データのみを生成する役割に限定されているためです。作成されたオブジェクトの実際の出力結果は、生成されたMLPの正規化出力を、入力データテンソルに乗算することで得られます。この演算結果は、親クラスから継承された対応バッファに格納されます。誤差勾配バッファについても、同様の方針が適用されます。
クラスの初期化メソッドが完了したら、次はfeedForwardメソッド内で順伝播(フォワードパス)アルゴリズムの構築に移ります。
bool CNeuronMHAttentionPooling::feedForward(CNeuronBaseOCL *NeuronOCL) { CNeuronBaseOCL *current = NULL; CObject *prev = NeuronOCL;
メソッドパラメータでは、ソースデータオブジェクトへのポインタを受け取ります。メソッドの本体では、オブジェクトへのポインタを一時的に保存するための2つのローカル変数を宣言します。ソースデータオブジェクトへのポインタをそのうちの1つに渡します。
次に、内部モデルの同じ名前のメソッドを順番に呼び出して、内部MLPオブジェクトをループします。
for(int i = 0; i < cNeurons.Total(); i++) { current = cNeurons[i]; if(!current || !current.FeedForward(prev) ) return false; prev = current;; }
ループのすべての反復が完了すると、シーケンス内の各要素に対するアテンションヘッドの影響係数が得られます。ここで前述のとおり、次におこなうのは、取得した係数と入力データテンソルを乗算して、アテンションヘッドの重み付き平均を計算することです。このテンソル乗算の結果は、本オブジェクトの結果バッファに格納されます。
if(!MatMul(current.getOutput(), NeuronOCL.getOutput(), Output, 1, iHeads, iWindow, iUnits)) return false; //--- return true; }
最後に、処理の成否を示すブール値を呼び出し元のプログラムに返し、メソッドを終了します。
このクラスのバックプロパゲーション(誤差逆伝播法)に関するメソッドについては、読者の自主的な学習に委ねることを提案します。このクラスおよびそのすべてのメソッドの完全なコードは、添付資料にて確認できます。
2.2 パターン抽出
次のステップでは、パターン抽出オブジェクトを作成します。理論セクションで述べたとおり、パターン埋め込みは、入力データテンソルに追加された上でモデルに渡されます。ただし、今回はこれとは異なるアプローチをとります。モデルには標準的なデータセットをそのまま入力とし、パターンの抽出と、それらの埋め込みの入力データテンソルへの連結は、モデル内部で実行することにします。
ここで重要なのは、入力データに追加される各パターン埋め込みが、単一のシーケンス要素と同じ次元を持ち、かつ同一の部分空間に存在していなければならないという点です。このうち1つ目の課題については、アーキテクチャ設計によって解決します。 2つ目の課題については、パターン埋め込みの訓練時に解決を試みます。
これらのタスクを実行するために、新しいクラスCNeuronMotifsを作成します。その構造を以下に示します。
class CNeuronMotifs : public CNeuronBaseOCL { protected: CNeuronConvOCL cMotifs; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronMotifs(void) {}; ~CNeuronMotifs(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint dimension, uint window, uint step, uint units_count, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronMotifs; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual void SetActivationFunction(ENUM_ACTIVATION value) override; };
このクラスでは、内部畳み込み層を1つだけ宣言しており、これはパターン埋め込み機能を実行する役割を担います。ただし、注目すべき点として、活性化関数を指定するメソッドをオーバーライドしていることが挙げられます。興味深いことに、このメソッドはこれまでの実装では一度もオーバーライドされていませんでした。今回の場合、このオーバーライドは、内部層の活性化関数をオブジェクト自身の活性化関数と同期させるためにおこなわれています。
void CNeuronMotifs::SetActivationFunction(ENUM_ACTIVATION value) { CNeuronBaseOCL::SetActivationFunction(value); cMotifs.SetActivationFunction(activation); }
宣言した畳み込み層および継承されたすべてのオブジェクトは、Initメソッド内で初期化されます。このメソッドのパラメータには、作成されるオブジェクトのアーキテクチャを一意に定義するための定数が渡されます。
bool CNeuronMotifs::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint dimension, uint window, uint step, uint units_count, ENUM_OPTIMIZATION optimization_type, uint batch ) { uint inputs = (units_count * step + (window - step)) * dimension; uint motifs = units_count * dimension;
しかし、以前に扱った類似のメソッドとは異なり、今回は親クラスの同名メソッドを直接呼び出すのに十分なデータが揃っていません。これは主に、出力用バッファのサイズに起因しています。前述のとおり、期待される出力は、入力データとパターン埋め込みのテンソルを連結したものです。したがって、まず利用可能なデータに基づいて、入力データのテンソルサイズとパターン埋め込みのテンソルサイズをそれぞれ算出し、それらの合計を親クラスの初期化メソッドに渡して呼び出すことにします。
if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, inputs + motifs, optimization_type, batch)) return false;
次のステップは、外部プログラムから受け取ったパラメータに従って、内部パターン埋め込み用畳み込み層を初期化することです。
if(!cMotifs.Init(0, 0, OpenCL, dimension * window, dimension * step, dimension, units_count, 1, optimization, iBatch)) return false;
返される埋め込みのサイズは入力データの次元と等しいことに注意してください。
上記でオーバーライドしたメソッドを使用して、活性化関数を強制的にキャンセルします。
SetActivationFunction(None); //--- return true; }
その後、処理結果の真偽値を呼び出し元のプログラムに渡すことで、メソッドを完了します。
オブジェクトの初期化が完了した後は、順伝播処理の構築に進みます。これらはfeedForwardメソッド内で実装されており、ここでは特に複雑なことはありません。ここではすべてが非常に簡単です。
bool CNeuronMotifs::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
このメソッドは、入力データオブジェクトへのポインタをパラメータとして受け取ります。最初のステップでは、このポインタが有効かどうかを検証します。その後、入力データ層と現在のオブジェクトの活性化関数を同期させます。
if(NeuronOCL.Activation() != activation)
SetActivationFunction((ENUM_ACTIVATION)NeuronOCL.Activation());
この操作により、埋め込み層の出力領域と入力データを同期させることができます。
そして、これらの準備作業をすべて終えた後に、内部層の順伝播処理を実行します。
if(!cMotifs.FeedForward(NeuronOCL)) return false;
次に、得られた埋め込みのテンソルを入力データと連結します。
if(!Concat(NeuronOCL.getOutput(), cMotifs.getOutput(), Output, NeuronOCL.Neurons(), cMotifs.Neurons(), 1)) return false; //--- return true; }
連結されたテンソルは、親クラスから継承された結果バッファに書き込みます。そして、処理が正常に完了したかどうかを示す真偽値を呼び出し元のプログラムに返すことで、メソッドを終了します。
次に、バックプロパゲーションメソッドの実装に進みます。ご想像のとおり、これらのアルゴリズムも同様にシンプルです。たとえば、誤差勾配を分配するcalcInputGradientsメソッドでは、親クラスから継承された誤差勾配バッファを連結解除し、その値を入力データオブジェクトと内部層のそれぞれに分配するという、ただ一つの操作のみをおこないます。
bool CNeuronMotifs::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false; if(!DeConcat(NeuronOCL.getGradient(),cMotifs.getGradient(),Gradient,NeuronOCL.Neurons(),cMotifs.Neurons(),1)) return false; //--- return true; }
しかし、この見かけ上の単純さにはいくつか補足説明が必要です。まず、入力データや内部層に渡される誤差勾配に対して、それぞれのオブジェクトの活性化関数の導関数による調整はおこなっていません。このケースでは、そのような操作は冗長だからです。この理由は、順伝播処理の設計時に、現在のオブジェクト・内部層・入力データの活性化関数ポインタを同期させたことにあります。このシンプルな操作により、すでに正しい活性化関数の導関数で調整された誤差勾配を、オブジェクトの結果レベルで取得できるようになりました。したがって、私たちは調整済みの誤差勾配に対して連結解除をおこなっていることになります。
次に注目すべき点として、内部のパターン抽出層から入力データへの誤差勾配は渡していないという点があります。興味深いことに、その理由は本タスクの性質にあります。すなわち、入力データからの「パターン抽出」です。私たちの目的は、入力を目的のパターンに「適合」させることではなく、有意義なパターンを識別することにあります。しかしご覧のとおり、入力データ自体は、直接的なデータフローを通じて独自の誤差勾配を受け取っています。
このクラスおよびそのすべてのメソッドの完全なコードは、添付ファイルにて確認できます。
2.3 マルチスケールアテンション
次に作成すべき「構成要素」は、マルチスケールアテンションオブジェクトです。ここで、私たちは元のMolformerアルゴリズムから最も大きく逸脱したかもしれません。Molformerフレームワークの著者たちは、対象から一定以上離れたオブジェクトを除外するマスキング機構を実装していました。これにより、アテンションは定義された範囲内のみに集中されていました。
しかし、私たちの実装では異なるアプローチを取りました。第一に、提案されたアテンション機構の代わりに、前回の記事で取り上げたRelative Self-Attentionを使用しています。これは、位置的なずれだけでなく、文脈情報も解析するものです。第二に、アテンションのスケールを調整するために、1つの解析対象要素のサイズを元のシーケンスの2個、3個、4個分にまで拡大します。これは、より上位の時間軸のチャートを分析することに似ています。私たちのソリューションの実装はCNeuronMultiScaleAttentionクラスにまとめられています。新クラスの構造は以下のとおりです。
class CNeuronMultiScaleAttention : public CNeuronBaseOCL { protected: uint iWindow; uint iUnits; //--- CNeuronBaseOCL cWideInputs; CNeuronRelativeSelfAttention cAttentions[4]; CNeuronBaseOCL cConcatAttentions; CNeuronMHAttentionPooling cPooling; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronMultiScaleAttention(void) {}; ~CNeuronMultiScaleAttention(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronMultiScaleAttention; } //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetOpenCL(COpenCLMy *obj) override; };
ここでは、相対アテンションオブジェクトの固定配列を宣言することで、スケールの数を明示的に定義しています。加えて、クラス構造内ではさらに3つのオブジェクトが宣言されていますが、それらの目的については、クラスメソッドの実装を通じて明らかにしていきます。
すべての内部オブジェクトはstaticとして宣言されているため、クラスのコンストラクタおよびデストラクタは空のままにしておくことができます。これらの宣言済みおよび継承されたオブジェクトの初期化は、Initメソッド内でおこなわれます。
bool CNeuronMultiScaleAttention::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count, optimization_type, batch)) return false;
メソッドのパラメータには、いつも通り作成されるオブジェクトのアーキテクチャを一意に定義する定数が渡されます。メソッドの本体では、すぐに親クラスの同名メソッドを呼び出します。このメソッドには、継承オブジェクトに必要なチェックや初期化アルゴリズムが既に含まれているため、繰り返し説明する必要はないと思います。
親クラスのメソッドが正常に実行された後、いくつかの定数を内部変数に格納します。
iWindow = window; iUnits = units_count;
新たに宣言したオブジェクトを初期化する前に、現段階では入力データテンソルのサイズが不明であることに注意する必要があります。さらに、その次元が私たちの解析スケールに適合しているかどうかもわかっていません。実際、受け取る入力テンソルは、スケールの倍数でない可能性もあります。しかし、大規模アテンションオブジェクトに渡すテンソルは、正しいサイズである必要があります。この要件を満たすために、入力データをコピーし、不足する要素にはゼロ値を追加して埋める内部オブジェクトを作成します。まずは、必要なバッファサイズを、スケールの中で最も近い大きい倍数の最大値として決定します。
uint units1 = (iUnits + 1) / 2; uint units2 = (iUnits + 2) / 3; uint units3 = (iUnits + 3) / 4; uint wide = MathMax(MathMax(iUnits, units1 * 2), MathMax(units2 * 3, units3 * 4));
次に、必要なサイズの入力データをコピーするためにオブジェクトを初期化します。
int idx = 0; if(!cWideInputs.Init(0, idx, OpenCL, wide * iWindow, optimization, iBatch)) return false; CBufferFloat *temp = cWideInputs.getOutput(); if(!temp || !temp.Fill(0)) return false;
この層の結果バッファをゼロ値で埋めます。
次のステップでは、他のパラメータを維持しながら、さまざまなスケールの内部アテンションオブジェクトを初期化します。
idx++; if(!cAttentions[0].Init(0, idx, OpenCL, iWindow, window_key, iUnits, heads, optimization, iBatch)) return false; idx++; if(!cAttentions[1].Init(0, idx, OpenCL, 2 * iWindow, window_key, units1, heads, optimization, iBatch)) return false; idx++; if(!cAttentions[2].Init(0, idx, OpenCL, 3 * iWindow, window_key, units2, heads, optimization, iBatch)) return false; idx++; if(!cAttentions[3].Init(0, idx, OpenCL, 4 * iWindow, window_key, units3, heads, optimization, iBatch)) return false;
ここで注意すべき点は、アテンション対象のオブジェクトが異なるスケールであっても、出力されるテンソルは概ね同じ大きさになることを想定しているということです。これは、本質的にすべてのオブジェクトが単一の初期データソースを使用しているためです。したがって、アテンション結果を連結するために、元のデータの4倍の大きさを持つオブジェクトを宣言します。
idx++; if(!cConcatAttentions.Init(0, idx, OpenCL, 4 * iWindow * iUnits, optimization, iBatch)) return false;
アテンションの結果を平均化するには、上記で作成した依存性ベースのプーリングクラスを使用します。
idx++; if(!cPooling.Init(0, idx, OpenCL, iWindow, iUnits, 4, optimization, iBatch)) return false;
次に、作成したオブジェクトの結果バッファおよび誤差勾配のポインタを、プーリング層の対応するバッファのポインタに置き換えます。
SetActivationFunction(None); if(!SetOutput(cPooling.getOutput()) || !SetGradient(cPooling.getGradient())) return false; //--- return true; }
メソッドの最後で、処理結果を呼び出し元のプログラムに渡します。
なお、本クラスでは、以前に説明したアテンションブロックで使用したような残差接続を実装するためのオブジェクトは用意していません。これは、内部で使用している相対的自己アテンションブロック自体にすでに残差接続が組み込まれているためです。そのため、アテンション結果の平均化処理は、これらの残差接続を考慮したものとなっています。さらなる操作を加えることは冗長となります。
オブジェクトの初期化が完了した後は、順伝播処理の構築に移ります。これはfeedForwardメソッド内で実装します。
bool CNeuronMultiScaleAttention::feedForward(CNeuronBaseOCL *NeuronOCL) { //--- Attention if(!cAttentions[0].FeedForward(NeuronOCL)) return false;
feedForwardメソッドのパラメータには、いつも通り入力データオブジェクトへのポインタが渡されます。このポインタはすぐに、内部の単一スケールアテンション層の同名メソッドに渡されます。内部オブジェクトのメソッド内では、コアな処理に加えて、受け取ったポインタの有効性もチェックします。そのため、内部クラスのメソッドが正常に実行された後は、外部プログラムから渡されたポインタを安全に利用できます。次のステップとして、入力データを対応する内部層のバッファに転送します。その後、活性化関数を同期させます。
if(!Concat(NeuronOCL.getOutput(), NeuronOCL.getOutput(), cWideInputs.getOutput(), iWindow, 0, iUnits)) return false; if(cWideInputs.Activation() != NeuronOCL.Activation()) cWideInputs.SetActivationFunction((ENUM_ACTIVATION)NeuronOCL.Activation());
ここで重要なのは、入力データのコピーに連結方式を用いている点です。この方法では、入力データオブジェクトの結果バッファのポインタを2回指定します。1つ目のバッファには入力データのウィンドウサイズを、2つ目には「0」を指定します。これらのパラメータ設定により、指定した結果バッファに入力データのコピーが得られます。同時に、オブジェクト初期化時に説明したような欠損データに対する明示的なゼロ埋め処理は行われません。
しかし、ゼロ値の追加は暗黙的に行われています。内部の入力データオブジェクトの初期化時に、その結果バッファをゼロで埋めているためです。学習や実行時には、同じサイズの入力データテンソルを受け取ることが想定されています。そのため、入力データをコピーするたびに同じ要素を上書きし、残りの要素はゼロのまま保持されます。
拡張された入力データオブジェクトを形成した後、多段階のマルチスケールアテンション処理をおこなうループを構築します。このループ内で、より大きなスケールのアテンションオブジェクトの順伝播メソッドを順番に呼び出し、拡張入力データオブジェクトのポインタを渡します。
//--- Multi scale attentions for(int i = 1; i < 4; i++) if(!cAttentions[i].FeedForward(cWideInputs.AsObject())) return false;
すべてのスケールのアテンション結果をひとつのテンソルに連結します。解析対象のスケールは異なりますが、出力されるテンソルは概ね同じ大きさであり、元のシーケンスの各要素はそれぞれの位置に留まっています。したがって、元のシーケンスの要素単位でテンソルの連結をおこないます。
//--- Concatenate Multi-Scale Attentions if(!Concat(cAttentions[0].getOutput(), cAttentions[1].getOutput(), cAttentions[2].getOutput(), cAttentions[3].getOutput(), cConcatAttentions.getOutput(), iWindow, iWindow, iWindow, iWindow, iUnits)) return false;
そして同様に、元のシーケンスの各要素に沿って、依存関係を考慮しながらマルチスケールアテンションの結果の重み付きプーリングをおこないます。
//--- Attention pooling if(!cPooling.FeedForward(cConcatAttentions.AsObject())) return false; //--- return true; }
メソッドの最後に、初期化の成否を示す真偽値を呼び出し元に返します。
補足として、オブジェクトの初期化段階で、結果バッファおよび誤差勾配バッファへのポインタを置き換えています。そのため、プーリングの結果はモデルのニューラルネットワーク層間の通信に用いられるバッファに直接格納されます。結果として、冗長なデータコピー操作は省略されています。
このクラスのバックプロパゲーションメソッドについては、読者の自主的な学習に委ねることを提案します。このクラスとそのすべてのメソッドの完全なコードは添付ファイルで提供されています。
2.4 Molformerフレームワークの構築
これまでに、Molformerフレームワークの個々の構成要素を構築するために多くの作業を行ってきました。ここからは、これらの構成要素を統合してフレームワーク全体のアーキテクチャを組み上げる段階です。そのために、新たにCNeuronMolformerクラスを作成します。この際、最もシンプルな線形モデルの仕組みを実装しているCNeuronRMATを親クラスとして使用します。新クラスの構造は以下のとおりです。
class CNeuronMolformer : public CNeuronRMAT { public: CNeuronMolformer(void) {}; ~CNeuronMolformer(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint layers, uint motif_window, uint motif_step, ENUM_OPTIMIZATION optimization_type, uint batch); //Molformer //--- virtual int Type(void) override const { return defNeuronMolformer; } };
これまでに実装したコンポーネントとは異なり、ここでは新クラスの初期化メソッドInitのみをオーバーライドしている点にご注意ください。これは、親クラスで整理された線形構造のおかげで可能となりました。現在は、親クラスから継承した動的配列に必要な順序でオブジェクトを格納するだけで十分です。これらのコンポーネント間のすべての連携アルゴリズムは、親クラスのメソッド内にすでに構築されています。
この唯一オーバーライドしたメソッドのパラメータには、ユーザーが意図する作成オブジェクトのアーキテクチャを一意に解釈するための一連の定数が渡されます。
bool CNeuronMolformer::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint units_count, uint heads, uint layers, uint motif_window, uint motif_step, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count, optimization_type, batch)) return false;
メソッドの本体では、まず全結合ニューラル層の基底クラスのメソッドを呼び出します。
重要なのは、直接の親クラスではなく、基底ニューラル層クラスのメソッドを呼び出している点です。このメソッド内では、全く新しいアーキテクチャを構築する必要があるため、親クラスのアーキテクチャ設計を再利用しません。
次のステップとして、作成するオブジェクトのポインタを格納する動的配列を準備します。
cLayers.Clear(); cLayers.SetOpenCL(OpenCL);
それでは、必要なオブジェクトの作成および初期化に関する処理に移ります。まず、パターン抽出オブジェクトを作成し初期化します。動的配列には、新しいオブジェクトのポインタを追加します。
int idx = 0; CNeuronMotifs *motif = new CNeuronMotifs(); uint motif_units = units_count - MathMax(motif_window - motif_step, 0); motif_units = (motif_units + motif_step - 1) / motif_step; if(!motif || !motif.Init(0, idx, OpenCL, window, motif_window, motif_step, motif_units, optimization, iBatch) || !cLayers.Add(motif) ) return false;
次に、オブジェクトのポインタを一時的に格納するためのローカル変数を作成し、エンコーダの内部層を生成するループを実行します。内部層の数はメソッドのパラメータで渡される定数によって決まります。
idx++; CNeuronMultiScaleAttention *msat = NULL; CResidualConv *ff = NULL; uint units_total = units_count + motif_units; for(uint i = 0; i < layers; i++) { //--- Attention msat = new CNeuronMultiScaleAttention(); if(!msat || !msat.Init(0, idx, OpenCL, window, window_key, units_total, heads, optimization, iBatch) || !cLayers.Add(msat) ) return false; idx++;
ループの本体では、まずマルチスケールアテンションオブジェクトを作成し初期化します。その後、残差接続を持つ畳み込みブロックを追加します。
//--- FeedForward ff = new CResidualConv(); if(!ff || !ff.Init(0, idx, OpenCL, window, window, units_total, optimization, iBatch) || !cLayers.Add(ff) ) return false; idx++; }
作成したオブジェクトのポインタを、内部オブジェクトの動的配列に追加します。
次に、マルチスケールアテンションブロックの出力では、入力データとパターン埋め込みが連結されたテンソルが得られます。これは内部の依存関係に関する情報で豊かになっています。しかし、クラスの出力としては、情報が付加された入力データのテンソルを返す必要があります。パターン埋め込みを単純に「破棄」する代わりに、個々の単位シーケンス内のデータに対してスケーリング関数を適用します。そのために、まず前段の結果を転置します。
//--- Out CNeuronTransposeOCL *transp = new CNeuronTransposeOCL(); if(!transp || !transp.Init(0, idx, OpenCL, units_total, window, optimization, iBatch) || !cLayers.Add(transp) ) return false; idx++;
次に、個々のユニタリシーケンスをスケーリングする機能を実行する畳み込み層を追加します。
CNeuronConvOCL *conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, idx, OpenCL, units_total, units_total, units_count, window, 1, optimization, iBatch) || !cLayers.Add(conv) ) return false; idx++;
出力を元のデータ表現にリセットします。
idx++; transp = new CNeuronTransposeOCL(); if(!transp || !transp.Init(0, idx, OpenCL, window, units_count, optimization, iBatch) || !cLayers.Add(transp) ) return false;
その後は、データバッファへのポインタを置き換え、操作の論理結果を呼び出し元プログラムに返すだけです。
if(!SetOutput(transp.getOutput()) || !SetGradient(transp.getGradient())) return false; //--- return true; }
これで、Molderフレームワーククラスについての説明は終わりです。紹介されているすべてのクラスとそのメソッドの完全なソースコードは添付ファイルに含まれています。添付ファイルには、記事で使用されているすべてのプログラムの完全なコードも含まれています。なお、以前の記事で紹介したインタラクションおよびトレーニング用プログラムを引き続き使用しています。環境状態エンコーダのアーキテクチャには若干の修正を加えており、こちらはぜひ独自に検証してみてください。学習可能なモデルのアーキテクチャの詳細な説明も添付ファイルにて確認してください。ここからは、作業の最終段階であるモデルの訓練と結果の検証に進みます。
3.テスト
本記事では、MQL5でMolformerフレームワークを実装し、いよいよ最終段階のモデル訓練および訓練済みのActorの行動方針の評価に移ります。訓練はこれまでの研究で説明したアルゴリズムに従い、State Encoder、Actor、Critic.の3モデルを同時に訓練します。Encoderは市場状況を解析し、Actorは学習済みの方針に基づいて取引を実行し、CriticはActorの行動を評価し行動方針の改善に役立てます。
訓練には、2023年の1年間にわたるEURUSDのH1(1時間足)実データを使用し、解析対象のインジケーターは標準パラメータで設定しています。
訓練は反復的に行われ、定期的に学習データセットの更新も含まれます。
訓練方針の有効性検証には、2024年1月の過去データを用います。以下にそのテスト結果を示します。
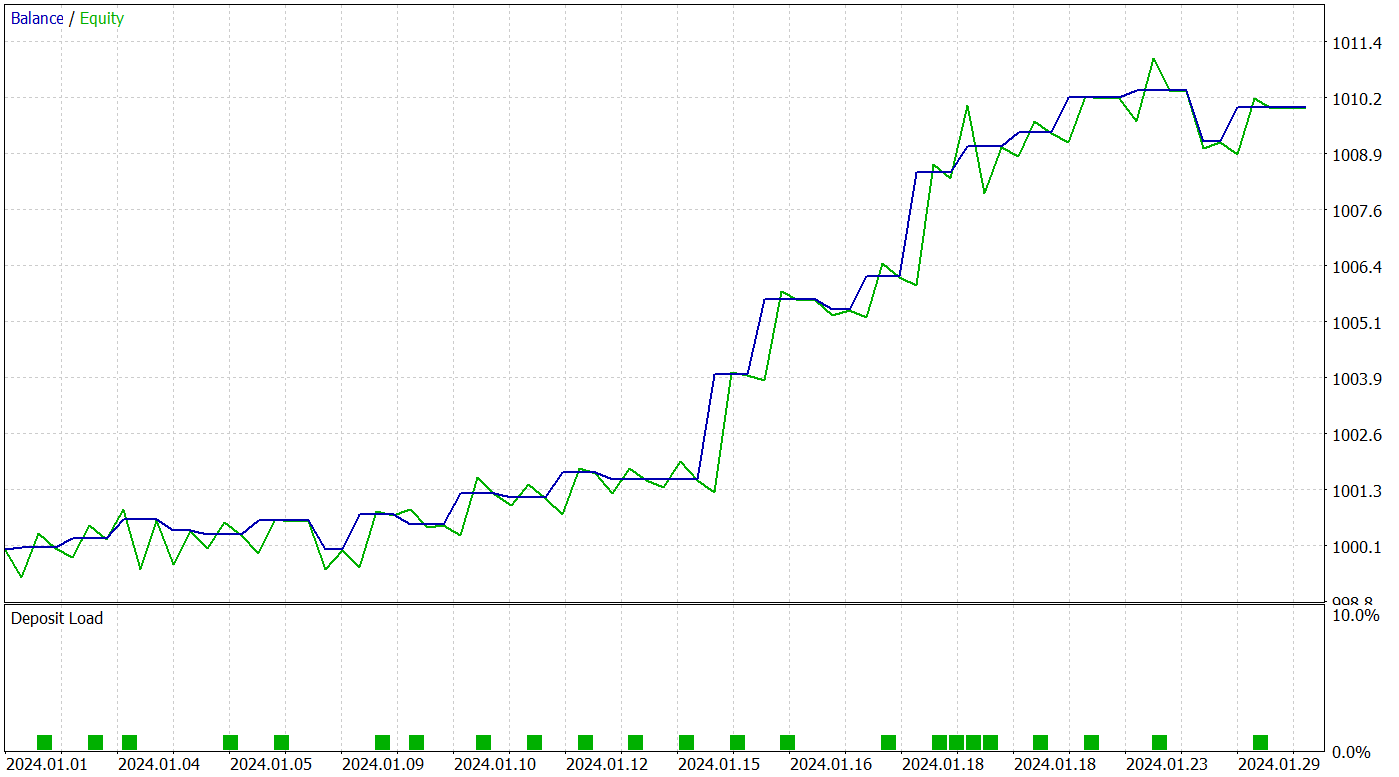
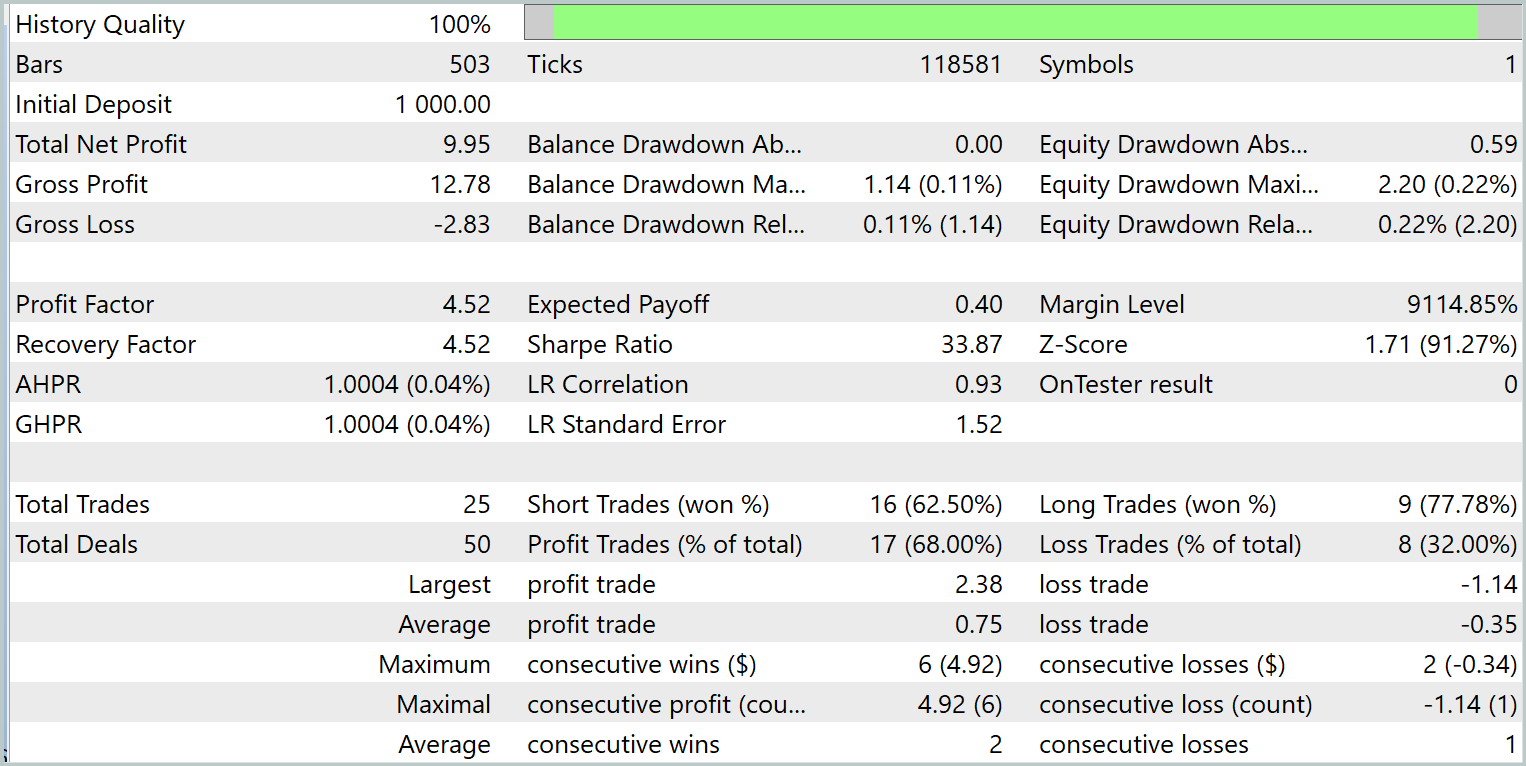
訓練済みモデルはテスト期間中に25回の取引をおこない、そのうち17回が利益を上げました。これは全体の68%に相当します。さらに、利益が出た取引の平均値および最大値は、損失が出た取引のそれらの2倍に達しています。
提案モデルの可能性は、明確な上昇傾向を示す資産曲線によっても裏付けられています。ただし、テスト期間が短く取引回数も限られているため、この結果はあくまで潜在能力の示唆にとどまることに注意が必要です。
結論
Molformer手法は、市場データの分析および予測の分野において大きな進歩をもたらします。個別資産と市場パターンという形での組み合わせを含む異種市場グラフを活用することで、モデルはより複雑な関係性やデータ構造を考慮でき、将来の価格変動の予測精度を大幅に向上させることが可能となりました。
本記事の実践部分では、MQL5を用いてMolformerアプローチのビジョンを実装しました。提案したソリューションをモデルに統合し、実際の過去データで訓練をおこないました。その結果、獲得した知識を新たな市場状況に一般化し、利益を生み出すモデルを作り上げることができました。これはテスト結果によって裏付けられています。私たちは、本手法が金融分析の分野におけるさらなる研究や応用の基盤となり、不確実性の中で意思決定をおこなうトレーダーやアナリストに新たなツールを提供すると信じています。
参照文献
記事で使用されているプログラム
| # | 名前 | 種類 | 詳細 |
|---|---|---|---|
| 1 | Research.mq5 | EA | 事例収集のためのEA |
| 2 | ResearchRealORL.mq5 | EA | Real-ORL法による事例収集のためのEA |
| 3 | Study.mq5 | EA | モデル訓練EA |
| 4 | Test.mq5 | EA | モデルテストEA |
| 5 | Trajectory.mqh | クラスライブラリ | システム状態記述の構造体 |
| 6 | NeuroNet.mqh | クラスライブラリ | ニューラルネットワークを作成するためのクラスのライブラリ |
| 7 | NeuroNet.cl | ライブラリ | OpenCLプログラムコードライブラリ |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/16130
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
こんにちは。test.mq5 Expert Advisorで注文が出せません。
配列の要素 temp[0]とtemp[3]は常にmin_lotより小さいのですが、どこに間違いがあるのでしょうか?