
未来のトレンドを見通す鍵としての取引量ニューラルネットワーク分析

すべての取引がますます自動化されていく時代において、過去のトレーダーの格言を思い出すことは有益です。そのうちの1つに「取引量こそがすべての鍵である」というものがあります。確かに、テクニカル分析や取引量分析は、機械学習に特徴量として取り入れることで有用かつ非常に興味深いものになるでしょう。正しい解釈が伴えば、それが良い結果をもたらすかもしれません。本記事では、LSTM構造を用いた取引量と取引量に基づく特徴量の分析手法を評価します。
私たちのシステムは、取引量の異常を分析し、将来の価格変動を予測します。特に注目すべきシステムの特徴は、異常取引量の検出、取引量のクラスタリング、そしてPythonとMetaTrader 5の連携によるモデルの直接的なトレーニングです。
また、結果の可視化を伴う包括的なバックテストも実施します。モデルはロシア株式市場の1時間足において特に高い効果を示しており、過去1年間のSberbank株の歴史的データによるテスト結果によって裏付けられています。本記事では、システムの構造、動作原理、そして実際の適用結果を詳しく検証します。
コードの詳細:データから予測へ
取引量の現状を真に理解するシステムを作るために、深く掘り下げていきましょう。まずは基本的なところから始めます。データの取得と処理の方法です。一見すると単純で、データをダウンロードして処理すれば良さそうですが、やはり細部にこそ落とし穴があります。
データソース:より深く掘り下げる
以下はデータ読み込み関数です。
def get_mt5_data(self, symbol, timeframe, start_date, end_date): try: self.logger.info(f"MT5 data request: {symbol}, {timeframe}, {start_date} - {end_date}") rates = mt5.copy_rates_range(symbol, timeframe, start_date, end_date) df = pd.DataFrame(rates)
かなり単純なようです。あえて簡単なcopy_rates_fromではなくcopy_rates_rangeを使っています。これは流動性の低い銘柄を扱う際に、ゼロの期間(取引がない時間帯)を見逃さないためです。
次に、特徴量やインジケーターの処理に取り掛かります。
前処理:データ準備の技術
特徴量の選択に時間をかけるのは避け、まずは最も明白なものに絞って取り組みましょう。
def preprocess_data(self, df): # Basic volume indicators df['vol_ma5'] = df['real_volume'].rolling(window=5).mean() df['vol_ma20'] = df['real_volume'].rolling(window=20).mean() df['vol_ratio'] = df['real_volume'] / df['vol_ma20'] # ML indicators df['price_momentum'] = df['close'].pct_change(24) df['volume_momentum'] = df['real_volume'].pct_change(24) df['volume_volatility'] = df['real_volume'].pct_change().rolling(24).std() df['price_volume_correlation'] = df['price_change'].rolling(24).corr( df['real_volume'].pct_change() )
特徴量選択の扱いは、まるでオーケストラの調律のようなものです。各特徴量はそれぞれ役割があり、データという交響曲の中で特有の響きを持っています。まずは基本的なセットを見てみましょう。
最初は最もシンプルなもので、移動平均を使った取引量の処理です。期間5の移動平均は微細な変動を捉え、期間20はより強力な取引量トレンドに反応します。
取引量とその移動平均の比率も興味深い特徴量です。将来的に急激なジャンプが起こるとき、強力な価格インパルスが生じることがよくあります。
また、過去24バーにおける価格モメンタムと取引量モメンタムも見ています。
さらに面白い特徴量として「取引量ボラティリティ」があります。これは市場の神経質さを示す指標と言えるでしょう。取引量ボラティリティが上昇すると、それは真剣なプレイヤーによる市場への強力な資金投入を示唆しているかもしれません。
価格と取引量の相関もモデルで考慮しています。最後には、これらすべての指標をリアルタイムで可視化しながら確認する予定です。
パフォーマンスのボトルネック
システムの負荷を避けるために、データのバッチ処理と並列計算を導入できます。つまり、データを小さな塊に分けて並行して処理するということです。
このシンプルな手法により、データ処理速度が数倍に向上し、大量データのメモリリーク問題も回避できます。
この記事の次の部分では、最も興味深いテーマである「システムが異常取引量をどのように検出し、その後何が起こるのか」について語ります。
「ブラックスワン」を探して:異常な取引量をどう見抜くか
異常な取引量とは何か、チャート上でどう見つけるかは誰もが聞いたことがあるでしょう。おそらく、経験豊富なトレーダーならすぐに見抜けるかもしれません。しかし、その経験をコードに組み込むにはどうすれば良いのでしょう。異常な取引量を探すロジックをどう形式化すれば良いのでしょうか。
異常検知の狩猟
一連の実験を経て、私の研究はIsolation Forestという手法に落ち着きました。なぜこの手法かというと、zスコアやパーセンタイルスコアのような古典的な方法は、局所的な異常、小さくても重要な異常を見逃してしまうことがあるからです。重要なのは絶対値やパーセンテージではなく、他と明確に異なり、全体の文脈から逸脱している取引量だからです。
def detect_volume_anomalies(self, df): scaler = StandardScaler() volume_normalized = scaler.fit_transform(df[['real_volume']]) iso_forest = IsolationForest(contamination=0.1, random_state=42) df['is_anomaly'] = iso_forest.fit_predict(volume_normalized)
もちろん、パラメータを調整して試行錯誤するのが望ましいですし、さらに良い方法としてはBGAのようなアルゴリズムを使ってモデルの設定をすべて自動選択することです。今回は教科書で推奨されている0.05、つまり5%の異常値に設定しました。しかし実際の市場は想像以上にノイズが多いため、閾値は少し引き上げています。また、異常値を実際に自分の目で確認し、価格変動とともにグルーピングして見ることも非常に有用です(この点については後ほど改めて触れます)。
クラスタリング:パターンを見つける
異常値だけでは良い予測はできません。取引量のクラスタリングも必要です。ここでは以下のクラスタリング手法に注目します。
def cluster_volumes(self, df, n_clusters=3): features = ['real_volume', 'vol_ratio', 'volatility'] X = StandardScaler().fit_transform(df[features]) kmeans = KMeans(n_clusters=n_clusters, random_state=42) df['volume_cluster'] = kmeans.fit_predict(X)
クラスタリングに選んだ特徴量はかなりシンプルです。実際の取引量だけをクラスタリングするのは不自然だと思います。なぜなら、特徴量やインジケーターをわざわざ作っている意味がなくなるからです。ただし、特徴量の数や取引量インジケーター自体は今後改善の余地があります。
3つのクラスタを選んだ理由は、取引量を大まかに「背景・蓄積」ボリューム、「駆け上がり・動き」ボリューム、「極端な動き」ボリュームに分けたいという意図からです。
予期せぬ発見
データを扱ううちにいくつかのパターンや連続性が見えてきました。たとえば、異常な取引量の後には第3のクラスタ(極端な動きの取引量)が続き、その後に活発な取引量が現れ、ようやく価格が一方向に動き出す、という流れです。
これは特に取引所のセッション開始直後の数時間に顕著です。ここでクラスタごとのヒートマップと、それに伴う価格変動を可視化するのが有効でしょう。
ニューラルネットワーク:市場を読み解く機械の学習方法
私は長くニューラルネットワークを使ってきたため、今回の取引量分析にもニューラルネットワークを適用するのが理にかなっていると考えました。LSTMアーキテクチャはまだ試していませんでしたが、他分野での成功例を見てついに挑戦する決心がつきました。
それでは詳しく見ていきましょう。
アーキテクチャ:少ないほど良い
シンプルさが勝負です。意外なほどシンプルな構成を思いつきました。
class LSTMModel(nn.Module): def __init__(self, input_size, hidden_size=64, num_layers=2, dropout=0.2): super(LSTMModel, self).__init__() self.lstm = nn.LSTM( input_size=input_size, hidden_size=hidden_size, num_layers=num_layers, dropout=dropout, batch_first=True ) self.dropout = nn.Dropout(dropout) self.linear = nn.Linear(hidden_size, 1)
一見すると、このアーキテクチャは非常に原始的に見えます。たった2つのLSTM層と1つの線形層だけです。しかし、力はシンプルさにあります。なぜなら、残念ながらより深く、より複雑なネットワークを構築すると過学習が発生するからです。最初は、3層のLSTMや追加の全結合層、複雑なドロップアウト構造を備えたかなり複雑なネットワークを作りました。テストデータ上では素晴らしい結果が出ました。しかし、実際の長期的な市場環境に触れるや否や、すべてが崩れました。つまり、過学習を起こしていたのです。
過学習との戦い
過学習は現代のニューラルネットワークにおける最大の課題です。ニューラルネットはテストデータの範囲内での関係性を学習するのは得意ですが、実際の市場環境では全く対応できなくなります。今回のアーキテクチャで私がこの問題に対処しようとしている方法は次の通りです。
- 単一層では、取引量と価格の関係性の複雑さを扱いきれない
- 3層にすると、実際には存在しない関係まで見つけてしまう
隠れ層のサイズは標準的に64ニューロンを選択します。もっと多くのニューロンを使うほうが良いかもしれませんが、過学習対策の仕組みが確立した段階で、より複雑なアーキテクチャに移行予定です。
入力データ:特徴量選択の芸術
それでは、学習に使う入力特徴量を見てみましょう。
features = [ 'vol_ratio', 'vol_ma5', 'volatility', 'volume_cluster', 'is_anomaly', 'price_momentum', 'volume_momentum', 'volume_volatility', 'price_volume_correlation' ]
特徴量のセットは自由に実験できます。テクニカル指標や価格の微分量、取引量の微分量、価格と取引量の組み合わせなど、好きなだけ追加可能です。しかし、特徴量を増やせば必ずしも予測精度が向上するわけではないことを忘れてはいけません。論理的に見える特徴量が、実は単なるノイズでしかないことも多々あります。
ここで注目したいのは、volume_clusterとis_anomalyの組み合わせです。単体では控えめな特徴量ですが、相乗効果によって非常に興味深い挙動を示します。特定のクラスタで異常な取引量が発生すると、予測に異例の影響を与えるのです。
予期せぬ発見
システムは価格変動が強い期間に最も効果的であることが分かりました。また、多くのトレーダーが「読めない」と呼ぶレンジ相場や調整局面でも良い結果を示しています。まさにこうした局面で、異常値や取引量クラスタを分析するシステムは私たちの視覚では捉えきれない情報を捉えています。
次のセクションでは、このシステムが実際の取引でどのように機能したか、具体的なシグナル例を交えてお話しします。
予測から取引まで:シグナルを利益に変える
アルゴリズムトレーダーなら誰でも知っていることですが、単純な予測モデルだけでは不十分です。それを実際に機能する取引戦略へと発展させる必要があります。では、私たちのモデルを実践にどう活かすのか、一緒に考えてみましょう。この記事の次の部分では、単なる理論ではなく、実際のテスト取引やアルゴリズムの強化、過学習対策の改善といったリアルな実践が紹介されますが、今回はまず研究の理論的な部分をおさえます。
取引シグナルの構造
取引戦略を開発する際、重要なポイントの一つが取引シグナルの生成です。私の戦略では、次期間の期待リターンを反映したモデルの予測値に基づいてシグナルを生成しています。
def backtest_prediction_strategy(self, df, lookback=24): # Generating signals based on predictions df['signal'] = 0 signal_threshold = 0.001 # Threshold 0.1% df.loc[df['predicted_return'] > signal_threshold, 'signal'] = 1 df.loc[df['predicted_return'] < -signal_threshold, 'signal'] = -1
シグナル閾値の選択
一方で、閾値を単純に0以上に設定する方法があります。この場合、多くのシグナルが発生しますが、スプレッドや手数料、市場のノイズによってノイズの多いシグナルになりがちです。このアプローチは誤シグナルの増加を招き、戦略の効率を悪化させる恐れがあります。
そこで、最も合理的な判断は予測利益率の閾値を0.1%〜0.2%に引き上げることです。これにより、多くのノイズを除去し、手数料の影響を抑えられます。なぜなら、シグナルは予測された価格変動が十分に大きい場合にのみ発生するためです。
signal_threshold = 0.001 # Threshold 0.1%
シグナル適用時のシフト考慮
シグナルが生成された後、それらは24期間の先行シフトを考慮して価格に適用されます。これにより、取引判断の実行までのタイムラグを反映できます。
df['strategy_returns'] = df['signal'].shift(24) * df['price_change']
24期間のシフトとは、時刻tで生成されたシグナルを時刻t + 24の価格に適用することを意味します。これは、実際には取引の判断が即座に実行されるわけではないため重要です。この手法により、より現実的な取引戦略の効率評価が可能になります。
戦略の収益性計算
戦略の収益性は、シフトされたシグナルと価格変動の積で計算されます。
df['strategy_returns'] = df['signal'].shift(24) * df['price_change']
シグナルが1の場合、戦略収益は価格変動(price_change)に等しくなります。シグナルが-1の場合、収益は価格変動の逆符号(-price_change)となり、シグナルが0の場合は収益はゼロです。
このように24期間のシフトをおこなうことで、取引判断と実行の遅延を考慮し、戦略の効率評価をより現実的にしています。
黄金比
数週間のテストを経て、閾値は0.1%に落ち着きました。その理由は以下の通りです。
- この閾値でシステムは比較的頻繁にシグナルを発生させる
- 約52〜63%の取引が利益を生んでいる
- 1取引あたりの平均利益は手数料の約2.5倍に相当する
そして最も意外だったのは、多くの誤シグナルも時間的にクラスタ化している点です。もしご興味があれば、そのような時間フィルタについても検討可能で、次回の記事で詳しく触れる予定です。
def apply_time_filter(self, df): # We trade only during active hours trading_hours = df['time'].dt.hour df.loc[~trading_hours.between(10, 12), 'signal'] = 0
リスク管理
ポジション取得のロジックとオープンポジションの管理(取引中のポジション維持)のロジックは別の重要なテーマです。一見すると、固定ストップやテイクプロフィットを使うのが最もシンプルな解決策に思えますが、市場はあまりにも予測不能で動的なため、損失や利益の限度を単純な形式的ロジックで表現することは困難です。
私たちの解決策は比較的単純で、予測されたボラティリティを使ってストップを動的に設定する方法です。
def calculate_stop_levels(self, predicted_return, predicted_volatility): base_stop = abs(predicted_return) * 0.7 volatility_adjust = predicted_volatility * 1.5 return max(base_stop, volatility_adjust)
このアプローチもさらに検証が必要です。また、古くから信頼されているVaRモデルを用いて、ストップやテイクを選定することも可能です。
予期せぬ発見
連続したシグナルの連なりが非常に強力な相場変動を予測できることがわかりました。一方で、市場の平均ボラティリティが急激に上昇する局面では、現行の閾値では十分に効果的なトレードができなくなる問題もあります。チャート上のドローダウン期間がちょうど高ボラティリティと結びついていることに気づくでしょう。しかし、これは私たちにとって問題ではありません。この問題は次のセクションで解決し、克服していきます。
可視化とログ管理:データに溺れないために
ログシステムを忘れないことも非常に重要です。一般的に、print文やログ、出力、プログラムのコメントはデバッグ段階で不可欠です。これがあれば、コードの問題の原因を素早く効率的に見つけられます。
ログシステム:細部が肝心
ログシステムはシンプルながら効率的なフォーマットを採用しています。
log_format = '%(asctime)s [%(levelname)s] %(message)s'
date_format = '%Y-%m-%d %H:%M:%S'
logger = logging.getLogger('VolumeAnalyzer')
logger.setLevel(logging.DEBUG)
何が難しいのかと疑問に思うかもしれませんが、私もシステムがなぜ特定のタイミングでポジションを取ったのか分からず苦労した経験から、このフォーマットを採用しました。
現在は、システムのあらゆる動作がログに明確に記録されます。特に異常取引量に関する瞬間は必ずログを残すようにしています。
self.logger.info(f"Abnormal volume detected: {volume:.2f}") self.logger.debug(f"Context: cluster {cluster}, volatility {volatility:.4f}")
可視化も欠かせません。手動取引の経験から、すべてを視覚的に確認する習慣が強く根付いています。データを見る際は、最も普通のチャートを見るのと同じ感覚で観察したいのです。以下はそのための可視化コードです。
def visualize_results(self, df): plt.figure(figsize=(15, 12)) # Price and signal chart plt.subplot(3, 1, 1) plt.plot(df['time'], df['close'], 'k-', label='Price', alpha=0.7) plt.scatter(df[df['signal'] == 1]['time'], df[df['signal'] == 1]['close'], marker='^', color='g', label='Buy')
最初のグラフは、Sberの価格チャートにモデルから得られたシグナルを重ねた最も一般的なものです。さらに、異常な取引量が発生したローソク足を強調表示しています。これにより、システムが市場の動きをまるで手に取るように読み取っている瞬間を把握しやすくなります。
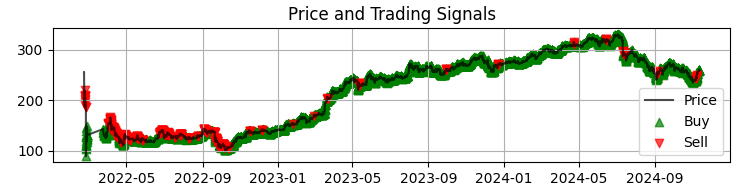
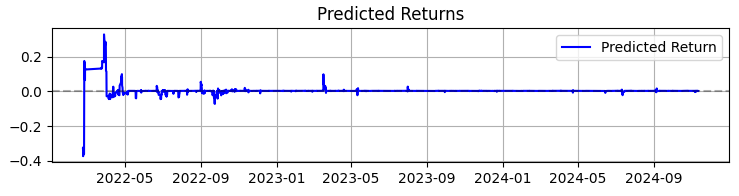
2つ目のグラフは予測リターンを示しています。ここでは、選択した資産の価格が大きく動く前に、非常に強力な予測の連続が始まることがはっきりと確認できます。これにより、まさにこの観察に基づいたシステム構築を検討するというアイデアが浮かびます。もちろん取引回数は減るかもしれませんが、私たちが追い求めているのは量ではなく質です。
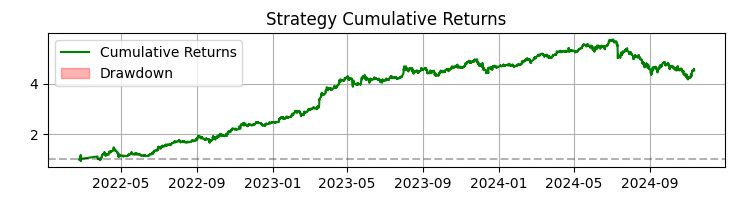
3番目のグラフは、ドローダウンが強調表示された累積リターンです。
理論から実践へ:結果と今後の展望
システムの運用結果を振り返りましょう。ただの数値ではなく、取引における取引量分析に興味のある方々に役立つ発見を共有したいと思います。
まず第一に、市場は実際に取引高や取引量を通じて私たちに語りかけています。しかし、その言語は想像以上に複雑です。私個人の意見としては、VSA (Volume Spread Analysis)などの古典的手法は市場の急速な進化に追いつけず、急速に陳腐化しつつあります。パターンは年々複雑化し、取引量も肉眼では捉えにくい非常に複雑な形を形成しています。
私のほぼ3年間にわたる機械学習経験を通じて言えることは、市場は年々複雑さを増しており、トレンドや蓄積の一部をOrderFlowで形成するアルゴリズムもまた高度化しているということです。これからは、ニューラルネットワーク同士の「市場を制する機械の戦い」が待ち受けています。
システムの成果まとめとして、数値だけでなく、取引量分析に携わるすべての方に役立つ主な発見を共有します。
SBER株の365日間のテストでは、システムは以下のような印象的な結果を示しました。
- 総リターン:年率365.0%(レバレッジなし)
- 利益の出た取引の割合:50.73%
しかし、これらの数値は最も重要なポイントではありません。もっと重要なのは、システムが多様な市場状況に対して耐性を持つことが証明された点です。トレンド相場でもレンジ相場でも同様に機能し、シグナルの性質は明確に変化しながらも安定したパフォーマンスを示しています。
特に興味深かったのは、高ボラティリティ期間中のシステムの挙動です。多くのトレーダーが市場から距離を置きたくなるそのタイミングで、ニューラルネットワークは取引量の流れに最も明確なパターンを見出しています。おそらく、こうした時期に機関投資家たちがより明確な「痕跡」を市場に残すためでしょう。
このプロジェクトで学んだこと- 取引における機械学習は魔法の薬ではありません。成功は市場の深い理解と慎重な特徴量設計から生まれます。
- シンプルさが持続可能性の鍵です。新しい層や特徴量を追加してモデルを複雑化させるたびに、システムは脆弱になりました。
- 取引量は文脈の中で分析されるべきです。異常な取引量やクラスタだけでは意味が薄く、他の要素との相互作用を見ることで真価が発揮されます。
次の段階
システムは進化を続けています。現在取り組んでいる改善点は以下の通りです。
- 市場フェーズに応じたパラメータの適応的調整
- より精度の高い分析のためのストリーミング注文データの統合
- ロシア市場の他の銘柄への展開
システムのソースコードは添付ファイルで提供しています。改善のためのご提案をお待ちしております。特に、他の銘柄やツールにこのシステムを適用しようとする方々の経験談を伺えると非常に興味深いです。
結論
最後に、ここ数ヶ月で私にとって最も価値ある発見は、本日ご紹介したような取引量分析といった古典的アプローチを、機械学習やニューラルネットワーク、ビッグデータといった新しい技術に適応させることだったと述べたいと思います。
過去の世代の経験は今も生きていて、強く息づいています。私たちの使命は、その経験を咀嚼し、抽出し、そして私たちの世代のトレーダーの視点から最新技術を使って改良していくことです。もちろん、現代の流れに遅れを取るわけにはいきません。量子機械学習、価格や取引量の予測に向けた量子アルゴリズム、さらには多次元特徴量による機械学習が私たちの前にあります。実はIBMの20量子ビット量子スパコンで市場分析を試みたこともあります。興味深い結果が出ており、今後の記事でぜひお伝えしたいと思います。
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/16062
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。


- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索