
Numbaを使用したPythonの高速取引ストラテジーテスター
高速なカスタムストラテジーテスターが重要な理由
機械学習に基づく取引アルゴリズムを開発する際には、過去のデータに対する取引結果を正確かつ迅速に評価することが重要です。長期間の大きな時間幅や浅い履歴深度での利用が稀であれば、Pythonのテスターでも十分適しています。しかし、複数回のテストや高頻度取引戦略が関わる場合、インタプリタ言語は遅すぎることがあります。
たとえば、スクリプトの実行速度に満足できないが、慣れ親しんだPython開発環境を手放したくない場合、ここでNumbaが役立ちます。NumbaはネイティブのPythonコードをその場で変換・コンパイルし、高速な機械語コードに変換します。このようなコードの実行速度は、CやFORTRANなどのプログラミング言語の実行速度に匹敵します。
Numbaライブラリの簡単な説明
NumbaはPythonのライブラリで、JIT(ジャストインタイム)コンパイルを用いて関数をバイトコードレベルで機械語に変換し、コードの実行速度を高速化します。特にループや複雑な数学演算を多用する科学技術計算で性能向上が期待できます。NumPy配列に対応しており、並列処理やGPU計算も効率的におこなうことができます。
Numbaの最も一般的な使い方は、Python関数にデコレータを付けてコンパイルを指示する方法です。デコレートされた関数が呼ばれると、その場で機械語にコンパイルされ、ネイティブコードの速度で実行されます。
現在、次のアーキテクチャがサポートされています。
-
OS:Windows(64ビット)、OSX、Linux(64ビット)
-
アーキテクチャ:x86、x86_64、ppc64le、armv8l (aarch64)、M1/Arm64
-
GPU:Nvidia CUDA
-
CPython
-
NumPy 1.22~1.26
なお、PandasパッケージはNumbaでサポートされていないため、データフレーム操作の速度は変わりません。
記事コードの取り扱い
すべてをすぐに機能させるには、次の準備手順を実行します。
- 必要なパッケージをすべてインストールします。
pip install numpy pyp install pandas pip install catboost pip install scikit-learn pip install scipy
- EURGBP_H1.csvデータをダウンロードし、Filesフォルダに配置します。
- すべてのPythonスクリプトをダウンロードして 1つのフォルダに配置します。
- Tester_ML.pyの最初の文字列を次のように編集します:from tester_lib import test_model;
- Tester_ML.pyスクリプトでファイルへのパスを指定します。
- p = pd.read_csv('C:/Program Files/MetaTrader 5/MQL5/Files/'EURGBP_H1'.csv', sep='\s+').
Numbaパッケージの使い方
一般的に、Numbaパッケージを使用するには、インストールする必要があります。
pip install numba conda install numba
高速化したい関数の前にデコレータを適用します。以下が例です。
@jit(nopython=True) def process_data(*args): ...
デコレータは2つの異なる方法で呼び出されます。
- nopythonモード
- objectモード
最初の方法は、デコレートされた関数を完全にPythonインタプリタを介さずに実行されるようにコンパイルするものです。これは最も高速な方法であり、使用が推奨されます。ただし、Numbaには制限があり、Pythonの組み込み操作やNumPy配列の操作のみをコンパイルできます。関数にPandasなどの他のライブラリのオブジェクトが含まれている場合、Numbaはコンパイルできず、コードはインタプリタによって実行されます。
Numbaはobjectモードを使用してサードパーティライブラリの使用制限を回避できます。このモードでは、Numbaは関数をすべてPythonオブジェクトとして扱い、基本的にコードをインタプリタで実行します。
@jit(forceobj=true, looplift=True) は純粋なobjectモードと比較してパフォーマンスを向上させる場合があります。これはNumbaがループを機械語で実行される関数にコンパイルし、それ以外のコードはインタプリタで実行しようとするためです。最高のパフォーマンスを得るためには、objectモードの使用は避けてください。
パッケージは可能な場合に並列計算もサポートしています(Parallel=True)。関数が初めて呼び出されるとき、機械語にコンパイルされるために時間がかかりますが、そのコードはキャッシュされ、次回以降の呼び出しは高速になります。
取引のマークアップ関数を高速化する例
テスターの高速化を始める前に、より簡単なものを高速化してみましょう。この役割に最適なのが取引マークアップ関数です。この関数は価格の入ったデータフレームを受け取り、取引を買い(0)と売り(1)としてマークします。このような関数は、後で分類器を訓練するためにデータに事前ラベルを付ける際によく使われます。
def get_labels(dataset, min = 1, max = 15) -> pd.DataFrame: labels = [] for i in range(dataset.shape[0]-max): rand = random.randint(min, max) curr_pr = dataset['close'].iloc[i] future_pr = dataset['close'].iloc[i + rand] if (future_pr + hyper_params['markup']) < curr_pr: labels.append(1.0) elif (future_pr - hyper_params['markup']) > curr_pr: labels.append(0.0) else: labels.append(2.0) dataset = dataset.iloc[:len(labels)].copy() dataset['labels'] = labels dataset = dataset.dropna() dataset = dataset.drop( dataset[dataset.labels == 2.0].index) return dataset
15年間分のEURGBPの1分足終値をデータとして使用します。
>>> pr = get_prices() >>> pr close time 2010-01-04 00:00:00 0.88810 2010-01-04 00:01:00 0.88799 2010-01-04 00:02:00 0.88786 2010-01-04 00:03:00 0.88792 2010-01-04 00:04:00 0.88802 ... ... 2024-10-09 19:03:00 0.83723 2024-10-09 19:04:00 0.83720 2024-10-09 19:05:00 0.83704 2024-10-09 19:06:00 0.83702 2024-10-09 19:07:00 0.83703 [5480021 rows x 1 columns]
このデータセットには500万件以上の観測データが含まれており、テストには十分な量です。
では、この関数を私たちのデータで実行したときの速度を測定してみましょう。
# get labels test start_time = time.time() pr = get_labels(pr) pr['meta_labels'] = 1.0 end_time = time.time() execution_time = end_time - start_time print(f"Execution time: {execution_time:.4f} seconds")
実行時間は74.1843秒でした。
では、Numbaパッケージを使ってこの関数を高速化してみましょう。元の関数はPandasパッケージも使用していることが分かりますが、これら2つのパッケージは互換性がありません。そこで、Pandasに関係する部分を別の関数に分けて、残りのコードを高速化しましょう。
@jit(nopython=True) def get_labels_numba(close_prices, min_val, max_val, markup): labels = np.empty(len(close_prices) - max_val, dtype=np.float64) for i in range(len(close_prices) - max_val): rand = np.random.randint(min_val, max_val + 1) curr_pr = close_prices[i] future_pr = close_prices[i + rand] if (future_pr + markup) < curr_pr: labels[i] = 1.0 elif (future_pr - markup) > curr_pr: labels[i] = 0.0 else: labels[i] = 2.0 return labels def get_labels_fast(dataset, min_val=1, max_val=15): close_prices = dataset['close'].values markup = hyper_params['markup'] labels = get_labels_numba(close_prices, min_val, max_val, markup) dataset = dataset.iloc[:len(labels)].copy() dataset['labels'] = labels dataset = dataset.dropna() dataset = dataset.drop(dataset[dataset.labels == 2.0].index) return dataset
最初の関数には@jitデコレーターが付けられています。これは、この関数がバイトコードにコンパイルされることを意味します。また、この関数内ではPandasを使わず、リスト、ループ、そしてNumPyのみを使用します。
2番目の関数は準備作業をおこないます。PandasのデータフレームをNumPy配列に変換し、それを最初の関数に渡します。その後、結果を受け取って再びPandasのデータフレームとして返します。こうすることで、マークアップの主要な計算が高速化されます。
それでは速度を測定してみましょう。計算時間は12秒に短縮されました。この関数では約6倍の高速化を達成できました。もちろん、中間処理にまだPandasが使われているため完全にクリーンなテストではありませんが、ラベル計算に関しては大幅な高速化が実現しました。
機械学習タスク向けストラテジーテスターの高速化
ストラテジーテスターを別のライブラリに分離しました。添付ファイルにtesterとslow_testerという比較用の関数が含まれています。
読者の中には、Pythonでの高速化の多くはベクトル化によるものだと考えるかもしれません。確かにその通りですが、それでもループを使わざるを得ない場合があります。たとえば、このテスターは履歴全体を通してストップロスやテイクプロフィットを考慮しながら合計利益を累積するというかなり複雑なループを持っています。これをベクトル化で実装するのは簡単な作業ではなさそうです。テスターのループ本体(最も時間がかかる部分)を参考用に以下に示します。
for i in range(dataset.shape[0]): line_f = len(report) if i <= forw else line_f line_b = len(report) if i <= backw else line_b pred = labels[i] pr = close[i] pred_meta = metalabels[i] # 1 = allow trades if last_deal == 2 and pred_meta == 1: last_price = pr last_deal = 0 if pred < 0.5 else 1 continue if last_deal == 0: if (-markup + (pr - last_price) >= take) or (-markup + (last_price - pr) >= stop): last_deal = 2 profit = -markup + (pr - last_price) report.append(report[-1] + profit) chart.append(chart[-1] + profit) continue if last_deal == 1: if (-markup + (pr - last_price) >= stop) or (-markup + (last_price - pr) >= take): last_deal = 2 profit = -markup + (last_price - pr) report.append(report[-1] + profit) chart.append(chart[-1] + (pr - last_price)) continue # close deals by signals if last_deal == 0 and pred > 0.5 and pred_meta == 1: last_deal = 2 profit = -markup + (pr - last_price) report.append(report[-1] + profit) chart.append(chart[-1] + profit) continue if last_deal == 1 and pred < 0.5 and pred_meta == 1: last_deal = 2 profit = -markup + (last_price - pr) report.append(report[-1] + profit) chart.append(chart[-1] + (pr - last_price)) continue
先ほど受け取ったデータでテスト速度を測定してみましょう。まず、低速テスターの速度を見てみましょう。
# native python tester test start_time = time.time() tester_slow(pr, hyper_params['stop_loss'], hyper_params['take_profit'], hyper_params['markup'], hyper_params['forward'], False) end_time = time.time() execution_time = end_time - start_time print(f"Execution time: {execution_time:.4f} seconds")
Execution time: 6.8639 seconds それほど遅くは見えません。インタプリタがかなり高速にコードを実行していると言っても良いでしょう。
再びテスター関数を2つに分割しましょう。1つは補助的な関数、もう1つは主要な計算をおこなう関数です。
process_data関数はテスターのメインループを実装しており、この部分を高速化する必要があります。なぜなら、Pythonのループは遅いためです。一方で、tester関数自体はまずprocess_data関数のためにデータを準備し、その結果を受け取ってグラフを描画します。
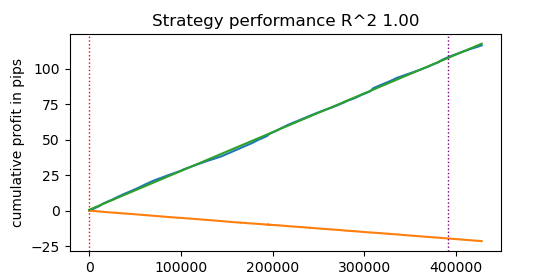
@jit(nopython=True) def process_data(close, labels, metalabels, stop, take, markup, forward, backward): last_deal = 2 last_price = 0.0 report = [0.0] chart = [0.0] line_f = 0 line_b = 0 for i in range(len(close)): line_f = len(report) if i <= forward else line_f line_b = len(report) if i <= backward else line_b pred = labels[i] pr = close[i] pred_meta = metalabels[i] # 1 = allow trades if last_deal == 2 and pred_meta == 1: last_price = pr last_deal = 0 if pred < 0.5 else 1 continue if last_deal == 0: if (-markup + (pr - last_price) >= take) or (-markup + (last_price - pr) >= stop): last_deal = 2 profit = -markup + (pr - last_price) report.append(report[-1] + profit) chart.append(chart[-1] + profit) continue if last_deal == 1: if (-markup + (pr - last_price) >= stop) or (-markup + (last_price - pr) >= take): last_deal = 2 profit = -markup + (last_price - pr) report.append(report[-1] + profit) chart.append(chart[-1] + (pr - last_price)) continue # close deals by signals if last_deal == 0 and pred > 0.5 and pred_meta == 1: last_deal = 2 profit = -markup + (pr - last_price) report.append(report[-1] + profit) chart.append(chart[-1] + profit) continue if last_deal == 1 and pred < 0.5 and pred_meta == 1: last_deal = 2 profit = -markup + (last_price - pr) report.append(report[-1] + profit) chart.append(chart[-1] + (pr - last_price)) continue return np.array(report), np.array(chart), line_f, line_b def tester(*args): ''' This is a fast strategy tester based on numba List of parameters: dataset: must contain first column as 'close' and last columns with "labels" and "meta_labels" stop: stop loss value take: take profit value forward: forward time interval backward: backward time interval markup: markup value plot: false/true ''' dataset, stop, take, forward, backward, markup, plot = args forw = dataset.index.get_indexer([forward], method='nearest')[0] backw = dataset.index.get_indexer([backward], method='nearest')[0] close = dataset['close'].to_numpy() labels = dataset['labels'].to_numpy() metalabels = dataset['meta_labels'].to_numpy() report, chart, line_f, line_b = process_data(close, labels, metalabels, stop, take, markup, forw, backw) y = report.reshape(-1, 1) X = np.arange(len(report)).reshape(-1, 1) lr = LinearRegression() lr.fit(X, y) l = 1 if lr.coef_[0][0] >= 0 else -1 if plot: plt.plot(report) plt.plot(chart) plt.axvline(x=line_f, color='purple', ls=':', lw=1, label='OOS') plt.axvline(x=line_b, color='red', ls=':', lw=1, label='OOS2') plt.plot(lr.predict(X)) plt.title("Strategy performance R^2 " + str(format(lr.score(X, y) * l, ".2f"))) plt.xlabel("the number of trades") plt.ylabel("cumulative profit in pips") plt.show() return lr.score(X, y) * l
それでは、Numbaで加速されたストラテジーテスターをテストしてみましょう。
start_time = time.time() tester(pr, hyper_params['stop_loss'], hyper_params['take_profit'], hyper_params['forward'], hyper_params['backward'], hyper_params['markup'], False) end_time = time.time() execution_time = end_time - start_time print(f"Execution time: {execution_time:.4f} seconds")
Execution time: 0.1470 seconds 観測された速度向上はほぼ50倍にもなりました。40万件以上の取引が完了しています。
もし1日に1時間アルゴリズムのテストに費やしていたとしたら、高速テスターを使うことでわずか1分で済む計算です。
ティックデータでの戦略のテスト
タスクを複雑にして、端末から過去3年間のティック履歴を.csvファイルにダウンロードしてみましょう。
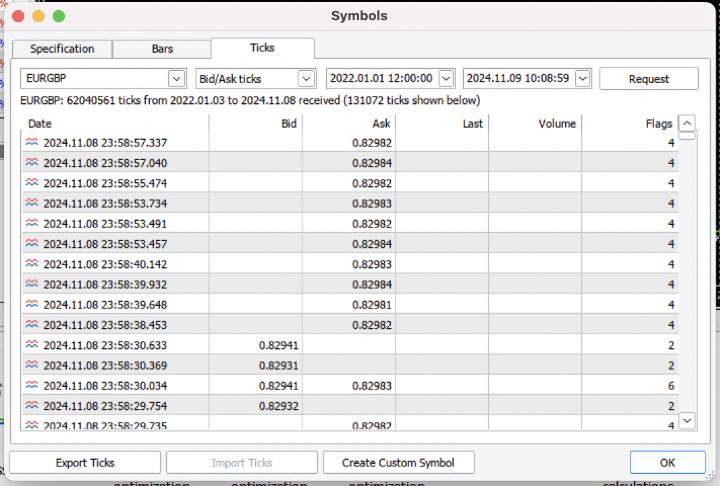
ファイルを正しく読み込むために、クオート読み込み関数を少し修正する必要があります。[Close]ではなく[Bid]の価格を使用します。また、同じインデックスの価格は削除する必要があります。
def get_prices() -> pd.DataFrame: p = pd.read_csv('files/'+hyper_params['symbol']+'.csv', sep='\s+') pFixed = pd.DataFrame(columns=['time', 'close']) pFixed['time'] = p['<DATE>'] + ' ' + p['<TIME>'] pFixed['time'] = pd.to_datetime(pFixed['time'], format='mixed') pFixed['close'] = p['<BID>'] pFixed.set_index('time', inplace=True) pFixed.index = pd.to_datetime(pFixed.index, unit='s') # Remove duplicate string by 'time' index pFixed = pFixed[~pFixed.index.duplicated(keep='first')] return pFixed.dropna()
結果として、約6200万件の観測データが得られました。テスターは価格をcloseという列名で受け取るため、Bid列をCloseに名前変更しました。
>>> pr close time 2022-01-03 00:05:01.753 0.84000 2022-01-03 00:05:04.032 0.83892 2022-01-03 00:05:05.849 0.83918 2022-01-03 00:05:07.280 0.83977 2022-01-03 00:05:07.984 0.83939 ... ... 2024-11-08 23:58:53.491 0.82982 2024-11-08 23:58:53.734 0.82983 2024-11-08 23:58:55.474 0.82982 2024-11-08 23:58:57.040 0.82984 2024-11-08 23:58:57.337 0.82982 [61896607 rows x 1 columns]
簡単なマークアップを実行して時間を測定してみましょう。
# get labels test start_time = time.time() pr = get_labels_fast(pr) pr['meta_labels'] = 1.0 end_time = time.time() execution_time = end_time - start_time print(f"Execution time: {execution_time:.4f} seconds")
マークアップ時間は9.5秒でした。
それでは、高速テスターを実行してみましょう。
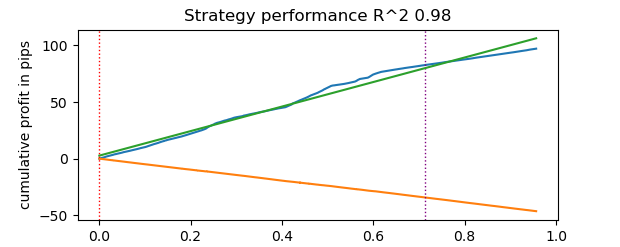
# numba tester test start_time = time.time() tester(pr, hyper_params['stop_loss'], hyper_params['take_profit'], hyper_params['forward'], hyper_params['backward'], hyper_params['markup'], True) end_time = time.time() execution_time = end_time - start_time print(f"Execution time: {execution_time:.4f} seconds")
テストは0.16秒かかりました。一方、低速テスターは5.5秒かかりました。
Numbaを使った高速テスターは、純粋なPythonのテスターよりも35倍速く処理を完了しました。実際、観察者の視点から見ると、高速テスターの場合はテストがほぼ瞬時におこなわれるのに対し、低速テスターを使うと多少の待ち時間が必要です。それでも、低速テスターも優れた働きをしており、ティックデータ上の戦略テストにも十分適していると言えます。
合計で100万件(1e6)の取引がおこなわれました。
機械学習タスクで高速テスターを使用する際の情報
提案されたテスターを実際に使うのであれば、以下の情報が役立つかもしれません。
分類器を訓練できるように、データセットに特徴量を追加しましょう。
def get_features(data: pd.DataFrame) -> pd.DataFrame: pFixed = data.copy() pFixedC = data.copy() count = 0 for i in hyper_params['periods']: pFixed[str(count)] = pFixedC-pFixedC.rolling(i).mean() count += 1 return pFixed.dropna()
これらは価格差や移動平均に基づくシンプルな指標です。
次に、モデルのハイパーパラメータをまとめた辞書を作成します。これは訓練とテストで使用し、新しいデータセットを生成する際に適用します。
hyper_params = {
'symbol': 'EURGBP_H1',
'markup': 0.00010,
'stop_loss': 0.01000,
'take_profit': 0.01000,
'backward': datetime(2010, 1, 1),
'forward': datetime(2023, 1, 1),
'periods': [i for i in range(50, 300, 50)],
}
# catboost learning
dataset = get_labels_fast(get_features(get_prices()))
dataset['meta_labels'] = 1.0
data = dataset[(dataset.index < hyper_params['forward']) & (dataset.index > hyper_params['backward'])].copy()
ここで注目すべきは、テスターがlabelsの値だけでなくmeta_labelsの値も受け取るという点です。これは、機械学習ベースの取引システムでフィルタを使いたい場合に必要になるかもしれません。この場合、1の値が取引を許可し、0の値が取引を禁止します。今回のデモ例ではフィルターを使わないため、単に追加の列を作成し、常に取引を許可するためにすべて1で埋めます。
dataset['meta_labels'] = 1.0
これで、生成したデータセットを使ってCatBoostモデルを訓練できます。その際、前方および後方のテストデータを履歴からあらかじめ除外し、それらに対してモデルが学習しないようにします。
data = dataset[(dataset.index < hyper_params['forward']) & (dataset.index > hyper_params['backward'])].copy() X = data[data.columns[1:-2]] y = data['labels'] train_X, test_X, train_y, test_y = train_test_split( X, y, train_size=0.7, test_size=0.3, shuffle=True) model = CatBoostClassifier(iterations=500, thread_count=8, custom_loss=['Accuracy'], eval_metric='Accuracy', verbose=True, use_best_model=True, task_type='CPU') model.fit(train_X, train_y, eval_set=(test_X, test_y), early_stopping_rounds=25, plot=False)
訓練後は、テストデータを含む全データセットでモデルを評価します。test_model関数は、高速テスターおよび低速テスターの関数と共にtester_lib.pyファイルにあります。この関数は高速テスターのラッパーであり、訓練済みの機械学習モデル(今回の例ではCatBoostですが、他のモデルでも可)の予測値を取得する役割を果たします。
def test_model(dataset: pd.DataFrame, result: list, stop: float, take: float, forward: float, backward: float, markup: float, plt = False): ext_dataset = dataset.copy() X = ext_dataset[dataset.columns[1:-2]] ext_dataset['labels'] = result[0].predict_proba(X)[:,1] # ext_dataset['meta_labels'] = result[1].predict_proba(X)[:,1] ext_dataset['labels'] = ext_dataset['labels'].apply(lambda x: 0.0 if x < 0.5 else 1.0) # ext_dataset['meta_labels'] = ext_dataset['meta_labels'].apply(lambda x: 0.0 if x < 0.5 else 1.0) return tester(ext_dataset, stop, take, forward, backward, markup, plt)
上記のコードには、取引の可否を示すメタラベルを取得するための行がコメントアウトされています。言い換えれば、2つ目の機械学習モデルをその目的で使うことも可能ですが、本記事では使用しません。
直接テストを始めましょう。
# test catboost model test_model(dataset, [model], hyper_params['stop_loss'], hyper_params['take_profit'], hyper_params['forward'], hyper_params['backward'], hyper_params['markup'], True)
結果が得られました。垂直線の右側にあるテストデータからわかるように、モデルは過学習しています。しかし、私たちにとって重要なのはテスターの動作確認なので、これは問題ではありません。
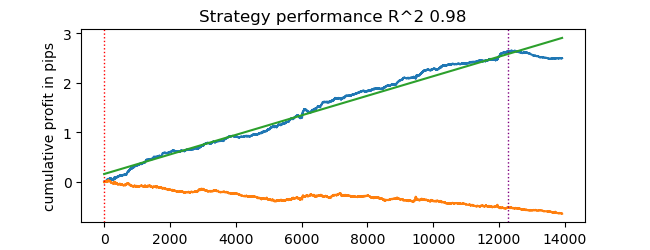
テスターはストップロスとテイクプロフィットの使用を想定しており、これらを最適化したい場合があります。幸い、テスターが非常に高速になったので、最適化を実行しましょう。
機械学習を用いた取引システムパラメータの最適化
ここではストップロスとテイクプロフィットの最適化について見ていきます。実際にはメタラベルなど他のパラメータの最適化も可能ですが、それはこの記事の範囲を超えるため、別の記事で扱う予定です。
次の2種類の最適化を実装します。
- パラメータグリッド検索
- L-BFGS-B法を用いた最適化
まず、各手法のコードを簡単に説明します。GRID_SEARCHメソッドを以下に示します。
引数には以下が渡されます。
- テスト用のデータセット
- 訓練されたモデル
- 上記のアルゴリズムのハイパーパラメータ辞書
- テスターオブジェクト
# stop loss / take profit grid search def optimize_params_GRID_SEARCH(pr, model, hyper_params, test_model_func): best_r2 = -np.inf best_stop_loss = None best_take_profit = None # Ranges for stop_loss and take_profit stop_loss_range = np.arange(0.00100, 0.02001, 0.00100) take_profit_range = np.arange(0.00100, 0.02001, 0.00100) total_iterations = len(stop_loss_range) * len(take_profit_range) start_time = time.time() for stop_loss in stop_loss_range: for take_profit in take_profit_range: # Create a copy of hyper_params current_hyper_params = hyper_params.copy() current_hyper_params['stop_loss'] = stop_loss current_hyper_params['take_profit'] = take_profit r2 = test_model_func(pr, [model], current_hyper_params['stop_loss'], current_hyper_params['take_profit'], current_hyper_params['forward'], current_hyper_params['backward'], current_hyper_params['markup'], False) if r2 > best_r2: best_r2 = r2 best_stop_loss = stop_loss best_take_profit = take_profit end_time = time.time() total_time = end_time - start_time average_time_per_iteration = total_time / total_iterations print(f"Total iterations: {total_iterations}") print(f"Average time per iteration: {average_time_per_iteration:.6f} seconds") print(f"Total time: {total_time:.6f} seconds") return best_stop_loss, best_take_profit, best_r2
それでは、L-BFGS_Bメソッドのコードを見てみましょう。詳しい情報については、こちらをご覧ください。
関数の引数は前述のものと同じです。ただし、ストラテジーテスターを呼び出す適合度関数を作成します。最適化パラメータの境界値と、L-BFGS-Bアルゴリズム用の初期化回数(パラメータセットのランダムな開始点の数)を指定します。ランダムな初期化は、最適化アルゴリズムが局所最小値に陥るのを防ぐために必要です。その後、minimize関数が呼び出され、最適化のパラメータが渡されます。
def optimize_params_L_BFGS_B(pr, model, hyper_params, test_model_func): def objective(x): current_hyper_params = hyper_params.copy() current_hyper_params['stop_loss'] = x[0] current_hyper_params['take_profit'] = x[1] r2 = test_model_func(pr, [model], current_hyper_params['stop_loss'], current_hyper_params['take_profit'], current_hyper_params['forward'], current_hyper_params['backward'], current_hyper_params['markup'], False) return -r2 bounds = ((0.001, 0.02), (0.001, 0.02)) # Let's try some random starting points n_attempts = 50 best_result = None best_fun = float('inf') start_time = time.time() for _ in range(n_attempts): # Random starting point x0 = np.random.uniform(0.001, 0.02, 2) result = minimize( objective, x0, method='L-BFGS-B', bounds=bounds, options={'ftol': 1e-5, 'disp': False, 'maxiter': 100} # Increase accuracy and number of iterations ) if result.fun < best_fun: best_fun = result.fun best_result = result # Get the end time and calculate the total time end_time = time.time() total_time = end_time - start_time print(f"Total time: {total_time:.6f} seconds") return best_result.x[0], best_result.x[1], -best_result.fun
これで、両方の最適化アルゴリズムを実行し、時間と精度を確認できます。
# using
best_stop_loss, best_take_profit, best_r2 = optimize_params_GRID_SEARCH(dataset, model, hyper_params, test_model)
best_stop_loss, best_take_profit, best_r2 = optimize_params_L_BFGS_B(dataset, model, hyper_params, test_model)
グリッド検索アルゴリズム
Total iterations: 400 Average time per iteration: 0.031341 seconds Total time: 12.536394 seconds Best parameters: stop_loss=0.004, take_profit=0.002, R^2=0.9742298702323458
L-BFGS-Bアルゴリズム
Total time: 4.733158 seconds Best parameters: stop_loss=0.0030492548809269732, take_profit=0.0016816794762543421, R^2=0.9733045271274298
私の標準設定では、L-BFGS-Bはグリッドサーチと同等の結果を示しつつ、2倍以上高速に動作しました。
このように、最適化するパラメータの数や範囲に応じて、両方のアルゴリズムを使い分けることが可能です。
結論
この記事では、機械学習ベースの戦略を迅速にテストするためのストラテジーテスターを高速化する方法を示しました。Numbaを使うことで50倍の速度向上が得られ、テストが高速化されるため複数回のテストやパラメータ最適化も可能になります。
添付ファイル
- tester_lib.py:テスターライブラリ
- test tester.py:低速テスター(Python)と高速テスター(Numba)を比較するためのスクリプト
- tester ticks.py:ティックデータでテスターを比較するためのスクリプト
- tester ML.py:分類器の学習とハイパーパラメータの最適化のためのスクリプト
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/14895
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
固定値のスライディング・ウィンドウにおける標準偏差は、ボラティリティによって正規化されていない変動幅を持つことになります。私の知る限りでは、通常、正規化された値であるz-スコアがこの目的に使用されます。以上で考察は終わりです。)
入手可能なすべての履歴から最小/最大値を取って境界とし、オプティマイザーの各反復でランダムな範囲に分割します。zscoreでもできます。このような正規化はオプティマイザにとってより良い(小数点以下のゼロの数が多い小さな値を取り除く)かもしれないと思ったが、そうする必要はないと思う。
こんにちは、maximさん、あなたはこのフォーラムで一番賢い人だと思います。
お褒めの言葉、ありがとうございます!面白いものを書けるように頑張ります。
時間ができたので、モデルのトレーニング+ハイパーパラメータの最適化を1つのボトルでほぼ完了した。
一度に多くのモデルをトレーニングし、それらを最適化し、最適化されたパラメーターで最良のモデルを選択する、といったことが可能になるだろう:
そして結果を出力する。
そして、最適なハイパーパラメータを持つモデルをターミナルにエクスポートすることができる。あるいは、ターミナル・オプティマイザそのものを使うこともできる。
後で記事を書き始めます。