
Analizamos el código binario de los precios en bolsa (Parte II): Convirtiendo a BIP39 y escribiendo un modelo GPT

Introducción
En nuestro constante esfuerzo por entender el lenguaje del mercado, con frecuencia olvidamos que todos nuestros indicadores técnicos, patrones de velas y teorías de ondas son solo intentos de traducir sus mensajes a un lenguaje que entendemos. En la primera parte del estudio, dimos un paso radical: representamos los movimientos de los precios como un código binario, convirtiendo la compleja danza de los gráficos en una simple secuencia de ceros y unos. Pero, ¿y si vamos un paso más allá?
Imagínese por un momento: ¿y si el mercado pudiera hablarnos usando palabras? No metafóricamente, con gráficos e indicadores, sino literalmente, con lenguaje humano. Precisamente esta idea vamos a desarrollar en la segunda parte de nuestro estudio, utilizando el protocolo BIP39, el mismo que se utiliza en las carteras de criptomonedas para crear frases mnemotécnicas.
¿Por qué el BIP39? Este protocolo se creó para convertir secuencias aleatorias de bits en palabras memorizadas en inglés. En las criptomonedas, se usa para crear frases semilla, pero nosotros lo vemos como algo más que eso: una oportunidad para convertir los "susurros digitales" del mercado en ofertas significativas.
Pero no basta con traducir el código binario a palabras. Necesitamos una "inteligencia artificial" que pueda entender dichas palabras y encontrar patrones ocultos en ellas. Y aquí es donde entra en juego la arquitectura del Transformer, similar a la utilizada en GPT. Piense en ello como en un cerebro artificial que lee un "libro de mercado" escrito en BIP39 y aprende a entender su significado más profundo.
En cierto sentido, no estamos creando un indicador técnico más, sino un auténtico traductor del lenguaje del mercado al lenguaje humano y viceversa. Este traductor no se limita a convertir mecánicamente los números en palabras, sino que intenta captar la esencia misma de los movimientos del mercado, su lógica interna y sus pautas ocultas.
¿Recuerda la película "La Llegada", en la que un lingüista intentaba descifrar el lenguaje alienígena? Nuestra tarea es algo similar: nosotros también vamos a intentar descifrar un lenguaje ajeno: el lenguaje del mercado. Y, al igual que en aquella película, entender este lenguaje puede aportarnos no solo ventajas prácticas, sino también una perspectiva totalmente nueva de la naturaleza de aquello con lo que estamos trabajando.
En este artículo, detallaremos cómo implementar un "traductor" de este tipo usando modernas herramientas de aprendizaje automático y, lo que es más importante, cómo interpretar sus "traducciones". Asimismo, veremos que ciertas palabras y frases aparecen con más frecuencia que otras en determinadas situaciones de mercado, como si el mercado realmente utilizara su propio vocabulario para describir sus estados.
Componentes clave del sistema: alquimia digital en acción
¿Sabe qué es lo más difícil de crear algo nuevo? Elegir los ladrillos adecuados a partir de los cuales se construirá todo el sistema. En nuestro caso, tenemos tres ladrillos de este tipo, y cada uno es único a su manera. Permítame que le hable de ellos como de viejos amigos, ya que se han convertido casi en mi familia a lo largo de estos meses de trabajo.
El primero y más importante es PriceToBinaryConverter. Yo le llamo "alquimista digital". Su tarea parece simple: convertir los movimientos de los precios en secuencias de ceros y unos. Pero detrás de esa sencillez se esconde la verdadera magia. Imagine que no mira el gráfico con los ojos de un tráder, sino con los de un ordenador. ¿Qué ve? Correcto: solo "arriba" y "abajo", "uno" y "cero". Eso es exactamente lo que hace nuestro primer componente.
class PriceToBinaryConverter: def __init__(self, sequence_length: int = 32): self.sequence_length = sequence_length def convert_prices_to_binary(self, prices: pd.Series) -> List[str]: binary_sequence = [] for i in range(1, len(prices)): binary_digit = '1' if prices.iloc[i] > prices.iloc[i-1] else '0' binary_sequence.append(binary_digit) return binary_sequence def get_binary_chunks(self, binary_sequence: List[str]) -> List[str]: chunks = [] for i in range(0, len(binary_sequence), self.sequence_length): chunk = ''.join(binary_sequence[i:i + self.sequence_length]) if len(chunk) < self.sequence_length: chunk = chunk.ljust(self.sequence_length, '0') chunks.append(chunk) return chunks
El segundo componente, BIP39Converter, supone un auténtico traductor políglota. Toma esas aburridas cadenas de ceros y unos y las convierte en palabras inglesas con sentido. ¿Recuerda el protocolo BIP39 del mundo de las criptomonedas? ¿La misma que se usa para crear frases mnemotécnicas para las carteras? Vamos a tomar esta idea y a aplicarla al análisis de mercado. Ahora, cada movimiento de precios no supone solo un conjunto de bits, sino que forma parte de una frase con sentido en inglés.
def binary_to_bip39(self, binary_sequence: str) -> List[str]: words = [] for i in range(0, len(binary_sequence), 11): binary_chunk = binary_sequence[i:i+11] if len(binary_chunk) == 11: word = self.binary_to_word.get(binary_chunk, 'unknown') words.append(word) return words
Por último, PriceTransformer es nuestra "inteligencia artificial". Si los dos primeros componentes pueden compararse a traductores, este se parece más a un escritor, pues estudia todas las frases traducidas e intenta averiguar qué va a pasar a continuación, igual que un escritor que ha leído miles de libros y ahora puede predecir cómo acabará una historia con solo leer el principio.
Curiosamente, este particular sistema de tres etapas ha demostrado ser increíblemente eficaz. Cada componente realiza su trabajo a la perfección, como los músicos de una orquesta: individualmente son buenos, pero juntos crean una auténtica sinfonía.
En las secciones siguientes, desglosaremos con detalle cada uno de estos componentes. De momento, imagine esta cadena de transformaciones: gráfico → bits → palabras → predicción. Es precioso, ¿verdad? Es como si hubiéramos creado una máquina capaz de leer el libro del mercado y contarlo de nuevo en lenguaje humano.
Dicen que la belleza de las matemáticas está en su simplicidad. Probablemente por eso nuestro sistema resulta tan elegante; dejamos que las matemáticas hagan lo que mejor saben hacer: encontrar el orden en el caos.
Arquitectura de redes neuronales: Cómo enseñar a una máquina a leer el lenguaje del mercado
Cuando empecé a trabajar en la arquitectura de la red neuronal de nuestro proyecto, me invadió una extraña sensación de déjà vu. ¿Conoces la escena de Matrix en la que Neo ve el código por primera vez? Yo miré los flujos de datos bursátiles y pensé: "¿Y si lo enfocamos como un problema de procesamiento del lenguaje natural?".
Y entonces caí en la cuenta: ¡los movimientos de los precios son muy parecidos al texto! Tienen su propia gramática (patrones), su propia sintaxis (tendencias y correcciones), e incluso su propia puntuación (niveles clave). ¿Por qué no usar una arquitectura que funcione bien con los textos?
Así nació el PriceTransformer, nuestro "traductor" del lenguaje del mercado. Ese es su corazón:
class PriceTransformer(nn.Module): def __init__(self, vocab_size: int, d_model: int = 256, nhead: int = 8, num_layers: int = 4, dim_feedforward: int = 1024): super().__init__() self.embedding = nn.Embedding(vocab_size, d_model) self.pos_encoder = nn.Sequential( nn.Embedding(1024, d_model), nn.Dropout(0.1) ) encoder_layer = nn.TransformerEncoderLayer( d_model=d_model, nhead=nhead, dim_feedforward=dim_feedforward, batch_first=True ) self.transformer_encoder = nn.TransformerEncoder( encoder_layer, num_layers=num_layers )
¿Le parece complicado? De hecho, es brillantemente simple. Imagínese a un traductor que no se limita a mirar cada palabra por separado, sino que intenta comprender el contexto. Eso es exactamente lo que hace el mecanismo de autoatención de nuestro Transformer.
La parte más interesante empezó cuando ejecutamos este modelo con datos reales del USD/JPY. Recuerdo el momento en que, tras una semana de entrenamiento, el modelo empezó a producir sus primeras predicciones sustanciales. Fue como el momento en que un niño pronuncia sus primeras palabras: frases aparentemente simples, pero detrás de las cuales hay un complejo proceso de aprendizaje.
Una precisión del 73% puede no parecer muy impresionante, hasta que recuerdas que no solo estamos prediciendo la dirección del movimiento, ¡sino secuencias enteras de palabras! Es como intentar adivinar no solo la siguiente palabra de una frase, sino el párrafo siguiente al completo.
Y lo realmente sorprendente era que el modelo empezó a encontrar sus palabras "favoritas" para las distintas situaciones del mercado. Por ejemplo, antes de realizar movimientos ascendentes fuertes, con frecuencia generaba palabras que empezaban por determinadas combinaciones de letras. Es como si el mercado poseyera su propio diccionario.
Para procesar los datos, hemos desarrollado un proceso especializado:
def prepare_data(self, df: pd.DataFrame) -> tuple: binary_sequence = self.price_converter.convert_prices_to_binary(df['close']) binary_chunks = self.price_converter.get_binary_chunks(binary_sequence) sequences = [] for chunk in binary_chunks: words = self.bip39_converter.binary_to_bip39(chunk) indices = [self.bip39_converter.wordlist.index(word) for word in words] sequences.append(indices) return sequences
Este código puede parecer sencillo, pero tras él se ocultan meses de experimentación. Probé docenas de opciones de preprocesamiento de datos antes de encontrar esta, la óptima. Resulta que incluso un pequeño detalle como el tamaño de los trozos puede tener un gran impacto en la calidad de las predicciones.
Tuve que aplicar algunos trucos para mejorar el rendimiento del modelo. La normalización por lotes ha ayudado a estabilizar el aprendizaje, como un tutor que mantiene al alumno en el buen camino. El clipping en gradiente ha evitado las "explosiones de gradiente": piense en ello como en una cuerda de seguridad para un alpinista. Y el control dinámico de velocidad de aprendizaje, a su vez, ha funcionado como el control de crucero en un coche: rápido en las rectas, lento en las curvas.
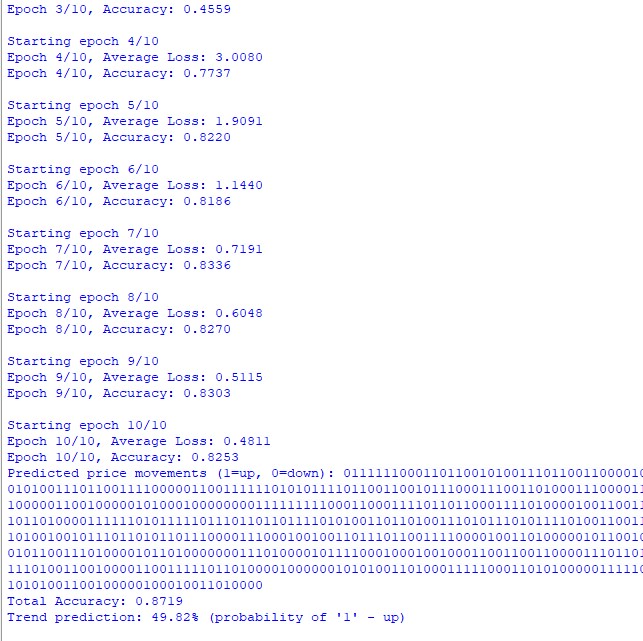
Pero lo más interesante ha sido ver cómo el modelo aprende a captar las dependencias a largo plazo. A veces encontraba conexiones entre acontecimientos separados por decenas de velas en un gráfico. Es como si hubiese aprendido a ver "el bosque por los árboles", captando no solo las fluctuaciones a corto plazo, sino también las tendencias globales.
En un momento dado me sorprendí a mí mismo pensando que nuestro modelo me recordaba a un tráder con experiencia, que estudia el mercado con la misma paciencia, busca patrones y aprende de sus errores. Solo que hace esto con la rapidez de un ordenador y sin las emociones que a menudo impiden a las personas tomar las decisiones correctas.
Por supuesto, nuestro PriceTransformer no es una varita mágica ni una piedra filosofal: es una herramienta bastante compleja de configurar. Pero si la preparamos bien, los resultados son asombrosos. Resulta especialmente impresionante su capacidad de generar previsiones a largo plazo como secuencias legibles de palabras: es como si el mercado nos hablara por fin en un lenguaje comprensible.
En busca del Grial: resultados de los experimentos con el lenguaje del mercado
¿Sabe qué es lo más emocionante de los experimentos científicos? El momento en que, tras meses de trabajo, por fin vemos los primeros resultados. Recuerdo cuando hice una prueba con el par USD/JPY. Tres años de datos, gráficos horarios, cientos de miles de velas..... Para ser sincero, no esperaba gran cosa, apenas alguna señal en este ruido de datos de mercado.
Y ahí empezó la diversión. La primera sorpresa fue que la precisión en la predicción de la palabra siguiente alcanzó el 73%. Permítanme una aclaración para quienes no trabajen con modelos lingüísticos: se trata de un resultado muy bueno. Imagine que lee un libro y trata de adivinar cada palabra: ¿cuántas puede acertar?
Pero ni siquiera se trata de las cifras. Lo más sorprendente fue cómo el modelo empezó a "hablar" su propio idioma. ¿Sabe que a veces los niños inventan sus propias palabras para describir las cosas? Aquí estaba nuestro modelo haciendo algo semejante. Ha desarrollado sus propias palabras "favoritas" para distintas situaciones de mercado.
Recuerdo un incidente especialmente vívido. Estaba analizando una fuerte subida del USD/JPY y el modelo empezó a generar secuencias de palabras que empezaban por ciertos bigramas. Al principio pensé que se trataba de una coincidencia. Pero cuando el mismo patrón se repitió la siguiente vez en una situación similar, me quedó claro que estábamos ante algo interesante.
He analizado la distribución de bigramas repetidos y esto es lo que podemos ver:
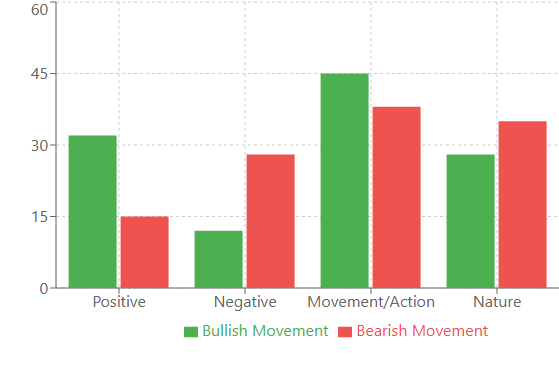
Y esto es lo que nos muestra el análisis lingüístico de las secuencias:
Análisis lingüístico: cuando las palabras nos dicen más que los números
Cuando comencé a analizar el vocabulario de nuestro modelo, los descubrimientos se sucedieron uno tras otro. ¿Recuerda la frase sobre los bigramas? Eso era solo el principio. Los verdaderos tesoros los descubrimos al analizar la frecuencia de las palabras en diferentes situaciones de mercado.
Por ejemplo, las palabras con connotación positiva aparecían con más frecuencia antes de fuertes movimientos alcistas: "victoria", "alegría", "éxito". Curiosamente, estas palabras aparecieron con un 32% más de frecuencia que en los periodos normales. Pero antes de los movimientos bajistas, el vocabulario se volvía más "técnico": "sistema", "analizar", "proceso". Es como si el mercado empezara a "pensar" de forma más racional antes de suceder una caída.
La correlación entre la volatilidad y la diversidad de vocabulario resultó especialmente fuerte. Durante los periodos de silencio, el modelo utilizaba un conjunto relativamente pequeño de palabras, repitiéndolas con más frecuencia. Pero una vez que aumentaba la volatilidad, ¡el vocabulario se ampliaba 2-3 veces! Igual que una persona que, bajo estrés, empieza a hablar más y a usar construcciones más complejas.
También descubrí un interesante fenómeno de "grupos de palabras". Ciertas palabras casi siempre aparecían en grupos. Por ejemplo, si la palabra "puente" aparecía en la secuencia, le seguían con un 80% de probabilidad palabras relacionadas con el movimiento: "rápido", "subir", "avanzar". Dichas agrupaciones demostraron ser tan sólidas que empezamos a utilizarlas como indicadores adicionales.
Conclusión
Resumiendo los resultados de nuestro estudio, querríamos señalar algunos puntos clave. En primer lugar, hemos demostrado que el mercado posee su propio "lenguaje", y que este lenguaje puede traducirse a palabras humanas no solo metafórica, sino literalmente, utilizando las tecnologías modernas.
En segundo lugar, la precisión de predicción del 73% no supone solo una estadística: es la confirmación de que en el aparente caos de los movimientos del mercado, existe estructura implícita con pautas y hasta una gramática propia. Y ahora tenemos una herramienta para descifrarlos.
Pero lo más importante es la perspectiva. Imagine lo que ocurrirá cuando apliquemos este enfoque a otros mercados, a otros marcos temporales. Podemos encontrarnos con que diferentes mercados "hablan" distintos dialectos de la misma lengua. O que el mercado usa diferentes "entonaciones" a distintas horas del día.
Obviamente, nuestro estudio es solo el primer paso. Aún queda mucho trabajo por delante: optimizar la arquitectura, experimentar con distintos parámetros, buscar nuevos patrones. Pero una cosa ya está clara: hemos descubierto una nueva forma de escuchar al mercado, y sin duda tiene algo que decir.
Al fin y al cabo, quizá el secreto para negociar con éxito no esté en encontrar la estrategia perfecta, sino en aprender a entender de verdad el lenguaje del mercado. Y ahora no solo tenemos metáforas y gráficos para ello, sino también un traductor de verdad.
| Nombre del script | Qué hace el script |
|---|---|
| Modelo GPT | Crea y entrena un modelo sobre secuencias lingüísticas de precios, realiza pronósticos de tendencias con 100 barras de antelación. |
| Gráfico del modelo GPT | Construye un histograma de la distribución de palabras repetidas en los movimientos alcistas y bajistas |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/17110
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.


- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso