
Prévisions économiques : Explorer le potentiel de Python

Introduction
Les prévisions économiques sont une tâche relativement complexe et exigeante en termes de main-d'œuvre. Elle nous permet d'analyser les mouvements futurs possibles à l'aide de données passées. En analysant les données historiques et les indicateurs économiques actuels, nous pouvons spéculer sur l'évolution de l'économie. Il s'agit d'une compétence très utile. Avec son aide, nous pouvons prendre des décisions plus éclairées en matière d'affaires, d'investissements et de politique économique.
Nous développerons cet outil en utilisant Python et des données économiques, de la collecte d'informations à la création de modèles prédictifs. Il analysera et fera également des prévisions pour l'avenir.
Les marchés financiers sont un bon baromètre de l'économie. Ils réagissent aux moindres changements. Le résultat peut être prévisible ou inattendu. Examinons des exemples où les lectures font fluctuer ce baromètre.
Lorsque le PIB augmente, les marchés réagissent généralement de manière positive. Lorsque l'inflation augmente, on s'attend généralement à des troubles. La baisse du chômage est généralement considérée comme une bonne nouvelle. Toutefois, il peut y avoir des exceptions. Balance commerciale, taux d'intérêt : chaque indicateur influe sur le sentiment du marché.
Comme le montre la pratique, les marchés réagissent souvent non pas au résultat réel, mais aux attentes de la majorité des acteurs. "Achetez les rumeurs, vendez les faits" - cette vieille sagesse boursière reflète le plus fidèlement l'essence de ce qui se passe. L'absence de changements significatifs peut également entraîner une plus grande volatilité sur le marché que des nouvelles inattendues.
L'économie est un système complexe. Ici, tout est lié et un facteur en influence un autre. La modification d'un paramètre peut déclencher une réaction en chaîne. Notre tâche consiste à comprendre ces liens et à apprendre à les analyser. Nous chercherons des solutions à l'aide de l'outil Python.
Mise en place de l'environnement : Importer les bibliothèques nécessaires
Alors, de quoi avons-nous besoin ? Tout d'abord, Python. Si vous ne l'avez pas encore installé, rendez-vous sur python.org. N'oubliez pas non plus de cocher la case "Add Python to PATH" pendant le processus d'installation.
L'étape suivante est celle des bibliothèques. Les bibliothèques élargissent considérablement les capacités de base de notre outil. Nous aurons besoin de :
- pandas - pour le traitement des données.
- wbdata - pour l'interaction avec la Banque Mondiale. Grâce à cette bibliothèque, nous obtiendrons les dernières données économiques.
- MetaTrader 5 - nous en aurons besoin pour interagir directement avec le marché lui-même.
- CatBoostRegressor de catboost - une petite IA artisanale.
- train_test_split et mean_squared_error de sklearn - ces bibliothèques nous aideront à évaluer l'efficacité de notre modèle.
Pour installer tout ce dont vous avez besoin, ouvrez une invite de commande et tapez :
pip install pandas wbdata MetaTrader5 catboost scikit-learn
Tout est prêt ? Excellent ! Écrivons maintenant nos premières lignes de code :
import pandas as pd import wbdata import MetaTrader5 as mt5 from catboost import CatBoostRegressor from sklearn.model_selection import train_test_split from sklearn.metrics import mean_squared_error import warnings warnings.filterwarnings("ignore", category=UserWarning, module="wbdata")
Nous avons préparé tous les outils nécessaires. Passons à autre chose.
Travailler avec l'API de la Banque Mondiale : Chargement des indicateurs économiques
Voyons maintenant comment nous recevrons les données économiques de la Banque Mondiale.
Tout d'abord, nous créons un dictionnaire avec des codes indicateurs :
indicators = {
'NY.GDP.MKTP.KD.ZG': 'GDP growth', # GDP growth
'FP.CPI.TOTL.ZG': 'Inflation', # Inflation
'FR.INR.RINR': 'Real interest rate', # Real interest rate
# ... and a bunch of other smart parameters
}
Chacun de ces codes donne accès à un type de données spécifique.
Continuons. Nous démarrons une boucle qui parcourra l'ensemble du code :
data_frames = [] for indicator in indicators.keys(): try: data_frame = wbdata.get_dataframe({indicator: indicators[indicator]}, country='all') data_frames.append(data_frame) except Exception as e: print(f"Error fetching data for indicator '{indicator}': {e}")
Nous essayons ici d'obtenir des données pour chaque indicateur. Si cela fonctionne, nous l'inscrivons sur la liste. En cas d'échec, imprimons une erreur et continuons.
Ensuite, nous rassemblons toutes nos données dans un grand DataFrame :
data = pd.concat(data_frames, axis=1) À ce stade, nous avons besoin de toutes les données économiques.
L'étape suivante consiste à enregistrer tout ce que nous avons reçu dans un fichier afin de pouvoir l'utiliser ultérieurement aux fins souhaitées :
data.to_csv('economic_data.csv', index=True) Nous venons de télécharger une série de données de la Banque Mondiale. C'est aussi simple que cela.
Aperçu des principaux indicateurs économiques à analyser
Si vous êtes novice, il peut être un peu difficile de comprendre un grand nombre de données et de chiffres. Examinons les principaux indicateurs pour faciliter le processus :
- La croissance du PIB est une sorte de revenu pour un pays. Les indicateurs en hausse sont positifs, tandis que ceux en baisse ont un impact négatif sur le pays.
- L'inflation est l'augmentation du prix des biens et des services.
- Taux d'intérêt réel - s'il augmente, les prêts deviennent plus chers.
- Les exportations et les importations indiquent ce qu'un pays vend et achète. L'augmentation des ventes est considérée comme une évolution positive.
- Balance des comptes courants - somme d'argent que les autres pays doivent à un pays donné. Des chiffres plus élevés indiquent la bonne situation financière d'un pays.
- La dette publique représente les emprunts d'un pays. Plus les chiffres sont petits, mieux c'est.
- Chômage - nombre de personnes sans emploi. Moins, c'est mieux.
- La croissance du PIB par habitant indique si une personne moyenne s'enrichit ou non.
Dans le code, cela se présente comme suit :
# Loading data from the World Bank
indicators = {
'NY.GDP.MKTP.KD.ZG': 'GDP growth', # GDP growth
'FP.CPI.TOTL.ZG': 'Inflation', # Inflation
'FR.INR.RINR': 'Real interest rate', # Real interest rate
'NE.EXP.GNFS.ZS': 'Exports', # Exports of goods and services (% of GDP)
'NE.IMP.GNFS.ZS': 'Imports', # Imports of goods and services (% of GDP)
'BN.CAB.XOKA.GD.ZS': 'Current account balance', # Current account balance (% of GDP)
'GC.DOD.TOTL.GD.ZS': 'Government debt', # Government debt (% of GDP)
'SL.UEM.TOTL.ZS': 'Unemployment rate', # Unemployment rate (% of total labor force)
'NY.GNP.PCAP.CD': 'GNI per capita', # GNI per capita (current US$)
'NY.GDP.PCAP.KD.ZG': 'GDP per capita growth', # GDP per capita growth (constant 2010 US$)
'NE.RSB.GNFS.ZS': 'Reserves in months of imports', # Reserves in months of imports
'NY.GDP.DEFL.KD.ZG': 'GDP deflator', # GDP deflator (constant 2010 US$)
'NY.GDP.PCAP.KD': 'GDP per capita (constant 2015 US$)', # GDP per capita (constant 2015 US$)
'NY.GDP.PCAP.PP.CD': 'GDP per capita, PPP (current international $)', # GDP per capita, PPP (current international $)
'NY.GDP.PCAP.PP.KD': 'GDP per capita, PPP (constant 2017 international $)', # GDP per capita, PPP (constant 2017 international $)
'NY.GDP.PCAP.CN': 'GDP per capita (current LCU)', # GDP per capita (current LCU)
'NY.GDP.PCAP.KN': 'GDP per capita (constant LCU)', # GDP per capita (constant LCU)
'NY.GDP.PCAP.CD': 'GDP per capita (current US$)', # GDP per capita (current US$)
'NY.GDP.PCAP.KD': 'GDP per capita (constant 2010 US$)', # GDP per capita (constant 2010 US$)
'NY.GDP.PCAP.KD.ZG': 'GDP per capita growth (annual %)', # GDP per capita growth (annual %)
'NY.GDP.PCAP.KN.ZG': 'GDP per capita growth (constant LCU)', # GDP per capita growth (constant LCU)
}
Chaque indicateur a sa propre importance. Individuellement, ils ne disent pas grand-chose, mais ensemble, ils donnent une image plus complète. Il convient également de noter que les indicateurs s'influencent mutuellement. Par exemple, un faible taux de chômage est généralement une bonne nouvelle, mais il peut entraîner une hausse de l'inflation. Par ailleurs, une forte croissance du PIB n'est peut-être pas si positive si elle est obtenue au prix d'un endettement considérable.
C'est pourquoi nous utilisons l'apprentissage automatique, qui nous aide à prendre en compte toutes ces relations complexes. Il accélère considérablement le processus de traitement de l'information et trie les données. Cependant, vous devrez également faire des efforts pour comprendre le processus.
Traitement et structuration des données de la Banque Mondiale
Bien sûr, à première vue, la richesse des données de la Banque Mondiale peut sembler difficile à comprendre. Pour faciliter le travail et l'analyse, nous rassemblerons les données dans un tableau.
data_frames = [] for indicator in indicators.keys(): try: data_frame = wbdata.get_dataframe({indicator: indicators[indicator]}, country='all') data_frames.append(data_frame) except Exception as e: print(f"Error fetching data for indicator '{indicator}': {e}") data = pd.concat(data_frames, axis=1)
Ensuite, nous prenons chaque indicateur et essayons d'obtenir des données le concernant. Il peut y avoir des problèmes avec des indicateurs individuels, nous en parlons et nous passons à autre chose. Nous rassemblons ensuite les données individuelles dans un grand DataFrame.
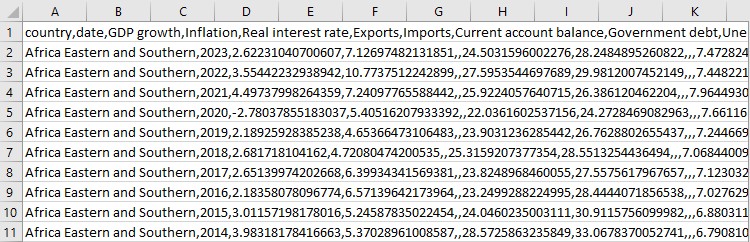
Mais nous ne nous arrêtons pas là. C'est maintenant que commence la partie la plus intéressante.
print("Available indicators and their data:")
print(data.columns)
print(data.head())
data.to_csv('economic_data.csv', index=True)
print("Economic Data Statistics:")
print(data.describe())
Nous regardons ce que nous avons accompli. Quels sont les indicateurs ? À quoi ressemblent les premières lignes de données ? C'est comme le premier coup d'œil sur un puzzle terminé : tout est en place ? Nous enregistrons ensuite toutes ces données dans un fichier CSV.
Enfin, quelques statistiques. Valeurs moyennes, hauts et bas. Il s'agit d'une vérification rapide : est-ce que tout va bien avec nos données ? C'est ainsi que nous transformons un ensemble de chiffres disparates en un système de données cohérent. Nous disposons aujourd'hui de tous les outils nécessaires à une analyse économique sérieuse.
Introduction à MetaTrader 5 : Établissement d'une connexion et réception de données
Parlons maintenant de MetaTrader 5. Nous devons d'abord établir une connexion. Voici à quoi cela ressemble :
if not mt5.initialize(): print("initialize() failed") mt5.shutdown()
L'étape suivante consiste à obtenir les données. Tout d'abord, nous devons vérifier quelles sont les paires de devises disponibles :
symbols = mt5.symbols_get()
symbol_names = [symbol.name for symbol in symbols]
Une fois le code ci-dessus exécuté, nous obtiendrons une liste de toutes les paires de devises disponibles. Ensuite, nous devons télécharger les données historiques de cotation pour chaque paire disponible :
historical_data = {}
for symbol in symbol_names:
rates = mt5.copy_rates_from_pos(symbol, mt5.TIMEFRAME_D1, 0, 1000)
df = pd.DataFrame(rates)
df['time'] = pd.to_datetime(df['time'], unit='s')
df.set_index('time', inplace=True)
historical_data[symbol] = df
Que se passe-t-il dans le code que nous avons saisi ? Nous avons demandé à MetaTrader de télécharger les données des 1000 derniers jours pour chaque instrument de trading. Les données sont ensuite chargées dans le tableau.
Les données téléchargées contiennent tout ce qui s'est passé sur le marché des devises au cours des 3 dernières années, dans les moindres détails. Les cotations reçues peuvent maintenant être analysées et des modèles peuvent être trouvés. Les possibilités sont pratiquement illimitées.
Préparation des données : Combinaison d'indicateurs économiques et de données de marché
À ce stade, nous nous occuperons directement du traitement des données. Nous avons deux secteurs distincts : le monde des indicateurs économiques et le monde des taux de change. Notre tâche consiste à réunir ces secteurs.
Commençons par notre fonction de préparation des données. Ce code sera le suivant dans notre tâche générale :
def prepare_data(symbol_data, economic_data): data = symbol_data.copy() data['close_diff'] = data['close'].diff() data['close_corr'] = data['close'].rolling(window=30).corr(data['close'].shift(1)) for indicator in indicators.keys(): if indicator in economic_data.columns: data[indicator] = economic_data[indicator] else: print(f"Warning: Data for indicator '{indicator}' is not available.") data.dropna(inplace=True) return data
Nous allons maintenant procéder étape par étape. Tout d'abord, nous créons une copie des données de la paire de devises. Mais pourquoi ? Il est toujours préférable de travailler avec une copie des données plutôt qu'avec l'original. En cas d'erreur, nous ne devrons pas recréer le fichier original.
Voici maintenant la partie la plus intéressante. Nous ajoutons 2 nouvelles colonnes : "close_diff" et "close_corr". La première montre l'évolution du prix de clôture par rapport à la veille. Nous saurons ainsi s'il s'agit d'un changement de prix positif ou négatif. La seconde est la corrélation du prix de clôture avec lui-même, mais avec un décalage d'un jour. À quoi cela sert-il ? En fait, il s'agit simplement de la manière la plus pratique de comprendre dans quelle mesure le prix d'aujourd'hui est similaire à celui d'hier.
Le plus dur est fait : nous essayons d'ajouter des indicateurs économiques à nos données monétaires. C'est ainsi que nous commençons à intégrer nos données dans une construction unique. Nous passons en revue tous nos indicateurs économiques et essayons de les retrouver dans les données de la Banque Mondiale. Si nous le trouvons, c'est parfait, nous l'ajoutons à nos données monétaires. Si ce n'est pas le cas, cela arrive. Nous rédigeons simplement un avertissement et nous passons à autre chose.
Après tout cela, il se peut que nous nous retrouvions avec des lignes de données manquantes. Nous les supprimons simplement.
Voyons maintenant comment appliquer cette fonction :
prepared_data = {}
for symbol, df in historical_data.items():
prepared_data[symbol] = prepare_data(df, data)
Nous prenons chaque paire de devises et lui appliquons notre fonction écrite. En sortie, nous obtenons un ensemble de données prêt à l'emploi pour chaque paire. Il y aura un jeu distinct pour chaque paire, mais ils sont tous assemblés selon le même principe.
Savez-vous quelle est la chose la plus importante dans ce processus ? Nous créons quelque chose de nouveau. Nous prenons différentes données économiques et des données de taux de change en direct et nous en tirons quelque chose de cohérent. Pris individuellement, ils peuvent sembler chaotiques, mais lorsqu'ils sont mis ensemble, nous pouvons identifier des modèles.
Nous disposons désormais d'un ensemble de données prêtes à être analysées. Nous pouvons y rechercher des séquences, faire des prédictions et tirer des conclusions. Cependant, nous devrons identifier les signes qui méritent vraiment d'être pris en compte. Dans le monde des données, il n'y a pas de détails sans importance. Chaque étape de la préparation des données peut être déterminante pour le résultat final.
L'apprentissage automatique dans notre modèle
L'apprentissage automatique est un processus assez complexe qui demande beaucoup de travail. CatBoost Regressor - cette fonction jouera un rôle important par la suite. Voici comment nous l'utilisons :
from catboost import CatBoostRegressor model = CatBoostRegressor(iterations=1000, learning_rate=0.1, depth=8, loss_function='RMSE', verbose=100) model.fit(X_train, y_train, verbose=False)
Chaque paramètre est important. 1000 itérations est le nombre de fois que le modèle parcourra les données. Taux d'apprentissage 0,1 - il n'est pas nécessaire de fixer une vitesse élevée tout de suite, nous devons apprendre progressivement. Profondeur 8 - recherche de connexions complexes. RMSE - c'est ainsi que nous évaluons les erreurs. La formation d'un modèle prend un certain temps. Nous montrons des exemples et évaluons les réponses correctes. CatBoost fonctionne particulièrement bien avec différents types de données. Il n'est pas limité à une gamme étroite de fonctions.
Pour prévoir les monnaies, nous procédons comme suit :
def forecast(symbol_data):
X = symbol_data.drop(columns=['close'])
y = symbol_data['close']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5, shuffle=False)
model = CatBoostRegressor(iterations=1000, learning_rate=0.1, depth=8, loss_function='RMSE', verbose=100)
model.fit(X_train, y_train, verbose=False)
predictions = model.predict(X_test)
mse = mean_squared_error(y_test, predictions)
print(f"Mean Squared Error for {symbol}: {mse}")
Une partie des données est destinée à la formation, l'autre au test. C'est comme aller à l'école : d'abord on étudie, ensuite on passe un examen
Nous divisons les données en deux parties. Mais pourquoi ? Une partie pour la formation, l'autre pour les tests. Après tout, nous devrons tester le modèle sur des données avec lesquelles il n'a pas encore travaillé.
Après l'entraînement, le modèle essaie de prédire. L'erreur quadratique moyenne montre l'efficacité de la méthode. Plus l'erreur est petite, meilleure est la prévision. CatBoost se distingue par le fait qu'il est en constante amélioration. Il apprend de ses erreurs.
Bien entendu, CatBoost n'est pas un programme automatique. Il faut de bonnes données. Sinon, nous obtenons des données inefficaces à l'entrée et des données inefficaces à la sortie. Mais avec les bonnes données, le résultat est positif. Parlons maintenant de la division des données. J'ai indiqué que nous avions besoin de cotations pour la vérification. Voici ce que cela donne dans le code :
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5, shuffle=False) 50% des données sont consacrées aux tests. Ne les mélangez pas - il est important de respecter l'ordre chronologique des données financières.
La création et la formation du modèle constituent la partie la plus intéressante. CatBoost démontre ici toutes ses capacités :
model = CatBoostRegressor(iterations=1000, learning_rate=0.1, depth=8, loss_function='RMSE', verbose=100) model.fit(X_train, y_train, verbose=False)
Le modèle absorbe avidement les données à la recherche de modèles. Chaque itération est un pas vers une meilleure compréhension du marché.
Et maintenant, le moment de vérité. Évaluation de la précision :
predictions = model.predict(X_test) mse = mean_squared_error(y_test, predictions)
L'erreur quadratique moyenne est également un point important dans notre travail. Cela montre à quel point le modèle est erroné. Moins, c'est mieux. Cela nous permet d'évaluer la qualité du programme. N'oubliez pas qu'il n'y a pas de garanties définitives en matière de trading. Mais avec CatBoost, le processus est plus efficace. Il voit des choses qui pourraient nous échapper. Et à chaque prévision, le résultat s'améliore.
Prévision des valeurs futures des paires de devises
Prévoir les paires de devises, c'est travailler avec des probabilités. Parfois, nous obtenons des résultats positifs, parfois nous subissons des pertes. L'essentiel est que le résultat final réponde à nos attentes.
Dans notre code, la fonction "forecast" fonctionne avec des probabilités. Voici comment elle effectue les calculs :
def forecast(symbol_data): X = symbol_data.drop(columns=['close']) y = symbol_data['close'] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, shuffle=False) model = CatBoostRegressor(iterations=1000, learning_rate=0.1, depth=8, loss_function='RMSE', verbose=100) model.fit(X_train, y_train, verbose=False) predictions = model.predict(X_test) mse = mean_squared_error(y_test, predictions) print(f"Mean Squared Error for {symbol}: {mse}") future_data = symbol_data.tail(30).copy() if len(predictions) >= 30: future_data['close'] = predictions[-30:] else: future_data['close'] = predictions future_predictions = model.predict(future_data.drop(columns=['close'])) return future_predictions
Tout d'abord, nous séparons les données déjà disponibles des données prédites. Nous divisons ensuite les données en deux parties : pour la formation et pour le test. Le modèle apprend à partir d'un ensemble de données et nous le testons sur un autre. Après l'entraînement, le modèle fait des prédictions. L'erreur quadratique moyenne permet d'évaluer le degré d'erreur. Plus le chiffre est bas, meilleures sont les prévisions.
Mais le plus intéressant est l'analyse des cotations en vue d'une éventuelle évolution future des prix. Nous prenons les données des 30 derniers jours et demandons au modèle de prédire ce qui se passera ensuite. Il semble que nous ayons recours aux prévisions d'analystes expérimentés. En ce qui concerne la visualisation... Malheureusement, le code ne fournit pas encore de visualisation explicite des résultats. Mais ajoutons-le et voyons à quoi il pourrait ressembler :
import matplotlib.pyplot as plt for symbol, forecast in forecasts.items(): plt.figure(figsize=(12, 6)) plt.plot(range(len(forecast)), forecast, label='Forecast') plt.title(f'Forecast for {symbol}') plt.xlabel('Days') plt.ylabel('Price') plt.legend() plt.savefig(f'{symbol}_forecast.png') plt.close()
Ce code crée un graphique pour chaque paire de devises. Visuellement, il est construit de manière linéaire. Chaque point correspond à un prix prévu pour un jour donné. Ces graphiques sont conçus pour montrer les tendances possibles, le travail a été fait avec un grand nombre de données, souvent trop complexes pour le commun des mortels. Si la ligne est orientée vers le haut, la monnaie deviendra plus chère. Elle tombe ? Préparez-vous à une baisse des taux.
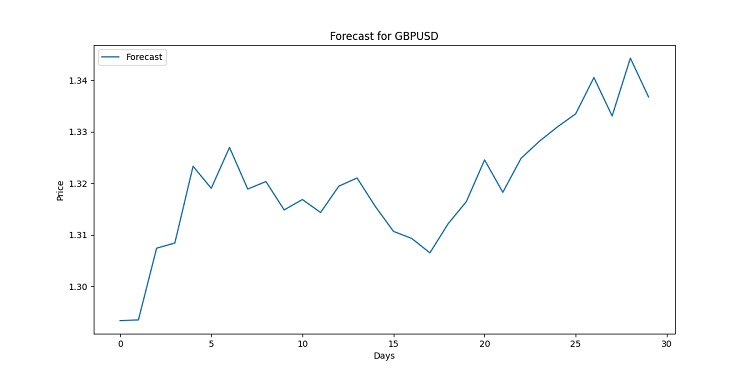
N'oubliez pas que les prévisions ne sont pas des garanties. Le marché peut apporter ses propres changements. Mais avec une bonne visualisation, vous saurez au moins à quoi vous attendre. En effet, dans cette situation, nous disposons d'une analyse de grande qualité.
J'ai également créé un code pour visualiser les résultats des prévisions dans MQL5 en ouvrant un fichier et en affichant les prévisions dans les commentaires :
//+------------------------------------------------------------------+ //| Economic Forecast| //| Copyright 2024, Evgeniy Koshtenko | //| https://www.mql5.com/fr/users/koshtenko | //+------------------------------------------------------------------+ #property copyright "Copyright 2023, Evgeniy Koshtenko" #property link "https://www.mql5.com/fr/users/koshtenko" #property version "4.00" #property strict #property indicator_chart_window #property indicator_buffers 1 #property indicator_plots 1 #property indicator_label1 "Forecast" #property indicator_type1 DRAW_SECTION #property indicator_color1 clrRed #property indicator_style1 STYLE_SOLID #property indicator_width1 2 double ForecastBuffer[]; input string FileName = "EURUSD_forecast.csv"; // Forecast file name //+------------------------------------------------------------------+ //| Custom indicator initialization function | //+------------------------------------------------------------------+ int OnInit() { SetIndexBuffer(0, ForecastBuffer, INDICATOR_DATA); PlotIndexSetDouble(0, PLOT_EMPTY_VALUE, EMPTY_VALUE); return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //| Draw forecast | //+------------------------------------------------------------------+ int OnCalculate(const int rates_total, const int prev_calculated, const datetime &time[], const double &open[], const double &high[], const double &low[], const double &close[], const long &tick_volume[], const long &volume[], const int &spread[]) { static bool first=true; string comment = ""; if(first) { ArrayInitialize(ForecastBuffer, EMPTY_VALUE); ArraySetAsSeries(ForecastBuffer, true); int file_handle = FileOpen(FileName, FILE_READ|FILE_CSV|FILE_ANSI); if(file_handle != INVALID_HANDLE) { // Skip the header string header = FileReadString(file_handle); comment += header + "\n"; // Read data from file while(!FileIsEnding(file_handle)) { string line = FileReadString(file_handle); string str_array[]; StringSplit(line, ',', str_array); datetime time=StringToTime(str_array[0]); double price=StringToDouble(str_array[1]); PrintFormat("%s %G", TimeToString(time), price); comment += str_array[0] + ", " + str_array[1] + "\n"; // Find the corresponding bar on the chart and set the forecast value int bar_index = iBarShift(_Symbol, PERIOD_CURRENT, time); if(bar_index >= 0 && bar_index < rates_total) { ForecastBuffer[bar_index] = price; PrintFormat("%d %s %G", bar_index, TimeToString(time), price); } } FileClose(file_handle); first=false; } else { comment = "Failed to open file: " + FileName; } Comment(comment); } return(rates_total); } //+------------------------------------------------------------------+ //| Indicator deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { Comment(""); } //+------------------------------------------------------------------+ //| Create the arrow | //+------------------------------------------------------------------+ bool ArrowCreate(const long chart_ID=0, // chart ID const string name="Arrow", // arrow name const int sub_window=0, // subwindow number datetime time=0, // anchor point time double price=0, // anchor point price const uchar arrow_code=252, // arrow code const ENUM_ARROW_ANCHOR anchor=ANCHOR_BOTTOM, // anchor point position const color clr=clrRed, // arrow color const ENUM_LINE_STYLE style=STYLE_SOLID, // border line style const int width=3, // arrow size const bool back=false, // in the background const bool selection=true, // allocate for moving const bool hidden=true, // hidden in the list of objects const long z_order=0) // mouse click priority { //--- set anchor point coordinates if absent ChangeArrowEmptyPoint(time, price); //--- reset the error value ResetLastError(); //--- create an arrow if(!ObjectCreate(chart_ID, name, OBJ_ARROW, sub_window, time, price)) { Print(__FUNCTION__, ": failed to create an arrow! Error code = ", GetLastError()); return(false); } //--- set the arrow code ObjectSetInteger(chart_ID, name, OBJPROP_ARROWCODE, arrow_code); //--- set anchor type ObjectSetInteger(chart_ID, name, OBJPROP_ANCHOR, anchor); //--- set the arrow color ObjectSetInteger(chart_ID, name, OBJPROP_COLOR, clr); //--- set the border line style ObjectSetInteger(chart_ID, name, OBJPROP_STYLE, style); //--- set the arrow size ObjectSetInteger(chart_ID, name, OBJPROP_WIDTH, width); //--- display in the foreground (false) or background (true) ObjectSetInteger(chart_ID, name, OBJPROP_BACK, back); //--- enable (true) or disable (false) the mode of moving the arrow by mouse //--- when creating a graphical object using ObjectCreate function, the object cannot be //--- highlighted and moved by default. Selection parameter inside this method //--- is true by default making it possible to highlight and move the object ObjectSetInteger(chart_ID, name, OBJPROP_SELECTABLE, selection); ObjectSetInteger(chart_ID, name, OBJPROP_SELECTED, selection); //--- hide (true) or display (false) graphical object name in the object list ObjectSetInteger(chart_ID, name, OBJPROP_HIDDEN, hidden); //--- set the priority for receiving the event of a mouse click on the chart ObjectSetInteger(chart_ID, name, OBJPROP_ZORDER, z_order); //--- successful execution return(true); } //+------------------------------------------------------------------+ //| Check anchor point values and set default values | //| for empty ones | //+------------------------------------------------------------------+ void ChangeArrowEmptyPoint(datetime &time, double &price) { //--- if the point time is not set, it will be on the current bar if(!time) time=TimeCurrent(); //--- if the point price is not set, it will have Bid value if(!price) price=SymbolInfoDouble(Symbol(), SYMBOL_BID); } //+------------------------------------------------------------------+
Voici comment se présentent les prévisions dans le terminal :
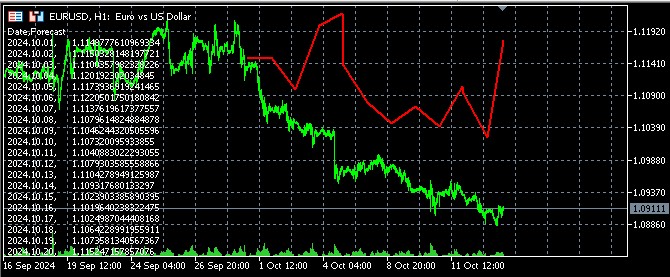
Interprétation des résultats : Analyse de l'influence des facteurs économiques sur les taux de change
Examinons maintenant de plus près l'interprétation des résultats en fonction de votre code. Nous avons rassemblé des milliers de faits disparates en données organisées qui doivent également être analysées.
Commençons par le fait que nous disposons d'un grand nombre d'indicateurs économiques - de la croissance du PIB au chômage. Chaque facteur a sa propre influence sur le contexte du marché. Les indicateurs individuels ont leur propre impact, mais l'ensemble de ces données influence les taux de change finaux.
Prenons l'exemple du PIB. Dans le code, elle est représentée par plusieurs indicateurs :
'NY.GDP.MKTP.KD.ZG': 'GDP growth', 'NY.GDP.PCAP.KD.ZG': 'GDP per capita growth',
La croissance du PIB renforce généralement la monnaie. Mais pourquoi ? En effet, les nouvelles positives attirent les acteurs à la recherche d'une opportunité d'investir des capitaux pour poursuivre leur croissance. Les investisseurs sont attirés par les économies en croissance, ce qui accroît la demande pour leurs monnaies.
En revanche, l'inflation ("FP.CPI.TOTL.ZG" : Inflation") est un signal alarmant pour les traders. Plus l'inflation est élevée, plus la valeur de la monnaie diminue rapidement. Une forte inflation affaiblit généralement une monnaie, simplement parce que les services et les biens deviennent beaucoup plus chers dans le pays en question.
Il est intéressant d'examiner la balance commerciale :
'NE.EXP.GNFS.ZS': 'Exports', 'NE.IMP.GNFS.ZS': 'Imports', 'BN.CAB.XOKA.GD.ZS': 'Current account balance',
Ces indicateurs sont comme des échelles. Si les exportations dépassent les importations, le pays reçoit davantage de devises étrangères, ce qui renforce généralement la monnaie nationale.
Voyons maintenant comment nous analysons cela dans le code. CatBoost Regressor est notre outil principal. Comme un chef d'orchestre expérimenté, il entend tous les instruments en même temps et comprend comment ils s'influencent mutuellement.
Voici ce que vous pouvez ajouter à la fonction de prévision pour mieux comprendre l'impact des facteurs :
def forecast(symbol_data):
# ......
feature_importance = model.feature_importances_
feature_names = X.columns
importance_df = pd.DataFrame({'feature': feature_names, 'importance': feature_importance})
importance_df = importance_df.sort_values('importance', ascending=False)
print(f"Feature Importance for {symbol}:")
print(importance_df.head(10)) # Top 10 important factors
return future_predictions
Cela nous permettra de savoir quels facteurs ont été les plus importants pour la prévision de chaque paire de devises. Il se peut que le facteur clé pour l'euro soit le taux de la BCE, tandis que pour le yen, c'est la balance commerciale du Japon. Exemple de sortie de données :
Interprétation pour EURUSD :
1. Tendance des prix : Les prévisions indiquent une tendance à la hausse pour les 30 prochains jours.
2. Volatilité : L'évolution prévue des prix montre une faible volatilité.
3. Facteur clé d'influence : La caractéristique la plus importante pour ces prévisions est la "faiblesse".
4. Implications économiques :
- Si la croissance du PIB est l'un des principaux facteurs, cela signifie que les bonnes performances économiques influencent la monnaie.
- L'importance du taux d'inflation peut indiquer que les changements de politique monétaire affectent la monnaie.
- Si les facteurs liés à la balance commerciale sont déterminants, la dynamique du commerce international est probablement à l'origine des mouvements monétaires.
5. Implications commerciales :
- La tendance à la hausse suggère un potentiel pour des positions longues.
- Une volatilité plus faible pourrait permettre d'élargir les seuils de perte.
6. Évaluation des risques :
- Il faut toujours tenir compte des limites du modèle et de la possibilité d'événements inattendus sur le marché.
- Les performances passées ne garantissent pas les résultats futurs.
Mais n'oubliez pas qu'il n'y a pas de réponses faciles en économie. Il arrive qu'une monnaie se renforce contre toute attente, ou qu'elle s'effondre sans raison apparente. Le marché vit souvent sur des attentes plutôt que sur la réalité actuelle.
Un autre point important est le décalage dans le temps. Les changements dans l'économie ne se reflètent pas immédiatement dans le taux de change. C'est comme diriger un grand navire - vous tournez la roue, mais le navire ne change pas de cap instantanément. Dans le code, nous utilisons des données quotidiennes, mais certains indicateurs économiques sont mis à jour moins fréquemment. Cela peut introduire une certaine erreur dans les prévisions. En fin de compte, l'interprétation des résultats est autant un art qu'une science. Le modèle est un outil puissant, mais les décisions sont toujours prises par un être humain. Utilisez ces données à bon escient et que vos prédictions soient exactes !
Recherche de modèles non évidents dans les données économiques
Le marché des changes est une vaste plateforme de trading. Il n'est pas caractérisé par des mouvements de prix prévisibles, mais en plus, il y a des événements spéciaux qui augmentent la volatilité et la liquidité en ce moment. Il s'agit d'événements mondiaux.
Dans notre code, nous nous appuyons sur des indicateurs économiques :
indicators = {
'NY.GDP.MKTP.KD.ZG': 'GDP growth',
'FP.CPI.TOTL.ZG': 'Inflation',
# ...
}
Mais que faire en cas d'imprévu ? Par exemple, une pandémie ou une crise politique ?
Une sorte d'"indice de surprise" serait utile à cet égard. Imaginons que nous ajoutions quelque chose comme ceci à notre code :
def add_global_event_impact(data, event_date, event_magnitude): data['global_event'] = 0 data.loc[event_date:, 'global_event'] = event_magnitude data['global_event_decay'] = data['global_event'].ewm(halflife=30).mean() return data # --- def prepare_data(symbol_data, economic_data): # ... ... data = add_global_event_impact(data, '2020-03-11', 0.5) # return data
Cela nous permettrait de prendre en compte les événements mondiaux soudains et leur atténuation progressive.
Mais la question la plus intéressante est de savoir comment cela affecte les prévisions. Parfois, des événements mondiaux peuvent complètement bouleverser nos attentes. Par exemple, en période de crise, les monnaies "sûres" comme l'USD ou le CHF peuvent se renforcer à l'encontre de la logique économique.
À ce moment-là, la productivité de notre modèle diminue. Et là, il est important de ne pas paniquer, mais de s'adapter. Peut-être vaut-il la peine de réduire temporairement l'horizon de prévision ou de donner plus de poids aux données récentes ?
recent_weight = 2 if data['global_event'].iloc[-1] > 0 else 1 model.fit(X_train, y_train, sample_weight=np.linspace(1, recent_weight, len(X_train)))
N'oubliez pas : dans le monde des devises, comme dans celui de la danse, l'essentiel est de savoir s'adapter au rythme. Même si ce rythme change parfois de manière inattendue !
La chasse aux anomalies : Comment trouver des modèles non évidents dans les données économiques ?
Passons maintenant à la partie la plus intéressante : trouver des trésors cachés dans nos données. C'est un peu comme un détective, sauf qu'au lieu de preuves, nous avons des chiffres et des graphiques.
Nous utilisons déjà un grand nombre d'indicateurs économiques dans notre code. Mais existe-t-il des liens non évidents entre eux ? Essayons de les trouver !
Pour commencer, nous pouvons examiner les corrélations entre les différents indicateurs :
correlation_matrix = data[list(indicators.keys())].corr() print(correlation_matrix)
Mais ce n'est qu'un début. La véritable magie commence lorsque nous commençons à rechercher des relations non linéaires. Par exemple, il peut s'avérer qu'une variation du PIB n'affecte pas immédiatement le taux de change, mais avec un retard de plusieurs mois.
Ajoutons quelques mesures "décalées" à notre fonction de préparation des données :
def prepare_data(symbol_data, economic_data): # ...... for indicator in indicators.keys(): if indicator in economic_data.columns: data[indicator] = economic_data[indicator] data[f"{indicator}_lag_3"] = economic_data[indicator].shift(3) data[f"{indicator}_lag_6"] = economic_data[indicator].shift(6) # ...
Désormais, notre modèle sera en mesure de saisir les dépendances avec un délai de 3 et 6 mois.
Mais ce qui est le plus intéressant, c'est la recherche de modèles qui ne sont pas du tout évidents. Par exemple, il pourrait s'avérer que le taux de l'euro est étrangement corrélé aux ventes de glaces aux États-Unis (c'est une blague, mais vous voyez l'idée).
À cette fin, des méthodes d'extraction de caractéristiques peuvent être utilisées, par exemple l'ACP (Analyse en Composantes Principales, ou PCA pour Principal Component Analysis) :
from sklearn.decomposition import PCA
def find_hidden_patterns(data):
pca = PCA(n_components=5)
pca_result = pca.fit_transform(data[list(indicators.keys())])
print("Explained variance ratio:", pca.explained_variance_ratio_)
return pca_result
pca_features = find_hidden_patterns(data)
data['hidden_pattern_1'] = pca_features[:, 0]
data['hidden_pattern_2'] = pca_features[:, 1]
Ces "modèles cachés" peuvent être la clé de prévisions plus précises.
N'oubliez pas non plus la saisonnalité. Certaines devises peuvent se comporter différemment selon la période de l'année. Ajoutez des informations sur le mois et le jour de la semaine à vos données - vous pourriez trouver quelque chose d'intéressant !
data['month'] = data.index.month data['day_of_week'] = data.index.dayofweek
N'oubliez pas que dans un monde de données, il est toujours possible de faire des découvertes. Soyez curieux, expérimentez et, qui sait, vous trouverez peut-être le modèle qui changera le monde du trading.
Conclusion : Perspectives pour les prévisions économiques dans les transactions algorithmiques
Nous sommes partis d'une idée simple : peut-on prédire l'évolution des taux de change à partir de données économiques ? Qu'avons-nous découvert ? Il s'avère que cette idée a un certain mérite. Mais ce n'est pas aussi simple qu'il n'y paraît à première vue.
Notre code simplifie considérablement l'analyse des données économiques. Nous avons appris à collecter des informations du monde entier, à les traiter et même à faire faire des prédictions à l'ordinateur. Mais n'oubliez pas que même le modèle d'apprentissage automatique le plus avancé n'est qu'un outil. Il s'agit d'un outil très puissant, mais il reste un outil.
Nous avons vu comment CatBoost Regressor peut trouver des relations complexes entre les indicateurs économiques et les taux de change. Cela nous permet d'aller au-delà des capacités humaines et de réduire considérablement le temps consacré à la manipulation et à l'analyse des données. Mais même un outil aussi performant ne peut prédire l'avenir avec une précision de 100%.
Mais pourquoi ? Parce que l'économie est un processus qui dépend de nombreux facteurs. Aujourd'hui, tout le monde surveille les prix du pétrole, alors que demain le monde entier pourrait être bouleversé par un événement inattendu. Nous avons mentionné cet effet en parlant de "l'indice de surprise". C'est précisément pour cela qu'il est si important.
Traduit du russe par MetaQuotes Ltd.
Article original : https://www.mql5.com/ru/articles/15998
Avertissement: Tous les droits sur ces documents sont réservés par MetaQuotes Ltd. La copie ou la réimpression de ces documents, en tout ou en partie, est interdite.
Cet article a été rédigé par un utilisateur du site et reflète ses opinions personnelles. MetaQuotes Ltd n'est pas responsable de l'exactitude des informations présentées, ni des conséquences découlant de l'utilisation des solutions, stratégies ou recommandations décrites.

- Applications de trading gratuites
- Plus de 8 000 signaux à copier
- Actualités économiques pour explorer les marchés financiers
Vous acceptez la politique du site Web et les conditions d'utilisation
Prenez-le à partir d'ici. Un vieil article sur le sujet.
Pour l'instant, le maximum que je puisse tirer de la mouche est la donnée actuelle pour aujourd'hui((((
Ce que je ne comprends pas, c'est ce que fait MQ.
C'est le signal de l'auteur ci-dessus.
Ce signal a été créé uniquement pour tester un modèle sur Sber. Mais je ne l'ai jamais testé, c'est juste de la monnaie dans le fonds du marché monétaire déjà. Fondamentalement, je ne trade pas moi-même sur mes modèles, je ne peux pas m'éloigner des idées d'amélioration et de développement)))) Il y a constamment de nouvelles idées d'amélioration) Et sur la bourse, j'investis principalement dans des actions, sur le long terme, j'achète des actions sur le MOEX en tant que non-rez, et sur le KASE des sociétés de l'indice Kazbirji.
Jusqu'à présent, le mieux que nous puissions obtenir de la mouche est la donnée actuelle pour aujourd'hui((((
Si j'ai bien compris, ils collectent des données sur les comptes connectés à la surveillance ? Même si tout est honnête, c'est une goutte d'eau dans l'océan.
Je pense que les données de la CFTC sont plus fiables, même s'il ne s'agit pas d'opérations au comptant mais de contrats à terme avec options. Il existe un historique depuis 2005, même si ce n'est pas sous une forme très pratique, mais il y a probablement des API pour Python.
C'est à vous de voir, bien sûr, je ne fais que partager mon opinion.
Ce signal a été créé uniquement pour tester un modèle sur Sber. Mais je ne l'ai jamais testé, c'est juste de la monnaie dans le fonds monétaire déjà. Fondamentalement, je ne trade pas moi-même sur mes modèles, je ne peux pas échapper aux idées d'amélioration et de développement)))) Il y a constamment de nouvelles idées d'amélioration) Et sur la bourse, j'investis principalement dans des actions, sur le long terme, j'achète des actions sur le MOEX en tant que non-rez, et sur le KASE des sociétés de l'indice Kazbirji.
Il y a là une divergence d'information, sans réclamation de votre part.