
경제 예측: 파이썬의 잠재력 살펴보기

소개
경제 예측은 다소 복잡하고 노동 집약적인 작업입니다. 그러나 이를 통해 과거 데이터를 사용하여 미래에 발생할 움직임을 분석할 수 있으며 과거 데이터와 현재 경제 지표를 분석하여 경제가 어디로 향할지 추측할 수 있습니다. 이는 매우 유용한 기술입니다. 이를 통해 우리는 비즈니스, 투자, 경제 정책에서 더 많은 정보에 기반한 의사 결정을 내릴 수 있습니다.
정보 수집부터 예측 모델의 생성까지 우리는 파이썬과 경제 데이터를 사용하여 이러한 도구를 개발할 것입니다. 이 도구는 미래를 분석하고 예측할 수도 있습니다.
금융 시장은 경제의 좋은 바로미터로 아주 작은 변화에도 반응합니다. 결과는 예측 가능하거나 예상치 못한 것일 수 있습니다. 판독값으로 인해 이 바로미터가 변동하는 예를 살펴보도록 해 봅시다.
GDP가 성장하면 시장은 일반적으로 긍정적으로 반응합니다. 인플레이션이 상승하면 일반적으로 불안정할 것이 예상됩니다. 실업률이 떨어지면 이는 일반적으로 좋은 소식으로 받아들여집니다. 예외가 있을 수 있기는 합니다. 무역 수지, 금리 등 각 지표들은 시장 심리에 영향을 미칩니다.
실제 사례를 보면 시장은 실제 결과가 아니라 대다수 플레이어의 기대에 따라 반응하는 경우가 많습니다. "루머에 사고 사실에 파는 것" - 이 오래된 주식 시장의 지혜는 현재 상황의 본질을 가장 정확하게 반영합니다. 또한 큰 변동이 없는 것이 예상치 못한 뉴스보다 더 큰 시장 변동성을 만들 수 있습니다.
경제는 복잡한 시스템입니다. 모든 것이 서로 연결되어 있고 한 요인이 다른 요인에 영향을 미칩니다. 하나의 매개변수가 변경되면 연쇄적인 반응이 시작될 수 있습니다. 우리가 할 일은 이러한 연관성을 이해하고 분석하는 방법을 배우는 것입니다. 이를 위해 파이썬 도구를 사용하여 해결책을 찾아보겠습니다.
환경 설정하기: 필요한 라이브러리 가져오기
이제 무엇이 필요할까요? 가장 먼저 해야 할 일은 파이썬입니다. 아직 설치하지 않았다면 python.org로 이동하세요. 또한 설치 과정에서 '경로에 파이썬 추가' 상자를 체크하는 것을 잊지 마세요.
다음 단계는 라이브러리입니다. 라이브러리는 도구의 기본적인 기능을 크게 확장합니다. 다음이 필요합니다:
- pandas - 데이터 처리용.
- wbdata - 세계은행과의 상호 작용을 위해. 이 라이브러리를 통해 우리는 최신 경제 데이터를 얻을 수 있습니다.
- MetaTrader 5 - 시장 자체와 직접 상호 작용하려면 MetaTrader 5가 필요합니다.
- 맞춤형 소형 AI인 catboost의 CatBoostRegressor.
- sklearn의 train_test_split 및 mean_squared_error - 이 라이브러리는 모델이 얼마나 효과적인지 평가하는 데 도움이 될 것입니다.
필요한 모든 것을 설치하려면 명령 프롬프트를 열고 다음을 입력합니다:
pip install pandas wbdata MetaTrader5 catboost scikit-learn
모든 것이 준비되었나요? 훌륭합니다! 이제 첫 번째 코드 문자열을 작성해 보겠습니다:
import pandas as pd import wbdata import MetaTrader5 as mt5 from catboost import CatBoostRegressor from sklearn.model_selection import train_test_split from sklearn.metrics import mean_squared_error import warnings warnings.filterwarnings("ignore", category=UserWarning, module="wbdata")
필요한 모든 도구를 준비했습니다. 계속 진행하겠습니다.
세계은행 API로 작업하기: 경제 지표 로드
이제 세계은행으로부터 경제 데이터를 어떻게 받을 수 있는지 알아봅시다.
먼저 지표 코드가 포함된 사전을 만듭니다:
indicators = {
'NY.GDP.MKTP.KD.ZG': 'GDP growth', # GDP growth
'FP.CPI.TOTL.ZG': 'Inflation', # Inflation
'FR.INR.RINR': 'Real interest rate', # Real interest rate
# ... and a bunch of other smart parameters
}
이러한 각 코드는 특정 유형의 데이터에 대한 액세스를 제공합니다.
계속해 보겠습니다. 전체 코드를 대상으로 하는 루프를 시작합니다:
data_frames = [] for indicator in indicators.keys(): try: data_frame = wbdata.get_dataframe({indicator: indicators[indicator]}, country='all') data_frames.append(data_frame) except Exception as e: print(f"Error fetching data for indicator '{indicator}': {e}")
여기서는 우리는 각 지표에 대한 데이터를 얻으려고 합니다. 효과가 있으면 목록에 추가합니다. 실패하면 오류를 인쇄하고 계속 진행합니다.
그 후 모든 데이터를 하나의 큰 데이터 프레임으로 수집합니다:
data = pd.concat(data_frames, axis=1) 이 단계에서는 모든 경제 데이터를 확보해야 합니다.
다음 단계는 수신한 모든 내용을 파일에 저장하여 나중에 필요한 용도로 사용할 수 있도록 하는 것입니다:
data.to_csv('economic_data.csv', index=True) 방금 세계은행에서 많은 데이터를 다운로드했습니다. 이렇게 간단합니다.
분석용 주요 경제 지표 개요
초보자라면 많은 데이터와 숫자를 이해하는 것이 다소 어려울 수 있습니다. 프로세스를 더 쉽게 진행할 수 있는 주요 지표를 살펴보세요:
- GDP 성장률은 한 국가의 일종의 소득입니다. 지표가 상승하는 것은 긍정적입니다. 그러나 하락하는 것은 국가에 부정적인 영향을 미칩니다.
- 인플레이션은 상품 및 서비스 가격의 상승을 의미합니다.
- 실질 이자율 - 이자율이 상승하면 대출이 더 비싸집니다.
- 수출 및 수입은 국가가 무엇을 판매하고 구매하는지 보여줍니다. 더 많이 팔린다는 것은 긍정적인 발전으로 간주됩니다.
- 경상수지 - 다른 국가들이 특정 국가에 빚진 금액입니다. 수치가 높을수록 국가의 재정 상태가 양호하다는 의미입니다.
- 정부 부채는 한 국가의 대출을 나타냅니다. 숫자는 작을수록 좋습니다.
- 실업률 - 실직자 수입니다. 적을수록 좋습니다.
- 1인당 GDP 성장률은 평균적인 사람들이 더 부유해지고 있는지 여부를 보여줍니다.
코드에서는 다음과 같이 보입니다:
# Loading data from the World Bank
indicators = {
'NY.GDP.MKTP.KD.ZG': 'GDP growth', # GDP growth
'FP.CPI.TOTL.ZG': 'Inflation', # Inflation
'FR.INR.RINR': 'Real interest rate', # Real interest rate
'NE.EXP.GNFS.ZS': 'Exports', # Exports of goods and services (% of GDP)
'NE.IMP.GNFS.ZS': 'Imports', # Imports of goods and services (% of GDP)
'BN.CAB.XOKA.GD.ZS': 'Current account balance', # Current account balance (% of GDP)
'GC.DOD.TOTL.GD.ZS': 'Government debt', # Government debt (% of GDP)
'SL.UEM.TOTL.ZS': 'Unemployment rate', # Unemployment rate (% of total labor force)
'NY.GNP.PCAP.CD': 'GNI per capita', # GNI per capita (current US$)
'NY.GDP.PCAP.KD.ZG': 'GDP per capita growth', # GDP per capita growth (constant 2010 US$)
'NE.RSB.GNFS.ZS': 'Reserves in months of imports', # Reserves in months of imports
'NY.GDP.DEFL.KD.ZG': 'GDP deflator', # GDP deflator (constant 2010 US$)
'NY.GDP.PCAP.KD': 'GDP per capita (constant 2015 US$)', # GDP per capita (constant 2015 US$)
'NY.GDP.PCAP.PP.CD': 'GDP per capita, PPP (current international $)', # GDP per capita, PPP (current international $)
'NY.GDP.PCAP.PP.KD': 'GDP per capita, PPP (constant 2017 international $)', # GDP per capita, PPP (constant 2017 international $)
'NY.GDP.PCAP.CN': 'GDP per capita (current LCU)', # GDP per capita (current LCU)
'NY.GDP.PCAP.KN': 'GDP per capita (constant LCU)', # GDP per capita (constant LCU)
'NY.GDP.PCAP.CD': 'GDP per capita (current US$)', # GDP per capita (current US$)
'NY.GDP.PCAP.KD': 'GDP per capita (constant 2010 US$)', # GDP per capita (constant 2010 US$)
'NY.GDP.PCAP.KD.ZG': 'GDP per capita growth (annual %)', # GDP per capita growth (annual %)
'NY.GDP.PCAP.KN.ZG': 'GDP per capita growth (constant LCU)', # GDP per capita growth (constant LCU)
}
각 지표에는 고유한 중요성이 있습니다. 개별적으로는 별다른 의미가 없지만 함께 사용하면 더 완벽한 그림을 그릴 수 있습니다. 또한 지표는 서로 영향을 미친다는 점에 유의해야 합니다. 예를 들어 낮은 실업률은 일반적으로 좋은 소식이지만 인플레이션의 상승으로 이어질 수 있습니다. 또는 높은 GDP 성장이 막대한 부채를 희생해서 달성한 것이라면 그다지 긍정적이지 않을 수도 있습니다.
머신 러닝을 사용하는 이유도 바로 여기에 있습니다. 이러한 복잡한 관계를 모두 고려하는 데 도움이 되기 때문입니다. 머신 러닝은 정보 처리 프로세스의 속도를 크게 높이고 데이터를 정렬합니다. 그러나 프로세스를 이해하려면 약간의 노력도 필요합니다.
세계은행 데이터 처리 및 구조화
물론 언뜻 보기에 세계은행의 방대한 데이터는 어려운 작업처럼 보일 수 있습니다. 작업과 분석을 더 쉽게 하기 위해 데이터를 표로 수집합니다.
data_frames = [] for indicator in indicators.keys(): try: data_frame = wbdata.get_dataframe({indicator: indicators[indicator]}, country='all') data_frames.append(data_frame) except Exception as e: print(f"Error fetching data for indicator '{indicator}': {e}") data = pd.concat(data_frames, axis=1)
그 다음 각 지표를 가져오고 해당 데이터를 가져옵니다. 개별 지표에 문제가 있을 수 있는 경우 노트해 놓고 계속 진행합니다. 그런 다음 개별 데이터를 하나의 큰 데이터프레임으로 수집합니다.
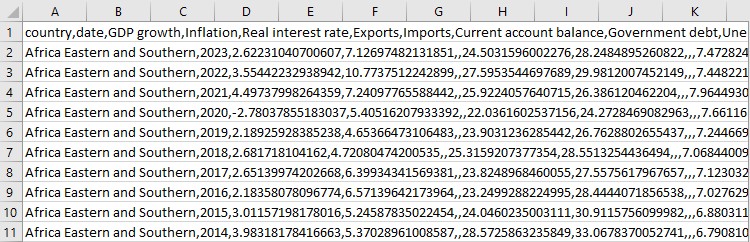
하지만 우리는 여기서 멈추지 않습니다. 이제 가장 흥미로운 부분이 시작됩니다.
print("Available indicators and their data:")
print(data.columns)
print(data.head())
data.to_csv('economic_data.csv', index=True)
print("Economic Data Statistics:")
print(data.describe())
우리가 이룬 성과를 살펴봅니다. 어떤 지표가 있나요? 데이터의 첫 번째 행은 어떻게 생겼나요? 완성된 퍼즐을 처음 보는 것과 같습니다. 모든 것이 제자리에 있나요? 그런 다음 이 모든 내용을 CSV 파일에 저장합니다.
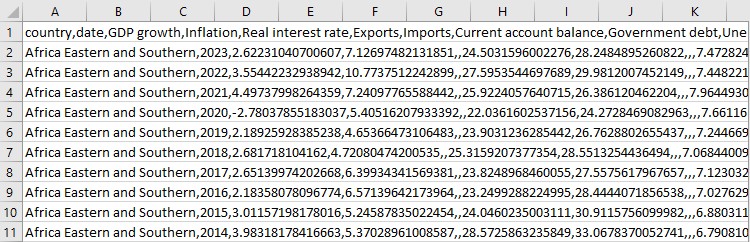
마지막으로 몇 가지 통계입니다. 평균값, 최고값, 최저값. 데이터에 문제가 없는지 간단히 확인하는 것과 같습니다. 이렇게 서로 다른 여러 숫자를 일관된 데이터 시스템으로 변환합니다. 이제 진지한 경제 분석을 위한 모든 도구를 갖추게 되었습니다.
MetaTrader 5 사용: 연결 설정 및 데이터 수신
이제 MetaTrader 5에 대해 알아보겠습니다. 먼저 연결을 설정해야 합니다. 이렇게 생겼습니다:
if not mt5.initialize(): print("initialize() failed") mt5.shutdown()
다음으로 중요한 단계는 데이터를 확보하는 것입니다. 먼저 어떤 통화 쌍을 사용할 수 있는지 확인해야 합니다:
symbols = mt5.symbols_get()
symbol_names = [symbol.name for symbol in symbols]
위의 코드가 실행되면 사용 가능한 모든 통화 쌍의 목록이 표시됩니다. 다음으로 사용 가능한 각 쌍에 대한 호가 히스토리 데이터를 다운로드해야 합니다:
historical_data = {}
for symbol in symbol_names:
rates = mt5.copy_rates_from_pos(symbol, mt5.TIMEFRAME_D1, 0, 1000)
df = pd.DataFrame(rates)
df['time'] = pd.to_datetime(df['time'], unit='s')
df.set_index('time', inplace=True)
historical_data[symbol] = df
우리가 입력한 이 코드에 무슨 일이 일어나고 있을까요? 우리는 MetaTrader에 각 트레이딩 상품에 대해 지난 1000일 동안의 데이터를 다운로드하도록 지시했습니다. 그런 다음 데이터가 테이블에 로드 됩니다.
다운로드한 데이터에는 지난 3년간 통화 시장에서 일어난 모든 일이 매우 상세하게 담겨 있습니다. 이제 수신된 호가를 분석하고 패턴을 찾을 수 있습니다. 여기서 우리가 할 수 있는 것은 사실상 무한합니다.
데이터 준비: 경제 지표와 시장 데이터 결합
이 단계에서 우리는 데이터 처리를 직접 다룹니다. 우리에게는 경제 지표의 세계와 환율의 세계라는 두 가지 부분이 있습니다. 우리의 임무는 이러한 부분을 하나로 모으는 것입니다.
데이터 준비 함수부터 시작하겠습니다. 이 코드는 우리의 일반적인 작업에서 다음과 같이 사용됩니다:
def prepare_data(symbol_data, economic_data): data = symbol_data.copy() data['close_diff'] = data['close'].diff() data['close_corr'] = data['close'].rolling(window=30).corr(data['close'].shift(1)) for indicator in indicators.keys(): if indicator in economic_data.columns: data[indicator] = economic_data[indicator] else: print(f"Warning: Data for indicator '{indicator}' is not available.") data.dropna(inplace=True) return data
이제 단계별로 살펴보겠습니다. 먼저 통화쌍 데이터의 복사본을 생성합니다. 왜 그럴까요? 항상 원본보다는 데이터 사본으로 작업하는 것이 좋습니다. 오류가 발생해도 원본 파일을 다시 만들 필요가 없게 됩니다.
이제 가장 흥미로운 부분이 나옵니다. 'close_diff'와 'close_corr'라는 두 개의 새로운 열을 추가합니다. 첫 번째는 전일 대비 종가가 얼마나 변동했는지 보여줍니다. 이렇게 하면 가격에 긍정적인 변화가 있는지 부정적인 변화가 있는지 알 수 있습니다. 두 번째는 종가와 종가 자체의 상관관계로 하루 단위로 변동하는 것입니다. 어디에 사용하는 것일까요? 사실 이는 오늘의 가격이 어제의 가격과 얼마나 비슷한지 이해하는 가장 편리한 방법입니다.
이제 어려운 부분이 시작됩니다. 통화 데이터에 경제 지표를 추가하려고 합니다. 이렇게 해서 우리는 데이터를 하나의 구조로 통합하기 시작하는 것입니다. 우리는 모든 경제 지표들을 검토하고 세계은행 데이터에서 이들을 찾을 것입니다. 만약 찾으면 통화 데이터에 추가합니다. 그렇지 않다면... 그런 경우도 있습니다. 그냥 경고만 작성하고 넘어갑니다.
이 모든 과정이 끝나면 누락된 데이터 행이 남을 수 있습니다. 그런 행들은 삭제합니다.
이제 이 함수를 어떻게 적용하는지 살펴보겠습니다:
prepared_data = {}
for symbol, df in historical_data.items():
prepared_data[symbol] = prepare_data(df, data)
각 통화 쌍을 가져와서 작성한 함수를 적용합니다. 출력에서 각 쌍에 대해 준비된 데이터 세트를 얻습니다. 각 쌍마다 별도의 세트가 있지만 모두 동일한 원리에 따라 조립됩니다.
이 과정에서 가장 중요한 것이 무엇인지 알고 계십니까? 우리는 새로운 것을 창조하고 있습니다. 다양한 경제 데이터와 실시간 환율 데이터를 취합하고 일관성 있는 무언가를 만들어냅니다. 개별적으로 보면 혼란스러워 보일 수 있지만 이를 종합하면 패턴을 파악할 수 있습니다.
이제 분석할 수 있는 데이터 세트가 준비되었습니다. 그 안에서 시퀀스를 찾고 예측을 하고 결론을 도출할 수 있습니다. 그러나 우리는 진정으로 주목할 만한 가치가 있는 징후를 알아차려야 합니다. 데이터의 세계에는 중요하지 않은 세부 사항이란 없습니다. 데이터 준비의 모든 단계는 최종 결과에 매우 중요할 수 있습니다.
모델 내 머신 러닝
머신 러닝은 다소 복잡하고 노동 집약적인 프로세스입니다. CatBoost Regressor - 이 함수는 나중에 중요한 역할을 하게 됩니다. 사용 방법은 다음과 같습니다:
from catboost import CatBoostRegressor model = CatBoostRegressor(iterations=1000, learning_rate=0.1, depth=8, loss_function='RMSE', verbose=100) model.fit(X_train, y_train, verbose=False)
여기서는 모든 매개변수가 중요합니다. 1000 iterations은 모델이 데이터를 실행하는 횟수입니다. Learning rate 0.1 - 바로 높은 속도를 설정할 필요 없이 서서히 학습해야 합니다. Depth 8 - 복잡한 연결을 찾습니다. RMSE - 오류를 평가하는 방법입니다. 모델을 훈련하는 데는 일정 시간이 걸립니다. 예시를 보여주고 정답을 평가합니다. CatBoost는 특히 다양한 유형의 데이터와 잘 작동합니다. 좁은 범위의 함수에만 국한되지 않습니다.
통화를 예측하기 위해 우리는 다음을 수행합니다:
def forecast(symbol_data):
X = symbol_data.drop(columns=['close'])
y = symbol_data['close']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5, shuffle=False)
model = CatBoostRegressor(iterations=1000, learning_rate=0.1, depth=8, loss_function='RMSE', verbose=100)
model.fit(X_train, y_train, verbose=False)
predictions = model.predict(X_test)
mse = mean_squared_error(y_test, predictions)
print(f"Mean Squared Error for {symbol}: {mse}")
데이터의 일부는 교육용이고 다른 일부는 테스트용입니다. 학교에 가는 것과 같습니다: 먼저 공부한 다음 시험을 치릅니다.
데이터를 두 부분으로 나눕니다. 왜 그럴까요? 하나는 교육용이고 다른 하나는 테스트용입니다. 우리는 아직 작업하지 않은 데이터에 대해 모델을 테스트해야 합니다.
학습 후 모델은 예측을 시도합니다. 평균 제곱근 오차는 예측이 얼마나 잘 작동했는지 보여줍니다. 오차가 작을수록 예측이 정확하다는 뜻입니다. CatBoost는 지속적으로 개선되고 있다는 점에서 주목할 만합니다. CatBoostsms 실수를 통해 학습합니다.
물론 자동 프로그램은 아닙니다. 좋은 데이터가 필요합니다. 그렇지 않으면 입력 시와 출력시 비효율적인 데이터를 얻게 됩니다. 하지만 올바른 데이터를 사용하면 결과는 긍정적입니다. 이제 데이터 분할에 대해 이야기해 보겠습니다. 확인을 위해 호가가 필요하다고 말씀드렸습니다. 코드에서는 다음과 같이 표시됩니다:
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5, shuffle=False) 데이터의 50%는 테스트에 사용됩니다. 이들을 섞지 마세요 - 재무 데이터의 시간 순서를 유지하는 것이 중요합니다.
모델을 만들고 훈련하는 것이 가장 흥미로운 부분입니다. 여기서 CatBoost는 그 기능을 최대한 발휘합니다:
model = CatBoostRegressor(iterations=1000, learning_rate=0.1, depth=8, loss_function='RMSE', verbose=100) model.fit(X_train, y_train, verbose=False)
이 모델은 패턴을 찾기 위해 탐욕스럽게 데이터를 흡수합니다. 각 반복은 시장을 더 잘 이해하기 위한 단계입니다.
그리고 이제 진실의 순간입니다. 정확도 평가:
predictions = model.predict(X_test) mse = mean_squared_error(y_test, predictions)
제곱근 평균 오차도 중요한 포인트입니다. 모델이 얼마나 잘못된 것인지 보여줍니다. 적을수록 좋습니다. 이를 통해 프로그램의 품질을 평가할 수 있습니다. 거래에서 무언가 보장하는 것은 없다는 점을 기억하세요. 하지만 CatBoost를 사용하면 프로세스가 더 효율적입니다. 우리가 놓칠 수 있는 것들을 포착합니다. 그리고 예측할 때마다 결과가 개선됩니다.
통화 쌍의 미래 가치 예측
통화 쌍을 예측하는 것은 확률로 작동합니다. 때로는 긍정적인 결과를 얻기도 하고 때로는 손해를 보기도 합니다. 가장 중요한 것은 최종 결과가 우리의 기대에 부응한다는 것입니다.
코드에서 '예측' 함수는 확률과 함께 작동합니다. 계산을 수행하는 방법은 다음과 같습니다:
def forecast(symbol_data): X = symbol_data.drop(columns=['close']) y = symbol_data['close'] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, shuffle=False) model = CatBoostRegressor(iterations=1000, learning_rate=0.1, depth=8, loss_function='RMSE', verbose=100) model.fit(X_train, y_train, verbose=False) predictions = model.predict(X_test) mse = mean_squared_error(y_test, predictions) print(f"Mean Squared Error for {symbol}: {mse}") future_data = symbol_data.tail(30).copy() if len(predictions) >= 30: future_data['close'] = predictions[-30:] else: future_data['close'] = predictions future_predictions = model.predict(future_data.drop(columns=['close'])) return future_predictions
먼저 이미 사용 가능한 데이터와 예측된 데이터를 분리합니다. 그런 다음 데이터를 교육용과 테스트용의 두 부분으로 나눕니다. 모델은 한 데이터 세트에서 학습하고 다른 데이터 세트에서 테스트합니다. 학습 후 모델은 예측을 수행합니다. 평균 제곱근 오차를 사용하여 얼마나 잘못되었는지 살펴봅니다. 숫자가 낮을수록 예측이 더 정확하다는 뜻입니다.
하지만 가장 흥미로운 것은 향후 가격 변동 가능성에 대한 시세 분석입니다. 지난 30일간의 데이터를 가지고 모델에 다음에 일어날 일을 예측하도록 요청합니다. 이는 마치 우리가 숙련된 애널리스트의 예측에 의존하는 상황처럼 보입니다. 시각화에 관해서는... 안타깝게도 이 코드는 아직 결과에 대한 명시적인 시각화를 제공하지 않습니다. 하지만 추후 추가해서 어떤 모습인지 확인해 보겠습니다:
import matplotlib.pyplot as plt for symbol, forecast in forecasts.items(): plt.figure(figsize=(12, 6)) plt.plot(range(len(forecast)), forecast, label='Forecast') plt.title(f'Forecast for {symbol}') plt.xlabel('Days') plt.ylabel('Price') plt.legend() plt.savefig(f'{symbol}_forecast.png') plt.close()
이 코드는 각 통화 쌍에 대한 차트를 생성합니다. 시각적으로는 선형적으로 구축되어 있습니다. 각 포인트는 특정 날짜의 예상 가격입니다. 이러한 차트는 가능한 추세를 보여주기 위해 고안된 것으로 일반인이 사용하기에는 너무 복잡한 방대한 양의 데이터로 작업을 수행합니다. 선이 위쪽으로 향하면 통화가 더 비싸질 것입니다. 아래쪽으로 향하나요? 하락에 대비하세요.
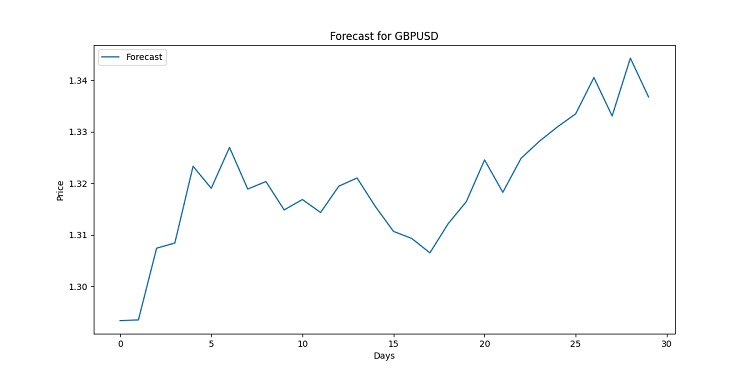
예측은 보장되지 않는다는 점을 기억하세요. 시장은 스스로 변화할 수 있습니다. 하지만 시각화가 잘 되어 있으면 최소한 무엇을 기대할 수 있는지 알 수 있을 것입니다. 결국 이 상황에서 우리는 손끝으로 고품질의 분석을 할 수 있습니다.
또한 파일을 열고 예측 결과를 코멘트로 출력하여 MQL5에서 예측 결과를 시각화 하는 코드를 만들었습니다:
//+------------------------------------------------------------------+ //| Economic Forecast| //| Copyright 2024, Evgeniy Koshtenko | //| https://www.mql5.com/en/users/koshtenko | //+------------------------------------------------------------------+ #property copyright "Copyright 2023, Evgeniy Koshtenko" #property link "https://www.mql5.com/en/users/koshtenko" #property version "4.00" #property strict #property indicator_chart_window #property indicator_buffers 1 #property indicator_plots 1 #property indicator_label1 "Forecast" #property indicator_type1 DRAW_SECTION #property indicator_color1 clrRed #property indicator_style1 STYLE_SOLID #property indicator_width1 2 double ForecastBuffer[]; input string FileName = "EURUSD_forecast.csv"; // Forecast file name //+------------------------------------------------------------------+ //| Custom indicator initialization function | //+------------------------------------------------------------------+ int OnInit() { SetIndexBuffer(0, ForecastBuffer, INDICATOR_DATA); PlotIndexSetDouble(0, PLOT_EMPTY_VALUE, EMPTY_VALUE); return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //| Draw forecast | //+------------------------------------------------------------------+ int OnCalculate(const int rates_total, const int prev_calculated, const datetime &time[], const double &open[], const double &high[], const double &low[], const double &close[], const long &tick_volume[], const long &volume[], const int &spread[]) { static bool first=true; string comment = ""; if(first) { ArrayInitialize(ForecastBuffer, EMPTY_VALUE); ArraySetAsSeries(ForecastBuffer, true); int file_handle = FileOpen(FileName, FILE_READ|FILE_CSV|FILE_ANSI); if(file_handle != INVALID_HANDLE) { // Skip the header string header = FileReadString(file_handle); comment += header + "\n"; // Read data from file while(!FileIsEnding(file_handle)) { string line = FileReadString(file_handle); string str_array[]; StringSplit(line, ',', str_array); datetime time=StringToTime(str_array[0]); double price=StringToDouble(str_array[1]); PrintFormat("%s %G", TimeToString(time), price); comment += str_array[0] + ", " + str_array[1] + "\n"; // Find the corresponding bar on the chart and set the forecast value int bar_index = iBarShift(_Symbol, PERIOD_CURRENT, time); if(bar_index >= 0 && bar_index < rates_total) { ForecastBuffer[bar_index] = price; PrintFormat("%d %s %G", bar_index, TimeToString(time), price); } } FileClose(file_handle); first=false; } else { comment = "Failed to open file: " + FileName; } Comment(comment); } return(rates_total); } //+------------------------------------------------------------------+ //| Indicator deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { Comment(""); } //+------------------------------------------------------------------+ //| Create the arrow | //+------------------------------------------------------------------+ bool ArrowCreate(const long chart_ID=0, // chart ID const string name="Arrow", // arrow name const int sub_window=0, // subwindow number datetime time=0, // anchor point time double price=0, // anchor point price const uchar arrow_code=252, // arrow code const ENUM_ARROW_ANCHOR anchor=ANCHOR_BOTTOM, // anchor point position const color clr=clrRed, // arrow color const ENUM_LINE_STYLE style=STYLE_SOLID, // border line style const int width=3, // arrow size const bool back=false, // in the background const bool selection=true, // allocate for moving const bool hidden=true, // hidden in the list of objects const long z_order=0) // mouse click priority { //--- set anchor point coordinates if absent ChangeArrowEmptyPoint(time, price); //--- reset the error value ResetLastError(); //--- create an arrow if(!ObjectCreate(chart_ID, name, OBJ_ARROW, sub_window, time, price)) { Print(__FUNCTION__, ": failed to create an arrow! Error code = ", GetLastError()); return(false); } //--- set the arrow code ObjectSetInteger(chart_ID, name, OBJPROP_ARROWCODE, arrow_code); //--- set anchor type ObjectSetInteger(chart_ID, name, OBJPROP_ANCHOR, anchor); //--- set the arrow color ObjectSetInteger(chart_ID, name, OBJPROP_COLOR, clr); //--- set the border line style ObjectSetInteger(chart_ID, name, OBJPROP_STYLE, style); //--- set the arrow size ObjectSetInteger(chart_ID, name, OBJPROP_WIDTH, width); //--- display in the foreground (false) or background (true) ObjectSetInteger(chart_ID, name, OBJPROP_BACK, back); //--- enable (true) or disable (false) the mode of moving the arrow by mouse //--- when creating a graphical object using ObjectCreate function, the object cannot be //--- highlighted and moved by default. Selection parameter inside this method //--- is true by default making it possible to highlight and move the object ObjectSetInteger(chart_ID, name, OBJPROP_SELECTABLE, selection); ObjectSetInteger(chart_ID, name, OBJPROP_SELECTED, selection); //--- hide (true) or display (false) graphical object name in the object list ObjectSetInteger(chart_ID, name, OBJPROP_HIDDEN, hidden); //--- set the priority for receiving the event of a mouse click on the chart ObjectSetInteger(chart_ID, name, OBJPROP_ZORDER, z_order); //--- successful execution return(true); } //+------------------------------------------------------------------+ //| Check anchor point values and set default values | //| for empty ones | //+------------------------------------------------------------------+ void ChangeArrowEmptyPoint(datetime &time, double &price) { //--- if the point time is not set, it will be on the current bar if(!time) time=TimeCurrent(); //--- if the point price is not set, it will have Bid value if(!price) price=SymbolInfoDouble(Symbol(), SYMBOL_BID); } //+------------------------------------------------------------------+
터미널에서 예측이 표시되는 방식은 다음과 같습니다:
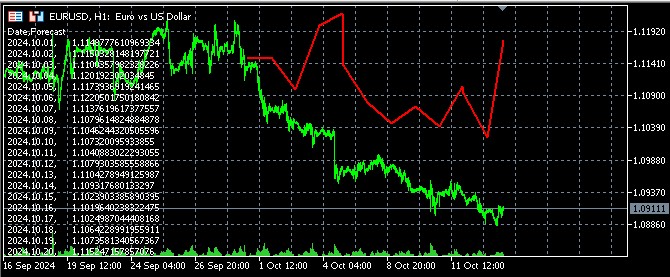
결과 해석: 환율에 대한 경제적 요인의 영향 분석
이제 코드를 기반으로 결과를 해석하는 방법을 자세히 살펴보겠습니다. 우리는 수천 개의 서로 다른 사실들을 수집하여 분석이 필요한 체계적인 데이터로 만들었습니다.
GDP 성장률부터 실업률까지 다양한 경제 지표가 있다는 사실부터 시작하겠습니다. 각 요인은 시장 배경에 고유한 영향을 미칩니다. 개별 지표는 그 자체로도 영향을 미치지만 이러한 데이터가 합쳐져 최종 환율에 영향을 미칩니다.
GDP를 예로 들어 보겠습니다. GDP는 코드에서 여러 지표로 표시됩니다:
'NY.GDP.MKTP.KD.ZG': 'GDP growth', 'NY.GDP.PCAP.KD.ZG': 'GDP per capita growth',
일반적으로 GDP 성장은 통화를 강세로 만듭니다. 왜 그럴까요? 긍정적인 소식은 더 큰 성장을 위해 자본을 투자할 기회를 찾는 플레이어를 끌어들이기 때문입니다. 투자자들은 경제가 성장하면서 해당 통화에 대한 수요가 늘어나는 것에 매력을 느낍니다.
반대로 인플레이션('FP.CPI.TOTL.ZG': '인플레이션')은 트레이더들에게 경고 신호입니다. 인플레이션이 높을수록 화폐의 가치는 더 빨리 하락합니다. 높은 인플레이션은 일반적으로 해당 국가에서 서비스와 상품이 훨씬 더 비싸지기 시작하기 때문에 통화를 약화시킵니다.
무역 수지를 살펴보는 것도 흥미롭습니다:
'NE.EXP.GNFS.ZS': 'Exports', 'NE.IMP.GNFS.ZS': 'Imports', 'BN.CAB.XOKA.GD.ZS': 'Current account balance',
이러한 지표는 저울과 같은 역할을 합니다. 수출이 수입보다 많으면 국가는 더 많은 외화를 수입하게 되고 이는 일반적으로 국가 통화를 강하게 합니다.
이제 이를 코드에서 어떻게 분석하는지 살펴보겠습니다. CatBoost Regressor는 우리의 주요 도구와 같습니다. 마치 숙련된 지휘자처럼 모든 악기를 한 번에 듣고 악기들이 서로에게 어떤 영향을 미치는지 파악합니다.
요인의 영향을 더 잘 이해하기 위해 예측 함수에 추가할 수 있는 항목은 다음과 같습니다:
def forecast(symbol_data):
# ......
feature_importance = model.feature_importances_
feature_names = X.columns
importance_df = pd.DataFrame({'feature': feature_names, 'importance': feature_importance})
importance_df = importance_df.sort_values('importance', ascending=False)
print(f"Feature Importance for {symbol}:")
print(importance_df.head(10)) # Top 10 important factors
return future_predictions
이렇게 하면 각 통화쌍의 예측에 가장 중요한 요인이 무엇인지 알 수 있습니다. 유로화의 경우 핵심 요인은 ECB 금리이고 엔화의 경우 일본의 무역 수지일 수 있습니다. 데이터 출력 예시:
EURUSD 해석:
1. 가격 동향: 향후 30일 동안의 상승 추세가 예측됩니다.
2. 변동성: 가격 움직임은 낮은 변동성이 예측됩니다.
3. 주요 영향 요인: 이 예측에서 가장 중요한 기능은 '낮음'입니다.
4. 경제적 영향:
- GDP 성장률이 가장 큰 요인이라면 경제 성과가 통화 가치에 영향을 미치고 있다는 뜻입니다.
- 인플레이션율의 중요도가 높다는 것은 통화 정책의 변화가 통화에 영향을 미치고 있음을 나타낼 수 있습니다.
- 무역 수지 요인이 중요한 경우 국제 무역의 역학이 통화 움직임을 주도할 가능성이 높습니다.
5. 트레이딩 시사점:
- 상승 추세는 매수 포지션의 가능성을 시사합니다.
- 변동성이 낮을수록 손절매 범위가 넓어질 수 있습니다.
6. 위험 평가:
- 항상 모델의 한계와 예상치 못한 시장 이벤트의 발생 가능성을 염두하세요.
- 과거의 성과가 미래의 결과를 보장하지는 않습니다.
하지만 경제학에 쉬운 답은 없다는 것을 기억하세요. 어떤 통화는 모든 예상을 깨고 강세를 보이기도 하고 때로는 뚜렷한 이유 없이 하락하기도 합니다. 시장은 종종 현재의 현실보다는 기대에 따라 움직입니다.
또 다른 중요한 점은 시간 지연입니다. 경제 상황의 변화는 환율에 즉시 반영되지 않습니다. 마치 거대한 배를 조종하는 것과 같습니다. 핸들을 돌리지만 배는 즉시 항로를 바꾸지 않습니다. 코드에서는 매일 데이터를 사용하지만 일부 경제 지표는 업데이트 빈도가 낮습니다. 이로 인해 예측에 약간의 오차가 발생할 수 있습니다. 궁극적으로 결과를 해석하는 것은 과학만큼이나 예술입니다. 모델은 강력한 도구이지만 의사 결정은 항상 사람이 내립니다. 이 데이터를 현명하게 사용하여 예측이 정확해지기를 바랍니다!
경제 데이터에서 명확하지 않은 패턴 찾기
외환 시장은 거대한 거래 플랫폼입니다. 예측 가능한 가격 변동으로 특징 지어지는 것은 아니지만 이 외에도 현재 변동성과 유동성을 증가시키는 특별한 이벤트가 있습니다. 글로벌 이벤트입니다.
저희 코드에서는 경제 지표에 의존합니다:
indicators = {
'NY.GDP.MKTP.KD.ZG': 'GDP growth',
'FP.CPI.TOTL.ZG': 'Inflation',
# ...
}
하지만 예상치 못한 일이 발생하면 어떻게 해야 할까요? 예를 들어 팬데믹이나 정치적 위기가 발생했을 경우는 어떨까요?
여기에는 일종의 '서프라이즈 인덱스'가 유용할 것입니다. 우리의 코드에 다음과 같은 내용을 추가한다고 상상해 보세요:
def add_global_event_impact(data, event_date, event_magnitude): data['global_event'] = 0 data.loc[event_date:, 'global_event'] = event_magnitude data['global_event_decay'] = data['global_event'].ewm(halflife=30).mean() return data # --- def prepare_data(symbol_data, economic_data): # ... ... data = add_global_event_impact(data, '2020-03-11', 0.5) # return data
이를 통해 갑작스러운 글로벌 이벤트와 그 이벤트의 점진적인 안정화를 고려할 수 있습니다.
하지만 여기서 가장 흥미로운 질문은 이것이 예측에 어떤 영향을 미치는지 입니다. 때때로 글로벌 이벤트는 우리의 기대를 완전히 뒤집어 놓을 수 있습니다. 예를 들어 위기 상황에서는 USD나 CHF와 같은 '안전한' 통화가 경제 논리에 반해 강세를 보일 수 있습니다.
이럴 때 우리의 모델은 기능이 떨어집니다. 여기서 중요한 것은 당황하지 않고 적응하는 것입니다. 이럴때 예측 기간을 일시적으로 줄이거나 최근 데이터에 더 많은 가중치를 부여하는 것이 좋을까요?
recent_weight = 2 if data['global_event'].iloc[-1] > 0 else 1 model.fit(X_train, y_train, sample_weight=np.linspace(1, recent_weight, len(X_train)))
기억하세요: 춤과 마찬가지로 통화의 세계에서 가장 중요한 것은 리듬에 적응할 수 있어야 한다는 것입니다. 이 리듬이 때때로 예상치 못한 방식으로 바뀌더라도 말입니다!
이상 징후 찾기: 경제 데이터에서 명확하지 않은 패턴을 찾는 방법
이제 가장 흥미로운 부분, 데이터에서 숨겨진 보물을 찾는 것에 대해 이야기해 보겠습니다. 마치 탐정이 된 것 같지만 우리에게는 증거 대신 숫자와 차트가 있습니다.
우리는 이미 코드에서 꽤 많은 경제 지표를 사용하고 있습니다. 하지만 이들 사이에 분명하지 않은 연관성이 있다면 어떨까요? 이제 찾아봅시다!
우선 여러 지표 간의 상관관계를 살펴볼 수 있습니다:
correlation_matrix = data[list(indicators.keys())].corr() print(correlation_matrix)
하지만 이것은 시작에 불과합니다. 진정한 마법은 비선형 관계를 찾기 시작할 때 시작됩니다. 예를 들어 GDP의 변화가 환율에 즉각적인 영향을 미치지 않고 몇 달의 시차를 두고 영향을 미치는 것으로 나타날 수 있습니다.
데이터 준비 함수에 '이동된' 메트릭을 추가해 보겠습니다:
def prepare_data(symbol_data, economic_data): # ...... for indicator in indicators.keys(): if indicator in economic_data.columns: data[indicator] = economic_data[indicator] data[f"{indicator}_lag_3"] = economic_data[indicator].shift(3) data[f"{indicator}_lag_6"] = economic_data[indicator].shift(6) # ...
이제 우리의 모델은 3개월과 6개월의 지연으로 종속성을 캡처할 수 있습니다.
하지만 가장 흥미로운 것은 완전히 명확하지 않은 패턴을 찾는 것입니다. 예를 들어 유로화 환율이 미국의 아이스크림 판매량과 이상하게 상관관계가 있다는 것이 밝혀질 수 있습니다(대략적인 아이디어를 상정하는 농담입니다).
이러한 목적을 위해 특징을 추출하는 메서드, 예를 들어 주성분 분석(PCA; Principal Component Analysis)을 사용할 수 있습니다:
from sklearn.decomposition import PCA
def find_hidden_patterns(data):
pca = PCA(n_components=5)
pca_result = pca.fit_transform(data[list(indicators.keys())])
print("Explained variance ratio:", pca.explained_variance_ratio_)
return pca_result
pca_features = find_hidden_patterns(data)
data['hidden_pattern_1'] = pca_features[:, 0]
data['hidden_pattern_2'] = pca_features[:, 1]
이러한 '숨겨진 패턴'이 더 정확한 예측을 위한 열쇠가 될 수 있습니다.
계절적 요인도 잊지 마세요. 일부 통화는 연중 시기에 따라 다르게 작동할 수 있습니다. 데이터에 월과 요일 정보를 추가하면 흥미로운 것을 발견할 수 있습니다!
data['month'] = data.index.month data['day_of_week'] = data.index.dayofweek
데이터의 세계에는 항상 새로운 발견의 여지가 있다는 것을 기억하세요. 호기심을 갖고 실험해 보면 트레이딩 세계를 바꿀 바로 그 패턴을 발견할 수 있을지도 모릅니다.
결론: 알고리즘 트레이딩에서 경제 예측 전망
우리는 경제 데이터를 기반으로 환율의 움직임을 예측할 수 있을까라는 간단한 아이디어에서 출발했습니다. 무엇을 알아냈나요? 이 아이디어에는 몇 가지 장점이 있는 것으로 밝혀졌습니다. 하지만 언뜻 보기만큼 간단하지는 않습니다.
이 코드는 경제 데이터 분석을 크게 간소화합니다. 우리는 전 세계의 정보를 수집하고 처리하는 법을 배웠으며 컴퓨터가 예측을 하도록 만들기도 했습니다. 하지만 가장 진보된 머신 러닝 모델이더라도 도구일 뿐이라는 점을 기억하세요. 매우 강력한 도구이지만 여전히 도구일 뿐입니다.
CatBoost Regressor가 어떻게 경제 지표와 환율 간의 복잡한 관계를 찾아내는지 살펴보았습니다. 이를 통해 사람의 능력을 뛰어넘어 데이터 처리 및 분석에 소요되는 시간을 크게 줄일 수 있습니다. 하지만 아무리 훌륭한 도구라도 100%의 정확도로 미래를 예측할 수는 없습니다.
왜 그럴까요? 경제는 여러 요인에 따라 달라지는 과정이기 때문입니다. 오늘은 모두가 유가를 주시하고 있지만 내일은 예상치 못한 사건으로 전 세계가 뒤집어질 수도 있습니다. 우리는 '서프라이즈 지수'에 대해 이야기할 때 이 효과에 대해 알아보았습니다. 이것이 바로 예상치 못한 사건이라는 것이 중요한 이유입니다.
MetaQuotes 소프트웨어 사를 통해 러시아어가 번역됨.
원본 기고글: https://www.mql5.com/ru/articles/15998
경고: 이 자료들에 대한 모든 권한은 MetaQuotes(MetaQuotes Ltd.)에 있습니다. 이 자료들의 전부 또는 일부에 대한 복제 및 재출력은 금지됩니다.
이 글은 사이트 사용자가 작성했으며 개인의 견해를 반영합니다. Metaquotes Ltd는 제시된 정보의 정확성 또는 설명 된 솔루션, 전략 또는 권장 사항의 사용으로 인한 결과에 대해 책임을 지지 않습니다.

여기서부터 시작하세요. 이 주제에 관한 오래된 기사입니다.
지금까지 제가 즉석에서 얻을 수 있는 것은 오늘의 현재 데이터입니다((((
이해가 안 되는 것은 MQ가 하는 일이 무엇인가요?
위의 작성자의 신호입니다.
이 신호는 순전히 Sber에서 하나의 모델을 테스트하기 위해 만들어졌습니다. 그러나 나는 그것을 테스트 한 적이 없으며 이미 머니 마켓 펀드의 통화 일뿐입니다. 기본적으로 나는 내 모델에서 자신을 거래하지 않고 개선 및 개발에 대한 아이디어에서 벗어날 수 없습니다)))) 개선에 대한 끊임없이 새로운 아이디어가 있습니다) 그리고 증권 거래소에서는 주로 주식에 투자하고 장기적으로는 MOEX에서 비 레즈로 주식을 매수하고 Kazbirji 지수 회사의 KASE에서 주식을 매수합니다.
지금까지 저희가 즉석에서 얻을 수 있는 최선은 오늘 현재 데이터입니다((((.
제가 알기로는 모니터링에 연결된 계정에 대한 데이터를 수집한다고 하던데요? 모든 것이 정직하더라도 그것은 바다의 한 방울입니다.
임호, 현물이 아니라 옵션이 있는 선물일지라도 CFTC의 데이터가 더 신뢰할 수 있습니다. 매우 편리한 형태는 아니지만 2005년부터의 역사가 있지만, 아마도 파이썬용 API가 있을 것입니다.
물론 제 의견을 공유하는 것은 여러분의 몫입니다.
이 신호는 순전히 Sber에서 하나의 모델을 테스트하기 위해 만들어졌습니다. 그러나 나는 그것을 테스트 한 적이 없으며 이미 머니 마켓 펀드의 통화 일뿐입니다. 기본적으로 나는 내 모델에서 자신을 거래하지 않고 개선 및 개발에 대한 아이디어에서 벗어날 수 없습니다)))) 개선에 대한 끊임없이 새로운 아이디어가 있습니다) 그리고 증권 거래소에서는 주로 주식에 투자하고 장기적으로는 MOEX에서 비 레즈로 주식을 매수하고 Kazbirji 지수 회사의 KASE에서 주식을 매수합니다.
거기에 정보의 불일치가 있으며 귀하에게 청구하지 않습니다.