
Previsioni economiche: Esplorare il potenziale di Python

Introduzione
Le previsioni economiche sono un compito piuttosto complesso e ad alta intensità di lavoro. Ci permette di analizzare i possibili movimenti futuri utilizzando i dati del passato. Analizzando i dati storici e gli indicatori economici attuali, possiamo fare ipotesi su dove potrebbe dirigersi l’economia. È un'abilità decisamente utile. Con il suo aiuto, possiamo prendere decisioni più informate in materia di affari, investimenti e politica economica.
Svilupperemo questo strumento utilizzando Python e i dati economici, dalla raccolta di informazioni alla creazione di modelli predittivi. Analizzerà e farà anche previsioni per il futuro.
I mercati finanziari sono un buon barometro dell'economia. Reagiscono ai minimi cambiamenti. Il risultato può essere prevedibile o inaspettato. Vediamo alcuni esempi di letture che fanno fluttuare questo barometro.
Quando il PIL cresce, i mercati di solito reagiscono positivamente. Quando l'inflazione aumenta, di solito si prevede agitazione. Quando la disoccupazione diminuisce, di solito viene vista come una buona notizia. Tuttavia, potrebbero esserci delle eccezioni. Bilancia commerciale, tassi di interesse - ogni indicatore influisce sul sentimento del mercato.
Come dimostra la pratica, i mercati spesso non reagiscono al risultato effettivo, ma alle aspettative della maggioranza degli operatori. "Compra voci, vendi fatti" - questa vecchia saggezza del mercato azionario riflette con precisione l'essenza di ciò che sta accadendo. Inoltre, l'assenza di cambiamenti significativi può causare una maggiore volatilità nel mercato rispetto alle notizie inaspettate.
L'economia è un sistema complesso. Qui tutto è interconnesso e un fattore influenza l'altro. La variazione di un parametro può innescare una reazione a catena. Il nostro compito è comprendere queste connessioni e imparare ad analizzarle. Cercheremo soluzioni utilizzando lo strumento Python.
Impostazione dell'ambiente: Importare le librerie necessarie
Quindi, di cosa abbiamo bisogno? Prima di tutto - Python. Se non l'avete ancora installato, andate su python.org. Inoltre, non dimenticate di selezionare la casella "Add Python to PATH" durante il processo di installazione.
Il passo successivo sono le librerie. Le librerie ampliano in modo significativo le capacità di base del nostro strumento. Avremo bisogno di:
- pandas - per la gestione dei dati.
- wbdata - per interagire con la Banca Mondiale. Con l'aiuto di queste librerie, otterremo i dati economici più recenti.
- MetaTrader 5 - ci servirà per interagire direttamente con il mercato stesso.
- CatBoostRegressor da catboost - una piccola intelligenza artificiale artigianale.
- train_test_split e mean_squared_error da sklearn - queste librerie ci aiutano a valutare l'efficacia del nostro modello.
Per installare tutto ciò di cui avete bisogno, aprite un prompt dei comandi e inserite:
pip install pandas wbdata MetaTrader5 catboost scikit-learn
È tutto pronto? Ottimo! Ora scriviamo le nostre prime stringhe di codice:
import pandas as pd import wbdata import MetaTrader5 as mt5 from catboost import CatBoostRegressor from sklearn.model_selection import train_test_split from sklearn.metrics import mean_squared_error import warnings warnings.filterwarnings("ignore", category=UserWarning, module="wbdata")
Abbiamo preparato tutti gli strumenti necessari. Andiamo avanti.
Lavorare con le API della Banca Mondiale: Caricamento degli indicatori economici
Ora cerchiamo di capire come riceveremo i dati economici dalla Banca Mondiale.
Per prima cosa creiamo un dizionario con i codici degli indicatori:
indicators = {
'NY.GDP.MKTP.KD.ZG': 'GDP growth', # GDP growth
'FP.CPI.TOTL.ZG': 'Inflation', # Inflation
'FR.INR.RINR': 'Real interest rate', # Real interest rate
# ... and a bunch of other smart parameters
}
Ciascuno di questi codici fornisce l’accesso a un tipo specifico di dati.
Proseguiamo. Avviamo un ciclo che attraverserà l'intero codice:
data_frames = [] for indicator in indicators.keys(): try: data_frame = wbdata.get_dataframe({indicator: indicators[indicator]}, country='all') data_frames.append(data_frame) except Exception as e: print(f"Error fetching data for indicator '{indicator}': {e}")
Qui cerchiamo di ottenere i dati per ogni indicatore. Se funziona, lo inseriamo nella lista. Se fallisce, stampa un errore e va avanti.
Successivamente, raccogliamo tutti i dati in un unico grande DataFrame:
data = pd.concat(data_frames, axis=1) In questa fase, dobbiamo ottenere tutti i dati economici.
Il passo successivo è quello di salvare tutto ciò che abbiamo ricevuto in un file, in modo da poterlo utilizzare in seguito per gli scopi di cui abbiamo bisogno:
data.to_csv('economic_data.csv', index=True) Abbiamo appena scaricato una serie di dati dalla Banca Mondiale. È così semplice.
Panoramica dei principali indicatori economici per l'analisi
Se siete alle prime armi, potrebbe essere un po' difficile capire molti dati e numeri. Vediamo i principali indicatori per facilitare il processo:
- La crescita del PIL è una sorta di reddito per un Paese. Gli indicatori in crescita sono positivi, mentre quelli in calo hanno un impatto negativo sul Paese.
- L'inflazione è l'aumento dei prezzi di beni e servizi.
- Tasso di interesse reale - se aumenta, rende i prestiti più costosi.
- Le esportazioni e le importazioni mostrano ciò che un Paese vende e acquista. L'aumento delle vendite è visto come uno sviluppo positivo.
- Saldo dei conti correnti - quanto denaro gli altri Paesi devono a un certo Paese. Numeri più alti indicano una buona condizione finanziaria di un Paese.
- Il debito pubblico rappresenta i prestiti di un Paese. Più i numeri sono piccoli, meglio è.
- Disoccupazione - quante persone sono senza lavoro. Meno è meglio.
- La crescita del PIL pro capite mostra se una persona media sta diventando più ricca o meno.
Il codice si presenta come segue:
# Loading data from the World Bank
indicators = {
'NY.GDP.MKTP.KD.ZG': 'GDP growth', # GDP growth
'FP.CPI.TOTL.ZG': 'Inflation', # Inflation
'FR.INR.RINR': 'Real interest rate', # Real interest rate
'NE.EXP.GNFS.ZS': 'Exports', # Exports of goods and services (% of GDP)
'NE.IMP.GNFS.ZS': 'Imports', # Imports of goods and services (% of GDP)
'BN.CAB.XOKA.GD.ZS': 'Current account balance', # Current account balance (% of GDP)
'GC.DOD.TOTL.GD.ZS': 'Government debt', # Government debt (% of GDP)
'SL.UEM.TOTL.ZS': 'Unemployment rate', # Unemployment rate (% of total labor force)
'NY.GNP.PCAP.CD': 'GNI per capita', # GNI per capita (current US$)
'NY.GDP.PCAP.KD.ZG': 'GDP per capita growth', # GDP per capita growth (constant 2010 US$)
'NE.RSB.GNFS.ZS': 'Reserves in months of imports', # Reserves in months of imports
'NY.GDP.DEFL.KD.ZG': 'GDP deflator', # GDP deflator (constant 2010 US$)
'NY.GDP.PCAP.KD': 'GDP per capita (constant 2015 US$)', # GDP per capita (constant 2015 US$)
'NY.GDP.PCAP.PP.CD': 'GDP per capita, PPP (current international $)', # GDP per capita, PPP (current international $)
'NY.GDP.PCAP.PP.KD': 'GDP per capita, PPP (constant 2017 international $)', # GDP per capita, PPP (constant 2017 international $)
'NY.GDP.PCAP.CN': 'GDP per capita (current LCU)', # GDP per capita (current LCU)
'NY.GDP.PCAP.KN': 'GDP per capita (constant LCU)', # GDP per capita (constant LCU)
'NY.GDP.PCAP.CD': 'GDP per capita (current US$)', # GDP per capita (current US$)
'NY.GDP.PCAP.KD': 'GDP per capita (constant 2010 US$)', # GDP per capita (constant 2010 US$)
'NY.GDP.PCAP.KD.ZG': 'GDP per capita growth (annual %)', # GDP per capita growth (annual %)
'NY.GDP.PCAP.KN.ZG': 'GDP per capita growth (constant LCU)', # GDP per capita growth (constant LCU)
}
Ogni indicatore ha la sua importanza. Singolarmente dicono poco, ma insieme danno un quadro più completo. Si dovrebbe notare inoltre che gli indicatori si influenzano a vicenda. Ad esempio, un basso tasso di disoccupazione è di solito una buona notizia, ma può portare a un aumento dell'inflazione. Oppure una crescita elevata del PIL potrebbe non essere così positiva se ottenuta a scapito di debiti enormi.
Per questo motivo utilizziamo l'apprendimento automatico, che ci aiuta a tenere conto di tutte queste relazioni complesse. Accelera notevolmente il processo di elaborazione delle informazioni e ordina i dati. Tuttavia, dovrete anche impegnarvi a comprendere il processo.
Gestione e strutturazione dei dati della Banca Mondiale
Naturalmente, a prima vista, la ricchezza di dati della Banca Mondiale può sembrare un compito scoraggiante da comprendere. Per facilitare il lavoro e l'analisi, raccoglieremo i dati in una tabella.
data_frames = [] for indicator in indicators.keys(): try: data_frame = wbdata.get_dataframe({indicator: indicators[indicator]}, country='all') data_frames.append(data_frame) except Exception as e: print(f"Error fetching data for indicator '{indicator}': {e}") data = pd.concat(data_frames, axis=1)
Successivamente, prendiamo ogni indicatore e cerchiamo di ottenere i relativi dati. Se ci sono problemi con i singoli indicatori, lo scriviamo e andiamo avanti. Quindi raccogliamo i singoli dati in un grande DataFrame.
Ma non ci fermiamo qui. Ora inizia la parte più interessante.
print("Available indicators and their data:")
print(data.columns)
print(data.head())
data.to_csv('economic_data.csv', index=True)
print("Economic Data Statistics:")
print(data.describe())
Guardiamo a ciò che abbiamo realizzato. Quali sono gli indicatori? Che aspetto hanno le prime righe di dati? È come la prima occhiata a un puzzle completato: è tutto al suo posto? E poi salviamo tutto questo in un file CSV.
Infine, alcune statistiche. Valori medi, massimi e minimi. È come un rapido controllo - è tutto a posto con i nostri dati? È così che trasformiamo un insieme di numeri eterogenei in un sistema di dati coerente. Ora abbiamo tutti gli strumenti per un'analisi economica seria.
Introduzione a MetaTrader 5: Stabilire una connessione e ricevere dati
Parliamo ora di MetaTrader 5. Per prima cosa è necessario stabilire una connessione. Ecco come appare:
if not mt5.initialize(): print("initialize() failed") mt5.shutdown()
Il passo successivo è quello di ottenere i dati. Per prima cosa, dobbiamo verificare quali coppie di valute sono disponibili:
symbols = mt5.symbols_get()
symbol_names = [symbol.name for symbol in symbols]
Una volta eseguito il codice di cui sopra, si otterrà un elenco di tutte le coppie di valute disponibili. Successivamente, è necessario scaricare i dati storici delle quotazioni per ogni coppia disponibile:
historical_data = {}
for symbol in symbol_names:
rates = mt5.copy_rates_from_pos(symbol, mt5.TIMEFRAME_D1, 0, 1000)
df = pd.DataFrame(rates)
df['time'] = pd.to_datetime(df['time'], unit='s')
df.set_index('time', inplace=True)
historical_data[symbol] = df
Cosa succede nel codice che abbiamo inserito? Abbiamo chiesto a MetaTrader di scaricare i dati degli ultimi 1000 giorni per ogni strumento di trading. Successivamente, i dati vengono caricati nella tabella.
I dati scaricati contengono tutto ciò che è accaduto nel mercato valutario negli ultimi tre anni, in modo estremamente dettagliato. A questo punto, è possibile analizzare le quotazioni ricevute e individuare i modelli. Le possibilità qui sono praticamente illimitate.
Preparazione dei dati: Combinazione di indicatori economici e dati di mercato
In questa fase ci occuperemo direttamente del trattamento dei dati. Abbiamo due settori separati: il mondo degli indicatori economici e quello dei tassi di cambio. Il nostro compito è quello di unire questi settori.
Iniziamo con la funzione di preparazione dei dati. Questo codice sarà il seguente nel nostro compito generale:
def prepare_data(symbol_data, economic_data): data = symbol_data.copy() data['close_diff'] = data['close'].diff() data['close_corr'] = data['close'].rolling(window=30).corr(data['close'].shift(1)) for indicator in indicators.keys(): if indicator in economic_data.columns: data[indicator] = economic_data[indicator] else: print(f"Warning: Data for indicator '{indicator}' is not available.") data.dropna(inplace=True) return data
Ora procediamo passo-passo. Innanzitutto, creiamo una copia dei dati della coppia di valute. Perché? È sempre meglio lavorare con una copia dei dati piuttosto che con l'originale. In caso di errore, non sarà necessario creare nuovamente il file originale.
Ora viene la parte più interessante. Aggiungiamo due nuove colonne: 'close_diff' e 'close_corr'. Il primo mostra la variazione del prezzo di chiusura rispetto al giorno precedente. In questo modo sapremo se c'è uno scostamento positivo o negativo del prezzo. La seconda è la correlazione del prezzo di chiusura con se stessa, ma con uno scostamento di un giorno. A cosa serve questo? In effetti, è semplicemente il modo più conveniente per capire quanto il prezzo di oggi sia simile a quello di ieri.
Ora viene la parte difficile: proviamo ad aggiungere gli indicatori economici ai nostri dati valutari. In questo modo iniziamo a integrare i nostri dati in un costrutto. Esaminiamo tutti i nostri indicatori economici e proviamo a trovarli nei dati della Banca Mondiale. Se la troviamo, bene, la aggiungiamo ai nostri dati valutari. In caso contrario, beh, succede. Scriviamo un avviso e andiamo avanti.
Dopo tutto questo, potrebbero rimanere delle righe di dati mancanti. Li cancelliamo e basta.
Vediamo ora come applicare questa funzione:
prepared_data = {}
for symbol, df in historical_data.items():
prepared_data[symbol] = prepare_data(df, data)
Prendiamo ogni coppia di valute e gli applichiamo la nostra funzione scritta. In uscita, si ottiene un set di dati già pronto per ogni coppia. Ci sarà un set separato per ogni coppia, ma tutti sono assemblati secondo lo stesso principio.
Sapete qual è la cosa più importante in questo processo? Stiamo creando qualcosa di nuovo. Prendiamo diversi dati economici e i dati sui tassi di cambio in tempo reale e ne creiamo qualcosa di coerente. Singolarmente possono apparire caotici, ma quando vengono messi insieme possiamo identificare dei modelli.
Ora abbiamo un set di dati pronto per l'analisi. Possiamo cercare sequenze, fare previsioni e trarre conclusioni. Tuttavia, dovremo identificare i segnali che sono veramente degni di attenzione. Nel mondo dei dati, non esistono dettagli poco importanti. Ogni fase della preparazione dei dati può essere fondamentale per il risultato finale.
L'apprendimento automatico nel nostro modello
L'apprendimento automatico è un processo piuttosto complesso e ad alta intensità di lavoro. CatBoost Regressor - questa funzione giocherà un ruolo importante in seguito. Ecco come la usiamo:
from catboost import CatBoostRegressor model = CatBoostRegressor(iterations=1000, learning_rate=0.1, depth=8, loss_function='RMSE', verbose=100) model.fit(X_train, y_train, verbose=False)
Ogni parametro è importante. 1000 iterazioni è il numero di volte in cui il modello viene eseguito sui dati. Learning rate 0.1 - non è necessario impostare subito una velocità elevata, ma è necessario imparare gradualmente. Depth 8 - ricerca di connessioni complesse. RMSE - è il modo in cui valutiamo gli errori. L'addestramento di un modello richiede una certa quantità di tempo. Mostriamo esempi e valutiamo le risposte corrette. CatBoost funziona particolarmente bene con diversi tipi di dati. Non si limita a una gamma ristretta di funzioni.
Per fare previsioni sulle valute, procediamo come segue:
def forecast(symbol_data):
X = symbol_data.drop(columns=['close'])
y = symbol_data['close']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5, shuffle=False)
model = CatBoostRegressor(iterations=1000, learning_rate=0.1, depth=8, loss_function='RMSE', verbose=100)
model.fit(X_train, y_train, verbose=False)
predictions = model.predict(X_test)
mse = mean_squared_error(y_test, predictions)
print(f"Mean Squared Error for {symbol}: {mse}")
Una parte dei dati serve per l'addestramento, l'altra per i test. È come andare a scuola: prima si studia, poi si sostiene un esame.
Dividiamo i dati in due parti. Perché? Una parte per la formazione, l'altra per i test. Dopo tutto, dovremo testare il modello su dati con cui non ha ancora lavorato.
Dopo l'addestramento, il modello cerca di prevedere. L'errore quadratico medio mostra quanto bene ha funzionato. Più piccolo è l'errore, migliore è la previsione. CatBoost si distingue per il suo costante miglioramento. Impara dagli errori.
Naturalmente, CatBoost non è un programma automatico. Ha bisogno di dati buoni. Altrimenti, otterremo dati inefficaci in ingresso e inefficaci in uscita. Ma con i dati giusti, il risultato è positivo. Parliamo ora della divisione dei dati. Ho detto che abbiamo bisogno di quotazioni per la verifica. Ecco come appare nel codice:
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5, shuffle=False) Il 50% dei dati è destinato ai test. Non mescolateli - è importante mantenere l'ordine temporale dei dati finanziari.
La creazione e l'addestramento del modello è la parte più interessante. Qui CatBoost dimostra le sue capacità al massimo:
model = CatBoostRegressor(iterations=1000, learning_rate=0.1, depth=8, loss_function='RMSE', verbose=100) model.fit(X_train, y_train, verbose=False)
Il modello assorbe avidamente i dati alla ricerca di pattern. Ogni iterazione è un passo avanti verso una migliore comprensione del mercato.
E ora il momento della verità. Valutazione della precisione:
predictions = model.predict(X_test) mse = mean_squared_error(y_test, predictions)
Anche l'errore quadratico medio è un punto importante del nostro lavoro. Dimostra quanto sia sbagliato il modello. Meno è meglio. Questo ci permette di valutare la qualità del programma. Ricordate che nel trading non ci sono garanzie finali. Ma con CatBoost il processo è più efficiente. Vede cose che a noi potrebbero sfuggire. E ad ogni previsione il risultato migliora.
Previsione dei valori futuri delle coppie di valute
Fare previsioni sulle coppie di valute significa lavorare con le probabilità. A volte otteniamo risultati positivi, altre volte subiamo perdite. L'importante è che il risultato finale sia all'altezza delle nostre aspettative.
Nel nostro codice, la funzione "forecast" lavora con le probabilità. Ecco come esegue i calcoli:
def forecast(symbol_data): X = symbol_data.drop(columns=['close']) y = symbol_data['close'] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, shuffle=False) model = CatBoostRegressor(iterations=1000, learning_rate=0.1, depth=8, loss_function='RMSE', verbose=100) model.fit(X_train, y_train, verbose=False) predictions = model.predict(X_test) mse = mean_squared_error(y_test, predictions) print(f"Mean Squared Error for {symbol}: {mse}") future_data = symbol_data.tail(30).copy() if len(predictions) >= 30: future_data['close'] = predictions[-30:] else: future_data['close'] = predictions future_predictions = model.predict(future_data.drop(columns=['close'])) return future_predictions
In primo luogo, separiamo i dati già disponibili da quelli previsti. Poi dividiamo i dati in due parti: per l'addestramento e per il test. Il modello impara da un insieme di dati e lo testiamo su un altro. Dopo l'addestramento, il modello fa delle previsioni. Guardiamo a quanto fosse sbagliato utilizzando la radice dell'errore quadratico medio. Più basso è il numero, migliore è la previsione.
Ma l'aspetto più interessante è l'analisi delle quotazioni per verificare i possibili movimenti futuri dei prezzi. Prendiamo gli ultimi 30 giorni di dati e chiediamo al modello di prevedere cosa accadrà in seguito. Sembra una situazione in cui si ricorre alle previsioni di analisti esperti. Per quanto riguarda la visualizzazione... Purtroppo, il codice non fornisce ancora una visualizzazione esplicita dei risultati. Ma aggiungiamolo e vediamo come potrebbe apparire:
import matplotlib.pyplot as plt for symbol, forecast in forecasts.items(): plt.figure(figsize=(12, 6)) plt.plot(range(len(forecast)), forecast, label='Forecast') plt.title(f'Forecast for {symbol}') plt.xlabel('Days') plt.ylabel('Price') plt.legend() plt.savefig(f'{symbol}_forecast.png') plt.close()
Questo codice creerebbe un grafico per ogni coppia di valute. Visivamente, è costruito in modo lineare. Ogni punto rappresenta un prezzo previsto per un giorno specifico. Questi grafici sono progettati per mostrare i possibili trend, il lavoro è stato fatto con un grande array di dati, spesso troppo complessi per la persona media. Se la linea è diretta verso l'alto, la valuta diventerà più costosa. Se scende? Preparatevi a un calo dei tassi.
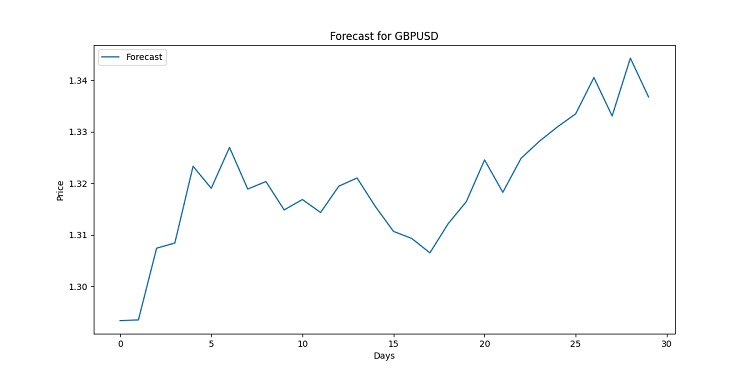
Ricordate che le previsioni non sono garanzie. Il mercato può apportare le proprie modifiche. Ma con una buona visualizzazione, saprete almeno cosa aspettarvi. Dopo tutto, in questa situazione abbiamo a portata di mano un'analisi di alta qualità.
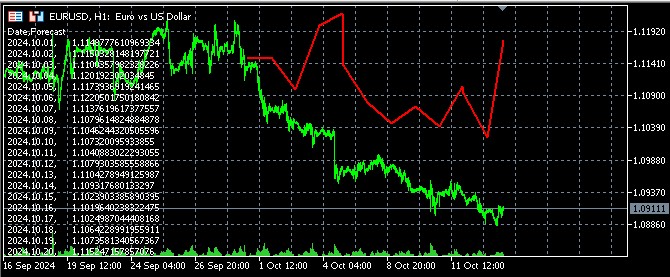
Ho anche creato un codice per visualizzare i risultati delle previsioni in MQL5, aprendo un file e inviando le previsioni a Comment:
//+------------------------------------------------------------------+ //| Economic Forecast| //| Copyright 2024, Evgeniy Koshtenko | //| https://www.mql5.com/en/users/koshtenko | //+------------------------------------------------------------------+ #property copyright "Copyright 2023, Evgeniy Koshtenko" #property link "https://www.mql5.com/en/users/koshtenko" #property version "4.00" #property strict #property indicator_chart_window #property indicator_buffers 1 #property indicator_plots 1 #property indicator_label1 "Forecast" #property indicator_type1 DRAW_SECTION #property indicator_color1 clrRed #property indicator_style1 STYLE_SOLID #property indicator_width1 2 double ForecastBuffer[]; input string FileName = "EURUSD_forecast.csv"; // Forecast file name //+------------------------------------------------------------------+ //| Custom indicator initialization function | //+------------------------------------------------------------------+ int OnInit() { SetIndexBuffer(0, ForecastBuffer, INDICATOR_DATA); PlotIndexSetDouble(0, PLOT_EMPTY_VALUE, EMPTY_VALUE); return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //| Draw forecast | //+------------------------------------------------------------------+ int OnCalculate(const int rates_total, const int prev_calculated, const datetime &time[], const double &open[], const double &high[], const double &low[], const double &close[], const long &tick_volume[], const long &volume[], const int &spread[]) { static bool first=true; string comment = ""; if(first) { ArrayInitialize(ForecastBuffer, EMPTY_VALUE); ArraySetAsSeries(ForecastBuffer, true); int file_handle = FileOpen(FileName, FILE_READ|FILE_CSV|FILE_ANSI); if(file_handle != INVALID_HANDLE) { // Skip the header string header = FileReadString(file_handle); comment += header + "\n"; // Read data from file while(!FileIsEnding(file_handle)) { string line = FileReadString(file_handle); string str_array[]; StringSplit(line, ',', str_array); datetime time=StringToTime(str_array[0]); double price=StringToDouble(str_array[1]); PrintFormat("%s %G", TimeToString(time), price); comment += str_array[0] + ", " + str_array[1] + "\n"; // Find the corresponding bar on the chart and set the forecast value int bar_index = iBarShift(_Symbol, PERIOD_CURRENT, time); if(bar_index >= 0 && bar_index < rates_total) { ForecastBuffer[bar_index] = price; PrintFormat("%d %s %G", bar_index, TimeToString(time), price); } } FileClose(file_handle); first=false; } else { comment = "Failed to open file: " + FileName; } Comment(comment); } return(rates_total); } //+------------------------------------------------------------------+ //| Indicator deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { Comment(""); } //+------------------------------------------------------------------+ //| Create the arrow | //+------------------------------------------------------------------+ bool ArrowCreate(const long chart_ID=0, // chart ID const string name="Arrow", // arrow name const int sub_window=0, // subwindow number datetime time=0, // anchor point time double price=0, // anchor point price const uchar arrow_code=252, // arrow code const ENUM_ARROW_ANCHOR anchor=ANCHOR_BOTTOM, // anchor point position const color clr=clrRed, // arrow color const ENUM_LINE_STYLE style=STYLE_SOLID, // border line style const int width=3, // arrow size const bool back=false, // in the background const bool selection=true, // allocate for moving const bool hidden=true, // hidden in the list of objects const long z_order=0) // mouse click priority { //--- set anchor point coordinates if absent ChangeArrowEmptyPoint(time, price); //--- reset the error value ResetLastError(); //--- create an arrow if(!ObjectCreate(chart_ID, name, OBJ_ARROW, sub_window, time, price)) { Print(__FUNCTION__, ": failed to create an arrow! Error code = ", GetLastError()); return(false); } //--- set the arrow code ObjectSetInteger(chart_ID, name, OBJPROP_ARROWCODE, arrow_code); //--- set anchor type ObjectSetInteger(chart_ID, name, OBJPROP_ANCHOR, anchor); //--- set the arrow color ObjectSetInteger(chart_ID, name, OBJPROP_COLOR, clr); //--- set the border line style ObjectSetInteger(chart_ID, name, OBJPROP_STYLE, style); //--- set the arrow size ObjectSetInteger(chart_ID, name, OBJPROP_WIDTH, width); //--- display in the foreground (false) or background (true) ObjectSetInteger(chart_ID, name, OBJPROP_BACK, back); //--- enable (true) or disable (false) the mode of moving the arrow by mouse //--- when creating a graphical object using ObjectCreate function, the object cannot be //--- highlighted and moved by default. Selection parameter inside this method //--- is true by default making it possible to highlight and move the object ObjectSetInteger(chart_ID, name, OBJPROP_SELECTABLE, selection); ObjectSetInteger(chart_ID, name, OBJPROP_SELECTED, selection); //--- hide (true) or display (false) graphical object name in the object list ObjectSetInteger(chart_ID, name, OBJPROP_HIDDEN, hidden); //--- set the priority for receiving the event of a mouse click on the chart ObjectSetInteger(chart_ID, name, OBJPROP_ZORDER, z_order); //--- successful execution return(true); } //+------------------------------------------------------------------+ //| Check anchor point values and set default values | //| for empty ones | //+------------------------------------------------------------------+ void ChangeArrowEmptyPoint(datetime &time, double &price) { //--- if the point time is not set, it will be on the current bar if(!time) time=TimeCurrent(); //--- if the point price is not set, it will have Bid value if(!price) price=SymbolInfoDouble(Symbol(), SYMBOL_BID); } //+------------------------------------------------------------------+
Ecco come appaiono le previsioni nel terminale:
Interpretazione dei risultati: Analizzare l'influenza dei fattori economici sui tassi di cambio
Ora diamo un'occhiata più da vicino all'interpretazione dei risultati in base al codice. Abbiamo raccolto migliaia di fatti disparati in dati organizzati che devono essere analizzati.
Partiamo dal fatto che abbiamo a disposizione una serie di indicatori economici - dalla crescita del PIL alla disoccupazione. Ogni fattore ha una propria influenza sul contesto di mercato. I singoli indicatori hanno un impatto proprio, ma l'insieme di questi dati influenza i tassi di cambio finali.
Prendiamo ad esempio il PIL. Nel codice è rappresentato da diversi indicatori:
'NY.GDP.MKTP.KD.ZG': 'GDP growth', 'NY.GDP.PCAP.KD.ZG': 'GDP per capita growth',
La crescita del PIL solitamente rafforza la valuta. Perché? Perché le notizie positive attraggono i giocatori che cercano un'opportunità di investire il capitale per un'ulteriore crescita. Gli investitori sono attratti dalle economie in crescita, che aumentano la domanda delle loro valute.
Al contrario, l'inflazione ("FP.CPI.TOTL.ZG": Inflation" ) è un segnale allarmante per i trader. Più l'inflazione è alta, più il valore del denaro diminuisce rapidamente. Un'inflazione elevata di solito indebolisce una valuta, semplicemente perché i servizi e i beni iniziano a diventare molto più costosi nel paese in questione.
È interessante osservare la bilancia commerciale:
'NE.EXP.GNFS.ZS': 'Exports', 'NE.IMP.GNFS.ZS': 'Imports', 'BN.CAB.XOKA.GD.ZS': 'Current account balance',
Questi indicatori sono come delle scale. Se le esportazioni superano le importazioni, il Paese riceve più valuta estera, che di solito rafforza la moneta nazionale.
Vediamo ora come analizzare questo aspetto nel codice. CatBoost Regressor è il nostro strumento principale. Come un direttore d'orchestra esperto, sente tutti gli strumenti contemporaneamente e capisce come si influenzano a vicenda.
Ecco cosa si può aggiungere alla funzione di previsione per comprendere meglio l'impatto dei fattori:
def forecast(symbol_data):
# ......
feature_importance = model.feature_importances_
feature_names = X.columns
importance_df = pd.DataFrame({'feature': feature_names, 'importance': feature_importance})
importance_df = importance_df.sort_values('importance', ascending=False)
print(f"Feature Importance for {symbol}:")
print(importance_df.head(10)) # Top 10 important factors
return future_predictions
Questo ci mostrerà quali fattori sono stati più importanti per la previsione di ogni coppia di valute. È possibile che per EUR il fattore chiave sia il tasso della BCE, mentre per lo JPY sia la bilancia commerciale del Giappone. Esempio di output di dati:
Interpretazione per EURUSD:
1. Andamento dei Prezzi: Le previsioni indicano una tendenza al rialzo per i prossimi 30 giorni.
2. Volatilità: Il movimento dei prezzi previsto mostra una bassa volatilità.
3. Fattore d'Influenza Chiave: La caratteristica più importante per questa previsione è "low".
4. Implicazioni Economiche:
- Se la crescita del PIL è uno dei fattori principali, ciò indica che la forte performance economica sta influenzando la valuta.
- L’elevata importanza del tasso di inflazione potrebbe indicare che i cambiamenti di politica monetaria stanno influenzando la valuta.
- Se i fattori della bilancia commerciale sono cruciali, è probabile che siano le dinamiche del commercio internazionale a guidare i movimenti valutari.
5. Implicazioni per il Trading:
- La tendenza al rialzo suggerisce potenziali posizioni lunghe.
- Una volatilità più bassa potrebbe consentire stop-loss più ampi.
6. Valutazione del Rischio:
- Considerare sempre i limiti del modello e potenziali eventi di mercato inattesi.
- Le performance passate non garantiscono i risultati futuri.
Ma ricordate che in economia non esistono risposte facili. A volte una valuta si rafforza contro ogni previsione, altre volte crolla senza un motivo apparente. Il mercato spesso vive di aspettative piuttosto che della realtà attuale.
Un altro punto importante è l'intervallo di tempo. I cambiamenti nell'economia non si riflettono immediatamente sul tasso di cambio. È come governare una grande nave: si gira il timone, ma la nave non cambia rotta all'istante. Nel codice si utilizzano dati giornalieri, ma alcuni indicatori economici vengono aggiornati con minore frequenza. Ciò può introdurre un certo errore nelle previsioni. In definitiva, l'interpretazione dei risultati è un'arte quanto una scienza. Il modello è uno strumento potente, ma le decisioni sono sempre prese da un essere umano. Utilizzate questi dati con saggezza e che le vostre previsioni siano accurate!
Ricerca di modelli non ovvi nei dati economici
Il mercato dei cambi è un'enorme piattaforma di trading. Non è caratterizzato da movimenti di prezzo prevedibili, ma in aggiunta a questo, ci sono eventi speciali che aumentano la volatilità e la liquidità del momento. Si tratta di eventi globali.
Nel nostro codice, ci basiamo su indicatori economici:
indicators = {
'NY.GDP.MKTP.KD.ZG': 'GDP growth',
'FP.CPI.TOTL.ZG': 'Inflation',
# ...
}
Ma cosa fare quando succede qualcosa di inaspettato? Ad esempio, una pandemia o una crisi politica?
Sarebbe utile una sorta di "indice sorpresa". Immaginiamo di aggiungere qualcosa di simile al nostro codice:
def add_global_event_impact(data, event_date, event_magnitude): data['global_event'] = 0 data.loc[event_date:, 'global_event'] = event_magnitude data['global_event_decay'] = data['global_event'].ewm(halflife=30).mean() return data # --- def prepare_data(symbol_data, economic_data): # ... ... data = add_global_event_impact(data, '2020-03-11', 0.5) # return data
Questo ci permetterebbe di tenere conto di eventi globali improvvisi e della loro graduale attenuazione.
Ma la domanda più interessante è come questo influisca sulle previsioni. A volte gli eventi globali possono stravolgere completamente le nostre aspettative. Ad esempio, durante una crisi, le valute "sicure" come USD o CHF possono rafforzarsi rispetto alla logica economica.
In questi momenti, la produttività del nostro modello diminuisce. E qui è importante non farsi prendere dal panico, ma adattarsi. Forse vale la pena di ridurre temporaneamente l'orizzonte di previsione o di dare maggior peso ai dati recenti?
recent_weight = 2 if data['global_event'].iloc[-1] > 0 else 1 model.fit(X_train, y_train, sample_weight=np.linspace(1, recent_weight, len(X_train)))
Ricordate: nel mondo delle valute, come nella danza, la cosa principale è sapersi adattare al ritmo. Anche se questo ritmo a volte cambia nei modi più inaspettati!
A caccia di anomalie: Come trovare modelli non ovvi nei dati economici
Ora parliamo della parte più interessante - trovare tesori nascosti nei nostri dati. È come essere un detective, solo che al posto delle prove abbiamo numeri e grafici.
Nel nostro codice utilizziamo già molti indicatori economici. Ma cosa succede se tra loro ci sono delle connessioni non ovvie? Proviamo a trovarle!
Per cominciare, possiamo osservare le correlazioni tra i diversi indicatori:
correlation_matrix = data[list(indicators.keys())].corr() print(correlation_matrix)
Tuttavia, questo è solo l'inizio. La vera magia inizia quando iniziamo a cercare relazioni non lineari. Ad esempio, potrebbe risultare che una variazione del PIL non influisca immediatamente sul tasso di cambio, ma con un ritardo di diversi mesi.
Aggiungiamo alcune metriche "spostate" alla nostra funzione di preparazione dei dati:
def prepare_data(symbol_data, economic_data): # ...... for indicator in indicators.keys(): if indicator in economic_data.columns: data[indicator] = economic_data[indicator] data[f"{indicator}_lag_3"] = economic_data[indicator].shift(3) data[f"{indicator}_lag_6"] = economic_data[indicator].shift(6) # ...
Ora il nostro modello sarà in grado di catturare dipendenze con un ritardo di 3 e 6 mesi.
Ma la cosa più interessante è la ricerca di modelli completamente non ovvi. Ad esempio, si potrebbe scoprire che il tasso di cambio dell'euro è stranamente correlato alle vendite di gelati negli Stati Uniti (è una battuta, ma rende l'idea).
A tale scopo, si possono utilizzare metodi di estrazione delle caratteristiche, come ad esempio la PCA (Principal Component Analysis):
from sklearn.decomposition import PCA
def find_hidden_patterns(data):
pca = PCA(n_components=5)
pca_result = pca.fit_transform(data[list(indicators.keys())])
print("Explained variance ratio:", pca.explained_variance_ratio_)
return pca_result
pca_features = find_hidden_patterns(data)
data['hidden_pattern_1'] = pca_features[:, 0]
data['hidden_pattern_2'] = pca_features[:, 1]
Questi "modelli nascosti" possono essere la chiave per previsioni più accurate.
Non dimenticate nemmeno la stagionalità. Alcune valute possono comportarsi in modo diverso a seconda del periodo dell'anno. Aggiungete ai vostri dati le informazioni sul mese e sul giorno della settimana - potreste trovare qualcosa di interessante!
data['month'] = data.index.month data['day_of_week'] = data.index.dayofweek
Ricordate che in un mondo di dati c'è sempre spazio per la scoperta. Siate curiosi, sperimentate e chissà, forse troverete proprio quel pattern che cambierà il mondo del trading.
Conclusione: Prospettive per le previsioni economiche nel trading algoritmico
Siamo partiti da un'idea semplice - possiamo prevedere i movimenti dei tassi di cambio sulla base dei dati economici? Cosa abbiamo scoperto? È emerso che questa idea ha qualche merito. Ma non è così semplice come sembra a prima vista.
Il nostro codice semplifica notevolmente l'analisi dei dati economici. Abbiamo imparato a raccogliere informazioni da tutto il mondo, elaborarle e persino a far fare previsioni al computer. Ma ricordate che anche il modello di apprendimento automatico più avanzato è solo uno strumento. È uno strumento molto potente, ma pur sempre uno strumento.
Abbiamo visto come CatBoost Regressor sia in grado di trovare relazioni complesse tra indicatori economici e tassi di cambio. Questo ci permette di andare oltre le capacità umane e di ridurre significativamente il tempo dedicato alla gestione e all'analisi dei dati. Ma anche uno strumento così grande non può prevedere il futuro con una precisione del 100%.
Perché? Perché l'economia è un processo che dipende da molti fattori. Oggi tutti guardano al prezzo del petrolio, mentre domani il mondo intero potrebbe essere messo sottosopra da qualche evento inaspettato. Abbiamo menzionato questo effetto parlando dell'"indice sorpresa". È proprio per questo che è così importante.
Tradotto dal russo da MetaQuotes Ltd.
Articolo originale: https://www.mql5.com/ru/articles/15998
Avvertimento: Tutti i diritti su questi materiali sono riservati a MetaQuotes Ltd. La copia o la ristampa di questi materiali in tutto o in parte sono proibite.
Questo articolo è stato scritto da un utente del sito e riflette le sue opinioni personali. MetaQuotes Ltd non è responsabile dell'accuratezza delle informazioni presentate, né di eventuali conseguenze derivanti dall'utilizzo delle soluzioni, strategie o raccomandazioni descritte.

- App di trading gratuite
- Oltre 8.000 segnali per il copy trading
- Notizie economiche per esplorare i mercati finanziari
Accetti la politica del sito e le condizioni d’uso
Prendete spunto da qui. Un vecchio articolo sull'argomento.
Finora, il massimo che posso ricavare dalla mosca sono i dati attuali per oggi((((
Quello che non capisco è: cosa fa MQ?
Questo è il segnale dell'autore qui sopra.
Questo segnale è stato fatto solo per testare un modello su Sber. Ma non l'ho mai testato, è solo una valuta già presente nel fondo monetario. Fondamentalmente non faccio trading sui miei modelli, non riesco a staccarmi dalle idee di miglioramento e sviluppo ()))) Ci sono sempre nuove idee di miglioramento) e in borsa investo principalmente in azioni, a lungo termine, compro azioni sul MOEX come non-rez, e sul KASE delle società dell'indice Kazbirji.
Per ora, il meglio che possiamo ricavare dalla mosca sono i dati attuali per oggi((((
A quanto ho capito, raccolgono dati sugli account collegati al monitoraggio? Anche se tutto è onesto, è una goccia nell'oceano.
Imho, più affidabili sono i dati della CFTC, anche se non si tratta di spot ma di futures con opzioni. C'è una storia dal 2005, anche se non in una forma molto comoda, ma probabilmente ci sono alcune API per Python.
Ovviamente dipende da voi, sto solo condividendo la mia opinione.
Questo segnale è stato fatto solo per testare un modello su Sber. Ma non l'ho mai testato, è solo valuta nel fondo monetario. Fondamentalmente non faccio trading sui miei modelli, non posso sottrarmi alle idee di miglioramento e sviluppo ()))) Ci sono sempre nuove idee di miglioramento) e in borsa investo principalmente in azioni, a lungo termine, compro azioni sul MOEX come non-rez, e sul KASE delle società dell'indice Kazbirji.
c'è una discrepanza di informazioni lì, nessuna pretesa a voi