MQL5 开发的自动交易示例的文章

MQL5 中的范畴论 (第 7 部分):多域、相对域和索引域
范畴论是数学的一个多样化和不断扩展的分支,直到最近才在 MQL5 社区中得到一些报道。 这些系列文章旨在探索和验证一些概念和公理,其总体目标是建立一个开放的函数库,提供洞察力,同时也希望进一步在交易者的策略开发中运用这个非凡的领域。

在您的 MQL 项目中使用 JSON 数据 API
想象一下,您可以使用 MetaTrader 中没有的数据,您只能通过价格分析和技术分析从指标中获得数据。现在想象一下,您可以访问数据,这将使你的交易能力更高。如果您通过 API(应用程序编程接口)数据混合其他软件、宏观分析方法和超高级工具的输出,您就可以倍增 MetaTrader 软件的力量。在本文中,我们将教您如何使用 API,并介绍有用和有价值的 API 数据服务。
多层感知器和反向传播算法(第 3 部分):与策略测试器集成 - 概述(I)
多层感知器是简单感知器的演变,可以解决非线性可分离问题。 结合反向传播算法,可以有效地训练该神经网络。 在多层感知器和反向传播系列的第 3 部分当中,我们将见识到如何将此技术集成到策略测试器之中。 这种集成将允许使用复杂的数据分析,旨在制定更好的决策,从而优化您的交易策略。 在本文中,我们将讨论这种技术的优点和问题。


神经网络变得轻松(第二十四部分):改进迁移学习工具
在上一篇文章中,我们创建了一款用于创建和编辑神经网络架构的工具。 今天我们将继续打造这款工具。 我们将努力令其对用户更加友好。 也许可以看到,我们的主题往上更进一步。 但是,您不认为规划良好的工作空间在实现结果方面起着重要作用吗?

创建一个基于布林带PIRANHA策略的MQL5 EA
在本文中,我们将创建一个MQL5 EA,它基于PIRANHA策略,并使用布林带来提升交易表现。我们会系统梳理该策略的核心原理、代码实现细节,以及测试与优化方法。并助您轻松将 EA 部署到实际的交易环境中。

神经网络变得轻松(第四十六部分):条件导向目标强化学习(GCRL)
在本文中,我们要看看另一种强化学习方式。 它被称为条件导向目标强化学习(GCRL)。 按这种方式,代理者经过训练,可以在特定场景中达成不同的目标。


构建K线趋势约束模型(第九部分):多策略智能交易系统(EA)(三)
欢迎来到本趋势系列文章的第三部分!今天,我们将深入探讨如何利用背离(Divergence)策略,在既有的日线趋势中识别最优入场点。同时,我们将引入一种定制化的利润锁定机制——其功能类似于追踪止损(Trailing Stop-Loss),但经过独特的优化升级。此外,我们还将把趋势约束智能交易系统升级为更高级版本,新增一项交易执行条件以完善现有策略框架。随着内容推进,我们将持续探索MQL5在算法开发中的实际应用,为您提供更深入的见解与可落地的技术方案。
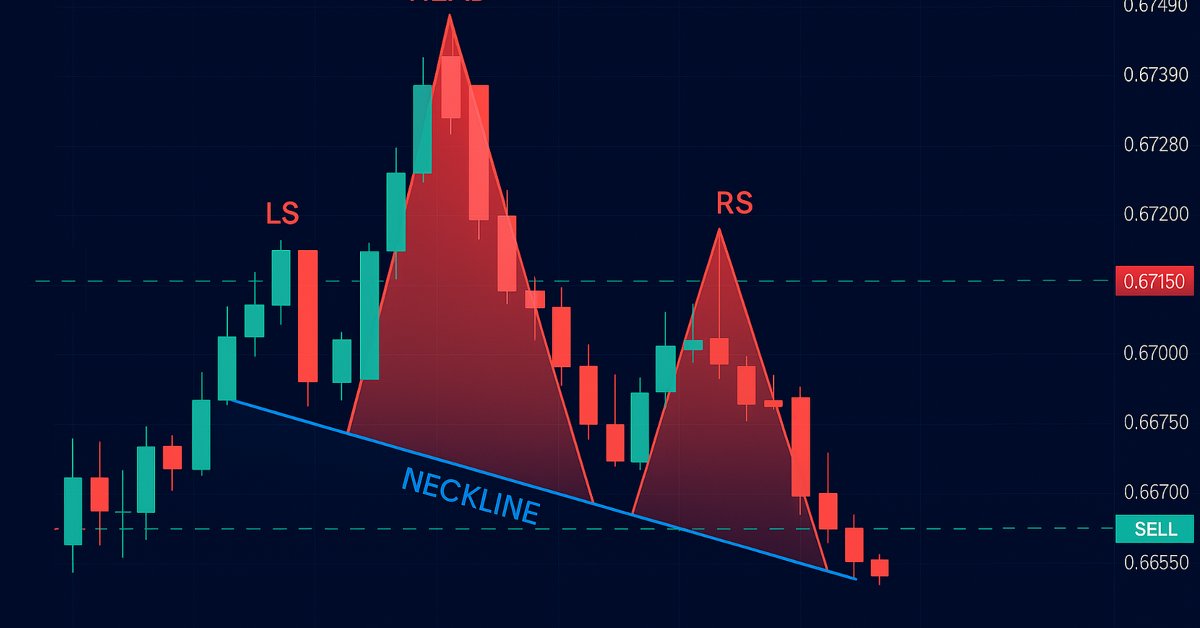
在 MQL5 中自动化交易策略(第 13 部分):构建头肩形态交易算法
在本文中,我们将自动化 MQL5 中的头肩形态。我们分析其架构,实现一个用于检测和交易该形态的 EA,并对结果进行回测。这个过程揭示了一个具有改进空间的实用交易算法。
DoEasy 函数库中的时间序列(第五十七部分):指标缓冲区数据对象
在本文中,开发一个对象,其中包含一个指标的一个缓冲区的所有数据。 这些对象对于存储指标缓冲区的数据序列将是必需的。 在其的辅助下,才有可能对任何指标的缓冲区数据,以及其他类似数据进行排序和比较。
构建自优化型MQL5智能交易系统(EA)(第3部分):动态趋势跟踪与均值回归策略
金融市场通常被静态划分为震荡市或趋势市两种模式。这种简化分类虽便于短期交易决策。然而,却与真实市场行为脱节。在本文中,我们将深入探讨市场如何精准地在这两种模式间切换,并利用这方面的认知提升算法交易策略的可靠性。


如何利用 MQL5 创建简单的多币种智能交易系统(第 2 部分):指标信号:多时间帧抛物线 SAR 指标
本文中的多币种智能交易系统是智能交易系统或交易机器人,它仅在一个品种图表上就能交易(开单、平单、和管理订单,例如:尾随停损和止盈)超过 1 个交易品种对。这次我们只用 1 个指标,即抛物线 SAR 或 iSAR, 将其应用在 PERIOD_M15 到 PERIOD_D1 的多个时间帧。
MQL5 交易策略自动化(第十部分):开发趋势盘整动量策略
在本文中,我们将基于MQL5开发趋势盘整动量策略EA。我们将结合双移动平均线交叉与 RSI 和 CCI 动量过滤器来生成交易信号。我们还将对EA进行回测,以及为提升其在真实交易环境下的表现而进行的优化。


使用 SMA 和 EMA 自动优化止盈和指标参数的示例
本文介绍了一种用于外汇交易的复杂 EA 交易,它能够将机器学习与技术分析相结合。它专注于交易苹果股票,具有自适应优化、风险管理和多策略的特点。回溯测试显示出良好的结果,盈利能力较高,但也有显著的回撤,表明还有进一步改进的潜力。

神经网络实验(第 5 部分):常规化传输到神经网络的输入参数
神经网络是交易者工具包中的终极工具。 我们来检查一下这个假设是否成立。 在交易中运用神经网络,MetaTrader 5 是最接近自给自足的媒介。 为此提供了一个简单的解释。
在 MQL5 中自动化交易策略(第三部分):用于动态交易管理的RSI区域反转系统
在本文中,我们将在MQL5中创建一个基于RSI区域反转策略的EA系统,该系统使用RSI信号来触发交易,并采用反转策略来管理亏损。我们实现了一个“ZoneRecovery”类,用以自动化交易入场、反转逻辑和仓位管理。文章最后将进行系统的回测,以优化性能并提升 EA 的有效性。


从头开始开发智能交易系统(第 11 部分):交叉订单系统
在本文中,我们将创建一个交叉订单系统。 有一种类型的资产让交易员的生涯变得非常困难 — 那就是期货合约。 但为什么令他们的职业生涯变得如此困难?

将ML模型与策略测试器集成(结论):实现价格预测的回归模型
本文描述了一个基于决策树的回归模型的实现。该模型应预测金融资产的价格。我们已经准备好了数据,对模型进行了训练和评估,并对其进行了调整和优化。然而,需要注意的是,该模型仅用于研究目的,不应用于实际交易。
模式搜索的暴力方法(第六部分):循环优化
在这篇文章中,我将展示改进的第一部分,这些改进不仅使我能够使MetaTrader 4和5交易的整个自动化链闭环,而且还可以做一些更有趣的事情。从现在起,这个解决方案使我能够完全自动化创建EA和优化,并最大限度地降低寻找有效交易配置的劳动力成本。

MQL5 简介(第 4 部分):掌握结构、类和时间函数
在我们的最新文章中揭开 MQL5 编程的秘密!深入了解结构、类和时间函数的基本要素,为您的编码之旅赋能。无论您是初学者还是经验丰富的开发人员,我们的指南都简化了复杂的概念,为掌握 MQL5 提供了宝贵的见解。提升你的编程技能,在算法交易领域保持领先!

MQL5自动化交易策略(第九部分):构建亚洲盘突破策略的智能交易系统(EA)
在本文中,我们将在MQL5中开发一款适用于亚洲盘突破策略的智能交易系统(EA),用来计算亚洲时段的高低价以及使用移动平均线(MA)进行趋势过滤。同时实现动态对象样式、用户自定义时间输入和完善的风险管理。最后演示回测与优化技术,进一步打磨策略表现。


理解编程范式(第 1 部分):开发价格行为智能系统的过程化方式
了解编程范式及利用 MQL5 代码的应用。本文探讨了过程化编程的细节,并通过一个实际示例提供了实经验。您将学习如何利用 EMA 指标和烛条价格数据开发价格行为智能系统。额外,本文还介绍了函数化编程范式。



算法交易中的风险管理器
本文的目标是证明在算法交易中使用风险管理器的必要性,并在一个单独的类中实现控制风险的策略,以便每个人都可以验证标准化的风险管理方法在金融市场日内交易和投资中的有效性。在本文中,我们将为算法交易创建一个风险管理类。本文是上一篇文章的延续,在前文中我们讨论了为手动交易创建风险管理器。

神经网络实验(第 4 部分):模板
在本文中,我将利用实验和非标准方法开发一个可盈利的交易系统,并验证神经网络是否对交易者有任何帮助。 若在交易中运用神经网络的话, MetaTrader 5 完全可作为一款自给自足的工具。 简单的解释。


MQL5 简介(第 5 部分):MQL5 数组函数入门指南
在第 5 部分中探索 MQL5 数组的世界,该部分专为绝对初学者设计。本文简化了复杂的编码概念,重点在于清晰性和包容性。加入我们的学习者社区,在这里解决问题,分享知识!

MQL5交易策略自动化(第八部分):构建基于蝴蝶谐波形态的智能交易系统(EA)
在本文中,我们将构建一个MQL5智能交易系统(EA),用于检测蝴蝶谐波形态。我们会识别关键转折点,并验证斐波那契(Fibonacci)水平以确认该形态。之后,我们会在图表上可视化该形态,并在得到确认时自动执行交易。

MQL5自动化交易策略(第十四部分):基于MACD-RSI统计方法的交易分层策略
本文将介绍一种结合MACD和RSI指标与统计方法的交易分层策略,通过MQL5实现动态自动化交易。我们将探讨这种级联式策略的架构设计,通过关键代码段详解其实现方式,并指导读者如何进行回测以优化策略表现。最后,我们将总结该策略的潜力,并为自动化交易的进一步优化奠定基础。
