
神经网络变得轻松(第四十二部分):模型拖延症、原因和解决方案

概述
在强化学习领域,当学习过程变慢或卡顿时,神经网络模型经常面临拖延症的问题。 模型拖延症会对达成既定目标产生严重后果,且需要采取相应的措施。 在本文中,我们将探查模型拖延症的主要原因,并提出解决这些问题的方法。
1. 拖延症问题
模型拖延症的主要原因之一是训练环境不足。 模型也许会遇到访问训练数据受限,或资源不足的情况。 解决这个问题涉及创建或更新数据集,增加训练样本的多样性,并应用额外的训练资源,例如算力、或预训练模型进行转移训练。
模型拖延症的另一个原因也许出于它欲解决任务的复杂性,或者用到需大量计算资源的训练算法。 在这种情况下,解决方案也许是简化问题或算法,优化计算过程,并采用更高效的算法、或分布式学习。
如果一个模型缺乏达成目标的动力,它也许就会拖延。 为模型设定明确且相关的目标,设计一个奖励函数,来激励达成这些目标,且运用强化技术(如奖励和惩罚),如此可有助于解决这个问题。
如果模型没有收到反馈,或没有根据新数据进行更新,它的进展也许就会拖延。 解决方案是基于新数据和反馈建立定期模型更新周期,并开发控制和监测学习进度的机制。
重要的是,定期评估模型的进度和学习成果。 这将帮助您查看取得的进展,并确定可能的问题或瓶颈。 定期评估能及时调整训练过程,以避免拖延。
为模型提供多样化任务,以及刺激环境,有助于避免拖延症。 任务的多样化将有助于保持模型的兴趣和动力,而刺激环境,譬如竞争或游戏元素,可以鼓励模型积极参与并进步。
由于缺乏更新和改进,也许就会发生模型拖延症。 重要的是,定期分析结果,并基于反馈和新思路迭代改进模型。 模型的逐步发展,和直观的进展,可以帮助应对拖延症。
为模型提供正面和支持性的学习环境是训练强化模型的一个重要方面。 研究表明,正面的样本可以带来更有效和更有针对性的模型学习。 这是因为该模型正在搜素最优选择,对不正确动作的惩罚会导致选择错误操作的概率降低。 与此同时,正面奖励清晰地表明模型选择正确,并显著增加了重复此类动作的可能性。
当一个模型针对某个动作获得正面奖励时,它会更加关注它,并在未来倾向于重复该动作。 这种激励机制有助于模型搜索和判定达成其目标的最成功策略。
最后,为了有效解决拖延症问题,有必要分析其背后的原因。 辨别拖延症的具体原因,令您能够采取有针对性的措施来消除它们。 这也许包括审核训练过程、识别瓶颈、资源问题、或次优模型设置。
考虑并适应不断变化的条件有助于避免拖延症。 基于新数据和学习任务的变化,定期更新模型,也会有助于保持相关性和有效性。 此外,要考虑新到若干因素,譬如新的需求或约束,模型应能够适应这些,并避免停滞。
设定小目标和里程碑,可以帮助将较大的任务分解为更易于管理和达成的片段。 这将有助于查看模型学习过程的进度,并保持活力。
为了成功克服强化学习模型中的拖延症,您需要运用各种方式和策略。 这种综合性方式将帮助模型有效地克服拖延症,并在训练中取得最佳效果。 通过结合各种技术,例如改善学习环境、设定明确的目标、定期评估进度和利用激励,该模型将能够克服拖延症,并朝着达成其学习目标前进。
2. 实施解决步骤
在理论研究之后,现在我们就转向这些思路应用的实施。
在上一篇文章中,我提到需要进一步的训练,从而尽量减少亏损交易。 然而,而当我们继续训练时,我们遇到了一个状况,即 EA 在整个训练期间没有进行任何业务。
这种现象被称为“模式拖延症”,是一个需要我们关注和解决的严重问题。

2.1. 分析原因
为了克服强化学习中的模型拖延症,首先要分析现状,并辨别这种现象的成因。 该分析将帮助我们了解为什么该模型没有进行交易,以及可以进行哪些调整来提高其性能。
使用 “Test.mq5” EA 测试训练模型,该 EA 以贪婪方式选择代理者和动作。 重点注意的是,相同参数和测试周期的 EA,后续每次启动都会导致高精度地复现前一次验算。 这令我们能够在每次启动时添加控制点,并分析 EA 操作。
在每次启动时添加控制点,并分析 EA 的工作,为我们提供了更高的可靠性,以及对于训练强化模型结果的信心。 我们能够更好地了解模型如何基于真实数据应用其知识和预测,并做出相应的结论及调整,从而提高其性能。
为了评估调度器的工作,我们引入了 ModelsCount 向量,它包含每个代理者被选中的次数。 为此,在全局变量模块里声明 ModelsCount 向量:
vector<float> ModelsCount;
然后,在 OnInit 函数中,初始化该向量的大小为零,与对应于用到的代理者数量:
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- ........ ........ //--- ModelsCount = vector<float>::Zeros(Models); //--- return(INIT_SUCCEEDED); }
在 OnTick 函数中,调度器的每次前向验算之后,增加 ModelsCount 向量中相应代理者的计数器:
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(!IsNewBar()) return; //--- ........ ....... //--- if(!Schedule.feedForward(GetPointer(State1), 12, false)) return; Schedule.getResults(Result); int model = GetAction(Result, 0, 1); ModelsCount[model]++; //--- ........ ........ }
最后,在逆初始化 EA 时,在日志中显示计算结果:
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- Print(ModelsCount); delete Result; }
因此,我们加入的功能计算每个代理者的选择数量,并在 EA 逆初始化时在日志中显示计数结果。 这令我们能够评估调度器的性能,并获取有关在 EA 执行期间每个代理者被选择频率的信息。
添加第一个控制点后,我们在策略测试器中启动该 EA,参数或测试周期都无变化。 获得的结果确认了我们的担忧。 我们可以看到,调度器在整个测试过程中只用到一个代理者。

这一观察结果表明,调度器也许偏向于特定代理者,而忽略了探索其他可用代理者。 这种偏向也许会阻碍我们的强化学习模型性能,并限制了其发现更有效策略的能力。
为了解决这个问题,我们需要探究调度器只选择用一个代理者的原因。
继续分析此行为的原因,我们加入两个额外的控制点。 现在,我们重点关注模型输出分布当中的变化动态,具体取决于环境状态的变化。 为此,我们引入了两个额外的向量:prev_scheduler 和 prev_actor。 在这些向量中,我们将分别存储调度器和代理者的上一次前向验算结果。
vector<float> prev_scheduler; vector<float> prev_actor;
这令我们能够将当前分布与以前的分布进行比较,并评估它们的变化。 如果我们发现分布随时间或响应环境的变化而发生显著改变,这也许表明模型可能对变化过于敏感、或策略不太稳定。
将这些向量添加到我们的模型中,令我们能够获得有关不断变化的策略和分配的更详细动态信息,这反过来又有助于我们了解偏向特定代理者的原因,并采取措施解决这个问题。
与前一种情况一样,我们在 OnInit 方法中初始化向量,以便为数据控制做好准备。
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- ........ ........ //--- ModelsCount = vector<float>::Zeros(Models); prev_scheduler.Init(Models); prev_actor.Init(Result.Total()); //--- return(INIT_SUCCEEDED); }
实际的数据控制是在 OnTick 方法中完成的。
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(!IsNewBar()) return; //--- ........ ........ //--- State1.AssignArray(sState.state); if(!Actor.feedForward(GetPointer(State1), 12, false)) return; Actor.getResults(Result); State1.AddArray(Result); if(!Schedule.feedForward(GetPointer(State1), 12, false)) return; vector<float> temp; Schedule.getResults(Result); Result.GetData(temp); float delta = MathAbs(prev_scheduler - temp).Sum(); int model = GetAction(Result, 0, 1); prev_scheduler = temp; Actor.getResults(Result); Result.GetData(temp); delta = MathAbs(prev_actor - temp).Sum(); prev_actor = temp; ModelsCount[model]++; //--- ........ ........ //--- }
在本例中,我们要评估环境状态的变化如何影响模型的结果。 该实验的结果就是,我们期望看到在模型输出中,测试样本中的每根蜡烛都有唯一的概率分布。 换言之,我们希望取决于市场条件的变化来观察模型策略的变化。
我们不会记录分析结果,因为它含有大量数据。 取而代之,我们将用调试模式来观察数值的变化。 为了减少所比较数值的体量,我们只检查向量的总偏差。
不幸的是,我们在测试过程中没有发现任何偏差。 这意味着在所有环境状态下,模型输出的概率分布几乎保持不变。
这一观察结果表明,该模型不适应不断变化的环境,也没有参考市场条件的差异。 模型的这种行为有多种可能的原因,并有对应解决它们的各种方式:
- 训练数据集的局限性:如果训练数据集没有包含足够多样的状况,模型也许无法学会充分响应新条件。 解决方案也许是扩展和多样化训练数据集,包括更广泛的场景,和不断变化的市场条件。
- 模型训练不足:模型可能没有接受足够的训练,或经历足够的训练世代,来适应不同的环境条件。 在这种情况下,增加训练时间、或使用额外方法,例如优调,能帮助模型更好地适应。
- 模型复杂度不足:模型复杂度也许不足以捕获环境状态的细微差异。 在这种情况下,增加模型的规模和复杂度,例如添加更多层、或增加神经元的数量,能帮助它更好地捕获和处理数据中的差异。
- 模型架构选择错误:目前的模型架构可能不适合解决环境不断变化的问题。 在这种情况下,修订模型的架构可以提高其适应环境变化的能力。
- 不正确的奖励函数:模型的奖励函数也许信息量不够,或者也许无法达到所需的目标。 在这种情况下,重新考虑奖励函数,并将更多相关因素纳入其中,这样就能帮助模型在不断变化的环境中做出更明智的决策。
所有这些方式都需要对模型进行额外的实验、测试和调整,从而更好地适应不断变化的环境,并提高其性能。
我们将分析每一层的架构,以便从模型中准确找出系统状态变化相关信息丢失的位置。 在调试模式下,我们将检查模型每一层输出的变化。
我们将从完全连接的 CNeuronBaseOCL 层开始。 在这一层中,我们将检查是否保留了系统状态变化相关信息。 接下来,我们将检查 CNeuronBatchNormOCL 批处理数据常规化层,确保它不会扭曲状态变化数据。 然后,我们将分析 CNeuronConvOCL 卷积层,看看它如何处理系统状态变化信息。 最后,我们将检查 CNeuronMultiModel 多模型全连接层,判定它如何解释跨模型的状态变化。
进行此分析将帮助我们判定在模型架构的哪一层丢失了系统状态变化相关信息,以及哪些层可以优化或修改,从而提高模型适应环境不断变化的性能。
为了控制和跟踪模型中每一层的输出,我们在 CNeuronBaseOCL 类中实现了prev_output 向量。 您可能还记得,该类是所有其它神经层类的基类,所有其它层都继承自它。 向该类的主体内添加向量,我们是为了确保它存在于模型的所有层当中。
class CNeuronBaseOCL : public CObject { protected: ........ ........ vector<float> prev_output;
在类初始化方法中,我们将为向量设置大小,其值等于该层中的神经元数量。
bool CNeuronBaseOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint numNeurons, ENUM_OPTIMIZATION optimization_type, uint batch) { ........ ........ //--- prev_output.Init(numNeurons); //--- ........ ........ //--- return true; }
在 feedForward 方法中,执行贯穿模型的前向验算,我们在所有迭代完成后,于方法末尾添加一个控制点。 请记住,此方法中的所有操作都是在 OpenCL 关联环境中执行的。 为了控制数据,我们需要将操作结果加载到主内存当中,但这可能需要花费大量时间。 以前,我们试图最小化这种加载,只保留加载模型结果。 在当前情况下,变成必须加载每个神经层的结果。 不过,如果不需要数据控制,则可稍后删除或注释掉该代码模块。
bool CNeuronBaseOCL::feedForward(CNeuronBaseOCL *NeuronOCL) { ........ ........ //--- vector<float> temp; Output.GetData(temp); float delta=MathAbs(temp-prev_output).Sum(); prev_output=temp; //--- return true; }
我们还将类似的控制添加到全部所分析神经层类别的正向验算方法之中。 这令我们能够监控每一层的输出值,并判定系统状态变化“丢失”的可能地方。 在每个层类的前向验算方法中添加相应的代码模块,我们就可在模型训练的每次迭代中存储和分析该层的结果。
在调试模式下监视数据。
在分析结果之后,我们发现由原始数据层、批量常规化层、两个连续卷积层和全连接神经层组成的数据预处理模块无法正常工作。 我们发现,在第二个卷积层之后,模型对所分析系统状态的变化没有响应。
CNeuronBaseOCL -> CNeuronBatchNormOCL -> CNeuronConvOCL -> CNeuronBaseOCL -> CNeuronConvOCL -> CNeuronBaseOCL
这在代理者和调度器两种情况下都可以观察到,其中我们用到类似的数据预处理单元。 两种情况的测试结果雷同。
尽管在以前的实验中,这种架构给出了积极的结果,但在这种情况下,亮明它是无效的。 因此,我们面临的需求是要更改所用模型的架构。
2.2. 更改模型架构
当前的模型架构已被证明是无效的。 现在,我们必须退后一步,从新的角度看待以前创建的架构,以便评估优化它的可能方式。
在当前模型中,我们将市场状况和账户状态提交给代理者的输入,代理者分析情况,并拟议可能的行动。 我们将代理者的工作结果添加到先前收集的初始数据中,并将其作为输入传递给调度器,调度器选择一个代理者来执行动作。
现在我们来想象一个投资部门,雇员分析市场状况,并将分析结果呈交给部门负责人。 部门负责人在获得这些结果后,将其与原始数据相结合,并进行附加的分析,以便选择一个与他(或她)的预测相匹配的代理者。 然而,这种方式可能会降低部门的效率。
在这种情况下,部门负责人必须自己分析市场状况,并研究雇员的工作成果。 这增加了额外的负担,且在做出决策时并不总是具有实用价值。 试图在每个步骤中提供尽可能多的信息,可能会导致错失分层模型的主要思路,即将问题切分为更小的组成部分。
在这种关联环境中,若基于分析我们的模型,这样一个部门的效率也许低于部门负责人的效率,由于他(或她)不仅要分析市场状况,还要检查雇员的表现,这在决策方面或许太低效。
据所述场景,如果我们在代理者和调度器之间共享对市场状况的分析,投资部门的效率将得到提高。 在这个模型中,代理者专注于市场分析,而调度器负责基于代理者的预测做出决策,而不再自行分析市场状况。
代理者负责分析市场数据,包括进行技术和基本面分析。 他们研究和评估当前的市场状况,辨别趋势,并提出可能的行动方向。 不过,他们在进行分析时不会考虑账户余额。
另一方面,调度器将负责风险管理,并基于代理者的分析做出决策。 它将采用代理者提供的预测和建议,并针对账户健康状况,以及与风险管理相关的其它因素进行额外分析。 基于这些信息,规划师将对投资策略中的具体行动做出最终裁决。
这种职责分工令代理者能够专注于市场分析,而不会被账户状态分心,从而提高了他们的专业性和预测的准确性。 反过来,调度者可以专注于评估风险,并基于代理者的预测做出决定,这令其能够有效地管理投资组合,并将风险降至最低。
这种方式改善了投资团队的决策过程,因为每个团队成员都专注于他们的专业领域,从而产生更准确的分析和预测。 这可以提升我们的模型性能,并带来更明智和成功的投资决策。
根据给定的信息,我们将继续修改模型的架构。 首先,我们将对代理者的源数据层进行更改,令其专注于分析市场形势,删除负责分析账户状态的神经元。
bool CreateDescriptions(CArrayObj *actor, CArrayObj *critic, CArrayObj *scheduler) { //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } //--- if(!critic) { critic = new CArrayObj(); if(!critic) return false; } //--- if(!scheduler) { scheduler = new CArrayObj(); if(!scheduler) return false; } //--- Actor actor.Clear(); CLayerDescription *descr; //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (int)(HistoryBars * 12); descr.window = 0; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
在数据预处理模块中,我们将删除全连接层。 我们只保留批量常规化层和 2 个卷积层。
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count=descr.count = prev_count-2; descr.window = 3; descr.step = 1; descr.window_out = 2; prev_count*=descr.window_out; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = (prev_count+1)/2; descr.window = 2; descr.step = 2; descr.window_out = 4; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
决策模块保持不变。
我们决定更改 Critic 的架构。 如以前一样,由 Critic 分析市场形势和账户状态。 这是因为下一个状态值不仅取决于最后采取的行动,还取决于之前的行动,以持仓和累积盈亏表达。
我们还得出结论,后续状态值不应取决于所选择的策略。 我们的目标是最大限度地提高潜在利润,无论我们采取何种具体策略。 考虑到这一点,我们对评论家的模型进行了一些更改。
具体来说,我们通过删除多模型全连接层来简化 Critic 架构。 取而代之,我们添加了一个完全参数化的决策模型。 这令我们能够达成一种更通用和灵活的方式,其中策略不会直接影响对状态值的评估。
Critic 模型架构的这种变化有助于我们将市场分析和决策分开,从而简化流程,并令我们能够专注于利润最大化,无论 选择何种策略。
附带,我们还针数据预处理模块进行了修改,与代理者架构的更改类似。 现在,于数据预处理模块当中,我们删除全连接层,并只保留一个批量常规化层和两个卷积层,以此来简化架构。
//--- Critic critic.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = (int)(HistoryBars * 12 + 9); descr.window = 0; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count=descr.count = prev_count-2; descr.window = 3; descr.step = 1; descr.window_out = 2; prev_count*=descr.window_out; descr.activation = LReLU; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = (prev_count+1)/2; descr.window = 2; descr.step = 2; descr.window_out = 4; descr.activation = SIGMOID; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = 150; descr.window = 2; descr.step = 2; descr.window_out = 4; descr.activation = SIGMOID; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 500; descr.optimization = ADAM; descr.activation = TANH; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 500; descr.activation = TANH; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFQF; descr.count = 4; descr.window_out = 32; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; }
接下来,我们大幅简化了调度器架构。 放弃市场形势分析可以显著减小源数据层的规模。 结果就是,我们几乎完全摆脱了数据预处理单元,只留下了批量常规化层。 我们决定采用批量常规化来分析帐户状态的绝对值。 我们目前使用来自代理者模型输出的完全常规化数值。 将来,我们也许会转向相对分数值,并剔除所用的数据常规化层。
在决策模块中,我们用了一个简单的感知器模型,在输出端有 SoftMax 层。 该模型令我们能够获得涵盖各种代理者的概率分布,并根据这些概率选择最合适的行动。
调度器架构的这种简化,令我们能够更有效地做出决策,只需考虑代理者的分析结果。 这降低了计算复杂性,并减少了对额外数据的依赖。
//--- Scheduler scheduler.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = (9 + 40); descr.window = 0; descr.activation = None; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = TANH; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = TANH; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 10; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = 10; descr.step = 1; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- return true; }
在训练模型的过程中,我们用到了三个 EA。 它们中的每一个都执行自己的功能。 为了避免混淆,并减少出错的可能性,我们决定将描述模型架构的函数移至 “Trajectory.mqh” 文件,该文件是函数库的一部分,描述模型中所用的类和结构。 这令我们能够在所有 EA 中采用单一模型架构,并确保所有三个 EA 的操作修改后能自动同步。
模型的结构发生了变化,包括源数据流的分离,这就需要对当前状态的描述结构进行修改。 我们分配了一个单独的数组来记录帐户状态,如此即可在分析和做出决策时参考其内容。 这般修改,令我们能够在模型训练和操作期间更有效地管理和使用帐户信息。
struct SState { float state[HistoryBars * 12]; float account[9]; //--- SState(void); //--- bool Save(int file_handle); bool Load(int file_handle); //--- overloading void operator=(const SState &obj) { ArrayCopy(state, obj.state); ArrayCopy(account, obj.account); } };
由于模型结构的变化,我们还必须对处理文件的方法进行修改。 更新后的结构和相应方法的完整代码可在附件中找到。
2.3. 数据收集过程的修改
在下一阶段,我们对数据收集过程进行了修改,该过程在 “Research.mq5” EA 中运作。
如早前所述,采用正面样本来训练模型可以提高其效率。 因此,我们对业务的最低盈利能力加以限制,以便将其保存在样本数据库之中。 此最低盈利能力的水平由 ProfitToSave 外部参数判定。
附带,我们还引入了限定止盈和止损水平的外部参数,从而减少长期持仓的情况。 这些参数的数值按存款货币设置,令我们能限制持仓时间,并间接控制持仓量。
//+------------------------------------------------------------------+ //| Input parameters | //+------------------------------------------------------------------+ input double ProfitToSave = 10; input double MoneyTP = 10; input double MoneySL = 5;
数据存储结构和模型构架的变化,导致需要针对供直接模型运行的数据收集和准备操作进行修改。 如以前一样,我们开始将市场状态数据收集到 “state” 数组之中。
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(!IsNewBar()) return; //--- int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), HistoryBars, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); //--- MqlDateTime sTime; for(int b = 0; b < (int)HistoryBars; b++) { float open = (float)Rates[b].open; TimeToStruct(Rates[b].time, sTime); float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); float atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- sState.state[b * 12] = (float)Rates[b].close - open; sState.state[b * 12 + 1] = (float)Rates[b].high - open; sState.state[b * 12 + 2] = (float)Rates[b].low - open; sState.state[b * 12 + 3] = (float)Rates[b].tick_volume / 1000.0f; sState.state[b * 12 + 4] = (float)sTime.hour; sState.state[b * 12 + 5] = (float)sTime.day_of_week; sState.state[b * 12 + 6] = (float)sTime.mon; sState.state[b * 12 + 7] = rsi; sState.state[b * 12 + 8] = cci; sState.state[b * 12 + 9] = atr; sState.state[b * 12 + 10] = macd; sState.state[b * 12 + 11] = sign; }
然后我们将帐户信息保存到 “account” 数组之中。
//--- sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); sState.account[2] = (float)AccountInfoDouble(ACCOUNT_MARGIN_FREE); sState.account[3] = (float)AccountInfoDouble(ACCOUNT_MARGIN_LEVEL); sState.account[4] = (float)AccountInfoDouble(ACCOUNT_PROFIT); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; int total = PositionsTotal(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += PositionGetDouble(POSITION_PROFIT); break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += PositionGetDouble(POSITION_PROFIT); break; } } sState.account[5] = (float)buy_value; sState.account[6] = (float)sell_value; sState.account[7] = (float)buy_profit; sState.account[8] = (float)sell_profit;
对于依据更新的代理者模型架构的正向验算,我们只需要来自 “state” 数组的市场状态。
State1.AssignArray(sState.state); if(!Actor.feedForward(GetPointer(State1), 12, false)) return;
为了给调度器的正向验算提供初始数据,必须将帐户状态数据与代理者模型的正向验算结果结合起来。
Actor.getResults(Result); State1.AssignArray(sState.account); State1.AddArray(Result); if(!Schedule.feedForward(GetPointer(State1), 12, false)) return;
作为直接经由这两个模型验算的结果,我们抽样并选择一个动作。 而该过程保持不变。 不过,我们增加了累计盈亏的分析。 如果累计盈亏值达到指定的阈值,我们指定全部平仓的动作。
重点注意的是,我们的模型只提供全部平仓的动作。 因此,在分析累计盈亏时,我们汇总了所有持仓的数值,无论其方向。
int act = GetAction(Result, Schedule.getSample(), Models); double profit = buy_profit + sell_profit; if(profit >= MoneyTP || profit <= -MathAbs(MoneySL)) act = 2;
我们还对奖励功能进行了更改。 做出这一决定是为了消除净值变化的影响,从而导致奖励稀疏。 然而,我们意识到,在金融市场交易过程中,只有余额的变化才具备终极价值。 在调整奖励函数时已考虑到了这一点。
所有 EA 的方法和函数的完整代码都可以在附件中找到。
2.4. 学习过程的变化
我们还对模型训练过程进行了更改,重点在于所有模型和代理者的并行训练。 特别是,我们改变了在反向验算期间传递奖励的方式。 以前,我们只为选定的代理者指定奖励,但现在我们希望将整个奖励分布传递给所有代理者。 这可调度器更全面地评估每个代理者的可能影响,并降低为所有状态选择单个代理者的可能性,正如我们之前观察到的那样。
从概率论中我们知道,复杂事件发生的概率等于其组成部分概率的乘积。 在我们的例子中,我们有一个代理者选择的概率分布,和每个代理者选择行动的概率分布。 在样本数据库中,我们也有特定动作,和来自系统的相应奖励。 为了准备规划者的反向验算数据,我们将代理者选择概率向量的元素,乘以每个代理者选择给定动作的概率向量的元素。
为了将全部奖励传递给调度器,我们调用 SoftMax 函数对结果概率进行常规化,然后将结果向量乘以外部奖励。 与此同时,我们根据状态值预先调整外部奖励,这令我们能够估算与最优轨迹的偏差。
void Train(void) { ........ ........ Actor.getResults(ActorResult); Critic.getResults(CriticResult); State1.AssignArray(Buffer[tr].States[i].account); State1.AddArray(ActorResult); if(!Scheduler.feedForward(GetPointer(State1), 12, false)) return; Scheduler.getResults(SchedulerResult); //--- ulong actions = ActorResult.Size() / Models; matrix<float> temp; temp.Init(1, ActorResult.Size()); temp.Row(ActorResult, 0); temp.Reshape(Models, actions); float reward=(Buffer[tr].Revards[i] - CriticResult.Max())/100; int action=Buffer[tr].Actions[i]; SchedulerResult=SchedulerResult*temp.Col(action); SchedulerResult.Activation(SchedulerResult,AF_SOFTMAX); SchedulerResult = SchedulerResult * reward; Result.AssignArray(SchedulerResult); //--- if(!Scheduler.backProp(GetPointer(Result))) return;
为了训练评论者,我们只需为相应的行动传递一个未经修正的外部奖励。
CriticResult[action] = Buffer[tr].Revards[i]; Result.AssignArray(CriticResult); //--- if(!Critic.backProp(GetPointer(Result), 0.0f, NULL)) return;
在按代理者模型工作时,我们考虑到采用任何策略都可能导致盈利或损失。 在某些情况下,在不成功的入场开仓后,重点是要有按时离场的决心,并限制损失。 因此,我们不能完全排除具有负面奖励的行动,因为在某些情况下,也许会有其它行为产生更严重的负面影响。 这同样适用于正面奖励。
在为代理者模型的向后验算准备数据时,我们只需调整最后一次向前验算的结果,同时要参考每个代理者选择动作的概率,和系统的外部奖励。 为了维护每个代理者的概率分布的完整性,我们调用 SoftMax 函数对调整后的分布进行常规化。
//--- for(int r = 0; r < Models; r++) { vector<float> row = temp.Row(r); row[action] += row[action] * reward; row.Activation(row, AF_SOFTMAX); temp.Row(row, r); } temp.Reshape(1, ActorResult.Size()); Result.AssignArray(temp.Row(0)); //--- if(!Actor.backProp(GetPointer(Result))) return;
在附件中,您可以看到所有 EA 的完整代码,以及它们在工作中调用的函数。
为了开始模型训练过程,我们在策略测试器优化模式下启动 “Research.mq5” EA,与 Go-Explore 算法文章中讲述的类似。此处的主要区别在于最低验算盈利阈值的规范,它判定样本是否保存到数据库当中。 这有助于提高模型训练的效率,因为我们专注于正面样本。
不过,值得注意的是一个重要的细节。 为了提供更多样化的环境探索,并增加行为策略的覆盖面,我们可以在样本收集过程中包括止盈和止损参数的优化。 这令我们的模型能够研究更多不同的策略,并找到最优离场点。

在创建样本数据库后,我们开始利用 “Study2.mq5” EA 训练模型。 为此,您需要将 EA 加载到所选交易品种的图表上,并指定迭代次数,这将决定模型参数将会更新多少次。
在图表上启动 “Study2.mq5” EA,令模型使用收集到的样本来训练和调整其参数。 在学习过程中,模型将改进和适应市场环境,以便做出更准确的决策,并提高其效率。
我们在策略测试器中运行 “Test.mq5” EA 的单次验算来检查模型训练结果。 可以预料的是,在第一次模型训练迭代之后,其结果与预期相距甚远。 它也许无利可图。


或也许它能会产生利润。 但余额曲线将与我们的预期相去甚远。

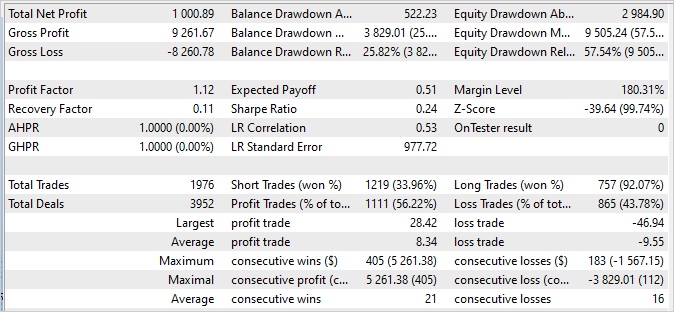
但与此同时,我们可以注意到,我们的调度器在某种程度上用到了几乎所有的代理者。


为了检测模型的错误操作,我们在测试 “Test.mq5” EA 中添加了一个模块,收集有关访问状态、已完成动作、和接收外部奖励的信息。 此数据收集模块与智能系统中收集样本数据的类似。
请记住,我们在测试 EA 中使用了贪婪方式选择代理者和动作。 这意味着所采取的所有步骤都由我们模型的策略决定。 因此,我们将所有验算加到样本数据库之中,无论其盈利能力如何。 将这些数据包含在样本数据库中,将令我们能够调整和优化模型的交易策略。
收集有关访问的状态、采取的行动、和所得奖励的信息,我们可以分析模型的性能,并判定哪些行动会导致预期的结果,哪些会导致不良结果。 这些信息将令我们能够在后续的训练迭代中提高模型的效率和决策准确性。
在策略测试器优化模式下运行样本收集 EA 的额外迭代,对于扩展正面样本的基础,并为我们的模型提供更多训练数据非常重要。
不过,重点注意的是,收集样本和训练模型的过程需要交替进行。 在样本收集过程中,我们从模型生成的概率分布中抽样动作。 这意味着样本的收集是定向的,并且新样本将在贪婪式动作选择的不远处。 这令我们能够在给定的方向上更全面地探索环境,并用有益数据丰富样本数据库。
在收集样本和训练模型之间交替进行,令模型能够充分利用新数据,从而基于收到的信息改进其策略。 与此同时,随着每一次新的迭代,该模型变得越来越有经验,并适应了所需的交易方向。
3. 测试
经过多次收集样本、训练和测试的迭代,我们得到了一个能够在训练集上产生盈利的模型,盈利因子为 114.53。 依据 2023 年前 4 个月,该模型进行了训练,完成了 286 笔业务。 其中,只有 16 笔是无盈利。 训练集的恢复因子为 1.3,这表明模型能够快速从损失中恢复。
持仓时间均匀分布在 1 至 198 小时之间,平均持仓时间为 72 小时 59 分钟。 这表明该模型可以根据当前的市场状况在短线和长线时间间隔内做出决策。
总体而言,这些结果表明,该模型表现出高盈利能力、低亏损率、快速恢复能力、以及时间节点上的灵活性。 这是对该模型的有效性、及其在真实交易条件下应用潜力的积极确认。



重点注意的是,接下来 2 周的余额图(不包括在训练集中)表现出稳定性,并且与训练集上的图表没有明显差异。 虽然它的结果较低,但它们仍然不错:
- 盈利因子为 15.64,这表明该模型相对于风险具有良好的盈利能力。
- 恢复因子为 1.07,表示该模型具备从亏损交易中恢复的能力。
- 在完成的 89 笔业务中,有 80 笔以盈利了结,这表明胜率很高。
这些结果确认了该模型在后续交易数据中的稳定性和稳健性。 尽管这些数值可能与训练集略有不同,但它们仍然令人印象深刻,并确认了模型在现实世界中成功交易的潜力。


策略测试器报告可在附件中找到。
结束语
在本文中,我们研究了模型拖延症的问题,并提出了克服该问题的有效方法。 使用调度者辅助控制算法,我们开发出一种训练金融市场自动交易模型的方式。
我们提出了一个分层架构,该架构由多个相互交互的模型组成。 每个模型都负责决策的某些方面。 这种模块化结构令我们能够把任务切分为更小、但相互关联的子任务,来有效地克服拖延症。
我们还涵盖了收集样本、训练模型和测试的方法,这令我们能够在真实数据上有效地训练模型,并适应不断变化的市场状况。 结合各种策略,并分析累积的盈亏,令我们能够做出明智的决策,并将风险降至最低。
我们的实验结果表明,所拟议的方式确实能够克服拖延症,达成稳定和可盈利交易。 我们的模型在训练和后续数据上表现出高盈利能力和稳定性,这确认了它们在现实条件下的有效性。
总体而言,我们的方式令模型能够有效地学习和适应市场状况,并做出明智的决策。 这种方式的进一步开发和优化,可以提升自动交易在金融市场里的盈利能力和稳定性。
参考文献列表
本文中用到的程序
| # | 名称 | 类型 | 说明 |
|---|---|---|---|
| 1 | Research.mq5 | 智能交易系统 | 样本收集 EA |
| 2 | Study2.mql5 | 智能交易系统 | 模型训练 EA |
| 3 | Test.mq5 | 智能交易系统 | 模型测试 EA |
| 4 | Trajectory.mqh | 类库 | 系统状态定义结构 |
| 5 | FQF.mqh | 类库 | 完全参数化模型的工作安排类库 |
| 6 | NeuroNet.mqh | 类库 | 用于创建神经网络的类库 |
| 7 | NeuroNet.cl | 代码库 | OpenCL 程序代码库 |
…
本文由MetaQuotes Ltd译自俄文
原文地址: https://www.mql5.com/ru/articles/12638
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。


你好,迪米特里。谢谢你的新作品。我也曾试图在图形上画出一条直线。现在我明白为什么了。您能告诉我 Study2 的结果可以接受吗?测试尚未显示任何有意义的操作,打开了一个买入并在每个条形图上成交。
顺便说一下,NeuroNet_DNG 文件夹必须从上一个 EA 中拖过来。如果你对它做了改动,那我就没办法了。
最新版本的文件在附件中
德米特里 你好。您能告诉我,您对这个智能交易系统进行了多少培训,使它至少能进行一些有意义的交易,甚至是减仓交易。我现在的情况是,它要么根本不尝试交易,要么就是开了一堆交易,却无法通过整个 4 个月的时间。与此同时,余额静止不动,股本却在浮动。它使用一两个代理,其余的都是零。初始样本尝试不同。
-从 50 美元开始,例如一开始 30-40 个示例,然后在 Stady2(默认为 100000)每次通过后,在一个周期内添加 1-2 个示例。
-例如,从 35 美元起,一开始输入 130-150 个示例,然后在每次通过 Stady2(默认值为 100000)后输入,然后在一个循环中添加 1-2 个示例。
- 从 50 美元起,开始时使用 15 个示例,在 500000 和 2000000 中不添加任何东西来训练 Stady2。
所有变体的结果都是一样的--不工作,不学习。此外,在经过 2-3 百万次迭代后,例如,它很可能什么也不会再显示--就是不交易。
到底要训练多少次(用数字表示)才能开始开仓和平仓?
你好,德米特里!您是一位伟大的老师和导师!
350668273_1631799953971007_1316803797828649367_n.png (1115×666) (fbcdn.net)经过一段时间的成功培训,我的胜率达到了 99%。但是,它只能卖出交易。no buy trades
以下是截图:
350733414_605596475011106_6366687350579423076_n.png (1909×682) (fbcdn.net)
德米特里
我一直在关注您的文章,以尽可能多地学习您的知识和专业技能,因为您的知识和专业技能远远超出了我的能力范围。 读完这篇文章后,我突然想到,虽然最终提出的模型在识别空头交易方面非常出色,但在识别多头交易方面却完全不成功,因此它可以成为两级交易解决方案的一部分。您认为可以通过推翻一些假设来开发多头模型,还是需要一个全新的模型,如第 39 号文章中的 "脚趾围棋探索"?
为您目前的努力干杯,并支持您未来的事业