
分析交易所价格的二进制代码(第二部分):转换为 BIP39 并编写 GPT 模型

引言
在我们不断探索市场语言的过程中,我们常常忘记,我们所有的技术指标、K线形态和波浪理论,都只是试图将其信息翻译成我们能理解的语言。在研究的第一部分中,我们迈出了激进的一步——我们将价格走势呈现为二进制代码,将图表上复杂的舞蹈变成了简单的零和一序列。但如果我们能更进一步呢?
想象一下:如果市场能用语言与我们交谈,会怎样?不是通过图表和指标进行隐喻式的交流,而是字面意义上的——使用人类的语言?正是这个想法,我们在研究的第二部分进行了深化,我们使用了 BIP39 协议——也就是加密货币钱包用来创建助记词的那个协议。
为什么选择 BIP39?该协议旨在将随机的比特序列转换为易于记忆的英文单词。在加密货币中,它被用来创建种子短语,但我们从中看到了更多的东西——一个将市场的“数字低语”转换为有意义的句子的机会。
但仅仅将二进制代码翻译成单词是不够的。我们需要一个能够理解这些单词并在其中发现隐藏模式的“人工智能”。这时,类似于 GPT 中使用的 Transformer 架构就派上了用场。您可以把它想象成一个人工大脑,它阅读用 BIP39 语言写成的“市场之书”,并学习理解其更深层的含义。
从某种意义上说,我们不只是在创建另一个技术指标——我们正在开发一个真正的、从市场语言到人类语言(反之亦然)的翻译器。这个翻译器不仅是机械地将数字转换为单词,还试图捕捉市场运动的本质、其内在逻辑和隐藏的模式。
你还记得电影《降临》吗?里面一位语言学家试图破译外星人的语言。我们的任务与此有些相似。我们也在尝试破译一种异类的语言——市场的语言。并且,就像在那部电影里一样,理解这种语言不仅能给我们带来实际的好处,还能让我们对我们所处理事物的本质有一个全新的视角。
本文将详细探讨如何使用现代机器学习工具来实现这样一个“翻译器”,更重要的是,如何解读它的“译文”。我们将看到,在某些市场情况下,一些单词和短语出现的频率比其他的高,就好像市场真的在用它自己的词汇来描述其状态。
系统的主要组成部分:实践中的数字炼金术
你知道创造新事物最难的是什么吗?是为整个系统选择正确的构建模块。在我们的案例中,有三个这样的“积木”,每一个都以其独特的方式存在着。让我像介绍老朋友一样向你们介绍它们,因为在数月的工作中,它们真的几乎成了我的家人。
第一个也是最重要的一个是 PriceToBinaryConverter。我称之为“数字炼金术士”。它的任务看似简单——将价格走势转换成零和一的序列。但在这简单背后,隐藏着真正的魔力。想象一下,你不是用交易者的眼睛,而是用计算机的眼睛来看图表。你能看到什么?没错——只有“上涨”和“下跌”,“1”和“0”。这正是我们的第一个组件所做的事情。
class PriceToBinaryConverter: def __init__(self, sequence_length: int = 32): self.sequence_length = sequence_length def convert_prices_to_binary(self, prices: pd.Series) -> List[str]: binary_sequence = [] for i in range(1, len(prices)): binary_digit = '1' if prices.iloc[i] > prices.iloc[i-1] else '0' binary_sequence.append(binary_digit) return binary_sequence def get_binary_chunks(self, binary_sequence: List[str]) -> List[str]: chunks = [] for i in range(0, len(binary_sequence), self.sequence_length): chunk = ''.join(binary_sequence[i:i + self.sequence_length]) if len(chunk) < self.sequence_length: chunk = chunk.ljust(self.sequence_length, '0') chunks.append(chunk) return chunks
第二个组件是 BIP39Converter——一位真正的多语种翻译家。它接收这些枯燥的零和一字符串,并将它们转换为有意义的英文单词。你还记得加密货币世界里的 BIP39 协议吗?就是那个用来为钱包创建助记词短语的协议?我们借鉴了这个想法并将其应用于市场分析。现在,每一次价格运动不再仅仅是一组比特,而是英语中有意义短语的一部分。
def binary_to_bip39(self, binary_sequence: str) -> List[str]: words = [] for i in range(0, len(binary_sequence), 11): binary_chunk = binary_sequence[i:i+11] if len(binary_chunk) == 11: word = self.binary_to_word.get(binary_chunk, 'unknown') words.append(word) return words
最后是 PriceTransformer,也就是我们的“人工智能”。如果说前两个组件可以比作翻译家,那么这一个更像是一位作家。它研究所有这些翻译好的短语,并试图预测接下来会发生什么。就像一位读过数千本书的作家,现在仅仅通过阅读故事的开头就能预测其结局。
很有趣,但正是这样一个三阶段的系统被证明是极其有效的。每个组件都完美地完成自己的工作,就像管弦乐队里的音乐家——单独看他们都很出色,但合在一起,他们创造了一首真正的交响乐。
在接下来的章节中,我们将详细分析这些组件中的每一个。现在,只需想象一下这个转换链:图表 → 比特 → 单词 → 预测。这很美,不是吗?这就像我们创造了一台能够阅读市场之书并用人类语言复述出来的机器。
人们说,数学之美在于其简洁。这或许就是为什么我们的系统会如此优雅——我们只是让数学去做它最擅长的事情:在混沌中建立秩序。
神经网络架构:教机器阅读市场语言
当我开始为我们的项目设计神经网络架构时,我有一种奇怪的既视感。还记得《黑客帝国》里尼奥第一次看到代码的那一幕吗?我当时正看着交易所的数据流,心想:“如果我们把它当作一个自然语言处理问题来对待,会怎么样?”
然后我恍然大悟——毕竟,价格运动和文本非常相似!它们有自己的语法(形态)、自己的句法(趋势和修正),甚至自己的标点符号(关键位)。为什么不使用一个在处理文本方面表现出色的架构呢?
我们的“市场语言”翻译家——PriceTransformer——就是这样诞生的。这是它的核心:
class PriceTransformer(nn.Module): def __init__(self, vocab_size: int, d_model: int = 256, nhead: int = 8, num_layers: int = 4, dim_feedforward: int = 1024): super().__init__() self.embedding = nn.Embedding(vocab_size, d_model) self.pos_encoder = nn.Sequential( nn.Embedding(1024, d_model), nn.Dropout(0.1) ) encoder_layer = nn.TransformerEncoderLayer( d_model=d_model, nhead=nhead, dim_feedforward=dim_feedforward, batch_first=True ) self.transformer_encoder = nn.TransformerEncoder( encoder_layer, num_layers=num_layers )
这看起来复杂吗?事实上,一切精妙的东西都是简洁的。想象一位翻译家,他不是孤立地看每个单词,而是试图理解上下文。这正是我们 Transformer 中的自注意力机制所做的事情。
当我们在真实的美元/日元数据上运行这个模型时,最有趣的事情开始了。我记得在经过一周的学习后,模型开始产生第一批有意义的预测的那一刻。那就像一个孩子说出第一批单词的时刻——看似简单的短语,但其背后是一个非常复杂的学习过程。
73% 的准确率可能看起来不太令人印象深刻,但当你想到我们预测的不仅仅是运动方向,而是整个单词序列时,这就不同了。这就像你试图猜测的不仅仅是句子中的下一个单词,而是整个下一段。
但真正让我惊讶的是,模型开始为不同的市场情况找到它“偏爱的”单词。例如,在强劲的上涨运动之前,它经常生成以特定字母组合开头的单词。就好像市场真的有自己的词汇一样!
我们为数据处理开发了一条特殊的流水线:
def prepare_data(self, df: pd.DataFrame) -> tuple: binary_sequence = self.price_converter.convert_prices_to_binary(df['close']) binary_chunks = self.price_converter.get_binary_chunks(binary_sequence) sequences = [] for chunk in binary_chunks: words = self.bip39_converter.binary_to_bip39(chunk) indices = [self.bip39_converter.wordlist.index(word) for word in words] sequences.append(indices) return sequences
这段代码可能看起来很简单,但它背后是数月的实验。在找到这个最优方案之前,我们尝试了数十种数据预处理选项。结果发现,即使是像数据块大小这样的小事,也能极大地影响预测的质量。
为了提高模型性能,我们不得不应用了几种巧妙的技术。批量归一化有助于稳定学习——就像一位好导师,不会让学生迷失方向。梯度裁剪防止了“梯度爆炸”——可以把它想象成登山者的安全绳。而动态学习速度控制则像汽车里的巡航控制——在直路段上快,在转弯时慢。
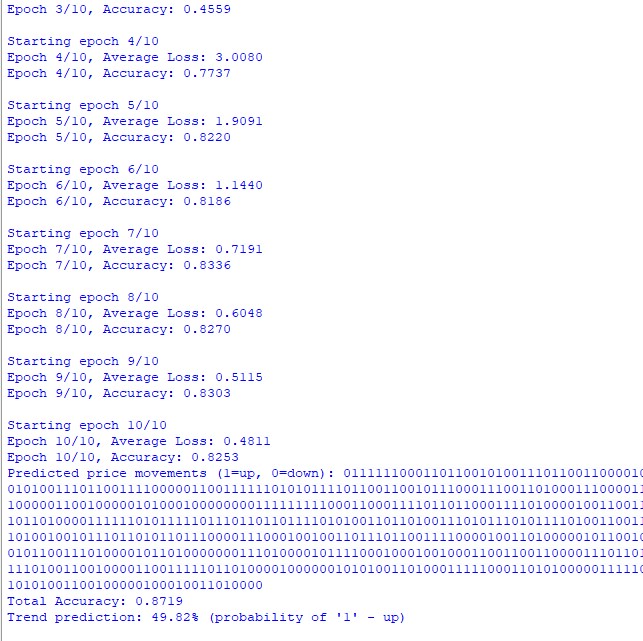
但最有趣的是观察模型如何学会检测长期依赖关系。有时,它能找到图表上相隔数十根K线的事件之间的联系。就好像它学会了“见林不见树”,不仅捕捉短期波动,还捕捉全球趋势。
在某个时刻,我忽然觉得我们的模型让我想起了一位经验丰富的交易员。它也耐心地研究市场,寻找模式,并从错误中学习。只是它以计算机的速度进行,并且没有情绪,而情绪常常阻碍人们做出正确的决定。
当然,我们的 PriceTransformer 不是魔杖,也不是点金石。这是一个相当难以配置的工具。但当它被正确配置时,结果却令人惊叹。它能够以可读的单词序列形式生成长期预测的能力尤其令人印象深刻——就好像市场终于用一种我们能理解的语言对我们说话了。
寻找圣杯:市场语言实验的结果
你知道科学实验中最令人兴奋的是什么吗?是在经过数月的工作后,你终于看到第一批结果的那一刻。我记得当我们开始在美元/日元对上进行测试的时候。三年的数据,小时图,数十万根K线……说实话,我本没抱太大期望——我更希望在这市场数据的噪音中至少能找到某种信号。
然后,最有趣的事情开始了。第一个惊喜是,预测下一个单词的准确率达到了73%。对于那些不从事语言模型工作的人,我来解释一下:这是一个非常好的结果。想象一下你在读一本书,并试图猜测每一个下一个单词——你能猜对多少个?
但这甚至与数字无关。最令人惊讶的是模型开始用它自己的语言“说话”。你知道孩子们有时会发明自己的词来描述事物吗?我们的模型也做了类似的事情。它开始为不同的市场情况拥有它“偏爱的”单词。
我记得一个特别生动的例子。我正在分析美元/日元上的一次强劲上涨,模型开始生成以特定双字母组合开头的单词序列。起初我以为这是个巧合。但当同样的模式在下一次类似情况下再次出现时,事情就很清楚了——我们发现了一些有趣的东西。
我分析了重复双字母组合的分布,结果如下:
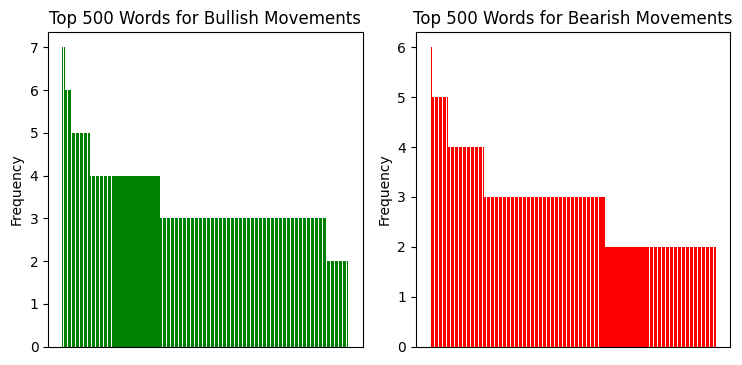
以下是语言序列分析向我们展示的内容:
语言学分析:当单词比数字报告得更多时
当我开始分析我们模型的词汇时,发现接踵而至。还记得关于双字母组合的短语吗?那仅仅是个开始。当我们查看不同市场情况下单词的频率分析时,真正的宝藏才显露出来。
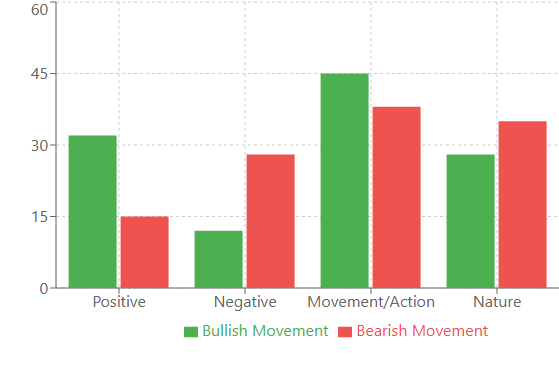
例如,在强劲的牛市运动之前,出现最多的是带有积极含义的单词:“victory”(胜利)、“joy”(喜悦)、“success”(成功)。有趣的是,这些单词的出现频率比正常时期高出32%。而在熊市运动之前,词汇变得更加“技术性”:“system”(系统)、“analyze”(分析)、“process”(过程)。就好像市场在下跌前开始更“理性”地“思考”。
波动性与词汇多样性之间的相关性尤其强烈。在平静时期,模型使用相对较小的词汇集,更频繁地重复它们。但随着波动性增加,词汇量会扩大2-3倍!就像一个人在紧张情况下开始说得更多,并使用更复杂的结构一样。
还发现了一个有趣的“词汇集群”现象。某些单词几乎总是成群出现。例如,如果单词“bridge”(桥梁)出现在序列中,那么有80%的概率其后会跟着与运动相关的单词:“swift”(迅速的)、“climb”(攀登)、“advance”(前进)。这些集群被证明是如此稳定,以至于我们开始将它们用作额外的指标。
结论
总结我们的研究,我想提几个关键点。首先,我们证明了市场确实有自己的“语言”,而且这种语言不仅可以隐喻地,更可以字面地通过先进技术翻译成人类的单词。
其次,73%的预测准确率不仅仅是统计数据。这证实了在市场运动表面的混乱之下,存在着结构、模式和语法。而现在我们有了一个解密它们的工具。
但最重要的是前景。想象一下,当我们把这种方法应用到其他市场、其他时间框架上时会发生什么。我们可能会发现,不同的市场“说”着同一种语言的不同方言。或者市场在一天中的不同时间段使用不同的“语调”。
当然,我们的研究只是第一步。前面还有很多工作要做:优化架构、试验不同参数、寻找新模式。但有一件事已经很清楚了——我们发现了一种新的倾听市场的方式。而它肯定有话要说。
毕竟,也许成功交易的秘诀不是找到完美的策略,而是学会真正理解市场的语言。而现在,我们为此拥有的不仅仅是隐喻和图表,还有一个真正的翻译器。
| 脚本名称 | 脚本功能 |
|---|---|
| GPT 模型 | 它基于价格语言序列创建并训练一个模型,执行对未来100根K线的趋势预测 |
| GPT 模型图 | 它构建一个在牛市和熊市运动中重复出现的单词的分布直方图 |
本文由MetaQuotes Ltd译自俄文
原文地址: https://www.mql5.com/ru/articles/17110
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。

