
使用 Python 创建波动率预测指标

概述
噢,糟糕!我的止损又被吹走了……
这是我在 2021 年每两个交易日开始时使用的短语。我记得我坐在那里,满脑子都是图表和数字,为我的新交易系统感到自豪,然后砰的一声,我的一半存款都没了。因为一些聪明人发表了关于加密货币的声明,市场就疯了。
听起来很熟悉,对吧?我相信每个算法交易者都经历过这种情况。我似乎已经计算并测试了所有内容,该系统在历史数据上运行良好......但真实的市场情况如何?“你好,我是波动,好久不见!”
在又一次经历这样的“冒险”之后,我感到愤怒,并决定查明真相。好吧,不可能以某种方式预测这些市场的歇斯底里!我想我已经挖掘了所有关于波动性的现有研究。你知道什么最有趣吗?事实证明,解决方案在于旧方法和新技术的结合。
在这篇文章中,我将分享我从绝望到有效波动预测系统的旅程。没有无聊的东西或学术术语 —— 只有真实的经验和可行的解决方案。我将向您展示如何将 MetaTrader 5 与 Python 结合起来(剧透:它们并没有立即相处融洽),如何让机器学习为我工作,以及我在此过程中遇到了哪些陷阱。
我从整个故事中获得的主要见解是,你不能盲目相信经典指标或流行的神经网络。我记得我花了一周时间建立了一个非常复杂的神经网络,然后一个简单的 XGBoost 显示了更好的结果。或者有一次,一个简单的布林带在所有智能算法都失败的情况下保住了一笔存款。
我也意识到,在交易中,就像在拳击中一样,最重要的不是打击的力量,而是预测打击的能力。我的系统不会做出超自然的预测。它只是帮助您为市场意外做好准备,并及时提高您的交易策略的安全边际。
简而言之,如果你厌倦了你的算法被每一点波动绊倒,欢迎来到我的世界。我会通过代码示例、图表和分析来原封不动地告诉你一切。让我们开始吧。
项目概念
经过数月的实验和对市场数据的深入分析,一个能够以惊人的准确性预测波动性的系统的概念诞生了。关键的发现是,与价格不同,波动性具有平稳性 —— 它往往会回到平均值并形成稳定的模式。正是这一特性使其预测不仅成为可能,而且在实际交易中也具有实际应用价值。
该系统基于 MetaTrader 5 和 Python 的强大组合,其中每个工具都展示了其优势。MetaTrader 5 是市场数据的可靠来源。它为我们提供了历史报价和实时数据流,延迟最小。Python 成为我们的分析实验室,其中丰富的机器学习库(Sklearn、XGBoost、PyTorch)有助于从这些数据中提取有价值的模式并确认有关波动平稳性的假设。
系统架构由三个关键层次组成:
- 数据管道是系统的基础。这是 MetaTrader 5 数据的主要处理方式:噪声去除、数十个波动率指标的计算以及模型特征的形成。特别关注优化 —— 系统运行时没有延迟和内存泄漏。在这个层面上,还测试了时间序列的平稳性,并识别出显著的波动模式。
- 分析核心。核心是基于一系列专门的机器学习模型。每一个都是根据自己的时间范围量身定制的:从日内波动到每周趋势。在测试中发现,即使是简单的 XGBoost 在预测准确性方面也常常优于复杂的神经网络,尤其是在波动性聚类检测任务中。
- 风险顾问是一个风险管理推荐系统。基于波动性预测,它建议最佳的止损和止盈水平。在未来波动加剧的时期,它建议扩大保护令,在未来较为平静的时间,缩小保护令范围,以便更精确地进入市场。这就是波动平稳性发挥关键作用的地方,使系统能够有效地调整交易参数。
这些模型是在独特的数据集上进行训练的,包括不同时间周期内的报价 —— 从分时报价到每日报价。这使得系统能够识别三个关键的市场条件:低波动性、趋势性和爆炸性。根据这些信息,形成关于最佳进场水平和保护订单的建议。由于波动性的平稳性,系统不仅能够识别当前状态,还能够预测这些状态之间的转换。
该系统的主要特点是适应性。它不仅仅发布固定的建议,而且会根据当前的市场情况进行调整。对于每种交易情况,系统都会根据对未来波动性的预测提供一组单独的参数。由于波动性行为的持续模式,这种适应性特别有效。
在接下来的部分中,我们将详细检查每个系统组件,展示实际代码,并分享回溯测试的结果。您将看到关于波动平稳性的理论概念是如何转化为市场分析的实用工具的。
安装所需软件
在我们深入系统开发之前,让我们先看看安装所有必要的软件。根据我自己的经验,我知道 MetaTrader 5 - Python 连接的设置导致许多人陷入困境,因此我将尝试不仅告诉您如何安装所有内容,而且还告诉您如何避免主要的陷阱。
让我们从 Python 开始。我们需要 3.8 或更高版本,可以从 python.org 官方网站下载。安装时一定要勾选 “将 Python 添加到 PATH”,否则后面需要手动添加路径。安装 Python 之后,我们要做的第一件事就是为项目创建一个虚拟环境。这不是强制性的步骤,但非常有用 —— 它可以保护我们免受库版本冲突的影响。
python -m venv venv_volatility venv_volatility\Scripts\activate # for Windows source venv_volatility/bin/activate # for Linux/MacOS
现在让我们安装必要的库。我们需要一些基本工具:用于处理数据的 numpy 和 pandas、用于机器学习的 scikit-learn 和 xgboost、用于神经网络的 pytorch,当然还有一个用于处理 MetaTrader 5 的库。以下是安装整个软件包的命令:
pip install numpy pandas scikit-learn xgboost pytorch MetaTrader5 pylint jupyter 让我们仔细看看如何安装 MetaTrader 5。您需要从经纪商的网站下载它 - 这很重要,因为版本可能有所不同。安装时,选择一个路径简单的文件夹,不要有西里尔字符或空格 —— 这将为您在设置与 Python 的通信时省去很多麻烦。
安装终端后,不要忘记在其设置中启用自动交易和 DLL 导入,以及启用算法交易。这听起来很明显,但我自己花了几个小时调试它,直到我想起这些设置。
现在到了有趣的部分 —— 检查 Python 和 MetaTrader 5 之间的连接。我开发了一个小脚本来确保一切正常运行:
import MetaTrader5 as mt5 def test_mt5_connection(): if not mt5.initialize(): print("MT5 initialization error:", mt5.last_error()) return False print("MetaTrader5 package author:", mt5.__author__) print("MetaTrader5 package version:", mt5.__version__) terminal_info = mt5.terminal_info() if terminal_info is None: print("Error getting terminal data:", mt5.last_error()) return False print(f"Connected to terminal '{terminal_info.name}' ({terminal_info.path})") print("Trade server:", terminal_info.connected) mt5.shutdown() return True if __name__ == "__main__": test_mt5_connection()
出现问题时要注意什么?最常见的障碍是 MetaTrader 5 初始化。如果脚本无法连接到终端,请首先检查 MetaTrader 5 本身是否正在运行。这似乎很明显,但相信我,即使是经验丰富的开发人员有时也会忘记这一点。
如果终端正在运行,但仍然没有连接,请检查您的管理员权限和防火墙设置。Windows 有时喜欢谨慎行事并阻止连接。
对于开发,我建议使用 VS Code 或 PyCharm —— 这两种编辑器都非常适合 Python 开发。安装 Python 和 Jupyter 的扩展 —— 这将大大简化代码的调试和测试。
最后的检查是尝试获取一些历史数据:
import MetaTrader5 as mt5 mt5.initialize() data = mt5.copy_rates_from_pos("EURUSD", mt5.TIMEFRAME_M1, 0, 1000) print(data is not None) mt5.shutdown()
如果代码运行时没有错误,那么您的开发环境就可以使用了!在下一节中,我们将介绍如何接收和处理来自 MetaTrader 5 的数据。
从 MetaTrader 5 获取数据
在深入进行复杂的计算之前,让我们确保我们正确地从交易终端接收数据。我写了一个简单的脚本来帮助您测试 MetaTrader 5 并查看数据结构:
import MetaTrader5 as mt5 import pandas as pd from datetime import datetime, timedelta pd.set_option('display.max_columns', 500) pd.set_option('display.width', 1500) pd.set_option('display.float_format', lambda x: '%.5f' % x) def check_mt5_data(symbol="EURUSD"): if not mt5.initialize(): print(f"MT5 initialization error: {mt5.last_error()}") return print("\n=== Symbol Information ===") symbol_info = mt5.symbol_info(symbol) if symbol_info is None: print(f"Failed to get {symbol} data") mt5.shutdown() return print(f"Current spread: {symbol_info.spread} points") print(f"Tick size: {symbol_info.trade_tick_size}") print(f"Contract size: {symbol_info.trade_contract_size}") # Last 100 ticks print("\n=== Latest Ticks ===") ticks = mt5.copy_ticks_from(symbol, datetime.now() - timedelta(minutes=5), 100, mt5.COPY_TICKS_ALL) ticks_frame = pd.DataFrame(ticks) ticks_frame['time'] = pd.to_datetime(ticks_frame['time'], unit='s') print(ticks_frame.head()) # 5-minute bars (last 100 bars) print("\n=== 5-Minute Bars (Last 100) ===") rates_5m = mt5.copy_rates_from_pos(symbol, mt5.TIMEFRAME_M5, 0, 100) rates_5m_frame = pd.DataFrame(rates_5m) rates_5m_frame['time'] = pd.to_datetime(rates_5m_frame['time'], unit='s') print(rates_5m_frame.head()) # Hourly bars (last 24 hours) print("\n=== Hourly Bars (Last 24) ===") rates_1h = mt5.copy_rates_from_pos(symbol, mt5.TIMEFRAME_H1, 0, 24) rates_1h_frame = pd.DataFrame(rates_1h) rates_1h_frame['time'] = pd.to_datetime(rates_1h_frame['time'], unit='s') print(rates_1h_frame.head()) # Daily bars (last 30 days) print("\n=== Daily Bars (Last 30) ===") rates_d1 = mt5.copy_rates_from_pos(symbol, mt5.TIMEFRAME_D1, 0, 30) rates_d1_frame = pd.DataFrame(rates_d1) rates_d1_frame['time'] = pd.to_datetime(rates_d1_frame['time'], unit='s') print(rates_d1_frame.head()) # Statistics for different timeframes print("\n=== 5-Minute Bars Statistics ===") print(f"Average volume: {rates_5m_frame['tick_volume'].mean():.2f}") print(f"Average spread: {rates_5m_frame['spread'].mean():.2f}") print(f"Average range: {(rates_5m_frame['high'] - rates_5m_frame['low']).mean():.5f}") print("\n=== Hourly Bars Statistics ===") print(f"Average volume: {rates_1h_frame['tick_volume'].mean():.2f}") print(f"Average spread: {rates_1h_frame['spread'].mean():.2f}") print(f"Average range: {(rates_1h_frame['high'] - rates_1h_frame['low']).mean():.5f}") print("\n=== Daily Bars Statistics ===") print(f"Average volume: {rates_d1_frame['tick_volume'].mean():.2f}") print(f"Average spread: {rates_d1_frame['spread'].mean():.2f}") print(f"Average range: {(rates_d1_frame['high'] - rates_d1_frame['low']).mean():.5f}") # Current quotes print("\n=== Current Market Depth ===") depth = mt5.market_book_get(symbol) if depth is not None: bid = depth[0].price if depth[0].type == 1 else depth[1].price ask = depth[0].price if depth[0].type == 2 else depth[1].price print(f"Bid: {bid}") print(f"Ask: {ask}") print(f"Spread: {(ask - bid):.5f}") mt5.shutdown() if __name__ == "__main__": check_mt5_data()
此代码将显示我们检查连接有效性和接收数据质量所需的所有信息。一旦启动它,您将看到:
- 交易工具的基本信息
- 最新分时报价表
- 每小时柱形表格
- 交易量和点差统计数据
- 市场深度的当前报价
启动后,我们立即发现一切运行正常。如果某个地方出现问题,脚本将显示出问题发生在哪个阶段。
在接下来的部分中,我们将使用这些数据来计算波动率,但首先重要的是要确保底层数据检索正常工作。
数据预处理
当我第一次开始研究波动率预测时,我认为最重要的是一个很酷的机器学习模型。实践很快表明,数据准备的质量才是真正重要的。让我来告诉你我是如何为我们的预测系统准备数据的。
以下是我使用的完整预处理代码:
import MetaTrader5 as mt5 import numpy as np import pandas as pd from sklearn.preprocessing import StandardScaler from datetime import datetime, timedelta pd.set_option('display.max_columns', 500) pd.set_option('display.width', 1500) pd.set_option('display.float_format', lambda x: '%.5f' % x) class VolatilityProcessor: def __init__(self, lookback_periods=(5, 10, 20)): self.lookback_periods = lookback_periods self.scaler = StandardScaler() def calculate_volatility_features(self, df): df = df.copy() # Basic calculations df['returns'] = df['close'].pct_change().fillna(0) df['log_returns'] = (np.log(df['close']) - np.log(df['close'].shift(1))).fillna(0) # True Range df['true_range'] = np.maximum( df['high'] - df['low'], np.maximum( abs(df['high'] - df['close'].shift(1).fillna(df['high'])), abs(df['low'] - df['close'].shift(1).fillna(df['low'])) ) ) # ATR and volatility for period in self.lookback_periods: df[f'atr_{period}'] = df['true_range'].rolling(window=period, min_periods=1).mean() df[f'volatility_{period}'] = df['returns'].rolling(window=period, min_periods=1).std() # Parkinson volatility df['parkinson_vol'] = np.sqrt( 1/(4 * np.log(2)) * np.power(np.log(df['high'].div(df['low'])), 2) ) # Garman-Klass volatility df['garman_klass_vol'] = np.sqrt( 0.5 * np.power(np.log(df['high'].div(df['low'])), 2) - (2*np.log(2)-1) * np.power(np.log(df['close'].div(df['open'])), 2) ) # Relative volatility changes for period in self.lookback_periods: df[f'vol_change_{period}'] = ( df[f'volatility_{period}'].div(df[f'volatility_{period}'].shift(1)) ) # Replace all infinities and NaN for col in df.columns: if df[col].dtype == float: df[col] = df[col].replace([np.inf, -np.inf], np.nan).fillna(0) return df def prepare_features(self, df): feature_cols = [] # Time-based features - correct time conversion time = pd.to_datetime(df['time'], unit='s') # Hours (0-23) -> radians (0-2π) hours = time.dt.hour.values df['hour_sin'] = np.sin(2 * np.pi * hours / 24.0) df['hour_cos'] = np.cos(2 * np.pi * hours / 24.0) # Week days (0-6) -> radians (0-2π) days = time.dt.dayofweek.values df['day_sin'] = np.sin(2 * np.pi * days / 7.0) df['day_cos'] = np.cos(2 * np.pi * days / 7.0) # Select features for period in self.lookback_periods: feature_cols.extend([ f'atr_{period}', f'volatility_{period}', f'vol_change_{period}' ]) feature_cols.extend([ 'parkinson_vol', 'garman_klass_vol', 'hour_sin', 'hour_cos', 'day_sin', 'day_cos' ]) # Create features DataFrame features = df[feature_cols].copy() # Final cleanup and scaling features = features.replace([np.inf, -np.inf], 0).fillna(0) scaled_features = self.scaler.fit_transform(features) return pd.DataFrame( scaled_features, columns=features.columns, index=features.index ) def create_target(self, df, forward_window=12): future_vol = df['returns'].rolling( window=forward_window, min_periods=1, center=False ).std().shift(-forward_window).fillna(0) return future_vol def prepare_dataset(self, df, forward_window=12): print("\n=== Preparing Dataset ===") print("Initial shape:", df.shape) df = self.calculate_volatility_features(df) print("After calculating features:", df.shape) features = self.prepare_features(df) target = self.create_target(df, forward_window) print("Final shape:", features.shape) return features, target def check_mt5_data(symbol="EURUSD"): if not mt5.initialize(): print(f"MT5 initialization error: {mt5.last_error()}") return None rates = mt5.copy_rates_from_pos(symbol, mt5.TIMEFRAME_H1, 0, 10000) mt5.shutdown() if rates is None: return None return pd.DataFrame(rates) def main(): symbol = "EURUSD" rates_frame = check_mt5_data(symbol) if rates_frame is not None: print("\n=== Processing Hourly Data for Volatility Analysis ===") processor = VolatilityProcessor(lookback_periods=(5, 10, 20)) features, target = processor.prepare_dataset(rates_frame) print("\nFeature statistics:") print(features.describe()) print("\nFeature columns:", features.columns.tolist()) print("\nTarget statistics:") print(target.describe()) else: print("Failed to process data: MT5 data retrieval error") if __name__ == "__main__": main()
工作原理
首先,我们从 MetaTrader 5 下载最后 10,000 个 H1 柱形。为什么要那么多?通过反复试验,我发现这是最佳数量 —— 足以进行学习,但又不会太多以至于市场发生重大变化。
现在,最有趣的部分开始了。VolatilityProcessor 类负责完成准备数据的所有繁重工作。以下是幕后发生的事情:
- 基本波动率指标的计算。这里我们考虑三种类型的波动:
- 经典的往返标准差
- 真实范围和 ATR 是老派的,但仍然有效。
- 帕金森和哈曼-克拉斯方法擅长捕捉日内走势。
- 处理时间。我使用正弦和余弦,而不是一周中的几个小时和几天通常的一个热编码。这不仅仅是一种炫耀 —— 我们告诉模型,晚上 11:00 和凌晨 12:00 的位置很接近,而不是处于光谱的两端。
- 数据规范化和清理。这是关键部分:
- 删除异常值和无限值
- 用零填充空白(只有在仔细检查不会扭曲数据后)
- 将所有特征缩放到相同范围
因此,我们得到了 15 个特征,这是我们任务的最佳数量。我试图添加更多(各种奇特的指标),但这只会让结果变得更糟。
目标变量是未来 12 个时期的未来波动率。为什么是 12?根据每小时的数据,这为我们提供了下半天的预测 —— 足以做出交易决策,但不会太多,以至于预测变得毫无意义。
需要注意什么
- min_periods=1 在滚动操作中随处使用 - 这使得我们不会丢失时间序列开始时的数据。
- 使用 .div() 代替通常的 / 不仅仅是一时兴起;pandas 可以通过这种方式更好地处理边缘情况。
- 无限值的替换是在每个阶段的最后完成的,这使我们不会错过问题领域。
在下一节中,我们将构建一个机器学习模型,该模型将使用这些准备好的数据。但请记住,无论我们使用多么酷的模型,它都不会保存准备不充分的数据。
创建机器学习模型
因此,我们已经到达最有趣的部分 —— 创建预测模型。最初,我采取了显而易见的路线 —— 回归来预测未来波动的确切值。逻辑很简单:我们得到一个特定的数字,将其乘以某个比率,就得到了止损水平。
第一次尝试:回归模型
我从最简单的代码开始 —— 具有最少设置的基本 XGBRegressor。参数很少:一百棵树,学习率 0.1,深度 5。认为这就足够了的想法是天真的,但是谁在旅程开始时没有犯过这样的错误呢?
委婉地说,结果并不令人印象深刻。R 平方徘徊在 0.05 到 0.06 左右,这意味着该模型仅解释了数据中 5% 到 6% 的变化。预测的标准差几乎比实际的标准差小三倍。平均绝对误差看起来不错,但这是一个陷阱。
import MetaTrader5 as mt5 import numpy as np import pandas as pd from sklearn.preprocessing import StandardScaler from sklearn.model_selection import TimeSeriesSplit import xgboost as xgb from xgboost import XGBRegressor from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score import matplotlib.pyplot as plt from datetime import datetime, timedelta # VolatilityProcessor class remains unchanged class VolatilityProcessor: def __init__(self, lookback_periods=(5, 10, 20)): self.lookback_periods = lookback_periods self.scaler = StandardScaler() def calculate_volatility_features(self, df): df = df.copy() # Basic calculations df['returns'] = df['close'].pct_change().fillna(0) df['log_returns'] = (np.log(df['close']) - np.log(df['close'].shift(1))).fillna(0) df['abs_returns'] = abs(df['returns']) # Price changes df['price_range'] = (df['high'] - df['low']) / df['close'] df['price_change'] = (df['close'] - df['open']) / df['open'] # True Range df['true_range'] = np.maximum( df['high'] - df['low'], np.maximum( abs(df['high'] - df['close'].shift(1).fillna(df['high'])), abs(df['low'] - df['close'].shift(1).fillna(df['low'])) ) ) # ATR and volatility for different periods for period in self.lookback_periods: # Standard features df[f'atr_{period}'] = df['true_range'].rolling(window=period, min_periods=1).mean() df[f'volatility_{period}'] = df['returns'].rolling(window=period, min_periods=1).std() # Additional rolling statistics df[f'mean_range_{period}'] = df['price_range'].rolling(window=period, min_periods=1).mean() df[f'mean_price_change_{period}'] = df['price_change'].rolling(window=period, min_periods=1).mean() df[f'max_price_change_{period}'] = df['price_change'].rolling(window=period, min_periods=1).max() df[f'min_price_change_{period}'] = df['price_change'].rolling(window=period, min_periods=1).min() # Advanced volatility measures # Parkinson volatility df['parkinson_vol'] = np.sqrt( 1/(4 * np.log(2)) * np.power(np.log(df['high'].div(df['low'])), 2) ) # Garman-Klass volatility df['garman_klass_vol'] = np.sqrt( 0.5 * np.power(np.log(df['high'].div(df['low'])), 2) - (2*np.log(2)-1) * np.power(np.log(df['close'].div(df['open'])), 2) ) # Rogers-Satchell volatility df['rogers_satchell_vol'] = np.sqrt( np.log(df['high'].div(df['close'])) * np.log(df['high'].div(df['open'])) + np.log(df['low'].div(df['close'])) * np.log(df['low'].div(df['open'])) ) # Relative changes for period in self.lookback_periods: df[f'vol_change_{period}'] = ( df[f'volatility_{period}'].div(df[f'volatility_{period}'].shift(1)) ) df[f'atr_change_{period}'] = ( df[f'atr_{period}'].div(df[f'atr_{period}'].shift(1)) ) # Replace all infinities and NaN for col in df.columns: if df[col].dtype == float: df[col] = df[col].replace([np.inf, -np.inf], np.nan).fillna(0) return df def prepare_features(self, df): feature_cols = [] # Time-based features time = pd.to_datetime(df['time'], unit='s') # Hours (0-23) -> radians (0-2π) hours = time.dt.hour.values df['hour_sin'] = np.sin(2 * np.pi * hours / 24.0) df['hour_cos'] = np.cos(2 * np.pi * hours / 24.0) # Days of week (0-6) -> radians (0-2π) days = time.dt.dayofweek.values df['day_sin'] = np.sin(2 * np.pi * days / 7.0) df['day_cos'] = np.cos(2 * np.pi * days / 7.0) # Select features for period in self.lookback_periods: feature_cols.extend([ f'atr_{period}', f'volatility_{period}', f'vol_change_{period}' ]) feature_cols.extend([ 'parkinson_vol', 'garman_klass_vol', 'hour_sin', 'hour_cos', 'day_sin', 'day_cos' ]) # Create features DataFrame features = df[feature_cols].copy() # Final cleanup and scaling features = features.replace([np.inf, -np.inf], 0).fillna(0) scaled_features = self.scaler.fit_transform(features) return pd.DataFrame( scaled_features, columns=feature_cols, index=features.index ) def create_target(self, df, forward_window=12): """Create target with log transformation""" future_vol = df['returns'].rolling( window=forward_window, min_periods=1, center=False ).std().shift(-forward_window) # Add small constant to avoid log(0) log_vol = np.log(future_vol + 1e-10) return log_vol.fillna(log_vol.mean()) def prepare_dataset(self, df, forward_window=12): print("\n=== Preparing Dataset ===") print("Initial shape:", df.shape) df = self.calculate_volatility_features(df) print("After calculating features:", df.shape) features = self.prepare_features(df) target = self.create_target(df, forward_window) print("Final shape:", features.shape) return features, target class VolatilityModel: def __init__(self, lookback_periods=(5, 10, 20), forward_window=12): self.processor = VolatilityProcessor(lookback_periods) self.forward_window = forward_window self.model = XGBRegressor( n_estimators=500, learning_rate=0.05, max_depth=10, min_child_weight=1, subsample=0.8, colsample_bytree=0.8, gamma=0.1, reg_alpha=0.1, reg_lambda=1, random_state=42, n_jobs=-1, objective='reg:squarederror' # Better for log-transformed targets ) self.feature_importance = None def prepare_data(self, rates_frame): """Prepare data using our processor""" features, target = self.processor.prepare_dataset(rates_frame) return features, target def create_train_test_split(self, features, target, test_size=0.2): """Split data preserving time order""" split_idx = int(len(features) * (1 - test_size)) X_train = features.iloc[:split_idx] X_test = features.iloc[split_idx:] y_train = target.iloc[:split_idx] y_test = target.iloc[split_idx:] return X_train, X_test, y_train, y_test def train(self, X_train, y_train, X_test, y_test): """Train model with validation""" print("\n=== Training Model ===") print("Training set shape:", X_train.shape) print("Test set shape:", X_test.shape) # Train the model eval_set = [(X_train, y_train), (X_test, y_test)] self.model.fit( X_train, y_train, eval_set=eval_set, verbose=True ) # Save feature importance importance = self.model.feature_importances_ self.feature_importance = pd.DataFrame({ 'feature': X_train.columns, 'importance': importance }).sort_values('importance', ascending=False) # Make predictions and evaluate predictions = self.predict(X_test) metrics = self.calculate_metrics(y_test, predictions) return metrics def calculate_metrics(self, y_true, y_pred): """Calculate model performance metrics with detailed R2""" # Basic metrics rmse = np.sqrt(mean_squared_error(y_true, y_pred)) mae = mean_absolute_error(y_true, y_pred) # Manual R2 calculation for verification y_true_mean = np.mean(y_true) total_sum_squares = np.sum((y_true - y_true_mean) ** 2) residual_sum_squares = np.sum((y_true - y_pred) ** 2) r2_manual = 1 - (residual_sum_squares / total_sum_squares) # Stats for debugging metrics = { 'RMSE': rmse, 'MAE': mae, 'R2 (sklearn)': r2_score(y_true, y_pred), 'R2 (manual)': r2_manual, 'RSS': residual_sum_squares, 'TSS': total_sum_squares, 'Mean Prediction': np.mean(y_pred), 'Mean Actual': np.mean(y_true), 'Std Prediction': np.std(y_pred), 'Std Actual': np.std(y_true), 'Min Prediction': np.min(y_pred), 'Max Prediction': np.max(y_pred), 'Min Actual': np.min(y_true), 'Max Actual': np.max(y_true) } print("\nDetailed Metrics Analysis:") print(f"Total Sum of Squares (TSS): {total_sum_squares:.8f}") print(f"Residual Sum of Squares (RSS): {residual_sum_squares:.8f}") print(f"R2 components: 1 - ({residual_sum_squares:.8f} / {total_sum_squares:.8f})") return metrics def predict(self, features): """Get volatility predictions with inverse log transform""" log_predictions = self.model.predict(features) return np.exp(log_predictions) - 1e-10 def plot_feature_importance(self): """Visualize feature importance""" plt.figure(figsize=(12, 6)) plt.bar( self.feature_importance['feature'], self.feature_importance['importance'] ) plt.xticks(rotation=45) plt.title('Feature Importance') plt.tight_layout() plt.show() def plot_predictions(self, y_true, y_pred, title="Model Predictions"): """Visualize predictions vs actual values""" plt.figure(figsize=(15, 7)) plt.plot(y_true.values, label='Actual', alpha=0.7) plt.plot(y_pred, label='Predicted', alpha=0.7) plt.title(title) plt.legend() plt.tight_layout() plt.show() def check_mt5_data(symbol="EURUSD"): if not mt5.initialize(): print(f"MT5 initialization error: {mt5.last_error()}") return None rates = mt5.copy_rates_from_pos(symbol, mt5.TIMEFRAME_H1, 0, 10000) mt5.shutdown() if rates is None: return None return pd.DataFrame(rates) def main(): # Get data symbol = "EURUSD" rates_frame = check_mt5_data(symbol) if rates_frame is not None: # Create and train model model = VolatilityModel(lookback_periods=(5, 10, 20), forward_window=12) features, target = model.prepare_data(rates_frame) # Split data X_train, X_test, y_train, y_test = model.create_train_test_split( features, target, test_size=0.2 ) # Train and evaluate metrics = model.train(X_train, y_train, X_test, y_test) print("\n=== Model Performance ===") for metric, value in metrics.items(): print(f"{metric}: {value:.6f}") # Make predictions predictions = model.predict(X_test) # Visualize results model.plot_feature_importance() model.plot_predictions(y_test, predictions, "Volatility Predictions") else: print("Failed to process data: MT5 data retrieval error") if __name__ == "__main__": main()
为什么说它是陷阱?这是因为该模型只是学会了预测接近平均值的值。在平静的时期,一切看起来都很棒,但一旦真正的行动开始,模特就会很高兴地错过它。
改进回归的实验
我花了数周时间尝试改进回归模型。我尝试了不同的神经网络架构,添加了越来越多的新功能,实验了不同的损失函数,并调整了超参数,直到我完全筋疲力尽。
一切都变得毫无用处。有时,我设法将 R 平方提高到 0.15 到 0.20,但代价是什么?该模型变得不稳定,过度拟合,最重要的是,仍然错过了高波动性的最重要时刻。
重新思考方法
然后我突然意识到:为什么我们需要一个精确的波动率值?交易者不在乎波动率是 0.00234 还是 0.00256。重要的是它是否会比平时高得多。
这就是将问题重新定义为分类的想法的诞生。我们不再预测具体的值,而是开始定义两种状态:正常/低波动性(标签 0)和高于第 75 个百分位数的高波动性(标签 1)。
为什么这样做效果更好?
一是信号更加清晰。现在有了一个明确的答案,而不是模糊的预测:是否会出现激增。事实证明,这种方法更容易解释和整合到交易系统中。
其次,该模型在处理极值方面做得更好。在回归中,异常值被 “抹除”,但在分类中,它们形成了高波动性类别的清晰模式。
三是实用性增强。交易者需要明确的信号来采取行动。事实证明,调整两个状态的保护订单水平比试图将它们调整为连续的值要容易得多。
import MetaTrader5 as mt5 import numpy as np import pandas as pd from sklearn.preprocessing import StandardScaler import xgboost as xgb from xgboost import XGBClassifier from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, confusion_matrix import matplotlib.pyplot as plt import seaborn as sns class VolatilityProcessor: def __init__(self, lookback_periods=(5, 10, 20), volatility_threshold=75): """ Args: lookback_periods: periods for feature calculation volatility_threshold: percentile for defining high volatility """ self.lookback_periods = lookback_periods self.volatility_threshold = volatility_threshold self.scaler = StandardScaler() def calculate_features(self, df): df = df.copy() # Basic calculations df['returns'] = df['close'].pct_change() df['abs_returns'] = abs(df['returns']) # True Range df['true_range'] = np.maximum( df['high'] - df['low'], np.maximum( abs(df['high'] - df['close'].shift(1)), abs(df['low'] - df['close'].shift(1)) ) ) # Signs of volatility for period in self.lookback_periods: # ATR df[f'atr_{period}'] = df['true_range'].rolling(window=period).mean() # Volatility df[f'volatility_{period}'] = df['returns'].rolling(period).std() # Extremes df[f'high_low_range_{period}'] = ( (df['high'].rolling(period).max() - df['low'].rolling(period).min()) / df['close'] ) # Volatility acceleration df[f'volatility_change_{period}'] = ( df[f'volatility_{period}'] / df[f'volatility_{period}'].shift(1) ) # Add sentiment indicators df['body_ratio'] = abs(df['close'] - df['open']) / (df['high'] - df['low']) df['upper_shadow'] = (df['high'] - df[['open', 'close']].max(axis=1)) / (df['high'] - df['low']) df['lower_shadow'] = (df[['open', 'close']].min(axis=1) - df['low']) / (df['high'] - df['low']) # Data clearing for col in df.columns: if df[col].dtype == float: df[col] = df[col].replace([np.inf, -np.inf], np.nan) df[col] = df[col].fillna(method='ffill').fillna(0) return df def prepare_features(self, df): # Select features for the model feature_cols = [] # Add time features time = pd.to_datetime(df['time'], unit='s') df['hour_sin'] = np.sin(2 * np.pi * time.dt.hour / 24) df['hour_cos'] = np.cos(2 * np.pi * time.dt.hour / 24) df['day_sin'] = np.sin(2 * np.pi * time.dt.dayofweek / 7) df['day_cos'] = np.cos(2 * np.pi * time.dt.dayofweek / 7) # Collect all features for period in self.lookback_periods: feature_cols.extend([ f'atr_{period}', f'volatility_{period}', f'high_low_range_{period}', f'volatility_change_{period}' ]) feature_cols.extend([ 'body_ratio', 'upper_shadow', 'lower_shadow', 'hour_sin', 'hour_cos', 'day_sin', 'day_cos' ]) # Create DataFrame with features features = df[feature_cols].copy() features = features.replace([np.inf, -np.inf], 0).fillna(0) # Scale features scaled_features = self.scaler.fit_transform(features) return pd.DataFrame( scaled_features, columns=feature_cols, index=features.index ) def create_target(self, df, forward_window=12): """Creates a binary label: 1 for high volatility, 0 for low volatility""" # Calculate future volatility future_vol = df['returns'].rolling( window=forward_window, min_periods=1, center=False ).std().shift(-forward_window) # Determine the threshold for high volatility vol_threshold = np.nanpercentile(future_vol, self.volatility_threshold) # Create binary labels target = (future_vol > vol_threshold).astype(int) target = target.fillna(0) return target def prepare_dataset(self, df, forward_window=12): print("\n=== Preparing Dataset ===") print("Initial shape:", df.shape) df = self.calculate_features(df) print("After calculating features:", df.shape) features = self.prepare_features(df) target = self.create_target(df, forward_window) print("Final shape:", features.shape) print(f"Positive class ratio: {target.mean():.2%}") return features, target class VolatilityClassifier: def __init__(self, lookback_periods=(5, 10, 20), forward_window=12, volatility_threshold=75): self.processor = VolatilityProcessor(lookback_periods, volatility_threshold) self.forward_window = forward_window self.model = XGBClassifier( n_estimators=200, max_depth=6, learning_rate=0.1, subsample=0.8, colsample_bytree=0.8, min_child_weight=1, gamma=0.1, reg_alpha=0.1, reg_lambda=1, scale_pos_weight=1, random_state=42, n_jobs=-1, eval_metric=['auc', 'error'] ) self.feature_importance = None def prepare_data(self, rates_frame): features, target = self.processor.prepare_dataset(rates_frame) return features, target def create_train_test_split(self, features, target, test_size=0.2): split_idx = int(len(features) * (1 - test_size)) X_train = features.iloc[:split_idx] X_test = features.iloc[split_idx:] y_train = target.iloc[:split_idx] y_test = target.iloc[split_idx:] return X_train, X_test, y_train, y_test def train(self, X_train, y_train, X_test, y_test): print("\n=== Training Model ===") print("Training set shape:", X_train.shape) print("Test set shape:", X_test.shape) # Train the model eval_set = [(X_train, y_train), (X_test, y_test)] self.model.fit( X_train, y_train, eval_set=eval_set, verbose=True ) # Maintain the importance of features importance = self.model.feature_importances_ self.feature_importance = pd.DataFrame({ 'feature': X_train.columns, 'importance': importance }).sort_values('importance', ascending=False) # Evaluate the model predictions = self.predict(X_test) metrics = self.calculate_metrics(y_test, predictions) return metrics def calculate_metrics(self, y_true, y_pred): metrics = { 'Accuracy': accuracy_score(y_true, y_pred), 'Precision': precision_score(y_true, y_pred), 'Recall': recall_score(y_true, y_pred), 'F1 Score': f1_score(y_true, y_pred) } # Error matrix cm = confusion_matrix(y_true, y_pred) print("\nConfusion Matrix:") print(cm) return metrics def predict(self, features): return self.model.predict(features) def predict_proba(self, features): return self.model.predict_proba(features) def plot_feature_importance(self): plt.figure(figsize=(12, 6)) plt.bar( self.feature_importance['feature'], self.feature_importance['importance'] ) plt.xticks(rotation=45, ha='right') plt.title('Feature Importance') plt.tight_layout() plt.show() def plot_confusion_matrix(self, y_true, y_pred): cm = confusion_matrix(y_true, y_pred) plt.figure(figsize=(8, 6)) sns.heatmap(cm, annot=True, fmt='d', cmap='Blues') plt.title('Confusion Matrix') plt.ylabel('True Label') plt.xlabel('Predicted Label') plt.tight_layout() plt.show() def check_mt5_data(symbol="EURUSD"): if not mt5.initialize(): print(f"MT5 initialization error: {mt5.last_error()}") return None rates = mt5.copy_rates_from_pos(symbol, mt5.TIMEFRAME_H1, 0, 10000) mt5.shutdown() if rates is None: return None return pd.DataFrame(rates) def main(): symbol = "EURUSD" rates_frame = check_mt5_data(symbol) if rates_frame is not None: # Create and train the model model = VolatilityClassifier( lookback_periods=(5, 10, 20), forward_window=12, volatility_threshold=75 ) features, target = model.prepare_data(rates_frame) # Separate data X_train, X_test, y_train, y_test = model.create_train_test_split( features, target, test_size=0.2 ) # Train and evaluate metrics = model.train(X_train, y_train, X_test, y_test) print("\n=== Model Performance ===") for metric, value in metrics.items(): print(f"{metric}: {value:.4f}") # Make predictions predictions = model.predict(X_test) # Visualize results model.plot_feature_importance() model.plot_confusion_matrix(y_test, predictions) else: print("Failed to process data: MT5 data retrieval error") if __name__ == "__main__": main()
新模型结果
转为分类后,结果显著改善。“Precision” 达到约 70%,这意味着在 10 个高波动性信号中,实际上有 7 个被触发。约 65% 的 “Recall” 意味着我们捕捉到了所有危险时刻的约三分之二。但最重要的是,该模型已经真正适用于交易。
既然已经定义了模型的基本结构,让我们在下一节中讨论如何将其集成到真实的交易系统中,以及可以根据其信号做出哪些具体的交易决策。我相信这将是我们进入波动预测世界之旅中最有趣的部分。
你觉得这种方法怎么样?如果你在练习中使用过类似的东西,那将很有趣。如果是这样,你认为哪些其他波动性指标有用?
未来极端波动指标
我开发的指标是预测外汇市场波动性飙升的综合工具。与仅显示当前状态的传统波动性指标不同,我们的指标预测了未来 12 小时内出现强劲波动的可能性。
import tkinter as tk from tkinter import ttk import matplotlib matplotlib.use('Agg') # Important to install before importing pyplot from matplotlib.figure import Figure from matplotlib.backends.backend_tkagg import FigureCanvasTkAgg import time import MetaTrader5 as mt5 class VolatilityPredictor(tk.Tk): def __init__(self): super().__init__() self.title("Volatility Predictor") self.geometry("600x600") # Initialize the model self.model = VolatilityClassifier( lookback_periods=(5, 10, 20), forward_window=12, volatility_threshold=75 ) # Load and train the model at startup self.initialize_model() # Create the interface self.create_gui() # Launch the update self.update_data() def initialize_model(self): rates_frame = check_mt5_data("EURUSD") if rates_frame is not None: features, target = self.model.prepare_data(rates_frame) X_train, X_test, y_train, y_test = self.model.create_train_test_split( features, target, test_size=0.2 ) self.model.train(X_train, y_train, X_test, y_test) def create_gui(self): # Top panel with settings control_frame = ttk.Frame(self) control_frame.pack(fill='x', padx=2, pady=2) ttk.Label(control_frame, text="Symbol:").pack(side='left', padx=2) self.symbol_var = tk.StringVar(value="EURUSD") symbol_list = ["EURUSD", "GBPUSD", "USDJPY"] # Simplified list ttk.Combobox(control_frame, textvariable=self.symbol_var, values=symbol_list, width=8).pack(side='left', padx=2) ttk.Label(control_frame, text="Alert:").pack(side='left', padx=2) self.threshold_var = tk.StringVar(value="0.7") ttk.Entry(control_frame, textvariable=self.threshold_var, width=4).pack(side='left') # Chart self.fig = Figure(figsize=(6, 4), dpi=100) self.canvas = FigureCanvasTkAgg(self.fig, self) self.canvas.draw() self.canvas.get_tk_widget().pack(fill='both', expand=True, padx=2, pady=2) # Probability indicator gauge_frame = ttk.Frame(self) gauge_frame.pack(fill='x', padx=2, pady=2) self.probability_var = tk.StringVar(value="0%") self.probability_label = ttk.Label( gauge_frame, textvariable=self.probability_var, font=('Arial', 20, 'bold') ) self.probability_label.pack() self.progress = ttk.Progressbar( gauge_frame, length=150, mode='determinate', maximum=100 ) self.progress.pack(pady=2) def update_data(self): try: rates = check_mt5_data(self.symbol_var.get()) if rates is not None: features, _ = self.model.prepare_data(rates) probability = self.model.predict_proba(features)[-1][1] self.update_indicators(rates, probability) threshold = float(self.threshold_var.get()) if probability > threshold: self.alert(probability) except Exception as e: print(f"Error updating data: {e}") finally: self.after(1000, self.update_data) def update_indicators(self, rates, probability): self.fig.clear() ax = self.fig.add_subplot(111) df = rates.tail(50) # Show fewer bars for compactness width = 0.6 width2 = 0.1 up = df[df.close >= df.open] down = df[df.close < df.open] ax.bar(up.index, up.close-up.open, width, bottom=up.open, color='g') ax.bar(up.index, up.high-up.close, width2, bottom=up.close, color='g') ax.bar(up.index, up.low-up.open, width2, bottom=up.open, color='g') ax.bar(down.index, down.close-down.open, width, bottom=down.open, color='r') ax.bar(down.index, down.high-down.open, width2, bottom=down.open, color='r') ax.bar(down.index, down.low-down.close, width2, bottom=down.close, color='r') ax.grid(False) # Remove the grid for compactness ax.set_xticks([]) # Remove X axis labels self.canvas.draw() prob_pct = int(probability * 100) self.probability_var.set(f"{prob_pct}%") self.progress['value'] = prob_pct if prob_pct > 70: self.probability_label.configure(foreground='red') elif prob_pct > 50: self.probability_label.configure(foreground='orange') else: self.probability_label.configure(foreground='green') def alert(self, probability): window = tk.Toplevel(self) window.title("Alert!") window.geometry("200x80") # Reduced alert window msg = f"High volatility: {probability:.1%}" ttk.Label(window, text=msg, font=('Arial', 10)).pack(pady=10) ttk.Button(window, text="OK", command=window.destroy).pack() def main(): app = VolatilityPredictor() app.mainloop() if __name__ == "__main__": main()
指标的主窗口分为三个主要部分。顶部显示最近 100 条 K 线,清晰显示当前价格动态。绿色和红色烛形传统上表示市场走势的上升和下降。
中心部分包含指标的主要元素 —— 半圆形概率刻度。它显示了当前波动率飙升的概率,以百分比表示,从 0 到 100。指示箭头根据风险等级以不同颜色显示:绿色表示 50% 的低概率,橙色表示 50% 至 70% 的中等概率,红色表示超过 70% 的高概率。
该预测基于对当前市场状况和历史波动模式的分析。该模型考虑了过去 20 个柱形的数据来建立预测,并预测了未来 12 小时内波动性加剧的可能性。信号发出后的最初 4 到 6 小时内预测准确度最高。
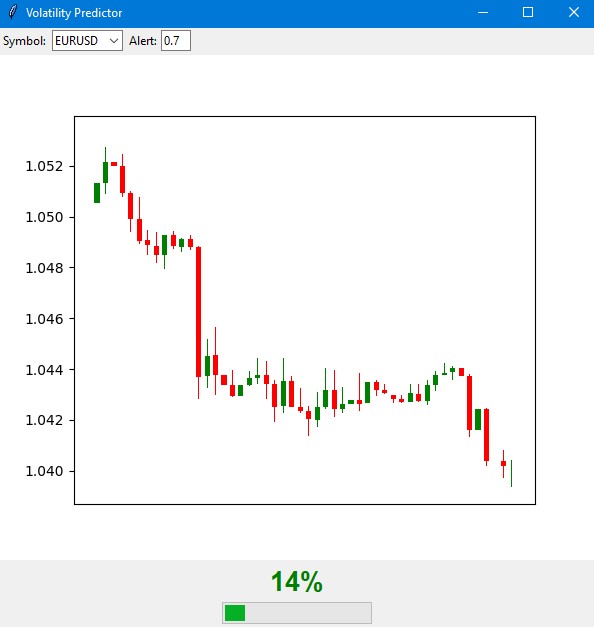
在低概率(绿色区域)下,市场可能会继续保持平静。这是使用交易系统标准设置的好时机。在此期间,可以使用常规止损水平。
当指标显示平均概率并且箭头变为橙色时,您应该格外小心。在这种情况下,建议将保护订单规模增加约四分之一的标准。
当出现峰值的概率很高并且箭头变为红色时,就应该认真审查风险管理。在这样的时期,建议将止损至少增加一倍半,并且可能在情况稳定之前不要开立新头寸。
控制元件位于指标的底部面板上。您可以在此处选择交易工具、时间间隔并设置接收通知的阈值。默认情况下,阈值设置为 70%,这是在信号数量和可靠性之间提供平衡的最佳值。
该指标对于高波动性信号的预测准确率达到 70%。这意味着,十次有关可能出现激增的警告中,有七次会成真。同时,该指标捕捉到了大约三分之二的所有重要市场走势。
重要的是要明白,该指标并不能预测价格走势的方向,而只能预测波动性增加的可能性。其主要目的是警告交易者可能出现的强劲市场走势,以便他们提前调整交易策略和保护订单水平。
在该指标的未来版本中,计划增加根据预测波动率自动调整止损的能力。这将进一步自动化风险管理流程,使交易更加安全。
该指标完美地补充了现有的交易系统,作为风险管理的额外过滤器。它的主要优点是能够提前警告潜在的强劲走势,让交易者有时间准备和调整策略。
结论
在现代交易中,预测波动性仍然是成功交易的关键任务之一。本文描述的从简单回归模型到高波动性分类器的路径表明,有时简单的解决方案比复杂的解决方案更有效。开发的系统实现了约 70% 的预测准确率,并捕获了所有重大市场变动的约三分之二。
主要结论是,在实际应用中,更重要的不是未来波动率的确切值,而是对其潜在激增的及时警告。创建的指标成功地解决了这个问题,允许交易者提前调整他们的交易策略和保护订单水平。经典分析方法与现代机器学习技术的结合为市场风险管理开辟了新的可能性。
成功的关键不在于算法的复杂性,而在于问题的正确表述和高质量的数据准备。这种方法可以适应不同的交易工具和时间周期,使交易更安全、更可预测。
本文由MetaQuotes Ltd译自俄文
原文地址: https://www.mql5.com/ru/articles/16960
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。

您好!非常感谢您。我并不只依赖一种方法。我有一个全面的 Python EA,其中包括天真模式分析、二进制代码的机器学习、三维条形图的机器学习、成交量分析的神经网络、波动率分析、基于世界银行和国际货币基金组织数据的经济模型、关于世界所有国家的数十万行的庞大数据集,以及所有....。建立所有可能的统计特征的统计模块,优化超参数的遗传算法,建立公平货币价格的套利模块,下载世界媒体关于特定货币的头条新闻和内容,分析所有新闻文章和说明的情绪色彩(在 80% 的情况下,当媒体鼓励你买东西时,就会出现崩盘,如果新闻是负面的--很可能会滞后 3-4 天上涨)。
您有什么其他补充意见吗?我得出的结论是,我还需要从一个著名的账户监控网站(我不知道是否可以在这里说出它的名字)上传头寸,我已经编写了代码,我也会写一篇关于它的文章,价格最常见的情况是与群众背道而驰。
我还在努力上传有关期货交易量、交易量集群和分析 COT 报告的数据 - 也是用 Python。
我同时使用回归模型和分类模型,不久我想做一个超级系统,接收所有模型的所有迹象和信号,以及浮动盈亏和账户历史盈亏,并将其全部输入 DQN 模型=)。
第一条命令的回复是 "Python",但这一行的回复是 "系统无法找到指定路径"。
(根据您的指导,我刚刚安装了 Python)