
梯度提升(CatBoost)在交易系统开发中的应用. 初级的方法
介绍
梯度提升是一种强大的机器学习算法。该方法产生了一个弱模型的集合(例如,决策树),其中(与bagging相反)模型是按顺序构建的,而不是独立地(并行地)构建的。这意味着下一棵树从上一棵树的错误中学习,然后重复这个过程,增加了弱模型的数量。这就建立了一个强大的模型,可以使用异构数据进行泛化。在这个实验中,我使用了Yandex开发的CatBoost库,它与 XGBoost和 LightGBM 一起是最流行的库之一。
本文的目的是演示如何创建一个基于机器学习的模型。创建过程包括以下步骤:
- 接收和预处理数据
- 使用准备好的数据训练模型
- 在自定义策略测试器中测试模型
- 将模型移植到 MetaTrader 5
Python 语言和 MetaTrader 5 库用于准备数据和训练模型。
准备数据
导入所需的 Python 模块:
import MetaTrader5 as mt5 import pandas as pd import numpy as np from datetime import datetime import random import matplotlib.pyplot as plt from catboost import CatBoostClassifier from sklearn.model_selection import train_test_split mt5.initialize() # check for gpu devices is availible from catboost.utils import get_gpu_device_count print('%i GPU devices' % get_gpu_device_count())
然后初始化所有全局变量:
LOOK_BACK = 250 MA_PERIOD = 15 SYMBOL = 'EURUSD' MARKUP = 0.0001 TIMEFRAME = mt5.TIMEFRAME_H1 START = datetime(2020, 5, 1) STOP = datetime(2021, 1, 1)
这些参数的作用如下:
- look_back — 分析历史的深度
- ma_period — 用于计算价格增量的移动平均周期数
- symbol — 应当在 MetaTrader 5 终端中载入的交易品种报价
- markup — 用于自定义测试器的点差大小
- timeframe — 应当载入数据的时间框架
- start, stop — 数据范围
让我们编写一个函数,直接接收原始数据并创建一个包含训练所需列的数据帧:
def get_prices(look_back = 15): prices = pd.DataFrame(mt5.copy_rates_range(SYMBOL, TIMEFRAME, START, STOP), columns=['time', 'close']).set_index('time') # set df index as datetime prices.index = pd.to_datetime(prices.index, unit='s') prices = prices.dropna() ratesM = prices.rolling(MA_PERIOD).mean() ratesD = prices - ratesM for i in range(look_back): prices[str(i)] = ratesD.shift(i) return prices.dropna()
函数接收指定时间段的收盘价并计算移动平均值,然后计算增量(价格和移动平均值之间的差)。在最后一步中,它通过 look_back 来计算额外的列,其中的行向后移动到历史中,这意味着向模型中添加额外的(滞后的)特性。
例如,对于 look_back=10,数据帧中将包含10个额外的列,其价格增量为:
>>> pr = get_prices(look_back=LOOK_BACK) >>> pr close 0 1 2 3 4 5 6 7 8 9 time 2020-05-01 16:00:00 1.09750 0.001405 0.002169 0.001600 0.002595 0.002794 0.002442 0.001477 0.001190 0.000566 0.000285 2020-05-01 17:00:00 1.10074 0.004227 0.001405 0.002169 0.001600 0.002595 0.002794 0.002442 0.001477 0.001190 0.000566 2020-05-01 18:00:00 1.09976 0.002900 0.004227 0.001405 0.002169 0.001600 0.002595 0.002794 0.002442 0.001477 0.001190 2020-05-01 19:00:00 1.09874 0.001577 0.002900 0.004227 0.001405 0.002169 0.001600 0.002595 0.002794 0.002442 0.001477 2020-05-01 20:00:00 1.09817 0.000759 0.001577 0.002900 0.004227 0.001405 0.002169 0.001600 0.002595 0.002794 0.002442 ... ... ... ... ... ... ... ... ... ... ... ... 2020-11-02 23:00:00 1.16404 0.000400 0.000105 -0.000581 -0.001212 -0.000999 -0.000547 -0.000344 -0.000773 -0.000326 0.000501 2020-11-03 00:00:00 1.16392 0.000217 0.000400 0.000105 -0.000581 -0.001212 -0.000999 -0.000547 -0.000344 -0.000773 -0.000326 2020-11-03 01:00:00 1.16402 0.000270 0.000217 0.000400 0.000105 -0.000581 -0.001212 -0.000999 -0.000547 -0.000344 -0.000773 2020-11-03 02:00:00 1.16423 0.000465 0.000270 0.000217 0.000400 0.000105 -0.000581 -0.001212 -0.000999 -0.000547 -0.000344 2020-11-03 03:00:00 1.16464 0.000885 0.000465 0.000270 0.000217 0.000400 0.000105 -0.000581 -0.001212 -0.000999 -0.000547 [3155 rows x 11 columns]
黄色高亮显示表示每列都有相同的数据集,但有一个偏移量。因此,每一行都是一个单独的训练实例。
创建训练标签(随机抽样)
训练实例是特征及其相应标签的集合。模型必须输出一定的信息,模型必须学会预测这些信息。让我们考虑二元分类,其中模型将预测将训练示例确定为类0或1的概率。0和1可用于交易方向:买入或卖出。换句话说,模型必须学会预测给定环境参数(一组特征)的交易方向。
def add_labels(dataset, min, max): labels = [] for i in range(dataset.shape[0]-max): rand = random.randint(min, max) if dataset['close'][i] >= (dataset['close'][i + rand]): labels.append(1.0) elif dataset['close'][i] <= (dataset['close'][i + rand]): labels.append(0.0) else: labels.append(0.0) dataset = dataset.iloc[:len(labels)].copy() dataset['labels'] = labels dataset = dataset.dropna() return dataset
add_labels 函数随机(在最小、最大范围内)设置每笔交易的持续时间(以柱形为单位)。通过更改最大和最小持续时间,您可以更改交易采样频率。因此,如果当前价格大于下一个“rand”柱向前的价格,这就是卖出标签(1)。在相反的情况下,标签是0。让我们看看应用上述函数后数据集的外观:
>>> pr = add_labels(pr, 10, 25) >>> pr close 0 1 2 3 4 5 6 7 8 9 labels time 2020-05-01 16:00:00 1.09750 0.001405 0.002169 0.001600 0.002595 0.002794 0.002442 0.001477 0.001190 0.000566 0.000285 1.0 2020-05-01 17:00:00 1.10074 0.004227 0.001405 0.002169 0.001600 0.002595 0.002794 0.002442 0.001477 0.001190 0.000566 1.0 2020-05-01 18:00:00 1.09976 0.002900 0.004227 0.001405 0.002169 0.001600 0.002595 0.002794 0.002442 0.001477 0.001190 1.0 2020-05-01 19:00:00 1.09874 0.001577 0.002900 0.004227 0.001405 0.002169 0.001600 0.002595 0.002794 0.002442 0.001477 1.0 2020-05-01 20:00:00 1.09817 0.000759 0.001577 0.002900 0.004227 0.001405 0.002169 0.001600 0.002595 0.002794 0.002442 1.0 ... ... ... ... ... ... ... ... ... ... ... ... ... 2020-10-29 20:00:00 1.16700 -0.003651 -0.005429 -0.005767 -0.006750 -0.004699 -0.004328 -0.003475 -0.003769 -0.002719 -0.002075 1.0 2020-10-29 21:00:00 1.16743 -0.002699 -0.003651 -0.005429 -0.005767 -0.006750 -0.004699 -0.004328 -0.003475 -0.003769 -0.002719 0.0 2020-10-29 22:00:00 1.16731 -0.002276 -0.002699 -0.003651 -0.005429 -0.005767 -0.006750 -0.004699 -0.004328 -0.003475 -0.003769 0.0 2020-10-29 23:00:00 1.16740 -0.001648 -0.002276 -0.002699 -0.003651 -0.005429 -0.005767 -0.006750 -0.004699 -0.004328 -0.003475 0.0 2020-10-30 00:00:00 1.16695 -0.001655 -0.001648 -0.002276 -0.002699 -0.003651 -0.005429 -0.005767 -0.006750 -0.004699 -0.004328 1.0
添加了“labels”列,其中分别包含买入和卖出的类别号(0或1)。现在,每个训练示例或功能集(这里是10个)都有自己的标签,它指示在什么条件下应该买入,在什么条件下应该卖出(即它属于哪个类)。模型必须能够记住和泛化这些例子-这个能力将在后面讨论。
开发自定义测试器
因为我们正在创建一个交易系统,所以最好有一个策略测试器来进行及时的模型测试。下面是此类测试器的示例:
def tester(dataset, markup = 0.0): last_deal = int(2) last_price = 0.0 report = [0.0] for i in range(dataset.shape[0]): pred = dataset['labels'][i] if last_deal == 2: last_price = dataset['close'][i] last_deal = 0 if pred <=0.5 else 1 continue if last_deal == 0 and pred > 0.5: last_deal = 1 report.append(report[-1] - markup + (dataset['close'][i] - last_price)) last_price = dataset['close'][i] continue if last_deal == 1 and pred <=0.5: last_deal = 0 report.append(report[-1] - markup + (last_price - dataset['close'][i])) last_price = dataset['close'][i] return report
tester 函数接受一个数据集和一个“标记”(可选)并检查整个数据集,类似于在 MetaTrader 5 测试器中的操作。在每一个新柱都会检查一个信号(标签),当标签改变时,交易就会反转。因此,卖出信号作为结束买入头寸和打开卖出头寸的信号。现在,让我们测试上述数据集:
pr = get_prices(look_back=LOOK_BACK) pr = add_labels(pr, 10, 25) rep = tester(pr, MARKUP) plt.plot(rep) plt.show()
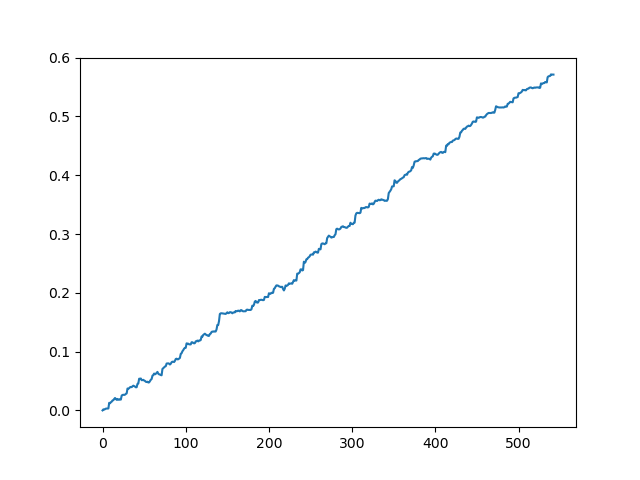
不计入点差测试原始数据集
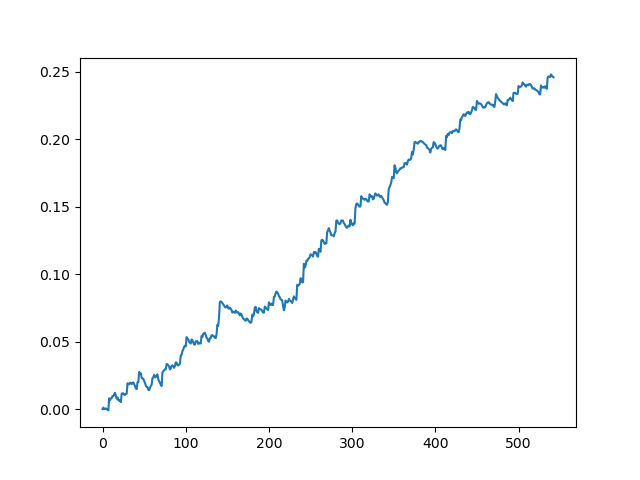
以70个五位小数点差测试原始数据集
这是一种理想化的图像(这就是我们希望模型工作的方式)。由于标签是随机抽样的,这取决于一系列参数,这些参数决定了交易的最短和最长寿命,因此曲线总是不同的。尽管如此,它们都会表现出一个很好的点增长(沿Y轴)和不同的交易数量(沿X轴)。
训练 CatBoost 模型
现在,让我们直接开始训练模型。首先,让我们将数据集分成两个样本:训练和验证。这用于减少模型过拟合。当模型继续在训练子样本上训练,试图最小化分类误差时,同样的误差也在验证子样本上测量。如果这些误差的差别很大,则该模型被称为过拟合。相反,接近值表示模型的训练是正确的。
#splitting on train and validation subsets X = pr[pr.columns[1:-1]] y = pr[pr.columns[-1]] train_X, test_X, train_y, test_y = train_test_split(X, y, train_size = 0.5, test_size = 0.5, shuffle=True)
在随机混合训练示例之后,让我们将数据分成两个长度相等的数据集。接下来,创建并训练模型:
#learning with train and validation subsets model = CatBoostClassifier(iterations=1000, depth=6, learning_rate=0.01, custom_loss=['Accuracy'], eval_metric='Accuracy', verbose=True, use_best_model=True, task_type='CPU') model.fit(train_X, train_y, eval_set = (test_X, test_y), early_stopping_rounds=50, plot=False)
该模型采用了许多参数,但并非所有参数都显示在本例中。如果您想微调模型,可以参考文档,这通常不是必需的。CatBoost 在开箱即用的情况下工作得很好,只需最少的调整。
以下是模型参数的简要说明:
- iterations — 模型中树的最大数目。模型在每次迭代后都会增加弱模型(树)的数量,因此请确保设置足够大的值。根据我的实践,对于这个特定的例子,1000次迭代通常已经足够了。
- depth — 每棵树的深度。深度越小,模型越粗糙-输出的交易越少。深度在6到10之间似乎是最佳的。
- learning_rate — 梯度步长值;这与神经网络中使用的原理相同。合理的参数范围为0.01~0.1。值越低,模型训练的时间就越长。但在这种情况下,它可以找到更好的结果。
- custom_loss, eval_metric — 用于评估模型的度量。分类的经典标准是“准确度”
- use_best_model — 在每一步中,模型都会评估“准确性”,这可能会随着时间的推移而改变。此标志允许以最小的误差保存模型,否则最后一次迭代得到的模型将被保存。
- task_type — 允许在GPU上训练模型(默认情况下使用CPU)。这只适用于非常大的数据;在其他情况下,在GPU内核上执行训练的速度比在处理器上执行训练的速度慢。
- early_stopping_rounds — 该模型有一个内置的过拟合检测器,其工作原理简单。如果度量在指定的迭代次数内停止减少/增加(对于“精确度”,它停止增加),则训练停止。
训练开始后,控制台将显示每个迭代中模型的当前状态:
170: learn: 1.0000000 test: 0.7712509 best: 0.7767795 (165) total: 11.2s remaining: 21.5s 171: learn: 1.0000000 test: 0.7726330 best: 0.7767795 (165) total: 11.2s remaining: 21.4s 172: learn: 1.0000000 test: 0.7733241 best: 0.7767795 (165) total: 11.3s remaining: 21.3s 173: learn: 1.0000000 test: 0.7740152 best: 0.7767795 (165) total: 11.3s remaining: 21.3s 174: learn: 1.0000000 test: 0.7712509 best: 0.7767795 (165) total: 11.4s remaining: 21.2s 175: learn: 1.0000000 test: 0.7726330 best: 0.7767795 (165) total: 11.5s remaining: 21.1s 176: learn: 1.0000000 test: 0.7712509 best: 0.7767795 (165) total: 11.5s remaining: 21s 177: learn: 1.0000000 test: 0.7740152 best: 0.7767795 (165) total: 11.6s remaining: 21s 178: learn: 1.0000000 test: 0.7719419 best: 0.7767795 (165) total: 11.7s remaining: 20.9s 179: learn: 1.0000000 test: 0.7747063 best: 0.7767795 (165) total: 11.7s remaining: 20.8s 180: learn: 1.0000000 test: 0.7705598 best: 0.7767795 (165) total: 11.8s remaining: 20.7s Stopped by overfitting detector (15 iterations wait) bestTest = 0.7767795439 bestIteration = 165
在上面的例子中,过拟合检测器在第180次迭代时触发并停止训练。此外,控制台还显示训练子样本(learn)和验证子样本(test)的统计信息,以及总的模型训练时间(仅20秒)。在输出时,训练子样本的准确度最好为1.0(与理想结果相对应),验证子样本的准确度为0.78,虽然更差,但仍高于0.5(被认为是随机的)。最佳迭代是165 - 模型已经保存了。现在,我们可以在测试器中测试:
#test the learned model p = model.predict_proba(X) p2 = [x[0]<0.5 for x in p] pr2 = pr.iloc[:len(p2)].copy() pr2['labels'] = p2 rep = tester(pr2, MARKUP) plt.plot(rep) plt.show()
X - 是包含特征但没有标签的源数据集。为了得到标签,有必要从训练模型中获得标签,并预测分配到0类或1类的“p”概率。由于该模型生成两个类的概率,而我们只需要0或1,因此“p2”变量只接收第一维(0)中的概率。此外,原始数据集中的标签将替换为模型预测的标签。以下是测试器中的结果:
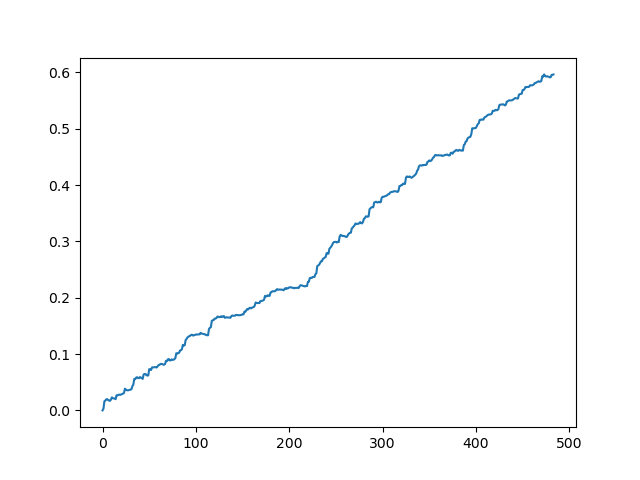
抽样交易后的理想结果
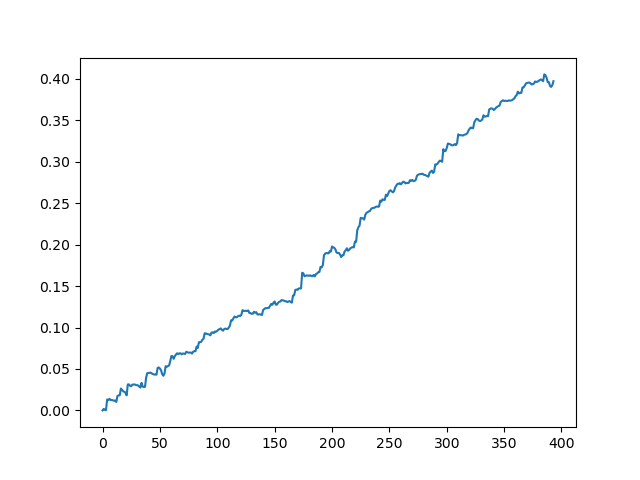
在模型输出时得到的结果
如您所见,模型学习得很好,这意味着它记住了训练示例,并且在验证集上显示了比随机结果更好的结果。让我们进入最后一个阶段:导出模型并创建一个交易机器人。
将模型移植到 MetaTrader 5
MetaTrader 5 Python API 允许直接从 Python 程序进行交易,因此不需要移植模型。但是,我想检查我的自定义测试器,并将其与标准策略测试器进行比较。此外,编译好的机器人的可用性在许多情况下都很方便,包括在VPS上的使用(在这种情况下,您不必安装Python)。因此,我编写了一个辅助函数,它将准备好的模型保存到 MQH 文件中。函数如下:
def export_model_to_MQL_code(model):
model.save_model('catmodel.h',
format="cpp",
export_parameters=None,
pool=None)
code = 'double catboost_model' + '(const double &features[]) { \n'
code += ' '
with open('catmodel.h', 'r') as file:
data = file.read()
code += data[data.find("unsigned int TreeDepth"):data.find("double Scale = 1;")]
code +='\n\n'
code+= 'return ' + 'ApplyCatboostModel(features, TreeDepth, TreeSplits , BorderCounts, Borders, LeafValues); } \n\n'
code += 'double ApplyCatboostModel(const double &features[],uint &TreeDepth_[],uint &TreeSplits_[],uint &BorderCounts_[],float &Borders_[],double &LeafValues_[]) {\n\
uint FloatFeatureCount=ArrayRange(BorderCounts_,0);\n\
uint BinaryFeatureCount=ArrayRange(Borders_,0);\n\
uint TreeCount=ArrayRange(TreeDepth_,0);\n\
bool binaryFeatures[];\n\
ArrayResize(binaryFeatures,BinaryFeatureCount);\n\
uint binFeatureIndex=0;\n\
for(uint i=0; i<FloatFeatureCount; i++) {\n\
for(uint j=0; j<BorderCounts_[i]; j++) {\n\
binaryFeatures[binFeatureIndex]=features[i]>Borders_[binFeatureIndex];\n\
binFeatureIndex++;\n\
}\n\
}\n\
double result=0.0;\n\
uint treeSplitsPtr=0;\n\
uint leafValuesForCurrentTreePtr=0;\n\
for(uint treeId=0; treeId<TreeCount; treeId++) {\n\
uint currentTreeDepth=TreeDepth_[treeId];\n\
uint index=0;\n\
for(uint depth=0; depth<currentTreeDepth; depth++) {\n\
index|=(binaryFeatures[TreeSplits_[treeSplitsPtr+depth]]<<depth);\n\
}\n\
result+=LeafValues_[leafValuesForCurrentTreePtr+index];\n\
treeSplitsPtr+=currentTreeDepth;\n\
leafValuesForCurrentTreePtr+=(1<<currentTreeDepth);\n\
}\n\
return 1.0/(1.0+MathPow(M_E,-result));\n\
}'
file = open('C:/Users/dmitrievsky/AppData/Roaming/MetaQuotes/Terminal/D0E8209F77C8CF37AD8BF550E51FF075/MQL5/Include/' + 'cat_model' + '.mqh', "w")
file.write(code)
file.close()
print('The file ' + 'cat_model' + '.mqh ' + 'has been written to disc')
函数代码看起来既奇怪又笨拙,经过训练的模型对象被输入到函数中,然后以C++格式保存对象:
model.save_model('catmodel.h',
format="cpp",
export_parameters=None,
pool=None)
然后创建一个字符串,并使用标准 Python 函数将 C++ 代码解析为MQL5:
code = 'double catboost_model' + '(const double &features[]) { \n' code += ' ' with open('catmodel.h', 'r') as file: data = file.read() code += data[data.find("unsigned int TreeDepth"):data.find("double Scale = 1;")] code +='\n\n' code+= 'return ' + 'ApplyCatboostModel(features, TreeDepth, TreeSplits , BorderCounts, Borders, LeafValues); } \n\n'
在上述操作之后,将插入此库中的“ApplyCatboostModel”函数。它根据保存的模型和传递的特征向量,返回(0;1)范围内的计算结果。
之后,我们需要指定 MetaTrader 5 终端的 \\Include 文件夹的路径,模型将保存到该文件夹中。因此,在设置所有参数后,只需单击一下即可对模型进行训练,并立即保存为MQH文件,这非常方便。这个选项也很好,因为这是用 Python 教授模型的常见和流行的实践。
在 MetaTrader 5 中编写一个 EA 交易
在训练和保存 CatBoost 模型之后,我们需要编写一个简单的 EA 进行测试:
#include <MT4Orders.mqh> #include <Trade\AccountInfo.mqh> #include <cat_model.mqh> sinput int look_back = 50; sinput int MA_period = 15; sinput int OrderMagic = 666; //Orders magic sinput double MaximumRisk=0.01; //Maximum risk sinput double CustomLot=0; //Custom lot input int stoploss = 500; static datetime last_time=0; #define Ask SymbolInfoDouble(_Symbol, SYMBOL_ASK) #define Bid SymbolInfoDouble(_Symbol, SYMBOL_BID) int hnd;
现在,连接保存的 cat_model.mqh 和由fxsaber提供的 MT4Orders.mqh。
look_back 和 MA_period 参数的设置必须与在 Python 程序中训练时指定的完全一致,否则将引发错误。
此外,在每一个柱上,我们检查模型的信号,其中输入增量向量(价格和移动平均值之间的差异):
if(!isNewBar()) return; double ma[]; double pr[]; double ret[]; ArrayResize(ret, look_back); CopyBuffer(hnd, 0, 1, look_back, ma); CopyClose(NULL,PERIOD_CURRENT,1,look_back,pr); for(int i=0; i<look_back; i++) ret[i] = pr[i] - ma[i]; ArraySetAsSeries(ret, true); double sig = catboost_model(ret);
交易开始逻辑与自定义测试程序逻辑类似,但它是以 mql5+MT4Orders 样式执行的:
for(int b = OrdersTotal() - 1; b >= 0; b--) if(OrderSelect(b, SELECT_BY_POS) == true) { if(OrderType() == 0 && OrderSymbol() == _Symbol && OrderMagicNumber() == OrderMagic && sig > 0.5) if(OrderClose(OrderTicket(), OrderLots(), OrderClosePrice(), 0, Red)) { } if(OrderType() == 1 && OrderSymbol() == _Symbol && OrderMagicNumber() == OrderMagic && sig < 0.5) if(OrderClose(OrderTicket(), OrderLots(), OrderClosePrice(), 0, Red)) { } } if(countOrders(0) == 0 && countOrders(1) == 0) { if(sig < 0.5) OrderSend(Symbol(),OP_BUY,LotsOptimized(), Ask, 0, Bid-stoploss*_Point, 0, NULL, OrderMagic); else if(sig > 0.5) OrderSend(Symbol(),OP_SELL,LotsOptimized(), Bid, 0, Ask+stoploss*_Point, 0, NULL, OrderMagic); return; }
测试这个使用了机器学习的EA
编译后的 EA 可以在标准的 MetaTrader 5 策略测试器中进行测试。选择一个合适的时间框架(必须与模型训练中使用的时间框架相匹配)和输入参数look_back 和 MA_period,这也应该与 Python 程序中的参数相匹配。让我们在训练期间检查模型(培训+验证子样本):
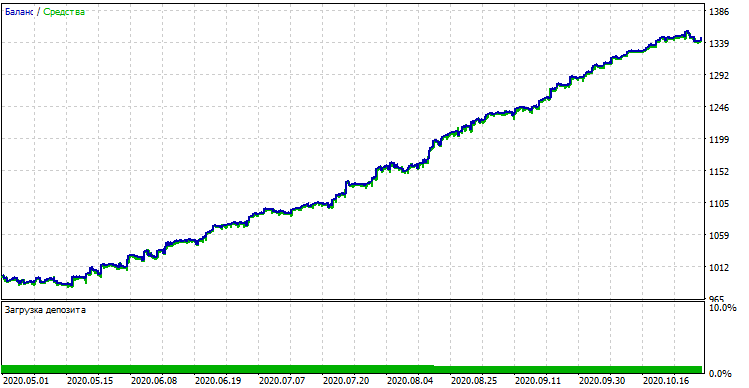
模型的效果(训练+验证子样本)
如果我们将结果与在定制测试器中获得的结果进行比较,这些结果是相同的,除了一些点差引起的偏差。现在,让我们从年初开始,用全新的数据来测试这个模型:
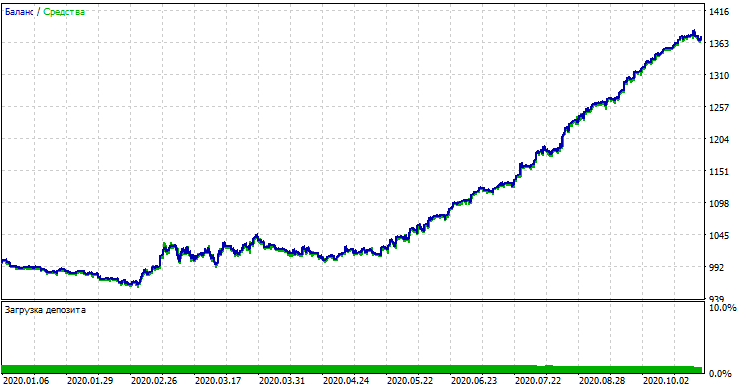
新数据的模型性能
该模型在新数据上的表现明显较差。如此糟糕的结果与客观原因有关,我将进一步阐述。
从初级模型到有意义的模型(进一步研究)
这篇文章的标题已经声明我们使用的是 "初级的方法",说它初级是因为以下原因:
- 该模型不包括任何关于模式的先验数据。任何模式的识别都是通过梯度提升来完成的,但是这种方法的可能性是有限的。
- 该模型采用了交易的随机抽样,因此在不同的训练周期中得到的结果会有所不同。这不仅是一个缺点,而且可以被认为是一个优点,因为该特性支持暴力方法。
- 在训练中不知道一般交易的特征。您永远不知道模型将如何处理新数据。
提高模型性能的可能方法(将在另一篇文章中介绍):
- 根据一些外部标准选择模型(例如,新数据的性能)
- 数据采样和模型训练的新方法,分类器叠加
- 根据先验知识和/或假设选择不同性质的特征
结论
本文探讨了一个优秀的机器学习模型 CatBoost:我们讨论了时间序列预测问题中模型建立和二分类训练的主要方面。我们准备并测试了一个模型,并将其作为一个现成的机器人移植到 MQL 语言中。Python 和 MQL 应用程序附在下面。
本文由MetaQuotes Ltd译自俄文
原文地址: https://www.mql5.com/ru/articles/8642
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。
 使用 DeMark Sequential 和 Murray-Gann 水平分析图表
使用 DeMark Sequential 和 Murray-Gann 水平分析图表
 无需 Python 或 R 语言知识的 Yandex CatBoost 机器学习算法
无需 Python 或 R 语言知识的 Yandex CatBoost 机器学习算法
 神经网络在交易中的实际应用 Python (第一部分)
神经网络在交易中的实际应用 Python (第一部分)
prices.dropna()最后还是不行。存档中仍然包含 Nan 值。只需删除几行即可解决。
我似乎无法重现 python 测试仪的结果。MT5 测试仪无法重现 python 测试仪中同一时期的结果。
此外,我按照说明移植了模型。
我把 cat_model.mqh 和 cat_trader.mql5(编译为 .ex5)放在一起。
但结果看起来不一样。
在这里,您可以看到模型的代码。注意 MA_Period、Look_Back 等。然后查看 python 代码测试器的利润曲线。然后查看 MT5 输入、设置和策略测试结果。
我似乎无法重现 python 测试仪的结果。MT5 测试仪无法重现 python 测试仪中同一时期的结果。
除此之外,我还按照说明移植了模型。
我把 cat_model.mqh 和 cat_trader.mql5(编译为 .ex5)放在一起。
但结果看起来不一样。
您好,写这篇文章时和现在解析模型的方式可能有所不同。在新版本中,CatBoost 可能已经更改了最终模型的代码逻辑,所以您必须弄清楚。
在我看来,这很有可能是一个问题。
我做了一些改动:
我修改了代码,以便根据数据的图表时间保存 mqh。
我将 mqh 改为每个时间框架 都不同,这样就可以训练所有时间框架并在 EA 中使用。
我将 EA 改为使用所有训练过的文件来分析和生成信号。
如果可能的话,所有文件都附在后面供您查看。
如果您能改进代码,我将不胜感激。
该策略和模型训练都需要极大的改进,如果可以,我将不胜感激。
我做了一些改动:
我修改了代码,以根据数据的图形时间保存 mqh。
修改了 mqh,使其在每个图表时间都不同,这样所有图表时间都可以训练并在 EA 中使用。
我将 EA 改为使用所有训练过的文件来分析和生成信号。
如果可能的话,我附上了所有文件供您分析。
如果您能改进代码,我将不胜感激。
该策略以及模型的训练都需要极大的改进,如果可能的话,请给予帮助,谢谢。