
Электронные таблицы на MQL5

Введение
Электронными таблицами принято называть табличные процессоры (программы по хранению и обработке данных), такие как MS Excel. И хотя код, приведенный в статье, не имеет таких мощных возможностей, он может стать базовым классом для полномасштабной реализации табличного процессора. Задача создать MS Excel с помощью MQL5 не ставилась, я лишь хотел реализовать класс для оперирования разнотипными данными в двумерном массиве.
И хотя реализованный мной класс не может состязаться по скорости с двумерным массивом однотипных данных (с прямым доступом к данным), класс все же получился удобным в обращении. К тому же, данный класс можно рассматривать как реализацию класса Variant в C++ как частный случай вырожденной таблицы до одного столбца.
Для особо нетерпеливых и тех, кто не хочет разбираться в особенностях алгоритма реализации, начну описание класса CTable с описания доступных методов.
1. Описание методов класса
Для начала рассмотрим доступные методы класса с более подробной расшифровкой назначения и особенностей использования.
1.1. FirstResize
Разбивка таблицы, определение типов столбцов, TYPE[] - массив типа ENUM_DATATYPE, определяющий размер строки и типы ячеек.
void FirstResize(const ENUM_DATATYPE &TYPE[]);
Метод фактически является дополнительным конструктором, имеющим параметр. Это удобно по двум причинам: во-первых, устраняет проблему передачи параметра внутрь конструктора, во-вторых, появляется возможность передать объект как параметр, и уже там сделать нужную разбивку массива. Именно эта особенность дает возможность использовать класс как класс Variant в C++.
К особенностям реализации можно отнести то, что хотя функция задает размер первого измерения и типы данных столбцов, она не требует указывать размер первого измерения в качестве параметра. Этот параметр берется от размера переданного массива TYPE.
1.2. SecondResize
Изменение количества строк до размера j.
void SecondResize(int j);
Функция задает указанный размер сразу всем массивам второго измерения. Таким образом, можно сказать, что она добавляет в таблицу строки.
1.3. FirstSize
Метод возвращает размер первого измерения (длина строки).
int FirstSize();
1.4. SecondSize
Метод возвращает размер второго измерения (длина столбца).
int SecondSize();
1.5. PruningTable
Устанавливает новый размер первого измерения, изменения возможны в пределах стартового размера.
void PruningTable(int count);
Функция не изменяет длину строки фактически, а лишь перезаписывает значение переменной, отвечающей за хранение значения длины строки. В классе имеется еще одна переменная, хранящая фактически выделенную память, которая задается при начальной разбивке таблицы. В пределах значений этой переменной возможно виртуальное изменение размера первого измерения. Функция задумывалась для обрезки лишней части при копировании одной таблицы в другую.
1.6. CopyTable
Метод копирования одной таблицы в другую, на всю длину второго измерения:
void CopyTable(CTable *sor);
Функция копирует одну таблицу в другую. Вызывает инициализацию принимающей таблицы. Может использоваться как дополнительный конструктор. Внутренняя структура вариантов сортировки не копируется. Копируется лишь размер исходной таблицы, типы столбцов и данные, содержащиеся в исходной таблице. В качестве параметра функция принимает указатель копируемого объекта типа CTable, передаваемый с помощью функции GetPointer.
Копирование одной таблицы в другую, новая таблица создается по образцу sor.
void CopyTable(CTable *sor,int sec_beg,int sec_end);
Перегрузка вышеописанной функции с дополнительными параметрами: sec_beg-начальная точка копирования исходной таблицы, sec_end-конечная точка копирования (не путайте с количеством копируемых данных). Оба параметра относятся ко второму измерению. Данные будут добавлены в начало принимающей таблицы. Размер принимающей таблицы будет задан как sec_end-sec_beg+1.
1.7. TypeTable
Возвращает значение type_table (типа ENUM_DATATYPE) столбца i.
ENUM_DATATYPE TypeTable(int i)
1.8. Change
Метод Change() меняет столбцы местами.
bool Change(int &sor0,int &sor1);
Как сказано выше, метод меняет местами столбцы (работает с первым измерением). Поскольку фактического перемещения данных не происходит, то скорость работы функции не зависит от размера второго измерения.
1.9. Insert
Метод Insert вставляет столбец в указанное место.
bool Insert(int rec,int sor);
Аналогичная вышеописанной функции, но с той разницей, что она делает подтягивание или выдавливание остальных столбцов, в зависимости от того, куда нужно переместить указанный столбец. Параметр rec указывает, куда будет перемещен столбец, sor - откуда.
1.10. Variant/VariantCopy
Далее идут три функции серии variant. В классе реализовано запоминание вариантов обработки таблицы.
Варианты напоминают записную книжку. Например, если вы сделали сортировку по третьему столбцу и не хотите, чтобы при последующей обработке данные были сброшены, то следует переключить вариант. Для доступа к прошлому варианту обработки данных следует вызвать функцию variant. Если последующая обработка должна основываться на результатах предыдущей, то следует скопировать варианты. По умолчанию устанавливается один вариант под номером 0.
Установка варианта (если такого варианта не существует, он будет создан, равно как и все недостающие варианты до ind) и получения действующего варианта. Метод variantcopy копирует вариант sor в вариант rec.
void variant(int ind); int variant(); void variantcopy(int rec,int sor);
Метод variant(int ind) переключает выбранный вариант. Производит автоматическое выделение памяти. Если заданный параметр меньше, чем какой-либо, установленный ранее, то распределение памяти не происходит.
Метод variantcopy позволяет скопировать вариант sor в вариант rec. Функция создана для упорядочивания вариантов. Она автоматически увеличивает количество вариантов, если варианта rec не существует, а так же переключается на вновь скопированный вариант.
1.11. SortTwoDimArray
Метод SortTwoDimArray сортирует таблицу по выбранному столбцу i.
void SortTwoDimArray(int i,int beg,int end,bool mode=false);
Функция сортировки таблицы по указанному столбцу. Параметры: i-столбец, beg-начальная точка сортировки, end-конечная точка сортировки (включительно), mode-булева переменная, указывающая направление сортировки. Значение mode=true означает, что с возрастанием индексов возрастают значения (по умолчанию стоит false, так как возрастание индексов идет вниз таблицы).
1.12. QuickSearch
Метод осуществляет быстрый поиск положения элемента в массиве по значению, равного образцу element.
int QuickSearch(int i,long element,int beg,int end,bool mode=false);
1.13. SearchFirst
Ищет первый элемент, равный образцу в сортированном массиве. Возвращает индекс первого значения, равного образцу element. Требуется указать тип ранее произведенной сортировки на этом участке (если такого элемента нет, возвращает -1).
int SearchFirst(int i,long element,int beg,int end,bool mode=false);
1.14. SearchLast
Ищет последний элемент, равный образцу в сортированном массиве.
int SearchLast(int i,long element,int beg,int end,bool mode=false);
1.15. SearchGreat
Ищет ближайший элемент, больший образца в сортированном массиве.
int SearchGreat(int i,long element,int beg,int end,bool mode=false);
1.16. SearchLess
Ищет ближайший элемент, меньший образца в сортированном массиве.
int SearchLess(int i,long element,int beg,int end,bool mode=false);
1.17. Set/Get
Функции Set и Get имеют тип void, и являются перегрузками по четырем типам данных, с которыми работает таблица. Функции распознают тип данных и при несоответствии параметра value типу столбца вместо присваивания выдают Print с предупреждением. Единственным исключением является тип string. Если входной параметр типа string, то он будет приведен к типу столбца. Это исключение сделано для более удобной передачи данных, когда нет возможности задать переменную, принимающую значение ячейки.
Методы установки значений (i-индекс первого измерения, j-индекс второго измерения).
void Set(int i,int j,long value); // установка значения i-той линии и j-того столбца void Set(int i,int j,double value); // установка значения i-той линии и j-того столбца void Set(int i,int j,datetime value);// установка значения i-той линии и j-того столбца void Set(int i,int j,string value); // установка значения i-той линии и j-того, столбца
Методы получения значений (i-индекс первого измерения, j-индекс второго измерения).
//--- получение значения void Get(int i,int j,long &recipient); // получение значения i-той линии и j-того столбца void Get(int i,int j,double &recipient); // получение значения i-той линии и j-того столбца void Get(int i,int j,datetime &recipient); // получение значения i-той линии и j-того столбца void Get(int i,int j,string &recipient); // получение значения i-той линии и j-того столбца
1.19. sGet
Получить значение типа string со столбца j строки i.
string sGet(int i,int j); // возврат значения i-той линии и j-того столбца
Единственная функция из серии Get, возвращающая значение не в параметрическую переменную, а через оператор return. Возвращает значение типа string, независимо от типа столбца.
1.20. StringDigits
При приведении типов к типу string можно использовать точность, задаваемую через функции:
void StringDigits(int i,int digits);
для задания точности double, и
int StringDigits(int i);
Для установки точности отображения секунд datetime передается любое значение, не равное -1. Заданное значение запоминается для столбца, и задавать его каждый раз при выводе данных не требуется. Задавать значение точности можно многократно, так как данные хранятся в оригинальных типах и преобразовываются до указанной точности лишь при выводе. Значение точности не запоминается при копировании, поэтому после копирования таблицы в новую таблицу точность столбцов в новой таблице будет соответствовать точности, задаваемой по умолчанию.
1.21. Пример использования:
#include <Table.mqh> ENUM_DATATYPE TYPE[7]= {TYPE_LONG,TYPE_LONG,TYPE_STRING,TYPE_DATETIME,TYPE_STRING,TYPE_STRING,TYPE_DOUBLE}; // 0 1 2 3 4 5 6 //7 void OnStart() { CTable table,table1; table.FirstResize(TYPE); // разбивка таблицы, определение типов столбцов table.SecondResize(5); // изменение количества строк line table.Set(6,0,"321.012324568"); // присвоение данных в 6-ой столбец, 0-ю строку table.Insert(2,6); // вставить 6-ой столбец на 2-ю позицию table.PruningTable(3); // обрезать таблицу до 3-х столбцов table.StringDigits(2,5); // задать точность до 5-го знака после запятой Print("table ",table.sGet(2,0)); // печать ячейки 2-го столбца, 0-ой строки table1.CopyTable(GetPointer(table)); // скопировать таблицу table в таблицу table1 целиком table1.StringDigits(2,8); // задать точность до 8-го знака после запятой Print("table1 ",table1.sGet(2,0)); // печать ячейки 2-го столбца, 0-ой строки таблицы table1 }
Результат работы - вывод на печать содержания ячейки (2;0). Как можно заметить, точность скопированных данных не превышает указанной точности исходящей таблицы.
2011.02.09 14:18:37 Table Script (EURUSD,H1) table1 321.01232000 2011.02.09 14:18:37 Table Script (EURUSD,H1) table 321.01232
Теперь перейдем к описанию самого алгоритма.
2. Выбор модели
Существует два способа организации данных: схема связных столбцов (реализованная в данной статье), и альтернативная схема связных строк.
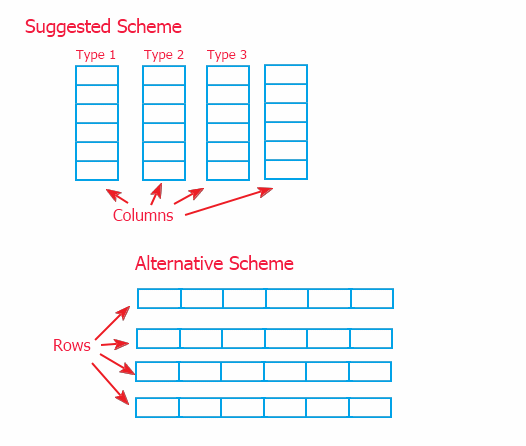
Благодаря способу обращения к данным через посредника (описанному в п.2), принципиальной разницы для реализации на верхнем уровне нет. Но мной была выбрана модель столбцов, так как она позволяет реализовывать методы обработки данных на низком уровне, в самих объектах хранения данных. Тогда как альтернативная схема потребует перегрузку методов оперирования данными в верхнем классе CTable. Это, в свою очередь, может затруднить доработку класса, если в этом возникнет необходимость.
При этом обе схемы имеют право на жизнь. Предложенная схема позволяет более быстро перемещать данные, а альтернативная более быстро добавлять данные (так как данные в таблицу чаще всего будут добавляться построчно) и получать строки.
Существует также способ организации таблицы как массива структур. И хотя он самый простой в реализации, у него есть существенный недостаток. Структура должна быть описана программистом. А значит, теряется возможность задать атрибуты таблицы из пользовательских настроек (без изменения кода).
3. Связывание данных в динамический массив
Для того чтобы иметь возможность связать разнотипные данные в один динамический массив, нужно решить вопрос назначения ячейкам массива разнообразных типов. Подобная задача уже решена в связных списках стандартной библиотеки. И первые мои разработки были как раз на основе стандартной библиотеки классов. Но по ходу развития проекта я понял, что мне придется слишком много править в базовом классе CObject.
Поэтому я принял решение разработать собственный класс. Для тех кто еще не разбирался со стандартной библиотекой поясню, как решается вышеописанная задача. Для решения нужно воспользоваться механизмом наследования.
class CBase { public: CBase(){Print(__FUNCTION__);}; ~CBase(){Print(__FUNCTION__);}; virtual void set(int sor){}; virtual void set(double sor){}; virtual int get(int k){return(0);}; virtual double get(double k){return(0);}; }; //+------------------------------------------------------------------+ class CA: public CBase { private: int temp; public: CA(){Print(__FUNCTION__);}; ~CA(){Print(__FUNCTION__);}; void set(int sor){temp=sor;}; int get(int k){return(temp);}; }; //+------------------------------------------------------------------+ class CB: public CBase { private: double temp; public: CB(){Print(__FUNCTION__);}; ~CB(){Print(__FUNCTION__);}; void set(double sor){temp=sor;}; double get(double k){return(temp);}; }; //+------------------------------------------------------------------+ void OnStart() { CBase *a; CBase *b; a=new CA(); b=new CB(); a.set(15); b.set(13.3); Print("a=",a.get(0)," b=",b.get(0.)); delete a; delete b; }
Графически механизм наследования можно представить как расческу:

Если объявлено создание динамичного объекта класса потомка, то это означает, что предварительно будет вызван конструктор базового класса. Именно это свойство и дает возможность создавать объект в два этапа. Перегрузив виртуальные функции в базовом классе, появляется возможность вызова из потомков функции с разными типами параметров.
Почему не ограничится простой перегрузкой? Дело в том, что исполняемые функции довольно большие по объему, и если описать их тела в базовом классе (без использования наследования), то каждому объекту в двоичном коде будут создаваться неиспользуемые функции с полным кодом тела. А при механизме наследования создаются неиспользуемые функции-пустышки, которые занимают намного меньше памяти, чем наполненные кодом функции.
4. Операции над массивами
Второй и главный краеугольный камень, заставивший меня отказаться от использования стандартных классов - это обращение к данным. Я использую не прямое обращение к ячейке массива по индексу, а через посредника в виде массива индексов. Это в свою очередь и обуславливает меньшую скорость работы, чем при прямом обращении через переменную. Все дело в том, что переменная, указывающая индекс, работает быстрее, чем ячейка массива, которую сначала нужно найти в памяти.
Давайте рассмотрим, чем принципиально отличается сортировка одномерного и многомерного массивов. Одномерный массив до сортировки имеет беспорядочное расположение данных, а после сортировки данные упорядочены. При сортировке двумерного массива требуется, чтобы упорядоченными были не все данные, а лишь данные того столбца, по которому велась сортировка. Все строки же должны сохранить свою структуру, но располагаться должны по-новому.
Сами строки тут как раз и выступают как связные структуры, имеющие в составе разнотипные данные. Для решения такой задачи требуется не только отсортировать данные в выбранном одномерном массиве, но и сохранить структуру исходных индексов. Тогда зная, в какой строке располагалась данная ячейка, можно отобразить всю строку. Таким образом, при сортировке двумерного массива стоит задача получить массив индексов отсортированного массива, не изменяя структуры данных.
Например:
до сортировки по 2-му столбцу 4 2 3 1 5 3 3 3 6 после сортировки 1 5 3 3 3 6 4 2 3 Исходный массив при этом выглядит так: a[0][0]= 4; a[0][1]= 2; a[0][2]= 3; a[1][0]= 1; a[1][1]= 5; a[1][2]= 3; a[2][0]= 3; a[2][1]= 3; a[2][2]= 6; А массив индексов сортировки по 2-му столбцу так: r[0]=1; r[1]=2; r[2]=0; Возврат отсортированных значений производится по такой схеме: a[r[0]][0]-> 1; a[r[0]][1]-> 5; a[r[0]][2]-> 3; a[r[1]][0]-> 3; a[r[1]][1]-> 3; a[r[1]][2]-> 6; a[r[2]][0]-> 4; a[r[2]][1]-> 2; a[r[2]][2]-> 3;
Таким образом, появляется возможность сортировать данные по инструменту, дате открытия ордера, прибыли и т.д.
Человечеством давно изобретено множество алгоритмов сортировки. Для данной разработки наилучшим решением будет алгоритм устойчивой сортировки.
Алгоритм Быстрой сортировки, который используется в стандартных классах, относится к алгоритмам неустойчивой сортировки. Поэтому в своем классическом исполнении он не подходит. Но даже после приведения быстрой сортировки к виду устойчивой (а это дополнительное копирование данных, перед передачей на сортировку и введения синхронного сортирования массива индексов вместе с копией данных) все равно быстрая сортировка обгоняет сортировку пузырьком (один из самых быстрых алгоритмов устойчивой сортировки). Алгоритм очень быстр, но использует рекурсию.
По этой причине при работе с массивом типа string (который требует намного больше стековой памяти) у меня используется Шейкерная сортировка.
5. Организация двумерного массива
И последний вопрос, который хотелось бы осветить, это организация динамичного двумерного массива. Для такой организации достаточно одномерному массиву сделать обертку в виде класса и вызывать объект-массив через массив указателей. Другими словами, создается массив массивов.
class CarrayInt { public: ~CarrayInt(){}; int array[]; }; //+------------------------------------------------------------------+ class CTwoarrayInt { public: ~CTwoarrayInt(){}; CarrayInt array[]; }; //+------------------------------------------------------------------+ void OnStart() { CTwoarrayInt two; two.array[0].array[0]; }
6. Структура программы
Коды класса CTable были написаны с помощью шаблонов, описанных в статье Применение псевдошаблонов, как альтернатива шаблонов С++. Именно применение шаблонов позволило быстро создать такой большой код. Поэтому я не буду детально разбирать весь код, тем более что коды алгоритмов в большей части являются доработкой кодов стандартных классов.
Приведу лишь общую структуру класса и некоторые интересные особенности отдельных функций, проясняющих важные моменты.

Правая часть блок-схемы в основном занята перегруженными методами, расположенными в классах-потомках CLONGArray, CDOUBLEArray, CDATETIMEArray и CSTRINGArray. В каждом из них (в приватной области) расположен массив соответствующего типа. Как раз вокруг этих массивов и идут все ухищрения по доступу к данным. Названия методов, перечисленных выше классов, идентично публичным методам.
Базовый класс CBASEArray заполнен перегрузкой виртуальных методов и нужен лишь для объявления динамичного массива объектов CBASEArray в приватной области класса CTable. Массив указателей класса CBASEArray объявляется как динамический массив динамических объектов. В функции FirstResize() происходит окончательное конструирование объектов, выбор нужного потомка. Так же это можно сделать в функции CopyTable() так как в своем теле она вызывает FirstResize().
В классе CTable также происходит согласование методов обработки данных (расположенных в потомках класса CBASEArray) и объекта управления индексами класса Cint2D. Все это согласование оборачивается перегруженными публичными методами.
Часто повторяющиеся участки перегрузок в классе CTable заменены определениями,чтобы не плодить длиннющие строки:
#define _CHECK0_ Print(__FUNCTION__+"("+(string)i+","+(string)j+")");return; #define _CHECK_ Print(__FUNCTION__+"("+(string)i+")");return(-1); #define _FIRST_ first_data[aic[i]] #define _PARAM0_ array_index.Ind(j),value #define _PARAM1_ array_index.Ind(j),recipient #define _PARAM2_ element,beg,end,array_index,mode
Таким образом, участок, имеющий более компактную форму:
int QuickSearch(int i,long element,int beg,int end,bool mode=false){if(!check_type(i,TYPE_LONG)){_CHECK_}return(_FIRST_.QuickSearch(_PARAM2_));};
будет заменен препроцессором на следующую строку:
int QuickSearch(int i,long element,int beg,int end,bool mode=false){if(!check_type(i,TYPE_LONG)){Print(__FUNCTION__+"("+(string)i+")");return(-1);} return(first_data[aic[i]].QuickSearch(element,beg,end,array_index,mode));};
В приведенном примере хорошо видно, как происходит обращение к методам обработки данных (участок внутри return).
Я уже говорил выше, что класс CTable не делает физического перемещения данных при обработке, а лишь изменяет значения в индексном объекте. Для того чтобы методы ведущие обработку имели возможность влиять на индексный объект, он передается во все функции обработки как параметр array_index.
Объект array_index хранит взаимное расположение элементов 2-го измерения. За индексацию 1-го измерения отвечает динамический массив aic[], объявленный в приватной зоне класса CTable. Это и дает возможность перемещать расположение столбцов (конечно же, не физически, а индексно).
Например, при операции Change() местами меняются лишь две ячейки памяти, отвечающие за хранение индекса столбцов. Хотя визуально, это выглядит как перемещение двух столбцов. Функции класса CTable довольно подробно документированы (в некоторых местах построчно).
Теперь перейдем к функциям классов потомков CBASEArray. Алгоритмы этих классов, по сути, являются алгоритмами, взятыми из стандартных классов. Чтобы можно было иметь представление о них, названия я взял стандартные. Доработка заключается лишь в том, что стандартные алгоритмы возвращают прямое значение, а доработанные - опосредованное через массив индексов.
В первую очередь, доработка коснулась Быстрой сортировки. Поскольку алгоритм относится к категории неустойчивых сортировок, то перед началом сортировки делается копия данных, которая и передается алгоритму. Также было добавлено синхронное изменение объекта индексов по образцу изменения данных.
void CLONGArray::QuickSort(long &m_data[],Cint2D &index,int beg,int end,bool mode=0)
Вот этот участок кода сортировки:
... if(i<=j) { t=m_data[i]; it=index.Ind(i); m_data[i++]=m_data[j]; index.Ind(i-1,index.Ind(j)); m_data[j]=t; index.Ind(j,it); if(j==0) break; else j--; } ...
В оригинальном алгоритме нет никакого объекта класса Cint2D. В остальных стандартных алгоритмах внесены похожие изменения. Шаблоны всех кодов я приводить не буду. Если у кого-то есть желание доработать код, он всегда может сделать шаблон, из реального кода просто заменив реальные типы шаблоном.
Для написания шаблона я использовал коды класса, работающего с типом long. В таких экономных алгоритмах разработчики стараются без необходимости лишний раз не пользоваться длинными целыми числами, если есть возможность применить int. Поэтому переменная типа long, скорее всего, является перегружаемым параметром. Вот их-то и стоит заменить на templat при использовании шаблонов.
Заключение
Надеюсь, данная статья будет хорошим подспорьем для начинающих программистов как в освоении объектного подхода, так и облегчит работу с данными. Класс CTable может стать базовым для многих еще более сложных программ. Приемы, освещенные в статье, могут лечь в основу разработки очень большого класса задач, так как являются общими подходами в работе с данными.
К тому же статья еще раз доказывает, что нападки на язык MQL5 безосновательны. Хотели тип Variant, вот он реализован средствами MQL5. При этом не потребовалось вводить изменения в стандарты и расшатывать безопасность языка. Удачи.
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

 Фильтрация сигналов на основе статистических данных о корреляции цен
Фильтрация сигналов на основе статистических данных о корреляции цен
 Применение псевдошаблонов как альтернатива шаблонов С++
Применение псевдошаблонов как альтернатива шаблонов С++
 Реализация автоматического анализа волн Эллиотта на MQL5
Реализация автоматического анализа волн Эллиотта на MQL5
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Николай,есть вопрос.
Можно ли так сделать, чтобы из МТ5 записалась таблица в Excel в таком виде?
Интересны мне те 2 макроназвания столбцов ("Абсолютные данные" и "Относительные данные"), которые выделил цветом. Они объединяют 3 ячейки каждое.
Может много хочу от MQL5 в плане форматирования excel'евских ячеек. А вдруг :-))
Какой физический смысл вы вкладываете в слова "объединяют 3 ячейки" ?
В принципе можно но без верхних 2-х строк, типы данных обосабливаются по столбцам, так что в один столбец впихнуть стринг и дубль не выйдет, но это можно сделать при печати. Или доработать класс так чтоб он содержал заглавные строки форматируемые отдельно от таблицы.
Самое просто это создать две таблицы и объеденить их.
Какой физический смысл вы вкладываете в слова "объединяют 3 ячейки" ?
Вот что сейчас:
Что хотелось бы иметь уже привёл...
Опубликована новая статья Электронные таблицы в MQL5:
Автор: Николай