
MQL5'te Elektronik Tablolar

Giriş
Genellikle elektronik tablolar EXCEL gibi tablo işlemcilerine (veri depolayan ve işleyen uygulamalar) başvurur. Makalede gösterilen kod o kadar güçlü olmasa da bir tablo işlemcisinin tam özellikli uygulanmasında temel sınıf olarak kullanılabilir. MQL5 kullanarak MS Excel oluşturmak gibi bir amacım yok ancak iki boyutlu bir dizide farklı türdeki verilerle çalışmaya yönelik bir sınıf uygulamak istiyorum.
Ve benim tarafımdan uygulanan sınıf, performansı açısından iki boyutlu tek tip veri dizisiyle (veriye doğrudan erişimi olan) karşılaştırılamasa da kullanım için uygun görünüyordu. Ek olarak, bu sınıf bir sütuna yozlaştırılmış bir tablonun özel bir durumu olarak C++'daki Varyant sınıfının bir uygulaması olarak düşünülebilir.
Sabırsız olanlar ve uygulama algoritmasını analiz etmek istemeyenler için mevcut yöntemlerden CTable sınıfını açıklamaya başlayacağım.
1. Sınıf Yöntemlerinin Tanımı
İlk olarak, sınıfın mevcut yöntemlerini, amaçlarını ve kullanım ilkelerini daha ayrıntılı bir şekilde açıklayalım.
1.1. FirstResize
Tablo düzeni, sütun türlerinin tanımı, TYPE[], satır boyutunu ve hücre türlerini belirleyen ENUM_DATATYPE türünün dizisi.
void FirstResize(const ENUM_DATATYPE &TYPE[]);
Pratik olarak bu yöntem parametresi olan ek bir oluşturucudur. Bu iki nedenden dolayı uygundur: birincisi, oluşturucu içinde bir parametrenin iletilmesi sorununu çözer; ikincisi de bir nesneyi parametre olarak geçirme ve ardından dizinin gerekli bölümünü uygulama olanağı verir. Bu özellik sınıfın C++'da Varyant sınıfı olarak kullanılmasına izin verir.
Uygulamanın özellikleri, fonksiyon ilk boyutu ve sütunların veri türünü belirlemesine rağmen ilk boyutun bir parametre olarak büyüklüğünün belirtilmesini gerektirmez. Bu parametre geçirilen TYPE dizisinin büyüklüğünden alınır.
1.2. SecondResize
Satır sayısını 'j' olarak değiştirir.
void SecondResize(int j);
Fonksiyon ikinci boyutun tüm dizileri için belirli bir büyüklük ayarlar. Böylece bir tabloya satır eklediğini söyleyebiliriz.
1.3. FirstSize
Yöntem ilk boyutun büyüklüğünü (satırın uzunluğu) döndürür.
int FirstSize();
1.4. SecondSize
Yöntem ikinci boyutun büyüklüğünü (sütun uzunluğu) döndürür.
int SecondSize();1.5. PruningTable
İlk boyut için yeni bir büyüklük belirler; değişiklik başlangıç büyüklüğü içinde mümkündür.
void PruningTable(int count);
Pratik olarak, fonksiyon satırın uzunluğunu değiştirmez; yalnızca satır uzunluğunun değerini depolamaktan sorumlu olan bir değişkenin değerini yeniden yazar. Sınıf bir tablonun ilk bölümünde ayarlanan, ayrılan belleğin gerçek büyüklüğünü saklayan başka bir değişken içerir. Bu değişkenin değerleri içinde birinci boyutun sanal büyüklüğünün değişmesi mümkündür. Fonksiyon bir tabloyu diğerine kopyalarken istenmeyen bir kısmı kesmeye yarar.
1.6. CopyTable
İkinci boyutun tüm uzunluğu boyunca bir tabloyu diğerine kopyalama yöntemidir:
void CopyTable(CTable *sor);Fonksiyon bir tabloyu diğerine kopyalar. Alma tablosunu başlatır. Ek bir oluşturucu olarak kullanılabilir. Sıralama varyantlarının iç yapısı kopyalanmaz. İlk tablodan yalnızca büyüklük, sütun türleri ve veriler kopyalanır. Fonksiyon GetPointer fonksiyonu tarafından geçirilen bir parametre olarak CTable türünden kopyalanan nesnenin referansını kabul eder.
Bir tablo diğerine kopyalanarak “sor” örneğine göre yeni bir tablo oluşturulur.
void CopyTable(CTable *sor,int sec_beg,int sec_end);
Ek parametrelerle yukarıda açıklanan fonksiyonun geçersiz kılınması: sec_beg, ilk tabloyu kopyalamanın başlangıç noktası, sec_end, kopyalamanın bitiş noktası (lütfen kopyalanan veri miktarıyla karıştırmayın). Her iki parametre de ikinci boyuta başvurur. Veriler alıcı tablosunun başına eklenecektir. Alma tablosunun büyüklüğü sec_end-sec_beg+1 olarak ayarlanır.
1.7. TypeTable
'i' sütununun type_table değerini (ENUM_DATATYPE türünün) döndürür.
ENUM_DATATYPE TypeTable(int i)
1.8. Change
Change() yöntemi sütunların değiş tokuşunu gerçekleştirir.
bool Change(int &sor0,int &sor1);
Yukarıda bahsedildiği gibi yöntem sütunları değiştirir (birinci boyutla çalışır). Bilgi fiilen hareket ettirilmediği için fonksiyonun çalışma hızı ikinci boyutun büyüklüğünden etkilenmez.
1.9. Insert
Insert yöntemi belirtilen bir pozisyona bir sütun ekler.
bool Insert(int rec,int sor);
Fonksiyon belirtilen sütunun nereye taşınması gerektiğine bağlı olarak diğer sütunların çekilmesi veya itilmesi dışında yukarıda açıklananla aynıdır. “Rec” parametresi sütunun nereye taşınacağını, “sor” ise nereye taşınacağını belirtir.
1.10. Variant/VariantCopy
“Varyant” serisinin üç fonksiyonu vardır. Tablo işleme varyantlarının hafızaya atılması sınıfta uygulanır.
Varyantlar bir not defterine benzer. Örneğin, üçüncü sütuna göre sıralama yapıyorsanız ve sonraki işleme sırasında verileri sıfırlamak istemiyorsanız varyantı değiştirmelisiniz. İşlemenin önceki varyantına erişmek için '”varyant” fonksiyonunu çağırın. Bir sonraki işleme bir öncekinin sonucuna dayanması gerekiyorsa varyantları kopyalamanız gerekir. Varsayılan olarak 0 numaralı bir varyant ayarlanır.
Bir varyantın kurulur (eğer böyle bir varyant yoksa “ind”e kadar tüm eksik varyantlarla birlikte oluşturulacaktır) ve aktif varyant alınır. “Varyantcopy” yöntemi “sor” varyantını “rec” varyantına kopyalar.
void variant(int ind); int variant(); void variantcopy(int rec,int sor);
Varyant(int ind) yöntemi seçilen varyantı değiştirir. Otomatik bellek ayırma işlemini gerçekleştirir. Belirtilen parametre daha önce belirtilenden küçükse, bellek yeniden ayrılmaz.
Variantcopy yöntemi “sor” varyantının “rec” varyantına kopyalanmasına izin verir. Fonksiyon varyantları düzenlemek için oluşturulur. “Rec” varyantı yoksa varyantların sayısını otomatik olarak arttırır; ayrıca yeni kopyalanan varyanta geçiş yapar.
1.11. SortTwoDimArray
SortTwoDimArray yöntemi bir tabloyu seçilen “i” satırına göre sıralar.
void SortTwoDimArray(int i,int beg,int end,bool mode=false);
Belirli bir sütuna göre bir tabloyu sıralama fonksiyonu. Parametre: i: sütun, beg: sıralamanın başlangıç noktası, end: sıralamanın bitiş noktası (dâhil), mod: sıralama yönünü belirleyen boole değişkeni. mode=true ise bu, değerlerin endekslerle birlikte arttığı anlamına gelir (“false” varsayılan değerdir çünkü endeksler tablonun üstünden altına doğru artar).
1.12. QuickSearch
Yöntem dizideki bir ögenin pozisyonunu “öge” modeline eşit olan değere göre hızlı bir şekilde arar.
int QuickSearch(int i,long element,int beg,int end,bool mode=false);
1.13. SearchFirst
Sıralanmış bir dizideki bir modele eşit olan ilk ögeyi arar. “Öge” modeline eşit olan ilk değerin dizinini döndürür. Bu aralıkta daha önce gerçekleştirilen sıralama türünü belirtmek gerekir (eğer böyle bir öge yoksa 1 değerini döndürür).
int SearchFirst(int i,long element,int beg,int end,bool mode=false);
1.14. SearchLast
Sıralanmış bir dizideki bir modele eşit olan son ögeyi arar.
int SearchLast(int i,long element,int beg,int end,bool mode=false);
1.15. SearchGreat
Sıralanmış bir dizideki bir modelden daha büyük olan en yakın ögeyi arar.
int SearchGreat(int i,long element,int beg,int end,bool mode=false);
1.16. SearchLess
Sıralanmış bir dizideki bir modelden daha küçük olan en yakın ögeyi arar.
int SearchLess(int i,long element,int beg,int end,bool mode=false);
1.17. Ayarla/Al
Ayarla ve Al fonksiyonları geçersiz türdedir; tablonun birlikte çalıştığı dört tür veri tarafından geçersiz kılınırlar. Fonksiyonlar veri türünü tanır ve ardından “değer” parametresi sütun türüne karşılık gelmezse atama yerine bir uyarı yazdırılır. Buradaki tek istisna dizgi türüdür. Giriş parametresi dizgi türündeyse sütun türüne dönüştürülür. Bu istisna, hücrenin değerini kabul edecek bir değişken ayarlama imkanı olmadığında bilginin daha uygun iletilmesi için yapılır.
Değer ayarlama yöntemleri (i: birinci boyutun endeksi, j: ikinci boyutun endeksi).
void Set(int i,int j,long value); // setting value of the i-th row and j-th column void Set(int i,int j,double value); // setting value of the i-th row and j-th columns void Set(int i,int j,datetime value);// setting value of the i-th row and j-tj column void Set(int i,int j,string value); // setting value of the i-th row and j-th column
Değer alma yöntemleri (i: birinci boyutun endeksi, j: ikinci boyutun endeksi).
//--- getting value void Get(int i,int j,long &recipient); // getting value of the i-th row and j-th column void Get(int i,int j,double &recipient); // getting value of the i-th row and j-th column void Get(int i,int j,datetime &recipient); // getting value of the i-th row and j-th column void Get(int i,int j,string &recipient); // getting value of the i-th row and j-th column
1.19. sGet
“j” sütunundan ve “i” satırından string (dizgi) türünde bir değer alır.
string sGet(int i,int j); // return value of the i-th row and j-th column
Alma serisinin değeri parametrik bir değişken yerine “getiri” operatörü aracılığıyla döndüren tek fonksiyonudur. Sütun türünden bağımsız olarak string (dizgi) türünde bir değer döndürür.
1.20. StringDigits
Türler “string”e (dizgi) dönüştürüldüğünde fonksiyonlar tarafından ayarlanan bir kesinlik kullanabilirsiniz:
void StringDigits(int i,int digits);
“double” (çifte) kesinliği ayarlamak ve
int StringDigits(int i);
“datetime” (tarih saat) cinsinden saniyelerin görüntülenme kesinliğini ayarlamak için -1'e eşit olmayan herhangi bir değer iletilir. Belirtilen değer sütun için hafızaya alınır, bu nedenle bilgileri her görüntülediğinizde bunu belirtmeniz gerekmez. Bilgiler orijinal türlerde saklandığından ve yalnızca çıktı sırasında belirtilen kesinliğe dönüştürüldüğü için birçok kez kesinlik ayarlaması yapabilirsiniz. Kesinlik değerleri kopyalama sırasında hafızaya alınmaz, bu nedenle bir tabloyu yeni bir tabloya kopyalarken yeni tablonun sütunlarının kesinliği varsayılan kesinliğe karşılık gelir.
1.21. Bu kullanıma bir örnek şöyledir:
#include <Table.mqh> ENUM_DATATYPE TYPE[7]= {TYPE_LONG,TYPE_LONG,TYPE_STRING,TYPE_DATETIME,TYPE_STRING,TYPE_STRING,TYPE_DOUBLE}; // 0 1 2 3 4 5 6 //7 void OnStart() { CTable table,table1; table.FirstResize(TYPE); // dividing table, determining column types table.SecondResize(5); // change the number of rows table.Set(6,0,"321.012324568"); // assigning data to the 6-th column, 0 row table.Insert(2,6); // insert 6-th column in the 2-nd position table.PruningTable(3); // cut the table to 3 columns table.StringDigits(2,5); // set precision of 5 digits after the decimal point Print("table ",table.sGet(2,0)); // print the cell located in the 2-nd column, 0 row table1.CopyTable(GetPointer(table)); // copy the entire table 'table' to the 'table1' table table1.StringDigits(2,8); // set 8-digit precision Print("table1 ",table1.sGet(2,0)); // print the cell located in the 2-nd column, 0 row of the 'table1' table. }
İşlemin sonucunda (2;0) hücresinin içeriği yazdırılır. Muhtemelen fark ettiğiniz üzere, kopyalanan verilerin kesinliği ilk tablonun kesinliğini geçmez.
2011.02.09 14:18:37 Table Script (EURUSD,H1) table1 321.01232000 2011.02.09 14:18:37 Table Script (EURUSD,H1) table 321.01232
Şimdi algoritmanın tanımına geçelim.
2. Model Seçme
Bilgiyi organize etmenin iki yolu vardır: bağlı sütunların şeması (bu makalede uygulanmaktadır) ve bunun bağlı satırlar biçimindeki alternatifi aşağıda gösterilmiştir.
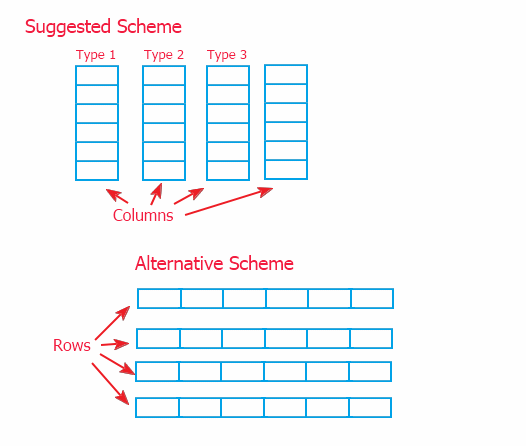
Bilgiye bir aracı vasıtasıyla başvurulması nedeniyle (sayfa 2'de açıklanmıştır) üst kapsamın uygulanmasında büyük bir fark yoktur. Ancak verileri depolayan nesnelerde düşük kapsamda veri yönteminin uygulanmasına izin verdiği için sütun modelini seçtim. Ve alternatif şema üst sınıf CTable'daki bilgilerle çalışma yöntemlerinin geçersiz kılınmasını gerektirecektir. Ve bu gerekli olması durumunda sınıfın geliştirilmesini zorlaştırabilir.
Bu durumda şemaların her biri kullanılabilir. Önerilen şema verilerin hızlı bir şekilde taşınmasına izin verir ve alternatifi de verilerin daha hızlı eklenmesine (çünkü bilgiler bir tabloya genellikle satır satır eklenir) ve satırların alınmasına izin verir.
Bir tabloyu bir dizi yapı olarak da düzenleyebiliriz. Ve uygulanması en kolay olanın bu olmasına rağmen, önemli bir dezavantaja da sahiptir. Yapı bir programcı tarafından tanımlanmalıdır. Bu yüzden özel parametreler aracılığıyla (kaynak kodunu değiştirmeden) tablonun niteliklerini ayarlama imkanından faydalanamayız.
3. Dinamik Dizide Verileri Birleştirme
Farklı veri türlerini tek bir dinamik dizide birleştirme imkanından faydalanmak için dizi hücrelerine farklı türler atama problemini çözmemiz gerekir. Bu sorun standart kütüphanenin bağlı listelerinde zaten çözülmüştür. İlk geliştirmelerim standart sınıf kütüphanesine dayanıyordu. Ancak projenin geliştirilmesi sırasında CObject temel sınıfında birçok değişiklik yapmam gerektiği ortaya çıktı.
Bu yüzden ben de kendi sınıfımı geliştirmeye karar verdim. Standart kütüphane üzerinde çalışmamış olanlar için yukarıda anlatılan problemin nasıl çözüldüğünü açıklayacağım. Sorunu çözmek için kalıtım mekanizmasını kullanmanız gerekir.
class CBase { public: CBase(){Print(__FUNCTION__);}; ~CBase(){Print(__FUNCTION__);}; virtual void set(int sor){}; virtual void set(double sor){}; virtual int get(int k){return(0);}; virtual double get(double k){return(0);}; }; //+------------------------------------------------------------------+ class CA: public CBase { private: int temp; public: CA(){Print(__FUNCTION__);}; ~CA(){Print(__FUNCTION__);}; void set(int sor){temp=sor;}; int get(int k){return(temp);}; }; //+------------------------------------------------------------------+ class CB: public CBase { private: double temp; public: CB(){Print(__FUNCTION__);}; ~CB(){Print(__FUNCTION__);}; void set(double sor){temp=sor;}; double get(double k){return(temp);}; }; //+------------------------------------------------------------------+ void OnStart() { CBase *a; CBase *b; a=new CA(); b=new CB(); a.set(15); b.set(13.3); Print("a=",a.get(0)," b=",b.get(0.)); delete a; delete b; }
Görsel açıdan kalıtım mekanizması bir tarak olarak ifade edilebilir:

Sınıfın dinamik bir nesnesinin oluşturulması bildirildiğinde bu, temel sınıfın oluşturucusunun çağrılacağı anlamına gelir. Bu özellik bir nesneyi iki adımda oluşturmayı mümkün kılar. Temel sınıfın sanal fonksiyonları geçersiz kılındığı için türetilmiş sınıflardan farklı türde parametrelerle fonksiyonu çağırma imkanını elde ederiz.
Basit geçersiz kılma işlemi neden yeterli değil? Mesele şu ki, çalıştırılan fonksiyonlar çok büyüktür; bu yüzden eğer onların içeriğini temel sınıfa tanımlasaydık (kalıtım kullanmadan) o zaman ikili koddaki her nesne için fonksiyonun tam içeriğiyle kullanılmayan fonksiyon yaratılırdı. Ve kalıtım mekanizmasını kullanırken kodla dolu fonksiyonlardan çok daha az bellek kaplayan boş fonksiyonlar oluşturulur.
4. Dizilerle İşlemler
Standart sınıfları kullanmayı reddetmeme neden olan ikinci ve ana temel sebep de verilere başvurulmasıdır. Hücre endekslerine başvurmak yerine bir ara endeks dizisi aracılığıyla dizi hücrelerine dolaylı olarak başvuruyorum. Bir değişken aracılığıyla doğrudan referans kullanmaktan daha düşük bir çalışma hızını şart koşar. Mesele, bir endeksin dizi hücresinden daha hızlı çalıştığını gösteren değişkendir ki bunun ilk başta bellekte bulunması gerekir.
Tek boyutlu ve çok boyutlu bir diziyi sıralamanın temel farkının ne olduğunu analiz edelim. Sıralamadan önce tek boyutlu bir dizide ögeler rastgele pozisyonlara sahiptir ve sıralamadan sonra ögeler düzenlenir. İki boyutlu bir diziyi sıralarken tüm dizinin sıralanmasına gerek yoktur ancak sıralama yalnızca sütunlarından biri tarafından gerçekleştirilir. Tüm sıralar yapılarını koruyarak pozisyonlarını değiştirmelidir.
Buradaki satırların kendileri farklı türlerdeki verileri içeren bağlı yapılardır. Böyle bir sorunu çözmek için hem seçilen bir dizideki verileri sıralamamız hem de ilk endekslerin yapısını kaydetmemiz gerekir. Eğer hücrenin hangi satırı içerdiğini biliyorsak tüm satırı görüntüleyebiliriz. Bu nedenle, iki boyutlu bir diziyi sıralarken veri yapısını değiştirmeden sıralanmış dizinin endeks dizisini almamız gerekir.
Örneğin:
before sorting by the 2-nd column 4 2 3 1 5 3 3 3 6 after sorting 1 5 3 3 3 6 4 2 3 Initial array looks as following: a[0][0]= 4; a[0][1]= 2; a[0][2]= 3; a[1][0]= 1; a[1][1]= 5; a[1][2]= 3; a[2][0]= 3; a[2][1]= 3; a[2][2]= 6; And the array of indexes of sorting by the 2-nd column looks as: r[0]=1; r[1]=2; r[2]=0; Sorted values are returned according to the following scheme: a[r[0]][0]-> 1; a[r[0]][1]-> 5; a[r[0]][2]-> 3; a[r[1]][0]-> 3; a[r[1]][1]-> 3; a[r[1]][2]-> 6; a[r[2]][0]-> 4; a[r[2]][1]-> 2; a[r[2]][2]-> 3;
Böylece bilgileri sembole, pozisyon açılış tarihine, kâra vb. göre sıralama imkanımız olur.
Birçok sıralama algoritması hâlihazırda geliştirilmiştir. Bu geliştirme için en iyi değişken kararlı sıralama algoritmasıdır.
Standart sınıflarda kullanılan Hızlı Sıralama algoritması kararsız sıralama algoritmalarını ifade eder. Bu yüzden klasik uygulama biçimi açısından bize uymaz. Ancak kararlı bir forma getirdikten sonra bile (ve bu, verilerin ek kopyalanması ve endeks dizilerinin sıralanmasıdır) hızlı sıralama, kabarcık sıralamasından (kararlı sıralamanın en hızlı algoritmalarından biridir) daha hızlı görünmektedir. Algoritma çok hızlıdır ancak özyineleme kullanır.
String (dizgi) türündeki dizilerle çalışırken Kokteyl sıralamasını kullanmamın nedeni budur (çok daha fazla yığın bellek gerektirir).
5. İki Boyutlu Dizinin Düzenlenmesi
Ve ele almak istediğim son soru da dinamik iki boyutlu bir dizinin düzenlenmesidir. Böyle bir düzenleme için tek boyutlu bir dizide bir sınıf olarak kaydırma yapmak ve işaretçiler dizisi aracılığıyla nesne dizisini çağırmak yeterlidir. Başka bir deyişle, diziler dizisini oluşturmamız gerekir.
class CarrayInt { public: ~CarrayInt(){}; int array[]; }; //+------------------------------------------------------------------+ class CTwoarrayInt { public: ~CTwoarrayInt(){}; CarrayInt array[]; }; //+------------------------------------------------------------------+ void OnStart() { CTwoarrayInt two; two.array[0].array[0]; }
6. Programın Yapısı
CTable sınıfının kodu Sözde Şablonları С++ Şablonlarına Alternatif Olarak Kullanma makalesinde açıklanan şablonlar kullanılarak yazılmıştır. Şablon kullandığım için bu kadar büyük bir kodu çok hızlı bir şekilde yazabiliyorum. Bu yüzden kodun tamamını ayrıntılı olarak anlatmayacağım; buna ek olarak, algoritma kodunun çoğu standart sınıfların bir modifikasyonudur.
Ben sadece sınıfın genel yapısını ve birkaç önemli noktayı açıklığa kavuşturan fonksiyonların bazı ilginç özelliklerini göstereceğim.

Blok diyagramın sağ kısmı temelde CLONGArray, CDOUBLArray, CDATETIMEArray ve CSTRINGArray türetilmiş sınıflarında bulunan geçersiz kılınan yöntemler tarafından kullanılır Her biri (özel bölümde) kendisine karşılık gelen türde bir dizi içerir. Bu diziler bilgiye erişim sağlanan tüm yollar için kullanılır. Yukarıda listelenen sınıfların yöntemlerinin adları genel yöntemlerle aynıdır.
Temel sınıf CBASEArray sanal yöntemlerin geçersiz kılınmasıyla doldurulur ve yalnızca CTable sınıfının özel bölümünde CBASEArray nesnelerinin dinamik dizisinin bildirilmesi için gereklidir. İşaretçiler dizisi CBASEArray dinamik nesnelerden oluşan dinamik bir dizi olarak bildirilir. Nesnelerin son oluşturulması ve gerekli örneğin seçimi FirstResize() fonksiyonunda gerçekleştirilir. Ayrıca bu kendi içeriğinde FirstResize() fonksiyonunu çağırdığı için CopyTable() fonksiyonunda da yapılabilir.
CTable sınıfı ayrıca veri işleme yöntemlerinin (CTable sınıfının örneklerinde bulunur) ve Cint2D sınıfının endekslerini kontrol etme nesnesinin koordinasyonunu gerçekleştirir. Tüm koordinasyon geçersiz kılınan genel yöntemlere kaydırılır.
CTable sınıfında sık sık tekrarlanan geçersiz kılma bölümleri çok uzun satırlar üretmekten kaçınmak için tanımlarla değiştirilir:
#define _CHECK0_ Print(__FUNCTION__+"("+(string)i+","+(string)j+")");return; #define _CHECK_ Print(__FUNCTION__+"("+(string)i+")");return(-1); #define _FIRST_ first_data[aic[i]] #define _PARAM0_ array_index.Ind(j),value #define _PARAM1_ array_index.Ind(j),recipient #define _PARAM2_ element,beg,end,array_index,mode
Böylece daha kompakt bir formun parçası
int QuickSearch(int i,long element,int beg,int end,bool mode=false){if(!check_type(i,TYPE_LONG)){_CHECK_}return(_FIRST_.QuickSearch(_PARAM2_));};
ön işlemci tarafından aşağıdaki satırla değiştirilecektir:
int QuickSearch(int i,long element,int beg,int end,bool mode=false){if(!check_type(i,TYPE_LONG)){Print(__FUNCTION__+"("+(string)i+")");return(-1);} return(first_data[aic[i]].QuickSearch(element,beg,end,array_index,mode));};
Yukarıdaki örnekte veri işleme yöntemlerinin nasıl adlandırıldığı açıktır (“getiri” içindeki kısım).
CTable sınıfının verinin işlenmesi sırasında veriyi fiziksel olarak taşımadığından daha önce bahsetmiştim; bu sınıf sadece endekslerin nesnesindeki değeri değiştirir. Veri işleme yöntemlerine endekslerin nesnesi ile etkileşim olanağı vermek için bu, işlemenin tüm fonksiyonlarına array_index parametresi olarak iletilir.
array_index nesnesi ikinci boyutun ögelerinin pozisyonel ilişkisini saklar. İlk boyutun endekslenme işlemi CTable sınıfının özel bölgesinde bildirilen aic[] dinamik dizisinin sorumluluğundadır. Bu, sütunların pozisyonunu değiştirme imkanı verir (fiziksel olarak değil ama dizinler aracılığıyla).
Örneğin, Change() işlemi yapılırken sütunların dizinlerini içeren yalnızca iki bellek hücresi yerlerini değiştirir. Baktığınızda iki sütun da taşınıyor gibi görünse de hareket etmezler. CTable sınıfının fonksiyonları belgelerde oldukça iyi tanımlanmıştır (hatta bazı yerlerde satır satır tanımlanmıştır).
Şimdi CBASEArray'den devralınan sınıfların fonksiyonlarına geçelim. Aslında bu sınıfların algoritmaları standart sınıflardan alınan algoritmalardır. Onlar hakkında bir fikir sahibi olmak için standart isimleri seçtim. Değişiklik değerlerin doğrudan getirildiği standart algoritmalardan farklı olarak bir dizi dizin kullanarak değerlerin dolaylı olarak döndürülmesini içerir.
Öncelikle Hızlı sıralamada değişiklik yapılmıştır. Algoritma kararsızlar kategorisinden olduğu için sıralamaya başlamadan önce algoritmaya iletilecek olan verilerin bir kopyasını almamız gerekiyor. Buna ek olarak, veri değiştirme modeline göre endeks nesnesinin senkronize modifikasyonunu da ekledim.
void CLONGArray::QuickSort(long &m_data[],Cint2D &index,int beg,int end,bool mode=0)
Kod sıralamasının bir kısmı şöyle:
... if(i<=j) { t=m_data[i]; it=index.Ind(i); m_data[i++]=m_data[j]; index.Ind(i-1,index.Ind(j)); m_data[j]=t; index.Ind(j,it); if(j==0) break; else j--; } ...
Orijinal algoritmada Cint2D sınıfının hiçbir örneği yoktur. Diğer standart algoritmalarda da benzer değişiklikler yapılmıştır. Tüm kodların şablonlarını anlatmayacağım. Kodu geliştirmek isteyen varsa gerçek türleri şablonla değiştirerek gerçek koddan bir şablon yapabilir.
Şablonları yazmak için long türüyle çalışan bir sınıfın kodlarını kullandım. Bu tür ekonomik algoritmalarda geliştiriciler int kullanma imkanı varsa tam sayıların gereksiz kullanımından kaçınmaya çalışırlar. Bu nedenle long türünden bir değişken büyük olasılıkla geçersiz kılınan bir parametredir. Şablonları kullanırken bunlar “templat” ile değiştirilmelidirler.
Sonuç
Bu makalenin nesne yönelimli yaklaşımı incelerken acemi programcılar için iyi bir yardımcı olacağını ve bilgi üzerinde çalışmayı kolaylaştıracağını umuyorum. CTable sınıfı birçok karmaşık uygulama için bir temel sınıf olabilir. Makalede açıklanan yöntemler verilerle çalışmak için genel bir yaklaşım uyguladıkları için büyük bir çözüm sınıfının geliştirilmesinin temeli olabilir.
Buna ek olarak, makale MQL5'i kötüye kullanmanın bir temele dayanmadığını kanıtlamaktadır. Varyant türünü mü istemiştiniz? Burada MQL5 aracılığıyla uygulanmaktadır. Haliyle standartları değiştirmeye ve dilin güvenliğini zayıflatmaya gerek yoktur. İyi şanslar!
MetaQuotes Ltd tarafından Rusçadan çevrilmiştir.
Orijinal makale: https://www.mql5.com/ru/articles/228
Uyarı: Bu materyallerin tüm hakları MetaQuotes Ltd'ye aittir. Bu materyallerin tamamen veya kısmen kopyalanması veya yeniden yazdırılması yasaktır.
Bu makale sitenin bir kullanıcısı tarafından yazılmıştır ve kendi kişisel görüşlerini yansıtmaktadır. MetaQuotes Ltd, sunulan bilgilerin doğruluğundan veya açıklanan çözümlerin, stratejilerin veya tavsiyelerin kullanımından kaynaklanan herhangi bir sonuçtan sorumlu değildir.

 MQL5 Sihirbazı: Risk ve Para Yönetimi Modülü Nasıl Oluşturulur
MQL5 Sihirbazı: Risk ve Para Yönetimi Modülü Nasıl Oluşturulur
 MQL5 Sihirbazı: Alım Satım Sinyalleri Modülü Nasıl Oluşturulur
MQL5 Sihirbazı: Alım Satım Sinyalleri Modülü Nasıl Oluşturulur
 Zaman Serilerinin Tahmini için MetaTrader 5 Göstergelerini ENCOG Makine Öğrenimi Çerçevesi ile Kullanma
Zaman Serilerinin Tahmini için MetaTrader 5 Göstergelerini ENCOG Makine Öğrenimi Çerçevesi ile Kullanma
 Grafiklerin Analizine Ekonometrik Yaklaşım
Grafiklerin Analizine Ekonometrik Yaklaşım
- Ücretsiz alım-satım uygulamaları
- İşlem kopyalama için 8.000'den fazla sinyal
- Finansal piyasaları keşfetmek için ekonomik haberler
Web sitesi politikasını ve kullanım şartlarını kabul edersiniz
Nikolay, bir sorum var.
MT5'ten Excel'e bu formda bir tablo yazmak mümkün mü?
Renkli olarak vurgulanan 2 makro sütun adıyla ("Mutlak veriler" ve "Göreceli veriler") ilgileniyorum. Her biri 3 hücreyi birleştirir.
Belki MQL5'ten excel hücrelerini biçimlendirme açısından çok şey istiyorum. Ama ya olursa :-)))
"3 hücreyi birleştir" kelimelerine hangi fiziksel anlamı yüklüyorsunuz?
Prensipte yapabilirsiniz, ancak üst 2 satır olmadan, veri türleri sütunlara göre özetlenir, bu nedenle bir sütunda string ve double'ı sıkıştırmak işe yaramaz, ancak yazdırırken yapılabilir. Ya da sınıfı, tablodan ayrı olarak biçimlendirilmiş büyük harf dizeleri içerecek şekilde geliştirmek.
En kolay yol iki tablo oluşturmak ve bunları birleştirmektir.
"3 hücreyi birleştirmek" sözcüklerine hangi fiziksel anlamı yüklüyorsunuz?
Şu anda elimizde olan bu:
Şimdiden getirmiş olmak istediklerim ....
MQL5'te Elektronik Tablolar adlı yeni makale yayınlandı:
Yazar: Николай