
Использование электронных таблиц для построения торговых стратегий

Введение
Электронные таблицы — довольно давнее изобретение. Современные программы этого типа имеют колоссальную мощь и позволяют наглядно анализировать данные, представимые в табличной форме. При этом анализ возможен в разных плоскостях, под разными углами зрения — и происходит довольно быстро. Графики, сводные таблицы, анализ "что, если", условное форматирование ячеек — и много чего еще, о чем пишут толстенные книги и читают длинные курсы.
Вот часть этой мощи я и предлагаю потестировать для анализа своих стратегий.
Лично я использую Libre Office Calc, потому что он бесплатный — и работает везде, где работаю я :-) Однако этот же подход подойдёт и для других таблиц: Microsoft Excel, Google таблиц и др. На сегодняшний день они все позволят конвертироваться друг в друга, и принципы построения формул в них тоже сходны.
Итак, я предполагаю, что у вас есть какая-то программа для работы с таблицами. Также у Вас есть данные в формате текстового файла (*.txt или *.csv), которые Вы хотите проанализировать. В статье кратко рассказывается как импортировать такие файлы. Я буду использовать историю из терминала MetaTrader, однако подойдут и любые другие данные, скажем, от Dukas Copy или от Финам. И ещё — надеюсь, понятно, что у Вас должна быть идея стратегии, чтобы можно было настроить сигналы. Это всё, что требуется для применения материалов статьи на практике.
Я надеюсь, что статья будет полезна разным категориям трейдеров, поэтому я постараюсь написать её так, чтобы было понятно даже людям, которые ни разу до этого не видели программ подобного типа, однако при этом охватить круг вопросов, которые известны не всем опытным пользователям-трейдерам.
Быстрый взгляд на таблицы — для новичков
На рисунке 1 показан типичный вид программы электронных таблиц.
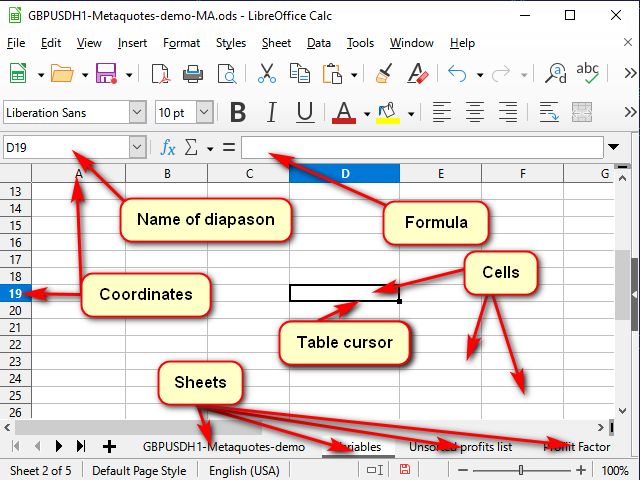
Рисунок 1. Типичный вид программы для работы с электронными таблицами.
Любая таблица представляется в виде некоего набора "листов". Можно их воспринимать как отдельные "вкладки" для разных задач.
Каждый лист состоит из "ячеек". Каждая ячейка, по сути, — это маленький, но очень мощный калькулятор.
Чтобы программа могла понимать, какую именно ячейку мы хотим обработать прямо сейчас, каждой ячейке присвоены координаты, как на шахматной доске или в "морском бое". Эти координаты вместе определяют уникальный "адрес" ячейки. Адрес состоит из номера или названия столбца и номера строки (например, на рисунке 1 табличным курсором выделена ячейка "D19". Это видно как по подсвеченным названиям координат, так и в строке имени.
Кроме собственно координат в адресе могут быть указаны и название листа, и даже имя файла таблицы. Как правило, этот же адрес является и именем этой ячейки. Но при желании можно задать и свои имена, чтобы было понятно, что конкретно хранит данная ячейка или диапазон ячеек. Эти имена можно посмотреть (и изменить) в строке имени.
Ячейка может содержать либо простые данные (например, котировки или объёмы), либо "формулы", по которым вычисляется её значение.
Что конкретно находится в выделенной ячейке, можно посмотреть в "строке формул" и, если необходимо, поменять эти значения или формулы.
Чтобы отредактировать значение в ячейке, нужно сделать на ней двойной щелчок или исправить то, что нужно, в строке формул. Можно также выделить ячейку и нажать клавишу "F2". А если надо создать новый текст, можно выделить ячейку и сразу что-то набирать. Только при этом надо учесть, что все данные из этой ячейки будут удалены.
Отменить редактирование, не сохраняя его, можно клавишей "ESC" (верхний правый угол клавиатуры). Подтвердить можно либо клавишей "Enter" (перевод курсора вниз), либо клавишей "Tab" (перевод в сторону).
Если выделено несколько ячеек, "Enter" и "Tab" работают только в выделенном фрагменте. Это можно использовать для ускорения работы.
С остальными кнопочками и менюшками, думаю, несложно будет разобраться и самостоятельно.
Начало работы: импорт котировок
Итак, начинаем готовить данные для тестирования наших стратегий. Как я уже сказал, я буду брать данные из терминала. Для этого в любом окне графика можно нажать сочетание клавиш Ctrl+S либо выбрать в меню терминала "Файл" -> "Сохранить". Терминал предложит обычное системное окно, в котором нужно будет ввести имя файла и путь.
Если расширение файла *.csv, то проблем обычно не бывает. Если же *.txt — то, как правило, нужно щелкнуть по файлу правой кнопкой мыши и выбрать "Открыть с помощью" ->"Выбрать другое приложение" или сначала открыть приложение для работы с таблицами, а уж из него открывать файл, так как по умолчанию система старается открывать файлы с таким расширением с помощью блокнота или другого текстового процессора.
Для того чтобы конвертировать числа, в окне конвертации нужно выбрать соответствующий столбец, а затем указать программе разделитель целой и дробной частей, а также, если необходимо, разделитель групп разрядов (для объёмов). В Excel это делается с помощью кнопки "Подробнее...", в Calc из списка "Тип столбца" выбрать пункт "Английский США".
И еще нюанс. После успешного импорта имеет смысл оставить в таблице с данными 5-7 тысяч строк. Дело в том, что, чем больше данных, тем сложнее программе рассчитывать результат каждой ячейки. При этом точность оценки увеличивается незначительно: так, при сравнении результатов проверки для данных из 5000 строк и 100000 строк, результаты отличались примерно на 1%, а время вычислений различалось очень заметно.
Некоторые клавиатурные сочетания для работы с таблицами
| Сочетание клавиш | Выполняемое действие |
|---|---|
| Ctrl + стрелки | Переход к ближайшей границе непрерывного ряда данных |
| Tab | Подтверждение ввода и переход в ячейку справа |
| Shift + Tab | Подтверждение ввода и переход в ячейку слева |
| Enter | Подтверждение ввода и переход в ячейку снизу |
| Shift + Enter | Подтверждение ввода и переход в ячейку сверху |
| Ctrl + D | Заполнить выделенные столбцы сверху вниз |
| Shift + Cttrl + стрелки | Выделение от текущего положения до конца непрерывного диапазона |
Как можно заполнить длинный столбец одинаковой формулой
Для небольших диапазонов можно использовать способ, показанный на рисунке 2: подвести мышку к "маркеру выделения" (квадратик в правом нижнем углу табличного курсора) и, когда курсор мыши превратится в тонкий крестик — протянуть этот маркер до нужной строки или столбца.
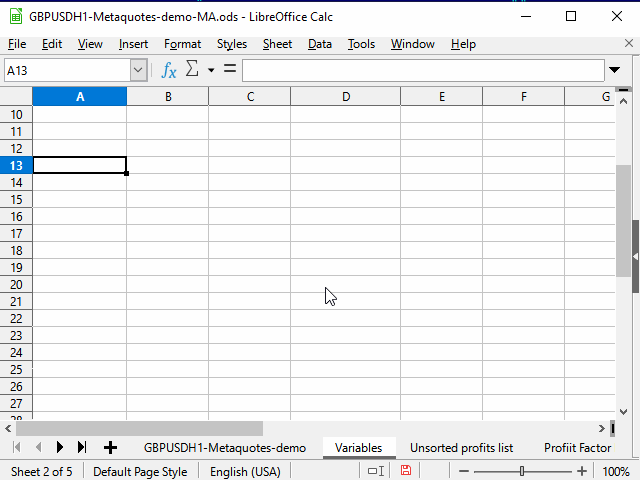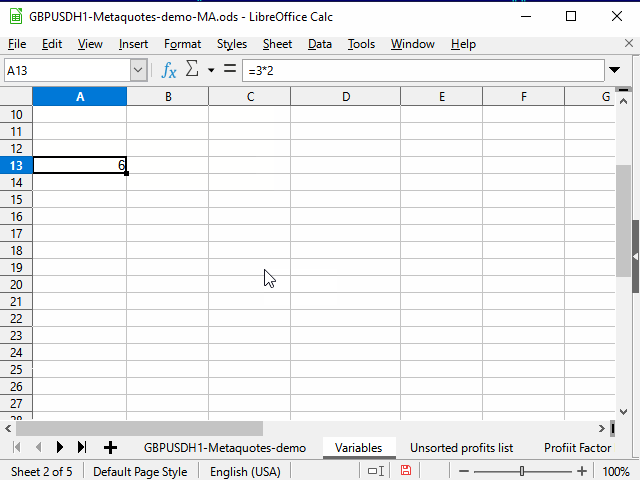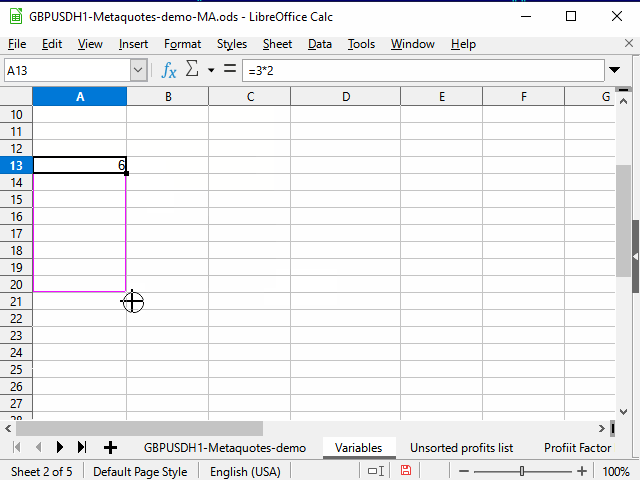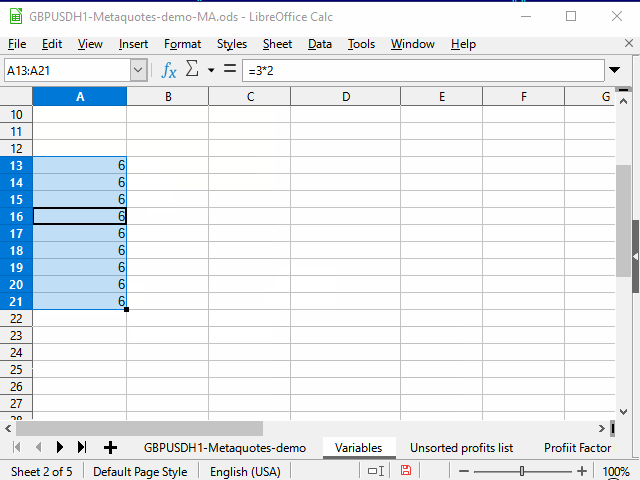
Рисунок 2. Заполнение протяжкой
Однако для больших объемов данных это будет очень неудобно.
Поэтому можно использовать любой из других способов.
Способ 1. Ограничение диапазона
Последовательность действий видна на рисунке 3.
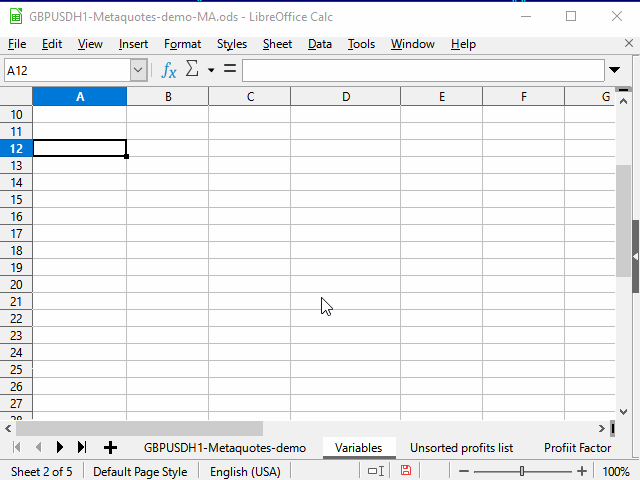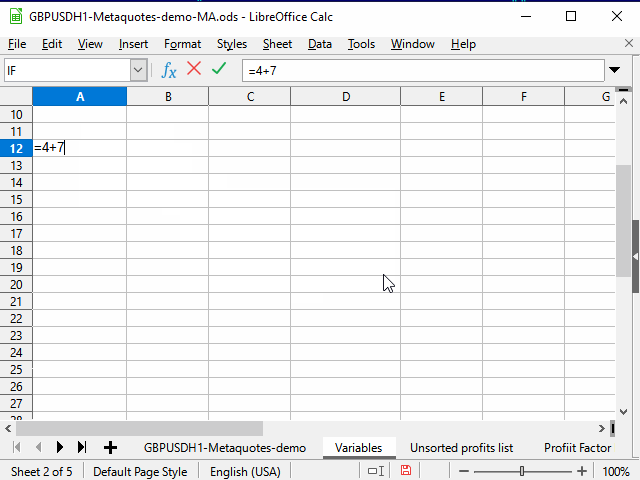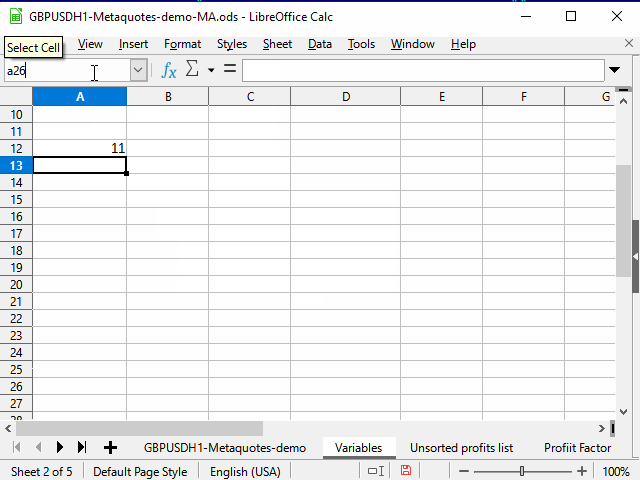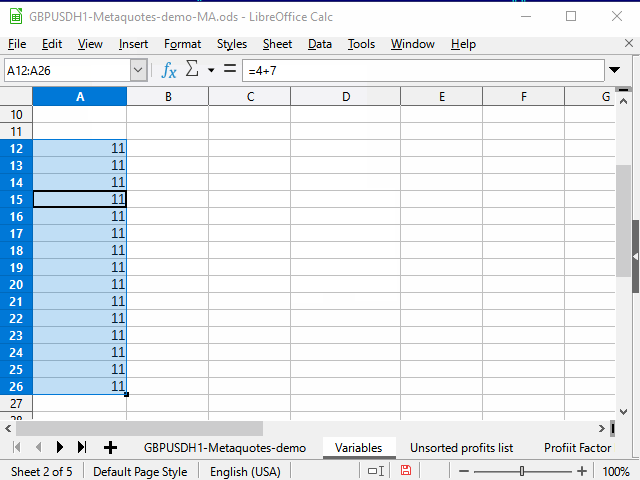
Рисунок 3. Заполнение с помощью ограничения диапазона
- Вводим нужную формулу в верхнюю ячейку диапазона и подтверждаем ввод.
- Переходим в самую нижнюю ячейку диапазона с помощью поля имени.
- Нажимаем клавиши Ctrl + Shift + стрелка вверх, чтобы перейти к самой верхней ячейке диапазона и выделить все промежуточные ячейки.
- Нажимаем сочетание Ctrl + D, чтобы заполнить ячейки данными.
Небольшим недостатком метода для меня является то, что нужно знать номер самой нижней строки диапазона.
Способ 2. Использование соседнего непрерывного диапазона
Последовательность действий — на рисунке 4.
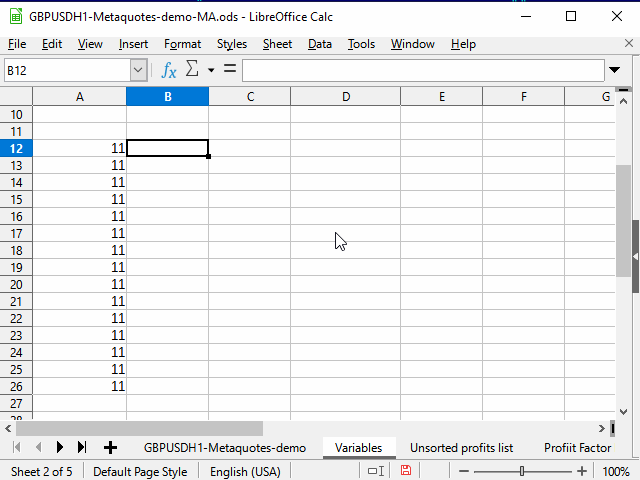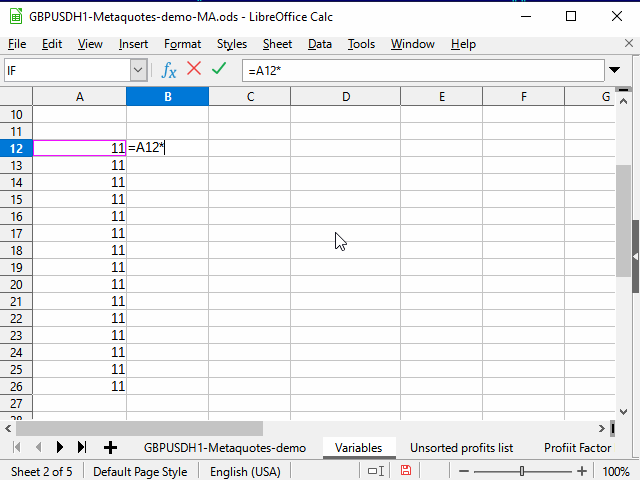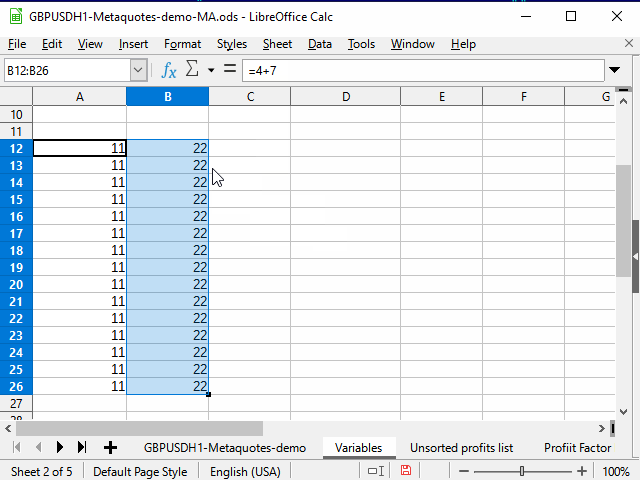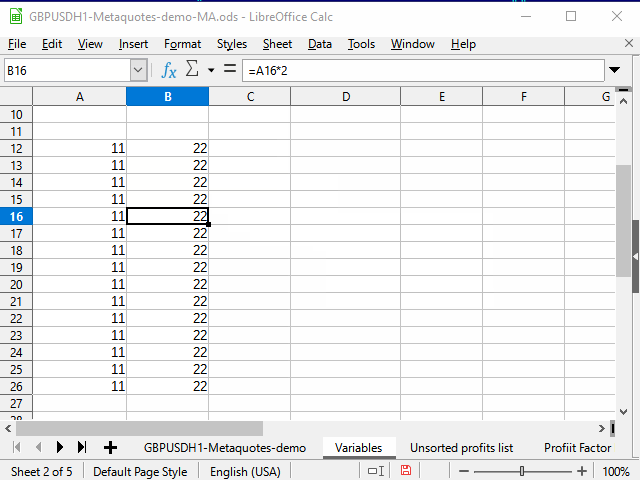
Рисунок 4. Заполнение с помощью соседнего диапазона.
- Выделяем ячейку с нужной формулой.
- С помощью сочетания Shift + стрелка влево выделяем соседнюю ячейку.
- Нажимаем клавишу Tab, чтобы табличный курсор переместился в левую ячейку. Здесь использована способность табличного курсора перемещаться только внутри выделения.
- Ctrl + Shift + стрелка вниз — выделяем два столбца до самой нижней строки непрерывного диапазона.
- Shift + стрелка вправо — снимаем выделение с левого столбца. Правый остаётся выделенным.
- Ctrl + D — заполняем столбец данными.
На рисунке обратите внимание на содержимое строки формул. Видно, что при копировании формулы, содержащей ссылку на другую ячейку, эта ссылка автоматически меняется в зависимости от положения курсора. Поэтому такая ссылка называется "относительной".
Если нужно, чтобы при копировании ссылка на ячейку оставалась постоянной, то нужно выделить эту ссылку и нажать клавишу F4. Перед номером строки и именем столбца появится знак $, и при копировании формулы значение меняться не будет.
Иногда бывает полезно, чтобы не изменялась не вся ссылка, а только столбец или только строка. Тогда знак доллара нужно оставить только в НЕизменяемой части (можно нажать F4 еще один или два раза).
Ну, и теперь, когда основные приёмы ускорения работы освоены, можем переходить непосредственно к описанию стратегии.
Описание стратегии
Для примера возьму стратегию, реализованную в стандартном советнике "Examples\Moving Average".
Позиция открывается, если:
- Нет открытых позиций и
- Свеча пересекает скользящую среднюю телом (Open — с одной стороны от МА, Close — с другой.)
Позиция закрывается, если:
- Есть открытая позиция и
- Свеча пересекает МА в обратном открытию направлении.
Добавление данных индикатора
Особенность вычисления с помощью электронных таблиц состоит в том, что промежуточные итоги вычислений, как правило, нужно сохранять отдельно. Это упрощает понимание формул и поиск ошибок, а также позволяет легче строить формулы на основе данных из соседних ячеек. Ну, и идеи приходят иногда именно благодаря этой "раздробленности".
Но вернёмся к нашей задаче.
После импорта и небольшого форматирования мои исходные котировки имеют следующий вид (рисунок 5):
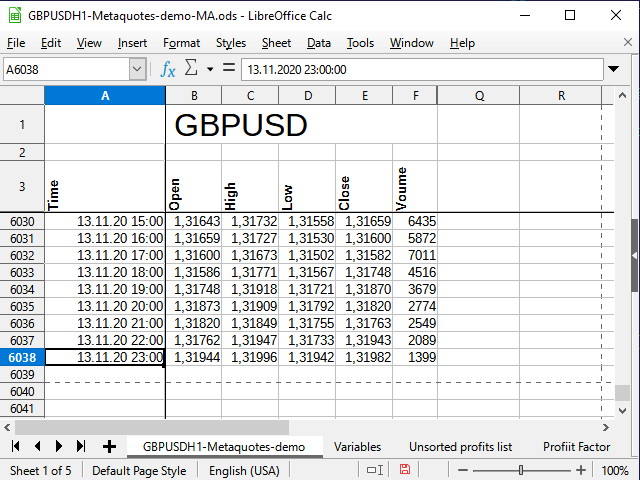
Рисунок 5. Внешний вид исходных котировок.
Обратите внимание на пустую строку между названием всей таблицы и названиями столбцов. Благодаря этой строке табличный процессор воспринимает эти два блока как отдельные таблицы, и, следовательно, я могу объединить ячейки для верхнего диапазона, но при этом использовать разные фильтры для нижнего — и они не будут мешать друг другу. Если эту строку не оставить, могут начаться проблемы.
Я зафиксировал первые строки и столбцы, чтобы скрыть лишнюю в данный момент информацию, но все данные по-прежнему присутствуют в этой таблице (как это сделать, смотрите в справке к вашему табличному процессору).
Время и дата находятся в столбце A, цены открытия в столбце B, и так далее. Последняя строка таблицы имеет номер 6038.
Первый шаг к построению стратегии — это построение индикатора. Для того чтобы индикатор можно было настраивать, добавим еще один лист и на нём создадим таблицу переменных. Каждой переменной с помощью строки имени зададим имя собственное, чтобы при написании формул было понятно, откуда что берётся.
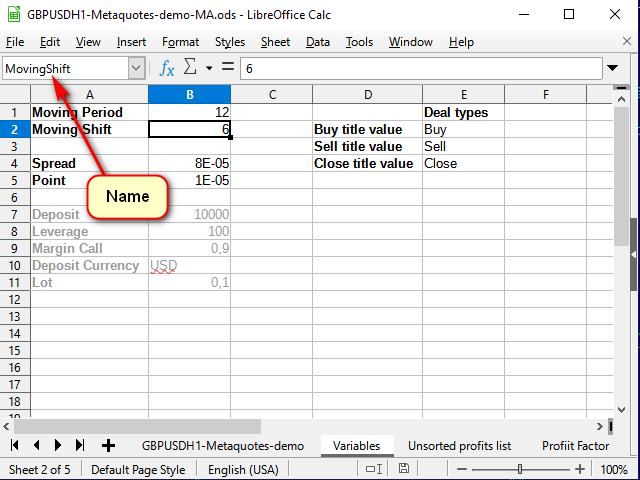
Рисунок 6. Лист переменных
Теперь вернёмся на лист данных. Для небольшого упрощения конечной формулы сначала в столбце G запишем номер котировки в списке. Он равен номеру строки минус 3:
=ROW()-3
Записав эту формулу в ячейке G4, распространим её на все нижние ячейки.
Это нужно для того, чтобы формула вычисления мувинга была универсальной. Если (смещение + период) МА больше, чем у нас есть данных, то вычисление среднего становится бессмысленным.
Сама формула для вычисления скользящей средней (SMA) будет записана в ячейку Н4 листа с основными данными и выглядеть она будет следующим образом:
=IF( G4>(MovingPeriod+MovingShift), AVERAGE( INDIRECT( "E" & ( ROW()-MovingShift-MovingPeriod) & ":" & "E" & ( ROW()-MovingShift) ) ), "" )
При вводе формул, требующих ссылки на другие ячейки, ячейки можно просто указывать мышью.
Текущая формула начинается с вызова функции IF(). Это, как несложно догадаться, функция проверки условия. Кстати, все логические выражения типа And, Or, Not, если они потребуются в дальнейшем, тоже будут функциями.
При вызове функций аргументы указываются в скобках и разделяются запятыми (как в данном случае) или точкой с запятой.
Функция IF принимает три аргумента: условие, значение, если условие истинно, значение, если условие ложно.
В данном случае я использовал её для того, чтобы проверить, хватает ли данных для расчета полноценной точки для кривой МА. Если данных не хватает, то просто сохраняем пустую строку, а иначе считаем среднее значение из некоторого диапазона.
Функция Indirect возвращает значение (или несколько значений) из диапазона, заданного текстовой строкой. Именно это мне и нужно, поскольку адреса нужных диапазонов для подсчета среднего надо формировать, основываясь на значениях входных переменных.
Символ "&" в программах электронных таблиц обозначает конкатенацию, проще говоря, склейку двух строк. Таким образом я "склеил" адрес из нескольких частей. Первая часть — имя столбца, в котором находятся цены закрытия ("Е"), вторая — "дальний" адрес, вычисляемый как номер текущей строки минус длина усреднения и минус сдвиг. Третий кусочек этого выражения — знак двоеточия, указывающий на непрерывность диапазона. И дальше — снова имя столбца и номер строки с учетом сдвига. Я не стал их слишком пёстро раскрашивать, надеюсь, перебивки амперсандами помогут разобраться.
Понятно, что эту формулу надо будет распространить на все нижележащие строки.
В итоге получим примерно такое:
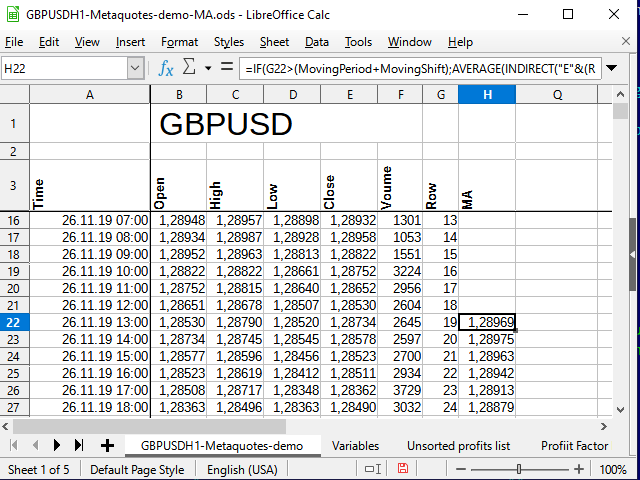
Рисунок 7. Таблица после добавления расчётов по МА.
Видно, что цифры в столбце Н начали появляться только в строке 22 (на 19 записи). Почему так — смотрите рисунок 6.
Итак, имеем исходные данные, имеем данные индикатора. Можем приступать к реализации стратегии.
Реализация стратегии
Стратегию будем реализовывать в виде простых сигналов. Если произошло пересечение МА вниз, в ячейку записываем значение "-1", если вверх — "1". Если в данный момент пересечений нет, в ячейке будет значение пустой строки.
Переходим в ячейку I4. Базовая формула для этой ячейки будет выглядеть следующим образом:
=IF( AND( B4>H4,E4<H4 ),-1 , IF( AND( B4<H4,E4>H4 ), 1 , "") )
Можно проверить на графике, она работает. Но это — формула простого переворота. Она не даёт возможности отслеживать состояние сделки. Можно поэкспериментировать и с ней, и получить интересные результаты, однако наша задач сейчас — реализовать стратегию, описанную в начале этой статьи. Поэтому нам нужно записать состояние сделки на каждом баре (то есть — в каждой строке).
Столбец J для этих целей вполне подойдёт. Формула в ячейке J4 будет такой:
=IF(AND(I4=-1,J3=""), -1 ,IF(AND(I4=1,J3=""), 1 ,IF(OR(AND(I4="",J3=1),AND(I4="",J3=-1),I4=J3), J3 ,"")))
Если произошло какое-то событие (пересечение), то проверяем статус предыдущей сделки. Если сделка открыта, и пересечение в противоположном направлении — закрываем её, если закрыта — открываем. Во всех остальных случаях просто сохраняем статус.
И для того чтобы наглядно видеть, где бы мы покупали и продавали, если бы реализовывали эту стратегию в тот период, которому соответствуют наши данные, а также для того, чтобы удобно было анализировать стратегию, введём еще один столбец — с сигналами.
Названия сигналов можно брать из справочника, который можно создать на листе переменных.
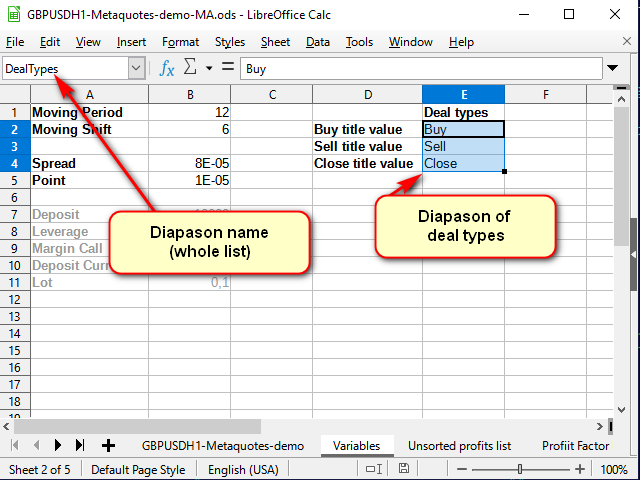
Рисунок 8. Лист "Переменные" после добавления справочника названий сделки
Обратите внимание на строку имени: здесь я задал имя всему выделенному диапазону, а не одной ячейке.
Теперь в ячейке К4 основного листа (с данными) можно записать следующее:
=IF(AND(J3=1,J2=""),INDEX(DealTypes,1),IF(AND(J3=-1,J2=""),INDEX(DealTypes,2),IF(OR(AND(J3="",J2=1),AND(J3="",J2=-1)),INDEX(DealTypes,3),"")))
Сделка открывается после сигнала, на открытии следующей свечи. Поэтому обратите внимание на сдвиг индексов в этой формуле.
Если сделки не было (предыдущая ячейка в колонке состояния — пустая) и пришел сигнал — указываем, какой тип сделки необходимо совершать. Если сделка была открыта, значит, по сигналу её закрываем.
Функция Index в качестве первого параметра принимает диапазон, в котором будет происходить поиск. В нашем случае он задан именем. Второй параметр — номер строки в этом диапазоне. При необходимости — если диапазон состоит из нескольких столбцов — можно указать нужный столбец, а если задано несколько диапазонов через точку с запятой, то и номер диапазона, начиная с 1 (третий и четвёртый параметры соответственно).
В итоге, после распространения этой формулы на все нижележащие ячейки и применения условного форматирования (для красоты, при анализе форматирование не нужно), мы получим примерно следующее:
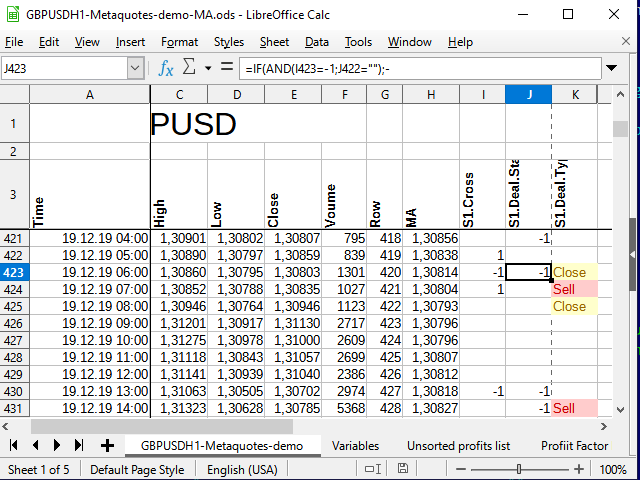
Рисунок 9. Сигналы для сделок.
Анализ стратегии
Для того чтобы проанализировать прибыльность стратегии, мне необходимо вычислить расстояние, пройденное ценой за период сделки. Проще всего это сделать в несколько этапов.
Для начала выберем цену сделки. Если сделка открывается, цену записываем в столбец рядом с сигналом (L) и копируем её в каждую последующую ячейку до тех пор, пока сделка не закроется. Если сделки нет, то в ячейку записывается пустая строка. Формула в ячейке L4:
=IF(K4=INDEX(DealTypes;1);B4+Spread;IF(K4=INDEX(DealTypes;2); B4 ;IF(OR(K4=INDEX(DealTypes;3);N(L3)=0); "" ;L3)))
Если в ячейке сигнала (К4) стоит слово "Buy", цена открытия сделки равна цене открытия свечи плюс спред. Если сигнал слово "Sell" — записываем просто цену открытия свечи, если "Close" (или предыдущая ячейка столбца не содержит число) — пустая строка, а если в предыдущей ячейке этого же столбца — число, и столбец сигнала не содержит никаких слов — просто копируем предыдущую ячейку.
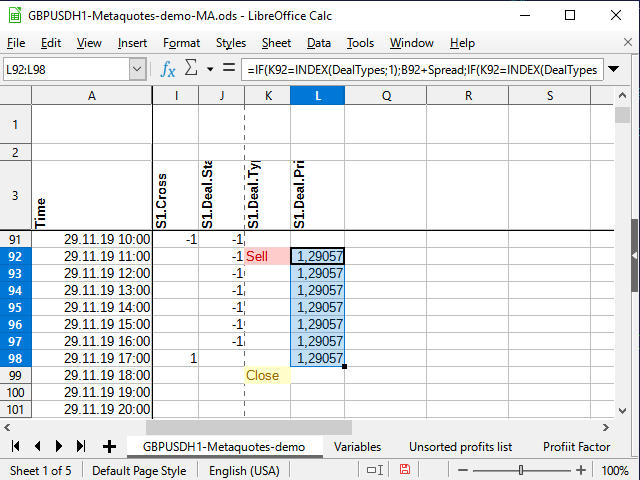
Рисунок 10. Цена открытия сделки
Таким образом мы получим возможность вычислить прибыль сделки в момент закрытия, приложив минимум усилий.
Не забудьте распространить формулу ниже.
В соседней колонке можно было бы сразу вычислять разницу цен открытия и закрытия, но мы поступим хитрее. Мы эту разницу будем вычислять в столбце N, чтобы иметь возможность отфильтровать только уникальные данные и посчитать затем их частотность.
В данном, простейшем случае оценки я не буду использовать никакого способа управления капиталом, поскольку мне интересно в принципе понять работоспособность стратегии. Поэтому разницу цен достаточно вычислять в пипсах. Например, так:
=IF(K4=INDEX(DealTypes;3);IF(I3=-1;ROUND((B4-L3)/Point);ROUND((L3-B4)/Point)); "" )
Понятно, что вместо проверки среднего условия можно было бы просто умножить (B3-L3)*I3 - но, по-моему, это было бы чуть менее наглядно для новичков.
И вот теперь — та самая хитрость. В столбце М пронумеруем все уникальные записи о диапазоне сделки, оставив неуникальные без номеров.
=IF(N4<>"";IF(COUNTIF(N$3:N4;N4)=1;MAX(M3:M$4)+1;"");"")
С внешним условием всё понятно: если в ячейке справа (N4) не пусто, то проверяем на уникальность и нумеруем, если нужно, иначе оставляем пустую строку.
А как же происходит нумерация?
Функция Countif подсчитывает количество чисел в указанном ей диапазоне при условии, что значение ячейки соответствует тому условию, что указано во втором параметре. Допустим, формула вычисляется для ячейки M71, и в ячейке N71 находится число 531 (см. рисунок 11). Раньше это число нигде не встречалось.
Если в ячейке с условием не указан знак действия, то предполагается, что мы хотим проверить равенство двух величин. Число равно самому себе (N71=N71), значит, пробуем подсчитывать. Расчёт всегда идёт, начиная с ячейки N$3 (о чём говорит знак доллара перед тройкой) и до текущей ячейки (знака доллара в формуле нет). Просматриваем весь диапазон N$3:N71 и пытаемся подсчитать общее количество чисел 531 в этом диапазоне. Поскольку раньше таких чисел не встречалось, общее количество равно 1 (только то, что нашли сейчас). Значит, условие выполняется: результат функции равен 1. Поэтому берём следующий диапазон: тот столбец, в котором находится данная формула, начиная от самой первой ячейки с цифрами (M$4) до ячейки, предшествующей текущей (M70). Если там раньше были какие-то числа, берём наибольшее из них и добавляем к ним 1. Если нет — наибольшее будет равно 0, и, соответственно, первый порядковый номер будет готов!
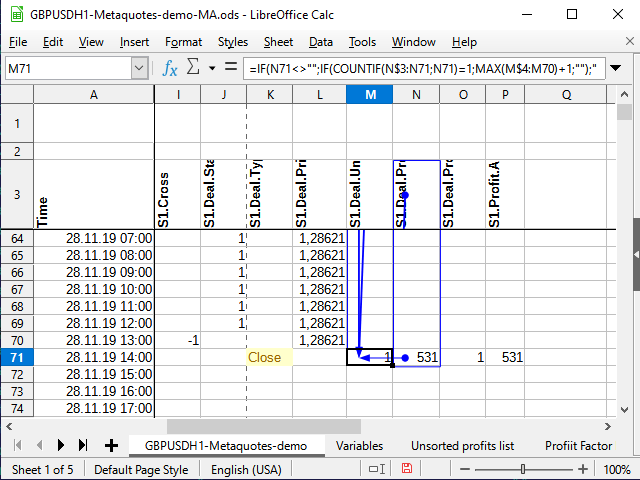
Рисунок 11. Нумерация. Влияющие ячейки (финальная точка диапазона)
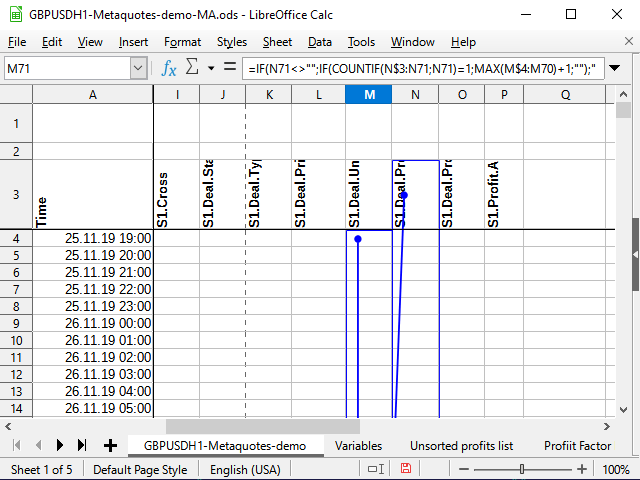
Рисунок 12. Нумерация (начальная точка диапазона)
На рисунке 11 я попытался использовать встроенное средство анализа, которое показывает влияющие на данную ячейки. Точкой со стрелкой показаны начала диапазонов или "точные" ячейки, прямоугольниками — диапазоны. Рисунок 12 прикрепил для наглядности, чтобы было видно, что стрелка непрерывна, и начинается именно на N$3, и чтобы были видны начала диапазонов, в которых происходит сравнение.И ко всему этому добавлю еще два столбца значений: тип результата и "модуль" сделки.
Для типа результата я использую цифры: если сделка была на покупку, то тип будет 1, если на продажу — 2. При этом результат может быть положительным или отрицательным, в зависимости от того, получили ли мы прибыль или убыток в результате сделки. Так будут короче итоговые формулы анализа.
Вот такая формула, записанная в ячейку О4:=IF(AND(N(N4)>0;I3=-1); 1 ;IF(AND(N(N4)<0;I3=-1); -1 ;IF(AND(N(N4)>0;I3=1); 2 ;IF(AND(N(N4)<0;I3=1); -2 ;""))))
"Модуль" — просто величина прибыли или убытка без учета знака, описание того, как далеко ушла цена в одном направлении, пока не пришёл сигнал к закрытию сделки. Это может помочь выбирать стопы и тейки (пусть именно для исходной стратегии они и не нужны).
=IF(N4<>"";ABS(N4);"")
Для построения частотного (вероятностного) графика данные о прибыльности-убыточности сделок лучше упорядочить по возрастанию. Для этого их нужно скопировать на другой лист, поскольку исходные данные упорядочены по времени, и иначе быть упорядочены не могут.
С учетом того, что каждый уникальный результат прибыли имеет свой уникальный номер (столбец М), есть минимум два способа скопировать несортированные данные на новый лист.
Один из них — просто с помощью стандартного фильтра выбрать "непустые" ячейки в столбце М, а затем скопировать данные из столбца N и вставить на другой лист с помощью специальной вставки (только значения).
Второй — с помощью формулы. Преимущество в том, что эти данные сами будут изменяться при изменении исходных данных (тех же переменных, или если вы решите использовать другой интервал тестирования), однако недостаток в том, что сортировать их всё равно, как правило, не получится, и для сортировки всё равно надо будет делать Copy / Paste.
Для меня удобнее, когда сортированные и несортированные данные находятся на одном листе, потому что для копирования данных нужно чуть меньше движений. Поэтому я покажу вариант, при котором несортированные данные копируются формулой, а затем для сортировки копируются еще раз вручную.
На новом листе с названием Profit data создадим формулу в ячейке А2:
=VLOOKUP( ROW(1:1);'GBPUSDH1-Metaquotes-demo'.$M$3:$N$6038; 2 )
Функция Row(1:1) возвращает номер первой строки. При заполнении ячеек вниз номер строки будет меняться, и, соответственно, будет выдаваться номер второй, третьей и т.д. строк.
Vlookup — ищет некоторое значение (первый параметр) в первом столбце диапазона (второй параметр), а затем возвращает значение, которое находится в этой же, найденной, строке, только в столбце, указанном в третьем параметре (в нашем случае — в столбце с номером 2 указанного диапазона). То есть последовательно, начиная с номера 1, из столбца N будут скопированы все пронумерованные (уникальные) числа.
Посмотрев с помощью стандартного фильтра последний номер на основном листе, можно методом ограничения диапазона скопировать все остальные данные.
Дальше — как в анимации на рисунке 13.
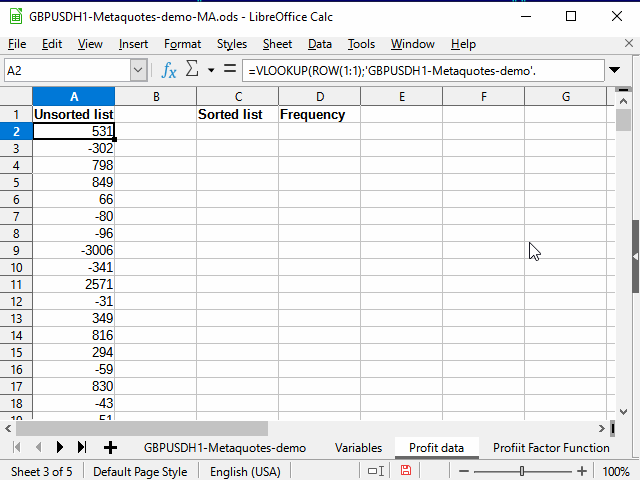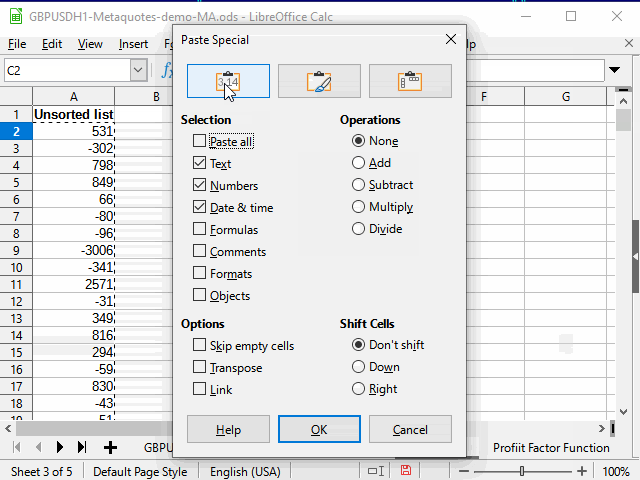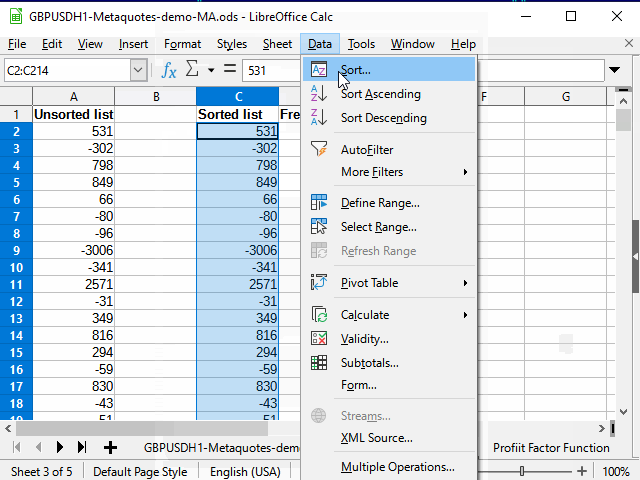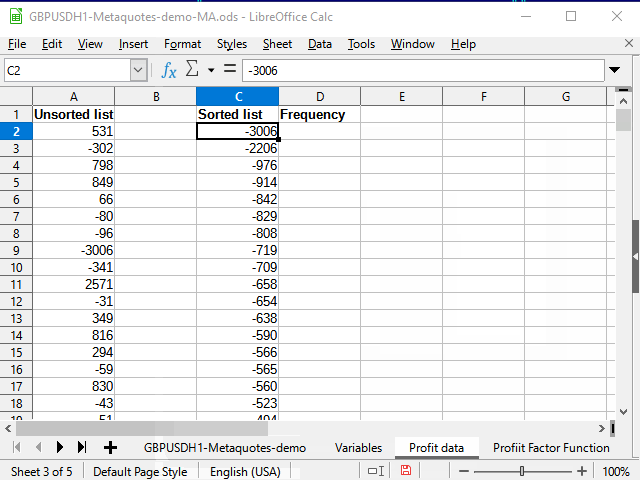
Рисунок 13. Копирование данных для сортировки.
Теперь нужно описать частотность прибыльных и убыточных сделок, то есть построить вероятностный ряд.
В ячейке D2 этого же листа (Profit data) можно записать следующую формулу:
=COUNTIF('GBPUSDH1-Metaquotes-demo'.$N$4:$N$6038;C2)/COUNT('GBPUSDH1-Metaquotes-demo'.$N$4:'GBPUSDH1-Metaquotes-demo'.$N$6038)
Она описывает частотность (или вероятность) встречаемости каждого значения прибыли.
Функция Count подсчитывает количество чисел в интервале, Countif делает то же самое, если выполняется условие (в данном случае — подсчитываются только те ячейки, значение в которых равно значению в ячейке столбца С).
В учебниках рекомендуют делать интервальные вариационные ряды. Теоретически ведь можно сказать, что количество сделок может быть достаточно велико?
Размер интервала учебники предлагают считать по формуле:
=(MAX($'Profit data'.C2:$'Profit data'.C214)-MIN($'Profit data'.C2:$'Profit data'.C214))/(1+3,222*LOG10(COUNT('GBPUSDH1-Metaquotes-demo'.$N$4:'GBPUSDH1-Metaquotes-demo'.$N$6038)))
Я поместил эту формулу в ячейку 'Variables'.E7 и назвал эту величину "Interval". Интервал оказался слишком большим, мне было неясно, как — в основном — распределяются вероятности, поэтому я разделил его еще на 4. Итоговое число — 344 — оказалось более приемлемым для моих целей.
На листе 'Profit data' в ячейку F2 я скопировал первое число из сортированного списка:
=C2
Все остальные ячейки заполнены формулой:
=F2+Interval
Ячейки заполнялись до тех пор, пока последнее значение не превысило максимальное значение размера сделки.
Ячейка G2 содержит следующую формулу:
=COUNTIFS('GBPUSDH1-Metaquotes-demo'.$N$4:$N$6038;">="&F2;'GBPUSDH1-Metaquotes-demo'.$N$4:$N$6038;"<"&F3)/COUNT('GBPUSDH1-Metaquotes-demo'.$N$4:$N$6038)
CountifS в отличие от Countif позволяет принимать несколько условий, объединяя их оператором "И". Остальное всё то же самое.
И когда эти два ряда построены, сразу хочется посмотреть не них графически. Благо, любой табличный процессор это позволяет.
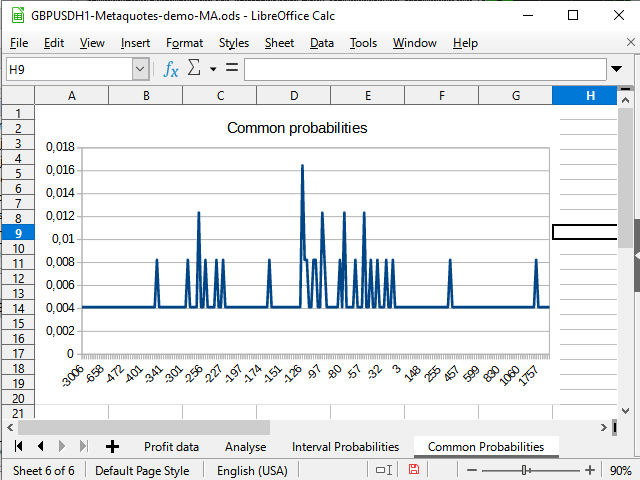
Рисунок 14. График распределения "непосредственных" вероятностей
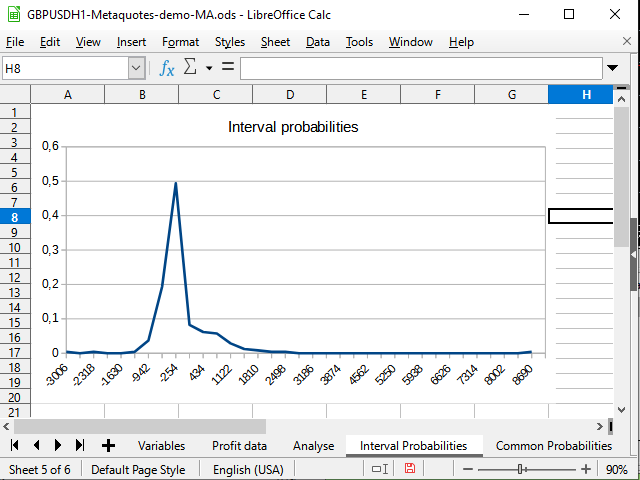
Рисунок 15. График интервальных распределений вероятностей совершённых сделок
На рисунке 14 я вижу смещение плотности вероятностей в отрицательную сторону. На рисунке 15 виден явно выраженный пик от -942 до 2154 и всплеск (1 сделка) на 8944.
Ну и лист анализа (с учётом всего разобранного), думаю, особых сложностей не вызовет.
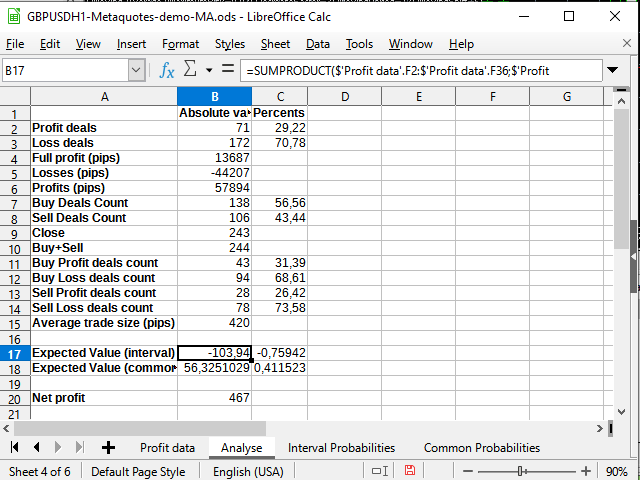
Рисунок 16. Некоторые статистические расчёты
Единственное новое здесь — использование функции Sumproduct, принимающей в качестве параметров два интервала и возвращающая сумму произведений членов этих интервалов (скажем, первая строка на первую строку, вторая — на вторую, и так далее). Именно с помощью этой функции я попытался посчитать матожидание. Со всякими более сложными методами интегрирования решил не связываться.
Видно, что матожидание существенно меньше полученной прибыли, и в процентном отношении колеблется в районе 0.
Таким образом, для себя могу сделать вывод: стратегия рабочая, но может иметь очень большие просадки. Вероятно, отлично может работать в очень сильном тренде (всплеск на ~9000 пипсов, в принципе, выглядел бы интересным, если бы не был таким одиноким), однако флет, скорее всего, возьмёт своё. Стратегия нуждается в серьезной доработке либо за счет отложенных ордеро, например, профитами (примерно на 420-500 пипсов) либо какими-нибудь фильтрами тренда. Доработки требуют дополнительных исследований.
Прогон стратегии в тестере
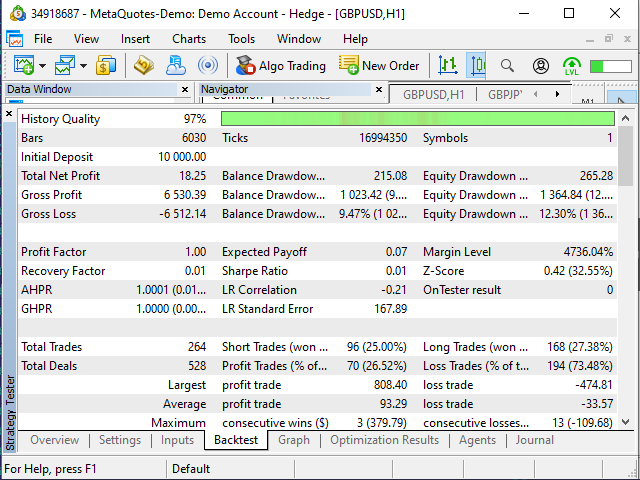
Рисунок 17. Результаты тестирования советника "Examples\Moving Average"
Результаты советника меня, честно говоря, удивили. Ну, то, что он открывал сделки там, где таблица предлагала закрывать и наоборот, в принципе, нормально, наверное. Он мог основываться на большем или меньшем количестве данных (скажем, у меня в таблице 25.11.2019 начинается с 19 часов, а советнику я дал задачу начинать именно с начала дня).
А вот то, что некоторые сделки у него выглядели примерно вот так...
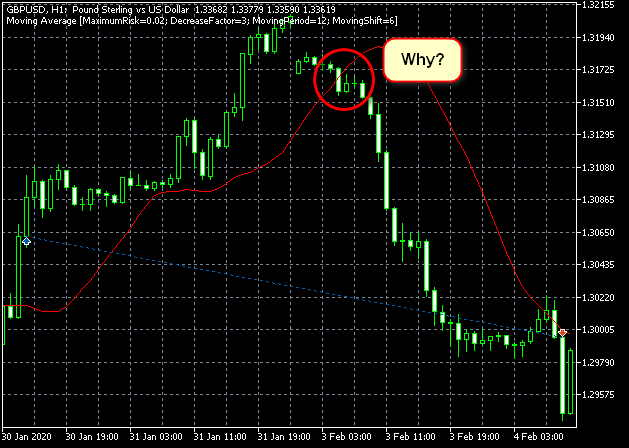
Рисунок 18. Ошибка моего понимания алгоритма? Или тестера?
Вероятнее всего, я просто плохо искал, поэтому не нашёл в алгоритме описания причины такого поведения.
Вторым странным фактом стало то, что советник совершил на 20 сделок больше, чем предполагала моя таблица. Но тем не менее, результаты, как ни парадоксально, близки к моим.
Итак:
| Советник в тестере | Таблица |
|---|---|
| Матожидание выигрыша — +0,07 (почти 0) | Матожидание выигрыша — -0,76 — +0,41 (колеблется вокруг 0) |
| Прибыльные/убыточные трейды — 26,52%/73,48% | Прибыльные/убыточные трейды — 29,22%/70,78% (разницу в 3% в данном случае — с учетом разницы 8% в количестве сделок — могу считать несущественной) |
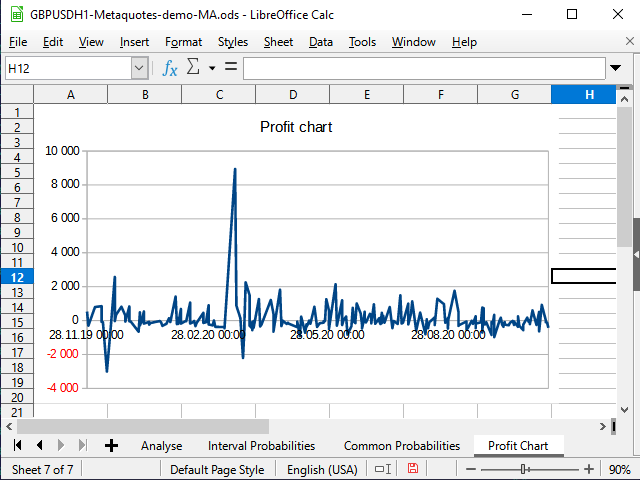
Рисунок 19. График прибыльности в таблице
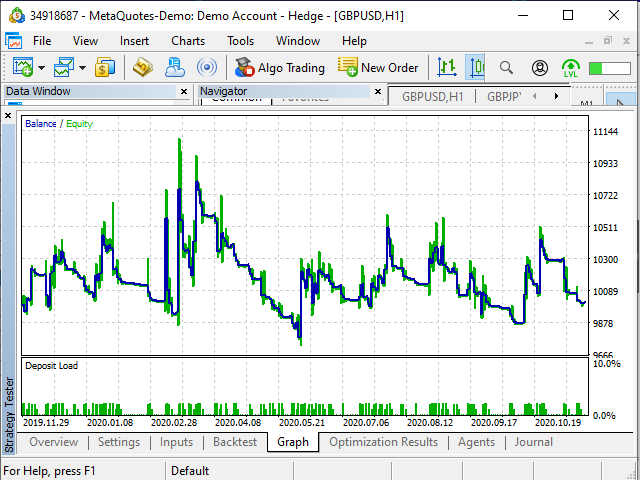
Рисунок 20. Вид графика прибыли в тестере
Время на подготовку таблицы и "игры" с цифрами — около получаса. Время на написание советника... Не писал, взял готового. Чтобы разобраться вчерне с алгоритмом, понадобилось около 10 минут. Однако писать нового советника, чтобы понять, что пользоваться им, скорее всего, не буду... Мне было бы лень. Вот когда я понимаю, что стратегия того стОит — ну, тогда да, можно. И то — для себя — руками пока проще :-)
Заключение
На мой взгляд электронные таблицы являются очень хорошим средством для тестирования и разработки своих стратегий, особенно для тех, кто не умеет или не любит программировать — или хочет быстро создать прототип, чтобы потом перевести его на MQL.
Формулы табличных процессоров, конечно, иногда очень напоминают программный код, и форматирование там... Менее наглядно, скажем так.
Однако наглядность самих таблиц, моментальная проверка новых идей, подсветка влияющих ячеек, возможность строить диаграммы любых видов и т.д. делает таблицы незаменимым помощником.
А если вы ведёте журнал сделок в таблице или можете его импортировать, то с помощью табличных процессоров легко можете улучшать свою стратегию и увидеть, есть ли ошибки в Вашей торговле.
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

 Разработка самоадаптирующегося алгоритма (Часть I): Поиск базовой закономерности
Разработка самоадаптирующегося алгоритма (Часть I): Поиск базовой закономерности
 Брутфорс-подход к поиску закономерностей (Часть II): Погружение
Брутфорс-подход к поиску закономерностей (Часть II): Погружение
 Нейросети — это просто (Часть 8): Механизмы внимания
Нейросети — это просто (Часть 8): Механизмы внимания
 Продвинутый ресемплинг и выбор CatBoost моделей брутфорс методом
Продвинутый ресемплинг и выбор CatBoost моделей брутфорс методом
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Олег Федоров,
Большое спасибо за написание этой статьи. Мне 75+ и у меня есть базовые знания Excel. Но благодаря более чем 35 годам работы в трейдинге я понимаю, что такое наборы данных и как их использовать для проведения вероятностного исследования.
Мы - группа пожилых людей, торгующих на небольших счетах для развлечения и поддержания мозгов. Создание и реализация идей, полученных в результате исследования вероятности, позволяет нам оставаться активными и счастливыми.
Поэтому я приветствую вашу статью. Кудос вам.
1. Подскажите, пожалуйста, инструмент для генерации исторических данных MT5 в формате, который я могу использовать и генерировать данные в соответствии с разработанной электронной таблицей.
В настоящее время, если индикатор имеет кнопку экспорта, я могу генерировать csv-файл, который я сохраняю как лист Excel и делаю анализ.
Мне сказали, что существует индикатор mql для создания csv, который может использовать логику любого другого индикатора и генерировать данные в формате csv в предварительно созданном файле, который может быть изменен для создания новых столбцов электронной таблицы.
Не могли бы вы сообщить, где я могу купить этот индикатор?
2. Я хочу проводить исследования вероятностей, создавая тепловые карты, подобные этой, в Excel. Не могли бы вы научить этому в своей новой статье?
Пример: Я хочу создать такую тепловую карту. После генерации csv-файла с помощью индикатора, как я могу пошагово преобразовать его в Excel, отфильтровать и создать тепловые карты или другие отчеты, как в этом прикрепленном файле?
Еще раз спасибо