
MQL5の電子テーブル

はじめに
通常、電子テーブルとはEXCELのようなテーブルプロセッサ(データを格納、処理するアプリケーション)を意味します。本稿で示されるコードはあまり力強いものではありませんが、テーブルプロセッサのフル装備の実装に対する基本クラスとして使用が可能です。MQL5を用いてMS Excelを作成するつもりはありませんが、二次元配列にて異なるタイプのデータを処理するクラスを実装したいと思います。
また、私が実装するクラスのパフォーマンスはシングルタイプデータ(データ直接アクセスできる)の二次元配列とは比較になりませんが、このクラスは使い勝手がよいように思えます。その上、このクラス C++言語でのバリアントクラス実装であり、あるコラムに再生成されたテーブルの特殊な例として考えることができます。
忍耐強くない方、または実装アルゴリズムの分析をしたくない方のために、使用可能な手法から CTable クラスについて述べていきます。
1. クラスメソッドの記述
まず始めに、使用可能なクラスメソッドに関して目的と基本用法について細かくお話します。
1.1. FirstResize
テーブルレイアウト、コラムタイプの記述、TYPE[] : 行サイズおよびセルタイプを決定するENUM_DATATYPE タイプの配列
void FirstResize(const ENUM_DATATYPE &TYPE[]);
実際には、このメソッドはパラメータを持つ追加のコンストラクタです。これは次の2つの理由により便利です。まず、コンストラクタ内部のパラメータを渡す際の問題を解決します。次に、オブジェクトをパラメータとして渡す機能を持ち、配列に必要な分割を行います。この機能によりクラスを C++言語クラスの異形として使用することができます。
関数セットが第一ディメンション、およびコラムデータタイプを設定するにもかかわらず、パラメータとして第一ディメンションのサイズ指定を要求しないこともこのメソッドの実装については特殊です。このパラメータは渡された配列 TYPEから取得されます。
1.2. SecondResize
行番号を 'j'に変更します。
void SecondResize(int j);
関数は第二ディメンションの配列すべての指定サイズを設定します。よって、それはテーブルに行を追加すると言えます。
1.3. FirstSize
このメソッドは第一ディメンションのサイズ(行の長さ)を返します。
int FirstSize();
1.4. SecondSize
このメソッドは第二ディメンションのサイズ(列の長さ)を返します。
int SecondSize();
1.5. PruningTable
このメソッドは第一ディメンションに新たなサイズを設定します。開始サイズ内で変更は可能です。
void PruningTable(int count);
この関数は行の長さを変えません。ただ行長の値を格納する変数の値を書きなおすだけです。このクラスには割り当てられたメモリの実サイズを格納する別の変数が含まれます。このメモリはテーブルの最初の部分に設定されます。この値の中では、第一ディメンションのサイズをバーチャルで変更することが可能です。あるテーブルを別のテーブルにコピーする際、不要な部分を切り離す機能があります。
1.6. CopyTable
第二ディメンションの全長であるテーブルを別のテーブルにコピーする手法
void CopyTable(CTable *sor);
この関数はあるテーブルを別のテーブルにコピーします。受け取るテーブルの初期化をはじめます。付加的なコンストラクタとして使用可能です。格納のバリアントの内部ストラクチャはコピーされません。サイズ、コラムタイプ、データのみ最初のテーブルからコピーされます。関数は、コピーされた CTable タイプのオブジェクト参照をパラメータとして受け取ります。それは GetPointer 関数によって渡されます。
テーブルを別のテーブルにコピーすることで 'sor' サンプルに従い新しいテーブルが作成されます。
void CopyTable(CTable *sor,int sec_beg,int sec_end);
追加パラメータを伴う上述関数のオーバーライド:sec_beg - 最初のテーブルのコピー開始ポイント、sec_end - コピーの終了ポイント(コピー済みデータ量と混同しないようにしてください。)どちらのパラメータも第二ディメンションを参照します。データは受け取り側テーブルの冒頭に追加されます。受け取りテーブルサイズは sec_end-sec_beg+1として設定されます。
1.7. TypeTable
'i' コラムの値 type_table (ENUM_DATATYPE タイプの)を返します。
ENUM_DATATYPE TypeTable(int i)
1.8. Change
Change() メソッドは列を入れ替えます。
bool Change(int &sor0,int &sor1);
上記のように、このメソッドは列(第一ディメンションと連携して)を入れ替えます。情報が実際には移動しないので、この関数の処理スピードは第二ディメンションのサイズには影響されません。
1.9. Insert
Insert メソッドは指定位置に列を挿入します。
bool Insert(int rec,int sor);
この関数は前出のものと同様ですが、異なる点は指定された列がどこに移動するかに応じて他の列をプルしたり、プッシュしたりすることです。パラメータ 'rec' が列の移動先を指定し、パラメータ 'sor' が列の移動元を指定します。
1.10. Variant/VariantCopy
そして『バリアント』シリーズの3関数です。テーブル処理のバリアント記憶をクラスに実装します。
バリアントはノートを連想させます。たとえば、3番目の列によりソートするが次の処理中データリセットをしたくない場合、バリアントを切り替える必要があります。前回の処理バリアントにアクセスするには、『バリアント』関数を呼びます。次の処理が前回の処理結果に依存する必要があれば、そのバリアントをコピーします。初期設定では、数値 0 のバリアントを設定します。
バリアント設定(そのようなバリアントがない場合、その他不足している全バリアント同様 'ind'まで作成します。) およびアクティブバリアント取得'variantcopy' メソッドがバリアント 'sor' を 'rec' にコピーします。
void variant(int ind); int variant(); void variantcopy(int rec,int sor);
variant(int ind) メソッドは選択したバリアントを切り替えます。自動メモリ割り当てを行います。指定されたパラメータが前回指定されたパラメータより小さければ、メモリは再割り当てされません。
variantcopy メソッドによりバリアント 'sor' を 'rec' にコピーすることができます。関数はバリアントを整理するために作成されます。'rec' バリアントがなければ、このメソッドは自動でバリアント数を増やします。また、新規にコピイーされたバリアントに切り替えます。
1.11. SortTwoDimArray
SortTwoDimArray メソッドは選択された行 'i'によりテーブルをソートします。
void SortTwoDimArray(int i,int beg,int end,bool mode=false);
指定列でテーブルをソートする関数パラメータ: i - 行、 beg - ソート開始ポイント、end - ソート終了ポイント( インクルーシブ)、 mode - ソート方向を判断するブール変数mode=trueの場合、値はインデックスと共に増加することを意味します。( 'false' は初期値です。なぜならインデックスはテーブルの上から下に増えていくからです。)
1.12. QuickSearch
メソッドは『エレメント』パターンに等しい値で配列内エレメント位置を素早く検索します。
int QuickSearch(int i,long element,int beg,int end,bool mode=false);
1.13. SearchFirst
ソートされた配列内パターンに等しい最初のエレメントを検索します。『エレメント』パターンに等しい最初の値のインデックスを返します。この範囲で前に行われたソートタイプを指定する必要があります。(そのようなエレメントがない場合は、1 を返します。)
int SearchFirst(int i,long element,int beg,int end,bool mode=false);
1.14. SearchLast
ソートされた配列内パターンに等しい最後のエレメントを検索します。
int SearchLast(int i,long element,int beg,int end,bool mode=false);
1.15. SearchGreat
ソートされた配列内のパターンより大きい、一番近いエレメントを検索します。
int SearchGreat(int i,long element,int beg,int end,bool mode=false);
1.16. SearchLess
ソートされた配列内のパターンより小さい、一番近いエレメントを検索します。
int SearchLess(int i,long element,int beg,int end,bool mode=false);
1.17. Set/Get
Set および Get 関数はボイドタイプです。テーブルが連携する4タイプのデータによりオーバーライドされます。関数はデータタイプを認識し、それから 'value' パラメータが列タイプに一致しなければ、割当てる代わりに警告が印刷されます。唯一の例外はストリングタイプです。入力パラメータがストリングタイプであれば、それはコラムタイプにキャストされます。この例外はセル値を受け付ける変数設定が不可能な場合、情報発信に都合がよいように作成されています。
値設定メソッド(i - 第一ディメンションのインデックス、 j - 第二ディメンションのインデックス)
void Set(int i,int j,long value); // setting value of the i-th row and j-th column void Set(int i,int j,double value); // setting value of the i-th row and j-th columns void Set(int i,int j,datetime value);// setting value of the i-th row and j-tj column void Set(int i,int j,string value); // setting value of the i-th row and j-th column
値取得のメソッド(i - 第一ディメンションのインデックス、 j - 第二ディメンションのインデックス)
//--- getting value void Get(int i,int j,long &recipient); // getting value of the i-th row and j-th column void Get(int i,int j,double &recipient); // getting value of the i-th row and j-th column void Get(int i,int j,datetime &recipient); // getting value of the i-th row and j-th column void Get(int i,int j,string &recipient); // getting value of the i-th row and j-th column
1.19. sGet
'j' 列および 'i' 行からstring タイプの値を取得します。
string sGet(int i,int j); // return value of the i-th row and j-th column
パラメータ系変数の代わりに 'return' オペレータによって値を返すGet シリーズ唯一の関数コラムタイプに関わらずstring タイプの値を返します。
1.20. StringDigits
タイプが 'string'にキャストされる場合、関数による精度設定が可能です。
void StringDigits(int i,int digits);
'double'の精度設定、および
int StringDigits(int i);
'datetime'で秒表示の精度設定のためには、1以外のあらゆる値が渡されます。指定値が列に記憶されます。よって情報表示のたびに指示する必要はありません。情報は元のタイプで格納され、出力中のみ指定の精度に変換されるため、精度は何度も設定可能です。精度値はコピーの際記憶されません。よって、テーブルを新しいテーブルにコピーするときには、新規テーブルのコラム精度は初期設定精度と一致しています。
1.21. 用例
#include <Table.mqh> ENUM_DATATYPE TYPE[7]= {TYPE_LONG,TYPE_LONG,TYPE_STRING,TYPE_DATETIME,TYPE_STRING,TYPE_STRING,TYPE_DOUBLE}; // 0 1 2 3 4 5 6 //7 void OnStart() { CTable table,table1; table.FirstResize(TYPE); // dividing table, determining column types table.SecondResize(5); // change the number of rows table.Set(6,0,"321.012324568"); // assigning data to the 6-th column, 0 row table.Insert(2,6); // insert 6-th column in the 2-nd position table.PruningTable(3); // cut the table to 3 columns table.StringDigits(2,5); // set precision of 5 digits after the decimal point Print("table ",table.sGet(2,0)); // print the cell located in the 2-nd column, 0 row table1.CopyTable(GetPointer(table)); // copy the entire table 'table' to the 'table1' table table1.StringDigits(2,8); // set 8-digit precision Print("table1 ",table1.sGet(2,0)); // print the cell located in the 2-nd column, 0 row of the 'table1' table. }
処理結果はセル(2;0)内容の印刷です。おそらくご存じのとおり、コピーされたデータの精度は初期テーブルの精度を超えることはありません。
2011.02.09 14:18:37 Table Script (EURUSD,H1) table1 321.01232000 2011.02.09 14:18:37 Table Script (EURUSD,H1) table 321.01232
それでは、そのアルゴリズム記述に進みましょう。
2. モデル選択
情報作成方法は2とおりあります。連結している列(本稿で実装しています)のスキームと連結した行形式のその代用を以下に示します。
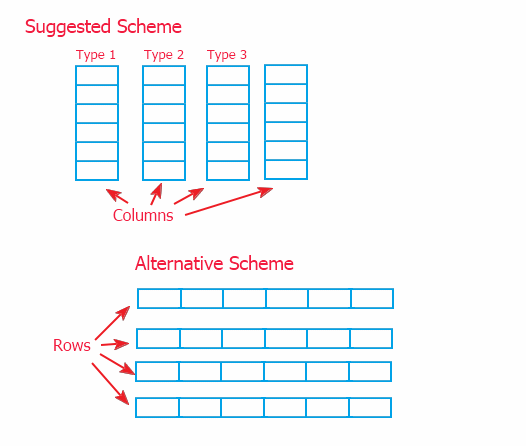
仲介者(p.2に記載)を通して情報を参照するため、アッパースコープの実装と大差はありません。ただ、ロースコープのデータ実装手法が可能なため、データを格納するオブジェクト内でコラムモデルを選択しました。また、代用スキームはアッパークラスCTable内情報と連携するためにメソッドのオーバーライドを要求します。必要な場合、これでクラス強化を面倒にする可能性があります。
そのときは、それぞれのスキームが使用可能です。提案のスキームにより、データ移動が速くでき、もうひとつのスキームでは、データ追加(一行ずつテーブルへの行追加がより頻繁に行われるため)と行取得が速くなります。
テーブルを整理する別の方法もあります。それはstructures配列です。実装は最も簡単なのですが、大きなデメリットがあります。ストラクチャはプログラマーの手で書かれなければならないことです。そのため、カスタムパラメータ(ソースコードに手を加えずに)によってテーブルの特性設定ができなくなります。
3. 動的配列でのデータとりまとめ
単一の動的配列内で異なるタイプのデータを取りまとめる機能を持つには、配列セルに異なるタイプを割り当てる問題を解決する必要があります。この問題は 標準ライブラリの連結リストですでに解決されています。私の最初の開発はクラス標準ライブラリを基にしたものでした。が、プロジェクト開発途中で、基本クラスCObjectには多くの点を変更する必要があることが判りました。
それで独自のクラスを作成することにしたのです。標準ライブラリを学んでいない方のために前述の問題をどのように解決したかご説明します。問題解決には 継承のメカニズム使用の必要があります。
class CBase { public: CBase(){Print(__FUNCTION__);}; ~CBase(){Print(__FUNCTION__);}; virtual void set(int sor){}; virtual void set(double sor){}; virtual int get(int k){return(0);}; virtual double get(double k){return(0);}; }; //+------------------------------------------------------------------+ class CA: public CBase { private: int temp; public: CA(){Print(__FUNCTION__);}; ~CA(){Print(__FUNCTION__);}; void set(int sor){temp=sor;}; int get(int k){return(temp);}; }; //+------------------------------------------------------------------+ class CB: public CBase { private: double temp; public: CB(){Print(__FUNCTION__);}; ~CB(){Print(__FUNCTION__);}; void set(double sor){temp=sor;}; double get(double k){return(temp);}; }; //+------------------------------------------------------------------+ void OnStart() { CBase *a; CBase *b; a=new CA(); b=new CB(); a.set(15); b.set(13.3); Print("a=",a.get(0)," b=",b.get(0.)); delete a; delete b; }
継承のメカニズムは櫛のように見えます。

クラスの動的オブジェクト作成が宣言されると、基本クラスのコンストラクタが呼ばれます。まさにこのプロパティが二弾下院でオブジェクト作成を可能にするのです。基本クラスのバーチャル関数がオーバーライドされるため、派生クラスからの異なるタイプのパラメータを伴う関数を呼ぶ可能性ができます。
ではなぜ単純なオーバーライドは十分でないのでしょうか?問題は、実行された関数は巨大で、そのため基本クラス(継承メカニズムを使用せず)にその本文を記述すれば、本文のコード全体を持つ使用されない関数がバイナリコードの中の各オブジェクトに対して作成されてしまいます。そして、継承メカニズムの使用により、コードをフルに書いた関数に比べメモリ容量の消費が少なくてすむ空の関数が作成されます。
4. 配列を使った処理
標準クラスの使用を拒ませる第二の、そして主要な基盤はデータ参照です。私はセルインデックスにより参照する代わりにインデックスの仲介配列を使って配列セルを間接的に参照しています。変数によって直接参照するよりも動作スピードは遅くなります。問題は、配列セルよりもインデックス動作を速くおこなうよう指示する変数にあります。それはまずメモリ内で見つける必要があります。
単次元配列と多次元配列をソートする基本的相違は何であるか分析します。ソート前、単次元配列のエレメントは無作為な位置にあり、ソート後エレメントは整列されます。二次元配列をソートするとき、全配列をソートする必要はなく、ソートを行う列のみでよいのです。すべての行はストラクチャは保ったまま位置を変更する必要があります。
行自体、ここでは異なるタイプのデータを含むです。そのような問題対処には、選択された配列でデータをソートし、初期インデックスのストラクチャを保存する必要があります。このようにしてどの行がセルを含むかわかれば、全行を表示することが可能です。よって、二次元配列をソートするとき、データストラクチャを変更することなく、ソートされた配列のインデックス配列を取得する必要があります。
例:
before sorting by the 2-nd column 4 2 3 1 5 3 3 3 6 after sorting 1 5 3 3 3 6 4 2 3 Initial array looks as following: a[0][0]= 4; a[0][1]= 2; a[0][2]= 3; a[1][0]= 1; a[1][1]= 5; a[1][2]= 3; a[2][0]= 3; a[2][1]= 3; a[2][2]= 6; And the array of indexes of sorting by the 2-nd column looks as: r[0]=1; r[1]=2; r[2]=0; Sorted values are returned according to the following scheme: a[r[0]][0]-> 1; a[r[0]][1]-> 5; a[r[0]][2]-> 3; a[r[1]][0]-> 3; a[r[1]][1]-> 3; a[r[1]][2]-> 6; a[r[2]][0]-> 4; a[r[2]][1]-> 2; a[r[2]][2]-> 3;
このようにシンボル、オープンポジション日、収益等で情報をソートすることも可能です。
ソートアルゴリズムの多くはすでに作成されています。この作成の最良のバリアントは 安定ソートのアルゴリズムではないでしょうか。
標準クラスで使用されるQuick Sorting アルゴリズムは不安定ソートアルゴリズムを参照します。よって、これは従来の実装においてここではふさわしくありません。クイックソートを安定形式(そしてこれは追加のデータコピーとインデックス配列のソートです)にもっていった後でも、そのクイックソートはバブルソート(安定ソートアルゴリズムで最も速いもののひとつ)よりも速く見えます。このアルゴリズムはたいへん速いですが反復を使用しています。
ストリングタイプ配列(より多くのスタックメモリを要求します。)と連携するときCocktail sortを使用するのはこの理由によります。
5. 二次元配列の整列
お話したい最後の問題は動的二次元配列の整列です。そのような整列には、単次元配列に対するクラスとしてラッピングをし、ポインター配列を使ってオブジェクト配列を呼べば十分です。すなわち、配列の配列を作成するわけです。
class CarrayInt { public: ~CarrayInt(){}; int array[]; }; //+------------------------------------------------------------------+ class CTwoarrayInt { public: ~CTwoarrayInt(){}; CarrayInt array[]; }; //+------------------------------------------------------------------+ void OnStart() { CTwoarrayInt two; two.array[0].array[0]; }
6. プログラムのストラクチャ
CTable クラスのコード『С++ 言語テンプレートの代用としての疑似テンプレート使用』 稿で述べているテンプレートを使用しました。テンプレートを使ったがために、そんなに長いコードをたいへん速く書くことができました。そのため、コード全体を詳細に述べることはしません。それ以上に、アルゴリズムのほとんどのコード部分は標準クラスの改良です。
クラスの一般的ストラクチャと重要点をいくつか明確にする関数の興味深い機能についていくつか見ていきます。

図の右側はほとんどが派生クラス、CLONGArray、CDOUBLEArray、 CDATETIMEArray、 CSTRINGArrayに配置されたオーバーライドされたメソッドです。それぞれ(プライベートセクション)には対応するタイプの配列が含まれています。まさにその配列は情報アクセスの全処理に使用されています。前述のクラスのメソッド名はパブリックメソッドと同一です。
基本クラスCBASEArrayはバーチャルメソッドのオーバーライドで書かれ、CTableクラスのプライベートセクションのCBASEArrayオブジェクトの動的配列を宣言するためにだけ必要とされます。ポインターの配列CBASEArrayは動的オブジェクトの動的配列として宣言されます。最後のオブジェクトコンストラクションと必要なインスタンスの選択はFirstResize()関数で行われます。それはまたCopyTable() 関数でも行うことが可能です。なぜならそれは本文内で FirstResize() を呼ぶためです。
CTableクラスもまたデータ処理メソッド(CTableクラスのインスタンスにセットされます)、およびCint2Dクラスのインデックスコントロールオブジェクトの調整を行います。調整は全体にオーバーライドされたパブリックメソッド内でラップされます。
CTable クラス内で繰り返されるオーバーライドする部分がひじょうに長い行を書かないような定義と置き換えられることがよくあります。
#define _CHECK0_ Print(__FUNCTION__+"("+(string)i+","+(string)j+")");return; #define _CHECK_ Print(__FUNCTION__+"("+(string)i+")");return(-1); #define _FIRST_ first_data[aic[i]] #define _PARAM0_ array_index.Ind(j),value #define _PARAM1_ array_index.Ind(j),recipient #define _PARAM2_ element,beg,end,array_index,mode
よって以下はよりコンパクトな形式です。
int QuickSearch(int i,long element,int beg,int end,bool mode=false){if(!check_type(i,TYPE_LONG)){_CHECK_}return(_FIRST_.QuickSearch(_PARAM2_));};
が preprocessorによって以下の行と置き換えられます。
int QuickSearch(int i,long element,int beg,int end,bool mode=false){if(!check_type(i,TYPE_LONG)){Print(__FUNCTION__+"("+(string)i+")");return(-1);} return(first_data[aic[i]].QuickSearch(element,beg,end,array_index,mode));};
上記の例では、データ処理メソッドがどのように呼ばれるか(内部で『返す』とある箇所)明白です。
CTable クラスは処理中データの物理的移動はしないということはすでにお伝えしました。インデックスのオブジェクト値を変えるだけです。データメソッドがインデックスオブジェクトと連携できるようにするためには、array_index パラメータとして処理を行う全関数に渡します。
array_index オブジェクトは第二ディメンションのエレメントの位置関係を格納します。第一ディメンションのインデクセーションは動的配列 aic[] に影響を与えます。それは CTable クラスのプライベートゾーンで宣言されます。それにより列の位置変更が可能となります。(もちろん物理的にではなく、インデックスを介してです。)
たとえば、Change() 処理中、列のインデックスを含むメモリセル2個だけ位置を変えます。視覚的には2列移動したように見えます。CTable クラスの関数についてはドキュメンテーションでよく記述されています。(ある箇所では一行ずつ)
CBASEArrayから派生するクラスの関数に話を進めます。実際、こういったクラスのアルゴリズムは標準クラスのアルゴリズムから取られているものです。そのことがわかるように標準名を付けました。値が直接返される標準アルゴリズムから区別するために、インデックス配列を使い間接的に値を返すよう改良しました。
まず第一に、改良はクイックソートに対して行いました。アルゴリズムが不安定ソートのカテゴリーからなので、ソートを開始する前にアルゴリズムに渡されるデータのコピーが必要です。また、データ変更パターンに応じてインデックスのオブジェクトの同期的変更も加えました。
void CLONGArray::QuickSort(long &m_data[],Cint2D &index,int beg,int end,bool mode=0)
ソートコードの一部を以下に記載します。
... if(i<=j) { t=m_data[i]; it=index.Ind(i); m_data[i++]=m_data[j]; index.Ind(i-1,index.Ind(j)); m_data[j]=t; index.Ind(j,it); if(j==0) break; else j--; } ...
元のアルゴリズムにはCint2Dクラスのインスタンスは存在しません。その他標準アルゴリズムにも同様の変更を加えました。全コードのテンプレートには触れません。コードを改善したい方は、テンプレートを実タイプと置き換えることで実コードからテンプレートを作成することが可能です。
テンプレートを書くには、私は ロング タイプと連携するクラスのコードを使いました。そのような経済的アルゴリズムでは、開発者はintが使用可能なら不要な整数使用は避けようとします。それがロングタイプの変数がおそらく最もオーバーライドされるパラメータである理由です。テンプレート使用時には、それらを 'templat' を使って置き換えます。
おわりに
本稿がオブジェクト指向 手法を学ぶ際、初心者プログラマーにとって役立つものとなり、より簡単に情報の作業ができるようになることを願っています。CTable クラスは多くの複雑なアプリケーションの基本クラスとなるものです。本稿で述べられているメソッドには、データ処理の一般的手法が取り入れられているため、ソリューションの巨大クラスを作成する基本となることでしょう。
その上、本稿ではMQL5を酷使するというのはいわれのないことだと証明しました。バリアントタイプをご要望ですか?MQL5を使用して実装されたものがあります。そのため、標準を変更し言語の安全性を損なう必要はないのです。ご成功を祈っています!
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/228
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

 MQL5 ウィザード:リスクおよび資金管理モジュール作成方法
MQL5 ウィザード:リスクおよび資金管理モジュール作成方法
 MQL5ウィザード:トレーディングシグナル用モジュール作成方法
MQL5ウィザード:トレーディングシグナル用モジュール作成方法
 価格変動の速度と傾向に基づくトレードアイディア
価格変動の速度と傾向に基づくトレードアイディア
 なぜ2014年8月1日までに、MetaTrader 4を最新のビルドにアップデートする必要があるのでしょうか?
なぜ2014年8月1日までに、MetaTrader 4を最新のビルドにアップデートする必要があるのでしょうか?
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
ニコライ、質問があります。
MT5からExcelにこのような形式で表を書くことは可能でしょうか?
私は、色でハイライトされている2つのマクロ列名(「絶対データ」と「相対データ」)に興味があります。それぞれ3つのセルを組み合わせています。
エクセルのセルをフォーマットするという点で、私はMQL5に多くを求めているのかもしれません。しかし、もしそうだとしたら:-))
3つのセルを結合する」という言葉に物理的な意味を込めるのですか?
原理的には可能ですが、上の2行がないと、データ型は 列ごとに要約されるので、1列に文字列とdoubleを詰め込むことはできません。あるいは、テーブルとは別にフォーマットされた大文字の文字列を含むようにクラスを改良することもできる。
最も簡単な方法は、2つのテーブルを作成し、それらをマージすることです。
3つの細胞を組み合わせる」という言葉に、どのような物理的な意味を込めますか?
これが今あるものだ:
すでに持ってきてほしいもの......。
新しい記事「MQL5の電子テーブル」が掲載されました:
著者Николай