
Tableaux Électroniques en MQL5

Introduction
D’habitude, les tableaux électroniques font référence à des processeurs de tableau (applications qui stockent et traitent des données), tels que EXCEL. Bien que le code présenté dans l'article ne soit pas si puissant, il peut être utilisé comme classe de base pour une implémentation complète d'un processeur de tableau. Je n'ai pas pour objectif de créer MS Excel à l'aide de MQL5, mais je souhaite implémenter une classe pour fonctionner avec des données de différents types dans un tableau à deux dimensions.
Et bien que la classe implémentée par moi ne puisse pas être comparée par ses performances à un tableau bidimensionnel de données de type unique (avec accès direct aux données), la classe semblait être pratique à utiliser. De plus, cette classe peut être considérée comme une implémentation de la classe Variant en C++, comme un cas particulier d'un tableau dégénérée en une colonne.
Pour les impatients et pour ceux qui ne souhaitent pas analyser l'algorithme d'implémentation, je vais commencer par décrire la classe CTable à partir des méthodes disponibles.
1. Description des Méthodes de Classe
Dans un premier temps, examinons les méthodes disponibles de la classe avec une description plus détaillée de leurs objectif et principes d'utilisation.
1.1. FirstResize
Disposition du tableau, description des types de colonnes, TYPE[] - tableau du type ENUM_DATATYPE qui détermine la taille des lignes et les types de cellules.
void FirstResize(const ENUM_DATATYPE &TYPE[]);
En pratique, cette méthode est un constructeur supplémentaire qui dispose d’un un paramètre. C'est pratique pour deux raisons : d'abord, cela résout le problème du passage d'un paramètre à l'intérieur du constructeur ; deuxièmement, il offre la possibilité de passer un objet en paramètre, puis d'effectuer la division nécessaire du tableau. Cette fonctionnalité permet d'utiliser la classe comme classe Variant en C++.
Les spécificités de l'implémentation comportent le fait que malgré que la fonction définit la première dimension et le type de données des colonnes, elle ne nécessite pas d’indiquer une taille de la première dimension comme paramètre. Ce paramètre est tiré de la taille du tableau transmis TYPE.
1.2. SecondResize
Modifie le nombre de lignes par « j ».
void SecondResize(int j);
La fonction définit une taille indiquée pour tous les tableaux de la deuxième dimension. Ainsi, on peut dire qu'elle ajoute des lignes à un tableau.
1.3. FirstSize
La méthode renvoie la taille de la première dimension (longueur de ligne).
int FirstSize();
1.4. SecondSize
La méthode renvoie la taille de la deuxième dimension (longueur de la colonne).
int SecondSize();1.5. PruningTable
Il définit une nouvelle taille pour la première dimension ; la modification est possible dans la taille de départ.
void PruningTable(int count);
En pratique, la fonction ne modifie pas la longueur de la ligne ; il ne réécrit que la valeur d'une variable, qui est en charge du stockage de la valeur de la longueur de ligne. La classe comporte une autre variable qui stocke la taille réelle de la mémoire attribuée, qui est définie lors de la division initiale d'un tableau A l'intérieur des valeurs de cette variable, la modification virtuelle de taille de la première dimension est possible. La fonction est destinée à couper une partie indésirable lors de la copie d'un tableau à un autre.
1.6. CopyTable
La méthode de copie d'un tableau à un autre sur toute la longueur de la deuxième dimension :
void CopyTable(CTable *sor);La fonction copie un tableau dans un autre. Il lance l'initialisation du tableau récepteur Il peut être utilisé comme constructeur supplémentaire. La structure interne des variantes de tri n'est pas copiée. Seuls la taille, les types de colonnes et les données sont copiés depuis le tableau initial. La fonction admet la référence de l'objet copié de type CTable en paramètre, qui est transmis par la fonctionGetPointer
Copie d'un tableau à un autre, un nouveau tableau est créée en fonction de l’échantillon 'sor'.
void CopyTable(CTable *sor,int sec_beg,int sec_end);
Dépassement de la fonction décrite ci-dessus avec les paramètres supplémentaires : sec_beg - point de départ de la copie du tableau initial, sec_end - point de fin de la copie (veuillez ne pas confondre avec la quantité de données copiées). Les deux paramètres se réfèrent à la deuxième dimension. Les données seront ajoutées au début du tableau des destinataires. La taille du tableau récepteur est définie sur sec_end-sec_beg+1.
1.7. TypeTable
Renvoie la valeur de type_table value (du type ENUM_DATATYPE de la colonne 'i' .
ENUM_DATATYPE TypeTable(int i)
1.8. Modifier
La méthode Change() effectue l'échange de colonnes.
bool Change(int &sor0,int &sor1);
Comme mentionné ci-dessus, la méthode permute les colonnes (fonctionne avec la première dimension). Étant donné que les informations ne sont pas réellement déplacées, la vitesse d’opération de la fonction n'est pas affectée par la taille de la deuxième dimension.
1.9. Insérer
La méthode Insert insère une colonne à une position indiquée.
bool Insert(int rec,int sor);
La fonction est la même que celle décrite ci-dessus, sauf qu'elle permet de tirer ou de pousser d'autres colonnes selon l'endroit où la colonne indiquée doit être déplacée. Le paramètre 'rec' indique où la colonne sera déplacée, 'sor' indique d'où elle sera déplacée.
1.10. Variant/VariantCopy
Viennent ensuite trois fonctions de la série 'variante'. La mémorisation des variantes du traitement des tableaux est implémentée dans la classe.
Les variantes rappellent un bloc-notes Par exemple, si vous effectuez un tri par la troisième colonne et que vous ne souhaitez pas réinitialiser les données lors du prochain traitement, vous devez changer de variante. Pour accéder à la variante précédente du traitement, appelez la fonction 'variant'. Si le prochain traitement doit être basé sur le résultat du précédent, vous devez copier les variantes. Par défaut, une variante avec le numéro 0 est configurée.
Définition d'une variante (s'il n'y a pas une telle variante, elle sera créée ainsi que toutes les variantes manquantes jusqu'à 'ind') et obtention de la variante active. La méthode 'variantcopy' copie la variante 'sor' dans la variante 'rec'.
void variant(int ind); int variant(); void variantcopy(int rec,int sor);
La méthode variant(int ind) permute la variante sélectionnée. Effectue l'attribution automatique de la mémoire. Si le paramètre indiqué est inférieur à celui indiqué précédemment, la mémoire n'est pas réattribuée
La méthode variantcopy permet de copier la variante 'sor' dans la variante 'rec'. La fonction est créée pour organiser les variantes. EIle augmente automatiquement le nombre de variantes si la variante 'rec' n'existe pas ; il passe également à la variante nouvellement copiée.
1.11. SortTwoDimArray
La méthode SortTwoDimArray trie un tableau par la ligne sélectionnée 'i'.
void SortTwoDimArray(int i,int beg,int end,bool mode=false);
La fonction de tri d'un tableau par une colonne indiquée. Paramètre : i - colonne, beg - point de départ du tri, fin - point de fin du tri (inclus), mode - variable booléenne qui détermine le sens du tri. Si mode=true, cela indique que les valeurs augmentent avec les index ('false' est la valeur par défaut, car les index augmentent de haut en bas du tableau).
1.12. QuickSearch
La méthode effectue une recherche rapide de la position d'un élément dans le tableau par la valeur égale au motif 'élément'.
int QuickSearch(int i,long element,int beg,int end,bool mode=false);
1.13. SearchFirst
Recherche le premier élément qui est égal à un motif dans un tableau trié. Renvoie l'index de la première valeur qui est égale au motif 'élément'. Il est nécessaire de l’indiquer le type de tri effectué précédemment à cette plage (s'il n'y a pas un tel élément, il renvoie -1).
int SearchFirst(int i,long element,int beg,int end,bool mode=false);
1.14. SearchLast
Recherche le dernier élément égal à un motif dans un tableau trié.
int SearchLast(int i,long element,int beg,int end,bool mode=false);
1.15. SearchGreat
Recherche l'élément le plus proche supérieur à un modèle dans un tableau trié.
int SearchGreat(int i,long element,int beg,int end,bool mode=false);
1.16. SearchLess
Recherche l'élément le plus proche inférieur à un modèle dans un tableau trié.
int SearchLess(int i,long element,int beg,int end,bool mode=false);
1.17. Définir/Obtenir
Les fonctions Set et Get ont le type void ; elles sont dépassées par quatre types de données avec lesquelles le tableau fonctionne. Les fonctions reconnaissent le type de données, puis si le paramètre 'valeur' ne correspond pas au type de colonne, un avertissement est imprimé au lieu d'assigner. La seule exception est le type de chaîne. Si le paramètre d'entrée est de type chaîne, il sera converti en type de colonne. Cette exception est faite pour une transmission plus pratique des informations lorsqu'il n'y a aucune possibilité de définir une variable qui accepterait la valeur de la cellule.
Les méthodes de réglage des valeurs (i - indice de la première dimension, j - indice de la deuxième dimension).
void Set(int i,int j,long value); // setting value of the i-th row and j-th column void Set(int i,int j,double value); // setting value of the i-th row and j-th columns void Set(int i,int j,datetime value);// setting value of the i-th row and j-tj column void Set(int i,int j,string value); // setting value of the i-th row and j-th column
Méthodes d'obtention des valeurs (i - indice de la première dimension, j- indice de la deuxième dimension).
//--- getting value void Get(int i,int j,long &recipient); // getting value of the i-th row and j-th column void Get(int i,int j,double &recipient); // getting value of the i-th row and j-th column void Get(int i,int j,datetime &recipient); // getting value of the i-th row and j-th column void Get(int i,int j,string &recipient); // getting value of the i-th row and j-th column
1.19. sGet
Obtient une valeur de typestring à partir de la colonne 'j' et de la ligne 'i'.
string sGet(int i,int j); // return value of the i-th row and j-th column
La seule fonction de la série Get qui renvoie la valeur via l'opérateur 'retour' au lieu d'une variable paramétrique. Renvoie une valeur du typestring quel que soit le type de colonne.
1.20. StringDigits
Lorsque les types sont convertis en 'string', vous pouvez utiliser une précision définie par les fonctions :
void StringDigits(int i,int digits);
pour définir la précision de 'double' et
int StringDigits(int i);
définir une précision d'affichage des secondes dans 'datetime'; toute valeur qui n'est pas égale à -1 est transmise. La valeur indiquée est mémorisée pour la colonne, vous n'avez donc pas besoin de l'indiquer à chaque fois lors de l'affichage des informations. Vous pouvez définir une précision plusieurs fois, car les informations sont stockées dans les types d'origine et ne sont transformées à la précision indiquée que lors de la sortie. Les valeurs de précision ne sont pas mémorisées à la copie, ainsi, lors de la copie d'un tableau dans un nouveau tableau la précision des colonnes du nouveau tableau correspondra à la précision par défaut.
1.21. Un exemple d'utilisation :
#include <Table.mqh> ENUM_DATATYPE TYPE[7]= {TYPE_LONG,TYPE_LONG,TYPE_STRING,TYPE_DATETIME,TYPE_STRING,TYPE_STRING,TYPE_DOUBLE}; // 0 1 2 3 4 5 6 //7 void OnStart() { CTable table,table1; table.FirstResize(TYPE); // dividing table, determining column types table.SecondResize(5); // change the number of rows table.Set(6,0,"321.012324568"); // assigning data to the 6-th column, 0 row table.Insert(2,6); // insert 6-th column in the 2-nd position table.PruningTable(3); // cut the table to 3 columns table.StringDigits(2,5); // set precision of 5 digits after the decimal point Print("table ",table.sGet(2,0)); // print the cell located in the 2-nd column, 0 row table1.CopyTable(GetPointer(table)); // copy the entire table 'table' to the 'table1' table table1.StringDigits(2,8); // set 8-digit precision Print("table1 ",table1.sGet(2,0)); // print the cell located in the 2-nd column, 0 row of the 'table1' table. }
Le résultat de l'opération est l'impression du contenu de la cellule (2; 0). Comme vous l'avez probablement remarqué, la précision des données copiées ne dépasse pas la précision du tableau initial.
2011.02.09 14:18:37 Table Script (EURUSD,H1) table1 321.01232000 2011.02.09 14:18:37 Table Script (EURUSD,H1) table 321.01232
Passons maintenant à la description de l'algorithme lui-même.
2. Choisir un modèle
Il existe deux modes d'organisation de l'information : le schéma des colonnes connectées (implémenté dans cet article) et son alternative sous forme de lignes connectées sont présentés ci-dessous.
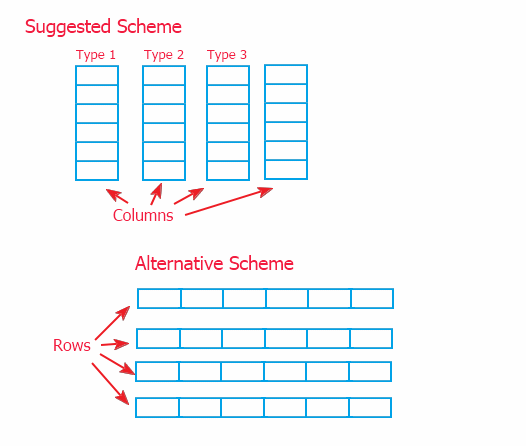
Du fait de la référence à l'information par un intermédiaire (décrit en p. 2), il n'y a pas de grande différence d’implémentation du périmètre supérieur. Mais j'ai choisi le modèle des colonnes, car il permet d'implémenter une méthode de données sur la faible portée, dans les objets qui stockent les données. Et le schéma alternatif nécessiterait de remplacer les méthodes de travail avec les informations de la classe supérieure CTable. Et cela peut compromettre l'amélioration de la classe, au cas où cela serait nécessaire.
À cela, chacun des schémas peut être utilisé. Le schéma suggéré permet un déplacement rapide des données, et l'autre permet un ajout de données plus rapide (car les informations sont plus souvent ajoutées à un tableau ligne par ligne) et l'obtention de lignes.
Il existe également une autre façon d'organiser un tableau - comme un tableau destructures Et bien que ce soit le plus simple à implémenter, il présente un inconvénient majeur.. La structure doit être décrite par un programmeur. Ainsi, nous perdons une possibilité de définir les attributs du tableau via des paramètres personnalisés (sans modifier le code source).
3. Unir des données dans un tableau dynamique
Pour avoir la possibilité d'unir différents types de données dans un seul tableau dynamique, nous devons résoudre le problème de l'attribution de différents types aux cellules du tableau. Ce problème est déjà résolu dans les listes connectées de la Bibliothèque standard . Mes premiers développements étaient basés sur la bibliothèque standard de classes. Mais lors de l’élaboration du projet, il est apparu que je devais apporter de nombreuses modifications à la classe de baseCObject.
C'est pourquoi j'ai décidé d’élaborer ma propre classe. Pour ceux qui n'ont pas étudié la bibliothèque standard, je vais expliquer comment le problème décrit ci-dessus est résolu. Pour résoudre le problème, vous devez utiliser le mécanisme d'héritage.
class CBase { public: CBase(){Print(__FUNCTION__);}; ~CBase(){Print(__FUNCTION__);}; virtual void set(int sor){}; virtual void set(double sor){}; virtual int get(int k){return(0);}; virtual double get(double k){return(0);}; }; //+------------------------------------------------------------------+ class CA: public CBase { private: int temp; public: CA(){Print(__FUNCTION__);}; ~CA(){Print(__FUNCTION__);}; void set(int sor){temp=sor;}; int get(int k){return(temp);}; }; //+------------------------------------------------------------------+ class CB: public CBase { private: double temp; public: CB(){Print(__FUNCTION__);}; ~CB(){Print(__FUNCTION__);}; void set(double sor){temp=sor;}; double get(double k){return(temp);}; }; //+------------------------------------------------------------------+ void OnStart() { CBase *a; CBase *b; a=new CA(); b=new CB(); a.set(15); b.set(13.3); Print("a=",a.get(0)," b=",b.get(0.)); delete a; delete b; }
Visuellement, le mécanisme de l'hérédité peut être représenté sous la forme d'un peigne :

Si la création d'un objet dynamique de la classe est déclarée, cela indique que le constructeur de la classe de base sera appelé. Cette propriété précise permet de créer un objet en deux étapes. Comme lesfonctions virtuelles de la classe de base sont surchargées, nous avons la possibilité d'appeler la fonction avec différents types de paramètres des classes dérivées.
Pourquoi le simpledépassementest insuffisant ? Le problème est que les fonctions exécutées sont énormes, donc si nous décrivions leurs corps dans la classe de base (sans utiliser l'héritage), alors une fonction inutilisée avec le code complet du corps serait créée pour chaque objet dans le code binaire. Et lors de l'utilisation du mécanisme d'héritage, des fonctions vides, qui occupent beaucoup moins de mémoire que les fonctions remplies de code, sont créées.
4. Opérations sur les Tableaux
La deuxième et principale pierre angulaire, qui m'a poussé à refuser l’utilisation des classes standard, est la référence aux données. J'utilise la référence indirecte aux cellules du tableau via un tableau intermédiaire d'index au lieu de faire référence aux index des cellules. Elle stipule une vitesse opérationnelle plus faible que lors de l'utilisation d'une référence directe via une variable. Le problème est la variable qui indique qu'un index fonctionne plus rapidement qu'une cellule de tableau, qui doit d'abord être trouvée dans la mémoire.
Analysons quelle est la différence fondamentale entre le tri d'un tableau unidimensionnel et multidimensionnel. Avant le tri, un tableau unidimensionnel dispose de positions aléatoires d'éléments, et après le tri, les éléments sont arrangés. Lors du tri d'un tableau à deux dimensions, nous n'avons pas besoin de trier tout le tableau, mais seulement une de ses colonnes par laquelle le tri est effectué. Toutes les lignes doivent modifier de position en gardant leur structure.
Les lignes elles-mêmes ici sont les structures liées qui comportent des données de différents types. Pour résoudre ce problème, nous devons à la fois trier les données dans un tableau sélectionné et enregistrer la structure des index initiaux. De cette façon, si nous savons quelle ligne contenait la cellule, nous pouvons afficher la ligne entière. Ainsi, lors du tri d'un tableau à deux dimensions, nous devons obtenir le tableau d'index du tableau trié sans modifier la structure des données.
Par exemple :
before sorting by the 2-nd column 4 2 3 1 5 3 3 3 6 after sorting 1 5 3 3 3 6 4 2 3 Initial array looks as following: a[0][0]= 4; a[0][1]= 2; a[0][2]= 3; a[1][0]= 1; a[1][1]= 5; a[1][2]= 3; a[2][0]= 3; a[2][1]= 3; a[2][2]= 6; And the array of indexes of sorting by the 2-nd column looks as: r[0]=1; r[1]=2; r[2]=0; Sorted values are returned according to the following scheme: a[r[0]][0]-> 1; a[r[0]][1]-> 5; a[r[0]][2]-> 3; a[r[1]][0]-> 3; a[r[1]][1]-> 3; a[r[1]][2]-> 6; a[r[2]][0]-> 4; a[r[2]][1]-> 2; a[r[2]][2]-> 3;
Ainsi, nous avons la possibilité de trier les informations par symbole, date d'ouverture de position, bénéfice, etc.
De nombreux algorithmes de tri sont déjà élaborés. La meilleure variante pour ce développement sera l'algorithme de tri stable.
L'algorithme Quick Sorting, qui est utilisé dans les classes standards, fait référence aux algorithmes de tri instable. C'est pourquoi il ne nous convient pas dans son implémentation classique. Mais même après avoir apporté le tri rapide à une forme stable (et il s'agit d'une copie supplémentaire de données et d'un tri de tableaux d'index), le tri rapide semble être plus rapide que le tri à bulles (l'un des algorithmes les plus rapides de tri stable). L'algorithme est très rapide, mais il utilise la récursivité.
C'est la raison pour laquelle j'utiliseTri Cocktail lors de travail avec les tableaux de string (cela nécessite beaucoup plus de mémoire de pile).
5. Disposition d'un Tableau Bidimensionnel
Et la dernière question que je souhaite aborder est l'arrangement d'un tableau dynamique à deux dimensions. Pour un tel arrangement, il suffit de créer une enveloppe en tant que classe pour un tableau unidimensionnel et d'appeler le tableau d'objets via le tableau de pointeurs. En d'autres termes, nous devons créer un tableau des tableaux.
class CarrayInt { public: ~CarrayInt(){}; int array[]; }; //+------------------------------------------------------------------+ class CTwoarrayInt { public: ~CTwoarrayInt(){}; CarrayInt array[]; }; //+------------------------------------------------------------------+ void OnStart() { CTwoarrayInt two; two.array[0].array[0]; }
6. Structure du Programme
Le code de la classe CTable a été écrit à l'aide des modèles décrits dans l'articleUsing Pseudo-Templates as Alternative of С++ Templates. Simplement à cause de l'utilisation de modèles, j'ai pu écrire un code aussi volumineux si rapidement. C'est pourquoi je ne vais pas décrire l'intégralité du code en détail ; de plus, la majeure partie du code des algorithmes est une modification desclasses standard .
Je vais simplement montrer la structure générale de la classe et certaines de ses fonctionnalités intéressantes de fonctions qui clarifient plusieurs points importants.

La partie droite du schéma fonctionnel est principalement occupée par les méthodes surchargées situées dans les classes dérivées CLONGArray, CDOUBLEArray, CDATETIMEArray et CSTRINGArray. Chacun d'eux (dans la section privée) comporte un tableau du type correspondant. Ces tableaux exacts sont utilisés pour toutes les astuces d'accès à l'information. Les noms des méthodes des classes listées ci-dessus sont les mêmes que celles des méthodes publiques.
La classe de base CBASEArray est remplie avec le dépassement des méthodes virtuelles et n'est nécessaire que pour la déclaration du tableau dynamique d'objets CBASEArray dans la section privée de la classe CTable. Le tableau de pointeurs CBASEArray est déclaré comme un tableau dynamique d'objets dynamiques. La construction finale des objets et le choix de l'instance nécessaire sont effectués dans la fonction FirstResize(). Cela peut également être fait dans la fonction CopyTable(), car elle appelle FirstResize() dans son corps.
La classe CTable assure également la coordination des méthodes de traitement des données (situées dans les instances de la classe CTable) et l'objet de contrôler les index de la classe Cint2D. L'ensemble de la coordination est enveloppé dans les méthodes publiques dépassées.
Les parties fréquemment répétées du dépassement dans la classe CTable sont remplacées par des définitions pour éviter de produire des lignes très longues :
#define _CHECK0_ Print(__FUNCTION__+"("+(string)i+","+(string)j+")");return; #define _CHECK_ Print(__FUNCTION__+"("+(string)i+")");return(-1); #define _FIRST_ first_data[aic[i]] #define _PARAM0_ array_index.Ind(j),value #define _PARAM1_ array_index.Ind(j),recipient #define _PARAM2_ element,beg,end,array_index,mode
Ainsi, la partie d'une forme plus compacte :
int QuickSearch(int i,long element,int beg,int end,bool mode=false){if(!check_type(i,TYPE_LONG)){_CHECK_}return(_FIRST_.QuickSearch(_PARAM2_));};
sera remplacé par la ligne suivante par lepréprocesseur:
int QuickSearch(int i,long element,int beg,int end,bool mode=false){if(!check_type(i,TYPE_LONG)){Print(__FUNCTION__+"("+(string)i+")");return(-1);} return(first_data[aic[i]].QuickSearch(element,beg,end,array_index,mode));};
Dans l'exemple ci-dessus, il est clair comment les méthodes de traitement des données sont appelées (la partie à l'intérieur de 'retour').
J'ai déjà mentionné que la classe CTable n'effectue pas le déplacement physique des données pendant le traitement ; cela modifie simplement la valeur dans l'objet des index. Pour donner aux méthodes de traitement de données une possibilité d'interagir avec l'objet d'index, il est transmis à toutes les fonctions de traitement en tant que paramètre array_index.
L'objet array_index stocke le rapport positionnel des éléments de la deuxième dimension. L'indexation de la première dimension est de la responsabilité du tableau dynamique aic[] qui est déclaré dans la zone privée de la classe CTable. Elle offre la possibilité de modifier la position des colonnes (bien sûr, pas physiquement, mais via des index).
Par exemple, lors de l'exécution de l'opération Change(), seules deux cellules mémoire, qui comportent les index des colonnes, changent de place. Bien que visuellement, cela ressemble à un déplacement de deux colonnes. Les fonctions de la classe CTable sont assez bien décrites dans la documentation (quelque part même ligne par ligne).
Passons maintenant aux fonctions des classes héritées de CBASEArray. En fait, les algorithmes de ces classes sont les algorithmes tirés des classes standards. J'ai pris les noms standards pour me faire une idée à leur sujet. La modification consiste en un retour indirect de valeurs à l'aide d'un tableau d'index distinct des algorithmes standards où les valeurs sont directement retournées.
Tout d'abord, la modification a été apportée au tri rapide. Étant donné que l'algorithme appartient à la catégorie des instables, avant de commencer le tri, nous devons faire une copie des données, qui seront transmises à l'algorithme. J'ai également ajouté la modification synchrone de l'objet des index conformément au modèle de modification des données.
void CLONGArray::QuickSort(long &m_data[],Cint2D &index,int beg,int end,bool mode=0)
Voici la partie du tri de code :
... if(i<=j) { t=m_data[i]; it=index.Ind(i); m_data[i++]=m_data[j]; index.Ind(i-1,index.Ind(j)); m_data[j]=t; index.Ind(j,it); if(j==0) break; else j--; } ...
Il n'y a pas d'instance de la classe Cint2D dans l'algorithme d'origine. Des modifications similaires sont apportées aux autres algorithmes standard. Je ne vais pas décrire les modèles de tous les codes. Si quelqu'un souhaite améliorer le code, il peut créer un modèle à partir du code réel en remplaçant les types réels par le modèle.
Pour écrire des modèles, j'ai utilisé les codes de la classe qui fonctionne avec le typelong . Dans de tels algorithmes économiques, les développeurs tentent d'éviter l'utilisation inutile d'entiers s'il est possible d'utiliserint. C'est pourquoi une variable de type long est très probablement un paramètre dépassé. EIles doivent être remplacées par 'templat' lors de l'utilisation des modèles.
Conclusion
J'espère que cet article sera d’une précieuse aide pour les programmeurs débutants lors de l'étude de l'approcheorientée-objet et simplifiera le travail avec l'information. La classe CTable peut devenir une classe de base pour de nombreuses applications complexes. Les méthodes décrites dans l'article peuvent devenir la base d’élaboration d'une vaste classe de solutions, car elles implémentent une approche générale du travail avec les données.
En plus de cela, l'article prouve que l'abus de MQL5 est sans fondement. Vous vouliez le type Variant ? Ici, il est implémenté au moyen de MQL5. À cela, il n'est pas nécessaire de modifier les normes et d'affaiblir la sécurité du langage. Bonne chance!
Traduit du russe par MetaQuotes Ltd.
Article original : https://www.mql5.com/ru/articles/228
Avertissement: Tous les droits sur ces documents sont réservés par MetaQuotes Ltd. La copie ou la réimpression de ces documents, en tout ou en partie, est interdite.
Cet article a été rédigé par un utilisateur du site et reflète ses opinions personnelles. MetaQuotes Ltd n'est pas responsable de l'exactitude des informations présentées, ni des conséquences découlant de l'utilisation des solutions, stratégies ou recommandations décrites.

 Assistant MQL5 : Comment Créer un Module de Gestion des Risques et de fonds
Assistant MQL5 : Comment Créer un Module de Gestion des Risques et de fonds
 Assistant MQL5 : Comment Créer un Module de Signaux de Trading
Assistant MQL5 : Comment Créer un Module de Signaux de Trading
 Assistant MQL5 : Comment Créer un Module de Suivi des Positions Ouvertes
Assistant MQL5 : Comment Créer un Module de Suivi des Positions Ouvertes
 Approche Économétrique de l'Analyse des Graphiques
Approche Économétrique de l'Analyse des Graphiques
- Applications de trading gratuites
- Plus de 8 000 signaux à copier
- Actualités économiques pour explorer les marchés financiers
Vous acceptez la politique du site Web et les conditions d'utilisation
Nikolay, j'ai une question.
Est-il possible d'écrire un tableau du MT5 vers Excel sous cette forme ?
Je suis intéressé par ces 2 noms de colonnes macro ("Données absolues" et "Données relatives"), qui sont surlignés en couleur. Elles combinent 3 cellules chacune.
J'attends peut-être beaucoup de MQL5 en termes de formatage des cellules Excel. Et si :-)))
Quelle signification physique donnez-vous aux mots "combiner 3 cellules" ?
En principe, vous pouvez mais sans les 2 lignes supérieures, les types de données sont résumés par colonnes, de sorte que dans une colonne, l'entassement d'une chaîne et d'un double ne fonctionnera pas, mais cela peut être fait lors de l'impression. Il est également possible d'affiner la classe de manière à ce qu'elle contienne des chaînes de caractères majuscules formatées séparément du tableau.
Le plus simple est de créer deux tableaux et de les fusionner.
Quelle signification physique donnez-vous aux mots "combiner 3 cellules" ?
C'est ce que nous avons aujourd'hui :
Ce que j'aimerais avoir déjà apporté ....
Un nouvel article Tables électroniques dans MQL5 est publié :
Auteur : Николай