
Elektronische Tabellen in MQL5

Einleitung
Elektronische Tabellen beziehen sich meist auf Tabellen-Verarbeiter (also Anwendungen zur Speicherung und Verarbeitung von Daten), wie z.B. EXCEL. Der in diesem Beitrag gezeigte Code ist zwar nicht so leistungsfähig, doch kann er als eine Basisklasse für eine voll-funktionsfähige Implementierung eines Tabelle-Verarbeiters verwendet werden. Ich habe nicht vor, mit Hilfe MQL5 MS Excel zu erzeugen, sondern ich möchte eine Klasse für die Arbeit mit Daten unterschiedlicher Arten in einem zweidimensionalen Array implementieren.
Und obwohl meine Implementierung der Klasse in Bezug auf seine Leistung nicht mit einem zweidimensionalen Array von single-Typ Daten verglichen werden kann (mit direktem Datenzugriff), hat sich diese Klasse dennoch als nützlich und bequem in ihrer Verwendung erwiesen. Darüber hinaus kann man diese Klasse als eine Implementierung der Variantenklasse in C++ betrachten, als einen Spezialfall einer Tabelle, die auf nur eine Spalte "degeneriert" wurde.
Für die Ungeduldigen unter den Lesern und für alle, die den Implementierungsalgorithmus nicht analysieren wollen, beginne ich mit der Beschreibung der CTabellen-Klasse von der zur Verfügung stehenden Methoden.
1. Beschreibung der Klassenmethoden
Betrachten wir uns zunächst die zur Verfügung stehenden Methoden der Klasse und beschreiben ihren Zweck und Verwendungsprinzip eingehender.
1.1 FirstResize
Layout der Tabelle, Beschreibung der Spaltenarten, TYPE[] - Array des Typs ENUM_DATATYPE, das die Reihengröße und Art der Zellen beschreibt.
void FirstResize(const ENUM_DATATYPE &TYPE[]);
Diese Methode ist praktisch ein zusätzlicher Constructor mit einem Parameter. Das ist aus zwei Gründen bequem: Zunächst wird so das Problem der Übertragung eines Parameters innerhalb des Constructors gelöst und zweitens, hat man die Möglichkeit, ein Objekt als einen Parameter zu übertragen und dann die notwendige Aufteilung des Arrays auszuführen. Das Feature erlaubt es uns, die Klasse als die Variantenklasse in C++ zu verwenden.
Die Eigenarten der Implementierung umfassen auch die Tatsache, dass die Funktion, trotzdem sie die erste Dimension und die Art der Daten der Spalten einrichtet, keine Festlegung der Größe der ersten Dimension als den Parameter verlangt. Dieser Parameter wird aus der Größe des übertragenen Arrays TYPE genommen.
1.2 SecondResize
Ändert die Anzahl der Reihen in 'j'.
void SecondResize(int j);
Die Funktion richtet eine festgelegte Größe für alle Arrays der zweiten Dimension ein. Sie fügt einer Tabelle quasi Reihen hinzu.
1.3 FirstSize
Die Methode liefert die Größe der ersten Dimension (Länge der Reihen).
int FirstSize();
1.4 SecondSize
Die Methode liefert die Größe der zweiten Dimension (Länge der Spalten).
int SecondSize();
1.5 PruningTable (Tabelle zuschneiden)
Sie errichtet eine neue Größe für die erste Dimension; diese Veränderung ist innerhalb der Startgröße möglich.
void PruningTable(int count);
Diese Funktion verändert die Länge der Reihen praktisch nicht, sondern schreibt nur den Wert einer Variable neu, die verantwortlich ist für die Speicherung des Werts der Reihenlänge. Die Kasse enthält eine weitere Variable, die die aktuelle Größe des zugewiesenen Memory speichert, das bei der ursprünglichen Teilung der Tabelle eingerichtet wurde. Innerhalb der Werte dieser Variable ist die virtuelle Veränderung der Größe der ersten Dimension möglich. Diese Funktion soll beim Kopieren einer Tabelle in eine andere jeden unerwünschten Bereich abschneiden.
1.6 CopyTable (Tabelle kopieren)
Das Kopieren einer Tabelle in eine andere auf der kompletten Länge der zweiten Dimension:
void CopyTable(CTable *sor);
Die Funktion kopiert eine Tabelle in eine andere und startet die Initialisierung der Empfänger-Tabelle, die als zusätzlicher Constructor verwendet werden kann. Die interne Struktur der Varianten der Sortierung wird nicht kopiert, sondern nur Größe, Arten der Spalten und Daten aus der ursprünglichen Tabelle. Die Funktion akzeptiert den Verweis des kopierten Objekts des Typs CTabelle als einen Parameter, der dann von der GetPointer Funktion übertragen wird.
Die Kopie einer Tabelle in eine andere erzeugt eine neue Tabelle in Übereinstimmung mit dem 'sor' Muster.
void CopyTable(CTable *sor,int sec_beg,int sec_end);
Man kann die oben beschriebene Funktion mit den zusätzlichen Parametern: sec_beg - Startpunkt des Kopierens der ursprünglichen Tabelle, sec_end - Endpunkt des Kopierens (bitte nicht mit der Menge der kopierten Daten verwechseln) aufheben. Beide Parameter beziehen sich auf die zweite Dimension. Daten werden am Anfang der Empfänger-Tabelle hinzugefügt und die Größe der Empfänger-Tabelle wird als sec_end-sec_beg+1 festgelegt.
1.7 TypeTable
Liefert den type_table Wert (des Typs ENUM_DATATYPE ) der 'i' Spalte.
ENUM_DATATYPE TypeTable(int i)
1.8 Change (Änderung)
Die Change() Methode übernimmt den Tausch der Spalten.
bool Change(int &sor0,int &sor1);
Wie oben bereits erwähnt, tauscht diese Methode Spalten (arbeitet mit der ersten Dimension). Das die Information nicht wirklich verschoben wird, wirkt sich die Größe der zweiten Dimension nicht auf die Arbeitsgeschwindigkeit der Funktion aus.
1.9 Insert (Einfügen)
Die Insert Methode fügt eine Spalte an einer festgelegten Stelle ein.
bool Insert(int rec,int sor);
Die Funktion ist die gleiche wie die oben beschriebene, zieht oder schiebt jedoch andere Spalten entsprechend, wohin die angegebene Spalte verschoben werden sollen. Der Parameter 'rec' gibt an, wohin die Spalte verschoben werden soll; 'sor' gibt an, von wo sie verschoben werden soll.
1.10 Variant/VariantCopy
Danach folgen drei Funktionen der Reihe 'Variante'. Das "Merken" der Varianten der Tabellenbearbeitung wird in der Klasse implementiert.
Die Varianten erinnern an ein Notizbuch. Wenn Sie beispielsweise nach der dritten Spalte sortieren und Sie während der nächsten Bearbeitung keine Daten mehr zurücksetzen wollen, dann sollten Sie die Variante wechseln. Und durch Aufrufen der Funktion 'Variante' können Sie auf die vorherige Bearbeitungsvariante zugreifen. Sollte die nächste Bearbeitung auf dem Ergebnis der vorherigen beruhen, dann empfiehlt es sich, die Varianten zu kopieren. Standardmäßig ist eine Variante mit der Ziffer 0 eingerichtet.
Einrichten einer Variante (sollte es keine solche Variante geben, wird sie sowie alle bis zu 'ind' fehlenden Varianten erzeugt) und Erhalt der aktiven Variante. Die 'variantcopy' Methode kopiert die 'sor' Variante in die 'rec' Variante.
void variant(int ind); int variant(); void variantcopy(int rec,int sor);
Die variant(int ind) Methode wechselt die ausgewählte Variante und führt einen automatische Zuweisung des Memory aus. Ist der festgelegte Parameter geringer als der zuvor festgelegte, wird das Memory nicht erneut zugewiesen.
Die variantcopy Methode erlaubt das Kopieren der 'sor' Variante in die 'rec' Variante. Diese Funktion ist zur Anordnung der Varianten erzeugt worden und erhöht die Anzahl der Varianten automatisch, wenn die 'rec' Variante nicht existiert und wechselt sie auch zur neu kopierten Variante.
1.11 SortTwoDimArray
Die SortTwoDimArray Methode sortiert eine Tabelle nach der gewählten Reihe 'i' und
void SortTwoDimArray(int i,int beg,int end,bool mode=false);
übernimmt die Funktion der Tabellensortierung nach einer festgelegten Spalte. Parameter: i - Spalte, beg - Startpunkt der Sortierung, end - Endpunkt der Sortierung (inklusive), Modus - boolesche Variable, die die Sortierrichtung festlegt. Bei Modus='true' nehmen die Werte zusammen mit den Indices zu ('false' ist die Standardeinstellung, da die Indices in der Tabelle von oben nach unten zunehmen).
1.12 QuickSearch
Die Methode führt nach dem Wert, der dem 'Element'muster gleicht, eine Schnellsuche des Standorts eines Elements im Array aus.
int QuickSearch(int i,long element,int beg,int end,bool mode=false);
1.13 SearchFirst
Sucht nach dem ersten Element, das einem Muster in einem sortierten Array gleicht. Liefert den Index des ersten Werts, der dem 'Element'muster gleicht. Hierbei muss die Art der zuvor in diesem Bereich ausgeführten Sortierung festgelegt werden (sollte kein derartiges Element vorhanden sein, wird -1 geliefert.
int SearchFirst(int i,long element,int beg,int end,bool mode=false);
1.14 SearchLast
Sucht nach dem letzten Element, das einem Muster in einem sortierten Array gleicht.
int SearchLast(int i,long element,int beg,int end,bool mode=false);
1.15 SearchGreat
Sucht nach dem nächstliegendsten Element, das größer ist, als ein Muster in einem sortierten Array.
int SearchGreat(int i,long element,int beg,int end,bool mode=false);
1.16 SearchLess
Sucht nach dem nächstliegendsten Element, das kleiner ist, als ein Muster in einem sortierten Array.
int SearchLess(int i,long element,int beg,int end,bool mode=false);
1.17 Set/Get
Die Set und Get Funktionen sind vom Typ 'nichtig' und werden von den vier Datenarten mit denen die Tabelle arbeitet, aufgehoben. Die Funktionen erkennen die Datenarten und drucken eine Warnung, sollte der 'Wert'parameter nicht zum Spaltentyp passen, anstatt zuzuweisen. Einzige Ausnahme ist der String-Typ. Ist der Eingabeparameter vom Typ String, wird er zum Spaltentyp umgeformt. Diese Ausnahme dient der bequemeren Übertragung von Informationen, wenn es nicht möglich ist, eine Variable einzurichten, die den Wert der Zelle akzeptieren würde.
Die Methoden zum Einrichten der Werte (i - Index der ersten Dimension, j - Index der zweiten Dimension).
void Set(int i,int j,long value); // setting value of the i-th row and j-th column void Set(int i,int j,double value); // setting value of the i-th row and j-th columns void Set(int i,int j,datetime value);// setting value of the i-th row and j-tj column void Set(int i,int j,string value); // setting value of the i-th row and j-th column
Methoden zum Abfragen der Werten (i - Index der ersten Dimension, j - Index der zweiten Dimension).
//--- getting value void Get(int i,int j,long &recipient); // getting value of the i-th row and j-th column void Get(int i,int j,double &recipient); // getting value of the i-th row and j-th column void Get(int i,int j,datetime &recipient); // getting value of the i-th row and j-th column void Get(int i,int j,string &recipient); // getting value of the i-th row and j-th column
1.19 sGet
Holt sich den Wert eines String-Typs aus der 'j' Spalte und 'i' Reihe.
string sGet(int i,int j); // return value of the i-th row and j-th column
Die einzige Funktion der "Get"-Reihe, die den Wert mittels des 'liefern' Operators anstatt mittels einer parametrischen Variable liefert. Liefert den Wert des String-Typs, ungeachtet des Spaltentyps.
1.20 StringDigits (StringZiffern)
Bei der Formung von Typen zu 'String' können Sie eine Exaktheit verwenden, die von folgenden Funktionen eingerichtet wird:
void StringDigits(int i,int digits);
Einrichten der Exaktheit von 'double' und
int StringDigits(int i);
Einrichten de Exaktheit der Sekundenanzeige in 'Datetime'; jeder Werte der nicht = -1 ist, wird übertragen Der festgelegte Wert wird für die Spalte gemerkt, damit Sie ihn nicht jedes Mal bei der Anzeige von Informationen angeben müssen. Sie können für so viele Male wie sie möchten Exaktheit einrichten, da die Information ja in Original-Typen gespeichert wird und nur während der Ausgabe in die festgelegte Exaktheit umgewandelt wird. Die Werte der Exaktheit werden beim kopieren nicht gemerkt, sodass also beim kopieren einer Tabelle in eine neue Tabelle, die Exaktheit der Spalten der neuen Tabelle der standardmäßig eingestellten Exaktheit entspricht.
1.21 Anwendungsbeispiel:
#include <Table.mqh> ENUM_DATATYPE TYPE[7]= {TYPE_LONG,TYPE_LONG,TYPE_STRING,TYPE_DATETIME,TYPE_STRING,TYPE_STRING,TYPE_DOUBLE}; // 0 1 2 3 4 5 6 //7 void OnStart() { CTable table,table1; table.FirstResize(TYPE); // dividing table, determining column types table.SecondResize(5); // change the number of rows table.Set(6,0,"321.012324568"); // assigning data to the 6-th column, 0 row table.Insert(2,6); // insert 6-th column in the 2-nd position table.PruningTable(3); // cut the table to 3 columns table.StringDigits(2,5); // set precision of 5 digits after the decimal point Print("table ",table.sGet(2,0)); // print the cell located in the 2-nd column, 0 row table1.CopyTable(GetPointer(table)); // copy the entire table 'table' to the 'table1' table table1.StringDigits(2,8); // set 8-digit precision Print("table1 ",table1.sGet(2,0)); // print the cell located in the 2-nd column, 0 row of the 'table1' table. }
Als Ergebnis dieser Handlung wird der Inhalt der Zelle gedruckt (2;0). Sie haben vielleicht bemerkt, das die Exaktheit der kopierten Daten die Exaktheit der ursprünglichen Tabelle nicht überschreitet.
2011.02.09 14:18:37 Table Script (EURUSD,H1) table1 321.01232000 2011.02.09 14:18:37 Table Script (EURUSD,H1) table 321.01232
Kommen wir nun zur Beschreibung des Algorithmus an sich.
2. Ein Modell auswählen
Die Organisation von Information kann auf zweierlei Weise erfolgen: via des Schemas der verknüpften Spalten (was wir in diesem Beitrag gemacht haben) und alternativ in Form der verknüpfen Reihen - so wie unten gezeigt
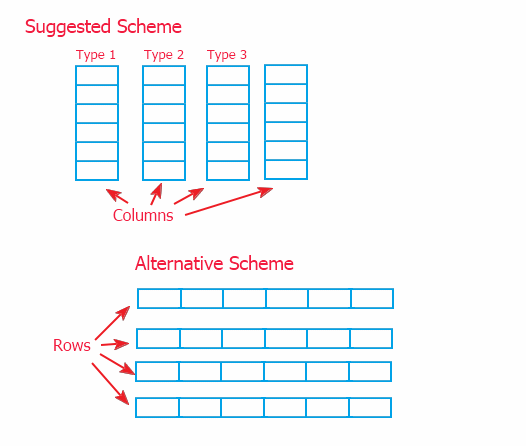
Da die Information durch einen "Mittler" (auf S. 2 beschrieben) weiter verwiesen wird, besteht bei der Implementierung des oberen Bereichs kein großer Unterschied. Ich habe mich jedoch für das Spaltenmodell entschieden, da es die Implementierung der Datenmethode im unteren Bereich erlaubt, in den Objekten, die die Daten speichern. Und das Alternativschema würde das Aufheben von Methoden zur Arbeit mit Informationen in der oberen CTabellen-Klasse bedeuten. Und dies kann bei Verbesserungen der Klasse, falls erforderlich, zu Schwierigkeiten führen.
Trotzdem kann durchaus jedes Schema verwendet werden.. Das vorgeschlagenen Schema erlaubt ein schnelles Verschieben von Daten - seine Alternative erlaubt das schnelle Hinzufügen von Daten (da Information einer Tabelle öfter Zeile per Zeile hinzugefügt wird) und Erhalt von Reihen.
Es gibt aber noch eine weitere Möglichkeit, eine Tabelle anzuordnen - als ein Array an Strukturen. Und obwohl dies die einfachste Art der Implementierung ist, besitzt sie einen großen Nachteil: die Struktur muss von einem Programmierer beschrieben werden. Und damit büßen wir die Möglichkeit ein, die Merkmale der Tabelle via individuell angepasster Parameter setzen zu können (ohne dazu den Quellcode verändern zu müssen).
3. Daten in einem dynamischen Array vereinen
Um unterschiedliche Datentypen in einem einzigen dynamischen Array vereinen zu können, müssen wir das Problem der Zuweisung unterschiedlicher Arten zu den Array-Zellen lösen. Dieses Problem wird bereits in den verknüpften Listen der Standard Library gelöst. Meine ersten Entwicklungen beruhten auf der Standard-Library an Klassen. Doch während der Entwicklung dieses Projekts, hatte ich den Eindruck, ich müsste viele Veränderungen in der CObject Basisklasse durchführen,
und deshalb habe ich beschlossen, meine eigenen Klasse zu entwickeln. Für alle, die die Standard-Library nicht studiert haben, erkläre ich im Folgenden wie das oben beschrieben Problem gelöst wurde. Dazu müssen Sie den Mechanismus der Vererbung anwenden.
class CBase { public: CBase(){Print(__FUNCTION__);}; ~CBase(){Print(__FUNCTION__);}; virtual void set(int sor){}; virtual void set(double sor){}; virtual int get(int k){return(0);}; virtual double get(double k){return(0);}; }; //+------------------------------------------------------------------+ class CA: public CBase { private: int temp; public: CA(){Print(__FUNCTION__);}; ~CA(){Print(__FUNCTION__);}; void set(int sor){temp=sor;}; int get(int k){return(temp);}; }; //+------------------------------------------------------------------+ class CB: public CBase { private: double temp; public: CB(){Print(__FUNCTION__);}; ~CB(){Print(__FUNCTION__);}; void set(double sor){temp=sor;}; double get(double k){return(temp);}; }; //+------------------------------------------------------------------+ void OnStart() { CBase *a; CBase *b; a=new CA(); b=new CB(); a.set(15); b.set(13.3); Print("a=",a.get(0)," b=",b.get(0.)); delete a; delete b; }
Dieser Vererbungsmechanismus kann als Kamm visualisiert werden:

Wird die Erzeugung eines dynamischen Objekts der Klasse deklariert, bedeutet das, dass der Constructor der Basisklasse aufgerufen wird. Diese exakte Eigenschaft ermöglicht die Erzeugung eines Objekts in zwei Schritten. Da die virtuellen Funktionen der Basisklasse aufgehoben werden, bekommen wir die Möglichkeit, die Funktion mit unterschiedlichen Parametertypen aus den abgeleiteten Klassen aufrufen zu können.
Warum reicht ein einfaches Aufheben nicht aus? Weil die ausgeführten Funktionen enorm sind. Wenn wir als ihren jeweiligen Korpus in der Basisklasse beschrieben haben (ohne Vererbung einzusetzen), würden für jedes Objekt nicht genutzte Funktionen mit dem kompletten Korpus-Code im Binärcode erzeugt werden. Wenn man nun den Mechanismus der Vererbung anwendet, erzeugt man leere Funktionen, die weit weniger Memory brauchen als die mit Code befüllten Funktionen.
4. Mit Arrays arbeiten
Zweitens und das ist der Hauptgrund, warum ich keine Standardklassen verwenden wollte, ist der Verweis auf Daten. Ich arbeite mit indirektem Verweis auf Arrayzellen mit Hilfe eines "Mittler-Arrays" an Indices anstatt direkt auf die Zell-Indices zu verweisen. Verweise auf Zell-Indices schreiben ein langsameres Arbeitstempo vor als direkte Verweise via einer Variable. Das liegt daran, dass die Variable, die einen Index angibt, schneller als eine Array-Zelle arbeitet, die ja zuerst im Memory gefunden werden muss.
Analysieren wir doch mal den fundamentalen Unterschied in der Sortierung eines eindimensionalen und multi-dimensionalen Arrays. Vor einer Sortierung hat ein eindimensionales Array zufällige Positionen an Elementen. Nach der Sortierung sind die Elemente angeordnet. Bei der Sortierung eines zweidimensionalen Arrays, müssen wir nicht das gesamte Array sortieren, sondern nur eine seiner Spalten nach der die Sortierung ausgeführt wird. Alle Reihen müssen ihre Position verändern, um die Struktur aufrecht zu erhalten.
Die Reihen selbst sind hier die gebundenen Strukturen, die Daten unterschiedlicher Arten enthalten. Um so ein Problem zu lösen, müssen wir sowohl Daten in einem ausgewählten Array sortieren und zugleich die Struktur der ursprünglichen Indices speichern. So können wir die gesamte Reihe anzeigen, wenn wir wissen in welcher Reihe sich die Zelle befand. Bei der Sortierung eines zweidimensionalen Arrays müssen wir daher das Array an Indices des sortierten Arrays bekommen, ohne dazu die Struktur der Daten zu verändern.
Zum Beispiel:
before sorting by the 2-nd column 4 2 3 1 5 3 3 3 6 after sorting 1 5 3 3 3 6 4 2 3 Initial array looks as following: a[0][0]= 4; a[0][1]= 2; a[0][2]= 3; a[1][0]= 1; a[1][1]= 5; a[1][2]= 3; a[2][0]= 3; a[2][1]= 3; a[2][2]= 6; And the array of indexes of sorting by the 2-nd column looks as: r[0]=1; r[1]=2; r[2]=0; Sorted values are returned according to the following scheme: a[r[0]][0]-> 1; a[r[0]][1]-> 5; a[r[0]][2]-> 3; a[r[1]][0]-> 3; a[r[1]][1]-> 3; a[r[1]][2]-> 6; a[r[2]][0]-> 4; a[r[2]][1]-> 2; a[r[2]][2]-> 3;
Wir haben also eine Möglichkeit, Informationen nach Symbol, Datum der Eröffnung einer Position, Gewinn, usw. sortieren zu können.
Es sind bereits eine ganze Menge an Algorithmen zur Sortierung entwickelt. Und die beste Variante für unsere Entwicklung stellt der Algorithmus zur stabilen Sortierung dar.
Der Algorithmus zur raschen Sortierung, der in den Standardklassen verwendet wird, verweist auf die Algorithmen der instabilen Sortierung. Und genau deshalb ist er in seiner klassischen Implementierung für uns nicht geeignet. Und selbst wenn man die rasche Sortierung in eine stabile Form bringt (und das heißt zusätzliches Kopieren von Daten und Sortieren von Arrays an Indices), ist die rasche Sortierung anscheinend immer noch schneller als die Blasen-Sortierung (eine der schnellsten Algorithmen der stabilen Sortierung). Der Algorithmus ist wirklich schnell, verwendet aber die Rekursion.
Und das ist der Grund, warum ich die Cocktail-Sortierung verwenden, wenn ich mit Arrays des String-Typs arbeite (benötigt weit mehr Stapelspeicher).
5. Anordnung eines zweidimensionalen Arrays
Die letzte Frage, auf die ich noch eingehen möchte, betrifft die Anordnung eines dynamischen zweidimensionalen Arrays. Für seine Anordnung genügt es für ein eindimensionales Array eine Hülle als eine Klasse zu machen und das Objekt-Array via des Arrays an Zeigern aufzurufen. Anders ausgedrückt: Wir müssen ein Array an Arrays erzeugen
class CarrayInt { public: ~CarrayInt(){}; int array[]; }; //+------------------------------------------------------------------+ class CTwoarrayInt { public: ~CTwoarrayInt(){}; CarrayInt array[]; }; //+------------------------------------------------------------------+ void OnStart() { CTwoarrayInt two; two.array[0].array[0]; }
6. Programmstruktur
Der Code der CTable-Klasse wurde mit Hilfe von Templates geschrieben, die im Beitrag Verwendung von Pseudo-Templates als Alternative für С++ Templates beschrieben sind. Und nur weil ich Templates verwendet habe, konnte ich so einen umfangreichen Code so schnell schreiben. Deshalb beschreibe ich den gesamten Code auch nicht im Detail, da darüber hinaus der Großteil des Codes des Algorithmus eine Modifikation der Standardklassen ist.
Ich zeige hier nur die allgemeine Struktur der Klasse und einige ihrer interessanten Funktion-Features, die verschiedene wichtige Punkte verdeutlichen.

Der rechte Teil des Blockdiagramms ist hauptsächlich von den aufgehobenen Methoden besetzt, die sich in den abgeleiteten Klassen CLONGArray, CDOUBLEArray, CDATETIMEArray und CSTRINGArray befinden. Jede einzelne (im private Bereich) enthält ein Array des entsprechenden Typs. Diese exakten Arrays werden für alle Tricks für den Informationszugriff verwendet. Die oben aufgeführten Namen der Methoden der Klassen sind dieselben wie in den public Methoden.
Die Basisklasse CBASEArray ist befüllt mit der Aufhebung der virtuellen Methoden und ist nur für die Deklarierung des dynamischen Objekte-Arrays CBASEArray im private Bereich der CTable Klasse notwendig Das Array an Zeigern CBASEArray wird als dynamisches Array dynamischer Objekte deklariert. Der letztendliche Zusammenbau der Objekte und die Auswahl der notwendigen Instanz wird in der FirstResize() Funktion ausgeführt. Dies kann aber auch in der CopyTable() Funktion geschehen, da sie FirstResize() in ihrem Korpus aufruft.
Die CTable Klasse führt auch die Koordination der Methoden der Datenverarbeitung (befindet sich in den Instanzen der CTable Klasse) und das Objekt der Kontrolle der Indices der Cint2D Klasse aus. Die komplette Koordination wird in den aufgehobenen public Methoden umhüllt.
Häufig wiederholte Teile der Aufhebung in der CTable Klasse werden durch Definitionen ersetzt, um sehr lange Zeilen zu vermeiden:
#define _CHECK0_ Print(__FUNCTION__+"("+(string)i+","+(string)j+")");return; #define _CHECK_ Print(__FUNCTION__+"("+(string)i+")");return(-1); #define _FIRST_ first_data[aic[i]] #define _PARAM0_ array_index.Ind(j),value #define _PARAM1_ array_index.Ind(j),recipient #define _PARAM2_ element,beg,end,array_index,mode
Daher wird der Teil einer kompakteren Form:
int QuickSearch(int i,long element,int beg,int end,bool mode=false){if(!check_type(i,TYPE_LONG)){_CHECK_}return(_FIRST_.QuickSearch(_PARAM2_));};
mittels des Präprozessors durch die folgende Zeile ersetzt:
int QuickSearch(int i,long element,int beg,int end,bool mode=false){if(!check_type(i,TYPE_LONG)){Print(__FUNCTION__+"("+(string)i+")");return(-1);} return(first_data[aic[i]].QuickSearch(element,beg,end,array_index,mode));};
Im obigen Beispiel wird klar wie die Methoden der Datenverarbeitung aufgerufen werden (der Teil innerhalb von 'liefern').
Ich habe bereits darauf hingewiesen, dass die CTable Klasse während der Verarbeitung keine physische Verschiebung von Daten durchführt - sie ändert nur den Wert im Objekt der Indices. Um den Methoden der Datenverarbeitung eine Möglichkeit der Interaktion mit dem Objekt der Indices zu geben, wird es an alle Verarbeitungsfunktionen als der array_index Parameter übertragen.
Das array_index Objekt speichert die örtliche Beziehung der Elemente in der zweiten Dimension Indizierung der ersten Dimension ist die Aufgabe des dynamischen Arrays aic[], das im private Bereich der CTable Klasse deklariert wird. Es gibt uns eine Möglichkeit, die Position der Spalten zu ändern (natürlich nicht physisch, sondern via Indices).
Wird z.B. der Change() Vorgang ausgeführt, ändern nur zwei Memory-Zellen, die die Indices der Spalten enthalten, ihre Plätze, obwohl es visuell so aussieht, als würde man zwei Spalten verschieben. Die Funktionen der CTable Klasse sind in der Dokumentation ziemlich gut beschrieben (irgendwo sogar Zeile um Zeile).
Wenden wir uns daher jetzt den Funktionen der vom CBASEArray geerbten Klassen zu. Die Algorithmen dieser Klassen sind in der Tat die Algorithmen, die von den Standardklassen hergenommen wurden. Ich habe auch die Standardnamen verwendet, um ein Gefühl für sie zu haben. +Die Modifikation besteht in der indirekten Lieferung von Werten mit Hilfe eines Arrays von Indices im Unterschied zu den Standard-Algorithmen, wo Werte direkt geliefert werden.
Zunächst wurde diese Veränderung auf die rasche Sortierung angewendet. Da der Algorithmus der Kategorie 'instabiler Algorithmus' angehört, müssen wir, bevor wir mit der Sortierung beginnen, die Daten kopieren, die an den Algorithmus übertragen werden. Ich habe auch entsprechend dem Muster der Veränderung der Daten die synchrone Veränderung des Objekts von Indices hinzugefügt..
void CLONGArray::QuickSort(long &m_data[],Cint2D &index,int beg,int end,bool mode=0)
Hier steht der Teil des Code zum Sortieren:
... if(i<=j) { t=m_data[i]; it=index.Ind(i); m_data[i++]=m_data[j]; index.Ind(i-1,index.Ind(j)); m_data[j]=t; index.Ind(j,it); if(j==0) break; else j--; } ...
Im ursprünglichen Algorithmus gibt es keine Instanz der Cint2D Klasse.. Ähnliche Veränderungen wurden auch bei den anderen Standardalgorithmen vorgenommen. Ich beschreibe die Templates all der Codes nicht. Möchte jemand unter Ihnen den Code verbessern, kann man sich ein Template des echten Codes machen, indem man die echten Typen durch das Template ersetzt.
Zum Schreiben von Templates habe ich die Codes der Klasse verwendet, die mit dem lang Typ arbeitet. Bei derartigen ökonomischen Algorithmen, versuchen Entwickler die unnötige Verwendung von ganzen Zahlen zu vermeiden, wenn man stattdessen nur int verwenden kann. Und deshalb ist eine Variable des 'lang' Typs höchstwahrscheinlich ein aufgehobener Parameter. Sie müssen durch 'templat' ersetzt werden, wenn man mit Templates arbeitet.
Fazit
Ich hoffe, dieser Beitrag wird Programmierneulingen beim Studium des Objekt-orientierten Ansatzes eine große Hilfe sein und ihnen die Arbeit mit Informationen erleichtern. Die CTable Klasse kann für viele komplexe Anwendungen eine Basisklasse werden. Die in diesem Beitrag beschriebenen Methoden können zur Grundlage der Entwicklung einer großen Klassen an Lösungen werden, da sie einen allgemeinen Ansatz zur Arbeit mit Daten implementieren.
Darüber hinaus beweist dieser Beitrag auch noch, dass ein Missbrauch von MQL5 unbegründet ist. Ach Sie wollten den Varianten-Typ? Hier ist er, implementiert mit Hilfe von MQL5. Vor diesem Hintergrund müssen die Standards nicht verändert und die Sicherheit der Sprache geschwächt werden. Viel Erfolg!
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/228
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

 MQL5 Assistent: Wie man ein Risiko- und Geldverwaltungsmodul erzeugt
MQL5 Assistent: Wie man ein Risiko- und Geldverwaltungsmodul erzeugt
 Der MQL5 Assistent: Wie man ein Modul an Handelssignalen erzeugt
Der MQL5 Assistent: Wie man ein Modul an Handelssignalen erzeugt
 MQL5 Assistent: Erstellen eines Moduls zum Verfolgen offener Positionen
MQL5 Assistent: Erstellen eines Moduls zum Verfolgen offener Positionen
 Ökonometrischer Ansatz zur Chartanalyse
Ökonometrischer Ansatz zur Chartanalyse
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Nikolay, ich habe eine Frage.
Ist es möglich, eine Tabelle von MT5 nach Excel in dieser Form zu schreiben?
Ich interessiere mich für die 2 Makro-Spaltennamen ("Absolute Daten" und "Relative Daten"), die farblich hervorgehoben sind. Sie fassen jeweils 3 Zellen zusammen.
Vielleicht will ich viel von MQL5 in Bezug auf die Formatierung von Excel-Zellen. Aber was wäre wenn :-)))
Welche physikalische Bedeutung haben die Worte "3 Zellen kombinieren" ?
Im Prinzip können Sie, aber ohne die oberen 2 Zeilen, Datentypen sind durch Spalten zusammengefasst, so dass in einer Spalte zu stopfen String und Double wird nicht funktionieren, aber es kann getan werden, wenn der Druck. Oder die Klasse so zu verfeinern, dass sie große Zeichenketten enthält, die getrennt von der Tabelle formatiert werden.
Der einfachste Weg ist, zwei Tabellen zu erstellen und sie zusammenzuführen.
Welche physikalische Bedeutung haben die Worte "3 Zellen kombinieren" für Sie?
Das ist, was wir jetzt haben:
Was ich gerne schon mitgebracht hätte ....
Neuer Artikel Elektronische Tabellen in MQL5 ist veröffentlicht:
Autor: Николай