
Нейросети в трейдинге: Параметроэффективный Transformer с сегментированным вниманием (Окончание)

Введение
В предыдущей статье мы познакомились с теоретическими аспектами фреймворка PSformer, который вносит в архитектуру ванильного Transformer две ключевые инновации: механизм совместного использования параметров (Parameter Shared — PS) и внимание к пространственно-временным сегментам (SegAtt).
Напомню, что авторы фреймворка PSformer предложили энкодер, основанный на архитектуре Transformer, с двухуровневой структурой внимания к сегментам. Каждый уровень включает блок с общими параметрами, состоящий из трёх полносвязных слоёв с остаточными связями. Такая архитектура позволяет уменьшить общее количество параметров, сохраняя эффективность обмена информацией внутри модели.
Для выделения сегментов используется метод патчинга, в котором временные ряды переменных делятся на патчи. Патчи с одинаковым положением по разным переменным объединяются в сегменты, которые представляют собой пространственное расширение патча одной переменной. Это разбиение позволяет эффективно организовать многомерный временной ряд в несколько сегментов.
Внутри каждого сегмента внимание направлено на выявление локальных пространственно-временных связей, в то время как интеграция информации между сегментами улучшает общее качество прогнозов.
Дополнительно, применение методов SAM-оптимизации в фреймворке PSformer помогает снизить вероятность переобучения, сохраняя его эффективность.
Результаты обширных экспериментов, проведённых авторами фреймворка на различных наборах данных для долгосрочного прогнозирования временных рядов, подтверждают высокую производительность PSformer. В 6 из 8 ключевых задач прогнозирования временных рядов данная архитектура демонстрирует конкурентные или лучшие результаты по сравнению с современными передовыми моделями.
Авторская визуализация фреймворка PSformer представлена ниже.
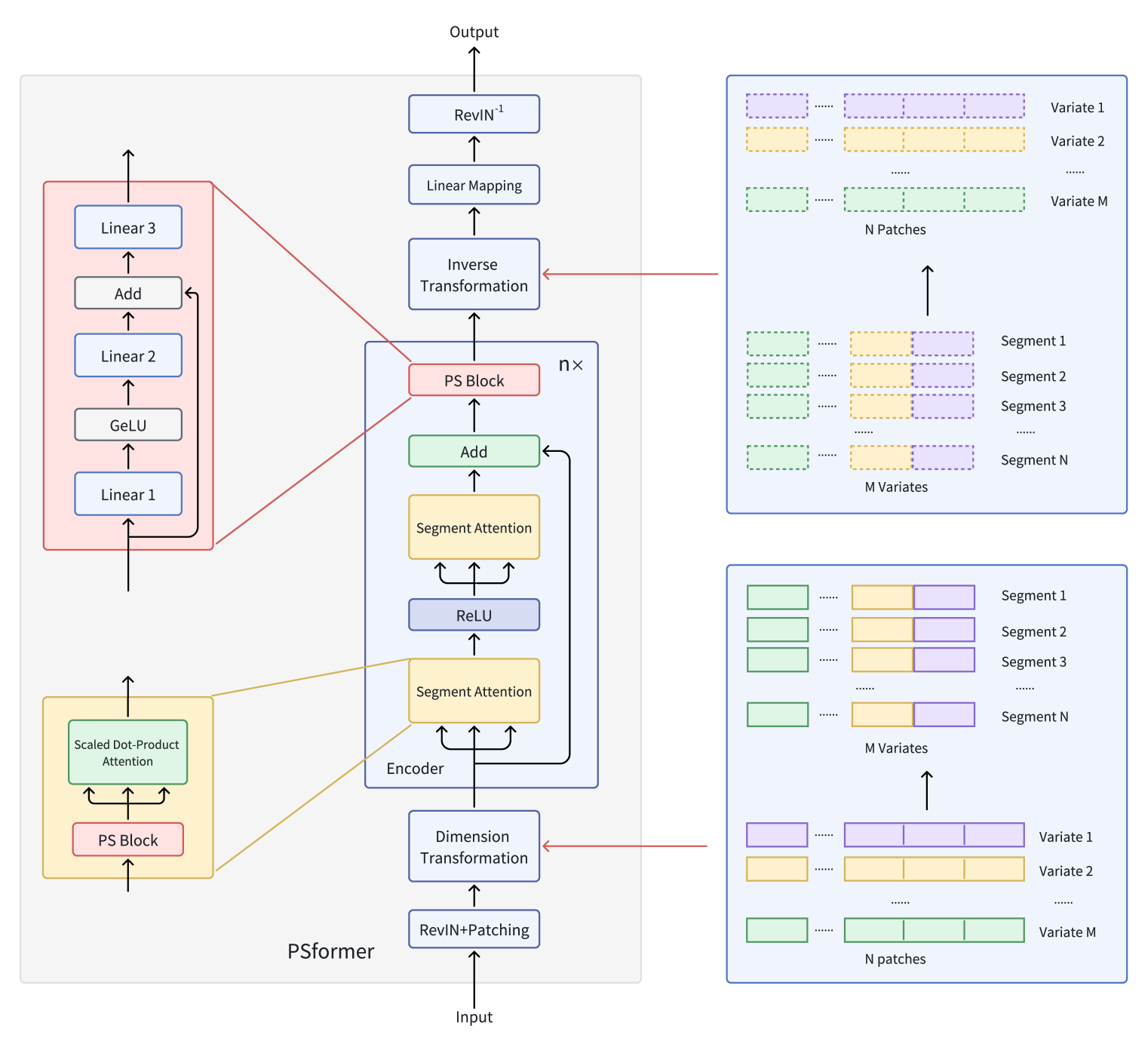
В предыдущей статье мы уже начали реализацию предложенных подходов средствами MQL5. И рассмотрели алгоритмы методов класса CNeuronPSBlock, в котором реализован функционал блока совместного использования параметров. Продолжаем начатую работу и переходим к построению функционала энкодера.
Создаем объект Энкодера PSformer
Прежде, чем приступить к реализации алгоритмов в коде, давайте немного их обсудим. Согласно представленного авторами фреймворка, исходные данные сначала проходят RevIn. Как вы знаете, модуль RevIn включает 2 блока. На входе модели он нормализует исходные данные, а на выходе возвращает ранее изъятые параметры распределения результатам работы модели. Это помогает привести результаты работы модели к распределению исходных данных. Что несомненно, очень важно при решении задач прогнозирования последующих значений временного ряда.
В рамках данной статьи мы, как и ранее, будем использовать лишь нормализацию исходных данных на входе модели, которую выполним отдельным слоем пакетной нормализации. И причина заключается в том, что нашей конечной целью является не прогнозирование последующих значений временного ряда, а обучение прибыльной политики Актера. Мы знаем, что модели лучше работают с нормализованными данными, поэтому осуществляем нормализацию исходных данных. По той же причине, на вход Актера логично передавать уже нормализованные данные из скрытого состояния энкодера. Следовательно, в случае обучения Энкодера окружающей среды совместно с Актером, блок линейного маппинга и обратный RevIn становятся излишними.
Конечно, нам потребуются блок маппинга и модуль обратного RevIn при поэтапном обучении моделей, когда сначала обучается Энкодер состояния окружающей среды прогнозированию последующих состояний анализируемого временного ряда, а только потом отдельно обучаются модели Актера и Критика. Но и в этом случае, на вход Актера лучше передавать скрытое состояние Энкодера, которое содержит более компактное и нормализованное представление исходных данных.
Поэтапное обучение моделей имеет как преимущества, так и недостатки. К преимуществам такого подхода можно отнести универсальность модели Энкодера. Ведь он обучается на исходных данных без привязки к конкретной задаче. Это позволяет его использовать для поиска решений различных задач на представленных исходных данных.
С другой стороны, универсальное часто бывает не лучшим вариантом для конкретной задачи, поскольку может не учитывать некоторую специфику.
К тому же, 2 этапа обучения в сумме могут быть более затратными, чем одновременное обучение всех моделей.
С учетом вышеприведенных рассуждений мы остановились на одновременном обучении моделей с сокращением архитектуры Энкодера.
После нормализации исходных данных в фреймворке PSformer идет модуль патчинга и трансформации данных. Авторы фреймворка описали довольно сложную трансформацию. Давайте попробуем с ней разобраться.
На вход модели подается мультимодальный временной ряд. Пока опустим нормализацию и рассмотрим только трансформацию данных.
Вначале мультимодальный временной ряд разделяется на M унитарных последовательностей, а затем, каждая унитарная последовательность разбивается на N равных патчей длиной P. После этого, патчи с одинаковыми временными метками объединяются в сегменты. Таким образом мы получаем N патчей размерностью M×P.
В нашем случае исходные данные представлены в виде последовательного описания исторических баров на глубину анализируемых данных. Иными словами, в нашем буфере исходных данных идет M элементов описания одного бара. За ними следует M элементов описания другого бара и так далее. Следовательно, для формирования сегмента нам достаточно взять P последовательных описаний баров. Очевидно, что для этого нам нет необходимости каким-либо образом трансформировать данные.
Далее авторы PSformer говорят о трансформации исходных данных в размерность (M×P)×N. Для этого нам достаточно лишь транспонировать тензор исходных данных.
Таким образом, блок патчинга и трансформирования исходных данных PSformer, в нашем случае, преображается в один слой транспонирования.
Ещё один вопрос, который необходимо обсудить, — это подход к созданию последовательных слоев Энкодера PSformer. Здесь есть 2 варианта. Мы можем использовать базовый подход и указать нужное количество слоев при создании описания архитектуры модели, или создать объект, который создает нужное количество внутренних слоев.
В первом случае, мы усложняем процесс описания архитектуры модели, но упрощаем процесс создания объекта Энкодера. Однако, в таком варианте мы можем гибко управлять архитектурой последовательных слоев Энкодера.
Во втором случае, мы наоборот упрощаем процесс описания архитектуры модели, но усложняем алгоритм нашего Энкодера. И в такой реализации все внутренние слои Энкодера будут иметь одинаковую архитектуру.
Очевидно, что первый вариант предпочтительнее для построения моделей с малым количеством слоев Энкодера. А второй — будет актуален для более глубоких моделей.
Для принятия решения по данному вопросу, мы обратимся к авторскому исследованию влияния количества слоев Энкодера на качество прогнозирования последующих значений временного ряда. Авторы фреймворка PSformer провели указанный эксперимент на данных стандартных наборов временных последовательностей ETTh1 и ETTm1. Это данные электрических трансформаторов. Каждая точка данных состоит из 8 характеристик, включая дату, температуру масла и 6 различных типов характеристик внешней силовой нагрузки. ETTh1 содержит данные с часовым интервалом, а ETTm1 — с минутным. Результаты авторского исследования представлены в таблице ниже.

Как можно заметить из представленной информации, для набора данных с часовым интервалом, которые обладают меньшей хаотичностью, лучшие результаты достигнуты с одним слоем Энкодера. А для более зашумленных данных, которые были собраны с минутным интервалом, оптимальными оказались 3 слоя Энкодера. Следовательно, мы не ожидаем построения моделей с большим количеством слоев Энкодера. Поэтому выбираем первый вариант реализации, с более простой структурой нового объекта и указанием параметров каждого отдельного слоя Энкодера в описании архитектуры модели.
Полная структура нового объекта CNeuronPSformer представлена ниже.
class CNeuronPSformer : public CNeuronBaseSAMOCL { protected: CNeuronTransposeOCL acTranspose[2]; CNeuronPSBlock acPSBlocks[3]; CNeuronRelativeSelfAttention acAttention[2]; CNeuronBaseOCL cResidual; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL); public: CNeuronPSformer(void) {}; ~CNeuronPSformer(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint units_count, uint segments, float rho, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defNeuronPSformer; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); //--- virtual CLayerDescription* GetLayerInfo(void); virtual void SetOpenCL(COpenCLMy *obj); };
Как уже было сказано ранее, в фреймворке PSformer используются подходы SAM-оптимизации. Поэтому наш новый класс наследует базовый функционал от соответствующего полносвязного слоя.
Кроме того, в структуру CNeuronPSformer мы добавили 2 слоя транспонирования данных, которые будут выполнять функционал прямого и обратного трансформирования данных.
Так же в структуре нового класса можно заметить 3 блока совместного использования параметров и 2 модуля относительного внимания, в которые мы ранее добавили функционал SAM-оптимизации. И в этом, наверное, наше самое большое отступление от авторского алгоритма PSformer.
Дело в том, что авторы фреймворка PSformer использовали блок совместного использования параметров для формирования сущностей Query, Key и Value. При этом, в PS-блоке используются матрицы параметров размером N×N. Из чего можно сделать вывод, что в качестве всех сущностей используется один и тот же тензор.
В своей реализации мы немного усложнили архитектуру Энкодера. И PS-блок выполняет лишь роль предварительной подготовки данных, а анализ зависимостей осуществляется в более сложном блоке относительного внимания.
Все внутренние объекты объявлены статично, что позволяет нам оставить пустыми конструктор и деструктор класса. Инициализация всех объявленных и унаследованных объектов осуществляется в методе Init. В параметрах метода мы получаем основные константы, которые позволяют однозначно определить архитектуру создаваемого слоя. Среди них:
- window—размер вектора описания одного элемента последовательности;
- units_count—глубина анализируемой истории (количество элементов в последовательности);
- segments—количество создаваемых сегментов;
- rho—коэффициент области размытия.
bool CNeuronPSformer::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint units_count, uint segments, float rho, ENUM_OPTIMIZATION optimization_type, uint batch) { if(units_count % segments > 0) return false;
В теле метода инициализации мы организуем контрольный блок, в котором проверим кратность анализируемой последовательности числу создаваемых сегментов. А затем вызовем одноименный метод родительского класса, в котором уже реализованы остальные точки контроля полученных констант и инициализация унаследованных объектов.
if(!CNeuronBaseSAMOCL::Init(numOutputs, myIndex, open_cl, window * units_count, rho, optimization_type, batch)) return false;
Далее мы определим размер одного сегмента.
uint count = Neurons() / segments;
И переходим к блоку инициализации вновь объявленных внутренних объектов. Здесь первым мы инициализируем слой транспонирования исходных данных. В качества количества строк транспонируемой матрицы мы указываем количество сегментов, а размер строки приравниваем к общему числу элементов в одном сегменте.
if(!acTranspose[0].Init(0, 0, OpenCL, segments, count, optimization, iBatch)) return false; acTranspose[0].SetActivationFunction(None);
При этом мы явным образом указываем отсутствие функции активации.
Стоит отметить, что указание функции активации для слоя транспонирования данных не является обязательным атрибутом. Ведь в алгоритме прямого прохода слоя транспонирования предусмотрена синхронизация функции активации с объектом исходных данных.
Следующим шагом мы инициализируем первый блок совместного использования параметров. Для него мы используем метод явной инициализации объекта.
if(!acPSBlocks[0].Init(0, 1, OpenCL, segments, segments, units_count / segments, 1, fRho, optimization, iBatch)) return false;
И затем организуем цикл, в теле которого инициализируем модули внимания и оставшиеся блоки совместного использования параметров.
for(int i = 0; i < 2; i++) { if(!acAttention[i].Init(0, i + 2, OpenCL, segments, segments, units_count / segments, 2, optimization, iBatch)) return false; if(!acPSBlocks[i + 1].InitPS((CNeuronPSBlock*)acPSBlocks[0].AsObject())) return false; }
Обратите внимание, что оставшиеся блоки совместного использования параметров мы инициализируем по образу первого PS-блока с копированием указателя на общие буферы параметров и их моментов.
Далее инициализируем слой записи данных остаточных связей. Здесь используем базовый полносвязный слой, так как мы будем использовать лишь его буферы данных для записи промежуточных результатов вычислений.
if(!cResidual.Init(0, 4, OpenCL, acAttention[1].Neurons(), optimization, iBatch)) return false; if(!cResidual.SetGradient(acAttention[1].getGradient(), true)) return false; cResidual.SetActivationFunction((ENUM_ACTIVATION)acAttention[1].Activation());
А для сокращения операций копирования данных, мы осуществим подмену буфера градиентов ошибки данного слоя на аналогичный последнего модуля внимания. И обязательно синхронизируем функции активации двух слоев.
Последним мы инициализируем слой обратного транспонирования данных.
if(!acTranspose[1].Init(0, 5, OpenCL, count, segments, optimization, iBatch)) return false; acTranspose[1].SetActivationFunction((ENUM_ACTIVATION)acPSBlocks[2].Activation());
И осуществим подмену буферов нашего объекта на аналогичные последнего внутреннего слоя транспонирования данных.
if(!SetOutput(acTranspose[1].getOutput(), true) || !SetGradient(acTranspose[1].getGradient(), true)) return false; //--- return true; }
После чего, завершаем работу метода инициализации нового объекта, но предварительно вернем логический результат выполнения операций вызывающей программе.
Следующим этапом нашей работы является построение алгоритмов прямого прохода, которые мы реализуем в методе feedForward. Построение указанного метода не отличается особой сложностью, ведь основной функционал скрыт в реализованных ранее внутренних объектах нашего класса.
В параметрах метода мы получаем указатель на объект исходных данных, который сразу передаем в одноименный метод внутреннего слоя транспонирования для первичного трансформирования.
bool CNeuronPSformer::feedForward(CNeuronBaseOCL *NeuronOCL) { //--- Dimension Transformation if(!acTranspose[0].FeedForward(NeuronOCL)) return false;
После чего, организуем цикл последовательного перебора двух блоков внимания к сегментам.
//--- Segment Attention CObject* prev = acTranspose[0].AsObject(); for(int i = 0; i < 2; i++) { if(!acPSBlocks[i].FeedForward(prev)) return false; if(!acAttention[i].FeedForward(acPSBlocks[i].AsObject())) return false; prev = acAttention[i].AsObject(); }
В теле цикла мы последовательно вызываем одноименные методы блока совместного использования параметров и модуля относительного внимания.
А после успешного выполнения всех итераций цикла, мы добавляем остаточные связи исходных данных с сохранением результатов в буфере нашего внутреннего слоя cResidual.
//--- Residual Add if(!SumAndNormilize(acTranspose[0].getOutput(), acAttention[1].getOutput(), cResidual.getOutput(), acAttention[1].GetWindow(), false, 0, 0, 0, 1)) return false;
Но обратите внимание, что для остаточных связей мы берем исходные данные после трансформирования — то есть, после нашего слоя транспонирования исходных данных. Только в таком случае мы сохраняем структуру данных для осуществления остаточных связей.
Полученные результаты мы проводим через последний блок совместного использования параметров.
//--- PS Block if(!acPSBlocks[2].FeedForward(cResidual.AsObject())) return false;
И осуществляем обратную трансформацию данных.
//--- Inverse Transformation if(!acTranspose[1].FeedForward(acPSBlocks[2].AsObject())) return false; //--- return true; }
Благодаря подмене указателей буферов данных интерфейсов нашего объекта на аналогичные буфера последнего слоя транспонирования, результат обратного транспонирования данных записывается непосредственно в буфера интерфейсов, и нам нет необходимости в дополнительном копировании данных. Поэтому после транспонирования результатов работы внутренних объектов мы просто завершаем работу метода прямого прохода, передав логический результат выполнения операций вызывающей программе.
После завершения работы с методом прямого прохода, мы переходим к организации процессов обратного прохода, который осуществляется в методах calcInputGradients и updateInputWeights. В первом осуществляется распределение градиентов ошибки, а во втором — обновление параметров модели.
В параметрах метода calcInputGradients мы получаем указатель на объект исходных данных, в который нам предстоит передать градиент ошибки, в соответствии с влиянием исходных данных на конечный результат.
bool CNeuronPSformer::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
И в теле метода мы сразу проверяем актуальность полученного указателя, ведь в противном случае, все дальнейшие операции не имеют смысла. А после успешного прохождения данного контроля, мы поочередно осуществляем передачу градиента ошибки между внутренними слоями нашего объекта в последовательности, обратной прямому проходу.
if(!acPSBlocks[2].calcHiddenGradients(acTranspose[1].AsObject())) return false; //--- if(!cResidual.calcHiddenGradients(acPSBlocks[2].AsObject())) return false; //--- if(!acPSBlocks[1].calcHiddenGradients(acAttention[1].AsObject())) return false; if(!acAttention[0].calcHiddenGradients(acPSBlocks[1].AsObject())) return false; if(!acPSBlocks[0].calcHiddenGradients(acAttention[0].AsObject())) return false; //--- if(!acTranspose[0].calcHiddenGradients(acPSBlocks[0].AsObject())) return false;
Дойдя до слоя трансформирования исходных данных, нам предстоит добавить градиент ошибки по магистрали остаточных связей. И здесь возможны 2 варианта развития событий, в зависимости от функции активации объекта исходных данных. При отсутствии функции мы просто суммируем значения из 2 буферов данных.
if(acTranspose[0].Activation() == None) { if(!SumAndNormilize(acTranspose[0].getGradient(), cResidual.getGradient(), acTranspose[0].getGradient(), acAttention[1].GetWindow(), false, 0, 0, 0, 1)) return false; }
В противном случае, нам необходимо сначала скорректировать градиент ошибки на производную соответствующей функции активации и лишь затем можно суммировать данные.
else { if(!DeActivation(acTranspose[0].getOutput(), cResidual.getGradient(), acTranspose[0].getPrevOutput(), acTranspose[0].Activation()) || !SumAndNormilize(acTranspose[0].getGradient(), acTranspose[0].getPrevOutput(), acTranspose[0].getGradient(), acAttention[1].GetWindow(), false, 0, 0, 0, 1)) return false; }
В завершении метода, нам остается передать градиент ошибки на уровень исходных данных путем обратной трансформации и завершить работу метода, вернув логический результат выполнения операций вызывающей программе.
if(!NeuronOCL.calcHiddenGradients(acTranspose[0].AsObject())) return false; //--- return true; }
Для завершения операций обратного прохода, нам остается обновить параметры модели в сторону снижения ошибки прогнозирования. Здесь нам необходимо вспомнить, что для изменения параметров модели мы используем подходы SAM-оптимизации. Как уже обсуждалось ранее, в процессе выполнения алгоритма SAM-оптимизации мы осуществляем повторный прямой проход со скорректированными параметрами модели. Это ведет к изменению значений в буфере результатов, что не критично для работы текущего слоя, но может исказить процесс корректировки параметров последующего слоя. Поэтому мы осуществляем обновление параметров внутренних слоев в очередности, обратной прямому проходу. Это позволяет нам скорректировать параметры внутренних слоев до изменения значений в буфере результатов предшествующего слоя.
bool CNeuronPSformer::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { if(!acPSBlocks[2].UpdateInputWeights(cResidual.AsObject())) return false; //--- CObject* prev = acAttention[0].AsObject(); for(int i = 1; i >= 0; i--) { if(!acAttention[i].UpdateInputWeights(acPSBlocks[i].AsObject())) return false; if(!acPSBlocks[i].UpdateInputWeights(prev)) return false; prev = acTranspose[0].AsObject(); } //--- return true; }
Несколько слов стоит сказать о методах работы с файлами. Вполне очевидно, что при использовании трех блоков совместного использования параметров, нам абсолютно нет необходимости 3 раза сохранять одни и те же данные. Достаточно их сохранить только один раз. Тогда метод сохранения объекта Save примет следующий вид.
В параметрах метода мы получаем хендл файла для сохранения данных и сразу передаем его в одноименный метод родительского класса.
bool CNeuronPSformer::Save(const int file_handle) { if(!CNeuronBaseSAMOCL::Save(file_handle)) return false;
Далее мы один раз сохраним блок совместного использования параметров.
if(!acPSBlocks[0].Save(file_handle)) return false;
После чего организуем цикл сохранения модулей внимания и слоев транспонирования данных.
for(int i = 0; i < 2; i++) if(!acTranspose[i].Save(file_handle) || !acAttention[i].Save(file_handle)) return false; //--- return true; }
После успешного выполнения всех итераций цикла, нам остается вернуть логический результат выполнения операций вызывающей программе и завершить работу метода.
Обратите внимание, что при сохранении данных мы не только сократили количество блоков совместного использования параметров, но и опустили слой остаточных связей. Он не имеет обучаемых параметров. Следовательно, в таком варианте сохранения объекта мы не теряем информацию.
Тем не менее, при восстановлении ранее сохраненного объекта, нам предстоит восстановить структуру и функциональность всех объектов. В том числе и пропущенных при сохранении. Поэтому предлагаю более детально посмотреть на метод восстановления функциональности объекта Load.
В параметрах метода мы получаем хендл файла с ранее сохраненными данными. И мы сразу передаем полученный хендл в одноимённый метод родительского класса, в котором уже реализован алгоритм восстановления функциональности унаследованных объектов.
bool CNeuronPSformer::Load(const int file_handle) { if(!CNeuronBaseSAMOCL::Load(file_handle)) return false;
Далее мы восстанавливаем сохраненные объекты в строгом соответствии последовательности их сохранения.
if(!LoadInsideLayer(file_handle, acPSBlocks[0].AsObject())) return false; for(int i = 0; i < 2; i++) if(!LoadInsideLayer(file_handle, acTranspose[i].AsObject()) || !LoadInsideLayer(file_handle, acAttention[i].AsObject())) return false;
После загрузки ранее сохраненных объектов, нам предстоит восстановить функциональность пропущенных при сохранении. Первыми мы восстановим блоки совместного использования параметров. Один мы загрузили из файла, а остальные инициализируем по его подобию с копированием указателей на буферы совместных параметров и их моментов.
for(int i = 1; i < 3; i++) if(!acPSBlocks[i].InitPS((CNeuronPSBlock*)acPSBlocks[0].AsObject())) return false;
Затем мы инициализируем слой сохранения результатов остаточных связей. Его размер равен тензору результатов последнего модуля относительного внимания.
if(!cResidual.Init(0, 4, OpenCL, acAttention[1].Neurons(), optimization, iBatch)) return false; if(!cResidual.SetGradient(acAttention[1].getGradient(), true)) return false; cResidual.SetActivationFunction((ENUM_ACTIVATION)acAttention[1].Activation());
И не забудем осуществить подмену указателя на буфер градиентов ошибки, что позволит нам исключить излишние операции копирования данных. И тут же синхронизируем функции активации.
После этого нам остается осуществить подмену указателей буферов интерфейсов нашего объекта на аналогичные буферы последнего слоя транспонирования данных.
if(!SetOutput(acTranspose[1].getOutput(), true) || !SetGradient(acTranspose[1].getGradient(), true)) return false; //--- return true; }
И завершаем работу метода, вернув логический результат выполнения операций вызывающей программе.
На этом мы завершаем работу с объектом энкодера CNeuronPSformer. Полный код данного класса и всех его методов вы можете найти во вложении.
Архитектура моделей
После построения объектов реализации подходов, предложенных авторами фреймворка PSformer, мы переходим к описанию архитектуры обучаемых моделей. И прежде всего нас интересует Энкодер состояния окружающей среды, в который мы и имплементируем предложенные подходы.
Архитектура Энкодера состояния окружающей среды задается в методе CreateEncoderDescriptions. В параметрах метода мы получаем указатель на объект динамического массива для записи описания архитектуры модели.
bool CreateEncoderDescriptions(CArrayObj *&encoder) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; }
В теле метода мы проверяем актуальность полученного указателя и, при необходимости, создаем новый экземпляр динамического массива.
Как и ранее, в качестве слоя исходных данных мы используем базовый полносвязный слой. Его размер должен быть достаточным для получения полного тензора исторических данных на заданную глубину анализа.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
За ним следует слой пакетной нормализации, в котором осуществляется первичная обработка "сырых" исходных данных.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Нормализованные исходные данные передаются в энкодер PSformer. В рамках данной статьи мы используем 3 последовательных слоя энкодера PSformer с идентичной архитектурой. Для создания описания требуемого количества слоев энкодера, мы создаем цикл, число итераций которого равно глубине создаваемого энкодера. В теле цикла на каждой итерации мы создаем описание одного объекта CNeuronPSformer.
//--- layer 2 - 4 for(int i = 0; i < 3; i++) { if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronPSformer; descr.window = BarDescr; descr.count = HistoryBars; descr.window_out = Segments; descr.probability = Rho; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } }
После энкодера PSformer мы используем блок маппинга, который включает по одному сверточному и полносвязному слою. Все используемые нейронные слои адаптированы к использованию SAM-оптимизации.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvSAMOCL; descr.count = HistoryBars; descr.window = BarDescr; descr.step = BarDescr; descr.window_out = int(LatentCount / descr.count); descr.probability = Rho; descr.activation = GELU; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseSAMOCL; descr.count = LatentCount; descr.probability = Rho; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- return true; }
После успешного составления описания архитектуры Энкодера состояния окружающей среды, мы завершаем работу метода, предварительно вернув логический результат выполнения операций вызывающей программе.
С полным кодом метода описания архитектуры Энкодера описания окружающей среды вы можете ознакомиться во вложении. Там же представлены архитектуры моделей Актера и Критика, которые перенесены из предыдущих статей без изменений.
Кроме того, мы перенесли без изменений программы взаимодействия с окружающей средой и обучения моделей. Их полный код вы можете самостоятельно изучить во вложении. А мы переходим к заключительному этапу нашей работы — проверке эффективности реализованных подходов на реальных исторических данных.
Тестирование
Мы провели большую работу по реализации подходов, предложенных авторами фреймворка PSformer, средствами MQL5. И теперь подошли к самому волнительному этапу нашей работы — оценке эффективности реализованных подходов на реальных исторических данных.
Здесь следует акцентировать внимание на "оценке эффективности реализованных", а не "предложенных" подходов. Ведь в своей реализации мы сделали некоторые отступления от авторского фреймворка.
Обучать модели будем на исторических данных за весь 2023 год финансового инструмента EURUSD, таймфрейм H1. Как и ранее, параметры всех анализируемых индикаторов используются по умолчанию.
Как уже было сказано выше, все модели Энкодера состояния окружающей среды, Актера и Критика обучаются одновременно. Для первичного обучения мы использовали обучающую выборку, собранную при работе с предыдущими моделями. И по мере обучения модели, периодически актуализировали её.
После нескольких итераций обучения моделей и актуализирования обучающей выборки, нам удалось получить политику, способную генерировать прибыль на обучающей и тестовой выборках.
Тестирование обученной политики актера осуществлялось на исторических данных Января 2024 года с сохранением прочих параметров. Результаты тестирования представлены ниже.
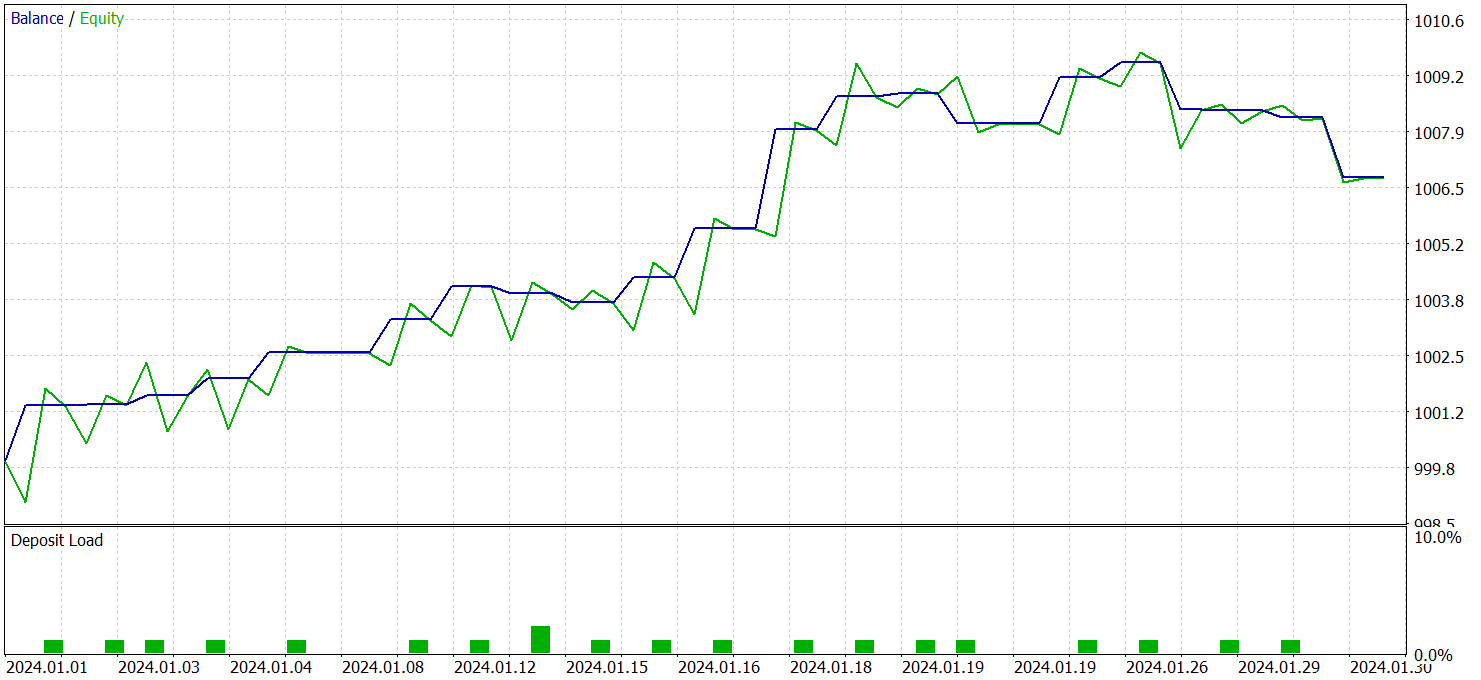
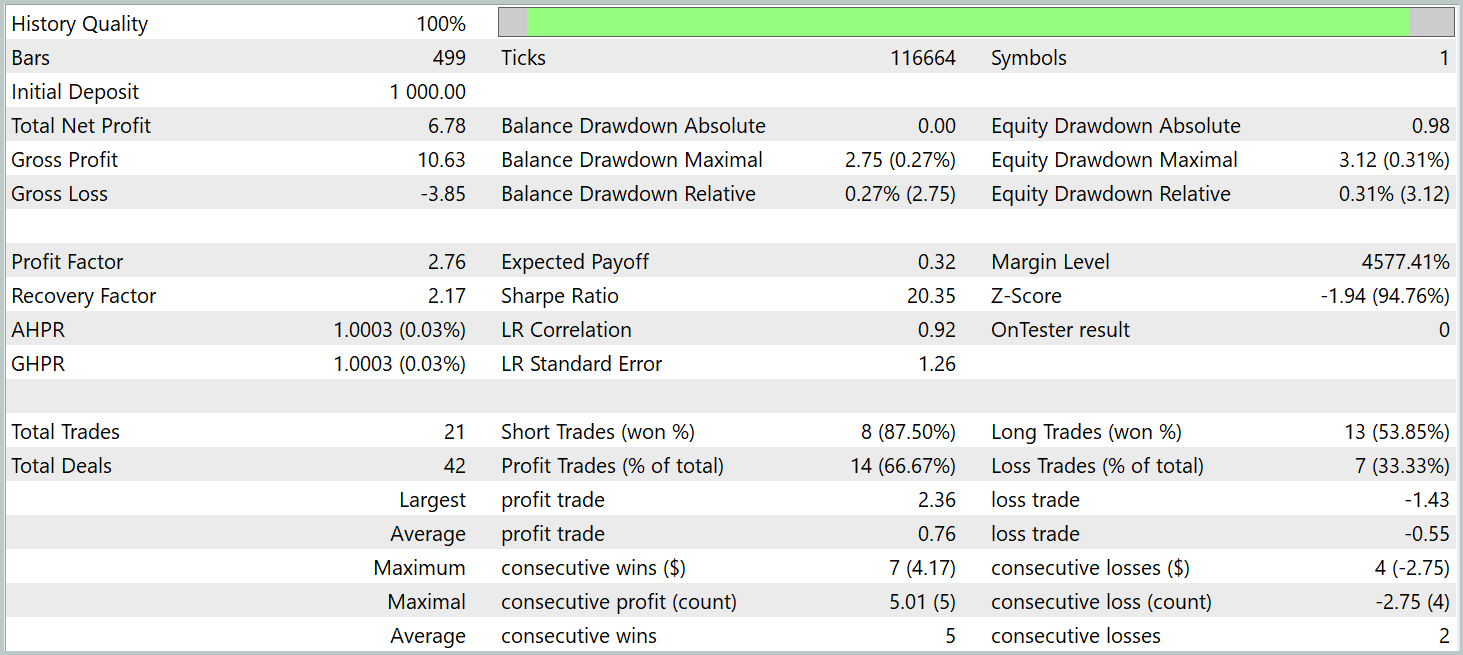
За период тестирования модель совершила 21 сделку, что в среднем составляет около 1 сделки в торговые сутки. Из них 14 было закрыто с прибылью, что составило более 66%. При этом средняя прибыльная сделка на 38% превышает среднюю убыточную.
Привлекает внимание график баланса, где наблюдается явная тенденция роста в первые 2 декады.
В целом, полученные результаты позволяют говорить об имеющемся потенциале. При соответствующих доработках и дополнительном обучении модели на большей обучающей выборке, модель может быть использована для реальной торговли.
Заключение
Мы познакомились с фреймворком PSformer, который отличается высокой точностью прогнозирования временных рядов и эффективным использованием вычислительных ресурсов. Ключевые архитектурные элементы PSformer — это блок совместного использования параметров (PS) и механизм внимания к пространственно-временным сегментам (SegAtt). Эти компоненты обеспечивают эффективное моделирование как локальных, так и глобальных зависимостей временных рядов, одновременно снижая количество параметров без ущерба для качества прогнозов.
Нами было реализовано свое видение предложенных подходов средствами MQL5. После чего, мы обучили модели с использованием реализованных подходов. Результаты тестирования на исторических данных, не за пределами обучающей выборки, свидетельствуют об имеющемся потенциале обученных моделей.
Ссылки
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Research.mq5 | Советник | Советник сбора примеров |
| 2 | ResearchRealORL.mq5 | Советник | Советник сбора примеров методом Real-ORL |
| 3 | Study.mq5 | Советник | Советник обучения Моделей |
| 4 | StudyEncoder.mq5 | Советник | Советник обучения Энкодера |
| 5 | Test.mq5 | Советник | Советник для тестирования модели |
| 6 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы |
| 7 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 8 | NeuroNet.cl | Библиотека | Библиотека кода программы OpenCL |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Я получаю ошибки из файла math.math/mqh. Если есть какие-либо решения этой проблемы, буду очень признателен.
Когда я компилирую файл Research.mq5, я получаю эту ошибку
и когда я компилирую файл ResearchRealORL.mq5, я получаю эту ошибку
и когда я компилирую файл Study.mq5, я получаю эту ошибку
Повторилась почти та же ошибка, что я сделал не так?
и когда я компилирую файл Test.mq5, я получаю эту ошибку
Я получаю ошибки из файла math.math/mqh. Если есть какие-то решения, буду очень признателен.