
Redes neuronales en el trading: Transformer parámetro-eficiente con atención segmentada (Final)

Introducción
En el artículo anterior aprendimos los aspectos teóricos del framework PSformer, que aporta dos innovaciones clave a la arquitectura del Transformer vainilla: el mecanismo de compartición de parámetros (Parameter Shared — PS) y la atención a los segmentos espaciotemporales (SegAtt).
Recordemos que los autores del framework PSformer propusieron un Codificador basado en la arquitectura del Transformer con una estructura de dos niveles de atención a los segmentos. Cada capa incluye un bloque de parámetros genéricos formado por tres capas completamente conectadas con enlaces residuales. Esta arquitectura reduce el número total de parámetros al tiempo que mantiene la eficacia del intercambio de información dentro del modelo.
El método de parcheo se usa para identificar segmentos dividiendo una serie temporal de variables en parches. Los parches con la misma posición en diferentes variables se combinan en segmentos, que suponen extensiones espaciales de un único parche variable. Esta partición permite organizar eficazmente las series temporales multidimensionales en segmentos múltiples.
Dentro de cada segmento, la atención se centra en identificar relaciones espaciotemporales localizadas, mientras que la integración de la información entre segmentos mejora la calidad global de las previsiones.
Además, la aplicación de técnicas de SAM-optimización en el framework PSformer ayuda a reducir la probabilidad de sobreentrenamiento manteniendo su eficacia.
Los resultados de los amplios experimentos realizados por los autores del framework sobre diversos conjuntos de datos para la previsión de series temporales a largo plazo confirman el alto rendimiento del PSformer. En 6 de las 8 tareas clave de previsión de series temporales, esta arquitectura obtiene resultados competitivos o mejores que los modelos modernos más avanzados.
A continuación le mostramos la visualización del framework PSformer por parte del autor.
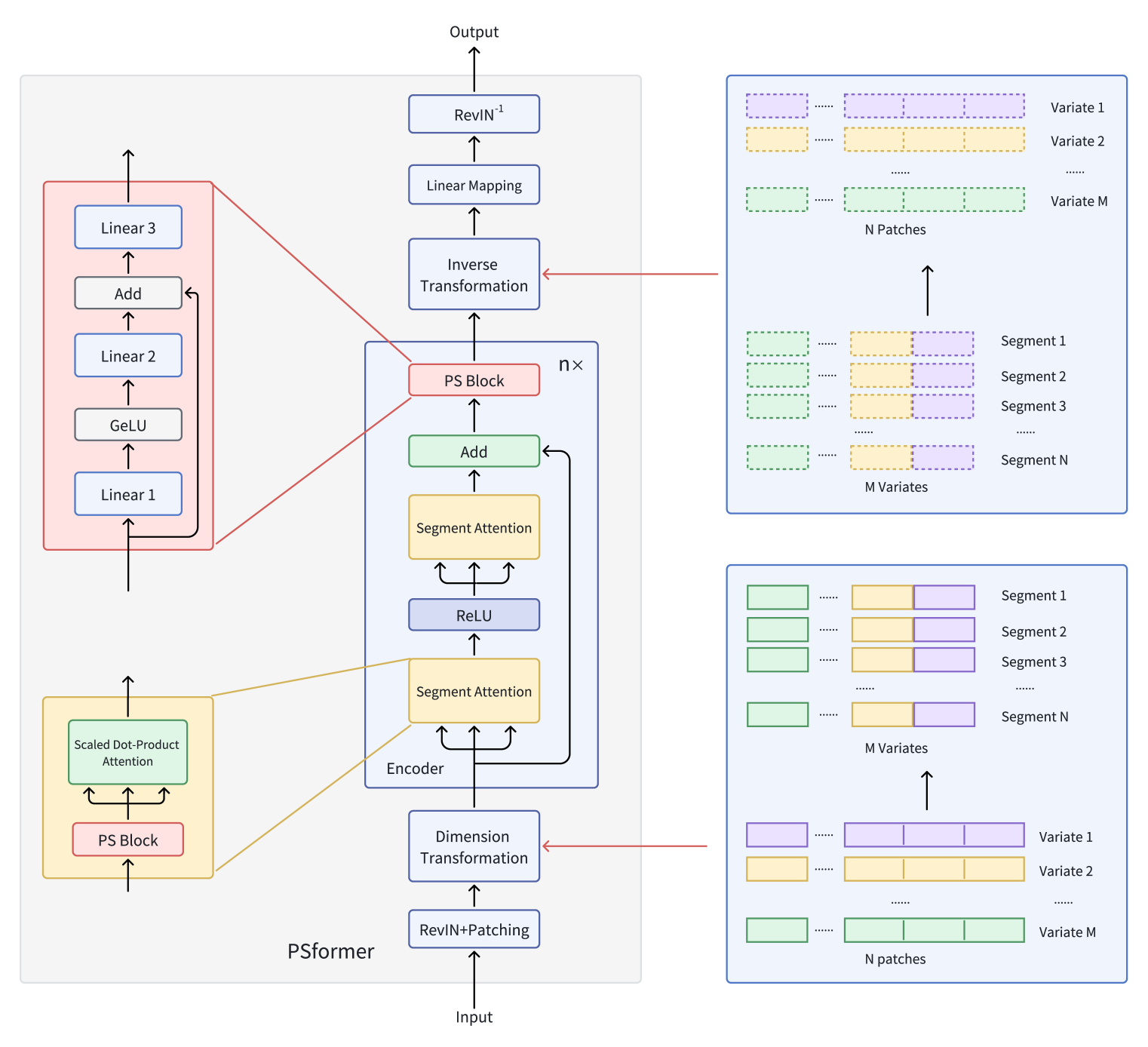
En el artículo anterior, ya empezamos a aplicar los enfoques propuestos utilizando las herramientas MQL5. Asimismo, analizamos los algoritmos de los métodos de la clase CNeuronPSBlock, en los que se implementa la funcionalidad del bloque de compartición de parámetros. Hoy continuaremos el trabajo iniciado y procederemos a construir la funcionalidad del Codificador.
Creamos el objeto de Codificador PSformer
Antes de empezar a implementar los algoritmos en código, le propongo discutirlos un poco. Según el framework presentado por los autores, los datos de origen se pasan primero por RevIn. Como sabe, el módulo RevIn incluye 2 bloques. A la entrada del modelo, este normaliza los datos de entrada, y a la salida del mismo, devuelve a los resultados del funcionamiento del modelo los parámetros de distribución anteriormente eliminados. Esto ayuda a acercar los resultados del modelo a la distribución de los datos de origen, lo cual es sin duda muy importante a la hora de resolver las tareas de previsión de los valores posteriores de una serie temporal.
En el marco de este artículo, al igual que antes, solo utilizaremos la normalización de los datos de origen a la entrada del modelo, que implementaremos como una capa aparte de normalización por lotes. Y la razón es que nuestro objetivo final no consiste en predecir los valores posteriores de la serie temporal, sino en entrenar una política del Actor rentable. Ya sabemos que los modelos funcionan mejor con datos normalizados, así que normalizaremos los datos de origen. Por la misma razón, será lógico enviar datos ya normalizados del estado oculto del Codificador a la entrada del Actor. Por lo tanto, si entrenamos el Codificador del entorno junto con el Actor, el bloque de mapeo lineal y la RevIn inversa se volverán redundantes.
Obviamente, necesitaremos un bloque de mapeo y un módulo RevIn inverso al entrenar los modelos por etapas, cuando primero se entrena el Codificador del estado del entorno para predecir los estados posteriores de la serie temporal analizada, y solo entonces se entrenarán por separado los modelos del Actor y el Crítico. Pero incluso en este caso, será mejor pasar el estado oculto del Codificador a la entrada del Actor, que contiene una representación más compacta y normalizada de los datos de origen.
El entrenamiento escalonado de modelos tiene ventajas y desventajas. Entre las ventajas de este enfoque se incluye la versatilidad del modelo de Codificador. Al fin y al cabo, este se entrena con datos de origen sin estar vinculado a una tarea específica, lo cual permite utilizarlo para encontrar soluciones a diversos problemas sobre los datos de origen presentados.
Por otra parte, una solución única para todos no suele ser la mejor opción para una tarea concreta, ya que puede no considerar algunos aspectos específicos.
Además, 2 fases de entrenamiento en total pueden resultar más costosas que entrenar todos los modelos al mismo tiempo.
Considerando el razonamiento anterior, hemos optado por el entrenamiento simultáneo de los modelos con la arquitectura reducida del Codificador.
Después de normalizar los datos de origen en el framework del PSformer, vendrá el módulo de parcheo y transformación de datos. Los autores del framework describen una transformación bastante compleja. Vamos a intentar aclararnos con ella.
A la entrada del modelo se introduce una serie temporal multimodal. Por ahora, omitiremos la normalización y consideraremos únicamente la transformación de datos.
En primer lugar, la serie temporal multimodal se dividirá en M secuencias unitarias y, a continuación, cada secuencia unitaria se dividirá en N parches iguales de longitud P. Después, los parches con las mismas marcas temporales se combinarán en segmentos. Así obtendremos N parches de dimensión M×P.
En nuestro caso, los datos de origen se presentarán como una descripción secuencial de barras históricas para la profundidad de los datos analizados. En otras palabras, en nuestro búfer de datos de origen, tendremos M elementos de descripción de una barra. A continuación, se describirán los elementos M de otra barra, y así sucesivamente. Por lo tanto, solo necesitaremos tomar P descripciones consecutivas de barras para formar un segmento. Obviamente, no necesitaremos transformar los datos de ninguna manera para hacer esto.
A continuación, los autores del PSformer hablan de transformar los datos de origen en la dimensionalidad (M×P)×N. Para ello, bastará con transponer el tensor de los datos de origen.
Así, el bloque de parcheo y transformación de datos de origen del PSformer, en nuestro caso, se convertirá en una sola capa de transposición.
Otra cuestión que deberemos discutir es el enfoque de creación de las capas secuenciales del Codificador del PSformer. Aquí tendremos dos opciones. Podemos usar el enfoque básico y especificar el número correcto de capas al crear la descripción de la arquitectura del modelo, o podemos crear un objeto que cree el número correcto de capas internas.
En el primer caso, complicaremos el proceso de descripción de la arquitectura del modelo, pero simplificaremos el proceso de creación del objeto del Codificador. Sin embargo, en una variante de este tipo, podremos controlar con flexibilidad la arquitectura de las capas posteriores del Codificador.
En el segundo caso, por el contrario, simplificaremos el proceso de descripción de la arquitectura del modelo, pero complicaremos el algoritmo de nuestro Codificador. Y en tal implementación, todas las capas internas del Codificador tendrán la misma arquitectura.
Obviamente, la primera opción resulta preferible para construir modelos con un número reducido de capas del Codificador, mientras que la segunda resultará relevante para modelos más profundos.
Para decidir sobre esta cuestión, recurriremos al estudio del autor sobre el efecto del número de capas del Codificador en la calidad de la predicción de los valores posteriores de una serie temporal. Los autores del framework PSformer realizaron el experimento anterior con los datos de los conjuntos de secuencias temporales estándar ETTh1 y ETTm1. Son datos de transformadores eléctricos. Cada punto de datos consta de 8 características, incluida la fecha, la temperatura del aceite y 6 tipos diferentes de características de carga de potencia externa. La ETTh1 contiene datos a intervalos de una hora, mientras que la ETTm1 contiene datos a intervalos de un minuto. Los resultados del estudio del autor se resumen en el siguiente recuadro.

Como podemos observar en la información presentada, para el conjunto de datos con intervalos de horas, que tiene menos aleatoriedad, los mejores resultados se obtienen con una sola capa del Codificador, mientras que para los datos más ruidosos, que se recogen a intervalos de minutos, las 3 capas del Codificador resultan óptimas. Como consecuencia, no esperamos construir modelos con un gran número de capas de Codificador. Por lo tanto, elegiremos la primera variante de implementación, con una estructura más simple del nuevo objeto y especificando los parámetros de cada capa individual del Codificador en la descripción de la arquitectura del modelo.
A continuación le mostramos la estructura completa del nuevo objeto CNeuronPSformer.
class CNeuronPSformer : public CNeuronBaseSAMOCL { protected: CNeuronTransposeOCL acTranspose[2]; CNeuronPSBlock acPSBlocks[3]; CNeuronRelativeSelfAttention acAttention[2]; CNeuronBaseOCL cResidual; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL); public: CNeuronPSformer(void) {}; ~CNeuronPSformer(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint units_count, uint segments, float rho, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defNeuronPSformer; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); //--- virtual CLayerDescription* GetLayerInfo(void); virtual void SetOpenCL(COpenCLMy *obj); };
Como ya hemos mencionado, el framework PSformer utiliza enfoques de optimización SAM. Por consiguiente, nuestra nueva clase heredará la funcionalidad básica de la capa totalmente conectada correspondiente.
Además, hemos añadido a la estructura CNeuronPSformer 2 capas de transposición de datos que realizarán las funciones de transformación de datos directa e inversa.
Asimismo, en la estructura de la nueva clase podrá observar 3 bloques de compartición de parámetros y 2 módulos de atención relativa, donde anteriormente añadimos la funcionalidad de optimización de SAM. Y esa es probablemente nuestra mayor desviación respecto al algoritmo PSformer del autor.
La cuestión es que los autores del framework PSformer usaron el bloque de compartición de parámetros para formar las entidades Query, Key y Value. En este caso, en el bloque PS se utilizan matrices de parámetros de tamaño N×N, de lo que podemos concluir que se utiliza el mismo tensor para todas las entidades.
En nuestra implementación, hemos hecho la arquitectura del Codificador un poco más compleja. Y el bloque PS solo desempeñará la función de preprocesamiento de datos, mientras que el análisis de dependencias se realizará en el bloque de atención relativa, más complejo.
Todos los objetos internos se declararán estáticamente, lo que nos permitirá dejar vacíos el constructor y el destructor de la clase. La inicialización de todos los objetos declarados y heredados se realizará en el método Init. En los parámetros del método obtendremos las constantes básicas que nos permitirán definir inequívocamente la arquitectura de la capa a crear. Entre ellas:
- window— tamaño del vector de descripción de un elemento de la secuencia;
- units_count— profundidad de la historia analizada (número de elementos de la secuencia);
- segments— número de segmentos a crear;
- rho— coeficiente rho del área de desenfoque.
bool CNeuronPSformer::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint units_count, uint segments, float rho, ENUM_OPTIMIZATION optimization_type, uint batch) { if(units_count % segments > 0) return false;
En el cuerpo del método de inicialización organizaremos un bloque de control en el que comprobaremos si la secuencia analizada es múltiplo del número de segmentos a crear. Y luego llamaremos al método homónimo de la clase padre, que ya implementará los otros puntos de control de las constantes recibidas y la inicialización de los objetos heredados.
if(!CNeuronBaseSAMOCL::Init(numOutputs, myIndex, open_cl, window * units_count, rho, optimization_type, batch)) return false;
A continuación, determinaremos el tamaño de un único segmento.
uint count = Neurons() / segments;
Y pasaremos al bloque de inicialización de los objetos internos recién declarados. En primer lugar, inicializaremos la capa de transposición de los datos de origen. Como número de filas de la matriz transpuesta especificaremos el número de segmentos, mientras que el tamaño de la fila se equiparará al número total de elementos de un segmento.
if(!acTranspose[0].Init(0, 0, OpenCL, segments, count, optimization, iBatch)) return false; acTranspose[0].SetActivationFunction(None);
En este caso, además, declararemos explícitamente la ausencia de una función de activación.
Cabe señalar que la especificación de una función de activación para la capa de transposición de datos no supone un atributo obligatorio. Al fin y al cabo, el algoritmo de pasada directa de la capa de transposición posibilita la sincronización de la función de activación con el objeto de datos de origen.
A continuación, inicializaremos el primer bloque de compartición de parámetros. Para ello, utilizaremos el método de inicialización explícita de objetos.
if(!acPSBlocks[0].Init(0, 1, OpenCL, segments, segments, units_count / segments, 1, fRho, optimization, iBatch)) return false;
Y a continuación organizaremos un ciclo, en cuyo cuerpo inicializaremos los módulos de atención y el resto de bloques de compartición de parámetros.
for(int i = 0; i < 2; i++) { if(!acAttention[i].Init(0, i + 2, OpenCL, segments, segments, units_count / segments, 2, optimization, iBatch)) return false; if(!acPSBlocks[i + 1].InitPS((CNeuronPSBlock*)acPSBlocks[0].AsObject())) return false; }
Nótese que inicializaremos el resto de bloques de parámetros compartidos según el primer bloque PS, es decir, con el copiado del puntero a los búferes de parámetros compartidos y sus momentos.
A continuación, inicializaremos la capa de registro de datos de los enlaces residuales. Aquí utilizaremos la capa básica completamente conectada, ya que solo utilizaremos sus búferes de datos para registrar los resultados intermedios de los cálculos.
if(!cResidual.Init(0, 4, OpenCL, acAttention[1].Neurons(), optimization, iBatch)) return false; if(!cResidual.SetGradient(acAttention[1].getGradient(), true)) return false; cResidual.SetActivationFunction((ENUM_ACTIVATION)acAttention[1].Activation());
Y para reducir las operaciones de copiado de datos, sustituiremos el búfer de gradiente de error de esta capa por el búfer similar del último módulo de atención. Y nos aseguraremos de sincronizar las funciones de activación de las dos capas.
Por último, inicializaremos la capa de transposición inversa de datos.
if(!acTranspose[1].Init(0, 5, OpenCL, count, segments, optimization, iBatch)) return false; acTranspose[1].SetActivationFunction((ENUM_ACTIVATION)acPSBlocks[2].Activation());
Y sustituiremos los búferes de nuestro objeto por las capas similares de la última capa interna de transposición de datos.
if(!SetOutput(acTranspose[1].getOutput(), true) || !SetGradient(acTranspose[1].getGradient(), true)) return false; //--- return true; }
A continuación, finalizaremos el método de inicialización de un nuevo objeto, pero antes retornaremos el resultado lógico de las operaciones al programa que realiza la llamada.
La siguiente etapa de nuestro trabajo consistirá en construir los algoritmos de pasada directa que implementaremos en el método feedForward. La construcción de este método no resulta muy complicada, ya que la funcionalidad principal está oculta en los objetos internos de nuestra clase previamente implementados.
En los parámetros del método obtendremos el puntero al objeto de datos de origen, que pasaremos inmediatamente al método homónimo de la capa interna de transposición para la transformación inicial.
bool CNeuronPSformer::feedForward(CNeuronBaseOCL *NeuronOCL) { //--- Dimension Transformation if(!acTranspose[0].FeedForward(NeuronOCL)) return false;
Después, organizaremos un ciclo de enumeración secuencial de dos bloques de atención a los segmentos.
//--- Segment Attention CObject* prev = acTranspose[0].AsObject(); for(int i = 0; i < 2; i++) { if(!acPSBlocks[i].FeedForward(prev)) return false; if(!acAttention[i].FeedForward(acPSBlocks[i].AsObject())) return false; prev = acAttention[i].AsObject(); }
En el cuerpo del ciclo, llamaremos secuencialmente a los métodos homónimos del bloque de compartición de parámetros y del módulo de atención relativa.
Y después de que todas las iteraciones del ciclo se hayan ejecutado con éxito, añadiremos los enlaces residuales de los datos de origen con el almacenamiento de los resultados en el búfer de nuestra capa interna cResidual.
//--- Residual Add if(!SumAndNormilize(acTranspose[0].getOutput(), acAttention[1].getOutput(), cResidual.getOutput(), acAttention[1].GetWindow(), false, 0, 0, 0, 1)) return false;
Pero tenga en cuenta que para los enlaces residuales, tomaremos los datos de origen después de la transformación, es decir, después de nuestra capa de transposición de datos de origen. Solo entonces almacenaremos la estructura de datos para realizar los enlaces residuales.
Los resultados obtenidos los pasaremos por el último bloque de compartición de parámetros.
//--- PS Block if(!acPSBlocks[2].FeedForward(cResidual.AsObject())) return false;
Y realizaremos la transformación inversa de los datos.
//--- Inverse Transformation if(!acTranspose[1].FeedForward(acPSBlocks[2].AsObject())) return false; //--- return true; }
Al sustituir los punteros de los búferes de datos de la interfaz de nuestro objeto por los búferes similares de la última capa de transposición, el resultado de la transposición inversa de datos se escribirá directamente en los búferes de la interfaz, y no necesitaremos realizar ningún copiado de datos adicional. Por lo tanto, después de transponer los resultados de los objetos internos, simplemente finalizaremos el método de pasada directa pasando el resultado lógico de las operaciones al programa que realiza la llamada.
Una vez finalizado el método de pasada directa, organizaremos los procesos de pasada inversa, lo cual realizaremos en los métodos calcInputGradients y updateInputWeights. El primero realiza la distribución de los gradientes de error, mientras que el segundo actualiza los parámetros del modelo.
En los parámetros del método calcInputGradients, obtendremos el puntero al objeto de datos de origen al que debemos pasar el gradiente de error, según el efecto de los datos de origen en el resultado final.
bool CNeuronPSformer::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
Y en el cuerpo del método comprobaremos inmediatamente la relevancia del puntero recibido, porque de lo contrario todas las operaciones posteriores carecerán de sentido. Después de pasar con éxito este control, realizaremos alternativamente la transferencia del gradiente de error entre las capas internas de nuestro objeto en la secuencia inversa de la pasada directa.
if(!acPSBlocks[2].calcHiddenGradients(acTranspose[1].AsObject())) return false; //--- if(!cResidual.calcHiddenGradients(acPSBlocks[2].AsObject())) return false; //--- if(!acPSBlocks[1].calcHiddenGradients(acAttention[1].AsObject())) return false; if(!acAttention[0].calcHiddenGradients(acPSBlocks[1].AsObject())) return false; if(!acPSBlocks[0].calcHiddenGradients(acAttention[0].AsObject())) return false; //--- if(!acTranspose[0].calcHiddenGradients(acPSBlocks[0].AsObject())) return false;
Una vez alcanzada la capa de transformación de los datos de origen, deberemos añadir el gradiente de error a lo largo de la línea troncal del enlace residual. Y aquí es posible que los eventos se desarrollen de dos formas, dependiendo de la función de activación del objeto de datos de origen. En ausencia de una función, simplemente sumaremos los valores de los 2 búferes de datos.
if(acTranspose[0].Activation() == None) { if(!SumAndNormilize(acTranspose[0].getGradient(), cResidual.getGradient(), acTranspose[0].getGradient(), acAttention[1].GetWindow(), false, 0, 0, 0, 1)) return false; }
De lo contrario, tendremos que corregir primero el gradiente de error mediante la derivada de la función de activación correspondiente y solo entonces podremos sumar los datos.
else { if(!DeActivation(acTranspose[0].getOutput(), cResidual.getGradient(), acTranspose[0].getPrevOutput(), acTranspose[0].Activation()) || !SumAndNormilize(acTranspose[0].getGradient(), acTranspose[0].getPrevOutput(), acTranspose[0].getGradient(), acAttention[1].GetWindow(), false, 0, 0, 0, 1)) return false; }
Al final del método, solo nos quedará pasar el gradiente de error al nivel de los datos de origen mediante la transformación inversa y finalizar el método devolviendo el resultado lógico de las operaciones al programa que realiza la llamada.
if(!NeuronOCL.calcHiddenGradients(acTranspose[0].AsObject())) return false; //--- return true; }
Para completar las operaciones de pasada inversa, nos quedará actualizar los parámetros del modelo para reducir el error de predicción. Recordemos que estamos usando métodos de optimización SAM para modificar los parámetros del modelo. Como ya hemos comentado, durante la ejecución del algoritmo SAM, realizaremos una segunda pasada directa con los parámetros del modelo corregidos. Esto provocará en el búfer de resultados un cambio de valores que no resultará crítico para la capa actual, pero que puede distorsionar el proceso de ajuste de los parámetros de la capa siguiente. Por lo tanto, actualizaremos los parámetros de las capas interiores en el orden inverso al de la pasada directa. Esto nos permitirá ajustar los parámetros de las capas interiores antes de cambiar los valores en el búfer de resultados de la capa anterior.
bool CNeuronPSformer::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { if(!acPSBlocks[2].UpdateInputWeights(cResidual.AsObject())) return false; //--- CObject* prev = acAttention[0].AsObject(); for(int i = 1; i >= 0; i--) { if(!acAttention[i].UpdateInputWeights(acPSBlocks[i].AsObject())) return false; if(!acPSBlocks[i].UpdateInputWeights(prev)) return false; prev = acTranspose[0].AsObject(); } //--- return true; }
Conviene decir unas palabras sobre los métodos de trabajo con archivos. Resulta bastante obvio que con tres bloques de compartición de parámetros, no necesitaremos en absoluto guardar los mismos datos tres veces. Bastará con almacenarlos una sola vez. A continuación, el método de guardado del objeto Save adoptará la forma siguiente.
En los parámetros del método obtendremos el manejador del archivo para guardar los datos e inmediatamente lo pasaremos al método homónimo de la clase padre.
bool CNeuronPSformer::Save(const int file_handle) { if(!CNeuronBaseSAMOCL::Save(file_handle)) return false;
A continuación, guardaremos el bloque de compartición de parámetros una sola vez.
if(!acPSBlocks[0].Save(file_handle)) return false;
Después, organizaremos un ciclo para guardar los módulos de atención y las capas de transposición de datos.
for(int i = 0; i < 2; i++) if(!acTranspose[i].Save(file_handle) || !acAttention[i].Save(file_handle)) return false; //--- return true; }
Una vez ejecutadas con éxito todas las iteraciones del ciclo, solo nos quedará devolver el resultado lógico de las operaciones al programa que realiza la llamada y finalizar el método.
Obsérvese que no solo hemos reducido el número de bloques de compartición de parámetros al guardar los datos, sino que también hemos omitido la capa de enlaces residuales. Esta no tiene parámetros entrenables. Por consiguiente, en esta variante de guardado de objetos, no perderemos ninguna información.
Sin embargo, al restaurar un objeto previamente guardado, tendremos que restaurar la estructura y funcionalidad de todos los objetos, incluidos los que se hayan omitido al realizar el guardado. Por lo tanto, le sugiero echar un vistazo más de cerca al método de restauración de la funcionalidad del objeto Load.
En los parámetros del método obtendremos el manejador del archivo con los datos previamente guardados. E inmediatamente pasaremos el manejador obtenido al método homónimo de la clase padre, en el que ya se ha implementado el algoritmo de restauración de la funcionalidad de los objetos heredados.
bool CNeuronPSformer::Load(const int file_handle) { if(!CNeuronBaseSAMOCL::Load(file_handle)) return false;
A continuación, restauraremos los objetos guardados siguiendo estrictamente la secuencia en la que se guardaron.
if(!LoadInsideLayer(file_handle, acPSBlocks[0].AsObject())) return false; for(int i = 0; i < 2; i++) if(!LoadInsideLayer(file_handle, acTranspose[i].AsObject()) || !LoadInsideLayer(file_handle, acAttention[i].AsObject())) return false;
Después de cargar los objetos guardados anteriormente, tendremos que restaurar la funcionalidad de los que omitimos al guardar. En primer lugar, restauraremos los bloques de compartición de parámetros. Luego cargaremos uno desde el archivo, e inicializaremos el resto de la misma forma copiando los punteros a los búferes de compartición de parámetros y sus momentos.
for(int i = 1; i < 3; i++) if(!acPSBlocks[i].InitPS((CNeuronPSBlock*)acPSBlocks[0].AsObject())) return false;
A continuación, inicializaremos la capa para guardar los resultados de los enlaces residuales. Su tamaño será igual al tensor de resultados del último módulo de atención relativa.
if(!cResidual.Init(0, 4, OpenCL, acAttention[1].Neurons(), optimization, iBatch)) return false; if(!cResidual.SetGradient(acAttention[1].getGradient(), true)) return false; cResidual.SetActivationFunction((ENUM_ACTIVATION)acAttention[1].Activation());
Y no nos olvidaremos de sustituir el puntero al búfer de gradiente de error, lo que nos permitirá eliminar operaciones innecesarias de copiado de datos. Luego sincronizamos las funciones de activación.
Después, solo nos quedará sustituir los punteros de los búferes de interfaces de nuestro objeto por los búferes similares de la última capa de transposición de datos.
if(!SetOutput(acTranspose[1].getOutput(), true) || !SetGradient(acTranspose[1].getGradient(), true)) return false; //--- return true; }
Y finalizaremos el método devolviendo el resultado lógico de las operaciones al programa que realiza la llamada.
Con esto daremos por completo el objeto de codificador CNeuronPSformer. Encontrará el código completo de esta clase y todos sus métodos en el archivo adjunto.
Arquitectura de los modelos
Tras construir los objetos de implementación de los enfoques propuestos por los autores del framework PSformer, pasaremos a describir la arquitectura de los modelos entrenados. Y en primer lugar nos interesará el Codificador del estado del entorno, en el que implementaremos los enfoques propuestos.
La arquitectura del Codificador del estado del entorno se especificará en el método CreateEncoderDescriptions. En los parámetros del método, obtendremos el puntero al objeto de array dinámico para registrar la descripción de la arquitectura del modelo.
bool CreateEncoderDescriptions(CArrayObj *&encoder) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; }
En el cuerpo del método comprobaremos la relevancia del puntero obtenido y, de ser necesario, crearemos una nueva instancia del array dinámico.
Al igual que antes, utilizaremos la capa básica completamente conectada como capa de datos de origen. Su tamaño deberá ser suficiente para obtener un tensor completo de datos históricos para una determinada profundidad de análisis.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
A continuación vendrá la capa de normalización por lotes, donde tiene lugar el procesamiento inicial de los datos de origen "en bruto".
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Los datos de origen normalizados se transferirán al Codificador del PSformer. En e marco del presente artículo, utilizaremos 3 capas consecutivas del Codificador del PSformer con idéntica arquitectura. Para crear una descripción del número necesario de capas del Codificador, crearemos un ciclo cuyo número de iteraciones sea igual a la profundidad del Codificador a crear. En el cuerpo del ciclo, en cada iteración crearemos una descripción del objeto CNeuronPSformer.
//--- layer 2 - 4 for(int i = 0; i < 3; i++) { if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronPSformer; descr.window = BarDescr; descr.count = HistoryBars; descr.window_out = Segments; descr.probability = Rho; descr.batch = 1e4; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } }
Tras el Codificador del PSformer, utilizaremos un bloque de mapeo que incluirá una capa convolucional y otra completamente conectada. Todas las capas neuronales utilizadas están adaptadas para utilizar la optimización SAM.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvSAMOCL; descr.count = HistoryBars; descr.window = BarDescr; descr.step = BarDescr; descr.window_out = int(LatentCount / descr.count); descr.probability = Rho; descr.activation = GELU; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseSAMOCL; descr.count = LatentCount; descr.probability = Rho; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- return true; }
Tras componer con éxito la descripción de la arquitectura del Codificador del estado del entorno, finalizaremos el método devolviendo primero el resultado lógico de las operaciones al programa que realiza la llamada.
Podrá leer el código completo del método para describir la arquitectura del Codificador de descripción del entorno en el archivo adjunto. También le presentamos las arquitecturas de los modelos del Actor y el Crítico, que se han trasladado de artículos anteriores sin modificaciones.
Además, hemos mantenido sin cambios los programas de interacción con el entorno y de entrenamiento de los modelos. Podrá explorar su código completo en el archivo adjunto. Vamos a pasar ahora a la fase final de nuestro trabajo: ahora probaremos la eficacia de los enfoques aplicados con datos históricos reales.
Simulación
Bien, hoy hemos realizado un trabajo considerable para aplicar los enfoques propuestos por los autores del framework PSformer utilizando las herramientas de MQL5. Ahora nos acercamos a la fase más emocionante de nuestro trabajo: la evaluación de la eficacia de los enfoques aplicados sobre datos históricos reales.
Aquí habría que hacer hincapié en la "evaluación de la eficacia de los enfoques aplicados" en lugar de "propuestos". Al fin y al cabo, en nuestra aplicación nos hemos desviado un poco del framework del autor.
Entrenaremos los modelos con los datos históricos de todo el año 2023 del instrumento financiero EURUSD y el marco temporal H1. Al igual que antes, los parámetros de todos los indicadores analizados se utilizarán por defecto.
Como ya hemos mencionado, los modelos del Codificador del estado del entorno, el Actor y el Crítico se entrenarán simultáneamente. Para el entrenamiento inicial, utilizaremos la muestra de entrenamiento recogida de modelos anteriores. Y a medida que se entrene el modelo, se actualizará periódicamente.
Tras realizar varias iteraciones de entrenamiento de los modelos y actualizar la muestra de entrenamiento, hemos logrado obtener una política capaz de generar beneficios en las muestras de entrenamiento y prueba.
Las pruebas de la política del Actor entrenada se han realizado con los datos históricos de enero de 2024 con los demás parámetros intactos. Ahora le presentamos los resultados de las pruebas.
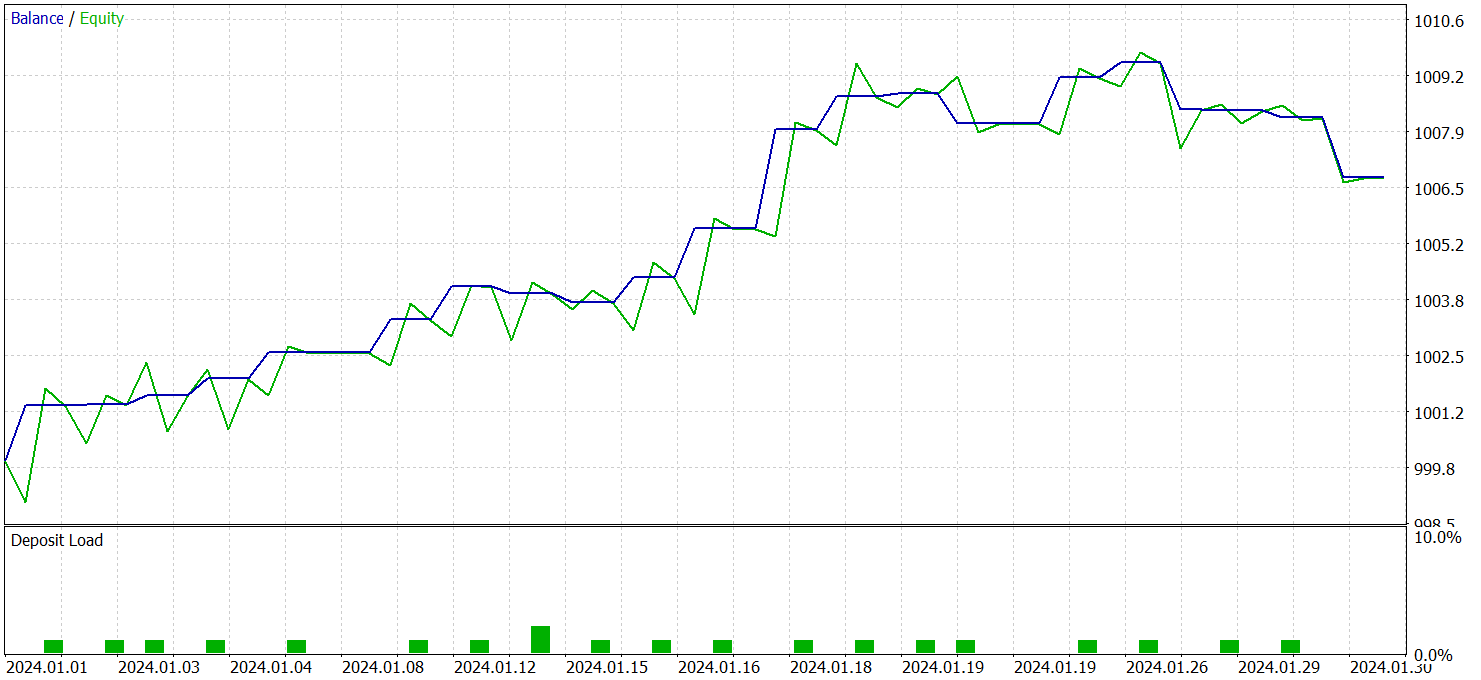
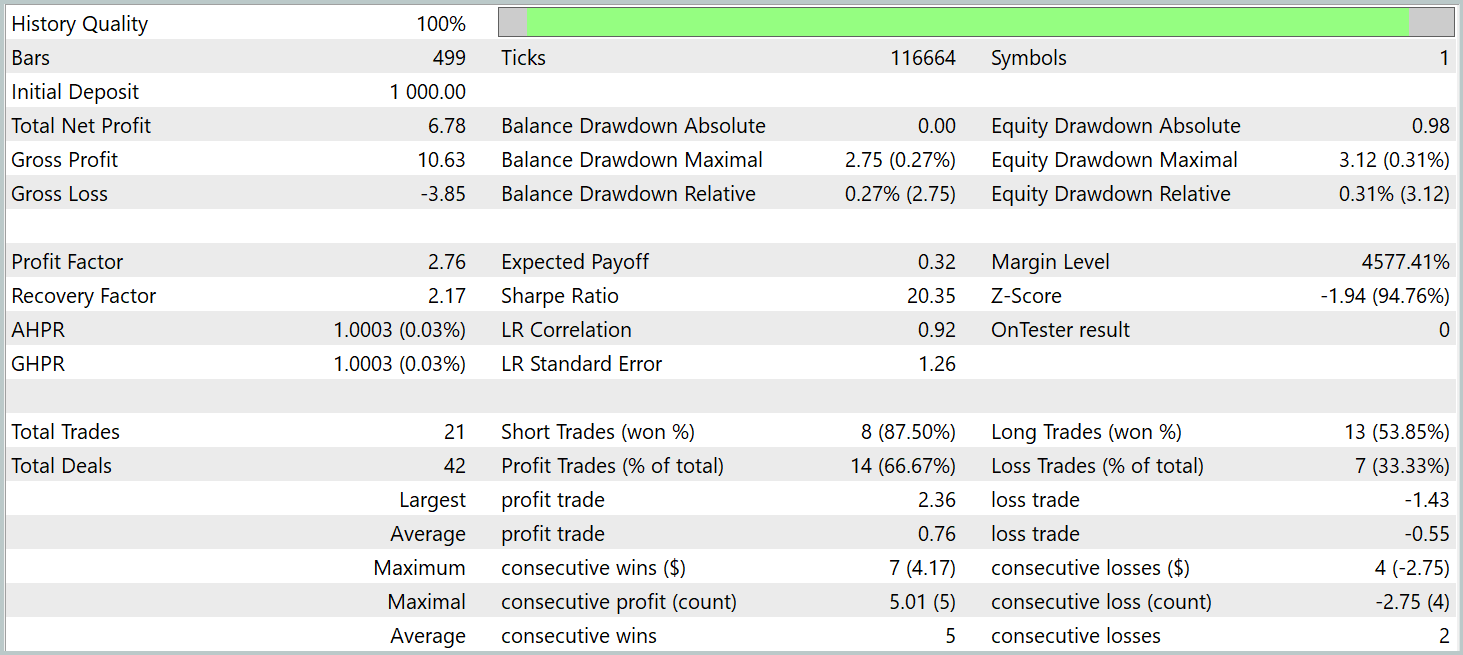
Durante el periodo de prueba, el modelo ha realizado 21 transacciones, lo que supone una media de 1 transacción por día de negociación. De ellas, 14 se han cerrado con beneficios, lo que supone más del 66%. Al mismo tiempo, la media de transacciones rentables es un 38% superior a la media de transacciones perdedoras.
Llama la atención el gráfico de balance, donde se aprecia una clara tendencia al alza en las 2 primeras décadas.
En general, los resultados obtenidos sugieren que existe potencial de desarrollo. Con las mejoras oportunas y un entrenamiento adicional del modelo con una muestra de entrenamiento mayor, el modelo podría utilizarse para el comercio real.
Conclusión
Hoy nos hemos familiarizado con el framework PSformer, que se caracteriza por una gran precisión en la previsión de series temporales y un uso eficiente de los recursos informáticos. Los elementos arquitectónicos clave del PSformer son el bloque de compartición de parámetros (PS) y el mecanismo de atención a segmentos espaciotemporales (SegAtt). Estos componentes posibilitan un modelado eficaz de las dependencias locales y globales de las series temporales, al tiempo que reducen el número de parámetros sin comprometer la calidad de las previsiones.
Asimismo, hemos implementado nuestra propia visión de los enfoques propuestos mediante MQL5. Luego hemos entrenado los modelos utilizando los enfoques aplicados. Los resultados de las pruebas con datos históricos ajenos a la muestra de entrenamiento indican el potencial de los modelos entrenados.
Enlaces
Programas usados en el artículo
| # | Nombre | Tipo | Descripción |
|---|---|---|---|
| 1 | Research.mq5 | Asesor | Asesor de recopilación de datos |
| 2 | ResearchRealORL.mq5 | Asesor | Asesor de recopilación de ejemplos con el método Real-ORL |
| 3 | Study.mq5 | Asesor | Asesor de entrenamiento de Modelos |
| 4 | StudyEncoder.mq5 | Asesor | Asesor de entrenamiento del Codificador |
| 5 | Test.mq5 | Asesor | Asesor para la prueba de modelos |
| 6 | Trajectory.mqh | Biblioteca de clases | Estructura de descripción del estado del sistema. |
| 7 | NeuroNet.mqh | Biblioteca de clases | Biblioteca de clases para crear una red neuronal |
| 8 | NeuroNet.cl | Biblioteca | Biblioteca de código de programa OpenCL |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/16483
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
cuando compilo el archivo Research.mq5 obtengo este error
y cuando compilo el archivo ResearchRealORL.mq5 obtengo este error
y cuando compilo el archivo Study.mq5 obtengo este error
Se repite casi el mismo error, ¿qué hice mal?
y cuando compilo el archivo Test.mq5 obtengo este error
He estado recibiendo errores del archivo math.math/mqh. Si hay alguna solución a esto, sería muy apreciada.